О степенях свободы в статистике
Время на прочтение
8 мин
Количество просмотров 197K
В одном из предыдущих постов мы обсудили, пожалуй, центральное понятие в анализе данных и проверке гипотез — p-уровень значимости. Если мы не применяем байесовский подход, то именно значение p-value мы используем для принятия решения о том, достаточно ли у нас оснований отклонить нулевую гипотезу нашего исследования, т.е. гордо заявить миру, что у нас были получены статистически значимые различия.
Однако в большинстве статистических тестов, используемых для проверки гипотез, (например, t-тест, регрессионный анализ, дисперсионный анализ) рядом с p-value всегда соседствует такой показатель как число степеней свободы, он же degrees of freedom или просто сокращенно df, о нем мы сегодня и поговорим.

Степени свободы, о чем речь?
По моему мнению, понятие степеней свободы в статистике примечательно тем, что оно одновременно является и одним из самым важных в прикладной статистике (нам необходимо знать df для расчета p-value в озвученных тестах), но вместе с тем и одним из самых сложных для понимания определений для студентов-нематематиков, изучающих статистику.
Давайте рассмотрим пример небольшого статистического исследования, чтобы понять, зачем нам нужен показатель df, и в чем же с ним такая проблема. Допустим, мы решили проверить гипотезу о том, что средний рост жителей Санкт-Петербурга равняется 170 сантиметрам. Для этих целей мы набрали выборку из 16 человек и получили следующие результаты: средний рост по выборке оказался равен 173 при стандартном отклонении равном 4. Для проверки нашей гипотезы можно использовать одновыборочный t-критерий Стьюдента, позволяющий оценить, как сильно выборочное среднее отклонилось от предполагаемого среднего в генеральной совокупности в единицах стандартной ошибки:
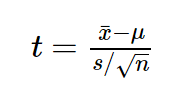
Проведем необходимые расчеты и получим, что значение t-критерия равняется 3, отлично, осталось рассчитать p-value и задача решена. Однако, ознакомившись с особенностями t-распределения мы выясним, что его форма различается в зависимости от числа степеней свобод, рассчитываемых по формуле n-1, где n — это число наблюдений в выборке:
Сама по себе формула для расчета df выглядит весьма дружелюбной, подставили число наблюдений, вычли единичку и ответ готов: осталось рассчитать значение p-value, которое в нашем случае равняется 0.004.
Но почему n минус один?
Когда я впервые в жизни на лекции по статистике столкнулся с этой процедурой, у меня как и у многих студентов возник законный вопрос: а почему мы вычитаем единицу? Почему мы не вычитаем двойку, например? И почему мы вообще должны что-то вычитать из числа наблюдений в нашей выборке?
В учебнике я прочитал следующее объяснение, которое еще не раз в дальнейшем встречал в качестве ответа на данный вопрос:
“Допустим мы знаем, чему равняется выборочное среднее, тогда нам необходимо знать только n-1 элементов выборки, чтобы безошибочно определить чему равняется оставшейся n элемент”. Звучит разумно, однако такое объяснение скорее описывает некоторый математический прием, чем объясняет зачем нам понадобилось его применять при расчете t-критерия. Следующее распространенное объяснение звучит следующим образом: число степеней свободы — это разность числа наблюдений и числа оцененных параметров. При использовании одновыборочного t-критерия мы оценили один параметр — среднее значение в генеральной совокупности, используя n элементов выборки, значит df = n-1.
Однако ни первое, ни второе объяснение так и не помогает понять, зачем же именно нам потребовалось вычитать число оцененных параметров из числа наблюдений?
Причем тут распределение Хи-квадрат Пирсона?
Давайте двинемся чуть дальше в поисках ответа. Сначала обратимся к определению t-распределения, очевидно, что все ответы скрыты именно в нем. Итак случайная величина:
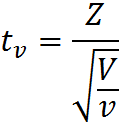
имеет t-распределение с df = ν, при условии, что Z – случайная величина со стандартным нормальным распределением N(0; 1), V – случайная величина с распределением Хи-квадрат, с ν числом степеней свобод, случайные величины Z и V независимы. Это уже серьезный шаг вперед, оказывается, за число степеней свободы ответственна случайная величина с распределением Хи-квадрат в знаменателе нашей формулы.
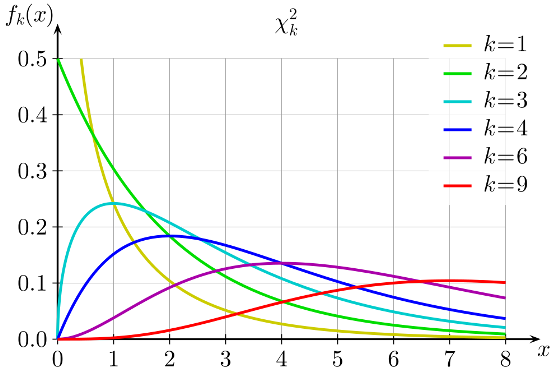
Давайте тогда изучим определение распределения Хи-квадрат. Распределение Хи-квадрат с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Кажется, мы уже совсем у цели, по крайней мере, теперь мы точно знаем, что такое число степеней свободы у распределения Хи-квадрат — это просто число независимых случайных величин с нормальным стандартным распределением, которые мы суммируем. Но все еще остается неясным, на каком этапе и зачем нам потребовалось вычитать единицу из этого значения?
Давайте рассмотрим небольшой пример, который наглядно иллюстрирует данную необходимость. Допустим, мы очень любим принимать важные жизненные решения, основываясь на результате подбрасывания монетки. Однако, последнее время, мы заподозрили нашу монетку в том, что у нее слишком часто выпадает орел. Чтобы попытаться отклонить гипотезу о том, что наша монетка на самом деле является честной, мы зафиксировали результаты 100 бросков и получили следующий результат: 60 раз выпал орел и только 40 раз выпала решка. Достаточно ли у нас оснований отклонить гипотезу о том, что монетка честная? В этом нам и поможет распределение Хи-квадрат Пирсона. Ведь если бы монетка была по настоящему честной, то ожидаемые, теоретические частоты выпадания орла и решки были бы одинаковыми, то есть 50 и 50. Легко рассчитать насколько сильно наблюдаемые частоты отклоняются от ожидаемых. Для этого рассчитаем расстояние Хи-квадрат Пирсона по, я думаю, знакомой большинству читателей формуле:
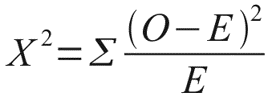
Где O — наблюдаемые, E — ожидаемые частоты.
Дело в том, что если верна нулевая гипотеза, то при многократном повторении нашего эксперимента распределение разности наблюдаемых и ожидаемых частот, деленная на корень из наблюдаемой частоты, может быть описано при помощи нормального стандартного распределения, а сумма квадратов k таких случайных нормальных величин это и будет по определению случайная величина, имеющая распределение Хи-квадрат.
Давайте проиллюстрируем этот тезис графически, допустим у нас есть две случайные, независимые величины, имеющих стандартное нормальное распределение. Тогда их совместное распределение будет выглядеть следующим образом:
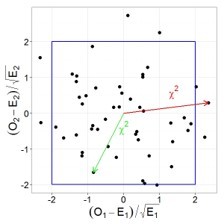
При этом квадрат расстояния от нуля до каждой точки это и будет случайная величина, имеющая распределение Хи-квадрат с двумя степенями свободы. Вспомнив теорему Пифагора, легко убедиться, что данное расстояние и есть сумма квадратов значений обеих величин.
Пришло время вычесть единичку!
Ну а теперь кульминация нашего повествования. Возвращаемся к нашей формуле расчета расстояния Хи-квадрат для проверки честности монетки, подставим имеющиеся данные в формулу и получим, что расстояние Хи-квадрат Пирсона равняется 4. Однако для определения p-value нам необходимо знать число степеней свободы, ведь форма распределения Хи-квадрат зависит от этого параметра, соответственно и критическое значение также будет различаться в зависимости от этого параметра.
Теперь самое интересное. Предположим, что мы решили многократно повторять 100 бросков, и каждый раз мы записывали наблюдаемые частоты орлов и решек, рассчитывали требуемые показатели (разность наблюдаемых и ожидаемых частот, деленная на корень из ожидаемой частоты) и как и в предыдущем примере наносили их на график.
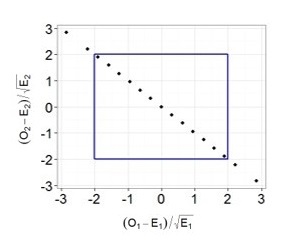
Легко заметить, что теперь все точки выстраиваются в одну линию. Все дело в том, что в случае с монеткой наши слагаемые не являются независимыми, зная общее число бросков и число решек, мы всегда можем точно определить выпавшее число орлов и наоборот, поэтому мы не можем сказать, что два наших слагаемых — это две независимые случайные величины. Также вы можете убедиться, что все точки действительно всегда будут лежать на одной прямой: если у нас выпало 30 орлов, значит решек было 70, если орлов 70, то решек 30 и т.д. Таким образом, несмотря на то, что в нашей формуле было два слагаемых, для расчета p-value мы будем использовать распределение Хи-квадрат с одной степенью свободы! Вот мы наконец-то добрались до момента, когда нам потребовалось вычесть единицу. Если бы мы проверяли гипотезу о том, что наша игральная кость с шестью гранями является честной, то мы бы использовали распределение Хи-квадрат с 5 степенями свободы. Ведь зная общее число бросков и наблюдаемые частоты выпадения любых пяти граней, мы всегда можем точно определить, чему равняется число выпадений шестой грани.
Все становится на свои места
Теперь, вооружившись этими знаниями, вернемся к t-тесту:
в знаменателе у нас находится стандартная ошибка, которая представляет собой выборочное стандартное отклонение, делённое на корень из объёма выборки. В расчет стандартного отклонения входит сумма квадратов отклонений наблюдаемых значений от их среднего значения — то есть сумма нескольких случайных положительных величин. А мы уже знаем, что сумма квадратов n случайных величин может быть описана при помощи распределения хи-квадрат. Однако, несмотря на то, что у нас n слагаемых, у данного распределения будет n-1 степень свободы, так как зная выборочное среднее и n-1 элементов выборки, мы всегда можем точно задать последний элемент (отсюда и берется это объяснение про среднее и n-1 элементов необходимых для однозначного определения n элемента)! Получается, в знаменателе t-статистики у нас спрятано распределение хи-квадрат c n-1 степенями свободы, которое используется для описания распределения выборочного стандартного отклонения! Таким образом, степени свободы в t-распределении на самом деле берутся из распределения хи-квадрат, которое спрятано в формуле t-статистики. Кстати, важно отметить, что все приведенные выше рассуждения справедливы, если исследуемый признак имеет нормальное распределение в генеральной совокупности (или размер выборки достаточно велик), и если бы у нас действительно стояла цель проверить гипотезу о среднем значении роста в популяции, возможно, было бы разумнее использовать непараметрический критерий.
Схожая логика расчета числа степеней свободы сохраняется и при работе с другими тестами, например, в регрессионном или дисперсионном анализе, все дело в случайных величинах с распределением Хи-квадрат, которые присутствуют в формулах для расчета соответствующих критериев.
Таким образом, чтобы правильно интерпретировать результаты статистических исследований и разбираться, откуда возникают все показатели, которые мы получаем при использовании даже такого простого критерия как одновыборочный t-тест, любому исследователю необходимо хорошо понимать, какие математические идеи лежат в основании статистических методов.
Онлайн курсы по статистике: объясняем сложные темы простым языком
Основываясь на опыте преподавания статистики в Институте биоинформатики , у нас возникла идея создать серию онлайн курсов, посвященных анализу данных, в которых в доступной для каждого форме будут объясняться наиболее важные темы, понимание которых необходимо для уверенного использования методов статистики при решении различного рода задача. В 2015 году мы запустили курс Основы статистики, на который к сегодняшнему дню записалось около 17 тысяч человек, три тысячи слушателей уже получили сертификат о его успешном завершении, а сам курс был награждён премией EdCrunch Awards и признан лучшим техническим курсом. В этом году на платформе stepik.org стартовало продолжение курса Основы статистики. Часть два, в котором мы продолжаем знакомство с основными методами статистики и разбираем наиболее сложные теоретические вопросы. Кстати, одной из главных тем курса является роль распределения Хи-квадрат Пирсона при проверке статистических гипотез. Так что если у вас все еще остались вопросы о том, зачем мы вычитаем единицу из общего числа наблюдений, ждем вас на курсе!
Стоит также отметить, что теоретические знания в области статистики будут определенно полезны не только тем, кто применяет статистику в академических целях, но и для тех, кто использует анализ данных в прикладных областях. Базовые знания в области статистики просто необходимы для освоения более сложных методов и подходов, которые используются в области машинного обучения и Data Mining. Таким образом, успешное прохождение наших курсов по введению в статистику — хороший старт в области анализа данных. Ну а если вы всерьез задумались о приобретении навыков работы с данными, думаем, вас может заинтересовать наша онлайн — программа по анализу данных, о которой мы подробнее писали здесь. Упомянутые курсы по статистике являются частью этой программы и позволят вам плавно погрузиться в мир статистики и машинного обучения. Однако пройти эти курсы без дедлайнов могут все желающие и вне контекста программы по анализу данных.
Many statistical inference problems require us to find the number of degrees of freedom. The number of degrees of freedom selects a single probability distribution from among infinitely many. This step is an often overlooked but crucial detail in both the calculation of confidence intervals and the workings of hypothesis tests.
There is not a single general formula for the number of degrees of freedom. However, there are specific formulas used for each type of procedure in inferential statistics. In other words, the setting that we are working in will determine the number of degrees of freedom. What follows is a partial list of some of the most common inference procedures, along with the number of degrees of freedom that are used in each situation.
Standard Normal Distribution
Procedures involving standard normal distribution are listed for completeness and to clear up some misconceptions. These procedures do not require us to find the number of degrees of freedom. The reason for this is that there is a single standard normal distribution. These types of procedures encompass those involving a population mean when the population standard deviation is already known, and also procedures concerning population proportions.
One Sample T Procedures
Sometimes statistical practice requires us to use Student’s t-distribution. For these procedures, such as those dealing with a population mean with unknown population standard deviation, the number of degrees of freedom is one less than the sample size. Thus if the sample size is n, then there are n — 1 degrees of freedom.
T Procedures With Paired Data
Many times it makes sense to treat data as paired. The pairing is carried out typically due to a connection between the first and second value in our pair. Many times we would pair before and after measurements. Our sample of paired data is not independent; however, the difference between each pair is independent. Thus if the sample has a total of n pairs of data points, (for a total of 2n values) then there are n — 1 degrees of freedom.
T Procedures for Two Independent Populations
For these types of problems, we are still using a t-distribution. This time there is a sample from each of our populations. Although it is preferable to have these two samples be of the same size, this is not necessary for our statistical procedures. Thus we can have two samples of size n1 and n2. There are two ways to determine the number of degrees of freedom. The more accurate method is to use Welch’s formula, a computationally cumbersome formula involving the sample sizes and sample standard deviations. Another approach, referred to as the conservative approximation, can be used to quickly estimate the degrees of freedom. This is simply the smaller of the two numbers n1 — 1 and n2 — 1.
Chi-Square for Independence
One use of the chi-square test is to see if two categorical variables, each with several levels, exhibit independence. The information about these variables is logged in a two-way table with r rows and c columns. The number of degrees of freedom is the product (r — 1)(c — 1).
Chi-Square Goodness of Fit
Chi-square goodness of fit starts with a single categorical variable with a total of n levels. We test the hypothesis that this variable matches a predetermined model. The number of degrees of freedom is one less than the number of levels. In other words, there are n — 1 degrees of freedom.
One Factor ANOVA
One factor analysis of variance (ANOVA) allows us to make comparisons between several groups, eliminating the need for multiple pairwise hypothesis tests. Since the test requires us to measure both the variation between several groups as well as the variation within each group, we end up with two degrees of freedom. The F-statistic, which is used for one factor ANOVA, is a fraction. The numerator and denominator each have degrees of freedom. Let c be the number of groups and n is the total number of data values. The number of degrees of freedom for the numerator is one less than the number of groups, or c — 1. The number of degrees of freedom for the denominator is the total number of data values, minus the number of groups, or n — c.
It is clear to see that we must be very careful to know which inference procedure we are working with. This knowledge will inform us of the correct number of degrees of freedom to use.
Число степеней
свободы это число свободно варьирующих
единиц в составе выборки. Так, если вся
выборка состоит из п
элементов
и характеризуется средней X,
то любой элемент этой совокупности
может быть получен как разность между
величиной n
• X
и суммой
всех остальных элементов, кроме самого
этого элемента.
52
Пример. Рассмотрим
ряд 4.5: 2468 10. Мы помним, что средняя
этого ряда равна 6.
В этом ряду
5 чисел, следовательно N
= 5. Предположим,
что мы хотим получить последний элемент
ряда
— 10, зная все
предыдущие элементы и среднее этого
ряда. Тогда:
5-6-2-4-6-8= 10
Предположим, что
мы хотим получить первый элемент ряда
— 2, зная все
последующие элементы и среднее этого
ряда. Тогда:
5-6-4-6-8-10 = 2и т.д.
Следовательно,
один элемент выборки не имеет свободы
вариации и всегда может быть выражен
через другие элементы и среднее. Это
означает, что число степеней свободы у
выборочного ряда обозначаемое в
таких случаях символом k
будет
определяться как k
= п -1, где п
— общее
число элементов ряда (выборки).
При наличии не
одного, а нескольких ограничений свободы
вариации, число степеней свободы,
обозначаемое как v
(гречес-и.ш буква ню) будет равно v
= п — k,
где k
соответствует
числу ограничений свободы вариации.
В общем случае для
таблицы экспериментальных данных число
степеней свободы будет определяться
по следующей формуле:
v
= (с — 1)•(n—
1)
(4.8)
где с
— число
столбцов, а п
— число
строк (число испытуемых).
Следует подчеркнуть,
однако, что для ряда статистических
методов расчет числа степеней свободы
имеет свою специфику.
4.7. Понятие нормального распределения
Нормальное
распределение играет большую роль в
математической статистике, поскольку
многие статистические методы предполагают,
что, анализируемые с их помощью
экспериментальные данные распределены
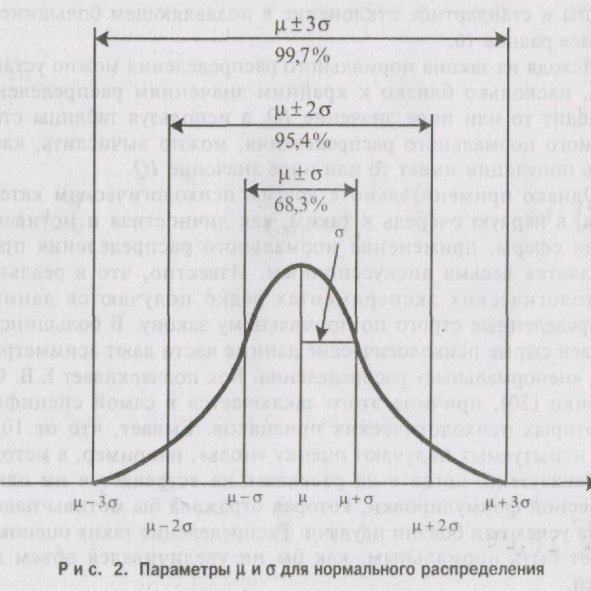
нормально. График нормального распределения
имеет вил колоколообразной кривой (см.
рис. 2).
53
Его важной
особенностью является то, что форма и
положение графика нормального
распределения определяется только
двумя параметрами: средней µ(мю) и
стандартным отклонением о (сигма).
Если стандартное отклонение σ постоянно,
а величина средней µ меняется, то
собственно форма нормальной кривой
остается неизменной, а лишь ее график
смещается вправо (при увеличении µ)
или влево (при уменьшении µ) по оси
абсцисс —ОХ.
При условии
постоянства средней ц изменение сигмы
влечет за собой изменение только ширины
кривой: при уменьшении сигмы кривая
делается более узкой, и поднимается при
этом вверх, а при увеличении сигмы кривая
расширяется, но опускается вниз.
Однако во всех случаях нормальная кривая
оказывается строго симметричной
относительно средней, сохраняя правильную
колоколообразную форму.
54
Для нормального
распределения характерно также
совпадение величин средней
арифметической, моды и медианы. Равенство
этих показателей указывает на нормальность
данного распределения. Это распределение
обладает еще одной важной особенностью:
чем больше величина признака отклоняется
от среднего значения, тем меньше
будет частота встречаемости (вероятность)
этого признака в распределении.
«Нормальным» такое распределение было
названо потому, что оно наиболее часто
встречалось в естественно-научных
исследованиях и казалось «нормой»
распределения случайных величин.
В психологических
исследованиях нормальное распределение
используется в первую очередь при
разработке и применении тестов
интеллекта и способностей. Так, отклонения
показателей интеллекта IQ
следуют
закону нормального распределения, имея
среднее значение равное 100 для любой
конкретной возрастной группы и стандартное
отклонение в подавляющем большинстве
случаев равное 16.
Исходя из закона
нормального распределения можно
установить, насколько близко к крайним
значениям распределения подходит то
или иное значение IQ,
а используя
таблицы стандартного нормального
распределения, можно вычислить, какая
часть популяции имеет то или иное
значение IQ.
Однако применительно
к другим психологическим категориям,
в первую очередь к таким, как личностная
и мотиваци-онная сферы, применение
нормального распределения представляется
весьма дискуссионным. Известно, что в
реальных психологических экспериментах
редко получаются данные, распределенные
строго по нормальному закону. В большинстве
случаев сырые психологические данные
часто дают асимметричные, «ненормальные»
распределения. Как подчеркивает Е.В.
Сидоренко (30), причина этого заключается
в самой специфике некоторых психологических
признаков. Бывает, что от 10 до 20% испытуемых
получают оценку «ноль», например, в
методике Хекхаузена, когда в их
рассказах не встречается ни одной
словесной формулировки, которая отражала
бы мотивы надежды на успех или боязни
неудачи. Распределение таких оценок не
может быть нормальным, как бы ни
увеличивался объем выборки.
55
Несмотря на это,
при обработке экспериментальных данных
всегда целесообразно проводить оценку
характера распределения (см. главу 8,
раздел 8.2). Эта оценка важна, потому что
в зависимости от характера распределения
решается вопрос о возможности
применения того или иного статистического
метода. Как будет понятно из дальнейшего
изложения, при нормальном распределении
экспериментальных данных применяются
особые методы статистической обработки.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Как найти степень свободы в статистике
Содержание
- Степени свободы, о чем речь?
- Но почему n минус один?
- Причем тут распределение Хи-квадрат Пирсона?
- Пришло время вычесть единичку!
- Все становится на свои места
- Онлайн курсы по статистике: объясняем сложные темы простым языком
Число степеней свободы (n) – это число свободно варьирующих единиц в составе выборки. Оно равно числу классов вариационного ряда минус число условий, при которых он был сформирован. К числу таких условий относятся объём выборки (n), средние и дисперсии.
Число степеней свободы у выборочного ряда определяется:
n = n – 1, где n – общее число элементов ряда (выборки).
При наличии не одного, а нескольких ограничений свободы вариации, число степеней свободы определяется по формуле:
ν = n – k, где k – число ограничений свободы вариации.
Для таблицы экспериментальных данных число степеней свободы определяется следующим образом:
ν = (c – 1) (n – 1), где c – число столбцов, а n – число строк таблицы (число испытуемых).
Для ряда статистических методов подсчёт числа степеней свободы оказывается необходимым и рассчитывается по-своему.
Понятие нормального распределения.
В статистике под рядом распределения понимают распределение частот по вариантам. Распределением признака называется закономерность встречаемости разных его значений.
Особое место в статистике занимает нормальное распределение. График нормального распределения представляет собой колоколообразную кривую. Форма и положение графика определяется только двумя параметрами: средней (µ) и стандартным отклонением (σ).
Для нормального распределения характерно совпадение величин средней арифметической, моды и медианы. Равенство этих показателей указывает на нормальность данного распределения.
Ещё одна особенность нормального распределения: чем больше величина признака отклоняется от среднего значения, тем меньше буде частота встречаемости (вероятность) этого признака в распределении. «Нормальным» распределение названо потому, что оно наиболее часто встречалось в естественнонаучных исследованиях и казалось «нормой» распределения случайных величин.
В психологии нормальное распределение используется при разработке и применении тестов интеллекта и способностей. Для показателей интеллекта IQ нормальное распределение имеет µ = 100, а σ = 16 для большинства возрастных групп.
Однако, для других психологических категорий (личностная и мотивационная сфера) применение нормального распределения оказывается дискуссионным.
При нормальном распределении экспериментальных данных применяются особые методы статистической обработки.
Кроме нормального существуют и другие распределения. При обработке экспериментальных данных целесообразно проводить оценку характера распределения. Это поможет решить вопрос о возможности применения того или иного статистического метода.
Вопросы для обсуждения
1. Мода и правила её нахождения. Какая выборка называется мономодальной, бимодальной, полимодальной?
2. Что можно назвать модой признака «оценка за экзамен в последнюю сессию» в вашей группе?
3. Медиана и правила её нахождения.
3. Среднее арифметическое, взвешенная средняя. Преимущества и недостатки средних значений при характеристике выборки.
4. Разброс выборки. Связь между размахом выборки и силой варьирования признака.
5. Дисперсия и стандартное отклонение. Их смысл и правила вычисления.
6. Число степеней свободы и правила его вычисления.
7. Распределение признака. Ряд распределения.
8. Нормальное распределение, его особенности. Распространённость нормального распределения в психологии.
ТЕМА №4. Общие принципы проверки статистических гипотез.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Да какие ж вы математики, если запаролиться нормально не можете. 8447 —  | 7339 —
| 7339 —  или читать все.
или читать все.
78.85.5.224 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
В одном из предыдущих постов мы обсудили, пожалуй, центральное понятие в анализе данных и проверке гипотез — p-уровень значимости. Если мы не применяем байесовский подход, то именно значение p-value мы используем для принятия решения о том, достаточно ли у нас оснований отклонить нулевую гипотезу нашего исследования, т.е. гордо заявить миру, что у нас были получены статистически значимые различия.
Однако в большинстве статистических тестов, используемых для проверки гипотез, (например, t-тест, регрессионный анализ, дисперсионный анализ) рядом с p-value всегда соседствует такой показатель как число степеней свободы, он же degrees of freedom или просто сокращенно df, о нем мы сегодня и поговорим.
Степени свободы, о чем речь?
По моему мнению, понятие степеней свободы в статистике примечательно тем, что оно одновременно является и одним из самым важных в прикладной статистике (нам необходимо знать df для расчета p-value в озвученных тестах), но вместе с тем и одним из самых сложных для понимания определений для студентов-нематематиков, изучающих статистику.
Давайте рассмотрим пример небольшого статистического исследования, чтобы понять, зачем нам нужен показатель df, и в чем же с ним такая проблема. Допустим, мы решили проверить гипотезу о том, что средний рост жителей Санкт-Петербурга равняется 170 сантиметрам. Для этих целей мы набрали выборку из 16 человек и получили следующие результаты: средний рост по выборке оказался равен 173 при стандартном отклонении равном 4. Для проверки нашей гипотезы можно использовать одновыборочный t-критерий Стьюдента, позволяющий оценить, как сильно выборочное среднее отклонилось от предполагаемого среднего в генеральной совокупности в единицах стандартной ошибки:
Проведем необходимые расчеты и получим, что значение t-критерия равняется 3, отлично, осталось рассчитать p-value и задача решена. Однако, ознакомившись с особенностями t-распределения мы выясним, что его форма различается в зависимости от числа степеней свобод, рассчитываемых по формуле n-1, где n — это число наблюдений в выборке:
Сама по себе формула для расчета df выглядит весьма дружелюбной, подставили число наблюдений, вычли единичку и ответ готов: осталось рассчитать значение p-value, которое в нашем случае равняется 0.004.
Но почему n минус один?
Когда я впервые в жизни на лекции по статистике столкнулся с этой процедурой, у меня как и у многих студентов возник законный вопрос: а почему мы вычитаем единицу? Почему мы не вычитаем двойку, например? И почему мы вообще должны что-то вычитать из числа наблюдений в нашей выборке?
В учебнике я прочитал следующее объяснение, которое еще не раз в дальнейшем встречал в качестве ответа на данный вопрос:
“Допустим мы знаем, чему равняется выборочное среднее, тогда нам необходимо знать только n-1 элементов выборки, чтобы безошибочно определить чему равняется оставшейся n элемент”. Звучит разумно, однако такое объяснение скорее описывает некоторый математический прием, чем объясняет зачем нам понадобилось его применять при расчете t-критерия. Следующее распространенное объяснение звучит следующим образом: число степеней свободы — это разность числа наблюдений и числа оцененных параметров. При использовании одновыборочного t-критерия мы оценили один параметр — среднее значение в генеральной совокупности, используя n элементов выборки, значит df = n-1.
Однако ни первое, ни второе объяснение так и не помогает понять, зачем же именно нам потребовалось вычитать число оцененных параметров из числа наблюдений?
Причем тут распределение Хи-квадрат Пирсона?
Давайте двинемся чуть дальше в поисках ответа. Сначала обратимся к определению t-распределения, очевидно, что все ответы скрыты именно в нем. Итак случайная величина:
имеет t-распределение с df = ν, при условии, что Z – случайная величина со стандартным нормальным распределением N(0; 1), V – случайная величина с распределением Хи-квадрат, с ν числом степеней свобод, случайные величины Z и V независимы. Это уже серьезный шаг вперед, оказывается, за число степеней свободы ответственна случайная величина с распределением Хи-квадрат в знаменателе нашей формулы.
Давайте тогда изучим определение распределения Хи-квадрат. Распределение Хи-квадрат с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Кажется, мы уже совсем у цели, по крайней мере, теперь мы точно знаем, что такое число степеней свободы у распределения Хи-квадрат — это просто число независимых случайных величин с нормальным стандартным распределением, которые мы суммируем. Но все еще остается неясным, на каком этапе и зачем нам потребовалось вычитать единицу из этого значения?
Давайте рассмотрим небольшой пример, который наглядно иллюстрирует данную необходимость. Допустим, мы очень любим принимать важные жизненные решения, основываясь на результате подбрасывания монетки. Однако, последнее время, мы заподозрили нашу монетку в том, что у нее слишком часто выпадает орел. Чтобы попытаться отклонить гипотезу о том, что наша монетка на самом деле является честной, мы зафиксировали результаты 100 бросков и получили следующий результат: 60 раз выпал орел и только 40 раз выпала решка. Достаточно ли у нас оснований отклонить гипотезу о том, что монетка честная? В этом нам и поможет распределение Хи-квадрат Пирсона. Ведь если бы монетка была по настоящему честной, то ожидаемые, теоретические частоты выпадания орла и решки были бы одинаковыми, то есть 50 и 50. Легко рассчитать насколько сильно наблюдаемые частоты отклоняются от ожидаемых. Для этого рассчитаем расстояние Хи-квадрат Пирсона по, я думаю, знакомой большинству читателей формуле:
Где O — наблюдаемые, E — ожидаемые частоты.
Дело в том, что если верна нулевая гипотеза, то при многократном повторении нашего эксперимента распределение разности наблюдаемых и ожидаемых частот, деленная на корень из наблюдаемой частоты, может быть описано при помощи нормального стандартного распределения, а сумма квадратов k таких случайных нормальных величин это и будет по определению случайная величина, имеющая распределение Хи-квадрат.
Давайте проиллюстрируем этот тезис графически, допустим у нас есть две случайные, независимые величины, имеющих стандартное нормальное распределение. Тогда их совместное распределение будет выглядеть следующим образом:
При этом квадрат расстояния от нуля до каждой точки это и будет случайная величина, имеющая распределение Хи-квадрат с двумя степенями свободы. Вспомнив теорему Пифагора, легко убедиться, что данное расстояние и есть сумма квадратов значений обеих величин.
Пришло время вычесть единичку!
Ну а теперь кульминация нашего повествования. Возвращаемся к нашей формуле расчета расстояния Хи-квадрат для проверки честности монетки, подставим имеющиеся данные в формулу и получим, что расстояние Хи-квадрат Пирсона равняется 4. Однако для определения p-value нам необходимо знать число степеней свободы, ведь форма распределения Хи-квадрат зависит от этого параметра, соответственно и критическое значение также будет различаться в зависимости от этого параметра.
Теперь самое интересное. Предположим, что мы решили многократно повторять 100 бросков, и каждый раз мы записывали наблюдаемые частоты орлов и решек, рассчитывали требуемые показатели (разность наблюдаемых и ожидаемых частот, деленная на корень из ожидаемой частоты) и как и в предыдущем примере наносили их на график.
Легко заметить, что теперь все точки выстраиваются в одну линию. Все дело в том, что в случае с монеткой наши слагаемые не являются независимыми, зная общее число бросков и число решек, мы всегда можем точно определить выпавшее число орлов и наоборот, поэтому мы не можем сказать, что два наших слагаемых — это две независимые случайные величины. Также вы можете убедиться, что все точки действительно всегда будут лежать на одной прямой: если у нас выпало 30 орлов, значит решек было 70, если орлов 70, то решек 30 и т.д. Таким образом, несмотря на то, что в нашей формуле было два слагаемых, для расчета p-value мы будем использовать распределение Хи-квадрат с одной степенью свободы! Вот мы наконец-то добрались до момента, когда нам потребовалось вычесть единицу. Если бы мы проверяли гипотезу о том, что наша игральная кость с шестью гранями является честной, то мы бы использовали распределение Хи-квадрат с 5 степенями свободы. Ведь зная общее число бросков и наблюдаемые частоты выпадения любых пяти граней, мы всегда можем точно определить, чему равняется число выпадений шестой грани.
Все становится на свои места
Теперь, вооружившись этими знаниями, вернемся к t-тесту:
в знаменателе у нас находится стандартная ошибка, которая представляет собой выборочное стандартное отклонение, делённое на корень из объёма выборки. В расчет стандартного отклонения входит сумма квадратов отклонений наблюдаемых значений от их среднего значения — то есть сумма нескольких случайных положительных величин. А мы уже знаем, что сумма квадратов n случайных величин может быть описана при помощи распределения хи-квадрат. Однако, несмотря на то, что у нас n слагаемых, у данного распределения будет n-1 степень свободы, так как зная выборочное среднее и n-1 элементов выборки, мы всегда можем точно задать последний элемент (отсюда и берется это объяснение про среднее и n-1 элементов необходимых для однозначного определения n элемента)! Получается, в знаменателе t-статистики у нас спрятано распределение хи-квадрат c n-1 степенями свободы, которое используется для описания распределения выборочного стандартного отклонения! Таким образом, степени свободы в t-распределении на самом деле берутся из распределения хи-квадрат, которое спрятано в формуле t-статистики. Кстати, важно отметить, что все приведенные выше рассуждения справедливы, если исследуемый признак имеет нормальное распределение в генеральной совокупности (или размер выборки достаточно велик), и если бы у нас действительно стояла цель проверить гипотезу о среднем значении роста в популяции, возможно, было бы разумнее использовать непараметрический критерий.
Схожая логика расчета числа степеней свободы сохраняется и при работе с другими тестами, например, в регрессионном или дисперсионном анализе, все дело в случайных величинах с распределением Хи-квадрат, которые присутствуют в формулах для расчета соответствующих критериев.
Таким образом, чтобы правильно интерпретировать результаты статистических исследований и разбираться, откуда возникают все показатели, которые мы получаем при использовании даже такого простого критерия как одновыборочный t-тест, любому исследователю необходимо хорошо понимать, какие математические идеи лежат в основании статистических методов.
Онлайн курсы по статистике: объясняем сложные темы простым языком
Основываясь на опыте преподавания статистики в Институте биоинформатики , у нас возникла идея создать серию онлайн курсов, посвященных анализу данных, в которых в доступной для каждого форме будут объясняться наиболее важные темы, понимание которых необходимо для уверенного использования методов статистики при решении различного рода задача. В 2015 году мы запустили курс Основы статистики, на который к сегодняшнему дню записалось около 17 тысяч человек, три тысячи слушателей уже получили сертификат о его успешном завершении, а сам курс был награждён премией EdCrunch Awards и признан лучшим техническим курсом. В этом году на платформе stepik.org стартовало продолжение курса Основы статистики. Часть два, в котором мы продолжаем знакомство с основными методами статистики и разбираем наиболее сложные теоретические вопросы. Кстати, одной из главных тем курса является роль распределения Хи-квадрат Пирсона при проверке статистических гипотез. Так что если у вас все еще остались вопросы о том, зачем мы вычитаем единицу из общего числа наблюдений, ждем вас на курсе!
Стоит также отметить, что теоретические знания в области статистики будут определенно полезны не только тем, кто применяет статистику в академических целях, но и для тех, кто использует анализ данных в прикладных областях. Базовые знания в области статистики просто необходимы для освоения более сложных методов и подходов, которые используются в области машинного обучения и Data Mining. Таким образом, успешное прохождение наших курсов по введению в статистику — хороший старт в области анализа данных. Ну а если вы всерьез задумались о приобретении навыков работы с данными, думаем, вас может заинтересовать наша онлайн — программа по анализу данных, о которой мы подробнее писали здесь. Упомянутые курсы по статистике являются частью этой программы и позволят вам плавно погрузиться в мир статистики и машинного обучения. Однако пройти эти курсы без дедлайнов могут все желающие и вне контекста программы по анализу данных.
Число степеней свободы — эго число свободно варьирующих единиц в составе выборки. Так, если вся выборка состоит из п элементов и характеризуется средней х, то любой элемент этой совокупности может быть получен как разность между величиной пх и суммой всех остальных элементов, кроме самого этого элемента.
Пример 4.1. Рассмотрим ряд: 2, 4, 6, 8, 10.
Средняя этого ряда равна 6. В ряду 5 чисел, следовательно, п = 5. Предположим, что мы хотим получить последний элемент ряда — 10, зная все предыдущие элементы и среднее этого ряда. Тогда:

Предположим, что мы хотим получить первый элемент ряда — 2, зная все последующие элементы и среднее этого ряда. Тогда:
5*6-4-б-8 — 10 = 2 и т.д.
Следовательно, один элемент выборки не имеет свободы вариации и всегда может быть выражен через другие элементы и среднее (или сумму этого ряда). Это означает, что число степеней свободы у выборочного ряда, обозначаемое в таких случаях символом k> будет определяться как k = п — 1, где п — общее число элементов ряда (выборки).
При наличии не одного, а нескольких ограничений свободы вариации, число степеней свободы, обозначаемое как v (греческая буква «ню»), будет равно v = п — k, где k соответствует числу ограничений свободы вариации.
В общем случае для таблицы экспериментальных данных число степеней свободы будет определяться по следующей формуле:

где с — число столбцов, а п — число строк (число испытуемых).
Следует подчеркнуть, однако, что для ряда статистических методов расчет числа степеней свободы имеет свою специфику.