Что такое дисперсия в статистике
Статистика, в частности, оперирует рядами данных, характеризующих какой-либо признак, явление. Интересует их изменение.
Вариация представляет собой отличие величин одинакового показателя у разных предметов. Ее изучение позволит понять причины отклонений от нормы, анализировать их и в какой-то мере прогнозировать. Также станет возможным выявить факторы, влияющие на значения, отсеяв случайные.
Характеристики равномерного распределения представлены на картинке:

При значительном объеме статистики, средняя величина очевидно близка к нормальной. Об этом говорят и законы распределения. Отклонения от нее будут являться объективной характеристикой.
Только вот отрицательные значения этих разбросов будут сбивать с толку при расчетах, погашая положительные. А оставлять лишь модули – для математика не корректно. Напрашивается возвести в четную степень, а именно – во вторую.
Решение оказалось не только удобным. Оно открыло бо́льшие возможности в изучении отклонений. А важны именно они, поскольку сама по себе средняя мало что дает.

В качестве одного из важных показателей вариации, вводится понятие «дисперсия» – усредненный квадрат отклонений численных значений каких-либо событий от средней величины.
Кратко записывается D[X] в русскоязычных источниках и Var[X] (от «variance») в английских. В статистических выкладках используется σ2.

Никакого наглядного смысла величина не несет. Другое дело, среднее квадратическое отклонение – корень квадратный из дисперсии.
Виды дисперсии дискретной случайной величины
Для анализа данных цифр в таком виде недостаточно. Гораздо больше можно выжать из последовательности, если разбить ее на группы по определенному признаку.
Общая дисперсия
Как можно заметить, вычисленная по приведенному выше определению величина характеризует отклонения в целом. Без учета определяющих вариацию факторов. Вернее, с учетом всех, включая совершенно случайные. Поэтому и называется «общей» и рассчитывается по формулам, указанным ниже.
Простая дисперсия, без разделения на группы:
![]()
Или в несколько преобразованном виде:
![]()
Взвешенная дисперсия, для вариационного ряда:

где xi – значение из ряда;
fi – частота, количество повторений;
k – групп;
n – число вариантов.
Черта сверху указывает на среднюю величину.
Межгрупповая дисперсия
Характеризует систематическое отклонение, возникающее из-за фактора, по которому производилось выделение признаков в группы. Поэтому также называется «факторной».
Как найти данную дисперсию? По формуле:

где k – количество групп;
nj – элементов в группе с индексом j.
Внутригрупповая дисперсия
Возникает по хаотичной причине, не связанной с причиной сделанной выборки. Неучтенный фактор. Еще обозначается как «остаточная».
Например, рассматривается количество выпущенных деталей за месяц каждым фрезеровщиком цеха.
В качестве критерия отбора в группу выбираем возраст оборудования. Он-то и не будет влиять на производительность внутри подборки: там станки у всех практически одинаковые.

Если вычислить среднюю величину от всех групповых,

то получим характеристику случайного разброса. Иными словами, составляющую вариации, зависящую от чего угодно, кроме фактора отбора.
Взаимосвязь
В соответствии с правилом сложения, общая D[X] включает средние выражения остаточной и факторной. И это логично, поскольку учитывает и случайное изменение в группе, и систематическое в факторной.
Свойства дисперсии

Опишем основные:
-
Если последовательность состоит из одинаковых чисел, то D[X] будет нулевой.
-
Уменьшение всех значений на постоянную величину на дисперсию не влияет. Иначе говоря, рассчитать σ2 можно по отклонениям от фиксированного числа.
-
Уменьшение всех цифр в k раз приведет к падению D[X] в k2 раз. Можно, например, иметь в виду значения в метрах, а результат вычислить в футах. Достаточно учесть один раз то, на что следует умножить.
-
Средний квадрат отклонений от постоянной величины X отличается в большую сторону от того же с использованием среднего значения. Разница составит (Xcр – X)2.
Показатели вариаций
Кроме размаха (разницы максимального и минимального значений), среднего линейного и дисперсии, изменения описываются коэффициентом вариации:
![]()
Оценить масштаб разброса проще по относительной величине. Тем более, что измеряются в одних единицах.
Пример расчета дисперсии
Компания объявила конкурсный отбор для приема сотрудников. В качестве критерия принят стаж работы по специальности. Приведем исходные данные и расчеты.

Усредненный стаж:

Дисперсия:

По альтернативной формуле:

Среднеквадратическое:
![]()
Коэффициент вариации:

Заключение
Статистика оперирует значительными объемами данных. Вариация, как одно из основных понятий – не исключение. И дисперсия в качестве основной характеристики.
Для упрощения расчетов существует масса онлайн калькуляторов. Имеется упомянутый инструмент в MS Excel.
Как найти дисперсию?
Понравилось? Добавьте в закладки
Дисперсия — это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая — значения сравнительно близки друг к другу, если большая — далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии — среднеквадратическое отклонение $sigma(X)=sqrt{D(X)}$, которое имеет ту же размерность, что и исходная величина и также описывает разброс.
Еще одно формальное определение дисперсии звучит так: «Дисперсия — это второй центральный момент случайной величины» (напомним, что первый начальный момент — это как раз математическое ожидание).
Нужна помощь? Решаем теорию вероятностей на отлично
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле:
$$
D(X)=M(X-M(X))^2,
$$
которую также часто записывают в более удобном для расчетов виде:
$$
D(X)=M(X^2)-(M(X))^2.
$$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2.
$$
Если же речь идет о непрерывной случайной величине (заданной плотностью вероятностей $f(x)$ в общем случае), формула дисперсии Х выглядит следующим образом:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения:
$$
x_i quad 1 quad 2 \
p_i quad 0.5 quad 0.5
$$
и
$$
y_i quad -10 quad 10 \
p_i quad 0.5 quad 0.5
$$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором — дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2 =\
= 1^2cdot 0.5 + 2^2 cdot 0.5 — (1cdot 0.5 + 2cdot 0.5)^2=2.5-1.5^2=0.25.
$$
$$
D(Y)=sum_{i=1}^{n}{y_i^2 cdot p_i}-left(sum_{i=1}^{n}{y_i cdot p_i} right)^2 =\
= (-10)^2cdot 0.5 + 10^2 cdot 0.5 — (-10cdot 0.5 + 10cdot 0.5)^2=100-0^2=100.
$$
Итак, значения случайных величин различались на 1 и 20 единиц, тогда как дисперсия показывает меру разброса в 0.25 и 100. Если перейти к среднеквадратическому отклонению, получим $sigma(X)=0.5$, $sigma(Y)=10$, то есть вполне ожидаемые величины: в первом случае значения отстоят в обе стороны на 0.5 от среднего 1.5, а во втором — на 10 единиц от среднего 0.
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Снова используем формулу для дисперсии дискретной случайной величины:
$$
D(X)=M(X^2)-(M(X))^2.
$$
В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Потом математическое ожидание квадрата случайной величины:
$$
M(X^2)=sum_{i=1}^{n}{x_i^2 cdot p_i}
= (-1)^2cdot 0.1 + 2^2 cdot 0.2 +5^2cdot 0.3 +10^2cdot 0.3+20^2cdot 0.1=78.4.
$$
А потом подставим все в формулу для дисперсии:
$$
D(X)=M(X^2)-(M(X))^2=78.4-6.8^2=32.16.
$$
Дисперсия равна 32.16 квадратных единиц.
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Вычислим сначала математическое ожидание:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{6} frac{x}{18} cdot x dx = int_{0}^{6} frac{x^2}{18} dx =
left.frac{x^3}{54} right|_0^6=frac{6^3}{54} = 4.
$$
Теперь вычислим
$$
M(X^2)=int_{-infty}^{+infty} f(x) cdot x^2 dx = int_{0}^{6} frac{x}{18} cdot x^2 dx = int_{0}^{6} frac{x^3}{18} dx = left.frac{x^4}{72} right|_0^6=frac{6^4}{72} = 18.
$$
Подставляем:
$$
D(X)=M(X^2)-(M(X))^2=18-4^2=2.
$$
Дисперсия равна 2.
Другие задачи с решениями по ТВ
Подробно решим ваши задачи на вычисление дисперсии
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку «Вычислить».
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Лучшее спасибо — порекомендовать эту страницу
Полезные ссылки
Не забывайте сначала прочитать том, как найти математическое ожидание. А тут можно вычислить также СКО: Калькулятор математического ожидания, дисперсии и среднего квадратического отклонения.
Что еще может пригодиться? Например, для изучения основ теории вероятностей — онлайн учебник по ТВ. Для закрепления материала — еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
![]()
Загрузить PDF
![]()
Загрузить PDF
Дисперсия случайной величины является мерой разброса значений этой величины. Малая дисперсия означает, что значения сгруппированы близко друг к другу. Большая дисперсия свидетельствует о сильном разбросе значений. Понятие дисперсии случайной величины применяется в статистике. Например, если сравнить дисперсию значений двух величин (таких как результаты наблюдений за пациентами мужского и женского пола), можно проверить значимость некоторой переменной.[1]
Также дисперсия используется при построении статистических моделей, так как малая дисперсия может быть признаком того, что вы чрезмерно подгоняете значения.[2]
-

1
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
2
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:[3]
-
3
Вычислите среднее значение выборки. Оно обозначается как x̅.[4]
Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
4
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность
— x̅, где – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.[5]
-
5
Возведите в квадрат каждый полученный результат. Как отмечалось выше, сумма разностей
— x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность — x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.[6]
-
6
-
7
Полученный результат разделите на n — 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n — 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.[7]
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
8
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как
, а стандартное отклонение выборки – как .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Реклама












-
1
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
-
2
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные: [8]
-
3
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = = 10,5
-
4
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере: — μ = 5 — 10,5 = -5,5 — μ = 5 — 10,5 = -5,5 — μ = 8 — 10,5 = -2,5 — μ = 12 — 10,5 = 1,5 — μ = 15 — 10,5 = 4,5 — μ = 18 — 10,5 = 7,5
- В нашем примере:
-
5
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( — μ) для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) = 30,25
(-5,5) = 30,25
(-2,5) = 6,25
(1,5) = 2,25
(4,5) = 20,25
(7,5) = 56,25
- В нашем примере:
-
6
Найдите среднее значение полученных результатов. Вы нашли, как далеко каждое значение совокупности расположено от ее среднего значения. Найдите среднее значение суммы квадратов разностей, поделив ее на количество значений в генеральной совокупности.
- В нашем примере:
Дисперсия совокупности = 24,25
- В нашем примере:
-
7
Соотнесите это решение с формулой. Если вы не поняли, как приведенное выше решение соотносится с формулой, ниже представлено объяснение решения:
Реклама
















Советы
- Дисперсию довольно сложно интерпретировать, поэтому в большинстве случаев она вычисляется как промежуточная величина, которая необходима для нахождения стандартного отклонения.
- При вычислении дисперсии выборки деление на n-1, а не просто на n, называется коррекцией Бесселя. Дисперсия выборки представляет собой только оценочное значение дисперсии генеральной совокупности, при этом выборочное среднее смещено, чтобы соответствовать этому оценочному значению. Коррекция Бесселя устраняет такое смещение.[9]
Это связано с тем, что при анализе n – 1 значения использование n-го значения уже ограничено, так как только определенные значения приводят к выборочному среднему (x̅), которое используется в формуле для вычисления дисперсии.[10]
Реклама
Об этой статье
Эту страницу просматривали 122 522 раза.
Была ли эта статья полезной?
Математическое ожидание, дисперсия, среднее квадратичное отклонение
Эти величины определяют некоторое
среднее значение, вокруг которого
группируются значения случайной
величины, и степень их разбросанности
вокруг этого среднего значения.
Математическое ожидание Mдискретной случайной величины — это
среднее значение случайной величины,
равное сумме произведений всех возможных
значений случайной величины на их
вероятности.
![]()
Свойства математического ожидания:
-
Математическое ожидание постоянной
величины равно самой постоянной . -
Постоянный множитель можно выносить
за знак математического ожидания . -
Математическое ожидание произведения
двух независимых случайных величин
равно произведению их математических
ожиданий . -
Математическое ожидание суммы двух
случайных величин равно сумме
математических ожиданий слагаемых
Для описания многих практически важных
свойств случайной величины необходимо
знание не только ее математического
ожидания, но и отклонения возможных ее
значений от среднего значения.
Дисперсия случайной величины— мера разброса случайной величины,
равная математическому ожиданию квадрата
отклонения случайной величины от ее
математического ожидания.
![]() .
.
Принимая во внимание свойства
математического ожидания, легко показать
что
![]()
Казалось бы естественным рассматривать
не квадрат отклонения случайной величины
от ее математического ожидания, а просто
отклонение. Однако математическое
ожидание этого отклонения равно нулю.
Это объясняется тем, что одни возможные
отклонения положительны, другие
отрицательны, и в результате их взаимного
погашения получается ноль. Можно было
бы принять за меру рассеяния математическое
ожидание модуля отклонения случайной
величины от ее математического ожидания,
но как правило, действия связанные с
абсолютными величинами, приводят к
громоздким вычислениям.
Свойства дисперсии:
-
Дисперсия постоянной равна нулю.
-
Постоянный множитель можно выносить
за знак дисперсии, возводя его в квадрат. -
Если x и y независимые случайные величины
, то дисперсия суммы этих величин равна
сумме их дисперсий.
Средним квадратическим отклонением
случайной величины(иногда применяется
термин «стандартное отклонение случайной
величины») называется число равное![]() .
.
Среднее квадратическое отклонение,
является, как и дисперсия, мерой рассеяния
распределения, но измеряется, в отличие
от дисперсии, в тех же единицах, которые
используют для измерения значений
случайной величины.
Решение задач:
1)Дана случайная величина Х:
-
xi
-3
-2
0
1
2
pi
0,1
0,2
0,05
0,3
0,35
Найти М(х), D(X).
Решение:
![]() .
.
![]() =9
=9![]() =2,31.
=2,31.
![]() .
.
2) Известно, что М(Х)=5, М(Y)=2.
Найти математическое ожидание случайной
величиныZ=6X-2Y+9-XY.
Решение:М(Z)=6М(Х)-2М(Y)+9-M(X)M(Y)=30-4+9-10=25.
Пример:Известно, чтоD(Х)=5,D(Y)=2. Найти
математическое ожидание случайной
величиныZ=6X-2Y+9.
Решение:D(Z)=62D(Х)-22D(Y)+0=180-8=172.
Тема 7. Непрерывные случайные величины
Задача 14
Случайная
величина, значения которой заполняют
некоторый промежуток, называется
непрерывной.
Плотностью распределениявероятностей непрерывной случайной
величины Х называется функцияf(x)– первая производная от функции
распределенияF(x).
![]()
Плотность
распределения также называют
дифференциальной
функцией.
Для описания дискретной случайной
величины плотность распределения
неприемлема.
Зная плотность распределения, можно
вычислить вероятность того, что некоторая
случайная величина Х примет значение,
принадлежащее заданному интервалу.
Вероятность того, что непрерывная
случайная величина Х примет значение,
принадлежащее интервалу (a,
b), равна определенному
интегралу от плотности распределения,
взятому в пределах от a
до b.
![]()
Функция распределения может быть легко
найдена, если известна плотность
распределения, по формуле:
![]()
Свойства плотности распределения.
1) Плотность распределения – неотрицательная
функция.
![]()
2) Несобственный интеграл
от плотности распределения в пределах
от -доравен единице.
![]()
Решение задач.
1.Случайная величина подчинена
закону распределения с плотностью:

Требуется найти коэффициент а,
определить вероятность того, что
случайная величина попадет в интервал
от 0 до![]() .
.
Решение:
Для нахождения коэффициента авоспользуемся свойством![]() .
.
![]()
![]()
![]()
2 .Задана непрерывная случайная
величинахсвоей функцией распределенияf(x).
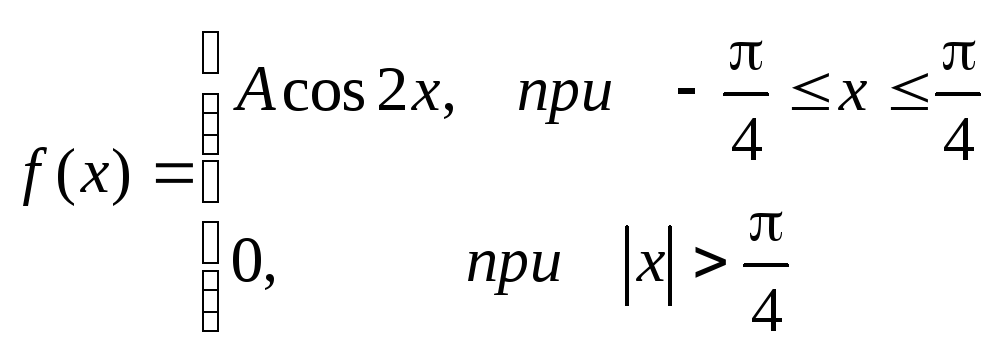
Требуется определить
коэффициент А, найти функцию распределения,
определить вероятность того, что
случайная величинахпопадет в
интервал![]() .
.
Решение:
Найдем коэффициент А.
![]()
Найдем функцию распределения:
1) На участке
![]() :
:![]()
2) На участке
![]()
![]()
3) На участке
![]()
![]()
Итого:


Найдем вероятность попадания случайной
величины в интервал
![]() .
.
![]()
Ту же самую вероятность можно искать
и другим способом:
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
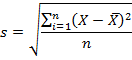
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях: