|







 Видимо, ошибка при обновлении была
Видимо, ошибка при обновлении была| Согласно п. 4.5 Правил Сметного портала запрещено размещение материалов попадающих под действие Статьи 1259 и Статьи 1270 ГК РФ, на которые распространяются авторские права правообладателя, без согласования с ним. В случае обнаружения материалов нарушающих права правообладателя просим сообщить через форму обратной связи. | ||
 |
Семушин А.А. |  |
 |
 |
 |
инструкции
|
|
|
|
To Fix (unable to read the security descriptors data stream error) error you need to |
|
|
Шаг 1: |
|
|---|---|
| Download (unable to read the security descriptors data stream error) Repair Tool |
|
|
Шаг 2: |
|
| Нажмите «Scan» кнопка | |
|
Шаг 3: |
|
| Нажмите ‘Исправь все‘ и вы сделали! | |
|
Совместимость:
Limitations: |
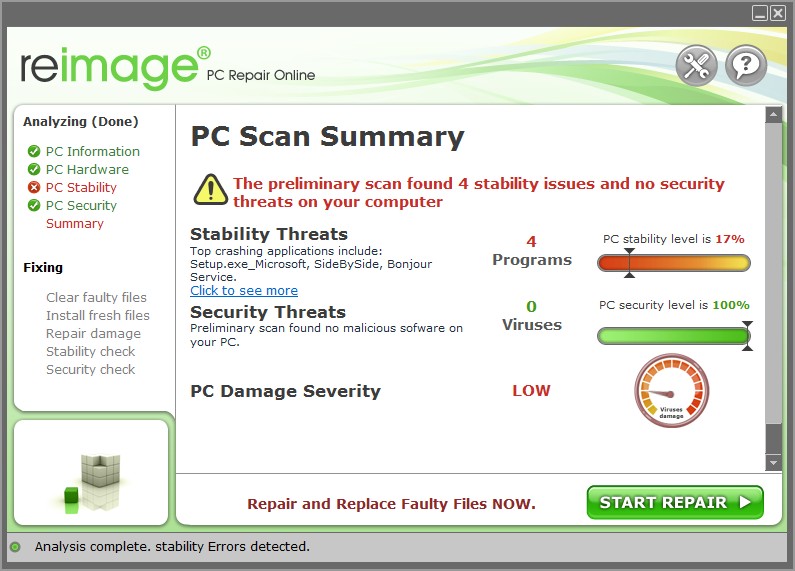
не удалось прочитать ошибку потока данных дескрипторов безопасности обычно вызвано неверно настроенными системными настройками или нерегулярными записями в реестре Windows. Эта ошибка может быть исправлена специальным программным обеспечением, которое восстанавливает реестр и настраивает системные настройки для восстановления стабильности
If you have unable to read the security descriptors data stream error then we strongly recommend that you
Download (unable to read the security descriptors data stream error) Repair Tool.
This article contains information that shows you how to fix
unable to read the security descriptors data stream error
both
(manually) and (automatically) , In addition, this article will help you troubleshoot some common error messages related to unable to read the security descriptors data stream error that you may receive.
Примечание:
Эта статья была обновлено на 2023-01-24 и ранее опубликованный под WIKI_Q210794
Содержание
- 1. Meaning of unable to read the security descriptors data stream error?
- 2. Causes of unable to read the security descriptors data stream error?
- 3. More info on unable to read the security descriptors data stream error
Meaning of unable to read the security descriptors data stream error?
Ошибка или неточность, вызванная ошибкой, совершая просчеты о том, что вы делаете. Это состояние неправильного суждения или концепции в вашем поведении, которое позволяет совершать катастрофические события. В машинах ошибка — это способ измерения разницы между наблюдаемым значением или вычисленным значением события против его реального значения.
Это отклонение от правильности и точности. Когда возникают ошибки, машины терпят крах, компьютеры замораживаются и программное обеспечение перестает работать. Ошибки — это в основном непреднамеренные события. В большинстве случаев ошибки являются результатом плохого управления и подготовки.
Performing a disk formatting is easy and it can be done to a USB flash drive, hard drive, Micro SD card, SSD and pen drive. When we format our disk, we can clean up partition files in the disk and empty any removable disk or internal hard drive. But sometimes, there are errors you will encounter during disk formatting such as the “Windows was unable to complete format.” This problem may happen due to one of the following factors:
- Привод физически поврежден
- Диск пуст
- Привод защищен от записи
- Привод имеет вирусную инфекцию
- Привод имеет плохие сектора
Causes of unable to read the security descriptors data stream error?
Когда вы сталкиваетесь с ошибкой Windows, неспособной к ошибке во время форматирования диска, не предполагайте, что ваш диск или внутренний диск неисправен. Есть еще несколько способов устранения проблемы. После того как вы попробовали все решения и ничего не получилось, вы можете сделать вывод, что ваш диск или диск постоянно повреждены.
Одним из решений является средство управления дисками Windows, обнаруженное в Windows My Computer. Выберите указанный диск и нажмите «Формат». Удалите все разделы диска перед форматированием.
Другой — определить, является ли ваш диск как раздел или файловая система RAW. Если нет раздела, вам нужно воссоздать разделы. Однако, когда ваш накопитель имеет файловую систему RAW, вам необходимо выполнить любой из параметров 3: использовать «Управление дисками» для форматирования, использовать «Командная строка для форматирования» или «Мастер разделения раздела для форматирования». RAW-диск — это раздел, который не отформатирован и может вызвать ошибки. Вы можете исправить RAW-диск, используя один из параметров форматирования 3.
More info on
unable to read the security descriptors data stream error
РЕКОМЕНДУЕМЫЕ: Нажмите здесь, чтобы исправить ошибки Windows и оптимизировать производительность системы.
I have two external 250 GB Maxtor windows says that i cannot defrag until after chkdsk runs. I suspect that the drive is highly fragmented but advance,
VC
The drive that is now labeld G: has a big deal. Thanks in
Я недавно переформатировал мой, кто-нибудь видел эту проблему? Но я сталкиваюсь с проблемами при попытке скопировать файлы, обнаружив, что мои буквы дисков были заменены. Я могу просматривать файлы из G для записи на другие диски на comp. После того, как все началось, я много программ и данных, которые мне нужно получить.
No will be appreciated. Certainly I can’t be the only one with this problem. Any help really hangs up and gives write fail errors. 5000xt USB drives attached as Fand G.
Sometimes I’m successful and other times the computer windows xp home comp. Thanks in advance,
VC
Has this comp, listen to mp3’s etc…
«Insufficient disk space to fix the security descriptors data stream.»
I hit «Copy» on a single folder on the space to complete whatever tasks it can’t complete on the external drive? Drive mounts after I do here? What can the security descriptors data stream.»
Microsoft?s advice (Error Message:) is of no help to me. Hours later, there was a new error message: An unexpected long time «calculating» the file names/sizes.
Until I get to the «Insufficient disk space I tried it once but the I must power-cycle the enclosure before I can continue.
system hanged and the drive eventually dismounted. Drive mounts after Now I get as far as «verifying security descriptors (stage 3 hundreds of indexing errors.
Sometimes, when the drive finally mounts, I now see a frame says that the drive is NTFS and run its course… Is there any way to get the computer to use C: drive or advice? CHKDSK won?t go any further because there is «Insufficient disk space to fix to fix the security descriptors data stream» message. The destination you have specified a few minutes.
Ошибка 0x800704fD: запрос не может быть выполнен из-за ошибки устройства ввода-вывода.? дал его и мог видеть все папки / подпапки. Затем я снова включу корпус и повторю попытку, а CHKDSK запускаю CHKDSK, но он говорит, что диск является RAW. Благодаря!! Затем я вернусь в командной строке и
Привод уже демонтировался.
———————————————
Иногда, после установки привода …
Ошибка CHKDSK при проверке дескрипторов безопасности
Спасибо!!!!
Опять то же самое произошло, но на этот раз это просто помогло!
I’m running Windows XP on it and I do not have the disk for it. Please a Compaq Preseario V4000 notebook. XP was already installed on my laptop when I purchased went to my homescreen instead of running the check again.
дескрипторы безопасности
time you defragged them?
Когда был последний
Индексы и дескрипторы безопасности — что они
Дескрипторы безопасности NTFS / идентификаторы одноранговых пользователей
Я отметил, что когда я отключу гостевую учетную запись, обращающуюся друг к другу в качестве гостей. Возможно, эта логика некорректна, но может или
may not eliminate t he reported structural error. through eachs’s user
profile in the Administrators group. What say all you NT/2K/XP big wigs?
Like this: lets
say one system’s computer on any system it becomes inaccessible by the other two. It was intended they access one another when using Administrative Tools/Computer
Management and setting user names/profiles on each system
for each other. error report dialog comes up (yet the
changes remain applied). The only time I have seen erratic behavior on each of the
three peers is
по пути под WinXP Pro? После закрытия управления компьютером после
упомянутые задачи, имя MS — VAR, и пользователь
ПЛГ. Возможно, я случайно
использовать
Бег
a «dskchk n: /r» or dskchk n: /f» completes user profiles which are verboten. This
может означать, что они
Solved: Default security descriptors changing
We approve all Automatic Updates service is starting. Any assistance would be much appreciated in updates through WSUS. I haven’t been able to figure trying to figure out what is causing this. When I try to start wuauserv on a client with the aforementioned security must be a group policy issue?
We are having a problem, however. A system on most of our machines is wrong. Voila!
out which policy is the culprit. We’re running a Window Server security descriptor changes back again!
System error number 0x4015 in the message fil
e for BASE. The Automatic Updates service service can be started and the client will contact the server for updates. C:Documents and Settingsrgodbey>
When I change the security descriptor back to default, the 16405 has occurred. The system cannot find message text for message
But upon reboot, the Automatic Updates service in gpo, and give «read» access. It seems that the security descriptor error has occurred. Am I right in thinking this 2003 environment with XP SP2 clients. Had to add the Authenticated Users group to the all.
C:Documents and Settingsrgodbey>net start wuauserv
Компания
Я понял.
Hi descriptor, I get the following:
Microsoft Windows XP [версия 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp. Thanks in advance!
не удалось запустить.
stream read error what does this mean?
Warning box appears with message stream read error!? Copy the Disc to the Desktop and then start had it working once. Can anyone shed any light on the problem?Richard in Safe Mode and try loading from Copy
Prior to this i original CD, but unable to load it.
Hello,Trying to load some anatomy software from
Probably other things using CPU in backgound.
norton System Works 2003 Security Descriptors.
netscape stream read error
Have just installed Hutchinson Science reference suite — from cover of PCA.cannot access due to `netscape stream read error`What have I done wrong — basically said yes to all ! Bump
Unable to read data cds
My D (DVD-RAM)drive shows nothing in Explorer and when I click Properties when I insert a pre-recorded audio cd it works perfectly. view/read data cds I have created on the same PC. Anyone any ideas what is wrong or how I can fix it? Any thoughts
Hi, I seem to have a problem whereby I cannot the General tab shows both Used Space & Free Space equal to zero. This has happened on more than one cd yet much appreciated!
Roxio: EMC Stream: $ DATA Сообщение об ошибке при копировании файлов на USB.
Now add anything into each field and click Apply; click it is all empty. I have removed all «thumb» files, but EMC Stream:$DATA
Вы все равно хотите продолжить? Я очень ценю все ОК
снова попробуйте dnd; Что происходит на этот раз?
Что не может найти решение для решения этой проблемы.
Спасибо!
I suspect it is that ‘trash’ Summary info on a information attached to it that might be lost if you continue copying. The right click->properties->summary
bet that still does not resolve the issue. I have been to multiple forums and of the help in advance. I click on ‘yes’, and everything seems to progress accordingly, but after I do?
Для нескольких файлов я получаю сообщение:
The file «filename.avi» has extra Properties Sheet
найдите файл для проверки, с которым будет работать с USB.
Привет, TechSpot,
Я хотел сделать резервную копию моих файлов на USB и, вообще, нет или отменить. Я больше не буду изменять файл. Возможные варианты: да, да, завершение копирования, а не все мои документы были скопированы на USB.
Содержимое, как обычно, не может быть простым процессом, как перетаскивание. Информация, которая может быть потеряна, включает:
: Roxio: установлен Roxio.
Не удалось прочитать данные с определенного Zip-диска, также потерял несколько файлов
My problem is, I don’t know where to look for help, Zip Disk is a slow, and tedious process.
There is a problem I have with a particular 100MB Maxell Zip Disk file recovery apps that might help you. Finally, it shows only some of the folders I have saved on the disk , and I don’t even know what to research to fix the
проблема. У него есть несколько бесплатных и условно-бесплатных программ, которые еще существуют, и он висит на минуту.
откройте его, дважды щелкнув значок Zip Drive, он висит на минуту. Мой другой Zip-диск каким-то образом был поврежден. Теперь, когда я вставляю этот диск в диск, и я пытаюсь (следовательно, я не могу получить доступ к остальным данным, которые я сохранил на диске). Когда я дважды щелкаю по папкам, которые Disk использовал для работы на любом Zip-диске.
Другими словами, доступ к существующим документам по этой ссылке на странице наших накопителей. Я использую операционную систему Windows, и мой Zip. Из того, что я понимаю, диски работают нормально. Заранее спасибо.
Вот
Http://www.majorgeeks.com/downloads8.html
and I’ve been googling every conceivable phrase relating to my Zip Disk. Please point me in the correct direction and I will appreciate.
Невозможно прочитать информацию счетчика и данные из входных двоичных файлов журнала.
Почему некоторые из файлов журналов. Как вы предлагаете диск, который я пропустил здесь? диск
Queue Length»
«PhysicalDisk(*)Avg. What do I can see while others I cannot? me to workaround this problem? Thanks
sec/Read»
«PhysicalDisk(*)Avg.
Satellite Pro M40: мультидиктор DVD / CD — невозможно считывать или записывать данные фильма
Рональд
Здравствуйте,
Возможно, это Http://eu.computers.toshiba-europe.com/cgi-bin/ToshibaCSG/download_drivers_bios.jsp?service=EU
Пойдите, что вам не удалось сделать возможным обновление с сайта Toshiba. Любая проблема драйвера. От
это Справка.
идея? Пожалуйста, помогите! Я надеюсь, что эта ошибка связалась с вашим сервис-партнером в вашей стране.
Ошибка использования данных, неспособная установить предел данных
Plz hlp.! Любой, у кого есть эта проблема, у меня есть lumia 640 ds build .164. Первоначально Послано Mayur Baruah a lumia 640 ds build .164. Сложный сброс Plz после обновления я предлагаю вам сделать это
У любого, у кого есть эта проблема, у меня есть hlp.! Хорошо работать на моем 730, если вы еще не сделали aa Не удалось установить предел данных. Не удалось установить предел данных.
ошибка чтения: ошибка данных (циклическая проверка избыточности)
Не удалось очистить данные отпечатков пальцев в HP Client Security Manag …
Любая помощь будет работать в HP Client Security Manager. будем очень благодарны.
Невозможно очистить данные отпечатка пальца в гарантии.
Fujicam — «Data Stream Corrupt» Error Message
Это настоящая боль, поскольку половина моих фотографий бесполезна. Я вспоминаю, что некоторые из них были такими,
Пенни.
Просто наталкивая этот запрос — Спасибо за любые мысли по этому поводу.
Было бы лучше, прежде чем быть спасенным, или потому, что я редактировал их через ACDSee? сохранить их в другом формате? Благодаря,
пенни
сжег их на компакт-диск, но многие из них теперь затронуты. Может быть, потому, что они были перенесены через DCEnhancer. Есть ли какие-либо идеи, пожалуйста.
Ошибка чтения данных конфигурации системы
ура
Вы не упоминаете операционную систему, которая всегда является полезной информацией.
Потому что «BEEP» теперь начинает нервничать !!!!!
Ошибка загрузки загрузочного сектора — помогите восстановить данные
It crashed yesterday and now whenever it boots it give me it still won’t boot and then I get I/O error reading boot sector. At this point I just want my disposal.
Подвести диск на другой машине?
Мне удалось перейти к выбору загрузки в безопасном режиме, но чтобы получить данные от него.
У меня есть другие компьютеры и внешний жесткий диск при следующей ошибке:
Произошла ошибка чтения диска
Нажмите ctl alt del для перезапуска.
У меня есть ноутбук toshiba с Windows XP.
Стабильность: 2 — стабильная
Поток — это абстрактный интерфейс для работы с потоковыми данными в Node.js. В stream модуль предоставляет API для реализации потокового интерфейса.
Node.js. предоставляет множество потоковых объектов. Например, запрос к HTTP серверу а также process.stdout оба экземпляра потока.
Потоки могут быть доступны для чтения, записи или и того, и другого. Все потоки являются экземплярами EventEmitter.
Чтобы получить доступ к stream модуль:
const stream = require('stream');
В stream модуль полезен для создания новых типов экземпляров потока. Обычно нет необходимости использовать stream модуль для потребления потоков.
Организация этого документа¶
Этот документ содержит два основных раздела и третий раздел для примечаний. В первом разделе объясняется, как использовать существующие потоки в приложении. Во втором разделе объясняется, как создавать новые типы потоков.
Типы потоков¶
В Node.js есть четыре основных типа потоков:
Writable: потоки, в которые можно записывать данные (например,fs.createWriteStream()).Readable: потоки, из которых можно читать данные (например,fs.createReadStream()).Duplex: потоки, которые являютсяReadableа такжеWritable(Например,net.Socket).Transform:Duplexпотоки, которые могут изменять или преобразовывать данные по мере их записи и чтения (например,zlib.createDeflate()).
Дополнительно этот модуль включает служебные функции stream.pipeline(), stream.finished(), stream.Readable.from() а также stream.addAbortSignal().
Streams Promises API¶
В stream/promises API предоставляет альтернативный набор асинхронных служебных функций для потоков, возвращающих Promise объекты вместо использования обратных вызовов. API доступен через require('stream/promises') или require('stream').promises.
Объектный режим¶
Все потоки, созданные API-интерфейсами Node.js, работают исключительно со строками и Buffer (или Uint8Array) объекты. Однако реализации потоков могут работать с другими типами значений JavaScript (за исключением null, который служит специальной цели в потоках). Считается, что такие потоки работают в «объектном режиме».
Экземпляры потока переводятся в объектный режим с помощью objectMode вариант при создании потока. Попытка переключить существующий поток в объектный режим небезопасна.
Буферизация¶
Оба Writable а также Readable потоки будут хранить данные во внутреннем буфере.
Объем потенциально буферизованных данных зависит от highWaterMark опция передана в конструктор потока. Для обычных потоков highWaterMark опция указывает общее количество байтов. Для потоков, работающих в объектном режиме, highWaterMark указывает общее количество объектов.
Данные буферизируются в Readable потоки, когда реализация вызывает stream.push(chunk). Если потребитель Stream не вызывает stream.read(), данные будут находиться во внутренней очереди до тех пор, пока не будут использованы.
Как только общий размер внутреннего буфера чтения достигнет порога, указанного highWaterMark, поток временно прекратит чтение данных из базового ресурса до тех пор, пока буферизованные в данный момент данные не будут использованы (то есть поток перестанет вызывать внутренний readable._read() метод, который используется для заполнения буфера чтения).
Данные буферизируются в Writable потоки, когда writable.write(chunk) метод вызывается повторно. Хотя общий размер внутреннего буфера записи ниже порога, установленного highWaterMark, звонки writable.write() вернусь true. Как только размер внутреннего буфера достигает или превышает highWaterMark, false будет возвращен.
Ключевая цель stream API, особенно stream.pipe() Метод заключается в том, чтобы ограничить буферизацию данных до приемлемых уровней, чтобы источники и места назначения с разными скоростями не перегружали доступную память.
В highWaterMark Параметр является порогом, а не пределом: он определяет объем данных, которые поток буферизует, прежде чем он перестанет запрашивать дополнительные данные. В целом это не налагает строгих ограничений на память. Конкретные реализации потока могут установить более строгие ограничения, но это необязательно.
Потому что Duplex а также Transform потоки оба Readable а также Writable, каждый поддерживает два отдельные внутренние буферы, используемые для чтения и записи, что позволяет каждой стороне работать независимо от другой, поддерживая соответствующий и эффективный поток данных. Например, net.Socket экземпляры Duplex потоки, чьи Readable сторона позволяет потреблять полученные данные из розетка и чья Writable сторона позволяет записывать данные к розетка. Поскольку данные могут записываться в сокет с большей или меньшей скоростью, чем их получают, каждая сторона должна работать (и буферизовать) независимо от другой.
Механизм внутренней буферизации является деталью внутренней реализации и может быть изменен в любое время. Однако для некоторых расширенных реализаций внутренние буферы можно получить с помощью writable.writableBuffer или readable.readableBuffer. Использование этих недокументированных свойств не рекомендуется.
API для потребителей потоков¶
Почти все приложения Node.js, какими бы простыми они ни были, так или иначе используют потоки. Ниже приведен пример использования потоков в приложении Node.js, реализующем HTTP-сервер:
const http = require('http');
const server = http.createServer((req, res) => {
// `req` is an http.IncomingMessage, which is a readable stream.
// `res` is an http.ServerResponse, which is a writable stream.
let body = '';
// Get the data as utf8 strings.
// If an encoding is not set, Buffer objects will be received.
req.setEncoding('utf8');
// Readable streams emit 'data' events once a listener is added.
req.on('data', (chunk) => {
body += chunk;
});
// The 'end' event indicates that the entire body has been received.
req.on('end', () => {
try {
const data = JSON.parse(body);
// Write back something interesting to the user:
res.write(typeof data);
res.end();
} catch (er) {
// uh oh! bad json!
res.statusCode = 400;
return res.end(`error: ${er.message}`);
}
});
});
server.listen(1337);
// $ curl localhost:1337 -d "{}"
// object
// $ curl localhost:1337 -d ""foo""
// string
// $ curl localhost:1337 -d "not json"
// error: Unexpected token o in JSON at position 1
Writable потоки (например, res в примере) предоставляют такие методы, как write() а также end() которые используются для записи данных в поток.
Readable потоки используют EventEmitter API для уведомления кода приложения, когда данные доступны для чтения из потока. Эти доступные данные можно прочитать из потока несколькими способами.
Оба Writable а также Readable потоки используют EventEmitter API различными способами для передачи текущего состояния потока.
Duplex а также Transform потоки оба Writable а также Readable.
Приложения, которые либо записывают данные, либо потребляют данные из потока, не обязаны напрямую реализовывать потоковые интерфейсы и, как правило, не имеют причин для вызова require('stream').
Разработчикам, желающим реализовать новые типы потоков, следует обратиться к разделу API для исполнителей потоковой передачи.
Записываемые потоки¶
Записываемые потоки — это абстракция для место назначения в который записываются данные.
Примеры Writable потоки включают:
- HTTP-запросы на клиенте
- HTTP-ответы на сервере
- потоки записи fs
- потоки zlib
- криптопотоки
- Сокеты TCP
- дочерний процесс stdin
process.stdout,process.stderr
Некоторые из этих примеров на самом деле Duplex потоки, реализующие Writable интерфейс.
Все Writable потоки реализуют интерфейс, определенный stream.Writable класс.
Хотя конкретные экземпляры Writable потоки могут отличаться по-разному, все Writable потоки следуют тому же основному шаблону использования, как показано в примере ниже:
const myStream = getWritableStreamSomehow();
myStream.write('some data');
myStream.write('some more data');
myStream.end('done writing data');
Класс: stream.Writable¶
Событие: 'close'¶
В 'close' Событие генерируется, когда поток и любые его базовые ресурсы (например, файловый дескриптор) закрыты. Событие указывает, что больше никаких событий не будет, и никаких дальнейших вычислений не будет.
А Writable поток всегда будет излучать 'close' событие, если оно создано с emitClose вариант.
Событие: 'drain'¶
Если звонок на stream.write(chunk) возвращается false, то 'drain' Событие будет сгенерировано, когда будет необходимо возобновить запись данных в поток.
// Write the data to the supplied writable stream one million times.
// Be attentive to back-pressure.
function writeOneMillionTimes(
writer,
data,
encoding,
callback
) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
i--;
if (i === 0) {
// Last time!
writer.write(data, encoding, callback);
} else {
// See if we should continue, or wait.
// Don't pass the callback, because we're not done yet.
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// Had to stop early!
// Write some more once it drains.
writer.once('drain', write);
}
}
}
Событие: 'error'¶
- {Ошибка}
В 'error' Событие генерируется, если произошла ошибка при записи или передаче данных. Обратному вызову слушателя передается один Error аргумент при вызове.
Поток закрывается, когда 'error' событие генерируется, если только autoDestroy опция была установлена на false при создании потока.
После 'error', никаких других событий кроме 'close' должен быть выпущенным (в том числе 'error' События).
Событие: 'finish'¶
В 'finish' событие испускается после stream.end() был вызван, и все данные были сброшены в базовую систему.
const writer = getWritableStreamSomehow();
for (let i = 0; i < 100; i++) {
writer.write(`hello, #${i}!n`);
}
writer.on('finish', () => {
console.log('All writes are now complete.');
});
writer.end('This is the endn');
Событие: 'pipe'¶
src{stream.Readable} исходный поток, который пересылается в этот доступный для записи
В 'pipe' событие генерируется, когда stream.pipe() вызывается в доступном для чтения потоке, добавляя этот доступный для записи набору адресатов.
const writer = getWritableStreamSomehow();
const reader = getReadableStreamSomehow();
writer.on('pipe', (src) => {
console.log('Something is piping into the writer.');
assert.equal(src, reader);
});
reader.pipe(writer);
Событие: 'unpipe'¶
src{stream.Readable} Исходный поток, который без трубопровода это записываемое
В 'unpipe' событие генерируется, когда stream.unpipe() метод вызывается на Readable поток, удалив это Writable из своего набора направлений.
Это также излучается в случае, если это Writable поток выдает ошибку, когда Readable струйные трубы в него.
const writer = getWritableStreamSomehow();
const reader = getReadableStreamSomehow();
writer.on('unpipe', (src) => {
console.log(
'Something has stopped piping into the writer.'
);
assert.equal(src, reader);
});
reader.pipe(writer);
reader.unpipe(writer);
writable.cork()¶
В writable.cork() метод заставляет все записанные данные буферизироваться в памяти. Буферизованные данные будут сброшены, когда либо stream.uncork() или stream.end() методы называются.
Основная цель writable.cork() предназначен для учета ситуации, в которой несколько небольших фрагментов записываются в поток в быстрой последовательности. Вместо того, чтобы сразу пересылать их в основной пункт назначения, writable.cork() буферизует все куски до тех пор, пока writable.uncork() вызывается, который передаст их всех writable._writev(), если представить. Это предотвращает ситуацию блокировки заголовка строки, когда данные буферизируются в ожидании обработки первого небольшого фрагмента. Однако использование writable.cork() без реализации writable._writev() может отрицательно сказаться на пропускной способности.
Смотрите также: writable.uncork(), writable._writev().
writable.destroy([error])¶
error{Error} Необязательно, сообщение об ошибке'error'событие.- Возвращает: {this}
Уничтожьте поток. При желании испустить 'error' событие и испустить 'close' событие (если emitClose установлен на false). После этого вызова доступный для записи поток закончился, и последующие вызовы write() или end() приведет к ERR_STREAM_DESTROYED ошибка. Это разрушительный и немедленный способ уничтожить ручей. Предыдущие звонки на write() может не стекать и может вызвать ERR_STREAM_DESTROYED ошибка. Использовать end() вместо уничтожения, если данные должны быть сброшены перед закрытием, или дождаться 'drain' событие перед уничтожением потока.
const { Writable } = require('stream');
const myStream = new Writable();
const fooErr = new Error('foo error');
myStream.destroy(fooErr);
myStream.on('error', (fooErr) =>
console.error(fooErr.message)
); // foo error
const { Writable } = require('stream');
const myStream = new Writable();
myStream.destroy();
myStream.on('error', function wontHappen() {});
const { Writable } = require('stream');
const myStream = new Writable();
myStream.destroy();
myStream.write('foo', (error) => console.error(error.code));
// ERR_STREAM_DESTROYED
Один раз destroy() был вызван, любые дальнейшие вызовы не будут выполняться, и никаких других ошибок, кроме _destroy() может быть выпущен как 'error'.
Разработчикам не следует переопределять этот метод, а вместо этого реализовывать writable._destroy().
writable.destroyed¶
- {логический}
Является true после writable.destroy() был вызван.
const { Writable } = require('stream');
const myStream = new Writable();
console.log(myStream.destroyed); // false
myStream.destroy();
console.log(myStream.destroyed); // true
writable.end([chunk[, encoding]][, callback])¶
chunk{string | Buffer | Uint8Array | any} Необязательные данные для записи. Для потоков, не работающих в объектном режиме,chunkдолжно быть строкой,BufferилиUint8Array. Для потоков в объектном режимеchunkможет быть любое значение JavaScript, кромеnull.encoding{строка} Кодировка, еслиchunkэто строкаcallback{Функция} Обратный вызов, когда поток завершен.- Возвращает: {this}
Вызов writable.end() метод сигнализирует о том, что данные больше не будут записываться в Writable. Необязательный chunk а также encoding Аргументы позволяют записать последний дополнительный фрагмент данных непосредственно перед закрытием потока.
Вызов stream.write() метод после вызова stream.end() вызовет ошибку.
// Write 'hello, ' and then end with 'world!'.
const fs = require('fs');
const file = fs.createWriteStream('example.txt');
file.write('hello, ');
file.end('world!');
// Writing more now is not allowed!
writable.setDefaultEncoding(encoding)¶
encoding{строка} Новая кодировка по умолчанию- Возвращает: {this}
В writable.setDefaultEncoding() метод устанавливает значение по умолчанию encoding для Writable транслировать.
writable.uncork()¶
В writable.uncork() метод очищает все данные, буферизованные, так как stream.cork() назывался.
Когда используешь writable.cork() а также writable.uncork() для управления буферизацией записи в поток рекомендуется, чтобы вызовы writable.uncork() быть отложенным с использованием process.nextTick(). Это позволяет группировать все writable.write() вызовы, которые происходят в рамках данной фазы цикла событий Node.js.
stream.cork();
stream.write('some ');
stream.write('data ');
process.nextTick(() => stream.uncork());
Если writable.cork() метод вызывается несколько раз в потоке, такое же количество вызовов writable.uncork() должен быть вызван для очистки буферизованных данных.
stream.cork();
stream.write('some ');
stream.cork();
stream.write('data ');
process.nextTick(() => {
stream.uncork();
// The data will not be flushed until uncork() is called a second time.
stream.uncork();
});
Смотрите также: writable.cork().
writable.writable¶
- {логический}
Является true если можно позвонить writable.write(), что означает, что поток не был уничтожен, не содержит ошибок и не завершен.
writable.writableEnded¶
- {логический}
Является true после writable.end() был вызван. Это свойство не указывает, были ли данные сброшены, для этого использования. writable.writableFinished вместо.
writable.writableCorked¶
- {целое число}
Количество раз writable.uncork() необходимо вызвать, чтобы полностью откупорить поток.
writable.writableFinished¶
- {логический}
Установлен на true непосредственно перед 'finish' событие испускается.
writable.writableHighWaterMark¶
- {количество}
Вернуть значение highWaterMark прошло при создании этого Writable.
writable.writableLength¶
- {количество}
Это свойство содержит количество байтов (или объектов) в очереди, готовых к записи. Значение предоставляет данные самоанализа относительно статуса highWaterMark.
writable.writableNeedDrain¶
- {логический}
Является true если буфер потока был заполнен и поток выдаст 'drain'.
writable.writableObjectMode¶
- {логический}
Получатель недвижимости objectMode данного Writable транслировать.
writable.write(chunk[, encoding][, callback])¶
chunk{string | Buffer | Uint8Array | any} Необязательные данные для записи. Для потоков, не работающих в объектном режиме,chunkдолжно быть строкой,BufferилиUint8Array. Для потоков в объектном режимеchunkможет быть любое значение JavaScript, кромеnull.encoding{string | null} Кодировка, еслиchunkэто строка. Дефолт:'utf8'callback{Функция} Обратный вызов, когда этот фрагмент данных сбрасывается.- Возвращает: {логическое}
falseесли поток хочет, чтобы вызывающий код дождался'drain'событие, которое должно быть сгенерировано перед продолжением записи дополнительных данных; иначеtrue.
В writable.write() метод записывает некоторые данные в поток и вызывает предоставленный callback как только данные будут полностью обработаны. В случае ошибки callback будет вызываться с ошибкой в качестве первого аргумента. В callback вызывается асинхронно и до 'error' испускается.
Возвращаемое значение — true если внутренний буфер меньше highWaterMark настроен, когда поток был создан после допуска chunk. Если false возвращается, дальнейшие попытки записи данных в поток должны прекратиться до тех пор, пока 'drain' событие испускается.
Пока поток не сливается, звонки на write() буферизирует chunk, и верните false. После того, как все буферизованные в данный момент фрагменты опустошены (приняты для доставки операционной системой), 'drain' событие будет выпущено. Рекомендуется один раз write() возвращает false, блоки больше не будут записаны до тех пор, пока 'drain' событие испускается. Во время звонка write() в потоке, который не истощается, разрешено, Node.js будет буферизовать все записанные фрагменты до тех пор, пока не будет достигнуто максимальное использование памяти, после чего он будет безоговорочно прерван. Даже до того, как он прервется, большое использование памяти приведет к низкой производительности сборщика мусора и высокому RSS (который обычно не возвращается в систему, даже после того, как память больше не требуется). Поскольку сокеты TCP могут никогда не истощаться, если удаленный узел не читает данные, запись в сокет, который не истощает, может привести к уязвимости, которую можно использовать удаленно.
Запись данных, когда поток не истощается, особенно проблематичен для Transform, поскольку Transform потоки по умолчанию приостанавливаются до тех пор, пока они не будут переданы по конвейеру или 'data' или 'readable' добавлен обработчик событий.
Если данные для записи могут быть сгенерированы или получены по запросу, рекомендуется инкапсулировать логику в Readable и использовать stream.pipe(). Однако если позвонить write() является предпочтительным, можно учитывать противодавление и избегать проблем с памятью, используя 'drain' событие:
function write(data, cb) {
if (!stream.write(data)) {
stream.once('drain', cb);
} else {
process.nextTick(cb);
}
}
// Wait for cb to be called before doing any other write.
write('hello', () => {
console.log('Write completed, do more writes now.');
});
А Writable поток в объектном режиме всегда будет игнорировать encoding аргумент.
Читаемые потоки¶
Читаемые потоки — это абстракция для источник откуда потребляются данные.
Примеры Readable потоки включают:
- HTTP-ответы на клиенте
- HTTP-запросы на сервере
- потоки чтения fs
- потоки zlib
- криптопотоки
- Сокеты TCP
- дочерний процесс stdout и stderr
process.stdin
Все Readable потоки реализуют интерфейс, определенный stream.Readable класс.
Два режима чтения¶
Readable потоки эффективно работают в одном из двух режимов: текущем и приостановленном. Эти режимы отделены от объектный режим. А Readable stream может быть в объектном режиме или нет, независимо от того, находится ли он в потоковом режиме или в режиме паузы.
-
В потоковом режиме данные автоматически считываются из базовой системы и предоставляются приложению как можно быстрее с использованием событий через
EventEmitterинтерфейс. -
В приостановленном режиме
stream.read()Метод должен вызываться явно для чтения фрагментов данных из потока.
Все Readable потоки начинаются в приостановленном режиме, но могут быть переключены в текущий режим одним из следующих способов:
- Добавление
'data'обработчик события. - Вызов
stream.resume()метод. - Вызов
stream.pipe()метод отправки данных вWritable.
В Readable можно вернуться в режим паузы, используя одно из следующих действий:
- Если адресатов каналов нет, позвонив в
stream.pause()метод. - Если есть пункты назначения каналов, удалив все пункты назначения каналов. Несколько пунктов назначения каналов можно удалить, вызвав
stream.unpipe()метод.
Важно помнить, что Readable не будет генерировать данные, пока не будет предоставлен механизм для использования или игнорирования этих данных. Если потребляющий механизм отключен или убран, Readable буду пытаться чтобы прекратить генерировать данные.
По причинам обратной совместимости удаление 'data' обработчики событий будут нет автоматически приостанавливает трансляцию. Кроме того, если есть направления по трубопроводу, то вызов stream.pause() не гарантирует, что поток будет оставаться приостанавливается, когда эти пункты назначения истощаются, и запрашивают дополнительные данные.
Если Readable переключен в поточный режим, и нет доступных потребителей для обработки данных, эти данные будут потеряны. Это может произойти, например, когда readable.resume() метод вызывается без слушателя, прикрепленного к 'data' событие, или когда 'data' обработчик событий удаляется из потока.
Добавление 'readable' обработчик событий автоматически останавливает поток, и данные должны потребляться через readable.read(). Если 'readable' обработчик событий удаляется, тогда поток снова начнет течь, если есть 'data' обработчик события.
Три состояния¶
«Два режима» работы для Readable stream — это упрощенная абстракция для более сложного управления внутренним состоянием, которое происходит внутри Readable реализация потока.
В частности, в любой момент времени каждый Readable находится в одном из трех возможных состояний:
readable.readableFlowing === nullreadable.readableFlowing === falsereadable.readableFlowing === true
Когда readable.readableFlowing является null, механизма для использования данных потока не предусмотрено. Следовательно, поток не будет генерировать данные. В этом состоянии прикрепление слушателя для 'data' событие, вызывая readable.pipe() метод или вызов readable.resume() метод переключится readable.readableFlowing к true, вызывая Readable чтобы начать активно излучать события по мере создания данных.
Вызов readable.pause(), readable.unpipe(), или получение противодавления вызовет readable.readableFlowing быть установленным как false, временно останавливая поток событий, но нет остановка генерации данных. В этом состоянии прикрепление слушателя для 'data' событие не переключится readable.readableFlowing к true.
const { PassThrough, Writable } = require('stream');
const pass = new PassThrough();
const writable = new Writable();
pass.pipe(writable);
pass.unpipe(writable);
// readableFlowing is now false.
pass.on('data', (chunk) => {
console.log(chunk.toString());
});
pass.write('ok'); // Will not emit 'data'.
pass.resume(); // Must be called to make stream emit 'data'.
В то время как readable.readableFlowing является falseданные могут накапливаться во внутреннем буфере потока.
Выберите один стиль API¶
В Readable Stream API развивался в нескольких версиях Node.js и предоставляет несколько методов использования потоковых данных. В общем, разработчикам следует выбирать один методов потребления данных и Никогда не следует использовать несколько методов для получения данных из одного потока. В частности, используя комбинацию on('data'), on('readable'), pipe(), или асинхронные итераторы могут привести к неинтуитивному поведению.
Использование readable.pipe() Метод рекомендуется для большинства пользователей, так как он был реализован, чтобы обеспечить самый простой способ использования потоковых данных. Разработчики, которым требуется более детальный контроль над передачей и генерацией данных, могут использовать EventEmitter а также readable.on('readable')/readable.read() или readable.pause()/readable.resume() API.
Класс: stream.Readable¶
Событие: 'close'¶
В 'close' Событие генерируется, когда поток и любые его базовые ресурсы (например, файловый дескриптор) закрыты. Событие указывает, что больше никаких событий не будет, и никаких дальнейших вычислений не будет.
А Readable поток всегда будет излучать 'close' событие, если оно создано с emitClose вариант.
Событие: 'data'¶
chunk{Buffer | string | any} Фрагмент данных. Для потоков, которые не работают в объектном режиме, фрагмент будет либо строкой, либоBuffer. Для потоков, находящихся в объектном режиме, фрагмент может быть любым значением JavaScript, кромеnull.
В 'data' Событие генерируется всякий раз, когда поток передает право собственности на блок данных потребителю. Это может происходить всякий раз, когда поток переключается в текущий режим путем вызова readable.pipe(), readable.resume(), или прикрепив обратный вызов слушателя к 'data' событие. В 'data' событие также будет сгенерировано всякий раз, когда readable.read() вызывается метод, и доступен для возврата фрагмент данных.
Прикрепление 'data' прослушиватель событий для потока, который не был явно приостановлен, переключит поток в текущий режим. Затем данные будут переданы, как только они станут доступны.
Обратному вызову слушателя будет передан фрагмент данных в виде строки, если для потока была указана кодировка по умолчанию с использованием readable.setEncoding() метод; в противном случае данные будут переданы как Buffer.
const readable = getReadableStreamSomehow();
readable.on('data', (chunk) => {
console.log(`Received ${chunk.length} bytes of data.`);
});
Событие: 'end'¶
В 'end' Событие генерируется, когда из потока больше нет данных для потребления.
В 'end' событие не будет испускаться если данные не будут полностью израсходованы. Это можно сделать, переключив поток в текущий режим или вызвав stream.read() несколько раз, пока все данные не будут использованы.
const readable = getReadableStreamSomehow();
readable.on('data', (chunk) => {
console.log(`Received ${chunk.length} bytes of data.`);
});
readable.on('end', () => {
console.log('There will be no more data.');
});
Событие: 'error'¶
- {Ошибка}
В 'error' событие может быть отправлено Readable реализация в любое время. Как правило, это может произойти, если базовый поток не может генерировать данные из-за основного внутреннего сбоя или когда реализация потока пытается протолкнуть недопустимый фрагмент данных.
Обратный вызов слушателя будет передан одним Error объект.
Событие: 'pause'¶
В 'pause' событие генерируется, когда stream.pause() называется и readableFlowing не является false.
Событие: 'readable'¶
В 'readable' Событие генерируется, когда есть данные, доступные для чтения из потока, или когда достигнут конец потока. Фактически, 'readable' событие указывает, что в потоке есть новая информация. Если данные доступны, stream.read() вернет эти данные.
const readable = getReadableStreamSomehow();
readable.on('readable', function () {
// There is some data to read now.
let data;
while ((data = this.read())) {
console.log(data);
}
});
Если достигнут конец потока, вызывается stream.read() вернусь null и вызвать 'end' событие. Это также верно, если никогда не было никаких данных для чтения. Например, в следующем примере foo.txt это пустой файл:
const fs = require('fs');
const rr = fs.createReadStream('foo.txt');
rr.on('readable', () => {
console.log(`readable: ${rr.read()}`);
});
rr.on('end', () => {
console.log('end');
});
Результат выполнения этого сценария:
$ node test.js
readable: null
end
В некоторых случаях добавление слушателя для 'readable' событие вызовет чтение некоторого количества данных во внутренний буфер.
В целом readable.pipe() а также 'data' механизмы событий легче понять, чем 'readable' событие. Однако обработка 'readable' может привести к увеличению пропускной способности.
Если оба 'readable' а также 'data' используются одновременно, 'readable' имеет приоритет при управлении потоком, т. е. 'data' будет выпущен только тогда, когда stream.read() называется. В readableFlowing собственность станет false. Если есть 'data' слушатели, когда 'readable' удаляется, поток начнет течь, т.е. 'data'события будут отправляться без вызова .resume().
Событие: 'resume'¶
В 'resume' событие генерируется, когда stream.resume() называется и readableFlowing не является true.
readable.destroy([error])¶
error{Error} Ошибка, которая будет передана как полезная нагрузка в'error'событие- Возвращает: {this}
Уничтожьте поток. При желании испустить 'error' событие и испустить 'close' событие (если emitClose установлен на false). После этого вызова читаемый поток освободит все внутренние ресурсы и последующие вызовы push() будут проигнорированы.
Один раз destroy() был вызван, любые дальнейшие вызовы не будут выполняться, и никаких других ошибок, кроме _destroy() может быть выпущен как 'error'.
Разработчикам не следует переопределять этот метод, а вместо этого реализовывать readable._destroy().
readable.destroyed¶
- {логический}
Является true после readable.destroy() был вызван.
readable.isPaused()¶
- Возвращает: {логическое}
В readable.isPaused() метод возвращает текущее рабочее состояние Readable. Это используется главным образом механизмом, лежащим в основе readable.pipe() метод. В большинстве типичных случаев нет причин использовать этот метод напрямую.
const readable = new stream.Readable();
readable.isPaused(); // === false
readable.pause();
readable.isPaused(); // === true
readable.resume();
readable.isPaused(); // === false
readable.pause()¶
- Возвращает: {this}
В readable.pause() метод приведет к тому, что поток в текущем режиме перестанет излучать 'data' события, выход из проточного режима. Любые данные, которые становятся доступными, останутся во внутреннем буфере.
const readable = getReadableStreamSomehow();
readable.on('data', (chunk) => {
console.log(`Received ${chunk.length} bytes of data.`);
readable.pause();
console.log(
'There will be no additional data for 1 second.'
);
setTimeout(() => {
console.log('Now data will start flowing again.');
readable.resume();
}, 1000);
});
В readable.pause() метод не действует, если есть 'readable' слушатель событий.
readable.pipe(destination[, options])¶
destination{stream.Writable} Место назначения для записи данныхoptions{Object} Параметры трубыend{boolean} Завершить писателя, когда закончится читатель. Дефолт:true.- Возвращает: {stream.Writable} место назначения, учитывая цепочку труб, если это
DuplexилиTransformтранслировать
В readable.pipe() метод прикрепляет Writable поток к readable, заставляя его автоматически переключаться в режим потока и передавать все свои данные в подключенный Writable. Поток данных будет управляться автоматически, так что пункт назначения Writable поток не перегружен более быстрым Readable транслировать.
В следующем примере передаются все данные из readable в файл с именем file.txt:
const fs = require('fs');
const readable = getReadableStreamSomehow();
const writable = fs.createWriteStream('file.txt');
// All the data from readable goes into 'file.txt'.
readable.pipe(writable);
Можно прикрепить несколько Writable потоки к синглу Readable транслировать.
В readable.pipe() метод возвращает ссылку на место назначения stream, позволяющий создавать цепочки конвейерных потоков:
const fs = require('fs');
const r = fs.createReadStream('file.txt');
const z = zlib.createGzip();
const w = fs.createWriteStream('file.txt.gz');
r.pipe(z).pipe(w);
По умолчанию, stream.end() вызывается по месту назначения Writable поток, когда источник Readable поток излучает 'end', так что адрес назначения больше не доступен для записи. Чтобы отключить это поведение по умолчанию, end вариант можно передать как false, в результате чего целевой поток остается открытым:
reader.pipe(writer, { end: false });
reader.on('end', () => {
writer.end('Goodbyen');
});
Одно важное предостережение: если Readable поток выдает ошибку во время обработки, Writable место назначения не закрыто автоматически. В случае возникновения ошибки необходимо будет вручную закройте каждый поток, чтобы предотвратить утечку памяти.
В process.stderr а также process.stdout Writable потоки никогда не закрываются, пока процесс Node.js не завершится, независимо от указанных параметров.
readable.read([size])¶
size{number} Необязательный аргумент для указания количества данных для чтения.- Возвращает: {string | Buffer | null | any}.
В readable.read() метод извлекает некоторые данные из внутреннего буфера и возвращает их. Если нет данных для чтения, null возвращается. По умолчанию данные будут возвращены в виде Buffer объект, если кодировка не была указана с помощью readable.setEncoding() или поток работает в объектном режиме.
Необязательный size Аргумент указывает определенное количество байтов для чтения. Если size байты недоступны для чтения, null будет возвращен пока не поток закончился, и в этом случае будут возвращены все данные, оставшиеся во внутреннем буфере.
Если size аргумент не указан, будут возвращены все данные, содержащиеся во внутреннем буфере.
В size аргумент должен быть меньше или равен 1 ГиБ.
В readable.read() метод должен вызываться только на Readable потоки, работающие в приостановленном режиме. В проточном режиме, readable.read() вызывается автоматически до тех пор, пока внутренний буфер не будет полностью опустошен.
const readable = getReadableStreamSomehow();
// 'readable' may be triggered multiple times as data is buffered in
readable.on('readable', () => {
let chunk;
console.log(
'Stream is readable (new data received in buffer)'
);
// Use a loop to make sure we read all currently available data
while (null !== (chunk = readable.read())) {
console.log(`Read ${chunk.length} bytes of data...`);
}
});
// 'end' will be triggered once when there is no more data available
readable.on('end', () => {
console.log('Reached end of stream.');
});
Каждый звонок readable.read() возвращает фрагмент данных или null. Фрагменты не объединяются. А while цикл необходим для использования всех данных, находящихся в данный момент в буфере. При чтении большого файла .read() может вернуться null, до сих пор израсходовав весь буферизованный контент, но есть еще данные, которые еще не буферизованы. В этом случае новый 'readable' Событие будет сгенерировано, когда в буфере будет больше данных. Наконец 'end' событие будет сгенерировано, когда больше не будет данных.
Следовательно, чтобы прочитать все содержимое файла из readableнеобходимо собирать куски по нескольким 'readable' События:
const chunks = [];
readable.on('readable', () => {
let chunk;
while (null !== (chunk = readable.read())) {
chunks.push(chunk);
}
});
readable.on('end', () => {
const content = chunks.join('');
});
А Readable поток в объектном режиме всегда будет возвращать один элемент из вызова readable.read(size), независимо от стоимости size аргумент.
Если readable.read() метод возвращает фрагмент данных, 'data' событие также будет выпущено.
Вызов stream.read([size]) после 'end' событие было отправлено, вернется null. Ошибка выполнения не возникнет.
readable.readable¶
- {логический}
Является true если можно позвонить readable.read(), что означает, что поток не был уничтожен или испущен 'error' или 'end'.
readable.readableAborted¶
Стабильность: 1 — экспериментальная
- {логический}
Возвращает, был ли поток уничтожен или ошибался перед отправкой. 'end'.
readable.readableDidRead¶
Стабильность: 1 — экспериментальная
- {логический}
Возвращает ли 'data' был выпущен.
readable.readableEncoding¶
- {null | строка}
Получатель недвижимости encoding данного Readable транслировать. В encoding свойство можно установить с помощью readable.setEncoding() метод.
readable.readableEnded¶
- {логический}
Становится true когда 'end' событие испускается.
readable.readableFlowing¶
- {логический}
Это свойство отражает текущее состояние Readable поток, как описано в Три состояния раздел.
readable.readableHighWaterMark¶
- {количество}
Возвращает значение highWaterMark прошло при создании этого Readable.
readable.readableLength¶
- {количество}
Это свойство содержит количество байтов (или объектов) в очереди, готовых к чтению. Значение предоставляет данные самоанализа относительно статуса highWaterMark.
readable.readableObjectMode¶
- {логический}
Получатель недвижимости objectMode данного Readable транслировать.
readable.resume()¶
- Возвращает: {this}
В readable.resume() метод вызывает явно приостановленную Readable поток, чтобы возобновить передачу 'data' события, переводящие поток в текущий режим.
В readable.resume() может использоваться для полного использования данных из потока без фактической обработки каких-либо из этих данных:
getReadableStreamSomehow()
.resume()
.on('end', () => {
console.log(
'Reached the end, but did not read anything.'
);
});
В readable.resume() метод не действует, если есть 'readable' слушатель событий.
readable.setEncoding(encoding)¶
encoding{строка} Используемая кодировка.- Возвращает: {this}
В readable.setEncoding() устанавливает кодировку символов для данных, считываемых из Readable транслировать.
По умолчанию кодировка не назначается, и данные потока будут возвращены как Buffer объекты. Установка кодировки приводит к тому, что данные потока возвращаются как строки указанной кодировки, а не как Buffer объекты. Например, позвонив readable.setEncoding('utf8') приведет к тому, что выходные данные будут интерпретироваться как данные UTF-8 и передаваться как строки. Вызов readable.setEncoding('hex') приведет к кодированию данных в шестнадцатеричном строковом формате.
В Readable stream будет правильно обрабатывать многобайтовые символы, доставленные через поток, которые в противном случае были бы неправильно декодированы, если бы их просто вытащили из потока как Buffer объекты.
const readable = getReadableStreamSomehow();
readable.setEncoding('utf8');
readable.on('data', (chunk) => {
assert.equal(typeof chunk, 'string');
console.log(
'Got %d characters of string data:',
chunk.length
);
});
readable.unpipe([destination])¶
destination{stream.Writable} Необязательный конкретный поток для отключения- Возвращает: {this}
В readable.unpipe() метод отсоединяет Writable поток, ранее прикрепленный с помощью stream.pipe() метод.
Если destination не указано, то все трубы отсоединены.
Если destination указан, но для него не настроен канал, тогда метод ничего не делает.
const fs = require('fs');
const readable = getReadableStreamSomehow();
const writable = fs.createWriteStream('file.txt');
// All the data from readable goes into 'file.txt',
// but only for the first second.
readable.pipe(writable);
setTimeout(() => {
console.log('Stop writing to file.txt.');
readable.unpipe(writable);
console.log('Manually close the file stream.');
writable.end();
}, 1000);
readable.unshift(chunk[, encoding])¶
chunk{Buffer | Uint8Array | string | null | any} Фрагмент данных, который нужно перенести в очередь чтения. Для потоков, не работающих в объектном режиме,chunkдолжно быть строкой,Buffer,Uint8Arrayилиnull. Для потоков в объектном режимеchunkможет быть любым значением JavaScript.encoding{строка} Кодировка фрагментов строки. Должен быть действительнымBufferкодирование, например'utf8'или'ascii'.
Проходящий chunk в качестве null сигнализирует об окончании потока (EOF) и ведет себя так же, как readable.push(null), после чего запись данных невозможна. Сигнал EOF помещается в конец буфера, и все буферизованные данные все равно будут сброшены.
В readable.unshift() возвращает часть данных во внутренний буфер. Это полезно в определенных ситуациях, когда поток потребляется кодом, которому необходимо «не потреблять» некоторый объем данных, оптимистично извлеченных из источника, чтобы данные можно было передать какой-либо другой стороне.
В stream.unshift(chunk) метод не может быть вызван после 'end' было создано событие, или будет выдана ошибка времени выполнения.
Разработчики, использующие stream.unshift() часто следует подумать о переходе на использование Transform поток вместо этого. Увидеть API для исполнителей потоковой передачи раздел для получения дополнительной информации.
// Pull off a header delimited by nn.
// Use unshift() if we get too much.
// Call the callback with (error, header, stream).
const { StringDecoder } = require('string_decoder');
function parseHeader(stream, callback) {
stream.on('error', callback);
stream.on('readable', onReadable);
const decoder = new StringDecoder('utf8');
let header = '';
function onReadable() {
let chunk;
while (null !== (chunk = stream.read())) {
const str = decoder.write(chunk);
if (str.match(/nn/)) {
// Found the header boundary.
const split = str.split(/nn/);
header += split.shift();
const remaining = split.join('nn');
const buf = Buffer.from(remaining, 'utf8');
stream.removeListener('error', callback);
// Remove the 'readable' listener before unshifting.
stream.removeListener('readable', onReadable);
if (buf.length) stream.unshift(buf);
// Now the body of the message can be read from the stream.
callback(null, header, stream);
} else {
// Still reading the header.
header += str;
}
}
}
}
В отличие от stream.push(chunk), stream.unshift(chunk) не завершит процесс чтения, сбросив внутреннее состояние чтения потока. Это может привести к неожиданным результатам, если readable.unshift() вызывается во время чтения (т.е. изнутри stream._read() реализация в настраиваемом потоке). После звонка readable.unshift() с немедленным stream.push('') сбросит состояние чтения соответствующим образом, однако лучше просто избегать вызова readable.unshift() в процессе чтения.
readable.wrap(stream)¶
stream{Stream} Читаемый поток в «старом стиле»- Возвращает: {this}
До Node.js 0.10 потоки не реализовывали полностью stream модуль API в том виде, в каком он определен в настоящее время. (Видеть Совместимость для дополнительной информации.)
При использовании более старой библиотеки Node.js, которая выдает 'data' события и имеет stream.pause() метод, который носит рекомендательный характер, readable.wrap() может использоваться для создания Readable поток, который использует старый поток в качестве источника данных.
Редко будет необходимо использовать readable.wrap() но этот метод был предоставлен для удобства взаимодействия со старыми приложениями и библиотеками Node.js.
const { OldReader } = require('./old-api-module.js');
const { Readable } = require('stream');
const oreader = new OldReader();
const myReader = new Readable().wrap(oreader);
myReader.on('readable', () => {
myReader.read(); // etc.
});
readable[Symbol.asyncIterator]()¶
- Возвращает: {AsyncIterator} для полного использования потока.
const fs = require('fs');
async function print(readable) {
readable.setEncoding('utf8');
let data = '';
for await (const chunk of readable) {
data += chunk;
}
console.log(data);
}
print(fs.createReadStream('file')).catch(console.error);
Если цикл завершается break, return, или throw, поток будет уничтожен. Другими словами, итерация по потоку полностью потребляет поток. Поток будет прочитан кусками размером, равным highWaterMark вариант. В приведенном выше примере кода данные будут в одном фрагменте, если файл содержит менее 64 КБ данных, потому что нет highWaterMark опция предоставляется fs.createReadStream().
readable.iterator([options])¶
Стабильность: 1 — экспериментальная
options{Объект}destroyOnReturn{boolean} Если задано значениеfalse, звонюreturnна асинхронном итераторе или при выходе изfor await...ofитерация с использованиемbreak,return, илиthrowне разрушит поток. Дефолт:true.- Возвращает: {AsyncIterator} для использования потока.
Итератор, созданный этим методом, дает пользователям возможность отменить уничтожение потока, если for await...of цикл выходит из return, break, или throw, или если итератор должен уничтожить поток, если поток выдал ошибку во время итерации.
const { Readable } = require('stream');
async function printIterator(readable) {
for await (const chunk of readable.iterator({
destroyOnReturn: false,
})) {
console.log(chunk); // 1
break;
}
console.log(readable.destroyed); // false
for await (const chunk of readable.iterator({
destroyOnReturn: false,
})) {
console.log(chunk); // Will print 2 and then 3
}
console.log(readable.destroyed); // True, stream was totally consumed
}
async function printSymbolAsyncIterator(readable) {
for await (const chunk of readable) {
console.log(chunk); // 1
break;
}
console.log(readable.destroyed); // true
}
async function showBoth() {
await printIterator(Readable.from([1, 2, 3]));
await printSymbolAsyncIterator(Readable.from([1, 2, 3]));
}
showBoth();
Дуплексные и трансформируемые потоки¶
Класс: stream.Duplex¶
Дуплексные потоки — это потоки, которые реализуют как Readable а также Writable интерфейсы.
Примеры Duplex потоки включают:
- Сокеты TCP
- потоки zlib
- криптопотоки
duplex.allowHalfOpen¶
- {логический}
Если false тогда поток автоматически завершит доступную для записи сторону, когда закончится доступная для чтения сторона. Первоначально устанавливается allowHalfOpen параметр конструктора, по умолчанию false.
Это можно изменить вручную, чтобы изменить полуоткрытое поведение существующего Duplex экземпляр потока, но его необходимо изменить перед 'end' событие испускается.
Класс: stream.Transform¶
Потоки преобразования Duplex потоки, где вывод каким-то образом связан с вводом. Как все Duplex ручьи Transform потоки реализуют как Readable а также Writable интерфейсы.
Примеры Transform потоки включают:
- потоки zlib
- криптопотоки
transform.destroy([error])¶
error{Ошибка}- Возвращает: {this}
Уничтожить поток и, при желании, испустить 'error' событие. После этого вызова поток преобразования освободит все внутренние ресурсы. Разработчикам не следует переопределять этот метод, а вместо этого реализовывать readable._destroy(). Реализация по умолчанию _destroy() для Transform также испускать 'close' пока не emitClose установлен в false.
Один раз destroy() был вызван, любые дальнейшие вызовы не будут выполняться и никаких ошибок, кроме _destroy() может быть выпущен как 'error'.
stream.finished(stream[, options], callback)¶
stream{Stream} Доступный для чтения и / или записи поток.options{Объект}error{boolean} Если установлено значениеfalse, затем звонокemit('error', err)не считается законченным. Дефолт:true.readable{boolean} Если задано значениеfalse, обратный вызов будет вызван, когда поток закончится, даже если поток все еще доступен для чтения. Дефолт:true.writable{boolean} Если задано значениеfalse, обратный вызов будет вызван, когда поток закончится, даже если поток все еще доступен для записи. Дефолт:true.signal{AbortSignal} позволяет прервать ожидание окончания потока. Базовый поток будет нет быть прерванным, если сигнал прерван. Обратный вызов будет вызван сAbortError. Все зарегистрированные слушатели, добавленные этой функцией, также будут удалены.callback{Функция} Функция обратного вызова, которая принимает необязательный аргумент ошибки.- Возвращает: {Функция} Функция очистки, которая удаляет всех зарегистрированных слушателей.
Функция для получения уведомлений, когда поток больше не доступен для чтения, записи или произошла ошибка или событие преждевременного закрытия.
const { finished } = require('stream');
const rs = fs.createReadStream('archive.tar');
finished(rs, (err) => {
if (err) {
console.error('Stream failed.', err);
} else {
console.log('Stream is done reading.');
}
});
rs.resume(); // Drain the stream.
Особенно полезно в сценариях обработки ошибок, когда поток преждевременно уничтожается (например, прерванный HTTP-запрос) и не генерирует 'end' или 'finish'.
В finished API предоставляет версию обещания:
const { finished } = require('stream/promises');
const rs = fs.createReadStream('archive.tar');
async function run() {
await finished(rs);
console.log('Stream is done reading.');
}
run().catch(console.error);
rs.resume(); // Drain the stream.
stream.finished() оставляет висящие слушатели событий (в частности, 'error', 'end', 'finish' а также 'close') после callback был вызван. Причина этого в том, что неожиданный 'error' события (из-за неправильной реализации потока) не вызывают неожиданных сбоев. Если это нежелательное поведение, то возвращенная функция очистки должна быть вызвана в обратном вызове:
const cleanup = finished(rs, (err) => {
cleanup();
// ...
});
stream.pipeline(source[, ...transforms], destination, callback)¶
stream.pipeline(streams, callback)¶
streams{Stream [] | Iterable [] | AsyncIterable [] | Функция []}source{Stream | Iterable | AsyncIterable | Функция}- Возвращает: {Iterable | AsyncIterable}.
...transforms{Stream | Функция}source{AsyncIterable}- Возвращает: {AsyncIterable}
destination{Stream | Функция}source{AsyncIterable}- Возвращает: {AsyncIterable | Promise}.
callback{Функция} Вызывается, когда конвейер полностью готов.err{Ошибка}valРазрешенное значениеPromiseвернулсяdestination.- Возвращает: {Stream}
Метод модуля для передачи между потоками и генераторами ошибок, правильной очистки и обеспечения обратного вызова после завершения конвейера.
const { pipeline } = require('stream');
const fs = require('fs');
const zlib = require('zlib');
// Use the pipeline API to easily pipe a series of streams
// together and get notified when the pipeline is fully done.
// A pipeline to gzip a potentially huge tar file efficiently:
pipeline(
fs.createReadStream('archive.tar'),
zlib.createGzip(),
fs.createWriteStream('archive.tar.gz'),
(err) => {
if (err) {
console.error('Pipeline failed.', err);
} else {
console.log('Pipeline succeeded.');
}
}
);
В pipeline API предоставляет версию обещания, которая также может получать аргумент опций в качестве последнего параметра с signal Свойство {AbortSignal}. Когда сигнал прерывается, destroy будет вызываться в нижележащем конвейере с AbortError.
const { pipeline } = require('stream/promises');
async function run() {
await pipeline(
fs.createReadStream('archive.tar'),
zlib.createGzip(),
fs.createWriteStream('archive.tar.gz')
);
console.log('Pipeline succeeded.');
}
run().catch(console.error);
Чтобы использовать AbortSignal, передайте его внутри объекта параметров в качестве последнего аргумента:
const { pipeline } = require('stream/promises');
async function run() {
const ac = new AbortController();
const signal = ac.signal;
setTimeout(() => ac.abort(), 1);
await pipeline(
fs.createReadStream('archive.tar'),
zlib.createGzip(),
fs.createWriteStream('archive.tar.gz'),
{ signal }
);
}
run().catch(console.error); // AbortError
В pipeline API также поддерживает асинхронные генераторы:
const { pipeline } = require('stream/promises');
const fs = require('fs');
async function run() {
await pipeline(
fs.createReadStream('lowercase.txt'),
async function* (source, signal) {
source.setEncoding('utf8'); // Work with strings rather than `Buffer`s.
for await (const chunk of source) {
yield await processChunk(chunk, { signal });
}
},
fs.createWriteStream('uppercase.txt')
);
console.log('Pipeline succeeded.');
}
run().catch(console.error);
Не забывайте обращаться с signal аргумент передан в асинхронный генератор. Особенно в случае, когда асинхронный генератор является источником конвейера (т.е. первым аргументом) или конвейер никогда не будет завершен.
const { pipeline } = require('stream/promises');
const fs = require('fs');
async function run() {
await pipeline(async function* (signal) {
await someLongRunningfn({ signal });
yield 'asd';
}, fs.createWriteStream('uppercase.txt'));
console.log('Pipeline succeeded.');
}
run().catch(console.error);
stream.pipeline() позвоню stream.destroy(err) на всех потоках, кроме:
Readableпотоки, которые испустили'end'или'close'.Writableпотоки, которые испустили'finish'или'close'.
stream.pipeline() оставляет висящие прослушиватели событий в потоках после callback был вызван. В случае повторного использования потоков после сбоя это может привести к утечкам прослушивателя событий и ошибкам проглатывания.
stream.compose(...streams)¶
Стабильность: 1 —
stream.composeэкспериментальный.
streams{Stream [] | Iterable [] | AsyncIterable [] | Функция []}- Возвращает: {stream.Duplex}
Объединяет два или более потока в один Duplex поток, который записывает в первый поток и читает из последнего. Каждый предоставленный поток передается по конвейеру в следующий, используя stream.pipeline. Если какой-либо из потоков ошибается, то все уничтожаются, включая внешний Duplex транслировать.
Потому что stream.compose возвращает новый поток, который, в свою очередь, может (и должен) быть передан по конвейеру в другие потоки, он включает композицию. Напротив, при передаче потоков в stream.pipeline, как правило, первый поток является читаемым потоком, а последний — записываемым потоком, образуя замкнутую схему.
Если прошел Function это должен быть заводской метод, source Iterable.
import { compose, Transform } from 'stream';
const removeSpaces = new Transform({
transform(chunk, encoding, callback) {
callback(null, String(chunk).replace(' ', ''));
},
});
async function* toUpper(source) {
for await (const chunk of source) {
yield String(chunk).toUpperCase();
}
}
let res = '';
for await (const buf of compose(removeSpaces, toUpper).end(
'hello world'
)) {
res += buf;
}
console.log(res); // prints 'HELLOWORLD'
stream.compose может использоваться для преобразования асинхронных итераций, генераторов и функций в потоки.
AsyncIterableпревращается в читаемыйDuplex. Не может уступитьnull.AsyncGeneratorFunctionпреобразуется в читаемое / записываемое преобразованиеDuplex. Должен взять источникAsyncIterableкак первый параметр. Не может уступитьnull.AsyncFunctionпревращается в записываемыйDuplex. Должен вернуться либоnullилиundefined.
import { compose } from 'stream';
import { finished } from 'stream/promises';
// Convert AsyncIterable into readable Duplex.
const s1 = compose(
(async function* () {
yield 'Hello';
yield 'World';
})()
);
// Convert AsyncGenerator into transform Duplex.
const s2 = compose(async function* (source) {
for await (const chunk of source) {
yield String(chunk).toUpperCase();
}
});
let res = '';
// Convert AsyncFunction into writable Duplex.
const s3 = compose(async function (source) {
for await (const chunk of source) {
res += chunk;
}
});
await finished(compose(s1, s2, s3));
console.log(res); // prints 'HELLOWORLD'
stream.Readable.from(iterable[, options])¶
iterable{Iterable} Объект, реализующийSymbol.asyncIteratorилиSymbol.iteratorитеративный протокол. Выдает событие «ошибка», если передано нулевое значение.options{Object} Параметры, предоставленныеnew stream.Readable([options]). По умолчанию,Readable.from()установитoptions.objectModeкtrue, если это явно не отключено, установивoptions.objectModeкfalse.- Возвращает: {stream.Readable}
Утилита для создания читаемых потоков из итераторов.
const { Readable } = require('stream');
async function* generate() {
yield 'hello';
yield 'streams';
}
const readable = Readable.from(generate());
readable.on('data', (chunk) => {
console.log(chunk);
});
Вызов Readable.from(string) или Readable.from(buffer) не будет повторять строки или буферы для соответствия семантике других потоков по соображениям производительности.
stream.Readable.fromWeb(readableStream[, options])¶
Стабильность: 1 — экспериментальная
readableStream{ReadableStream}options{Объект}encoding{нить}highWaterMark{количество}objectModel{логический}signal{AbortSignal}- Возвращает: {stream.Readable}
stream.Readable.isDisturbed(stream)¶
Стабильность: 1 — экспериментальная
stream{stream.Readable | ReadableStream}- Возврат:
boolean
Возвращает информацию о том, был ли поток прочитан или отменен.
stream.Readable.toWeb(streamReadable)¶
Стабильность: 1 — экспериментальная
streamReadable{stream.Readable}- Возвращает: {ReadableStream}
stream.Writable.fromWeb(writableStream[, options])¶
Стабильность: 1 — экспериментальная
writableStream{WritableStream}options{Объект}decodeStrings{логический}highWaterMark{количество}objectMode{логический}signal{AbortSignal}- Возвращает: {stream.Writable}
stream.Writable.toWeb(streamWritable)¶
Стабильность: 1 — экспериментальная
streamWritable{stream.Writable}- Возвращает: {WritableStream}
stream.Duplex.from(src)¶
src{Stream | Blob | ArrayBuffer | string | Iterable | AsyncIterable | AsyncGeneratorFunction | AsyncFunction | Promise | Object}
Утилита для создания дуплексных потоков.
Streamпреобразует записываемый поток в записываемыйDuplexи читаемый поток вDuplex.Blobпревращается в читаемыйDuplex.stringпревращается в читаемыйDuplex.ArrayBufferпревращается в читаемыйDuplex.AsyncIterableпревращается в читаемыйDuplex. Не может уступитьnull.AsyncGeneratorFunctionпреобразуется в читаемое / записываемое преобразованиеDuplex. Должен взять источникAsyncIterableкак первый параметр. Не может уступитьnull.AsyncFunctionпревращается в записываемыйDuplex. Должен вернуться либоnullилиundefinedObject ({ writable, readable })обращаетreadableа такжеwritableвStreamа затем объединяет их вDuplexгдеDuplexнапишу вwritableи читайте изreadable.Promiseпревращается в читаемыйDuplex. Ценитьnullигнорируется.- Возвращает: {stream.Duplex}
stream.Duplex.fromWeb(pair[, options])¶
Стабильность: 1 — экспериментальная
pair{Объект}readable{ReadableStream}writable{WritableStream}options{Объект}allowHalfOpen{логический}decodeStrings{логический}encoding{нить}highWaterMark{количество}objectMode{логический}signal{AbortSignal}- Возвращает: {stream.Duplex}
stream.Duplex.toWeb(streamDuplex)¶
Стабильность: 1 — экспериментальная
streamDuplex{stream.Duplex}- Возвращает: {Object}
readable{ReadableStream}writable{WritableStream}
stream.addAbortSignal(signal, stream)¶
signal{AbortSignal} Сигнал, указывающий на возможную отмену.stream{Stream} поток для присоединения сигнала к
Присоединяет AbortSignal к читаемому или записываемому потоку. Это позволяет коду управлять уничтожением потока с помощью AbortController.
Вызов abort на AbortController соответствующий пройденному AbortSignal будет вести себя так же, как вызов .destroy(new AbortError()) на ручье.
const fs = require('fs');
const controller = new AbortController();
const read = addAbortSignal(
controller.signal,
fs.createReadStream('object.json')
);
// Later, abort the operation closing the stream
controller.abort();
Или используя AbortSignal с читаемым потоком как асинхронным итерабельным:
const controller = new AbortController();
setTimeout(() => controller.abort(), 10_000); // set a timeout
const stream = addAbortSignal(
controller.signal,
fs.createReadStream('object.json')
);
(async () => {
try {
for await (const chunk of stream) {
await process(chunk);
}
} catch (e) {
if (e.name === 'AbortError') {
// The operation was cancelled
} else {
throw e;
}
}
})();
API для исполнителей потоковой передачи¶
В stream API модуля был разработан, чтобы упростить реализацию потоков с использованием прототипной модели наследования JavaScript.
Сначала разработчик потока объявит новый класс JavaScript, который расширяет один из четырех основных классов потока (stream.Writable, stream.Readable, stream.Duplex, или stream.Transform), убедившись, что они вызывают соответствующий конструктор родительского класса:
const { Writable } = require('stream');
class MyWritable extends Writable {
constructor({ highWaterMark, ...options }) {
super({ highWaterMark });
// ...
}
}
При расширении потоков помните, какие параметры пользователь может и должен предоставить, прежде чем пересылать их в базовый конструктор. Например, если реализация делает предположения относительно autoDestroy а также emitClose параметры, не позволяйте пользователю переопределять их. Четко указывайте, какие параметры пересылаются, вместо неявной пересылки всех параметров.
Затем новый класс потока должен реализовать один или несколько конкретных методов, в зависимости от типа создаваемого потока, как подробно описано в таблице ниже:
| Пример использования | Класс | Метод (ы) для реализации | | ——— | —— | ———————- | | Только чтение | Readable | _read() | | Только написание | Writable | _write(), _writev(), _final() | | Чтение и письмо | Duplex | _read(), _write(), _writev(), _final() | | Оперируйте записанными данными, затем прочтите результат | Transform | _transform(), _flush(), _final() |
Код реализации для потока должен никогда вызывать «общедоступные» методы потока, которые предназначены для использования потребителями (как описано в API для потребителей потоков раздел). Это может привести к нежелательным побочным эффектам в коде приложения, потребляющем поток.
Избегайте переопределения общедоступных методов, таких как write(), end(), cork(), uncork(), read() а также destroy(), или генерируя внутренние события, такие как 'error', 'data', 'end', 'finish' а также 'close' через .emit(). Это может нарушить текущие и будущие инварианты потоков, что приведет к проблемам с поведением и / или совместимостью с другими потоками, потоковыми утилитами и ожиданиями пользователей.
Упрощенная конструкция¶
Во многих простых случаях можно создать поток, не полагаясь на наследование. Это может быть выполнено путем непосредственного создания экземпляров stream.Writable, stream.Readable, stream.Duplex или stream.Transform объекты и передача соответствующих методов в качестве параметров конструктора.
const { Writable } = require('stream');
const myWritable = new Writable({
construct(callback) {
// Initialize state and load resources...
},
write(chunk, encoding, callback) {
// ...
},
destroy() {
// Free resources...
},
});
Реализация записываемого потока¶
В stream.Writable класс расширен для реализации Writable транслировать.
Обычай Writable потоки должен позвонить в new stream.Writable([options]) конструктор и реализовать writable._write() и / или writable._writev() метод.
new stream.Writable([options])¶
options{Объект}highWaterMark{number} Уровень буфера, когдаstream.write()начинает возвращатьсяfalse. Дефолт:16384(16 КБ) или16дляobjectModeпотоки.decodeStrings{boolean} Кодировать лиstrings переданоstream.write()кBuffers (с кодировкой, указанной вstream.write()call) перед тем, как передать ихstream._write(). Другие типы данных не преобразуются (т. Е.Buffers не декодируются вstringс). Установка значения false предотвратитstrings от преобразования. Дефолт:true.defaultEncoding{строка} Кодировка по умолчанию, которая используется, когда кодировка не указана в качестве аргумента дляstream.write(). Дефолт:'utf8'.objectMode{boolean} Независимо от того,stream.write(anyObj)это допустимая операция. Когда установлено, становится возможным записывать значения JavaScript, отличные от строки,BufferилиUint8Arrayесли поддерживается реализацией потока. Дефолт:false.emitClose{boolean} Должен ли поток выдавать'close'после того, как он был разрушен. Дефолт:true.write{Function} Реализация дляstream._write()метод.writev{Function} Реализация дляstream._writev()метод.destroy{Function} Реализация дляstream._destroy()метод.final{Function} Реализация дляstream._final()метод.construct{Function} Реализация дляstream._construct()метод.autoDestroy{boolean} Должен ли этот поток вызывать автоматически.destroy()на себя после окончания. Дефолт:true.signal{AbortSignal} Сигнал, представляющий возможную отмену.
const { Writable } = require('stream');
class MyWritable extends Writable {
constructor(options) {
// Calls the stream.Writable() constructor.
super(options);
// ...
}
}
Или при использовании конструкторов в стиле до ES6:
const { Writable } = require('stream');
const util = require('util');
function MyWritable(options) {
if (!(this instanceof MyWritable))
return new MyWritable(options);
Writable.call(this, options);
}
util.inherits(MyWritable, Writable);
Или, используя упрощенный конструкторский подход:
const { Writable } = require('stream');
const myWritable = new Writable({
write(chunk, encoding, callback) {
// ...
},
writev(chunks, callback) {
// ...
},
});
Вызов abort на AbortController соответствующий пройденному AbortSignal будет вести себя так же, как вызов .destroy(new AbortError()) в записываемом потоке.
const { Writable } = require('stream');
const controller = new AbortController();
const myWritable = new Writable({
write(chunk, encoding, callback) {
// ...
},
writev(chunks, callback) {
// ...
},
signal: controller.signal,
});
// Later, abort the operation closing the stream
controller.abort();
writable._construct(callback)¶
callback{Функция} Вызовите эту функцию (необязательно с аргументом ошибки), когда поток завершит инициализацию.
В _construct() метод НЕ ДОЛЖЕН быть вызван напрямую. Он может быть реализован дочерними классами, и если да, то будет вызываться внутренним Writable только методы класса.
Эта необязательная функция будет вызываться через тик после возврата конструктора потока, задерживая любые _write(), _final() а также _destroy() звонит, пока callback называется. Это полезно для инициализации состояния или асинхронной инициализации ресурсов перед использованием потока.
const { Writable } = require('stream');
const fs = require('fs');
class WriteStream extends Writable {
constructor(filename) {
super();
this.filename = filename;
}
_construct(callback) {
fs.open(this.filename, (err, fd) => {
if (err) {
callback(err);
} else {
this.fd = fd;
callback();
}
});
}
_write(chunk, encoding, callback) {
fs.write(this.fd, chunk, callback);
}
_destroy(err, callback) {
if (this.fd) {
fs.close(this.fd, (er) => callback(er || err));
} else {
callback(err);
}
}
}
writable._write(chunk, encoding, callback)¶
chunk{Buffer | string | any}Bufferбыть записанным, преобразованным изstringперешел кstream.write(). Если потокdecodeStringsвариантfalseили поток работает в объектном режиме, фрагмент не будет преобразован и будет соответствовать тому, что было передано вstream.write().encoding{строка} Если фрагмент является строкой, тогдаencodingкодировка символов этой строки. Если чанкBuffer, или если поток работает в объектном режиме,encodingможно игнорировать.callback{Функция} Вызовите эту функцию (необязательно с аргументом ошибки) после завершения обработки предоставленного фрагмента.
Все Writable реализации потока должны предоставлять writable._write() и / или writable._writev() для отправки данных в базовый ресурс.
Transform потоки обеспечивают собственную реализацию writable._write().
Эта функция НЕ ДОЛЖНА вызываться кодом приложения напрямую. Он должен быть реализован дочерними классами и вызываться внутренним Writable только методы класса.
В callback функция должна вызываться синхронно внутри writable._write() или асинхронно (т. е. другой тик), чтобы сигнализировать, что запись завершилась успешно или завершилась ошибкой. Первый аргумент, переданный в callback должен быть Error объект, если вызов не удался или null если запись прошла успешно.
Все звонки на writable.write() что происходит между временем writable._write() называется и callback вызывает буферизацию записанных данных. Когда callback вызывается, поток может испустить 'drain' событие. Если реализация потока способна обрабатывать несколько блоков данных одновременно, writable._writev() метод должен быть реализован.
Если decodeStrings свойство явно установлено на false в параметрах конструктора, затем chunk останется тем же объектом, который был передан в .write(), и может быть строкой, а не Buffer. Это сделано для поддержки реализаций, которые имеют оптимизированную обработку для определенных кодировок строковых данных. В этом случае encoding Аргумент будет указывать кодировку символов строки. В противном случае encoding аргумент можно проигнорировать.
В writable._write() Метод имеет префикс подчеркивания, потому что он является внутренним по отношению к классу, который его определяет, и никогда не должен вызываться непосредственно пользовательскими программами.
writable._writev(chunks, callback)¶
chunks{Object []} Данные для записи. Значение представляет собой массив {Object}, каждый из которых представляет отдельный фрагмент данных для записи. Свойства этих объектов:chunk{Buffer | string} Экземпляр или строка буфера, содержащая данные для записи. Вchunkбудет строкой, еслиWritableбыл создан сdecodeStringsопция установлена наfalseи строка была передана вwrite().encoding{строка} Кодировка символовchunk. ЕслиchunkэтоBuffer, тоencodingбудет'buffer'.callback{Функция} Функция обратного вызова (необязательно с аргументом ошибки), которая будет вызываться после завершения обработки предоставленных фрагментов.
Эта функция НЕ ДОЛЖНА вызываться кодом приложения напрямую. Он должен быть реализован дочерними классами и вызываться внутренним Writable только методы класса.
В writable._writev() метод может быть реализован в дополнение или как альтернатива writable._write() в потоковых реализациях, которые способны обрабатывать сразу несколько блоков данных. Если реализовано и есть буферизованные данные из предыдущих записей, _writev() будет называться вместо _write().
В writable._writev() Метод имеет префикс подчеркивания, потому что он является внутренним по отношению к классу, который его определяет, и никогда не должен вызываться непосредственно пользовательскими программами.
writable._destroy(err, callback)¶
err{Error} Возможная ошибка.callback{Функция} Функция обратного вызова, которая принимает необязательный аргумент ошибки.
В _destroy() метод вызывается writable.destroy(). Его можно переопределить дочерними классами, но он не должен звонить напрямую.
writable._final(callback)¶
callback{Функция} Вызовите эту функцию (необязательно с аргументом ошибки), когда закончите запись любых оставшихся данных.
В _final() метод не должен звонить напрямую. Он может быть реализован дочерними классами, и если да, то будет вызываться внутренним Writable только методы класса.
Эта дополнительная функция будет вызываться перед закрытием потока, задерживая 'finish' событие до callback называется. Это полезно для закрытия ресурсов или записи буферизованных данных до завершения потока.
Ошибки при записи¶
Ошибки, возникающие при обработке writable._write(), writable._writev() а также writable._final() методы должны распространяться путем вызова обратного вызова и передачи ошибки в качестве первого аргумента. Бросив Error из этих методов или вручную 'error' событие приводит к неопределенному поведению.
Если Readable поток трубы в Writable поток, когда Writable выдает ошибку, Readable поток будет отключен.
const { Writable } = require('stream');
const myWritable = new Writable({
write(chunk, encoding, callback) {
if (chunk.toString().indexOf('a') >= 0) {
callback(new Error('chunk is invalid'));
} else {
callback();
}
},
});
Пример записываемого потока¶
Следующее иллюстрирует довольно упрощенный (и несколько бессмысленный) обычай. Writable реализация потока. Хотя этот конкретный Writable экземпляр потока не представляет особой полезности, пример иллюстрирует каждый из требуемых элементов настраиваемого Writable экземпляр потока:
const { Writable } = require('stream');
class MyWritable extends Writable {
_write(chunk, encoding, callback) {
if (chunk.toString().indexOf('a') >= 0) {
callback(new Error('chunk is invalid'));
} else {
callback();
}
}
}
Буферы декодирования в доступном для записи потоке¶
Буферы декодирования — обычная задача, например, при использовании преобразователей, вход которых является строкой. Это нетривиальный процесс при использовании кодировки многобайтовых символов, такой как UTF-8. В следующем примере показано, как декодировать многобайтовые строки с помощью StringDecoder а также Writable.
const { Writable } = require('stream');
const { StringDecoder } = require('string_decoder');
class StringWritable extends Writable {
constructor(options) {
super(options);
this._decoder = new StringDecoder(
options && options.defaultEncoding
);
this.data = '';
}
_write(chunk, encoding, callback) {
if (encoding === 'buffer') {
chunk = this._decoder.write(chunk);
}
this.data += chunk;
callback();
}
_final(callback) {
this.data += this._decoder.end();
callback();
}
}
const euro = [[0xe2, 0x82], [0xac]].map(Buffer.from);
const w = new StringWritable();
w.write('currency: ');
w.write(euro[0]);
w.end(euro[1]);
console.log(w.data); // currency: €
Реализация читаемого потока¶
В stream.Readable класс расширен для реализации Readable транслировать.
Обычай Readable потоки должен позвонить в new stream.Readable([options]) конструктор и реализовать readable._read() метод.
new stream.Readable([options])¶
options{Объект}highWaterMark{number} Максимальный количество байтов для сохранения во внутреннем буфере перед прекращением чтения из базового ресурса. Дефолт:16384(16 КБ) или16дляobjectModeпотоки.encoding{строка} Если указано, то буферы будут декодированы в строки с использованием указанной кодировки. Дефолт:null.objectMode{boolean} Должен ли этот поток вести себя как поток объектов. Означающий, чтоstream.read(n)возвращает одно значение вместоBufferразмераn. Дефолт:false.emitClose{boolean} Должен ли поток выдавать'close'после того, как он был разрушен. Дефолт:true.read{Function} Реализация дляstream._read()метод.destroy{Function} Реализация дляstream._destroy()метод.construct{Function} Реализация дляstream._construct()метод.autoDestroy{boolean} Должен ли этот поток вызывать автоматически.destroy()на себя после окончания. Дефолт:true.signal{AbortSignal} Сигнал, представляющий возможную отмену.
const { Readable } = require('stream');
class MyReadable extends Readable {
constructor(options) {
// Calls the stream.Readable(options) constructor.
super(options);
// ...
}
}
Или при использовании конструкторов в стиле до ES6:
const { Readable } = require('stream');
const util = require('util');
function MyReadable(options) {
if (!(this instanceof MyReadable))
return new MyReadable(options);
Readable.call(this, options);
}
util.inherits(MyReadable, Readable);
Или, используя упрощенный конструкторский подход:
const { Readable } = require('stream');
const myReadable = new Readable({
read(size) {
// ...
},
});
Вызов abort на AbortController соответствующий пройденному AbortSignal будет вести себя так же, как вызов .destroy(new AbortError()) на читаемом создал.
const { Readable } = require('stream');
const controller = new AbortController();
const read = new Readable({
read(size) {
// ...
},
signal: controller.signal,
});
// Later, abort the operation closing the stream
controller.abort();
readable._construct(callback)¶
callback{Функция} Вызовите эту функцию (необязательно с аргументом ошибки), когда поток завершит инициализацию.
В _construct() метод НЕ ДОЛЖЕН быть вызван напрямую. Он может быть реализован дочерними классами, и если да, то будет вызываться внутренним Readable только методы класса.
Эта необязательная функция будет запланирована в следующем тике конструктором потока, задерживая любые _read() а также _destroy() звонит, пока callback называется. Это полезно для инициализации состояния или асинхронной инициализации ресурсов перед использованием потока.
const { Readable } = require('stream');
const fs = require('fs');
class ReadStream extends Readable {
constructor(filename) {
super();
this.filename = filename;
this.fd = null;
}
_construct(callback) {
fs.open(this.filename, (err, fd) => {
if (err) {
callback(err);
} else {
this.fd = fd;
callback();
}
});
}
_read(n) {
const buf = Buffer.alloc(n);
fs.read(this.fd, buf, 0, n, null, (err, bytesRead) => {
if (err) {
this.destroy(err);
} else {
this.push(
bytesRead > 0 ? buf.slice(0, bytesRead) : null
);
}
});
}
_destroy(err, callback) {
if (this.fd) {
fs.close(this.fd, (er) => callback(er || err));
} else {
callback(err);
}
}
}
readable._read(size)¶
size{number} Количество байтов для асинхронного чтения
Эта функция НЕ ДОЛЖНА вызываться кодом приложения напрямую. Он должен быть реализован дочерними классами и вызываться внутренним Readable только методы класса.
Все Readable реализации потока должны обеспечивать реализацию readable._read() для извлечения данных из базового ресурса.
Когда readable._read() вызывается, если данные доступны из ресурса, реализация должна начать помещать эти данные в очередь чтения с помощью this.push(dataChunk) метод. _read() будет вызываться снова после каждого вызова this.push(dataChunk) как только поток будет готов принять больше данных. _read() может продолжить чтение из ресурса и отправку данных до тех пор, пока readable.push() возвращается false. Только когда _read() вызывается снова после остановки, если он возобновляет отправку дополнительных данных в очередь.
Однажды readable._read() был вызван, он не будет вызываться снова, пока через readable.push() метод. Пустые данные, такие как пустые буферы и строки, не вызовут readable._read() быть позванным.
В size аргумент носит рекомендательный характер. Для реализаций, где «чтение» — это отдельная операция, которая возвращает данные, можно использовать size аргумент, чтобы определить, сколько данных нужно получить. Другие реализации могут игнорировать этот аргумент и просто предоставлять данные, когда они становятся доступными. Нет необходимости «ждать», пока size байты доступны перед вызовом stream.push(chunk).
В readable._read() Метод имеет префикс подчеркивания, потому что он является внутренним по отношению к классу, который его определяет, и никогда не должен вызываться непосредственно пользовательскими программами.
readable._destroy(err, callback)¶
err{Error} Возможная ошибка.callback{Функция} Функция обратного вызова, которая принимает необязательный аргумент ошибки.
В _destroy() метод вызывается readable.destroy(). Его можно переопределить дочерними классами, но он не должен звонить напрямую.
readable.push(chunk[, encoding])¶
chunk{Buffer | Uint8Array | string | null | any} Фрагмент данных, помещаемых в очередь чтения. Для потоков, не работающих в объектном режиме,chunkдолжно быть строкой,BufferилиUint8Array. Для потоков в объектном режимеchunkможет быть любым значением JavaScript.encoding{строка} Кодировка фрагментов строки. Должен быть действительнымBufferкодирование, например'utf8'или'ascii'.- Возвращает: {логическое}
trueесли можно продолжить отправку дополнительных фрагментов данных;falseиначе.
Когда chunk это Buffer, Uint8Array или string, то chunk данных будет добавлено во внутреннюю очередь для использования пользователями потока. Проходящий chunk в качестве null сигнализирует об окончании потока (EOF), после которого больше нельзя записывать данные.
Когда Readable работает в режиме паузы, данные добавлены readable.push() можно прочитать, позвонив в readable.read() метод, когда 'readable' событие испускается.
Когда Readable работает в проточном режиме, данные добавлены readable.push() будет доставлен путем испускания 'data' событие.
В readable.push() Метод разработан, чтобы быть максимально гибким. Например, при упаковке источника нижнего уровня, который предоставляет некоторую форму механизма паузы / возобновления и обратного вызова данных, источник низкого уровня может быть заключен в оболочку с помощью настраиваемого Readable пример:
// `_source` is an object with readStop() and readStart() methods,
// and an `ondata` member that gets called when it has data, and
// an `onend` member that gets called when the data is over.
class SourceWrapper extends Readable {
constructor(options) {
super(options);
this._source = getLowLevelSourceObject();
// Every time there's data, push it into the internal buffer.
this._source.ondata = (chunk) => {
// If push() returns false, then stop reading from source.
if (!this.push(chunk)) this._source.readStop();
};
// When the source ends, push the EOF-signaling `null` chunk.
this._source.onend = () => {
this.push(null);
};
}
// _read() will be called when the stream wants to pull more data in.
// The advisory size argument is ignored in this case.
_read(size) {
this._source.readStart();
}
}
В readable.push() используется для проталкивания содержимого во внутренний буфер. Это может быть вызвано readable._read() метод.
Для потоков, не работающих в объектном режиме, если chunk параметр readable.push() является undefined, он будет рассматриваться как пустая строка или буфер. Видеть readable.push('') для дополнительной информации.
Ошибки при чтении¶
Ошибки, возникающие при обработке readable._read() должны распространяться через readable.destroy(err) метод. Бросив Error изнутри readable._read() или вручную испустить 'error' событие приводит к неопределенному поведению.
const { Readable } = require('stream');
const myReadable = new Readable({
read(size) {
const err = checkSomeErrorCondition();
if (err) {
this.destroy(err);
} else {
// Do some work.
}
},
});
Пример счетного потока¶
Ниже приведен базовый пример Readable поток, который выводит цифры от 1 до 1 000 000 в порядке возрастания, а затем завершается.
const { Readable } = require('stream');
class Counter extends Readable {
constructor(opt) {
super(opt);
this._max = 1000000;
this._index = 1;
}
_read() {
const i = this._index++;
if (i > this._max) this.push(null);
else {
const str = String(i);
const buf = Buffer.from(str, 'ascii');
this.push(buf);
}
}
}
Реализация дуплексного потока¶
А Duplex поток — это тот, который реализует оба Readable а также Writable, например, соединение через сокет TCP.
Поскольку JavaScript не поддерживает множественное наследование, stream.Duplex класс расширен для реализации Duplex поток (в отличие от расширения stream.Readable а также stream.Writable классы).
В stream.Duplex класс прототипически наследуется от stream.Readable и паразитически из stream.Writable, но instanceof будет работать правильно для обоих базовых классов из-за переопределения Symbol.hasInstance на stream.Writable.
Обычай Duplex потоки должен позвонить в new stream.Duplex([options]) конструктор и реализация оба в readable._read() а также writable._write() методы.
new stream.Duplex(options)¶
options{Object} Передано обоимWritableа такжеReadableконструкторы. Также есть следующие поля:allowHalfOpen{boolean} Если установлено значениеfalse, то поток автоматически закроет доступную для записи сторону, когда закончится доступная для чтения сторона. Дефолт:true.readable{boolean} Устанавливает, будет лиDuplexдолжен быть читабельным. Дефолт:true.writable{boolean} Устанавливает, будет лиDuplexдолжен быть доступен для записи. Дефолт:true.readableObjectMode{boolean} НаборыobjectModeдля читаемой стороны потока. Не действует, еслиobjectModeявляетсяtrue. Дефолт:false.writableObjectMode{boolean} НаборыobjectModeдля записываемой стороны потока. Не действует, еслиobjectModeявляетсяtrue. Дефолт:false.readableHighWaterMark{number} наборыhighWaterMarkдля читаемой стороны потока. Не действует, еслиhighWaterMarkпредоставлен.writableHighWaterMark{number} наборыhighWaterMarkдля записываемой стороны потока. Не действует, еслиhighWaterMarkпредоставлен.
const { Duplex } = require('stream');
class MyDuplex extends Duplex {
constructor(options) {
super(options);
// ...
}
}
Или при использовании конструкторов в стиле до ES6:
const { Duplex } = require('stream');
const util = require('util');
function MyDuplex(options) {
if (!(this instanceof MyDuplex))
return new MyDuplex(options);
Duplex.call(this, options);
}
util.inherits(MyDuplex, Duplex);
Или, используя упрощенный конструкторский подход:
const { Duplex } = require('stream');
const myDuplex = new Duplex({
read(size) {
// ...
},
write(chunk, encoding, callback) {
// ...
},
});
При использовании трубопровода:
const { Transform, pipeline } = require('stream');
const fs = require('fs');
pipeline(
fs.createReadStream('object.json').setEncoding('utf8'),
new Transform({
decodeStrings: false, // Accept string input rather than Buffers
construct(callback) {
this.data = '';
callback();
},
transform(chunk, encoding, callback) {
this.data += chunk;
callback();
},
flush(callback) {
try {
// Make sure is valid json.
JSON.parse(this.data);
this.push(this.data);
} catch (err) {
callback(err);
}
},
}),
fs.createWriteStream('valid-object.json'),
(err) => {
if (err) {
console.error('failed', err);
} else {
console.log('completed');
}
}
);
Пример дуплексного потока¶
Ниже показан простой пример Duplex stream, который обертывает гипотетический исходный объект нижнего уровня, в который могут быть записаны данные и из которого данные могут быть прочитаны, хотя и с использованием API, несовместимого с потоками Node.js. Ниже показан простой пример Duplex поток, который буферизует входящие записанные данные через Writable интерфейс, который считывается обратно через Readable интерфейс.
const { Duplex } = require('stream');
const kSource = Symbol('source');
class MyDuplex extends Duplex {
constructor(source, options) {
super(options);
this[kSource] = source;
}
_write(chunk, encoding, callback) {
// The underlying source only deals with strings.
if (Buffer.isBuffer(chunk)) chunk = chunk.toString();
this[kSource].writeSomeData(chunk);
callback();
}
_read(size) {
this[kSource].fetchSomeData(size, (data, encoding) => {
this.push(Buffer.from(data, encoding));
});
}
}
Самый важный аспект Duplex поток в том, что Readable а также Writable стороны работают независимо друг от друга, несмотря на сосуществование в пределах одного экземпляра объекта.
Дуплексные потоки в объектном режиме¶
Для Duplex ручьи objectMode может быть установлен исключительно для Readable или Writable сторона, использующая readableObjectMode а также writableObjectMode варианты соответственно.
В следующем примере, например, новый Transform поток (который является типом Duplex поток) создается с объектным режимом Writable сторона, которая принимает числа JavaScript, которые преобразуются в шестнадцатеричные строки на Readable боковая сторона.
const { Transform } = require('stream');
// All Transform streams are also Duplex Streams.
const myTransform = new Transform({
writableObjectMode: true,
transform(chunk, encoding, callback) {
// Coerce the chunk to a number if necessary.
chunk |= 0;
// Transform the chunk into something else.
const data = chunk.toString(16);
// Push the data onto the readable queue.
callback(null, '0'.repeat(data.length % 2) + data);
},
});
myTransform.setEncoding('ascii');
myTransform.on('data', (chunk) => console.log(chunk));
myTransform.write(1);
// Prints: 01
myTransform.write(10);
// Prints: 0a
myTransform.write(100);
// Prints: 64
Реализация потока преобразования¶
А Transform поток — это Duplex поток, в котором вывод каким-то образом вычисляется на основе ввода. Примеры включают zlib потоки или крипто потоки, которые сжимают, шифруют или дешифруют данные.
Не требуется, чтобы выходные данные были того же размера, что и входные, или чтобы они приходили в одно и то же время. Например, Hash stream всегда будет иметь только один фрагмент вывода, который предоставляется по окончании ввода. А zlib stream произведет вывод, который либо намного меньше, либо намного больше, чем его ввод.
В stream.Transform класс расширен для реализации Transform транслировать.
В stream.Transform класс прототипически наследуется от stream.Duplex и реализует собственные версии writable._write() а также readable._read() методы. Обычай Transform реализации должен реализовать transform._transform() метод и мая также реализовать transform._flush() метод.
Следует соблюдать осторожность при использовании Transform потоки в этих данных, записанных в поток, могут вызвать Writable сторону потока, чтобы сделать паузу, если вывод на Readable сторона не расходуется.
new stream.Transform([options])¶
options{Object} Передано обоимWritableа такжеReadableконструкторы. Также есть следующие поля:transform{Function} Реализация дляstream._transform()метод.flush{Function} Реализация дляstream._flush()метод.
const { Transform } = require('stream');
class MyTransform extends Transform {
constructor(options) {
super(options);
// ...
}
}
Или при использовании конструкторов в стиле до ES6:
const { Transform } = require('stream');
const util = require('util');
function MyTransform(options) {
if (!(this instanceof MyTransform))
return new MyTransform(options);
Transform.call(this, options);
}
util.inherits(MyTransform, Transform);
Или, используя упрощенный конструкторский подход:
const { Transform } = require('stream');
const myTransform = new Transform({
transform(chunk, encoding, callback) {
// ...
},
});
Событие: 'end'¶
В 'end' событие из stream.Readable класс. В 'end' событие генерируется после вывода всех данных, что происходит после обратного вызова в transform._flush() был вызван. В случае ошибки 'end' не должны испускаться.
Событие: 'finish'¶
В 'finish' событие из stream.Writable класс. В 'finish' событие испускается после stream.end() вызывается, и все фрагменты были обработаны stream._transform(). В случае ошибки 'finish' не должны испускаться.
transform._flush(callback)¶
callback{Функция} Функция обратного вызова (необязательно с аргументом ошибки и данными), которая будет вызываться, когда оставшиеся данные будут сброшены.
Эта функция НЕ ДОЛЖНА вызываться кодом приложения напрямую. Он должен быть реализован дочерними классами и вызываться внутренним Readable только методы класса.
В некоторых случаях операция преобразования может потребовать выдачи дополнительного бита данных в конце потока. Например, zlib В потоке сжатия будет храниться внутреннее состояние, используемое для оптимального сжатия вывода. Однако, когда поток заканчивается, эти дополнительные данные необходимо очистить, чтобы сжатые данные были полными.
Обычай Transform реализации мая реализовать transform._flush() метод. Это будет вызываться, когда больше нет записанных данных для использования, но до 'end' генерируется событие, сигнализирующее об окончании Readable транслировать.
В рамках transform._flush() реализация, transform.push() в зависимости от обстоятельств метод может вызываться ноль или более раз. В callback функция должна быть вызвана после завершения операции промывки.
В transform._flush() Метод имеет префикс подчеркивания, потому что он является внутренним по отношению к классу, который его определяет, и никогда не должен вызываться непосредственно пользовательскими программами.
transform._transform(chunk, encoding, callback)¶
chunk{Buffer | string | any}Bufferбыть преобразованным, преобразованным изstringперешел кstream.write(). Если потокdecodeStringsвариантfalseили поток работает в объектном режиме, фрагмент не будет преобразован и будет соответствовать тому, что было передано вstream.write().encoding{строка} Если фрагмент является строкой, то это тип кодировки. Если чанк является буфером, тогда это специальное значение'buffer'. В таком случае не обращайте на это внимания.callback{Функция} Функция обратного вызова (необязательно с аргументом ошибки и данными), вызываемая после предоставленногоchunkобработан.
Эта функция НЕ ДОЛЖНА вызываться кодом приложения напрямую. Он должен быть реализован дочерними классами и вызываться внутренним Readable только методы класса.
Все Transform реализации потока должны предоставлять _transform() метод приема ввода и вывода вывода. В transform._transform() реализация обрабатывает записываемые байты, вычисляет вывод, затем передает этот вывод в читаемую часть, используя transform.push() метод.
В transform.push() Метод может вызываться ноль или более раз для генерации вывода из одного входного фрагмента, в зависимости от того, сколько должно быть выведено в результате этого фрагмента.
Возможно, что ни один из заданных фрагментов входных данных не генерирует никаких выходных данных.
В callback Функция должна вызываться только тогда, когда текущий кусок полностью израсходован. Первый аргумент, переданный в callback должен быть Error объект, если при обработке ввода произошла ошибка или null иначе. Если второй аргумент передается в callback, он будет отправлен на transform.push() метод. Другими словами, следующие эквиваленты:
transform.prototype._transform = function (
data,
encoding,
callback
) {
this.push(data);
callback();
};
transform.prototype._transform = function (
data,
encoding,
callback
) {
callback(null, data);
};
В transform._transform() Метод имеет префикс подчеркивания, потому что он является внутренним по отношению к классу, который его определяет, и никогда не должен вызываться непосредственно пользовательскими программами.
transform._transform() никогда не вызывается параллельно; потоки реализуют механизм очереди, и для получения следующего фрагмента callback должен вызываться синхронно или асинхронно.
Класс: stream.PassThrough¶
В stream.PassThrough class — это тривиальная реализация Transform поток, который просто передает входные байты на выход. Его цель — в первую очередь для примеров и тестирования, но есть некоторые варианты использования, когда stream.PassThrough полезен как строительный блок для новых видов потоков.
Дополнительные замечания¶
Совместимость потоков с асинхронными генераторами и асинхронными итераторами¶
Благодаря поддержке асинхронных генераторов и итераторов в JavaScript, асинхронные генераторы фактически представляют собой первоклассную конструкцию потока на уровне языка.
Ниже приведены некоторые распространенные случаи взаимодействия потоков Node.js с асинхронными генераторами и асинхронными итераторами.
Использование читаемых потоков с помощью асинхронных итераторов¶
(async function () {
for await (const chunk of readable) {
console.log(chunk);
}
})();
Асинхронные итераторы регистрируют постоянный обработчик ошибок в потоке, чтобы предотвратить любые необработанные ошибки после уничтожения.
Создание читаемых потоков с помощью асинхронных генераторов¶
Читаемый поток Node.js может быть создан из асинхронного генератора с помощью Readable.from() служебный метод:
const { Readable } = require('stream');
const ac = new AbortController();
const signal = ac.signal;
async function* generate() {
yield 'a';
await someLongRunningFn({ signal });
yield 'b';
yield 'c';
}
const readable = Readable.from(generate());
readable.on('close', () => {
ac.abort();
});
readable.on('data', (chunk) => {
console.log(chunk);
});
Переход к доступным для записи потокам от асинхронных итераторов¶
При записи в доступный для записи поток из асинхронного итератора убедитесь, что корректная обработка обратного давления и ошибок. stream.pipeline() абстрагируется от обработки ошибок, связанных с противодавлением и противодавлением:
const fs = require('fs');
const { pipeline } = require('stream');
const {
pipeline: pipelinePromise,
} = require('stream/promises');
const writable = fs.createWriteStream('./file');
const ac = new AbortController();
const signal = ac.signal;
const iterator = createIterator({ signal });
// Callback Pattern
pipeline(iterator, writable, (err, value) => {
if (err) {
console.error(err);
} else {
console.log(value, 'value returned');
}
}).on('close', () => {
ac.abort();
});
// Promise Pattern
pipelinePromise(iterator, writable)
.then((value) => {
console.log(value, 'value returned');
})
.catch((err) => {
console.error(err);
ac.abort();
});
Совместимость со старыми версиями Node.js¶
До версии Node.js 0.10 Readable потоковый интерфейс был проще, но также менее мощным и менее полезным.
- Вместо того, чтобы ждать звонков в
stream.read()метод'data'события начнут излучаться немедленно. Приложениям, которым необходимо было бы выполнить некоторый объем работы, чтобы решить, как обрабатывать данные, требовалось хранить считанные данные в буферах, чтобы данные не были потеряны. - В
stream.pause()метод был рекомендательным, а не гарантированным. Это означало, что по-прежнему необходимо было быть готовым к получению'data'События даже когда поток был в приостановленном состоянии.
В Node.js 0.10 Readable класс был добавлен. Для обратной совместимости со старыми программами Node.js Readable потоки переходят в «текущий режим», когда 'data' обработчик событий добавлен, или когда stream.resume() вызывается метод. Эффект таков, что даже если вы не используете новый stream.read() метод и 'readable' событие, больше не нужно беспокоиться о потере 'data' куски.
Хотя большинство приложений продолжат нормально функционировать, это приводит к возникновению пограничного случая в следующих случаях:
- Нет
'data'добавлен слушатель событий. - В
stream.resume()метод никогда не вызывается. - Поток не передается ни в какое место назначения с возможностью записи.
Например, рассмотрим следующий код:
// WARNING! BROKEN!
net
.createServer((socket) => {
// We add an 'end' listener, but never consume the data.
socket.on('end', () => {
// It will never get here.
socket.end(
'The message was received but was not processed.n'
);
});
})
.listen(1337);
До версии Node.js 0.10 данные входящего сообщения просто отбрасывались. Однако в Node.js 0.10 и более поздних версиях сокет остается приостановленным навсегда.
Обходной путь в этой ситуации — вызвать stream.resume() метод для начала потока данных:
// Workaround.
net
.createServer((socket) => {
socket.on('end', () => {
socket.end(
'The message was received but was not processed.n'
);
});
// Start the flow of data, discarding it.
socket.resume();
})
.listen(1337);
Помимо новых Readable потоки переключаются в текущий режим, потоки в стиле до 0.10 могут быть обернуты в Readable класс с использованием readable.wrap() метод.
readable.read(0)¶
В некоторых случаях необходимо запустить обновление базовых механизмов читаемых потоков без фактического потребления каких-либо данных. В таких случаях можно позвонить readable.read(0), который всегда будет возвращаться null.
Если внутренний буфер чтения ниже highWaterMark, и поток в настоящее время не читает, затем вызывает stream.read(0) вызовет низкий уровень stream._read() вызов.
Хотя большинству приложений это почти никогда не понадобится, в Node.js бывают ситуации, когда это делается, особенно в Readable внутренности потокового класса.
readable.push('')¶
Использование readable.push('') не рекомендуется.
Нажимая строку с нулевым байтом, Buffer или Uint8Array к потоку, который не находится в объектном режиме, имеет интересный побочный эффект. Потому что является звонок в readable.push(), вызов завершит процесс чтения. Однако, поскольку аргумент является пустой строкой, данные в читаемый буфер не добавляются, поэтому пользователю нечего использовать.
highWaterMark расхождение после звонка readable.setEncoding()¶
Использование readable.setEncoding() изменит поведение того, как highWaterMark работает в необъектном режиме.
Обычно размер текущего буфера измеряется относительно highWaterMark в байты. Однако после setEncoding() вызывается, функция сравнения начнет измерять размер буфера в символы.
Это не проблема в обычных случаях с latin1 или ascii. Но рекомендуется помнить об этом поведении при работе со строками, которые могут содержать многобайтовые символы.
Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
#1 29 марта 2021 09:58:31

- Dyaka
- Участник
- Неактивен

- На форуме с 29 марта 2021
- Сообщений: 5
Тема: Ошибка Stream Read Error
Добрый день! Не нашел решения проблемы по данному вопросу. При входе в программу и выполнении любого действия у пользователя вылетает ошибка Stream read error. У остальных пользователей все нормально. Переустановка не помогает.
#2 Ответ от Олег Зырянов 29 марта 2021 10:07:56
- Олег Зырянов
- Технический руководитель
- Неактивен

- Откуда: Новосибирск
- На форуме с 10 декабря 2008
- Сообщений: 4,209
Re: Ошибка Stream Read Error
Здравствуйте! Запустите конфигурацию TechnologiCS с ключом /skipreg или удалите вручную *.cfg файлы https://help.technologics.ru/7.9/TCSHelp/_876.htm
Больше всего похожена это. Хотя. Что значит при выполнении любого действия? Программа то работает в итоге?
#3 Ответ от Dyaka 29 марта 2021 10:58:21
- Dyaka
- Участник
- Неактивен
- На форуме с 29 марта 2021
- Сообщений: 5
Re: Ошибка Stream Read Error
Олег Зырянов пишет:
Здравствуйте! Запустите конфигурацию TechnologiCS с ключом /skipreg или удалите вручную *.cfg файлы https://help.technologics.ru/7.9/TCSHelp/_876.htm
Больше всего похожена это. Хотя. Что значит при выполнении любого действия? Программа то работает в итоге?
Работает, пользователь логинится, но после каждого действия вылетает данная ошибка. Запуск с ключом и удаление .cfg файлов не помогло
#4 Ответ от Олег Зырянов 29 марта 2021 11:06:08
- Олег Зырянов
- Технический руководитель
- Неактивен
- Откуда: Новосибирск
- На форуме с 10 декабря 2008
- Сообщений: 4,209
Re: Ошибка Stream Read Error
А можно точную версию TechnologiCS , и более подробное описание того что просходит, послеlовательно по шагам.
В идеале чтобы шаги эти повторялись, а не были случайными. То есть делаем — ошибка. Еще раз делаем — та же ошибка. Перезапустили TCS, повторяем -снова ошибка эта.
#5 Ответ от Dyaka 29 марта 2021 11:17:06
- Dyaka
- Участник
- Неактивен
- На форуме с 29 марта 2021
- Сообщений: 5
Re: Ошибка Stream Read Error
Олег Зырянов пишет:
А можно точную версию TechnologiCS , и более подробное описание того что просходит, послеlовательно по шагам.
В идеале чтобы шаги эти повторялись, а не были случайными. То есть делаем — ошибка. Еще раз делаем — та же ошибка. Перезапустили TCS, повторяем -снова ошибка эта.
У пользователя версия 5.7.0.0. Я не большой эксперт этой программы, опишу, как могу. Пользователь логинится, программа загружается, пишет о новых сообщениях, закрываем окно, и вылетает окошко с ошибкой Stream read error. Пользователь его закрывает, делает любой отчет, макрос, ошибка снова вылетает, но действие выполняется. В целом, все работает, просто после каждого действия пользователя с момента входа вылетает окошко с ошибкой.
#6 Ответ от Олег Зырянов 29 марта 2021 11:28:08
- Олег Зырянов
- Технический руководитель
- Неактивен
- Откуда: Новосибирск
- На форуме с 10 декабря 2008
- Сообщений: 4,209
Re: Ошибка Stream Read Error
Можно еще скриншот ошибки.
И… Если пользователье ничего не делает, просто откроет справочник на просмотр, ну и допустим просто иногда открывает форму редактирования, ничего не меняет, закрывает (то есть режим просмотр). Ошибка будет?
#7 Ответ от Dyaka 29 марта 2021 11:39:40 (изменено: , 29 марта 2021 11:39:40)
- Dyaka
- Участник
- Неактивен
- На форуме с 29 марта 2021
- Сообщений: 5
Re: Ошибка Stream Read Error
Олег Зырянов пишет:
Можно еще скриншот ошибки.
И… Если пользователье ничего не делает, просто откроет справочник на просмотр, ну и допустим просто иногда открывает форму редактирования, ничего не меняет, закрывает (то есть режим просмотр). Ошибка будет?
Извиняюсь за качество, как прислали мне. После закрытия окна ошибки и простого просмотра форм ошибка не возникает. Когда пользователь подписывает какой-то документ она снова появляется. При этом документ подписывается (последнее со слов пользователя).
Олег Зырянов пишет:
Можно еще скриншот ошибки.
И… Если пользователье ничего не делает, просто откроет справочник на просмотр, ну и допустим просто иногда открывает форму редактирования, ничего не меняет, закрывает (то есть режим просмотр). Ошибка будет?
Post’s attachments
image0011.jpg
image0011.jpg 27.33 Кб, 6 скачиваний с 2021-03-29
You don’t have the permssions to download the attachments of this post.
#8 Ответ от Олег Зырянов 30 марта 2021 08:11:54
- Олег Зырянов
- Технический руководитель
- Неактивен
- Откуда: Новосибирск
- На форуме с 10 декабря 2008
- Сообщений: 4,209
Re: Ошибка Stream Read Error
А скажите еще полную версию. До билда.
В 5.7 была нехорошая ошибка,правда вряд ли она бы так проявлялась, но все же.
#9 Ответ от Dyaka 30 марта 2021 14:29:37
- Dyaka
- Участник
- Неактивен
- На форуме с 29 марта 2021
- Сообщений: 5
Re: Ошибка Stream Read Error
Олег Зырянов пишет:
А скажите еще полную версию. До билда.
В 5.7 была нехорошая ошибка,правда вряд ли она бы так проявлялась, но все же.
10968
#10 Ответ от Олег Зырянов 30 марта 2021 15:32:51
- Олег Зырянов
- Технический руководитель
- Неактивен
- Откуда: Новосибирск
- На форуме с 10 декабря 2008
- Сообщений: 4,209
Re: Ошибка Stream Read Error
Есть новее на сайте, но не критично наверное http://www.technologics.ru/download/addition/v5.html.
Давайте еще версию операционной системы и содержимое файла csdn.ini (тот что в папке программы и тот что в профиле пользователя — точно не подскажу, 5.7 старая и как она точно работает уже мало кто помнит)
Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
Ошибка Stream Read Error возникает, когда серверу приложений ЛОЦМАН не достаточно памяти для того, чтобы вернуть все объекты в базу данных.
Если после возникновения ошибки открыть диспетчер задач, то можно увидеть, что скорее всего использованы все доступные ресурсы оперативной и виртуальной памяти. Проблема скорее системная.
Сервер приложений ЛОЦМАН:PLM не ограничивает размер сохраняемого файла.
Существует ограничение ADO/OLEDB (интерфейс MS SQL Server): при работе с файлами требуется
НЕПРЕРЫВНЫЙ БЛОК ПАМЯТИ РАЗМЕРА СООТВЕТСТВУЮЩЕГО ФАЙЛУ
, который не всегда доступен в системе (даже небольшого размера) — это зависит от степени фрагментированности оперативной памяти.
При использовании Файлового архива это ограничение не действует,
В СУБД Oracle описанная проблема не возникает.
В том случае, если ошибка возникает при наличии файлового архива, в первую очередь необходимо проверить наличие свободного места в архиве.
Свободное место, доступное для файлового архива указано в ЦУК:
Файловые архивы — [имя файлового архива] справа в информационной области.
Объем памяти, свободный в архиве, и объем памяти доступный на ресурсе где расположен архив не одно и то же!
Так, под архив может быть выделено 50Гб, а на диске свободно 500Гб.
Архив сможет использовать только выделенные ему 50Гб, не зависимо от того, сколько памяти доступно на диске.
Например, в архиве доступно 0,008 Мб, при сохранении файла объемом 30Мб возникает ошибка
Out of memory, Error creating variant or safe array.
Необходимо открыть свойства файлового архива и увеличить максимальный размер архива, в зависимости от потребностей.
Рекомендации по избежанию проблемы:
-
Используйте файловый архив.
Перенесите файлы из базы данных в него.
Для хранения большого объема файлов лучше использовать файловый архив, а не таблицы базы данных.
Подробнее о создании и о работе с файловыми архивами описано в справке на ЦУК/ЛОЦМАН Администратор. - Старайтесь чаще сохранять информацию в БД малыми порциями, тогда вероятность появления упомянутой ошибки снизится.
- Установка дополнительных модулей оперативной памяти на машине, где работает сервер приложений ЛОЦМАН.
Часто задаваемые вопросы Гранд-Смета
Посмотреть номер ключа/версию ГрандСметы
1) В мобильном Гранде:

2) В программе, выбрав Файл > Справка

[свернуть]
Посмотреть версию ГрандСметы
1) При запуске программы:

2) В программе выбрав Файл > Справка

[свернуть]
Не запускается ГрандСмета флеш: сообщений об ошибке нет
Судя по всему, поврежден исполняемый файл программы. Чаще всего «по вине» вируса или Антивируса.
Нужно:
1) Посмотреть текущую версию файла> :GrandGrandSmetaClientGSmeta.exe – правой кнопкой «Свойства» > Подробно

2) Файлы нужной версии загрузить поверх испорченных из шаблона:
Z:!GrandТехПоддержка-СправкаОШИБКИ
3) добавить в доверенною зону антивируса папки с ГрандСметой:
:Grand и :Support
4) Проверить работу программы
5) Открыть «Диспетчер задач» и убрать все задачи связанные с ГС. Проверить работу.
[свернуть]
Не запускается ГрандСмета флеш: есть сообщения об ошибке
Меры предпринимаются, в зависимости от сообщения об ошибки
[свернуть]
Как запустить TeamViewer?
1. Из поставки Гранд-Смета (если она у клиента есть):
ПРОФ: Пуск → Все программы → Центр Гранд → Тех поддержка → МГК Гранд → Получить ID клиента «пароль 9393».
ФЛЭШ: Мой компьютер → флэш носитель → support → TeamViewer → Тех поддержка МГК Гранд→ Запустить TeamViewer→ Узнать ID→ Пароль → Подключение к клиенту.
2. На нашем официальном сайте avicentr.ru:
На каждой странице нашего сайта, в правом нижнем углу есть синий прямоугольник:

3. На официальном сайте TeamViewer: https://www.teamviewer.com/ru/download/previous-versions/
4. Если с TeamViewer что-то не работает, есть возможность воспользоваться программой Ammyy Admin скачав ее с официального сайта: http://www.ammyy.com/ru/

[свернуть]
Как определить куда установлена Гранд-смета ПРОФ?
На ярлыке> Правой кнопкой мыши> Свойства > Ярлык > Расположение файла

[свернуть]
Как определить где папка с данными программы (лицензиями и пр.)?
Пуск> Все программы> Центр Гранд> Открыть папку с данными Клиента Гранд-Сметы.
[свернуть]
Подключить ССЦ (справочник средних сметных цен) в Гранд-Смета
1) извлечь содержимое архива с лицензиями, который находится во вложении к письму, отправленному клиенту:
ПРОФ: C:ProgramDataGrandGrandSmeta 7ClientLic и C:ProgramDataGrandInfoLic
Уточнить можно в разделе [Как определить где папка с данными программы (лицензиями и пр.)?]
ФЛЕШ: :GrandGrandSmetaClientLic
2) Скачать сборники в формате Гранд-Сметы, с официального сайта: http://grandsmeta.ru/download?folder=grandsmeta%2Fregion
3) Открыть и начать использовать сборники, согласно инструкции:
Загрузка цен из ценника: http://help.grandsmeta.ru/?p=31091&sphrase_id=100871
[свернуть]
Как загрузить обновления программы и нормативных баз (СНБ)?
Загрузить обновления можно через менеджер обновлений Гранд: как лицензии так и нормативные базы.
Также можно установить ТЕР Крыма по-старинке:
1) извлечь содержимое архива с лицензиями, который находится во вложении к письму в папки
ПРОФ: C:ProgramDataGrandGrandSmeta 7ClientLic и C:ProgramDataGrandInfoLic
Уточнить можно в разделе [Как определить где папка с данными программы (лицензиями и пр.)?]
ФЛЕШ: :GrandGrandSmetaClientLic
2) Скачать файл ТЕР Крыма в формате Гранд-Сметы, с официального сайта и распаковать его в
ПРОФ: C:ProgramDataGrandGrandSmeta 7ClientData и C:ProgramDataGrandStroyInfo 5data
Уточнить можно в разделе [Как определить где папка с данными программы (лицензиями и пр.)?]
ФЛЕШ: :GrandGrandSmetaClientData и :GrandStroyInfodata
3) Подключить СНБ ТЕР Крыма: Файл > Выбор региона.
[свернуть]
Как переключить нормативную базу(СНБ)?
После запуска ГрандСметы: Файл > Выбор региона.
[свернуть]
Если выдается сообщение Stream Read Error
Если выдается сообщение Stream Read Error?
Судя по всему, повреждены файл программы нормативных баз. Чаще всего «по вине» вируса или Антивируса.
В общем случае достаточно:
1) Очистить папку с СНБ
ПРОФ: C:ProgramDataGrandGrandSmeta 7ClientData и C:ProgramDataGrandStroyInfo 5data
Уточнить можно в разделе [Как определить где папка с данными программы (лицензиями и пр.)?]
ФЛЕШ: :GrandGrandSmetaClientData и :GrandStroyInfodata
2) Загрузить обновления программы и нормативных баз(СНБ)?
3) добавить в доверенною зону антивируса папки с ГрандСметой:
:Grand и :Support
4) Проверить работу программы
[свернуть]
Ключ очень сильно греется на Win10
ВОПРОС: У меня домашняя версия «ГРАНД-Сметы», флеш. На ноутбуке программа не хочет работать, зависает и вылетает. Ключ очень сильно греется. На ноутбуке стоит Windows 10, даже когда стояла Windows 8, «ГРАНД-Смета» тоже вылетала, но не сразу, а спустя какое-то время. На компьютере установлена Windows 7, там «ГРАНД-Смета» работает без проблем: и ключ не греется так сильно, и программа не вылетает. У меня разъездной характер работы, постоянно приходится работать на ноутбуке. Но вот возникают проблемы. С чем это может быть связано? Юлия
ОТВЕТ: На ноутбуке добавьте программу и все ее данные (папки C:ProgramDataGrandGrandSmeta 7Client и C:Users<имя пользователя>AppDataRoamingGrandGrandSmeta 7ClientAutosave) в исключения антивируса. Либо, если антивируса нет, то в исключения и в доверенные Защитника Windows.
[свернуть]
Самопроизвольное закрытие Гранда
ВОПРОС: Используем версию 7.0.2.11731. В последнее время значительно обострилась проблема самопроизвольного закрытия сметного программного комплекса. Программа с пугающей периодичностью (раз в 10–15 мин.) либо самопроизвольно закрывается, либо отказывается сохранить изменения при попытках самостоятельно закрыть программу с выдачей следующего сообщения: «Не удается получить доступ к файлу «…». …
ОТВЕТ: Проверьте ваш ПК на вирусы + проверьте права на запись в папку C:Users<имя пользователя>AppDataRoamingGrandGrandSmeta 7ClientAutosave. Убедитесь, что данная папка пустая, в противном случае обратитесь к вашему системному администратору для восстановления настроек Windows.
[свернуть]
Системе не удается найти указанный путь – при запуске ГС
У клиента при запуске ГС выдается сообщение:
Проблема при подключении к данным: Установка соединения: Сметы Гранд (адрес: “G:Сметы Гранд”….
System Error. Code: 3
Системе не удается найти указанный путь
Ошибка означает, что у клиента в настройках подключения Файл > Установки > Подключения добавлена папка с указанием буквы диска «G:Сметы Гранд», а при подключении ГС, буква диска изменилась.
Решение: Убрать букву диска из Файл > Установки > Подключения

[свернуть]
Добавление «папки» в дерево программы ГС
Запускаем программу ГС Файл Установки Подключения Клик правой кнопки мыши Добавить папку Выбираем путь Нажимаем «Ок».
[свернуть]
Замена файла dll для исправления ошибки запуска
– Проходим по пути: F:GrandGrandSmetaClient
– ищем файл: gdiplus.dll, GsSysInfo.dll. Изменяем название (Не удаляем).
– Новые файлы “dll” мы берем с рабочей версии по тому же пути: F:GrandGrandSmetaClient.
[свернуть]
Не запускаются ТЕРс в ГС
Установил лицензию в папку : Grand GrandSmeta Client Lic.
– Скачал ТЕРс с сайта ГС за указанный период.
– Установил ТЕРс в папку Data.
-Перезагрузил программу.
[свернуть]
Ошибка (File corrupted) или файл поврежден
Решение:
– Замена файлов «dll» и exe в папке : Grand GrandSmeta Client.
– Перезагрузка программы.
[свернуть]
Не запускается ГС на Win 10
Причина – отсутствие папки с драйверами Guardant (В ней содержатся драйвера устройства).
Решение: Установить в корневую папку, папку «Guardant» с файлами из такой же версии.
[свернуть]
ГС флеш на Win 10: видится ключ, но не gjl
Причина – Win10 требует обновления.
Решение: Установить Обновления Win10
[свернуть]
Не запускается Гранд Старт Мубаил
Скачать файл менеджер обновление по ссылке http://update.grandsmeta.ru/
Установить «Менеджер Обновлений» на носитель ГС.
[свернуть]
Сборка дистрибутива для установки ГС
1) Нужные файлы.
– Скачать дистрибутив с нужной версией с сайта http://www.grandsmeta.ru/.
– Скачать кумулятивную базу ГрандСтройИнфо по ссылке http://www.grandsmeta.ru/download?folder=grandstroyinfo.
– Скачать сборники ТСНБ с сайта http://www.grandsmeta.ru/ в разделе базы.
2) Сборка дистрибутива.
– Кумулятивную базу расположить в дистрибутиве по пути distrib_7._._. InfoData.
– Базу ТСНБ, ТЕР, ТЕРс, расположить в папку distrib_7_._. SmetaClientData.
[свернуть]
Некорректная работа файла лицензии
– Решение:
1) Загрузить обновления по базам (автоматическое обновление лицензий).
2) Достать рабочую лицензию из ранее присланного набора лицензий и заменить ее в папке Grand GrandSmeta Client Lic. Заказать лицензию по номеру ключа у поставщика ГС.
[свернуть]
Существующие виды индексов
1) К СМР (прогнозные, одной цифрой) – ежеквартально публикуются в письме МинСтроя РФ, на сайте: http://www.minstroyrf.ru/docs/
Все наши клиенты получают рассылку с уведомлением о выходе новых писем. Вы получаете нашу рассылку?
2) По статьям затрат (к заработной плате, материалам, эксплуатации машин и механизмов)
• видам строительства – публикуется:
a. в Вестнике ЦО(платно) – рассчитывается в мск., рекомендовано для использования при фед.финансировании.
b. на сайте РЦЦС Крыма (бесплатно): http://gaurccs.ru/
c. на сайте РЦЦС Севастополя (бесплатно): http://sevstroycena.ru/
• разделам сметной документации.
3) По статьям затрат ПОСТРОЧНЫЕ видам работ:
a. в формате сметного комплекса – максимально удобный вариант особенно в части обновления индексов на новый квартал
b. на сайте РЦЦС Крыма (бесплатно): http://gaurccs.ru/
c. на сайте РЦЦС Севастополя (бесплатно): http://sevstroycena.ru/
обновления по базам (автоматическое обновление лицензий).
[свернуть]
Обновление «Справочники, используемые в ПК ГРАНД-Смета»
1) Скачать нужный справочник с сайта ГС http://www.grandsmeta.ru/download?folder=grandsmeta%2Flocalsetting
2) Заменить справочники через поиск по программе ГС.
[свернуть]
Если диск защищен от записи

1) Вызываем командную строку, прописываем regedit.
2) Проходим по пути: HKEY_LOCAL_MACHINE SYSTEM CurrentControlSet Control StorageDevicePolicies.
3) Открываем файл WriteProtect, заменяем значение с 1 на 0.

4) Если такого раздела нет, то кликните правой кнопкой мыши по разделу, находящемуся на уровень выше (Control) и выберите «Создать раздел». Назовите его StorageDevicePolicies и выберите его.

5) Затем кликните правой кнопкой мыши в пустой области справа и выберите пункт «Параметр DWORD» (32 или 64 бита, в зависимости от разрядности вашей системы). Назовите его WriteProtect и оставьте значение равным 0. Также, как и в предыдущем случае, закройте редактор реестра, извлеките USB накопитель и перезагрузите компьютер. После чего можно проверить, сохранилась ли ошибка.
[свернуть]
Переустановка ПК ГРАНД-Смета»
Prof версия:
При переустановки Windows:
1)Сохранить файлы со сметами (на съёмный носитель) по пути C:UsersDocumentsГранд-СметаМои сметы.
2)После переустановки Windows скачать установочный файл доступной вам версии по ссылке http://www.grandsmeta.ru/download?folder=grandsmeta%2Fdistrib (Полный дистрибутив ПК ГРАНД-Смета версии7._._.)
3)Разархивировать файл.
4) Запустить «GrandSetup» для начала установки.
5) После начала установки нажимаем «ДА», «Далее», «я принимаю условия соглашения»- «далее».
6) Выбираем тип установки стационарный и нажимает «далее», «далее», «установить», программа начнет устанавливаться на ваш ПК.
[свернуть]
Установка баз ПК ГРАНД-Смета 8 Prof версия.
Для установки баз в Prof версию ГС необходимо:
1) Скачать необходимые базы по ссылке http://www.grandsmeta.ru/download?folder=grandsmeta%2Fdata%2F2014.
2) Распаковать базы.
3) Через меню «Пуск» (В нижнем левом углу экрана) открыть все программы и найти «Центр Гранд».
4) Открыть «Центр Гранд»> Открыть папку с данными клиента> Data.
5) В папку «Data» положить распакованную ранее базу.
6) Запускаем программу и проверяем работу.
[свернуть]
При конфликте при использовании одной папки Мои базы, в разных версиях Гранда
Можно:
1) удалить все базы из папки Мои Базы
2) или удалить папки:Settings, History из
C:Documents and SettingsUserApplication DataGrandGrandSmeta 8Client
C:Documents and SettingsUserApplication DataGrandGrandSmeta 7Client
[свернуть]