Знакомимся с вектором
Основы линейной алгебры для тех, кого это миновало в универе.
Вы наверняка слышали много историй о программистах, которые учились в технических вузах, изучали высшую математику и теперь пользуются этими знаниями в программировании. И если кого-то это не коснулось, может быть ощущение, что он пропустил в жизни что-то важное.
Будем это исправлять. Попробуем разобрать некоторые базовые понятия из математики за пределами школьной программы. И заодно покажем, как оно связано с программированием и для каких задач полезно.
⚠️ Математики, помогайте. Мы тут многое упростили, поэтому будем рады увидеть ваши уточнения и замечания в комментариях.
Линейная алгебра
Есть математика: она изучает абстрактные объекты и их взаимосвязи. Благодаря математике мы знаем, что если сложить два объекта с ещё двумя такими же объектами, то получится четыре объекта. И неважно, что это были за объекты: яблоки, козы или ракеты. Математика берёт наш вещественный мир и изучает его более абстрактные свойства.
Внутри математики есть алгебра: если совсем примитивно, то в алгебре мы вместо чисел начинаем подставлять буквы и изучать ещё более абстрактные свойства объектов.
Например, мы знаем, что если a + b = c , то a = c − b . Мы не знаем, что стоит на местах a, b или c, но для нас это такой абстрактный закон, который подтверждается практикой.
Внутри алгебры есть линейная алгебра — она изучает векторы, векторные пространства и другие абстрактные понятия, которые в целом относятся к некой упорядоченной информации. Например, координаты ракеты в космосе, биржевые котировки, расположение пикселей в изображении — всё это примеры упорядоченной информации, которую можно описывать векторами. И вот их изучает линейная алгебра.
В программировании линейная алгебра нужна в дата-сайенс, где из упорядоченной информации создаются алгоритмы машинного обучения.
Если представить линейную алгебру в виде дома, то вектор — это кирпич, из которого всё состоит. Сегодня разберёмся, что такое вектор и как его понимать.
Что такое вектор
Вы наверняка помните вектор из школьной программы — это такая стрелочка. Она направлена в пространство и измеряется двумя параметрами: длиной и направлением. Пока длина и направление не меняются, вектор может перемещаться в пространстве.
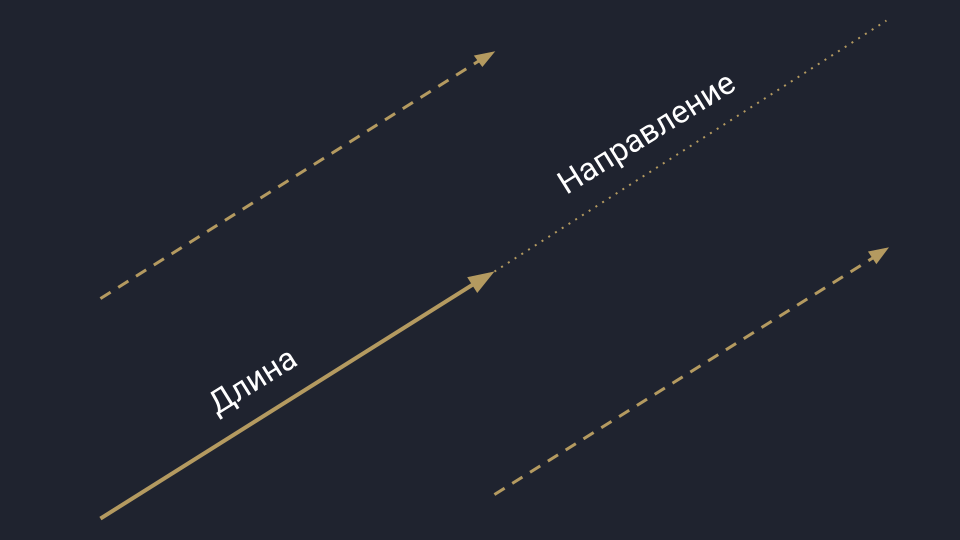 Физическое представление вектора: есть длина, направление и нет начальной точки отсчёта. Такой вектор можно как угодно двигать в пространстве
Физическое представление вектора: есть длина, направление и нет начальной точки отсчёта. Такой вектор можно как угодно двигать в пространстве
У аналитиков вектор представляется в виде упорядоченного списка чисел: это может быть любая информация, которую можно измерить и последовательно записать. Для примера возьмём рынок недвижимости, который нужно проанализировать по площади и цене домов — получаем вектор, где первая цифра отвечает за площадь, а вторая — за цену. Аналогично можно сортировать любые данные.
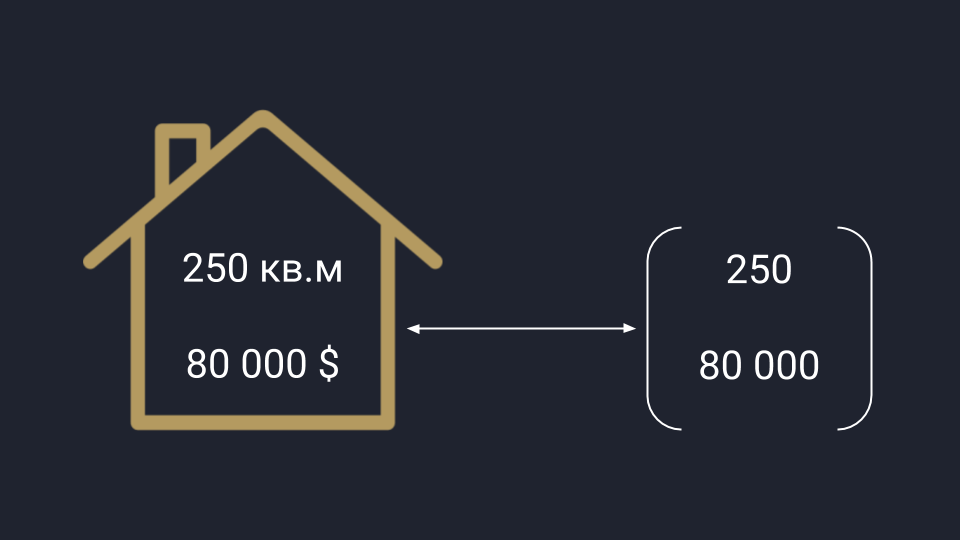 Аналитическое представление вектора: данные можно перевести в числа
Аналитическое представление вектора: данные можно перевести в числа
Математики обобщают оба подхода и считают вектор одновременно стрелкой и числом — это связанные понятия, перетекающие друг в друга в зависимости от задачи. В одних случаях удобней считать, а в других — показать всё графически. В обоих случаях перед нами вектор.
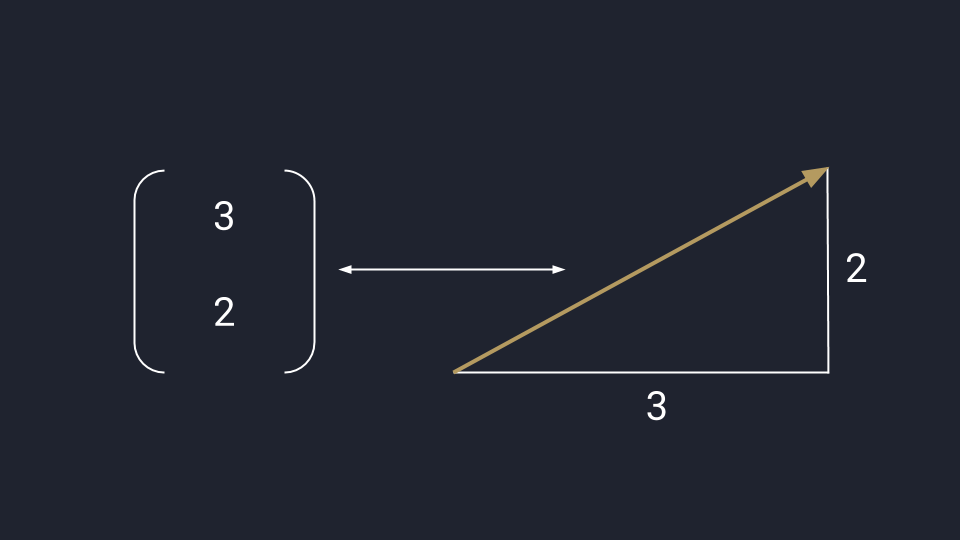 Математическое представление вектора: данные можно перевести в числа или график
Математическое представление вектора: данные можно перевести в числа или график
В дата-сайенс используется математическое представление вектора — программист может обработать данные и визуализировать результат. В отличие от физического представления, стрелки векторов в математике привязаны к системе координат Х и У — они не блуждают в пространстве, а исходят из нулевой точки.
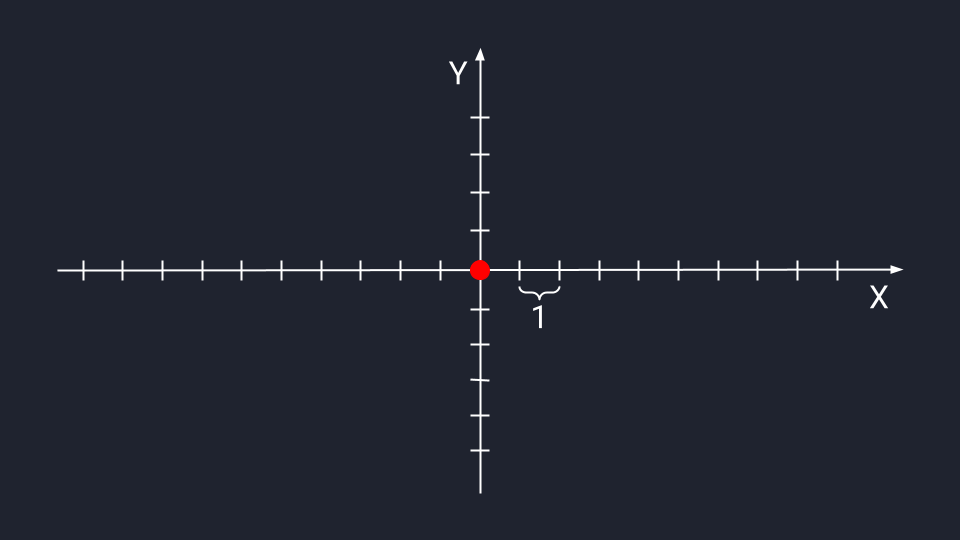 Векторная система координат с базовыми осями Х и Y. Место их пересечения — начало координат и корень любого вектора. Засечки на осях — это отрезки одной длины, которые мы будем использовать для определения векторных координат
Векторная система координат с базовыми осями Х и Y. Место их пересечения — начало координат и корень любого вектора. Засечки на осях — это отрезки одной длины, которые мы будем использовать для определения векторных координат
👉 Получается, вектор – это такой способ записывать, хранить и обрабатывать не одно число, а какое-то организованное множество чисел. Благодаря векторам мы можем представить это множество как единый объект и изучать его взаимодействие с другими объектами.
Например, можно взять много векторов с ценами на недвижимость, как-то их проанализировать, усреднить и обучить на них алгоритм. Без векторов это были бы просто «рассыпанные» данные, а с векторами — порядок.
Как записывать
Вектор можно записать в строку или в столбец. Для строчной записи вектор обозначают одной буквой, ставят над ней черту, открывают круглые скобки и через запятую записывают координаты вектора. Для записи в столбец координаты вектора нужно взять в круглые или квадратные скобки — допустим любой вариант.
Строгий порядок записи делает так, что каждый набор чисел создаёт только один вектор, а каждый вектор ассоциируется только с одним набором чисел. Это значит, что если у нас есть координаты вектора, то мы их не сможем перепутать.
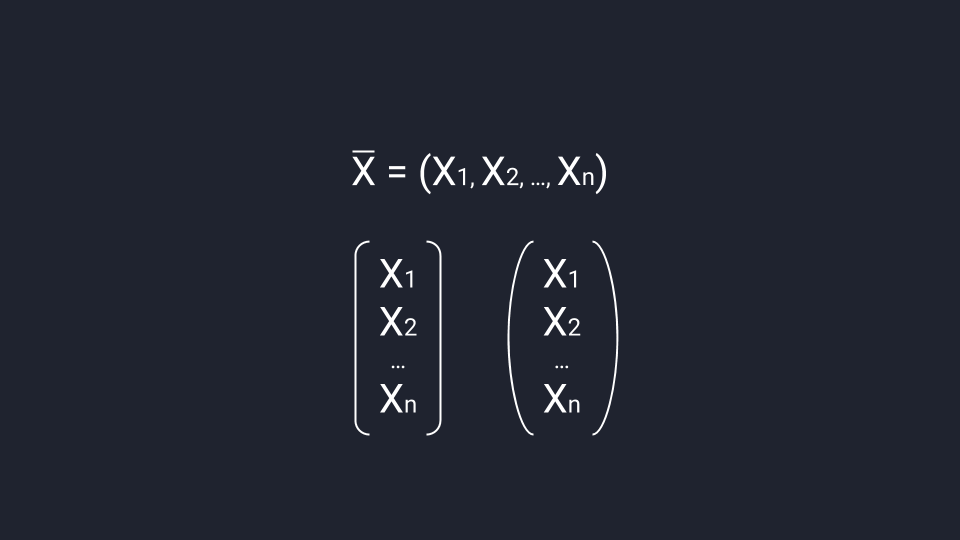 Способы записи вектора
Способы записи вектора
Скаляр
Помимо понятия вектора есть понятие скаляра. Скаляр — это просто одно число. Можно сказать, что скаляр — это вектор, который состоит из одной координаты.
Помните физику? Есть скалярные величины и есть векторные. Скалярные как бы описывают просто состояние, например, температуру. Векторные величины ещё и описывают направление.
Как изображать
Вектор из одного числа (скаляр) отображается в виде точки на числовой прямой.
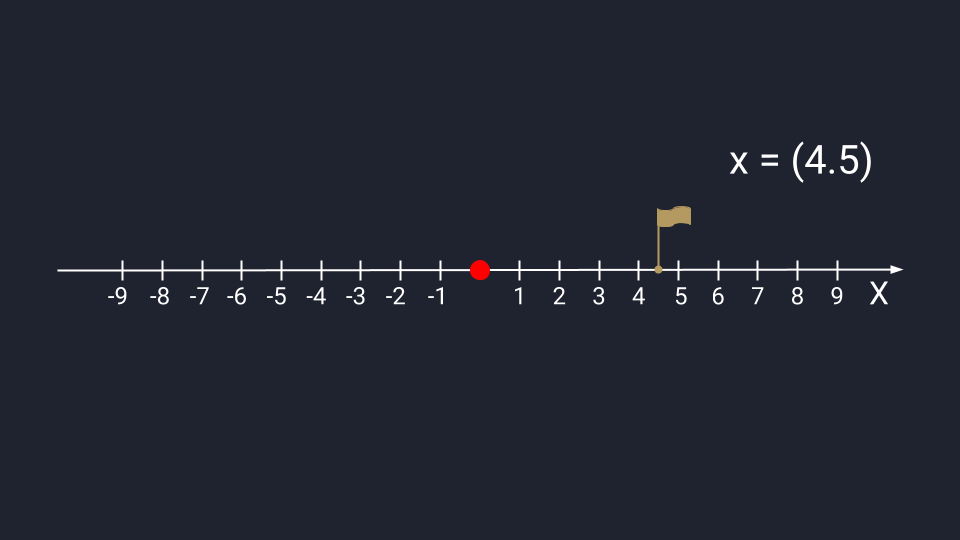 Графическое представление скаляра. Записывается в круглых скобках
Графическое представление скаляра. Записывается в круглых скобках
Вектор из двух чисел отображается в виде точки на плоскости осей Х и Y. Числа задают координаты вектора в пространстве — это такая инструкция, по которой нужно перемещаться от хвоста к стрелке вектора. Первое число показывает расстояние, которое нужно пройти вдоль оси Х; второе — расстояние по оси Y. Положительные числа на оси Х обозначают движение вправо; отрицательные — влево. Положительные числа на оси Y — идём вверх; отрицательные — вниз.
Представим вектор с числами −5 и 4. Для поиска нужной точки нам необходимо пройти влево пять шагов по оси Х, а затем подняться на четыре этажа по оси Y.
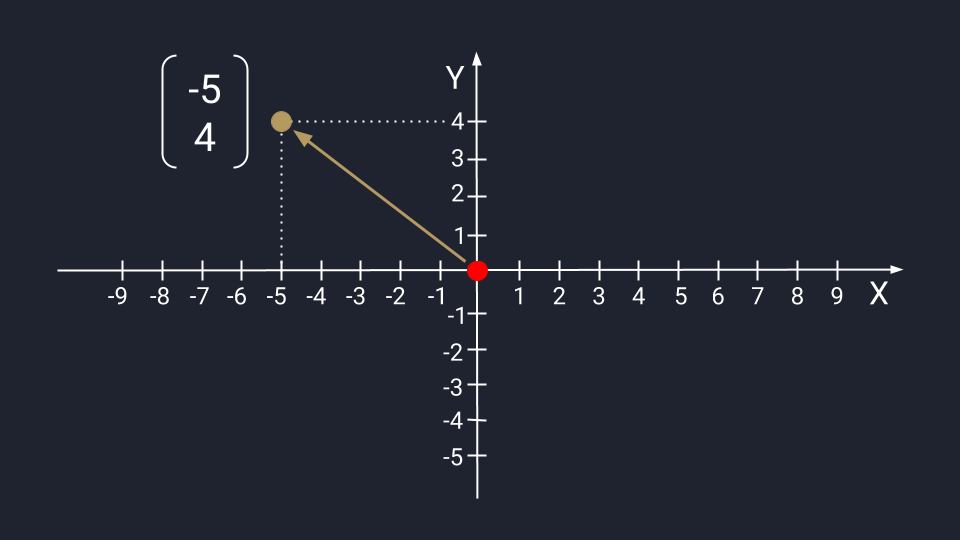 Графическое представление числового вектора в двух измерениях
Графическое представление числового вектора в двух измерениях
Вектор из трёх чисел отображается в виде точки на плоскости осей Х, Y и Z. Ось Z проводится перпендикулярно осям Х и У — это трёхмерное измерение, где вектор с упорядоченным триплетом чисел: первые два числа указывают на движение по осям Х и У, третье — куда нужно двигаться вдоль оси Z. Каждый триплет создаёт уникальный вектор в пространстве, а у каждого вектора есть только один триплет.
Если вектор состоит из четырёх и более чисел, то в теории он строится по похожему принципу: вы берёте координаты, строите N-мерное пространство и находите нужную точку. Это сложно представить и для обучения не понадобится.
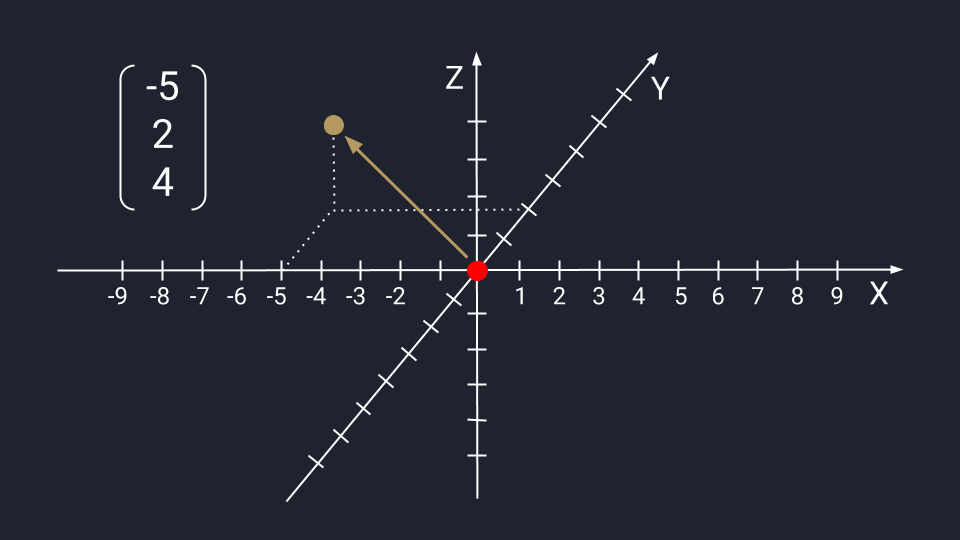 Графическое представление числового вектора в трёх измерениях. Для примера мы взяли координаты −5, 2, 4
Графическое представление числового вектора в трёх измерениях. Для примера мы взяли координаты −5, 2, 4
Помните, что все эти записи и изображения с точки зрения алгебры не имеют отношения к нашему реальному трёхмерному пространству. Вектор — это просто какое-то количество абстрактных чисел, собранных в строгом порядке. Вектору неважно, сколько там чисел и как их изображают люди. Мы же их изображаем просто для наглядности и удобства.
Например, в векторе спокойно может быть 99 координат. Для его изображения нам понадобилось бы 99 измерений, что очень проблематично на бумаге. Но с точки зрения вектора это не проблема: перемножать и складывать векторы из двух координат можно так же, как и векторы из 9999999 координат, принципы те же.
И зачем нам это всё
Вектор — это «кирпичик», из которого строится дата-сайенс и машинное обучение. Например:
- На основании векторов получаются матрицы. Если вектор — это как бы линия, то матрица — это как бы плоскость или таблица.
- Машинное обучение в своей основе — это перемножение матриц. У тебя есть матрица с данными, которые машина знает сейчас; и тебе нужно эту матрицу «дообучить». Ты умножаешь существующую матрицу на какую-то другую матрицу и получаешь новую матрицу. Делаешь так много раз по определённым законам, и у тебя обученная модель, которую на бытовом языке называют искусственным интеллектом.
Кроме того, векторы используются в компьютерной графике, работе со звуком, инженерном и просто любом вычислительном софте.
И давайте помнить, что вектор — это не какая-то сложная абстрактная штука, а просто сумка, в которой лежат числа в определённом порядке. То, что мы называем это вектором, — просто нюанс терминологии.
Что дальше
В следующий раз разберём операции с векторами. Пока мы готовим материал — рекомендуем почитать интервью с Анастасией Никулиной. Анастасия ведёт ютуб-канал по дата-сайнс и работает сеньором дата-сайентистом в Росбанке.
Линейная алгебра для разработчиков игр
Эта статья является переводом цикла из четырёх статей «Linear algebra for game developers», написанных David Rosen и посвящённых линейной алгебре и её применению в разработке игр. С оригинальными статьями можно ознакомиться тут: часть 1, часть 2, часть 3 и часть 4. Я не стал публиковать переводы отдельными топиками, а объединил все статьи в одну. Думаю, что так будет удобнее воспринимать материал и работать с ним. Итак приступим.
Зачем нам линейная алгебра?
Одним из направлений в линейной алгебре является изучение векторов. Если в вашей игре применяется позиционирование экранных кнопок, работа с камерой и её направлением, скоростями объектов, то вам придётся иметь дело с векторами. Чем лучше вы понимаете линейную алгебру, тем больший контроль вы получаете над поведением векторов и, следовательно, над вашей игрой.
Что такое вектор?
В играх вектора используются для хранения местоположений, направлений и скоростей. Ниже приведён пример двухмерного вектора: 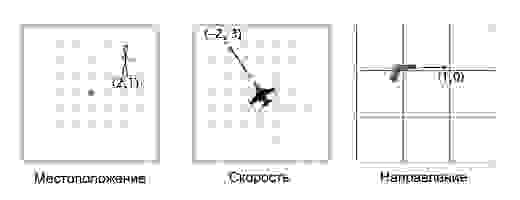
Вектор местоположения (также называемый «радиус-вектором») показывает, что человек стоит в двух метрах восточнее и в одном метре к северу от исходной точки. Вектор скорости показывает, что за единицу времени самолёт перемещается на три километра вверх и на два — влево. Вектор направления говорит нам о том, что пистолет направлен вправо.
Как вы можете заметить, вектор сам по себе всего лишь набор цифр, который обретает тот или иной смысл в зависимости от контекста. К примеру, вектор (1, 0) может быть как направлением для оружия, как показано на картинке, так и координатами строения в одну милю к востоку от вашей текущей позиции. Или скоростью улитки, которая двигается вправо со скоростью в 1 милю в час (прим. переводчика: довольно быстро для улитки, 44 сантиметра в секунду).
Важно отслеживать единицы измерения. Допустим у нас есть вектор V (3,5,2). Это мало что говорит нам. Три чего, пять чего? В нашей игре Overgrowth расстояния указываются в метрах, а скорости в метрах в секунду. Первое число в этом векторе — это направление на восток, второе — направление вверх, третье — направление на север. Отрицательные числа обозначают противоположные направления, на запад, вниз и на юг. Местоположение, определяемое вектором V (3,5,2), находится в трёх метрах к востоку, в пяти метрах вверху и в двух метрах к северу, как показано на картинке ниже.
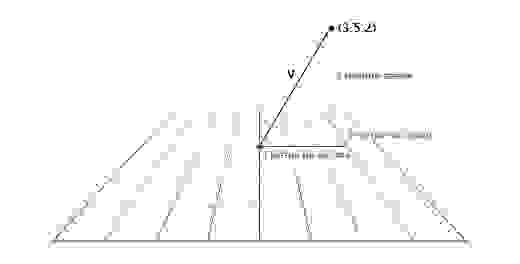
Итак, мы изучили основы работы с векторами. Теперь узнаем как вектора использовать.
Сложение векторов
Чтобы сложить вектора, нам надо просто сложить каждую их составляющую друг с другом. Например:
(0, 1, 4) + (3, -2, 5) = (0+3, 1-2, 4+5) = (3, -1, 9)
Зачем нам нужно складывать вектора? Наиболее часто сложение векторов в играх применяется для физического интегрирования. Любой физический объект будет иметь вектора для местоположения, скорости и ускорения. Для каждого кадра (обычно это одна шестидесятая часть секунды), мы должны интегрировать два вектора: добавить скорость к местоположению и ускорение к скорости.
Давайте рассмотрим пример с прыжками Марио. Он начинает с позиции (0, 0). В момент начала прыжка его скорость (1, 3), он быстро двигается вверх и вправо. Его ускорение равно (0, -1), так как гравитация тянет его вниз. На картинке показано, как выглядит его прыжок, разбитый на семь кадров. Чёрным текстом показана его скорость в каждом фрейме.
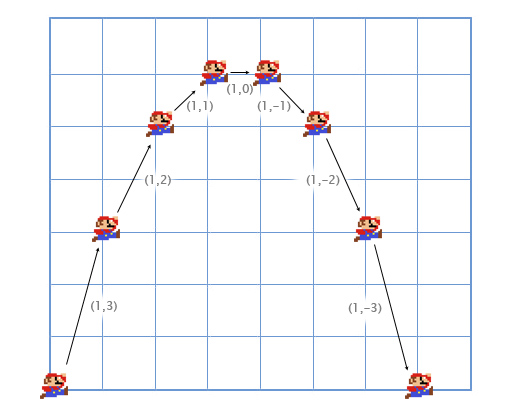
Давайте рассмотрим первые кадры поподробнее, чтобы понять как всё происходит.
Для первого кадра, мы добавляем скорость Марио (1, 3) к его местоположению (0, 0) и получаем его новые координаты (1, 3). Затем мы складываем ускорение (0, -1) с его скоростью (1, 3) и получаем новое значение скорости Марио (1, 2).
Делаем то-же самое для второго кадра. Добавляем скорость (1, 2) к местоположению (1, 3) и получаем координаты (2, 5). Затем добавляем ускорение (0, -1) к его скорости (1, 2) и получаем новую скорость (1, 1).
Обычно игрок контролирует ускорение игрового персонажа с помощью клавиатуры или геймпада, а игра, в свою очередь, рассчитывает новые значения для скоростей и местоположения, используя физическое сложение (через сложение векторов). Это та-же задача, которая решается в интегральном исчислении, просто мы его сильно упрощаем для нашей игры. Я заметил, что мне намного проще внимательно слушать лекции по интегральному исчислению, думая о практическом его применении, которое мы только что описали.
Вычитание векторов
Вычитание рассчитывается по тому-же принципу что и сложение — вычитаем соответствующие компоненты векторов. Вычитание векторов удобно для получения вектора, который показывает из одного местоположения на другое. Например, пусть игрок находится по координатам (1, 2) с лазерным ружьём, а вражеский робот находится по координатам (4, 3). Чтобы определить вектор движения лазерного луча, который поразит робота, нам надо вычесть местоположение игрока из местоположения робота. Получаем:
(4, 3) — (1, 2) = (4-1, 3-2) = (3, 1).
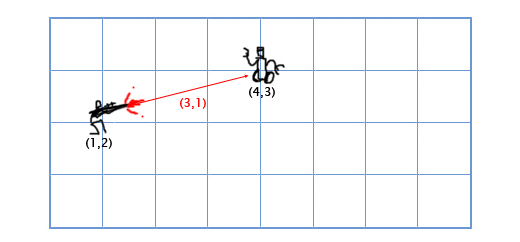
Умножение вектора на скаляр
Когда мы говорим о векторах, мы называем отдельные числа скалярами. Например (3, 4) — вектор, а 5 — это скаляр. В играх, часто бывает нужно умножить вектор на число (скаляр). Например, моделируя простое сопротивление воздуха путём умножения скорости игрока на 0.9 в каждом кадре. Чтобы сделать это, нам надо умножить каждый компонент вектора на скаляр. Если скорость игрока (10, 20), то новая скорость будет:
0.9*(10, 20) = (0.9 * 10, 0.9 * 20) = (9, 18).
Длина вектора
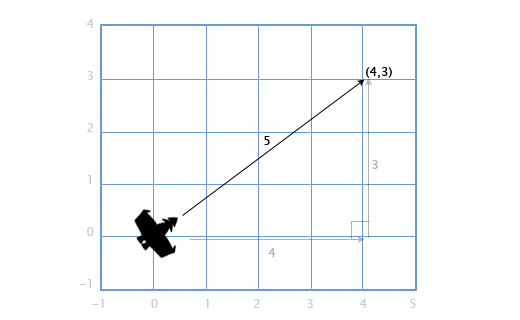
Если у нас есть корабль с вектором скорости V (4, 3), нам также понадобится узнать как быстро он двигается, чтобы посчитать потребность в экранном пространстве или сколько потребуется топлива. Чтобы сделать это, нам понадобится найти длину (модуль) вектора V. Длина вектора обозначается вертикальными линиями, в нашем случае длина вектора V будет обозначаться как |V|.
Мы можем представить V как прямоугольный треугольник со сторонами 4 и 3 и, применяя теорему Пифагора, получить гипотенузу из выражения: x 2 + y 2 = h 2
В нашем случае — длину вектора H с компонентами (x, y) мы получаем из квадратного корня: sqrt(x 2 + y 2 ).
Итак, скорость нашего корабля равна:
|V| = sqrt(4 2 + 3 2 ) = sqrt(25) = 5
Этот подход используется и для трёхмерных векторов. Длина вектора с компонентами (x, y, z) рассчитывается как sqrt(x 2 + y 2 + z 2 )
Расстояние
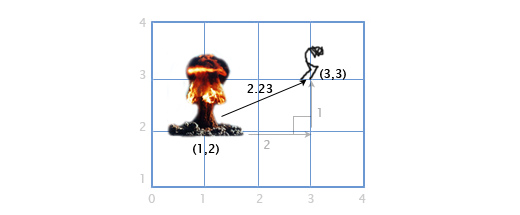
Если игрок P находится в точке (3, 3), а взрыв произошёл в точке E по координатам (1, 2), нам надо определить расстояние между игроком и взрывом, чтобы рассчитать степень ущерба, нанесённого игроку. Это легко сделать, комбинируя две вышеописанных операции: вычитание векторов и их длину.
Мы вычитаем P — E, чтобы получить вектор между ними. А затем определяем длину этого вектора, что и даёт нам искомое расстояние. Порядок следования операндов тут не имеет значения, |E — P| даст тот-же самый результат.
Расстояние = |P — E| = |(3, 3) — (1, 2)| = |(2, 1)| = sqrt(2 2 +1 2 ) = sqrt(5) = 2.23
Нормализация
Когда мы имеем дело с направлениями (в отличие от местоположений и скоростей), важно, чтобы вектор направления имел длину, равную единице. Это сильно упрощает нам жизнь. Например, допустим орудие развёрнуто в направлении (1, 0) и выстреливает снаряд со скоростью 20 метров в секунду. Каков в данном случае вектор скорости для выпущенного снаряда?
Так как вектор направления имеет длину равную единице, мы умножаем направление на скорость снаряда и получаем вектор скорости (20, 0). Если-же вектор направления имеет отличную от единицы длину, мы не сможем сделать этого. Снаряд будет либо слишком быстрым, либо слишком медленным.
Вектор с длиной равной единице называется «нормализованным». Как сделать вектор нормализованным? Довольно просто. Мы делим каждый компонент вектора на его длину. Если, к примеру, мы хотим нормализовать вектор V с компонентами (3, 4), мы просто делим каждый компонент на его длину, то есть на 5, и получаем (3/5, 4/5). Теперь, с помощью теоремы Пифагора, мы убедимся в том, что его длина равна единице:
(3/5) 2 + (4/5) 2 = 9/25 + 16/25 = 25/25 = 1
Скалярное произведение векторов
Что такое скалярное произведение (записывается как •)? Чтобы рассчитать скалярное произведение двух векторов, мы должны умножить их компоненты, а затем сложить полученные результаты вместе
(a1, a2) • (b1, b2) = a1b1 + a2b2
Например: (3, 2) • (1, 4) = 3*1 + 2*4 = 11. На первый взгляд это кажется бесполезным, но посмотрим внимательнее на это:
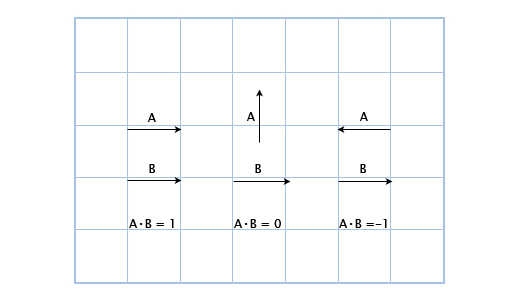
Здесь мы можем увидеть, что если вектора указывают в одном направлении, то их скалярное произведение больше нуля. Когда они перпендикулярны друг другу, то скалярное произведение равно нулю. И когда они указывают в противоположных направлениях, их скалярное произведение меньше нуля.
В основном, с помощью скалярного произведения векторов можно рассчитать, сколько их указывает в одном направлении. И хоть это лишь малая часть возможностей скалярного произведения, но уже очень для нас полезная.
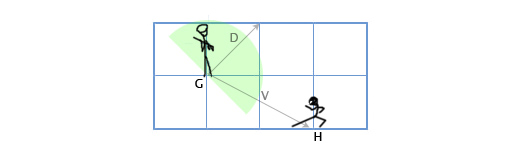
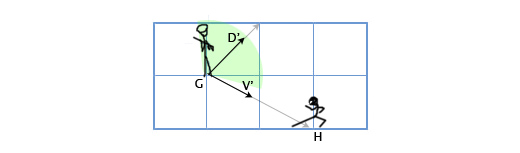
Допустим у нас есть стражник, расположенный в G(1, 3) смотрящий в направлении D(1,1), с углом обзора 180 градусов. Главный герой игры подсматривает за ним с позиции H(3, 2). Как определить, находится-ли главный герой в поле зрения стражника или нет? Сделаем это путём скалярного произведения векторов D и V (вектора, направленного от стражника к главному герою). Мы получим следующее:
V = H — G = (3, 2) — (1, 3) = (3-1, 2-3) = (2, -1)
D•V = (1, 1) • (2, -1) = 1*2 + 1*-1 = 2-1 = 1
Так как единица больше нуля, то главный герой находится в поле зрения стражника.
Мы уже знаем, что скалярное произведение имеет отношение к определению направления векторов. А каково его более точное определение? Математическое выражение скалярного произведения векторов выглядит так:
Где Θ (произносится как «theta») — угол между векторами A и B.
Это позволяет нам найти Θ (угол) с помощью выражения:
Как я говорил ранее, нормализация векторов упрощает нашу жизнь. И если A и B нормализованы, то выражение упрощается следующим образом:
Давайте опять рассмотрим сценарий со стражником. Пусть теперь угол обзора стражника будет равен 120 градусам. Получим нормализованные вектора для направления взгляда стражника (D’) и для направления от стражника к главному герою (V’). Затем определим угол между ними. Если угол более 60 градусов (половина от угла обзора), то главный герой находится вне поля зрения стражника.
D’ = D / |D| = (1, 1) / sqrt(1 2 + 1 2 ) = (1, 1) / sqrt(2) = (0.71, 0.71)
V’ = V / |V| = (2, -1) / sqrt(2 2 + (-1) 2 ) = (2,-1) / sqrt(5) = (0.89, -0.45)
Θ = acos(D’V’) = acos(0.71*0.89 + 0.71*(-0.45)) = acos(0.31) = 72
Угол между центром поля зрения стражника и местоположением главного героя составляет 72 градуса, следовательно стражник его не видит.
Понимаю, что это выглядит довольно сложно, но это потому, что мы всё делаем вручную. В программе это всё довольно просто. Ниже показано как я сделал это в нашей игре Overgrowth с помощью написанных мной С++ библиотек для работы с векторами:
Векторное произведение
Допустим у нас есть корабль с пушками, которые стреляют в правую и в левую стороны по курсу. Допустим, что лодка расположена вдоль вектора направления (2, 1). В каких направлениях теперь стреляют пушки?
Это довольно просто в двухмерной графике. Чтобы повернуть направление на 90 градусов по часовой стрелке, достаточно поменять местами компоненты вектора, а затем поменять знак второму компоненту.
(a, b) превращается в (b, -a). Следовательно у корабля, расположенного вдоль вектора (2, 1), пушки справа по борту будут стрелять в направлении (1, -2), а пушки с левого борта, будут стрелять в противоположном направлении. Меняем знаки у компонент вектора и получаем (-1, 2).
А что если мы хотим рассчитать это всё для трехмерной графики? Рассмотрим пример с кораблём.
У нас есть вектор мачты M, направленной прямо вверх (0, 1, 0) и направление ветра: север-северо-восток W (1, 0, 2). И мы хотим вычислить вектор направления паруса S, чтобы наилучшим образом «поймать ветер».
Для решения этой задачи мы используем векторное произведение: S = M x W.
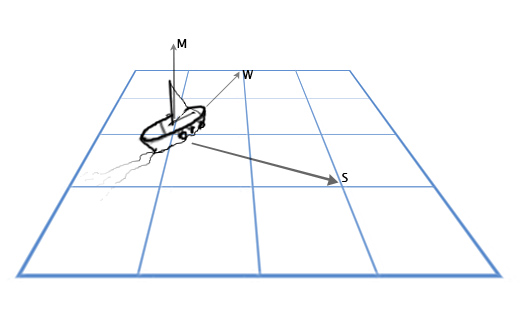
Подставим теперь нужные нам значения:
S = MxW = (0, 1, 0) x (1, 0, 2) = ([1*2 — 0*0], [0*1 — 0*2], [0*0 — 1*1]) = (2, 0, -1)
Для расчётов вручную довольно сложно, но для графических и игровых приложений я рекомендую написать функцию, подобную той, что указана ниже и не вдаваться более в детали подобных расчётов.
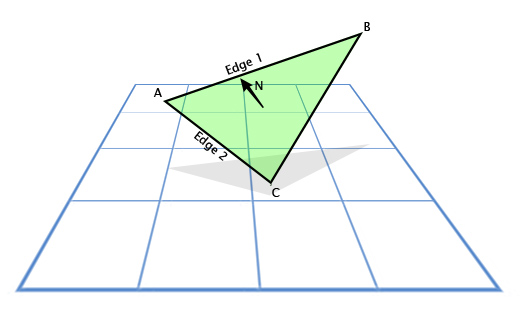
Векторное произведение часто используется в играх, чтобы рассчитать нормали к поверхностям. Направления, в которых «смотрит» та или иная поверхность. Например, рассмотрим треугольник с векторами вершин A, B и С. Как мы найдем направление в котором «смотрит» треугольник, то есть направление перпендикулярное его плоскости? Это кажется сложным, но у нас есть инструмент для решения этой задачи.
Используем вычитание, для определения направления из A в С (C — A), пусть это будет «грань 1» (Edge 1) и направление из A в B (B — A), пусть это будет «грань 2» (Edge 2). А затем применим векторное произведение, чтобы найти вектор, перпендикулярный им обоим, то есть перпендикулярный плоскости треугольника, также называемый «нормалью к плоскости».
Вот так это выглядит в коде:
В играх основное выражение освещённости записывается как N • L, где N — это нормаль к освещаемой поверхности, а L — это нормализованный вектор направления света. В результате поверхность выглядит яркой, когда на неё прямо падает свет, и тёмной, когда этого не происходит.
Теперь перейдем к рассмотрению такого важного для разработчиков игр понятия, как «матрица преобразований» (transformation matrix).
Для начала изучим «строительные блоки» матрицы преобразований.
Базисный вектор
Допустим мы пишем игру Asteroids на очень старом «железе» и нам нужен простой двухмерный космический корабль, который может свободно вращаться в своей плоскости. Модель корабля выглядит так:
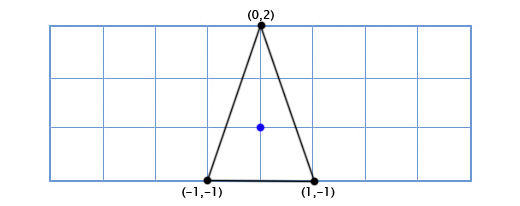
Как нам рисовать корабль, когда игрок поворачивает его на произвольный градус, скажем 49 градусов против часовой стрелки. Используя тригонометрию, мы можем написать функцию двухмерного поворота, которая принимает координаты точки и угол поворота, и возвращает координаты смещённой точки:
Применяя эту функцию ко всем трём точкам, мы получим следующую картину:
Операции с синусами и косинусами работают довольно медленно, но так как мы делаем расчёты лишь для трёх точек, это будет нормально работать даже на старом «железе» (прим. переводчика: в случаях, когда предполагается интенсивное использование тригонометрических функций, для ускорения вычислений, в памяти организуют таблицы значений для каждой функции и рассчитывают их во время запуска приложения. Затем при вычислении той или иной тригонометрической функции просто производится обращение к таблице).
Пусть теперь наш корабль выглядит вот так:
Теперь старый подход будет слишком медленным, так как надо будет поворачивать довольно большое количество точек. Одно из элегантных решений данной проблемы будет звучать так — «Что если вместо поворота каждой точки модели корабля, мы повернём координатную решётку нашей модели?»
Как это работает? Давайте посмотрим внимательнее, что собой представляют координаты.
Когда мы говорим о точке с координатами (3, 2), мы говорим, что её местоположение находится в трех шагах от точки отсчёта по координатной оси X, и двух шагах от точки отсчёта по координатной оси Y.
По-умолчанию координатные оси расположены так: вектор координатной оси X (1, 0), вектор координатной оси Y (0, 1). И мы получим расположение: 3(1, 0) + 2(0, 1). Но координатные оси не обязательно должны быть в таком положении. Если мы повернём координатные оси, в это-же время мы повернём все точки в координатной решётке.
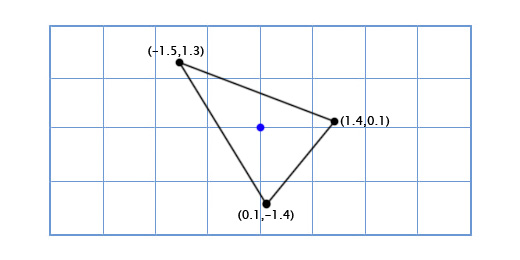
Чтобы получить повернутые оси X и Y мы применим тригонометрические функции, о которых говорили выше. Если мы поворачиваем на 49 градусов, то новая координатная ось X будет получена путём поворота вектора (0, 1) на 49 градусов, а новая координатная ось Y будет получена путём поворота вектора (0, 1) на 49 градусов. Итак вектор новой оси X у нас будет равен (0.66, 0.75), а вектор новой оси Y будет (-0.75, 0.66). Сделаем это вручную для нашей простой модели из трёх точек, чтобы убедиться, что это работает так, как нужно:
Координаты верхней точки (0, 2), что означает, что её новое местоположение находится в 0 на новой (повёрнутой) оси X и 2 на новой оси Y:
0*(0.66,0.75) + 2*(-0.75, 0.66) = (-1.5, 1.3)
Нижняя левая точка (-1, -1), что означает, что её новое местоположение находится в -1 на повернутой оси X, и -1 на повернутой оси Y:
-1*(0.66,0.75) + -1*(-0.75, 0.66) = (0.1, -1.4)
Нижняя правая точка (1, -1), что означает её новое местоположение находится в 1 на повернутой оси X, и -1 на повернутой оси Y
1*(0.66,0.75) + -1*(-0.75, 0.66) = (1.4, 0.1)
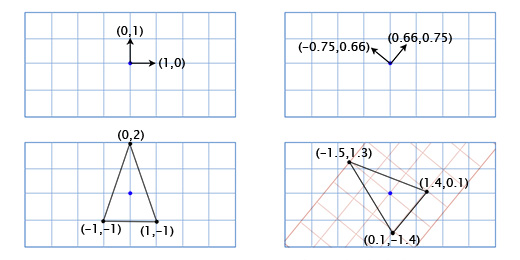
Мы показали, как координаты корабля отображаются в другой координатной сетке с повернутыми осями (или «базисными векторами»). Это удобно в нашем случае, так как избавляет нас от необходимости применять тригонометрические преобразования к каждой из точек модели корабля.
Каждый раз, когда мы изменяем базисные вектора (1, 0) и (0, 1) на (a, b) и (c, d), то новая координата точки (x, y) может быть найдена с помощью выражения:
Обычно базисные вектора равны (1, 0) и (0, 1) и мы просто получаем x(1, 0) + y(0, 1) = (x, y), и нет необходимости заботиться об этом дальше. Однако, важно помнить, что мы можем использовать и другие базисные вектора, когда нам это нужно.
Матрицы
Матрицы похожи на двухмерные вектора. Например, типичная 2×2 матрица, может выглядеть так:
Когда вы умножаете матрицу на вектор, вы суммируете скалярное произведение каждой строки с вектором, на который происходит умножение. Например, если мы умножаем вышеприведённую матрицу на вектор (x, y), то мы получаем:
Будучи записанным по-другому, это выражение выглядит так:
Выглядит знакомо, не так-ли? Это в точности такое-же выражение, которые мы использовали для смены базисных векторов. Это означает, что умножая 2×2 матрицу на двухмерный вектор, мы тем самым меняем базисные вектора. Например, если мы вставим стандартные базисные вектора в (1, 0) и (0, 1) в колонки матрицы, то мы получим:
Это единичная матрица, которая не даёт эффекта, который мы можем ожидать от нейтральных базисных векторов, которые мы указали. Если-же мы повернём базисные вектора на 49-градусов, то мы получим:
Эта матрица будет поворачивать двухмерный вектор на 49 градусов против часовой стрелки. Мы можем сделать код нашей игры Asteriods более элегантным, используя матрицы вроде этой. Например, функция поворота нашего корабля может выглядеть так:
Однако, наш код будет ещё более элегантным, если мы сможем также включить в эту матрицу перемещение корабля в пространстве. Тогда у нас будет единая структура данных, которая будет заключать в себе и применять информацию об ориентации объекта и его местоположении в пространстве.
К счастью есть способ добиться этого, хоть это и выглядит не очень элегантно. Если мы хотим переместиться с помощью вектора (e, f), мы лишь включаем его в нашу матрицу преобразования:
И добавляем дополнительную единицу в конец каждого вектора, определяющего местоположение объекта, например так:
Теперь, когда мы перемножаем их, мы получаем:
(a, c, e) • (x, y, 1) + (b, d, f) • (x, y, 1) + (0, 0, 1) • (x, y, 1)
Что, в свою очередь, может быть записано как:
x(a, b) + y(c, d) + (e, f)
Теперь у нас есть полный механизм трансформации, заключённый в одной матрице. Это важно, если не принимать в расчёт элегантность кода, так как с ней мы теперь можем использовать все стандартные манипуляции с матрицами. Например перемножить матрицы, чтобы добавить нужный эффект, или мы можем инвертировать матрицу, чтобы получить прямо противоположное положение объекта.
Трехмерные матрицы
Матрицы в трехмерном пространстве работают так-же как и в двухмерном. Я приводил примеры с двухмерными векторами и матрицами, так как их просто отобразить с помощью дисплея, показывающего двухмерную картинку. Нам просто надо определить три колонки для базисных векторов, вместо двух. Если базисные вектора это (a,b,c), (d,e,f) and (g,h,i) то наша матрица будет выглядеть так:
Если нам нужно перемещение (j,k,l), то мы добавляем дополнительную колонку и строку, как говорили раньше:
И добавляем единицу [1] в вектор, как здесь:
Вращение в двухмерном пространстве
Так как в нашем случае у нас только одна ось вращения (расположенная на дисплее), единственное, что нам надо знать, это угол. Я говорил об этом ранее, упоминая, что мы можем применять тригонометрические функции для реализации функции двухмерного вращения наподобие этой:
Более элегантно это можно выразить в матричной форме. Чтобы определить матрицу, мы можем применить эту функцию к осям (1, 0) и (0, 1) для угла Θ, а затем включить полученные оси в колонки нашей матрицы. Итак, начнём с координатной оси X (1, 0). Если мы применим к ней нашу функцию, мы получим:
(1*cos(Θ) — 0*sin(Θ), 1*sin(Θ) + 0*cos(Θ)) = (cos(Θ), sin(Θ))
Затем, мы включаем координатную ось Y (0, 1). Получим:
(0*cos(Θ) — 1*sin(Θ), 0*sin(Θ) + 1*cos(Θ)) = (-sin(Θ), cos(Θ))
Включаем полученные координатные оси в матрицу, и получаем двухмерную матрицу вращения:
Применим эту матрицу к Сюзанне, мартышке из графического пакета Blender. Угол поворота Θ равен 45 градусов по часовой стрелке.
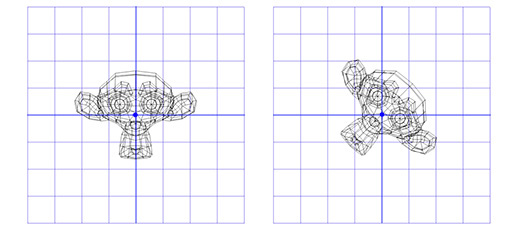
Как видите — это работает. Но что если нам надо осуществить вращение вокруг точки, отличной от (0, 0)?
Например, мы хотим вращать голову мартышки вокруг точки, расположенной в её ухе:
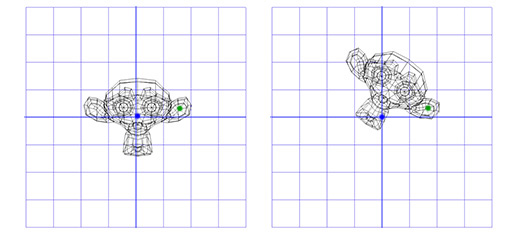
Чтобы сделать это, мы можем начать с создания матрицы перемещения (translation matrix) T, которая перемещает объект из начальной точки в точку вращения в ухе мартышки, и матрицу вращения R, для вращения объекта вокруг начальной точки. Теперь для вращения вокруг точки, расположенной в ухе, мы можем сперва переместить точку в ухе на место начальной точки, с помощью инвертирования матрицы T, записанной как T -1 . Затем, мы вращаем объект вокруг начальной точки, с помощью матрицы R, а затем применяем матрицу T для перемещения точки вращения назад, к своему исходному положению.
Ниже дана иллюстрация к каждому из описанных шагов:
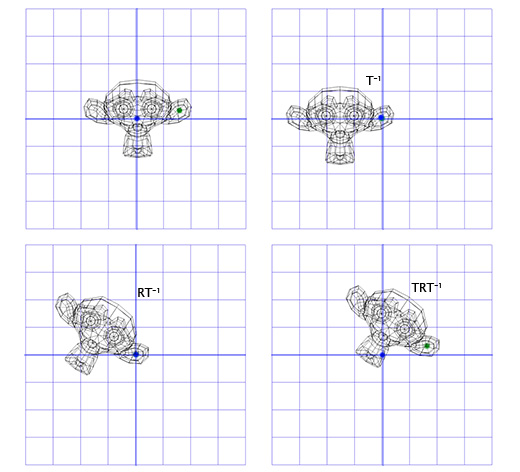
Это важный шаблон, который мы будем применять позднее — применение вращения для двух противоположных трансформаций позволяет нам вращать объект в другом «пространстве». Что очень удобно и полезно.
Теперь рассмотрим трёхмерное вращение.
Трёхмерное вращение
Вращение вокруг оси Z работает по тому-же принципу, что и вращение в двухмерном пространстве. Нам лишь нужно изменить нашу старую матрицу, добавив к ней дополнительную колонку и строку:
Применим эту матрицу к трехмерной версии Сюзанны, мартышки из пакета Blender. Угол поворота Θ пусть будет равен 45 градусов по часовой стрелке.
То-же самое. Вращение только вокруг оси Z ограничивает нас, как насчёт вращения вокруг произвольной оси?
Вращение, определяемое осью и углом (Axis-angle rotation)
Представление вращения, определяемого осью и углом, также известно как вращение в экспоненциальных координатах, параметризованное вращением двух величин. Вектора, определяющего вращение направляющей оси (прямая линия) и угла, описывающего величину поворота вокруг этой оси. Вращение осуществляется согласно правилу правой руки.
Итак, вращение задаётся двумя параметрами (axis, angle), где axis — вектор оси вращения, а angle — угол вращения. Этот приём довольно прост и являет собой отправную точку для множества других операций вращения, с которыми я работаю. Как практически применить вращение, определяемое осью и углом?
Допустим мы имеем дело с осью вращения, показанной на рисунке ниже:
Мы знаем как вращать объект вокруг оси Z, и мы знаем как вращать объект в других пространствах. Итак, нам лишь надо создать пространство, где наша ось вращения будет являться осью Z. И если эта ось будет осью Z, то что будет являться осями X и Y? Займемся вычислениями сейчас.
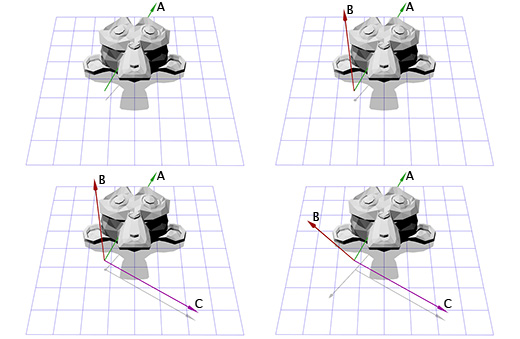
Чтобы создать новые оси X и Y нам нужно лишь выбрать два вектора, которые перпендикулярны новой оси Z и перпендикулярны друг другу. Мы уже говорили ранее о векторном умножении, которое берёт два вектора и даёт в итоге перпендикулярный им вектор.
У нас есть один вектор сейчас, это ось вращения, назовём его A. Возьмём теперь случайный другой вектор B, который находится не в том-же направлении, что и вектор A. Пусть это будет (0, 0, 1) к примеру.
Теперь мы имеем ось вращения A и случайный вектор B, мы можем получить нормаль C, через векторное произведение A и B. С перпендикулярен векторам A и B. Теперь мы делаем вектор B перпендикулярным векторам A и C через их векторное произведение. И всё, у нас есть все нужные нам оси координат.
На словах это звучит сложно, но довольно просто выглядит в коде или будучи показанным в картинках.
Ниже показано, как это выглядит в коде:
Тут показана иллюстрация для каждого шага:
Теперь, имея информацию о новых координатных осях, мы можем составить матрицу M, включив каждую ось как колонку в эту матрицу. Нам надо убедиться, что вектор A является третьей колонкой, чтобы он был нашей новой осью координат Z.
Теперь это похоже на то, что мы делали для поворота в двухмерном пространстве. Мы можем применить инвертированную матрицу M, чтобы переместиться в новую систему координат, затем произвести вращение, согласно матрице R, чтобы повернуть объект вокруг оси Z, затем применить матрицу M, чтобы вернуться в исходное координатное пространство.
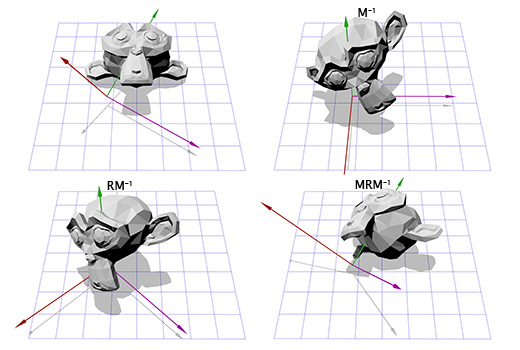
Теперь мы можем вращать объект вокруг произвольной оси. В конце концов мы можем просто создать матрицу T = T = M -1 RM и использовать её много раз, без дополнительных усилий с нашей стороны. Есть более эффективные способы конвертирования вращений, определяемых осью и углом во вращения, определяемые матрицами. Просто описанный нами подход показывает многое из того, о чём мы говорили ранее.
Вращение, определяемое осью и углом, возможно, самый интуитивно понятный способ. Применяя его, очень легко инвертировать поворот, поменяв знак у угла, и легко интерполировать, путём интерполяции угла. Однако тут есть серьёзное ограничение, и заключается оно в том, что такое вращение не является суммирующим. То есть вы не можете комбинировать два вращения, определяемых осью и углом в третье.
Вращение, определяемое осью и углом — хороший способ для начала, но оно должно быть преобразовано во что-то другое, чтобы использоваться в более сложных случаях.
Эйлеровские углы
Эйлеровские углы представляют собой другой способ вращения, заключающийся в трёх вложенных вращениях относительно осей X, Y и Z. Вы, возможно, сталкивались с их применением в играх, где камера показывает действие от первого лица, либо от третьего лица.
Допустим вы играете в шутер от первого лица и вы повернулись на 30 градусов влево, а затем посмотрели на 40 градусов вверх. В конце-концов в вас стреляют, попадают, и, в результате удара, камера поворачивается вокруг своей оси на 45 градусов. Ниже показано вращение с помощью углов Эйлера (30, 40, 45).
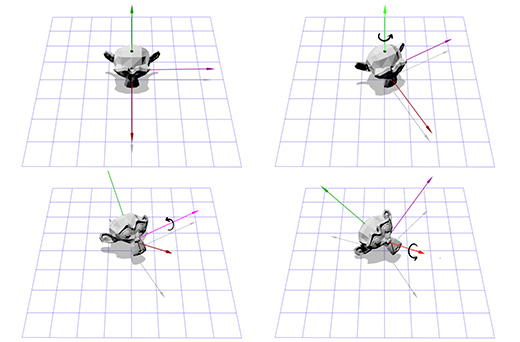
Углы Эйлера — удобное и простое в управлении средство. Но у этого способа есть два недостатка.
Первый, это вероятность возникновения ситуации под названием «блокировка оси» или «шарнирный замок» (gimbal lock). Представьте, что вы играете в шутер от первого лица, где вы можете посмотреть влево, вправо, вверх и вниз или повернуть камеру вокруг зрительной оси. Теперь представьте, что вы смотрите прямо вверх. В этой ситуации попытка взглянуть налево или направо будет аналогична попытке вращения камеры. Всё что мы можем вы этом случае, это вращать камеру вокруг своей оси, либо посмотреть вниз. Как вы можете представить, это ограничение делает непрактичным применение углов Эйлера в лётных симуляторах.
Второе — интерполяция между двумя эйлеровскими углами вращения не даёт кратчайшего пути между ними.
Например, у вас две интерполяции между двумя одинаковыми вращениями. Первая использует интерполяцию эйлеровского угла, вторая использует сферическую линейную интерполяцию (spherical linear interpolation (SLERP)), чтобы найти кратчайший путь.

Итак, что-же больше подойдет для интерполяции вращений? Может быть матрицы?
Вращение с помощью матриц
Как мы уже говорили ранее, матрицы вращения хранят в себе информацию о трёх осях. Это означает, что интерполяция между двумя матрицами лишь линейно интерполирует каждую ось. В результате это даёт нам эффективный путь, то так-же привносит новые проблемы. Например, тут показаны два вращения и одно интерполированное полу-вращение:
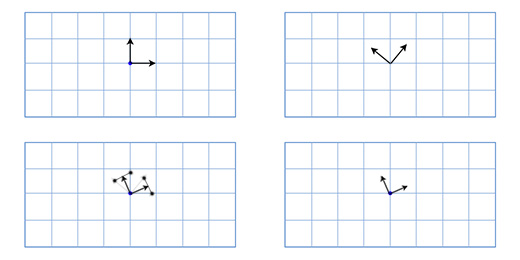
Как вы можете заметить, интерполированное вращение значительно меньше, чем любое из исходных вращений, и две оси более не перпендикулярны друг другу. Это логично, если вдуматься — середина отрезка, соединяющего любые две точки на сфере будет расположена ближе к центру сферы.
Это в свою очередь порождает известный «эффект фантика» (candy wrapper effect), при применении скелетной анимации. Ниже показана демонстрация этого эффекта на примере кролика из нашей игры Overgrowth (прим. переводчика: обратите внимание на середину туловища кролика).

Вращение, основанное на матричных операциях, очень полезно, так как они могут аккумулировать вращения без всяких проблем, вроде блокировки оси (gimbal lock), и может очень эффективно применяться к точкам сцены. Вот почему поддержка вращения на матрицах встроена в графические карты. Для любого типа трёхмерной графики матричный формат вращения — это всегда итоговый применяемый способ.
Однако, как мы уже знаем, матрицы не очень хорошо интерполируются, и они не столь интуитивно понятны.
Итак, остался только один главный формат вращения. Последний, но тем не менее, важный.
Кватернионы
Что-же такое кватернионы? Если очень кратко, то это альтернативный вариант вращения, основанный на оси и угле (axis-angle rotation), который существует в пространстве.
Подобно матрицам они могут аккумулировать вращения, то есть вы можете составлять из них цепочку вращений, без опаски получить блокировку оси (gimbal lock). И в то-же время, в отличие от матриц, они могут хорошо интерполироваться из одного положения в другое.
Являются-ли кватернионы лучшим решением, нежели остальные способы вращений (rotation formats)?
На сегодняшний день они комбинируют все сильные стороны других способов вращений. Но у них есть два слабых места, рассмотрев которые, мы придём к выводу, что кватернионы лучше использовать для промежуточных вращений. Итак, каковы недостатки кватернионов.
Во-первых кватернионы непросто отобразить на трёхмерном пространстве. И мы вынуждены всегда реализовывать вращение более простым способом, а затем конвертировать его. Во-вторых, кватернионы не могут эффективно вращать точки, и мы вынуждены конвертировать их в матрицы, чтобы повернуть значительное количество точек.
Это означает, что вы скорее всего не начнете или не закончите серию вращений с помощью кватернионов. Но с их помощью можно реализовать промежуточные вращения более эффективно, нежели при применении любого другого подхода.
«Внутренняя кухня» механизма кватернионов не очень понятна и не интересна мне. И, возможно, не будет интересна и вам, если только вы не математик. И я советую вам найти библиотеки, которые работают с кватернионами, чтобы облегчить вам решение ваших задач с их помощью.
Математические библиотеки «Bullet» или «Blender» будут хорошим вариантом для начала.
Векторы в C++: для начинающих
Всем привет! До этого дня мы использовали чистые массивы. Чистые — это значит простые массивы, не имеющие у себя в багаже различных функций. В этом уроке мы пройдем нечистые массивы — векторы.
Быстрый переход по статье:
 Что такое вектор (vector)
Что такое вектор (vector)
 Что такое вектор (vector)
Что такое вектор (vector)Вектор — это структура данных, которая уже является моделью динамического массива.
Давайте вспомним о том, что для создания динамического массива (вручную) нам нужно пользоваться конструктором new и вдобавок указателями. Но в случае с векторами всего этого делать не нужно.
Вообще, по стандарту пользоваться динамическим массивом через конструктор new — не есть правильно. Так как в компьютере могут происходить различные утечки памяти.
Как создать вектор (vector) в C++
Сначала для создания вектора нам понадобится подключить библиотеку — , в ней хранится шаблон вектора.
Кстати, сейчас и в будущем мы будем использовать именно шаблон вектора. Например, очередь или стек, не созданные с помощью массива или вектора, тоже являются шаблонными.
Далее, чтобы объявить вектор, нужно пользоваться конструкцией ниже:
- Вначале пишем слово vector .
- Далее в угольных скобках указываем тип, которым будем заполнять ячейки.
- И в самом конце указываем имя вектора.
В примере выше мы создали вектор строк.
Кстати, заполнить вектор можно еще при инициализации (другие способы мы пройдем позже — в методах вектора). Делается это также просто, как и в массивах. Вот так:
После имени вектора ставим знак равенства и скобки, в которых через пробел указываем значение элементов.
Такой способ инициализации можно использовать только в C++!
Так, чтобы заполнить вектор строками, нам нужно использовать кавычки — «строка» .
Второй способ обратиться к ячейке
Мы знаем, что в векторе для обращения к ячейке используются индексы. Обычно мы их используем совместно с квадратными скобками [] .
Но в C++ есть еще один способ это сделать благодаря функции — at(). В скобках мы должны указать индекс той ячейки, к которой нужно обратиться.
Вот как она работает на практике:
Давайте запустим эту программу:
Как указать количество ячеек для вектора
Указывать размер вектора можно по-разному. Можно это сделать еще при его инициализации, а можно хоть в самом конце программы. Вот, например, способ указать длину вектора на старте:
Так в круглых скобках () после имени вектора указываем первоначальную длину. А вот второй способ:
Первая строчка нам уже знакома. А вот во второй присутствует незнакомое слово — reserve , это функция, с помощью которой мы говорим компилятору, какое количество ячеек нам нужно использовать.
Вы можете задать логичный вопрос:»А в чем разница?». Давайте создадим два вектора и по-разному укажем их количество ячеек.
Как видим, в первом случае мы вывели три нуля, а во втором: 17, 0, 0.
Все потому, что при использовании первого способа все ячейки автоматически заполнились нулями.
При объявлении чего-либо (массива, вектора, переменной и т.д) мы выделяем определенное количество ячеек памяти, в которых уже хранится ненужный для ПК мусор. В нашем случае этим мусором являются числа.
Поэтому, когда мы вывели второй вектор, в нем уже находились какие-то рандомные числа — 17, 0, 0. Обычно они намного больше. Можете кстати попробовать создать переменную и вывести ее значение.
Нужно помнить! При использовании второго способа есть некоторый плюс — по времени. Так как для первого способа компилятор тратит время, чтобы заполнить все ячейки нулями.
Как сравнить два вектора
 Как сравнить два вектора
Как сравнить два вектораЕсли в середине программы нам понадобиться сравнить два массива, мы, конечно, используем цикл for и поочередно проверим все элементы.
Вектор снова на шаг впереди! Чтобы нам сравнить два вектора, потребуется применить всего лишь оператор ветвления if.
http://habr.com/ru/post/131931/
Вектор (std::vector) и строка (std::string) — это важные базовые контейнеры стандартной библиотеки C++. Они хранят свои элементы в непрерывном фрагменте памяти. Оба этих контейнера предоставляют доступ к элементам по индексу и позволяют эффективно добавлять новые элементы в конец.
Контейнер std::vector
В стандартной библиотеке C++ вектором (std::vector) называется динамический массив, обеспечивающий быстрое добавление новых элементов в конец и меняющий свой размер при необходимости. Вектор гарантирует отсутствие утечек памяти (об этом мы поговорим в других главах, сейчас просто считайте, что это хорошо).
Для работы с вектором нужно подключить заголовочный файл vector.
Элементы вектора должны быть одинакового типа, и этот тип должен быть известен при компиляции программы. Он задаётся в угловых скобках после std::vector: например, std::vector<int> — это вектор целых чисел типа int, а std::vector<std::string> — вектор строк.
Само имя std::vector не является типом данных: это шаблон, в который требуется подставить нужные параметры (тип элемента), чтобы получился конкретный тип данных. Подробнее о том, что такое шаблоны и как их применять, мы расскажем в главе 1.9.
Рассмотрим пример программы, которая заполняет вектор элементами и печатает их через пробел:
#include <iostream>
#include <vector>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
for (int elem : data) {
std::cout << elem << " ";
}
std::cout << "n";
}
Здесь мы инициализируем вектор через список инициализации, в котором элементы перечислены через запятую. Другой способ инициализации вектора — указать число элементов и (при необходимости) образец элемента:
#include <string>
#include <vector>
int main() {
std::vector<std::string> v1; // пустой вектор строк
std::vector<std::string> v2(5); // вектор из пяти пустых строк
std::vector<std::string> v3(5, "hello"); // вектор из пяти строк "hello"
}
Обращение к элементам
Выше мы использовали для печати элементов вектора цикл range-for. Но иногда удобнее работать с индексами. Вектор хранит элементы в памяти последовательно, поэтому по индексу элемента можно быстро найти его положение в памяти. Индексация начинается с нуля:
std::vector<int> data = {1, 2, 3, 4, 5};
int a = data[0]; // начальный элемент вектора
int b = data[4]; // последний элемент вектора (в нём пять элементов)
data[2] = -3; // меняем элемент 3 на -3
Чтобы узнать общее количество элементов в векторе, можно воспользоваться функцией size:
std::cout << data.size() << "n";
Отрицательные индексы, как в некоторых других языках программирования, не допускаются.
Обратите внимание: когда мы обращаемся по индексу через квадратные скобки, проверки его корректности не происходит. Это ещё одно проявление принципа «мы не должны платить за то, что не используем».
Встроенные валидаторы замедляют программу: предполагается, что программист пишет правильный код и уверен, что индекс i в выражении data[i] неотрицателен и удовлетворяет условию i < data.size(). В этом случае они ему не нужны.
Если всё же обратиться к вектору по некорректному индексу, то программа во время выполнения попадёт в неопределённое поведение: фактически она попробует прочитать память, не принадлежащую вектору.
Если вам не хочется делать много лишних проверок, а в корректности индекса вы не уверены, то можно использовать функцию at:
std::vector<int> data = {1, 2, 3, 4, 5};
std::cout << data[42] << "n"; // неопределённое поведение: может произойти всё что угодно
std::cout << data.at(0) << "n"; // напечатается 1
std::cout << data.at(42) << "n"; // произойдёт исключение std::out_of_range — его можно будет перехватить и обработать
Про работу с исключениями мы поговорим отдельно в главе 3.5.
Рассмотрим функции вектора front и back, которые возвращают его первый и последний элемент без использования индексов:
std::vector<int> data = {1, 2, 3, 4, 5};
std::cout << data.front() << "n"; // то же, что data[0]
std::cout << data.back() << "n"; // то же, что data[data.size() - 1]
Важно учитывать, что вызов этих функций на пустом векторе приведёт к неопределённому поведению.
Для проверки вектора на пустоту вместо сравнения data.size() == 0 принято использовать функцию empty, которая возвращает логическое значение:
if (!data.empty()) {
// вектор не пуст, с ним можно работать
}
Итерация по индексам
Так сложилось, что в стандартной библиотеке индексы и размеры контейнеров имеют беззнаковый тип. Вместо unsigned int или unsigned long int для него используется традиционный псевдоним size_t (а точнее, std::vector<T>::size_type). Тип size_t на самом деле совпадает с uint32_t или uint64_t в зависимости от битности платформы. Его использование в программе дополнительно подчёркивает, что мы имеем дело с индексами или с размером.
Итерацию по элементам data с помощью индексов можно записать так:
for (size_t i = 0; i != data.size(); ++i) {
std::cout << data[i] << " ";
}
Это каноническая форма записи такого цикла: в ней принято использовать сравнение != и префиксный ++i. Для целых чисел не будет разницы, если написать это как-то иначе (например, через < и постфиксный i++), но потом, когда вы будете писать аналогичные циклы для итераторов других контейнеров, разница появится. Давайте привыкнем всегда оформлять цикл по индексам так.
Беззнаковость типа возвращаемого значения функции size порождает следующую проблему. По правилам, унаследованным ещё от языка C, результат арифметических действий над беззнаковым и знаковым типами приводится к беззнаковому типу. Поэтому выражение data.size() - 1, например, тоже будет беззнаковым. Если data.size() окажется нулём, то такое выражение будет вовсе не минус единицей, а самым большим беззнаковым целым (для 64-битной платформы это $2^{64} — 1$).
Рассмотрим следующий ошибочный код, который проверяет, есть ли в векторе дубликаты, идущие подряд:
// итерация по всем элементам, кроме последнего:
for (size_t i = 0; i < data.size() - 1; ++i) {
if (data[i] == data[i + 1]) {
std::cout << "Duplicate value: " << data[i] << "n";
}
}
Эта программа будет некорректно работать на пустом векторе. Условие i < data.size() - 1 на первой итерации окажется истинным, и произойдёт обращение к элементам пустого вектора. Правильнее было бы переписать это условие через i + 1 < data.size() или воспользоваться внешней функцией std::ssize, которая появилась в C++20. Она возвращает знаковый размер вектора:
for (std::int64_t i = 0; i < std::ssize(data) - 1; ++i) {
if (data[i] == data[i + 1]) {
std::cout << "Duplicate value: " << data[i] << "n";
}
}
Добавление и удаление элементов
В вектор можно эффективно добавлять элементы в конец и удалять их с конца. Для этого существуют функции push_back и pop_back. Рассмотрим программу, считывающую числа с клавиатуры в вектор и затем удаляющую все нули в конце:
#include <iostream>
#include <vector>
int main() {
int x;
std::vector<int> data;
while (std::cin >> x) { // читаем числа, пока не закончится ввод
data.push_back(x); // добавляем очередное число в вектор
}
while (!data.empty() && data.back() == 0) {
// Пока вектор не пуст и последний элемент равен нулю
data.pop_back(); // удаляем этот нулевой элемент
}
}
Добавление элементов в другие части вектора или их удаление неэффективно, так как требует сдвига соседних элементов. Поэтому отдельных функций, например, для добавления или удаления элементов из начала у вектора нет. Это можно сделать с помощью общих функций insert/erase и итераторов. Мы рассмотрим такие примеры позже.
Удалить все элементы из вектора можно с помощью функции clear.
Резерв памяти
Вектор хранит элементы в памяти в виде непрерывной последовательности, друг за другом. При этом в конце последовательности резервируется дополнительное место для быстрого добавления новых элементов. Когда этот резерв заканчивается, при вставке очередного элемента происходит реаллокация: элементы вектора копируются в новый, более просторный блок памяти.
Реаллокация — довольно дорогая процедура, но если она происходит достаточно редко, то её влияние незначительно. Можно доказать, что если размер нового блока выбирать в два раза больше предыдущего размера, то амортизационная сложность добавления элемента будет константной.
Текущий резерв вектора можно узнать с помощью функции capacity (не путайте её с функцией size).

Рассмотрим программу, в которой в вектор последовательно добавляются элементы и после каждого шага печатается размер и резерв:
#include <iostream>
#include <vector>
int main() {
std::vector<int> data = {1, 2};
std::cout << data.size() << "t" << data.capacity() << "n";
data.push_back(3);
std::cout << data.size() << "t" << data.capacity() << "n";
data.push_back(4);
std::cout << data.size() << "t" << data.capacity() << "n";
data.push_back(5);
std::cout << data.size() << "t" << data.capacity() << "n";
}
Вот вывод этой программы:
2 2 3 4 4 4 5 8
Видно, что размер вектора увеличивается на единицу, а резерв удваивается после исчерпания. Так, при добавлении четвёрки используется имеющаяся в резерве память, а при добавлении тройки и пятёрки происходит реаллокация.

Иногда требуется заполнить вектор элементами, причём число элементов известно заранее. В таком случае можно сразу зарезервировать нужный размер памяти с помощью функции reserve, чтобы при добавлении элементов не происходили реаллокации. Пусть, например, нам сначала задаётся число слов, а потом сами эти слова, и нам требуется сложить их в вектор:
#include <iostream>
#include <string>
#include <vector>
int main() {
std::vector<std::string> words;
size_t words_count;
std::cin >> words_count;
// Размер вектора остаётся нулевым, меняется только резерв:
words.reserve(words_count);
for (size_t i = 0; i != words_count; ++i) {
std::string word;
std::cin >> word;
// Все добавления будут дешёвыми, без реаллокаций:
words.push_back(word);
}
}
Если передать в reserve величину меньше текущего резерва, то ничего не поменяется — резерв останется прежним.
Функцию reserve не следует путать с функцией resize, которая меняет количество элементов в векторе. Если аргумент функции resize меньше текущего размера, то лишние элементы в конце вектора удаляются. Если же он больше текущего размера, то при необходимости происходит реаллокация и в вектор добавляются новые элементы с дефолтным значением данного типа.
#include <vector>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
data.reserve(10); // поменяли резерв, но размер вектора остался равным пяти
data.resize(3); // удалили последние элементы 4 и 5
data.resize(6); // получили вектор 1, 2, 3, 0, 0, 0
}
Многомерные векторы
Воспользуемся вектором векторов, чтобы сохранить матрицу (таблицу) целых чисел. Пусть на вход программы сначала поступают число строк и число столбцов матрицы, а потом — сами элементы построчно:
#include <iostream>
#include <vector>
int main() {
size_t m, n;
std::cin >> m >> n; // число строк и столбцов
// создаём матрицу matrix из m строк, каждая из которых — вектор из n нулей
std::vector<std::vector<int>> matrix(m, std::vector<int>(n));
for (size_t i = 0; i != m; ++i) {
for (size_t j = 0; j != n; ++j) {
std::cin >> matrix[i][j];
}
}
// напечатаем матрицу, выводя элементы через табуляцию
for (size_t i = 0; i != m; ++i) {
for (size_t j = 0; j != n; ++j) {
std::cout << matrix[i][j] << "t";
}
std::cout << "n";
}
}
В этом примере мы заранее создали матрицу из нулей, а потом просто меняли её элементы.
Сортировка вектора
Рассмотрим типичную задачу — отсортировать вектор по возрастанию. Для этого в стандартной библиотеке в заголовочном файле algorithm есть готовая функция sort. Гарантируется, что сложность её работы в худшем случае составляет $O(n log n)$, где $n$ — число элементов в векторе. Типичные реализации используют алгоритм сортировки Introsort.
#include <algorithm>
#include <vector>
int main() {
std::vector<int> data = {3, 1, 4, 1, 5, 9, 2, 6};
// Сортировка диапазона вектора от начала до конца
std::sort(data.begin(), data.end());
// получим вектор 1, 1, 2, 3, 4, 5, 6, 9
}
В функцию sort передаются так называемые итераторы, ограничивающие рассматриваемый диапазон. В нашем случае мы передаём диапазон, совпадающий со всем вектором, от начала до конца. Соответствующие итераторы возвращают функции begin и end (не путать с front и back!). Итераторы можно считать обобщёнными индексами (но они могут быть и у контейнеров, не допускающих обычную индексацию). Подробнее про итераторы мы поговорим в отдельной главе.
Для сортировки по убыванию можно передать на вход обратные итераторы rbegin() и rend(), представляющие элементы вектора в перевёрнутом порядке:
std::sort(data.rbegin(), data.rend()); // 9, 6, 5, 4, 3, 2, 1, 1
В C++20 доступен более элегантный способ сортировки через std::ranges::sort:
#include <algorithm>
#include <vector>
int main() {
std::vector<int> data = {3, 1, 4, 1, 5, 9, 2, 6};
std::ranges::sort(data); // можно передать сам вектор, а не его диапазоны
}
Для сортировки по умолчанию используется сравнение элементов с помощью оператора <. Этот оператор работает и для самих векторов: они сравниваются лексикографически. Поэтому можно без проблем отсортировать, например, строки в матрице (векторе векторов целых чисел).
Строки
Контейнер std::string можно рассматривать как особый случай вектора символов std::vector<char>, имеющий набор дополнительных функций. В частности, у строки есть все те же рассмотренные нами функции, что и у вектора (например, pop_back или resize). Рассмотрим некоторые специфические функции строки:
#include <iostream>
#include <string>
int main() {
std::string s = "Some string";
// приписывание символов и строк
s += ' '; // добавляем отдельный символ в конец, это аналог push_back
s += "functions"; // добавляем строку в конец
std::cout << s << "n"; // Some string functions
// выделение подстроки
// подстрока "string" из 6 символов начиная с 5-й позиции
std::string sub1 = s.substr(5, 6);
// подстрока "functions" с 12-й позиции и до конца
std::string sub2 = s.substr(12);
// поиск символа или подстроки
size_t pos1 = s.find(' '); // позиция первого пробела, в данном случае 4
size_t pos2 = s.find(' ', pos1 + 1); // позиция следующего пробела (11)
size_t pos3 = s.find("str"); // вернётся 5
size_t pos4 = s.find("#"); // вернётся std::string::npos
}
Вставку, замену и удаление подстрок можно сделать через указание индекса начала и длины подстроки:
#include <iostream>
#include <string>
int main() {
std::string s = "Some string functions";
// вставка подстроки
s.insert(5, "std::");
std::cout << s << "n"; // Some std::string functions
// замена указанного диапазона на новую подстроку
s.replace(0, 4, "Special");
std::cout << s << "n"; // Special std::string functions
// удаление подстроки
s.erase(8, 5); // Special string functions
}
Аналогичные действия для других контейнеров (например, для того же вектора) можно сделать через итераторы. Мы рассмотрим такие примеры в одной из следующих глав.
В C++20 появились удобные функции starts_with и ends_with для проверки префикса или суффикса строк:
#include <iostream>
#include <string>
int main() {
std::string phrase;
std::getline(std::cin, phrase);
if (phrase.starts_with("hello")) {
std::cout << "Greetingn";
}
if (phrase.ends_with("bye")) {
std::cout << "Farewelln";
}
}
Всем привет! До этого дня мы использовали чистые массивы. Чистые — это значит простые массивы, не имеющие у себя в багаже различных функций. В этом уроке мы пройдем нечистые массивы — векторы.
Быстрый переход по статье:
- Вектор векторов (массив векторов)
- Функции векторов
 Что такое вектор (vector)
Что такое вектор (vector)
Вектор — это структура данных, которая уже является моделью динамического массива.
Давайте вспомним о том, что для создания динамического массива (вручную) нам нужно пользоваться конструктором new и вдобавок указателями. Но в случае с векторами всего этого делать не нужно.
Вообще, по стандарту пользоваться динамическим массивом через конструктор new — не есть правильно. Так как в компьютере могут происходить различные утечки памяти.
![Как это сделать]() Как создать вектор (vector) в C++
Как создать вектор (vector) в C++
Сначала для создания вектора нам понадобится подключить библиотеку — <vector>, в ней хранится шаблон вектора.
Кстати, сейчас и в будущем мы будем использовать именно шаблон вектора. Например, очередь или стек, не созданные с помощью массива или вектора, тоже являются шаблонными.
Далее, чтобы объявить вектор, нужно пользоваться конструкцией ниже:
|
vector < тип данных > <имя вектора>; |
- Вначале пишем слово
vector. - Далее в угольных скобках указываем тип, которым будем заполнять ячейки.
- И в самом конце указываем имя вектора.
Вот пример:
В примере выше мы создали вектор строк.
Кстати, заполнить вектор можно еще при инициализации (другие способы мы пройдем позже — в методах вектора). Делается это также просто, как и в массивах. Вот так:
|
vector <int> ivector = {<элемент [0]>, <[1]>, <[2]>}; |
После имени вектора ставим знак равенства и скобки, в которых через пробел указываем значение элементов.
Такой способ инициализации можно использовать только в C++!
Так, чтобы заполнить вектор строками, нам нужно использовать кавычки — "строка".
Второй способ обратиться к ячейке
Мы знаем, что в векторе для обращения к ячейке используются индексы. Обычно мы их используем совместно с квадратными скобками [].
Но в C++ есть еще один способ это сделать благодаря функции — at(). В скобках мы должны указать индекс той ячейки, к которой нужно обратиться.
Вот как она работает на практике:
|
vector <int> ivector = {1, 2, 3}; ivector.at(1) = 5; // изменили значение второго элемента cout << ivector.at(1); // вывели его на экран |
Давайте запустим эту программу:
5
Process returned 0 (0x0) execution time : 0.010 s
Press any key to continue.
Как указать количество ячеек для вектора
Указывать размер вектора можно по-разному. Можно это сделать еще при его инициализации, а можно хоть в самом конце программы. Вот, например, способ указать длину вектора на старте:
|
vector <int> vector_first(5); |
Так в круглых скобках () после имени вектора указываем первоначальную длину. А вот второй способ:
|
vector <int> vector_second; // создали вектор vector_second.reserve(5); // указали число ячеек |
Первая строчка нам уже знакома. А вот во второй присутствует незнакомое слово — reserve, это функция, с помощью которой мы говорим компилятору, какое количество ячеек нам нужно использовать.
Вы можете задать логичный вопрос:»А в чем разница?». Давайте создадим два вектора и по-разному укажем их количество ячеек.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#include <iostream> #include <vector> // подключили библиотеку using namespace std; int main() { setlocale(0, «»); vector <int> vector_first(3); // объявили // два vector <int> vector_second; // вектора vector_second.reserve(3); cout << «Значения первого вектора (с помощью скобок): «; for (int i = 0; i < 3; i++) { cout << vector_first[i] << » «; } cout << «Значения второго вектора (с помощью reserve): « << endl; for (int i = 0; i < 3; i++) { cout << vector_second[i] << » «; } system(«pause»); return 0; } |
Запускаем программу:
Значения первого вектора (с помощью скобок): 0 0 0
Значения второго вектора (с помощью reserve): 17 0 0
Process returned 0 (0x0) execution time : 0.010 s
Press any key to continue.
Как видим, в первом случае мы вывели три нуля, а во втором: 17, 0, 0.
Все потому, что при использовании первого способа все ячейки автоматически заполнились нулями.
При объявлении чего-либо (массива, вектора, переменной и т.д) мы выделяем определенное количество ячеек памяти, в которых уже хранится ненужный для ПК мусор. В нашем случае этим мусором являются числа.
Поэтому, когда мы вывели второй вектор, в нем уже находились какие-то рандомные числа — 17, 0, 0. Обычно они намного больше. Можете кстати попробовать создать переменную и вывести ее значение.
Нужно помнить! При использовании второго способа есть некоторый плюс — по времени. Так как для первого способа компилятор тратит время, чтобы заполнить все ячейки нулями.
Как сравнить два вектора
Если в середине программы нам понадобиться сравнить два массива, мы, конечно, используем цикл for и поочередно проверим все элементы.
Вектор снова на шаг впереди! Чтобы нам сравнить два вектора, потребуется применить всего лишь оператор ветвления if.
|
if (vec_first == vec_second) { // сравнили! cout << «Они равны!»; } else { cout << «Они не равны»; } |
Конечно, компилятор все равно прогонит эти два вектора по циклу, проверяя ячейки. Но посмотрите на код ниже и скажите насколько программа стала меньше, разве это не хорошо?
Вот так бы выглядела программа выше, если бы мы не использовали знак равенства для векторов.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
bool flag = true; if (vec_first.size() == vec_second.size()) { for (int i = 0; i < vec_first.size(); i++) { if (vec_first[i] != vec_second[i]) { cout << «Они не равны!»; flag = false; break; // выходим из цикла } } } else { flag = false; cout << «Они не равны!»; } if (flag) { cout << «Они равны!»; } |
- Сначала мы создали булеву переменную
flagравнуюtrue. У нее задача такая:- Если в условии (строки 5 — 10) она станет равна
false— то значит эти векторы не равны и условие (строки 14 — 16) не будет выполняться. - Если же она после цикла (строки 3 — 12) останется равна
true— то в условии (строки 14 — 16) мы сообщим пользователю, что они равны.
- Если в условии (строки 5 — 10) она станет равна
- В условии (строка 3) проверяем размеры двух векторов на равенство.
- И если условие (строки 5 — 10) будет равно
true— то мы сообщим пользователю, что эти два вектора не равны.
![Как это сделать]() Как создать вектор векторов
Как создать вектор векторов
Понятно, что вам может понадобиться записать числа в двумерный массив. Но зачем использовать массив, если можно оперировать векторами.
Сейчас вы узнаете, как создать вектор векторов или простым языком массив векторов.
|
vector < vector < тип данных > >; |
Как можно увидеть, нам пришлось только добавить слова vector и еще его <тип>.
А чтобы указать количества векторов в векторе нам потребуется — метод resize().
|
vector < vector <int> > vec; vec.resize(10); // десять векторов |
Но есть еще одни способ добавления векторов в вектор. Для этого способа мы будем использовать функцию push_back() (читайте ниже, что она делает).
|
vec.push_back(vector <int>()); |
- В аргументах функции
push_back()находится — имя контейнера который мы хотим добавить. В нашем случае —vector. - А дальше идет тип контейнера —
<тип>. - И все заканчивается отрывающей и закрывающей скобкой
().
Для двумерного вектора тоже можно указать значения еще при инициализации:
|
vector < vector <int> > ivector = {{1, 4, 7}, {2, 5, 8}, {3, 6, 9}}; |
{1, 4, 7} — это значения элементов первого массива (первого слоя). Такие блоки значений {1, 4, 7} должны разделяться запятыми.
Методы для векторов:
Сейчас мы разберем некоторые методы, которые часто используются вместе с векторами. Метод — это функция, которая относится к определенному STL контейнеру.
В нашем случае этим STL контейнером является вектор. Если вы дальше собираетесь оперировать векторами — лучше все перечисленные функции запомнить.
1) size() и empty()
Если нам требуется узнать длину вектора, понадобится функция — size(). Эта функция практически всегда используется вместе с циклом for.
|
for (int i = 0; i < ivector.size(); i++) { // … } |
Также, если нам требуется узнать пуст ли стек, мы можем использовать функцию — empty().
- При отсутствии в ячейках какого-либо значения это функция возвратит —
true. - В противном случае результатом будет —
false.
Вот пример с ее использованием:
|
if (ivector.empty()) { // … } |
2) push_back() и pop_back()
Как мы сказали выше, у векторов имеются методы, которые помогают оптимизировать и улучшить жизнь программистов. Одни из самых используемых функций это — push_back() и pop_back().
- С помощью функции
push_back()мы можем добавить ячейку в конец вектора. - А функция
pop_back()все делает наоборот — удаляет одну ячейку в конце вектора.
Использование функции
push_back()без указания значения ячейки — невозможно. Так или иначе, придется это значение указать!
Давайте разберемся, как работают эти функции на практике:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#include <iostream> #include <vector> using namespace std; int main() { setlocale(0, «»); vector <string> vec_string; vec_string.push_back(«апельсин»); // добавляем vec_string.push_back(«груша»); // четыре vec_string.push_back(«яблока»); // элемента vec_string.push_back(«вишня»); // в конец вектора for (int i = 0; i < vec_string.size(); i++) { cout << vec_string[i] << » «; } cout << endl; vec_string.pop_back(); // удаляем элемент for (int i = 0; i < vec_string.size(); i++) { cout << vec_string[i] << » «; } system(«pause»); return 0; } |
Вот что будет при запуске:
апельсин груша яблоко вишня
апельсин груша яблоко
Process returned 0 (0x0) execution time : 0.010 s
Press any key to continue.
Кстати, можно сделать вот так:
|
vec_string.push_back(«апельсин»); vec_string.push_back(«груша»); string val = vec_string.pop_back(); // присвоили значение удаляемой ячейке cout << val; |
Мы сохранили значение удаляемой ячейки в переменную — val.
Давайте запустим эту программу:
груша
Process returned 0 (0x0) execution time : 0.010 s
Press any key to continue.
3) insert()
Выше мы вам показали функцию push_back(), но то же самое можно сделать, используя функцию — insert(). Только с помощью нее еще можно добавлять элементы в начало вектора.
Эта функция имеет такую конструкцию:
|
<имя вектора>.insert(<итератор>, <значение>); |
<итератор> — про него мы поговорим в другом уроке. Это тема которая требует подробного изучения. Сейчас вам нужно знать только о том, что функция:
begin()— указывает на начала вектора.-
end()— указывает на конец вектора.
<значение> — сюда мы должны вписать значение добавляемой ячейки.
Если вы в
<итератор>указали именно итератор, а не функцииbegin()иend(), то элемент будет добавлен именно после той ячейки, на которую указывает итератор.
Давайте посмотрим, как insert() работает на примере:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
int main() { setlocale(0, «»); vector vec_string(2); vec_string[0] = 2; // заполнили две vec_string[1] = 3; // ячейки for (int i = 0; i < vec_string.size(); i++) { cout << vec_string[i] << » «; } cout << endl; vec_string.insert(vec_string.begin(), 1); // добавили элемент в начало for (int i = 0; i < vec_string.size(); i++) { cout << vec_string[i] << » «; } cout << endl; vec_string.insert(vec_string.end(), 4); // добавили элемент в конец for (int i = 0; i < vec_string.size(); i++) { cout << vec_string[i] << » «; } system(«pause»); return 0; } |
При запуске программы, мы увидим это:
2 3
1 2 3
1 2 3 4
Process returned 0 (0x0) execution time : 0.010 s
Press any key to continue.
На иллюстрациях ниже показано, как vec_string изменялся в программе:




Вы должны знать! Если вы хотите, чтобы ваша программа работала как можно быстрее — вам нужно добавлять элементы именно в конец.
Так как при добавлении элемента в начало, с помощью той же функции insert(), в векторе происходит смещение всех ячеек вправо. К тому же, смещение идет по одной ячейке, а это у нас линейный поиск, который работает, мягко сказать, не быстро. При этом, чем больше у нас будет вектор, тем медленнее будет происходить добавление элементов!
4) front() и back()
Для того, чтобы мы могли просматривать первую и последнюю ячейки у нас имеются функции: front() и back().
|
int front_num = ivector.front(); int back_num = ivector.back(); |
Упражнение
Чтобы как следует запомнить этот материал, создайте вектор и поочередно примените все выше сказанные функции.
Тест на тему «Векторы». Проверь себя!
Пожалуйста, подождите пока страница загрузится полностью.
Если эта надпись не исчезает долгое время, попробуйте обновить страницу. Этот тест использует javascript. Пожалуйста, влкючите javascript в вашем браузере.
If loading fails, click here to try again
Если ты полностью разобрался в данном материале, то попробуй пройти несложный тест, который сможет выявить твои слабые стороны.
На этом все! Надеемся, вы узнали для себя что-то новое! Если хотите задать вопрос, то пишите в комментарии. Удачи!
Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Вычислительная геометрия
Напомним, что отрезок, для которого указано, какой из его концов считается началом, а какой — концом, называется вектором. Вектор на плоскости можно задать двумя числами — его координатами по горизонтали и вертикали.

Помимо очевидных сложения, вычитания и умножения на константу (скаляр — одно число), у векторов можно ввести и свои особенные операции, которые нам упростят жизнь.
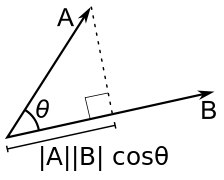
Скалярное произведение (англ. dot product) — произведение длин векторов на косинус угла между ними. Для него справедлива следующая формула:
[
a cdot b = x_a x_b + y_a y_b
]
Она доказывается муторно и чисто технически, так что мы это делать не будем.
Геометрически, она равна проекции вектора (b) на вектор (a), помноженный на длину (а):
У него есть полезные свойства:
- Скалярное произведение симметрично ((a cdot b = b cdot a)).
- Перпендикулярные вектора должны иметь нулевое скалярное произведение.
- Если угол острый, то скалярное произведение положительное.
- Если угол тупой, то скалярное произведение отрицательное.
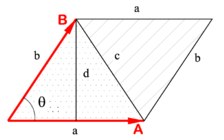
Векторное произведение (англ. cross product) — произведение длин векторов на синус угла между ними, причём знак этого синуса зависит от порядка операндов. Оно тоже удобно выражается в координатах:
[
a times b = x_a y_b — y_a x_b
]
Геометрически, это ориентированный объем параллелограмма, натянутого на вектора (a) и (b):
Его свойства:
- Векторное произведение антисимметрично: (a times b = — (b times a)).
- Коллинеарные вектора должны иметь нулевое векторное произведение.
- Если (b) «слева» от (a), то векторное произведение положительное.
- Если (b) «справа» от (a), то векторное произведение отрицательное.
Вообще говоря, векторное произведение определяется не так. Оно определено как вектор такой же длины, но перпендикулярный обоим исходным векторам. Это имеет применение в трёхмерной геометрии и физике, но нам об этом думать не надо.
Всякие проверки
Благодаря этим свойствам, почти все проверки в геометрии можно описать через них, а не уравнениями.
Принадлежность точки треугольнику. Пусть у нас есть треугольник (ABC) (заданный против часовой стрелки) и точка (P). Тогда она должна лежать слева от всех трёх векторов (AB), (BC) и (CA). Это условие задаст пересечение трёх полуплоскостей, которое и будет нужным треугольником.
[
text{P лежит внутри ABC} iff begin{cases}
(B-A) times (P-A) geq 0 \
(C-B) times (P-B) geq 0 \
(A-C) times (P-C) geq 0 \
end{cases}
]
Площадь треугольника. Можно пользоваться готовыми формулами, а можно и свойством векторного произведения.
[
V = frac{1}{2} (B-A) times (C-A)
]
Площадь произвольного многоугольника. Если многоугольник задан последовательностью вершин в каком-то порядке, то можно считать так: для каждого ребра добавим его ориентированную площадь от начала координат. Какие-то слагаемые будут положительными (которые на последнем слое, а какие-то — отрицательными).
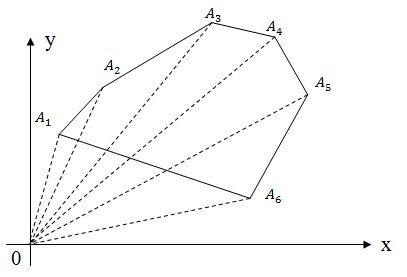
Забудьте о формуле Герона и всегда считайте площади через векторное произведение.
Кстати, из формулы для площади треугольника следует, что площадь любой фигуры будет либо целым числом, либо рациональным с двойкой в знаменателе. Часто в в задачах входные данные целочисленные, и, чтобы оставаться в целых числах, когда мы считаем какую-нибудь площадь, иногда имеет смысл умножить все входные числа на (2) (см. «точность»).
Проверка на выпуклость. Можно пройтись по сторонам многоугольника и проверять векторным произведением, что мы поворачиваем всегда в одну сторону, то есть для всех последовательных точек (a), (b), (c) проверить, что ((b-a)times(c-a) > 0).
Пересекаются ли отрезки.
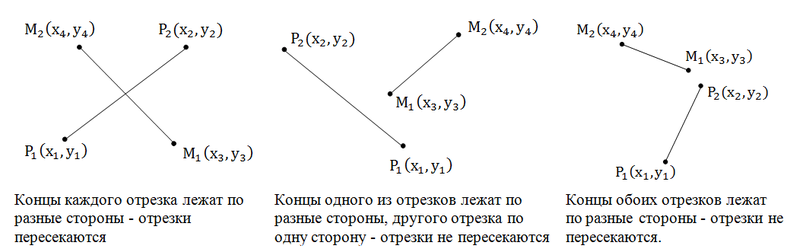
Уравнение прямой
Прямую можно задать уравнением вида (Ax + By + C = 0). Полуплоскость можно задать таким же неравенством.
У прямой есть вектор нормали с координатами ((A, B)). Он перпендиуклярен прямой, а в случае с полуплоскостью (Ax + By + C geq 0) будет указывать в сторону самой полуплоскости.
Чтобы найти расстояние от точки ((x_0, y_0)) до прямой (Ax + By + C = 0), можно воспользоваться следующей формулой:
[
d = frac{|Ax_0+By_0+C|}{sqrt{A^2+B^2}}
]
Точка пересечения. По сути, найти точку пересечения двух прямых — это то же самое, что и найти точку, которая удовлетворяет обоим условиям их уравнений:
[
begin{cases}
A_1 x + B_1 y + C_1 = 0 \
A_2 x + B_2 y + C_2 = 0
end{cases}
implies
begin{cases}
-x = frac{B_1 y + C_1}{A_1} \
-x = frac{B_2 y + C_2}{A_2}
end{cases}
implies
frac{B_1 y + C_1}{A_1} = frac{B_2 y + C_2}{A_2}
implies
y = — frac{A_1 C_2 — A_2 C_1}{A_1 B_2 — A_2 B_1}
]
Аналогично, (x = frac{B_1 C_2 — B_2 C_1}{A_1 B_2 — A_2 B_1}) (обратите внимание на знаки).
Заметим, что знаменатель может оказаться нулем. Это означает, что векторное произведение векторов нормали нулевое, а значит прямые параллельны (в частности, это могут быть совпадающие прямые). Этот случай нужно обрабатывать отдельно.
Как это кодить в C++
Небольшой ликбез по объектно-ориентированному программированию в C++. Создадим класс, который будет отвечать за все операции с точками. В C++ есть два способа это сделать: через struct и через class. Их основное отличие в том, что по умолчанию в class все поля приватные — к ним нет прямого доступа снаружи. Это нужно для дополнительной защиты, чтобы в крупных промышленных проектах никто случайно ничего не поломал, но на олимпиадах это не очень актуально.
Точка (simeq) вектор. Будем считать точка и вектор это один и тот же объект, так как они оба — это просто пара чисел. Будем сопоставлять точке её радиус-вектор — вектор из начала координат, ведущий в эту точку. По принятой в математике и физике нотации, будем обозночать вектора как r. Вы можете обозвать их как point, pt, vec — как угодно.
struct r {
double x, y;
r() {}
r(int _x, int _y) { x = _x, y = _y; }
};Функция r внутри класса вызывается при инциализации объекта. Её называют конструктором, и её можно указывать разную для разных параметров. Здесь r()вернёт точку с неопределенными (какие оказались в памяти в тот момент) координатами, а r(x, y) вернет точку с координатами ((x, y)).
Операции над векторами
Давайте напишем функцию, которая принимает вектора и что-то с ними делает. Например, считает длину:
double len(r a) { return sqrt(a.x*a.x + a.y*a.y); }Операторы
В C++ можно перегружать почти все стандартные операторы, например, +, -, << и т. д.
Переопределим для будущих нужд + и -:
r operator+(r a, r b) { return r(a.x+b.x, a.y+b.y); }
r operator-(r a, r b) { return r(a.x-b.x, a.y-b.y); }Скалярное произведение:
int operator*(r a, r b) { return a.x*b.x + a.y*b.y; }Векторное произведение:
int operator^(r a, r b) { return a.x*b.y - b.x*a.y; }Ввод-вывод
Как вы думаете, как на самом деле работает cin >> x? Это тоже перегрузка оператора — >>. Делается это так:
istream& operator>>(istream &in, r &p) {
in >> p.x >> p.y;
return in;
}
ostream& operator<<(ostream &out, r &p) {
out << p.x << " " << p.y << endl;
return out;
}Почему алгебра это плохо
Мы могли не создавать никаких структур и работать с уравнениями, описывающими геометрические объекты. Такой подход будет популярен на олимпиадах по математике, а не по программированию. Когда математик говорит «пересечем две прямые», он представляет громоздкое уравнение, с которым он потом будет работать.
Программист же хочет абстрагироваться и просто написать intersect(a, b), в корректности которого он точно уверен. Программист хочет разбить задачу на много маленьких кусочков и делать по отдельности, а не возиться с формулами.
Приведем несколько примеров конструктивного подхода.
Векторное представление прямой
Прямую можно задать не через уравнение, а через два вектора (a) и (b):
[
Ax + By + C = 0 rightarrow r = at + b
]
Чтобы это сделать, достаточно выбрать две любые точки на прямой:
// даны A, B, C (A^2 + B^2 != 0)
r a, b;
if (eq(A, 0)) // значит, это горизонтальная прямая
a = r(0, -C/B), b = r(1, -C/B);
else
a = r(-C/A, 0), b = (1, -(C+B)/A, 1)Отражение от прямой
Пусть нам надо отразить точку ((x_0, y_0)) симметрично относительно заданной прямой (ax+by+c=0). Чисто в педагогических целях, начнём решать эту задачу как математики, чтобы никогда потом так не делать.
[
Pr_a b = frac{a cdot b}{|a|} frac{a}{|a|} = frac{|a| |b| cos alpha}{|a|} frac{a}{|a|} = |b| cos alpha frac{a}{|a|}
]
Геометрический смысл: длина на единичный вектор направления.
Мы не хотим раскрывать эти формулы покоординатно и предъявлять готовый ответ. Мы знаем, что он получится громоздким. Нам не жалко посчитать всё по частям — здесь нет смысла заниматься оптимизациями. Также мы хотим делать всё по частям, потому что так становится более наглядной логика алгоритма, и, как следствие, его проще дебажить.
// прямая r = at + b, точка c
r pr (r a, r b, r c) {
c -= b; // пусть c и a выходят из одной точки
return b + (a*b / len(a) / len(a)) * a;
}
r reflect (r a, r b, r c) {
return c + 2*(pr(a, b, c)-c);
}Типичные баги
Точность
Первое правило действительных чисел — не использовать действительные числа
Все переменные типа double хранятся в компьютере неточно (ну а как вы представите ⅓ в двоичной системе счисления?). Поэтому при работе с даблами нужно всегда учитывать эту погрешность. Например, чтобы сравнить два дабла, надо проверить, что они отличаются по модулю меньше, чем на очень маленькое число eps:
const double eps = 1e-8;
bool eq (double a, double b) { return abs(a-b) < eps }Чтобы так не делать, старайтесь по возможности использовать только инты и абсолютную точность. Иногда есть трюки, позволяющие так делать: например, если в задаче все входные точки целочисленные и нас просят посчитать какую-то площадь, то можно все координаты домножить на два, и тогда ответ тоже будет целым (см. векторное произведение), который только при выводе нужно будет поделить на четыре.
(0 neq -0)
Действительные числа так хранятся, что (0) и (-0) могут быть разными числами. Имейте это ввиду.
Область определения обратных функций
acos, asin и прочие обратные тригонометрические функций требуют, чтобы им на вход подавалось число от -1 до 1. Для безопасности, отмасштабируйте числа, перед тем как брать от них эти функции.
На чтение 9 мин Просмотров 13.7к. Опубликовано 15.09.2021
Вектор C ++ не имеет функции-члена поиска. Однако в библиотеке алгоритмов есть функции find () разных типов, которые можно использовать для поиска чего-либо в векторе C ++. В библиотеке алгоритмов есть четыре группы функций find (), которые можно классифицировать как «Найти», «Найти конец», «Найти сначала» и «Найти по соседству».
Чтобы использовать библиотеки векторов и алгоритмов, программа на C ++ должна начинаться с:
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
В этом руководстве приведены основы поиска значения в векторе C ++. Весь код в этом руководстве находится в функции main (), если не указано иное. Если вектор состоит из строк, используйте строковый класс; и не используйте «const char *». В этом случае также должен быть включен строковый класс, например:
Содержание
- Find
- Чувствительность к регистру
- Range Within Limits
- More Than One Occurrence
- Finding Integer
- Predicate
- Заключение
Find
InputIterator find (сначала InputIterator, последним InputIterator, const T & value);
Следующий код использует эту функцию, чтобы узнать, входит ли цветок «Василек» в векторный список цветов:
#include <algorithm>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
int main()
{
vectorvtr = {«Dog Rose», «Honeysuckle», «Enchanter’s nightshade», «Columbine», «Kingcup», «Cornflower», «Water avens», «Forget-me-not»};vector::iterator it = find(vtr.begin(), vtr.end(), «Cornflower»);
if (it == vtr.end())
cout<< «Flower was not found!» <<endl;
else
cout<< «Flower found at index: « << it — vtr.begin() <<endl;return 0;
}
Результат:
Целый список вектора был целью поиска. Судя по синтаксису функции find (), «first» — это vtr.begin () в коде, а «last» — это vtr.end () в коде. Значение, которое нужно искать в синтаксисе функции find (), обозначенное как const-T & -value, в коде имеет значение «Василек».
Функция find () просматривает список векторов с самого начала. Если он не видит искомого значения, он достигнет конца вектора. Конец вектора — это официально vtr.end (), который находится сразу за последним элементом. Если он не видит искомого значения, он вернет итератор, указывающий на vtr.end ().
Значение, которое он ищет, может находиться в разных местах одного и того же вектора. Когда он видит первое из искомых значений, он останавливается на нем и возвращает итератор, указывающий на это значение.
Каждое значение в векторе имеет индекс. Первое значение имеет индекс 0, соответствующий vtr.begin (). Второе значение имеет индекс 1, соответствующий vtr.begin () + 1. Третье значение имеет индекс 2, соответствующий vtr.begin () + 2. Четвертое значение имеет индекс 3, соответствующий vtr.begin () + 3. ; и так далее. Итак, индекс первого найденного значения определяется как:
Чувствительность к регистру
Поиск в векторе чувствителен к регистру. Если бы значение, которое нужно было найти, было «CORNFLOWER» для указанной выше программы, оно не было бы найдено и была бы возвращена vtr.end ().
Range Within Limits
Диапазон не обязательно должен составлять весь вектор. Для приведенной выше программы диапазон мог быть от индекса 1 до индекса 4. То есть от «vtr.begin () + 1» до «vtr.end () — 4». «Vtr.end () — 4» получается вычитанием из обратного с учетом того, что vtr.end () находится сразу за самым последним элементом.
Когда весь список векторов является диапазоном, проверка того, является ли итератор возврата vtr.end (), показывает, было ли значение найдено или нет. Если итератором возврата является vtr.end (), это означает, что значение не было найдено. Теперь, когда диапазон меньше, если итератор возврата является последним элементом выбранного диапазона, это означает, что значение либо не было найдено, либо это последнее значение диапазона.
Примечание. Поиск останавливается на последнем элементе выбранного (меньшего) диапазона, если значение не было найдено в этом диапазоне или если найденное значение является последним элементом выбранного диапазона. Если найденное значение было этим последним элементом, будет возвращен итератор, указывающий на него. Если значение было найдено раньше, поиск остановится на этом элементе перед последним элементом выбранного диапазона. Итератор этого элемента будет возвращен.
Следующий код иллюстрирует эту схему:
#include <algorithm>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
int main()
{
vectorvtr = {«Dog Rose», «Honeysuckle», «Enchanter’s nightshade», «Columbine», «Kingcup», «Cornflower», «Water avens», «Forget-me-not»};vector::iterator it = find(vtr.begin() + 1, vtr.end() — 4, «Cornflower»);
if (it == vtr.end())
cout<< «Flower was not found!» <<endl;
else if (it — vtr.begin() == 4) { //last element in chosen range
if (*it == string(«Cornflower»))
cout<< «Flower found at index: « << it — vtr.begin() <<endl;
else
cout<< «Flower was not found in range!» <<endl;
}
else {
cout<< «Flower found at index: « << it — vtr.begin() <<endl;
}return 0;
}
Результат:
Flower was not found in range!
Теперь «Василек» имеет индекс 5, а «Kingcup» — индекс 4. Последний элемент в небольшом диапазоне, выбранном для поиска, — «Kingcup». Итак, соответствующее условие теста — «it — vtr.begin () == 4». Обратите внимание, что выражения «vtr.end () — 4» и «it — vtr.begin () == 4», каждое из которых имеет 4, являются просто совпадением.
Чтобы «Василек» был в малом диапазоне поиска, соответствующее условие проверки должно быть «it — vtr.begin () == 5». Следующий код иллюстрирует это:
#include <algorithm>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
int main()
{
vectorvtr = {«Dog Rose», «Honeysuckle», «Enchanter’s nightshade», «Columbine», «Kingcup», «Cornflower», «Water avens», «Forget-me-not»};vector::iterator it = find(vtr.begin() + 1, vtr.end() — 3, «Cornflower»);
if (it == vtr.end())
cout<< «Flower was not found!» <<endl;
else if (it — vtr.begin() == 5) {
if (*it == string(«Cornflower»))
cout<< «Flower found at index: « << it — vtr.begin() <<endl;
else
cout<< «Flower was not found in range!» <<endl;
}
else {
cout<< «Flower found at index: « << it — vtr.begin() <<endl;
}return 0;
}
Результат:
More Than One Occurrence
В следующей программе «Василек» встречается более чем в одном месте. Чтобы найти все индексы вхождений, используйте цикл while для продолжения поиска после предыдущего вхождения до конца (vtr.end ()) вектора. Программа:
#include <algorithm>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
int main()
{
vectorvtr = {«Dog Rose», «Cornflower», «Enchanter’s nightshade», «Columbine», «Kingcup», «Cornflower», «Water avens», «Cornflower»};vector::iterator it = find(vtr.begin(), vtr.end(), «Cornflower»);
while (it != vtr.end()) {
if (*it == string(«Cornflower»))
cout<< «Flower found at index: « << it — vtr.begin() <<endl;
it++;
}return 0;
}
Результат:
Flower found at index: 1
Flower found at index: 5
Flower found at index: 7
Finding Integer
Вектор может состоять из целых чисел. Первое целочисленное значение можно найти с помощью функции find () (из библиотеки алгоритмов). Следующая программа иллюстрирует это:
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
vectorvtr = {1, 2, 3, 1, 2, 3, 1, 2, 3};vector::iterator it = find(vtr.begin(), vtr.end(), 3);
if (it == vtr.end())
cout<< «Number was not found!» <<endl;
else
cout<< «Number found at index: « << it — vtr.begin() <<endl;return 0;
}
Результат:
Number found at index: 2
for the first occurrence of the value, 3.
Predicate
InputIterator find_if (сначала InputIterator, затем — InputIterator, предикат предиката);
Здесь используется функция find_if (), а не просто find (). Pred — это имя функции, которая дает критерии поиска. Этот третий аргумент принимает только имя функции, без аргументов и без скобок. Если функция-предикат принимает аргумент, тогда в определении функции указываются параметры для аргументов. Следующая программа иллюстрирует это, ища первое четное число в списке векторов:
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
bool fn(int n) {
if ((n % 2) == 0)
return true;
else
return false;
}int main()
{
vectorvtr = {1, 3, 5, 7, 8, 9, 10, 11, 12};vector::iterator it = find_if(vtr.begin(), vtr.end(), fn);
if (it == vtr.end())
cout<< «Number was not found!» <<endl;
else
cout<< «Number found at index: « << it — vtr.begin() <<endl;return 0;
}
Результат:
Обратите внимание, что был выполнен поиск по всему вектору с диапазоном «vtr.begin (), vtr.end ()».
Имя функции-предиката здесь — fn. Требуется один аргумент — целое число. Когда функция find_if () начинает сканирование вектора с первого элемента, она вызывает функцию предиката с каждым числом в векторе в качестве аргумента. Сканирование останавливается, когда он достигает первого элемента в векторе, для которого предикат возвращает истину.
Заключение
Функция find () в библиотеке алгоритмов существует в четырех категориях: «Найти», «Найти конец», «Найти сначала» и «Найти по соседству». Только категория «Найти» была объяснена выше, и в значительной степени. Приведенное выше объяснение является основой для всех функций find () в библиотеке алгоритмов. Функции Find () имеют дело с итераторами напрямую и косвенно с индексами. Программист должен знать, как преобразовать итератор в индексную и общую арифметику итератора, как показано выше.