|
|
|
Неприметный искатель данных
Этот объект может быть найден в следующих зонах: Пещера Заралек
.
Дополнительная информация
Внести вклад
Известный инструмент Microsoft Office Excel необходим практически в каждом офисе по всему миру. Этот конкретный инструмент позволяет выполнять множество функций, поэтому зная, как создать поисковая система в Excel — одна из тех вещей, которые вам нужно знать, чтобы упростить использование приложения.
В любом случае процесс, которому мы собираемся научить вас сегодня, не следует путать с найти слова в диапазоне или диапазоне ячеек и выделить их в Excel с другой стороны, указанный процесс тоже вполне возможен.
Как мы указали ранее, с Excel функции работы упрощаются, с помощью этого полезного инструмента мы можем организовать огромное количество информации , мгновенно производите сложные расчеты и наблюдайте за развитием нашей работы или нашей компании.
В этом руководстве мы узнаем, как создать внутреннюю поисковую систему, которая еще больше использует все замечательные функции, которые у нас есть в Excel , действие, которое добавляет поиск значений и поиск числа в столбце , может быть очень полезным для поддержания порядка в ваших таблицах.
Чтобы создать поисковик в Excel, это вы должны сначала иметь организованный стол. Этот тип поисковой машины используется именно для поиска конкретных данных в базах данных значительной длины.
Чтобы создать поисковую систему в таблице, сделайте следующее:
Есть много способов создать поисковая система в Excel Однако следующий метод применим практически ко всем типам таблиц. Сегодня мы сосредоточимся на самых основных таблицах данных, но также возможно найти данные на двух или более листах Excel .
Создание Finder в Excel (часть первая)
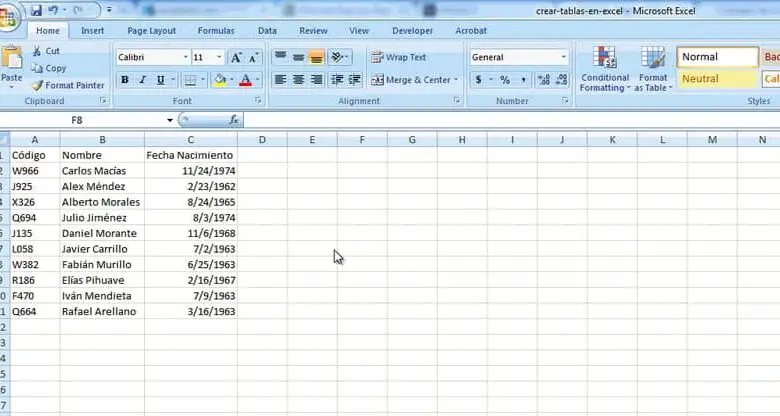
- На этот раз мы сосредоточимся на простой таблице пользовательских данных. Наша цель — захватить код де Автора пользователя (который для других целей может быть DNI, ID-картой или номером ID-карты), чтобы отображалась информация о пользователе, которая в этом случае будет имя и дата рождения .
- Первым шагом является создание заголовка, аналогичного тому, который объединяет данные, в нашем случае это будет создание заголовка, который включает столбцы Код, Имя и Дата рождения где-нибудь еще в таблице. Для удобства выберем в столбце F, но местоположение значения не имеет, вы можете выбрать то, которое вам больше всего подходит.
- Следующим шагом является открытие опции «Формулы». В этой вкладке вам нужно открыть Исследования и рекомендации .
Создание Finder в Excel (часть вторая)
- В Search and Reference есть формула, которая нам нужна для » Исследовать», нажмите на него. Появится новая вкладка с двумя вариантами, выберите Valeur желанный : Вектор .
- Вот три фактора, которые вам необходимо установить: Lookup_Value, Compare_Vector и Result_Vector.
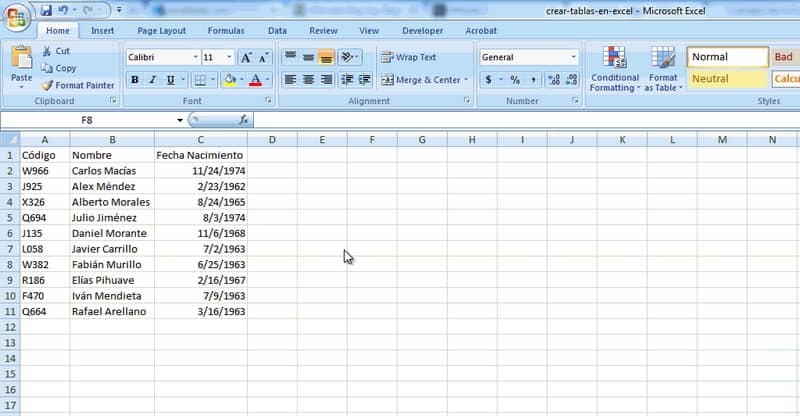
- Искомое значение является объектом исследования, в данном случае это код. Щелкните пустое место, чтобы Search_Value потом по таблице куда напишешь в поиск. В нашем случае это будет прямо под дополнительным заголовком, который мы создали, в частности, в разделе Code .
- Значение для сравнения, как следует из названия, — это значение, которое будет сравниваться со значением поиска. В данном случае нас интересуют коды пользователей. По этой причине вы должны выбрать здесь все существующие коды пользователей. Двигайтесь от первого к последнему.
- Значение результата — это то, что будет отображаться после ввода и сравнения кода. В этом случае нам понадобится имя. Поэтому выберите весь столбец имени и нажмите OK .
- После этого при поиске значения, в данном случае кода пользователя, имя указанного пользователя будет отражено в нашем новом заголовке.

Вы также можете применить поисковую систему к другим столбцам
- Чтобы показать нам информацию из других столбцов, просто скопируйте формулу и переосмыслите ее. В этом случае вам нужно скопировать формулу имени, которую мы будем использовать в столбце День рождения .
- Мы собираемся скопировать эту формулу, которая в нашем случае должна выглядеть примерно так: «ПРОСМОТР (F3; ТАБЛИЦА2 [КОД]; 3ТАБЛИЦА2 [ИМЯ])», а затем продолжаем вставлять ее в данные de Naissance нового заголовка.
- После этого измените имя на «= ПОИСК (F3; ТАБЛИЦА2 [КОД]; ТАБЛИЦА2 [ДАТА РОЖДЕНИЯ])».
- Выполнив этот процесс, при написании кода пользователя появится информация об имени и дате рождения. Чтобы большие столы, процедура такая же, вы можете изменить формулу, но все же изменить второе значение, т.е. результат.
В предыдущем руководстве по созданию Finder в Excel , вы можете легко получить доступ к данным из больших таблиц. Это особенно полезно для баз данных значительной длины, таких как платежные ведомости или оценки студентов. Примените этот полезный инструмент Excel прямо сейчас!
В свою очередь, с помощью функции ВПР или ГПР на листе Excel обычно очень полезен для расширения его возможностей при использовании этого популярного приложения, поскольку он относительно похож на функцию, которую мы обсуждали в предыдущем руководстве.
Содержание
- Как узнать местоположение человека без его согласия? Seeker Kali
- Инструменты Kali Linux
- Список инструментов для тестирования на проникновение и их описание
- ace-voip
- Описание ace-voip
- Справка по ace-voip
- Руководство по ace-voip
- Примеры запуска ace-voip
- Установка ace-voip
- 21 лучший инструмент Kali Linux для взлома и тестирования на проникновение
- Лучшие инструменты Kali Linux для взлома и тестирования на проникновение
- 1. Nmap
- 2. Lynis
- 3. WPScan
- 4. Aircrack-ng
- 5. Hydra
- 6. Wireshark
- 7. Metasploit Framework
- 8. Skipfish
- 9. Maltego
- 10. Nessus
- 11. Burp Suite Scanner
- 12. BeEF
- Этичный хакинг с Михаилом Тарасовым (Timcore)
- #42 Kali Linux для начинающих. Взламываем базу данных. Атаки на пароли.
Как узнать местоположение человека без его согласия? Seeker Kali
 Zip File, мамкины хацкеры. Как вы думаете, способен ли злоумышленник узнать точный адрес человека в Интернете без его согласия? Нет, теоретически это конечно возможно, однако на практике гораздо проще прибегнуть к методам старой-доброй социальной инженерии и простеньким утилитам способным при грамотном подходе ввести в заблуждение практически любого среднестатистического пользователя глобальной сети.
Zip File, мамкины хацкеры. Как вы думаете, способен ли злоумышленник узнать точный адрес человека в Интернете без его согласия? Нет, теоретически это конечно возможно, однако на практике гораздо проще прибегнуть к методам старой-доброй социальной инженерии и простеньким утилитам способным при грамотном подходе ввести в заблуждение практически любого среднестатистического пользователя глобальной сети.
Сегодня, я расскажу вам о скрипте Seeker. С его помощью можно определить точное месторасположение устройства, с которого производится сёрфинг, внешний IP-адрес, версию браузера, процессор, видюху и ещё массу полезных вещей.
Я изучил множество программ в этом сегменте. Популярный TrackUrl, малоизвестный Trape и в итоге пришёл к выводу, что самый эффективный, за счёт своей простоты и незаурядного подхода, всё-таки Seeker.
Напоминаю, что я крайне не рекомендую вам самостоятельно повторять аналогичные действия. Я это делаю исключительно в образовательных целях. Сугубо для того, чтобы повысить уровень осведомлённости моих дорогих подписчиков.
Друзья, если вам интересно узнать о том, как злоумышленники пробивают адреса наивных людей пренебрегающими базовыми правилами информационной безопасности, тогда устраивайтесь по удобнее и будем начинать.
Шаг 1. Запускаем нашу любимую Kali Linux. Ссылка на ролик, в котором я рассказываю о том, как установить такую на свой компьютер всплывёт в углу. Для тех, кто уже в теме, вводим привычную команду «apt-get update» для обновления списка пакетов.

Шаг 2. И следующим шагом копируем из репозитория гитхаба на машинку скрипт Seeker. Что в переводе на русский означает Искатель.

Шаг 3. После того, как искатель скопируется, переходим в каталог с содержимым.

Шаг 4. И чмодим install.

Шаг 5. Далее запускаем его и ждём, когда система проинсталлирует все зависимости необходимые для корректной работы.

Шаг 6. Как только это произойдёт, запускаем PY’шку на третьем питоне в мануальном режиме. К великому сожалению, в рашке заблочен сервис Serveo. Поэтому далее придётся нам тунелить внешнюю ссылку на нашу тачку.

Шаг 7. Но сначала давайте донастроим Seeker. Выбираем из списка вариант 1. Тот, что Google Drive. В этом случае программа эмитирует страничку загрузки файла с гугловского облака.

Шаг 8. Вводим ссылку на какой-нибудь реальный файлик с диска. Я кину ссылку на выдуманное расписание консультаций. Согласитесь, вполне реально представить ситуацию, когда одногруппник из ВУЗа скидывает тебе нечто подобное.

Шаг 9. Окей. Наш локальный сервер успешно стартанул. Теперь открываем браузер и загружаем установщик ngrok. С помощью этой утилиты мы сделаем наш локальный сервак с левой страничкой доступным для всех обитателей интернета.

Шаг 10. Дождавшись загрузки распаковываем содержимое архива. И затем перемещаем его на рабочий стол.

Шаг 11. Открываем новое окно терминала и вводим «cd Desktop/».

Шаг 12. Далее перемещаем файл в каталог bin.

Шаг 13. И наконец запускаем ngrok.

Шаг 14. Туннель прокинут. Копируем сгенерированную внешнюю ссылку HTTPS.

Шаг 15. И переходим на какой-нибудь сервис, предназначенный для сокращения ссылок. Жаль, конечно, что гугловский Short канул в лету, а то было б вообще шоколадно. Да чёрт с ним. Для демонстрации принципа вполне подойдёт и отечественный клик.ру

Шаг 16. Ну а далее всё просто, как дважды два. Злоумышленник скидывает эту ссылку жертве со словами, «хей братиш, глянь, нам там консультацию перенесли. Просто пздц. Ты точно успеешь?». Человек на панике открывает ссылку, видит предупреждение, мол что-то нужно разрешить. Но вроде ведь пишет знакомый человек. И никаких подозрений по поводу того, что страница могла быть взломана нет, поэтому наивный хомячок клацает «разрешить».

Шаг 17. И таки действительно получает доступ к расписанию консультаций. Всё, как говорится, по-честному. Мы русские, своих не обманываем.

Шаг 18. Ладненько. Давайте посмотрим, какие успехи нас ожидают за проделанный труд. Видим подробную информацию о железе жертве, программном обеспечении, через которое сёрфит, ip-адрес и самое главное, ссылку на точку с геолокацией с точностью до 100 метров. Пробуем перейти.

Шаг 19. Вуаля. Весь расклад, как на ладони. К слову, с мобилы работает ещё бодрее. Так что, если заставить перейти по такой ссылочке со смартфона, можно определить местоположение с точностью до подъезда.

Но такие вещи я уже демонстрировать не намерен. Всё-таки личная жизнь, должна оставаться личной. Даже у блогера. Так что пожалуйста, уважайте вышеупомянутый тезис и никогда не повторяйте подобных действий самостоятельно.
А чтобы защитить себя и своих близких от вмешательства подобного рода, достаточно всего лишь соблюдать одно из краеугольных правил информационной безопасности. Никогда не переходить по неизвестным ссылкам.
Благодаря этому ролику теперь вы точно знаете, чем это чревато и к каким последствиям может привести. Сразу после просмотра обязательно поделитесь им со своими близкими, чтобы защитить и их личное пространство от злоумышленников.
С вами был Денис Курец. Если понравилось видео, то не забудь поставить лайк, а тем, кто впервые заглянул на наш канал, советую тупить и скорее клацать на колокол. Нажмёшь на него и в твоей ленте будут регулярно появляться крутые ролики на тему взломов, информационной безопасности и пентестинга.
Олдам по традиции удачи, успехов, отличного настроения. Берегите себя и свои данные. Никогда не переходите по мутным ссылкам и главное. Всегда думайте, прежде чем разрешить браузеру или приложению что-то передавать. Ведь как говорил мудрый Винни Пух, это всё не спроста… До новых встреч, братцы. Всем пока.
Источник
Инструменты Kali Linux
Список инструментов для тестирования на проникновение и их описание
ace-voip
Описание ace-voip
ACE (Automated Corporate Enumerator — автоматизированный корпоративный перечислитель) — простой, но в то же время мощный инструмент для перебора корпоративной директории VoIP, который имитирует поведение IP телефона чтобы загрузить имя и расширенные записи, которые данный телефон может отобразить на своём экране. Таким же образом эта функция «корпоративной директории» VoIP телефонов делает возможным для пользователей с лёгкостью звонить по имени через их VoIP телефоны. Создание ACE было вдохновлено программой «VoIP Hopper» для автоматизации атак VoIP, которые могут быть нацелены на имена в корпоративной директории. Концепт в том, что в будущем атаки будут выполняться против пользователей и основываться на их имени, а не на нацеливании VoIP трафика на случайные RTP аудио потоки или IP адреса. ACE работает с использованием DHCP, TFTP и HTTP чтобы загружать корпоративные директории VoIP. Затем она выгружает эти директории в текстовый файл, который может быть использован в качестве ввода для других инструментов оценки VoIP. ACE является отдельной утилитой, но её функции интегрированы в UCSniff.
Автор: Sipera VIPER Lab
Справка по ace-voip
Руководство по ace-voip
Страница man отсутствует.
Примеры запуска ace-voip
Режим автоматического обнаружения TFTP сервера IP через DHCP опция 150 (-m)
Режим с указанием IP адресаTFTP сервера
Режим с указанием Voice VLAN ID
Режим удаления интерфейса vlan
Режим автоматического поиска голосового vlan ID в режиме прослушивания для CDP
Режим автоматического поиска голосового vlan ID в режиме спуфинга для CDP
Установка ace-voip
Программа предустановлена в Kali Linux.
Информация об установке в другие операционные системы будет добавлена позже.
Источник
21 лучший инструмент Kali Linux для взлома и тестирования на проникновение
Вот наш список лучших инструментов Kali Linux, которые позволят вам оценить безопасность веб-серверов и помочь в проведении взлома и ручного тестирования на проникновение.
Если вы читаете обзор на Kali Linux, вы поймете, почему он считается одним из лучших дистрибутивов Linux для взлома и пентеста.
Он поставляется с множеством инструментов, облегчающих вам тестирование, взлом и все, что связано с цифровой криминалистикой.
Это один из наиболее рекомендуемых дистрибутивов Linux для этичных хакеров.
Даже если вы не хакер, а веб-мастер – вы все равно можете использовать некоторые инструменты, чтобы легко запустить сканирование вашего веб-сервера или веб-страницы.
В любом случае, независимо от вашей цели, мы рассмотрим некоторые из лучших инструментов Kali Linux, которые вы должны использовать.
Обратите внимание, что не все инструменты, упомянутые здесь, имеют открытый исходный код.
Лучшие инструменты Kali Linux для взлома и тестирования на проникновение

Существует несколько типов инструментов, которые предустановлены.
Если вы не нашли установленный инструмент, просто скачайте его и установите.
1. Nmap

Nmap или «Network Mapper» – один из самых популярных инструментов Kali Linux для сбора информации
Другими словами, чтобы получить представление о хосте, его IP-адресе, обнаружении ОС и аналогичных деталях сетевой безопасности (таких как количество открытых портов и их значения).
Он также предлагает функции для уклонения от брандмауэра и подмены.
2. Lynis

Lynis – это мощный инструмент для аудита безопасности, тестирования соответствия и защиты системы.
Конечно, вы также можете использовать его для обнаружения уязвимостей и тестирования на проникновение.
Он будет сканировать систему в соответствии с обнаруженными компонентами.
Например, если он обнаружит Apache – он запустит связанные с Apache тесты для получения информации о его слабых местах.
3. WPScan

WordPress – это одна из лучших CMS с открытым исходным кодом, и это будет лучший бесплатный инструмент аудита безопасности WordpPress.
Он бесплатный, но не с открытым исходным кодом.
Если вы хотите узнать, уязвим ли блог WordPress, WPScan – ваш лучший друг.
Кроме того, он также дает вам подробную информацию об активных плагинах.
Конечно, хорошо защищенный блог может не дать вам много подробностей о себе, но он все еще является лучшим инструментом для сканирования безопасности WordPress для поиска потенциальных уязвимостей.
4. Aircrack-ng

Aircrack-ng – это набор инструментов для оценки безопасности сети WiFi.
Он не ограничивается только мониторингом и получением информации, но также включает возможность взлома сети (WEP, WPA 1 и WPA 2).
Если вы забыли пароль своей собственной сети WiFi – вы можете попробовать использовать его для восстановления доступа.
Он также включает в себя различные беспроводные атаки, с помощью которых вы можете нацеливаться / отслеживать сеть WiFi для повышения ее безопасности.
5. Hydra

Если вы ищете интересный инструмент для взлома пары логин / пароль, Hydra будет одним из лучших предустановленных инструментов Kali Linux.
Возможно, она больше не поддерживается, но теперь она есть на GitHub, так что вы также можете внести свой вклад в его работу.
6. Wireshark

Wireshark – самый популярный сетевой анализатор, который поставляется с Kali Linux.
Его также можно отнести к категории лучших инструментов Kali Linux для анализа сети.
Он активно поддерживается, поэтому я определенно рекомендую попробовать его в работе.
7. Metasploit Framework

Metsploit Framework – наиболее часто используемая среда тестирования на проникновение.
Он предлагает две редакции – одна (с открытым исходным кодом), а вторая – профессиональная версия.
С помощью этого инструмента вы можете проверить уязвимости, протестировать известные эксплойты и выполнить полную оценку безопасности.
Конечно, бесплатная версия не будет иметь всех функций, поэтому, если вы увлечены серьезными вещами, вам следует сравнить выпуски.
8. Skipfish

Аналогично WPScan, но не только для WordPress.
Skipfish – это сканер веб-приложений, который даст вам представление практически о каждом типе веб-приложений.
Он быстрый и простой в использовании.
Кроме того, его метод рекурсивного сканирования делает его еще лучше.
Для профессиональных оценок безопасности веб-приложений пригодится отчет, созданный Skipfish.
9. Maltego

Maltego – это впечатляющий инструмент для анализа данных, позволяющий анализировать информацию в сети и соединять точки (если есть).
Согласно информации, он создает ориентированный граф, чтобы помочь проанализировать связь между этими частями данных.
Обратите внимание, что это не инструмент с открытым исходным кодом.
Он поставляется предварительно установленным, однако вам нужно будет зарегистрироваться, чтобы выбрать, какую версию вы хотите использовать.
Если вы хотите использовать его в личных целях, вам будет достаточно версии сообщества (вам просто нужно зарегистрировать учетную запись), но если вы хотите использовать ее в коммерческих целях, вам нужна подписка на классическую версию или версию XL.
10. Nessus

Если у вас есть компьютер, подключенный к сети, Nessus может помочь найти уязвимости, которыми может воспользоваться потенциальный злоумышленник.
Конечно, если вы являетесь администратором нескольких компьютеров, подключенных к сети, вы можете использовать его и защитить эти компьютеры.
Тем не менее, это больше не бесплатный инструмент, вы можете попробовать его бесплатно в течение 7 дней на официальном сайте.
11. Burp Suite Scanner

Burp Suite Scanner – это фантастический инструмент для анализа веб-безопасности.
В отличие от других сканеров безопасности веб-приложений, Burp предлагает графический интерфейс и довольно много продвинутых инструментов.
Тем не менее, редакция сообщества ограничивает возможности только некоторыми необходимыми ручными инструментами.
Для профессионалов, вам придется рассмотреть вопрос об обновлении.
Как и в предыдущем инструменте, он также не является открытым исходным кодом.
Я использовал бесплатную версию, но если вы хотите получить более подробную информацию о ней, вы должны проверить функции, доступные на их официальном сайте.
12. BeEF

BeEF (Browser Exploitation Framework) – еще один впечатляющий инструмент.
Он был специально разработан для тестировщиков на проникновение для оценки безопасности веб-браузера.
Это один из лучших инструментов Kali Linux, потому что многие пользователи хотят знать и исправлять проблемы на стороне клиента, когда говорят о веб-безопасности.
Источник
Этичный хакинг с Михаилом Тарасовым (Timcore)
Блог об Этичном Хакинге
#42 Kali Linux для начинающих. Взламываем базу данных. Атаки на пароли.
Давайте рассмотрим еще один способ, как взломать нашу цель. В этом уроке мы будем атаковать сервис базы данных.
Посмотрим на результат сканирования «nmap», а именно нас интересует порт 3306, который используется сервисом «mysql». Это сервис базы данных, и, как Вы знаете, он содержит множество чувствительной информации, такую как имена пользователей, пароли, и т.д.
Нам нужно подключиться к этой базе данных, но у меня нет соответствующего логина и пароля, но я попробую подобрать их с помощью инструмента sqldict. Это сокращение от sql dictionary.
Данный инструмент не стоял у меня в системе, поэтому нужно установить его с помощью команды: «apt-get install sqldict»:


С помощью sqldict можно производить подбор паролей, и данный процесс называется «атака по словарю». Другими словами, я создам список возможных паролей. При первом запуске sqldict в терминале мы видим ошибку, так как нужно сперва выполнить установку «wine32»:

Wine32 – это программа на Kali и других дистрибутивах Linux, которая позволяет запускать программы на Windows в линукс системах. В Windows программа имеет расширение «.exe». Это исполняемые файлы, и они созданы для работы в Windows.

Данная программа будет загружаться какое-то время, поэтому мы опустим данный процесс для загрузки в систему.
Рассмотрим еще один инструмент, который можно использовать для достижения той же самой цели. Его можно найти в разделе «Passwords Attacks», и он называется «wordlists»:

В разделе «Атаки на пароли» существует несколько инструментов для проведения подобных атак, но нас интересуют простые атаки, т.е. атаки на онлайн сервисы. Ранее мы уже атаковали запущенные сервисы SSH и FTP. Как правило, для этих сервисов существует подбор имени пользователя и пароль. И если мы атакуем работающий сервис, для попытки подобрать имя пользователя и пароль, то такая атака называется онлайн-атака на пароли. И сейчас нашей целью будет mysql, который работает на атакуемой машине. Нам нужно подобрать имя пользователя и пароль. Это называется онлайн-атака на пароли. Далее я хочу показать Вам директорию «worldlists». Нас интересует словарь «rockyou.txt»:

Далее нам нужно распаковать текстовый файл rockyou.txt.gz с помощью команды gunzip rockyou.txt.gz:

Давайте воспользуемся этим файлом, и скопируем путь к нему, так как он в дальнейшем нам понадобится.
Сразу хотелось бы отметить, что при работе с инструментами, некоторые из них не будут работать в штатном режиме. Тогда нужно переходить к следующему, и не зацикливаться только на одном. Я постоянно это повторяю, и это очень важно понимать.
Также в этом уроке я буду использовать инструмент «Hydra»:

Для того, чтобы подобрать пароль, мне нужен словарь или список слов для атаки. В интернете я нашел список самых худших паролей всех времен:

Скопируем первые 50 паролей:

С помощью текстового редактора nano создаем файл «temp»:

Обратите внимание на то, что все области, которые выделены в розовый цвет являются разделителями, при помощи табуляции. Имейте ввиду, что таком формате файл бесполезен. Нам нужно создать последовательный список из всех этих слов. Мы воспользуемся командами, которые изучили в предыдущих уроках.
Введем команду cat в терминале:

Нам нужно привести этот файл в порядок. Команда будет выглядеть как: «cat temp | cut –d$’t’ –f 2».
Значок $ используется для того, чтобы вырезать только текст. Можно загуглить данную команду, и Вы быстро разберетесь, как все работает. Просто помните, что после разделителя «Tab», необходимо указать значок доллара, затем добавить –f 2 (второе поле):

И, как видим, у нас появился список всех возможных паролей, которые были скопированы. Разумеется, весь этот вывод на экране нужно сохранить в отдельный файл. Команда будет выглядеть как: «cat temp | cut –d$’t’ –f 2 > worst-50»:
 worst-50″ srcset=»https://timcore.ru/wp-content/uploads/2022/04/screenshot_14-6.png 805w, https://timcore.ru/wp-content/uploads/2022/04/screenshot_14-6-300×244.png 300w, https://timcore.ru/wp-content/uploads/2022/04/screenshot_14-6-768×625.png 768w» sizes=»(max-width: 805px) 100vw, 805px»/>
worst-50″ srcset=»https://timcore.ru/wp-content/uploads/2022/04/screenshot_14-6.png 805w, https://timcore.ru/wp-content/uploads/2022/04/screenshot_14-6-300×244.png 300w, https://timcore.ru/wp-content/uploads/2022/04/screenshot_14-6-768×625.png 768w» sizes=»(max-width: 805px) 100vw, 805px»/>
Обратите внимание на то, что я указал файл worst-50 без какого-либо расширения. На самом деле в линуксе можно не указывать расширение, так как файлы являются текстовыми по-умолчанию, и можно прочесть их содержимое.
Давайте внесем последние правки в наш словарь:

Нам нужно удалить строку top, так как она нам не нужна. Жмем горячую клавишу Ctrl+K для удаления первой строки, а перейдя на последнюю жмем «Enter», что будет являться пустой строкой:

Пустая строка будет выполняться, если кто-то будет использовать какой-либо логин и пустой пароль.
Давайте вернемся к инструменту «Hydra», и можем воспользоваться примером, который нам указывают разработчики:

На самом деле половина успеха будет заключаться в правильном использовании имени пользователя. Если у нас нет правильного имени пользователя, то будет проблематично с авторизацией.
Команда для перебора по словарю будет выглядеть следующим образом:
«hydra –l root –P worst-50 mysql://192.168.119.130»:

Hydra сработала практически сразу и был подобран один пароль. Также можем видеть 51 попытку подбора пароля. Обратите внимание, что здесь не указан подобранный пароль, а это значит, что пароль был пустым.
Теперь у нас есть имя пользователя и пароль, для авторизации в базе данных mysql. В случае с FTP, для авторизации нам нужен был FTP-клиент (например, FileZilla). Чтобы пройти SSH-авторизацию, нам нужен был SSH-клиент, а на Windows мы использовали Putty. На Linux – SSH-клиент. В случае с авторизацией в MySQL, нам нужен MySQL-клиент. Для подключения к базе данных нам нужно ввести в терминале следующую команду: «mysql –u root –p –h 192.168.119.130», где опция –u – это имя пользователя, —p – порт, —h – айпи-адрес:

MySQL просит ввести пароль. Мы просто оставляем пустым и жмем «Enter».
Обратите внимание, что консоль изменилась, и мы взаимодействуем с базой данных.
Если Вы никогда не сталкивались с базой данных SQL, то можно использовать графические клиенты, которые выглядят нагляднее, чем то, что мы используем сейчас.
Мы разберем простые команды, которые можно использовать. Давайте посмотрим какие базы данных есть на этом MySQL сервере. Их может быть несколько, и для этого выполним простую команду «show databases;»:

Не забудьте в конце записи ввести точку с запятой, так как это является концом команды. Таков синтаксис SQL-запросов.
Как видим, существует несколько баз данных. Начнем с базы «dvwa». Обратите внимание что «information_schema» — это база данных баз данных, так как она содержит информацию об остальных базах данных.
Чтобы открыть «dvwa», просто пишем команду «use dvwa;»:

Нам нужно просмотреть таблицы этой базы данных. Для этого пишем команду: «show tables;»:

Как видим, существует две таблицы «guestbook» и «users».
Нас будет интересовать таблица «users», так как в ней могут содержаться имена пользователей и пароли. Команда выглядит как: «select * from users;»:

В данной таблице содержатся id пользователей, имена, логины, пароли, аватары. Именно так выглядят украденные учетные данные.
Те, кто интересуется информационной безопасностью часто слышат о том, что хакеры то и дело сливают информацию из баз данных самых разных сайтов, компаний и т.д.
Обратите внимание, что выведенные пароли не похожи на обычные пароли, и если присмотреться, то у них одинаковая длина. Это хэши паролей. Иными словами, мы не сможем просто авторизироваться в системе с такими паролями, потому что это не сами пароли, а их скрытое значение.
Очень часто злоумышленники пытаются взломать данные пароли, т.е. расшифровать их. Не волнуйтесь, что какая-то информация непонятна. Мы еще поговорим об этом. Сейчас для нас актуально то, что мы авторизировались в базе данных нашли некоторую информацию с данного сервиса.
Так что же делать дальше? Вспомним, что я говорил то, что если у Вас есть имена пользователей – это половину успеха, и для взлома этих пользователей нам понадобится пароли. Можно подобрать пароли этих пользователей с помощью гидры или подобного инструмента. Можно также поискать в интернете расшифрованные хэши, которые мы нашли в базе данных. Возможно, кто-то до Вас уже делал подобное и выложил в сети данную информацию.
Погуглить найденные хэши.
Использовать инструменты Kali Linux для взлома хэшей, к примеру, John the Ripper.
Источник
Обзор программ для поиска документов и данных
Говорить о том, что в наше время информационных технологий и бесконечного роста объема данных, доступных как отдельно взятому человеку, так и обществу, существует много проблем с обработкой информации и ее поиском — это уже кощунство. Кто только эту тему не поднимает. И дабы не загружать вас субъективными и, частью, объективными суждениями, почерпнутыми из различных информационных источников касательно проблемы, я перейду непосредственно к ее решению. Сегодня поговорим о поиске. То есть о программах и серьезных информационных системах, осуществляющих поиск нужных нам документов и данных.
Апгрейд «прямого поиска»
Не так давно, когда деревья были большими, и информации даже в локальной сети предприятия было не так много, любой поиск осуществлялся банальным перебором горстки доступных файлов и последовательной проверкой их названий и содержимого. Такой поиск называется прямым, и программы (утилиты), использующие технологию прямого поиска, традиционно присутствуют во всех операционных системах и инструментальных пакетах. Но, даже мощности современных компьютеров не хватит для быстрого и адекватного поиска в гигантских объемах данных при прямом поиске. Перебор пары сотен документов на диске и поиск в громадной библиотеке и нескольких десятках почтовых ящиков — разные вещи. Поэтому, программы прямого поиска сегодня явно уходят на второй план — если речь идет об универсальных средствах.
Конечно, в корпоративном секторе такой вид поиска уже давно не востребован. Объемы не те. И, поэтому, уже который год, а в последнее время однозначно, технологии, способные осуществлять быстрый и точный поиск документов различных форматов и из различных источников, более чем актуальны. Не так давно «папа» Microsoft Билл Гейтс, позавидовав, судя по всему, феноменальному успеху Интернет-поисковика Google, на одной из пресс-конференций обнародовал желание софтверного (уже и не только) всячески способствовать, развивать и углублять создание поисковых систем и технологий. Но до создания какой-либо феноменально работающей программы от Microsoft или конкурентоспособного сервера в Интернет пока рано (MSN все равно до Google не дотягивает). Поэтому обратимся к уже существующим разработкам.
В «КИБ СёрчИнформ» реализовано 8 базовых поисковых алгоритма, которые можно комбинировать, составляя сложные запросы.
Индекс, запрос, релевантность
В основе современных технологий лежат два основополагающих процесса. Во-первых, это индексация доступной информации и обработка запроса с последующим выводом результатов. Что касается первого, то любая программа (будь то настольный поисковик, корпоративная информационная система или Интернет поисковый движок) создает свою область поиска. То есть обрабатывает документы и формирует индекс этих документов (организованная структура, в которой содержится информация об обработанных данных). В дальнейшем именно созданный индекс используется для работы — быстрого получения списка нужных документов согласно запросу. Дальнейшее хоть и отнюдь не просто в плане технологии, но зато вполне понятно обычному пользователю. Программа обрабатывает запрос (по ключевому слову-фразе) и выводит список документов, в которых эта ключевая фраза содержится. Так как информация содержится в структурированном индексе, то обработка запроса проходит значительно (в десятки и сотни раз!) быстрее, чем в случае с прямым поиском (выборка документов осуществляется не перебором файлов, а анализом текстовой информации в индексе).
Найденные документы программа выводит в результирующем списке согласно релевантности — соответствия документа тексту запроса. В различных технологиях, конечно, присутствуют различные методы поиска и определения релевантности документа (количество «вхождений» слова и его частота упоминания в документе, соотношение этих параметров к общему количеству слов в документе, расстояние между словами фразы запроса в искомых файлах и так далее). На основе этих параметров определяется «вес» документа и, в зависимости от него тот или иной файл оказывается в списке результатов на определенной позиции. В случае с Интернет-поиском дело обстоит еще сложнее. Ведь в данном случае надо учитывать и множество иных факторов (Page Rank Google тому пример). Но это тема для отдельной статьи, поэтому Интернет трогать не будем.
Обзор поисковиков
В данном материале рассмотрены возможности нескольких популярных программ поиска, которые могут похвастаться как приличными скоростями, так и неплохим функционалом. Но хвастаться в рекламных проспектах — это одно, а вот выдержать пристальный взгляд эксперта — совсем другое. А экспертов нашлось ни много, ни мало полный офис любителей поковырять софт на предмет его юзабилити. На подопытный компьютер (Athlon 2,2 MHz, с объемом оперативной памяти 1 Гб, 160 гигабайтным IDE жестким диском Seagate на 7200 оборотов в минуту и системой Windows XP) был установлен набор программ: dtSearch Desktop, Ищейка Проф Deluxe, Google Desktop Search, SearchInform, Copernic Desktop Search, ISYS Desktop. Для тестов была скомпонована текстовая база документов в форматах doc, txt и html общим размером ни много, ни мало, а 20 гигабайт. Группа товарищей под руководством вашего покорного слуги тестировала, сравнивала и делилась своими субъективными впечатлениями по каждой софтине. Сводное изложение полученных данных читайте ниже.
dtSearch Desktop
Программа, претендующая, по заявлению разработчиков, на самую быструю, удобную и лучшую поисковую систему. Как, в общем, и все остальные из данного обзора. Интерфейс dtSearch довольно прост, но некоторые окна или вкладки несколько перегружены элементами, из-за чего создается впечатления сложности использования. Но на самом деле особых трудностей не возникает. Единственным действительно неприятным моментом является отсутствие поддержки софтиной русского языка (не смотря на то, что искать документы программа может на нескольких языках, интерфейс ее исключительно английский).
Зато dtSearch одна из немногих программ, которая может индексировать веб-страницы на заданную пользователем «глубину» (правда, с учетом «дозакупки» в комплект адд-она dtSearch Spider). Это кроме поддержки файлов на диске различных текстовых форматов и электронных писем из почтового ящика Outlook. В то же время, программа не умеет работать с базами данных, которые являются таким лакомым кусочком для поисковиков из-за больших объемов информации, находящихся в них, и широкого распространения в компаниях, а значит и в корпоративных сетях. Скорость индексирования документов dtSearch оказалась на должном уровне. Забегая вперед, скажу, что эта программа справилась с индексацией заданного объема информации на уровне с другим конкурсантом — iSYS — и поделила с ним второе место в списке самых быстрых систем. Тестовые 20 гигабайт информации dtSearch проиндексировала за 6 часов 13 минут, создав для нужд последующего поиска индекс размером 7.9 Гб.
Что касается возможностей поиска, то здесь они на должном уровне. Во-первых, в dtSearch присутствует морфологический поиск (поиск слова во всех его морфологических формах). Используя данную возможность, вы освобождаете себя от, скажем, таких раздумий, как «в каком же падеже было употреблено некоторое слово в необходимом мне документе?». Использование морфологического поиска почти всегда оправдано, поэтому должно присутствовать в любом профессиональном поисковике.
Поиск по звучанию является нестандартной возможностью даже для профессиональных поисковиков. Суть его заключается в том, что программа будет искать слова, которые звучат так же, как введенное вами слово. И что самое приятное, эта функция работает и для русского языка! Например, набирая слово «ухо» в поисковом запросе, вы увидите в результате не только слова «ухо», но и «уха».
Поиск с коррекцией ошибок — очень важная функция. Применяется для поиска слов, содержащих синтаксические ошибки — это могут быть как опечатки, так ошибки в документах, полученных при помощи систем распознавания символов, например. Простой пример — вы ищете слово клавиатура. В некотором документе содержится слово «клавиатупа», очевидно, что на самом деле это слово «клавиатура», просто человек при наборе текста опечатался. Так вот, поиск с коррекцией ошибок, это обнаружит и включит документ со словом «клавиатупа» в результат. Также в dtSearch есть настройка, позволяющая определять степень возможных ошибочных символов.
Поиск с использованием синонимов. Эта возможность использует список синонимов для различных слов. Так, например, введя слово «быстрый», программа также найдет слова «скоростной» и другие, являющиеся синонимами для слова «быстрый», если таковые, конечно, присутствуют в списке синонимов. Готового списка синонимов вместе с программой dtSearch не поставляется, однако есть возможность воспользоваться списками в Интернет (соответственно, требуется подключение, что не всегда удобно), либо можно составить свой список синонимов.
Кроме перечисленных возможностей, dtSearch может производить поиск с использованием фраз, состоящих из слов, соединенных логическими операциями. Каждому слову в запросе можно устанавливать свой «вес», то есть значимость. Полезная опция — использование словаря, состоящего из не значимых слов для того, чтобы не учитывать их при поиске, однако этот словарь также пуст и его придется заполнять самостоятельно.
Далее рассмотрим возможности программы при работе в сети. По сути, никаких специфических возможностей для работы с сетью dtSearch не предлагает. Тем не менее, использовать его в сети вполне возможно. Как вариант, можно создать некоторый индекс и положить его в общедоступную (расшаренную) папку. Саму же программу можно установить каждому пользователю на компьютер, либо выложить ее также на папку, открытую для общего доступа, и создать специальным образом ярлыки для каждого пользователя отдельно, используя параметры командной строки, предназначение которых описано в файле помощи, поставляемым с программой. Также, есть возможность автоматической установки программы в сеть при помощи MSI файла. При этом будут учтены настройки для каждого подключаемого пользователя.
В общем и целом — неплохая программа из разряда профессиональных поисковиков. Может претендовать на хорошую оценку, однако завоевание доверия и уважения со стороны пользователей может оказаться непростым для dtSearch в силу некоторых факторов (не все гладко с интерфейсом, русские пользователи обделены, нет ярких особенностей для работы с сетью). Что касается непосредственно поиска документов, то накладок с русским текстом у программы не было. Как не было их ни с заявленной морфологией, ни с нечетким поиском. Система вполне адекватно находила нужные документы и по простому запросу в одно слово и по использовании в качестве ключевой фразы пары абзацев, какого-либо документа.
Официальный сайт: www.dtsearch.com Размер дистрибутива: 23 Mb
Ищейка Проф Deluxe
Исходя из названия, можно догадаться, что поддержка русского языка в этой программе есть. Это уже приятно. Что касается интерфейса, в общем-то, он несколько необычен, но с виду весьма привлекателен. Другое дело — удобство. Весьма спорный критерий, но все же, наверно, многооконное решение — не самый удачный вариант (запрос вводится в одном окне, результат отображается в другом и тому подобное).
Ищейка использует все те же индексы для осуществления быстрого поиска, однако индексирование проходит значительно медленнее, нежели у других программ. Это весьма странно, особенно учитывая то, что возможности по обработке поисковых запросов у нее весьма слабые, а значит и структура индекса не сложная. Скорее всего, дело тут в неоптимизированных алгоритмах. Эта программа оказалась явным аутсайдером скоростей индексации и поиска: время, затраченное на создание индекса, в шесть раз больше, чем у тех же dtSearch и iSYS. Индексация 20 гигабайт текстов для ищейки вылилась в 38 часов 46 минут работы. А созданная «область поиска» заняла на жестком диске тот же размер, что и исходные данные за небольшим минусом — 19 гигабайт.
Ищейка может быть представлена как альтернатива стандартному поиску в Windows, на большее она вряд ли способна. О том, что первоочередная задача Ищейки — простейший поиск файлов указывает не только малое количество функций для анализа текста поисковых запросов и расширенный поиск по атрибутам файлов, но даже окно результатов, выдающее прямые ссылки на найденные файлы, а также на папки, содержащие эти файлы. Окно результатов не слишком информативно в том плане, что прочитать весь найденный файл можно, только запустив его, то есть, встроенного просмотрщика файлов у него нет. Зато выдается выдержка из файла, где встретилось искомое слово, в общем, такая схема отображения очень напоминает Интернет поисковики.
Говоря о конкретных возможностях по обработке поисковых запросов, стоит отметить, что здесь нет такого понятия как «искать текст», максимум, что можно искать — это фраза, хотя бы потому, что здесь нет многострочного поля ввода текста. Тем не менее, анализировать можно и введенную фразу и Ищейка предлагает нам здесь стандартный поисковый набор: логические операции, поиск по маске и цитатный поиск… не густо. В программе присутствуют некоторые зачатки морфологического поиска, но, наверно, настолько сырого, что он, скорее, мешает корректной работе (во время тестов было замечено множество накладок с неправильным использованием морфологии).
Зато программа позволяет указывать при поиске атрибуты файлов (дата документа, имя файла, имя папки), причем в этих запросах также можно использовать тот же поисковый набор. Также, можно осуществлять поиск писем, указывая параметры (От, Тема…. и т.п.).
Итак, с самим поиском разобрались, чем же еще интересным обладает программа, за что она получила столь многочисленные награды, по информации с официального сайта? Трудно сказать, что в ней такого особенного, скорее всего, интерфейс Ищейки располагает к себе (именно внешне, не говоря о юзабилити).
Операции с индексами весьма стандартны, приятным моментом является возможность обновления индексов по расписанию. Кроме того, индексы также могут использоваться в сети. С этого момента надо поподробнее.
Несмотря на примитивность поисковых запросов, программу можно использовать для поиска файлов, поэтому ее применение может быть оправдано в сетях. Хоть и с большой натяжкой, так как в большой сети приоритетной задачей является быстрый поиск данных с использованием сложных поисковых запросов из-за огромного количества информации — а со скоростью поиска и программы явно проблемы. Надо сказать, что работа с сетью у Ищейки продумана, как следует. Специально для этого предназначено отдельное приложение — Ищейка Сервер. Оно работает так же, как и просто Ищейка (поисковой движок у них один), только для документов, размещенных на центральном сервере или на общих ресурсах в корпоративной сети. Ищейка Сервер создает новые индексы на общих ресурсах, либо использует ранее созданные. Любой пользователь корпоративной сети может подключиться к Ищейке Сервер и использовать ее для доступа к любому документу (находящемуся в текущем индексе) используя Интернет браузер. Согласитесь, такая схема является крайне удобной: получается, что файлы в собственной сети можно искать таким же образом, как информацию в Интернете через, например, Google.
Оценивая все преимущества и недостатки этой программы, сам собой напрашивается вывод, что для корпоративных сетей ее возможностей, скорее всего, не хватит (несмотря доже на неплохую организацию работы с сетью), а вот для домашнего компьютера или даже для домашней сети она, в принципе, может и подойти. Хотя ни скорость работы, ни возможности по поиску не внушают оптимизма…
Официальный сайт на русском языке: www.isleuthhound.com/ru Размер дистрибутива: 6 Mb
Google Desktop Search + GDS Enterprise
Конечно, мы не могли обойти стороной такого именитого разработчика. Имя Google уже говорит о многом. Народ, годами пользовавшийся мощнейшим Интернет поисковиком, наверняка без единого сомнения решит установить на компьютере именно этот поисковик. Это же подумать: Google на домашнем компьютере! Однако, не поддаваясь на провокации с широко раскрученным брэндом, попробуем трезво, а главное объективно, рассмотреть возможности «настольного» поисковика от Google.
Первое, что бросается в глаза — отсутствие собственной оболочки для программы. Google Desktop Search по-прежнему находится в окне браузера, соответственно, весь интерфейс настольной версии достался софтине от старшего Интернет-брата. Хорошо это или плохо — спорный вопрос: кому-то по душе минимализм в дизайне этого поисковика, а кому-то хочется видеть полноценное приложение, наполненное всякого рода кнопочками и так далее.
Что бросается в глаза сразу после дизайна? А то, что этот самый Google Desktop Search начинает индексировать на компьютере все подряд, без всякого на то спроса! И что самое интересное, выбрать пути индексации при помощи Google Desktop Search невозможно. Придется скачать отдельную программку (TweakGDS), которая позволит несколько расширить настройки Google Desktop, в том числе и указать необходимые для индексации места. Хотя, пока со всем этим разберешься, стандартный винчестер он уже проиндексирует, так что такая настройка нужна скорее при работе с большими массивами данных, что очень актуально при использовании в корпоративных сетях (версии Enterprise). Однако не факт, что после скачивания TweakGDS, ваши проблемы решатся. Ведь для работы ей необходимы Microsoft .NET Framework и Microsoft Scripting Runtime. Да уж… установку, как и доступ к настройкам, можно было сделать и проще, хотя, наверно разработчиков можно понять: зачем писать что-то новое, когда есть уже готовый поисковик, портировал его на локальный компьютер и пускай пользователь «наслаждается», а известное имя сделает из «этого» очередной шедевр. Да ладно, закончим на этом лирическое отступление и перейдем к поиску.
Что касается анализа поисковых запросов и выдачи результатов, то здесь все абсолютно идентично Google в Интернет: такая же система отображения результатов, тот же стандартный набор логических операций для поисковых запросов. В общем Google Desktop Search, как и предыдущая программа, предназначен исключительно для поиска файлов — внутреннего просмотрщика этих файлов в нем, разумеется, нет. Количества форматов файлов, поддерживаемых Google Desktop Search, вполне достаточно, а также приятно, что он осуществляет поиск по посещенным Интернет страницам, беря данные из кэша. Скорости поиска и индексирования вполне приемлемые. Правда, для домашнего использования. С внушительными 20 гигабайтами текстов Google Desktop Search справилась за 8 часов 17 минут. Потратить несколько дней на обработку информации из корпоративной сети крупного предприятия не улыбается ни одному сисадмину. Из плюсов: размер создаваемого индекса оказался на уровне (4,5 Гб) с другим поисковиком, протестированном в этом обзоре — SearchInform.
Большое преимущество (или упущение — решать вам) Google Desktop Search заключается в том, что он поддерживает плагины, которые способны многое переменить к лучшему. Другое дело, что подключение плагинов и их настройка настолько усложняет задачу установки поисковика, что начинаешь задумываться — а надо ли все это, когда можно установить нормальную, полноценную программу, в которой уже будет все присутствовать. Ведь для задействования каждой возможности придется устанавливать новый плагин. Даже для того, чтобы программа могла полноценно работать с архивами, нужна отдельная примочка. Завораживает и прельщает бесплатность всех этих дополнительных модулей. Однако если не брать в расчет десктоповую версию поисковика, то грамотная настройка GDS Enterprise может оказаться вам не под силу — ведь не зря специалисты из Google предлагают свои услуги по настройке их же программного обеспечения для вашей сети всего лишь за 10000$.
Если же вы все-таки осилите процедуру настройки и установки (или заплатите 10000$ бригаде быстрого реагирования из конторы Google), то поймете, что сложность установки с лихвой компенсируется очень гибкими настройками при использовании в корпоративных сетях. Немаловажным моментом работы Google Desktop в корпоративной сети является использование групповых политик, что дает возможность установить настройки для каждого пользователя.
Подводя итог, следует сказать, что самое разумное применение для этой программы — домашний или рабочий компьютер. Ведь для обычного компьютера достаточно просто установить программу — остальное она сделает сама (вас даже ни о чем не спросит).
Тем не менее, Google Desktop Search Enterprise будет приемлема в случаях острой необходимости гибкой настройки сетевой политики для использования поисковика, при этом возможности обработки поисковых запросов будут на втором месте по значимости, а время (или деньги), затраченное на настройку программы, — на первом месте.
Официальный сайт: www.google.com Размер дистрибутива вместе с TweakGDS: 1,2 Mb
Copernic Desktop Search
Интерфейс программы вызывает исключительно положительные эмоции — все сделано в соответствии с общепринятыми стандартами, ничего лишнего, одним словом приятный дизайн. Новичку разобраться в интерфейсе Copernic Desktop Search будет очень просто. Хотя, несколько смущает то, что дизайнеры явно создавали интерфейс программы с учетом того, что программа будет работать в стандартной теме оформления Windows XP. При использовании же классической темы, программа смотрится уже не настолько симпатичной. Но это уже скорее дело вкуса.
При первом же запуске, программа предлагает создать индексы для поиска. Несколько необычным показалось то, что после выбора папок для индексирования, программа не предлагает нажать какую-нибудь кнопку, вроде «Начать индексацию», при этом индексация не начинается автоматически, только потом было замечено, что Copernic пытается начать индексацию во время простоя компьютера. Придется несколько покопаться в опциях программы, чтобы настроить все должным образом. Следует отметить, что здесь представлены довольно широкие возможности по настройке автоматического создания индекса: встроенный планировщик, возможность индексации во время простоя компьютера, в фоновом режиме, с низким приоритетом. Индексация проходила не слишком быстро — 10 часов 51 минута — это медленнее, чем в других поисковиках (кроме Ищейки, все же Copernic быстрее разработки iSleuthHound Technologies на порядок.
Теперь о структуре индекса. В общем, ничего особенного в ней нет. Есть возможность выбора типов файлов, причем, как в обобщенном виде, так и в подробном. То есть изначально вы можете выбрать, что требуется индексировать — Документы, Изображения, Видео, Музыку. На другой же вкладке окна опций будет возможность выбрать конкретно типы файлов по расширению. Дополнительно можно настроить индекс таким образом, чтобы, например, не индексировались картинки, размером менее 16х16 или не индексировались звуковые файлы длиной менее 10 секунд. Помимо индексации файлов из папок, Copernic умеет работать с электронными письмами и контактами из адресной книги Microsoft Outlook и Microsoft Outlook Express, возможна индексация Избранного и Истории из Internet Explorer.
Что касается возможностей поиска, то здесь они весьма слабы. Во время тестов даже было выявлено, что программа не ищет документы форматов txt и html на русском языке, позволяя найти их только по заголовкам, а отнюдь не по содержанию. Единственное, что программа предоставляет для повышения эффективности поиска — это использование стандартного набора логических операций, да и то, эта возможность была обнаружена экспериментальным путем, так как документирована она не была. Кстати, со справкой у программы также не все в порядке — она доступна только через Интернет, что, согласитесь, весьма неудобно, да и в сети справочной информации не слишком много. Видимо, разработчики решили, что простой интерфейс программы не предполагает наличия нормальной справки. Продолжая разговор о возможностях поиска, следует отметить, что, несмотря на слабый анализ запросов, программа предоставляет интересную систему поиска — пользователь может выбрать тип файлов (изображения, видео, музыка и т.п.), ввести поисковый запрос и выбрать атрибуты, присущие именно выбранному типу файлов. Например, для звуковых файлов, это могут быть значения из mp3 тегов (артист, альбом, дата и т.п.), для изображений, например, можно выбирать их размер (по разрешению), в общем, каждому типу — свои настройки. После осуществления поиска по определенному типу файлов, программа выдаст весьма информативный список в окне результатов, причем, если под ваш запрос попали файлы других типов, то вы сможете открыть и их, нажав на определенную ссылку.
Отдельно стоит упомянуть про окно отображения результатов. Под списком найденных файлов отображается содержимое этих файлов (аналогичная схема часто используется в почтовых клиентах). Правда, просмотр текста можно осуществлять лишь в родном формате, а режима отображения plain текста нет, что не всегда удобно, так как открытие документа в этом случае занимает больше времени. Зато, учитывая, что Copernic умеет искать изображения и музыку, здесь есть возможность просмотра и этих мультимедийных файлов.
Основные принципы работы этой программы описаны, теперь посмотрим, что Copernic Desktop Search может нам предложить для работы с сетью… В принципе смотреть можно очень долго, но увидеть что-либо вряд ли удастся. Другими словами, эта программа и не задумывалась как сетевая. Copernic Desktop Search — исключительно домашний поисковик.
Очевидно, что единственное (самое логичное) применение этой программы — домашний компьютер. Здесь она вполне справится со всеми незамысловатыми поисковыми запросами пользователей, состоящими из одного двух слов, найдет нужную информацию, а разделение поиска по типам файлов и поддержка мультимедийных файлов вместе с фоновой индексацией в режиме низкого приоритета вкупе с приятным интерфейсом только придают программе сил для завоевания доверия среди неискушенных пользователей.
Официальный сайт www.copernic.com Размер дистрибутива: 2,6 Mb
ISYS Desktop
Очень мощная программа. По уровню оснащенности всевозможными функциями она находится где-то рядом со следующей в списке системой поиска SearchInform. При этом размер установочного файла более 40Mb! Сложно сказать, что можно было засунуть в такие размеры, ведь тот же SearchInform, с похожей функциональностью занимает 15Mb.
Процесс установки здесь также не слишком приятен, точнее даже не процесс установки. Еще до скачивания программы вас попросят зарегистрироваться, а иначе — никак. Далее, интерфейс. Сделан он весьма симпатично, ничего лишнего в глаза не бросается, однако — это впечатления человека, уже несколько привыкшего к нему. Разобраться, где и что находится, куда нажимать и где осуществить наконец-то поиск новичку будет непросто. Очень рекомендуется прочитать справку перед началом работы — сэкономите много нервов и времени. Ко всему прочему добавляется также полное отсутствие поддержки русского языка в программе. Нехорошо. Вдобавок, окна здесь не перегружены элементами управления, однако расплатиться за это пришлось многомодульностью и использованием дополнительных окон. Например, запросы для поиска вводятся при помощи запуска одной программы, а управление индексами производится при помощи уже другой программки. Поисковые запросы вводятся здесь также в отдельных, появляющихся окошках. Что лучше — перегруженность интерфейса или повсеместная многооконность — сказать трудно, скорее, это дело вкуса.
Что касается создания индексов, то программа предоставляет возможности по упрощению процесса установки опций для нового индекса. Эти возможности включают в себя несколько готовых шаблонов для создания индексов по папке «Мои документы», «Почта», «Почта и документы», «Определенная папка», «Папка с выбором типов файлов» и др. Такие шаблоны упрощают создание индексов на первом этапе. Утилита для работы с индексами обладает не слишком удачным интерфейсом, отпугивающим некоторой сложностью (это весьма субъективная оценка, по правде говоря), однако, если разобраться, он предоставляет множество полезных опций и в целом его использование особого труда не вызывает. ISYS Desktop умеет индексировать данные из различных источников данных, а также предоставляет множество гибких настроек для такой индексации. Среди дополнительных возможностей по индексированию: поддержка SQL, FTP, TRIM Context, WORLDOX 2002, скрипты. При создании индекса, если вы выбирали пункт «Папка с выбором типов файлов», у вас есть возможность выбрать типы файлов для индексации вручную (по расширению). Надо сказать, что поддерживаемых типов файлов просто огромное количество, однако свой тип (расширение) добавить в существующий список не удастся. Можно также отметить наличие планировщика индексации. Созданием индекса и обработкой 20 гигабайт информации ISYS Desktop занималась 6 часов 13 минут, в конечном итоге показав неплохое время и размер созданного файла — 7.9 Гб.
Возможности поиска у этой программы неплохи. То, что используется в ISYS, значительно мощнее обычной поддержки логических операций. Из продвинутых возможностей по поиску программа предлагает использование синонимов, фильтра сортировки (по пути, имени и дате создания файла). Набор логических операторов несколько шире стандартного набора. Помимо логических операций, программа позволяет работать со многими другими операторами, которые в принципе способны заменить некоторые виды поиска, например, поиск с синтаксическим разбором вполне можно заменить использованием специальных операторов. Очень удивило то, что в программе отсутствует поиск с использованием морфологии. Это серьезное упущение, так как эффективность поиска сильно повышается при использовании морфологического анализа. Кроме того, нет списка значимых слов, зато присутствует обширный список незначимых слов. Также заявлены такие функции при поиске как «приблизительный поиск» и «эвристический анализ».
ISYS предоставляет на выбор несколько видов поисковых запросов, именно, видов — визуальных. Это осуществлено при помощи разных видов окон для ввода поисковых запросов, однако, фактически, ни одно окно не позволяет использовать технологии, отличные от перечисленных выше.
Результаты поиска весьма информативны, отображаются в виде списка документов, отсортированных по релевантности. Ниже отображается предпросмотр выбранного документа. В отличие от Copernic Desktop Search, предпросмотр здесь доступен лишь в виде plain текста, добиться отображения документов в родном формате, будь то Word, Html или PDF так и не удалось, хотя это в принципе и не слишком критично. Программа позволяет разбивать найденные документы на группы по определенным признакам (по умолчанию они разделены по релевантности). Можно также просматривать уже найденные документы, выбирая отдельные папки (это удобно, когда результат выдает очень большое количество документов).
Использование программы в корпоративной сети также весьма оправдано, так как она предоставляет неплохие возможности по организации сетевого поиска. Система поиска основана на создании общедоступного индекса, который содержит проиндексированные данные с общедоступных сетевых ресурсов.
По сути, программа от ISYS достойна внимания, хотя бы ознакомления с ней. Эта программа — зрелый проект, обладающий огромным количеством функций (не всегда и не всем, конечно, они бывают нужны, но все же). Шансы на то, что в программе появятся некоторые улучшения со стороны обработки поисковых запросов, не известны, но и на данный момент ее можно рекомендовать практически для повсеместного использования. А учитывая, что для домашних систем она все же слишком грузная, то основные места ее инсталляции — корпоративные сети.
Официальный сайт: www.isys-search.com Размер дистрибутива: 40 Mb
SearchInform
Сразу начинать с описания интерфейса SearchInform, наверно, не стоит. Следует для начала описать процесс установки, а точнее одну его деталь: вы не сможете установить программу без подключения к Интернет. Дело в том, что перед первым запуском программа требует регистрации пользователя (бесплатной) и отправляет все введенные данные на сервер. Видимо, разработчикам пришлось принять такие меры в борьбе с пиратством, однако на удобстве установки это положительным образом не отразилось.
«КИБ СёрчИнформ» не только ищет по сложным запросам, но и составляет наглядные отчеты по результатам поиска.
Интерфейс программы выполнен с соблюдением всех общепринятых правил, однако, на первый взгляд, несколько громоздок. Используя программу в первый раз, кажется, что он чересчур сложный, иногда бывает не просто вспомнить в каком меню или на какой вкладке находится нужная опция, однако, при более длительном использовании, интерфейс уже не кажется таким ужасающе сложным. Главное, предварительно почитать справку.
Немного разобравшись с интерфейсом, можно приступить к созданию индекса. Сам процесс весьма прост и скорость индексации даже на глаз значительно выше всех других поисковиков из обзора. Четкие цифры тестов показывают, SearchInform в два раза обогнала dtSearch и iSYS по скорости индексации! Программа проиндексировала предоставленные данные в размере 20 гигабайт за рекордное время — 3 часа 17 минут. Да и размер созданного индекса оказался самым небольшим 4.4 Гб — на 100 мегабайт меньше, чем у Google Desktop Search.
Программа поддерживает, помимо обычных файлов и папок, также индексацию электронных писем, подключение и индексацию баз данных (!) и других внешних источников (DMS, CRM), сразу же при индексации можно указать словарь для проведения морфологического поиска, а также индексироваться могут все атрибуты файлов. После создания индекса, при попытке провести первый пробный поиск документов, можно прийти в некоторое замешательство: «здесь присутствует два вида поиска, а какой же из них нужен мне?». Как уже говорилось ранее — главное прочитать справку, тогда все станет понятно. Программа действительно умеет осуществлять два вида поиска — это фразовый поиск и поиск документов, похожих по содержанию на текст запроса.
Описание всех основных функций для анализа поискового запроса было приведено выше, поэтому сейчас лишь перечислим возможности поиска, предоставляемые этой программой. Начнем с фразового поиска: конечно, морфологический поиск, цитатный поиск, логические операции, поиск с синтаксическим разбором слова (поиск по началу слова, по окончанию, по средней части, либо полное совпадение), смешанный цитатный поиск (когда все слова из запроса должны присутствовать в документе, но необязательно во введенном порядке), поиск с коррекцией ошибок, использование синонимов, «почти цитатный поиск» (поиск введенной фразы как цитаты, но между введенными словами могут присутствовать другие слова) и т.п. Некоторые из перечисленных опций имеют свои специфические настройки. Кроме того, есть возможность использования словаря незначимых слов, причем в программе уже есть готовый список этих слов, также для поиска можно использовать словарь приоритетных слов (его, разумеется, придется заполнять самостоятельно).
Вот, в принципе, вкратце пробежали все основные возможности фразового поиска.
Загрузка…