Рефакторинг схем баз данных
Время на прочтение
19 мин
Количество просмотров 19K
Я хочу рассказать о рефакторинге схем баз данных MS SQL Server.
Рефакторинг — изменение во внутренней структуре программного обеспечения, имеющее целью облегчить понимание его работы и упростить модификацию, не затрагивая наблюдаемого поведения.
— Martin Fowler
О рефакторинге кода говорят уже давно. На данный момент написано немало литературы, создано множество инструментов, помогающих выполнять рефакторинг кода.
А вот про рефакторинг схем баз данных не так уж и много информации. Я решил немного восполнить этот пробел и поделиться своим опытом.
Как понять что настала пора проводить рефакторинг?
Делая что-то в первый раз, вы просто это делаете. Делая что-то аналогичное во второй раз, вы морщитесь от необходимости повторения, но все-таки повторяете то же самое. Делая что-то похожее в третий раз, вы начинаете рефакторинг.
— Don Roberts
Мартин Фаулер ввел понятие «Код с душком», обозначив так код который нужно подвергнуть рефакторингу.
С душком называется код в котором:
- встречается дублирование
- есть большие методы
- существуют методы с большим количеством параметров
- встречается оператор switch
По аналогии с этим можно выделить общие недостатки схемы базы данных, которые указывают на необходимость применения рефакторинга. К этим недостаткам можно выделить следующие.
- Многоцелевые столбцы (или столбцы используемые не по назначению). Допустим у нас есть таблица содержащая информацию по заказам. В таблице есть необязательное для заполнения поле InvoiceId типа int. Представим что процесс продаж в компании построен таким образом, что это поле никогда не заполняется. Начиная с нового года менеджерам стало необходимо проставлять у заказов оценку клиента (от 1 до 10 по результатам обзвона). Такого поля в таблице нет и менеджеры начинают вбивать эти данные в поле InvoiceId (например потому, что IT-шники сказали им что на добавление нового поля уйдет целый месяц). Это приведет к проблемам когда поле InvoiceId станет использоваться по назначению.
- Многоцелевые таблицы. Примером может послужить таблица Customer в которой хранится информация о физических и юридических лицах. В подобном случае неизбежно появляются столбы с NULL значениями.
- Избыточные данные. Например, наличие поля Адрес клиента в таблице заказов может привести к случаю когда у нескольких заказов одного и того же клиента будут разные адреса.
- Таблицы с большим количеством столбцов. Наличие большого количества столбцов может означать что в таблице хранятся атрибуты более чем одной сущности. В таком случае вероятно нужно применить рефакторинг «Разбиение таблицы».
- Многозначные столбцы. Многозначными называются столбцы, в которых в различных позициях представлено несколько разных фрагментов информации. Например в таблице заказов есть поле OrderNumber содержащее данные вида XXX20150908000125. Где XXX — код товара, 20150908 — дата заказа, 000125 — порядковый номер заказа. На практике часто обнаруживается необходимость разбить поле на части, чтобы можно было проще обрабатывать эти поля в виде отдельных элементов.
Несколько полезных советов по применению рефакторинга
- Оцените масштаб бедствий.
Прежде чем что-то менять убедитесь что Вы не сломаете внешние приложения, использующие Вашу базу данных. Если Вам пришлось поддерживать базу данных, которая досталась «по наследству», вероятнее всего Вы не знаете кто (что) и как ее используют. Составьте список приложений, использующих Вашу базу. Попросите, по возможности, коллег разрабатывающих эти приложения выдать Вам список объектов, которые они используют. После чего согласуйте с ними Ваши изменения, договоритесь о совместном тестировании.
Особое внимание уделите таблицам базы на которые выданы права. Это потенциальный источник проблем.
Обсудите с коллегами чтобы они вместо таблиц перешли на использование представлений (процедур).
Когда все обращения к базе будут реализованы посредством процедур/представлений/функций, Вам будет намного легче проводить рефакторинг. - Не делайте много изменений за один раз.
Чем меньше будет изменение, тем проще будет найти ошибку в случае сбоя. - Проверяйте изменения тестами.
После каждого изменения запускайте тесты, чтобы убедиться что ничего не сломалось. - Используйте песочницы.
Не нужно заниматься рефакторингом на продуктиве, даже если изменение ничтожно мало. Используйте для рефакторинга тестовые площадки. После чего проводите полное регрессионное тестирование. И только после этого выполняйте изменение в продуктивной базе данных.
Практические примеры
Я покажу применение некоторых методов рефакторинга на примере базы данных Northwind (ссылка на скачивание).
В качестве инструмента я буду использовать SQL Server Management Studio (SSMS) с установленным плагином SQL Refactor Studio. Данный плагин добавляет в SSMS функции рефакторинга.
Исходная схема
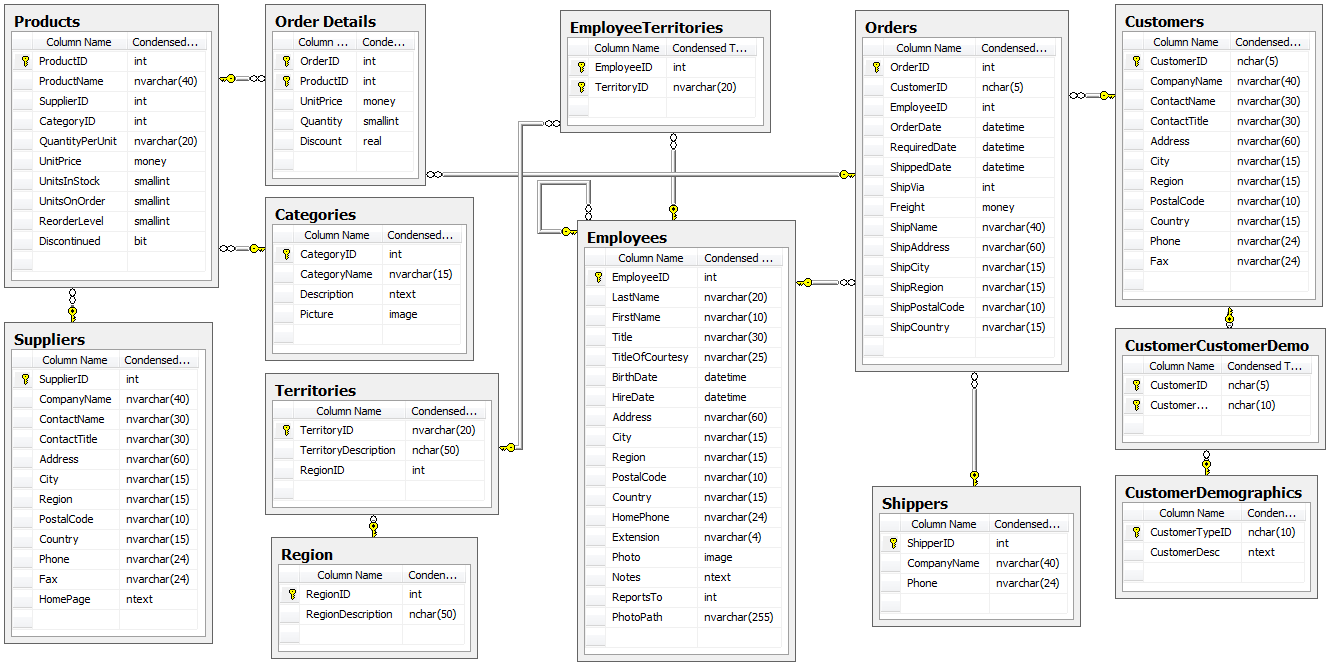
Тестирование
После каждого изменения мы будем запускать тест, чтобы убедиться что все по прежнему работает.
Для примера я создал процедуру dbo.RunTests, которая выбирает данные из всех представлений в базе (разумеется это не обеспечивает нам полное покрытие тестами).
Если в процессе работы процедуры не было ошибок, процедура выдает OK, иначе Failed.
CREATE PROCEDURE dbo.RunTests
AS
DECLARE
@Script nvarchar(max) = '',
@Failed bit = 0
DECLARE crs CURSOR FOR
SELECT 'IF OBJECT_ID(''tempdb..#tmp'') IS NOT NULL DROP TABLE #tmp
SELECT * INTO #tmp FROM [' + object_schema_name(o.object_id) + '].[' + o.name + ']'
FROM sys.objects o
WHERE o.type = 'V'
OPEN crs
FETCH NEXT FROM crs INTO @Script
WHILE @@fetch_status = 0
BEGIN
BEGIN TRY
EXEC sp_executesql @Script
END TRY
BEGIN CATCH
SET @Failed = 1
SELECT 'Failed' AS Status, ERROR_MESSAGE() AS Details, @Script AS [Script]
END CATCH
FETCH NEXT FROM crs INTO @Script
END
CLOSE crs
DEALLOCATE crs
IF @Failed = 0
SELECT 'OK' AS [Status]
RETURN 0
/*
EXEC dbo.RunTests
*/
GO
Рефакторинг «Переименование объекта»
Не знаю конечно как Вы, но я при создании таблицы даю ей имя в единственном числе (dbo.Entry а не dbo.Entrie
s
).
Итак, давайте попробуем переименовать таблицу dbo.Customers в dbo.Customer. Тут есть один неприятный (и очень рутинный) процесс. Нужно переименовать таблицу так чтобы не сломался код использующий ее. Для этого его нужно найти и внести в него исправление. Воспользовавшись стандартным View Dependencies видим что таблица используется в одном преставлении и есть две таблицы ссылающиеся на dbo.Customers.
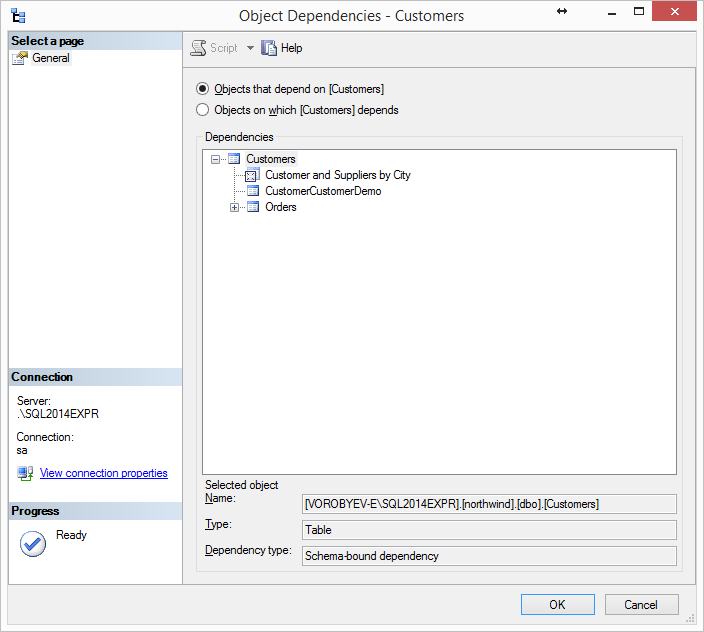
В принципе, внести исправление в одно представление после переименования таблицы — плевое дело.
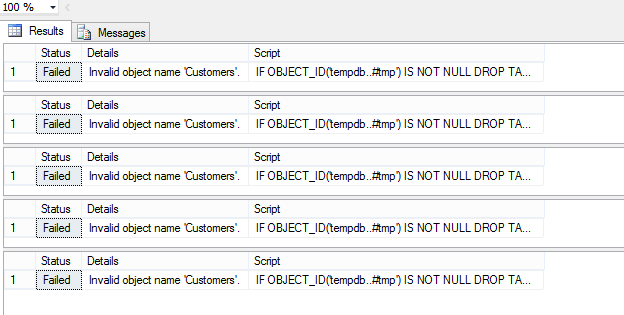
Ну что же, в бой! Переименовываем таблицу и запускаем тест (должна сломаться вьюха dbo.Customer and Suppliers by City).
Однако, вместо ожидаемой одной строки тест мне выдал целых пять.
Тогда я решил проверить зависимости таблицы используя расширенный View Dependencies входящий в состав пакета SQL Refactor Studio. Он уже насчитал пять вьюшек (тест показал что сломалось именно пять представлений) и нашел одну процедуру (не покрыта тестами).
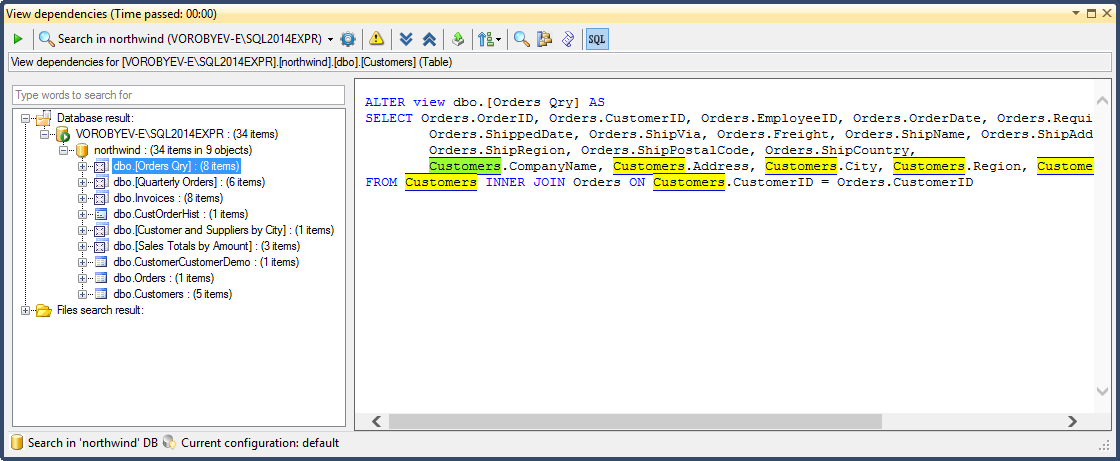
Шесть объектов — это уже посерьезнее. А представьте себе что Вам нужно поправить код в 50+ объектах. Вы все еще хотите переименовать таблицу?  Ручками будет уже тяжело, поэтому, прибегнем к автоматизации.
Ручками будет уже тяжело, поэтому, прибегнем к автоматизации.
Воспользуемся функцией Rename входящий в пакет SQL Refactor Studio. Выбираем таблицу в Object Explorer (далее OE), из контекстного меню выбираем пункт SQL Refactor Studio -> Rename. Вводим новое имя (Customer) и нажимаем кнопку Genarate rename script. Тут также есть возможность посмотреть зависимости и снять галочки напротив объектов в которых не нужно производить переименование.
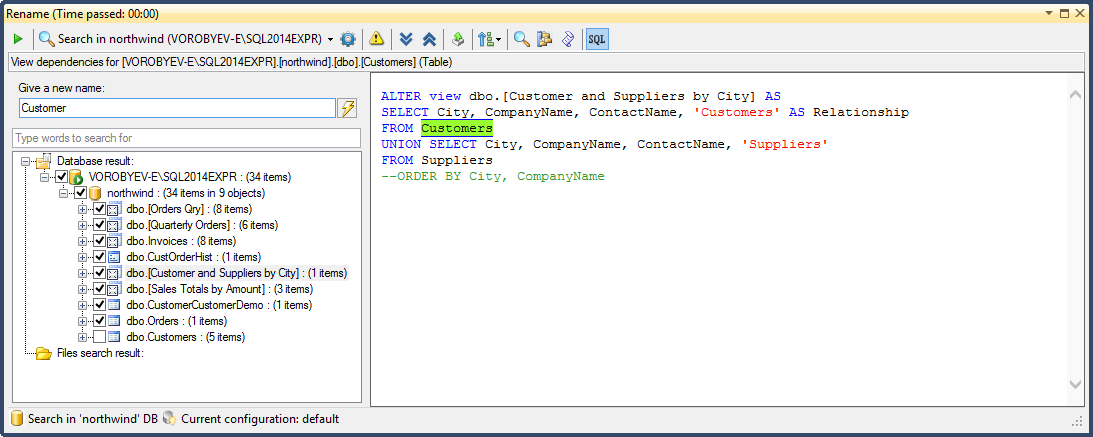
В результате открылась новая вкладка с сформированным скриптом.
Сгенерированный скрипт
use northwind
go
set transaction isolation level serializable
set xact_abort on
go
if object_id('tempdb..#err') is not null
drop table #err
go
create table #err(flag bit)
go
begin transaction
go
exec sp_rename 'dbo.Customers', 'Customer', 'OBJECT'
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Orders Qry] AS
SELECT Orders.OrderID, Orders.CustomerID, Orders.EmployeeID, Orders.OrderDate, Orders.RequiredDate,
Orders.ShippedDate, Orders.ShipVia, Orders.Freight, Orders.ShipName, Orders.ShipAddress, Orders.ShipCity,
Orders.ShipRegion, Orders.ShipPostalCode, Orders.ShipCountry,
Customer.CompanyName, Customer.Address, Customer.City, Customer.Region, Customer.PostalCode, Customer.Country
FROM Customer INNER JOIN Orders ON Customer.CustomerID = Orders.CustomerID
go
raiserror('update view <dbo.Orders Qry>...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Quarterly Orders] AS
SELECT DISTINCT Customer.CustomerID, Customer.CompanyName, Customer.City, Customer.Country
FROM Customer RIGHT JOIN Orders ON Customer.CustomerID = Orders.CustomerID
WHERE Orders.OrderDate BETWEEN '19970101' And '19971231'
go
raiserror('update view <dbo.Quarterly Orders>...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.Invoices AS
SELECT Orders.ShipName, Orders.ShipAddress, Orders.ShipCity, Orders.ShipRegion, Orders.ShipPostalCode,
Orders.ShipCountry, Orders.CustomerID, Customer.CompanyName AS CustomerName, Customer.Address, Customer.City,
Customer.Region, Customer.PostalCode, Customer.Country,
(FirstName + ' ' + LastName) AS Salesperson,
Orders.OrderID, Orders.OrderDate, Orders.RequiredDate, Orders.ShippedDate, Shippers.CompanyName As ShipperName,
"Order Details".ProductID, Products.ProductName, "Order Details".UnitPrice, "Order Details".Quantity,
"Order Details".Discount,
(CONVERT(money,("Order Details".UnitPrice*Quantity*(1-Discount)/100))*100) AS ExtendedPrice, Orders.Freight
FROM Shippers INNER JOIN
(Products INNER JOIN
(
(Employees INNER JOIN
(Customer INNER JOIN Orders ON Customer.CustomerID = Orders.CustomerID)
ON Employees.EmployeeID = Orders.EmployeeID)
INNER JOIN "Order Details" ON Orders.OrderID = "Order Details".OrderID)
ON Products.ProductID = "Order Details".ProductID)
ON Shippers.ShipperID = Orders.ShipVia
go
raiserror('update view <dbo.Invoices>...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER PROCEDURE dbo.CustOrderHist @CustomerID nchar(5)
AS
SELECT ProductName, Total=SUM(Quantity)
FROM Products P, [Order Details] OD, Orders O, Customer C
WHERE C.CustomerID = @CustomerID
AND C.CustomerID = O.CustomerID AND O.OrderID = OD.OrderID AND OD.ProductID = P.ProductID
GROUP BY ProductName
go
raiserror('update storedprocedure <dbo.CustOrderHist>...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Customer and Suppliers by City] AS
SELECT City, CompanyName, ContactName, 'Customers' AS Relationship
FROM Customer
UNION SELECT City, CompanyName, ContactName, 'Suppliers'
FROM Suppliers
--ORDER BY City, CompanyName
go
raiserror('update view <dbo.Customer and Suppliers by City>...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Sales Totals by Amount] AS
SELECT "Order Subtotals".Subtotal AS SaleAmount, Orders.OrderID, Customer.CompanyName, Orders.ShippedDate
FROM Customer INNER JOIN
(Orders INNER JOIN "Order Subtotals" ON Orders.OrderID = "Order Subtotals".OrderID)
ON Customer.CustomerID = Orders.CustomerID
WHERE ("Order Subtotals".Subtotal >2500) AND (Orders.ShippedDate BETWEEN '19970101' And '19971231')
go
raiserror('update view <dbo.Sales Totals by Amount>...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
if exists (select * from #err)
begin
print 'the database <northwind> update failed'
rollback transaction
end
else
begin
print 'the database <northwind> update succeeded'
commit transaction
end
go
Запускаем скрипт на выполнение.
Запускаем тест.
Вуаля! Мы переименовали таблицу и не сломали существующий код.
Поступим также со всеми таблицами, имена которых заканчиваются на s. Это ведь так просто, неправда ли?
Рефакторинг «Добавление поисковой таблицы»
Эта операция позволяет создать поисковую таблицу для существующего столбца.
Необходимость этой операции может быть обусловлена следующими причинами:
- Введение ссылочной целостности для обеспечения качества данных;
- Предоставление подробных описаний. Например, может понадобится добавить в описание той или иной сущности новый атрибут. Если сущность при этой не выделена в таблицу — придется добавлять этот атрибут в нужные таблицы, что приведет к денормализации схемы.
Посмотрим еще раз на нашу таблицу dbo.Customer. Вас не смущает наличие полей City, Region и Country в одном месте? Это ведь атрибуты одной сущности.
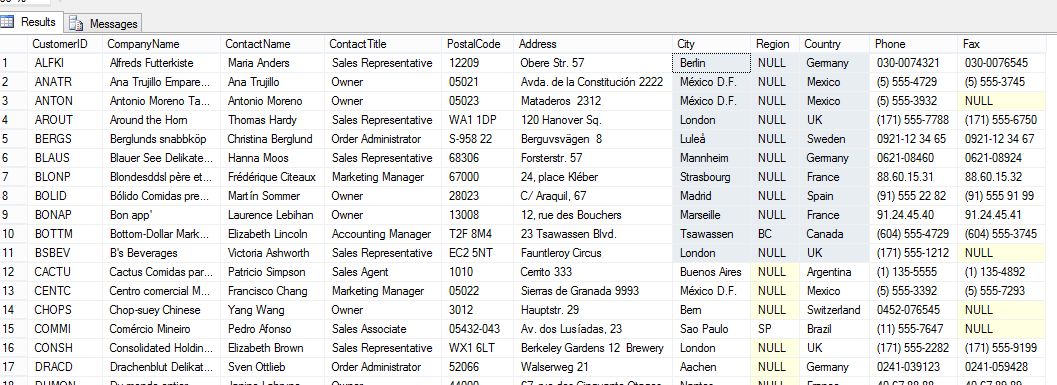
В таблице dbo.Employees та же беда. На вид явное нарушение 3-й нормальной формы.
Давайте начинать исправлять дело следующим образом:
1. Создадим справочник dbo.City(CityId, CityName)
2. В таблице dbo.Customer добавим поле CityId.
3. Создадим внешний ключ.
Опять же, для экономии времени, используем функцию Add Lookup Table. В OE выбираем поле City таблицы dbo.Customer и в контекстном меню вызываем пункт SQL Refactor Studio -> Add Lookup Table.
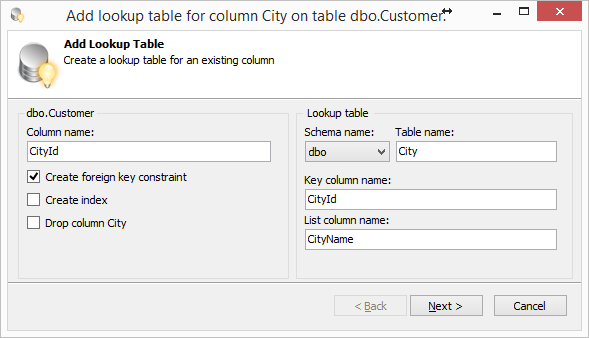
В появившемся окне заполняем поля. Жмем Next, потом Finish и в новом окне формируется скрипт.
Скрипт создает таблицу dbo.City, заполняет ее данными, создает поле CityId в таблице dbo.Customer, создает внешний ключ.
Сгенерированный скрипт
use northwind
go
-- Step 1. Create lookup table.
CREATE TABLE dbo.City (
CityId INT NOT NULL identity(1, 1)
,CityName NVARCHAR(15) NULL
,CONSTRAINT PK_City PRIMARY KEY CLUSTERED (CityId)
,CONSTRAINT City_ixCityName UNIQUE (CityName)
)
GO
-- Step 2. Fill lookup table.
INSERT dbo.City (CityName)
SELECT DISTINCT City
FROM dbo.Customer
GO
-- Step 3. Add column.
ALTER TABLE dbo.Customer ADD CityId INT NULL
GO
-- Step 4. Update table dbo.Customer.
UPDATE s
SET s.CityId = t.CityId
FROM dbo.Customer s
INNER JOIN dbo.City t ON s.City = t.CityName
GO
-- Step 5. Create foreign key constraint.
ALTER TABLE dbo.Customer ADD CONSTRAINT FK_Customer_City FOREIGN KEY (CityId) REFERENCES dbo.City (CityId)
GO
Запускаем скрипт и тесты (хотя тут мы вроде ничего не должны были сломать).
Все готово. Идем далее.
Рефакторинг «Перемещение полей»
Итак, с полем City мы разобрались. Осталось разобраться с полями Region и Country. Данные поля являются атрибутами сущности City. Так давайте же перенесем их из таблицы dbo.Customer в dbo.City.
Опять же, SQL Refactor Studio предоставляет функцию Move Columns. Ею и воспользуемся!
Выбираем в OE таблицу dbo.Customer, в контекстном меню выбираем пункт «SQL Refactor Studio -> Move columns». В появившемся диалоге, в выпадающем списке, выбираем таблицу dbo.City. Переносим поля Region и Country в dbo.City.
Если при переносе поля, вы получите сообщение о том, что нельзя переместить поле на котором построен индекс — удалите на время этот индекс.
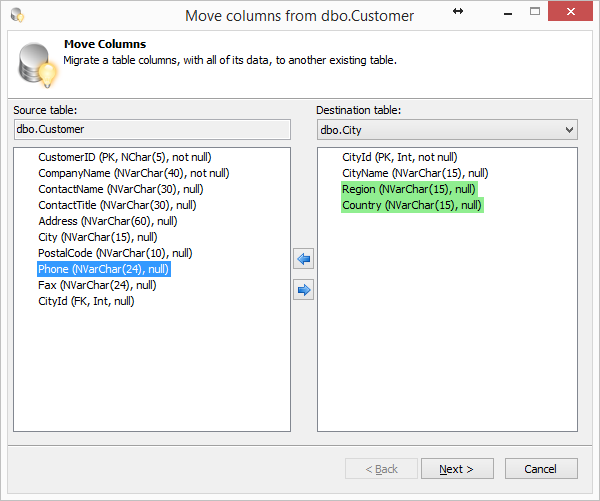
Нажимаем Next, потом Finish. Получаем скрипт в новом окне.
Скрипт создает поля Region и Country в таблице dbo.City и заполняет их данными.
В скрипте есть также закомментированный код удаляющий поля и приведен список объектов в которых нужно внести изменения.
Давайте не будем сейчас удалять поля, сделаем это на следующем шаге.
Сгенерированный скрипт
USE northwind
GO
-- STEP 1. Add new column(s) --
IF NOT EXISTS (
SELECT *
FROM syscolumns s
WHERE s.NAME = 'Region'
AND s.id = object_id(N'dbo.City')
)
BEGIN
ALTER TABLE dbo.City ADD Region NVARCHAR(15) NULL
END
GO
IF NOT EXISTS (
SELECT *
FROM syscolumns s
WHERE s.NAME = 'Country'
AND s.id = object_id(N'dbo.City')
)
BEGIN
ALTER TABLE dbo.City ADD Country NVARCHAR(15) NULL
END
GO
GO
-- STEP 2. Copy data --
-- (You can modify this query if needed)
SET IDENTITY_INSERT dbo.City ON
INSERT INTO dbo.City WITH (TABLOCKX) (CityId)
SELECT CityId
FROM dbo.Customer src
WHERE NOT EXISTS (
SELECT *
FROM dbo.City dest
WHERE src.CityId = dest.CityId
)
SET IDENTITY_INSERT dbo.City OFF
UPDATE dest
WITH (TABLOCKX)
SET dest.Region = src.Region
,dest.Country = src.Country
FROM dbo.City dest
INNER JOIN dbo.Customer src ON (src.CityId = dest.CityId)
GO
-- STEP 3. Check and modify this dependent objects --
/*
northwind.dbo.[Orders Qry] /*View*/
northwind.dbo.[Quarterly Orders] /*View*/
northwind.dbo.Invoices /*View*/
northwind.dbo.CustOrderHist /*StoredProcedure*/
northwind.dbo.[Customer and Suppliers by City] /*View*/
northwind.dbo.[Sales Totals by Amount] /*View*/
*/
-- STEP 4. Drop column(s) --
-- (Uncomment or run separately this query)
/*
alter table dbo.Customer drop column Region
alter table dbo.Customer drop column Country
*/
GO
Выполняем скрипт и тесты.
Переходим к следующему шагу.
Рефакторинг «Удаление объекта»
Выполняя предыдущие рефакторинги, мы оставили немного мусора (поля City, Region, Country в таблице dbo.Customer).
Давайте наводить чистоту! Но если мы просто так удалим поля, у нас опять все сломается.
Можно воспользоваться рефакторингом Encapsulate Table With View.
Создадим представление dbo.CustomerV и заменим использование таблицы его представлением во всей базе данных.
CREATE VIEW dbo.CustomerV
AS
SELECT
c.CustomerID,
c.CompanyName,
c.ContactName,
c.ContactTitle,
c.Address,
ct.CityName City,
ct.Region,
c.PostalCode,
ct.Country,
c.Phone,
c.Fax,
c.CityId
FROM dbo.Customer AS c
LEFT JOIN dbo.City AS ct
ON c.CityId = ct.CityId
Далее, при помощи View Dependencies смотрим зависимости для таблицы dbo.Customer:
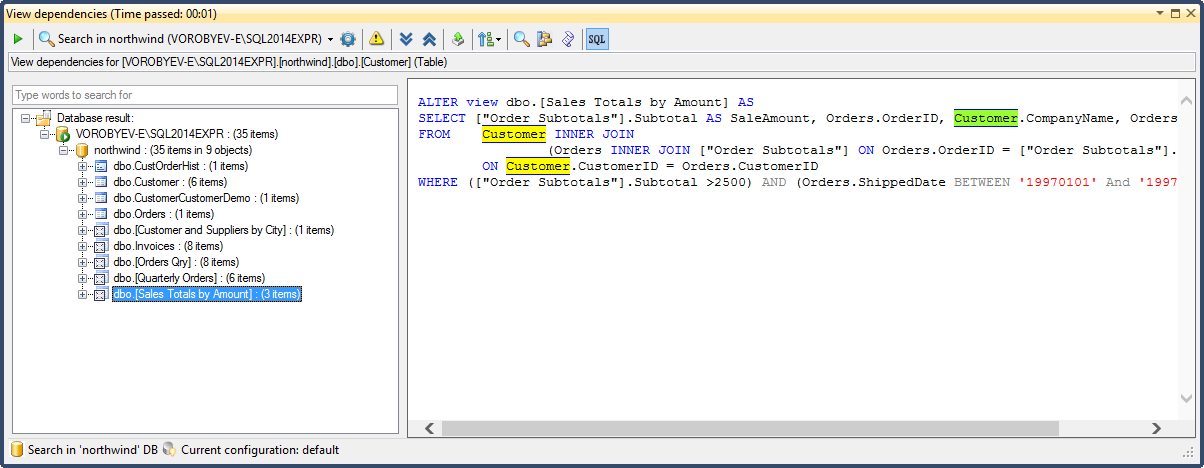
Просматриваем каждый объект. Если в каком-либо объекте используются наши поля, скриптуем объект (кнопка Script object на тулбаре) и вносим изменения.
В результате у меня получился вот такой скрипт:
Encapsulate Table With View
ALTER view dbo.[Sales Totals by Amount] AS
SELECT st.Subtotal AS SaleAmount, o.OrderID, c.CompanyName, o.ShippedDate
FROM dbo.CustomerV c
JOIN (
dbo.Orders o
JOIN "Order Subtotals" st
ON o.OrderID = st.OrderID
)
ON c.CustomerID = o.CustomerID
WHERE (st.Subtotal >2500) AND (o.ShippedDate BETWEEN '19970101' And '19971231')
GO
ALTER view dbo.[Quarterly Orders]
AS
SELECT DISTINCT c.CustomerID, c.CompanyName, c.City, c.Country
FROM dbo.CustomerV c
RIGHT JOIN dbo.Orders o
ON c.CustomerID = o.CustomerID
WHERE
o.OrderDate BETWEEN '19970101' And '19971231'
GO
ALTER view dbo.[Orders Qry]
AS
SELECT o.OrderID, o.CustomerID, o.EmployeeID, o.OrderDate, o.RequiredDate,
o.ShippedDate, o.ShipVia, o.Freight, o.ShipName, o.ShipAddress, o.ShipCity,
o.ShipRegion, o.ShipPostalCode, o.ShipCountry,
c.CompanyName, c.Address, c.City, c.Region, c.PostalCode, c.Country
FROM dbo.CustomerV c
INNER JOIN dbo.Orders o
ON c.CustomerID = o.CustomerID
GO
ALTER view dbo.Invoices AS
SELECT Orders.ShipName, Orders.ShipAddress, Orders.ShipCity, Orders.ShipRegion, Orders.ShipPostalCode,
Orders.ShipCountry, Orders.CustomerID, Customer.CompanyName AS CustomerName, Customer.Address, Customer.City,
Customer.Region, Customer.PostalCode, Customer.Country,
(FirstName + ' ' + LastName) AS Salesperson,
Orders.OrderID, Orders.OrderDate, Orders.RequiredDate, Orders.ShippedDate, Shippers.CompanyName As ShipperName,
"Order Details".ProductID, Products.ProductName, "Order Details".UnitPrice, "Order Details".Quantity,
"Order Details".Discount,
(CONVERT(money,("Order Details".UnitPrice * Quantity*(1-Discount)/100))*100) AS ExtendedPrice, Orders.Freight
FROM Shippers INNER JOIN
(Products INNER JOIN
(
(Employees INNER JOIN
(dbo.CustomerV Customer INNER JOIN Orders ON Customer.CustomerID = Orders.CustomerID)
ON Employees.EmployeeID = Orders.EmployeeID)
INNER JOIN "Order Details" ON Orders.OrderID = "Order Details".OrderID)
ON Products.ProductID = "Order Details".ProductID)
ON Shippers.ShipperID = Orders.ShipVia
GO
ALTER view dbo.[Customer and Suppliers by City] AS
SELECT City, CompanyName, ContactName, 'Customers' AS Relationship
FROM dbo.CustomerV
UNION SELECT City, CompanyName, ContactName, 'Suppliers'
FROM Suppliers
--ORDER BY City, CompanyName
GO
Запускаем скрипт, после чего удаляем поля и прогоняем тесты.
Если все ОК — Вы молодец, все аккуратно сделали.
Рефакторинг «Добавление методов CRUD»
Данный рефакторинг предусматривает создание хранимых процедур, обеспечивающих доступ (SELECT, INSERT, UPDATE, DELETE) к таблицам базы данных.
Можно выделить следующие причины использовать этот рефакторинг:
- Скрыть от внешних приложений структуру базы данных. Внешние приложения будут обращаться к базе данных только посредством хранимых процедур. Это позволит с легкостью изменять структуру базы данных без изменения внешних приложений.
- Реализация в процедурах дополнительных проверок (бизнес-логики, прав доступа и т.д.);
- Сохранение информации о том кто и когда какие данные запрашивал;
- Проблемы с производительностью эффективнее решать когда SQL-код находится в базе данных.
Итак, давайте создадим для нашей замученной таблицы dbo.Customer методы доступа. Воспользуемся методом Add CRUD Methods из пакета SQL Refactor Studio. Выбираем в OE таблицу, далее в контекстном меню выбираем пункт SQL Refactor Studio -> Add CRUD Methods.
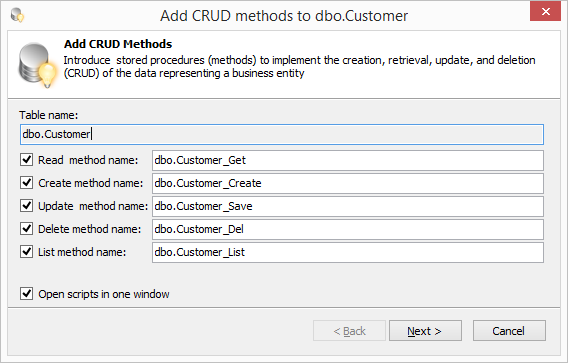
В появившемся диалоге выбираем какие методы нам нужно создать. При необходимости меняем названия методов. Жмем Next. При желании можно настроить права на процедуры, для этого нужно отметить нужные роли. Нажимаем Finish и получаем скрипт с хранимыми процедурами. Выполняем скрипт.
Сгенерированный скрипт
IF (object_id(N'dbo.Customer_Create') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Create as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Create
--
-- Create method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Create
@CustomerID NCHAR(5)
,@CompanyName NVARCHAR(40)
,@ContactName NVARCHAR(30) = NULL
,@ContactTitle NVARCHAR(30) = NULL
,@Address NVARCHAR(60) = NULL
,@PostalCode NVARCHAR(10) = NULL
,@Phone NVARCHAR(24) = NULL
,@Fax NVARCHAR(24) = NULL
,@CityId INT = NULL
AS
BEGIN
SET NOCOUNT ON
INSERT INTO dbo.Customer (
CustomerID
,CompanyName
,ContactName
,ContactTitle
,Address
,PostalCode
,Phone
,Fax
,CityId
)
VALUES (
@CustomerID
,@CompanyName
,@ContactName
,@ContactTitle
,@Address
,@PostalCode
,@Phone
,@Fax
,@CityId
)
RETURN 0
END
/*
declare
@CustomerID NChar(5),
@CompanyName NVarChar(40),
@ContactName NVarChar(30),
@ContactTitle NVarChar(30),
@Address NVarChar(60),
@PostalCode NVarChar(10),
@Phone NVarChar(24),
@Fax NVarChar(24),
@CityId Int
select
@CustomerID = 'CustomerID',
@CompanyName = 'CompanyName',
@ContactName = 'ContactName',
@ContactTitle = 'ContactTitle',
@Address = 'Address',
@PostalCode = 'PostalCode',
@Phone = 'Phone',
@Fax = 'Fax',
@CityId = null
exec dbo.Customer_Create
@CustomerID = @CustomerID,
@CompanyName = @CompanyName,
@ContactName = @ContactName,
@ContactTitle = @ContactTitle,
@Address = @Address,
@PostalCode = @PostalCode,
@Phone = @Phone,
@Fax = @Fax,
@CityId = @CityId
*/
GO
IF (object_id(N'dbo.Customer_Get') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Get as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Get
--
-- Read method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Get
@CustomerID NCHAR(5)
AS
BEGIN
SET NOCOUNT ON
SELECT
CustomerID
,CompanyName
,ContactName
,ContactTitle
,Address
,PostalCode
,Phone
,Fax
,CityId
FROM dbo.Customer
WHERE
CustomerID = @CustomerID
RETURN 0
END
/*
declare
@CustomerID NChar(5)
select
@CustomerID = ?
exec dbo.Customer_Get
@CustomerID = @CustomerID
*/
GO
IF (object_id(N'dbo.Customer_Save') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Save as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Save
--
-- Update method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Save
@CustomerID NCHAR(5)
,@CompanyName NVARCHAR(40)
,@ContactName NVARCHAR(30) = NULL
,@ContactTitle NVARCHAR(30) = NULL
,@Address NVARCHAR(60) = NULL
,@PostalCode NVARCHAR(10) = NULL
,@Phone NVARCHAR(24) = NULL
,@Fax NVARCHAR(24) = NULL
,@CityId INT = NULL
AS
BEGIN
SET NOCOUNT ON
UPDATE t
SET t.CompanyName = @CompanyName
,t.ContactName = @ContactName
,t.ContactTitle = @ContactTitle
,t.Address = @Address
,t.PostalCode = @PostalCode
,t.Phone = @Phone
,t.Fax = @Fax
,t.CityId = @CityId
FROM dbo.Customer AS t
WHERE
t.CustomerID = @CustomerID
RETURN 0
END
/*
set nocount on
set quoted_identifier, ansi_nulls, ansi_warnings, arithabort, concat_null_yields_null, ansi_padding on
set numeric_roundabort off
set transaction isolation level read uncommitted
declare
@CustomerID NChar(5),
@CompanyName NVarChar(40),
@ContactName NVarChar(30),
@ContactTitle NVarChar(30),
@Address NVarChar(60),
@PostalCode NVarChar(10),
@Phone NVarChar(24),
@Fax NVarChar(24),
@CityId Int
select
@CustomerID = 'CustomerID',
@CompanyName = 'CompanyName',
@ContactName = 'ContactName',
@ContactTitle = 'ContactTitle',
@Address = 'Address',
@PostalCode = 'PostalCode',
@Phone = 'Phone',
@Fax = 'Fax',
@CityId = null
begin try
begin tran
exec dbo.Customer_Save
@CustomerID = @CustomerID,
@CompanyName = @CompanyName,
@ContactName = @ContactName,
@ContactTitle = @ContactTitle,
@Address = @Address,
@PostalCode = @PostalCode,
@Phone = @Phone,
@Fax = @Fax,
@CityId = @CityId
select t.*
from dbo.Customer as t
where
t.CustomerID = @CustomerID
if @@trancount > 0
rollback tran
end try
begin catch
if @@trancount > 0
rollback tran
declare
@err nvarchar(2000)
set @err =
'login: ' + suser_sname() + char(10)
+ 'ErrorNumber: ' + cast(isnull(error_number(), 0) as varchar) + char(10)
+ 'ErrorProcedure: ' + isnull(error_procedure(), '') + char(10)
+ 'ErrorLine: ' + cast(isnull(error_line(), 0) as varchar) + char(10)
+ 'ErrorMessage: ' + isnull(error_message(), '') + char(10)
+ 'Date: ' + cast(getdate() as varchar) + char(10)
print @err
raiserror(@err, 16, 1)
end catch
*/
GO
IF (object_id(N'dbo.Customer_Del') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Del as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Del
--
-- Delete method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Del @CustomerID NCHAR(5)
AS
BEGIN
SET NOCOUNT ON
BEGIN TRY
BEGIN TRAN
/* uncomment if needed
delete from dbo.CustomerCustomerDemo where CustomerID = ?
delete from dbo.Orders where CustomerID = ?
*/
DELETE
FROM dbo.Customer
WHERE CustomerID = @CustomerID
COMMIT TRAN
END TRY
BEGIN CATCH
IF @@trancount > 0
ROLLBACK TRAN
-- catch exception (add you code here)
DECLARE @err NVARCHAR(2000)
SET @err = ERROR_MESSAGE()
RAISERROR (@err, 16, 1)
END CATCH
RETURN 0
END
/*
declare
@CustomerID NChar(5)
select
@CustomerID = ?
exec dbo.Customer_Del
@CustomerID = @CustomerID
*/
GO
IF (object_id(N'dbo.Customer_List') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_List as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_List
--
-- List method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_List
AS
BEGIN
SET NOCOUNT ON
SELECT
CustomerID
,CompanyName
,ContactName
,ContactTitle
,Address
,PostalCode
,Phone
,Fax
,CityId
FROM dbo.Customer
/* uncomment if needed
left join dbo.City as t1 on t1.CityId = t.CityId
*/
RETURN 0
END
/*
exec dbo.Customer_List
*/
GO
Если Вам нужно поправить тело генерируемых процедур, заходим в настройки.
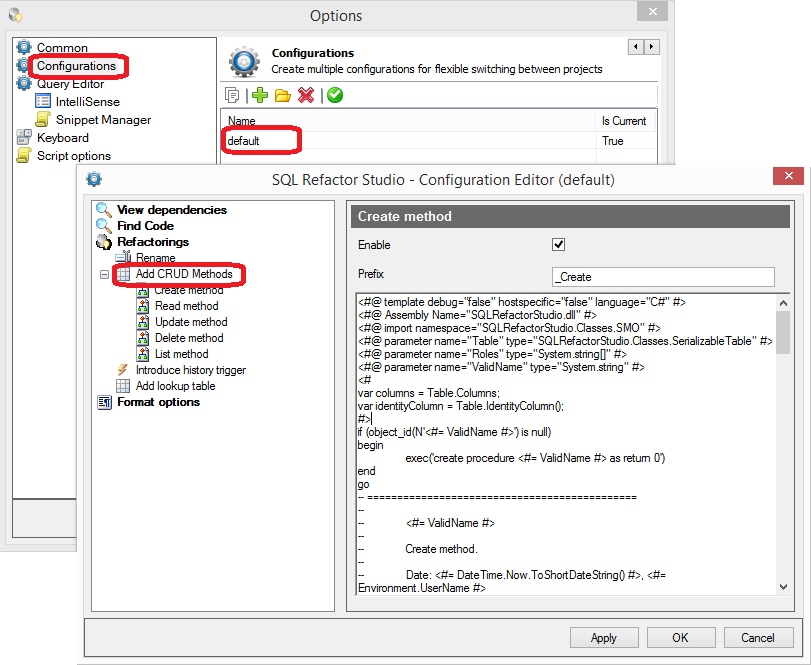
Каждая процедура представляет собой шаблон T4. Про T4 можно почитать тут и тут.
Рефакторинг «Введение триггера для накопления исторических данных»
Эта операция позволяет ввести новый триггер, предназначенный для накопления информации об изменениях в данных в целях изучения истории внесения изменений или проведения аудита.
Необходимость в применении операции «Введение триггера для накопления исторических данных» в основном обусловлена требованием передать функции отслеживания изменений в данных самой базе данных. Такой подход гарантирует, что в случае модификации важных данных в любом внешнем приложении это изменение можно будет отследить и подвергнуть аудиту.
Единственным недостатком, на мой взгляд, является тот факт что наличие триггера будет увеличивать время выполнения операции DML.
Как альтернативу данному методу можно рассмотреть Change Data Capture (работает асинхронно, тем самым не увеличивает время операции, но имеет ряд особенностей).
Давайте для таблицы dbo.Customer применим данный рефакторинг.
Выбираем таблицу в OE, выбираем в контекстном меню пункт SQL Refactor Studio — Introduce Trigger for History. Выбираем поля таблицы для отслеживания изменений.
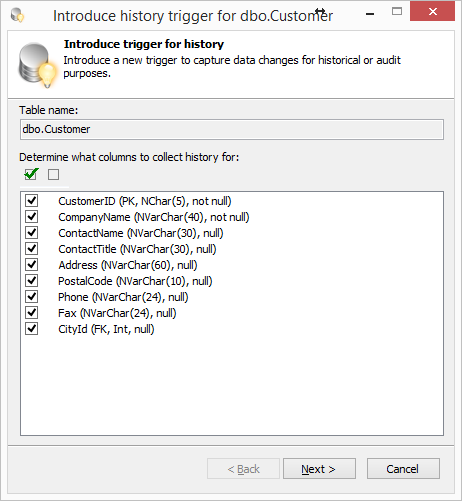
Жмем Next. Изменяем при необходимости имя создаваемой таблицы и триггера.
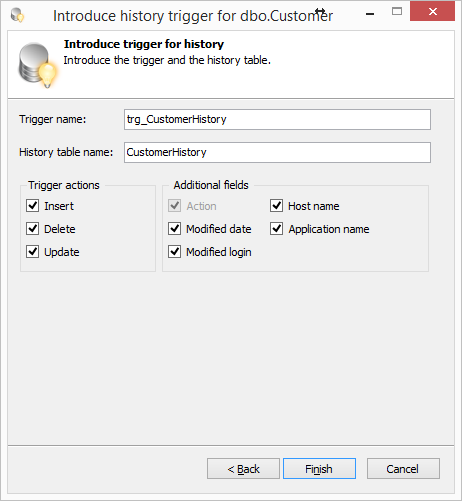
Жмем Finish и получаем скрипт. Скрипт создает триггер и таблицу для хранения истории изменений.
Сгенерированный скрипт
CREATE TABLE [dbo].[CustomerHistory] (
[id] [bigint] IDENTITY NOT NULL
,[action_type] [char](1) NOT NULL
,[modified_date] [datetime] CONSTRAINT [DF_CustomerHistory_modified_date] DEFAULT getdate()
,[modified_login] [sysname] CONSTRAINT [DF_CustomerHistory_modified_login] DEFAULT suser_sname()
,[host_name] [nvarchar](128) CONSTRAINT [DF_CustomerHistory_host_name] DEFAULT host_name()
,[program_name] [nvarchar](128) CONSTRAINT [DF_CustomerHistory_program_name] DEFAULT program_name()
,[CompanyName_old] [nvarchar](40)
,[CompanyName_new] [nvarchar](40)
,[ContactName_old] [nvarchar](30)
,[ContactName_new] [nvarchar](30)
,[ContactTitle_old] [nvarchar](30)
,[ContactTitle_new] [nvarchar](30)
,[Address_old] [nvarchar](60)
,[Address_new] [nvarchar](60)
,[PostalCode_old] [nvarchar](10)
,[PostalCode_new] [nvarchar](10)
,[Phone_old] [nvarchar](24)
,[Phone_new] [nvarchar](24)
,[Fax_old] [nvarchar](24)
,[Fax_new] [nvarchar](24)
,[CityId_old] [int]
,[CityId_new] [int]
,[CustomerID_old] [nchar](5)
,[CustomerID_new] [nchar](5)
,CONSTRAINT [PK_CustomerHistory] PRIMARY KEY ([id])
)
GO
CREATE TRIGGER [dbo].[trg_CustomerHistory] ON [dbo].[Customer]
AFTER INSERT, DELETE, UPDATE
AS
SET NOCOUNT ON
DECLARE @action_type CHAR(1)
IF EXISTS (SELECT *FROM inserted) AND EXISTS (SELECT * FROM deleted)
SET @action_type = 'U'
ELSE IF EXISTS (SELECT * FROM inserted) AND NOT EXISTS (SELECT * FROM deleted)
SET @action_type = 'I'
ELSE IF NOT EXISTS (SELECT * FROM inserted) AND EXISTS (SELECT * FROM deleted)
SET @action_type = 'D'
INSERT INTO dbo.CustomerHistory (
action_type
,CompanyName_old
,CompanyName_new
,ContactName_old
,ContactName_new
,ContactTitle_old
,ContactTitle_new
,Address_old
,Address_new
,PostalCode_old
,PostalCode_new
,Phone_old
,Phone_new
,Fax_old
,Fax_new
,CityId_old
,CityId_new
,CustomerID_old
,CustomerID_new
)
SELECT
@action_type
,d.CompanyName
,i.CompanyName
,d.ContactName
,i.ContactName
,d.ContactTitle
,i.ContactTitle
,d.Address
,i.Address
,d.PostalCode
,i.PostalCode
,d.Phone
,i.Phone
,d.Fax
,i.Fax
,d.CityId
,i.CityId
,d.CustomerID
,i.CustomerID
FROM inserted i
FULL OUTER JOIN deleted d
ON (i.CustomerID = d.CustomerID)
GO
На этом пока всё. Надеюсь информация Вам пригодится и в Ваших базах данных всегда будет полный порядок.
Удачи!
Полезные ресурсы
- http://databaserefactoring.com
- Скотт Амблер, Прамодкумар Дж. Садаладж Рефакторинг баз данных. Эволюционное проектирование
- Мартин Фаулер Рефакторинг.Улучшение существующего кода
- Плагин для SSMS SQL Refactor Studio
В нашем предыдущем материале Как эффективно управлять ростом объема данных речь шла о том, как с самого начала не допустить ошибок при работе с базами данных. В этой же статье предлагаем рассмотреть ситуации, когда с самого начала вы совершили просчеты и столкнулись с тем, что уже поздно менять структуру данных, но все еще есть возможность их оптимизировать.
- Как работать с индексами бд?
- Индексы в бд: о чем еще стоит помнить
- Критические ошибки: запросы
- Оптимизация индексов: о чем еще стоит задуматься?
Даже если вы прислушались к нашим рекомендациям и сделали все как по учебнику, после того как ваша система заработала и накопила определенное количество данных, с ними могут случаться проблемы, например, медленное выполнение запросов. Это самое частое явление, с которым обычно сталкиваются, когда работают с данными. И это нормально, потому что на этапе разработки структуры вы не всегда сможете предугадать, как будет развиваться ваша база данных. Предположим, вы запускаете MVP-проект, но впоследствии тестовый продукт может обрасти не тем функционалом, который был запланирован. С самого начала сложно все предусмотреть, поэтому заниматься оптимизацией не всегда имеет смысл, нужно сперва посмотреть, во что выльется проект. Все оптимизации, которые на этом этапе надо выполнять, обычно связаны с двумя вещами: во-первых, вы начинаете индексировать все, что индексировали до этого, а во-вторых, вы смотрите, как вообще осуществляются запросы, возможно, они выполняются неэффективно.
Как работать с индексами
Учимся читать план выполнения запроса.
Разработчики зачастую плохо понимают, как устроены базы данных. Нужно уметь разбираться в том, как их структурировать и проектировать. Также большинство разработчиков не понимает, что такое план выполнения запроса в СУБД. Но это несложно: достаточно изучить документацию и понять, где в запросах теряется время. Чаще всего помогает «навешивание» каких-нибудь индексов.
Частичный индекс компактнее полного.
По умолчанию индекс, который вы навешиваете на таблицу, индексирует вообще все значения. Но в большинстве случаев вам не нужны NULL-значения, если они есть базе. Так выкиньте их и постройте такой индекс (любая СУБД это позволяет), который NULL-значения не учитывает. Размер индекса в этом случае у вас сильно уменьшится и будет содержать в себе только то, что нужно. То же самое касается ситуации, когда значения, которые вы индексируете, тоже вам не нужны. В поле могут быть значения от 1 до 100, но вы чаще всего делаете запрос по значениям 1, 2, 3, поэтому можете легко проиндексировать только эти значения. В этом случае индекс у вас будет небольшого размера, и работать он будет быстро. Разницу между полным индексом и частичным можно даже увидеть на глаз в вашей системе мониторинга: время отклика резко упадет.
Кластеризованные индексы идеальны для дат.
Кластеризованным называют индекс, который гарантирует, что данные в вашей таблице идут друг за другом и так, как надо. Это бывает очень полезно, когда вы в своих запросах используете интервалы, и, чаще всего, интервалы по датам. Например, вы делаете запрос о поиске всех строк с 18 по 19 июня, и если вы используете на дате кластеризованный индекс, то строки будут идти подряд, а это значит, что СУБД их очень быстро считает с диска, а не будет «бегать» по всему диску и искать. Это минимизирует количество операций чтения и может значительно уменьшить время отклика.
Функциональный индекс поддерживают все СУБД.
С помощью него вы можете индексировать данные по какой-либо функции. Бывают ситуации, когда вам нужно найти всех людей, у которых день рождения 19 июня (не важно какого года). И именно функциональный индекс эффективен в данном случае.
Индексы по числам эффективнее, чем по строкам.
Храните все, что является числом, как число (номера телефонов, ИНН и так далее), потому что индекс по номерам телефонов и ИНН (его часто приходится навешивать и на одно, и на другое) будет занимать меньше места, а если что-либо в СУБД занимает меньше места, то оно быстрее находится, считывается, оптимально кэшируется и быстрее выдается. Все это влияет на производительность. Пока у вас маленькая база данных, это незаметно, а когда она вырастает до гигабайтов и количество запросов в секунду переваливает за несколько десятков, вы сразу это ощущаете.
Индексы: о чем стоит помнить?
Не все можно эффективно индексировать.
Не все понимают, что индексы имеют свои пределы и ограничения. Встречаются разработчики, которые при создании таблицы навешивали индексы на каждое поле с надеждой, что база будет работать быстрее. Вообще не рекомендуется индексы навешивать сразу при создании таблицы, нужно сначала дождаться результата, а потом смотреть, какая у вас логика и план выполнения запроса. Не нужно торопиться.
Поиск по нескольким индексированным полям — лотерея. Надо помнить, что если в одной таблице есть несколько индексированных полей и вы не по всем из них ищите данные, то результат будет непредсказуемым, как в лотерее. Ситуация может отличаться от сервера к серверу и от машины к машине. Почему? Разные условия, нагрузка, количество памяти, скорость работы с диском. Поэтому индексировать данные надо, изучая план запроса на том самом «боевом» сервере, на котором у вас возникли проблемы.
За индексами нужно ухаживать. Индексы со временем «разбухают», становятся большими, и их нужно постоянно чистить, сжимать, дефрагментировать — только тогда они будут работать эффективно.
Много индексов на таблице — признак перегруженной структуры.
Критические ошибки: запросы
Нижеприведенные рекомендации — это классика жанра, об этом написано в любом руководстве по тому, как правильно работать с SQL-базами данных. Никогда нельзя запрашивать все разом (SELECT *), запрашивайте только то, что вы ищите, это, если хотите, закон. Скорость работы СУБД зависит в том числе и от того, сколько вы из нее запрашиваете. Если вы запрашиваете много ненужных вещей, которые потом выкинете, значит вы делаете работу вхолостую. Такой запрос — зло, особенно в ситуации, когда таблица большая.
За SELECT COUNT (*) и LIMIT/OFFSET надо винить разработчиков таких интерфейсов, где есть списки с постраничным выводом данных. Это, может, выглядит красиво, но даже по опыту использования поисковиков мы знаем, что пользователи дальше второй страницы заходят редко. А если список длинный, то они и первую страницу просматривают не до конца. Нужно давать в интерфейсах возможность делать такие фильтры, чтобы данные можно было получить быстро и именно столько, сколько нужно.
Арифметика в фильтрах, функции и полнотекстовый поиск убивают индексы. Если в условиях поиска вы используете арифметику, функции или полнотекстовый поиск, то чаще всего это убивает любые индексы. Запросы не будут быстрыми: вам нужно будет или упрощать их, или использовать какие-то специфические решения (например, для полнотекстового поиска есть плагин либо функциональный индекс, о котором шла речь ранее).
Оптимизация: о чем еще стоит задуматься?
Настройка ORM.
На это месте нам начинает сильно мешать ORM. Разработчики любят ее использовать, это сильно упрощает работу, но она часто делает много лишних действий. Это могут быть как неоптимальные запросы, так и просто лишние. На практике при разборе ошибок мы видели ситуации, когда ORM запрашивает из базы что попало, когда ее об этом не просили. Ее нужно уметь настраивать, чтобы она этого не делала.
Рефакторинг бизнес-логики.
Иногда проще сделать два маленьких запроса, чем один большой — он будет медленнее. Но здесь каждый случай индивидуален, нужно уметь экспериментировать. Поэтому чтобы ускорить работу с базами, стоит и настроить ORM, и отрефакторить запросы к ним.
Контроль ссылочной целостности.
Речь идет о ситуациях, когда настроены каскадные удаления и обновления. В то время, как вы пытаетесь что-то удалить, СУБД ищет все связанные сущности и пытается понять, стоит их удалять или нет. В этом случае можно не удалять, а помечать как удаленную. Либо пытаться ссылочную целостность как-то порвать, но это может привести к несогласованности, когда вы случайно забудете удалить вместе с основной записью и все связанные с ней. В этом случае в вашей базе будут накапливаться «потерянные» записи. Они, как минимум, будут зря занимать место. Но в перспективе это может привести к неправильной работе бизнес-логики, что гораздо хуже. Так что, если вы очень часто удаляете что-то из БД, то рвать ссылочную целостность надо очень аккуратно, семь раз проверив, что вы удалили действительно всё.
Оптимизация структуры БД — исправление ошибок, совершенных ранее. Если к тому времени, когда у вас начались первые проблемы со скоростью вы видите, что ошиблись на первой стадии, настало время их поправить, потому что далее проблемы будут усугубляться.
Эта статья описывает опыт Braintree Payments, подразделения PayPal, и рассказывает о том, как им удаётся обновлять схему баз данных PostgreSQL в условиях, когда приостановка работы API для подобных технических работ недопустима — даже если речь идёт о минутах.
В этой статье будут рассмотрены следующие темы:
- Транзакционный DDL (Data Definition Language);
- Блокирование строк;
- Операции над таблицей;
- Операции над столбцами;
- Операции над индексами;
- Ограничения;
- Перечисляемые типы;
- Бонус: библиотека для Ruby on Rails.
Немного основ
Ко всему коду и ко всем изменениям баз данных в Braintree выдвигаются следующие требования:
- Актуальный код и схемы БД должны иметь прямую совместимость с новым кодом и новыми схемами. Это позволяет вносить изменения постепенно, а не сразу на всех используемых серверах.
- Новый код и новые схемы должны быть обратно совместимы с актуальным кодом и схемами. Это позволяет без особых проблем отменить любые изменения, в случае возникновения непредвиденных ошибок.
Для всех DDL операций важно, чтобы:
- Любые блокировки таблиц или индексов держались не более двух секунд.
- Способы отмены вносимых изменений не требовали откатывать схему базы данных к предыдущей версии.
Транзакционный DDL
PostgreSQL поддерживает транзакции при выполнении DDL операций. В большинстве случаев вы можете выполнять несколько DDL запросов внутри одной транзакции и придерживаться стратегии «всё или ничего». К сожалению, у такого подхода есть существенный недостаток: если вы меняете несколько объектов, вам придётся заблокировать их все. Блокировка нескольких таблиц, во-первых, создаёт вероятность взаимной блокировки (deadlock), а, во-вторых, вынуждает пользователей ждать выполнения всей транзакции. Поэтому для каждого запроса рекомендуется использовать отдельную транзакцию.
Заметьте: параллельное создание индексов — это особый случай. PostgreSQL запрещает выполнять CREATE INDEX CONCURRENTLY внутри явно описанной транзакции; вместо этого PostgreSQL самостоятельно создаёт транзакции и управляет ими. Если по каким-то причинам построение индекса прерывается до успешного завершения, то может потребоваться вручную удалить его, прежде чем пробовать ещё раз. Впрочем, такой индекс всё равно никогда не будет использоваться для обслуживания запросов.
Блокирование строк
У PostgreSQL множество разных уровней блокировки. Нас интересуют в основном блокировки уровня таблицы (потому что DDL обычно оперирует на этом уровне):
ACCESS EXCLUSIVE: запрещено любое использование заблокированной таблицы.SHARE ROW EXCLUSIVE: запрещены команды DDL, выполняющиеся параллельно, а также модификация строк (чтение разрешено).SHARE UPDATE EXCLUSIVE: запрещены только команды DDL, выполняющиеся параллельно.
Заметьте: Понятие “команды DDL, выполняющиеся параллельно” в данном контексте включают в себя операции VACUUM и ANALYZE.
Все операции DDL обязательно блокируют таблицу одним из этих способов. К примеру, если вы выполните:
ALTER TABLE foos ADD COLUMN bar INTEGER; PostgreSQL попытается получить блокировку уровня ACCESS EXCLUSIVE на всей таблице foos.
Когда вы применяете блокировку такого уровня, ни один из последующих запросов к таблице не выполняется. Вместо этого они откладываются в очередь до тех пор, пока самый долгий из запущенных вами запросов не закончит выполнение. Выполнение запросов, отложенное на определённый срок, нельзя отличить от отключения сервера для выполнения технических работ. Поэтому такой ситуации лучше избегать.
Основные подходы
Вместо того чтобы полагаться на PostrgeSQL, осуществляйте явную блокировку самостоятельно. Это позволяет аккуратно контролировать время, на которое запросы откладываются в очередь. Если у вас не получается осуществить блокировку в течение нескольких секунд, рекомендуется добавить небольшую задержку перед следующей попыткой. Таким образом вы позволите отложенным запросам выполниться и не создавать слишком большую нагрузку в будущем. И, наконец, прежде чем пытаться осуществить блокировку, запросите из pg_locks1 список долго выполняющихся запросов. Это позволит избежать постановки в очередь команд, которые, скорее всего, не выполнятся.
Начиная с PostgreSQL 9.3, вы можете настроить параметр lock_timeout, чтобы контролировать то, насколько долго PostgreSQL будет ожидать получения контроля над таблицей. Если вы вдруг используете версию 9.2 или более раннюю (они, к слову, не поддерживаются, вам стоит обновиться!), вы можете добиться того же результата, используя параметр statement_timeout с явным выражением LOCK<table>.
Зачастую блокировка уровня ACCESS EXCLUSIVE действительно необходима только на очень короткий период, который требуется PostgreSQL, чтобы обновить его catalog tables (таблицы с метаинформацией). Ниже мы рассмотрим случаи, когда достаточно более слабой блокировки или когда можно применить альтернативные подходы, чтобы избежать длительной приостановки SELECT/INSERT/UPDATE/DELETE.
Обратите внимание: иногда удержание блокировки уровня ACCESS EXCLUSIVE для чего-то большего, чем обновление каталога (или перезаписи) может быть оправдано. Например, если размер таблицы относительно мал. Рекомендуется проверять конкретные случаи использования на реалистичных размерах данных и оборудовании, чтобы увидеть, является ли операция достаточно быстрой. Если вы используете хорошее оборудование, и ваша таблица легко помещается в память, то полное сканирование таблицы или перезапись тысяч строк всё ещё могут быть достаточно быстрыми.
Операции над таблицей
Создание таблицы
В общем случае добавление таблицы — одна немногих операций, о которых не стоит слишком заботиться. Ведь объект, который мы «изменяем», просто технически не может использоваться в этот момент.
Большинство параметров создания таблицы никак не влияют на другие объекты базы данных. Добавление внешнего ключа при определении таблицы заставит PostgreSQL получить блокировку уровня SHARE ROW EXCLUSIVE на упомянутой таблице. Это остановит все DDL запросы, направленные к ней, и модификации строк. Несмотря на то что эта блокировка не должна быть слишком долгой, о ней стоит помнить, как и о любой другой операции, вызывающей блокировку. Рекомендуется разделять эти две операции: создайте таблицу, и только потом добавьте внешний ключ.
Удаление таблицы
Удаление таблицы по понятным причинам требует блокировки уровня ACCESS EXCLUSIVE. Если таблица уже не используется, вы можете спокойно её удалить. Но прежде чем на самом деле выполнить DROP TABLE ... вам следует проверить документацию и код, чтобы удостовериться, что все упоминания о ней на самом деле стёрты. Чтобы перепроверить это, вы можете запросить у PostgreSQL статистику использования таблицы (используя представление pg_stat_user_tables2).
Переименование таблицы
Вероятно, ни для кого не станет открытием, что переименование таблицы требует ACCESS EXCLUSIVE. Очень маловероятно, что ваш код сможет безопасно обработать переименование таблицы прямо налету — это возможно только если в таблицу никто не пишет и не берёт из неё данные.
Рекомендуется избегать переименований таблиц везде, где это возможно. Но если переименование действительно необходимо, то для безопасности:
- Создайте новую таблицу с такой же схемой, как предыдущая.
- Скопируйте данные из старой таблицы в новую.
- Создайте триггеры на
INSERTиUPDATEк старой таблице, чтобы при её использовании поддерживалось актуальное состояние новой таблицы. - Начните использовать новую таблицу.
Другие подходы, основанные на использовании представлений (views) и/или правил (RULE), также могут вам подойти, всё зависит от производительности, которая вам необходима.
Операции над столбцами
Обратите внимание: установка ограничений, накладываемых на столбцы (например NOT NULL), и прочих ограничений (например EXCLUDES) описана в отдельной части статьи.
Добавить столбец
Добавление столбца в существующую таблицу обычно требует короткой блокировки уровня ACCESS EXCLUSIVE на таблице на то время, пока обновляются системные таблицы каталогов (catalog tables).
Значения по умолчанию. Установка значения по умолчанию одновременно с созданием столбца заблокирует таблицу на время установки значений. Вместо этого следует:
- Добавить новый столбец (без значений по умолчанию).
- Назначить столбцу значение по умолчанию.
- Заполнить этим значением уже существующие строки по отдельности.
Обратите внимание: В недавно выпущенном PostgreSQL 11 эти советы больше не актуальны для неволатильных значений по умолчанию. Теперь добавление столбца со значением по умолчанию требует только обновления таблиц каталогов, а все обращения к строкам без значения будут магическим образом возвращать нужное значение.
Ограничения not null. Добавление столбца с ограничением NOT NULL возможно только в двух случаях: если в таблице нет строк или если был указан DEFAULT. Первый случай тривиален — потребуется только изменение каталога. Во втором же случае следует проделать все описанные выше действия для значений по умолчанию.
Заметьте: После добавления нового столбца все запросы вида SELECT * FROM ... начнут возвращать новый столбец. Важно, чтобы код, который будет работать с этой таблицей, мог безопасно обработать новый столбец. Лучше просто не использовать *, всегда указывая столбцы явно.
Изменить тип столбца
Обычно изменение типа столбца приводит к полной блокировке всей таблицы до тех пор, пока все строки не будут обновлены в соответствии с новым типом. Однако есть несколько исключений:
- Приведение
VARCHARк типуTEXT(начиная с версии 9.1); а точнее всегда, когда старый тип бинарно совместим с новым типом и для преобразования не требуется никаких фактических операций. - Старый тип является частным случаем нового (начиная с версии 9.1).
- Когда увеличивается или удаляется заданное ограничение на длину или точность: например
VARCHAR(5)→VARCHAR(10)иVARCHAR(5)→VARCHAR(начиная с версии 9.2).
Обратите внимание: Несмотря на то что некоторые из исключений выше были введены ещё в версии 9.1, изменение типа индексируемого столбца в этой версии всегда приводит к переписыванию индекса. Начиная с версии 9.2, индекс не переписывается, если не переписывалось содержимое таблицы. Если вы хотите удостовериться, что ваше изменение не инициирует перезапись, вы можете сделать запрос к pg_class3 и проверить, что столбец relfilenode не изменился.
Если вам требуется изменить тип столбца, и описанные выше исключения к вашему случаю не относятся, то:
- Добавьте новый столбец
new_<column>. - Осуществляйте запись одновременно в оба столбца (например, с помощью триггеров
BEFORE INSERT/UPDATE). - Заполните новый столбец копиями значений из старого.
- Переименуйте
<column>вold_<column>, аnew_<column>, соответственно, в<column>; делайте это внутри единой транзакции и явного выраженияLOCK <table>. - Удалите старый столбец.
Удалить столбец
Удалять столбец нужно с крайней осторожностью. Для обновления каталога оно требует полной блокировки таблицы, но не влечёт за собой физического изменения строк. Если в настоящее время столбец не используется, вы можете безопасно удалить его. Важно, однако, проверить, что на этот столбец не ссылаются никакие зависимые объекты (которые небезопасно удалять). В частности, любые индексы, использующие столбец, должны быть удалены отдельно с использованием безопасного DROP INDEX CONCURRENTLY. В противном случае, они будут автоматически удалены вместе со столбцом, и всё это время будет действовать блокировка уровня ACCESS EXCLUSIVE. Чтобы проверить, есть ли у вас такие объекты, вы можете сделать запрос к pg_depend4.
Прежде чем запускать ALTER TABLE ... DROP COLUMN ... на продакшне, стоит удостовериться, что все ссылки на этот столбец в документации и коде были окончательно убраны. Это позволит безопасно откатиться к релизам, выпущенным до того, как был удалён столбец.
Заметьте: Удаление столбца потребует от вас обновления всех представлений, триггеров, функций и т. д., которые были завязаны на этот столбец.
Операции над индексами
Создать индекс
Если вы просто запустите CREATE INDEX ..., то получите блокировку уровня ACCESS EXCLUSIVE на всей индексируемой таблице. А вот если вы выполните CREATE INDEX CONCURRENTLY ... , то блокировка будет всего лишь уровня SHARE UPDATE EXCLUSIVE. Правда, вместо одного сканирования таблицы придётся выполнить два. При уровне блокировки во втором случае будут разрешены и чтение, и запись в таблицу.
Предостережения:
- Несколько созданий индексов, выполняющиеся параллельно на одной таблице, не завершат выполнение ни одного из
CREATE INDEX CONCURRENTLY ...до тех пор, пока самый медленный из них ещё работает. CREATE INDEX CONCURRENTLY ...не может быть выполнен внутри транзакции, вместо этого транзакциями неявно управляет PostgreSQL. Из-за этого никакие auto-vacuum’ы не смогут очистить ненужные кортежи, которые появились после начала построения индекса, и до завершения этого процесса. Если у таблицы большой объём изменений (особенно плохо, если сама таблица при этом мала), это может привести к крайне неоптимальному времени выполнения запроса.CREATE INDEX CONCURRENTLY ...завершит выполнение только после того, как завершатся все транзакции, использующие таблицу.
Удалить индекс
Стандартное выражение DROP INDEX ... получает ACCESS EXCLUSIVE на всей таблице на всё время удаления индекса. Для небольших индексов это может не быть проблемой — это должна быть весьма короткая операция. Однако для огромных индексов работа с файловой системой может занять значительное время. Нам на помощь придёт DROP INDEX CONCURRENTLY ..., которая потребует блокировку уровня SHARE UPDATE EXCLUSIVE; запись и чтение будут продолжаться, пока мы удаляем индекс.
Подводные камни использования DROP INDEX CONCURRENTLY ...:
- Этот запрос не может быть использован для удаления индекса, который поддерживал какое-либо ограничение (например
PRIMARY KEYилиUNIQUE). - Он не может быть использован как часть транзакции, ими управляет PostgreSQL «под капотом». Из-за этого никакие auto-vacuum’ы не смогут очистить ненужные кортежи, которые появились после начала построения индекса, и до завершения этого процесса. Если у вас есть таблица с большим объёмом изменений (особенно плохо, если сама таблица при этом мала) это может привести к крайне неоптимальному времени выполнения запроса.
- Запрос завершит выполнение только после того, как завершатся все транзакции, использующие таблицу.
Обратите внимание: DROP INDEX CONCURRENTLY ... был добавлен только в Postgres 9.2. Если вы всё ещё работаете с версией 9.1 или ниже, вы можете добиться примерно такого же результата, если отметите индекс как некорректный (invalid) и не готовый к записи; затем вам нужно будет сбросить буфер с помощью расширения pgfincore. После этого можно просто удалять индекс.
Переименовать индекс
ALTER INDEX ... RENAME TO ... требует блокировку уровня ACCESS EXCLUSIVE на переименовываемом индексе, блокируя чтение и запись в соответствующую таблицу. Однако коммит, который должен стать частью PostgreSQL 12 понижает это требование до SHARE UPDATE EXCLUSIVE.
Произвести переиндексацию
REINDEX INDEX ... также требует ACCESS EXCLUSIVE на индексе. Чтобы этого не допускать, рекомендуется следующий алгоритм:
- Создать новый индекс, как это описано выше, который повторял бы существующий.
- Удалить старый индекс, наименее затратным способом (описан выше).
- Переименовать новый индекс, чтобы он повторял имя старого.
Заметьте: Если индекс, который вам необходимо перестроить, содержал ограничения, не забудьте добавить их и в новый индекс (как это сделать, мы как раз рассмотрим в следующей части).
Ограничения
NOT NULL
Удаление существующего ограничения NOT NULL из столбца требует полной блокировки таблицы. Это не так существенно, так как выполняется простое обновление каталога.
А вот добавление ограничения NOT NULL к существующему столбцу требует ACCESS EXCLUSIVE на время проведения полного скана таблицы, чтобы удостовериться, что в ней нет null-значений. Вместо этого вам следует:
- Добавить ограничение проверки
CHECK, которое бы требовало от значений столбца не бытьnull-ами. Сделать это можно с помощьюALTER TABLE <table> ADD CONSTRAINT <name> CHECK (<column> IS NOT NULL) NOT VALID;. ЗдесьNOT VALIDсообщает PostgreSQL, что нет необходимости проводить полную проверку, чтобы удостовериться, что все строки соответствуют условию. - Вручную проверить, что все строки содержат значения, отличные от
null. - Валидировать наложенное ограничение с помощью
ALTER TABLE <table> VALIDATE CONSTRAINT <name>;. Выполнение этого выражения заблокирует получение другихEXCLUSIVEблокировок таблицы, но не будет мешать записи или чтению.
Бонус: сейчас в работе находится патч (и, возможно, он войдёт в релиз PostgreSQL 12), который позволит создавать ограничение NOT NULL без полного просмотра таблицы при ограничении CHECK вроде того, что мы создали выше.
Внешний ключ
ALTER TABLE ... ADD FOREIGN KEY требует блокировку SHARE ROW EXCLUSIVE (по крайней мере с версии 9.5) на обеих таблицах — и на изменяемой, и на той, на которую мы ссылаемся. Такая блокировка, конечно, не будет блокировать запросы SELECT, однако длительный запрет на внесение изменений тоже неприемлем.
Чтобы избежать длительной блокировки, можно поступить следующим образом:
ALTER TABLE ... ADD FOREIGN KEY ... NOT VALID: добавит внешний ключ и начнёт применять ограничение ко всем новым выражениямINSERT/UPDATE. При этом существующие строки не будут проверены на соответствие ограничению. Это операция тоже требуетSHARE ROW EXCLUSIVE, но лишь на очень короткое время.ALTER TABLE ... VALIDATE CONSTRAINT <constraint>проверит все существующие строки на соответствие указанному ограничению. Проверка требует толькоSHARE UPDATE EXCLUSIVE, поэтому может работать параллельно с чтением данных и записью.
Ограничение проверки (CHECK)
ALTER TABLE ... ADD CONSTRAINT ... CHECK (...) требует блокировку уровня ACCESS EXCLUSIVE. Однако, как и в случае с внешними ключами, эту операцию можно разделить на две:
ALTER TABLE ... ADD CONSTRAINT ... CHECK (...) NOT VALIDдобавит ограничение проверки и начнёт применять ограничение ко всем новым выражениямINSERT/UPDATE. При этом существующие строки проверяться не будут. Это операция требуетACCESS EXCLUSIVE.ALTER TABLE ... VALIDATE CONSTRAINT <constraint>проверит все существующие строки. Проверка требуетSHARE UPDATE EXCLUSIVEна таблице. Если ограничение ссылается на другую таблицу, на ней будет установлена блокировка уровняROW SHARE. Напомним, она лишь откладывает операции, которые требуют полной блокировки таблицы.
Ограничение уникальности (UNIQUE)
ALTER TABLE ... ADD CONSTRAINT ... UNIQUE (...) требует блокировку уровня ACCESS EXCLUSIVE. И снова делим операцию на две:
- Конкурентно создайте индекс с ограничением на уникальность (как описано выше). Это действие само по себе будет требовать уникальности значений. Однако, если вам нужно именно ограничение в смысле constraint (или первчиный ключ), то вы можете добавить его следующим шагом.
ALTER TABLE ... ADD CONSTRAINT ... UNIQUE USING INDEX <index>создаст ограничение, используя уже существующий индекс. Операция всё ещё требуетACCESS EXCLUSIVE, но лишь для быстрых операций над каталогом.
Обратите внимание: если вы указываете PRIMARY KEY вместо UNIQUE, то все столбцы, которые могли содержать null‘ы получат ограничение NOT NULL. Это потребует полного скана таблицы, и на данный момент этого никак нельзя избежать. Детали описаны в разделе про NOT NULL.
Ограничение-исключение (EXCLUDE)
ALTER TABLE ... ADD CONSTRAINT ... EXCLUDE USING ... требует блокировки ACCESS EXCLUSIVE. Если вы добавите ограничение исключительности, то это потянет за собой создание индекса, и, к сожалению, не получится использовать уже сформированный индекс (как мы делали с ограничением уникальности выше).
Перечисляемые типы
CREATE TYPE <name> AS (...) и DROP TYPE <name> (после проверки, что тип нигде не используются) могут быть безопасно выполнены без всяких блокировок.
Изменение используемых значений
В PostgreSQL добавили выражение ALTER TYPE <enum> RENAME VALUE <old> TO <new>. Оно не требует блокировки таблиц, которые используют перечислимый тип.
Удаление значений
Перечислимые типы хранятся в виде целых чисел. Пропуски в диапазоне допустимых значений не поддерживаются. Из-за этого удаление одного допустимого значения привело бы к необходимости изменять данные во всех строках, которые использовали этот тип. PostgreSQL в настоящее время не поддерживает удаление одного значения из существующего перечислимого типа.
Библиотека для Ruby on Rails
Braintree Payments, в дополнение к статье, выложили исходный код своей библиотеки для Ruby on Rails — pg_ha_migrations. Этот gem позволяет безопасно использовать DDL в проектах, которые используют Ruby on Rails и/или ActiveRecord. Её основная задача — позволить явно указывать способ выполнения операции, выбирая между различными видами издержек. Подробнее можно прочитать в README проекта.
Примечания
1 Вы можете получить активные запросы, которые долго исполняются, выполнив следующий системный запрос:
SELECT
psa.datname as database,
psa.query as current_query,
clock_timestamp() - psa.xact_start AS transaction_age,
array_agg(distinct c.relname) AS tables_with_locks
FROM pg_catalog.pg_stat_activity psa
JOIN pg_catalog.pg_locks l ON (psa.pid = l.pid)
JOIN pg_catalog.pg_class c ON (l.relation = c.oid)
JOIN pg_catalog.pg_namespace ns ON (c.relnamespace = ns.oid)
WHERE psa.pid != pg_backend_pid()
AND ns.nspname != 'pg_catalog'
AND c.relkind = 'r'
AND psa.xact_start < clock_timestamp() - '5 seconds'::interval
GROUP BY psa.datname, psa.query, psa.xact_start;2 Посмотреть внутреннюю статистику PostgrSQL об использовании заданной таблицы можно, выполнив следующий запрос:
SELECT
seq_scan,
seq_tup_read,
idx_scan,
idx_tup_fetch,
n_tup_ins,
n_tup_upd,
n_tup_del
FROM pg_catalog.pg_stat_user_tables
WHERE relname = '<table>';3 Если вы хотите узнать, вызывает ли DDL перезапись связанных объектов, вам стоит посмотреть меняются ли значения relfilenode после выполнения следующего выражения:
SELECT
relname,
relfilenode
FROM pg_catalog.pg_class
WHERE relname in (
'<table>',
'<index>'
)
-- Сортируем по oid для удобства, если вы проверяете несколько отношений.
ORDER BY oid;
4 Следующее выражение поможет вам найти любые зависимые от столбца объекты (в частности, индексы):
SELECT
d.objid::regclass AS owning_object,
d.refobjid::regclass AS dependent_object,
a.attname AS dependent_column,
d.deptype -- Значение этого дипа задокументировано на https://www.postgresql.org/docs/current/catalog-pg-depend.html
FROM pg_catalog.pg_depend d
LEFT JOIN pg_catalog.pg_attribute a ON d.refobjid = a.attrelid
AND d.refobjsubid = a.attnum
WHERE refobjid = '<table>'::regclass
AND a.attname = '<column>';
Перевод статьи «PostgreSQL at Scale: Database Schema Changes Without Downtime»
Содержание
1. Спасти рядовую пятницу
2. Конфигуратор, у нас проблемы
3. Что делать, шеф?
4. Второй шаг – круг задач
5. Попытки решения
5.1. Попытка 1 — тестирование-исправление ИБ через директиву командной строк
5.2. Попытка 2 — копирование таблиц Config, Configsave, Params и DBSchema из работоспособной копии ИБ средствами MS SQL
5.3. Попытка 3 — очистка таблицы configsave средствами MS SQL
5.4. Попытка 4 — копирование разрушенных таблиц из работоспособной копии ИБ средствами MS SQL
6. Решение, которое помогло:
6.1. Подключение
6.2. Перенос справочников 1С
6.3. Перенос документов 1С
6.4. Проведение документов 1С
7. Выводы. Как избежать поломки структуры данных базы 1С
Спасти рядовую пятницу
Пятница – это не только друг Робинзона. Это – почти выходной. Должен же быть в рабочем календаре день, когда можно подумать о горячих выходных и прохладных напитках. Как минимум, стоит остерегаться резких движений, чтобы сберечь настоящие выходные для команды и пользователей. Во многих софтверных компаниях считается дурным тоном выпускать новые релизы в конце недели. К примеру, Apple «катит» по вторникам. В Яндексе запрещено «катить» по пятницам и перед Новым Годом.
Но однажды пятнице не повезло. Когда сроки горят, а дедлайны давят, всегда найдется чему пойти не так. И дальнейшее развитие событий сильно зависит от компетенций вашей uber-команды.
Конфигуратор, у нас проблемы
Это было обычное обновление конфигурации. Структура данных не поменялась, бизнес-логика тоже. По «большой просьбе» одного из пользователей, решили обновить рабочую базу.
Одно «но»: технологическое окно уже закончилось и основные изменения конфигурации уже были запущены в работу.
«Надо!» – пользователь просит. Что ж, надо – значит надо: программист привычно нажал F7 и согласился с предложением Конфигуратора «обновить динамически».
Через пару часов стало понятно, что база умерла: попытка войти в режиме «1С:Предприятие» отправляло систему «в дамп» после исполнения нескольких строк модуля приложения. Конфигуратор открывался и работал, но попытки внести изменения также приводили к краху без подробностей в журнале регистрации и технологическом журнале.

В результате база перестала открываться. Совсем.
Попытки войти в «1С:Предприятие» не пускали пользователей дальше окна авторизации. Конфигуратор открывался и работал, но без толку для решения задачи: попытки обновить информационную базу и/или выполнить восстановление также приводили к краху.
Анализ СУБД показал, что динамическое обновление разрушило структуру таблиц. Теперь-то каждый разработчик в команде знает, что «динамические обновления» – это зло. И все знают неформальное название – «демоническое обновление». Да, с этого момента динамические обновления в компании для рабочей базы запрещены. Но «фарш невозможно провернуть назад» и утерянная база не запускается.
Утеряно несколько сотен документов реализации, с сотнями товарных позиций.
Что делать, шеф?
Сначала мы оценили, чем в итоге располагаем.
Не так много, но не безнадежно:
* Слепок информационной базы, который делается регулярно по расписанию каждые два часа. Нам «повезло» и восстанавливать потребуется 1 час 53 минуты работы пользователей.
* База, работоспособна на уровне СУБД.
* На уровне COM-соединения работоспособность также сохранилась,
* Проектная команда собралась из разных проектов. (Да, специалист в фирме франчайзи – это универсальный боец и швец, и тд. Пожалуй, это главное, что помогло решить вопрос оперативно).
С этим понятно. Какие потери?
* Примерно два часа работы нескольких сотен пользователей. В основном – документы реализации и заказы покупателей.
* Да, можно восстановить данные по первичке. Но! Представьте себе пару часов работы сотен пользователей в разгар рабочего дня.
* На календаре конец первого квартала – это годовая бухгалтерская, налоговая отчетность. Плюс квартальная отчетность перед партнерами.
* Плюс скоро начислять зарплату и вознаграждения по договорам.
Второй шаг – круг задач
Оценив масштаб последствий, стало очевидно, что ситуация исправима. Как выяснилось позже – это оптимистичный вывод, но оптимистам везет.
Итак, утерян относительно небольшой по времени период – чуть меньше двух часов работы пользователей.
Это сотни документов с табличными частями до сотен строк. Несколько сотен элементов справочников.
И надо было определить, какие из потерь критичны для результата, а что можно пропустить и решить в дальнейшем другими путями.
Например, очень непросто восстанавливать записи (а тем более, итоги) регистров бухгалтерии по двум причинам. Первая – это низкая производительность по сравнению с другими структурами данных. Вторая – сложность организации как в СУБД, так и на уровне объектной модели «1С:Предприятие».
Но так как за эти два часа ручные корректировки регистров бухгалтерии не выполнялись, то можно записи отдельно от документов не восстанавливать. Все движения, подчиненные регистраторам, можно восстановить перепроведением восстановленных документов.
Попытки решения
Попытка 1. Тестирование-исправление ИБ через директиву командной строки Конфигуратора. Примерно так:
1cv8.exe config /IBCheckAndRepair -Rebuild
А также тестирование/исправление СУБД
dbcc checkdb(‘<db_name>’, REPAIR_ALLOW_DATA_LOSS )
Конфигуратор стартовал, висел в списке процессов некоторое время и дальше падал без объяснения причин. Технологический журнал при этом с упорством Капитана Очевидность сообщал о разрушении таблицы с планом обмена.
Попытка 2. Копирование таблиц Config, Configsave, Params и DBSchema из работоспособной копии ИБ средствами MS SQL
ins ert into [base2009].[Dbo].[Config] sel ect * from [BaseCopy].[Dbo].[Config]
Это помогло – удалось пройти дальше окна авторизации. Но модуль приложения все равно падал с исключением при попытке опросить планы обмена. Отключить проверку в этом куске кода не удалось, так как попытки сохранить конфигурацию приводили к падению Конфигуратора на этапе анализа структуры ИБ
То есть мы продвинулись дальше, но какая разница – перепрыгнул ты пропасть на четверть или наполовину? Как говорится, go fish.
Попытка 3. Очистка таблицы configsave средствами MS SQL
Примерно так:
DR OP TABLE [ConfigSave]
CRE ATE TABLE [ConfigSave]( [FileName] [nvarchar](128) NOT NULL, [Creation] [datetime] NOT NULL, [Modified] [datetime] NOT NULL, [Attributes] [smallint] NOT NULL, [DataSize] [int] NOT NULL, [BinaryData] [image] NOT NULL)
INS ERT IN TO ConfigSave SELECT * FR OM Config
Тоже помогло, Но с тем же эффектом, что и предыдущая попытка.
Попытка 4. Копирование разрушенных таблиц из работоспособной копии ИБ средствами MS SQL
Оценив количество модифицированных таблиц, мы прикинули сколько SELE CT’ов придется написать… и решили, что несколько дней без базы компания не выдержит
Решение, которое помогло
1. Была восстановлена база из «слепка», снятого за два часа до разрушения таблиц.
2. Дальше немного магии: код на 1С, который помог восстановить данные, накопленные пользователями со времени снятия крайнего слепка.
3. Так как платформа в режиме COM-соединения гораздо легче и более прозрачно оперирует с СУБД, то система успешно стартует и дает выполнить запросы.
Итак, код решения, которое сработало:
Подключение
1. Из копии подключаемся к разрушенной рабочей базе через COM-соединение. В отличие от обычного подключения, сеанс стартует успешно

Перенос справочников 1С
2. Загружаем те справочники, которых еще нет в копии


Перенос документов 1С
3. Загружаем те документы, которых еще нет в копии


Проведение документов 1С
4. Чтобы восстановить движения, перепроводим проведенные документы, загруженные в копию

Выводы. Как избежать поломки структуры данных базы 1С?
Удалось ли нам спасти ту пятницу? И да, и нет.
У пользователей случился «сокращенный рабочий день» и тут, пожалуй, да – отдыхать полезно.
Большинство проектной команды получило свою порцию адреналина. И ушли с работы тоже вовремя.
Руководитель проекта и эксперт по технологическим вопросам крупных внедрений получили много интересной и поучительной работы на выходные
Успеху в этой ситуации способствовали регулярные бэкапы и быстрая диагностика. Бэкап облегчил восстановление. А диагностика «в восемь рук» позволила быстро найти тот вариант, который сработал. То ,что он оказался пятым по счету и его не было на Инфостарте, в школе или на форумах только подтверждает ценность проектного опыта команды.
Что делать в будущем во избежание подобных ситуаций? Всю округу соломкой не устелить, но вот чек-лист для критичных ситуаций.
• Диагностика
o Команде знать и уметь работать с:
— техническим журналом;
— подсистемой «Инструменты разработчика» (Сергей, привет и огромное спасибо за твой многолетний труд);
— Sql + инструменты администрирования субд;
— инструментом диагностики операционной системы и оборудования.
o Держать под рукой эти инструменты, желательно в виде коротких пошаговых инструкций и скриптов
• Лечение
— Будьте экспертом. Неважно в данном случае, лучший ты сыщик с дипломом или без диплома. Важен экспертный подход к решению задач
o Мыслить гибко
•Профилактика
— Бэкапы — регулярно
— Каждому знать, где лежат и как часто делаются
— Админам написать инструкции (а лучше скрипты) для оперативного восстановления.
Если Вы дочитали эту статью до конца, можно с уверенностью пожелать спокойных выходных!
Анатолий Бурнашев,
руководитель отдела внедрения ООО “Кодерлайн”
 Существуют вещи настолько привычные, что кажется все про них знают, но это весьма обманчивое впечатление. Да, о них почти все знают, почти все используют, но мало кто представляет происходящие при этом процессы, скрытые за привычной внешней формой инструмента. При этом те, кто знает не спешат делиться, ведь это «общеизвестно», а те, кто не знает стесняются спросить по той же самой причине. Но мы не будем стесняться, а подробно расскажем о том, что делает каждая опция данного инструмента, заглянув каждый раз немного глубже простого описания.
Существуют вещи настолько привычные, что кажется все про них знают, но это весьма обманчивое впечатление. Да, о них почти все знают, почти все используют, но мало кто представляет происходящие при этом процессы, скрытые за привычной внешней формой инструмента. При этом те, кто знает не спешат делиться, ведь это «общеизвестно», а те, кто не знает стесняются спросить по той же самой причине. Но мы не будем стесняться, а подробно расскажем о том, что делает каждая опция данного инструмента, заглянув каждый раз немного глубже простого описания.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Давно известно: как вы лодку назовете — так она и поплывет. Это в полной мере применимо к такому известному инструменту как Тестирование и исправление информационной базы, название выбрано крайне неудачно, так как предполагает, что использовать представленные в нем возможности следует при возникновении проблем с информационной базой и исправлении ошибок. На самом деле это не так. Любой имеющий опыт работы с «серьезными» СУБД найдет в этом списке привычные ему инструменты обслуживания баз данных, которые следует применять регулярно для поддержания высокой производительности сервера. Но речь сейчас не о них, а о начинающих, либо имеющих к 1С опосредованное отношение.
 Описание этой таблички можно найти много где, но в большинстве случаем там будут стандартные абзацы вроде:
Описание этой таблички можно найти много где, но в большинстве случаем там будут стандартные абзацы вроде:
Проверка логической целостности информационной базы проверяет и исправляет логические ошибки в структурах таблиц
Что это за ошибки, откуда они берутся, чем чреваты? Кто в теме — тот знает, а кто нет? Спросить? Да как бы неудобно, это же все знают… Вот и сводится большинство «знания» к тому, как правильно расставить в этой форме галочки и не забыть перед этим обязательно сделать резервную копию, а то мало ли…
Поэтому давайте разбираться, мы специально упростили многие вопросы, постаравшись сделать их понятными даже тем, кто имеет смутное представление о структуре и принципах работы баз данных.
Реиндексация таблиц информационной базы
Начнем с того, что такое индексы и для чего они нужны. Если рассматривать базу данных логически — то это некая совокупность связанных друг с другом таблиц, которые в свою очередь содержат какие-либо данные. Физически таблицы хранятся на диске в виде страниц и чем больше размер таблицы, тем большее количество страниц она будет содержать.
Допустим у нас есть некая таблица и мы хотим получить из нее все данные, связанные с фамилией Иванов. Для этого программе нужно последовательно считать все страницы, принадлежащие данной таблице и найти в них записи, соответствующие запросу.
 Но ведь это чудовищно неэффективно, скажет внимательный читатель и будет прав. Что же делать? К счастью, все уже давно придумано. Хранение данных в СУБД можно сравнить с библиотекой, где таблицы — это залы библиотеки, а страницы — стеллажи. И когда вам нужна какая-то книга библиотекарь ведь не обходит физически все стеллажи, а сразу идет куда надо и приносит вам то, что вы просили. Чтобы быстро искать книги в библиотеках существуют каталоги, где книги перечислены в упорядоченном виде, и каждая карточка содержит сведения о том, где именно хранится тот или иной экземпляр.
Но ведь это чудовищно неэффективно, скажет внимательный читатель и будет прав. Что же делать? К счастью, все уже давно придумано. Хранение данных в СУБД можно сравнить с библиотекой, где таблицы — это залы библиотеки, а страницы — стеллажи. И когда вам нужна какая-то книга библиотекарь ведь не обходит физически все стеллажи, а сразу идет куда надо и приносит вам то, что вы просили. Чтобы быстро искать книги в библиотеках существуют каталоги, где книги перечислены в упорядоченном виде, и каждая карточка содержит сведения о том, где именно хранится тот или иной экземпляр.
В нашем случае роль такого каталога выполняет индекс. Это — специальный набор записей, связанный с определенным ключом — полем таблицы, в нашем случае фамилией, и указывающий на каких страницах хранятся интересующие записи. После того как мы создали индекс программе больше не нужно последовательно считывать всю таблицу, потому что известно, что записи, связанные с ключом Иванов, хранятся только на первой и третьей страницах.
 По мере работы с программой эффективность индексов снижается, особенно если вы активно удаляли или добавляли данные. Также индексы могут подвергаться фрагментации. Если снова сравнить с библиотекой, то за день работы посетители перепутали несколько ящиков, а работники библиотеки карточки новых книг поставили в конец и забыли убрать отсутствующие. Но все равно поиск по такому каталогу окажется быстрее, чем обход всех стеллажей в зале. А что нужно сделать, чтобы вернуть поиску прежнюю эффективность? Правильно, навести порядок в каталоге. Именно этим и занимается реиндексация, которая заново формирует индексы таблиц базы данных и устраняет их фрагментацию, что важно, если вы используете обычные жесткие диски или недорогие SSD.
По мере работы с программой эффективность индексов снижается, особенно если вы активно удаляли или добавляли данные. Также индексы могут подвергаться фрагментации. Если снова сравнить с библиотекой, то за день работы посетители перепутали несколько ящиков, а работники библиотеки карточки новых книг поставили в конец и забыли убрать отсутствующие. Но все равно поиск по такому каталогу окажется быстрее, чем обход всех стеллажей в зале. А что нужно сделать, чтобы вернуть поиску прежнюю эффективность? Правильно, навести порядок в каталоге. Именно этим и занимается реиндексация, которая заново формирует индексы таблиц базы данных и устраняет их фрагментацию, что важно, если вы используете обычные жесткие диски или недорогие SSD.
Реиндексация — это простой и достаточно недорогой способ повысить эффективность работы с информационной базой, причем эффект может быть виден сразу, особенно в файловых базах. Поэтому реиндексацию делать нужно и желательно регулярно, включив ее в обязательный план регламентного обслуживания информационных баз.
Проверка логической целостности информационной базы
Если говорить о СУБД, то любая система управления базами данных, в том числе и та, которая используется файловой версией 1С, обеспечивает целостность данных встроенными средствами и вам вряд ли придется заниматься этим вопросом, если только, конечно, не произошло физического повреждения базы данных. Как мы уже говорили выше, база данных — это набор взаимосвязанных таблиц и самой СУБД в общем то все равно что мы храним в этих таблицах, для нее таблица Документа ничем не отличается от таблицы Справочника, кроме состава полей.
Но на уровне информационной базы 1С существует совсем иной набор объектов: Справочники, Документы, Регистры сведений и накопления и т.д. и т.п. При этом они связаны определенной внутренней логикой. Так элементы справочника могут иметь иерархическую структуру, являться подчиненными для другого справочника, а документы быть основанием для других документов, формировать проводки, записи регистров и т.д. и т.п. В процессе работы данная логика может быть нарушена, как по причине ошибок в программе, так и в результате некоторых действий пользователя.
Давайте рассмотрим следующую схему, отражающую некоторый набор бизнес-логики. У нас есть два документа: Реализация и Оплата, которые делают движения по некоторым регистрам. Так при реализации мы списываем нужное количество товара со склада и вносим в регистр взаиморасчетов задолженность покупателя. В момент оплаты мы вносим полученную сумму в регистр денежных средств и закрываем задолженность покупателя по отгрузке полностью или частично. Но как мы определим, какую именно задолженность погасил клиент? А для этого мы введем в документе оплата обязательное поле Основание, в котором будем указывать нужную реализацию.
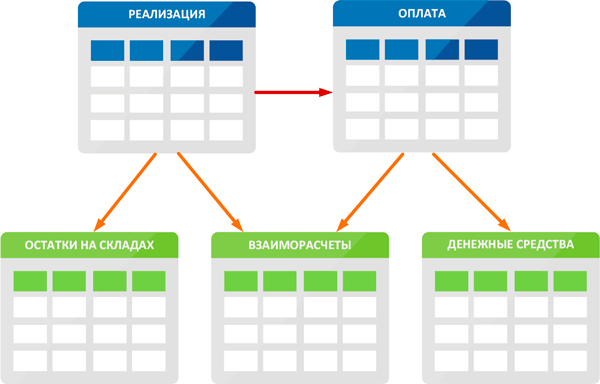 При этом документ Оплата будет являться подчиненным к документу Реализация и в случае его отмены также должен быть отменен, так как перестает существовать основание для оплаты. Теперь представим, что в результате какой-то нештатной ситуации или некорректных действий пользователя у нас в документе Оплата пропала ссылка на документ основание, т.е. нарушилась структура подчиненности. Найти такую ошибку будет не так-то просто. Потому что все записи в базе данных останутся, и каждая из них по отдельности будет верная. Так правильным останется количество товаров на складах и суммы денежных средств предприятия, а вот взаиморасчеты враз станут неверны.
При этом документ Оплата будет являться подчиненным к документу Реализация и в случае его отмены также должен быть отменен, так как перестает существовать основание для оплаты. Теперь представим, что в результате какой-то нештатной ситуации или некорректных действий пользователя у нас в документе Оплата пропала ссылка на документ основание, т.е. нарушилась структура подчиненности. Найти такую ошибку будет не так-то просто. Потому что все записи в базе данных останутся, и каждая из них по отдельности будет верная. Так правильным останется количество товаров на складах и суммы денежных средств предприятия, а вот взаиморасчеты враз станут неверны.
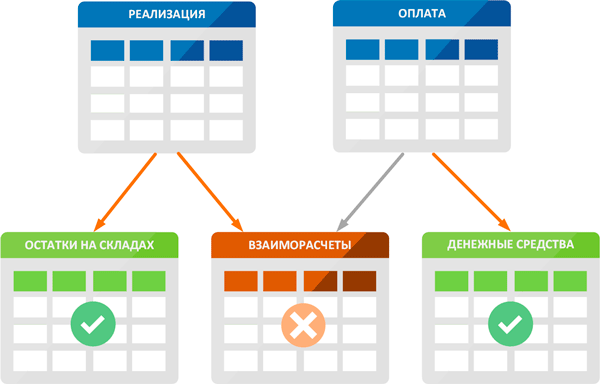 Внешне это может проявляться так: отчеты по реализациям и оплатам от контрагента совпадают, а вот отчет по взаиморасчетам или акт сверки формируется неправильно. При этом вы можете раз за разом пересчитывать суммы руками, все будет сходиться, но отчет снова и снова будет давать неверный результат.
Внешне это может проявляться так: отчеты по реализациям и оплатам от контрагента совпадают, а вот отчет по взаиморасчетам или акт сверки формируется неправильно. При этом вы можете раз за разом пересчитывать суммы руками, все будет сходиться, но отчет снова и снова будет давать неверный результат.
Поэтому во всех подобных случаях, когда отчеты показывают неверные результаты или не сходятся друг с другом, следует запускать проверку логической целостности. Но не следует ожидать от нее какого-либо чуда, потому что она способна исправить только некоторые, самые очевидные ошибки (проводка без регистратора, неверный родитель элемента справочника и т.д.), в остальных случаях потребуется анализ ситуации и ручное исправление обнаруженных проблем. При этом нарушение логической целостности очень часто бывает связано с нарушением ссылочной целостности, о которой мы поговорим ниже.
Как часто нужно запускать эту проверку? Время от времени, особенно в файловых базах с обязательным изучением лога проверки, чем раньше вы узнаете о возможных проблемах в структуре данных и устраните их — тем лучше.
Проверка ссылочной целостности информационной базы
Данная проверка является одним из вариантов проверки логической целостности базы и выявляет проблемы со ссылками на отсутствующие элементы базы данных. Как мы уже говорили, база — это набор связанных между собой таблиц. В одной из них мы можем хранить контрагентов, в другой номенклатуру, в третьей — список складов, а внося запись о реализации товаров просто делаем ссылки на нужные элементы других таблиц. Например, наш условный документ Реализация может ссылаться на справочники Контрагенты, Номенклатура, Склады, выбирая и указывая в документе соответствующие значения мы не создаем дополнительных записей в таблице реализации, а даем ссылки на элементы связанных таблиц.
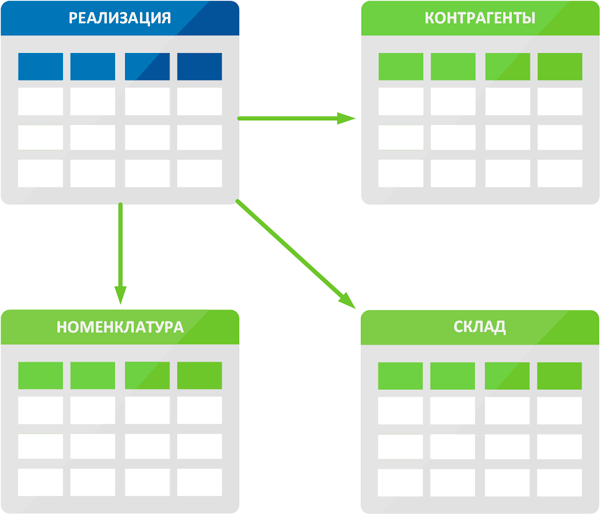 Контроль ссылочной целостности является подмножеством контроля логической целостности и осуществляется на уровне конфигурации. С ним сталкивался каждый, кто пытался удалить какой-либо объект их базы, а в ответ получал сообщение, что это невозможно, так как данный объект используется и приводился список мест использования.
Контроль ссылочной целостности является подмножеством контроля логической целостности и осуществляется на уровне конфигурации. С ним сталкивался каждый, кто пытался удалить какой-либо объект их базы, а в ответ получал сообщение, что это невозможно, так как данный объект используется и приводился список мест использования.
Но что будет, если используемый объект все-таки удалить? Возникнет битая ссылка. Внешне она выглядит как запись со ссылкой на уникальный идентификатор отсутствующего объекта:
<Объект не найден> (95:bc09ecd68a04705d11eb44а671518376)Если подходить с чисто теоретических позиций, то битых ссылок в информационной базе быть не должно. Но не все так просто, если в базе используется РИБ, либо иные технологии обмена с другими базами и внешними источниками, то ряд второстепенных реквизитов может не передаваться. Например, сведения о подключаемом оборудовании.
В данном случае это нормально (Конфигурация Розница 2.3), так как конкретный экземпляр оборудования подключен именно к конкретному рабочему месту и передавать эти данные куда-то еще лишено особого смысла.
Но чаще к этой ошибке приводит повреждение базы или некорректные действия пользователя, скажем, удалившего объекты без контроля ссылочной целостности. В любом случае появление битых ссылок — это серьезный симптом и повод для отдельного разбирательства, рубить с плеча здесь неуместно. Поэтому сами разработчики при активации этой проверки переводят ее в безопасный режим, устанавливая действие Не изменять, по сути проверка лишь проинформирует вас о наличии битых ссылок, не более.
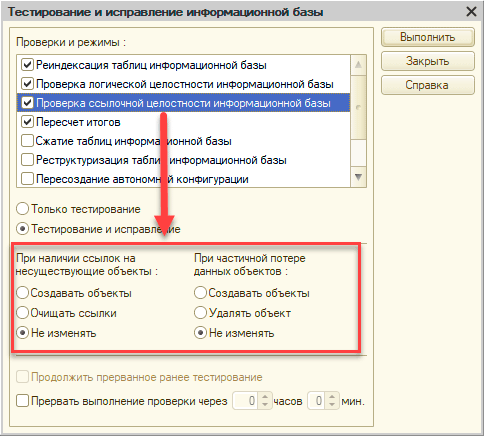
А вот после, установив сам факт их наличия следует думать. В ряде случаев, если выявленные ссылки являются второстепенными объектами подчиненных баз не нужно делать ничего. Наоборот, любая попытка «исправления» может привести к нарушению нормальной работы информационной базы. А вот в других надо предпринимать какие-либо действия.
Давайте посмотрим какие варианты у нас есть. Начнём со ссылок на несуществующие объекты. Здесь все довольно просто, мы можем или очистить ссылку, или создать новый объект нужного типа. Допустим, если запись справочника Номенклатура оказалась повреждена, но мы точно знаем по бумажным документам, что именно реализовывали, то ставим Создавать объекты, после чего переходим к ним и заполняем нужные реквизиты. Если же это какой-то второстепенный реквизит, то можем просто очистить ссылки. Второй вариант довольно часто применяется в тех случаях, когда надо быстро почистить базу и ряд объектов удаляется без контроля ссылочной целостности.
Теперь о частичной потере данных объектов. К ним могут относиться элемент подчиненного справочника без владельца или движение без регистратора. Мы можем либо удалить такие объекты, либо создать связанные с ними. Чаще всего такие объекты имеет смысл удалять, особенно если это движения, хотя если это элемент справочника, владелец которого потерян, то в ряде случаев имеет смысл создать владельца.
Внимание! Перед любыми исправлениями ссылочной целостности в базе обязательно создайте резервную копию. Помните, что данная операция необратима и может привести к полной или частичной потере данных!
Но даже имея показания к исправлению некоторых битых ссылок следует иметь ввиду, что данный инструмент применит выбранное действие ко всем ссылкам без разбора, что во многих случаях неприемлемо. Поэтому чаще всего проблему битых ссылок следует решать иными путями, один из них — выгрузка необходимых справочников или документов в XML из резервной копии и загрузка их в целевую базу в тех случаях когда просто восстановиться из бекапа невозможно.
Когда следует запускать эту проверку? В тех случаях, когда в базе не обнаружены битые ссылки или когда проверка логической целостности выявляет ошибки. Но в любом случае первый запуск следует производить с действиями Не изменять, а последующие решения принимать на основании глубокого анализа ситуации.
Пересчет итогов
В составе конфигурации 1С имеются специальные объекты — регистры, которые предназначены для хранения записей в разрезе определенных измерений. Например, регистр сведения Цены хранит сведения о ценах в разрезе измерений Номенклатура и Дата, а регистр накопления Товары хранит сведения об остатках товаров в разрезе Номенклатуры, Вида движения (расход или приход), Количества и Даты.
Начем с более простого, регистров сведения, допустим мы хотим получить действующие цены на определенную дату. Но если мы просто получим записи за этот день, то увидим, что цены менялись только для некоторых позиций номенклатуры, чтобы получить полный набор цен нам надо прочитать записи регистра на неопределенное количество дней назад, пока мы не получим последние цены для каждой позиции номенклатуры. Чтобы этого не делать регистр сведений имеет специальную виртуальную таблицу — СрезПоследних, которая содержит последние актуальные цены на каждый день. Теперь нам достаточно один раз обратиться к этой таблице, чтобы получить нужные сведения на интересующую дату.
Немного сложнее с регистрами накопления, записи в них содержат только сведения о движениях, скажем, такого-то числа в такое-то время на склад пришло 10 позиций некоторой номенклатуры, затем тем же днем продали 1 шт, потом 3 шт, за ней снова 5 шт и после еще 1 шт. При этом ряд вопросов, которые могут нас интересовать гораздо шире. Нас могут интересовать остатки на произвольный момент времени, либо обороты за некоторый период.
Чтобы не делать глубоких выборок по регистрам накоплений в них предусмотрены виртуальные таблицы Остатки, Обороты, Остатки и обороты. Каждая из них содержит актуальные данные за определенный период, в нашем случае день. И если таблица остатков в особом пояснении не нуждается, то таблица оборотов на нашей схеме может вызвать вопросы, так как ее содержимое полностью совпадает со значениями регистра. На самом деле редко когда регистр содержит единственную запись за день, чаще всего там множество записей движения: утром привезли на склад товар, потом его активно продавали, затем довезли еще немного и продолжили торговлю. При этом таблица обороты отобразит общий оборот за период.
Собственно, как и индексы, итоги предназначены для ускорения получения данных из информационной базы, теперь вам не нужно считывать весь или почти весь регистр, чтобы получить данные на определенный момент времени, достаточно обратиться к одной из виртуальных таблиц. Но со временем итоги тоже начинают терять эффективность: в них могут накапливаться мусорные записи, они могут фрагментироваться. Пересчет итогов решает эту проблему, заново создавая нужные виртуальные таблицы.
Пересчет итогов, как и реиндексация, простой и эффективный способ поддержания производительности информационной базы. Следует выполнять его регулярно в рамках обслуживания, а также каждый раз после исправления ошибок логической или ссылочной целостности.
Сжатие таблиц информационной базы
По мере работы информационной базы объем добавляемых в нее данных растет, вместе с ним растет и объем файла (файлов) базы данных. Но если мы удалим из базы часть информации, то объем файла базы данных не уменьшится, просто некоторые страницы будут помечены как пустые и снова доступные для записи. Если мы хотим уменьшить физически занимаемый объем, то следует произвести операцию сжатия таблиц информационной базы. В этом случае база переместит текущие данные на место освободившихся страниц, а затем уменьшит файл базы данных на объем освободившегося пространства.
 Какой практический смысл этой операции? Да особо никакого, фрагментация данных от этого не уменьшится, а скорее всего даже увеличится. Единственный смысл сжатия базы — это если вы удалили из нее значительный объем данных и теперь просто оптимизируете общее занимаемое место.
Какой практический смысл этой операции? Да особо никакого, фрагментация данных от этого не уменьшится, а скорее всего даже увеличится. Единственный смысл сжатия базы — это если вы удалили из нее значительный объем данных и теперь просто оптимизируете общее занимаемое место.
Когда следует выполнять данное действие? Только если вы удалили из базы значительный объем данных, ну или если размер файла базы для вас критичен.
Реструктуризация таблиц информационной базы
Если реиндексация только перестраивала индексы, то реструктуризация полностью перестраивает содержимое базы данных, для каждой таблицы создается копия и записывается в отдельное место на диске, затем вся база данных полностью замещается копией. В чем смысл этого действия? Фактически мы произвели дефрагментацию базы данных, если ранее данные таблицы могли быть разбросаны по диску, то теперь они будут расположены последовательно.
 Есть ли в этом практический смысл? В общем и целом, нет, чтение из страниц таблицы носит преимущественно случайный характер, последовательно считывание все таблицы — это уже ошибка построителя запросов. Но реструктуризация все-таки имеет смысл, скажем если вы добавили в базу собственный набор реквизитов или обновили релиз конфигурации (в этом случае реструктуризация будет выполнена автоматически). В любом случае лучше, чтобы связанные данные лежали рядом. Но следует понимать, что в процессе реструктуризации придется переместить весь объем информационной базы, а это может занять весьма продолжительное время.
Есть ли в этом практический смысл? В общем и целом, нет, чтение из страниц таблицы носит преимущественно случайный характер, последовательно считывание все таблицы — это уже ошибка построителя запросов. Но реструктуризация все-таки имеет смысл, скажем если вы добавили в базу собственный набор реквизитов или обновили релиз конфигурации (в этом случае реструктуризация будет выполнена автоматически). В любом случае лучше, чтобы связанные данные лежали рядом. Но следует понимать, что в процессе реструктуризации придется переместить весь объем информационной базы, а это может занять весьма продолжительное время.
И как раз-таки после реструктуризации будет уместно выполнить сжатие. Так как данные перемещать уже не надо, а пустое пространство уже сосредоточено в одном месте.
Как часто следует запускать? По необходимости, в том случае если вы изменили набор метаданных.
Пересоздание автономной конфигурации
Достаточно специфическая функция и относится к мобильному клиенту с возможностью автономной работы. Потеряв связь с основной базой данных такой клиент переключается в автономный режим и начинает использовать автономную конфигурацию. Если в данном режиме автономный клиент ведет себя неадекватно, то автономную конфигурацию следует пересоздать.
Проверка логической целостности расширений конфигурации
Не так давно фирма 1С добавила еще один способ доработки конфигураций — расширения. Основное их преимущество, что нет необходимости править код основной конфигурации или снимать ее с поддержки. Но современные расширения позволяют добавлять в базу новые реквизиты, справочники, документы, регистры и организовывать логические связи между ними.
Данная проверка аналогична проверке логической целостности, только с учетом подключенных расширений, которых может быть и не одно. Если вы используете расширения, то обязательно включайте данную проверку вместе с проверкой логической целостности.
Заключение
По умолчанию фирма 1С предлагает достаточно сбалансированный набор действий: реиндексация и пересчет итогов благотворно влияют на производительность, а проверка логической целостности позволяет на ранних этапах выявить возможные проблемы. Если вы используете расширения, то добавьте туда проверку логической целостности расширений.
Остальные проверки и действия следует выполнять только при наличии необходимости. Так обнаружив ошибки в логической целостности следует выполнить проверку ссылочной целостности, а существенно изменив структуру базы данных имеет смысл выполнить реструктуризацию.
Надеемся, что данный материал окажется вам полезен, а также поможет по-новому взглянуть и глубже понять привычные действия.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.