Привет, Вы узнаете про алгоритмы исправления опечаток, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка
, настоятельно рекомендую прочитать все из категории Обработка естественного языка.
Постановка задачи
Итак, нам пришел опечатанный запрос и его надо исправить. Обычно математически задача ставится таким образом:
- дано слово s, переданное нам с ошибками;
- есть словарь Σ правильных слов;
- для всех слов w в словаре есть условные вероятности P(w|s) того, что имелось в виду слово w, при условии, что получили мы слово s;
- нужно найти слово w из словаря с максимальной вероятностью P(w|s).
Эта постановка — самая элементарная — предполагает, что если нам пришел запрос из нескольких слов, то мы исправляем каждое слово по отдельности. В реальности, конечно, мы захотим исправлять всю фразу целиком, учитывая сочетаемость соседних слов; об этом я расскажу ниже, в разделе “Как исправлять фразы”.
Неясных моментов здесь два — где взять словарь и как посчитать P(w|s). Первый вопрос считается простым. В 1990 году словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
Второй вопрос сложнее. Хотя бы потому, что его решение обычно начинается с применения формулы Байеса!
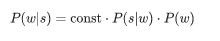
Теперь вместо исходной непонятной вероятности нам нужно оценить две новые, чуть более понятные: P(s|w) — вероятность того, что при наборе слова w можно опечататься и получить s, и P(w) — в принципе вероятность использования пользователем слова w.
Как оценить P(s|w)? Очевидно, что пользователь с большей вероятностью путает А с О, чем Ъ с Ы. А если мы исправляем текст, распознанный с отсканированного документа, то велика вероятность путаницы между rn и m. Так или иначе, нам нужна какая-то модель, описывающая ошибки и их вероятности.
Такая модель называется noisy channel model (модель зашумленного канала; в нашем случае зашумленный канал начинается где-то в центре Брока пользователя и заканчивается по другую сторону его клавиатуры) или более коротко error model —
модель ошибок . Эта модель, которой ниже посвящен отдельный раздел, будет ответственна за учет как орфографических ошибок, так и, собственно, опечаток.
Оценить вероятность использования слова — P(w) — можно по-разному. Самый простой вариант — взять за нее частоту, с которой слово встречается в некотором большом корпусе текстов. Для нашего опечаточника, учитывающего контекст фразы, потребуется, конечно, что-то более сложное — еще одна модель. Эта модель называется language model,
модель языка .
Системы автоматической коррекции орфографии
Мы предоставляем два типа конвейеров для исправления орфографии: levenshtein_corrector использует простое расстояние Дамерау-Левенштейна для поиска кандидатов на исправление, а brillmoore использует для него статистическую модель ошибок. В обоих случаях кандидаты на исправление выбираются на основе контекста с помощью языковой модели кенлм .
Сравнение автоматической коррекции орфографии для русского языка с использованием разлиных алгоритмов:
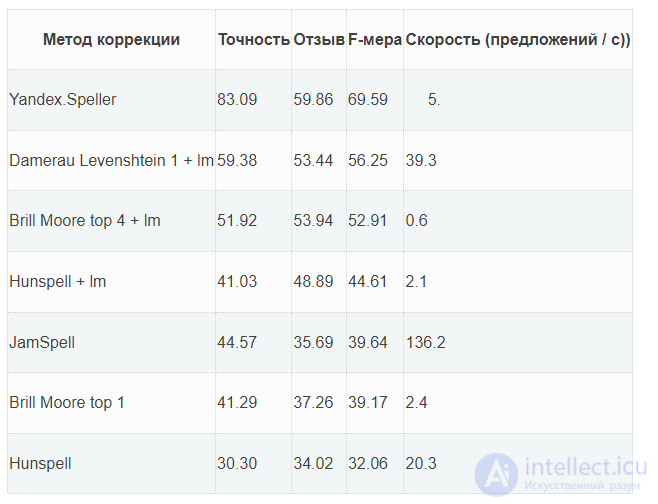
Алгоритмы для исправления опечаток без уета контекста
У каждого пользователя когда-либо были опечатки при написании поисковых запросов. Отсутствие механизмов, которые исправляют опечатки, приводит к выдаче нерелевантных результатов, а то и вовсе к их отсутствию. Поэтому, чтобы поисковая система была более ориентированной на пользователей, в нее встраивают механизмы исправления ошибок.
Задача исправления опечаток, на первый взгляд, кажется довольно несложной. Но если отталкиваться от разнообразия ошибок, реализация решения может оказаться трудной. В целом, исправление опечаток разделяется на контекстно-независимое и контекстно-зависимое (где учитывается словарное окружение). В первом случае ошибки исправляются для каждого слова в отдельности, во втором – с учетом контекста (например, для фразы «она пошле домой» в контекстно-независимом случае исправление происходит для каждого слова в отдельности, где мы можем получить «она пошел домой», а во втором случае правильное исправление выдаст «она пошла домой»).
В поисковых запросах русскоязычного пользователя можно выделить четыре основные группы ошибок только для контекстно-независимого исправления :
1) ошибки в самих словах (пмрвет → привет), к этой категории относятся всевозможные пропуски, вставки и перестановки букв – 63,7%,
2) слитно-раздельное написание слов – 16,9%,
3) искаженная раскладка (ghbdtn → привет) – 9,7 %,
4) транслитерация (privet → привет) – 1,3%,
5) смешанные ошибки – 8,3%.
Пользователи совершают опечатки приблизительно в 10-15% случаях. При этом 83,6% запросов имеют одну ошибку, 11,7% –две, 4,8% – более трех. Контекст важен в 26% случаев.
Эта статистика была составлена на основе случайной выборки из дневного лога Яндекса в далеком 2013 году на основе 10000 запросов. В открытом доступе есть гораздо более ранняя презентация от Яндекса за 2008 год, где показано похожее распределение статистики . Отсюда можно сделать вывод, что распределение разновидностей ошибок для поисковых запросов, в среднем, с течением времени не изменяется.
В общем виде механизм исправления опечаток основывается на двух моделях: модель ошибок и языковая модель. Причем для контекстно-независимого исправления используется только модель ошибок, а в контекстно-зависимом – сразу две. В качестве модели ошибок обычно выступает либо редакционное расстояние (расстояние Левенштейна, Дамерау-Левенштейна, также сюда могут добавляться различные весовые коэффициенты, методы на подобие Soundex и т. д. – в таком случае расстояние называется взвешенным), либо модель Бриля-Мура, которая работает на вероятностях переходов одной строки в другую. Бриль и Мур позиционируют свою модель как более совершенную, однако на одном из последних соревнований SpellRuEval подход Дамерау-Левенштейна показал результат лучше , несмотря на тот факт, что расстояние Дамерау-Левенштейна (уточнение – невзвешенное) не использует априори информацию об опечаточной статистике. Это наблюдение особо показательно в том случае, если для разных реализаций автокорректоров в библиотеке DeepPavlov использовались одинаковые обучающие тексты.
Очевидно, что возможность контекстно-зависимого исправления усложняет построение автокорректора, т. к. дополнительно к модели ошибок добавляется необходимость в языковой модели. Но если обратить внимание на статистику опечаток, то ¾ всех неверно написанных поисковых запросов можно исправлять без контекста. Это говорит о том, что польза как минимум от контекстно-независимого автокорректора может быть весьма существенной.
Также контекстно-зависимое исправление для корректировки опечаток в запросах очень требовательно по ресурсам. Например, в одном из выступлений Яндекса список пар для исправления опечаток (биграмм) слов отличался в 10 раз по сравнению с количеством слов (униграмм), что тогда говорить про триграммы? Очевидно, что это существенно зависит от вариативности запросов. Немного странно выглядит, когда автокорректор занимает половину памяти от предлагаемого продукта компании, целевое назначение которого не ориентировано на решение проблемы правописания. Так что вопрос внедрения контекстно-зависимого исправления в поисковых системах программных продуктов может быть весьма спорным.
На первый взгляд, складывается впечатление, что существует много готовых решений под любой язык программирования, которые можно использовать без особого погружения в подробности работы алгоритмов, в том числе – в коммерческих системах. Но на практике продолжается разработка своих решений. Например, сравнительно недавно в Joom было сделано собственное решение по исправлению опечаток с использованием языковых моделей для поисковых запросов . Действительно ли ситуация непроста с доступностью готовых решений? С этой целью был сделан, по возможности, широкий обзор существующих решений. Перед тем как приступить к обзору, определимся с тем, как проверяется качество работы автокорректора.
Проверка качества работы
Вопрос проверки качества работы автокорректора весьма неоднозначен. Один из простых подходов проверки — через точность (Precision) и полноту (Recall). В соответствии со стандартом ISO, точность и полнота дополняются правильностью (на англ. «corectness»).
Полнота (Recall) рассчитывается следующим образом: список из правильных слов подается автокорректору (Total_list_true), и, количество слов, которое автокорректор считает правильными (Spellchecker_true), разделенное на общее количество правильных слов (Total_list_true), будет считаться полнотой.
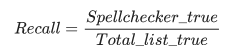
Для определения точности (Precision) на вход автокорректора подается список из неправильных слов (Total_list_false), и, количество слов, которое автокорректор считает неправильным (Spell_checker_false), разделенное на общее количество неправильных слов (Total_list_false), определяют как точность.
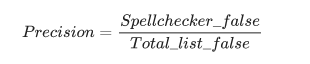
Насколько вообще эти метрики информативны и как могут быть полезны, каждый определяет самостоятельно. Ведь, фактически, суть данной проверки сводится к тому, что проверяется вхождение слова в обучающий словарь. Более наглядной метрикой можно считать correctness, согласно которой автокорректор для каждого слова из тестового множества неправильных слов формирует список кандидатов-замен, на которые можно исправить это неправильное слово (следует иметь в виду, что здесь могут оказаться слова, которые не содержатся в обучающем словаре). Допустим, размер такого списка кандидатов-замен равен 5. Исходя из того, что размер списка равен 5, будет сформировано 6 групп, в одну из которых мы будем помещать наше каждое исходное неправильное слово по следующему принципу: в 1-ую группу — если в списке кандидатов-замен предполагаемое нами правильное слово стоит 1-ым, во 2-ую если стоит 2-ым и т. д., а в последнюю группу — если предполагаемого правильного слова в списке кандидатов-замен не оказалось. Разумеется, чем больше слов попало в 1-ую группу и чем меньше в 6-ую, тем лучше работает автокорректор.
Рассмотренного выше подхода придерживались авторы в статье , в которой сравнивались контекстно-независимые автокорректоры с уклоном на стандарт ISO. Там же приведены ссылки на другие способы оценки качества.
С одной стороны, такой подход не базируется на опечаточной статистике, в основу которого может быть положена модель ошибок Бриля-Мура , либо модель ошибок взвешенного расстояния Дамерау-Левенштейна.
Для проверки качества работы контекстно-независимого автокорректора был создан собственный генератор опечаток, который генерировал опечатки неверной раскладки и орфографические опечатки исходя из статистики по опечаткам, представленной Яндексом. Для орфографических опечаток генерировались произвольные вставки, замены, удаления, перестановки, а количество ошибок так же варьировалось в соответствии с этой статистикой. Для ошибок искаженной раскладки, правильное слово посимвольно изменялось целиком в соответствии с таблицей перевода символов.
Далее была проведена серия экспериментов для всего списка слов обучающего словаря (слова обучающего словаря исправлялись на неправильные в соответствии с вероятностью возникновения той или иной опечатки). В среднем, автокорректор исправляет слова верно в 75% случаев. Вне всякого сомнения, это количество будет сокращаться при пополнении обучающего словаря близкими по редакционному расстоянию словами, большом многообразии словоформ. Эта проблема может решаться за счет дополнения языковыми моделями, но здесь следует учитывать, что количество требуемых ресурсов ощутимо возрастет.
Модель ошибок
Первые модели ошибок считали P(s|w), подсчитывая вероятности элементарных замен в обучающей выборке: сколько раз вместо Е писали И, сколько раз вместо ТЬ писали Т, вместо Т — ТЬ и так далее . Получалась модель с небольшим числом параметров, способная выучить какие-то локальные эффекты (например, что люди часто путают Е и И).
В наших изысканиях мы остановились на более развитой модели ошибок, предложенной в 2000 году Бриллом и Муром и многократно использованной впоследствии (например, специалистами Google ). Представим, что пользователи мыслят не отдельными символами (спутать Е и И, нажать К вместо У, пропустить мягкий знак), а могут изменять произвольные куски слова на любые другие — например, заменять ТСЯ на ТЬСЯ, У на К, ЩА на ЩЯ, СС на С и так далее. Вероятность того, что пользователь опечатался и вместо ТСЯ написал ТЬСЯ, обозначим P(тся→ться) — это параметр нашей модели. Если для всех возможных фрагментов α,β мы можем посчитать P(α→β), то искомую вероятность P(s|w) набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины P(s|w):

Давайте посмотрим на пример разбиения, возникающего при вычислении вероятности напечатать «аксесуар» вместо «аксессуар»:
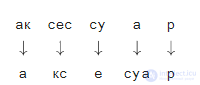
Как вы наверняка заметили, это пример не очень удачного разбиения: видно, что части слов легли друг под другом не так удачно, как могли бы. Если величины P(ак→а) и P(р→р) еще не так плохи, то P(су→е) и P(а→суа), скорее всего, сделают итоговый «счет» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:

Здесь все сразу стало на свои места, и видно, что итоговая вероятность будет определяться преимущественно величиной 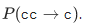 .
.
Как вычислить P(s|w)
Несмотря на то, что возможных разбиений для двух слов имеется порядка 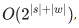 , с помощью динамического программирования алгоритм вычисления P(s|w) можно сделать довольно быстрым — за
, с помощью динамического программирования алгоритм вычисления P(s|w) можно сделать довольно быстрым — за 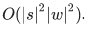 . Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
. Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
Мы заведем прямоугольную таблицу, строки которой будут соответствовать буквам правильного слова, а столбцы — опечатанного. В ячейке на пересечении строки i и столбца j к концу алгоритма будет лежать в точности вероятность получить s[:j] при попытке напечатать w[:i]. Для того, чтобы ее вычислить, достаточно вычислить значения всех ячеек в предыдущих строках и столбцах и пробежаться по ним, домножая на соответствующие P(α→β). Например, если у нас заполнена таблица
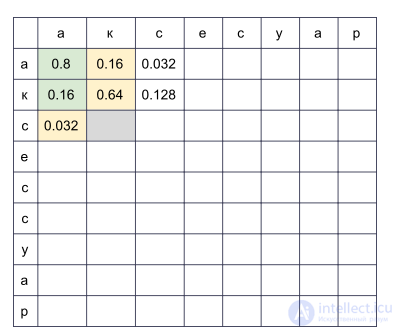
, то для заполнения ячейки в четвертой строке и третьем столбце (серая) нужно взять максимум из величин 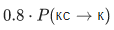 и
и 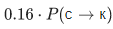 . При этом мы пробежались по всем ячейкам, подсвеченным на картинке зеленым. Если также рассматривать модификации вида пустаястрока P(α→пустая строка) и пустаястрока P(пустая строка→β), то придется пробежаться и по ячейкам, подсвеченным желтым.
. При этом мы пробежались по всем ячейкам, подсвеченным на картинке зеленым. Если также рассматривать модификации вида пустаястрока P(α→пустая строка) и пустаястрока P(пустая строка→β), то придется пробежаться и по ячейкам, подсвеченным желтым.
Сложность этого алгоритма, как я уже упомянул выше, составляет 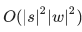 : мы заполняем таблицу |s|×|w|, и для заполнения ячейки (i, j) нужно O(i⋅j) операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины L (например, не больше двух букв, как в ), сложность уменьшится до
: мы заполняем таблицу |s|×|w|, и для заполнения ячейки (i, j) нужно O(i⋅j) операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины L (например, не больше двух букв, как в ), сложность уменьшится до 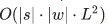 . Для русского языка в своих экспериментах я брал L=3.
. Для русского языка в своих экспериментах я брал L=3.
Как максимизировать P(s|w)
Мы научились находить P(s|w) за полиномиальное время — это хорошо. Но нам нужно научиться быстро находить наилучшие слова во всем словаре. Причем наилучшие не по P(s|w), а по P(w|s)! На деле нам достаточно получить какой-то разумный топ (например, лучшие 20) слов по P(s|w), который мы потом отправим в модель языка для выбора наиболее подходящих исправлений (об этом ниже).
Чтобы научиться быстро проходить по всему словарю, заметим, что таблица, представленная выше, будет иметь много общего для двух слов с общими префиксами. Действительно, если мы, исправляя слово «аксесуар», попробуем заполнить ее для двух словарных слов «аксессуар» и «аксессуары», мы заметим, что первые девять строк в них вообще не отличаются! Если мы сможем организовать проход по словарю так, что у двух последующих слов будут достаточно длинные общие префиксы, мы сможем круто сэкономить вычисления.
И мы сможем. Давайте возьмем словарные слова и составим из них trie. Идя по нему поиском в глубину, мы получим желаемое свойство: большинство шагов — это шаги от узла к его потомку, когда у таблицы достаточно дозаполнить несколько последних строк.
Этот алгоритм, при некоторых дополнительных оптимизациях, позволяет нам перебирать словарь типичного европейского языка в 50-100 тысяч слов в пределах сотни миллисекунд . А кэширование результатов сделает процесс еще быстрее.
Как получить P(α→β)
Вычисление P(α→β) для всех рассматриваемых фрагментов — самая интересная и нетривиальная часть построения модели ошибок. Именно от этих величин будет зависеть ее качество.
Подход, использованный в [2, 4], сравнительно прост. Давайте найдем много пар (si,wi), где wi — правильное слово из словаря, а si — его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
Для каждой пары возьмем составляющие ее w и s и построим соответствие между их буквами, минимизирующее расстояние Левенштейна:
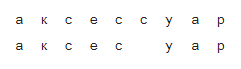
Теперь мы сразу видим замены: а → а, е → и, с → с, с → пустая строка и так далее . Об этом говорит сайт https://intellect.icu . Также мы видим замены двух и более символов: ак → ак, се → си, ес → ис, сс → с, сес → сис, есс → ис и прочая, и прочая. Все эти замены необходимо посчитать, причем каждую столько раз, сколько слово s встречается в корпусе (если мы брали слова из корпуса, что очень вероятно).
После прохода по всем парам (si,wi) за вероятность P(α→β) принимается количество замен α → β, встретившихся в наших парах (с учетом встречаемости соответствующих слов), деленное на количество повторений фрагмента α.
Как найти пары (si,wi)? В предлагается такой подход. Возьмем большой корпус сгенерированного пользователями контента (UGC). В случае Google это были просто тексты сотен миллионов веб-страниц; в нашем — миллионы пользовательских поисковых запросов и отзывов. Предполагается, что обычно правильное слово встречается в корпусе чаще, чем любой из ошибочных вариантов. Так вот, давайте для каждого слова находить близкие к нему по Левенштейну слова из корпуса, которые значительно менее популярны (например, в десять раз). Популярное возьмем за w, менее популярное — за s. Так мы получим пусть и шумный, но зато достаточно большой набор пар, на котором можно будет провести обучение.
Этот алгоритм подбора пар оставляет большое пространство для улучшений. В предлагается только фильтр по встречаемости (w в десять раз популярнее, чем s), но авторы этой статьи пытаются делать опечаточник, не используя какие-либо априорные знания о языке. Если мы рассматриваем только русский язык, мы можем, например, взять набор словарей русских словоформ и оставлять только пары со словом w, найденном в словаре (не лучшая идея, потому что в словаре, скорее всего, не будет специфичной для сервиса лексики) или, наоборот, отбрасывать пары со словом s, найденном в словаре (то есть почти гарантированно не являющимся опечатанным).
Чтобы повысить качество получаемых пар, я написал несложную функцию, определяющую, используют ли пользователи два слова как синонимы. Логика простая: если слова w и s часто встречаются в окружении одних и тех же слов, то они, вероятно, синонимы — что в свете их близости по Левенштейну значит, что менее популярное слово с большой вероятностью является ошибочной версией более популярного. Для этих расчетов я использовал построенную для модели языка ниже статистику встречаемости триграмм (фраз из трех слов).
Модель языка
Итак, теперь для заданного словарного слова w нам нужно вычислить P(w) — вероятность его использования пользователем. Простейшее решение — взять встречаемость слова в каком-то большом корпусе. Вообще, наверное, любая модель языка начинается с собирания большого корпуса текстов и подсчета встречаемости слов в нем. Но ограничиваться этим не стоит: на самом деле при вычислении P(w) мы можем учесть также и фразу, слово в которой мы пытаемся исправить, и любой другой внешний контекст. Задача превращается в задачу вычисления P(w1w2…wk), где одно из wi — слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем P(w), а остальные wi — слова, окружающие исправляемое слово в пользовательском запросе.
Чтобы научиться учитывать их, стоит пройтись по корпусу еще раз и составить статистику n-грамм, последовательностей слов. Обычно берут последовательности ограниченной длины; я ограничился триграммами, чтобы не раздувать индекс, но тут все зависит от вашей силы духа (и размера корпуса — на маленьком корпусе даже статистика по триграммам будет слишком шумной).
Традиционная модель языка на основе n-грамм выглядит так. Для фразы w1w2…wk ее вероятность вычисляется по формуле
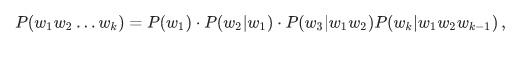
где P(w1) — непосредственно частота слова, а P(w3|w1w2) — вероятность слова w3 при условии, что перед ним идут w1w2 — не что иное, как отношение частоты триграммы w1w2w3 к частоте биграммы w1w2. (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
Иными словами, если мы захотим вычислить мамамыларамуP(мама мыла раму), обозначив частоту произвольной n-граммы за f, мы получим формулу
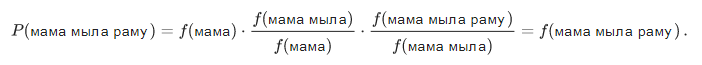
Логично? Логично. Однако трудности начинаются, когда фразы становятся длиннее. Что, если пользователь ввел впечатляющий своей подробностью поисковый запрос в десять слов? Мы не хотим держать статистику по всем 10-граммам — это дорого, а данные, скорее всего, будут шумными и не показательными. Мы хотим обойтись n-граммами какой-то ограниченной длины — например, уже предложенной выше длины 3.
Здесь-то и пригождается формула выше. Давайте предположим, что на вероятность слова появиться в конце фразы значительно влияют только несколько слов непосредственно перед ним, то есть что
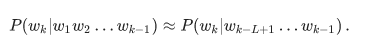
Положив L=3, для более длинной фразы получим формулу

Обратите внимание: фраза состоит из пяти слов, но в формуле фигурируют n-граммы не длиннее трех. Это как раз то, чего мы добивались.
Остался один тонкий момент. Что, если пользователь ввел совсем странную фразу и соответствующих n-грамм у нас в статистике и нет вовсе? Было бы легко для незнакомых n-грамм положить f=0, если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьезных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
Как исправлять фразы
Обговорим последний тонкий момент перед тем, как перейти к реализации. Постановка задачи, которую я описал выше, подразумевала, что есть одно слово и его надо исправить. Потом мы уточнили, что это одно слово может быть в середине фразы среди каких-то других слов и их тоже нужно учесть, выбирая наилучшее исправление. Но в реальности пользователи просто присылают нам фразы, не уточняя, какое слово написано с ошибкой; нередко в исправлении нуждается несколько слов или даже все.
Подходов здесь может быть много. Можно, например, учитывать только левый контекст слова в фразе. Тогда, идя по словам слева направо и по мере необходимости исправляя их, мы получим новую фразу какого-то качества. Качество будет низким, если, например, первое слово оказалось похоже на несколько популярных слов и мы выберем неправильный вариант. Вся оставшаяся фраза (возможно, изначально вообще безошибочная) будет подстраиваться нами под неправильное первое слово и мы можем получить на выходе полностью нерелевантный оригиналу текст.
Можно рассматривать слова по отдельности и применять некий классификатор, чтобы понимать, опечатано данное слово или нет, как это предложено в . Классификатор обучается на вероятностях, которые мы уже умеем считать, и ряде других фичей. Если классификатор говорит, что нужно исправлять — исправляем, учитывая имеющийся контекст. Опять-таки, если несколько слов написаны с ошибкой, принимать решение насчет первого из них придется, опираясь на контекст с ошибками, что может приводить к проблемам с качеством.
В реализации нашего опечаточника мы использовали такой подход. Давайте для каждого слова si в нашей фразе найдем с помощью модели ошибок топ-N словарных слов, которые могли иметься в виду, сконкатенируем их во фразы всевозможными способами и для каждой из NK получившихся фраз, где K — количество слов в исходной фразе, посчитаем честно величину
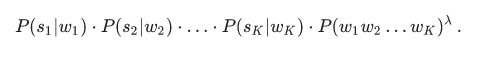
Здесь si — слова, введенные пользователем, wi — подобранные для них исправления (которые мы сейчас перебираем), а λ — коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в . Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и еще домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
Так, стоп, что? Перебор NK фраз?
К счастью, за счет того, что мы ограничили длину n-грамм, найти максимум по всем фразам можно гораздо быстрее. Вспомните: выше мы упростили формулу для P(w1w2…wK) так, что она стала зависеть только от частот n-грамм длины не выше трех:
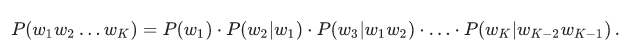
Если мы домножим эту величину на 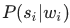 и попытаемся максимизировать по wK, мы увидим, что достаточно перебрать всевозможные wK−2 и wK−1 и решить задачу для них — то есть для фраз w1w2…wK−2wK−1. Итого задача решается динамическим программированием за O(KN3).
и попытаемся максимизировать по wK, мы увидим, что достаточно перебрать всевозможные wK−2 и wK−1 и решить задачу для них — то есть для фраз w1w2…wK−2wK−1. Итого задача решается динамическим программированием за O(KN3).
Реализация алгоритма исправления ошибок
Собираем корпус и считаем n-граммы
Сразу оговорюсь: данных в моем распоряжении было не так много, чтобы заводить какой-то сложный MapReduce. Так что я просто собрал все тексты отзывов, комментариев и поисковых запросов на русском языке (описания товаров, увы, приходят на английском, а использование результатов автоперевода скорее ухудшило, чем улучшило результаты) с нашего сервиса в один текстовый файл и поставил сервер на ночь считать триграммы простым скриптом на Python.
В качестве словарных я брал топ слов по частотности так, чтобы получалось порядка ста тысяч слов. Исключались слишком длинные слова (больше 20 символов) и слишком короткие (меньше трех символов, кроме захардкоженных известных русских слов). Отдельно пощадил слова по регулярке r»^[a-z0-9]{2}$» — чтобы уцелели версии айфонов и другие интересные идентификаторы длины 2.
При подсчете биграмм и триграмм во фразе может встретиться несловарное слово. В этом случае это слово я выбрасывал и бил всю фразу на две части (до и после этого слова), с которыми работал отдельно. Так, для фразы «А вы знаете, что такое «абырвалг»? Это… ГЛАВРЫБА, коллега» учтутся триграммы “а вы знаете”, “вы знаете что”, “знаете что такое” и “это главрыба коллега” (если, конечно, слово “главрыба” попадет в словарь…).
Обучаем модель ошибок
Дальше всю обработку данных я проводил в Jupyter. Статистика по n-граммам грузится из JSON, производится постобработка, чтобы быстро находить близкие друг к другу по Левенштейну слова, и для пар в цикле вызывается (довольно громоздкая) функция, выстраивающая слова и извлекающая короткие правки вида сс → с (под спойлером).
Код на Python
короткие правки вида сс → с (под спойлером).
def generate_modifications(intended_word, misspelled_word, max_l=2):
# Выстраиваем буквы слов оптимальным по Левенштейну образом и
# извлекаем модификации ограниченной длины. Чтобы после подсчета
# расстояния восстановить оптимальное расположение букв, будем
# хранить впродолжение следует…
Продолжение:
Часть 1 Алгоритмы исправления опечаток с и без учёта контекста
Часть 2 Результаты — Алгоритмы исправления опечаток с и без учёта контекста
См.также
- Фильтр Блума
- Расстояние Дамерау-Левенштейна
- metaphone , soundex , approximate string matching , fuzzy string searching ,
- инвертированный индекс , расстояние левенштейна , расстояние редактирования , редакционным расстоянием ,
В общем, мой друг ты одолел чтение этой статьи об алгоритмы исправления опечаток. Работы в переди у тебя будет много. Смело пишикоментарии, развивайся и счастье окажется в ваших руках.
Надеюсь, что теперь ты понял что такое алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Обработка естественного языка
Ошибаться, конечно же, неприятно. Однако ошибки — это главный источник нашего жизненного опыта. Каждая из них делает нас немного мудрее, помогает лучше понять окружающий мир и самих себя, помогает вывести на новый уровень наши навыки и личные качества.
Проблема в том, что у большинства людей «обучение на своих ошибках» происходит спонтанно и неосознанно. В результате многие совершенные ошибки ничего не добавляют в копилку их личного опыта: они воспринимаются исключительно как источник страданий, а потому очень часто повторяются снова и снова.
Сегодня мы поговорим об одной простой, но очень мощной технике саморазвития, которая называется «Работа над ошибками». Она помогает учиться на своих ошибках более сознательно, извлекать из них максимум опыта и почти сразу менять свою жизнь к лучшему.
Дневник «Работа над ошибками»
Для использования этой техники вам потребуется завести специальный дневник, который будет называться «Работа над ошибками». Это может быть бумажная тетрадь, текстовый файл на компьютере или электронная таблица.
Обратите внимание на следующее:
1. Дневник должен быть по-настоящему тайным. Не показывайте его никому, даже друзьям и близким. Еще лучше, если никто вообще не будет знать о его существовании. Дело в том, что вам придется записывать в него довольно неприятные факты о себе. И если вы знаете, что эти записи кто-то будет читать, то невольно начнете все цензурировать и приукрашать, из-за чего эффективность техники упадет в разы.
Храните дневник там, где на него никто не сможет натолкнуться даже случайно. Если вы делайте записи в файл, уберите его в какую-нибудь неприметную папку и закройте паролем.
2. Работа с дневником должна быть регулярной. Лучше всего заполнять его вечером, пока свежи воспоминания, но можно это делать и по утрам (в этом случае вы будете разбирать вчерашний день). Также можно работать с дневником один раз в неделю, например, по воскресеньям. Имейте в виду: чем больший период времени вы рассматриваете, тем больше событий ускользает от вашего взора.
Дневник может быть как обычным текстом, так и таблицей — это дело вкуса.
Если вы решили работать с электронной таблицей, закрепите в ней верхнюю строку и установите в свойствах ячеек «перенос текста». Саму таблицу размечаем следующим образом:

Если вы решили работать с обычным текстом, вам не нужно ничего размечать: просто по очереди записывайте все этапы.
Итак, приступим. Анализ ошибок в дневнике состоит из 5 этапов:
Этап 1. Вспомнить и записать ошибки
На этом этапе мы выписываем все ошибки, которые совершили за день или за неделю. Ошибками будут считаться не только наши явные промахи, но и любые неприятные события.
Дело в том, что каждое такое событие — это всегда в какой-то степени следствие наших поступков. Если же мы воспринимаем неприятности как сугубо внешние явления, мы словно говорим себе, что не контролируем ситуацию. А поверив в это, мы становимся пассивными жертвами обстоятельств и уже ничего не можем изменить.
Безусловно, бывают такие ситуации, когда от нас действительно ничего не зависит. Но очень часто это не так.
Предположим, что сегодня на нас накричал начальник. Он хам, псих и самодур? Очень может быть. Но была ли у нас возможность предотвратить конфликт? Наверняка да. Например:
- Мы могли сдать ему этот злосчастный отчет еще вчера.
- Мы могли вежливо, но твердо поставить его на место (хамство вообще терпеть не стоит).
- Мы могли найти работу с нормальным руководителем и т. д.
Если же мы снимаем с себя ответственность за эту ситуацию, мы отказываемся от активной жизненной позиции и начинаем пассивно плыть по течению.
Итак, записываем ошибки. Для этого мысленно «прокрутите» в голове весь прошедший день (или неделю) и попробуйте вспомнить следующее:
1. Какие явные промахи вы совершили?
2. Какие дела не удалось сделать? Какие планы сорвались?
3. Какие неприятности с вами произошли?
4. Из-за чего у вас портилось настроение?
5. С кем возникали конфликты и недопонимания?
Вот такой примерно список у вас может получиться:

Здесь, кстати, удобно пользоваться методом пяти пальцев, о котором мы как-то уже писали. Суть его в том, чтобы перебирать прошедшие события по жизненным сферам: мысли, знания, эмоции, общение, здоровье и т. д.
Также полезно делать пометки в течение всего дня или недели. Формулировать сами ошибки не надо: просто запишите в блокнот или на диктофон пару слов, которые помогут вам вспомнить о событии. Например: «автобус», «продавец в магазине», «удалил файл», «забыл ключи» и т. д.
После того как вы записали все ошибки, посидите еще 2–3 минуты, прежде чем двигаться дальше. Часто в эти минуты в голову приходят всякие неприметные события, о которых мы сразу не вспомнили.
Этап 2. Выявить причины ошибок
Теперь мы должны найти причину каждой записанной ошибки. Этот этап поможет нам выявить свои «слабые места» и понять, что конкретно нужно исправить. Подумайте: почему произошло то, что произошло?
Вот что примерно должно у вас получиться:

При анализе причин важно придерживаться принципа «Mea culpa» (в переводе с латыни — «моя вина»). Иными словами, мы должны в первую очередь искать причину произошедшего в своих действиях. Еще раз: мы можем что-то изменить лишь тогда, когда берем на себя ответственность за то, что произошло.
Даже если у неприятного события есть явные внешние причины, подумайте: могли ли вы его предотвратить? Могли ли вы к нему как-то подготовиться? Если да, то именно это и следует записать как причину.
Например, мы пошли в лес за грибами, попали под дождь и до нитки промокли. Дождь, естественно, случился сам по себе и на это мы повлиять никак не могли. Однако мы могли перед выходом из дома посмотреть прогноз погоды или взять с собой плащ-дождевик.
У некоторых событий может быть несколько причин — это нормально. В этом случае можно записать их все или же выбрать из них только самую главную.
Этап 3. Исправление ошибок
На этом этапе мы выясним: а нельзя ли эти ошибки хоть как-нибудь исправить? Подумайте:
- Можно ли изменить то, что произошло?
- Если нельзя, то можно ли минимизировать или компенсировать последствия этих ошибок?
Каждая ошибка — это всегда какой-то ущерб, нанесенный нашей жизни, нашим планам и нашему душевному равновесию. И в идеале было бы здорово этот ущерб если не ликвидировать, то хотя бы чуть-чуть «сгладить».
Вот как это может выглядеть:

Увы, но многие ошибки в нашей жизни исправлению не подлежат. И если эта графа часто будет оставаться у вас пустой, не переживайте: так и должно быть. Просто переходите к следующему этапу.
Этап 4. Меры профилактики
Теперь самое главное: мы должны понять, как не допустить повторения этих ошибок. На данном этапе нужно для каждой ошибки придумать свои меры профилактики. Обычно это либо правила, которые следует соблюдать, либо задачи, которые следует выполнить. Например:

Этот этап — «сердце» нашей техники. Каждая такое правило и каждая задача — это то, что помогает нам изменить свою жизнь к лучшему. Даже если сами изменения выглядят совсем небольшими, со временем они будут накапливаться и давать потрясающий результат.
Как разрабатывать меры профилактики? В первую очередь нужно смотреть в раздел «Причины»: именно там обычно и скрыт «корень проблем». Если мы устраняем причину ошибки, то исчезает и сама ошибка.
Например, я проспал на работу. У этой неприятности есть две причины: я поздно лег спать, а утром не услышал будильник на смартфоне. Теперь у меня появятся одно новое правило и одна регулярная задача:
- Ложиться спать не позднее 23–00.
- Устанавливать на смартфоне сразу два будильника с интервалом в 5 минут.
Как вы уже поняли, для одной ошибки может быть создано сразу несколько правил и задач.
Этап 5. Внедрение улучшений
Недостаточно просто придумать правила: еще нужно сделать так, чтобы эти правила сразу же начали работать и менять жизнь к лучшему. Если не внедрять их специально, они будут мертвым грузом «пылиться» в нашем дневнике. Высока вероятность, что вскоре мы о них забудем и снова допустим уже проработанные ошибки.
Поэтому на последнем этапе нужно определить: с помощью какого инструмента мы будем внедрять эти правила? Вот как это выглядит:

Рассмотрим эти инструменты чуть более подробно.
1. Разовая задача. Это задача, которую нужно выполнить всего один раз, чтобы предотвратить дальнейшее повторение ошибки или проблемы. Например, если у нас есть проблема «тормозит компьютер», нам достаточно «купить дополнительный блок ОЗУ на 16 Гб».
Задачу записываем в органайзер (если у вас его еще нет, то обязательно заведите) на тот день, когда ее удобно будет выполнить.

2. Регулярная задача. Это задача, которую нам нужно периодически повторять: каждое день, каждую субботу, каждый месяц и т. д. Например, если мы по дороге с работы постоянно забываем купить продукты, нам потребуется создать регулярную задачу-напоминание «Не нужно ли зайти в магазин?».

То же самое: создаем в органайзере новую задачу (можно привязать ее к конкретному времени) и настраиваем ее повторение. Подробнее о том, как работать с такими задачами, вы можете прочитать в нашей статье «Повторяющиеся задачи».
3. Рабочий чек-лист. Чек-листы — это очень удобный инструмент для организации любых повторяющихся процессов. Сюда относятся тренировки и занятия спортом, мероприятия по уборке, уход за питомцами, проверки, аудиты, создания типовых продуктов и т. д. Если вы регулярно пользуетесь чек-листами, вам будет легче предотвращать ошибки: допустив какой-нибудь промах, просто добавьте в чек-лист новый пункт для его профилактики.

О создании рабочих чек-листов у нас была отдельная статья.
4. Трекер привычек. Некоторые правила потребуют от нас выработки новых привычек или изменения старых. Для этой цели в тайм-менеджменте используется несколько инструментов, из которых самым популярным является трекер привычек:

Работает он очень просто: каждую привычку, которую нам нужно выработать или изменить, мы добавляем в трекер и отслеживаем ее соблюдение.
5. Личный кодекс. Это еще один очень мощный инструмент саморазвития, о котором следует как-нибудь рассказать отдельно. Он представляет собой свод персональных правил и принципов на все случаи жизни: от общения с людьми, до ухода за домом.
Для создания кодекса можно использовать блокнот, общую тетрадь или текстовый файл.

В кодексе может быть несколько разделов. Например:
- Главные правила;
- Мои моральные принципы;
- Общение с людьми;
- Бизнес;
- Клиенты;
- Здоровье;
- Автомобиль и т. п.
Чтобы кодекс работал, его нужно регулярно и вдумчиво перечитывать. В этом случае правила будут «впитываться» и становиться неотъемлемой частью нашей личности.
Теперь, когда мы разобрались с инструментами, можно подобрать для каждого правила подходящий способ внедрения. Обратите внимание: после этого вам нужно сразу же разложить все задачи и правила по «своим местам»: в органайзер, в трекер привычек и т. д. В противном случае о них можно очень быстро забыть.
Заключение
Алгоритм только на первый взгляд кажется большим и громоздким, но на практике он не отнимает много времени. Обычно «работа над ошибками» занимает не более 10–15 минут в день.
Если у вас совсем мало времени, попробуйте выполнять эту технику один раз в неделю. Также можно использовать ее упрощенный вариант: записывать не все ошибки, а только 3 самых значительных.
Наиболее частая проблема с дневником — это повторение ошибок. То есть, мы анализируем ошибку, внедряем профилактические меры, а она все равно повторяется. Здесь есть два варианта:
Вариант 1. Неправильно установлены причины. Подумайте, что еще может вызывать эту ошибку? Что вы могли упустить?
Лайфхак. У ошибки может быть много причин. Но есть и одна универсальная причина: мы совершаем ошибку потому, что у нас есть возможность ее совершать. И чтобы ошибка исчезла, достаточно устранить эту возможность.
Например, мы отвлекаемся на социальные сети во время работы. Как сделать, чтобы это стало невозможным? Тут много вариантов: выйти из всех аккаунтов, использовать другой профиль браузера или даже отключать интернет.
Вариант 2. Неправильно выбраны меры профилактики или способы их внедрения. Здесь, к сожалению, нет универсальных решений: вам придется немного поэкспериментировать.
Лайфхак. Лучше всего работают простые «механические» методы, которые не требуют размышлений и самоконтроля.
Например, ежедневно по дороге с работы мы заходим в кондитерский магазин и покупаем пирожные, набирая лишний вес и лишние комплексы. Мы, конечно же, можем здесь использовать и трекер привычек, и личный кодекс. Но гораздо проще и эффективней будет изменить свой обычный маршрут с работы.
Еще одна частая ситуация с дневником — это отсутствие серьезных поводов для записи. В этом случае, если есть настроение, можно совершить «экскурсию в прошлое» и поразмышлять над старыми ошибками. Однако вполне допустимо просто наградить себя «выходным» за удачный день.
Поделиться:

Все совершают ошибки. Мы говорим необдуманные вещи, нарушаем обещания или выносим плохое суждение о ком-либо — и это лишь малая часть того, что может случиться в жизни и на рабочем месте. Немногие знают, как исправить собственную ошибку, даже если последствия будут крайне неприятны. Если вы не пытаетесь исправлять свои ошибки из-за неправильных поступков, ваши взаимоотношения и репутация могут серьезно пострадать. Хорошая новость в том, что признание своих ошибок и правильные выводы могут исправить ситуацию и даже сделать ее лучше.
Есть огромная разница между извинением и исправлением ошибки. В первом случае вы просто просите прощения за то, что причинили кому-то боль. Во втором случае вы совершаете определенные действия, которые восстанавливают баланс в отношениях с человеком.
1
Признайте свою роль в ситуации
Если конфликтная ситуация произошла только что, дайте себе время успокоиться. Даже если вы сразу осознали, что оскорбили человека, все равно должно пройти какое-то время.
Осознайте свою роль в этой ситуации. Часто люди не замечают своей вины за своими гневом, обвинениями, агрессивностью и оборонительной позицией. Даже через некоторое время они не признают своей роли в конфликте, если были полностью виновны.
Посмотрите на ситуацию глазами человека, которого вы обидели. Как ваша ошибка повлияла на него? Вы ему причинили неудобство или нанесли обиду? Развивать эмпатию полезно все равно, однако в этом случае ее роль неоценима.
Первый шаг очень важен, потому что без осознания своей вины вы будете неискренними, а уж тем более не захотите исправлять ошибку, которую таковой не считаете.
2
Тщательно все продумайте
Подумайте о том, что вы можете сделать для того, чтобы возместить нанесенный ущерб. Вам придется восстановить утраченное доверие.
Проще говоря, у вас должна быть хоть какая-то идея и твердое намерение воплотить ее в жизнь. Дайте человеку понять, что вам есть дело до случившегося.
Однако ваша вина может привести к гиперкомпенсации. Опасность такой ситуации в том, что вы можете выглядеть неискренним, если ваше наказание самого себя будет в стократ больше самого преступления.
Создайте мини-план будущего разговора и выясните, куда он может завести. Четко решите, что не будете реагировать на раздражительный тон собеседника. Возможно он захочет говорить совершенно о другом, тогда вам придется согласиться и надеяться на экспромт.
3
Начните разговор первым
- В первую очередь признайте свою ошибку и будьте точны в датах, тщательно подбирайте слова: «Мне очень жаль что я нарушил свое обещание в прошлую пятницу».
- Скажите о том, что понимаете, как ваши действия или слова обидели чувства этого человека. Как только захотите сказать, что это и его вина тоже, сдержитесь и следуйте своему плану: «Я поступил эгоистично и тебе пришлось остаться на работе допоздна. Я подвел тебя и понимаю, что ты чувствуешь. На твоем месте мне бы тоже было неприятно».
- Скажите о том, насколько важен человек для вас: «Для меня важна наша дружба и я ценю то время, которое провожу с тобой».
- Загладьте вину: «Знаю, ты просил моей помощи, а я тебе не помог. Давай я заглажу свою вину и возьму всю работу на себя».
4
Сделайте выводы из своей ошибки
Из любой ошибки можно сделать правильные выводы и стать лучше. Однако если вы думаете, что теперь нужно совершать ошибки, то помните, что главный вывод — не повторять одни и те же.
Еще одним выводом может стать ваше решение научиться контролировать свои эмоции. Или грамотно справляться со стрессом. Задайте себе простой вопрос: «Что мне нужно сделать, чтобы такого не повторилось?». Если ответом будет «Я уверен, что не повторится», это плохой ответ, потому что не предполагает работы над собой.
В особых случаях человек может быть неготовым простить вас и не принимает вашего прощения. Не давите на этого человека и не требуйте простить вас. Дайте ему время и пространство для того, чтобы оправиться от этого удара.
Желаем вам удачи!
Код Хэмминга. Пример работы алгоритма
Время на прочтение
4 мин
Количество просмотров 514K
Вступление.
Прежде всего стоит сказать, что такое Код Хэмминга и для чего он, собственно, нужен. На Википедии даётся следующее определение:
Коды Хэмминга — наиболее известные и, вероятно, первые из самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Другими словами, это алгоритм, который позволяет закодировать какое-либо информационное сообщение определённым образом и после передачи (например по сети) определить появилась ли какая-то ошибка в этом сообщении (к примеру из-за помех) и, при возможности, восстановить это сообщение. Сегодня, я опишу самый простой алгоритм Хемминга, который может исправлять лишь одну ошибку.
Также стоит отметить, что существуют более совершенные модификации данного алгоритма, которые позволяют обнаруживать (и если возможно исправлять) большее количество ошибок.
Сразу стоит сказать, что Код Хэмминга состоит из двух частей. Первая часть кодирует исходное сообщение, вставляя в него в определённых местах контрольные биты (вычисленные особым образом). Вторая часть получает входящее сообщение и заново вычисляет контрольные биты (по тому же алгоритму, что и первая часть). Если все вновь вычисленные контрольные биты совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится сообщение об ошибке и при возможности ошибка исправляется.
Как это работает.
Для того, чтобы понять работу данного алгоритма, рассмотрим пример.
Подготовка
Допустим, у нас есть сообщение «habr», которое необходимо передать без ошибок. Для этого сначала нужно наше сообщение закодировать при помощи Кода Хэмминга. Нам необходимо представить его в бинарном виде.
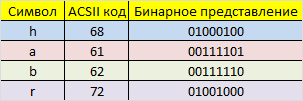
На этом этапе стоит определиться с, так называемой, длиной информационного слова, то есть длиной строки из нулей и единиц, которые мы будем кодировать. Допустим, у нас длина слова будет равна 16. Таким образом, нам необходимо разделить наше исходное сообщение («habr») на блоки по 16 бит, которые мы будем потом кодировать отдельно друг от друга. Так как один символ занимает в памяти 8 бит, то в одно кодируемое слово помещается ровно два ASCII символа. Итак, мы получили две бинарные строки по 16 бит:
 и
и 
После этого процесс кодирования распараллеливается, и две части сообщения («ha» и «br») кодируются независимо друг от друга. Рассмотрим, как это делается на примере первой части.
Прежде всего, необходимо вставить контрольные биты. Они вставляются в строго определённых местах — это позиции с номерами, равными степеням двойки. В нашем случае (при длине информационного слова в 16 бит) это будут позиции 1, 2, 4, 8, 16. Соответственно, у нас получилось 5 контрольных бит (выделены красным цветом):
Было:
Стало:

Таким образом, длина всего сообщения увеличилась на 5 бит. До вычисления самих контрольных бит, мы присвоили им значение «0».
Вычисление контрольных бит.
Теперь необходимо вычислить значение каждого контрольного бита. Значение каждого контрольного бита зависит от значений информационных бит (как неожиданно), но не от всех, а только от тех, которые этот контрольных бит контролирует. Для того, чтобы понять, за какие биты отвечает каждых контрольный бит необходимо понять очень простую закономерность: контрольный бит с номером N контролирует все последующие N бит через каждые N бит, начиная с позиции N. Не очень понятно, но по картинке, думаю, станет яснее:
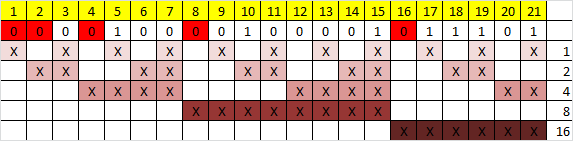
Здесь знаком «X» обозначены те биты, которые контролирует контрольный бит, номер которого справа. То есть, к примеру, бит номер 12 контролируется битами с номерами 4 и 8. Ясно, что чтобы узнать какими битами контролируется бит с номером N надо просто разложить N по степеням двойки.
Но как же вычислить значение каждого контрольного бита? Делается это очень просто: берём каждый контрольный бит и смотрим сколько среди контролируемых им битов единиц, получаем некоторое целое число и, если оно чётное, то ставим ноль, в противном случае ставим единицу. Вот и всё! Можно конечно и наоборот, если число чётное, то ставим единицу, в противном случае, ставим 0. Главное, чтобы в «кодирующей» и «декодирующей» частях алгоритм был одинаков. (Мы будем применять первый вариант).
Высчитав контрольные биты для нашего информационного слова получаем следующее:

и для второй части:

Вот и всё! Первая часть алгоритма завершена.
Декодирование и исправление ошибок.
Теперь, допустим, мы получили закодированное первой частью алгоритма сообщение, но оно пришло к нас с ошибкой. К примеру мы получили такое (11-ый бит передался неправильно):

Вся вторая часть алгоритма заключается в том, что необходимо заново вычислить все контрольные биты (так же как и в первой части) и сравнить их с контрольными битами, которые мы получили. Так, посчитав контрольные биты с неправильным 11-ым битом мы получим такую картину:

Как мы видим, контрольные биты под номерами: 1, 2, 8 не совпадают с такими же контрольными битами, которые мы получили. Теперь просто сложив номера позиций неправильных контрольных бит (1 + 2 + 8 = 11) мы получаем позицию ошибочного бита. Теперь просто инвертировав его и отбросив контрольные биты, мы получим исходное сообщение в первозданном виде! Абсолютно аналогично поступаем со второй частью сообщения.
Заключение.
В данном примере, я взял длину информационного сообщения именно 16 бит, так как мне кажется, что она наиболее оптимальная для рассмотрения примера (не слишком длинная и не слишком короткая), но конечно же длину можно взять любую. Только стоит учитывать, что в данной простой версии алгоритма на одно информационное слово можно исправить только одну ошибку.
Примечание.
На написание этого топика меня подвигло то, что в поиске я не нашёл на Хабре статей на эту тему (чему я был крайне удивлён). Поэтому я решил отчасти исправить эту ситуацию и максимально подробно показать как этот алгоритм работает. Я намеренно не приводил ни одной формулы, дабы попытаться своими словами донести процесс работы алгоритма на примере.
Источники.
1. Википедия
2. Calculating the Hamming Code
![]()
Загрузить PDF
![]()
Загрузить PDF
Все мы время от времени совершаем ошибки. К повседневным ошибкам можно отнести погрешность в конкретной задаче (в письме, наборе текста, диаграмме и тому подобное), оскорбление человека, действие, о котором вы впоследствии сожалеете, участие в рискованных ситуациях. Так как неприятные случайности довольно распространены, всем нам необходимо научиться исправлять их и справляться с ними. Исправление любого промаха включает: понимание своей ошибки, составление плана, забота о себе и правильное общение.
-

1
Распознайте свою ошибку. Чтобы что-то исправить, сначала нужно понять, что же вы сделали неправильно.
- Определите ошибку. Вы что-то не то сказали? Случайно допустили ошибку в школьном или рабочем проекте? Забыли помыть ванную, как обещали?
- Поймите, как и почему вы совершили ошибку. Вы сделали это нарочно, но позже пожалели об этом? Или же вы просто не были достаточно внимательным? Поразмышляйте над ситуацией, например: “Как же я забыл убраться в ванной? Я не хотел убираться там, хотел избежать этой работы? Я был слишком занят?”.
- Если вы не уверены, что же сделали не так, спросите друга, члена семьи, учителя, сотрудника, начальника, чтобы этот человек помог вам узнать, в чем ошибка. Например, если кто-то зол на вас, можете спросить: “Я вижу, что ты зол на меня, можешь объяснить почему?”. Человек может ответить: “Я зол на тебя, потому что ты сказал, что уберешься в ванной, но ты этого не сделал”.
-
2
Помните свои прошлые ошибки.[1]
Обратите внимание на свои модели поведения и на то, какие подобные проблемы были у вас в прошлом. Было ли так, что вы и в прошлом забывали что-то сделать?- Запишите все паттерны и темы, которые, как вы заметили, продолжают возникать. Это поможет вам определить более крупную цель, над которой вам нужно работать (сосредоточение, определенные навыки, и так далее). Например, возможно, вы склонны забывать о тех задачах, которые не хотите выполнять, например, об уборке. Это будет признаком того, что вы уклоняетесь от задания или что вам нужно стать более организованным, чтобы не забывать выполнять определенные обязательства.
-
3
Берите ответственность на себя. Поймите, что это ваша и только ваша ошибка. Берите на себя ответственность за собственные ошибки и не пытайтесь свалить вину на кого-то другого.[2]
Если вы играете в поиски виноватого, то не сможете учиться на собственных промахах, так как можете продолжать совершать одни и те же ошибки снова и снова.- Запишите те части проблемы, которым вы посодействовали, или конкретную ошибку, которую совершили.
- Определите, что конкретно вы могли бы сделать по-другому, чтобы получить лучший результат.
Реклама



-
1
Подумайте о прошлых решениях. [3]
Один из лучших способов решить проблему или исправить ошибку – определить, как вы справлялись с подобными проблемами или ошибками в прошлом. Поразмышляйте над следующим: “В прошлом я не забывал, что мне нужно сделать, как у меня это получалось? Ах, точно, я записывал дела в календарь и заглядывал в него несколько раз в день!”.- Составьте список подобных совершенных вами ошибок. Определите, как вы обошлись с каждой из этих ошибок, и было ли это полезным для вас или нет. Если нет, то, вероятно, подобное решение не сработает и в этот раз.
-
2
Рассмотрите возможные варианты.[4]
Придумайте как можно больше способов исправить ошибку. В нашем примере есть множество вариантов: вы могли бы убрать ванную, извиниться, предложить убраться и в другой части квартиры, договориться, сделать это на следующий день, и так далее.- Используйте свои навыки решения проблем, чтобы придумать возможные варианты решения текущей проблемы.
- Составьте список плюсов и минусов для каждого возможного решения. Например, если вы определили, что одним из возможных вариантов решения вашей проблемы невымытой ванной будет “обязательно убраться в ванной завтра”, то список плюсов и минусов может выглядеть так: плюс – ванная в конечном итоге будет чистой, минусы – сегодня она будет неубранной, завтра я могу забыть об уборке (я не могу полностью гарантировать, что это будет сделано), это не поможет решить проблему того, что я забыл убраться в ванной. Основываясь на этой оценке, было бы лучше навести порядок в ванной в тот же день, а не следующий, если это возможно, и разработать план того, как в будущем не забывать убираться в этой комнате.
-
3
Определитесь с порядком действий и выполняйте их. Чтобы решить проблему, вам нужен план. Определите наилучшее возможное решение, основываясь на прошлом и на возможных вариантах, и будьте привержены его осуществлению.[5]
- Доводите дело до конца. Если вы пообещали исправить проблему, сделайте это. Надежность очень важна в построении доверительных отношений с людьми и формировании прочных связей.[6]
- Доводите дело до конца. Если вы пообещали исправить проблему, сделайте это. Надежность очень важна в построении доверительных отношений с людьми и формировании прочных связей.[6]
-
4
Сформулируйте запасной план. Каким бы надежным ни казался план, существует вероятность того, что он не решит проблему. Например, возможно, вы уберетесь в ванной, но человек, который попросил вас это сделать, все еще будет зол на вас.
- Определите другие возможные решения и запишите их от наиболее полезных до наименее полезных. Пройдитесь по списку сверху донизу. К возможным вариантам могут относиться: предложить убраться в другой комнате, искренне извиниться, спросить человека, как вы можете загладить вину, или предложить ему то, что ему нравится (еду, занятия, и так далее).
-
5
Не допускайте ошибок в будущем. Если вы сможете успешно найти решение вашей ошибки, то вы начинаете процесс успеха в будущем избежании ошибок.[7]
- Запишите, что, по-вашему, вы сделали неправильно. Затем запишите цель того, что вы хотите сделать в будущем. Например, если вы забыли убраться в ванной, у вас могут быть такие цели: записывать список заданий на каждый день, два раза в день проверять его, отмечать галочкой выполненные задания, наклеить на холодильник стикеры с напоминанием для наиболее приоритетных задач.
Реклама





-
1
Не будьте слишком строги к себе. Поймите, что все совершают ошибки, это нормально. Вы можете чувствовать себя виноватым, но необходимо принимать себя таким, какой вы есть, несмотря на свои слабости.[8]
- Простите себя и двигайтесь дальше, вместо того чтобы зацикливаться на своей проблеме.
- Сосредоточьтесь на том, чтобы сейчас и впредь поступать правильно.
-
2
Держите под контролем свои эмоции. Когда мы совершаем ошибку, нас легко могут настигнуть чувства разочарования, подавленности, может возникнуть желание сдаться вообще. Если вы испытываете чрезмерно сильные эмоции или стресс, сделайте перерыв. Повышенные эмоции не принесут вам пользу в попытках исправить свою ошибку.
-
3
Справляйтесь. Сосредоточьтесь на способах борьбы с негативными эмоциями, которые могут заставить вас почувствовать себя лучше. Подумайте о том, как вы справлялись с совершением ошибок в прошлом. Определите способы, которые помогли вам правильно справиться с проблемой, и способы, которые только усугубили ваше состояние.
- К распространенным стратегиям относятся: позитивный внутренний диалог (говорите о себе хорошие вещи), физические упражнения, расслабляющие занятия (например, чтение или игра).
- К вредным и бесполезным стратегиям борьбы с ошибками относится саморазрушающее поведение, например: употребление алкоголя или других веществ, причинение себе физического вреда, повторяющиеся мысли и негативные размышления о себе.
Реклама



-
1
Будьте убедительны. Используйте навыки позитивного взаимодействия, говорите о своих мыслях и чувствах уместным образом и с уважением к собеседнику.[9]
Когда вы утвердительны, вы признаете, что были неправы и берете на себя ответственность за собственную вину. Вы не обвиняете других в своих ошибках.- Не будьте пассивным: не стоит избегать разговоров о своей ошибке, прятаться, соглашаться с тем, чего хотят от вас другие, и не отстаивать себя.
- Не проявляйте агрессии: не повышайте тон, не кричите, не унижайте людей, не проклинайте, не проявляйте насильственного поведения (не бросайтесь вещами, не распускайте руки).
- Избегайте пассивно-агрессивного поведения. Это смешение пассивной и агрессивной форм общения, когда вы можете злиться, но не высказываете своих чувств. Поэтому вы можете сделать что-то у человека за спиной, чтобы отомстить, или устроить бойкот-молчанку. Это не лучшая форма общения, кроме того человек может не понять, о чем вы пытаетесь сообщить ему и почему вы так поступаете.
- Посылайте положительные невербальные сообщения. Наше невербальное общение тоже посылает определенные сообщения людям вокруг нас. Улыбка, например, говорит: “Да, я должен хмуриться, но я могу быть храбрым и пройти через это”.
-
2
Используйте навыки активного слушания. Позвольте расстроенному человеку излить свое разочарование и не торопитесь с ответом.[10]
- Постарайтесь сосредоточиться только на том, чтобы слушать человека, вместо того чтобы думать о том, как ему ответить. Сосредоточьтесь на мыслях и чувствах человека, которого слушаете, а не на своих.
- Сделайте краткие заявления и задайте уточняющие вопросы, например: “Я так понял, что ты был зол и расстроен из-за того, что я не убрался в ванной, правильно?”.
- Сопереживайте. Проявите понимание и поставьте себя на место другого человека.
-
3
Извинитесь. Иногда, когда мы делаем ошибки, мы можем причинить боль другим людям. Извинитесь перед человеком, так вы покажете, что сожалеете о совершенной ошибке, чувствуете вину за причиненный вред и хотите поступать лучше в будущем.[11]
- Не пытайтесь найти оправдания и все объяснить. Просто признайте свой промах. Скажите: “Я признаю, что забыл убраться в ванной. Мне очень жаль ”.
- Будьте осторожны, не обвиняйте других. Не стоит говорить что-то вроде: “Если бы ты напомнил мне, что нужно там убраться, то, может быть, я не забыл бы, и ванная была бы уже чистой”.
-
4
Проявите стремление к позитивным изменениям. Расскажите человеку о способах исправить проблему и пообещайте работать над этим вопросом. Это будет эффективным способом исправить ошибку, которая задела другого человека.
- Постарайтесь разработать решение. Спросите человека, что вы можете для него сделать, чтобы компенсировать ошибку. Можете прямо сказать: “Могу ли я что-то для тебя сделать?”.
- Поймите, как можно поступить по-другому в будущем. Можете спросить у человека: “Как ты думаешь, что может помочь мне избежать этой ошибки в будущем?”.
- Скажите человеку, что вы готовы приложить свои усилия, чтобы снизить вероятность совершения этой ошибки в будущем. Можно сказать следующее: “Я не хочу, чтобы в будущем это произошло снова, поэтому я буду прилагать усилия, чтобы…”. Скажите, что конкретно вы будете делать, например: “Я обязательно составлю список домашних дел, чтобы не забыть об этом снова”.
Реклама




Советы
- Если задание слишком сложное или непреодолимое, сделайте перерыв или попросите о помощи.
- Если вы никак не можете исправить ошибку или улучшить ситуацию прямо сейчас, сосредоточьтесь на том, как поступить лучше в будущем.
Реклама
Предупреждения
- Не пытайтесь исправить ошибку, если это может быть потенциально опасным для вас или кого-то другого. Будьте внимательны к безопасности, здоровью и благополучию, как своему, так и других людей.
Реклама
Об этой статье
Эту страницу просматривали 20 219 раз.