Наверное, любой сервис, на котором вообще есть поиск, рано или поздно приходит к потребности научиться исправлять ошибки в пользовательских запросах. Errare humanum est; пользователи постоянно опечатываются и ошибаются, и качество поиска от этого неизбежно страдает — а с ним и пользовательский опыт.
При этом каждый сервис обладает своей спецификой, своим лексиконом, которым должен уметь оперировать исправитель опечаток, что в значительной мере затрудняет применение уже существующих решений. Например, такие запросы пришлось научиться править нашему опечаточнику:
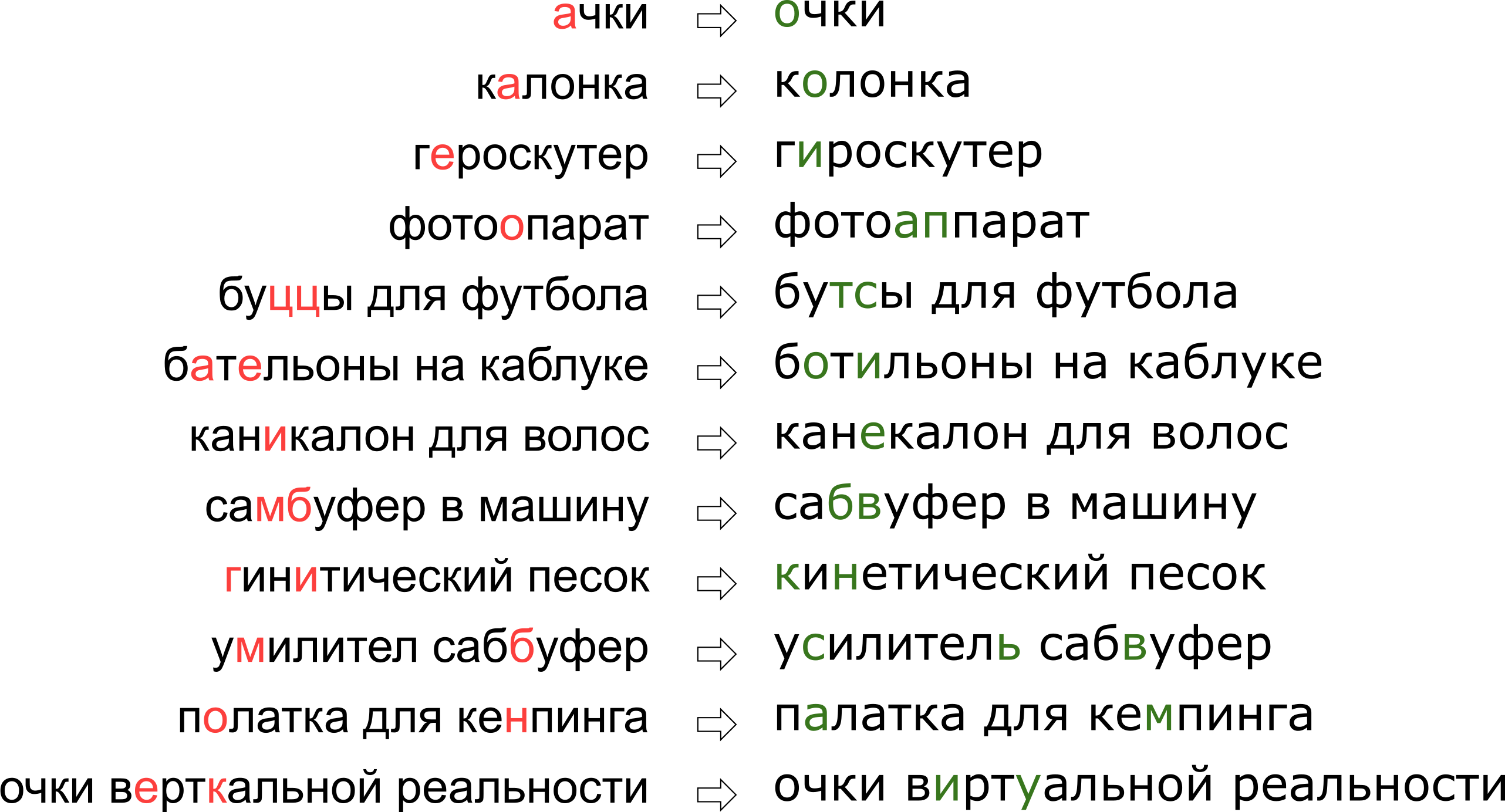
Может показаться, что мы отказали пользователю в его мечте о вертикальной реальности, но на самом деле буква К просто стоит на клавиатуре рядом с буквой У.
В этой статье мы разберём один из классических подходов к исправлению опечаток, от построения модели до написания кода на Python и Go. И в качестве бонуса — видео с моего доклада «”Очки верткальной реальности”: исправляем опечатки в поисковых запросах» на Highload++.
Постановка задачи
Итак, нам пришёл опечатанный запрос и его надо исправить. Обычно математически задача ставится таким образом:
Эта постановка — самая элементарная — предполагает, что если нам пришёл запрос из нескольких слов, то мы исправляем каждое слово по отдельности. В реальности, конечно, мы захотим исправлять всю фразу целиком, учитывая сочетаемость соседних слов; об этом я расскажу ниже, в разделе “Как исправлять фразы”.
Неясных моментов здесь два — где взять словарь и как посчитать
 . Первый вопрос считается простым. В 1990 году [1] словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google [4] поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
. Первый вопрос считается простым. В 1990 году [1] словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google [4] поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
Второй вопрос сложнее. Хотя бы потому, что его решение обычно начинается с применения формулы Байеса!

Теперь вместо исходной непонятной вероятности нам нужно оценить две новые, чуть более понятные:
 — вероятность того, что при наборе слова
— вероятность того, что при наборе слова
 можно опечататься и получить
можно опечататься и получить
 , и
, и
 — в принципе вероятность использования пользователем слова
— в принципе вероятность использования пользователем слова
.
Как оценить
? Очевидно, что пользователь с большей вероятностью путает А с О, чем Ъ с Ы. А если мы исправляем текст, распознанный с отсканированного документа, то велика вероятность путаницы между rn и m. Так или иначе, нам нужна какая-то модель, описывающая ошибки и их вероятности.
Такая модель называется noisy channel model (модель зашумлённого канала; в нашем случае зашумлённый канал начинается где-то в центре Брока пользователя и заканчивается по другую сторону его клавиатуры) или более коротко error model — модель ошибок. Эта модель, которой ниже посвящен отдельный раздел, будет ответственна за учёт как орфографических ошибок, так и, собственно, опечаток.
Оценить вероятность использования слова —
— можно по-разному. Самый простой вариант — взять за неё частоту, с которой слово встречается в некотором большом корпусе текстов. Для нашего опечаточника, учитывающего контекст фразы, потребуется, конечно, что-то более сложное — ещё одна модель. Эта модель называется language model, модель языка.
Модель ошибок
Первые модели ошибок считали
, подсчитывая вероятности элементарных замен в обучающей выборке: сколько раз вместо Е писали И, сколько раз вместо ТЬ писали Т, вместо Т — ТЬ и так далее [1]. Получалась модель с небольшим числом параметров, способная выучить какие-то локальные эффекты (например, что люди часто путают Е и И).
В наших изысканиях мы остановились на более развитой модели ошибок, предложенной в 2000 году Бриллом и Муром [2] и многократно использованной впоследствии (например, специалистами Google [4]). Представим, что пользователи мыслят не отдельными символами (спутать Е и И, нажать К вместо У, пропустить мягкий знак), а могут изменять произвольные куски слова на любые другие — например, заменять ТСЯ на ТЬСЯ, У на К, ЩА на ЩЯ, СС на С и так далее. Вероятность того, что пользователь опечатался и вместо ТСЯ написал ТЬСЯ, обозначим
 — это параметр нашей модели. Если для всех возможных фрагментов
— это параметр нашей модели. Если для всех возможных фрагментов
 мы можем посчитать
мы можем посчитать
 , то искомую вероятность
, то искомую вероятность
набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины
:

Давайте посмотрим на пример разбиения, возникающего при вычислении вероятности напечатать «аксесуар» вместо «аксессуар»:

Как вы наверняка заметили, это пример не очень удачного разбиения: видно, что части слов легли друг под другом не так удачно, как могли бы. Если величины
 и
и
 ещё не так плохи, то
ещё не так плохи, то
 и
и
 , скорее всего, сделают итоговый «счёт» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:
, скорее всего, сделают итоговый «счёт» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:

Здесь всё сразу стало на свои места, и видно, что итоговая вероятность будет определяться преимущественно величиной
 .
.
Как вычислить 
Несмотря на то, что возможных разбиений для двух слов имеется порядка
 , с помощью динамического программирования алгоритм вычисления
, с помощью динамического программирования алгоритм вычисления
можно сделать довольно быстрым — за
 . Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
. Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
Мы заведём прямоугольную таблицу, строки которой будут соответствовать буквам правильного слова, а столбцы — опечатанного. В ячейке на пересечении строки i и столбца j к концу алгоритма будет лежать в точности вероятность получить s[:j] при попытке напечатать w[:i]. Для того, чтобы её вычислить, достаточно вычислить значения всех ячеек в предыдущих строках и столбцах и пробежаться по ним, домножая на соответствующие
. Например, если у нас заполнена таблица
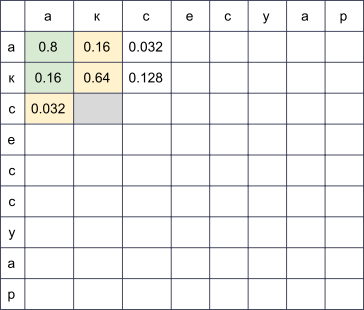
, то для заполнения ячейки в четвёртой строке и третьем столбце (серая) нужно взять максимум из величин
 и
и
 . При этом мы пробежались по всем ячейкам, подсвеченным на картинке зелёным. Если также рассматривать модификации вида
. При этом мы пробежались по всем ячейкам, подсвеченным на картинке зелёным. Если также рассматривать модификации вида
 и
и
 , то придётся пробежаться и по ячейкам, подсвеченным жёлтым.
, то придётся пробежаться и по ячейкам, подсвеченным жёлтым.
Сложность этого алгоритма, как я уже упомянул выше, составляет
: мы заполняем таблицу
 , и для заполнения ячейки (i, j) нужно
, и для заполнения ячейки (i, j) нужно
 операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины
операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины
 (например, не больше двух букв, как в [4]), сложность уменьшится до
(например, не больше двух букв, как в [4]), сложность уменьшится до
 . Для русского языка в своих экспериментах я брал
. Для русского языка в своих экспериментах я брал
 .
.
Как максимизировать
Мы научились находить
за полиномиальное время — это хорошо. Но нам нужно научиться быстро находить наилучшие слова во всём словаре. Причём наилучшие не по
, а по
! На деле нам достаточно получить какой-то разумный топ (например, лучшие 20) слов по
, который мы потом отправим в модель языка для выбора наиболее подходящих исправлений (об этом ниже).
Чтобы научиться быстро проходить по всему словарю, заметим, что таблица, представленная выше, будет иметь много общего для двух слов с общими префиксами. Действительно, если мы, исправляя слово «аксесуар», попробуем заполнить её для двух словарных слов «аксессуар» и «аксессуары», мы заметим, что первые девять строк в них вообще не отличаются! Если мы сможем организовать проход по словарю так, что у двух последующих слов будут достаточно длинные общие префиксы, мы сможем круто сэкономить вычисления.
И мы сможем. Давайте возьмём словарные слова и составим из них trie. Идя по нему поиском в глубину, мы получим желаемое свойство: большинство шагов — это шаги от узла к его потомку, когда у таблицы достаточно дозаполнить несколько последних строк.
Этот алгоритм, при некоторых дополнительных оптимизациях, позволяет нам перебирать словарь типичного европейского языка в 50-100 тысяч слов в пределах сотни миллисекунд [2]. А кэширование результатов сделает процесс ещё быстрее.
Как получить
Вычисление
для всех рассматриваемых фрагментов — самая интересная и нетривиальная часть построения модели ошибок. Именно от этих величин будет зависеть её качество.
Подход, использованный в [2, 4], сравнительно прост. Давайте найдём много пар
 , где
, где
 — правильное слово из словаря, а
— правильное слово из словаря, а
 — его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
— его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
Для каждой пары возьмём составляющие её
и
и построим соответствие между их буквами, минимизирующее расстояние Левенштейна:

Теперь мы сразу видим замены: а → а, е → и, с → с, с → пустая строка и так далее. Также мы видим замены двух и более символов: ак → ак, се → си, ес → ис, сс → с, сес → сис, есс → ис и прочая, и прочая. Все эти замены необходимо посчитать, причём каждую столько раз, сколько слово s встречается в корпусе (если мы брали слова из корпуса, что очень вероятно).
После прохода по всем парам
за вероятность
принимается количество замен α → β, встретившихся в наших парах (с учётом встречаемости соответствующих слов), делённое на количество повторений фрагмента α.
Как найти пары
? В [4] предлагается такой подход. Возьмём большой корпус сгенерированного пользователями контента (UGC). В случае Google это были просто тексты сотен миллионов веб-страниц; в нашем — миллионы пользовательских поисковых запросов и отзывов. Предполагается, что обычно правильное слово встречается в корпусе чаще, чем любой из ошибочных вариантов. Так вот, давайте для каждого слова находить близкие к нему по Левенштейну слова из корпуса, которые значительно менее популярны (например, в десять раз). Популярное возьмём за
, менее популярное — за
. Так мы получим пусть и шумный, но зато достаточно большой набор пар, на котором можно будет провести обучение.
Этот алгоритм подбора пар оставляет большое пространство для улучшений. В [4] предлагается только фильтр по встречаемости (
в десять раз популярнее, чем
), но авторы этой статьи пытаются делать опечаточник, не используя какие-либо априорные знания о языке. Если мы рассматриваем только русский язык, мы можем, например, взять набор словарей русских словоформ и оставлять только пары со словом
, найденном в словаре (не лучшая идея, потому что в словаре, скорее всего, не будет специфичной для сервиса лексики) или, наоборот, отбрасывать пары со словом s, найденном в словаре (то есть почти гарантированно не являющимся опечатанным).
Чтобы повысить качество получаемых пар, я написал несложную функцию, определяющую, используют ли пользователи два слова как синонимы. Логика простая: если слова w и s часто встречаются в окружении одних и тех же слов, то они, вероятно, синонимы — что в свете их близости по Левенштейну значит, что менее популярное слово с большой вероятностью является ошибочной версией более популярного. Для этих расчётов я использовал построенную для модели языка ниже статистику встречаемости триграмм (фраз из трёх слов).
Модель языка
Итак, теперь для заданного словарного слова w нам нужно вычислить
— вероятность его использования пользователем. Простейшее решение — взять встречаемость слова в каком-то большом корпусе. Вообще, наверное, любая модель языка начинается с собирания большого корпуса текстов и подсчёта встречаемости слов в нём. Но ограничиваться этим не стоит: на самом деле при вычислении P(w) мы можем учесть также и фразу, слово в которой мы пытаемся исправить, и любой другой внешний контекст. Задача превращается в задачу вычисления
 , где одно из
, где одно из
— слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем
, а остальные
— слова, окружающие исправляемое слово в пользовательском запросе.
Чтобы научиться учитывать их, стоит пройтись по корпусу ещё раз и составить статистику n-грамм, последовательностей слов. Обычно берут последовательности ограниченной длины; я ограничился триграммами, чтобы не раздувать индекс, но тут всё зависит от вашей силы духа (и размера корпуса — на маленьком корпусе даже статистика по триграммам будет слишком шумной).
Традиционная модель языка на основе n-грамм выглядит так. Для фразы
 её вероятность вычисляется по формуле
её вероятность вычисляется по формуле

где
 — непосредственно частота слова, а
— непосредственно частота слова, а
 — вероятность слова
— вероятность слова
 при условии, что перед ним идут
при условии, что перед ним идут
 — не что иное, как отношение частоты триграммы
— не что иное, как отношение частоты триграммы
 к частоте биграммы
к частоте биграммы
. (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
Иными словами, если мы захотим вычислить
 , обозначив частоту произвольной n-граммы за
, обозначив частоту произвольной n-граммы за
 , мы получим формулу
, мы получим формулу

Логично? Логично. Однако трудности начинаются, когда фразы становятся длиннее. Что, если пользователь ввёл впечатляющий своей подробностью поисковый запрос в десять слов? Мы не хотим держать статистику по всем 10-граммам — это дорого, а данные, скорее всего, будут шумными и не показательными. Мы хотим обойтись n-граммами какой-то ограниченной длины — например, уже предложенной выше длины 3.
Здесь-то и пригождается формула выше. Давайте предположим, что на вероятность слова появиться в конце фразы значительно влияют только несколько слов непосредственно перед ним, то есть что

Положив
, для более длинной фразы получим формулу

Обратите внимание: фраза состоит из пяти слов, но в формуле фигурируют n-граммы не длиннее трёх. Это как раз то, чего мы добивались.
Остался один тонкий момент. Что, если пользователь ввёл совсем странную фразу и соответствующих n-грамм у нас в статистике и нет вовсе? Было бы легко для незнакомых n-грамм положить
 , если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьёзных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
, если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьёзных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
Как исправлять фразы
Обговорим последний тонкий момент перед тем, как перейти к реализации. Постановка задачи, которую я описал выше, подразумевала, что есть одно слово и его надо исправить. Потом мы уточнили, что это одно слово может быть в середине фразы среди каких-то других слов и их тоже нужно учесть, выбирая наилучшее исправление. Но в реальности пользователи просто присылают нам фразы, не уточняя, какое слово написано с ошибкой; нередко в исправлении нуждается несколько слов или даже все.
Подходов здесь может быть много. Можно, например, учитывать только левый контекст слова в фразе. Тогда, идя по словам слева направо и по мере необходимости исправляя их, мы получим новую фразу какого-то качества. Качество будет низким, если, например, первое слово оказалось похоже на несколько популярных слов и мы выберем неправильный вариант. Вся оставшаяся фраза (возможно, изначально вообще безошибочная) будет подстраиваться нами под неправильное первое слово и мы можем получить на выходе полностью нерелевантный оригиналу текст.
Можно рассматривать слова по отдельности и применять некий классификатор, чтобы понимать, опечатано данное слово или нет, как это предложено в [4]. Классификатор обучается на вероятностях, которые мы уже умеем считать, и ряде других фичей. Если классификатор говорит, что нужно исправлять — исправляем, учитывая имеющийся контекст. Опять-таки, если несколько слов написаны с ошибкой, принимать решение насчёт первого из них придётся, опираясь на контекст с ошибками, что может приводить к проблемам с качеством.
В реализации нашего опечаточника мы использовали такой подход. Давайте для каждого слова
в нашей фразе найдём с помощью модели ошибок топ-N словарных слов, которые могли иметься в виду, сконкатенируем их во фразы всевозможными способами и для каждой из
 получившихся фраз, где
получившихся фраз, где
 — количество слов в исходной фразе, посчитаем честно величину
— количество слов в исходной фразе, посчитаем честно величину

Здесь
— слова, введённые пользователем,
— подобранные для них исправления (которые мы сейчас перебираем), а
 — коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в [4]. Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и ещё домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
— коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в [4]. Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и ещё домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
Так, стоп, что? Перебор
фраз?
К счастью, за счёт того, что мы ограничили длину n-грамм, найти максимум по всем фразам можно гораздо быстрее. Вспомните: выше мы упростили формулу для
 так, что она стала зависеть только от частот n-грамм длины не выше трёх:
так, что она стала зависеть только от частот n-грамм длины не выше трёх:

Если мы домножим эту величину на
 и попытаемся максимизировать по
и попытаемся максимизировать по
 , мы увидим, что достаточно перебрать всевозможные
, мы увидим, что достаточно перебрать всевозможные
 и
и
 и решить задачу для них — то есть для фраз
и решить задачу для них — то есть для фраз
 . Итого задача решается динамическим программированием за
. Итого задача решается динамическим программированием за
 .
.
Реализация
Собираем корпус и считаем n-граммы
Сразу оговорюсь: данных в моём распоряжении было не так много, чтобы заводить какой-то сложный MapReduce. Так что я просто собрал все тексты отзывов, комментариев и поисковых запросов на русском языке (описания товаров, увы, приходят на английском, а использование результатов автоперевода скорее ухудшило, чем улучшило результаты) с нашего сервиса в один текстовый файл и поставил сервер на ночь считать триграммы простым скриптом на Python.
В качестве словарных я брал топ слов по частотности так, чтобы получалось порядка ста тысяч слов. Исключались слишком длинные слова (больше 20 символов) и слишком короткие (меньше трёх символов, кроме захардкоженных известных русских слов). Отдельно пощадил слова по регулярке r"^[a-z0-9]{2}$" — чтобы уцелели версии айфонов и другие интересные идентификаторы длины 2.
При подсчёте биграмм и триграмм во фразе может встретиться несловарное слово. В этом случае это слово я выбрасывал и бил всю фразу на две части (до и после этого слова), с которыми работал отдельно. Так, для фразы «А вы знаете, что такое «абырвалг»? Это… ГЛАВРЫБА, коллега» учтутся триграммы “а вы знаете”, “вы знаете что”, “знаете что такое” и “это главрыба коллега” (если, конечно, слово “главрыба” попадёт в словарь…).
Обучаем модель ошибок
Дальше всю обработку данных я проводил в Jupyter. Статистика по n-граммам грузится из JSON, производится постобработка, чтобы быстро находить близкие друг к другу по Левенштейну слова, и для пар в цикле вызывается (довольно громоздкая) функция, выстраивающая слова и извлекающая короткие правки вида сс → с (под спойлером).
Код на Python
def generate_modifications(intended_word, misspelled_word, max_l=2):
# Выстраиваем буквы слов оптимальным по Левенштейну образом и
# извлекаем модификации ограниченной длины. Чтобы после подсчёта
# расстояния восстановить оптимальное расположение букв, будем
# хранить в таблице помимо расстояний указатели на предыдущие
# ячейки: memo будет хранить соответствие
# i -> j -> (distance, prev i, prev j).
# Дальше немного непривычно страшного Python кода - вот что
# бывает, когда язык используется не по назначению!
m, n = len(intended_word), len(misspelled_word)
memo = [[None] * (n+1) for _ in range(m+1)]
memo[0] = [(j, (0 if j > 0 else -1), j-1) for j in range(n+1)]
for i in range(m + 1):
memo[i][0] = i, i-1, (0 if i > 0 else -1)
for j in range(1, n + 1):
for i in range(1, m + 1):
if intended_word[i-1] == misspelled_word[j-1]:
memo[i][j] = memo[i-1][j-1][0], i-1, j-1
else:
best = min(
(memo[i-1][j][0], i-1, j),
(memo[i][j-1][0], i, j-1),
(memo[i-1][j-1][0], i-1, j-1),
)
# Отдельная обработка для перепутанных местами
# соседних букв (распространённая ошибка при
# печати).
if (i > 1
and j > 1
and intended_word[i-1] == misspelled_word[j-2]
and intended_word[i-2] == misspelled_word[j-1]
):
best = min(best, (memo[i-2][j-2][0], i-2, j-2))
memo[i][j] = 1 + best[0], best[1], best[2]
# К концу цикла расстояние по Левенштейну между исходными словами # хранится в memo[m][n][0].
# Теперь восстанавливаем оптимальное расположение букв.
s, t = [], []
i, j = m, n
while i >= 1 or j >= 1:
_, pi, pj = memo[i][j]
di, dj = i - pi, j - pj
if di == dj == 1:
s.append(intended_word[i-1])
t.append(misspelled_word[j-1])
if di == dj == 2:
s.append(intended_word[i-1])
s.append(intended_word[i-2])
t.append(misspelled_word[j-1])
t.append(misspelled_word[j-2])
if 1 == di > dj == 0:
s.append(intended_word[i-1])
t.append("")
if 1 == dj > di == 0:
s.append("")
t.append(misspelled_word[j-1])
i, j = pi, pj
s.reverse()
t.reverse()
# Генерируем модификации длины не выше заданной.
for i, _ in enumerate(s):
ss = ts = ""
while len(ss) < max_l and i < len(s):
ss += s[i]
ts += t[i]
yield ss, ts
i += 1
Сам подсчёт правок выглядит элементарно, хотя длиться может долго.
Применяем модель ошибок
Эта часть реализована в виде микросервиса на Go, связанного с основным бэкендом через gRPC. Реализован алгоритм, описанный самими Бриллом и Муром [2], с небольшими оптимизациями. Работает он у меня в итоге примерно вдвое медленнее, чем заявляли авторы; не берусь судить, дело в Go или во мне. Но по ходу профилировки я узнал о Go немного нового.
- Не используйте
math.Max, чтобы считать максимум. Это примерно в три раза медленнее, чемif a > b { b = a }! Только взгляните на реализацию этой функции:// Max returns the larger of x or y. // // Special cases are: // Max(x, +Inf) = Max(+Inf, x) = +Inf // Max(x, NaN) = Max(NaN, x) = NaN // Max(+0, ±0) = Max(±0, +0) = +0 // Max(-0, -0) = -0 func Max(x, y float64) float64 func max(x, y float64) float64 { // special cases switch { case IsInf(x, 1) || IsInf(y, 1): return Inf(1) case IsNaN(x) || IsNaN(y): return NaN() case x == 0 && x == y: if Signbit(x) { return y } return x } if x > y { return x } return y }Если только вам ВДРУГ не нужно, чтобы +0 обязательно был больше -0, не используйте
math.Max. - Не используйте хэш-таблицу, если можете использовать массив. Это, конечно, довольно очевидный совет. Мне пришлось перенумеровывать символы юникода в числа в начале программы так, чтобы использовать их как индексы в массиве потомков узла trie (такой lookup был очень частой операцией).
- Коллбеки в Go недёшевы. В ходе рефакторинга во время код ревью некоторые мои потуги сделать decoupling ощутимо замедлили программу при том, что формально алгоритм не изменился. С тех пор я остаюсь при мнении, что оптимизирующему компилятору Go есть, куда расти.
Применяем модель языка
Здесь без особых сюрпризов был реализован алгоритм динамического программирования, описанный в разделе выше. На этот компонент пришлось меньше всего работы — самой медленной частью остаётся применение модели ошибок. Поэтому между этими двумя слоями было дополнительно прикручено кэширование результатов модели ошибок в Redis.
Результаты
По итогам этой работы (занявшей примерно человекомесяц) мы провели A/B тест опечаточника на наших пользователях. Вместо 10% пустых выдач среди всех поисковых запросов, которые мы имели до внедрения опечаточника, их стало 5%; в основном оставшиеся запросы приходятся на товары, которых просто нет у нас на платформе. Также увеличилось количество сессий без второго поискового запроса (и ещё несколько метрик такого рода, связанных с UX). Метрики, связанные с деньгами, впрочем, значимо не изменились — это было неожиданно и сподвигло нас к тщательному анализу и перепроверке других метрик.
Заключение
Стивену Хокингу как-то сказали, что каждая включенная им в книгу формула вдвое уменьшит число читателей. Что ж, в этой статье их порядка полусотни — поздравляю тебя, один из примерно
 читателей, добравшихся до этого места!
читателей, добравшихся до этого места!
Бонус
Ссылки
[1] M. D. Kernighan, K. W. Church, W. A. Gale. A Spelling Correction Program Based on a Noisy Channel Model. Proceedings of the 13th conference on Computational linguistics — Volume 2, 1990.
[2] E.Brill, R. C. Moore. An Improved Error Model for Noisy Channel Spelling Correction. Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, 2000.
[3] T. Brants, A. C. Popat, P. Xu, F. J. Och, J. Dean. Large Language Models in Machine Translation. Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing.
[4] C. Whitelaw, B. Hutchinson, G. Y. Chung, G. Ellis. Using the Web for Language Independent Spellchecking and Autocorrection. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 2.
Обновлено 21 января 2021
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Когда вы путешествуете по интернету, то используете два обязательных для этого дела инструмента — браузер и поисковую систему (в рунете это чаще всего Яндекс).
Оба они умеют вести и хранить историю ваших посещений, просмотров страниц и поисковых запросов, которые вы вводили. В случае необходимости вы можете восстановить хронологию событий и найти ту страницу, которую открывали вчера, или тот запрос, что вводили в поиск Яндекса полгода назад. Это очень удобно.

Но зачастую возникает и обратная ситуация, когда нужно стереть все следы вашей жизнедеятельности в сети. В этом случае у вас возникает вопрос: как удалить историю в Яндексе? Как «почистить за собой» в вашем браузере? Как найти и убрать все прочие следы?
Сегодня я как раз и хочу заострить ваше внимание на этой теме. Мы поговорим как про очистку ваших поисков, так и про удаления в браузере (включая и Яндекс браузер) всех следов вашей деятельности в сети.
Как посмотреть историю поисков и просмотров в Яндексе?
Как я уже упоминал выше, историю ведет не только браузер, но и поисковые системы. Например, в Яндексе за ее хранение отвечает специальный набор инструментов под названием «Мои находки».
P.S. К сожалению, разработчики Яндекса посчитали этот функционал не нужным (невостребованным пользователями) и полностью его удалили. Теперь покопаться в истории своих поисков не получится. Хотя, возможность очистить этот список, вроде бы оставили.
Приведенную ниже информацию я решил не удалять, чтобы можно было увидеть, как это все выглядело раньше, если кому-то сие окажется интересным.
Именно там можно будет удалить всю историю вашего общения с этим поисковиком и, при желании, вообще отказаться от того, чтобы велся журнал ваших просмотров и посещений (хотя он может пригодиться, например, для того, чтобы восстановить утерянную в закладках страницу, на которую вы попали из Яндекса, что очень удобно).
Яндекс — это в первую очередь поисковая система, которой пользуется более половины пользователей рунета. Недавно мы с вами уже рассматривали его настройки, в частности, подробно поговорили про настройку виджетов на главной странице Яндекса, а также подробно обсудили вопрос: как искать в Яндексе на профессиональном уровне. Но этим настройки этой поисковой не ограничиваются, ибо есть еще настойки истории ваших посещений, которых обязательно стоит коснуться.
Итак, для начала вам нужно будет перейти на главную страницу этого поисковика. Именно с нее можно будет попасть в нужный нам раздел настроек, которые доступны из выпадающего меню шестеренки, живущей в правом верхнем углу.
Выбираем самый нижний пункт «Другие настройки», а на отрывшейся странице нам будут интересны, в плане изучения истории ваших действий в Яндексе, два пункта приведенного там меню:

При клике по пункту «Настройки результатов поиска» вы сможете в самом низу открывшейся странице разрешить или запретить поисковику вести журнал с историей ваших поисковых запросов, посещенных страниц, поиска товаров в Яндекс Маркете, а также отдельно можете запретить или разрешить использовать эти данные для формирования результатов поиска и поисковых подсказок.

Здесь вы можете только как бы отключить или включить запись истории, а вот посмотреть то, что уже было записано, можно будет кликнув по надписи «Мои находки» (на обоих приведенных выше скриншотах). Здесь вы найдете много чего интересного и сможете восстановить ранее найденную, но затем утерянную информацию. История Яндекс поиска — это довольно-таки мощный инструмент:

Здесь с помощью расположенного в левом верхнем углу переключателя опять же можно будет остановить или снова включить запись журнала событий. В левой колонке можно будет отдельно просмотреть историю ваших поисковых запросов, историю поиска картинок, товаров в магазине Яндекс Маркет, а также все эти данные при необходимости сможете сохранить и скачать (экспортировать).
В самом верху расположена временная линия, которая очень оперативно позволит переместиться на тот момент, где вы что-то желаете найти или, наоборот, удалить из истории ваших посещений на Яндексе. Если у вас накопилось огромное число запросов, просмотров и других обращений, то можете воспользоваться поиском по истории, строка которого расположена прямо над временной линией. Как ни странно, но это вовсе не очевидное действие — поиск по результатам поиска.
Как удалить историю Yandex веб-обозревателя на телефоне
Очистить историю браузера Яндекс на телефоне можем по аналогии со вторым способом для компьютера. Разница между ними небольшая.
3 способа очистить историю в Яндекс браузере на Андроид
Очистить историю Yandex browser на Android можно тремя методами, все они доступны без установки дополнительных приложений
Первый способ. Полная очистка истории через сам browser:
- Открываем веб-обозреватель, нажимаем на троеточие в правой части «Умной строки» и выбираем «Настройки».
- Ищем раздел «Конфиденциальность» и выбираем пункт «Очистить данные».
- Делаем выделение в разделе «История» и жмём «Очистить данные».
- В новом меню нажимаем «Да».
Второй способ. Очистка истории веб-обозревателя Yandex на Андроид через приложение «Настройки»:
- Переходим в меню смартфона «Настройки».
- В разделе «Приложения» нажимаем на «Все приложения».
- Выбираем элемент «Браузер» с изображением Яндекс веб-обозревателя.
- Жмём на «Очистить» и в новом меню также нажимаем на одноимённый пункт.
- Выделяем элемент «История» и жмём на «Очистить данные».
Третий способ. Очистка истории браузера Яндекс на телефоне от отдельных записей:
- Открываем любую страницу в браузере.
- Нажимаем на изображение цифры (в квадрате снизу экрана) для перехода между вкладками.
- Кликаем на графическое изображение часов (второй пункт слева), так мы перейдём в меню «История».
- Находим запись, подлежащую удалению, и удерживаем палец на ней.
- Во всплывающем меню выбираем «Удалить».
Существует возможность удалить историю Yandex browser на Андроид через посторонние приложения, но в таком методе обычно нет необходимости. Перечисленных способов должно быть достаточно.
Как очистить историю Яндекс браузера на Айфоне
Подобные способы почистить историю в Yandex browser, как в прошлом разделе, применимы и для телефона с системой iOS. Веб-обозреватель имеет сходный дизайн как на iPhone, так и на гаджетах с Android.
Инструкция по очистке истории Яндекс браузера на iPhone:
- В браузере нажимаем на три вертикальные полосы и выбираем элемент «Настройки».
- Ищем графу «Конфиденциальность», а в ней — «Очистить данные».
- Выбираем строку «История» и жмём на кнопку «Очистить».
- Последний шаг – подтверждаем, что уверены в действии «Да».
Как удалить частично или совсем очистить историю в Яндексе?
P.S. Как я уже писал выше, Яндекс полностью изничтожил сервис «Мои находки», но осталась возможность «Очистить историю запросов» на приведенной по ссылке странице. Там можно будет нажать на одноименную кнопочку.

Как вы уже, наверное, заметили, можно не очищать всю историю целиком, а удалить какие-то отдельные запросы или посещенные страницы, просто кликнув напротив них по крестику. Удалится данный запрос и все страницы, на которые вы перешли при поиске ответа на него.
Например, при просмотре журнала Яндекса Маркета можно будет удалить из него отдельные просмотренные товары, а можно будет и всю историю очистить с помощью расположенной вверху одноименной кнопки:

Кстати, забыл сказать, что история поиска будет сохраняться (писаться) только в том случае, если вы авторизованы в Яндексе (в правом верхнем углу вы видите свой логин-ник). Если вы не авторизованы, то никакие «Мои находки» вам будут не доступны, а значит и очищать будет нечего.
Яндекс, понятное дело, все равно ведет свою внутреннюю статистику, но там вы будет фигурировать только как IP адрес вашего компьютера или как куки браузера (которые тоже можно почистить), через который вы осуществляли поиск. Удалить эту историю у вас не получится (только из браузера, очистив его кэш, т.е. историю), но доступ к ней практически никто получить не сможет, так что можно об этом не беспокоится. ИМХО.
Если хотите, чтобы и ваш IP поисковик не узнал, то используйте анонимайзеры (Хамелеон, Spools). Если и этого покажется мало, то , который позволяет не оставлять практически никаких следов в сети, так что и удалять историю на Яндексе или где бы то ни было вам не придется.
Да, чуть не забыл рассказать, как очистить всю историю Яндекса скопом, а не по одному. Для этого на странице «Мои находки» вам нужно будет кликнуть по расположенной в правом верхнем углу кнопке «Настройки»:

Ну, и на открывшейся странице вы сможете как остановить запись, так и полностью очистить уже накопленную историю с помощью имеющейся там кнопочки:

Это все, что касалось поисковой системы и ведущейся в ней статистики вашей активности.
Удаление истории в мобильной версии
Помимо удаления записей о посещенных страницах на компьютере, нужно знать, как очистить историю в яндексе на телефоне. Для устройств производства компании Apple и на телефонах Android очень похожи.
На айфоне
Чтобы удалить историю поиска на айфоне, необходимо:
Открыть меню: кликнуть три вертикальные полоски в правом нижнем углу экрана.
- Затем последовательно открыть «Настройки» — «Конфиденциальность».
- Нажать «Очистить данные».
Выбрать, какие данные будут очищены: история, кэш, cookie и т.д.
Нажать «Очистить», подтвердить действие кликом по кнопке «Да».
Возможность выбрать и удалить некоторые посещенные страницы из истории Яндекс.Браузера есть и на мобильных устройствах. Для этого достаточно:
- Зайти в меню яндекс браузера.
- Перейти на вкладку «История».
Выбрать страницу которую нужно удалить и коротким движением смахнуть её влево.
После этого вам останется кликнуть по кнопке «Удалить».
На андроид
- Удалить информацию о посещенных сетевых ресурсах в Яндекс.Браузере на андроиде тоже очень просто.
- Необходимо в меню открыть «Настройки» и перейти в раздел «Конфиденциальность».
- Нажать «Очистить данные», выбрать блоки, которые нужно очистить и нажать кнопку для выполнения действия.
Как посмотреть и очистить историю Яндекс Браузера?
Однако, историю ведет не только поисковая система, но и браузер, которым вы пользуетесь. Если это довольно популярный в рунете Яндекс браузер (смотрите ), то в нем тоже ведется история просмотров и посещенных вами страницы, а значит может возникнуть срочная необходимость ее очистить. Как это сделать? Давайте посмотрим.
Для вызова окна очистки истории можно воспользоваться комбинацией клавиш Ctrl+Shift+Delete, находясь в окне браузера, либо перейти из меню кнопки с тремя горизонтальными полосками в настройке браузера и найти там кнопку «Очистить историю».

В обоих случаях откроется одно и то же окно удаления истории ваших блужданий по интернету с помощью браузера Яндекса:

Здесь нужно выбрать период, за который вся история будет удалена (для полной очистки лучше выбирать вариант «За все время»), поставить галочки в нужных полях, ну и нажать на соответствующую кнопку внизу. Все, история вашего браузера будет почищена до основания.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Расширение «Улучшенная история для Хром» для Яндекс.Браузера
Кроме стандартного функционала Яндекс.Браузер мы можем также задействовать расширение для браузера Хром « Улучшенная история для Chrome ». Оно отлично подойдёт для нашего случая, а его функционал позволяет удобно сортировать историю на Yandex, а также выполнять удобный поиск нужной ссылки.
Для установки расширения на телефон выполните следующее:
- Перейдите в магазин Хром на страницу расширения «Улучшенная история для Хром»;
- Нажмите на кнопку « Установить »;
Просмотр истории на ПК
Для открытия журнала посещений, содержащего сведения о просматриваемых сайтах, на персональном компьютере пользуются одним из следующих способов:
- на клавиатуре нажимают определенное сочетание клавиш;
- выбирают соответствующий раздел в настройках меню браузера;
- через проводник открывают папку History, в которой хранится информация о действиях пользователя на посещаемых страницах;
- в адресную строку веб-обозревателя вводят специфическую буквенную комбинацию.
Следует помнить, что удаленные записи в Яндекс Браузере восстанавливаются, если история не была предварительно очищена для освобождения свободного пространства на жестком диске. В противном случае данные в компьютерной памяти не сохранятся.
Сочетание клавиш
Для вызова на дисплей списка посещений нужно открыть веб-обозреватель и одновременно нажать на компьютерной клавиатуре комбинацию Ctrl и H. На экране появится новое окно, где находится история просмотров.
Просматривать историю Яндекс Браузера можно с помощью комбинации горячих клавиш.
Программисты советуют периодически удалять записи и очищать кэш и cookie. Для этого используется сочетание клавиш Ctrl+Shift+Delite (Del). Система предложит выбрать временной интервал и элементы для ликвидации. Отметив галочкой отдельные позиции, следует подтвердить действие, кликнув мышкой кнопку «Очистить».
Меню браузера
Простейший вариант просмотра истории поиска — обращение к меню Яндекса. Порядок действий:
- открыть веб-обозреватель;
- в верхнем правом углу интерфейса нажать на 3 горизонтальные полоски;
- во всплывающем окне выбрать соответствующую строку.
В новой вкладке на экране появится журнал посещений. Для этого необязательно входить в свою учетную запись. Доступ к информации открыт неавторизованным пользователям стационарного компьютера.
Используя контекстное меню, можно увидеть, какие 7 сайтов просматривались на компьютере последними:
- кликнуть на 3 горизонтальные черты;
- навести мышь на строку «История».
В выпадающем окне отразятся 7 страниц, закрытых недавно. Чтобы открыть портал, завершающий список, на клавиатуре одновременно нажимают Ctrl+Shift+T.
Посмотреть историю посещений в Яндекс браузере можно используя контекстное меню.
Использование сторонних программ
История просмотров хранится в отдельном файловом массиве профиля Яндекс. Браузера. Для вывода на дисплей выполняется ряд действий:
- в проводнике ввести C:UsersИМЯ ПОЛЬЗОВАТЕЛЯAppDataLocalYandexYandexBrowserUser Data;
- открыть папку Default;
- найти файл History.
Информация представлена в виде стандартной базы данных в формате SQL3. Для обработки требуются знания и навыки. Непосвященному пользователю разобраться сложно.
Через поисковую строку
Вариант удобен тем, что не нужно каждый раз вводить все символы из запроса. После первого ввода команда автоматически заносится в память обозревателя. В следующий раз достаточно написать несколько начальных букв набора и система подскажет конечный результат.
Открыть историю браузера от Яндекс можно через адресную строку.
Для просмотра списка посещаемых сайтов в адресную строку открытого браузера необходимо ввести browser://history и нажать на компьютере клавишу Enter.
Записи за определенную дату
В сервисе Яндекса вся информация сортируется по дате и времени. Данные размещаются в порядке убывания. Первыми в списке стоят страницы, которые пользователь открывал последними.
Поиск по названию
При желании отыскать просматриваемую информацию по ключевому слову или адресу интернет-площадки можно воспользоваться диспетчером задач. Для этого вводится соответствующий запрос или URL в специальное поле на странице истории. Допускается искать данные в журнале посещений по названию сайта.
Чтобы не сохранять в памяти сервиса Yandex сведения об открывавшихся страницах, операции в веб-обозревателе проводятся в режиме «Инкогнито».
Как удалить историю поиска Youtube?
Совсем не обязательно удалять всю историю действий из персонального аккаунта Google. Например, иногда необходимо очищать поисковые запросы только в Youtube. Если у вас возникает потребность избирательного удаления своих запросов на этом видео-хостинге, то запомните последовательность действий:
— Нажмите на вертикальное троеточие в главном синем меню вашего аккаунта (Гугл называет эти точки пунктом «Главные настройки»)
— Кликните по призыву «Выберите параметры удаления»
— В поле «Продукты» прокрутите до строчки YouTube
— Удалите историю запрашиваемого поиска
Как видим – всё достаточно просто. Напомним, что, благодаря описанным действиям, история запросов в Youtube удаляется со всех ваших устройств.
Что такое история браузера?
История сайтов в Яндекс браузере – это раздел веб-обозревателя, где хранятся все посещённые сайты. Если никогда не удаляли историю, здесь можем найти самый первый просмотренный сайт, неважно, когда это было: вчера или два года назад. За счёт сохранения URL-сайтов, их названий и времени посещения, мы всегда можем вернуться на ранее посещённую страницу.
Важно! Чтобы посмотреть историю посещения сайтов в Яндекс веб-обозревателе, не нужно вводить пароли. Это незащищённые данные, к которым может получить доступ любой пользователь. Таким образом, в истории нельзя хранить личные данные, способные нанести ущерб конфиденциальности или авторитету человека.
Как теперь смотреть историю запросов
Ну а теперь собственно к теме — как можно посмотреть историю поиска в Яндексе. Раньше можно было управлять своими запросами вручную. Для этого предназначался инструмент «Мои находки». Благодаря ему, пользователь получал индивидуальные подсказки, сохранял свои запросы и результаты выдачи. Со временем сервис потерял актуальность и его решили свернуть. В качестве обоснования закрытия «Моих находок» команда Яндекса привела следующие аргументы:
- запросы конкретного пользователя в Яндексе сохраняются автоматически и служат основой для создания индивидуальных подсказок;
- историю запросов и посещенные страницы можно просмотреть в истории любого браузера.
Если вы хотите, чтобы подсказки и результаты поиска формировались исходя из ваших вкусов и предпочтений, нажмите на «Результаты поиска» и в последнем разделе «Персональный поиск» поставьте галочку напротив первой графы.

Таким образом, вы затачиваете поиск под себя, при этом поисковик сохраняет ваши запросы в своей базе данных.
При работе на компьютере
Если вы являетесь пользователем этого браузера в персональном компьютере, то наверняка хотя бы раз искали, как очистить поиск в «Яндексе» на компьютере.
Итак, пошаговая инструкция:
- Нажмите на три точки в правом верхнем углу экрана и откройте меню «Настройки». Не пугайтесь, если не найдете его именно там. В более ранних и более поздних версиях браузера меню может иметь другое расположение, например в панели задач, которая находится чуть ниже.
- Далее необходимо перейти в пункт «Параметры конфиденциальности», где вы увидите пункт «История браузера». Они могут иметь немного другое название в разных версиях браузера!
- Необходимо перейти в этот пункт и выбрать «Удалить историю поисков». Всего доступно несколько режимов: удаление за все время, за месяц, за неделю и за час. Выберите нужный режим и нажмите «Очистить».
- Также есть еще один способ: непосредственно через меню «История», которое находится там же, где и «Настройки».
- Вам нужно перейти в данное меню и выбрать необходимый параметр. Всего их несколько. Можно так же выбрать нужный режим и очистить историю, а можно выбрать отдельно ресурс, который вы бы хотели удалить, и нажать на значок «x», который находится напротив ссылки на этот ресурс.
- Теперь можно закрыть меню. История будет удалена.
Также полезно будет знать, как очистить строку поиска на компьютере. Делается это тоже через меню «История». Необходимо перейти в него и выбрать интересующий нас пункт. Однако такой способ не является актуальным, ведь в последних версиях «Яндекс»-браузера строка поиска очищается вместе с удалением истории.
Просмотр и удаление истории посещений на Android
Часто бывает такое, что телефон попадает в руки к другим людям, и во избежание разглашения важной, либо личной информации советую периодически чистить историю и сохраненные пароли Яндекс браузера. Для того что бы просмотреть историю посещений Яндекс браузера на устройствах, работающих на операционной системе Android нажимаем на кнопку «Вкладки» рядом с адресной строкой
Для того что бы просмотреть историю посещений Яндекс браузера на устройствах, работающих на операционной системе Android нажимаем на кнопку «Вкладки» рядом с адресной строкой.

При открытии вкладок, нам становится доступно нижнее меню, в котором есть иконка для перехода к просмотру «Истории посещений» и «Истории скачиваний». Нажимаем на неё.

Перед нами откроется история Яндекс браузера.

Что бы очистить историю необходимо открыть браузер и перейти в меню, нажав на 3 точки в правом нижнем углу.

В открывшемся меню выбираем пункт «Настройки».

В открывшемся меню настроек переходим к разделу «Конфиденциальность» и выбираем «Очистить данные».

- История
- Кэш
- Сохраненные пароли
- Открытые вкладки
И нажимаем «Очистить историю».

Можно настроить автоматическое удаление истории Яндекс браузера. Если активировать такую функцию, тогда при каждом закрытии браузера история посещений, закачек и сохраненные пароли будут автоматически удаляться.
Что бы настроить автоматическое удаление открываем «Настройки Яндекс браузера» (3 точки в правом нижнем углу экрана) и в открывшееся меню листаем до пункта «Конфиденциальности», убираем галку с пункта «Сохранять историю».

Удаление расчета ремонта из Автотека. Начало войны с Audatex

Всем доброго времени суток! Недавно имел счастье столкнуться со всеми так любимыми и почитаемыми отчетами, посланной нам цифровыми богами Автотеки. Теми самыми отчетами, зеленые галочки в которых, важнее чем осмотр самого автомобиля, теми, где тотал не так уж и важен, если история «ровная»
И все бы ничего, если не 2 НО… Не обнаружил бы расчет на 2мл руб, и это не был бы мой автомобиль!
Курьезность заключается в том, что автомобиль никогда не был в ДТП и не имеет ни одной окрашенной детали вторично. Открыв расчет, я был крайне удивлен. Рассчитали весь салон автомобиля, плюс приятным бонусом был вписан пробег в 1.5 мл километров.


Однако…Изучив, откуда ноги растут, было принято решение писать не в филиал зла «Автотеку», а непосредственно в главный офис «Аудатекс»
Поскольку по заверению всех цитатников Вконтакте — Сила в правде, письмо было составлено в крайне нейтральном и спокойном тоне… мол прошу разобраться, тут ошибка… чуть ли не поблагодарил заранее за удаление.
После пары дней ожидания, получаю на почту ответ;

Понятно было мало чего, четко я понял одно — просто не будет. Собрав все юридические познания, применимые в данной стране, сгенерировал, как я думал гениальное письмо.

Ну все, теперь то точно закон на моей стороне — предположил я!
Что дое…ся? Подумал Аудатекс и прислал следующий ответ;

На данном этапе, бесполезное общение с Аудатекс было решено приостановить.
Принято решение обратиться к юристу для составления досудебной претензии и искового заявления непосредственно для обращения в суд!
Всю информацию, по прогрессу и процессу буду обновлять.
всем удачи!
P.S хотел вставить Ozzy Osbourne & Busta Rhymes — This Means War, но она и так в голове играет
Источник
Ошибки Автотеки и Авито, не застрахован никто!

Все наверное заметили, что в данный момент крупнейшая площадка по размещению бесплатных объявлений Авито плотно сотрудничает с компанией Автотека. Автотека интегрировалась в Авито и при поиске любого авто выдаёт кое-какие сведенья о нём, ну и предлагает докупить оставшиеся.

При продаже авто на Авито, необходимо ввести его ВИН номер, по нему в последствии Автотека сделает свой экспресс отчёт под объявлением. Также Автотека ищет по базе Авито старые объявления с этим же ВИНом и если находит, вставляет их в свой отчёт, показывая указанную ранее цену, пробег, описание, а и иногда и фото.
Функция эта безусловно полезная и позволяет выявить перекупов и других сомнительных личностей, которые раз в месяц делают новые фото затоталенного корыта (что-бы сбросить счётчик просмотров объявления) и пытаются снова его впарить. Вот только к сожалению ошибки тоже случаются.
Задумываясь о продаже своего авто, решил посмотреть, что же увидит потенциальный покупатель, оплатил отчёт по ВИНу, и понял, что сделал это не зря.
В моём отчёте фигурировало аж 3 объявления о продажи моего авто, все от 2019 года, хотя само собой я их не публиковал.



Т.е. предприимчивые ребята из какого-то салона-стоянки, где-то раздобыли мой ВИН (что в наше время думаю не является проблемой вообще), разместили свои авто с очевидно тёмным прошлым под этим ВИНом (при этом совершенно не парясь с пробегом и вбивая его от балды) и вуаля, теперь их фейковые объявления попадают в историю к истинному владельцу, который в свою очередь обретает геморрой на пустом месте, в виде:
— потери потенциальных покупателей;
— снижения рыночной стоимости авто;
— увеличения срока продажи авто.
Вот например, что увидит потенциальный покупатель в сводке по пробегу:

Если вы думаете, что проблема решается письмом в поддержку, вы ошибаетесь. Вопрос вообще никак не решается с МАРТА месяца. Я писал и в Авито и в Автотеку, скидывал туда и туда все документы по их запросам, а воз и ныне там, прошло уже почти ПЯТЬ месяцев.



И как результат, только стандартные отписки:


При этом Автотека говорит, что передали всю информацию в Авито, Авито говорит, что передали в Автотеку, ждите. Класс ребята, БРАВО. Вы создали действительно удобный сервис, но не можете решить элементарную проблему, создающую большие неудобства порядочным владельцам. Или может вам эти серые автосалоны тоже все документы прислали, а?
Вместо выводов:
— У компаний абсолютно не отлажен механизм отклонения фейковых объявлений и исправления истории настоящих авто. Судя по отзывам в интернете и слов одного трейдинщика, проблема далеко не еденичная.
— Каждый может получить такой нежданчик, поэтому перед продажей рекомендую купить отчёт по своему авто.
— Размещайте объявления на авто.ру и дроме, туда автотека пока не добралась.
Друзья, прошу максимальный репост, без публичного порицания эта проблема обретёт массовый характер, тут никто не застрахован.
Источник
Новости автомира
Автотека как удалить информацию об автомобиле

Автотека пользуется заслуженной популярностью в России, как добротный сервис по предпродажной проверке автомобиля. Не последнюю (даже первую) роль в её повсеместном использовании стал тот факт, что разработчиком является крупнейшая площадка по продаже автомобилей в нашей стране — Авито.
Вот только всё чаще у пользователей возникает вопрос: а врёт ли автотека?
Про развод с VIN и Автотекой:
Некоторые хитрые продавцы, решая обмануть автотеку указывают вин-код от другой машины (иногда разница только в последних двух цифрах).
Машина маркой и цветом такая же — но это совершенно другая машина. Наиболее ушлые просто подставляют VIN от абсолютно такой же машины, только чистой с юридической и технической стороны. Проверяется это очень легко — нужно сфоткать VIN и госномер автомобиля и сравнить их с тем, что висит в объявлении. Несмотря на банальный, в общем-то, развод — некоторые до сих пор попадают в эти неприятные ситуации
Дисклеймер: мы не ставим цель разоблачить «Автотеку», это не статья в стиле «Как нас разводят». Данная платформа действительно помогает тысячам автолюбителей не быть обманутыми многочисленными перекупами. Прилагает расчет ремонтных работ, которые были произведены на автомобиле. Но можно ли 100% положиться на информацию, предоставленную сервисом?

Для начала определимся, что из гуляющих в интернете слухов про Автотеку — истина, а что не соответствует действительности:

Что проверяет Автотека?
Автотека предоставляет следующие сведения:
— Год выпуска и комплектация ТС; — Сведения о технических характеристиках ТС; — Сведения о количестве владельцев ТС; — Сведения о пробеге ТС; — Сведения о выдаче дубликата ПТС; — Сведения о наличии обременений (залога); — Сведения о фактах угона ТС; — Сведения об использовании ТС в качестве такси; — Сведение об участии ТС в ДТП; — Сведения о проведении профилактических и ремонтных работ в отношении ТС;
Наличие ограничений / нахождение в розыске и залоге
Как это выглядит в отчете?

Подвоха здесь ждать не стоит — Автотека корректно определяет данный параметр. Интернет знает единичные случаи, когда эта проверка была некорректной, но едва ли есть вина самого сервиса (скорей, вопросы к gibdd.ru). Т.е. если Автотека не определила ограничения, то некорректно отработал сторонний сервис. Просто проверьте продавца по другим базам
Проблемы с финансами у продавца автомобиля легко пробиваются:
ssprus.ru/iss/ip — исполнительные производства в отношении физиков и их долги перед приставами. Нужно ФИО и дату рождения продавца reestr–zalogov.ru/state/index — Поиск по реестру залогов
egrul.nalog.ru/ — Проверка юридического лица — существует ли оно вообще, кто директор, адрес и т.п.. kad.arbitr.ru — судебные дела в отношении юриков/ИП (если продавец — юридическое лицо, можете посмотреть историю)
Периоды владения (количество владельцев)
Количество владельцев прямо пропорционально техническому и косметическому состоянию автомобиля. Это не панацея, но найти автомобиль пробывший длительное время в «одних руках» несоизмеримо выше, чем на транспорт, где уже нет места в ПТС (везде есть исключения). Здесь есть данные по типу владельца — если там юридическое лицо, то значит машиной оформлена на какую-либо фирму. Процесс продажи при этом существенно меняется и весьма опасен в плане чистоты сделки (почитать о покупке автомобиля у юридического лица можно здесь)
Как это выглядит в отчете?

Автотека не всегда корректно обрабатывает информацию о том, что ПТС — дубликат. Даже если в отчете стоит зелёная галочка «Оригинальный ПТС (Не обнаружены сведения о выдаче дубликата ПТС)», то это далеко не факт, что этого не было. В качестве совета — обращайте внимание на строку «Смена госномера» : иногда выдача дубликата ПТС обозначается в отчете именно так
Можно воспользоваться сервисом adaperio.ru. На нем дополнительно можно узнать количество штрафов, которые были выписаны на данный автомобиль — тоже косвенный признак отношения к автомобилю его прошлым владельцем
Битые машины стоят ниже. В объявлениях крайне редко фигурирует факт повреждений кузова — кому хочется сбрасывать цену за сколы или царапины, не говоря уже о крашенных элементах или кривых лонжеронах. Эти сведения — одни из самых значимых в Автотеке, но тут есть огромные нюансы
Как это выглядит в отчете?

Самый верный способ — проверять только в живую с экспертом или толщиномером — только так можно на 99,9% убедиться в отсутствии коррозии, ржавчины или некачественного окраса. Проверьте автомобиль через сайт gibdd.ru — там будет самая свежая информация по участию в ДТП.

Проверим автомобиль по автотеке — VIN не указываем по этическим причинам. Автомобиль 2008 года выпуска, т.е. теоретически (и скорее всего) аварии на нём были. Автотека показывает — «Чисто»

Смотрим реальное положение дел:




Если пороги еще можно списать на страну производитель (Китай), то зазоры дверей, различающийся цвет пластика, кривой бампер уже практически выдает автомобиль, который был бит, как минимум в правую сторону
Самый часто модифицируемый параметр в «карточке» автомобиля. Можете быть уверены, что в двух случаях из трех, при покупке поддержанной машины, пробег будет скручен, при этом нынешний владелец может даже не подозревать об этом. Впрочем, продавец всё равно скажет, что действительно ничего не знает об этом и пробег скручен до него. Так или иначе, на пробег ориентируются большинство покупателей в нашей стране. И тут полный провал — изменить пробег в Автотеке можно
Как это выглядит в отчете?

Необходимо проверять пробег сканером и ноутбуком, подключаясь к диагностическому разъему автомобиля. В «мозгах» проверять особой нужды нет — скорее всего, там значение уже тоже подправили — необходимо считывать пробег с других модулей управления.
История обслуживания может дать примерную картину о том, как следили за машиной, какие кузовные работы делались, а не верить на слову владельцу и прохладным былинам а-ля «сел и поехал». Автотека сотрудничает с многими крупными холдингами, т.е. любой ваш ремонт, вплоть до замены лампочки в габаритах попадает в отчет Автотеки. Это касается многих официальных дилеров
Если продавец утверждает или показывает документы об обслуживании в каком-либо сервисе, которого нет в отчете Автотеки, то самый простой способ — это съездить туда и уточнить историю ремонтных работ по данному автомобилю.
Прохождение техосмотра — хороший звоночек. Значит, машина худо-бедно обслуживалась и отмечалась в пунктах осмотра
Как это выглядит в отчете?

Проверка (не бесплатная) технического обслуживания можно проверить через бот в Телеграме: @AvinfoBot
И ещё очень интересный факт: программа сведения о дтп берет в страховой базе. Получается если авто был в дтп, но не был застрахован, ремонтировался за наличные, в отчете информации не будет.

Давайте поговорим о платных сервисах для проверки авто не выходя из дома.
Ничего не имею против таких сервисов, очень удобно иногда, но мы редко ими пользуемся. Обязательные для проверки — сайт ГИБДД, реестр залогов и база ФССП, они бесплатные и максимально объективные. Большинство платных сервисов просто отправляют запросы на эти сайты, а данные отображаются в приложении или на сайте.
Если пользоваться этими приложениями с головой, то можно получить много информации, например, когда вы уже осмотрели автомобиль и есть какие — то сомнения, можно их развеять, сделав запрос.
Меня напрягает их навязчивая и даже агрессивная реклама, типа за 100 рублей ты проверишь машину просто досконально, зачем же платить такие деньжищи подборщикам, если все так просто и недорого?) В рекламе они обещают проверку на угон, на запрет, на ДТП, на достоверность пробега прям все в одном! Не знающий человек и впрямь, может поверить во всемогущество этих сервисов, но давайте рассмотрим их подробнее.
1. Вин номер, проверка на аресты, угоны, регистрацию. Приложения выдают информацию по указанному вину, а кто проверит правильность указанного вина? Кто гарантирует, что указанный вин в документах соответствует вину на автомобиле? Никто не продает угнанную машину с угнанными документами) Для угнанного авто всегда есть чистые документы, по которым приложение вам выдаст информацию — «все ок, берите!»
2. Количество хозяев. Например, в объявлении указано 1 хозяин, вы делаете запрос в приложении, а там 2 записи на физ. лицо, обманывают, думаете вы и правильно делаете, но в жизни бывают всякие случаи. К примеру, машину переоформляют на родственника для освобождения от уплаты налогов. Всегда надо смотреть документы вживую, ну или же попросить фото у продавца, если речь идет о дистанционном варианте.
3. Проверка на ДТП. Тут есть два варианта, когда в базе нет ДТП по автомобилю, а значит все хорошо и когда они есть, а значит все плохо и машину брать нельзя. Первый вариант очень сомнительный в том плане, что в этой базе хранятся ДТП только с 2015 года и естественно только те, что были зарегистрированы ГИБДД и страховой соответственно. Но аварии даже с сильными повреждениями не всегда регистрируются, участники могут договориться об оплате на месте, а если участник был один (съезд в кювет, к примеру) то и регистрировать смысла нет. В таком случае приложение выдаст информацию, об отсутствии ДТП, но на деле все может оказаться совсем иначе. Второй вариант — когда отображается информация об аварии и даже указано, какие элементы были повреждены. У моего отца опель астра, по базе будет две аварии. Если верить сервису, то и спереди, и сзади все было разбито, а по факту крашен один элемент.
4. Пробег. В рекламе так уверенно заявляют, что укажут вам реальный пробег любого автомобиля. А как же они его узнают? Неужели машины уже отправляют данные о пробеге в реальном времени на какой-то сервер, с которого любой желающий может с ним ознакомиться. К сожалению все не так) Информация о пробеге берется из данных о ТО, в этом случае даже не техническом обслуживании, а техническом осмотре. А кто его сейчас проходит как положено? Процентов 30 от всех автомобилей и то хорошо, а в большинстве случаев пробег просто записывается со слов хозяина. В приложении просто будет указан пробег на последнем ТО, его же могут скрутить до этого. Машины до 3х лет вообще не проходят ТО каждый год, а за год можно проехать и 30 и 50 тысяч.
Четыре основания не доверять на 100% платным сервисам для проверки авто при выборе автомобиля. Пользоваться ими можно и даже нужно, это может облегчить поиск и выбор, но делать это надо с умом.
В конце покажу наглядно на примере моей машины, что обащают и что получаешь в итоге. Обратите внимание, «в отчете найдено 9 записей» из списка ниже. В нем и пробег, и история размещения на авито, и история обслуживания у диллера.
Теперь смотрим, что мы получили в отчете. Он аж на трех страницах) Но информации не густо… 90 процентов это информация с сайта ГИБДД, а так же два сервиса по залогам. А где же пробег? А где же участие в ДТП? А они были даже оформлялись, на двери есть небольшая вмятина. А где же обслуживание у дилера? А машина там обслуживалась пока в Белгороде был дилер.
Информация о дубликате или оригинале ПТС полезная информация, но ее можно получить просто увидев ПТС на фото или в живую. Пользуясь случаем хочу поделиться с читатетелями человеком который поможет в сложной ситуации с удаление ДТП из Базы ГИБДД, а так же с чисткой информации в «Автотеке» WhatsApp для связи: +79656085365
Источник
Мошенник обещает подчистить историю моего автомобиля
Я хочу продать машину, но она несколько раз побывала в ДТП. Отремонтирована она хорошо, и внешне это почти незаметно, но запрос в сервисе «Автотека» выдает, что машина побывала в серьезной аварии.
Насколько это реально и стоит ли с таким связываться?
Артем, я бы не советовал платить таким сервисам. Если бы предложение было правдой, оно подпадало бы под статью 272 УК РФ. За неправомерный доступ к компьютерной информации можно лишиться свободы на срок до 2 лет. Но речь в таких телеграм-каналах обычно идет о мошенничестве: продавцы предлагают услугу, оказывать которую не собираются, а покупатель сам ничего не нарушает и выступает только в роли потерпевшего. В любом случае вы в проигрыше.
Кроме того, даже если представить, что информация об аварии испарилась, вмятины на кузове от этого никуда не денутся, да и выплатить автокредит все равно придется.
Давайте приглядимся к предложению телеграм-канала и разберемся, что с ним не так.
Вот почему очевидно, что вас хотят обмануть
👎 Продавец услуги предлагает почистить отчет об автомобиле, но путается в том, что и где надо чистить, чтобы выполнить обещание.
👎 Даже если информация об авто чудом изменится, это не исправит вмятины на кузове, не отменит обязательства по кредиту и не заставит исчезнуть исполнительный лист.
👎 Продавец просит предоплату, но про него самого ничего не известно. Если он исчезнет с деньгами, вернуть их будет практически невозможно.
Что за история автомобиля
При покупке и продаже авто на вторичном рынке каждый недостаток автомобиля — повод для снижения цены. Поэтому покупатель стремится найти в автомобиле как можно больше недостатков, чтобы сбить цену, а продавец заинтересован в том, чтобы эти недостатки не заметили.
Еще несколько лет назад покупателю приходилось полагаться только на собственный опыт. Смог найти в автомобиле недостатки или узнать о проблемах с регистрацией — значит, повезло. Но везло не всегда. Мы много раз писали о ситуациях, когда купленная машина доставляла людям множество проблем. Вот несколько примеров:
Самозащита от мошенников
Когда хватало денег, покупатели обращались к профессиональным подборщикам автомобилей. Если попадался добросовестный, это имело определенный смысл, но расходы возрастали, и в итоге могло оказаться, что подержанное авто стоит лишь немного дешевле нового.
Со временем появились общедоступные базы данных. ГИБДД открыла доступ к сведениям о ДТП, служба судебных приставов — к информации об исполнительных производствах, нотариальная палата — к информации о залоговом имуществе. Продать проблемную машину стало сложнее: покупатель мог в любой момент проверить ее с помощью этих сервисов и узнать о проблемах.
Потом появились сервисы, которые упрощали жизнь покупателей, потому что сами запрашивали информацию в базах данных — не только государственных, но и частных. Услуга платная, но обычно недорогая, несколько сотен рублей. Сейчас таких сервисов десятки.
Далеко не всегда информация о ремонтах, залогах, ограничениях на регистрацию отражается в базе сразу. Тут действует и технический фактор, и человеческий: иногда люди загружают сведения с задержкой или не загружают вообще. Но если информация о проблемах попала в открытый доступ, у владельца автомобиля могут возникнуть проблемы с продажей. Желающих купить машину, возможно, меньше не станет, но у них появится аргумент, чтобы попросить скидку.
Что предлагают «чистильщики истории»
«Чистильщики» обещают удалить все негативные данные об автомобиле из всех баз данных. Можно уменьшить пробег, избавиться от ДТП, залогов, исполнительных производств — было бы желание и деньги. Если потом покупатель запросит отчет об авто, выяснится, что оно в идеальном состоянии.
Цена услуги зависит от марки автомобиля и года выпуска. На первый взгляд это может показаться логичным: чем дороже и старше автомобиль, тем выше стоимость «чистки». Но мне такая логика представляется сомнительной: трудоемкость уменьшения пробега на 10 тысяч и на 100 тысяч километров в базах данных вряд ли сильно различается.
Телеграм-канал, как это принято в подобных кругах, анонимный. Про продавцов ничего не известно, захотят обмануть — обманут.
А еще, по утверждению продавцов, у них 150 постоянных клиентов, но на канал почему-то подписано только 98 человек Стоимость услуг зависит от марки, модели и года выпуска, в среднем — 20—30 тысяч рублей
Как я заказывал изменение истории
Я связался с менеджером одного из каналов, предлагающих услуги по очистке. Представился перекупщиком и сказал, что у меня в ассортименте есть проблемные автомобили, которые я не могу продать, потому что в истории видны все проблемы.
После общения с менеджером я пришел к выводу, что никакой чистки истории и удаления информации из баз данных не будет. Менеджер поясняет, что информацию о залоге удалят «свои люди в ГИБДД». Причем вопрос о том, кто будет удалять информацию, я задал два раза — и оба раза мне ответили: да, именно сотрудники ГИБДД, не извольте сомневаться.
Но проблема в том, что база данных ГИБДД с реестром залогового имущества вообще никак не связана. Регистрацией автомобилей и внесением информации о них в базу данных действительно занимается МВД. А вот реестр уведомлений о залоге ведут нотариусы. Касается это не только автомобилей, в нем содержится еще и информация об объектах недвижимости. Нотариусы получают эти сведения от банка, выдавшего кредит, или от кредитора — частного лица. ГИБДД эту информацию просто не видит. Изменить ее даже очень коррумпированный сотрудник не сможет при всем желании.
Менеджер по очистке истории автомобилей об этом, по всей видимости, не знает. А раз он предлагает услугу, оказать которую не может, — значит, скроется с деньгами. Например, после ликвидации канала по вине злой «Автотеки».
Как победить выгорание
Что в итоге
Даже если бы информацию об авто в базах данных и правда можно было изменить, это не имело бы большого смысла. Она все равно дублируется в других источниках, а проблемы с самой машиной можно обнаружить при осмотре.
Залог имущества возникает на основании кредитного договора или договора займа. Если человек не платит по кредиту, банк имеет право забрать автомобиль и продать его кому-нибудь другому, чтобы компенсировать убытки. И отсутствие в отчете сведений о залоге этого не изменит.
Стирание информации об исполнительном производстве не уничтожит исполнительный лист. Удаление информации о ДТП не вылечит вмятины на кузове. Даже если они хорошо спрятаны, покупатель найдет их с помощью толщиномера.
В такой ситуации уже неважно, изменена ли информация в базах данных, или отчет об авто нарисован в фотошопе. Покупатель сможет увидеть недостатки машины, и у него появится повод для торга. А продавец останется в минусе вдвойне: кроме скидки за недостатки он потеряет еще и деньги на оплату услуг «чистильщиков».
Мнение редакции может не совпадать с мнением автора.
Если сталкивались с подозрительными предложениями, пишите. Прищуримся.




Павел, у меня тоже была неприятная ситуация.
Как-то раз из интереса купил отчет на свою машину и сильно удивился, так как в автотеке высвечивались фото другого авто. История пробега, ремонтов и дтп была моя, но после корректной отметки о ремонте с пробегом 190 тыс. км следовала информация о размещении объявления о продаже с фотографиями другого авто и указанным пробегом 60 тыс. км.
Автомобиль на фото оказался мне знаком и его хозяин мне рассказал, что он при продаже своего авто по определенным причинам не хотел указывать свой VIN и на одном из сайтов в объявлении указал мой. При этом он не подумал, что это может отразиться в чужой истории.
Я зла ни на кого не держу, но мой и Ваш случай показывают, что отчет любого авто с автотеки и прочих сервисов может быть испорчен намеренно (если знать VIN жертвы) или ошибочно (если кто-то внес не те цифры пробега или ошибся в VIN-коде). Для себя теперь понимаю, что не нужно слепо верить всем данным подобных отчетов.
Главное чтобы не было залога, угона или розыска, хотя и в этих ведомствах человеческий фактор не исключен.
Источник
Не путайте с историей браузера.

Chrome, Firefox, Opera и другие браузеры могут запоминать посещённые вами сайты и введённые запросы.
Аналогичную информацию сохраняют и поисковики. Google и «Яндекс» отображают её в виде подсказок: если ввести в поисковой форме ключевое слово или сайт, появятся совпадающие с ним старые запросы и ранее посещённые ресурсы. Эти данные хранятся в облаке и синхронизируются между всеми гаджетами, подключёнными к общему аккаунту.
Если вы хотите, чтобы другие пользователи устройства не видели этих подсказок, удаляйте историю не только в браузере, но и в поисковике. Вот как это сделать.
Как очистить историю поиска «Яндекса»
Зайдите на страницу yandex.ru с компьютера или мобильного устройства. Если используете второе, опуститесь в самый низ страницы и нажмите «Версия для компьютеров». Если вы не авторизованы, войдите в свою учётную запись.
В верхнем правом углу кликните «Настройки» и выберите «Настройки портала».
Нажмите «Очистить историю запросов». При желании можете отключить показ истории поиска и посещённых сайтов.
Также не забудьте очистить историю в браузере.
Как очистить историю поиска Google
В браузере компьютера или мобильного устройства откройте страницу google.ru. Если вы не авторизованы, войдите в свою учётную запись. Скриншоты в статье сделаны на ПК, но в мобильной версии сайта порядок действий будет аналогичным.
Нажмите на иконку «Приложения Google» в верхнем правом углу и выберите «Аккаунт».
Затем кликните «Данные и персонализация». Это пункт управления вашей информацией, которую Google заносит в историю поиска. Здесь вы можете удалить свои запросы вручную, настроить их автоочистку или вовсе запретить поисковику их сохранять.
Как удалить поисковые запросы вручную
В разделе «Действия и хронология» откройте пункт «Мои действия».
Нажмите «Фильтровать по дате и продукту».
Выберите период, за который нужно удалить запросы, и отметьте в списке продуктов все элементы, связанные с поиском: «Поиск», «Поиск картинок» и «Поиск видео». Нажмите «Применить».
Нажмите на три точки рядом с поисковой строкой, выберите «Удалить результаты» и подтвердите удаление.
Если вам нужно удалить только один или несколько запросов, можете не использовать фильтр. Просто нажмите на три точки рядом с нежелательным элементом истории и выберите «Удалить»
Когда закончите, не забудьте очистить историю в браузере.
Как настроить автоочистку поисковых запросов
В разделе «Отслеживание действий» кликните «История приложений и веб-поиска» → «Управление историей».
Нажмите на три точки рядом с поисковой строкой и выберите «Период хранения данных».
Отметьте подходящий вариант: «Хранить 18 месяцев» или «Хранить 3 месяца». Все запросы старше этого срока Google будет удалять автоматически. Нажмите «Далее» и подтвердите удаление.
Как отключить сохранение поисковых запросов
В разделе «Отслеживание действий» кликните «Настройки отслеживания действий».
Переведите в нерабочий режим функцию «История приложений и веб-поиска». Чтобы подтвердить действие, нажмите «Отключить».
После этого Google не будет сохранять данные, введённые в поисковике.
Читайте также 🌐🌐🌐
- 7 скрытых настроек Chrome для Android, которые делают браузер заметно удобнее
- Как очистить кеш браузера
- 6 лучших браузеров для компьютера
- 6 причин не сохранять пароли в браузере
- Как включить режим инкогнито в «Яндекс.Браузере»
Как говорил один известный философ, только тот, кто на многое отваживается, неизбежно во многом и ошибается. Невозможно прожить жизнь без ошибок и ситуаций, за которые не было бы стыдно даже через несколько десятков лет. Но вместо того, чтобы “копаться” глубоко в себе, выясняя, как исправить ошибки прошлого, может стоит задуматься о том, а какой урок вы вынесли из прошлых ошибок? Ведь все, что нам дается – для чего-то, а не вопреки.
Исправление ошибок прошлого: 2 нюанса
Исправить ошибки прошлых лет часто бывает просто невозможно. К примеру, ваша ошибка связана с человеком, которого давно рядом нет. В таком случае, изменить что бы то ни было – физически невозможно. Тогда важно в корне изменить свое отношение к проблеме: научится воспринимать ошибки, принять их как часть пути решения проблемы.
Не загоняйте себя в угол
Занимаясь “самокопанием” и ища причины того, почему вы так поступили, почему не сделали иначе, вы рискуете прийти к сложным хроническим заболеваниям и расстройствам нервной системы, в частности. Поэтому не стоит испытывать свой организм на прочность. Маниакальное исправление ошибок прошлого может серьезно отразиться на вашем настоящем.
Поиск виноватых в прошлом ничего вам не даст
Вторым моментом является анализ произошедшего: не ищите виноватых и не осуждайте их за некоторые поступки. Ведь никто не может сказать с точностью, как бы он поступил на месте виновного. Проще всего осудить и поставить клеймо – “виновен”, чем разобраться в ситуации целиком и полностью.
Это и есть основные принципы, по которым советуют воспринимать информацию с негативным обрамлением и психологи, и многие мудрецы.
Семь шагов к прощению: как простить себя за ошибки прошлого?

Важно не столько исправить, сколько принять свою ошибку. Причем, второй пункт куда важнее первого. Нужно уметь воспринимать все свои ошибки и делать нужные выводы из них. Вот семь подробных шагов, которые помогут правильно проанализировать и сделать выводы из сложившейся ситуации:
1. Принять свою ошибку как данность
Самый сложный шаг. Здесь нужно переступить через собственный характер, посмотреть на ситуацию со стороны, где часто ваша позиция – не в выигрышном положении. Без обид и, как говорится, “на холодную голову” нужно принять ситуацию, осознать ее. Такой период редко длится один-два дня. Часто для такого восприятия потребуются недели, месяца. Но только после этого можно перейти к другим шагам исправления ошибок.
2. Признать правду
После того, как вы сказали сами себе: кто виноват, в чем виноват, и почему виноват, последует череда облегчения и смирения. Вы понимаете, что сколько бы времени ни прошло, но без признания правды вы будете только усложнять ситуацию. Какая бы эта правда не была – она есть, и ее важно осознать. Только так вы сможете сделать сегодня хоть что-то, чтобы исправить ошибки прошлых лет.
3. Простить себя за ошибку прошлого
Часто для того, чтобы оправдать самого себя, свои поступки, можно обвинить окружающих: не помог, не подсказал, промолчал. Остановитесь! Не нужно винить – просто примите и простите. И себя, и того, кто виноват, и кто участвовал (косвенно или непосредственно).
4. Раскаяться
Простить и раскаяться для многих – одно и то же. Но, это совершенно разные вещи. Раскаяться – значит принять ситуацию, и сделать так, чтобы она больше не повторялась. Вы не можете обещать за других, но самому себе вы врать не будете: сделаете все возможное, чтобы впредь предотвратить похожие ситуации. Вы не исправите то, что было в прошлом, но можете не совершать этих ошибок в будущем.
5. Оставаться благодарным
Любая ошибка – это урок. И насколько правильно вы усвоили тот самый урок, настолько правильным и эффективным будет результат от содеянного. Часто ошибка в прошлом – вовсе не ошибка, а очередная ступень к новому периоду в жизни. Умейте мысленно поблагодарить за такие уроки.
6. Постараться забыть
После того, как вами усвоен урок, пусть даже и жестокий, вы навсегда извлечете из него все полезное, а плохое оставьте позади. Перестаньте думать и винить себя за ошибки прошлого. Только осознанная польза и хорошие воспоминания помогут сбросить напряженность и продолжить полноценную жизнь без оглядки на прошлые ошибки.
7. Не сравнивать
Какой бы урок вы ни вынесли, это – ваш личный опыт. Не стоит перенимать опыт других или, тем более, советовать и приводить собственную ситуацию в пример. Люди все разные, и то, что вам может показаться полезным, для другого окажется травматическим и жестоким.

Исправить ошибки прошлых лет или извлекать из них уроки – индивидуальная потребность каждого из нас. Нужно только понимать, что все, что ни делается, действительно – к лучшему. Это понимает каждый, спустя время. А ошибки прошлого потому и в прошлом, чтобы там остаться. Не зацикливайтесь и не переносите их в настоящее.