Mir Pay – популярная система бесконтактных платежей разработанная российской национальной системой «МИР». С ее помощью можно оплачивать товары и услуги со смартфона. Мобильное приложение «Мир Пэй» было запущено весной 2019 года. С момента его выхода большинство багов было исправлено, однако многие пользователи не перестают жаловаться на различные ошибки возникающие при эксплуатации. Одна из самых распространенных проблем – «Ошибка работы с клиентскими данными Мир Пэй». О способах ее устранения будет рассказано в нижеследующей статье.
Содержание
- Что означает «Ошибка работы с клиентскими данными» в Mir Pay?
- Способы исправления ошибки
- Очистка кэша и данных приложения в настройках телефона
- Синхронизация времени
- Отключение от Wi-Fi в незащищенной сети
- Подключение к мобильному интернету
- Добавление банковской карты
- Удаление приложения Google Play Services
- Обновление приложения Мир Пэй
- Что делать в случае временных технических неполадок
- Заключение
Что означает «Ошибка работы с клиентскими данными» в Mir Pay?
Чаще всего данная ошибка наблюдается при регистрации в мобильном приложении «Мир Пэй» и добавлении карты. Программа поддерживает работу с различными картами. Для клиентов некоторых банков ее функционал недоступен. Перед тем как добавлять новый платежный инструмент нужно убедиться в том что:
- он поддерживается платежной системой МИР;
- он не был заблокирован;
- банк выпустивший карту является участником Mir Pay.
Ошибка может быть вызвана как случайным сбоем в работе смартфона или программы «Mir Pay», так и следующими причинами:
- Попыткой подключиться к незащищенной Wi-Fi сети. Если система считает подключение небезопасным, она автоматически блокирует работу приложения.
- Наличием ошибок в кэше или сохраненных данных программы Mir Pay.
Также нужно учитывать, что каждая карта обладает определенным сроком действия.
Способы исправления ошибки
Для работы мобильного приложения требуется доступ к интернету. Для того чтобы убедиться в наличии соединения нужно попробовать открыть в браузере новую web-страницу либо обновить открытую. Если данный шаг не помог устранить ошибку, стоит воспользоваться одним из следующих способов:
Очистка кэша и данных приложения в настройках телефона
Прежде всего стоит выполнить очистку кэша и данных через раздел настроек смартфона. Для этого нужно выполнить такие действия:
- Зайти в настройки и выбрать «Приложения».
- Тапнуть по клавише «Отобразить все приложения».
- В открывшемся списке найти «Mir Pay».
- Перейти на страницу настроек приложения и нажать на кнопку «Хранилище и кэш».


Остается тапнуть по клавише очистки хранилища и кэша.
Синхронизация времени
Некорректно установленное время на смартфоне может стать причиной множества ошибок. Для настройки синхронизации часов нужно проделать следующие шаги:
- Найти в настройках раздел «Время и дата».

- Активировать синхронизацию в «Автоопределении времени».

Названия разделов отличаются в разных моделях смартфонов.
Отключение от Wi-Fi в незащищенной сети
После того как хранилище и кэш будут очищены необходимо отключиться от незащищенной Wi-Fi сети. Нужно сменить точку доступа на защищенную. При работе с ней риск того что данные будут перехвачены сводится к минимуму.
Подключение к мобильному интернету
Мобильный интернет – хорошая альтернатива незащищенному Wi-Fi доступу. После чистки данных и кэша нужно отключиться от незащищенной Wi-Fi сети, а затем подключиться к мобильному интернету в настройках своего смартфона.
Добавление банковской карты
В отличие от СБПэй который не использует данные банковских карт, для работы «Мир Пэй» требуется привязка к платежному инструменту. После того как хранилище данных и кэш будут очищены а тип соединения сменен на защищенный, потребуется повторное добавление банковской карты. Для этого нужно запустить мобильное приложение Mir Pay, тапнуть по клавише добавления карты и сделать ее фотографию либо вбить номер и CVC-код вручную. Необходимо установить Mir Pay в качестве основного средства оплаты. Сделать это можно через раздел настроек передвинув бегунок напротив соответствующей строки в активное положение.
Удаление приложения Google Play Services
 Если ни один из вышеперечисленных способов не помог исправить ошибку, нужно деинсталлировать либо временно отключить Google Play Services. Для этого необходимо зайти в раздел настроек мобильного телефона, выбрать «Приложения», затем «Показывать все приложения», найти в списке «Google Play Services» и тапнуть по клавише «Отключить» или «Остановить».
Если ни один из вышеперечисленных способов не помог исправить ошибку, нужно деинсталлировать либо временно отключить Google Play Services. Для этого необходимо зайти в раздел настроек мобильного телефона, выбрать «Приложения», затем «Показывать все приложения», найти в списке «Google Play Services» и тапнуть по клавише «Отключить» или «Остановить».
Обновление приложения Мир Пэй
Проблема часто возникает из-за использования устаревшей версии программы Мир Пэй. Для обновления нужно зайти в Play Market, отыскать в списке название приложения и нажать на кнопку «Обновить».
Что делать в случае временных технических неполадок
У любого сервиса бывают сбои. Обычный пользователь никак не может повлиять на решение проблемы. Ему остается только ждать когда специалисты устранят ошибки и восстановят работоспособность сервиса. Из-за высокой нагрузки на платежную систему МИР увеличившуюся после введения санкций в «Mir Pay» могут наблюдаться технические неполадки.
Для получения информации о сбоях и ориентировочном времени их устранения стоит обратиться в службу поддержки по номеру 8-800-1005464 (бесплатная линия для звонков по Российской Федерации) или через электронную почту info@nspk.ru.
Заключение
Если при использовании «Mir Pay» появилось системное уведомление «Ошибка работы с клиентскими данными Мир Пэй», для решения проблемы нужно убедиться в наличии доступа к интернету, очистить кэш и данные программы, подключиться к защищенной сети и повторно добавить карту. Ошибка бывает связана с работой Google Play Services, отсутствием обновлений и временными техническими неполадками.
( 1 оценка, среднее 5 из 5 )
К сожалению, игра-песочница Minecraft от Mojang печально известна тем, что портит миры и делает их неиграбельными. Если вы провели сотни часов в определенном мире, может быть душераздирающе узнать, что вы больше не можете получить к нему доступ.
К счастью, в зависимости от уровня повреждения, можно восстановить мир Minecraft из резервной копии. Вот как.

Быстрое исправление поврежденных миров на ПК
Во-первых, попробуйте создать новый мир с тем же именем и семя мира, что и ваш потерянный мир. Иногда это приводит к тому, что Minecraft загружает ваш предыдущий мир с неповрежденным инвентарем. Это исправление потенциально будет работать для любой версии Minecraft.
Примечание. В этом уроке мы будем называть затерянный мир CorruptedWorld.
Чтобы создать новый мир с тем же семенем мира:
- Откройте Майнкрафт.
- Выберите исходный мир, затем нажмите «Изменить».
- Нажмите «Экспортировать настройки генерации мира». Это экспортирует файл .JSON в вашу папку сохранения.
- Вернитесь в меню мира. Нажмите «Создать новый мир» и назовите мир так же, как исходный мир.
- Выберите Дополнительные параметры мира.
- Щелкните Импорт настроек. Это откроет Проводник.
- В адресной строке введите %appdata%.
- Откройте .minecraft.
- Двойной щелчок сохраняет. Здесь хранятся папки вашего мира Minecraft.
- Откройте CorruptedWorld, выберите файл worldgen_settings_export.json и нажмите «Открыть». Подождите, пока сгенерируется мир, затем закройте Minecraft.
Если это не работает, перейдите к более подробным исправлениям ниже.
Более длительное исправление для Corrupted Worlds на ПК
Если быстрое исправление не сработало для вас, вручную создайте новый мир и скопируйте старые файлы игры, чтобы решить проблему. Это исправление должно работать как для Java Edition, так и для Bedrock Edition в Windows.
Этот процесс также должен работать на Mac, но файлы игры хранятся в скрытой папке Library/Application Support.
Шаг 1: Создайте новый мир
Первый шаг — открыть Minecraft с помощью лаунчера и создать новый мир с тем же семенем, что и исходный мир. Если у вас нет сида под рукой, вы можете найти его, следуя руководству в первом исправлении.
Шаг 2: Перенесите файлы Level.dat
Следующим шагом будет перенос необходимых файлов в ваш новый мир. Мы рекомендуем создать резервную копию вашего мира перед выполнением этого шага. Ниже мы расскажем, как это сделать.
Чтобы передать файлы мира:
- Нажмите клавишу Windows + R, чтобы открыть «Выполнить».
- Введите %appdata% и нажмите Enter.
Дважды щелкните .minecraft.
4. Дважды щелкните папку сохранения.
5. Откройте CorruptedWorld и найдите level.dat, level.dat_mcr (не всегда присутствует), level.dat_old и session.lock. Щелкните правой кнопкой мыши и скопируйте / вставьте каждый из этих файлов в папку вашего нового мира. В Minecraft Bedrock Edition вам нужно только перенести level.dat.
6. Перезапустите Minecraft и загрузите свой мир.
Если у вас есть резервная копия вашего мира Minecraft, восстановить ваш мир несложно. Все, что вам нужно сделать, это перенести резервную копию мира в папку с сохранениями.
Примечание. Перед этим мы рекомендуем создать резервную копию ваших сохраненных игр, так как это приведет к удалению ваших локальных сохранений. Вы можете сделать это в игре, выбрав свой мир, нажав «Изменить» и выбрав «Создать резервную копию». Резервные копии хранятся в папке .minecraft во второй папке, называемой резервными копиями.
Как восстановить свой мир на ПК / Mac
Чтобы восстановить свои резервные копии миров Minecraft на ПК, просто перейдите в папку сохранения игры, как указано выше, удалите поврежденный мир и скопируйте / вставьте туда резервную копию мира. Процесс такой же для Mac. Чтобы легко найти файлы игры на Mac или Windows, откройте Minecraft, щелкните поврежденный мир, выберите «Изменить», затем нажмите «Открыть папку резервных копий».
Как восстановить свой мир в Pocket Edition
Если вы играете в Minecraft на Android или iPhone, Minecraft PE теперь пытается автоматически восстановить поврежденные сохранения (начиная с Pocket Edition v0.11.0 alpha). Если это не сработает, вы можете попытаться восстановить сохраненный файл, воспользовавшись автоматическим резервным копированием вашего телефона (например, Samsung Backup, Google Backup или iCloud на iOS). Надеюсь, они сделали резервную копию ваших данных Minecraft и смогут восстановить ваш мир.
Если вы не знаете, вот как вы можете создавать резервные копии и восстанавливать данные на Android и iPhone.
Как восстановить свой мир на консоли
На Xbox и PlayStation процесс восстановления вашего мира совершенно другой.
На Xbox:
- Удалите Майнкрафт.
- Удалите данные сохраненной игры, выбрав «Система»> «Хранилище»> «Удалить локальные сохраненные игры».
- Очистите свой MAC-адрес, выбрав «Сеть»> «Настройки сети»> «Дополнительные настройки»> «Альтернативный MAC-адрес»> «Очистить».
- Переустановите Майнкрафт и запустите его. Он должен синхронизировать ваши сохранения с облачного сервера резервного копирования Xbox Live.
На PlayStation:
Чтобы восстановить сохраненный мир на PlayStation, вам потребуется учетная запись PS Plus до того, как игра будет повреждена. Чтобы восстановить свой мир, откройте «Настройки»> «Управление сохраненными данными приложения»> «Сохраненные данные в онлайн-хранилище».
Здесь выберите «Загрузить в системное хранилище», затем выберите мир, который вы хотите восстановить, и нажмите «Загрузить».
Как восстановить предыдущую версию на ПК с Windows
Minecraft автоматически сохраняет файлы резервных копий для каждого из ваших миров в Microsoft Windows. Конечно, возвращение к этому будет означать, что вы потеряете часть своего прогресса, но это лучше, чем полная потеря мира.
Чтобы вернуться к предыдущей версии мира Minecraft:
- Перейдите в папку saves, как указано выше.
- Найдите свой мир и дважды щелкните папку.
- Найдите файл level.dat и скопируйте его в другое место, чтобы создать резервную копию. Затем удалите файл из папки мира.
- Переименуйте level.dat_old в level.dat.
- Перезагрузите Minecraft и посмотрите, правильно ли теперь работает ваш мир.
Проблема в том, что вы начнете в случайном месте (часто очень далеко от ваших построек) и должны будете найти их, поэтому, надеюсь, у вас есть записанные координаты. Кроме того, любая информация о модах, плагинах или надстройках будет потеряна, а ваш инвентарь будет пуст. К сожалению, это неизбежные проблемы с этим методом.
Как частично восстановить свой мир
Если ничего не работает и вы не знаете исходное семя мира, вы все равно можете частично восстановить свой мир Minecraft. Для этого:
- Создайте новый мир с любым семенем и именем.
- Перейдите в свою мировую папку, как указано выше, и перенесите файл CorruptedWorld level.dat в новую мировую папку.
- Откройте Minecraft и загрузите свой новый мир. Все фрагменты, которые вы сохранили в исходном мире, будут загружены в новый сид. Однако между новым и старым миром, скорее всего, будут большие скалы / странные образования, где они не выстраиваются в линию.
Резервное копирование данных — самый безопасный вариант
Надеюсь, эти методы помогли вам восстановить поврежденные файлы Minecraft, и вы сможете вернуться к игре. Просто имейте в виду, что лучший способ защитить ваши сохранения Minecraft (и все ваши личные данные) — это часто создавать резервные копии ваших данных.

При работе с big data ошибок не избежать. Вам нужно докопаться до сути данных, расставить приоритеты, оптимизировать, визуализировать данные, извлечь правильные идеи. По результатам опросов, 85 % компаний стремятся к управлению данными, но только 37% сообщают об успехах в этой области. На практике изучать негативный опыт сложно, поскольку о провалах никто не любит говорить. Аналитики с удовольствием расскажут об успехах, но как только речь зайдет об ошибках, будьте готовы услышать про «накопление шума», «ложную корреляцию» и «случайную эндогенность», и без всякой конкретики. Действительно ли проблемы с big data существуют по большей части лишь на уровне теории?
Сегодня мы изучим опыт реальных ошибок, которые ощутимо повлияли на пользователей и аналитиков.
Ошибки выборки

В статье «Big data: A big mistake?» вспомнили об интересной истории со стартапом Street Bump. Компания предложила жителям Бостона следить за состоянием дорожного покрытия с помощью мобильного приложения. Софт фиксировал положение смартфона и аномальные отклонения от нормы: ямы, кочки, выбоины и т.д. Полученные данные в режиме реального времени отправлялись нужному адресату в муниципальные службы.
Однако в какой-то момент в мэрии заметили, что из богатых районов жалоб поступает гораздо больше, чем из бедных. Анализ ситуации показал, что обеспеченные жители имели телефоны с постоянным подключением к интернету, чаще ездили на машинах и были активными пользователями разных приложений, включая Street Bump.
В результате основным объектом исследования стало событие в приложении, но статистически значимой единицей интереса должен был оказаться человек, использующий мобильное устройство. Учитывая демографию пользователей смартфонов (на тот момент это в основном белые американцы со средним и высоким уровнем дохода), стало понятно, насколько ненадежными оказались данные.
Проблема неумышленной предвзятости десятилетиями кочует из одного исследования в другое: всегда будут люди, активнее других пользующиеся соцсетями, приложениями или хештегами. Самих по себе данных оказывается недостаточно — первостепенное значение имеет их качество. Подобно тому, как вопросники влияют на результаты опросов, электронные платформы, используемые для сбора данных, искажают результаты исследования за счет воздействия на поведение людей при работе с этими платформами.
По словам авторов исследования «Обзор методов обработки селективности в источниках больших данных», существует множество источников big data, не предназначенных для точного статистического анализа — опросы в интернете, просмотры страниц в Твиттере и Википедии, Google Trends, анализ частотности хештегов и др.
Одной из самых ярких ошибок такого рода является прогнозирование победы Хилари Клинтон на президентских выборах в США в 2016 году. По данным опроса Reuters/Ipsos, опубликованным за несколько часов до начала голосования, вероятность победы Клинтон составляла 90%. Исследователи предполагают, что методологически сам опрос мог быть проведен безупречно, а вот база, состоящая из 15 тыс. человек в 50 штатах, повела себя иррационально — вероятно, многие просто не признавались, что хотят проголосовать за Трампа.
Ошибки корреляций
Непонятная корреляция и запутанная причинно-следственная связь часто ставят в тупик начинающих дата-сайнтистов. В результате появляются модели, безупречные с точки зрения математики и совершенно не жизнеспособные в реальности.

На диаграмме выше показано общее количество наблюдений НЛО с 1963 года. Число зарегистрированных случаев из базы данных Национального центра отчетности по НЛО в течение многих лет оставалось примерно на одном уровне, однако в 1993 году произошел резкий скачок.
Таким образом, можно сделать совершенно логичный вывод, что 27 лет назад пришельцы всерьез взялись за изучение землян. Реальная же причина заключалась в том, что в сентябре 1993 года вышел первый эпизод «Секретных материалов» (на пике его посмотрели более 25 млн человек в США).

Теперь взгляните на данные, которые показывают частоту наблюдений НЛО в зависимости от времени суток и дня недели: желто-оранжевым окрашена наибольшая частота случаев наблюдения. Очевидно, что пришельцы чаще высаживаются на Землю в выходные, потому что в остальное время они ходят на работу. Значит, исследование людей для них — хобби?
Эти веселые корреляции имеют далеко идущие последствия. Так, например, исследование «Доступ к печати в сообществах с низким уровнем дохода» показало, что школьники, имеющие доступ к большему количеству книг, получают лучшие оценки. Руководствуясь данными научной работы, власти Филадельфии (США) занялись реорганизацией системы образования.
Пятилетний проект предусматривал преобразование 32 библиотек, что обеспечило бы равные возможности для всех детей и семей в Филадельфии. На первый взгляд, план выглядел великолепно, но, к сожалению, в исследовании не учитывалось, действительно ли дети читали книги — в нем лишь рассматривался вопрос, доступны книги или нет.
В итоге значимых результатов добиться не удалось. Дети, не читавшие книги до исследования, не полюбили вдруг чтение. Город потерял миллионы долларов, оценки у школьников из неблагополучных районов не улучшились, а дети, воспитанные на любви к книгам, продолжили учиться так же, как учились.
Потеря данных

(с)
Иногда выборка может быть верной, но авторы просто теряют необходимые для анализа данные. Так произошло в работе, широко разошедшейся по миру под названием «Фрикономика». В книге, общий тираж которой превысил 4 млн экземпляров, исследовался феномен возникновения неочевидных причинно-следственных связей. Например, среди громких идей книги звучит мысль, что причиной спада подростковой преступности в США стал не рост экономики и культуры, а легализация абортов.
Авторы «Фрикономики», профессор экономики Чикагского университета Стивен Левитт и журналист Стивен Дабнер, через несколько лет признались, что в итоговое исследование абортов попали не все собранные цифры, поскольку данные просто исчезли. Левитт объяснил методологический просчет тем, что в тот момент «они очень устали», и сослался на статистическую незначимость этих данных для общего вывода исследования.
Действительно ли аборты снижают количество будущих преступлений или нет — вопрос все еще дискуссионный. Однако у авторов подметили множество других ошибок, и часть из них удивительно напоминает ситуацию с популярностью уфологии в 1990-х годах.
Ошибки анализа

(с)
Биотех стал для технологических предпринимателей новым рок-н-роллом. Его также называют «новым IT-рынком» и даже «новым криптомиром», имея ввиду взрывную популярность у инвесторов компаний, занимающихся обработкой биомедицинской информации.
Являются ли данные по биомаркерам и клеточным культурам «новой нефтью» или нет — вопрос второстепенный. Интерес вызывают последствия накачки индустрии быстрыми деньгами. В конце концов, биотех может представлять угрозу не только для кошельков венчурных фондов, но и напрямую влиять на здоровье людей.
Например, как указывает генетик Стивен Липкин, для генома есть возможность делать высококлассные анализы, но информация о контроле качества часто закрыта для врачей и пациентов. Иногда до заказа теста вы не можете заранее узнать, насколько велика глубина покрытия при секвенировании. Когда ген прочитывают недостаточное число раз для адекватного покрытия, программное обеспечение находит мутацию там, где ее нет. Зачастую мы не знаем, какой именно алгоритм используется для классификации аллелей генов на полезные и вредные.
Тревогу вызывает большое количество научных работ в области генетики, в которых содержатся ошибки. Команда австралийских исследователей проанализировала около 3,6 тыс. генетических работ, опубликованных в ряде ведущих научных журналов. В результате обнаружилось, что примерно одна из пяти работ включала в свои списки генов ошибки.
Поражает источник этих ошибок: вместо использования специальных языков для статистической обработки данных ученые сводили все данные в Excel-таблице. Excel автоматически преобразовывал названия генов в календарные даты или случайные числа. А вручную перепроверить тысячи и тысячи строк просто невозможно.
В научной литературе гены часто обозначаются символами: например, ген Септин-2 сокращают до SEPT2, а Membrane Associated Ring Finger (C3HC4) 1 — до MARCH1. Excel, опираясь на настройки по умолчанию, заменял эти строки датами. Исследователи отметили, что не стали первооткрывателями проблемы — на нее указывали более десятилетия назад.
В другом случае Excel нанес крупный удар по экономической науке. Знаменитые экономисты Гарвардского университета Кармен Рейнхарт и Кеннет Рогофф в исследовательской работе проанализировали 3,7 тыс. различных случаев увеличения госдолга и его влияние на рост экономики 42 стран в течение 200 лет.
Работа «Рост за время долга» однозначно указывала, что при уровне госдолга ниже 90 % ВВП он практически не влияет на рост экономики. Если же госдолг превышает 90 % ВВП, медианные темпы роста падают на 1 %.
Исследование оказало огромное влияние на то, как мир боролся с последним экономическим кризисом. Работа широко цитировалась для оправдания сокращения бюджета в США и Европе.
Однако несколько лет спустя Томас Херндорн, Майкл Эш и Роберт Поллин из Университета Массачусетса, разобрав по пунктам работу Рогоффа и Рейнхарта, выявили банальные неточности при работе с Excel. Статистика, на самом деле, не показывает никакой зависимости между темпами роста ВВП и госдолгом.
Заключение: исправление ошибок как источник ошибок

(с)
Учитывая огромное количество информации для анализа, некоторые ошибочные ассоциации возникают просто потому, что такова природа вещей. Если ошибки редки и близки к случайным, выводы итогового анализа могут не пострадать. В некоторых случаях бороться с ними бессмысленно, так как борьба с ошибками при сборе данных может привести к возникновению новых ошибок.
Знаменитый статистик Эдвард Деминг сформулировал описание этого парадокса следующим образом: настройка стабильного процесса для компенсации небольших имеющихся отклонений с целью достижения наиболее высоких результатов может привести к худшему результату, чем если бы не происходило вмешательства в процесс.
В качестве иллюстрации проблем с чрезмерным исправлением данных используется моделирование корректировок в процессе случайного падения шариков через воронку. Корректировать процесс можно с помощью нескольких правил, основная цель которых — предоставить возможность попасть как можно ближе к центру воронки. Однако чем больше вы будете следовать правилам, тем более разочаровывающими будут результаты.
Проще всего эксперимент с воронкой провести онлайн, для чего создали симулятор. Пишите в комментариях, каких результатов вам удалось достичь.
Правильно анализировать большие данные мы можем научить в Академии MADE — бесплатном образовательном проекте от Mail.ru Group. Заявки на обучение принимаем до 1 августа включительно.
Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
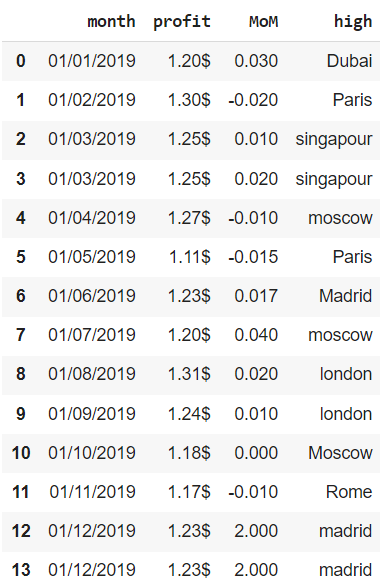
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
financials = pd.DataFrame({‘month’ : [’01/01/2019′, ’01/02/2019′, ’01/03/2019′, ’01/03/2019′, ’01/04/2019′, ’01/05/2019′, ’01/06/2019′, ’01/07/2019′, ’01/08/2019′, ’01/09/2019′, ’01/10/2019′, ’01/11/2019′, ’01/12/2019′, ’01/12/2019′], ‘profit’ : [‘1.20$’, ‘1.30$’, ‘1.25$’, ‘1.25$’, ‘1.27$’, ‘1.11$’, ‘1.23$’, ‘1.20$’, ‘1.31$’, ‘1.24$’, ‘1.18$’, ‘1.17$’, ‘1.23$’, ‘1.23$’], ‘MoM’ : [0.03, —0.02, 0.01, 0.02, —0.01, —0.015, 0.017, 0.04, 0.02, 0.01, 0.00, —0.01, 2.00, 2.00], ‘high’ : [‘Dubai’, ‘Paris’, ‘singapour’, ‘singapour’, ‘moscow’, ‘Paris’, ‘Madrid’, ‘moscow’, ‘london’, ‘london’, ‘Moscow’, ‘Rome’, ‘madrid’, ‘madrid’] }) financials |
Воспользуемся методом .info() для получения общей информации о датасете.
|
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype — —— ————— —— 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
# keep = ‘first’ (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = ‘first’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# keep = ‘last’ соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = ‘last’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
# с параметром keep = ‘last’ будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = ‘last’)] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = [‘month’]) |
|
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = [‘month’]).sum() |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
# укажем параметр keep = ‘last’, больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = [‘month’], keep = ‘last’)] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
( ~ financials.duplicated(subset = [‘month’])).sum() |
Этот логический массив можно также использовать как фильтр.
|
financials[ ~ financials.duplicated(subset = [‘month’], keep = ‘last’)] |
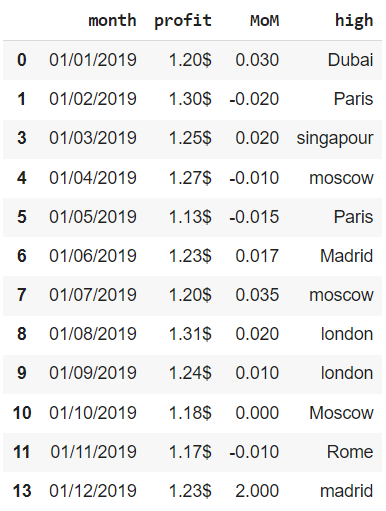
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
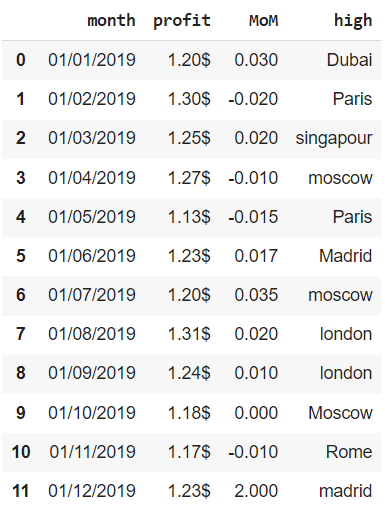
Удаление дубликатов
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = ‘last’, subset = [‘month’], ignore_index = True, inplace = True) financials |
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
# рассчитаем среднемесячный рост financials.MoM.mean() |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
‘1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$’ |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
# вначале удалим знак доллара с помощью метода .strip() financials[‘profit’] = financials[‘profit’].str.strip(‘$’) # затем воспользуемся знакомым нам методом .astype() financials[‘profit’] = financials[‘profit’].astype(‘float’) |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , ‘На ноль делить нельзя’ return round(a / b, 2) |
|
# попробуем разделить 5 на 0 division(5, 0) |

Выражение
b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
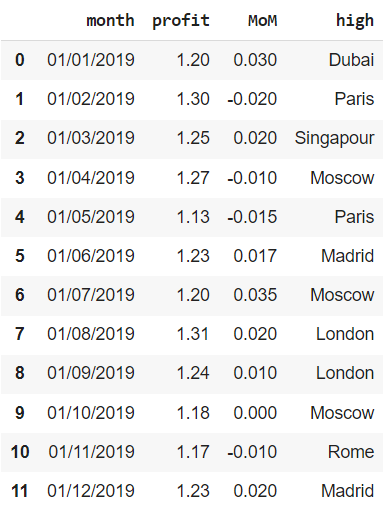
Названия городов с заглавной буквы
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
financials[‘high’] = financials[‘high’].str.title() financials |
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
# запишем дату в формате datetime в столбец date1 financials[‘date1’] = pd.to_datetime(financials[‘month’], format = ‘%d/%m/%Y’) financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
# для этого подойдет параметр infer_datetime_format = True financials[‘date2’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials[‘date3’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
Удалим избыточные столбцы и сделаем дату индексом.
|
financials.set_index(‘date3’, drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = [‘month’, ‘date1’, ‘date2’], axis = 1, inplace = True) financials.index.rename(‘month’, inplace = True) financials |
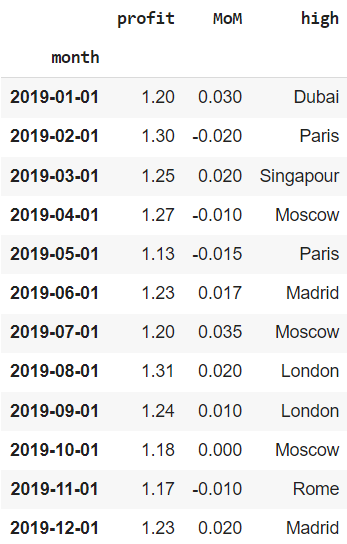
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
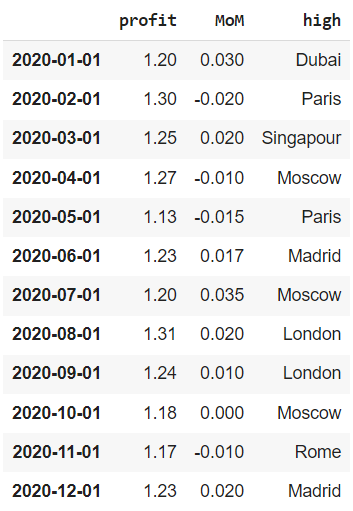
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = ‘1/1/2020’, periods = 12, freq = ‘MS’) # сделаем эту последовательность индексом датафрейма financials.index = range financials |
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
# напоминаю, что для datetime конечная дата входит в срез financials[‘2020-01’: ‘2020-06’] |

Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime(‘%B’) financials |

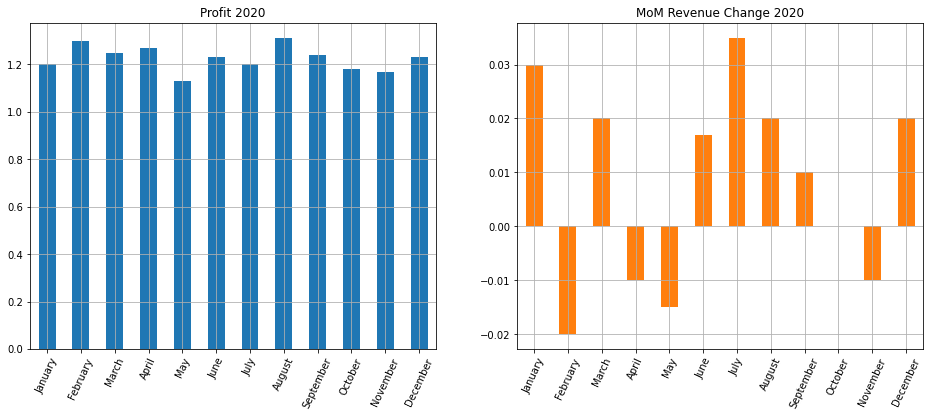
Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
# построим графики для размера прибыли и изменения выручки за месяц financials[[‘profit’, ‘MoM’]].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = ‘bar’, # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = [‘Profit 2020’, ‘MoM Revenue Change 2020’]); # добавим заголовки |
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.
На чтение 3 мин. Просмотров 9k. Опубликовано 03.09.2019
Исправить поврежденные куски или целые миры в Minecraft не обязательно сложно. Такие повреждения редко встречаются в ванильной версии игры, но моды время от времени ломают игру.
Если вы на этом получаете, мы уверены, что вы хотите восстановить испорченный мир, а не начинать с нуля. Есть несколько способов исправить поврежденные миры Minecraft, и мы предоставили вам два из них ниже.
Содержание
- Как исправить испорченный мир Minecraft за несколько простых шагов
- Решение 1 – Создайте новый мир
- Решение 2 – Попробуйте с Fixer Region
Как исправить испорченный мир Minecraft за несколько простых шагов
- Создайте новый мир и получите данные
- Попробуйте с помощью Fixer Region
Решение 1 – Создайте новый мир
Первое, что вы можете сделать, если ваш мир Minecraft испортится, – это создать новый мир и использовать некоторые файлы данных для извлечения как можно большей части старого мира. Имейте в виду, что это относится только к миру, так как все ваши вещи и одежда не подлежат восстановлению. Что вам нужно сделать, это сделать резервную копию поврежденного файла сохранения и использовать некоторые из его файлов данных, чтобы восстановить его в новый
Выполните следующие действия, чтобы восстановить поврежденный мир Minecraft:
-
-
В строке поиска Windows скопируйте и вставьте следующую строку и нажмите Enter:
- % AppData% . Minecraft сохраняет
- В оставшейся части руководства мы назовем поврежденный мир World C. Скопируйте папку World C, переименуйте ее в World C и сохраните ее в папке S aves .
- Запустите Minecraft и воссоздайте испорченный мир как новый. Назовите это Blank, сохраните его и закройте Minecraft.
- Вернитесь в папку Saves (% appdata% . Minecraft saves), и вы должны увидеть только что созданный пустой мир.
-
Скопируйте следующие файлы из пустой папки в резервную копию World C:
- level.dat
- level.dat_mcr (не всегда присутствует)
- level.dat_old
- Session.lock
- Перезапустите Minecraft и загрузите World C.
-
В строке поиска Windows скопируйте и вставьте следующую строку и нажмите Enter:
Решение 2 – Попробуйте с Fixer Region
Если у вас есть более старая резервная копия вашего мира, вы можете использовать Region Fixer, чтобы восстановить его или удалить все со своего сервера локально. Поврежденные миры приведут к сбою вашего сервера, и это последнее, что мы хотим. Что вам нужно сделать, это загрузить вашу резервную копию и серверный мир. Теперь вы можете использовать более старую резервную копию, чтобы восстановить мир, а не начинать с нуля.
- ЧИТАЙТЕ ТАКЖЕ: как исправить код ошибки Minecraft 5 на ПК с Windows
Вот как использовать Region Fixer:
-
- В панели управления мультикрафтом в игре выберите Файл , а затем Резервное копирование . Спасите свой мир и выйдите из игры.
- Загрузите свой серверный мир Minecraft на свой компьютер.
- Скачайте Region Fixer с Gitbub и распакуйте его.
-
Откройте командную строку в извлеченном окне Fixer региона (Shift + правый клик) и введите следующие команды:
- CD
- egionfixer.exe -p 4 –delete-поврежден
- Не забудьте заменить « полный путь к каталогу » на путь к извлеченному фиксатору областей и « полный путь к папке мира » на путь к мировой папке .
- Загрузите свой мир снова с помощью инструмента FTP и ищите изменения.
С учетом сказанного мы можем завершить эту статью. Не забудьте поделиться альтернативными решениями или вопросами в разделе комментариев ниже. Если вы все еще сталкиваетесь с ошибкой, рассмотрите возможность размещения вашего запроса на официальном форуме или обратитесь в службу поддержки.