
Четкая система отслеживания товаров и их идентификации – залог успешной и эффективной работы склада. Маркировка товара помогает складу работать быстро, исключает вероятность ошибок, позволяет комплектовать заказы в необходимом объеме. Если товары маркированы, сотрудники склада лучше ориентируются на территории хранилища и определяют местоположение необходимых товаров – это сокращает трудовые и временные издержки, оптимизирует работу склада.
Существует три способа организации адресного хранения: индивидуальное кодирование, маркировка с помощью штрих-кодов и радиочастотная идентификация. В этой статье подробно остановимся на каждом из них.
Методы идентификации товаров
Индивидуальное кодирование
Индивидуальное кодирование – простой и наименее затратный способ из представленных. Данный метод подойдет для небольших складов производственного или товарного назначения и помещений со стеллажным типом хранения. Для больших складов, где ассортимент регулярно меняется, тот метод использовать нецелесообразно – при индивидуальном кодировании слишком больших объемов товаров возникает риск ошибок в силу человеческого фактора.
Существует два типа индивидуального кодирования: смысловое и несмысловое.
- Смысловое кодирование – это кодирование, при котором каждый товар наделяется собственным уникальным номером. Этот номер отражает характеристики товара: производителя, поставщика, типа товара, назначение и так далее. Таким образом, товары на складе группируются по смыслам – например, назначение или один и тот же поставщик.
- Несмысловое кодирование также предполагает присвоение товару определенного номера, но, в отличие от первого способа, этот номер не имеет привязки к конкретной группе или характеристике.
Маркировка с помощью штрих-кодов
Этот метод часто используется на торговых складах, где требуется регулярно и быстро отгружать товары. Эффективность этого метода во многом зависит от сотрудников, которые контролируют процесс, и позволяют своевременно и правильно отгружать заказы.
Система работы при данном методе строится следующим образом: каждый товар маркируется индивидуальным штрих-кодом, сканируя который сотрудники склада в дальнейшем смогут быстро определить его местонахождение. Маркированные товары укладываются на паллеты и устанавливаются на металлические стеллажи. Их необходимо укладывать маркированной стороной наружу, иначе при поиске товара работникам склада придется снимать каждый элемент с полки, чтобы найти нужный. В таком случае смысл штрих-кодов теряется вовсе: работа склада не оптимизирована, сотрудники теряют много времени и сил при подборе заказа.
Несмотря на плюсы такого способа организации хранения у него есть ряд существенных недостатков. В первую очередь – финансовые издержки, связанные с закупкой необходимого оборудования, последующим обучением персонала и общего внедрения системы в помещение склада. Кроме того, такая система работы требует внимания от сотрудников, чтобы избежать ошибок.
Радиочастотная идентификация
Система радиочастотной идентификации (или по-другому RFID) – это наиболее современный и инновационный способ адресного хранения товаров в складских помещениях. Так как этот способ появился сравнительно недавно, он пока не широко распространен в России, однако пользуется популярностью за рубежом.
Принцип работы следующий: на каждый товар наносится метка с микрочипом, при этом метка может помещаться как снаружи товара (на упаковке), так и непосредственно внутри. С помощью специального считывателя информация о товаре, его характеристики и местонахождение загружаются на компьютер. Таким образом можно отследить местоположение любой метки в радиусе 11 метров.
Такой метод позволяет быстро и безошибочно вести учет товаров на складе, контролировать место хранения и выдачу. Очевидный минус такого способа работы – высокая цена оборудования RFID.
Способы отслеживания товаров
Склад – это сложная многоуровневая система, требующая четкого контроля и внимательного наблюдения за происходящими внутри процессами. Система контроля товаров (сокращенно СКТ) – процесс, в ходе которого фиксируются все передвижения товара по складу с момента его приема.
Контролировать учет товаров можно вручную. Сначала рядовые сотрудники вносят полную информацию о поступившем товаре, его размещении и месте хранения – так формируются учетные записи. Затем все учетные записи проверяются главным бухгалтером, задача которого заключается в том, чтобы проверить корректность составленных документов.
Для более эффективного контроля существуют специальные WMS-системы. WMS расшифровывается с английского как Warehouse Management System, а переводится как система управления складом. По сути своей WMS-система – это информационная система, позволяющая автоматизировать все бизнес-процессы и контроль за ними в рамках складского помещения. Для внедрения такой системы территория склада зонируется. Зоны формируются исходя из их целей и назначения, стандартно выделяют пять таких отсеков: прием, размещение, хранение, обработка и отгрузка. Подобное зонирование позволяет согласовать работу сотрудников на всех участках и четко распределить ответственность между ними.
Первый этап при внедрении WMS-системы на складское помещение подразумевает внесение данных и характеристик склада в электронную систему. Заносятся все подробности начиная от физических характеристик (площадь, высота потолков), заканчивая списком оборудования, используемого на складе.
Грузы, поступающие в зону приема, маркируются штрих-кодами, с помощью которых система будет в дальнейшем контролировать перемещение товара. Сотрудники склада и техника, используемая в процессе погрузки, оснащаются радиотерминалами, главная задача которых – ввод и вывод данных. В процессе инвентаризации сотрудники с помощью терминалов сбора данных (мобильный персональный компьютер) сканируют штрих-коды, которые система самостоятельно заносит в базу. Помимо этого, система отслеживает условия хранения, необходимые каждому типу товаров, что позволяет эффективно распределить их по складу и избежать потерь. Учитываться могут следующие параметры: влажность, уровень температуры, срок хранения, поставщик, производитель, правила совместимости и так далее. WMS-система сама определяет оптимальное место для каждого груза, сотрудникам остается лишь доставить его до назначенного места. Кроме того, WMS-система подбирает наиболее выгодный для транспортировки маршрут – таким образом сокращается время доставки товара и снижается пробег погрузочных транспортных средств. При подборе погрузочного средства система также выбирает самый подходящий вариант, опираясь на специфику товара, его вес, объемы и особенности транспортировки.
Перед выполнением задачи, поставленной системой, сотрудники склада должны отсканировать штрих-код. С помощью такого сканирования система контролирует не только перемещение товара, но и действия сотрудника, таким образом исключая вероятность ошибки или неправильного размещения груза.
WMS-система позволяет контролировать запасы и вести контроль учета товаров, находящихся на складе. Целесообразность внедрение подобной системы кроется не только в оптимизации работы склада, но и в сокращении издержек. Данные, собранные системой, отражают объективное положение дел, что позволяет оценить прибыльность того или иного товара. Кроме того, автоматизация контроля товаров снижает риск ошибок, виной которых часто становится человеческий фактор.
Алгоритм идентификации и отслеживания товаров
Процесс отслеживания и контроля товара начинается еще до того, как непосредственно товар поступит на склад – в момент планирования его прихода. Ниже рассмотрим подробный алгоритм движения товаров на складе, на каждом этапе которого они находятся под чутким контролем и ответственностью сотрудников.
Стадии контроля товара на складе:
1. Прием товара
Это этап, на котором товар непосредственно поступает на склад, а сотрудники вносят факт его наличия на складе в базу данных. Работник, уполномоченный принимать товар, вносит всю необходимую информацию в “план приема” – это документ, в котором отражается какой товар, когда, от кого, откуда и в каком объеме поступит на склад.
Как только товар доставлен на склад, приемщик обязан сравнить информацию из плана приема с заявками, которые были оставлены на поставку: фактическая информация должна совпасть с той, что указана в документах. В случае если информация совпадает и товар принимается на склад, статус обновляется на “Принят на склад”.
2. Передача товара в зону хранения
На этом этапе материальная ответственность за принятый груз переходит от сотрудника, принявшего товар на склад, к управляющему зоной хранения. Вместе с тем меняется статус товара и его местоположение соответственно. Статус “Принят на склад” меняется на “Принят на хранение”.
3. Отбор товара, контроль складских остатков
На этой стадии отслеживается объем остатков товара, хранящихся на складе, сверяются контрольные цифры и проводится выборочная инвентаризация товара.
Корректное количество оставшегося на складе товара является необходимой информацией для эффективной работы склада. Ориентируясь на эти цифры, можно понять, каких продуктов на хранении в избытке, а каких не хватает.
Статус товара на этом этапе – “Отобран”.
4. Комплектация и контроль заказов
Данный этап предполагает сбор и упаковку заказа, а также формирование упаковочных листов. Как только на склад поступает запрос на формирование нового заказа, контролер (сотрудник, ответственный за сбор заказа) последовательно собирает все его части, совершает их контрольный пересчет и упаковывает необходимый груз.
Статус товара на данном этапе обычно звучит как “Собран и проверен”, а материальную ответственность за него несет непосредственно контролер.
5. Зона хранения заказов
Упакованный под руководством контролера товар поступает в зону хранения заказов. На этом этапе заказ полностью укомплектован и готов к выдаче, поэтому его статус обновляется на “Готов к отгрузке”.
В этой зоне товары легко контролировать, можно отследить не только местоположение каждого из них, но и время, которое он пролежал в ожидании выдачи или отгрузки.
6. Передача товара заказчику / отгрузка товара
После получения сотрудником документов об отгрузке или выдаче товара, он передается в зону отгрузки. В этой зоне может быть два пути развития: товар либо будет передан клиенту и принят им, либо будет отправлен на дальнейшую отгрузку и доставку.
На данном этапе материальную ответственность за товар несет непосредственно клиент, а статус заказа определяется как “Отгружен”.
Это последняя точка контроля. Товар официально выдается со склада и передается заказчику, либо отправляется транспортным средством на дальнейшую доставку.
Существуют и другие алгоритмы отслеживания товаров на складе. Ниже рассмотрим некоторые из них:
- Оперативный способ – при таком способе переучет товара происходит в соответствии с данными склада, т.е. фактическая информация сверяется с той, что на бумаге;
- Обычный способ – при таком методе учитывается весь товар, размещенный на хранение, а в карточке товара указываются конкретные его количественные остатки;
- По партиям – при таком способе для каждого типа товаров формируется учетная карточка по принципу “партия товара = карточка”;
- Циклический пересчет – при таком способе товары, хранящиеся на складе пересчитываются регулярно через определенный промежуток времени.
Во избежание порчи хранящегося товара и своевременной его реализации часто учет составляют следующим образом:
- в зависимости от срока реализации товара;
- по времени производства;
- в зависимости от срока годности товара;
- по опасным характеристикам товара.
Также складские запасы можно контролировать по типу тары, в которой содержится товар:
- месторасположение коробки;
- месторасположение единицы товара;
- по присвоенному номеру месторасположения товара;
Еще один популярный способ отслеживания товара на складе – по карточке. Здесь также существует несколько вариантов:
- по имеющемуся коду товара;
- по конечной дате реализации товара;
- по местоположению тары в ячейках, поддонах, коробках.
Система контроля товаров необходима не только для удобства, но и для конкурентоспособности склада и компании в целом. Склады должны работать бесперебойно и регулярно, так как именно от них зависит, вовремя ли получит потребитель товар, будет ли он удовлетворен качеством самого товара и его доставкой.
Как выбрать алгоритм для склада с учетом его специфики
Алгоритмов для организации работы склада существует много – как выбрать тот, который подойдет вам?
Первое и главное от чего нужно отталкиваться – размер склада.
Для локальных небольших складов подойдет “ручной” контроль остатков, в ходе которого сотрудники самостоятельно ведут учетные сметы, а главный бухгалтер их проверяет.
Если на складе несколько подразделений, целесообразно будет формировать для каждого из них не только отдельные учетные сметы, но и назначить непосредственного “контролера”, который будет сверять контрольные документы после их составления, а уже потом передавать главному бухгалтеру.
Для крупных складов, товарооборот которых слишком большой, такой метод не подойдет – при высокой загрузке сотрудники будут тратить много времени и сил на учет поступившего груза. В таком случае целесообразно внедрить WMS-систему, о которой мы уже говорили выше.
WMS решает сразу несколько ключевых задач в вопросе управления складом:
- позволяет автоматизировать производство, минимизировать количество ошибок из-за человеческого фактора;
- обрабатывает огромные объемы информации и загружает их в общую систему, доступ к которой есть у других сотрудников;
- увеличивает продуктивность работы склада;
- позволяет грамотно организовать складское пространство;
- сокращение издержек, снижение риска избытка товаров на складе;
- освобождает трудовой ресурс – выявляет неэффективных сотрудников, дает понимание, какое количество персонала необходимо на данном этапе.
При выборе WMS следует обратить внимание на стоимость и функционал каждой из них. Расходы на внедрение такой системы должны быть соразмерными. Перед покупкой и началом процедуры внедрения взвесьте все “за” и “против”, оцените собственные силы. Функционал также важен, так как от него напрямую зависит, будет ли WMS полезна в работе склада. Перед покупкой изучите набор функций, включенных в пакет WMS – обычно пакетные предложения делятся по областям и нишам бизнеса, чтобы было удобнее в них ориентироваться. Лучше всего выбирать систему с оптимальным набором функций и возможностью дальнейшего масштабирования бизнеса без смены WMS.
Таким образом, идеальная WMS-система должна обладать следующим набором характеристик:
- Должна существовать возможность загрузки и выгрузки прайс-листов товаров в разных форматах.
- Система должна четко показывать путь движения товара: когда и кем был принят, сколько единиц ушло на отгрузку, сколько осталось и так далее.
- Статус товара на складе должен регулярно обновляться – принят, на хранении, собран и отгружен. Это позволит избежать ситуаций, когда клиент оплатил товар, отсутствующий на складе.
- Система должна быть совместим с онлайн-кассами;
- WMS-система должна самостоятельно и в режиме онлайн обновлять статус позиций на складе, контролировать наличие, количество, время приемки и отгрузки. Если система делает это с задержкой, это ведет к ошибкам и некорректной работе склада.
- Автоматическое формирования заказа от разных поставщиков позволит быстро собирать заказы и не тратить время на поиск и создание вручную.
- Функция сортировки позиций по спросу на товар поможет контролировать вам сроки хранения и реализации товаров, избежать переизбытка и недостатка сезонных товаров.
- Функционал должен включать в себя возможность возврата товара, в том числе и частично. Если система может самостоятельно вносить эти данные в базу, это поможет сделать работу склада продуктивной, избежать лишней документации и структурировать работу.
- Автоматическая корректировка цен, их изменение в соответствии с актуальными данными.
- Документооборот: программа, умеющая не только собирать информацию о товарах складе и поступающих заказах, но и формирующая соответствующие документы существенно облегчит жизнь предприятию и сбережет огромное количество времени ваших сотрудников.
- С WMS должна быть возможность различных интеграций: от CRM-систем до онлайн-бухгалтерии и других программ. Также должна существовать возможность загружать и выгружать данные, внесенные в базу WMS в другие сервисы и программы при необходимости.
Заключение
Вне зависимости от того, каким способом ведется контроль товаров на складе, сверять остатки нужно в подходящий для того момент. Как минимум, нецелесообразно проводить контрольный учет в разгар рабочего дня, когда уровень работы на складе высокий – это собьет процессы и нарушит алгоритм работы, из-за чего вырастет время приема груза, выдачи, комплектования заказов и так далее. Подходящий отрезок времени для сверки остатков товаров на складе – время после полуночи. Как правило, в эти часы работа на складе минимизируется, что помогает быстро и в полном объеме провести контроль. Кроме того, после полуночи исчезает путаница в датах – сверка остатков начнется и закончится в один и тот же день.
Применение описанных инструментов и методов, внедрение WMS-систем и грамотный контроль складских товаров помогают грамотно и организовать работу склада.
Всем добрый день! Меня зовут Александр Трубенков, о VC.RU узнал пару месяцев назад от Олега Тинькова, с тех пор регулярно просматриваю этот ресурс, в нем столько полезного материала, всем кто пишет большое спасибо!
И я решил тоже поделиться имеющимся у меня опытом, я предприниматель и сдаю в аренду свои складские площади, занимаюсь этим уже больше 25 лет, с тех пор я обзавелся разными складами в основном это площади 120, 400, 600, 1000 метров кв., всего складских площадей у меня 10 000 метров кв.
Покупал и продавал, ремонтировал и строил, хлебнул сполна с арендаторами, об этом и хочу делиться здесь.
Сегодня я расскажу о своем опыте на тему: «Как БЫСТРО найти ХОРОШЕГО арендатора на склад»
Раньше я особо не задумывался, каким должен быть «идеальный арендатор» для моих складов, всегда было желание быстрее и по дороже сдать склад и избавиться от проблемы простоя помещения. Хватал первого желающего и заключал договор, и зря!
Большая часть таких быстрых сделок заканчивалась убытками: просрочки платежей, непогашенной задолженности, порчи имущества и пр., порчей отношений.
8 лет назад мы разработали критерии отбора арендаторов и следуем им и теперь у нас таких проблем больше нет, у нас отличные отношения с арендаторами, нет просрочек и долгов, все помещения сданы и платят выше рынка!
Теперь все по порядку! Как театр начинается с вешалки, так и хорошего арендатора нужно ИСКАТЬ правильно!
Шаг 1. Понять, что у вас за склад, какие особенности он имеет, для кого он может идеально подойти. На любой склад найдется арендатор! Вам нужен только тот, кто оценит Ваш склад, кому он идеально подойдет.
Шаг 2. Сделать «Продающее объявление» именно на вашу ЦА! (как есть продающие тексты, так и есть продающие объявления, советую прочитать интереснейшую книгу отца американского копирайтинга Д.Шугермана «Искусство написания коммерческих текстов»).
— Сделать красивое фото склада, по фото потенциальный арендатор дорисует в воображении свою мечту. Плохое, неинтересное фото отпугнет ваших клиентов, и они не позвонят
— Четко прописать все плюсы расположения, особенности исходя из образа предполагаемого клиента. Используйте «буи внимания», например цепляйтесь за известные точки, например: «склад напротив Леруа Мерлен», или расположен на транспортной развязке рядом с…., чтоб было понятно где находится ваш склад, это упрощает принятие решения ПОЗВОНИТЬ!
Шаг 3. Разместить объявление на АВИТО, это самый эффективный вариант на сегодня.
— создайте личный аккаунт на Авито и указывайте свой телефон, а не жены, секретаря, сотрудника. Вы более заинтересованы, больше всех владеете информацией о вашем складе. Иначе сольют реального клиента, а это могу быть приличные деньги если посчитать сумму за год!
— обязательно платно продвигайте свое объявление 1 раз в неделю (понедельник в 9.00), деньги не большие порядка 2-3 тыс в неделю, но эффект не заставит себя ждать!
— следите как сохраняют ваше объявление в избранное, как звонят, кто звонит и корректируйте, постоянно меняя текст, экспериментируйте, пока не добьетесь нужного результата- Вам звонят те, кто нужен и подходят!
— сделайте цену в объявлении ниже рынка! Даже если у вас наилучшее помещение в городе! Будет больше откликов на ваше объявление, всем ведь хочется подешевле.
Шаг 4. Вежливо приглашайте на просмотр помещения, ваша задача чтоб пришел каждый позвонивший! По телефону может вам не понравится клиент, а в реальности это то, что вы ищете!
— постарайтесь сами показывать помещение, вы ближе познакомитесь и поймете, что ищут и можете ли вы быть полезны друг другу.
Шаг 5. Смело отсеивайте не подходящих! Сразу на очной встрече проговорите все важные вопросы, условия порядка на территории, даты по платежам и прочие важные для вас пункты.
Наши критерии по выбору арендатора они достаточно жесткие, но они позволяют отсеять тех, кто принесет нам убытки в будущем:
— только по предоплате сдаем склад, арендатор должен (и мы это проговариваем) оплачивать до 5 числа текущего месяца аренду вперед, если этого не происходит мы блокируем доступ к складу (у нас это прописано в договоре)
— если клиент не платит, мы его срочно выселяем, никаких поблажек (мы это проговариваем на встрече и это есть в договоре)
Мы присваиваем рейтинг арендатору А, В, или С. В течение 2 первых месяцев аренды мы присматриваемся к нашему клиенту.
— Клиенты с рейтингом А никогда не нарушают договора, не портят имущество, не сорят на территории и не хамят нашим сотрудникам (нервы сотрудников, это тоже убытки)
— Клиенты В, это промежуточный рейтинг клиента А или С, своего рода это карантин, для нас всех. Мы начинаем взаимодействовать и становится понятным нужен нам такой арендатор или нет.
— Рейтинг С. Как только мы присваиваем рейтинг С, тут же начинается процедура расторжения договора, выставляем помещение на АВИТО ищем нового арендатора.
— не сдаем в аренду предпринимателям «новичкам» которые только начинают бизнес (риски 98% что у них не взлетит)
— наводим справки если это возможно, со старых мест где они арендовали помещение ( можно много узнать интересного о будущих арендаторах, и лучше до чем после заключения договора
Смысл такого жесткого отбора в том, чтоб все ваши арендаторы имели рейтинг А, и тогда вы с удовольствием будете предоставлять им самый высокий сервис, ведь они платят вовремя, не портят имущество, не доставляют хлопот, и как правило такие предприятия готовы платить за удобство, которое вы им создадите дополнительно! Работаем для лучших и с Удовольствием!
Итог. Грамотное предложение + максимальный показ + жесткий отбор + максимальный дружелюбный сервис = процветание вашего бизнеса.
P.S. Если у читателей возникнут вопросы, с удовольствием отвечу на любые темы, связанные со стройкой, эксплуатацией, арендными отношениями, все о складах (100-1000 метров кв.), в инстаграмм @trubenkov_alexandr у меня тоже много информации по этой теме.
Применение расстояния Левенштейна с целью оптимизации работы склада
Время на прочтение
14 мин
Количество просмотров 8.3K
Мы активно изучаем различные алгоритмы (поиск k-ближайших соседей, задача о рюкзаке, всякие алгоритмы сортировки, поиска и т. п.). А часто ли удаётся почитать пример их практического внедрения на каком-нибудь предприятии? Такие истории встречаются реже, чем даже обзоры книг по этим же алгоритмам.
Предлагаю всем вместе начать исправлять эту ситуацию и приглашаю почитать о том, как на промышленном складе применяли — внезапно! — алгоритм Левенштейна (способ нечёткого сравнения строк).
Значительная часть нюансов спрятана под спойлеры, чтобы не отвлекать от сути статьи, а также не отпугивать маленьких. Обычно такие статьи становятся очень длинными, но мне удалось уместиться примерно в 3200 слов.
Для понимания статьи читателю хватит самого поверхностного умения чуть-чуть читать код си-подобного синтаксиса. Познания в области работы склада не обязательны.
Дано: большой склад с развитым адресным хранением, а также список товаров на нём. Список составляет многие тысячи наименований.
Сразу опишем проблему, которую нам озвучил склад. Посмотрите на изображение ниже:

Вы сумеете найти на ней гель-лак для маникюра «Soline»? Сколько времени у вас на это ушло? Много. С аналогичной проблемой сталкиваются сборщики товара: на одной ячейке может оказаться много похожих товаров. Ситуация усугубляется тем, что многие неопытные сотрудники даже не знают заранее, как выглядит этот товар. Это мешает им найти нужный, даже если он выделяется внешне (но и это бывает не всегда). Если на товаре есть текст, то это тоже не означает, что его быстро найдут. Таким образом, сборщик тратит время не только на то, чтобы найти полку (ячейку) на складе, но и на поиски внутри самой ячейки.
Как эту проблему решали раньше?
На складе с самого начала было адресное хранение. WMS хранила как перечень ячеек во всех помещениях, так и то, какой товар на какой из них лежит. Система сама показывала сборщикам из какой ячейки брать товар, который сейчас нужно собрать. Она же автоматически этот товар списывала с ячейки, поддерживая актуальность информации о текущих запасах.
До поры до времени использовали монотоварные ячейки. На таких ячейках разрешено размещать только идентичный товар. При сборке достаточно найти нужную ячейку, а потом набрать из него столько товара, сколько нужно и даже не читать его название.
Почему решение перестало работать? Потому что количество наименований уже давно превысило количество имеющихся ячеек. Также один и тот же товар разных серий с разными сроками годности нежелательно хранить вместе. Иными словами, ячейки закончились, а уменьшать их размер, чтобы увеличить их количество, все уже устали. Вдобавок, монотоварные ячейки часто стоят полупустые: на полке лежит последняя оставшаяся коробочка зубных щёток редкой разновидности, а из-за монотоварного ограничения на полку больше нельзя ничего положить. Это приводит к неэффективному использованию пространства.
Ситуация осложняется тем, что среди товаров достаточно много похожих, но разных. Сравните:
-
Ибупрофен 20 мг №30
-
Ибупрофен 30 мг №20
-
Индовазин 30 мг №20
Сотрудники могут легко перепутать дозировку с количеством и наоборот. У первых двух препаратов почти идентичны не только названия, но и упаковки. Ближе к концу рабочей смены ещё и появляется усталость сборщиков, которые начинают путать даже отдалённо похожие названия. Самая больная сфера, где названия имеют огромную схожесть — это лекарственные препараты со своими дозировками и формами, а также изделия медицинского назначения типа шприцов, бинтов и перчаток. Отдельно можно отметить материалы для маникюрного сервиса — не пытайтесь самостоятельно разобраться в многообразии гелей и лаков, алмазных головок, которые в каких-то местах могут называться фрезами, в каких-то других — ёлочками (вполне официально). Средства гигиены для женщин и детей имеют свою специфику, но тоже часто путаются. Я бы ещё отметил уголь — его названия не сильно схожи (берёзовый, сосновый, для шашлыков, деревенский), но упаковки похожи как две капли воды, а крупными буквами написано только одно слово — «уголь». Остальные — более важные слова — могут быть написаны мелким шрифтом и не бросаться в глаза.
Предложенное решение: процесс сборки оставить как есть, но усовершенствовать приёмку и размещение товара в ячейках. Нужно, чтобы в каждой ячейке лежали только очень разные товары, например: зубная паста, перчатки, салфетки, пластиковые банки и какие-нибудь витаминки. Нельзя, чтобы в ячейке лежали перчатки сразу нескольких размеров, ровно как и других похожих товаров.
Первое везение: большинство похожих товаров имели и похожие названия, поэтому в статье мы остановимся только на этом аспекте. В реальности, конечно, это не был единственный критерий.
Реализация сделана так, что сотрудник приёмки при поступлении нового товара автоматически получал от WMS рекомендуемую ячейку, куда этот товар следует положить. Ячейка выбирается:
-
либо пустая
-
либо не содержащая товаров с похожим названием
Конечно, и тут было гораздо больше критериев, но в статье мы их опустим.
Ищем решения
Как мы определим, что название «Хлорид натрия 500 мл №6» больше похоже на «Натрия хлорид 0,5 л 6 шт», чем «Кальция глюконат 500 мг №30»? Начинать искать ответ нужно в любимом поисковике по фразе типа: «Нечёткое сравнение строк». В ответ мы получаем несколько изобретённых алгоритмов и выбираем любой из них. Для примера — расстояние Левенштейна. Далее воспользуемся таким изобретением как «лень», и снова пойдём в поисковую систему с запросом вида: «расстояние Левенштейна ваш_любимый_язык_программирования». Если находим готовый общедоступный код — идём дальше. В нашем случае образцов хватает: тут примеры сразу на 15 языках, а в некоторых языках даже есть готовая функция.
Забегая вперёд скажу, что результат работы любого такого алгоритма будет немного грустным. Нам всегда придётся доработать алгоритм, чтобы он подходил конкретно нам. Для этого потребуется глубокое, не побоюсь этого слова, проникновение во внутренний мир алгоритма. Отмечу, что найти алгоритм — это не то же самое, что применять его. Фраза «всё уже придумано до нас» тут не работает.
Да, когда алгоритм найден — это только самое начало работы! Любое применение универсального алгоритма на практике — это в какой-то мере подгонка под ответ желаемый результат. Далее статья будет состоять последовательных шагов, которые позволят приспособить алгоритм для реального применения.
Проба пера
На уровне кода алгоритм представляет собой функцию, принимающую два параметра — строчку №1 и строчку №2. Функция возвращает в ответ число, которое показывает «похожесть» первой строки на вторую. Если число равно нулю, значит строки одинаковые. Если число небольшое, значит строки разные, но похожие. Чем больше число — тем строчки различаются сильней.
Тестировать будем вот таким кодом
Образец взят без изменений с первых страниц поисковика:
function levenshtein_distance($source, $dest)
{
if ($source == $dest)
return 0;
list($slen, $dlen) = [mb_strlen($source), mb_strlen($dest)];
if ($slen == 0 || $dlen == 0) {
return $dlen ? $dlen : $slen;
}
$dist = range(0, $dlen);
for ($i = 0; $i < $slen; $i++)
{
$_dist = [$i + 1];
for ($j = 0; $j < $dlen; $j++)
{
$cost = ($source[$i] == $dest[$j]) ? 0 : 1;
$_dist[$j + 1] = min(
$dist[$j + 1] + 1, // удаление
$_dist[$j] + 1, // вставка
$dist[$j] + $cost // замена
);
}
$dist = $_dist;
}
return $dist[$dlen];
}Данную функцию сохраняем в файл, который, например, можно открывать в браузере или запускать из командой строки.
Сравним строчки ниже. Например, дописав этот код в наш файл и запустив его из командой строки:
$text_1 = 'Амлодипин-Веро 5мг таб. №30';
$text_2 = 'Амлодипин-Прана 5мг таб. №90';
echo levenshtein_distance($text_1, $text_2) . PHP_EOL;Результат: 7. Если заменить первый товар на «Анвифен 250мг капс. №20», то результат будет уже 17. Похоже, мы на верном пути. Но давайте теперь сравним эти два товара:
$text_1 = 'Амиодарон 50мл/мл конц. д/приг. р-р д/в/в 3мл амп. №10';
$text_2 = 'Амиодарон амп. 50 мл/мл конц. д/приг. р-ра в/в 3 мл №10';
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Результат: 17Что?! Это ведь один и тот же товар, просто во втором случае сокращённое слово «ампулы» переместили с предпоследнего места на второе! А ещё во втором наконец-то поставили пробелы между числами и единицами измерения. Выходит, качество нашей работы зависит не только от алгоритма, но и от конкретных данных.
Неглубокое, снова простите за каламбур, погружение в суть работы этого алгоритма говорит, что он учитывает обычные перестановки символов и слов местами, что лучше видно на таком примере:
$text_1 = 'Я зарабатываю хорошо';
$text_2 = 'Я хорошо зарабатываю';
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Результат: 12А ещё всё это дело является регистрозависимым. Как избавиться от этих недостатков?
Для этого мы введём предварительную обработку сравниваемых строк, а уже потом будем вычислять расстояние Левенштейна между получившимися. Назовём этот процесс нормализацией. Кому-то может понравится иной термин, но на вкус и цвет всё равно все фломастеры разные.
Первое, что приходит на ум и действительно будет работать — привести все символы к одному регистру. Второе — отсортировать все слова в алфавитном порядке.
Функция, которая это сделает, может быть примерно такой
function normalize($string)
{
$string = mb_strtolower($string);
$array_of_words = explode(' ', $string);
sort($array_of_words);
$sorted_string = implode(' ', $array_of_words);
return $sorted_string;
}Напомню, выше мы получили расстояние 12, здесь уже всё стало хорошо:
$text_1 = 'Я хорошо зарабатываю';
$text_2 = 'Я зарабатываю хорошо';
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Результат: 0Но и тут можно увидеть недостаток, если изменить данные так:
$text_1 = 'Я, Лена, хорошо зарабатываю';
$text_2 = 'Я, Елена, хорошо зарабатываю';
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Результат: 19В реальности строка отличается одной буквой, но алгоритм всё равно выдаёт достаточно сильное расхождение. Одно-единственное отличающееся слово занимает разную позицию в алфавитном порядке, а это резко влияет на алгоритм. Фразы ниже тоже отличаются на одну букву, но расстояние уже очень маленькое, потому что алфавитный порядок остаётся прежним:
$text_1 = 'Я, Лена, хорошо зарабатываю';
$text_2 = 'Я, Ленка, хорошо зарабатываю';
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Результат: 1Как быть здесь? Тут уже нужно проявить творчество. Можно, например, убрать из сравнения все одинаковые слова — зачем их вообще сравнивать, раз они идентичные? Можно же сравнивать только различные части строк. Иногда это работает отменно.
Функция, выбирающая только отличающиеся слова, могла бы быть такой
function get_different_words(&$string_1, &$string_2)
{
// Я опущу проверку корректности входных аргументов — статья не об этом
$string_1 = explode(' ', $string_1);
$string_2 = explode(' ', $string_2);
$unique_words_1 = array_diff($string_1, $string_2);
$unique_words_2 = array_diff($string_2, $string_1);
$string_1 = implode(' ', $unique_words_1);
$string_2 = implode(' ', $unique_words_2);
}Результат работы можно показать вот так:
$text_1 = 'Светлана! Я не пью!';
$text_2 = 'Света! Я вообще не пью!';
get_different_words($text_1, $text_2);
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Результат: 9Без вызова get_different_words() результат был бы 17. Уже хорошо, но и на эту косу можно найти свой камень. Смотрите:
$text_1 = 'Невероятно, но химическое вещество "земляничный альдегид" не является альдегидом, а ещё не входит в состав земляники. На самом деле это этиловый эфир, а название просто исторически сложилось. Ошибка!';
$text_2 = 'Невероятно, но химическое вещество "земляничный альдегид" не является альдегидом, а ещё не входит в состав земляники. На самом деле это этиловый эфир, а название просто исторически сложилось. Ошибка первооткрывателя!';
get_different_words($text_1, $text_2);
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Разница: 17А вот два несвязанных (почти) слова выдали довольно скромное расстояние:
$text_1 = 'Байкал';
$text_2 = 'Эльбрус';
get_different_words($text_1, $text_2);
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo levenshtein_distance($text_1, $text_2) . PHP_EOL; // Разница: 6Математически всё верно, но интуитивно мы ожидаем противоположного результата. Ведь первый пример состоит из почти идентичных кусков текста. Наши же доработки приводят к тому, что фактически вместо них сравниваются строки «» (пустая строка) и «первооткрывателя». Получается, нельзя так просто удалять общие для обеих строк слова?
Выходит, нужно придумать алгоритм, учитывающий исключённые из сравнения части текста. Такого алгоритма нет, но мы можем не изобретать велосипед, а пойти в том же русле, что и исходный алгоритм Левенштейна. Попробуем для начала учитывать количество удалённых из сравнения слов и рассматривать его как своеобразное «расстояние». Чем больше таких слов, тем строчки текста являются более похожими. Останется это только испытать. Чтобы это хорошо вписывалось в модель исходного алгоритма сделаем это расстояние отрицательным и в качестве новой метрики будем использовать алгебраическую сумму «обычного» расстояния и «необычного».
Для реализации нам потребуется функция примерно такого вида
function calculate_convergence(&$string_1, &$string_2)
{
$string_1 = explode(' ', $string_1);
$string_2 = explode(' ', $string_2);
$unique_words_1 = array_diff($string_1, $string_2);
$unique_words_2 = array_diff($string_2, $string_1);
$quantity_common_words = count($string_1) - count($unique_words_1);
$string_1 = implode(' ', $unique_words_1);
$string_2 = implode(' ', $unique_words_2);
return $quantity_common_words;
}Да, я знаю, что функция слишком перегружена и выполняет слишком много работы: и параметры принимает по ссылке, изменяя их после выполнения, и возвращаемое значение есть в виде количества совпавших слов, но для иллюстрации идеи подойдёт. А вообще, хорошая функция всё-таки должна выполнять лишь одно действие и делать это хорошо.
Испытание двух строк из предыдущего примера можно провести теперь вот так:
$quantity_common_words = calculate_convergence($text_1, $text_2);
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo (levenshtein_distance($text_1, $text_2) - $quantity_common_words) . PHP_EOL;Полученные результаты будут -10 и 6, что вписывается в нашу модель: чем меньше число, тем строчки более похожи и наоборот. Но всё равно это как-то грустно. Посмотрите на следующие два отрывка:
-
А знаете ли вы, что самый массовый танк в битву за Москву собирался из автомобильных запчастей, а вооружался авиационной пушкой? Это был результат хардкорной борьбы за производственную технологичность машины, которой пытались компенсировать откровенно слабые боевые качества и нецелевое использование.
-
А знаете ли вы, что самый массовый танк в битву за Москву собирался из автомобильных запчастей, а вооружался авиационной пушкой? Это был результат хардкорной борьбы за производственную технологичность машины, которой пытались компенсировать откровенно слабые боевые качества и нецелевое использование. Конструктор — Николай Астров.
Результат: -10. А вот так:
-
Волга начинается в Тверской области и течёт в Каспийское море.
-
Волга начинается в Тверской области и течёт в северную часть Каспийского моря.
Результат: -8. Алгоритм явно работает, но хотелось бы получить более ярко выраженный результат. Да, на совсем разных строках алгоритм выдаёт большое расстояние — это прекрасно, но нам хочется более чётко различать именно похожие названия.
Можно сделать ещё лучше? Не факт, но попробуем и посмотрим на результат. Давайте добавим для каждого исключённого общего слова некий «вес». Тогда при вычислении «компонента похожести» мы будем суммировать именно вес каждого одинакового слова, а не просто считать их количество. Почему так? Если какое-то слово длиннее, то и важность у него больше, а если слово короткое, то оно не сильно-то и влияет на сходство. Небольшой вес у коротких слов поможет избежать проблем, которые создают союзы или какие-нибудь другие короткие слова, ведь они часто не несут какой-то полезной (для наших целей!) нагрузки.
Функция, рассчитывающая вес, может быть такой
function calculate_weight(&$string_1, &$string_2)
{
$length_1 = mb_strlen($string_1);
$length_2 = mb_strlen($string_2);
$words_1 = explode(' ', $string_1);
$words_2 = explode(' ', $string_2);
$unique_words_1 = array_diff($words_1, $words_2);
$unique_words_2 = array_diff($words_2, $words_1);
$common_words = array_diff($words_1, $unique_words_1);
// Для вычисления суммарного веса потребуется перебрать все общие слова в обоих строчках:
$weight = 0;
foreach ($common_words as $word)
{
$word_length = mb_strlen($word);
$weight_in_string_1 = $word_length / $length_1;
$weight_in_string_2 = $word_length / $length_2;
$word_weight = ($weight_in_string_1 + $weight_in_string_2) / 2; // смелое предположение?
$weight = $weight + $word_weight;
}
return $weight;
}Хорошо, а как этот вес учесть? Сложить? Вычесть? Умножить? Поделить? Смотрите:
$weight = calculate_weight($text_1, $text_2);
$text_1 = normalize($text_1);
$text_2 = normalize($text_2);
echo (levenshtein_distance($text_1, $text_2) * (1 - $weight)) . PHP_EOL;Как видно, новой мерой решено взять не сам вес, а величину (1 — weight). И да, этот коэффициент используется как множитель, а не слагаемое. Поведение у этой доработки такое:
-
Если общие слова составляют 0% от обеих строк (общих слов нет), то тогда похожесть не отличается от расстояния Левенштейна.
-
Если общие слова составляют 100%, то расстояние нулевое, как и в исходном алгоритме.
-
Если общих слов много и они имеют большой вес, то коэффициент (1 — weight) сильно уменьшает расстояние, рассчитанное для оставшихся слов.
-
Если общих слов много и они имеют небольшой вес, новый коэффициент тоже уменьшает расстояние, но слабо.
Конкретный пример:
$text_1 = 'Блины - это очень вкусное блюдо. Вероятно, лучшее, что есть в мировой кухни. Я настолько люблю блины, что мог бы разместить здесь один из их многочисленных рецептов. Целиком. Но для наших экспериментов это будет излишне.';
$text_2 = 'Блины - это очень вкусное блюдо. Вероятно, лучшее, что есть в мировой кухни. Я настолько люблю блины, что мог бы разместить здесь один из их многочисленных рецептов. Целиком. Однако для наших экспериментов это будет излишне, поэтому воздержусь.';
// Результат: 5.98.
$text_1 = 'Завтра я пойду в гости и буду есть вкусные блины.';
$text_2 = 'Завтра я пойду в гости и буду есть мои любимые блины.';
// Результат: 6.69Если присмотреться, то первая пара строк отличается одним словом — короткому «но» в первой соответствует более длинное «однако». Вторая отличается заменой «вкусные» на «мои любимые». И, в общем-то, я соглашусь с тем, что первые строчки сильней похожи, чем вторые, но в целом мне этот результат не кажется фантастическим, если сравнивать с предыдущим — хотелось бы более прорывного шага вперёд.
Наконец, мы перешли к финальной части статьи. В ней приступим к обработке мелких нюансов. Наши основные примеры были намеренно не из названий товаров, чтобы ход мыслей был выразительней. Для реальных названий алгоритм останется тот, который мы только что создали, но принципы нормализации будут другие. Назовём мы это борьбой с результатами человеческой жизнедеятельности. Как по мне, это сильней всего смахивает на подгонку результатов алгоритма под желаемый результат. То, от чего нас отучали в школе, но активно используется вне её. Для подобных процессов есть более политкорректные названия: калибровка, юстировка или настройка. Приступим.
У пользователей есть мания на сокращения и спецсимволы, с которыми нужно что-то делать. Давайте прикинем, глубже изучив матчасть. В медикаментах, например, часто встречаются сокращения: в/в, в/м, д/п, р-р (внутривенное, внутримышечное, для приготовления, раствор) и т. п. Очень (!) часто встречаются единицы измерения: мл, ед, шт, мг, ЕМ, уп, фл, которые имеют решающее значение в применении на людях, но не для сравнения. Так уж вышло, что один и тот же препарат в разных дозировках производители измеряют одной единицей измерения: «Озверин 250 мг», «Озверин 500 мг» и «Озверин 1000 мг», хотя с точки зрения какого-нибудь метролога последний логичней было бы назвать «Озверин 1 г». Давайте зацепимся за этот факт?
С сокращениями понятно, а спецсимволы?
Разные символы могут использовать с одной целью. Для примера, слово «раствор» могут сокращать как «р-р» и «р/р». Напрашивается тотальное удаление спецсимволов, но не всё так просто!
Единичный спецсимвол имеет крайне небольшой вес в сравнении, поэтому их удаление может не оказать существенного влияния. А ещё удаление спецсимволов может привести к нежелательному объединению двух слов в одно, например: «мужской/женский» превратится в «мужскойженский», хотя в похожем названии спецсимвола могло не быть и там два слова так и будут двумя словами.
Отдельного упоминания заслуживают запятая и точка. Удалять их страшно, так как оба используются как разделитель в числах: 0,9%, 82.5, 72.5 и т. п. Однако оставлять их без внимания тоже нельзя, ведь «1,5 мг» и «1.5 мг» — это одно и то же по сути, но не одно и то же для алгоритма.
Общее решение для всего этого: заменить все запятые на точки, а остальные спецсимволы — на пробелы. По итогу в строках могут появиться сразу двойные и тройные пробелы, которые тоже нужно заменить на одинарные.
Ещё в названиях, если их копировали из какого-нибудь pdf, могли попасть и управляющие символы возврата каретки или переноса строки — их нужно удалить вовсе.
Напоминаю, что ранее у нас была функция нормализации строки:
function normalize($string)
{
$string = mb_strtolower($string);
$array_of_words = explode(' ', $string);
sort($array_of_words);
$sorted_string = implode(' ', $array_of_words);
return $sorted_string;
}В ней-то и нужно выполнить всю «чистку». В большинстве языков программирования уже есть подходящие для этого инструменты. Перед вызовом sort() мы могли бы вставить такие строчки:
$black_list = array('мл', ' мг', 'шт', 'уп', 'мл.', ' мг.', 'шт.', 'уп.');
$array_of_words = array_diff($array_of_words, $black_list);Разумеется, реальный «словарь» безвозвратно удаляемых сочетаний у каждой товарной области будет свой, а сама замена — не такой прямолинейной. Но это уже детали реализации.
А каков результат-то?
В глубине души мы всегда ожидаем кратного увеличения прежних показателей. На практике такого почти не бывает. Дело в том, что мы чаще оптимизируем не с нуля, а уже после многолетнего улучшения. Поэтому показатели даже в 30% увеличения эффективности нам не снятся. Но «жалкие» 3,75% — это уже миллионы экономии в год. Когда бизнес-процессы предприятия уже хорошо отработаны, других результатов ждать не стоит даже от самых хитроумных алгоритмов. Но вы всегда пытайтесь!
В этой статье описан принцип работы поиска на складе для более быстрой и эффективной работы с товарами.
В первую очередь рекомендуем промаркировать все товары штрихкодами. Вы можете загрузить имеющиеся штрихкоды товаров или сгенерировать их в РемОнлайн. Подробнее о возможностях использования штрихкодов в этой статье.
Обратите внимание, что некоторые товары могут быть серийными и для них существует или генерируется отдельный штрихкод.
После того как все товары будут промаркированы, для них можно распечатать этикетки и наклеить их на товары. Особенно полезным это будет для товаров, у которых на упаковке нет штрихкода и вы генерировали его отдельно в системе.
Вы можете использовать любой сканер штрихкода и термопринтер для печати этикеток. Главное, чтобы они были подключены к ПК. Для удобства можно взять беспроводной сканер штрихкода или установить специальное приложение на телефон. Это позволит вам сканировать товары и не быть привязанным к рабочему месту. При выборе термопринтера можно рассмотреть вариант с печатью этикеток разных размеров. Для этого в РемОнлайн предусмотрена настройка нескольких шаблонов этикеток.
Поиск на складе можно проводить на любой из вкладок. Рассмотрим подробнее возможности поиска на каждой из них.
Поиск товаров на странице “Склад > Остатки”
Важно: на всех страницах РемОнлайн в строке поиска установлен автофокус. Поэтому вам необязательно устанавливать курсор в поле, вы можете сразу начать писать поисковый запрос или сканировать штрихкод.
После написания запроса обязательно нажмите кнопку Enter!
Поиск товара по его штрихкоду или серийному номеру
В строку поиска можно отсканировать просто штрихкод или штрихкод серийного номера, таким образом в таблице сразу отобразится необходимый товар. Так как штрихкод является уникальным идентификатором и в РемОнлайн не может быть двух разных товаров с одинаковым штрихкодом.

Поиск товара по системным и пользовательским полям
По умолчанию поиск происходит только по системным полям из формы товара: “Наименование”, “Код”, “Артикул”, “Описание”.
При поиске товара по наименованию, вы можете указать слова из названия товара в любом порядке.
Например, у вас на складе есть товар с названием “Micro SD Kingston 64 GB”, если вы напишете в строке поиска SD 64, в таблице остатков отобразится этот товар.

Если у вас несколько разных производителей такого товара, отобразятся все эти товары.

Подобным образом можно осуществлять поиск по коду, артикулу или описанию товара. Обратите внимание, что эти параметры не являются уникальными и могут повторяться или пересекаться в разных товарах.
Например, на складе есть товар “Зарядное устройство” с артикулом “10324”, и есть другой товар, у которого в описании указана такая же комбинация цифр. В таком случае при поиске по коду отобразятся оба этих товара.

Поля “Код”, “Артикул” и “Описание” можно использовать для определения аналогичных товаров. Например, есть 10 запчастей с разным названием, ценой и назначением. При этом все эти запчасти подходят для ремонта определенного устройства. Можно указать одинаковые коды / артикулы для этих товаров или в поле “Описание” указать модель устройства, для которого подходят эти запчасти. Таким образом, когда вы введете в строке поиска модель устройства, в таблице отобразятся все товары, которые совместимы с этим устройством.

Если поисковый запрос начинается с символа +, то поиск начинает происходить и по пользовательским полям из формы товара.

При установке определенных фильтров поиск осуществляется согласно заданным параметрам.

Поиск товара по всем складам
Если у вас большое количество складов и необходимо найти на каком из них лежит определенный товар, в поле “Наличие” необходимо выбрать “Все”.
После этого к поиску будут доступны товары со всех складов. Затем открываете диалоговое окно товара и на вкладке “Остатки” вы сможете увидеть где и в каком количестве находится товар. Использование функции адресного хранения значительно упростит и ускорит процесс поиска товара на складе.

Поиск на страницах “Оприходования”, “Списания”, “Перемещения”, “Инвентаризации”, “Возвраты поставщику”
Поиск на этих вкладках осуществляется по следующим данным:
С помощью этих параметров вы быстро сможете найти определенный документ или документы от определенного поставщика, склада и т.д.
Челом Вам, добрый народ! С самого рождения Алексей Север слыл знатным балагуром и сказочником, но сегодня мне не до смеха. Возьмите скальпель, оденьте халат, бахилы, маску. Сейчас без наркоза и анестезии мы начнем удаление злокачественной опухоли, которая возникает и фатально прогрессирует на каждом втором складе. И имя ей НЕЛИКВИД.
На эту тему я видел много разномастного читва, прилично послушал всевозможных консалтеров, коучей и бизнес-гуру и, в очередной раз, убедился, что все эти новоиспеченные Верховные Жрецы засирают нам мозг какой-то теоретической ересью, но не один из них не может взять и просто, без понтов и умняков показать, как быстро найти неликвидные позиции на своем складе.
Я Вас обрадую, миссия выполнима!
Сейчас, впрочем как и всегда, я покажу Вам свой эксклюзивный, на 100% авторский, многократно проверенный жизнью и гарантированно результативный алгоритм вычисления неликвидов на своих складах. Поехали.
Для начала разберемся с мат. частью, уяснив что такое неликвид.
НЕЛИКВИД — это запас нормального товара в ненормальных количествах, реализация которого обычными методами в стандартные сроки с приемлемой нормой доходности маловероятна.
Проще говоря, мы не можем взять и продать этот кондиционный, небракованный товар в нужные нам сроки и заработать на нем нужные нам деньги.
Внимание! Бракованный, некондиционный, просроченный товар мы не включаем в неликвиды.
Место этих заек на складе брака, именно там мы и будем с ними разбираться, но это тема отдельной короткометражки. А сегодня наш главный вопрос: «Как найти этот самый неликвид на своем складе».
Для этого нам будет нужна информация из вашей учетной системы, причем со стандартной ведомостью «Движение товаров на складах» в нашем районе ловить вообще нечего. Тут нужен специальный отчет с набором специфических показателей.
Так вот, ставлю сто к одному, что в вашей учетке такого отчета нет. Это грустно, но не смертельно, потому что у Вас всегда есть возможность абсолютно бесплатно получить его за пару дней.
Кстати, умные люди давно прочухали эту фишку. Они заказывают на topcontrol.ru демо-версию системы ТопКонтроль, ставят ее у себя на компе и через день абсолютно бесплатно получают исчерпывающую инфу по своим неликвидам, нажав три кнопки в модуле «Управление запасами».
Собственно, этот отчет перед Вами.

Он сгруппирован по товарам, ибо неликвиды — это всегда конкретные ассортиментные позиции.
Все данные приведены Без учета клиентских возвратов, то есть все цифры считаются от чистых продаж.
А вот список показателей этого отчета, которые нам будут нужны — остатки рубли, остатки штуки, продажи штуки, дни на складе, рентабельность запасов, глубина остатков штук.
Отчет сформирован за период 6 месяцев. С 1-го января по 30 июня. Почему я выбрал именно такой период объясню позже.
Так вот, этот отчет решит все вопросы и расставит все точки над И, показав, кто есть кто на Вашем складе.
Сегодня у меня пример из Индустрии красоты, поэтому в списке товаров всякие парикмахерские причиндалы, понятно, что в вашем отчете будут свои табуреточки.
Как найти СУПЕРНЕЛИКВИДЫ на своем складе
И наша первая задача в этом списке: из тысячи позиций найти фатально мертвые висяки. Для этого выгрузим отчет в Excel и выведем автофильтр по всем столбцам.
На первом шаге из этого списка нужно удалить товары с нулевыми остатками. Для этого в фильтре Остатки штуки выбираем значение ПУСТО. Вот они.
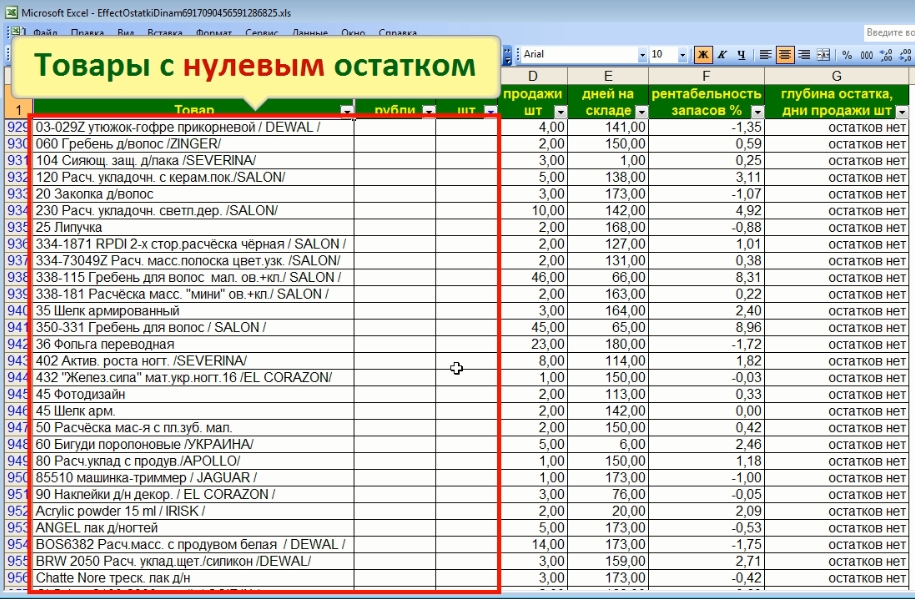
Сразу отвечу на вопрос: «Откуда приплыли эти пингвины?». Тут все просто.
У этих товаров нулевой остаток на конец периода, у нас это 30 июня, то есть их тупо нет на складе. Но в течение 6 месяцев они могли спокойно продаваться и продавались, верно? А так как у нас в отчете есть столбец с показателем «продажи штуки», то естественно программа вывела эти товары независимо от того, есть они на складе или нет, что в общем-то логично.
Именно поэтому здесь появились эти товарищи, которые будут незамедлительно удалены, ибо товар, которого нет на складе, не может быть неликвидом по определению. То есть в отчете оставляем товары с реальным остатком. Теперь нам нужно вычислить среди них полный шлак, который я и мои парни называют Супернеликвиды. Что это такое?
СУПЕРНЕЛИКВИД — это позиции, у которых в течение всего выбранного периода не было ни одной продажи, то есть вообще ни одной.
 Для этого в столбце Продажи штуки, нужно выбрать значение ПУСТО. И вот перед нами окажется список товаров, которые лежат на складе мертвым грузом. Никто их не покупает, потому что эти огурцы-переростки никому не нужны.
Для этого в столбце Продажи штуки, нужно выбрать значение ПУСТО. И вот перед нами окажется список товаров, которые лежат на складе мертвым грузом. Никто их не покупает, потому что эти огурцы-переростки никому не нужны.
Вот это и есть наши супернеликвиды, согласны? Какой к черту согласны, НЕТ конечно!
Потому что любой из этих товаров мог приехать к нам вчера. Понимаете?
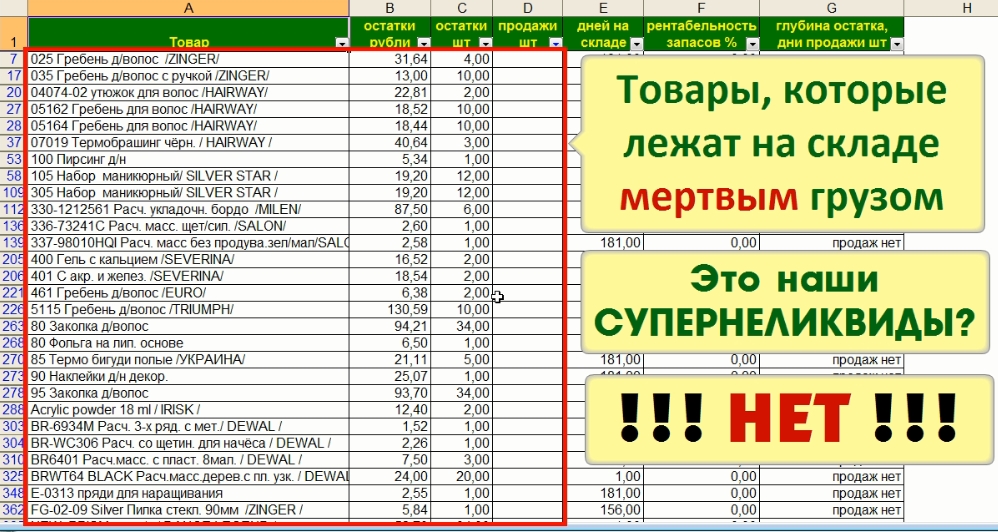
То есть мы выбрали товары, по которым не было продаж полгода. Но мы не знаем, когда они к нам легли на склад, на прошлой неделе или 1-го января.
Так вот для того, чтобы не выплеснуть с водой ребеночка, нам нужен показатель Дней на складе. С его помощью мы отберем товары, по которым нет продаж и которые давно лежат на складе.

В фильтре Дней на складе последнее число 181, это значит, что период с 1 января по 30 июня равен 181 дню. Для себя мы решили, что товар можно отнести к Cупернеликвиду, если он приехал на склад и по нему не было продаж два месяца и более. То есть в моем случае «давно» составляет 60 дней. Мы эту цифру называем Норматив для Новинки, естественно, что у Вас он может быть другим.
В отчете нам нужно оставить только те товары, для которых показатель Дней на складе ВЫШЕ норматива, то есть более 60 дней. Они перед вами.

Эти позиции и есть наш Супернеликвид, который нужно выжигать напалмом со своего склада. И для этого в последнем столбце, который я назову Статус, всем этим товарам я ставлю признак Супернеликвид.
Внимание! Это очень важный момент, ибо, не указав в учетке, какой товар является неликвидом, мы не сможем в будущем контролировать его слив, а собственно ради этого мы здесь репу и чешем.
Как найти ОБЫЧНЫЕ НЕЛИКВИДЫ на своем складе
С Супернеликвидами все понятно, мы их нашли и обозвали. Переходим к Обычным неликвидам, с которыми придется повозиться чуть подольше. Показываю, как их найти.
В фильтре Продажи нужно выбирать НЕПУСТЫЕ, чтобы оставить в отчете только те товары, которые продавались, ибо с тотальным мертвяком мы разобрались выше. А теперь следите за руками.
Во-первых, из отчета нужно убрать товары-новинки, которые приехали к нам только-только и по которым еще нет вменяемой статистики продаж. Но фильтр по Нормативу для Новинок (60 дней), мы уже выставили при поиске Супернеликвидов. То есть сейчас товары- новинки исключены по умолчанию.
Таким образом, в отчете остались товары, у которых есть продажи, есть остатки и лежат они на складе больше 60 дней. А теперь вопрос.
Какой критерий нужно использовать, чтобы вычислить среди них неликвид?

Ответ: Глубину остатка! Это мега полезный показатель, который дает нам инфу за сколько дней мы распродадим каждую из позиций, если будем продавать ее так же, как продавали раньше.
То есть нужно установить Норматив Глубины Остатка, и мы получим то, что нужно. Понятно, что этот норматив должен быть не меньше, чем количество дней в нашем периоде, у нас это 181 день. Почему так? Да потому, что товар, который лежит на складе и будет продаваться больше 6 месяцев, это не просто товар, это реально мертвый запас, а еще точнее, замороженные деньги и прямые финансовые потери.
Поэтому я устанавливаю фильтр по показателю глубина остатка, в котором ставлю условие отображать товары с глубиной остатка более 181 дней. Они перед Вами.

На этом можно было бы остановиться, но есть один нюанс, который в очном обучении я величаю Хлеб с Коньяком.
Представьте, что у вас продуктовый магазин. Каждый день вы продаете 20 буханок хлеба с наценкой 5%, а на вино-водочной полке стоит коньячок XO, который продается по 1 бутылке в неделю с наценкой в 50%. Теперь вопрос, на чем вы зарабатываете больше при условии, что на вашей полке должны постоянно лежать 10 буханок хлеба и стоять 3 бутылки коньяка в качестве неснижаемого остатка.
То есть в нашем списке потенциальных неликвидов, которые мы будем продавать больше 181 дня, необходимо вычислить такой коньяк, который редко продается, но у него такая наценка, что с лихвой окупает затраты на складское хранение. Как найти этих буржуев?
С помощью показателя Рентабельность запасов, который считается следующим образом:
Рентабельность запасов — это валовая прибыль по позиции за выбранный период деленная на среднедневную стоимость запасов, которые мы храним на нашем складе.
Само собой, этот показатель должен быть, как минимум больше единицы, и чем он выше, тем эффективней работают Ваши денежки, вложенные в товар на складе.
Так вот, на последнем шаге нужно отфильтровать товары, которые приносят высокую прибыль при низких остатках, то есть соответствуют заданному Нормативу Рентабельности.
Исходя из личного опыта, для наших целей этот норматив должен быть выше 5. Поэтому из нашего отчета нужно исключить товары, у которых рентабельность запасов выше этой цифры.

Итак, перед Вами список по настоящему Неликвидных товаров, которые валяются на складе с китайской пасхи, продаются, как прошлогодний снег, и вместо прибыли генерят сплошной убыток. Вообщем, это реальный хлам. Осталось присвоить им признак Неликвид в столбце Статус, загрузить этот список в ТопКонтроль, чтобы всерьез начать работу над их сливом.Но это уже совсем другая история, которую я задвину в следующий раз. Главное, не забудьте подписаться на канал, дабы не прощелкать.

А сейчас, только для Вас, только один раз в году, моя Вишенка на торте.
Расчет критического срока хранения товара
Отвечаю на вопрос, который постоянно задают мои клиенты:
«За какой период необходимо формировать такой отчет для поиска неликвидов?»
Я в своем примере выбрал период 6 месяцев, а какой период выбрать Вам? Правильный и точный метод называется Критический срок хранения запаса.
Критический срок хранения запаса показывает, сколько дней можно хранить товар на складе без убытка.
Смысл в том, что если товар лежит на складе сверх этого количества дней, то мы несем прямые убытки, и чем больше он будет лежать, тем выше будут потери.
Чтобы посчитать критический срок хранения используется вот такая формула.

Начнем с числителя.
Р — это показатель Рентабельность продаж, который вычисляется как сумма «валовой прибыли деленная на объем продаж товара». Его на раз считает 1С в отчете Валовая прибыль, естественно, у нас в ТопКонтроль его увидеть — дело одной минуты.
АД — расшифровывается как Альтернативная доходность. Он показывает сколько мы заработаем, если вместо закупки товара, тупо положим эти деньги в банк на депозит. Сейчас средняя банковская ставка по депозиту 8% в месяц, в пересчете на день около 0,27%. Эту циферку и введем в наш пример. Далее идут два показателя отсрочки.
ОтПост — это средняя отсрочка в днях, которую дают нам наши Поставщики.
ОтПок — сколько дней отсрочки даем Покупателям уже мы.
В ТопКонтроль эти показатели считаются в модуле «Дебиторская задолженность», как сделать это в вашей системе, я не знаю. Если вы тоже не в курсе, то можно заморочиться и посчитать ее в ручную, вытащив эти цифры из договоров с Поставщиками и Покупателями. Не буду на эту элементарщину тратить время, будут вопросы, пишите в личку, отвечу.
Ну и последний самый сложный показатель под символом З.
З — это затраты на хранение товара на складе, выраженные в % к себестоимости реализованных товаров. Считается он так. Сначала берем все затраты на хранение товара за период, например последний месяц, далее берем себестоимость реализованных за этот месяц товаров, а теперь делим эти затраты друг на друга. В результате имеем циферку, которую и подставляем в нашу формулу как переменная З.
Итоговый результат формулы показывает нам количество дней, после которого хранить товар будет дороже, чем слить его по себестоимости, а то и в минус. За этот период мы и строим наш отчет.
В моем случае Критический срок хранения запаса 175 дней. В примере я поставил пол года, потому что такой период покруглей и понаглядней. Стоп машина. Резюмирую сегодняшнюю лекцию вот такой схемой, где поэтапно показано все, о чем я сегодня рассказал. Теперь вы знаете, как найти неликвиды на своем складе, аминь.
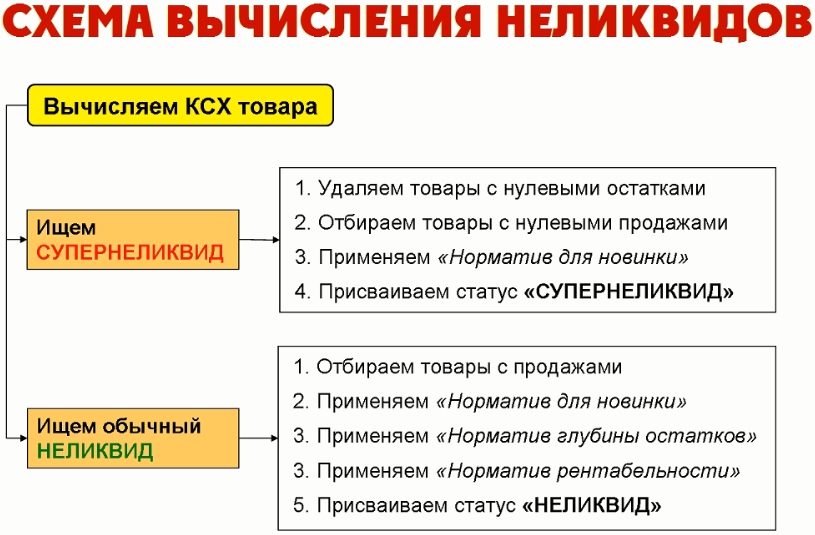
Естественно, что все показанное мной — вариант для тупых и горбатых, для тех, кто работает много, а думает мало и результат получает копеечный.
Потому что умные и успешные работают мало, но получают много, а, главное, категорически отказываются копаться в таких отчетах и тратить на них свою жизнь, напрягая хрусталик.
Эти ребята уже давно в высшей лиге, где вывозить деньги со своих складов на свалку -абсолютный моветон, и они не знают, что такое сливать в минус свой товар, на их уровне не нужно разгребать утиль на своем складе, потому что его там нет и никогда не будет.
Интеллектуальный анализ данных, мониторинг «дней без продаж» и «дней в заморозке», эксклюзивный метод расчета глубины остатков от дней на складе и ежедневный автоконтроль выполнения складских нормативов в модуле Инфостена позволяют им предвидеть появление неликвидных гадин на своих складах и во время вводить по ним план «Перехват».
Сами посудите, куда дешевле и почетней предотвратить появление мертвяков на своем складе, чем потом тратить время на их героический слив или дорогие похороны.
Короче, знайте, что технология беззаботной складской жизни существует, зашита она в ТопКонтроль и, понятное дело, крестьяне о ней никогда не узнают, ибо настоящая эффективность -это привилегия способных и талантливых, которым я всегда рад и говорю велком в наш узкий круг реальных профи.
Пусть мы не можем изменить мир. Но мы, блин, обязаны изменить себя. Вы знаете, где меня найти, так что ловите шанс. За сим откланиваюсь с наилучшими пожеланиями удачи вам и больших продаж.