Мощность исследования¶
Статистическая мощность — вероятность, с которой искомый эффект будет обнаружен, при условии, что он имеет место.
Величина мощности также используется для вычисления размера выборки, необходимой для подтверждения гипотезы с необходимой мерой эффекта.
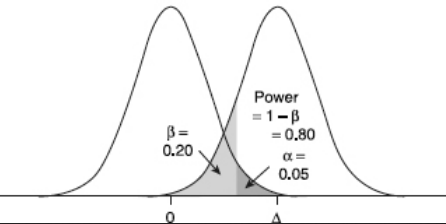
Рис. 10 Параметры для определения мощности критерия¶
Уровень значимости ((alpha)) выбирается исследователем и определяет вероятность совершения ошибки первого рода — «обнаружения» эффекта, которого на самом деле нет, когда случайность принимаем за истинный результат. Вероятность того, что альтернативная гипотеза верна, но решение принимается в пользу нулевой гипотезы (ошибка второго рода), обозначается греческой буквой (beta). Тогда вероятность принятия правильного решения при истинной альтернативной гипотезе (мощность) равна (1-beta).
При планировании исследования желаемая мощность обычно принимается равной 0.8 или 0.9.
Эффект действия фактора — это разница между нулевой и альтернативной гипотезами, выраженная в сигмах.
G*Power — популярная программа для вычисления статистической мощности для многих различных тестов. G*Power также может использоваться для вычисления размеров эффекта.
Расчет мощности с параметрами для экспресс варианта теста Баланс внимания приведен на рисунке Рис. 11.
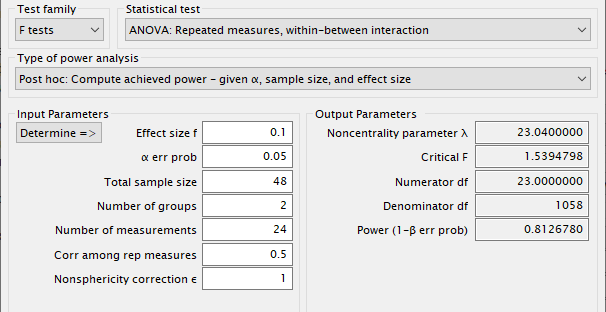
Рис. 11 Окно результатов программы G*Power при выполнении расчета мощности¶
Другой «априорный» тип анализа мощности применяют, когда надо найти размер выборки для заданных уровня значимости и мощности, 0.05 и 0.8 соответственно. При сбалансированных выборках одинакового размера отношение N1 к N2 равно 1.
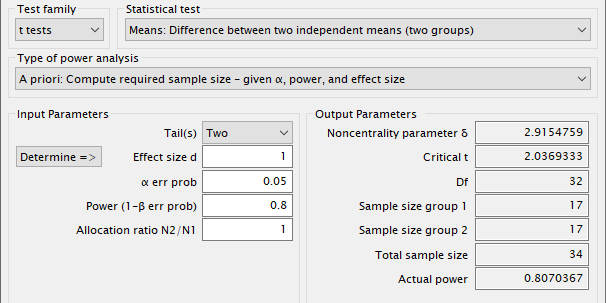
Рис. 12 Окно результатов программы G*Power при расчете размера выборки¶
Таким образом, мы отвечаем на вопрос, сколько наблюдений требуется для выборки каждого типа, чтобы, по крайней мере, обнаружить эффект в 1 сигму с 80%-ной вероятностью обнаружения эффекта, если он истинен (20% ошибки типа II), и 5%-ной вероятностью обнаружения эффекта, если такого эффекта нет (ошибка типа I).
Анализ мощности обычно выполняется до проведения исследования. Перспективный или априорный анализ мощности может быть использован для оценки любого из четырех параметров мощности, но чаще всего используется для оценки требуемых размеров выборки.
Для несложных видов анализа вроде теста Стьюдента вычисление мощности сводится к расчету доли одного распределения, разрезанного в точке, рассчитанной как доля в другом распределении, сдвинутом на размер эффекта Рис. 10.
import scipy.stats as stats n = 48 ncond = 2 effect = 1. power = 0.8 alpha = 0.05 beta = 1 - power n_group = n // ncond df = n_group - 1 # позиция относительно H0 crit = stats.t.ppf(1-alpha/2, df) # доля в H1 до позиции, сдвинутой на эффект stats.t.cdf(crit + effect, df)
Для точного расчёта используют нецентральное распределение Стьюдента, у которого ошибка растет с ростом «нецентральности».
Уровень значимости делим на 2, поскольку для двухстороннего теста вероятность распределяется на два хвоста в случае положительного и отрицательного эффекта.
crit = stats.t.ppf(1-alpha/2, df) 1 - stats.nct.cdf(crit, df, effect*np.sqrt(n_group))
Поскольку приходится отнимать от единицы, то можно заменить на прямую и инвертированную «функции выживания» (англ. survival function).
crit = stats.t.isf(alpha/2, df) stats.nct.sf(crit, df, effect*np.sqrt(n_group))
from statsmodels.stats.power import ttest_power ttest_power(effect, n_group, alpha)
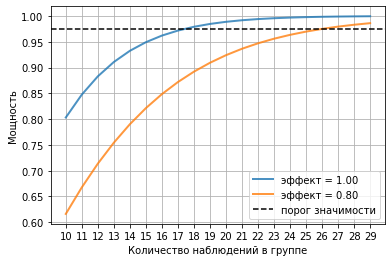
Построим график роста мощности с увеличением размера выборки для заданных эффектов.
nn = arange(10,30) popo = ttest_power(effect, nn, alpha) plot(nn, popo, lw=2, alpha=0.8, label='эффект = %4.2F' % effect) effect2 = 0.8 popo = ttest_power(effect2, nn, alpha) plot(nn, popo, lw=2, alpha=0.8, label='эффект = %4.2F' % effect2) axhline(1 - alpha/2, color='k', ls='--', label='порог значимости') xticks(nn) grid(True) xlabel('Количество наблюдений в группе') ylabel('Мощность'); legend();
В пакете statsmodels есть специальные средства для решения этой задачи. При этом используют scipy.optimize для нахождения значения, удовлетворяющего уравнению расчета мощности.
Параметр, который нужно найти, передается в метод ...solve_power() с пустым значением None.
from statsmodels.stats.power import tt_ind_solve_power result = tt_ind_solve_power(effect, power=power, nobs1=None, ratio=1.0, alpha=alpha) print(f'Размер выборки: {result:.3f}')
Для достоверного обнаружения разницы в 1 сигму (для времени реакции это около 100 мс) нужно по крайней мере 17 значений на группу.
Если выборку сделать больше, то можно будет обнаруживать разницу менее 1 сигмы. Помните, что рост дискриминационной способности статистического метода (размер ошибки) обратно пропорционален корню квадратному от размера выборки, т.е. значительное увеличение выборки ведет лишь к незначительному росту мощности.
Так в надежном варианте теста «Баланс внимания» 32 предъявления для каждого из шести видов стимуляции (2 модальности и 3 частоты предъявления). С учётом того, что 1-2 стимула могут быть пропущены, рабочий размер выборки можно считать 30 штук.
result = tt_ind_solve_power(effect_size=None, power=power, nobs1=30, ratio=1.0, alpha=alpha) print(f'Обнаруживаемая разница: {result:.3f} σ')
Обнаруживаемая разница: 0.736 σ
[This article was first published on Milano R net, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Abstract
This article provide a brief background about power and sample size analysis. Then, power and sample size analysis is computed for the Z test.
Next articles will describe power and sample size analysis for:
- one sample and two samples t test;,
- p test, chi-square test, correlation;
- one-way ANOVA;
- DOE
 .
.

Finally, a PDF article showing both the underlying methodology and the R code here provided, will be published.
Background
Power and sample size analysis are important tools for assessing the ability of a statistical test to detect when a null hypothesis is false, and for deciding what sample size is required for having a reasonable chance to reject a false null hypothesis.
The following four quantities have an intimate relationship:
- sample size
- effect size
- significance level = P(Type I error) = probability of finding an effect that is not there
- power = 1 – P(Type II error) = probability of finding an effect that is there
Given any three, we can determine the fourth.
Z test
The formula for the power computation can be implemented in R, using a function like the following:
powerZtest = function(alpha = 0.05, sigma, n, delta){
zcr = qnorm(p = 1-alpha, mean = 0, sd = 1)
s = sigma/sqrt(n)
power = 1 - pnorm(q = zcr, mean = (delta/s), sd = 1)
return(power)
}
In the same way, the function to compute the sample size can be built.
sampleSizeZtest = function(alpha = 0.05, sigma, power, delta){
zcra=qnorm(p = 1-alpha, mean = 0, sd=1)
zcrb=qnorm(p = power, mean = 0, sd = 1)
n = round((((zcra+zcrb)*sigma)/delta)^2)
return(n)
}
The above code is provided for didactic purpose. In fact, the pwr package provide a function to perform power and sample size analysis.
install.packages("pwr")
library(pwr)
The function pwr.norm.test() computes parameters for the Z test. It accepts the four parameters see above, one of them passed as NULL. The parameter passed as NULL is determined from the others.
Some examples
Power at  for
for  against
against  100″ />.
100″ />.
 ,
,  ,
, 
sigma = 15 h0 = 100 ha = 105
This is the result with the self-made function:
> powerZtest(n = 20, sigma = sigma, delta = (ha-h0)) [1] 0.438749
And here the same with the pwr.norm.test() function:
> d = (ha - h0)/sigma
> pwr.norm.test(d = d, n = 20, sig.level = 0.05, alternative = "greater")
Mean power calculation for normal distribution with known variance
d = 0.3333333
n = 20
sig.level = 0.05
power = 0.438749
alternative = greater
The sample size of the test for power equal to 0.80 can be computed using the self-made function
> sampleSizeZtest(sigma = sigma, power = 0.8, delta = (ha-h0)) [1] 56
or with the pwr.norm.test() function:
> pwr.norm.test(d = d, power = 0.8, sig.level = 0.05, alternative = "greater")
Mean power calculation for normal distribution with known variance
d = 0.3333333
n = 55.64302
sig.level = 0.05
power = 0.8
alternative = greater
The power function can be drawn:
ha = seq(95, 125, l = 100) pwrTest = pwr.norm.test(d = d, n = 20, sig.level = 0.05, alternative = "greater")$power plot(d, pwrTest, type = "l", ylim = c(0, 1))

View (and download) the full code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
### Self-made functions to perform power and sample size analysis
powerZtest = function(alpha = 0.05, sigma, n, delta){
zcr = qnorm(p = 1-alpha, mean = 0, sd = 1)
s = sigma/sqrt(n)
power = 1 - pnorm(q = zcr, mean = (delta/s), sd = 1)
return(power)
}
sampleSizeZtest = function(alpha = 0.05, sigma, power, delta){
zcra=qnorm(p = 1-alpha, mean = 0, sd=1)
zcrb=qnorm(p = power, mean = 0, sd = 1)
n = round((((zcra+zcrb)*sigma)/delta)^2)
return(n)
}
### Load pwr package to perform power and sample size analysis
library(pwr)
### Data
sigma = 15
h0 = 100
ha = 105
### Power analysis
# Using the self-made function
powerZtest(n = 20, sigma = sigma, delta = (ha-h0))
# Using the pwr package
pwr.norm.test(d = (ha - h0)/sigma, n = 20, sig.level = 0.05, alternative = "greater")
### Sample size analysis
# Using the self-made function
sampleSizeZtest(sigma = sigma, power = 0.8, delta = (ha-h0))
# Using the pwr package
pwr.norm.test(d = (ha - h0)/sigma, power = 0.8, sig.level = 0.05, alternative = "greater")
### Power function for the two-sided alternative
ha = seq(95, 125, l = 100)
d = (ha - h0)/sigma
pwrTest = pwr.norm.test(d = d, n = 20, sig.level = 0.05, alternative = "greater")$power
plot(d, pwrTest, type = "l", ylim = c(0, 1))
|
Перевод
Ссылка на автора
Статистическая сила теста гипотезы — это вероятность обнаружения эффекта, если для обнаружения присутствует настоящий эффект.
Мощность может быть рассчитана и сообщена для завершенного эксперимента, чтобы прокомментировать уверенность, которую можно было бы получить в выводах, сделанных по результатам исследования. Он также может использоваться в качестве инструмента для оценки количества наблюдений или размера выборки, необходимых для обнаружения эффекта в эксперименте.
В этом руководстве вы откроете для себя важность статистической мощности теста гипотезы, а теперь вычисляете анализ мощности и кривые мощности как часть экспериментального проекта.
После завершения этого урока вы узнаете:
- Статистическая мощность — это вероятность проверки гипотезы о том, что эффект найден, если эффект найден.
- Анализ мощности может использоваться для оценки минимального размера выборки, необходимого для эксперимента, с учетом желаемого уровня значимости, размера эффекта и статистической мощности.
- Как рассчитать и построить анализ мощности для t-теста Стьюдента в Python, чтобы эффективно спланировать эксперимент.
Давайте начнем.

Обзор учебника
Этот урок разделен на четыре части; они есть:
- Статистическая проверка гипотез
- Что такое статистическая сила?
- Анализ мощности
- Анализ силы t-критерия Стьюдента
Статистическая проверка гипотез
Тест статистической гипотезы делает предположение о результате, называемом нулевой гипотезой.
Например, нулевая гипотеза для корреляционного теста Пирсона состоит в том, что нет никакой связи между двумя переменными. Нулевая гипотеза для критерия Стьюдента состоит в том, что нет разницы между средствами двух групп населения.
Тест часто интерпретируется с использованием p-значения, которое представляет собой вероятность наблюдения результата, учитывая, что нулевая гипотеза верна, а не обратная, как это часто бывает с неправильными интерпретациями.
- р-значение (р): Вероятность получения результата, равного или более экстремального, чем наблюдалось в данных.
При интерпретации p-значения критерия значимости необходимо указать уровень значимости, часто называемый греческой строчной буквой alpha (a). Общим значением для уровня значимости является 5%, записанное как 0,05.
Значение p интересует контекст выбранного уровня значимости. Результатом теста значимости считается «статистически значимый”Если значение p меньше уровня значимости. Это означает, что нулевая гипотеза (что нет результата) отклоняется.
- p & lt; = альфа: отклонить H0, другое распределение.
- p & gt; альфа: не удается отклонить H0, то же распределение.
Куда:
- Уровень значимости (альфа): Граница для определения статистически значимого результата при интерпретации значения p.
Мы можем видеть, что значение p является просто вероятностью и что в действительности результат может быть другим. Тест может быть неверным. Учитывая р-значение, мы могли бы сделать ошибку в нашей интерпретации.
Есть два типа ошибок; они есть:
- Ошибка типа I, Отклонить нулевую гипотезу, когда на самом деле нет значительного эффекта (ложное срабатывание). Значение р оптимистично мало.
- Ошибка типа II, Не отвергайте нулевую гипотезу, когда есть значительный эффект (ложноотрицательный). Значение p пессимистически велико.
В этом контексте мы можем думать об уровне значимости как о вероятности отклонения нулевой гипотезы, если бы она была верной. Это вероятность ошибки типа I или ложного срабатывания.
Что такое статистическая сила?
Статистическая сила или сила проверки гипотезы — это вероятность того, что проверка правильно отклоняет нулевую гипотезу.
То есть вероятность истинно положительного результата. Это полезно только тогда, когда нулевая гипотеза отвергается.
… Статистическая сила — это вероятность того, что тест правильно отклонит ложную нулевую гипотезу. Статистическая сила имеет значение только тогда, когда ноль ложен.
— страница 60, Основное руководство по размерам эффектов: статистическая мощность, мета-анализ и интерпретация результатов исследований, 2010.
Чем выше статистическая мощность для данного эксперимента, тем ниже вероятность ошибки типа II (ложноотрицательная). Это выше вероятность обнаружения эффекта, когда есть эффект. На самом деле, мощность точно обратна вероятности ошибки типа II.
Power = 1 - Type II Error
Pr(True Positive) = 1 - Pr(False Negative)Более интуитивно, статистическая сила может рассматриваться как вероятность принятия альтернативной гипотезы, когда альтернативная гипотеза верна.
При интерпретации статистической мощности мы ищем экспериментальные установки, которые имеют высокую статистическую мощность.
- Низкая статистическая мощность: Большой риск совершения ошибок типа II, например, ложный минус.
- Высокая статистическая мощность: Небольшой риск совершения ошибок типа II
Экспериментальные результаты со слишком низкой статистической мощностью приведут к неверным выводам о значении результатов. Поэтому необходимо искать минимальный уровень статистической мощности.
Обычно планируют эксперименты со статистической мощностью 80% или лучше, например 0,80. Это означает 20% вероятности столкновения с областью типа II. Это отличается от 5% вероятности возникновения ошибки типа I для стандартного значения уровня значимости.
Анализ мощности
Статистическая сила — это одна часть головоломки, которая состоит из четырех взаимосвязанных частей; они есть:
- Размер эффекта, Количественная величина результата, присутствующего в популяции. Размер эффекта рассчитывается с использованием определенной статистической меры, такой как коэффициент корреляции Пирсона для взаимосвязи между переменными или d Коэна для разницы между группами.
- Размер образца, Количество наблюдений в выборке.
- Значимость, Уровень значимости, используемый в статистическом тесте, например, альфа. Часто устанавливается на 5% или 0,05.
- Статистическая мощность, Вероятность принятия альтернативной гипотезы, если она верна.
Все четыре переменные связаны между собой. Например, больший размер выборки может облегчить обнаружение эффекта, а статистическая мощность в тесте может быть увеличена путем уменьшения уровня значимости.
Анализ мощности включает в себя оценку одного из этих четырех параметров с заданными значениями для трех других параметров. Это мощный инструмент как при разработке, так и при анализе экспериментов, который мы хотим интерпретировать с помощью статистических тестов гипотез.
Например, статистическая мощность может быть оценена с учетом размера эффекта, размера выборки и уровня значимости. Альтернативно, размер выборки может быть оценен с учетом различных желаемых уровней значимости.
Анализ силы отвечает на такие вопросы, как «какая статистическая мощность у моего исследования?» И «какой объем выборки мне нужен?».
— Страница 56, Основное руководство по размерам эффектов: статистическая мощность, мета-анализ и интерпретация результатов исследований, 2010.
Возможно, наиболее распространенное использование энергетического анализа заключается в оценке минимального размера выборки, необходимого для эксперимента.
Анализ мощности обычно проводится перед проведением исследования. Предполагаемый или априорный анализ мощности может использоваться для оценки любого из четырех параметров мощности, но чаще всего используется для оценки требуемых размеров выборки.
— страница 57, Основное руководство по размерам эффектов: статистическая мощность, мета-анализ и интерпретация результатов исследований, 2010.
Как практик, мы можем начать с разумных значений по умолчанию для некоторых параметров, таких как уровень значимости 0,05 и уровень мощности 0,80. Затем мы можем оценить желаемый минимальный размер эффекта, характерный для проводимого эксперимента. Затем можно использовать анализ мощности для оценки минимального требуемого размера выборки.
Кроме того, можно провести многократный анализ мощности, чтобы получить кривую зависимости одного параметра от другого, такого как изменение размера эффекта в эксперименте с учетом изменения размера выборки. Могут быть созданы более сложные графики, варьирующиеся по трем параметрам. Это полезный инструмент для экспериментального дизайна.
Анализ силы t-критерия Стьюдента
Мы можем конкретизировать идею статистической мощности и анализа мощности на проработанном примере.
В этом разделе мы рассмотрим t-критерий Стьюдента, который является статистическим тестом гипотезы для сравнения средних значений двух выборок гауссовых переменных. Предположение или нулевая гипотеза теста состоит в том, что выборочные популяции имеют одинаковое среднее значение, например что нет никакой разницы между выборками или что образцы взяты из одной и той же популяции.
Тест вычислит p-значение, которое может быть интерпретировано относительно того, являются ли выборки одинаковыми (не в состоянии отклонить нулевую гипотезу), или существует статистически значимая разница между выборками (отклонить нулевую гипотезу). Общий уровень значимости для интерпретации значения p составляет 5% или 0,05.
- Уровень значимости (альфа): 5% или 0,05.
Размер эффекта сравнения двух групп можно определить количественно с помощью меры размера эффекта. Распространенной мерой для сравнения разницы в среднем по двум группам является мера Коэна. Он рассчитывает стандартную оценку, которая описывает разницу с точки зрения количества стандартных отклонений, что средства разные. Большой размер эффекта для d Коэна составляет 0,80 или выше, что обычно принимается при использовании меры.
- Размер эффекта: D Коэна не менее 0,80.
Мы можем использовать значение по умолчанию и принять минимальную статистическую мощность в 80% или 0,8.
- Статистическая мощность: 80% или 0,80.
Для данного эксперимента с этими значениями по умолчанию нас может заинтересовать оценка подходящего размера выборки. То есть сколько наблюдений требуется от каждой выборки, чтобы по крайней мере обнаружить эффект 0 80 с вероятностью 80% обнаружения эффекта, если он истинный (20% ошибки типа II), и вероятностью 5% обнаружения эффекта, если такого эффекта нет (ошибка типа I).
Мы можем решить это с помощью анализа мощности.
Библиотека statsmodels предоставляет TTestIndPower класс для расчета энергетического анализа для теста Стьюдента с независимыми образцами. Следует отметить, что TTestPower класс, который может выполнить тот же анализ для парного теста Стьюдента.
Функция solve_power () может быть использован для расчета одного из четырех параметров в анализе мощности. В нашем случае мы заинтересованы в расчете размера выборки. Мы можем использовать функцию, предоставив три части информации, которую мы знаем (альфа,эффект, а такжемощность) и установить размер аргумента, который мы хотим вычислить ответ (nobs1) к «Никто«. Это говорит функции, что рассчитать.
Примечание о размере выборки: у функции есть аргумент под названием ratio, который представляет собой отношение количества выборок в одной выборке к другой. Если ожидается, что обе выборки будут иметь одинаковое количество наблюдений, тогда коэффициент будет равен 1,0. Если, например, ожидается, что вторая выборка будет иметь вдвое меньше наблюдений, то отношение будет 0,5.
Экземпляр TTestIndPower должен быть создан, тогда мы можем вызватьsolve_power ()с нашими аргументами, чтобы оценить размер выборки для эксперимента.
# perform power analysis
analysis = TTestIndPower()
result = analysis.solve_power(effect, power=power, nobs1=None, ratio=1.0, alpha=alpha)Полный пример приведен ниже.
# estimate sample size via power analysis
from statsmodels.stats.power import TTestIndPower
# parameters for power analysis
effect = 0.8
alpha = 0.05
power = 0.8
# perform power analysis
analysis = TTestIndPower()
result = analysis.solve_power(effect, power=power, nobs1=None, ratio=1.0, alpha=alpha)
print('Sample Size: %.3f' % result)При выполнении примера вычисляется и печатается примерное количество образцов для эксперимента как 25. Это будет рекомендуемое минимальное количество образцов, необходимое для получения эффекта желаемого размера.
Sample Size: 25.525Мы можем пойти еще дальше и рассчитать кривые мощности.
Кривые мощности — это линейные графики, которые показывают, как изменение переменных, таких как размер эффекта и размер выборки, влияет на мощность статистического теста.
функция plot_power () может быть использован для создания кривых мощности. Зависимая переменная (ось x) должна быть указана по имени в ‘dep_var‘Аргумент. Массивы значений могут быть указаны для размера выборки (Nobs), размер эффекта (effect_size) и значение (альфа) параметры. Затем будет построена одна или несколько кривых, показывающих влияние на статистическую мощность.
Например, мы можем принять значение 0,05 (значение по умолчанию для функции) и исследовать изменение размера выборки между 5 и 100 при низких, средних и высоких эффектах.
# calculate power curves from multiple power analyses
analysis = TTestIndPower()
analysis.plot_power(dep_var='nobs', nobs=arange(5, 100), effect_size=array([0.2, 0.5, 0.8]))Полный пример приведен ниже.
# calculate power curves for varying sample and effect size
from numpy import array
from matplotlib import pyplot
from statsmodels.stats.power import TTestIndPower
# parameters for power analysis
effect_sizes = array([0.2, 0.5, 0.8])
sample_sizes = array(range(5, 100))
# calculate power curves from multiple power analyses
analysis = TTestIndPower()
analysis.plot_power(dep_var='nobs', nobs=sample_sizes, effect_size=effect_sizes)
pyplot.show()При выполнении примера создается график, показывающий влияние на статистическую мощность (ось Y) для трех разных размеров эффекта (эс), поскольку размер выборки (ось X) увеличивается.
Мы можем видеть, что, если мы заинтересованы в большом эффекте, точка снижения доходности с точки зрения статистической мощности возникает в пределах 40-50 наблюдений.

Полезно, statsmodels имеет классы для выполнения анализа мощности с другими статистическими тестами, такими как F-тест, Z-тест и критерий хи-квадрат.
расширения
В этом разделе перечислены некоторые идеи по расширению учебника, которые вы, возможно, захотите изучить.
- Постройте кривые мощности различных стандартных уровней значимости в зависимости от размера выборки.
- Найдите пример исследования, которое сообщает статистическую силу эксперимента.
- Подготовьте примеры анализа производительности для других статистических тестов, предоставляемых statsmodels.
Если вы исследуете какое-либо из этих расширений, я хотел бы знать.
Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
документы
- Использование размера эффекта — или почему значение P недостаточно 2012.
книги
- Основное руководство по размерам эффектов: статистическая мощность, мета-анализ и интерпретация результатов исследований, 2010.
- Понимание новой статистики: размеры эффектов, доверительные интервалы и метаанализ 2011
- Статистический анализ мощности для поведенческих наук 1988
- Прикладной анализ мощности для поведенческих наук, 2010.
API
- Statsmodels Расчет мощности и размера выборки
- statsmodels.stats.power.TTestPower API
- statsmodels.stats.power.TTestIndPower
- API statsmodels.stats.power.TTestIndPower.solve_power ()
API statsmodels.stats.power.TTestIndPower.plot_power () - Статистическая мощность в Statsmodels, 2013.
- Графики власти в стат-моделях, 2013.
статьи
- Статистическая мощность в Википедии
- Статистическая проверка гипотез в Википедии
- Статистическая значимость в Википедии
- Определение размера выборки в Википедии
- Размер эффекта в Википедии
- Ошибки типа I и типа II в Википедии
Резюме
В этом уроке вы обнаружили статистическую мощность теста гипотез и способы расчета анализа мощности и кривых мощности как части экспериментального проекта.
В частности, вы узнали:
- Статистическая мощность — это вероятность проверки гипотезы о том, что эффект найден, если эффект найден.
- Анализ мощности может использоваться для оценки минимального размера выборки, необходимого для эксперимента, с учетом желаемого уровня значимости, размера эффекта и статистической мощности.
- Как рассчитать и построить анализ мощности для t-теста Стьюдента в Python, чтобы эффективно спланировать эксперимент.
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.