Поддерживаемые языки:
Afrikaans, Amharic, Arabic, Azerbaijani, Azerbaijani — Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Breton, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese — Simplified, Chinese — Simplified Vertical, Chinese — Traditional, Chinese — Traditional Vertical, Cherokee; Tsalagi, Corsican, Welsh, Danish, German, Divehi, Dzongkha, Greek, English, English, Middle (1100-1500), Esperanto, Estonian, Basque, Faroese, Persian, Filipino (old — Tagalog), Finnish, French, German — Fraktur, French, Middle (1400-1600), Western Frisian, Scottish Gaelic, Irish, Galician, Greek, Ancient (to 1453), Gujarati, Haitian; Haitian Creole, Hebrew, Hindi, Croatian, Hungarian, Armenian, Inuktitut, Indonesian, Icelandic, Italian, Italian — Old, Javanese, Japanese, Japanese Vertical, Kannada, Georgian, Georgian — Old, Kazakh, Central Khmer, Kyrgyz, Kurmanji (Kurdish — Latin Script), Korean, Korean Vertical, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Malayalam, Marathi, Macedonian, Maltese, Mongolian, Maori, Malay, Burmese, Nepali, Flemish, Norwegian, Occitan (post 1500), Oriya, Punjabi, Polish, Portuguese, Pashto, Quechua, Romanian; Moldovan, Russian, Sanskrit, Sinhala; Sinhalese, Slovak, Slovenian, Sindhi, Spanish; Castilian, Spanish; Castilian — Old, Albanian, Serbian, Serbian — Latin, Sundanese, Swahili, Swedish, Syriac, Tamil, Tatar, Telugu, Tajik, Thai, Tigrinya, Tonga, Turkish, Uyghur, Ukrainian, Urdu, Uzbek, Uzbek — Cyrillic, Vietnamese, Yiddish, Yoruba
Конвертируем в docx, pdf, txt, odf. Быстро, бесплатно
Поддерживаемые языки
- Английский
- Испанский
- Итальянский
- Немецкий
- Русский
- Турецкий
- Украинский
- Французский
Файлы, которые могут быть распознаны
PDF, JPG, BMP, GIF, PNG, TIFF, WEBP, HEIC, JFIF, DJVU
Поддержка PDF файлов защищённых паролем
При условии, что просмотр документа возможен
Для бизнеса
- Массовое распознавание документов
- Индексация текстовой информации распознанных файлов и гибкий поиск по этой информации. Поиск внутри изображений, PDF
- Группировка документов в зависимости от контента
- Помощь в интеграции, разработка ПО под ваши потребности
Эти сайты и программы помогут извлечь текстовое содержимое изображений и бумаг, чтобы вам было удобнее с ним работать.
1. Office Lens
- Платформы: Android, iOS, Windows.
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.
2. Adobe Scan
- Платформы: Android, iOS.
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB*2.
FineReader славится высокой точностью распознавания. Увы, бесплатные возможности инструмента ограниченны: после регистрации вам позволят отсканировать всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Подписка стоимостью 129 евро позволяет сканировать до 5 000 страниц в год, а также открывает доступ к десктопному редактору PDF‑файлов.
Перейти на сайт FineReader →
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
Перейти на сайт Online OCR →
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
Перейти на сайт img2txt →
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
Скачать Microsoft OneNote →
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
Скачать Readiris 17 →
Читайте также 💻📎🖌
- 7 лучших текстовых редакторов, работающих в браузере
- Easy Screen OCR для Windows и macOS распознает текст с картинок или прямо с экрана
- Лучшие инструменты для массового переименования файлов в Windows, macOS и Linux
- 7 лучших текстовых редакторов, поддерживающих Markdown
- 10 отличных текстовых редакторов для разных платформ
*Деятельность Meta Platforms Inc. и принадлежащих ей социальных сетей Facebook и Instagram запрещена на территории РФ.
Как распознать текст на картинке?
Когда нужно извлечь текст с изображения, то самый простой способ очевиден — нужно просто его переписать. Но если надписей или картинок очень много, то выполнить задачу вручную становится сложнее. В этом случае помогут специальные программы и сервисы по автоматическому распознаванию. Рассказываю, как легко распознать текст на картинке и какие инструменты в этом помогут.
Как работает распознавание текста на картинках
Извлечение текста из изображения основано на технологии OCR — оптического распознавания символов. Она включает в себя такие этапы:
Получение и анализ изображения. Программа сканирует картинку и определяет светлые области как фон, а тёмные — как символы и буквы.
Подготовка к распознаванию. Изображение проходит очистку — сглаживается контраст, удаляются пятна, стираются рамки и линии, распознаются шрифты.
Распознавание текста. Программа сравнивает символы с шаблонами из базы или по отдельным элементам символа ищет наибольшие соответствия.
Итоговая обработка. Результат отображается в текстовом формате. Некоторые системы могут преобразовать извлечённые данные в текстовые файлы — PDF, TXT, DOC.
Для качественного распознавания нужно, чтобы надписи отличались от фона и иллюстраций. Все символы должны быть разборчивыми и чёткими, а строки на картинке — идти ровно, без перекосов и искажений.
Вот какие сервисы можно использовать для извлечения текста из изображений.
Google Lens
Приложение «Google Объектив» может не только извлечь текст с картинки, но и перевести его на другой язык. Распознанные символы можно скопировать с изображения как в обычном текстовом файле.
Кликните по изображению в браузере для вызова контекстного меню и выберите пункт «Найти через Google Объектив». После открытия картинки в Google Lens нажмите на «Текст» и скопируйте символы с картинки через меню или Ctrl + C.
При распознавании текста в Google Lens можно скопировать любой фрагмент
Если кликнуть на «Переводчик», можно сразу перевести результат на любой язык с помощью Google Translate.
Аналогично функция работает и в браузере Google на мобильных устройствах. Нужно нажать на картинку для вызова меню, выбрать «Найти через Google Объектив» и скопировать результат.
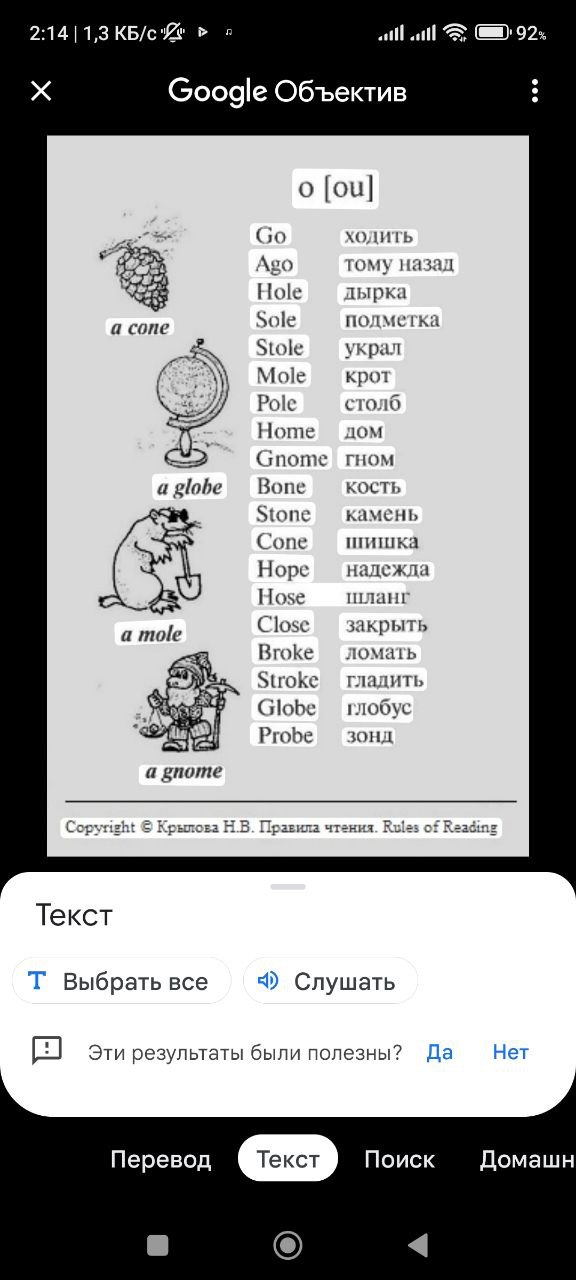
Распознанный в Google Lens текст можно прослушать
Кстати, с помощью Google Lens можно распознавать текст на изображениях, сохранённых на мобильном устройстве. Для этого откройте нужный файл в «Галерее» и нажмите на «Поделиться». В разделе «Отправить файлы через…» выберите «Google Поиск по изображению». Картинка откроется в Google Lens, и вы сможете скопировать надписи.
Google Docs
Извлечь текст с картинки помогают и Google Документы. Причём в этом случае можно обрабатывать даже довольно большие файлы — например, длинные сканы страниц. Порядок действий будет таким:
- Загрузите фото, скан или изображение на Google Drive.
- Кликните по загруженному файлу для вызова меню.
- Выберите пункт «Открыть с помощью Google Документы».
- В открывшемся документе скопируйте текст, отображаемый под картинкой.
При необходимости результат преобразования можно сразу отредактировать и исправить в нём ошибки.

В Google Docs можно преобразовать в текстовый формат объёмные изображения
Длительность обработки картинки в Google Docs зависит от объёма загруженного файла. Но, по личному опыту, на обработку уходит не больше одной минуты.
Яндекс.Картинки
Функция распознавания текста есть и в Яндексе.
Кликните на изображение с надписями и в меню выберите «Найти это изображение в Яндексе». Картинка откроется в новом окне. Нажмите на «Распознать текст» в правой части страницы, если автоматического преобразования не произошло.
В Яндекс.Картинки в браузере можно загрузить фото с компьютера
Результат можно скопировать или отправить в «Яндекс.Переводчик».
В Яндексе можно перевести любую распознанную картинку
Если нужно извлечь только определённую часть текста, то используйте функцию «Выбрать фрагмент». Выделите нужную часть изображения и активируйте распознавание.
Яндекс умеет извлекать текст из выбранного фрагмента
Извлечение текста с картинок поддерживается и в мобильной версии Яндекса. При этом для обработки можно загружать изображения из «Галереи» смартфона.
Дополнительные сервисы
Помимо встроенных инструментов Яндекса и Google, можно применять для распознавания текста и другие сервисы.
Convertio
Сайт
Онлайн-сервис Convertio преобразует отсканированные документы и изображения в редактируемые форматы DOC, PDF, XLS и TXT. Бесплатно и без регистрации можно обработать до 10 страниц. После загрузки файла можно выбрать язык документа, формат сохранения результата, номера страниц в файле. Готовый текст доступен для скачивания или отправки в Google Drive либо Dropbox.
На платной версии сервиса потребуется регистрация. Стоимость зависит от объёма предоплаченного пакета — от $4.99 за 50 страниц.
Aspose
Сайт
В Aspose можно бесплатно конвертировать в текст отсканированные документы, изображения, фотографии. Можно загрузить файл, сделать снимок на камеру или указать URL картинки. В списке поддерживаемых языков — 45 вариантов. Есть возможность настроить формат загруженного документа, включить коррекцию контраста и переноса, отрегулировать уровень разрешения.
Тестирование сервиса показало, что он хорошо обрабатывает картинки с небольшим количеством текста. А вот более объёмные документы содержат много ошибок. Хотя, возможно, сервис не устроило качество файлов или что-то ещё.
Цифра Р
Сайт
В сервисе от типографии «Цифра Р» можно бесплатно преобразовать изображения в текст. Поддерживаются только форматы JPG и JPEG. Результат выводится в отдельном окне и доступен для копирования.
В этом сервисе нет никакого дополнительного функционала и настроек. Но именно своей простотой он и привлекает: загрузить файл, нажать кнопку и скопировать результат. Обработка файлов происходит достаточно быстро.
Online-convert
Сайт
Ещё один инструмент для извлечения текста из изображений, фотографий и других рисунков. В Online-convert поддерживается обработка файлов формата JPG, PNG, TIFF, SVG, BMP, WEBP. Результат сохраняется в текстовый файл TXT. В дополнительных настройках сервиса можно указать все языки, которые используются в файле.
В бесплатной версии сервиса доступны только самые простые функции. Также есть ограничения по размеру файла, количеству задач в сутки, времени обработки. Платный тариф позволяет обрабатывать файлы от 4–8 ГБ и более, без ограничений по количеству документов и с высоким приоритетом. Стоимость платной версии по подписке — от $6.42 в сутки.
«Фото в текст»
Сайт
Бесплатный сервис «Фото в текст» умеет преобразовывать в текстовый формат изображения JPG, JPEG, BMP, PNG, GIF И TIFF. Результат можно скопировать или скачать в виде файла TXT. Сервис поддерживает множество языков, при этом автоматически распознаёт язык документа. Также можно самостоятельно выбрать нужный язык. Картинки загружаются с компьютера, из Dropbox или по URL.
Текст получается довольно качественным. Потестировав сервис, я обнаружила только одну ошибку в тексте объёмом на половину страницы. Конечно, результат во многом зависит от качества исходного оригинала.
Есть и другие инструменты на основе OCR. Например, десктопные программы, которые позволяют локально обрабатывать документы большого объёма. Но для периодического применения и обработки относительно небольших файлов онлайн-сервисы вполне подходят.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
The service will help you convert online pictures of the format: jpg, jpeg, png, bmp, pbm to text.
This will make it easier to work with the text: it will allow you to copy it into a convenient file of any format, check spelling or conduct SEO analysis.
Image conversion is available in 30+ languages (list at the bottom of the page), spell check is available on most of them.
How does it work?
OCR is an optical image recognition technology that works online at tesseract.js. It identifies and converts scanned hardcopy characters into a digital format, which is more easily recognized by PCs and various applications. Simply put, the technology recognizes text by examining it and translating the characters into code for subsequent data processing, meaning a physical document becomes machine-readable.
OCR software converts your document into a black-and-white or two-color version. The bitmap image is then analyzed for dark areas (text) and light areas (background). The dark areas are then recognized as characters and the software analyzes them to discern numbers and letters.
What are the possible uses of this software?
The service is useful for those who need to transfer text from a scanner into digital form, or recognize text on a photo and get it in the form of a text document. This technology is often used by professionals whose work involves processing large amounts of printed material and physical documents – so large that it is not feasible to manually type them out.
The recognized text can be edited and formatted in a regular text editor. This simplifies the processing of large amounts of text that originally do not come in digital format.
What kind of texts are the easiest to recognize?
For a text to be recognized with no errors, it must meet the following requirements:
- it must be a scanned copy of a text or a clear photo made with a smartphone camera;
- all characters must be straight;
- there must be a clear contrast between the symbols and the background;
- the text must be easily legible;
- the background of the text must be monochromatic.
The service cannot recognize handwritten texts, captchas, and texts with an uneven or noisy background.
How do I optimize a photo, screenshot, or image for better conversion quality?
Refer to the previous paragraph and try to maximize the contrast between the symbols and the background, while keeping the background as monochromatic as possible.
How do I use the service?
For users like you, it is quite simple:
- Take a picture of a text with your phone/camera or scan the text you want to recognize. The supported formats are: jpg, jpeg, png, bmp, and pbm.
- Click on «Upload file.»
- Select the file on your computer.
- Wait for the document to be processed – it takes less than a minute.
- Copy the text and save the result in your preferred format:
- Plain text (.txt)
- Adobe Acrobat (.pdf)
- Microsoft Word (.docx)
- OpenOffice (.odf)
- etc.
Functionality for downloading files in a set/selected format will be implemented at a later date.
There is no limit on the number of files that can be recognized at no charge. No registration or payment required.
What can I do with the recognized text?
Now you have a wide range of choices of what to do with the converted text. You can:
- copy;
- check spelling;
- edit;
- perform a SEO analysis to calculate the number of words and symbols;
- save for further use on your device.
Service features
- In a few clicks, you get a text converted from a picture, ready for editing and processing.
- The processing it strictly confidential and is protected by the SSL+ certificate.
- Your files and recognized texts are not stored within the service and are not evaluated in any way.
- Recognition of a file of any size never takes no more than a minute.
- No registration required.
- No installation required: all the work is done in a browser (any browser).
Translation into other languages
If you are interested in the service being able to translate large amounts of converted text, make sure to send us an email(contactistio@gmail.com) – we will work to implement such functionality.
List of languages to convert
Afrikaans, Albanian, Ancient Greek, Arabic, Azerbaijani, Basque, Belarusian, Bengali, Bulgarian, Catalan, Cherokee, Chinese, Croatian, Czech, Danish, Dutch, English, English (Old), Esperanto, Esperanto alternativ, Estonian, Finnish, Frankish, French, French (Old), Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Internet Meme, Italian, Italian (Old), Japanese, Kannada, Korean, Latvian, Lithuanian, Macedonian, Malay, Malayalam, Maltese, Math, Norwegian, Old Spanish, Polish, Portuguese, Romanian, Russian, Serbian (Latin), Slovakian, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Telugu, Thai, Traditional Chinese, Turkish, Ukrainian, Vietnamese