1 ) Скачиваешь и устанавливаешь Python. ( ставишь галочку для PATH )https://www.python.org/downloads/
2) Win+R -> pip install requests > OK
3) Win+R -> pip install bs4 > OK
4) Создаешь папку на рабочем столе.
5) Создаешь два фаила в папке.
5.1) Первый фаил например get_links.py , туда вставляешь этот
КОД
import requests
from bs4 import BeautifulSoup
main_url = 'https://uristhome.ru'
docs_url = "https://uristhome.ru/document"
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
down_link = []
r = requests.get(docs_url, headers=headers)
soup = BeautifulSoup(r.content, 'html.parser')
for doc in soup.find("ul",{"class": "y_articles-document-list"}):
down_link.append(main_url+doc.find("a").attrs['href'])
with open('download_link.txt', 'a') as nf:
nf.writelines('n'.join(docs)) потом сохраняешь фаил.
5.2) Создаешь второй фаил например download_links.py туда вставляешь уже этот
КОД
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
down_link = open('download_links.txt', 'r')
docs = []
counter = 0
for links in down_link.readlines():
try:
r = requests.get(links, headers=headers)
soup = BeautifulSoup(r.content, 'html.parser')
x = soup.find("div",{"class": "filefield-file"}).find("a").attrs['href']
counter += 1
print(counter)
print(x)
docs.append(x)
except:
pass
with open('documents_link.txt', 'a') as nf:
nf.writelines('n'.join(docs))Как это работает:
1) открываешь get_links.py в папке создается текстовой файл с ссылками на документы
2) отрываешь download_links.py он будет обрабатывать тот текстовой файл. по окончанию создаст еще 1 текстовой файл documents_link.txt с ссылками на документы.
Несмотря на то, что сегодня интернетом пользуются как никогда, все же бывают моменты, когда нужно сохранить видеофайл на компьютер.
Проблема: нужно найти URL проигрываемого видео
Представим ситуацию: вы зашли на сайт xxx.xx и там вы смотрите видео, смотрите его прямо в браузере Google Chrome, но видео показывается плохо, то зависает, то что-нибудь еще и вам гораздо удобнее скачать это видео и потом посмотреть на компьютере. Но проблема в том, что вы знаете как включить видео в браузере, но не знаете по какой ссылке это видео можно скачать, ссылки на скачивание видео на сайте нет.
Логично полагать, если браузер показывает видео, значит откуда-то он его качает. В этой заметке я покажу вам, как узнать ссылку с которой качается видео, т.е. как найти ссылку на поток с который проигрывает видеоплеер Google Chome.
Решение
Для примера возьмем любой сайт с видео онлайн, пусть это будет kino50.com. Заходим в просмотр фильма «Пингвины Мадагаскара». Прокручиваем ниже, видим плеер:
Теперь открываем «инструменты разработчика» (Ctrl+Shift+I) и переключаемся на вкладку «Network» (Сеть):

Запускаем проигрывание видео и смотрим какая строка грузится дольше всего (или можно сориентироваться по колонке type). Именно это соединение (строка) является ссылкой на видео файл:
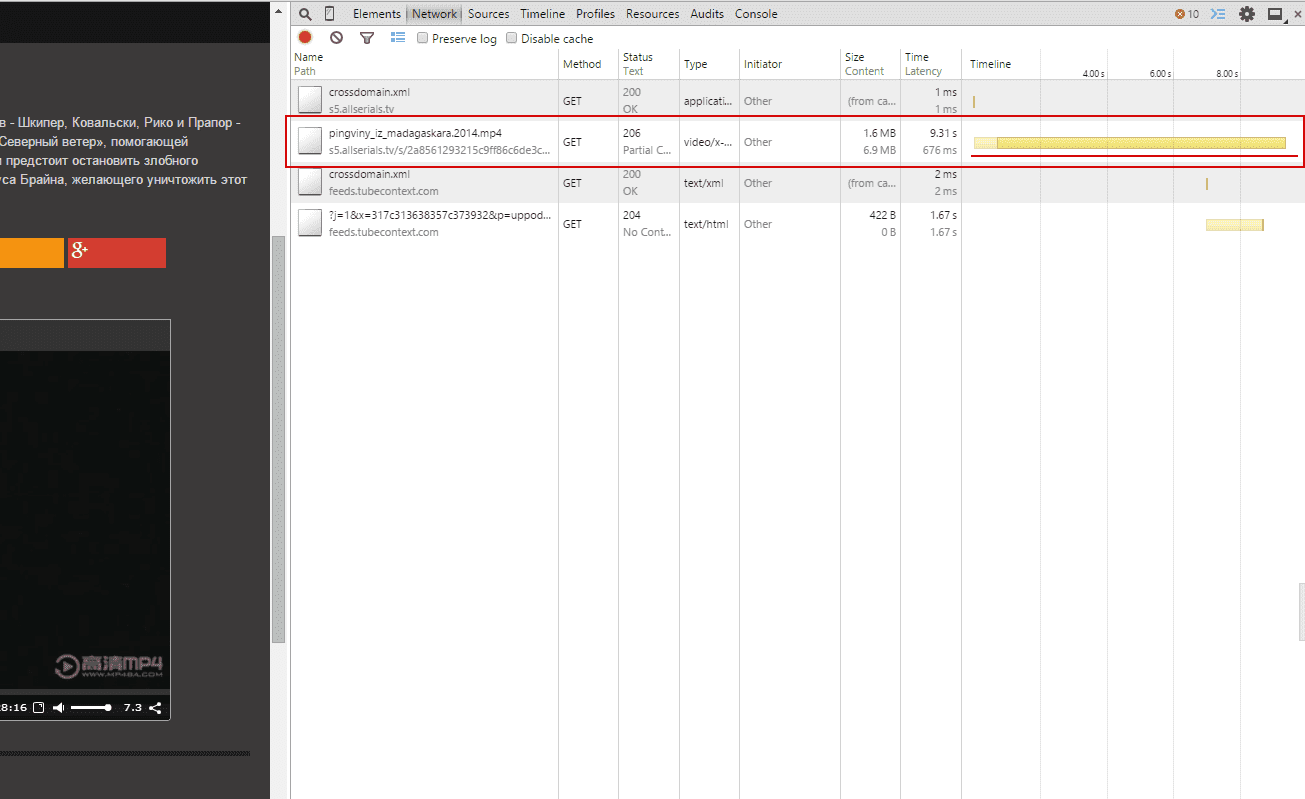
Теперь, кликаем на строку и копируем ссылку на видео:

Видео где показано, как скачивать сегменты и потоки
Не всегда можно найти прямую ссылку на файл, потому что на некоторых сайтах файл разделен на сегменты, а где-то видео показывается из потока. В таких случаях как правило все равно можно скачать видео, но придется найти нужный URL (для сегментов) или использовать видеоплеер в Windows для сохранения потока в файл.
Все это показано в этом видео:
Заключение
В качестве примера был взят случайный сайт. Подобным образом можно получить ссылку на видео практически на любом сайте. Так можно получить ссылку на любой файл, не только на видео, а на любой объемный файл, ссылка на который явно не указана или скрыта. Таким файлом может например быть не видео а аудио файл. Т.е. таким образом вы можете узнать реальную ссылку на файл, который скрыт.
Также, не забывайте, что если вы скачали какой-то файл, то ссылку откуда был скачан файл можно в «Менеджере загрузок» (Ctrl+J):

КАК ВЫЯСНИТЬ URL АДРЕС ССЫЛКИ ДЛЯ СКАЧИВАНИЯ ФАЙЛА
Чем привлекателен интернет, так это тем, что там почти всегда можно найти что-то полезное и интересное для пользователей интернета. Зачастую это могут быть различные файлы, или просто какая-либо информация (развлекательная или познавательная). Вся эта информация (и файлы в т.ч.) размещены на серверах, а доступ к ней мы получаем посредством указания URL адресов (или, попросту, ссылок) на эту информацию в специализированных программах интернет-браузерах, предназначенных для соединения компьютера пользователя с сервером (фактически, тоже компьютером), на котором хранится эта информация.
Общие понятия и рекомендации о поиске информации в интернете описаны в статье «ПОИСК ИНФОРМАЦИИ В ИНТЕРНЕТЕ (Освоение компьютера)» на этом сайте. Там же раскрывалось понятие и отмечалось значение URL-адреса в процессе доступа к информации, размещенной в интернете. Эта статья является продолжением вышеуказанной и посвящена вопросу, как выяснить URL-адрес ссылки для скачивания файла.
Вся информация, размещенная в интернете, обычно систематизирована по определенным признакам. В большинстве случаев отдельные файлы, предназначенные для скачивания, размещены на сайтах в разделах «файловый менеджер» или в облачных хранилищах, а сам процесс скачивания заключается в указании браузеру ссылок (точнее URL-адресов этих ссылок).

На Рис.1 представлен один из примеров процесса скачивания файлов из интернета и выяснения URL-адресов ссылок. В текстовом документе указана ссылка для скачивания торрент файла (см.1 Рис.1). При наведении на нее курсора и нажатии левой кнопкой мыши на эту ссылку происходит скачивание файла (см.2 Рис.1).
Чтобы узнать и скопировать URL-адрес этой ссылки, достаточно навести на нее курсор, и щелкнуть по ней правой кнопкой мыши. При этом появится контекстное меню (см.3 Рис.1). Если вы выберете пункт контекстного меню «Копировать адрес ссылки» (см.4 Рис.1), URL-адрес этой ссылки сохранится в буфере обмена компьютера. Вы можете сохранить его в документе, созданном с помощью любого текстового редактора, к примеру, в блокноте, или просто вставить в адресную строку вашего браузера (см.1 Рис.2). Правда, в последнем случае, после нажатия кнопки «Enter» на клавиатуре, вкладка с введенным в нее URL-адресом ссылки закроется (зависит от браузера), но скачивание файла произойдет.

Приведенный выше вариант – это способ узнать URL-адрес ссылки, который указан в явном виде. Т.е. на сайте не используется защиты от копирования адреса ссылки, и любой пользователь интернета, сохранив эту ссылку, имеет возможность повторно обратиться к ней в любое время или переслать ее своему знакомому. Но существует множество случаев, когда владельцы сайтов пытаются скрыть URL-адрес ссылки. Обычно, это делается в тех случаях, когда кто-то зарабатывает на предоставлении ссылок на файлы, пользующиеся популярностью, или хотят увеличить посещаемость своих сайтов за счет повторного посещения страницы пользователем интернета, на которой размещена эта ссылка. Обычно это (создание ссылок в неявном виде) делается с помощью кнопок «Скачать», размещенных на страницах сайтов.
Если ссылка для скачивания файла явно не указана на страницах сайта или в облачных хранилищах, но вам необходимо ее получить и сохранить, вы можете воспользоваться свойствами браузера, с помощью которого вы ранее уже скачивали этот файл. Для этого в окне браузера нажмите кнопку «Настройки» (см.2 Рис.2). Обращаю внимание, что для разных браузеров ее название может отличаться. В случае Google Chrome, как на моих рисунках, она сейчас называется «Настройка и управление Google Chrome». В случае Microsoft Edge, сейчас она называется «Настройки и прочее».
После нажатия кнопки «настройка браузера» перед вами откроется меню (см.3 Рис.2), в котором необходимо выбрать пункт «Загрузки» (см.4 Рис.2).

После нажатия на кнопку «Загрузки» перед вами откроется окно, в котором будут отражены все выполненные загрузки с помощью вашего браузера (см.1 Рис.3). Теперь вам остается только скопировать ссылку скачанного вами файла в буфер обмена (см.2 Рис.3) и сохранить ее в каком-нибудь текстовом файле.
И еще несколько особенностей выяснения URL-адресов файлов с помощью настроек браузеров и скачивания файлов из интернета:

- Метод копирования ссылок в буфер обмена для разных браузеров может отличаться. Например, метод выделения URL-адреса, описанный выше, подходит для Google Chrome. Для браузера Microsoft Edge копировать нужно с помощью контекстного меню, выбрав пункт «Копировать ссылку». И еще нужно учитывать, что разработчики интернет-браузеров постоянно вносят изменения (обновления) в свое ПО.
- Если скачиваемые файлы размешены на обычных сайтах в разделах «файловый менеджер», то, обычно, прямая ссылка, выявленная приведенными способами, должна работать. Если файл размещен в облачном хранилище, то, обычно, прямая ссылка на файл для скачивания работать не будет, т.к. в программном обеспечении облачных хранилищ существует 2-ух и более ступенчатая защита от несанкционированного скачивания. Попытка скачать файл, указав в браузере непосредственно его URL-адрес, приведет к появлению приблизительно такого окна, как на Рис.4. В таком случае вам придется получить «Ссылку на скачивание» от владельца файла, размещенного в облачном хранилище (см. Рис.5), которая не является прямой ссылкой на файл, или же поискать способ, как обойти защиту облачного хранилища (к примеру, получить логин и пароль доступа владельца сайта), что является незаконным действием.

Иценко Александр Иванович
Когда вы загружаете приложение, будь то проигрыватель VLC или iTunes, вы не получаете прямой ссылки на то, где на самом деле хранится файл. В большинстве случаев вы увидите кнопку «Загрузить», которую вы нажмете, и затем файл будет извлечен из этого местоположения, чтобы его можно было загрузить. В некоторых случаях, если вы посетите диспетчер загрузок своего браузера, вы сможете получить прямую ссылку на файл. Однако, если вы хотите сделать это намного проще, попробуйте FileChef. Это очень простое веб-приложение, которое отправляет поисковый запрос в Google, используя параметры поиска, чтобы найти прямую ссылку для загрузки файла.
Посетите FileChef и введите то, что вы хотите найти. Вы можете открыть раскрывающееся меню и указать тип файла, который вы ищете, чтобы уточнить результаты поиска. Введите имя приложения (или чего-то еще), которое вы ищете, и нажмите Enter.
Откроется новая вкладка с поиском, отправленным на Google.com. Поисковый запрос не будет выглядеть так, как если бы вы сами вводили его непосредственно в Google. Он будет сильно изменен параметрами поиска, которые поддерживает Google. Результаты поиска направят вас на FTP-серверы и другие места, где находится файл, который вы ищете.
Это приложение невероятно полезно, если вы используете его этично. Однако его можно использовать неэтично для поиска и загрузки материалов, защищенных авторским правом. Мы смогли использовать его, чтобы найти и загрузить первую серию первого сезона «Во все тяжкие». Само приложение не делает ничего плохого. Он просто отправляет поисковый запрос в Google, и это совершенно законно. Совершенно другая история, что некоторые файлы, которые не должны быть доступны, появляются в поиске Google.
Также стоит отметить, что не все ссылки указывают на официальный источник для загрузки файла, поэтому будьте осторожны при загрузке файла и запускайте его сканирование, чтобы быть в безопасности.
Одно из замечательных применений этого приложения — вы можете использовать его для загрузки ISO-образа Windows 7 (при условии, что у вас есть действующая лицензия) и выполнить новую установку, если вы потеряли или сломали установочный диск. Используйте это хорошо.
Посетить FileChef
![]() Как извлечь все ссылки с веб-страницы? Задался я вопросом когда возникла необходимость пакетной загрузки большого числа файлов по ссылкам с веб-страницы публичного ФТП серванта.
Как извлечь все ссылки с веб-страницы? Задался я вопросом когда возникла необходимость пакетной загрузки большого числа файлов по ссылкам с веб-страницы публичного ФТП серванта.
Туда-сюда из браузера в менеджер загрузки тыкать заколебёт, а файлы потребно скачать все и разом…
Искать сторонний спец.софт не вариант, нужно уметь обойтись стандартным набором инструментов входящих Дебиан Линух репозиторий или в сам браузер.
Подумалось сначала извлечь все ссылки с веб-страницы путём парсинга curl запроса, но на это не было времени и побежал я анонировать поиском, и наанонировал вот такой кусок JavaScript кода:
var x = document.querySelectorAll("a"); var myarray = [] for (var i=0; i<x.length; i++){ var nametext = x[i].textContent; var cleantext = nametext.replace(/s+/g, ' ').trim(); var cleanlink = x[i].href; myarray.push([cleantext,cleanlink]); }; function make_table() { var table = '<table><thead><th>Name</th><th>Links</th></thead><tbody>'; for (var i=0; i<myarray.length; i++) { table += '<tr><td>'+ myarray[i][0] + '</td><td>'+myarray[i][1]+'</td></tr>'; }; var w = window.open(""); w.document.write(table); } make_table()
Куда его вставлять? В «Инструменты разработчика» браузера, открываем комбинацией на клаве «CTRL + SHIFT + i». На вкладке «Console» в левом нижнем углу окна браузера есть неприметные две синие стрелки указывающие на узкую строку — ото туды и вставляем весь тот код, жмём/давим ENTER. В новой вкладке (всплывающие/выползающие окна нужно будет разрешить) появится список ссылок:




В данном примере извлекались ссылки с веб-страницы ФТП-серванта download.mapsforge.org для пакетной загрузки карт оффлайн-навигации. Можно также использовать для пакетной загрузки голых сисек/писек или кому чего угодно.
Для насквозь мобилизированных киборгов/челоботов/андроидов, т.е. для мобильных юзеров, данный метод извлечения ссылок с веб-страницы наверно не вариант ибо могут возникнуть проблемы с комбинацией на клаве «CTRL + SHIFT + i» — тогда смотрим в сторону дополнений/плагинов к браузерам.
Дале хрен знает шо то за плагины и как они арбайтен, афтор не в курсе и тупо нарыл их по поисковому запросу «extract links plugin for browser» — сами ставьте, юзайте, пишите в комменты шо то за хрень такая и какая от них польза.
Для сатанинского шпионского гугляцкого Chrome:
- Link Klipper — Extract all links — Chrome Web Store
Extract all links on a webpage and export them to a file.
Для браузера Firefox:
- Link Gopher – Get this Extension for Firefox (en-US)
Extracts all links from web page, sorts them, removes duplicates, and displays them in a new tab for inspection or copy and paste into other systems.
Извлечение ссылок через онлайн сервисы — это ещё тот квэст!
Куча сайто-говно-кодеров развелось, клепающих монструозные говно-сайты фреймворком «хуяк-хуяк» + конченная reCaptcha, и в продакшын. На такие «хуяк-хуяк-сервисы» уходит десятки МБ траффика, ресурсов железа, и хороший пучок нервов на пробивание пиЗЕ!данутой reCaptcha и часто + завал окна рекламой. В последнее время у меня впечатление, что кроме reCaptcha никакой иной на всей Планете уже нигде не осталось!
Но, местами нормальные онлайн сервисы извлечения ссылок попадаются (нарыто по запросу «Online Tool to Extract Links»):
- URL Extractor, Free Online Links Extractor, Extract HTML Links
На момент публикации был реально рабочий вариант онлайн сервиса для извлечения ссылок с веб-страницы
Через что ещё можно извлекать веб-ссылки? Через «питона»? Через «Ц», через «Ц++» или может через «Ж»? Вам через что бы ещё хотелося? В комменты пишите письма.
Пока усё, дасвидос/допобачендос/гудбай/аухфидерзейн.