Организация памяти
Время на прочтение
7 мин
Количество просмотров 228K
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
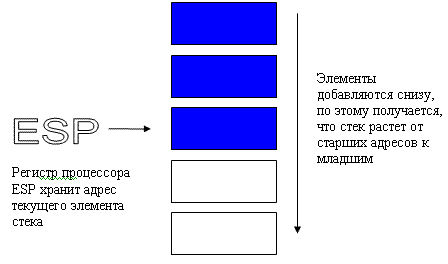
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес —> Линейный (виртуальный)—> Физический
Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.

Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.

Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке: 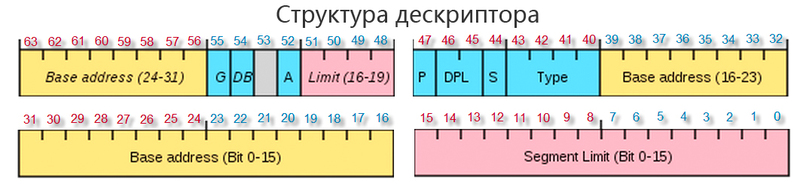
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
С помощью такой нехитрой операции процессор может обращаться по нужному адресу линейной памяти.
Рассмотрим другие биты дескриптора, очень важным является Segment Limit или предел, он имеет 20битное значение от 0-15 и 48-51 бит. Предел задает размер сегмента. Для сегментов данных и кода доступными являются все адреса, расположенные в интервале:
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Условные обозначения битовых позиций
В вычислениях, нумерация битов — это соглашение, используемое для идентификации позиций бита в двоичном числе или контейнере такого значения. Номер бита начинается с нуля и увеличивается на единицу для каждой последующей битовой позиции.
Содержание
- 1 Младший бит
- 1.1 Младший бит в цифровой стеганографии
- 1.2 Младший бит
- 2 Старший бит
- 2.1 Старший значащий байт
- 3 Пример беззнакового целого
- 4 Первый старший бит против наименее значимого
- 5 Нумерация битов LSB 0
- 6 Нумерация битов MSB 0
- 7 Другое
- 8 Использование
- 9 См. Также
- 10 Ссылки
- 11 Внешние ссылки
Наименьший бит
![]() двоичное представление десятичного числа 149 с выделенным младшим битом. MSB в 8-битном двоичном числе представляет собой десятичное значение 128. LSB представляет значение 1.
двоичное представление десятичного числа 149 с выделенным младшим битом. MSB в 8-битном двоичном числе представляет собой десятичное значение 128. LSB представляет значение 1.
В вычислении младший бит (LSB ) является позицией бита в двоичное целое число, дающее значение единиц измерения, то есть определяющее, является ли число четным или нечетным. LSB иногда называют битом младшего разряда или самым правым битом из-за соглашения в позиционной записи о записи менее значимых цифр дальше вправо. Он аналогичен младшей цифре десятичного целого числа, которая является цифрой в позиции единиц (крайняя правая).
Обычно назначают каждый бит — это номер позиции в диапазоне от нуля до N-1, где N — количество битов в используемом двоичном представлении. Обычно это просто показатель степени для соответствующего веса бита в базе 2 (например, в 2..2). Хотя некоторые производители ЦП присваивают номера битов противоположным образом (что не то же самое, что и другой порядок байтов ), сам термин наименее значимый бит остается однозначным как псевдоним для единичного бита.
В более широком смысле наименее значимые биты (множественное число) представляют собой биты числа, ближайшего к младшему разряду и включающего его.
Младшие значащие биты обладают полезным свойством быстрого изменения, если число изменяется даже незначительно. Например, если 1 (двоичный 00000001) добавлен к 3 (двоичный 00000011), результатом будет 4 (двоичный 00000100), а три младших бита изменятся (с 011 на 100). Напротив, три старших бита (MSB) остаются неизменными (от 000 до 000).
Наименьшие значащие биты часто используются в генераторах псевдослучайных чисел, стеганографических инструментах, хэш-функциях и контрольных суммах.
Наименее значимых бит в цифровой стеганографии

В цифровой стеганографии конфиденциальные сообщения могут быть скрыты путем манипулирования и сохранения информации в младших битах изображения или звукового файла. В контексте изображения, если бы пользователь манипулировал последними двумя битами цвета в пикселе, значение цвета изменилось бы не более чем на ± 3 разряда, что, вероятно, будет неразличимо для человеческого глаза. Пользователь может позже восстановить эту информацию, извлекая младшие биты обработанных пикселей, чтобы восстановить исходное сообщение.
Это позволяет скрывать хранение или передачу цифровой информации.
Младший байт
LSB также может означать младший байт . Значение аналогично приведенному выше: это байт (или октет ) в той позиции многобайтового числа, которая имеет наименьшее потенциальное значение. Если значение наименее значимого байта сокращения не очевидно из контекста, его следует указать явно, чтобы избежать путаницы с наименьшим значащим битом.
Чтобы избежать этой двусмысленности, можно использовать менее сокращенные термины «lsbit» или «lsbyte».
Старший бит
В вычислениях самый старший бит (MSB, также называемый старшим -order bit ) — это позиция бита в двоичном числе, имеющем наибольшее значение. MSB иногда называют старшим битом или крайним левым битом из-за соглашения в позиционной нотации о записи более значимых цифр после осталось.
MSB может также соответствовать знаку бит двоичного числа со знаком. В нотации до единицы и с дополнением до двух «1» означает отрицательное число, а «0» означает положительное число.
Обычно каждому биту присваивается номер позиции в диапазоне от нуля до N-1, где N — количество битов в используемом двоичном представлении. Обычно это просто показатель степени для соответствующего веса бита в базе 2 (например, в 2..2). Хотя некоторые производители ЦП присваивают номера битов противоположным образом (что не то же самое, что различие порядка байтов ), MSB однозначно остается наиболее значимым битом. Это может быть одной из причин, почему термин MSB часто используется вместо числа битов, хотя основная причина, вероятно, состоит в том, что разные представления чисел используют разное количество битов.
В более широком смысле, старшие биты (множественное число) являются битами, ближайшими к MSB и включающими его.
![]() Беззнаковое двоичное представление десятичного числа 149 с выделенным старшим битом. MSB в 8-битном двоичном числе представляет собой десятичное значение 128. LSB представляет собой значение 1.
Беззнаковое двоичное представление десятичного числа 149 с выделенным старшим битом. MSB в 8-битном двоичном числе представляет собой десятичное значение 128. LSB представляет собой значение 1.
Старший байт
MSB также может означать «старший значащий байт ». Смысл аналогичен приведенному выше: это байт (или октет ) в той позиции многобайтового числа, которая имеет наибольшее потенциальное значение.
Чтобы избежать этой двусмысленности, часто используются менее сокращенные термины «MSbit » или «MSbyte ».
Пример беззнакового целого числа
В этой таблице показан пример десятичного значения 149 и расположения LSB. В этом конкретном примере позиция значения единицы (десятичная 1 или 0) находится в позиции бита 0 (n = 0). MSB обозначает наиболее значимый бит, а LSB обозначает наименьший значительный бит.
| Двоичный (Десятичный: 149) | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
|---|---|---|---|---|---|---|---|---|
| Битовый вес для данной битовой позиции n (2) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Метка битовой позиции | MSB | LSB |
Позиция LSB не зависит от того, как передается позиция бита (некоторые системы сначала передают старший бит, другие сначала передают младший бит), что является скорее вопросом темы Порядок байтов.
Сначала старший / младший бит
Выражения наиболее первый значащий бит и первый младший значащий бит — это указания на порядок последовательности битов в байтах, отправляемых по проводу в протоколе передачи или в потоке (например, аудиопотоке).
Самый старший бит первым означает, что самый старший бит прибудет первым: отсюда, например, шестнадцатеричное число 0x12, 00010010в двоичном представлении прибудет в виде последовательности 0 0 0 1 0 0 1 0.
Сначала младший бит означает, что младший бит прибудет первым: отсюда, например, то же шестнадцатеричное число 0x12, снова 00010010в двоичном представлении, прибудет в виде (обратной) последовательности 0 1 0 0 1 0 0 0.
Нумерация битов LSB 0
 LSB 0: контейнер для 8-битного двоичного числа с выделенным младшим значащим битом, которому назначен номер бита 0
LSB 0: контейнер для 8-битного двоичного числа с выделенным младшим значащим битом, которому назначен номер бита 0
Когда нумерация битов начинается с нуля для младшего значащего бита (LSB) схема нумерации называется «LSB 0». Этот метод нумерации битов имеет то преимущество, что для любого беззнакового числа значение числа может быть вычислено с использованием возведения в степень с номером бит и основанием, равным 2.. Следовательно, значение двоичного числа без знака целое равно
- ∑ i = 0 N — 1 bi ⋅ 2 i { displaystyle sum _ {i = 0} ^ {N-1} b_ {i } cdot 2 ^ {i}}


где b i обозначает значение бита с номером i, а N обозначает общее количество битов.
Нумерация битов MSB 0
 MSB 0: контейнер для 8-битного двоичного числа с выделенным старшим битом, которому назначен номер бита 0
MSB 0: контейнер для 8-битного двоичного числа с выделенным старшим битом, которому назначен номер бита 0
Аналогично, когда битовая нумерация начинается с нуля для старшего разряда (MSB), схема нумерации называется «MSB 0».
Следовательно, значение двоичного целого числа без знака равно
- ∑ i = 0 N — 1 bi ⋅ 2 N — 1 — i { displaystyle sum _ {i = 0} ^ {N-1} b_ {i} cdot 2 ^ {N-1-i}}

Оператор elem другого
ALGOL 68 фактически является «нумерацией MSB 1 бит», поскольку биты пронумерованы слева направо, причем первый бит (биты elem 1) является «старшим значащим битом», а выражение (биты elem ширины битов) дает «младший значащий бит. «. Аналогично, когда биты приводятся (приведение типов) к массиву Boolean ([] bool бит), первый элемент этого массива (биты [lwb биты]) снова является «старшим битом».
Для нумерации MSB 1 значение двоичного целого числа без знака равно
- ∑ i = 1 N bi ⋅ 2 N — i { displaystyle sum _ {i = 1} ^ {N} b_ { i} cdot 2 ^ {Ni}}

PL / I нумерует BITстроки, начинающиеся с 1 для крайнего левого бита.
Функция Fortran BTESTиспользует нумерацию LSB 0.
Использование
Little-endian CPU обычно используют нумерацию битов «LSB 0», однако оба соглашения о нумерации битов можно увидеть на машинах big-endian. Некоторые архитектуры, такие как SPARC и Motorola 68000, используют нумерацию битов «LSB 0», в то время как S / 390, PowerPC и PA-RISC используют «MSB 0».
Рекомендуемый стиль для документов Request for Comments (RfC) — это нумерация битов «MSB 0».
Нумерация битов обычно прозрачна для программное обеспечение, но некоторые языки программирования, такие как Ada, и языки описания оборудования, такие как VHDL и verilog, позволяют указать соответствующий порядок битов для представления типа данных.
См. Также
- ARINC 429
- Двоичная система счисления
- Представления чисел со знаком
- Дополнение до двух
- Порядок байтов
- Двоичный логарифм
- Последняя единица измерения (ULP)
- Найти первый набор
- MAC-адрес: Обращение к битам
Ссылки
Внешние ссылки
- Номера битов
- Нумерация битов для разных процессоров:
- Motorola 68000 (разделы «Обработка битов» и «Обратная битовая нумерация»)
- IBM Cell Broadband Processors («Порядок байтов и бит n umbering «)
Перед изучением команд и регистров процессора 8086, очень важно понять, как он получает доступ к оперативной памяти, чтобы записывать в нее значения и читать их от туда.
Почему именно процессор 8086? Просто потому, что режим совместимости с командами этого процессора есть во всех старших моделях. И начинать изучать язык ассемблера проще с этого процессора.
Процессор 8086, мог работать только в одном режиме адресации памяти. Все следующие модели, начиная с процессора 80286, сохранили режим совместимости с 8086. Этот режим получил название реального режима (Real Address Mode), или R-режима.
Итак, ближе к делу.
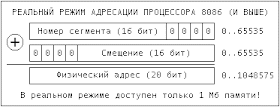
Наименьшим адресуемым блоком памяти является байт (8 бит). Каждый байт памяти имеет уникальное местоположение, называемое физическим адресом, по которому в него может записываться и читаться информация. Очевидно, что для того, чтобы получить доступ к ячейке памяти процессору надо знать ее физический адрес. Для доступа к памяти процессор имеет адресную шину, на которой выставляет адрес ячейки памяти к которой ему необходим доступ. Грубо говоря, адресная шина – это «ноги» (pins) процессора на которых он выставляет адрес ячейки в двоичной системе счисления. Например, чтобы адресовать память размером в четыре байта (у каждого байта свой адрес), процессору, было бы, достаточно адресной шины в два бита (две «ноги). Так как, с помощью двух бит можно было бы адресовать 4 ячейки памяти: адрес 00b – 1-ая ячейка (байт), адрес 01b – 2-ая ячейка (байт), адрес 10b – 3-я ячейка (байт), 11 – 4-ая ячейка (байт). Таким образом, очевидно, что чем большую разрядность имеет адресная шина процессора, с тем большим объемом памяти он может работать.
Процессор 8086 имел 20 битную адресную шину. Что позволяло адресовать 1048576 байт (220) памяти или округленно 1 Мбайт. Проблема состояла в том, что процессор 8086 имел 16 битную архитектуру. То есть все его регистры были 16 битными. А с помощью 16 бит можно адресовать только 65536 (216) байт памяти или округленно 64 Кбайт. Тогда каким же образом процессор 8086 адресовал 1 Мбайт памяти?
Решением стала сегментная адресация памяти. С помощью этого метода физический адрес конкретного байта памяти может логически определятся двумя 16-разрядными значениями. Для того, чтобы с помощью 16-разрядных регистров можно было обращаться в любую точку 20-разрядного адресного пространства, введён двухкомпонентный логический адрес из двух 16-разрядных компонент:
Segment (сегмент) : Offset (смещение)
Пример: 13DF:0100
Где Segment – адрес сегмента, а Offset – смещение от начала этого сегмента.
Но постойте! Два 16-разрядных регистра дают 32 разряда. Как же из этого получается 20 битный адрес? Давайте разбираться где тут собака порылась.
Для определения начала сегментов памяти процессор 8086 использует четыре 16-битных сегментных регистра (CS, DS, SS, ES). Смещение внутри сегмента выбирается из регистров-указателей SP, BP, SI, DI или регистра IP (указателя команд — Instructions Pointer). Для получения 20-битного физического адреса, процессор размещает на адресной шине значение сегментного регистра и сдвигает его влево на четыре бита, заполняя младшие четыре бита адресной шины нулями (умножение на десятичное 16 или шестнадцатеричное 10 ), затем к этому значению прибавляется смещение и адрес сформирован.
Исходя из этого получается что границы сегментов (16-битное значение + 4 нулевых бита) располагаются через каждые 16 байт физических адресов. 4 битами можно адресовать 16 (байт) ячеек памяти, каждая из которых как мы помним содержит один байт. Каждый из этих 16-байтовых фрагментов называется параграфом. 16-разрядные сегментные регистры могут адресовать 65536 (216) параграфов (границ сегментов). А параграф, как уже говорилось, это 16 байт. 65536(параграфов) умножаем 16(байт) получаем 1048576 байт или округленно 1 Мбайт. Хотя и тут не все гладко :). Здесь порылась вторая собака. Откапывать ее будет чуть позже.
Ниже приведен вывод регистров и сегмента кода в программе debug.exe, чтобы можно было все это наглядно увидеть.
-r
AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000
DS=13DF ES=13DF SS=13DF CS=13DF IP=0100 NV UP EI PL NZ NA PO NC
13DF:0100 0000 ADD [BX+SI],AL DS:0000=CD
-d cs:100
13DF:0100 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 …………….
13DF:0110 00 00 00 00 00 00 00 00-00 00 00 00 34 00 CE 13 …………4…
Например, в сегментном регистре (CS -выделен ярким желтым цветом) хранится значение 13DFh, при умножении его на 10h получаем 13DF0h. Стоит обратить внимание, что младшая шестнадцатеричная цифра в адресе каждого сегмента всегда равна 0. То есть адрес любого сегмента всегда кратен 16 десятичному (10h). Поскольку последняя цифра в адресе сегмента всегда равна 0, то ее можно не хранить. В действительности 8086 вместо умножения на 16 использовал содержимое регистра так, как если бы оно имело четыре дополнительных нулевых бита (см. картинку).
 Максимальный размер сегмента определяется теми же 16 битами регистра, в котором хранится смещение. Следовательно, максимальный размер сегмента может быть 65536 байт (216). Минимальный – 16 байт (размер параграфа). Таким образом, сегменты – это виртуальные умозрительные части с максимальным объемом 64 Кбайт каждая.
Максимальный размер сегмента определяется теми же 16 битами регистра, в котором хранится смещение. Следовательно, максимальный размер сегмента может быть 65536 байт (216). Минимальный – 16 байт (размер параграфа). Таким образом, сегменты – это виртуальные умозрительные части с максимальным объемом 64 Кбайт каждая.
Теперь будем откапывать вторую собаку. Возьмем максимальное значение, которое может адресовать сегментный регистр FFFF, применим к нему сдвиг влево на 4 бита, получим FFFF0h (1048560d). Теперь прибавим к этому числу максимальное значение которое может хранится в регистре смещения – FFFF. Таким образом, FFFF0+FFFF= 10FFEF (1114095d). И что это такое? Мы же явно вышли за пределы 1048576 байт памяти. 20 битная адресная шина позволяет максимально адресовать 1048576 байт памяти с адресами от 00000h до FFFFFh. При адресации же памяти свыше 100000h и до 10FFEFh происходил «заворот» — старший единичный бит адреса игнорировался и доступ шёл к 64 килобайтам в начальных адресах (0000h…FFEFh).
Вместе со второй собакой мы откопали и большую свинью, которую, сами того не ведая, подложили разработчики процессора 8086 и сегментной адресации памяти.
Факты о «свинье»:
* Нет никаких препятствий для обращения к физически не существующей памяти.
* При обращении к несуществующей памяти результат непредсказуем (все зависит от разработчика материнской платы и другого аппаратного обеспечения компьютера).
* Программа может обращаться к любому сегменту как для считывания, так и для записи данных и команд.
И еще немного правды о сегментах:
* Сегменты физически не выделены в памяти. Сегменты — это логические окна, через которые программы просматривают области памяти удобными, в 64 Кбайт порциями.
* Размеры сегментов могут изменятся от 16 байт до 64 Кбайт (65536 байт).
* Сегменты не обязательно в памяти располагаются один за другим. Хотя такое бывает достаточно часто.
* Сегменты могут перекрываться один другим; поэтому один и тот же физический байт памяти может иметь различные логические адреса, определяемые разными, но при этом эквивалентными парами сегмент-смещение. Например, пары логических адресов 0000:0010 и 0001:0000 указывают на один и тот же физический адрес ячейки памяти — 0010h.
* Назначением базовых адресов сегментов занимается операционная система, а внутри каждого сегмента адреса формируются программой.
* сегментная организация обеспечивает создание позиционно – независимых или динамически перемещаемых в памяти программ.
Более подробный материал по теме можно взять здесь.
Как найти широковещательный адрес
Эта статья не относится напрямую к операционой системе линукс, но тем не менее эта ось создавалась изначально как сетевая ОС и понимание этой информации лишним не будет.
В терминологии сетей TCP/IP маской подсети или маской сети называется битовая маска, определяющая, какая часть IP-адреса узла сети относится к адресу сети.
с помощью маски подсети можно определить, что один диапазон IP-адресов будет в одной подсети, а другой диапазон соответственно в другой подсети.
У маски подсети существует три наиболее часто используемые формы записи:
1. десятичный вид ( 255.255.255.192 );
2. двоичный вид( 11111111.11111111.11111111.11000000 ).
3. /ХХ (/26) — колличество единиц в двоичном представлении маски подсети.
Адрес подсети.
Это адрес который используется для организации маршрутизации между несколькими подсетями. При получении IP-адреса хоста маршрутизатор накладывает на него маску и определяет адрес подсети, затем по этому адресу определяется адрес шлюза на который нужно отправить пакет.
Адреса хостов в подсети.
Это набор IP-адресов, которые могут быть выданы хостам (устройствам, подключенным к ip-сети). Чтобы подсчитать количество адресов, нужно от общего количества адресов подсети отнять два адреса(адрес сети и широковещательный). При обмене пакетами между хостами в одной подсети маршрутизатор и шлюз не нужны.
Широковещательный адрес (Broadcast).
Это адрес который не присвоен ни одному хосту в подсети. Данный адрес используется для отправки широковещательных пакетов, которые предназначены каждому хосту подсети.
Пример 1.
Найдем адрес сети, зная IP-адрес (192.168.1.2) и маску подсети (255.255.255.0). Для этого необходимо применить к ним операцию поразрядной конъюнкции (логическое И).
Для этого переводим в двоичную систему счисления.
IP-адрес: 11000000 10101000 00000001 00000010 (192.168.1.2)
Маска подсети: 11111111 11111111 11111111 00000000 (255.255.255.0)
Адрес сети: 11000000 10101000 00000001 00000000 (192.168.1.0)
Пример 2, обратный, найдем адреса хостов и широковещательный адрес
подсети 192.168.111.64/26 .
/26 = 11111111.11111111.11111111.11000000 = 255.255.255.192
192.168.111.64 = 11000000.10101000.01101111.01000000
По маске видим что наша сеть будет иметь диапазон ip-адресов
от: 11000000.10101000.01101111.01000000 = 192.168.111.64
до: 11000000.10101000.01101111.01111111 = 192.168.111.127
Где последний адрес будет широковещательный (broadcast).
Адреса хостов нашей сети:
min(в большинстве случаев является шлюзом*
(gateway)): 11000000.10101000.01101111.01000001 = 192.168.111.65
max: 11000000.10101000.01101111.01111110 = 192.168.111.126
т.е. всего хостов в сети — 62.
Пример 3. Новым сотрудникам техподдержки ПетерСтар посвящается 😉
Наиболее популярная маска подсети для юридических клиентов /30 .
маска: 11111111.11111111.11111111.11111100 = 255.255.255.252
IP-адрес: 01010100.11001100.10100110.01001100 = 84.204.166.76
По маске видим что наша сеть будет иметь диапазон ip-адресов
от 01010100.11001100.10100110.01001100 = 84.204.166.76
до 01010100.11001100.10100110.01001111 = 84.204.166.79
Адреса хостов подсети:
min(шлюз*
(gateway)): 01010100.11001100.10100110.01001101 = 84.204.166.77
модемкомп(если bridge)
: 01010100.11001100.10100110.01001110 = 84.204.166.78
broadcast : 01010100.11001100.10100110.01001111 = 84.204.166.79
*Сетевой шлюз — аппаратный маршрутизатор (англ. gateway) или программное обеспечение для сопряжения компьютерных сетей, использующих разные протоколы (например, локальной и глобальной). Сетевые шлюзы могут быть аппаратным решением, программным обеспечением или тем и другим вместе, но обычно это программное обеспечение, установленное на роутер или компьютер.
Subnetting. Разбиение сети на подсети, суммироваеие, нахождение адреса сети и широковещательного адреса.
При подготовке к CCIE RS Written есть тема, которая посвящена маскам подсети, и прочему.
Я напишу небольшую заметку о том как разбивать сети на подсети, как суммировать их, как найти адреса сети и широковещательных адресов и так далее.
Нахождение адреса сети, широковещательного адреса, первого и последнего допустимых адресов, которые могут быть назначены хостам.
Допустим нам дан некий IP адрес, с маской подсети, например 152.21.121.37 /26, нам необходимо найти адрес сети и широковещательный адрес, а так же первый и последний адреса которые можно присвоить хосту.
Алгоритм действий такой:
Префикс 26 нам говорит о том, что с последнего октета, под сеть выделено 2 бита, и на хосты у нас осталось 6 бит (64 хоста).
Представим этот префикс в двоичном виде и далее переведем последний октет в IP адресе в двоичную систему (нет смысла переводить весь IP адрес в бинарку)
/26 — 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 0 0 0 0 0 0
x.x.x.37 — x x x x x x x x . x x x x x x x x . x x x x x x x x . 0 0 1 0 0 1 0 1
Теперь можем определить адрес сети.
Для этого проведем линию по нашему префиксу. Теперь это будет выглядеть так.
/26 — 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 | 0 0 0 0 0 0
x.x.x.37 — x x x x x x x x . x x x x x x x x . x x x x x x x x . 0 0 | 1 0 0 1 0 1
И выпишем значения которые могут быть минимальным (все биты равны нулю) и максимальное (когда все биты равны единицы) в хостовой части.
это соответственно — 0 0 0 0 0 0 — что в 10-ной системе равно «0» и 1 1 1 1 1 1 что в 10-ой системе равно 63
Значит адрес нашей сети равен: 152.21.121.0.
Широковещательный адрес: 152.21.121.63
Соответственно первый IP адрес, который можно назначить хосту: 152.21.121.1
Последний IP адрес, который можно назначить хосту: 152.21.121.62
Нахождение IP адреса по номеру подсети и номеру хоста.
Не представляю особо где может понадобиться, но тем не менее
Дана сеть, скажем 49.0.0.0, которая поделена маской /25 на множество подсетей.
Необходимо найти IP адрес, если известно что он принадлежит 429 подсети и имеет номер 41.
49.0.0.0 согласно классификации сетей принадлежит классу А, следовательно префикс такой сети равен /8, Запишем его в бинарном виде.
8/ — 1 1 1 1 1 1 1 1 . 0 0 0 0 0 0 0 0 . 0 0 0 0 0 0 0 0 . 0 0 0 0 0 0 0 0
Представим префикс /25 так же в бинарном виде:
/25 — 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 0 0 0 0 0 0 0
Так как разрешено использовать для подсети все единицы и нули, то из требуемой подсети 429 вычитаем 1. Получаем 428, это число нам нужно представить в бинарном ввиде, на том месте где у нас «единички» в подсети.
428 — 0 0 0 0 0 0 0 0 . 0 0 0 0 0 0 0 0 . 1 1 0 1 0 1 1 0 . 0 0 0 0 0 0 0 0
Представим в бинарном виде 41 (номер нашего искомого хоста в нужной подсети).
41 — 0 0 1 0 1 0 0 0
Что у нас получилось?
49.0.1 1 0 1 0 1 1 0 . 0 0 1 0 1 0 0 1
Переведем весь адрес в десятичный вид:
Суммирование сетей очень важно уметь делать, ибо применяется в маршрутизации повсеместно, а именно там, где нам нужно объединить кучу сетей, в одну, тоесть иными словами «суммировать».
Давайте также разберемся на примере.
Дано:
Сети адреса которых:
* 140.176.2.128 / 25
* 140.176.3.0 / 25
* 140.176.3.192 / 26
* 140.176.3.128 / 26
* 140.176.2.0 / 25
Необходимо заменить все эти подсети — одной, которая будет объеденять все вышеуказанные, с наименьшей потерей адресов. Можно конечно не сильно присматриваясь сделать так: 140.176.0.0 /16 , да, это будет работать, но это грубое суммирование и не корректное.
Для правильного суммирования нам необходимо опять же поработать с бинарными числами, а именно перевести изменяемые части адреса в двоичный код.
В данном примере 140.176. является статичной, поэтому ее трогать не будем, будем переводить последние два октета:
2.128 / 25 — 0 0 0 0 0 0 1 0 . 1 0 0 0 0 0 0 0
3.0 / 25 — 0 0 0 0 0 0 1 1 . 0 0 0 0 0 0 0 0
3.192 / 26 — 0 0 0 0 0 0 1 1 . 1 1 0 0 0 0 0 0
3.128 / 26 — 0 0 0 0 0 0 1 1 . 1 0 0 0 0 0 0 0
2.0 / 25 — 0 0 0 0 0 0 1 0 . 0 0 0 0 0 0 0 0
Далее нам необходимо найти неизменяемые не в одной подсети значения, я отметил их жирным.
Таким образом получается что префикс новой сумированной сети будет: /23
Полностью суммированная сеть будет выглядеть так: 140.176.2.0/23
Разбиение сети на подсети.
Например, есть у нас сеть класса С, 192.168.0.0 / 24
Нам необходимо разбить эту сеть на две одинаковые подсети.
Разбиение осуществляется путем заимствования бита из поля, которое предназначено для хоста, в поле которое предназначено для маски.
Наша основная сеть имеет префикс 24 бита, мы добавляем к нему 1, и получаем новый префикс /25
Так как мы взяли всего один бит, следовательно и сетей у нас может быть только две (бит может принимать значение 1 или 0).
В каждой такой сети есть 128 адреса (2 в 7 степени (32 — 25 = 7 ) ).
Итак у нас получилось две подсети с адресами:
192.168.0.0 — 192.168.0.127 /25 (Доступные адреса для хостов: 192.168.0.1 — 192.168.0.126)
192.168.0.128 — 192.168.0.255/25 (Доступные адреса для хостов: 192.168.0.129 — 192.168.0.254)
Это был очень простой пример.
Так же каждую такую сеть вы можете еще разбить на несколько подсетей, не обязательно поровну, но и на различное количество хостов в каждой подсети.
Например, мы хотим разбить сеть 192.168.0.128/25 на одну сеть которая бы имела не менее 30 адресов, и другую сеть, которая имела бы не менее 60 адресов.
Находим необходимые префиксы наших новых сетей.
30 адресов, ищим ближайшее значение степени двойки, 2^5 = 32. Это то, что нужно.
Тоесть для этой сети нам достаточно сети пяти бит. (32 -5 = 27), итак префикс нашей новой подсети будет /27
Для второй сети, 60 адресов, ближайшая степень двойки — 64, 2^6 = 64.
Тоесть для новой сети нам необходимо 6 бит (32-6 = 26), префикс будет /26
Ну и запишем что у нас получилось:
1. 192.168.0.128 — 192.168.0.159/27
2. 192.168.0.160 — 192.168.0.123/26
Когда перед нами стоят такие задачи, то нужно начинать разбиение сети с наибольшего количества, адресов, и так по убыванию (в моем примере наоборот).
Определение принадлежности адресов IPv4-сети
Может кто разбирается в этих IPv4, и сможет растолковать мне как это все работает..А то я ничего понять не могу, как найти эти адреса. Нужен только ход рассуждений, и понятное разъяснение решения данной задачи.
Маска сети для IPv4 адресации – это 4-х байтное число, которое делит IP адрес на адрес сети (первая часть) и адрес узла (вторая часть). Для части IP адреса, соответствующей адресу сети в маске сети содержатся двоичные единицы, а для части IP адреса, соответствующей адресу узла в маске сети содержаться двоичные нули. IP адрес, в котором в части адреса узла содержаться только двоичные нули – служебный адрес сети. IP адрес, в котором в части адреса узла содержаться только двоичные единицы – адрес ограниченного широковещания. Эти два адреса нельзя использоваться для адресации узлов.
Сеть с IPv4 адресацией задана одним из адресов, принадлежащих этой сети (192.168.3.17) и маской сети (255.255.192.0) . Определите, какие из перечисленных ниже адресов могут быть назначены устройствам в этой сети.
-
192.168.3.255
-
192.168.65.3
-
192.168.33.0
-
192.168.192.0
-
192.168.63.255
Ох не мучили вас в институте или не мучают.
Ну что ж смотри, мой юный падаван, дан хост с адресом 192.168.3.17 , и маска 255.255.192.0 , сказали еще что хост принадлежит сети.
Давай для начала переведем в человеко-формат.
Делаем вот что, все рассчитывают в двоичной системе а мы с тобой сделаем хак и через десятичную рассчитаем.
Берем с лева первый октет который не равен 255 , это октет номер 3 он равен 192 .
Именно он нам интересен.
256-192 = 64 , 64 это шаг, который поможет найти адрес сети.
Он еще не раз встретится в решении. Берем адрес который нам дали в задаче 192.168.3.17 , и смотрим на 3-ий октет, так как именно он нам интересен.
Берем число 64, и 3-ий октет — это 3. Так как 3 < 64, то, ахтунг, адрес сети будет 192.168.0.0 .
Если бы нам дали хост 192.168.73.17 , то адрес сети был бы 192.168.64.0 , а если 192.168.128.17 то 192.168.128.0 .
Понимаешь к чему я?
То есть, с шагом в 64 мы смотрим если число <= 64 то ставим 64 , если больше то 64+64=128 и тоже самое с 128 .
Если больше 128 , то 128+64=192 и т.д.
Круто знаем адрес сети 192.168.0.0 .
Далее найдем broadcast-широковещательный адрес .
Это уже проще.
К 3 октету адреса сети прибавляем шаг, он у нас 64 .
Получаем 192.168.64.0 , дальше нужно просто от 64 отнять константу, она равна 1 , а последний октет заменить на 255 .
Получим 192.168.63.255 .
Это широковещательный адрес.
Все!
Получили диапазон от 192.168.0.0 до 192.168.63.255 .
Теперь смотрим какие адреса в него попадают, 192.168.3.255,192.168.33.0 .
Вообще конечно такие адреса фактически могут и не работать но касательно задачи это скорее всего будет правильным ответом.
![]()
Лабораторная работа: расчёт подсетей IPv4
Задачи
•Определите адрес сети.
•Определите широковещательный адрес.
•Определите количество узлов.
Часть 2. Расчёт данных сети по IPv4-адресу
•Определите количество созданных подсетей.
•Определите количество узлов для каждой подсети.
•Определите адрес подсети.
•Определите диапазон узлов для подсети.
•Определите широковещательный адрес для подсети.
Исходные данные/сценарий
Умение работать с подсетями IPv4 и определять информацию о сетях и узлах на основе известного IP-адреса и маски подсети необходимо для понимания принципов работы IPv4-сетей. Цель первой части — закрепить знания о том, как рассчитывать IP-адрес сети на основе известного IP-адреса и маски подсети. Зная IP-адрес и маску подсети, вы всегда сможете установить следующие данные подсети:
•Сетевой адрес
•Широковещательный адрес
•Общее количество битов узлов
•Количество узлов в подсети
Во второй части лабораторной работы вы определите следующие данные для указанного IP-адреса
имаски подсети:
•Сетевой адрес этой подсети
•Широковещательный адрес этой подсети
•Диапазон адресов узлов для этой подсети
•Количество созданных подсетей
•Количество узлов для каждой подсети
Необходимые ресурсы
•1 ПК (Windows 7, Vista или XP с выходом в Интернет)
•Дополнительно: калькулятор IPv4-адресов
Часть 1: Определение данных сети по IPv4-адресу
В части 1 вам необходимо определить сетевой и широковещательный адреса, а также количество узлов, зная IPv4-адрес и маску подсети.
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 1 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |

Лабораторная работа: расчёт подсетей IPv4
ОБЗОР. Чтобы определить сетевой адрес, выполните бинарную операциюи для IPv4-адреса, используя указанную маску подсети. В результате вы получите сетевой адрес. Совет: если маска подсети имеет в октете десятичное значение255, результатом ВСЕГДА будет исходное значение этого октета. Если маска подсети имеетв октете десятичное значение 0, результатом для этого октета ВСЕГДА будет 0.
Пример.
|
IP-адрес |
192.168.10.10 |
|
Маска подсети |
255.255.255.0 |
|
========== |
|
|
Результат (сеть) |
192.168.10.0 |
Зная это, вы можете выполнить бинарную операцию И только для того октета, значение которого в маске подсети отличается от 255 или 0.
Пример.
|
IP-адрес |
172.30.239.145 |
|
Маска подсети |
255.255.192.0 |
Проанализировав этот пример, вы увидите, что бинарная операция И требуется только для третьего октета. В этой маске подсети первые два октета дадут результат 172.30, а четвертый — 0.
|
IP-адрес |
172.30.239.145 |
|
Маска подсети |
255.255.192.0 |
|
========== |
|
|
Результат (сеть) |
172.30.?.0 |
Выполните бинарную операцию И для третьего октета.
|
Десятичное |
Двоичное |
|
239 |
11101111 |
|
192 |
11000000 |
|
======= |
|
|
Результат 192 |
11000000 |
Анализ этого примера снова даст следующий результат:
|
IP-адрес |
172.30.239.145 |
|
Маска подсети |
255.255.192.0 |
|
========== |
|
|
Результат (сеть) |
172.30.192.0 |
Рассчитать количество узлов для каждой сети в данном примере можно путём анализа маски подсети. Маска подсети будет представлена в десятичном формате с точкой-разделителем, например 255.255.192.0, или в формате сетевого префикса, например /18. IPv4-адрес всегда содержит 32 бита. Отняв количество битов, используемых сетевой частью (как показано в маске подсети), вы получите количество битов, используемых для узлов.
В нашем примере маска подсети 255.255.192.0 равна /18 в префиксной записи. Вычитание 18 бит сети из 32 бит даст нам 14 бит, оставшихся для узловой части. Исходя из этого, можно выполнить простой расчёт:
2 (количество битов узла)– 2 = количество узлов
214 = 16 384 – 2 = 16 382 узла
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 2 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |

Лабораторная работа: расчёт подсетей IPv4
Определите сетевые и широковещательные адреса и количество битов узлов для IPv4-адресов и префиксов, указанных в приведённой ниже таблице.
|
Общее |
||||
|
Адрес |
Сетевой |
Широковещательный |
количество |
Общее количество |
|
IPv4/префикс |
адрес |
адрес |
битов узлов |
узлов |
|
192.168.100.25/28 |
192.168.100.16 |
192.168.100.31 |
4 |
14 |
|
172.30.10.130/30 |
172.30.10.128 |
172.30.10.131 |
2 |
2 |
|
10.1.113.75/19 |
10.1.113.75 |
10.1.127.255 |
13 |
8190 |
|
198.133.219.250/24 |
198.133.219.0 |
198.133.219.255 |
8 |
254 |
|
128.107.14.191/22 |
128.107.12.0 |
128.107.15.255 |
10 |
1022 |
|
172.16.104.99/27 |
172.16.104.96 |
172.16.104.127 |
5 |
30 |
Часть 2: Расчёт данных сети по IPv4-адресу
Зная IPv4-адрес, а также исходную и новую маски подсети, можно определить следующие параметры:
•Сетевой адрес этой подсети
•Широковещательный адрес этой подсети
•Диапазон адресов узлов этой подсети
•Количество созданных подсетей
•Количество узлов в подсети
Вприведённом ниже примере показана одна из задач и её решение.
|
Дано: |
|
|
IP-адрес узла |
172.16.77.120 |
|
Исходная маска подсети |
255.255.0.0 |
|
Новая маска подсети |
255.255.240.0 |
|
Найти: |
|
|
Количество битов подсети |
4 |
|
Количество созданных подсетей |
16 |
|
Количество битов узлов в подсети |
12 |
|
Количество узлов в подсети |
4094 |
|
Сетевой адрес этой подсети |
172.16.64.0 |
|
Адрес IPv4 первого узла в этой подсети |
172.16.64.1 |
|
Адрес IPv4 последнего узла в этой |
|
|
подсети |
172.16.79.254 |
|
Широковещательный адрес IPv4 в этой |
|
|
подсети |
172.16.79.255 |
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 3 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |

Лабораторная работа: расчёт подсетей IPv4
Давайте рассмотрим, как была получена такая таблица.
Исходная маска подсети имела вид 255.255.0.0 или /16. Новая маска подсети — 255.255.240.0 или /20. Полученная разница составляет 4 бита. Так как 4 бита были заимствованы, мы можем определить, что были созданы 16 подсетей, так как 24= 16.
В новой маске, равной 255.255.240.0 или /20, остаётся 12 бит для узлов. Если для узлов осталось 12 бит, воспользуемся следующей формулой: 212= 4096–2=4094 узла для каждой подсети.
Бинарная операция И поможет определить подсеть для этой задачи, в результате чего мы получим сеть 172.16.64.0.
Взаключение необходимо установить первый узел, последний узел и широковещательный адрес для каждой подсети. Один из способов определения диапазона узлов — использовать двоичные значения для узловой части адреса. В нашем примере узловая часть — это последние 12 бит адреса. В первом узле для всех старших битов будет установлено значение 0, а для младшего бита — значение 1.
Впоследнем узле для всех старших битов будет установлено значение 1, а для младшего бита — значение 0. В этом примере узловая часть адреса находится в третьеми четвёртомоктетах.
|
Описание |
1-й октет |
2-й октет |
3-й октет |
4-й октет |
Описание |
|
|
Сеть/узел |
сссссссс |
сссссссс |
ссссуууу |
уууууууу |
Маска подсети |
|
|
Двоичное |
10101100 |
00010000 |
01000000 |
00000001 |
Первый узел |
|
|
Десятичное |
172 |
16 |
64 |
1 |
Первый узел |
|
|
Двоичное |
10101100 |
00010000 |
01001111 |
11111110 |
Последний узел |
|
|
Десятичное |
172 |
16 |
79 |
254 |
Последний узел |
|
|
Двоичное |
10101100 |
00010000 |
01001111 |
11111111 |
Широковещательный |
|
|
Десятичное |
172 |
16 |
79 |
255 |
Широковещательный |
|
Шаг 1: Заполните приведённые ниже таблицы, указав необходимые значения для указанного IPv4-адреса, а также исходной и новой масок подсети.
a. Задача 1.
|
Дано: |
||
|
IP-адрес узла |
192.168.200.139 |
|
|
Исходная маска подсети |
255.255.255.0 |
|
|
Новая маска подсети |
255.255.255.224 |
|
|
Найти: |
||
|
Количество битов подсети |
3 |
|
|
Количество созданных подсетей |
8 |
|
|
Количество битов узлов в подсети |
5 |
|
|
Количество узлов в подсети |
30 |
|
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 4 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |

Лабораторная работа: расчёт подсетей IPv4
|
Сетевой адрес этой подсети |
192.168.200.128 |
||
|
Адрес IPv4 первого узла в этой подсети |
192.168.200.129 |
||
|
Адрес IPv4 последнего узла в этой подсети |
192.168.200.158 |
||
|
Широковещательный адрес IPv4 в этой подсети |
192.168.200.159 |
||
|
b. |
Задача 2. |
||
|
Дано: |
|||
|
IP-адрес узла |
10.101.99.228 |
||
|
Исходная маска подсети |
255.0.0.0 |
||
|
Новая маска подсети |
255.255.128.0 |
||
|
Найти: |
|||
|
Количество битов подсети |
9 |
||
|
Количество созданных подсетей |
512 |
||
|
Количество битов узлов в подсети |
15 |
||
|
Количество узлов в подсети |
32766 |
||
|
Сетевой адрес этой подсети |
10.101.0.0 |
||
|
Адрес IPv4 первого узла в этой подсети |
10.101.0.1 |
||
|
Адрес IPv4 последнего узла в этой подсети |
10.101.127.254 |
||
|
Широковещательный адрес IPv4 в этой подсети |
10.101.127.255 |
||
|
c. |
Задача 3. |
||
|
Дано: |
|||
|
IP-адрес узла |
172.22.32.12 |
||
|
Исходная маска подсети |
255.255.0.0 |
||
|
Новая маска подсети |
255.255.224.0 |
||
|
Найти: |
|||
|
Количество битов подсети |
3 |
||
|
Количество созданных подсетей |
8 |
||
|
Количество битов узлов в подсети |
13 |
||
|
Количество узлов в подсети |
8190 |
||
|
Сетевой адрес этой подсети |
172.22.32.0 |
||
|
Адрес IPv4 первого узла в этой подсети |
172.22.32.1 |
||
|
Адрес IPv4 последнего узла в этой подсети |
172.22.63.254 |
||
|
Широковещательный адрес IPv4 в этой подсети |
172.22.63.255 |
||
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 5 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |

Лабораторная работа: расчёт подсетей IPv4
|
d. |
Задача 4. |
||
|
Дано: |
|||
|
IP-адрес узла |
192.168.1.245 |
||
|
Исходная маска подсети |
255.255.255.0 |
||
|
Новая маска подсети |
255.255.255.252 |
||
|
Найти: |
|||
|
Количество битов подсети |
6 |
||
|
Количество созданных подсетей |
64 |
||
|
Количество битов узлов в подсети |
2 |
||
|
Количество узлов в подсети |
2 |
||
|
Сетевой адрес этой подсети |
192.168.1.244 |
||
|
Адрес IPv4 первого узла в этой подсети |
192.168.1.245 |
||
|
Адрес IPv4 последнего узла в этой подсети |
192.168.1.246 |
||
|
Широковещательный адрес IPv4 в этой подсети |
192.168.1.247 |
||
|
e. |
Задача 5. |
||
|
Дано: |
|||
|
IP-адрес узла |
128.107.0.55 |
||
|
Исходная маска подсети |
255.255.0.0 |
||
|
Новая маска подсети |
255.255.255.0 |
||
|
Найти: |
|||
|
Количество битов подсети |
8 |
||
|
Количество созданных подсетей |
256 |
||
|
Количество битов узлов в подсети |
8 |
||
|
Количество узлов в подсети |
254 |
||
|
Сетевой адрес этой подсети |
128.107.0.0 |
||
|
Адрес IPv4 первого узла в этой подсети |
128.107.0.1 |
||
|
Адрес IPv4 последнего узла в этой подсети |
128.107.0.254 |
||
|
Широковещательный адрес IPv4 в этой подсети |
128.107.0.255 |
||
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 6 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |

Лабораторная работа: расчёт подсетей IPv4
f. Задача 6.
|
Дано: |
||
|
IP-адрес узла |
192.135.250.180 |
|
|
Исходная маска подсети |
255.255.255.0 |
|
|
Новая маска подсети |
255.255.255.248 |
|
|
Найти: |
||
|
Количество битов подсети |
5 |
|
|
Количество созданных подсетей |
32 |
|
|
Количество битов узлов в подсети |
3 |
|
|
Количество узлов в подсети |
6 |
|
|
Сетевой адрес этой подсети |
192.135.250.176 |
|
|
Адрес IPv4 первого узла в этой подсети |
192.135.250.177 |
|
|
Адрес IPv4 последнего узла в этой подсети |
192.135.250.182 |
|
|
Широковещательный адрес IPv4 в этой подсети |
192.135.250.183 |
|
Вопросы на закрепление
Почему маска подсети имеет такое значение при анализе IPv4-адреса?
_______________________________________________________________________________________
_______________________________________________________________________________________
_______________________________________________________________________________________
|
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены. |
Стр. 7 из 7 |
|
В данном документе содержится общедоступная информация корпорации Cisco. |
Соседние файлы в папке WinRAR archive
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #