УДК 004.912+004.8 Дата подачи статьи: 10.05.22, после доработки: 29.08.22
DOI: 10.15827/0236-235X.140.698-706 2022. Т. 35. № 4. С. 698-706
Извлечение аспектов из текстов научных статей
А.Э. Маршалова 1, студент,, а.тагзНа1оиа@д.пэи.ги
Е.П. Бручес 2, младший научный сотрудник,, ст. преподаватель, bruches@fck.ru Т.В. Батура 2, к.ф.-м.н, доцент, старший научный сотрудник, 1аИапа. V. batura@gm.ail. сот
1 Новосибирский государственный университет, г. Новосибирск, 630090, Россия
2 Институт систем информатики им. А.П. Ершова СО РАН, г. Новосибирск,, 630090, Россия
Статья посвящена автоматическому извлечению аспектов из текстов русскоязычных научных статей. Актуальность проблемы обусловлена увеличением числа научных публикаций и возрастающей в связи с этим потребностью в автоматизированном извлечении из них основной информации и ее структурировании.
В рамках исследования был создан корпус, состоящий из 291 аннотации научных статей на русском языке, размеченных следующими аспектами: задача, цель, вклад, метод, инструмент, применение, преимущество, пример и вывод. Для каждого из выделяемых аспектов в статье приведены описания и примеры. В результате разметки корпуса были выделены 1 494 аспекта, 44 % из которых составил аспект «вклад».
В работе также предложен и реализован алгоритм автоматического извлечения аспектов из текста. Извлечение аспектов рассматривается как задача тегирования последовательности. Для реализации алгоритма используется нейронная сеть BERT. Проведен ряд экспериментов, связанных с использованием векторов, полученных из различных языковых моделей, а также с заморозкой весов модели. Лучший результат показала мультиязыковая модель, дообученная на данных авторов исследования, то есть обученная без заморозки весов. Для улучшения качества извлечения аспектов разработаны эвристики, перечисленные в статье, и произведено дообучение модели на новых данных, полученных в результате автоматической разметки с последующим ручным редактированием.
Разработанная система может быть полезна другим исследователям, так как позволяет облегчить выбор публикаций по определенной теме, обзор методов решения той или иной задачи и анализ ранее полученных результатов.
Ключевые слова: обработка естественного языка, анализ текстовой информации, извлечение информации из текста, обработка данных, машинное обучение, нейронная сеть.
С увеличением числа научных публикаций растет потребность в автоматизированном извлечении из них основной информации и ее структурировании, например, информации о задаче, рассматриваемой в статье, результате исследования, использованных в работе методах.
У такого рода информации нет общепризнанного названия. Например, в [1] это ключевые моменты, в работе [2] — категории научного дискурса. В данной работе такая информация названа аспектами статьи.
Возможность извлекать аспекты из научных статей может значительно облегчить выбор публикаций по определенной теме, обзор методов решения той или иной задачи и анализ результатов, полученных другими исследователями. Кроме того, аспекты могут использоваться для автореферирования статей [3].
Проблеме автоматического извлечения аспектов из научных статей посвящен ряд исследова-
ний. В частности, в [4] предложен подход для извлечения информации о методах: их использовании, преимуществах, альтернативных названиях и способах реализации, основанный на применении лексико-синтаксических шаблонов в сочетании со статистическим алгоритмом машинного обучения Conditional Random Fields (CRF).
В работе [2] для извлечения аспектов предлагается использовать бинарные байесовские классификаторы, количество которых соответствует количеству рассматриваемых аспектов: каждый классификатор определяет вероятность, с которой предложение относится к соответствующему аспекту.
Некоторые методы классификации предложений — Linear SVM, Random Forest, полиномиальный наивный байесовский анализ (MNB), сверточные нейронные сети, LSTM, BERT и SciBERT сравнивались в [5]. Лучший результат показала модель SciBERT.
В [6] извлечение аспектов рассматривается как задача распознавания сущностей. Под сущностью понимается совокупность всех ее упоминаний, например, Penn Treebank Tokenizer и сокращенный вариант PTB Tokenizer. Для поиска упоминаний применяется CRF-модель, обученная на векторных представлениях слов, полученных с помощью предобученной модели SciBERT и нейронной сети с архитектурой BiLSTM, после чего упоминания объединяются в сущности с помощью алгоритмов кластеризации.
Следует отметить, что описываемые в литературе методы извлечения аспектов предназначены для работы с текстами на английском языке. Кроме того, в настоящее время не существует русскоязычных корпусов научных текстов с разметкой аспектов.
Данная работа посвящена созданию корпуса русскоязычных научных текстов с ручной разметкой аспектов, а также реализации алгоритма автоматического извлечения аспектов из них.
В статье приведен список аспектов, выделяемых в текстах корпуса, и проанализированы результаты разметки. Кроме того, сделан обзор методов автоматического извлечения аспектов, подробно описаны подход, реализованный в данной работе, и метрики, полученные при тестировании предложенного алгоритма.
Создание корпуса
Формирование списка аспектов. Для формирования списка аспектов был проведен анализ литературы на предмет того, какие аспекты извлекаются другими исследователями (табл. 1). В результате выяснено, что чаще всего выделяются аспекты задача, цель, вклад, методы, результат, вывод и предпосылки работы, менее — объект исследования, гипотеза, связанная работа, новизна, модель, инструмент, данные, метрика, будущая работа. Такой набор оказался не вполне релевантным для данного исследования.
Во-первых, аспект «предпосылки» оказался трудно формализуемым. При этом он чаще всего выражен, как минимум, несколькими предложениями, в то время как выбранный авторами подход предполагает, что аспект не может выходить за границы одного предложения.
Во-вторых, понятие «вклад» включает большую часть информации, относимой в некоторых работах к аспекту «результат», поэтому в последнем нет необходимости.
В-третьих, упоминания об использованных в работе инструментах обычно выделяются в тот же аспект, что и описания методов, но эти понятия следует разделять.
Наконец, анализ данных для данного исследования показал, что список можно дополнить такими аспектами, как применение, преимущество и пример.
Таблица 1
Аспекты, выделяемые в других работах
Table 1
Aspects identified in other papers
Работа Выделяемый аспект
Предпосылка Задача Цель Вклад Метод Результат Вывод Другие
Dayrell et al., 2012 [7] + + + + + +
Hanyurwimfura et al., 2012 [8] + +
Houngubo and Mercer, 2012 [4] +
Liakata et al., 2012 [9] + + + + +
Ronzano and Saggion, 2015 [2] + + + + +
QasemiZadeh and Schumann, 2016 [10] +
Augenstein et al., 2017 [11] + +
He J. et al., 2020 [3] + + +
Huang T.H.K. et al., 2020 [5] + + +
Jain S. et al., 2020 [6] + + +
Таким образом, был сформирован следующий список аспектов.
1. Задача (Task) — направление, проблема, с которой связана статья: Статья посвящена задаче <Task> рефакторинга UML-диаграмм классов </Task>.
2. Цель (Goal) — часть задачи, которую намерены решить авторы: Цель представленного исследования — <Goal> компьютерный поиск генов и их изоформ </Goal>.
3. Вклад (Contrib): <Contrib> Предложена методика поиска субоптимального разбиения </Contrib>.
4. Метод (Method): <Method> методом ча-стиц-в-ячейках </Method>.
5. Инструмент (Tool): <Tool> система MTSS </Tool>. Аспекты «метод» и «инструмент» похожи, так как и тот, и другой не создаются авторами, а лишь используются в работе. Однако к методам относятся последовательности действий, подходы, алгоритмы, в то время как инструмент — это то, что используется исследователями непосредственно для реализации алгоритмов: это могут быть языки программирования, фреймворки, устройства.
6. Применение (Use) — то, для чего можно использовать результаты исследования, без указания на положительные стороны работы: Предложенный в статье подход может быть полезен при <Use> построении рекомендательных систем </Use>.
7. Преимущество (Adv): <Adv> полученный метод обладает сравнительно высокой точностью и быстродействием </Adv>.
8. Пример (Example) — выбранный авторами объект для демонстрации практической части работы: Приведен пример <Example> описания с помощью ПООП продукционных правил системы логического вывода </Example>.
9. Вывод (Conc): Доказано, что <Conc> любая точка этой окружности является точкой сопряжения пары круговых дуг </Conc>.
При этом каждый аспект может быть вложенным, то есть входить в текст другого аспекта: <Contrib> предложен базирующийся на <Tool> архиваторах </Tool> алгоритм прогнозирования временных рядов </Contrib>.
Разметка. Созданный авторами корпус (https://github.com/iis-research-team/ruserrc-da-taset/tree/master/ruserrc_aspects) состоит из аннотаций научных статей по информационным технологиям и разделен на две части, содержащие 79 и 212 текстов соответственно. Разметка выполнялась двумя асессорами, мера согласованности между которыми составила 84 %.
В ходе разметки были выделены 1 494 аспекта, при этом почти половину из них (44 %) составил аспект Contrib (табл. 2). Вероятно, это связано с тем, что корпус состоит из аннотаций, цель которых — описать проделанную авторами работу и дать представление о вкладе исследования в науку. Количество аспектов в одном тексте варьируется от 0 до 18, при этом в среднем текст содержит 5 аспектов, а один аспект состоит из 9 токенов, однако его длина во многом зависит от его типа (табл. 2).
Таблица 2 Количество и средняя длина выделенных аспектов
Table 2
Number and average length of the identified aspects
Аспект Количество Средняя длина в токенах
Task 186 6,3
Goal 36 12,6
Contrib 661 13,2
Method 231 3,5
Tool 106 3,0
Use 104 6,6
Adv 90 9,9
Example 36 6,7
Conc 44 16,2
Анализ длин аспектов приводит к выводу о том, что некоторые аспекты выражены терминами или короткими фразами (Method, Tool), а другие — целыми предложениями или частями сложных предложений (Goal, Contrib, Conc).
Разработка алгоритма автоматического извлечения аспектов
В рамках данной работы задача автоматического извлечения аспектов из текстов была сведена к определению для каждого токена его принадлежности к тому или иному классу, иными словами, к тегированию последовательности (sequence labeling).
Согласно разработанному алгоритму, текст сначала пропускается через предобученную языковую модель BERT [12], которая преобразует текстовые данные в векторные представления — наборы числовых признаков, характеризующих каждый токен. Затем линейный классификатор по векторному представлению каждого токена определяет, к какому аспекту он должен быть отнесен.
Схема алгоритма изображена на рисунке 1.
Contrib Contrib Contrib Contrib|Task Contrib|Task Contrib|Task
1_1_1
1
Классификатор
T
едл< 1
T T T
ЕПредложен Еподход Едля Еавтоматизации Епроверки
1_Î_1
Е гипотез
1_1
BERT
Т т т т
г т
Предложен подход для автоматизации проверки
Рис. 1. Схема работы алгоритма автоматического извлечения аспектов Fig. 1. A scheme of the automatic aspect extraction algorithm
Символом E обозначены векторные представления. На рисунке показано, что в результате классификации по их векторным представлениям, полученным с помощью BERT, все изображенные слова отнесены к аспекту Contrib, при этом слова «автоматизации», «проверки» и «гипотез» также отнесены к аспекту Task.
Алгоритм реализован на языке программирования Python с использованием сторонних библиотек tensorflow, transformers и pymor-phy2. Программная реализация содержит модуль предобработки текста, модуль для извлечения аспектов и модуль постобработки извлеченных аспектов. Код программы выложен в открытый доступ (https://github.com/iis-re-search-team/terminator#aspect-extraction).
Преобразование данных в подходящий для задачи sequence labelling формат. Чаще всего для задачи sequence labelling используется формат BIO, то есть каждому токену присваивается тег O. Когда токен не относится ни к одному из классов, присваивается тег B-X, если токен стоит первым в последовательности, относящейся к классу X, или тег I-X, если токен входит в последовательность, относящуюся к классу X, но не является в ней первым. При такой системе тегов в два раза увеличивается количество классов, что может негативно влиять на качество предсказаний модели.
Основное преимущество этого формата в том, что он позволяет отделять друг от друга
подряд идущие сущности. Однако при анализе размеченных текстов было выяснено, что аспекты одного типа никогда не следуют друг за другом подряд и разделяются, по крайней мере, запятой или союзом, поэтому нет необходимости разделения на B-теги и I-теги.
Таким образом, было предложено различать не 19, а 10 классов (девять из которых — Goal, Task, Contrib, Method, Tool, Adv, Use, Conc, Example — вышеупомянутые аспекты, а десятый — O — отсутствие аспекта).
Для учета вложенности аспектов был использован подход, предложенный в [13], согласно которому одному токену присваиваются несколько тегов (в рассматриваемом случае от одного до двух), после чего используется классификация с пересекающимися классами, где одному токену может быть присвоено более одного тега.
На рисунке 2 приведен пример текста, преобразованного в выбранный формат. Фраза «в статье» не относится ни к одному из аспектов, поэтому токенам 1 и 2 присвоен тег O, а фраза «методов аппроксимации Розенблатта-Пар-зена» входит одновременно в два аспекта -Contrib и Method, поэтому каждому из токенов 7-9 присвоены оба тега, разделенные вертикальной чертой.
Разработка алгоритма интерпретации предсказаний модели. Под языковой моделью понимается распределение вероятностей по по-
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Id Token Tag
0 В O
1 статье O
2 приведен Contrib
3 сравнительный Contrib
4 анализ Contrib
5 результатов Contrib
6 применения Contrib
7 методов Contrib|Method
8 аппроксимации Contrib|Method
9 Розенблатта-Парзена Contrib|Method
Рис. 2. Пример размеченного текста,
преобразованного подходящий для задачи
sequence labelling формат
Fig. 2. An example of an annotated text converted
into a format suitable for the sequence
labeling task
следовательностям токенов, то есть функция, которая принимает на вход токены и выдает на выходе вероятность присутствия каждого то-кена в словаре. Для подсчета вероятности каждый токен в такой модели представляется в виде вектора.
Предсказание модели — это набор вероятностей отнесения объекта к каждому из классов. Для стандартной задачи классификации (когда объект нужно отнести только к одному классу) эти вероятности вычисляются с помощью функции softmax таким образом, чтобы их сумма была равна единице, после чего выбирается наиболее вероятный класс [14]. Для классификации с пересекающимися классами используется функция sigmoid, которая определяет вероятность каждого класса вне зависимости от других классов. Затем выбираются несколько (в нашем случае до двух) самых вероятных классов при условии, что их вероятности больше определенного порогового значения, со следующими исключениями:
— если набор пуст, то есть классов, прошедших порог, не оказалось, токену присваивается класс O;
— если самый вероятный класс — O, он и присваивается токену;
— если O оказался вторым, токену присваивается только класс, оказавшийся на первом месте.
Выбор модели для обучения и получения векторных представлений. Для обучения использовалась вторая часть корпуса (212 текстов). Был проведен ряд экспериментов, связанных с использованием векторных представлений слов, полученных из различных
предобученных языковых моделей: bert-base-multilingual-cased (https://huggingface.co/bert-base-multilingual-cased) [12], rubert-base-cased от DeepPavlov (https://huggingface.co/Deep Pavlov/rubert-base-cased) [15], rubert-tiny2 от cointegrated (https://huggingface.co/cointe
grated/rubert-tiny2), обучением модели с замороженными весами и ее дообучением на данных настоящего исследования. Лучший результат показала мультиязыковая модель bert-base-multilingual-cased, дообученная на этих данных.
Эвристики для постобработки полученных результатов. Несмотря на то, что созданная модель учитывает контекст при классификации, отнесение токенов к аспектам происходит отдельно для каждого из них, вследствие чего могут возникать ошибки, связанные с неправильным выделением границ или появлением лишних аспектов. Для устранения таких ошибок были разработаны следующие эвристики.
1. В аспект Contrib включается предшествующее ему страдательное причастие или возвратный глагол 3-го лица настоящего времени: В статье предлагается <Contrib> полный минимальный список свойств, присущих интеллектуальным системам на человеческом уровне</СопМЬ>. ^ В статье <Contrib> предлагается полный минимальный список свойств, присущих интеллектуальным системам на человеческом уровне</СопМЬ>.
2. Аспект не может начинаться или заканчиваться на непарный знак препинания, союз или предлог: с использованием <ЫеШо^>ме-тодов спектрального анализа </Method> <Method> и метода главных компо-нент</Method> ^ с использованием <Method> методов спектрального анализа </Method> и <Method> метода главных компо-нент</Method>.
3. В аспект включается стоящая перед ним частица «не»: разработанные модули не <Adv> влияют на работу других модулей </Adv> ^ разработанные модули <Adv> не влияют на работу других модулей </Adv>.
4. Однословные аспекты Contrib, Conc, Goal удаляются: на <Contrib> основании </Contrib> <Method> оригинального принципа компенсации первичного поля генераторной катушки </Method> ^ на основании <Method> оригинального принципа компенсации первичного поля генераторной катушки </Method>.
5. Разрывы между одинаковыми аспектами удаляются: если между одинаковыми аспектами стоит другой тег и при этом сам он не является знаком препинания или союзом «и», то он заменяется на окружающие его теги, например:
а) <Contrib> Представлено </Contrib> описание <Contrib> реализации … </Contrib> ^ <Contrib> Представлено описание реализации … </Contrib>;
б) …что обеспечило <Adv> прозрачный </Adv> <Goal> доступ </Goal> <Adv> к TCP-сервисам на буровой </Adv> ^ … что обеспечило <Adv> прозрачный доступ к TCP-сервисам на буровой </Adv>.
Использование эвристик повысило качество извлечения аспектов (табл. 3).
Добавление новых обучающих данных. Для увеличения количества обучающих данных с помощью выбранной модели и разработанных эвристик было автоматически размечено 300 новых текстов. Впоследствии разметка отредактирована вручную.
В результате комбинированной разметки из текстов извлечено 2 810 аспектов. Модель была вновь обучена на совокупности старых (вторая часть корпуса, 212 текстов) и новых (полученных в результате полуавтоматической разметки) данных, что позволило повысить качество извлечения аспектов (табл. 3).
Результаты экспериментов
Тестирование моделей проводилось на первой части корпуса (79 текстов). Для оценки качества алгоритма использовались метрики: «точность», «полнота» и «F-1 мера» для отдельных токенов, а также «точность полного совпадения аспектов» — отношение количества полностью правильно выделенных аспектов к общему числу аспектов.
В таблице 3 представлены метрики качества отдельных токенов для исследуемых моделей.
Таблица 4 содержит метрики по каждому аспекту для лучшей модели. В работе [5] для оценки качества автоматического извлечения аспектов с помощью SciBERT приведены следующие значения F-1:
— для аспекта Finding (соответствует аспекту Contrib, выделяемому в данной работе) -0,779;
— для аспекта Method — 0,673;
— для аспекта Purpose (соответствует аспекту Goal, выделяемому в данной работе) -0,626.
Таблица 3
Макроусреднение по точности, полноте и F-1 для отдельных токенов для различных моделей
Table 3
Macro-average precision, recall and F-1 for individual tokens for different models
Модель Точность Полнота F1
rubert-base-cased 0,174 0,200 0,178
гиЬегМшу2 0,217 0,309 0,245
bert-base-multilingual-cased 0,252 0,316 0,268
bert-base-multilingual-cased + эвристики 0,272 0,307 0,276
bert-base-multilingual-cased, обученная на новых данных, + эвристики 0,303 0,361 0,302
Таким образом, полученные метрики оказались выше, чем в данной работе. Однако авторы использовали данные большего объема (168 286 текстов) и на английском языке.
Таблица 4 Метрики для лучшей модели
Table 4
Metrics for the best model
Тег Точность Полнота F-1 Full-match accuracy
O 0,803 0,742 0,771 —
Goal 0,211 0,040 0,067 0,000
Task 0,262 0,564 0,358 0,030
Contrib 0,589 0,730 0,652 0,317
Method 0,215 0,320 0,257 0,133
Tool 0,485 0,213 0,296 0,057
Adv 0,064 0,275 0,104 0,160
Use 0,202 0,311 0,245 0,077
Conc 0,199 0,411 0,268 0,000
Example 0,000 0,000 0,000 0,000
Macro/total 0,302 0,170
Пример текста, размеченного лучшей моделью: <СопМЬ> Определена модель для визуализации <Task> связей между объектами </Task> и <Task> их атрибутами в различных процессах </Task> </СопМЬ>. На основании модели <СопМЬ> разработан универсальный абстрактный компонент графического пользовательского интерфейса </СопМЬ> и <СопМЬ> приведены примеры его программной реализации </СопМЬ>. Также проведена
апробация компонента для <Use> решения прикладной задачи по извлечению информации из документов </Use>.
Заключение
В ходе исследования был создан корпус русскоязычных научных текстов с ручной разметкой аспектов, разработан и реализован алгоритм автоматического извлечения аспектов из текста.
Авторы планируют продолжать эксперименты для повышения качества извлечения аспектов. Например, было замечено, что модели по-разному справляются с различными типами
аспектов, поэтому ансамбль моделей видится перспективным решением для данной задачи. Кроме того, авторы планируют добавить новые эвристики, а также увеличить количество обучающих данных, так как выяснилось, что это помогает улучшить качество автоматической разметки. Наконец, результаты исследовний показали, что некоторые аспекты извлекаются плохо или не извлекаются совсем, что может быть обусловлено их неоднородностью или недостаточной представленностью в данных. В будущем необходимо пересмотреть набор аспектов и скорректировать его для того, чтобы извлекать наиболее релевантные типы информации.
Литература
1. Nasar Z., Jaffry S.W., Malik M.K. Information extraction from scientific articles: A survey. Scientomet-rics, 2018, vol. 117, no. 3, pp. 1931-1990. DOI: 10.1007/s11192-018-2921-5.
2. Ronzano F., Saggion H. Dr. inventor framework: Extracting structured information from scientific publications. Proc. Int. Conf. Discovery Science, 2015, pp. 209-220. DOI: 10.1007/978-3-319-24282-8_18.
3. He J., Kryscinski W., McCann B., Rajani N., Xiong C. CTRLsum: Towards generic controllable text summarization. ArXiv, 2020, art. 2012.04281. URL: https://arxiv.org/abs/2012.04281 (дата обращения: 23.04.2022).
4. Houngbo H., Mercer R.E. Method mention extraction from scientific research papers. Proc. COLING, 2012, pp. 1211-1222.
5. Huang T.H.K., Huang C.Y., Ding C.K.C., Hsu Y.C., Giles C.L. CODA-19: Using a non-expert crowd to annotate research aspects on 10,000+ abstracts in the COVID-19 open research dataset. Proc. I Workshop on NLP for COVID-19 at ACL, 2020. URL: https://arxiv.org/pdf/2005.02367v3.pdf (дата обращения: 23.04.2022).
6. Jain S., Van Zuylen M., Hajishirzi H., Beltagy I. SciREX: A challenge dataset for document-level information extraction. Proc. LVIII Annual Meeting ACL, 2020, pp. 7506-7516. DOI: 10.18653/v1/2020.acl-main.670.
7. Dayrell C., Candido Jr.A., Lima G., Machado Jr.D., Copestake A. et al. Rhetorical move detection in english abstracts: Multi-label sentence classifiers and their annotated corpora. Proc. VIII Int. Conf. LREC, 2012, pp. 1604-1609.
8. Hanyurwimfura D., Liao B., Njogu H., Ndatinya E. An automated cue word based text extraction. J. of Convergence Information Technology, 2012, vol. 7, no. 10, pp. 421-429. DOI: 10.4156/JCIT.VOL7. ISSUE10.50.
9. Liakata M., Saha S., Dobnik S., Batchelor C., Rebholz-Schuhmann D. Automatic recognition of conceptualization zones in scientific articles and two life science applications. Bioinformatics, 2012, vol. 28, no. 7, pp. 991-1000. DOI: 10.1093/bioinformatics/bts071.
10. QasemiZadeh B., Schumann A.K. The ACL RD-TEC 2.0: A language resource for evaluating term extraction and entity recognition methods. Proc. X Int. Conf. LREC, 2016, pp. 1862-1868.
11. Augenstein I., Das M., Riedel S., Vikraman L., McCallum A. SemEval 2017 task 10: ScienceIE — extracting keyphrases and relations from scientific publications. Proc. XI Int. Workshop SemEval, 2017, pp. 546-555. DOI: 10.18653/v1/S17-2091.
12. Devlin J., Chang M.W., Lee K., Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. Proc. Conf. of the North, 2019, vol. 15, pp. 4171-4186. DOI: 10.18653/v1/N19-1423.
13. Strakova J., Straka M., Hajic J. Neural architectures for nested NER through linearization. Proc. CVII Annual Meeting of the ACL, 2019, pp. 5326-5331. DOI: 10.18653/v1/P19-1527.
14. Nwankpa C.E., Ijomah W., Gachagan A., Marshall S. Activation functions: Comparison of trends in practice and research for deep learning. Proc. II Int. Conf. on Computational Sciences and Technology, 2021, pp. 124-133.
15. Kuratov Y., Arkhipov M. Adaptation of deep bidirectional multilingual transformers for Russian language // Computational Linguistics and Intellectual Technologies. Proc. Int. Conf. Dialogue. 2019.
С. 333-339.
Software & Systems
DOI: 10.15827/0236-235X.140.698-706
Received 10.05.22, Revised 29.08.22 2022, vol. 35, no. 4, pp. 698-706
Aspect extraction from scientific paper texts
A.E. Marshalova 1, Student, a.marshalova@g.nsu.ru
E.P. Bruches 1 2, Junior Researcher, Senior Lecturer, bruches@bk.ru
T. V. Batura 2, Ph.D. (Physics and Mathematics), Associate Professor, Senior Researcher,
tatiana.v.batura@gmail.com
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
1 Novosibirsk State University Novosibirsk, 630090, Russian Federation 2A.P. Ershov Institute of Informatics Systems SB RASNovosibirsk, 630090, Russian Federation
Abstract. The paper focuses on the problem of automatic aspect extraction from the texts of Russian scientific papers. This problem is relevant due to the increase in the number of scientific publications and the growing need for automated extraction and structuring of key information from them.
The study involved the creation of a corpus consisting of 291 abstracts of Russian scientific papers annotated with the following aspects: task, goal, contribution, method, tool, use, advantage, example, and conclusion. The paper provides descriptions and examples for each aspect. As a result of the corpus annotation, 1494 aspects were identified with 44 % of them were the contribution aspect.
In addition, the paper proposes an algorithm for automatic aspect extraction. The paper considers the aspect extraction problem as a sequence-labeling problem. The BERT neural network is used to implement the algorithm. The authors have conducted a number of experiments related to the use of vectors obtained from various language models, as well as to freezing the weights of the model. A multilingual model fine-tuned on our data, that is, trained without freezing of the weights, has shown the best result. To improve the quality of aspect extraction, some heuristics, which are listed in the paper, have been developed, and the model has been further trained on the new data obtained from automatic labeling followed by manual editing.
The developed system can be useful to other researchers, as it simplifies selection of publications on a particular topic, review of methods for solving a particular problem, and analysis of results obtained in other works.
Keywords: natural language processing, text information analysis, information extraction from text, data processing, machine learning, neural networks.
1. Nasar Z., Jaffry S.W., Malik M.K. Information extraction from scientific articles: A survey. Scientomet-rics, 2018, vol. 117, no. 3, pp. 1931-1990. DOI: 10.1007/s11192-018-2921-5.
2. Ronzano F., Saggion H. Dr. inventor framework: Extracting structured information from scientific publications. Proc. Int. Conf. Discovery Science, 2015, pp. 209-220. DOI: 10.1007/978-3-319-24282-8_18.
3. He J., Kryscinski W., McCann B., Rajani N., Xiong C. CTRLsum: Towards generic controllable text summarization. ArXiv, 2020, art. 2012.04281. Available at: https://arxiv.org/abs/2012.04281 (accessed April 23, 2022).
4. Houngbo H., Mercer R.E. Method mention extraction from scientific research papers. Proc. COLING, 2012, pp. 1211-1222.
5. Huang T.H.K., Huang C.Y., Ding C.K.C., Hsu Y.C., Giles C.L. CODA-19: Using a non-expert crowd to annotate research aspects on 10,000+ abstracts in the COVID-19 open research dataset. Proc. I Workshop on NLP for COVID-19 at ACL, 2020. Available at: https://arxiv.org/pdf/2005.02367v3.pdf (accessed April 23, 2022).
6. Jain S., Van Zuylen M., Hajishirzi H., Beltagy I. SciREX: A challenge dataset for document-level information extraction. Proc. LVIII Annual Meeting ACL, 2020, pp. 7506-7516. DOI: 10.18653/v1/2020.acl-main.670.
7. Dayrell C., Candido Jr.A., Lima G., Machado Jr.D., Copestake A. et al. Rhetorical move detection in english abstracts: Multi-label sentence classifiers and their annotated corpora. Proc. VIII Int. Conf. LREC, 2012, pp. 1604-1609.
8. Hanyurwimfura D., Liao B., Njogu H., Ndatinya E. An automated cue word based text extraction. J. of Convergence Information Technology, 2012, vol. 7, no. 10, pp. 421-429. DOI: 10.4156/JCIT.VOL7. ISSUE10.50.
9. Liakata M., Saha S., Dobnik S., Batchelor C., Rebholz-Schuhmann D. Automatic recognition of conceptualization zones in scientific articles and two life science applications. Bioinformatics, 2012, vol. 28, no. 7, pp. 991-1000. DOI: 10.1093/bioinformatics/bts071.
References
10. QasemiZadeh B., Schumann A.K. The ACL RD-TEC 2.0: A language resource for evaluating term extraction and entity recognition methods. Proc. XInt. Conf. LREC, 2016, pp. 1862-1868.
11. Augenstein I., Das M., Riedel S., Vikraman L., McCallum A. SemEval 2017 task 10: SciencelE — extracting keyphrases and relations from scientific publications. Proc. XI Int. Workshop SemEval, 2017, pp. 546-555. DOI: 10.18653/v1/S17-2091.
12. Devlin J., Chang M.W., Lee K., Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. Proc. Conf. oftheNorth, 2019, vol. 15, pp. 4171-4186. DOI: 10.18653/v1/N19-1423.
13. Strakova J., Straka M., Hajic J. Neural architectures for nested NER through linearization. Proc. CVII Annual Meeting ofthe ACL, 2019, pp. 5326-5331. DOI: 10.18653/v1/P19-1527.
14. Nwankpa C.E., Ijomah W., Gachagan A., Marshall S. Activation functions: Comparison of trends in practice and research for deep learning. Proc. II Int. Conf. on Computational Sciences and Technology, 2021, pp. 124-133.
15. Kuratov Y., Arkhipov M. Adaptation of deep bidirectional multilingual transformers for Russian language. Computational Linguistics and Intellectual Technologies. Proc. Int. Conf. Dialogue, 2019, pp. 333-339.
Для цитирования
Маршалова А.Э., Бручес Е.П., Батура Т.В. Извлечение аспектов из текстов научных статей // Программные продукты и системы. 2022. Т. 35. № 4. С. 698-706. DOI: 10.15827/0236-235X.140.698-706.
For citation
Marshalova A.E., Bruches E.P., Batura T.V. Aspect extraction from scientific paper texts. Software & Systems, 2022, vol. 35, no. 4, pp. 698-706 (in Russ.). DOI: 10.15827/0236-235X.140.698-706.
-
Выявление аспектов содержания первоисточника с помощью формальных текстовых признаков
Использование
поаспектного метода реферирования на
первых порах было сопряжено с рядом
трудностей, связанных с неопределенностью
границ смысловых аспектов (случаи
«пересечения» аспектов, «вхождения»
их друг в друга). Поэтому проводились
работы, направленные на оптимизацию
метода путём выявления и использования
текстовых признаков — устойчивых
словесных оборотов, характеризующих
конкретные аспекты содержания.
-
И. Гендина,
занимавшаяся выявлением и анализом
таких признаков в текстах первичных
документов [174], по примеру А.А. Авдеевой,
анализировавшей рефераты [167], назвала
эти слова, словосочетания и устойчивые
текстовые обороты «маркерами».
В настоящее время их называют иногда
также «метками».
В отличие от ключевых
слов
они характеризуют текст не
содержательно,
а описательно.
Эксперимент
Н.И. Гендиной, базирующийся на содержательном
анализе
аспектным методом
200 статей по информатике, показал, что
список выявленных текстовых признаков
аспектов содержания может, во- первых,
облегчить
работу референта
по составлению рефератов, во- вторых,
использоваться для обучения
аналитико-синтетической переработке
боку ментов,
и, наконец, в-третьих, использоваться
редактором
научно-технической литературы
соответствующего профиля. Таким образом,
выявление устойчивых текстовых оборотов,
однозначно характеризующих смысловые
аспекты, является еще одним направлением
реализации преимуществ метода по
аспектоного реферирования.
Ввиду
важности работы Н.И. Гендиной [174]
остановимся на ней подробней. Выделение
формальных текстовых признаков
производилось в три этапа. На первом
этапе
разрабатывался подробный
перечень аспектов содержания,
которые объединились в следующие
семантические блоки:
-
(Вводная
часть). Актуальность проблемы.
П.
(Основное содержание). Предлагаемый
вариант решения проблемы.
Ш.
Заключение.
На
втором
этапе выявлялись
формальные текстовые признаки,
характеризующие
аспекты содержания. Для их выделения
была специально разработана анкета
анализа первоисточников,
в которой фиксировались смысловые
аспекты и соответствующие им маркеры.
Каждое предложение текста предварительно
нумеровалось. Анкета содержала следующие
графы:
-
. Имя
аспекта (название смыслового аспекта) -
. Количество
предложений (выражающих данный аспект) -
. Номера
предложений (выражающих данный аспект) -
. Маркеры
(присущие данному аспекту.
На
третьем
этапе анализировались
способы
выражения формальных смысловых признаков
в текстах изучаемых статей. (Ясно, что
подобная анкета с переставленными
графами может быть использована для
обратного смыслового анализа текста
первоисточника, то есть нахождения
основных смысловых аспектов содержания
по их маркерам, таблицы которых приведены
во многих работах. Особый интерес
подобная анкета может представлять для
студентов).
Н.И.
Гендиной пришлось значительно расширить
и уточнить перечень основных аспектов
содержания, предложенный В.И. Соловьёвым
[168], так как большая часть статей не
укладывалась в его «жесткую» схему.
После содержательного анализа текстов
первоисточников этот список стал
включать следующие аспекты: предмет
рассмотрения, целевая установка,
авторский подход, актуальность проблемы,
известные варианты решения, недостатки
известных вариантов решения, описание
предлагаемого варианта решения,
особенности предложенного варианта,
область применения, места исследования,
назначение предмета рассмотрения,
технические средства реализации,
математический аппарат, наглядное
представление информации, примеры,
выводы, результаты, рекомендации,
преимущества предложенного варианта
решения (для сравнения см. главу 7.1).
Интересно,
что уточнённый перечень аспектов был
получен в результате анализа первых 50
статей, обработка же последующих 150
первоисточников не привела к изменению
этого перечня. Перечисляемые аспекты
существенно
различались по своему <<удельному
весу».
Так аспекты «Наглядное
представление информации», «Математический
аппарат», «Примеры»
не
вполне самостоятельны, а входят составной
частью в какой- либо из содержательных
аспектов. Ведь они характеризуют не
столько содержание работы, сколько
форму.
В
целом разработка детального перечня
аспектов была направлена на изучение
сочетаемости
аспектов и нахождения их (встречаемости
в определённых частях текста). Это
позволяло говорить о границах аспектов
в тексте.
Анализ
сочетаемости
и порядка следования аспектов
в тексте позволил выявлять наиболее
характерную последовательность изложения
материала
в статьях, которая в общем виде выглядит
следующим образом:
обоснование
актуальности темы —> констатация
неудовлетворительного состояния
проблемы —> предлагаемый вариант
решения проблемы,
его
описание —> выводы, результаты,
рекомендации.
Блок
«Вводная
часть»
чаще всего состоит из таких аспектов
как «Обоснование
актуальности», «Известный вариант
решения», «Недостатки известного
варианта решения»,
«Авторский
подход»,
причём характерно, что они выступают в
одном из первых абзацев текста. Читающий
сразу понимает, что имеет дело лишь с
«предисловием» к основной информации.
В
блок «Основное
содержание»
входят, как правило, аспекты «Описание
предлагаемого варианта решения»,
«Особенности предложенного варианта
решения», «Назначение предмета
рассмотрения, «Технические средства
реализации», «Математический аппарат»
и др.
Блок
«Заключение»
содержит чаще всего аспекты «Выводь^,
«Результаты», «Преимущества»,
«Рекомендации».
Однако
основное внимание в данной работе было
уделено отысканию
формальных признаков аспектов содержания
в тексте первоисточника.
На
основе содержательного анализа 200 статей
замечено [ ], что изложение
материала
обычно начинается с характерных
для каждого смыслового аспекта слов
и словосочетаний. Например, словесным
признаком аспекта «Цель
исследования»
в тексте чаще всего являются конструкции
типа: «Целью
(цель, задача) настоящей
(данной) статьи
(работы) является
(была, заключается в …)».
Для
аспекта «Результаты»
признаком служат слова: «В
результате (проведённых
исследований) получен
(а,о,ы) …», «Результаты
оказались следующими»
и т. п.
Когда
речь идёт о
назначении предмета исследования
(описания), то словесный признак аспекта
выражается, как правило, сочетанием
глагола с предлогом «для»: «Предназначен
(а?о,ы) для …»,
«Используются
для
…», или словосочетаниями типа: «Основное
назначение состоит в…», «Устройство
предназначено…».
Таким
образом, формальный словесный признак
в тексте первичного документа часто
предопределён самим названием аспекта:
«Предметом
исследования является…», «Целью
исследования было…», «Устройство
предназначено
для…», «Встаёт проблема
(вопрос)…»,
«Исследование
проведено с
использованием (в
условиях…)»
и
т. п. В работе подробно представлены
типичные конструкции маркеров наиболее
часто встречающихся аспектов содержания
статей по информатике.
Маркеры,
которые не приводились в вышеизложенном
тексте, мы свели в таблицу 7.
Таблица
7
Основные
аспекты содержания и их маркеры
(по
результатам анализа Н.И. Гендиной [174])
|
Наименование аспекта |
Типичные |
|
1 |
2 |
|
Актуальность проблемы Авторский подход Известный вариант решения Недостатки известного варианта решения Описание поддаваемого варианта решения Место исследования |
Одной
Большим
При
Мы
Известно,
В
Все
Для
В
Основной
является
В
Однако
В
В
Рассмотрим В |
Рассмотрим
на
примере…

Примеры
Особенности
предлагаемого
варианта
решения
Преимущ
ества предлагаемого варианта решения
Выводы
Рекомендации
Например:…
Приведём
пример…
Поясним
на примере
…
Существенной
особенностью
является…
Особенность…,
отличающая …от…, состоит в том, что…
Проанализированы особенности…
Особенность
заключается…
Этот
способ имеет то преимущество,
что…
Следовательно,
преимущества
ИПС состоят в том, что… (или: не в том…,
а …; не только в…, но и в…).
Данный
метод не
даёт потерь
при поиске…; применение.. сократило
время,
исключило
субъективность (положительные
стороны).
Метод
даёт возможность рассчитать
и обеспечить…;
применение… новыми … и позволит…
Итак,
можно сделать вывод…
Проведённые
исследования позволяют сделать следующие
выводы.
Анализ
позволяетутверждать,
что…
Система
может быть рекомендована
для…; … может быть рекомендовано
в качестве…
Код
может быть использован для…; разработанный
язык может применяться в… для…
Как…
таки… может быть использован в
качестве…; в заключение можно отметить,
что… могут использоваться не только
в…, но и в…
Эти
же словесные признаки могут быть в
текстах всех научных документов,
относящихся к области знания, причём
в текстах различных областей знания
маркеры одних и тех же аспектов не имеют
существенных отличий! Задать полный
список маркеров для каждого аспекта
содержания невозможно в силу богатства
естественного языка, его вариантности.
Примерный
сокращённый перечень маркеров, отражающих
основные наиболее часто встречающиеся
в текстах научных документов аспекты
содержания, сгруппированные по блокам
[1], приведён также в таблице 8.
Таблица
8
Перечень
маркеров наиболее распространенных
аспектов содержания научных документов
|
Наименование аспекта |
Маркер |
|
1 |
2 |
|
Семантический |
|
|
Актуальность пробемы |
Одной
Огромную
Особое
Социальная
Среди В |
|
Известный |
Известно,
Известны
Широкое
Проблеме Вопросу |
|
Достоинства |
Предложенный
К
Преимуществом Концепция |
|
Недостатки |
Недостатком
Однако
Тем
Однако Предложенный |
|
Целевая |
Цель
Целью
Цель
В
Настоящая К |
|
Семантический |
|
|
Описание |
Предлагаемая |
|
Особенность |
Особенность
Отличительная
Характерным
Новизна
Новизна Принципиальное |
|
Назначение |
…
…
… … |
|
Место |
В
Сотрудниками
В На |
|
Технические средства, оборудование |
Система
В
Технической С |
|
Метод |
В
Исследование
Для
Сочетание
В
… … |
|
Экспериментальная проверка |
Эксперимент
Эксперимент
Цель
Наши
Опыты
Испытания Серия |
|
Примеры |
Например
Рассмотрим
Приведём
Обратимся
Этот Данный |
|
М |
Воспользуемся
Расчёты Исходя |
|
Наглядное направление информации |
См.
См. На |
|
Данные,
График На |
|
|
Семантический |
|
|
Результаты |
Результаты
Результаты
Из
Основные
Главным Полученные |
|
Выводы |
Итак,
Проведённые
Итак,
В
Резюмируя
Подводя
Таким … |
|
Преимущества |
Этот Анализ |
|
Рекомендации |
Система
Как … |
Анализ
таблиц 7 и 8 показывает, что наиболее
чёткие группы маркеров составляют
выражения, в которых имеется характерное
слово.
Важную роль для выражения маркеров
имеют устойчивые
фразеологические обороты,
которые составляют ядро
маркеров.
С
точки зрения синтаксиса предложений
маркеры могут выражаться простыми
предложениями
или их фрагментами,
главной частью
101
сложноподчинённого
или сложного бессоюзного предложения,
фрагментами текста из
нескольких предложений
(обычно двух).
Лексический
признак
(характерное слово) играет ведущую роль
в таких аспектах как «Место исследования»,
«Назначение предмета рассмотрения»,
«Технические средства реализации»,
«Примерь^, «Наглядное представление
информации», «Экспериментальная
проверка», «Математический аппарат» н
частично «Целеваяустановка».
Для
аспектов «Актуальность проблемы»,
«Известный вариант решения», «Недостатки
известного варианта решения», «Результатъ^,
«Выводы, «Преимущества предложенного
варианта решений», «Рекомендации»
лексический
признак не являетея единственным.
Здесь при выделении аспектов важную
роль играет также порядок
следования аспектов
в тексте, их
совместимость
в блоках. Кроме того, в роли вспомогательного
признака может выступать абзац.
Маркер может также входить в заглавие
документа или подзаголовки.
Следовательно,
все перечисленные признаки при
выявлении основных аспектов содержания
надо рассматривать в
комплексе.
Формальные
текстовые признаки могут быть использованы
как для
совершенствования обычного
(ручного) реферирования,
так и для разработки алгоритмов
автоматического
реферирования.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Находим главное в отзывах. Опыт разработчиков геопоиска Яндекса
Время на прочтение
9 мин
Количество просмотров 4.2K
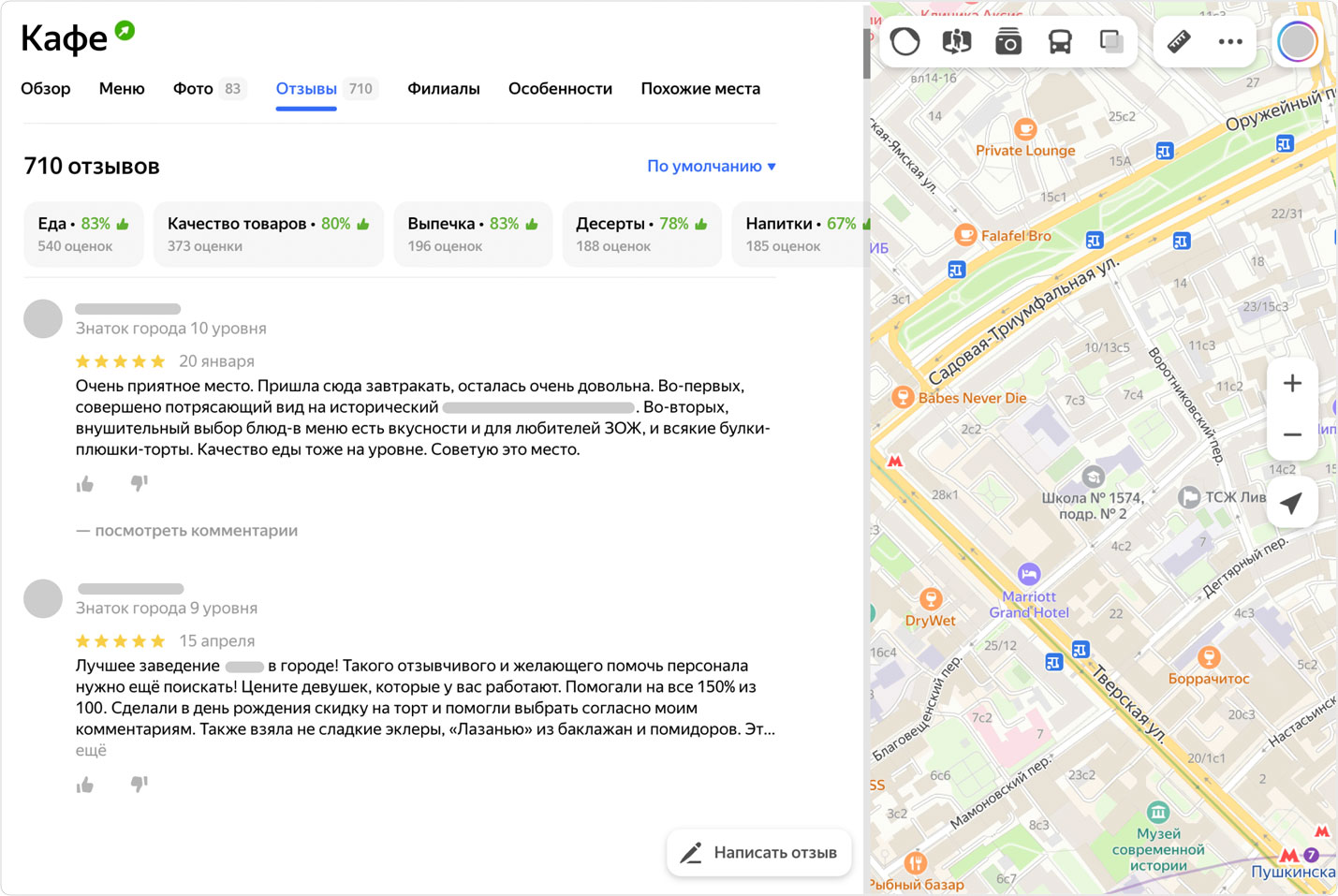
Существует классический способ выбрать, в какое кафе сходить или в какую организацию обратиться: достаточно почитать отзывы (которые, конечно, должны быть защищены от ботов). И такой способ правда популярен — в том числе, уверен, и среди читателей этого поста.
Для тех, кому важно выбрать быстрее, существует топ отзывов, а также рейтинг заведения. Но в случае с топом по-прежнему нужно вчитываться в мнения людей, а рейтинг скрывает за собой множество деталей — непонятно, учитывает ли он нюансы про еду, обслуживание, спектр услуг и так далее.
Мы поняли, что нужно учиться систематизировать отзывы и выделять главное. Этот пост — про то, как мы стремились состыковать интересы пользователей с доступными нам технологиями в машинном обучении и на фронтенде. Рассказывать буду достаточно подробно, чтобы вы прошли этот путь вместе со мной и увидели все пробы и ошибки. Возможно, по дороге у вас возникнут свои мысли о том, как можно решать подобную задачу.
Первые шаги
С 2017 года мы активно собирали мнения посетителей о заведениях и компаниях и накопили огромное количество отзывов в разных категориях. Например, есть рестораны и медцентры с тысячами, а иногда и с десятками тысяч отзывов. Наше решение должно было помочь людям за несколько секунд оценить, хотят они в это место или нет. А владельцам компаний — быстро узнать, чем довольны клиенты, а чем нет.
В целом нам хотелось получить своего рода суммаризацию: 3–4 предложения о том, почему то или иное заведение классное и его стоит посетить. Зачастую суммаризация предполагает работу с большими генеративными текстовыми моделями, куда надо «положить» все отзывы. Но на первом этапе мы решили не вкладываться в большие генеративные модели, так как они требовали больших вложений при неподтверждённых продуктовых гипотезах.
Для начала мы решили собрать MVP и работать с аспектами — характеристиками, которые есть у каждого заведения: хорошо ли там готовят, как там внутри, удобное ли расположение, насколько чисто и всё в этом духе. По сути, это любое произвольное свойство организации. Оно может быть более общее — «чистота», а может более узкое — «суши». В аспекты мы включили те сущности, которые можно похвалить или поругать.
Чтобы двигаться дальше, нам надо было научиться делать несколько вещей:
- определять, что важно людям в разных заведениях. То есть какие аспекты искать;
- выделять эти аспекты в отзывах;
- оценивать тональность высказываний.
Первый этап. MVP
Мы начали со внутреннего инструмента Яндекса — библиотеки регулярных выражений под названием Remorph. С её помощью мы писали шаблоны, по которым фильтруется текст. Для старта выбрали категорию «Кафе и рестораны», в которой люди очень часто ищут подходящее место, и с этим есть реальная сложность. К тому же эта тематика и нам самим очень нравилась.
Что мы сделали? Взяли аспект, подобрали к нему синонимы и подготовили схемы, как находить отзывы на этот аспект. Например, мы ищем «бургер» и слова вокруг него. Если они подходят по некоторой схеме, которую мы сделали, — берём. Грубо говоря, мы просим Remorph: «Найди в этом тексте кусок отзыва, который подходит под эту регулярку». А сама регулярка при этом формулируется примерно так: «Дай мне прилагательное для этого существительного».
Так Remorph начал находить аспект и какой-то контекст, например: «Бургер» → «лучший» или «вкусный». То есть часть задачи решалась. Кроме этого, нам надо было научиться автоматически понимать, почему слово «лучший» или «вкусный» — это позитивная тональность, а «пресный» или «непрожаренный» — негативная. Если с позитивной и негативной всё понятно, то нейтральная тональность — это чаще всего констатация факта: «В этом отеле есть бассейн».
Для расчёта примерной тональности мы тоже сделали простой подход:
- Взяли контекстное слово. Например, «лучший».
- Нашли все отзывы, где это слово встречалось рядом с аспектом: «лучший» → «бургер».
- Посчитали средний рейтинг этих отзывов.
- Выбрали порог, когда считаем отзыв негативным, а когда позитивным. Например: для отзывов, где есть слово «недожаренный», средний рейтинг — 3. Такие определили как негативные.
В процессе работы с регулярками мы сразу поняли плюсы этого подхода: они очень точные и находят ровно то, что ты попросишь их искать. Также мы поняли и минусы: умрёшь, пока будешь писать все возможные регулярки. А ещё с ними нельзя находить синонимы.
Поиск формы
При этом мы не только постигали регулярки и разрабатывали классификатор тональности на коленке, но также искали продуктовую форму для аспектов. Для этого команда провела уйму UX-исследований, а затем онлайн-экспериментов в продакшене. Всё это заняло почти полгода. В итоге путём проб и ошибок мы нашли победителя. Между собой мы назвали это «градусниками»:

Это агрегированные аспекты, которые мы посчитали важными для конкретной организации. Они показываются над отзывами, а сами отзывы мы не трогаем.
Название «градусников» было говорящим: они отражали температуру того, как посетители заведения относятся к определённому аспекту.
Такая форма тоже вызывала некоторое недопонимание, поэтому и тут мы проводили дополнительные исследования. В итоге решили убрать разноцветные части и доработать вариант с процентами. К ним добавили «рукавички», и после этого всё стало гораздо понятнее:

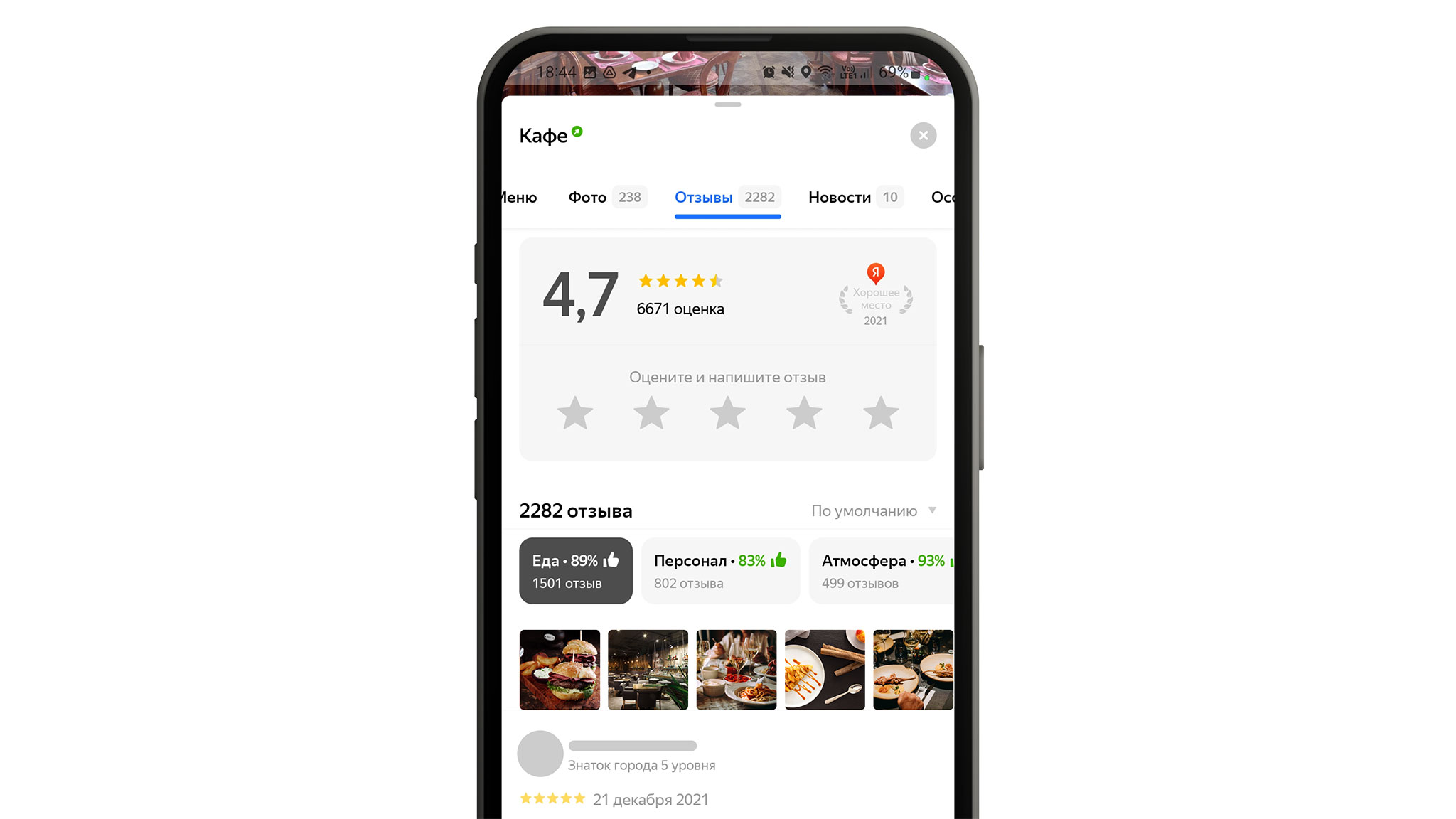
Такие блоки с оценкой появляются, когда есть как минимум десять позитивных или негативных отзывов о конкретном аспекте — при таком количестве мы считаем, что на основе этих данных уже можно сделать какие-то выводы. Сейчас пользователи могут увидеть «градусники» в профиле компаний в поиске Яндекса, в десктопной версии Яндекс Карт, а с недавнего времени и в мобильном приложении Карт. А владельцы могут посмотреть оценку характеристик их заведения в личном кабинете Яндекc Бизнеса.

Итоги первого этапа
Что мы поняли из MVP-подхода? Регулярки работают и находят то, что нам было нужно, но далеко не всё. К тому же они находят только однотипные отзывы, которые не выходят за рамки того, что мы в них вложили. Это значило: будут случаи, когда аспект не находится, но в отзыве про него говорится.
Чтобы идти дальше, нам нужно было подготовить какое-то количество синонимов. И если для аспекта «бургер» это было просто, то для более общего аспекта «еда» перечислять синонимы долго. И ещё проблема — наш язык очень сложный. Мы увидели, что если аспект в отзыве хвалят, то обычно пишут как-то просто: «бургер отличный, понравился». А если ругают, то рассказывают почему: «развалился по дороге», «несли полчаса», «положили не тот соус». То есть сколько бы синтаксических конструкций мы ни составили для Remorph, велика вероятность, что мы не нашли бы все возможные варианты описания.
«А может, BERT?»
Мы подумали: «А не взять ли нам какую-то взрослую модель, которая умеет работать с текстами и избавит нас от проблем с низкой полнотой? А ещё смотрит не только на слова рядом с аспектом, а вообще на все слова в отзыве». И взяли модель BERT. Это всего лишь несколько энкодеров, применяемых ко входу последовательно. Сейчас мы не будем сильно углубляться в то, что это такое. Если коротко — это модель, которая предобучена на огромном массиве текстов и знает, как устроен язык.
Мы могли взять эту модель и достаточно дёшево по времени её обучить и настроить под свою задачу. А точнее, под две задачи: сделать классификацию по наличию аспекта в тексте отзыва и классификацию по тональности.
В этот момент нам сильно повезло, потому что у нас был размеченный массив текстов для категории «Кафе и рестораны». То есть в отзывах были специальные метки о том, есть ли там аспект и как о нём говорится: позитивно или негативно. Всё это мы делали в Яндекс Толоке — краудсорсинговом проекте для обработки больших массивов данных. У нас было восемь общих аспектов: «еда», «чистота», «цена», «расположение», «персонал», «напитки», «музыка», «завтраки». На них мы попробовали дообучить BERT и просто посмотреть, что получится. Спойлер: результаты оказались классными.
Мы договорились, что будем считать работу BERT успешной при определённых показателях. Если и точность, и полнота по экспертной разметке не ниже 0,9, то модель хорошо справляется с выделением аспекта. Если же качество не дотягивает, то мы повторяем цикл дообучения.
Что же мы получили? Во-первых, эта модель хорошо находила синонимы. Например, если задавался аспект «персонал», то кроме него находились и другие отзывы, где было написано, скажем, «официанты». Ещё мы увидели, что BERT не просто смотрит на наличие в отзыве каких-то позитивных или негативных слов, а находит те, что относятся именно к аспекту. Важно понимать, что часть этого знания заложена самой языковой моделью. Но всё же данные, которые мы давали на дообучении, тоже на это влияли, потому что для многих аспектов невозможно добиться хорошего качества без разметки.
На примере аспекта «Еда» в таблице хорошо видны недочёты первого подхода:
- Всю еду в регулярках не перечислишь. Отсюда полнота 0,3.
- На самом деле BERT, помимо названий самой еды, реагирует и на контекст. То есть в словосочетании «вкусный бешбармак» BERT находит аспект «Еда» скорее из-за слова «вкусный».
Что мы получили при сравнении Remorph и BERT?
- Показатель 0,3 означает, что из десяти отзывов об этом аспекте Remorph находит только три. А чтобы подобрать все синонимы для этой категории, мы вручную собирали и отбирали часто встречающиеся слова в отзывах про кафе («пицца», «суши» и т. д.). И всё равно полнота получилась 0,3.
- Показатель полноты с BERT по аспекту «еда» выше 0,9 — и это фантастический результат. По остальным аспектам результаты в среднем такие же.
Кроме того, мы заметили забавную особенность этой модели (напомню, она обучалась на восьми аспектах). BERT находила аспекты, которые на самом деле не видела в подготовленной разметке.

Например, мы не давали аспект «кофе» на этапе дообучения. Но BERT находила его в отзывах с весьма внушительной долей уверенности. А ещё примечательно, что она научилась находить в отзывах те признаки, которые определяют тональность. Например, BERT видела словосочетание «кофе не очень» и определяла тональность как –0,9.
Всё это придало нам окончательной уверенности в том, что надо масштабироваться. Для этого нам пришлось переделать все процессы: сбор разметки, метод обучения, принятия и валидации результатов. Потому что разработать прототип — одна задача, а масштабировать его — совсем другая.
Масштабирование
Для масштабирования нам надо было научить модель BERT работать с бóльшим количеством категорий и аспектов. Например, в «Кафе и ресторанах» к уже привычным «еде» и «персоналу» добавились более сложные аспекты: «интерьер» и «атмосфера». В других категориях мы столкнулись с вещами вроде «окрашивания волос», «шиномонтажа» и «схода-развала».
Сначала мы попробовали собрать разметку для новых аспектов и дообучить модель. Но эта попытка провалилась: мы добавили 50 аспектов и лишь для 20 удалось получить приемлемые показатели качества. При этом сколько разметки мы ни добавляли, лучше не становилось.
Оказалось, что проблема была в низком качестве самой разметки для новых аспектов. Толокеры — работники Яндекс Толоки — размечали отзывы и хорошо справлялись с простыми вещами, но с узкоспециализированными вроде «аппаратного маникюра» у них начинались проблемы.
Например, когда в отзывах упоминалось что-нибудь про «уют», толокеры не могли понять, к какому аспекту это отнести — к «интерьеру» или к «атмосфере». С «шиномонтажом» и «сходом-развалом» толокеры путались, так как эти услуги часто оказывают в одном месте. «Шиномонтаж» вообще оказался сложным аспектом. К примеру, в отзывах встречалось такое: «разварки огонь» — это про работу с дисками, но не про шиномонтаж. Или писали: «Заклеиваюсь уже 5 раз, всегда на высшем уровне», но речь шла не про ремонт резины, а про тонирование стёкол. Такие кейсы толокеры размечали плохо из-за специфики аспекта: не всегда было понятно, что это и с какой тональностью об этом говорится в отзыве.
Чтобы преодолеть эти проблемы, мы переработали инструкции и экзамены для толокеров. И это помогло: теперь они гораздо лучше справляются с заданиями, а мы получаем качественную разметку. Кроме этого, мы стали по-другому выбирать отзывы, которые отправляем на разметку. Например, начали использовать метод Active Learning: размечать отзывы, в которых модель сомневалась. Всё это позволило нам улучшить работу BERT с новыми категориями и довольно непростыми аспектами.
Автоматизация
В итоге мы собрали конвейер по автоматизированному созданию аспектов. Сейчас на входе мы даём модели новый аспект и описание того, что он из себя представляет, а на выходе получаем новый размеченный аспект в продакшене.
Как работает этот контур?
- Собирает метрики для приёмки нового аспекта: добирает разметку для обучения, применяет Active learning.
- Контролирует качество по метрикам: итеративно переобучает новую модель, пока не добьётся для новых аспектов нужного качества, при этом без потери качества для старых.
- Находит аспект в отзывах и выкладывает новую базу отзывов в продакшен.
Как визуально выделить аспект в отзыве
У нас была ещё одна задача: упростить чтение длинных отзывов. Мы хотели научиться показывать пользователю сразу тот кусок текста, в котором говорят о конкретном аспекте. Это позволило бы не просматривать весь текст целиком и не выискивать там нужное предложение.
Тут нам помогло знание устройства BERT: при обработке текста модель ищет аспект и выделяет в отзыве те участки, которые относятся к этому аспекту. Этот механизм называется Self-attention. Мы научились использовать его, чтобы выделять в отзывах нужные места.
Теперь пользователю достаточно нажать на какой-нибудь аспект в «градуснике», и откроются все отзывы с этим аспектом. А механизм выделит жирным релевантную часть текста:

Итоги
Главный результат: у нас есть более 200 размеченных аспектов в продакшене и они уже покрывают достаточное количество категорий, кроме «Кафе и ресторанов». Например: «салоны красоты», «отели», «автосервисы» и «горнолыжные курорты». Конечно же, на этом работа не заканчивается, и мы будем развивать «градусники» дальше. Можно подвести итоги того, сколько времени ушло на их создание:
— четыре месяца на эксперименты с Remorph;
— параллельно четыре–пять месяцев мы думали о том, как всё это показать в продукте;
— месяц на сборку BERT;
— полгода на масштабирование.
И главные выводы:
— Разметка is the King!
— Надо было не стесняться и не пытаться собрать что-то на регулярках, а сразу брать BERT.
Семантический анализ текста Адвего для SEO онлайн — профессиональный инструмент для оценки качества текстов, seo оптимизации статей и поиска ключевых слов в тексте.
Проверьте количество символов, тошноту и водность, плотность ключевых слов и фраз онлайн, семантическое ядро текста бесплатно!
Язык: по умолчанию — русский
| Текст: обязательно | длина текста, символов: 0 |
Напишите текст для анализа и нажмите кнопку «Проверить»
Максимальная длина текста — 100 000 символов.
Зачем нужен SEO анализ текста
Поисковые системы оценивают качество и релевантность статьи по содержащимся в ней словам и словосочетаниям (коллокациям). Чем больше в тексте тематичных ключевых фраз, тем больше шансов, что он получит высокую оценку.
Соответственно, если в тексте будет мало ключевых слов, но много «воды» — стоп-слов, вставных слов, шаблонных фраз, качество статьи будет низким.
Но и слишком большое количество ключевиков — тоже плохо, такой документ получит отметку «переспам» и вряд ли будет показан в поисковой выдаче.
Оценить эти показатели поможет сервис семантического анализа, который покажет процент ключевых слов и количество стоп-слов в тексте.
SEO анализ текста Адвего определяет:
- плотность ключевых слов, процент ключевых фраз;
- частотность слов;
- количество стоп-слов;
- объем текста: количество символов с пробелами и без пробелов;
- количество слов: уникальных, значимых, всего;
- водность, процент воды;
- тошноту текста, классическую и академическую;
- количество грамматических ошибок.
Наш онлайн сервис показывает семантическое ядро текста страницы — все значимые и ключевые слова, что позволит оценить, по каким запросам она будет показываться выше после того, как проведет поиск ключевых слов в тексте.
Также семантический анализ показывает все стоп-слова и грамматические ошибки.
Пример отчета проверки семантического SEO анализа текста онлайн

Как рассчитывается тошнота текста
Классическая тошнота определяется по самому частотному слову — как квадратный корень из количества его вхождений. Например, слово «текст» встречается на этой странице 16 раз, классическая тошнота будет равна 4.
Важно! Максимально допустимое значение классической тошноты зависит от объема текста — для 20 000 знаков тошнота, равная 5, будет нормальной, а для 1000 знаков — слишком высокой.
Академическая тошнота определяется как отношение самых частотных и значимых слов по специальной формуле. Нормальное значение — в пределах 5-15%.
По тошноте текста можно судить о натуральности текста и его SEO-оптимизации под поисковые запросы. Высокий показатель тошноты онлайн для поисковиков является плохим знаком.
Как рассчитывается водность текста
Процент воды в Адвего определяется как отношение незначимых слов к общему количеству слов. То есть чем больше в статье значимых слов, тем меньше в итоге «воды».
Конечно, невозможно написать сео текст совсем без воды, нормальный показатель — 55%-75%.
Чтобы уменьшить процент водности, необходимо почистить текст от широко распространенных фраз и терминов, вставных слов: «в современном мире», «так сказать», «всем известно» и т. п. Также повышает качество текста употребление специализированных терминов и профессиональной лексики.
Семантический анализ текста показывает, из каких слов и словосочетаний состоит контент и какие из них встречаются чаще всего. Преимущественно его используют для SEO-текстов с ключевыми словами и LSI-шлейфами: анализ позволяет примерно представить, как на контент отреагирует поисковая система. Но не всегда цифры бывают понятны, а результат правок по советам семантического анализа — хорошим. Мы расскажем, как сделать анализ, на что обратить внимание и что делать с показателями.
Кстати, в качестве примера для разбора мы будем использовать анализ статьи о вебинарах из нашего блога.
Реклама: 2VtzqvbDur1

Advego.com. Семантический анализ от биржи контента Адвего — один из самых популярных сервисов у SEO-специалистов. Он бесплатен, доступен всем незарегистрированным и зарегистрированным пользователям. Показывает:
- Академическую тошноту;
- Классическую тошноту;
- Количество стоп-слов;
- Показатель «воды»;
- И другие менее значимые параметры.

Istio.com. Это — сервис, разработанный специально для семантического анализа текста. Доступен всем, регистрация не обязательна. Не требует оплаты подписки. Показывает:
- Показатель водности;
- Тошноту;
- Топ-10 самых используемых слов;
- Тематику текста;
- Другие параметры.

Miratext.ru. Это — еще один сервис от биржи копирайтинга. Тоже бесплатный, доступный зарегистрированным и незарегистрированным пользователям. Показывает:
- Тошноту;
- «Водянистость»;
- Качество по закону Ципфа;
- Облако частотности слов;
- Другие менее значимые цифры.

Внимание! У каждого сервиса свой алгоритм, поэтому единых цифр, на которые стоит ориентироваться, нет. Например, наш текст показал тошноту 4,12/8,7%, 4,79% и 4,8% на трех разных сервисах. Цифры похожи, но не совпадают. Поэтому обязательно читайте описание самого сервиса проверки и ориентируйтесь на рекомендованные им показатели.
Проверка текста на уникальность
Пример семантического анализа текста
Давайте разберем показатели на примере анализа текста по семантическому анализатору от Адвего. Первые несколько строк — количество знаков с пробелами и без, количество слов, уникальных и значимых слов — не так важны. Важны следующие показатели:
- Вода — 67,7%;
- Классическая тошнота документа — 4,12%;
- Академическая тошнота документа — 8,7%;
- Семантическое ядро;
- Частота слов в семантическом ядре.

Давайте остановимся на каждом показателе подробнее.
Водность текста
Семантический анализатор Адвего показывает самую высокую водность — на других сервисах при проверке нашего текста она 44% и 5%. Показатель водности — это соотношение незначимых слов к общему количеству слов. Чем больше в тексте стоп-слов, не несущих смысловой нагрузки, тем выше процент воды.
Слова, которые сервис считает «водой», выводятся в отдельной таблице «Стоп-слова». Чаще всего в нее попадают предлоги и местоимения. Кстати, нормальный показатель, упомянутый в описании семантического анализа по Адвего — 55-75%. Значит, в нашем тексте уровень воды нормальный.
Это интересно: Как повысить уникальность текста
Классическая тошнота документа
Она рассчитывается по самому частотному слову, как квадратный корень из количества его вхождений. Другие сервисы проверки используют подобный алгоритм, поэтому их «тошноту» можно приравнять к показателю «классическая тошнота» на Адвего.
Определенные нормы по классической тошноте в описании анализатора не указаны. Создатели лишь рассказали, что она зависит от длины текста — например, для статьи длиной в 20 000 символов тошнота 5% нормальная, а для заметки в 1 000 символов — слишком высокая. Многие агентства и SEO-специалисты придерживаются мнения, что тошнота не должна быть выше 4-6%.
SEO-оптимизация страниц сайта
Академическая тошнота текста
Она определяется как соотношение самых частотных и значимых слов ко всему тексту. Саму формулу подсчета не раскрывают.
В описании указано, что нормальный процент академической тошноты — 5-15%. Это косвенно подтверждено самим Яндексом: в его блоге привели пример переоптимизированного текста, и академическая тошнота этой заметки составила 19%. На практике многие SEO-специалисты требуют писать статьи с тошнотой не больше 10%.
Семантическое ядро
Блок семантического ядра показывает самые часто встречающиеся слова в тексте. Именно они задают тематику материала. Поэтому на первом месте должны быть слова, релевантные теме — иначе поисковая система не поймет, о чем вы пишете, и понизит сайт в выдаче или вообще не будет показывать страницу по нужным ключевым словосочетаниям.
В нашем примере в семантическом ядре на первом месте стоит слово «вебинар». Понятно, что статья о вебинарах — это подтверждают следующие позиции ядра из тематических слов.
Частота слов в семантическом ядре
Этот показатель рассчитывается по самым распространенным в тексте словам. Чем выше процент — тем чаще встречается слово. Этот показатель тесно связан с процентом самой тошноты.
В описании семантического анализа Адвего нет рекомендуемых параметров. Многие SEO-специалисты и агентства требуют не превышать показатель в 3-4%. А в переоптимизированной заметке Яндекса максимальная частота слова в семантическом ядре превысила 8%.
В Istio.com также показывают семантическое ядро, а в анализаторе Miratext.ru его заменяет облако слов. Самые часто встречающиеся слова написаны крупным шрифтом. Семантический анализ Miratext.ru такжп показывает качество текста по Ципфа. Точный алгоритм анализа по Ципфа неизвестен, но его создатели утверждают, что он проверяет «естественность» текста, а нормальный показатель начинается от 50%. Проверка нашего текста на анализаторе выдала показатель в 34%. А при проверке на самом сервисе Ципфа — 77%. Поэтому на эту строчку при проверке на Miratext.ru можно не обращать внимания — цифры не совпадают.
Золотые правила написания продающего текста
Как доработать текст
Если показатели вашего текста не совпадают с рекомендуемыми параметрами, его желательно доработать. Сделать это просто, и мы подготовили небольшую шпаргалку:
- Если «вода» высокая, удалите малозначимые слова и словосочетания, переформулируйте предложения так, чтобы в них встречалось меньше предлогов; если показатель низкий, разбавьте текст или не трогайте его
- Если классическая тошнота высокая, удалите несколько вхождений самого часто встречающегося слова, если низкая — добавьте вхождения ключевых слов
- Если академическая тошнота текста высокая, удалите несколько вхождений ключевых слов, если низкая — добавьте вхождения главного ключа
- Если в семантическом ядре находятся нетематические слова, добавьте в текст вхождения ключей и других тематических слов
- Если частота слов в семантическом ядре слишком высокая, удалите несколько вхождений
Не забывайте о том, что в первую очередь текст должен нравиться людям. Поэтому не стоит воспринимать семантический анализ текста как истину в последней инстанции — даже далеко не идеальные в плане SEO статьи попадают в топ. Например, в первой в выдаче по запросу «что такое инфляция» статье показатель воды по Адвего приближается к верхней планке, составляет 72,6%.
А на странице со второго места показатель академической тошноты превышает рекомендованную многими SEO-специалистами отметку в 10%, а частота слова в семантическом ядре превысила 5%.
Если текст интересный, полезный, структурированный, но немного не соответствует рекомендуемым показателям, можете оставить все как есть.
А какими показателями при проверке руководствуетесь вы? Поделитесь своим мнением в комментариях!