Как научиться искать баги — Серьезность и приоритет — Алгоритм действий — Лучшие практики — Шпаргалка
Типы багов:
- Функциональные
- Синтаксические
- Логические
- Производительности
- Ошибки вычислений
- Безопасности
- Уровня модуля
- Интеграционные баги
- Юзабилити-баги
- Потока управления
- Совместимости
Функциональные
Каждая программа должна работать корректно, то есть делать то что нужно. Как можно понять из названия, функциональные баги — это когда программа не делает нужное.
Могут быть самыми разнообразными, начиная с бага в простой нечасто используемой функции, типа неработающей кнопки “Связаться” где-то в углу, и до полной неработоспособности всего приложения или сайта.
Еще пример: функция кнопки “Сохранить” заключается в том, что она сохраняет внесенные изменения в документе. Если изменения при нажатии кнопки не сохраняются, это функциональный баг.
Поиском багов этого типа занимается функциональное тестирование — отдельная важная сфера в QA (мини-гайд по ссылке).
Синтаксические баги
Ошибка в коде программы. Вероятно, самая частая ошибка, статистически. Случается обычно по невнимательности. Заключается, например, в неправильном/пропущенном символе, неправильно прописанной команде, или пропущенной скобке.
Логические ошибки
Коварная ошибка, труднее выявляемая. Приложение выдает неправильный вывод, или вообще падает.
Логические дефекты это например бесконечные циклы или некорректные переходы, допущенные разработчиком по неопытности или незнанию синтаксиса, вызывающие сложно определяемые ошибки в user flow (“маршруте пользователя по приложению” в процессе пользования им).
Бесконечные циклы — больное место тестировщика, так же как утечки памяти, проблемы с типами данных во многих языках, с компилятором в С++ или сборщиком мусора в Java. Несоблюдение хороших практик в программировании и недостаток опыта у разработчиков добавляют задач QA-отделу.
Еще примеры: переменной присвоено некорректное значение; деление чисел вместо умножения, и т.п.
Подробнее о логических ошибках.
Проблемы производительности
Такие ошибки влияют на скорость, на стабильность, на время отклика, или на потребление ресурсов, из-за чего их находят довольно быстро. Чаще их находят сами разработчики, а не тестировщики. Очень распространенный тип багов.
Ошибки вычислений
Когда приложение выдает некорректное значение пользователю или другой программе.
- Когда в приложении применен некорректный, неподходящий алгоритм
- Несоответствие типа данных
Уязвимости в безопасности
Дефекты в системе безопасности, видимо, наиболее опасные из тех, с которыми сталкивается junior QA. Они “компроментируют” весь проект, всю компанию, и разумеется, QA-команду, если она их пропустила.
Баг в безопасности ставит продукт, компанию, и данные клиента под риск потери очень больших денег. Такие ошибки обходятся дороже всего, в плане денег и деловой репутации, что может быть еще хуже.
Самыми частыми, статистически, ошибками безопасности являются: ошибки шифрования; подверженность SQL-инъекциям; XSS-уязвимости; переполнения буфера; логические ошибки в подсистеме безопасности; некорректная аутентификация.
Баги уровня модуля
На уровне отдельного модуля. Принято, чтобы разработчики сами делали юнит-тестирование модулей (им это сделать проще, т.к. они лучше понимают свой код), но в принципе к этому могут привлекать и QA.
Итак, в процессе юнит-тестирования находят ошибки в модулях: чаще всего это (случайные) ошибки вычислений и ошибки в логике, обычно они заметные и легко вылавливаемые. Такие баги хорошо изолируются (потому что они влияют только на небольшую часть кода), и быстро устраняются.
Интеграционные баги
Это ошибки взаимодействия между несколькими подсистемами приложения. Из-за того, что подсистемы чаще написаны разными разработчиками, командами и даже компаниями, интеграционные баги бывают достаточно сложными.
Становятся заметны они, когда например два (или больше) модулей кода ошибочно взаимодействуют, из-за программной несовместимости между ними. Такие баги довольно сложно определить и пофиксить, разработчикам, как правило, приходится переписывать довольно большие объемы кода.
Статистически, это бывают ошибки переполнения памяти, и некорректные взаимодействия между подсистемой пользовательского интерфейса и базами данных.
Юзабилити-баги
Такие дефекты не позволяют пользователю легко и приятно работать с приложением. Например, это проблемы с разметкой контента, его недоступностью, или например чрезмерно усложненная процедура регистрации/входа. К тестированию юзабилити привлекают и разработчиков и тестировщиков, а также, конечно, UX-дизайнеров. Проверяется соблюдение соответствующих гайдлайнов (если они соблюдаются с самого начала, эти ошибки можно предотвратить).
Баги потока управления (Control Flow)
Ошибки Control Flow (потока управления, путей выполнения программы) мешают ей корректно переходить к выполнению следующих задач, то есть корректно “передавать управление”, что стопорит весь workflow компании. Обычно это “мертвый код” (отсутствует вход), или “бесконечный цикл” (отсутствует выход).
Пример: в опроснике пользователь нажимает “Сохранить”, предполагается переход к концу опросника/теста, а перехода к следующей странице не происходит.
Проблемы совместимости (Compatibility issues)
Приложение оказывается несовместимым с неким устройством, целым классом устройств какого-то производителя, или операционной системой. Такие ошибки обычно проявляются довольно поздно в цикле тестирования. Во избежание, проводят тестирование совместимости с наиболее распространенными устройствами (смартфонами) и ОС.
Итак, уже примерно знаем, ЧТО искать, постараемся понять, КАК искать.
Как научиться искать баги
“Быстрая проверка” на реальных устройствах и в браузерах
Трудно идет тестирование, если у тестировщика нет сформулированных требований к софту — потому что трудно написать тестовые сценарии. В такой ситуации можно “атаковать систему”, вводя неправильные значения во все возможные поля. Если баги есть, они обычно проявляются.
Или, оставлять некоторые поля пустыми, перегружать интерфейс запросами, вводить числа там где предполагается ввод букв и наоборот, превышать лимит символов, вводить запрещенные символы, многократно вводить неправильные пароли, и так далее.
Это техника экспресс-анализа системы, позволяющая опытному тестировщику быстро оценить устойчивость системы к багам и примерно количество их, анализируя сообщения об ошибках и характер проявляемых ошибок.
Даже если таким образом будет найдено сравнительно мало багов, логично предположить, что все-таки есть проблемы в основной части функциональности. Отсутствие багов при “экспресс-анализе” (“quick attack”) обычно показывает, что основная часть функциональности более-менее в порядке.
Такая “быстрая атака” должна выполняться в стандартном пользовательском окружении — как можно более близком к тем условиям, в которых будет работать конечный пользователь.
Внимание тестовому окружению
Обычно у тестировщиков есть время на подготовку сценариев, прописывание таймлайна и настройку процедур. А также на подготовку тестовой инфраструктуры, или тестового окружения.
Из-за проблем с плохо подготовленным тестовым окружением возникают задержки в получении результатов тестирования. Проявляются баги, вызванные именно тестовым окружением, а не самим софтом. Мало что так раздражает, как некорректно работающее окружение.
Например, тестировщик нашел и отрепортил баг, а когда разработчик проверил его, в коде проблем не нашел, потому что проблема была с окружением. От этого возникает задержка.
Проблемы с окружением часто вызывают нестабильность тестов: один и тот же тест при запуске каждый раз выдает разный результат. Это не позволяет воспроизвести баг.
Тщательное исследование
Перед началом тестирования нужно внимательно изучить приложение или тестируемый модуль.
Подготовить достаточно тестовых данных. Этот датасет должен включать и базы данных, если тестируется приложение, использующее базы данных (а это почти все приложения сейчас).
Полезно вставлять в код своих автотестов указатели (если язык это поддерживает), для облегчения поиска нужных блоков. А также точки останова (брейкпойнты, контрольные точки), останавливающие выполнение в какой-то точке, чтобы точнее определить “место бага”.
Принцип Парето
Согласно этому принципу, 20% усилий дают 80% результата.
А 80% усилий дают лишь 20% результата.
Применительно к QA-индустрии, принцип Парето гласит, что 80% багов сосредоточены в 20% модулей. (Необязательно такое точное соотношение, но в целом). По принципу Парето, большинство багов затаились в одном-двух модулях (или даже еще меньшей части кода).
Если всерьез взяться за эти модули и вычистить из них баги, можно считать работу на 80% сделанной.
Подробно о принципе Парето в тестировании.
Четкие цели
Тестировщик должен учитывать стандарты и лучшие практики и придерживаться их, это даст понимание, какие ошибки искать тщательнее и в первую очередь. Должен понимать логику действий конечного пользователя. Что пользователь ожидает от этого софта? Какой его user experience? Какой функциональности ожидает? На какие баги вообще не обратит внимания, а какие заставят отказаться от приложения?
Четче изложенные цели тестирования помогут писать хорошие тестовые сценарии и тест-кейсы. Если главная функция, “главная потребность пользователя” уточнена и дан приоритет, тестировщик может сначала протестировать эту функцию, а остальные отложить, или поручить стажерам.
Серьезность и приоритет
По серьезности (Severity)
- Блокирующий баг, так называемый “блокер”, который делает абсолютно невозможной дальнейшую работу с приложением. Срочно исправляют.
- Критический баг. “Критикал”. Некорректно работает все приложение, или его важнейший модуль. Тестирование остальных, менее существенных багов прекращается, все силы бросают на фикс такого бага. Сюда входит, например, кейс, когда приложение выдает ошибку сервера при попытке входа в приложение.
- Существенный. “Мажор”. Влияет на ключевую функцию, и приложение ведет себя с отклонением от прописанных требований. Например, email-провайдер не дает добавить больше одного адреса в поле получателя.
- Средней серьезности. “Минор”. Когда не очень важная функция не ведет себя соответственно требованиям. Например, ссылка в “Условиях использования” продукта ведет в никуда.
(Перечисленные выше баги коротко обозначаются S1, S2, S3, S4 по серьезности.)
- Низкой серьезности. “Тривиал”. Обычно это небольшие дефекты пользовательского интерфейса. Например, кнопки, которые должны быть одинаковыми, немножко отличаются по цвету и размеру.
По приоритету
Срочные. (Топ-приоритет, ургентный, безотлагательный). Должны быть устранены в 24 часа после получения репорта. Обычно это блокеры и критикалы. Но такой приоритет могут получить и дефекты с низкой серьезностью. Например, опечатка в названии компании на главной странице сайта никак не ухудшает функциональность, однако имеет сильнейшее негативное влияние на имидж компании, поэтому это срочный баг.
Приоритеты выставляются менеджером проекта:
Высокий приоритет. Это ошибки, которые должны быть устранены до релиза, согласно критериям завершения тестирования (exit-criteria). Например, это ошибка, несмотря на корректность всех введенных данных мешающая переходу со страницы входа на главную.
Средний приоритет. Должны быть устранены до релиза или сразу после релиза. Это например дефект, не нарушающий требования, но некорректно отображающий контент в одном из браузеров.
Низкий приоритет. Их можно не фиксить, и критериям завершения это не противоречит, но такие дефекты надо устранить до финального релиза. Обычно это опечатки, небольшие дефекты в дизайне (например выравнивание текста), не очень заметные ошибки в размере элементов, и прочие “косметические” дефекты.
(Перечисленные выше баги обозначаются P1, P2, P3 от высокого к низкому.)
Также баги классифицируют по частоте проявления, от высокой до очень низкой (4 степени).
Подробнее о серьезности и приоритете, а также о глобальном приоритете и частоте багов.
Стандартный порядок действий при обнаружении бага
- Проверить дополнительные (связанные) вещи
Обычно баги “по одному не ходят”, то есть где-то поблизости есть аналогичные, или связанные с уже найденными.
- Зафиксировать текущее состояние приложения
Состояние приложения и состояние окружения. Это поможет примерно определить причину бага — внутренняя или внешняя, и воспроизвести баг.
- Проверить, может баг уже есть в репортах
Чтобы не делать уже сделанную кем-то работу.
- Репорт
Теперь надо написать классный баг-репорт, не затягивая время — это сокращает цикл фидбека между написанием кода и валидацией.
Статусы багов (в жизненном цикле)
- Открыт (добавлен в репорт)
- В работе (принят к исправлению)
- Исправлен (и передан на перепроверку)
- Закрыт (уже не воспроизводится)
также дополнительно:
- Отклонен (ошибка в репорте)
- Отсрочен (как неприоритетный)
- Переоткрыт (после двух предыдущих статусов)
Подробнее о системах контроля багов — здесь
Лучшие практики
- Сначала хорошо исследовать и понять приложение (модуль)
- Создать специальные тест-кейсы, а именно функциональные тест-кейсы, посвященные критически важным функциям
- Подготовить достаточно тестовых данных
- Запустить тесты снова, в другом тестовом окружении
- Сравнивать полученные результаты с ожидаемыми
- Проанализировать тестовый сет, используя старые тестовые данные
- Выполнить стандартные тест-кейсы, которые ранее показывали себя надежными. Например, если тестировалось поле ввода для стандартного текста, ввести HTML-теги и проверить, что получится
- После завершения большей части тестов, если есть усталость, отдохнуть, занявшись обезьяньим тестированием (monkey testing)
Тестирование на реальных девайсах и в реальных окружениях
Тестирование в реальных окружениях является хорошей практикой в QA, а в тестировании мобильных приложений — обязательной практикой. Реальное окружение быстрее “апгрейдит” тестировщика. Но оно требует закупки/аренды довольно-таки внушительного парка устройств. Вообще, тестирование всех возможных комбинаций браузер/ОС/девайс — отдельная головная боль. Здесь помогают облачные платформы.
***
Шпаргалка QA Trainee/Junior
Серьезность бага
- Blocker
- Critical
- Major
- Minor
- Trivial
Приоритет
- Top
- High
- Normal
- Low
Типы багов
- Функциональные
- Синтаксические
- Логические
- Производительности
- Ошибки вычислений
- Безопасности
- Уровня модуля
- Интеграционные баги
- Юзабилити-баги
- Потока управления
- Совместимости
Частота бага
- Высокая
- Средняя
- Низкая
- Очень низкая
Статус бага
- Открыт
- В работе
- Исправлен
- Закрыт
- Отклонен
- Отсрочен
- Переоткрыт
Что делает тестировщик, когда находит баг
- Проверяет связанные или аналогичные вещи
- Фиксирует текущее состояние приложения и тестового окружения
- Проверяет, нет ли этого бага в репорте
- Пишет репорт
***
Пять технических и пять нетехнических навыков хорошего QA
Регрессионное тестирование: подборка инструментов
Эмуляторы и симуляторы: в чем разница
Где искать баги фаззингом и откуда вообще появился этот метод
Время на прочтение
8 мин
Количество просмотров 6K
Подход фаззинг-тестирования родился еще в 80-х годах прошлого века. В некоторых языках он используется давно и плодотворно — соответственно, уже успел занять свою нишу. Сторонние фаззеры для Go были доступны и ранее, но в Go 1.18 появился стандартный. Мы в «Лаборатории Касперского» уже успели его пощупать и тестируем с его помощью довольно большой самостоятельный сервис.

Меня зовут Владимир Романько, я — Development Team Lead, и именно моя команда фаззит баги на Go. В этой статье я расскажу про историю фаззинга, про то, где и как искать баги, а также как помочь фаззинг-тестам эффективнее находить их в самых неожиданных местах. И покажу этот подход на примере обнаружения SQL-инъекций.
Немного истории
Когда я первый раз услышал о фаззинге, сама идея прозвучала для меня довольно странно. Казалось, это магия, с помощью которой сторонняя программа может найти баги в моем коде.
Все встало на свои места, когда я узнал, как фаззинг появился. Поэтому свой рассказ я также хочу начать с интересной истории, которая, вероятно, ждет своего Кристофера Нолана для экранизации. В ней есть все необходимые компоненты отличного голливудского блокбастера: зловещая ночь с грозой, гениальный ученый, а также древний артефакт, который принял во всем этом участие. Забегая вперед, отмечу, что роль древнего артефакта исполнил модем на 1200 бод. В итоге случайное стечение обстоятельств привело к появлению хорошего изобретения.
Так что же произошло?
Тем ученым был Бартон Миллер. В 1988 году он работал профессором в университете и решил из дома подключиться через модем к своему любимому университетскому мейнфрейму. Он пытался выполнить команду Unix… История умалчивает о том, какая именно это была команда. Предположим, это был grep.
grep -R "hello world"
В этот момент где-то недалеко ударила молния. А старый модем если и имел код коррекции ошибок, тот оказался недостаточно эффективным. Вместо «Hello world» до мейнфрейма долетел мусор:
grep -R "hello ~3#зеШwкACh"
Который внезапно вызвал segmentation fault. И grep упал.
Бартон Миллер задумался, почему это произошло. Grep к тому времени уже был старой, надежной, многократно протестированной командой, у которой явно есть какие-то проверки ввода. Но тем не менее он упал. И ученому пришла в голову идея написать программу, которая специально будет генерировать мусор и отправлять на вход в различные unix-овые утилиты. Так появился первый фаззер.
Вместе со студентами Бартон Миллер нашел очень много ошибок в командах Unix. К этому моменту все эти команды уже использовались инженерами по всему миру в течение длительного времени, но тем не менее содержали ошибки. Такова суперспособность фаззера, за которую мы его и любим, — находить баги в хорошо протестированном коде.
Как фаззер находит баги
Тесты можно классифицировать по-разному. Но давайте распределим их по уровню семантического знания о коде, которое использовано при написании теста.

Больше всего знаний о тестируемом коде используется при построении тестов по тест-кейсам, например в юнит-, ручных или интеграционных тестах. Они содержат некие пред- и постусловия — конкретные проверки того, что на вход программы мы передали А, а на выходе должны получить Б. Для написания таких тестов однозначно придется изучить код и требования к нему.
Левее по этой шкале находятся property based тесты. В них уже нет конкретных входов и выходов. Данные на вход генерируются случайным образом, но проверяются определенные свойства кода (поэтому тесты и называются property based). К примеру, если мы проверяем функцию сортировки, на выходе ожидаем массив, каждый последующий элемент которого больше либо равен предыдущему.
В крайней левой части шкалы находятся фаззинг-тесты, имеющие минимальные знания о продукте. Им известно только то, что код не должен падать, зависать или отъедать какое-то безумное количество памяти. С точки зрения теста сам продукт представляет собой черный ящик.
В том, что при фаззинге используются минимальные знания, есть как плюсы, так и минусы. Если тесты по тест-кейсам позволяют находить так называемые known unknowns (т. е. проверяют неизвестное поведение в известных сценариях), то фаззинг ищет unknown unknowns (проверяет неизвестное поведение в неизвестных сценариях). Именно эта особенность позволяет фаззингу находить баги в хорошо протестированном коде — он обнаруживает сценарии, про которые разработчик никогда и не подумал бы.
Для примера приведу тесты для функции сортировки, которая принимает слайс int.

Функцию можно протестировать с помощью тестов по тест-кейсам. В этом случае на вход мы передаем (2, 1, 3) и проверяем ожидание, что на выходе будет 1, 2, 3.
В property based тестах на входе случайная последовательность, а на выходе надо убедиться, что каждый последующий элемент больше или равен предыдущему (т. е. проверяется свойство).
Фаззинг также передаст случайную последовательность, но удостоверится, что функция не упала.
Фаззинг не заменяет классическое тестирование. Он нужен, когда проверяется уже оттестированный код, а фантазия тестировщиков подходит к концу. В общем случае фаззер найдет меньше ошибок, чем тесты по тест-кейсам. Но эти ошибки будут наиболее разнообразны. Это хорошо заметно в Go-шной реализации фаззера — go fuzz, которая модифицирует корпус входных тестовых данных так, чтобы отработали все ветви кода. Стандартный фаззер Go вообще одинаково хорошо подходит как для написания property based тестов, так и для классического фаззинга. Официальная документация Go по фаззингу не делает различия между этими видами тестов.
Как помочь фаззеру
Давайте рассмотрим нехитрую программу на Go.
Наш код объявляет неинициализированный нулевой указатель и что-то по нему пишет.

Если запустить этот код, он упадет с ошибкой. Проблема в пятой строке.
Чисто теоретически ее можно было бы проигнорировать и продолжить выполнение. Если кто-то помнит, в Visual Basic был такой режим: при ошибке программа не падала, а просто переходила к следующей строке кода. Получалось, что они надежны, но поведение этих программ непредсказуемо. Это никак не помогло бы фаззеру.
Вернемся к Бартону Миллеру. Что было бы, если бы grep проигнорировал обращение к невалидному указателю? Скорее всего, фаззер не нашел бы багов в команде. Команда обработала бы мусор на входе и выдала мусор на выходе. Никто не понял бы, что произошло нечто плохое. Т. е. фаззер в принципе смог найти ошибку только благодаря крэшу (программа проверила свой собственный внутренний инвариант, согласно которому нельзя обращаться к некорректному указателю, и упала, когда он оказался нарушен).
Так мы приходим к выводу: падать с ошибкой полезно.
Чем больше код проверяет своих внутренних инвариантов, тем больше фаззер может найти багов.
Вот несколько примеров с проверкой внутренних инвариантов:
- Инвариант может заключаться в том, что оба потомка красного узла в красно-черном дереве — черные. Если он нарушен, код может как-то сообщить об этом фаззеру.
- Можно проверять, что количество элементов в контейнере неотрицательно — в очереди не может содержаться «-1» элемент.
- Проверка может выявлять, что в стеке количество операций Pop меньше или равно количеству Push.
- Бизнес-логика может контролировать отсутствие превышения некоего программного лимита. Тот факт, что мы обнаружим нарушение этого инварианта, будет свидетельствовать об ошибке в бизнес-логике.
- Кэш должен отсекать повторные запросы. Это особенно актуально, если база вычисляет тяжелые запросы и нужно проверить бизнес-логику, которая хранит в памяти результаты нескольких последних запросов. В этом случае фаззер может найти ошибку в логике работы с кэшем.
- SQL-запрос не должен возвращать ошибку некорректного синтаксиса. Если же мы получаем такую ошибку, в нашем коде однозначно есть проблема. Скорее всего, мы неправильно формируем тело SQL-запроса или в это тело без какой-либо санитизации попадает пользовательский ввод (SQL-инъекция).
Все эти примеры объединяет тот факт, что если проверка сработает, это однозначно указывает на некорректно написанный код. Это никак не связано с окружением. По сути это ничем не отличается от обращения к невалидному указателю, упомянутому выше.
Инвариант мало проверить, нужно еще донести до фаззера информацию о том, что есть нарушение. Самый простой способ — кинуть panic. Это можно сделать с любого уровня абстракции.
Среди Go-феров есть предубеждение против panic, поэтому можно использовать более лайтовые варианты:
- Кидать panic не всегда, а только в специальном фаззинг-режиме: ввести переменную окружения, и если она задана, при нарушении инвариантов кидать panic. Фаззинг-режим, кстати, помогает решить проблему с «дорогими» проверками инвариантов, когда на них уходит много ресурсов.
- Можно использовать специальный уровень логирования, доступный фаззеру. Когда тот увидит запись с этим уровнем, он поймет, что нарушен некий внутренний инвариант (и сделает вывод, что код написан некорректно). Этот подход требует более сложной инфраструктуры. И важно не писать в лог на этом уровне, когда наблюдаются проблемы с инфраструктурой (например, если отвалилась сеть).
При проверке инвариантов у фаззинг-теста нет никакого ожидания относительно кода. За счет этого он более стабильный — его не нужно менять при малейших изменениях. С развитием продукта его также нужно поддерживать, но усилий на это будет уходить гораздо меньше, чем в случае с тестами по тест-кейсам. Возвращаясь к примеру с grep — если мы сменим движок обработки регулярных выражений, суть теста никак не изменится.
Фаззинг имеет смысл, если функции работают достаточно быстро. Если функция выдает ответ через несколько минут после передачи в нее начальных данных, за разумное время фаззер просто не успеет ничего проверить. А проверив слишком мало вариантов, он ничего не найдет. Возможно, в этой ситуации процесс ускорят моки, но работать с ними надо всегда очень осторожно. Также можно гонять тесты на маленьких частях кода.
Помогаем фаззеру искать SQL-уязвимости
Теперь применим этот подход, чтобы обрабатывать ошибки работы с базой данных на примере SQLite.
Предположим, у нас есть нативный код, в котором присутствует уязвимость SQL-инъекции. Мы формируем строку, и если получаем ошибку, смотрим, что это было. Если это ошибка SQLite, которая говорит, что синтаксис некорректный, и при этом включена переменная окружения FUZZING, мы кидаем panic. В ином случае мы обрабатываем ошибки стандартным путем.

Каждый раз писать такой код неудобно, поэтому его можно разбить на вспомогательные функции и уже их использовать по всему коду.
Я бы предложил такой вариант разбиения.
Мы выделяем функцию ProcessCriticalErr, которая на вход принимает критическую ошибку (в нашем случае — нарушение синтаксиса) и кидает panic, если выставлена переменная окружения. Когда переменная окружения не выставлена, она просто возвращает ошибку.
Дополнительно нам потребуется функция, которая определяет, является ли данная ошибка критической. У SQLite есть несколько кодов ошибок, подходящих под нашу ситуацию.
Третья функция — также вспомогательная. Она принимает на вход ошибку базы данных, проверяет ее «критичность» и при необходимости вызывает процедуру обработки таких ошибок.
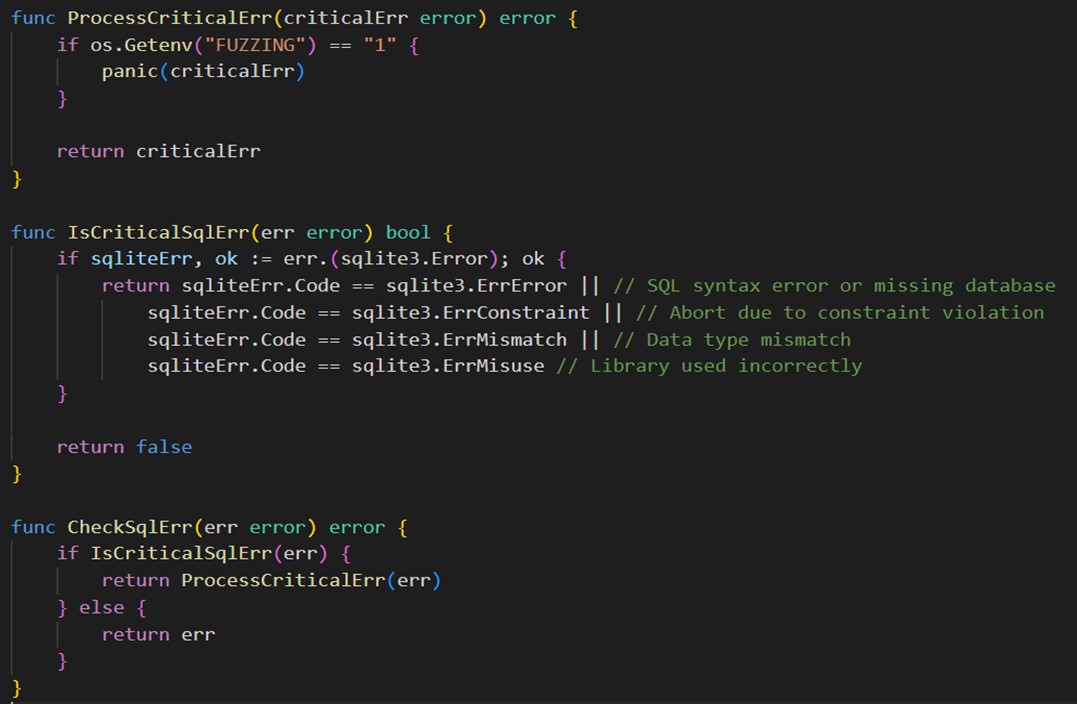
В этом случае наша стандартная функция работы с базой данных упрощается до такого вида:

При обнаружении критической ошибки в фаззинг=-режиме мы сообщаем об этом фаззеру, который и запоминает, что подобрал входные данные, ломающие внутреннюю логику. В данном случае фаззер помогает найти SQL-инъекцию.
Напоследок я бы рекомендовал ознакомиться с двумя ссылками:
- https://go.dev/doc/tutorial/fuzz — о том, как вообще пользоваться фаззингом в Go, конкретно go fuzz. Он подходит для написания как классических фаззинг- тестов, о которых я рассказывал, так и для property based тестов.
- https://www.fuzzingbook.org/ — очень полезный сайт, который посвящен фаззингу в целом. Это отдельный большой мир с огромным количеством способов разработки таких тестов. Рекомендую ознакомиться с информацией, которая есть на этом сайте. Если фаззинг применять «в лоб», он просто будет нагревать поверхность нашей атмосферы. Чтобы он находил баги, требуется включать голову, и этот ресурс подскажет, в каком направлении думать. Нужно просто научиться замечать в коде возможности для написания фаззинг-теста.
В нашей команде мы пока только пробуем стандартный фаззинг Go, но уже тестируем с его помощью довольно большой самостоятельный сервис конвертации данных из различных источников к стандартизированному виду. Для ускорения работы мы убрали из фаззинга работу с сетью и очередями, оставив только внутренности сервиса. Приходите к нам в разработку на Go — сможете пощупать все это своими руками. Тем более, у нас не надо доказывать руководству необходимость применения подобных методик. А в том, что касается фаззинга, он еще и регламентируется нормативными документами, если уж мы хотим сертифицировать свой код для каких-либо целей.
Искать ошибки в программах — непростая задача. Здесь нет никаких готовых методик или рецептов успеха. Можно даже сказать, что это — искусство. Тем не менее есть общие советы, которые помогут вам при поиске. В статье описаны основные шаги, которые стоит предпринять, если ваша программа работает некорректно.
Шаг 1: Занесите ошибку в трекер
После выполнения всех описанных ниже шагов может так случиться, что вы будете рвать на себе волосы от безысходности, все еще сидя на работе, когда поймете, что:
- Вы забыли какую-то важную деталь об ошибке, например, в чем она заключалась.
- Вы могли делегировать ее кому-то более опытному.
Трекер поможет вам не потерять нить размышлений и о текущей проблеме, и о той, которую вы временно отложили. А если вы работаете в команде, это поможет делегировать исправление коллеге и держать все обсуждение в одном месте.
Вы должны записать в трекер следующую информацию:
- Что делал пользователь.
- Что он ожидал увидеть.
- Что случилось на самом деле.
Это должно подсказать, как воспроизвести ошибку. Если вы не сможете воспроизвести ее в любое время, ваши шансы исправить ошибку стремятся к нулю.
Шаг 2: Поищите сообщение об ошибке в сети
Если у вас есть сообщение об ошибке, то вам повезло. Или оно будет достаточно информативным, чтобы вы поняли, где и в чем заключается ошибка, или у вас будет готовый запрос для поиска в сети. Не повезло? Тогда переходите к следующему шагу.
Шаг 3: Найдите строку, в которой проявляется ошибка
Если ошибка вызывает падение программы, попробуйте запустить её в IDE под отладчиком и посмотрите, на какой строчке кода она остановится. Совершенно необязательно, что ошибка будет именно в этой строке (см. следующий шаг), но, по крайней мере, это может дать вам информацию о природе бага.
Шаг 4: Найдите точную строку, в которой появилась ошибка
Как только вы найдете строку, в которой проявляется ошибка, вы можете пройти назад по коду, чтобы найти, где она содержится. Иногда это может быть одна и та же строка. Но чаще всего вы обнаружите, что строка, на которой упала программа, ни при чем, а причина ошибки — в неправильных данных, которые появились ранее.
Если вы отслеживаете выполнение программы в отладчике, то вы можете пройтись назад по стектрейсу, чтобы найти ошибку. Если вы находитесь внутри функции, вызванной внутри другой функции, вызванной внутри другой функции, то стектрейс покажет список функций до самой точки входа в программу (функции main()). Если ошибка случилась где-то в подключаемой библиотеке, предположите, что ошибка все-таки в вашей программе — это случается гораздо чаще. Найдите по стектрейсу, откуда в вашем коде вызывается библиотечная функция, и продолжайте искать.
Шаг 5: Выясните природу ошибки
Ошибки могут проявлять себя по-разному, но большинство из них можно отнести к той или иной категории. Вот наиболее частые.
- Ошибка на единицу
Вы начали циклforс единицы вместо нуля или наоборот. Или, например, подумали, что метод.count()или.length()вернул индекс последнего элемента. Проверьте документацию к языку, чтобы убедиться, что нумерация массивов начинается с нуля или с единицы. Эта ошибка иногда проявляется в виде исключенияIndex out of range. - Состояние гонки
Ваш процесс или поток пытается использовать результат выполнения дочернего до того, как тот завершил свою работу. Ищите использованиеsleep()в коде. Возможно, на мощной машине дочерний поток выполняется за миллисекунду, а на менее производительной системе происходят задержки. Используйте правильные способы синхронизации многопоточного кода: мьютексы, семафоры, события и т. д. - Неправильные настройки или константы
Проверьте ваши конфигурационные файлы и константы. Я однажды потратил ужасные 16 часов, пытаясь понять, почему корзина на сайте с покупками виснет на стадии отправки заказа. Причина оказалась в неправильном значении в/etc/hosts, которое не позволяло приложению найти ip-адрес почтового сервера, что вызывало бесконечный цикл в попытке отправить счет заказчику. - Неожиданный null
Бьюсь об заклад, вы не раз получали ошибку с неинициализированной переменной. Убедитесь, что вы проверяете ссылки наnull, особенно при обращении к свойствам по цепочке. Также проверьте случаи, когда возвращаемое из базы данных значениеNULLпредставлено особым типом. - Некорректные входные данные
Вы проверяете вводимые данные? Вы точно не пытаетесь провести арифметические операции с введенными пользователем строками? - Присваивание вместо сравнения
Убедитесь, что вы не написали=вместо==, особенно в C-подобных языках. - Ошибка округления
Это случается, когда вы используете целое вместоDecimal, илиfloatдля денежных сумм, или слишком короткое целое (например, пытаетесь записать число большее, чем 2147483647, в 32-битное целое). Кроме того, может случиться так, что ошибка округления проявляется не сразу, а накапливается со временем (т. н. Эффект бабочки). - Переполнение буфера и выход за пределы массива
Проблема номер один в компьютерной безопасности. Вы выделяете память меньшего объема, чем записываемые туда данные. Или пытаетесь обратиться к элементу за пределами массива. - Программисты не умеют считать
Вы используете некорректную формулу. Проверьте, что вы не используете целочисленное деление вместо взятия остатка, или знаете, как перевести рациональную дробь в десятичную и т. д. - Конкатенация строки и числа
Вы ожидаете конкатенации двух строк, но одно из значений — число, и компилятор пытается произвести арифметические вычисления. Попробуйте явно приводить каждое значение к строке. - 33 символа в varchar(32)
Проверяйте данные, передаваемые вINSERT, на совпадение типов. Некоторые БД выбрасывают исключения (как и должны делать), некоторые просто обрезают строку (как MySQL). Недавно я столкнулся с такой ошибкой: программист забыл убрать кавычки из строки перед вставкой в базу данных, и длина строки превысила допустимую как раз на два символа. На поиск бага ушло много времени, потому что заметить две маленькие кавычки было сложно. - Некорректное состояние
Вы пытаетесь выполнить запрос при закрытом соединении или пытаетесь вставить запись в таблицу прежде, чем обновили таблицы, от которых она зависит. - Особенности вашей системы, которых нет у пользователя
Например: в тестовой БД между ID заказа и адресом отношение 1:1, и вы программировали, исходя из этого предположения. Но в работе выясняется, что заказы могут отправляться на один и тот же адрес, и, таким образом, у вас отношение 1:многим.
Если ваша ошибка не похожа на описанные выше, или вы не можете найти строку, в которой она появилась, переходите к следующему шагу.
Шаг 6: Метод исключения
Если вы не можете найти строку с ошибкой, попробуйте или отключать (комментировать) блоки кода до тех пор, пока ошибка не пропадет, или, используя фреймворк для юнит-тестов, изолируйте отдельные методы и вызывайте их с теми же параметрами, что и в реальном коде.
Попробуйте отключать компоненты системы один за другим, пока не найдете минимальную конфигурацию, которая будет работать. Затем подключайте их обратно по одному, пока ошибка не вернется. Таким образом вы вернетесь на шаг 3.
Шаг 7: Логгируйте все подряд и анализируйте журнал
Пройдитесь по каждому модулю или компоненту и добавьте больше сообщений. Начинайте постепенно, по одному модулю. Анализируйте лог до тех пор, пока не проявится неисправность. Если этого не случилось, добавьте еще сообщений.
Ваша задача состоит в том, чтобы вернуться к шагу 3, обнаружив, где проявляется ошибка. Также это именно тот случай, когда стоит использовать сторонние библиотеки для более тщательного логгирования.
Шаг 8: Исключите влияние железа или платформы
Замените оперативную память, жесткие диски, поменяйте сервер или рабочую станцию. Установите обновления, удалите обновления. Если ошибка пропадет, то причиной было железо, ОС или среда. Вы можете по желанию попробовать этот шаг раньше, так как неполадки в железе часто маскируют ошибки в ПО.
Если ваша программа работает по сети, проверьте свитч, замените кабель или запустите программу в другой сети.
Ради интереса, переключите кабель питания в другую розетку или к другому ИБП. Безумно? Почему бы не попробовать?
Если у вас возникает одна и та же ошибка вне зависимости от среды, то она в вашем коде.
Шаг 9: Обратите внимание на совпадения
- Ошибка появляется всегда в одно и то же время? Проверьте задачи, выполняющиеся по расписанию.
- Ошибка всегда проявляется вместе с чем-то еще, насколько абсурдной ни была бы эта связь? Обращайте внимание на каждую деталь. На каждую. Например, проявляется ли ошибка, когда включен кондиционер? Возможно, из-за этого падает напряжение в сети, что вызывает странные эффекты в железе.
- Есть ли что-то общее у пользователей программы, даже не связанное с ПО? Например, географическое положение (так был найден легендарный баг с письмом за 500 миль).
- Ошибка проявляется, когда другой процесс забирает достаточно большое количество памяти или ресурсов процессора? (Я однажды нашел в этом причину раздражающей проблемы «no trusted connection» с SQL-сервером).
Шаг 10: Обратитесь в техподдержку
Наконец, пора попросить помощи у того, кто знает больше, чем вы. Для этого у вас должно быть хотя бы примерное понимание того, где находится ошибка — в железе, базе данных, компиляторе. Прежде чем писать письмо разработчикам, попробуйте задать вопрос на профильном форуме.
Ошибки есть в операционных системах, компиляторах, фреймворках и библиотеках, и ваша программа может быть действительно корректна. Но шансы привлечь внимание разработчика к этим ошибкам невелики, если вы не сможете предоставить подробный алгоритм их воспроизведения. Дружелюбный разработчик может помочь вам в этом, но чаще всего, если проблему сложно воспроизвести вас просто проигнорируют. К сожалению, это значит, что нужно приложить больше усилий при составлении багрепорта.
Полезные советы (когда ничего не помогает)
- Позовите кого-нибудь еще.
Попросите коллегу поискать ошибку вместе с вами. Возможно, он заметит что-то, что вы упустили. Это можно сделать на любом этапе. - Внимательно просмотрите код.
Я часто нахожу ошибку, просто спокойно просматривая код с начала и прокручивая его в голове. - Рассмотрите случаи, когда код работает, и сравните их с неработающими.
Недавно я обнаружил ошибку, заключавшуюся в том, что когда вводимые данные в XML-формате содержали строкуxsi:type='xs:string', все ломалось, но если этой строки не было, все работало корректно. Оказалось, что дополнительный атрибут ломал механизм десериализации. - Идите спать.
Не бойтесь идти домой до того, как исправите ошибку. Ваши способности обратно пропорциональны вашей усталости. Вы просто потратите время и измотаете себя. - Сделайте творческий перерыв.
Творческий перерыв — это когда вы отвлекаетесь от задачи и переключаете внимание на другие вещи. Вы, возможно, замечали, что лучшие идеи приходят в голову в душе или по пути домой. Смена контекста иногда помогает. Сходите пообедать, посмотрите фильм, полистайте интернет или займитесь другой проблемой. - Закройте глаза на некоторые симптомы и сообщения и попробуйте сначала.
Некоторые баги могут влиять друг на друга. Драйвер для dial-up соединения в Windows 95 мог сообщать, что канал занят, при том что вы могли отчетливо слышать звук соединяющегося модема. Если вам приходится держать в голове слишком много симптомов, попробуйте сконцентрироваться только на одном. Исправьте или найдите его причину и переходите к следующему. - Поиграйте в доктора Хауса (только без Викодина).
Соберите всех коллег, ходите по кабинету с тростью, пишите симптомы на доске и бросайте язвительные комментарии. Раз это работает в сериалах, почему бы не попробовать?
Что вам точно не поможет
- Паника
Не надо сразу палить из пушки по воробьям. Некоторые менеджеры начинают паниковать и сразу откатываться, перезагружать сервера и т. п. в надежде, что что-нибудь из этого исправит проблему. Это никогда не работает. Кроме того, это создает еще больше хаоса и увеличивает время, необходимое для поиска ошибки. Делайте только один шаг за раз. Изучите результат. Обдумайте его, а затем переходите к следующей гипотезе. - «Хелп, плиииз!»
Когда вы обращаетесь на форум за советом, вы как минимум должны уже выполнить шаг 3. Никто не захочет или не сможет вам помочь, если вы не предоставите подробное описание проблемы, включая информацию об ОС, железе и участок проблемного кода. Создавайте тему только тогда, когда можете все подробно описать, и придумайте информативное название для нее. - Переход на личности
Если вы думаете, что в ошибке виноват кто-то другой, постарайтесь по крайней мере говорить с ним вежливо. Оскорбления, крики и паника не помогут человеку решить проблему. Даже если у вас в команде не в почете демократия, крики и применение грубой силы не заставят исправления магическим образом появиться.
Ошибка, которую я недавно исправил
Это была загадочная проблема с дублирующимися именами генерируемых файлов. Дальнейшая проверка показала, что у файлов различное содержание. Это было странно, поскольку имена файлов включали дату и время создания в формате yyMMddhhmmss. Шаг 9, совпадения: первый файл был создан в полпятого утра, дубликат генерировался в полпятого вечера того же дня. Совпадение? Нет, поскольку hh в строке формата — это 12-часовой формат времени. Вот оно что! Поменял формат на yyMMddHHmmss, и ошибка исчезла.
Перевод статьи «How to fix bugs, step by step»
Подход фаззинг-тестирования родился еще в 80-х годах прошлого века. В некоторых языках он используется давно и плодотворно — соответственно, уже успел занять свою нишу. Сторонние фаззеры для Go были доступны и ранее, но в Go 1.18 появился стандартный. Мы в «Лаборатории Касперского» уже успели его пощупать и тестируем с его помощью довольно большой самостоятельный сервис.

Меня зовут Владимир Романько, я — Development Team Lead, и именно моя команда фаззит баги на Go. В этой статье я расскажу про историю фаззинга, про то, где и как искать баги, а также как помочь фаззинг-тестам эффективнее находить их в самых неожиданных местах. И покажу этот подход на примере обнаружения SQL-инъекций.
Немного истории
Когда я первый раз услышал о фаззинге, сама идея прозвучала для меня довольно странно. Казалось, это магия, с помощью которой сторонняя программа может найти баги в моем коде.
Все встало на свои места, когда я узнал, как фаззинг появился. Поэтому свой рассказ я также хочу начать с интересной истории, которая, вероятно, ждет своего Кристофера Нолана для экранизации. В ней есть все необходимые компоненты отличного голливудского блокбастера: зловещая ночь с грозой, гениальный ученый, а также древний артефакт, который принял во всем этом участие. Забегая вперед, отмечу, что роль древнего артефакта исполнил модем на 1200 бод. В итоге случайное стечение обстоятельств привело к появлению хорошего изобретения.
Так что же произошло?
Тем ученым был Бартон Миллер. В 1988 году он работал профессором в университете и решил из дома подключиться через модем к своему любимому университетскому мейнфрейму. Он пытался выполнить команду Unix… История умалчивает о том, какая именно это была команда. Предположим, это был grep.
grep -R "hello world"
В этот момент где-то недалеко ударила молния. А старый модем если и имел код коррекции ошибок, тот оказался недостаточно эффективным. Вместо «Hello world» до мейнфрейма долетел мусор:
grep -R "hello ~3#зеШwкACh"
Который внезапно вызвал segmentation fault. И grep упал.
Бартон Миллер задумался, почему это произошло. Grep к тому времени уже был старой, надежной, многократно протестированной командой, у которой явно есть какие-то проверки ввода. Но тем не менее он упал. И ученому пришла в голову идея написать программу, которая специально будет генерировать мусор и отправлять на вход в различные unix-овые утилиты. Так появился первый фаззер.
Вместе со студентами Бартон Миллер нашел очень много ошибок в командах Unix. К этому моменту все эти команды уже использовались инженерами по всему миру в течение длительного времени, но тем не менее содержали ошибки. Такова суперспособность фаззера, за которую мы его и любим, — находить баги в хорошо протестированном коде.
Как фаззер находит баги
Тесты можно классифицировать по-разному. Но давайте распределим их по уровню семантического знания о коде, которое использовано при написании теста.

Больше всего знаний о тестируемом коде используется при построении тестов по тест-кейсам, например в юнит-, ручных или интеграционных тестах. Они содержат некие пред- и постусловия — конкретные проверки того, что на вход программы мы передали А, а на выходе должны получить Б. Для написания таких тестов однозначно придется изучить код и требования к нему.
Левее по этой шкале находятся property based тесты. В них уже нет конкретных входов и выходов. Данные на вход генерируются случайным образом, но проверяются определенные свойства кода (поэтому тесты и называются property based). К примеру, если мы проверяем функцию сортировки, на выходе ожидаем массив, каждый последующий элемент которого больше либо равен предыдущему.
В крайней левой части шкалы находятся фаззинг-тесты, имеющие минимальные знания о продукте. Им известно только то, что код не должен падать, зависать или отъедать какое-то безумное количество памяти. С точки зрения теста сам продукт представляет собой черный ящик.
В том, что при фаззинге используются минимальные знания, есть как плюсы, так и минусы. Если тесты по тест-кейсам позволяют находить так называемые known unknowns (т. е. проверяют неизвестное поведение в известных сценариях), то фаззинг ищет unknown unknowns (проверяет неизвестное поведение в неизвестных сценариях). Именно эта особенность позволяет фаззингу находить баги в хорошо протестированном коде — он обнаруживает сценарии, про которые разработчик никогда и не подумал бы.
Для примера приведу тесты для функции сортировки, которая принимает слайс int.

Функцию можно протестировать с помощью тестов по тест-кейсам. В этом случае на вход мы передаем (2, 1, 3) и проверяем ожидание, что на выходе будет 1, 2, 3.
В property based тестах на входе случайная последовательность, а на выходе надо убедиться, что каждый последующий элемент больше или равен предыдущему (т. е. проверяется свойство).
Фаззинг также передаст случайную последовательность, но удостоверится, что функция не упала.
Фаззинг не заменяет классическое тестирование. Он нужен, когда проверяется уже оттестированный код, а фантазия тестировщиков подходит к концу. В общем случае фаззер найдет меньше ошибок, чем тесты по тест-кейсам. Но эти ошибки будут наиболее разнообразны. Это хорошо заметно в Go-шной реализации фаззера — go fuzz, которая модифицирует корпус входных тестовых данных так, чтобы отработали все ветви кода. Стандартный фаззер Go вообще одинаково хорошо подходит как для написания property based тестов, так и для классического фаззинга. Официальная документация Go по фаззингу не делает различия между этими видами тестов.
Как помочь фаззеру
Давайте рассмотрим нехитрую программу на Go.
Наш код объявляет неинициализированный нулевой указатель и что-то по нему пишет.

Если запустить этот код, он упадет с ошибкой. Проблема в пятой строке.
Чисто теоретически ее можно было бы проигнорировать и продолжить выполнение. Если кто-то помнит, в Visual Basic был такой режим: при ошибке программа не падала, а просто переходила к следующей строке кода. Получалось, что они надежны, но поведение этих программ непредсказуемо. Это никак не помогло бы фаззеру.
Вернемся к Бартону Миллеру. Что было бы, если бы grep проигнорировал обращение к невалидному указателю? Скорее всего, фаззер не нашел бы багов в команде. Команда обработала бы мусор на входе и выдала мусор на выходе. Никто не понял бы, что произошло нечто плохое. Т. е. фаззер в принципе смог найти ошибку только благодаря крэшу (программа проверила свой собственный внутренний инвариант, согласно которому нельзя обращаться к некорректному указателю, и упала, когда он оказался нарушен).
Так мы приходим к выводу: падать с ошибкой полезно.
Чем больше код проверяет своих внутренних инвариантов, тем больше фаззер может найти багов.
Вот несколько примеров с проверкой внутренних инвариантов:
- Инвариант может заключаться в том, что оба потомка красного узла в красно-черном дереве — черные. Если он нарушен, код может как-то сообщить об этом фаззеру.
- Можно проверять, что количество элементов в контейнере неотрицательно — в очереди не может содержаться «-1» элемент.
- Проверка может выявлять, что в стеке количество операций Pop меньше или равно количеству Push.
- Бизнес-логика может контролировать отсутствие превышения некоего программного лимита. Тот факт, что мы обнаружим нарушение этого инварианта, будет свидетельствовать об ошибке в бизнес-логике.
- Кэш должен отсекать повторные запросы. Это особенно актуально, если база вычисляет тяжелые запросы и нужно проверить бизнес-логику, которая хранит в памяти результаты нескольких последних запросов. В этом случае фаззер может найти ошибку в логике работы с кэшем.
- SQL-запрос не должен возвращать ошибку некорректного синтаксиса. Если же мы получаем такую ошибку, в нашем коде однозначно есть проблема. Скорее всего, мы неправильно формируем тело SQL-запроса или в это тело без какой-либо санитизации попадает пользовательский ввод (SQL-инъекция).
Все эти примеры объединяет тот факт, что если проверка сработает, это однозначно указывает на некорректно написанный код. Это никак не связано с окружением. По сути это ничем не отличается от обращения к невалидному указателю, упомянутому выше.
Инвариант мало проверить, нужно еще донести до фаззера информацию о том, что есть нарушение. Самый простой способ — кинуть panic. Это можно сделать с любого уровня абстракции.
Среди Go-феров есть предубеждение против panic, поэтому можно использовать более лайтовые варианты:
- Кидать panic не всегда, а только в специальном фаззинг-режиме: ввести переменную окружения, и если она задана, при нарушении инвариантов кидать panic. Фаззинг-режим, кстати, помогает решить проблему с «дорогими» проверками инвариантов, когда на них уходит много ресурсов.
- Можно использовать специальный уровень логирования, доступный фаззеру. Когда тот увидит запись с этим уровнем, он поймет, что нарушен некий внутренний инвариант (и сделает вывод, что код написан некорректно). Этот подход требует более сложной инфраструктуры. И важно не писать в лог на этом уровне, когда наблюдаются проблемы с инфраструктурой (например, если отвалилась сеть).
При проверке инвариантов у фаззинг-теста нет никакого ожидания относительно кода. За счет этого он более стабильный — его не нужно менять при малейших изменениях. С развитием продукта его также нужно поддерживать, но усилий на это будет уходить гораздо меньше, чем в случае с тестами по тест-кейсам. Возвращаясь к примеру с grep — если мы сменим движок обработки регулярных выражений, суть теста никак не изменится.
Фаззинг имеет смысл, если функции работают достаточно быстро. Если функция выдает ответ через несколько минут после передачи в нее начальных данных, за разумное время фаззер просто не успеет ничего проверить. А проверив слишком мало вариантов, он ничего не найдет. Возможно, в этой ситуации процесс ускорят моки, но работать с ними надо всегда очень осторожно. Также можно гонять тесты на маленьких частях кода.
Помогаем фаззеру искать SQL-уязвимости
Теперь применим этот подход, чтобы обрабатывать ошибки работы с базой данных на примере SQLite.
Предположим, у нас есть нативный код, в котором присутствует уязвимость SQL-инъекции. Мы формируем строку, и если получаем ошибку, смотрим, что это было. Если это ошибка SQLite, которая говорит, что синтаксис некорректный, и при этом включена переменная окружения FUZZING, мы кидаем panic. В ином случае мы обрабатываем ошибки стандартным путем.
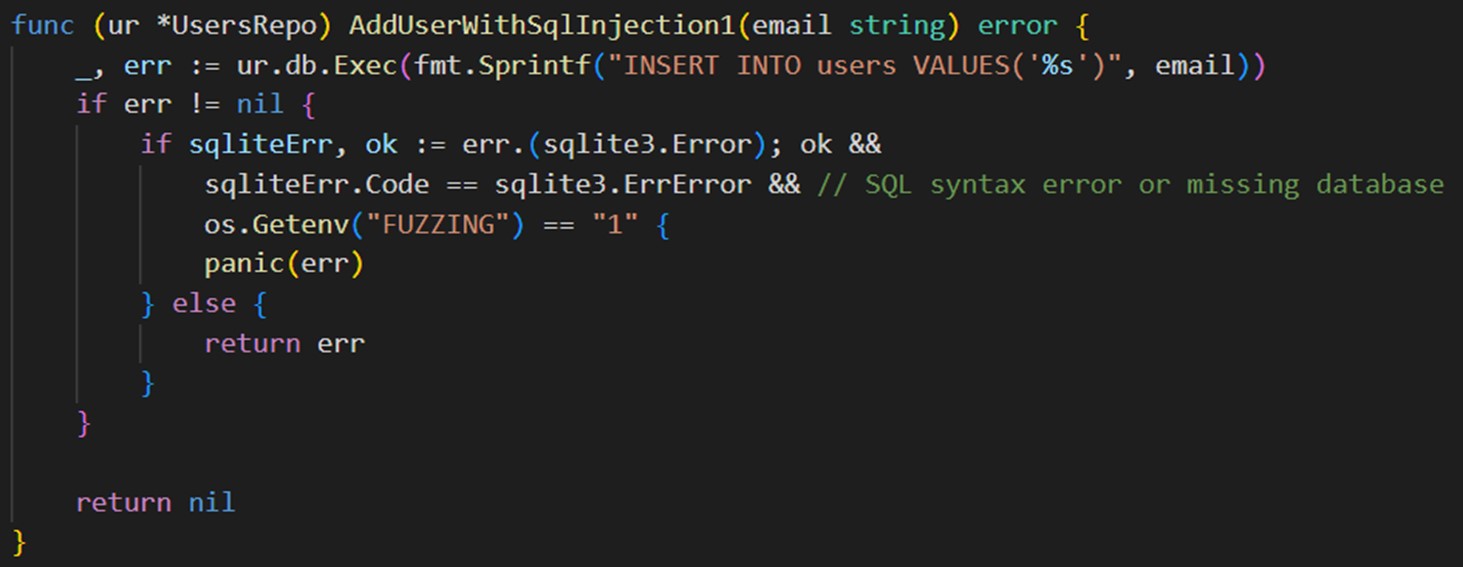
Каждый раз писать такой код неудобно, поэтому его можно разбить на вспомогательные функции и уже их использовать по всему коду.
Я бы предложил такой вариант разбиения.
Мы выделяем функцию ProcessCriticalErr, которая на вход принимает критическую ошибку (в нашем случае — нарушение синтаксиса) и кидает panic, если выставлена переменная окружения. Когда переменная окружения не выставлена, она просто возвращает ошибку.
Дополнительно нам потребуется функция, которая определяет, является ли данная ошибка критической. У SQLite есть несколько кодов ошибок, подходящих под нашу ситуацию.
Третья функция — также вспомогательная. Она принимает на вход ошибку базы данных, проверяет ее «критичность» и при необходимости вызывает процедуру обработки таких ошибок.

В этом случае наша стандартная функция работы с базой данных упрощается до такого вида:

При обнаружении критической ошибки в фаззинг=-режиме мы сообщаем об этом фаззеру, который и запоминает, что подобрал входные данные, ломающие внутреннюю логику. В данном случае фаззер помогает найти SQL-инъекцию.
Напоследок я бы рекомендовал ознакомиться с двумя ссылками:
- https://go.dev/doc/tutorial/fuzz — о том, как вообще пользоваться фаззингом в Go, конкретно go fuzz. Он подходит для написания как классических фаззинг- тестов, о которых я рассказывал, так и для property based тестов.
- https://www.fuzzingbook.org/ — очень полезный сайт, который посвящен фаззингу в целом. Это отдельный большой мир с огромным количеством способов разработки таких тестов. Рекомендую ознакомиться с информацией, которая есть на этом сайте. Если фаззинг применять «в лоб», он просто будет нагревать поверхность нашей атмосферы. Чтобы он находил баги, требуется включать голову, и этот ресурс подскажет, в каком направлении думать. Нужно просто научиться замечать в коде возможности для написания фаззинг-теста.
В нашей команде мы пока только пробуем стандартный фаззинг Go, но уже тестируем с его помощью довольно большой самостоятельный сервис конвертации данных из различных источников к стандартизированному виду. Для ускорения работы мы убрали из фаззинга работу с сетью и очередями, оставив только внутренности сервиса. Приходите к нам в разработку на Go — сможете пощупать все это своими руками. Тем более, у нас не надо доказывать руководству необходимость применения подобных методик. А в том, что касается фаззинга, он еще и регламентируется нормативными документами, если уж мы хотим сертифицировать свой код для каких-либо целей.
Обсудить в форуме
Перед тем как начать поиск, вспомним что такое баги. Баги и дефекты обнаруживаются тестировщиком при сравнении ожидаемого и реального результата работы программы. Багом может быть любая ошибка, которая вызывает неправильную или непредсказуемую работу приложения.
Что должен знать тестировщик?
В процессе тестирования специалисту приходится работать с большими объемами информации. QA-инженер старается удержать в голове различные варианты проверок. Структурно их можно заключить в следующие вопросы:
- Что необходимо протестировать?
Ответом на этот вопрос должна быть четко сформулированная цель и назначение программы. В случае если тестировщик знаком с продуктом поверхностно, процент пропущенных дефектов сильно возрастет. Определите области, которые будут протестированы, а также основные пользовательские сценарии.
- Как может использоваться приложение?
Это взаимосвязь глобальной цели приложения и его более мелких задач. После того как мы удостоверились, что основная функциональность работает, переходим к менее стандартным сценариям.
- Как сломать программу?
Провести тестирование программы с негативной точки зрения. Сюда входит ввод неверных данных и вызов исключительных ситуаций. Сценарии в этом случае направлены на проверку устойчивости системы.
- Кто будет использовать приложение?
В этом случае речь идет о пользователях, для которых предназначена разработка. Зачастую тестировщики проверяют продукт, ничего не зная о тех людях, которые будут использовать приложение.
Как взаимодействуют с приложением разные пользователи?
Попробуйте описать портреты разных пользователей и их взаимодействие с приложением в зависимости от определенных параметров. Такими параметрами могут быть сфера занятости, интересы, особенности поведения, черты характера и привычки.
Сценарии тестирования, построенные на основе этих данных, помогут оптимизировать продукт под потребности потенциальных пользователей.
Персонализирование – это мощный инструмент, который позволяет осознанно перенять чувства и привычки разных людей. Применение такого инструмента в тестировании помогает обнаруживать различные по типу дефекты и прийти к нестандартным сценариям. В то время как отсутствие персонализации может привести к потере контакта между приложением и потенциальными пользователями.
Приведем пример из шести универсальных персонажей, которые могут использовать приложение.
Менеджер
Менеджер – занятой человек, он работает с приложением между встречами. Он нетерпелив и иногда не сосредоточен, так как все делает в спешке.
Для менеджера будут приоритетными горячие клавиши, максимально быстрое заполнение полей, отсутствие ошибок при быстром завершении, автосохранение, скорость загрузки.
Ищем баги в процессе заполнения форм, скорости их отправки, адресов, по которым идет отправка, проверяем точно ли описаны этапы заполнения и требования к итоговому варианту.

Хипстер
Хипстер любит исследовать новые функциональные возможности и области приложения, которые находятся за пределами главного экрана. Он заядлый исследователь.
Хипстера будут интересовать новые функции, недавно добавленные в приложение, непопулярные области приложения, нестандартный ввод данных, доступ к приложению из необычных браузеров, операционных систем, устройств.
Баги стоит искать в кроссплатформенности, адаптивности, проверке введенных данных, взаимодействии старой и новой функциональности приложения.

Осторожный
Осторожный пользователь предпочитает рутинные операции, которые должны хорошо работать. Его процессы будут повторяться в каждой сессии.
В этом случае для пользователя будут важны популярные функции приложения. Он также обратит внимание на любые изменения интерфейса, заполнит все поля в форме наиболее полно, будет многословен в полях для комментариев и терпеливо подождет ответа приложения.
Поиск багов стоит начать с наиболее используемых функций, затем следует проверить ограничения по количеству символов в полях форм, убедиться в работоспособности всех элементов интерфейса, а также в том, что при долгой загрузке приложение остается работоспособным.

Проказник
Проказник любит ломать вещи. Он знает о проблемах безопасности и любит исследовать, чтобы убедиться в том, что приложение может защитить его данные.
Его заинтересуют SQL и JavaScript-инъекции, манипулирование URL-адресами, получение доступа к личной информации, нарушение ограничений на поля ввода и генерация сообщений об ошибках.
Ищем баги в доступе к секретной информации, проверяем работоспособность всех уведомлений об ошибках и ограничений.

Путешественник
Путешественник сейчас на другом конце света. Он использует приложение редко и в основном в нерабочее время.
Путешественник будет получать доступ к приложению из разных мест и часовых поясов. Он попытается использовать различные браузеры и устройства, а также медленный и ненадежный интернет.
Проверяем наличие дефектов в кроссплатформенности и адаптивности, возможности использования различных раскладок клавиатуры, ограничений на ввод символов иностранных языков, а также стабильности работы приложения при плохом подключении к сети.

Взрослый
Взрослый относится к старшему поколению и имеет небольшие знания в области вычислительной техники. Имеет определенные трудности с пониманием работы приложения.
Взрослый пользователь будет медленно прокручивать экран и подолгу оставаться на одной странице, часто использовать кнопки «Назад» и «Отменить».
Здесь необходимо искать баги в настройках шрифта, яркости и других элементах интерфейса. Проверяем, срабатывают ли окна онлайн-помощи, работает ли приложение с устаревшими технологиями, включая старые версии браузеров и операционных систем.

В заключение
Как мы видим, даже тестировщик без опыта работы сможет справиться с поиском некоторых багов. Попробуйте протестировать знакомый сайт или приложение, а если понравится – обязательно подавайте заявку на курсы по тестированию.
Изучайте теорию, практикуйтесь в тест-дизайне. Чтобы стать QA-инженером, важно желание разбираться в том, как этот продукт работает сейчас и как он должен работать в принципе.
Если же вы уверены в своих силах, перед собеседованием на должность тестировщика обязательно подготовьтесь к задачкам на логику.
Успехов!