
В сфере распознавания эмоций голос – второй по важности после лица источник эмоциональных данных. Голос можно охарактеризовать по нескольким параметрам. Высота голоса – одна из основных таких характеристик, однако в сфере акустических технологий корректнее называть этот параметр частотой основного тона.
Частота основного тона имеет непосредственное отношение к тому, что мы называем интонацией. А интонация, например, связана с эмоционально-экспрессивными характеристиками голоса.
Тем не менее, определение частоты основного тона является не совсем тривиальной задачей с интересными нюансами. В этой статье мы обсудим особенности алгоритмов для ее определения и сравним существующие решения на примерах конкретных аудиозаписей.
Введение
Для начала вспомним, чем, по сути, является частота основного тона и в каких задачах она может понадобиться. Частота основного тона, которую еще обозначают как ЧОТ, Fundamental Frequency или F0 – это частота колебания голосовых связок при произнесении тоновых звуков (voiced). При произнесении нетоновых звуков (unvoiced), например говорении шепотом или произнесении шипящих и свистящих звуков, связки не колеблются, а значит эта характеристика для них не релевантна.
* Обратите внимание, что деление на тоновые и не тоновые звуки не эквивалентно делению на гласные и согласные.
Вариабельность частоты основного тона довольно велика, причем она может сильно отличаться не только между людьми (для более низких в среднем мужских голосов частота составляет 70-200 Гц, а для женских может достигать 400 Гц), но и для одного человека, особенно в эмоциональной речи.
Определение частоты основного тона применяется для решения широкого спектра задач:
- Распознавание эмоций, как мы уже сказали выше;
- Определение пола;
- При решении задачи сегментации аудио с несколькими голосами или разделения речи на фразы;
- В медицине для определения патологических характеристик голоса (например, с помощью акустических параметров Jitter and Shimmer). Например, определение признаков заболевания Паркинсона [1]. Jitter and Shimmer также могут быть использованы для распознавания эмоций [2].
Однако при определении F0 существует ряд сложностей. К примеру, часто можно перепутать F0 с гармониками, что может привести к так называемым эффектам pitch doubling/pitch halving [3]. А в аудиозаписи плохого качества F0 вычислить бывает довольно сложно, так как нужный пик на низких частотах практически исчезает.
Кстати, помните историю про Laurel и Yanny? Различия в том, какие слова слышат люди при прослушивании одной и той же аудиозаписи, возникли как раз из-за разницы в восприятии F0, на которую влияют много факторов: возраст слушающего, степень усталости, устройство воспроизведения. Так, при прослушивании записи в колонках с качественным воспроизведением низких частот, вы будете слышать Laurel, а в аудиосистемах, где низкие частоты воспроизводятся плохо, Yanny. Эффект перехода можно заметить и на одном устройстве, например здесь. А в этой статье в качестве слушателя выступает нейросеть. В другой статье можно почитать, как объясняется феномен Yanny/Laurel с позиций речеобразования.
Поскольку подробный разбор всех методов определения F0 был бы чересчур объемным, статья носит обзорный характер и может помочь сориентироваться в теме.
Методы определения F0
Методы определения F0 можно разделить на три категории: основанные на временной динамике сигнала, или time-domain; основанные на частотной структуре, или frequency-domain, а также комбинированные методы. Предлагаем ознакомиться с обзорной статьей по теме, где подробно разбираются обозначенные методы выделения F0.
Отметим, что любой из обсуждаемых алгоритмов состоит из 3 основных шагов:
Препроцессинг (фильтрация сигнала, разделение его на фреймы)
Поиск возможных значений F0 (кандидатов)
Трекинг — выбор наиболее вероятной траектории F0 (поскольку для каждого момента времени мы имеем несколько конкурирующих кандидатов, нам необходимо найти среди них наиболее вероятный трек)
Time-domain
Очертим несколько общих моментов. Перед применением методов time-domain сигнал предварительно фильтруют, оставляя только низкие частоты. Задаются пороги – минимальная и максимальная частоты, например от 75 до 500 Гц. Определение F0 производится только для участков с гармонической речью, поскольку для пауз или шумовых звуков это не только бессмысленно, но и может внести ошибки в соседние фреймы при применении интерполяции и/или сглаживании. Длину фрейма выбирают так, чтобы в ней содержалось как минимум три периода.
Основной метод, на базе которого впоследствии появилось целое семейство алгоритмов – автокорреляционный. Подход достаточно прост — необходимо рассчитать автокорреляционную функцию и взять ее первый максимум. Он и будет отображать самую выраженную частотную компоненту в сигнале. В чем может быть сложность в случае использования автокорреляции и почему далеко не всегда первый максимум будет соответствовать нужной частоте? Даже в близких к идеальным условиям на записях высокого качества метод может ошибаться из-за сложной структуры сигнала. В условиях близких к реальным, где помимо прочего мы можем столкнуться с исчезновением нужного пика на шумных записях или записях изначально низкого качества, число ошибок резко возрастает.
Несмотря на ошибки, автокорреляционный метод довольно удобен и привлекателен своей базовой простотой и логичностью, поэтому именно он взят за основу во многих алгоритмах, в том числе в YIN (Инь). Даже само название алгоритма отсылает нас к балансу между удобством и неточностью метода автокорреляции: “The name YIN from ‘‘yin’’ and ‘‘yang’’ of oriental philosophy alludes to the interplay between autocorrelation and cancellation that it involves.” [4]
Создатели YIN попытались исправить слабые места автокорреляционного подхода. Первое изменение – использование функции Cumulative Mean Normalized Difference, которая должна снизить чувствительность к амплитудным модуляциям, сделать пики более явными:
begin{equation}
d’_t(tau)=
begin{cases}
1, & tau=0 \
d_t(tau) bigg/ bigg[ frac{1}{tau} sumlimits_{j=1}^{tau} d_t(j) bigg], & text{otherwise}
end{cases}
end{equation}
Также YIN пытается избежать ошибок, возникающих в случаях, когда длина оконной функции не делится нацело на период колебания. Для этого используется параболическая интерполяция минимума. На последнем шаге обработки аудиосигнала выполняется функция Best Local Estimate для предотвращения резких скачков значений (хорошо это или плохо – вопрос спорный).
Frequency-domain
Если говорить о частотной области, то на первый план выходит гармоническая структура сигнала, то есть наличие спектральных пиков на частотах, кратных F0. “Свернуть” этот периодический паттерн в явный пик можно при помощи кепстрального анализа. Кепстр — преобразование Фурье от логарифма спектра мощности; кепстральный пик соответствует наиболее периодической компоненте спектра (про него можно почитать здесь и здесь).
Гибридные методы определения F0
Следующий алгоритм, на котором стоит остановиться поподробнее, имеет говорящее название YAAPT — Yet Another Algorithm of Pitch Tracking — и фактически является гибридным, потому что использует как частотную, так и временную информацию. Полное описание есть в статье, здесь мы опишем только основные этапы.

Рисунок 1. Схема алгоритма YAAPTalgo (ссылка).
YAAPT состоит из нескольких основных этапов, первым из которых является препроцессинг. На этом этапе значения изначального сигнала возводят в квадрат, получают вторую версию сигнала. Этот шаг преследует ту же цель, что и Cumulative Mean Normalized Difference Function в YIN – усиление и восстановление “затертых” пиков автокорреляции. Обе версии сигнала фильтруют — обычно берут диапазон 50-1500 Гц, иногда 50-900 Гц.
Затем по спектру преобразованного сигнала рассчитывается базовая траектория F0. Кандидаты на F0 определяются с помощью функции Spectral Harmonics Correlation (SHC).
begin{equation}
SHC(t,f) = sumlimits_{f’=-WL/2}^{WL/2} prodlimits_{r=1}^{NH+1}S(t,rf+f’)
end{equation}
где S(t,f) — магнитудный спектр для фрейма t и частоты f, WL — длина окна в Гц, NH — число гармоник (авторы рекомендуют использовать первые три гармоники). Также по спектральной мощности происходит определение фреймов voiced-unvoiced, после чего ищется наиболее оптимальная траектория, при этом учитывается возможность pitch doubling/pitch halving [3, Section II, C].
Далее, как для изначального сигнала, так и для преобразованного производится определение кандидатов на F0, и вместо автокорреляционной функции здесь используется Normalized Cross Correlation (NCCF).
begin{equation}
NCCF(m) = frac{sumlimits_{n=0}^{N-m-1} x(n)*x(n+m)}{sqrt{sumlimits_{n=0}^{N-m-1} x^2(n) * sumlimits_{n=0}^{N-m-1} x^2(n+m)}}text{,} hspace{0.3cm} 0 < m < M_{0}
end{equation}
Следующий этап — оценка всех возможных кандидатов и вычисление их значимости, или веса (merit). Вес кандидатов, полученных по аудио сигналу, зависит не только от амплитуды пика NCCF, но и от их близости к траектории F0, определенной по спектру. То есть частотный домен считается хоть и грубым в плане точности, но зато устойчивым [3, Section II, D].
Затем для всех пар оставшихся кандидатов рассчитывается матрица Transition Cost — цены перехода, по которой в итоге и находят оптимальную траекторию [3, Section II, E].
Примеры
Теперь применим все вышеописанные алгоритмы к конкретным аудиозаписям. В качестве отправной точки будем использовать Praat — инструмент, который является основным для многих исследователей речи. А затем на Python посмотрим реализацию YIN и YAAPT и сравним полученные результаты.
В качестве аудио-материала можно использовать любые доступные аудио. Мы взяли несколько отрывков из нашей базы RAMAS — мультимодального датасета, созданного при участии актеров ВГИК. Можно также воспользоваться материалом из других открытых баз, например LibriSpeech или RAVDESS.
Для наглядного примера мы взяли отрывки из нескольких записей с мужским и женским голосами, как нейтральными, так и эмоционально-окрашенными, и для наглядности соединили их в одну запись. Посмотрим на наш сигнал, его спектрограмму, интенсивность (оранжевый цвет), и F0 (синий цвет). В Praat это можно сделать при помощи Ctrl+O (Open — Read from file) и затем кнопки View & Edit.

Рисунок 2. Спектрограмма, интенсивность (оранжевый цвет), F0 (синий цвет) в Praat.
На аудио довольно четко видно, что при эмоциональной речи высота голоса повышается как у мужчин, так и у женщин. При этом F0 для эмоциональной мужской речи вполне может сравниться с F0 женского голоса.
Трекинг
Выберем в меню Praat вкладку Analyze periodicity – to Pitch (ac), то есть определение F0 при помощи автокорреляции. Появится окно для задания параметров, в котором есть возможность задать 3 параметра для определения кандидатов на F0 и еще 6 параметров для алгоритма поиска пути (path-finder), который выстраивает наиболее вероятную траекторию F0 среди всех кандидатов.
Много параметров (в Praat их описание есть также по кнопке Help)
- Silence threshold — порог относительной амплитуды сигнала для определения тишины, стандартное значение 0.03.
- Voicing threshold — вес unvoiced candidate, максимальное значение равно 1. Чем выше этот параметр, тем больше фреймов будут определены как unvoiced, то есть не содержащие тоновых звуков. В этих фреймах F0 определяться не будет. Значение этого параметра — пороговое для пиков автокорреляционной функции. Значение по умолчанию — 0.45
- Octave cost — определяет, насколько больший вес имеют высокочастотные кандидаты по отношению к низкочастотным. Чем выше значение, тем большее предпочтение отдается высокочастотным кандидатом. Стандартное значение — 0.01 на октаву.
- Octave-jump cost — при увеличении этого коэффициента уменьшается количество резких скачкообразных переходов между последовательными значениями F0. Значение по умолчанию — 0.35.
- Voiced/Unvoiced cost — при увеличении этого коэффициента уменьшается количество Voiced/Unvoiced переходов. Значение по умолчанию — 0.14.
- Pitch ceiling (Hz) — кандидаты выше этой частоты не рассматриваются. Стандартное значение — 600 Гц.
Подробное описание алгоритма можно найти в статье 1993 года.
Как выглядит результат работы трекера (path-finder) можно посмотреть, нажав ОК и затем просмотрев (View & Edit) получившийся файл Pitch. Видно, что помимо выбранной траектории были еще довольно значимые кандидаты с частотой ниже.
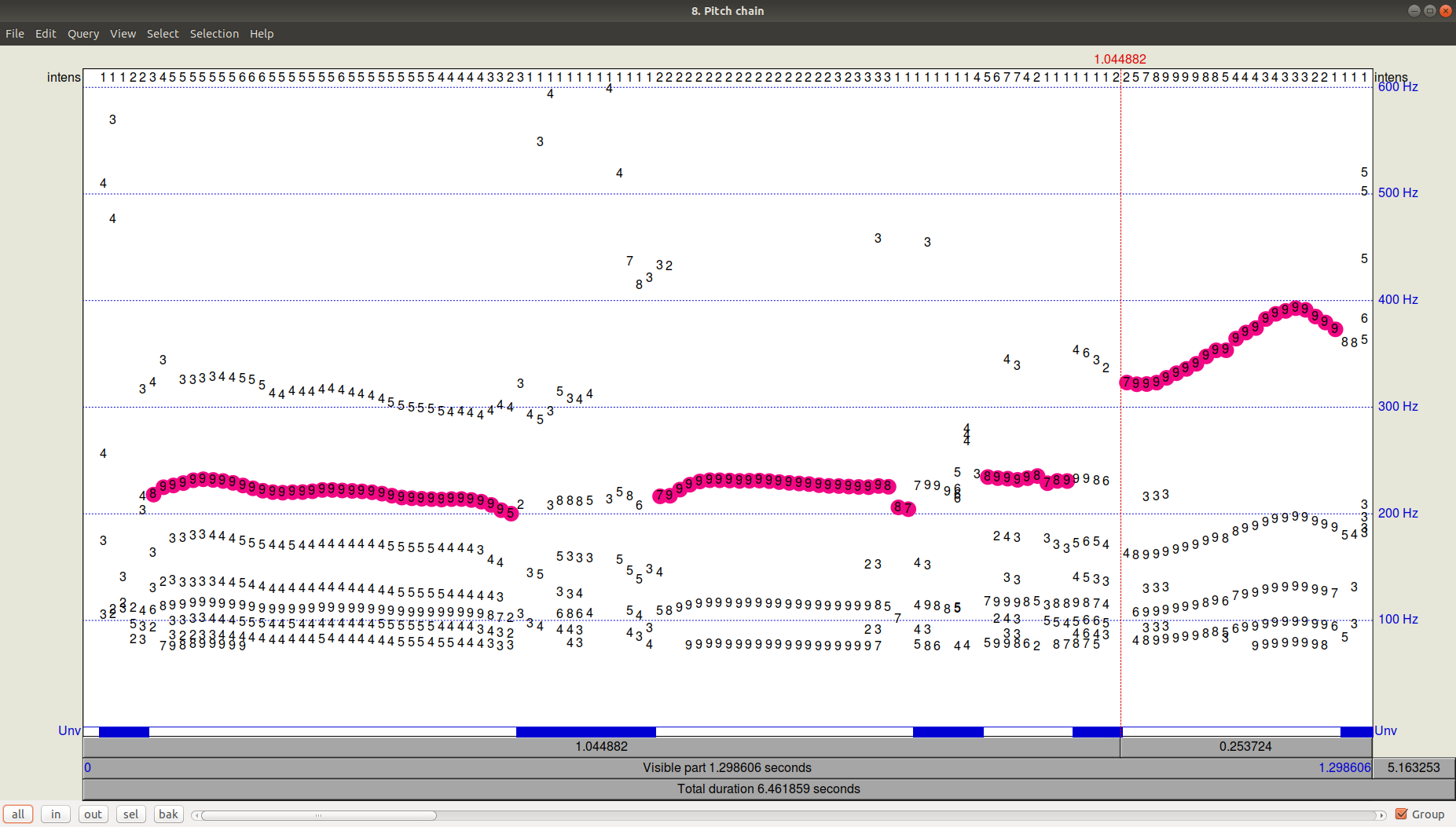
Рисунок 3. PitchPath для первых 1,3 секунд аудиозаписи.
А что же в Python?
Возьмем две библиотеки, предлагающих питч-трекинг – aubio, в которой алгоритмом по умолчанию является YIN, и библиотеку AMFM_decompsition, в которой есть реализация алгоритма YAAPT. В отдельный файл (файл PraatPitch.txt) вставим значения F0 из Praat (это можно сделать вручную: выбрать звуковой файл, нажать View & Edit, выделить весь файл и выбрать в верхнем меню Pitch-Pitch listing).
Теперь сравним результаты по всем трем алгоритмам (YIN, YAAPT, Praat).
Много кода
import amfm_decompy.basic_tools as basic
import amfm_decompy.pYAAPT as pYAAPT
import matplotlib.pyplot as plt
import numpy as np
import sys
from aubio import source, pitch
# load audio
signal = basic.SignalObj('/home/eva/Documents/papers/habr/media/audio.wav')
filename = '/home/eva/Documents/papers/habr/media/audio.wav'
# YAAPT pitches
pitchY = pYAAPT.yaapt(signal, frame_length=40, tda_frame_length=40, f0_min=75, f0_max=600)
# YIN pitches
downsample = 1
samplerate = 0
win_s = 1764 // downsample # fft size
hop_s = 441 // downsample # hop size
s = source(filename, samplerate, hop_s)
samplerate = s.samplerate
tolerance = 0.8
pitch_o = pitch("yin", win_s, hop_s, samplerate)
pitch_o.set_unit("midi")
pitch_o.set_tolerance(tolerance)
pitchesYIN = []
confidences = []
total_frames = 0
while True:
samples, read = s()
pitch = pitch_o(samples)[0]
pitch = int(round(pitch))
confidence = pitch_o.get_confidence()
pitchesYIN += [pitch]
confidences += [confidence]
total_frames += read
if read < hop_s:
break
# load PRAAT pitches
praat = np.genfromtxt('/home/eva/Documents/papers/habr/PraatPitch.txt', filling_values=0)
praat = praat[:,1]
# plot
fig, (ax1,ax2,ax3) = plt.subplots(3, 1, sharex=True, sharey=True, figsize=(12, 8))
ax1.plot(np.asarray(pitchesYIN), label='YIN', color='green')
ax1.legend(loc="upper right")
ax2.plot(pitchY.samp_values, label='YAAPT', color='blue')
ax2.legend(loc="upper right")
ax3.plot(praat, label='Praat', color='red')
ax3.legend(loc="upper right")
plt.show()

Рисунок 4. Сравнение работы алгоритмов YIN, YAAPT и Praat.
Мы видим, что при заданных по умолчанию параметрах YIN довольно сильно выбивается, получая очень плоскую траекторию с заниженными относительно Praat значениями и полностью теряя переходы между мужским и женским голосом, а также между эмоциональной и не эмоциональной речью.
YAAPT зарезал совсем высокий тон при эмоциональной женской речи, но в целом справился явно лучше. За счет каких своих особенностей YAAPT работает лучше — сразу ответить точно, конечно, нельзя, но можно предположить, что роль играет получение кандидатов из трех источников и более скрупулезный расчет их веса, чем в YIN.
Заключение
Поскольку вопрос определения частоты основного тона (F0) в том или ином виде встает почти перед каждым, кто работает со звуком, путей для его решения достаточно много. Вопрос необходимой точности и особенности аудиоматериала в каждом конкретном случае определяют, насколько внимательно необходимо подбирать параметры, или в ином случае можно ограничиться базовым решения наподобие YAAPT. Принимая Praat за эталон алгоритма для обработки речи (все же им пользуется огромное количество исследователей), можно сделать вывод о том, что YAAPT в первом приближении надежнее и точнее, чем YIN, хотя и для него наш пример оказался сложноват.
Автор: Ева Казимирова, научный сотрудник Neurodata Lab, специалист по обработке речи.
Оффтоп: Понравилась статья? На самом деле у нас куча подобных интересных задач по ML, математике и программированию, и нам нужны мозги. Тебе такое интересно? Приходи к нам! E-mail: hr@neurodatalab.com
Ссылки
- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Quantitative acoustic measurements for characterization of speech and voice disorders in early untreated Parkinson’s disease. The Journal of the Acoustical Society of America, vol. 129, issue 1 (2011), pp. 350-367. Access
- Farrús, M., Hernando, J., Ejarque, P. Jitter and Shimmer Measurements for Speaker Recognition. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Access
- Zahorian, S., Hu, HA. Spectral/temporal method for robust fundamental frequency tracking. The Journal of the Acoustical Society of America, vol. 123, issue 6 (2008), pp. 4559-4571. Access
- De Cheveigné, A., Kawahara, H. YIN, a fundamental frequency estimator for speech and music. The Journal of the Acoustical Society of America, vol. 111, issue 4 (2002), pp. 1917-1930. Access
Определение частоты колебаний голосовых связок диктора (Исследование измерителя основного тона речевого сигнала)
Страницы работы
Содержание работы
2. Лабораторная работа
Определение частоты колебаний голосовых связок диктора
(Исследование измерителя основного тона речевого
сигнала)
Цель
работы. Исследовать точность работы
измерителя основного тона.
Краткие
теоретические сведения
При идентификации личности широко
применяются биометрические методы. В частности, при идентификации личности по
голосу измеряется частота вибраций голосовых связок (частота основного тона
речевого сигнала) при производстве вокализованных звуков (то есть тех звуков, в
создании которых участвуют голосовые связки). Назначение измерителя основного
тона (ИОТ) — классификация сегментов (коротких отрезков) речевых сигналов на
невокализованные и вокализованные, а также определение периода (частоты)
основного тона в последнем случае.
Принцип работы ИОТ основан на анализе
автокорреляционной функции сигнала или связанной с ней функции с целью
определения их периода. В последнее время широко используется кратковременная
функция среднего значения разности – AMDF(AverageMagnitudeDifferenceFunction):
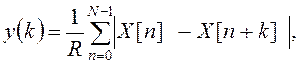
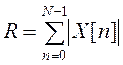 , где R –
, где R –
нормирующий делитель; Х[n] – значение входного
сигнала ИОТ в момент времени nTд; Tд – период дискретизации; N
– число выборок в сегменте сигнала. В общем случае Х[n]
– сумма периодического и случайного компонентов, поэтому данная функция
является случайной. Типичная форма ее математического ожидания для
вокализованных звуков изображена на рис. 2.1 (сплошная линия). Штриховыми
линиями указана зона наиболее вероятных значений y(k).
Период Тот основного
тона определяется расстоянием между двумя минимумами функции. Измерительный
порог rи служит
для фиксации минимумов. Минимальные значения функции определяются лишь для тех
значений k, которые обеспечивают выполнение условия y(k)
≤ rи. Из рис.
2.1. следует, что чем больше разброс значений y(k),
меньших rи, тем
больше разброс значений измеренного периода (Тmin … Тmax), а следовательно, и больше погрешность измерения.
Если шумовая составляющая в сигнале достаточно велика, то принимается решение о
невокализованности звука. При этом наименьшее значение функции превышает
«классификационный» порог rк.
Необходимо отметить, что значения y(k) в точках
локальных минимумов определяются не только периодичностью исследуемого сигнала,
то есть соотношением шумового и детерминированного компонентов в данном случае,
но и уровнем формант (области «всплеска» мощности в спектре сигнала).
 |
Рис. 2.1
Если форманты достаточно мощные, то
появляются дополнительные глубокие «провалы» в функции, которые могут привести
к грубым ошибкам измерения периода основного тона Тот.
Поэтому часто на вход ИОТ подается не сам сегмент сигнала, а его остаток
предсказания на выходе анализирующего фильтра. В остатке предсказания
формантная структура сигнала значительно разрушена при сохранении
периодичности, обусловленной импульсами основного тона.
Так как наиболее вероятные значения
частоты основного тона лежат в пределах (50…500)Гц, то для повышения точности
измерения перед вычислением AMDF сигнал
пропускают через фильтр нижних частот (ФНЧ) с частотой среза 1 кГц.
Схема
обработки сигналов в лабораторной работе
На рис. 2.2 приведена схема обработки
сигналов, проводимой в лабораторной работе. Фильтр нижних частот ФНЧ,
вычислитель AMDF и
измеритель И, где определяется признак вокализованности сегмента «Т/Ш» и
временной интервал между соседними минимумами AMDF,
составляют измеритель основного тона ИОТ. С помощью генераторов: шума – ГШ,
импульсов – ГИ и гармонических колебаний – Г формируется модель сегмента
сигнала на входе ИОТ с различным отношением сигнал — шум. Оно изменяется с
помощью перемножителя П в зависимости от коэффициента усиления G.
По команде «И/С» (импульс – синусоидальный сигнал) ключ подключает либо ГИ –
при этом моделируется ситуация, когда на входе ИОТ присутствует остаток
предсказания, либо Г – при этом моделируется случай анализа вокализованного
сегмента непосредственно.
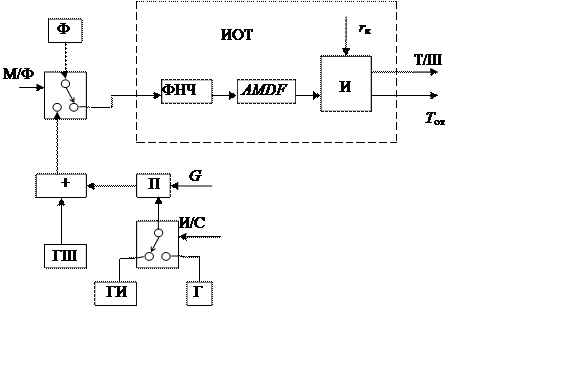 |
Рис. 2.2
В лабораторной работе имеется также
возможность подачи на вход ИОТ сигнала из файла Ф записанного заранее реального
звука. При этом можно оценить качество работы ИОТ с реальными сигналами.
Подключение файла Ф осуществляется по команде «М/Ф» (модель – запись реального
сигнала). Фильтр нижних частот ФНЧ, вычислитель функции AMDF и измеритель
периода основного тона И образуют собственно структуру ИОТ.
В лабораторной работе предусмотрена
возможность наблюдения «осциллограмм» сигналов на входе ИОТ, а также графика AMDF.
Порядок
выполнения работы
1. Для заданной формы входного сигнала определить
зависимость минимального значения AMDF от отношения сигнал – шумymin(c/ш).
Построить график зависимости.
Порядок выполнения данного пункта работы:
-установить значение порога классификации достаточно большим
(примерно 1,5), чтобы результаты последующего анализа AMDF соответствовали
вокализованным звукам;
-значение коэффициента усиления Кус установить
достаточно большим, чтобы минимум AMDF составил примерно 0,1 от
максимума AMDF. Зафиксировать значение минимума AMDF
как результат произведения максимального модуля на относительное значение
минимума AMDF (провести
три замера и найти среднее значение минимума);
-уменьшить Кус и вновь зафиксировать
значение минимума AMDF как результат произведения максимального модуля на
относительное значение минимума AMDF (провести
три замера и найти среднее значение минимума);
-повторить указанные действия, пока минимум AMDF
не увеличится примерно до 0,5 от максимума. Построить требуемый график (получив
7 – 10 точек).
2. Найти такое наибольшее значение Кус,
при котором каждые 5 замеров частоты основного тона из 10 замеров в несколько
раз отличаются от заданного значения частоты основного тона – имеют место сбои
в определении частоты основного тона. Зафиксировать соответствующее значение
минимума AMDF. Эта ситуация соответствует границе разделения звуков
на вокализованные и невокализованные.
3. Установить
порог классификации равным определенному выше значению минимума AMDF.
Зафиксировать «осциллограммы» входного
сигнала ИОТ, выходного сигнала ФНЧ и график AMDF для
данного случая.
4. Найти вокализованные сегменты заданного
звукового файла и сопоставить их с осциллограммами речевого сигнала в звуковом
редакторе COOLEDIT.95. По результатам сравнения скорректировать найденное ранее
значение классификационного порога.
5. Зафиксировать график AMDF и
«осциллограммы» для заданного вокализованного сегмента реального звукового
сигнала. Установив найденный порог классификации, определить частоту основного
тона.
Содержание отчета
1. Структурная схема
процесса обработки сигнала при исследовании измерителя основного тона.
2. Таблицы и графики
определенных зависимостей, «осциллограммы» сигналов.
3. Выводы по работе.
Контрольные
вопросы
1. К чему приведет чрезмерное уменьшение
значения порога классификации?
2. С какой целью при определении
периода основного тона вводится измерительный порог?
3. К чему приведет исключение фильтра
нижних частот из состава измерителя основного тона?
Похожие материалы
- Изучение приемов работы с массивами и файлами, а также средств визуализации результатов работы
- Проектирование радиоприемного устройства. Расчет структурной схемы линейного тракта
- Передаточные функции разомкнутой и замкнутой систем. Дифференциальное уравнение системы
Информация о работе
Тип:
Отчеты по лабораторным работам
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.
Вася Иванов
Мореплаватель — имя существительное, употребляется в мужском роде. К нему может быть несколько синонимов.
1. Моряк. Старый моряк смотрел вдаль, думая о предстоящем опасном путешествии;
2. Аргонавт. На аргонавте были старые потертые штаны, а его рубашка пропиталась запахом моря и соли;
3. Мореход. Опытный мореход знал, что на этом месте погибло уже много кораблей, ведь под водой скрывались острые скалы;
4. Морской волк. Старый морской волк был рад, ведь ему предстояло отчалить в долгое плавание.
Данные задачи: λ (длина волны в воздухе для самого низкого мужского голоса) = 4,25 м.
Справочные данные: υ (скорость распространения звуковой волны в воздухе) = 340м/с.
Частоту колебаний голосовых связок рассматриваемого человека вычислим по формуле: ν = υ / λ.
Произведем вычисление: ν = 340 / 4,25 =80 Гц.
Ответ: 80 Гц,Частота колебаний голосовых связок рассматриваемого человека составляет Гц.
Как определить частоту звука
Звук представляет собой колебания той или иной среды. Такой средой может быть воздух, вода или другое вещество, способное передавать продольные волны. Звуку той или иной высоты соответствует определенное количество колебаний. Измерениями параметров звука занимается акустика. Необходимость измерить частоту колебаний нередко возникает и в быту при настройке различных устройств, от музыкальных инструментов до двигателей внутреннего сгорания.

Вам понадобится
- — чувствительные микрофон;
- — частотомер;
- — осциллограф;
- — камертон:
- — отградуированный звуковой генератор;
- — усилитель низкой частоты.
Инструкция
Самый доступный метод — замерить частоту по частотомеру. Подключите к нему микрофон и поднесите к источнику звука. По шкале частотомера посмотрите, звук какой частоты вы получили. Если уровень сигнала недостаточен для измерения, усильте его с помощью электронного усилителя звуковой частоты.
Если частотомера под рукой не окажется, замерьте частоту колебаний с помощью осциллографа и звукового генератора. При этом цепь микрофона и усилителя звуковой частоты подключите к одной из пар пластин осциллографа (например, Y), а выход звукового генератора — к другой паре пластин, то есть Х.
Включите собранную цепь приборов и определите частоту звукового сигнала по фигурам Лиссажу на экране осциллографа. При этом можно использовать имеющиеся в осциллографе настройки усиления и, если таковые есть, делители и умножители частоты.
Все изложенные методы основаны на преобразовании звукового сигнала в электрический. Но существует и более старый проверенный метод определения звуковой частоты с помощью камертона. Если звук достаточно громкий, то ножку камертона просто жестко закрепите к источнику звука. Движущуюся перемычку сместите по делениям так, чтобы возникла максимальная вибрация усиков прибора. Частоту определите по делениям шкалы, нанесенной на один из усов. Для такого опыта необходим старинный классический камертон с движущейся перекладиной. Приборы, предназначенные для настройки на определенные ноты, для измерения неизвестных звуковых частот непригодны.
Для измерения камертонным методом частоты более слабых звуков прибор оснащают специальными резонаторами в виде раструбов, коробов и т.д. Их делают из дерева или металла. Такие же резонаторы применяются для измерения звуков от отдаленных источников.
По тому же принципу, что и камертон, работает струнный измеритель частоты звука. У него есть второе название — монохорд. В этом случае перемычка с указателем частоты движется вдоль натянутой струны, а шкала нанесена на станину прибора. Монохорд дает большую точность, нежели камертон. Но он требует обязательной настройки и поверки непосредственно перед измерением.
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.