![]()
Загрузить PDF
![]()
Загрузить PDF
С абсолютной частотой все довольно просто: она определяет, сколько раз конкретное число содержится в имеющемся наборе данных (объектов или значений). А вот относительная частота характеризует отношение количества конкретного числа в наборе данных. Другими словами, относительная частота – это отношение количества определенного числа к общему количеству чисел в наборе данных. Имейте в виду, что вычислить относительную частоту достаточно легко.
-

1
Соберите данные. Если вы решаете математическую задачу, в ее условии должен быть дан набор данных (чисел). В противном случае проведите эксперимент или исследование и соберите необходимые данные. Подумайте, в какой форме записать исходные данные.
- Например, нужно собрать данные о возрасте людей, которые посмотрели определенный фильм. Конечно, можно записать точный возраст каждого человека, но в этом случае вы получите довольно большой набор данных с 60-70 числами в пределах от 10 до 70 или 80. Поэтому лучше сгруппировать данные по категориям, таким как «Моложе 20», «20-29», «30-39» «40-49», «50-59» и «Старше 60». Получится упорядоченный набор данных с шестью группами чисел.
- Другой пример: врач собирает данные о температуре пациентов в определенный день. Если записать округленные числа, например, 37, 38, 39, то результат будет не слишком точным, поэтому здесь данные нужно представить в виде десятичных дробей.
-
2
Упорядочьте данные. Когда вы соберете данные, у вас, скорее всего, получится хаотичный набор чисел, например, такой: 1, 2, 5, 4, 6, 4, 3, 7, 1, 5, 6, 5, 3, 4, 5, 1. Такая запись кажется практически бессмысленной и с ней сложно работать. Поэтому упорядочьте числа по возрастанию (от меньшего к большему), например, так: 1,1,1,2,3,3,4,4,4,5,5,5,5,6,6,7.[1]
- Упорядочивая данные, будьте внимательны, чтобы не пропустить ни одного числа. Посчитайте общее количество чисел в наборе данных, чтобы убедиться, что вы записали все числа.
-
3
Создайте таблицу с данными. Собранные данные можно организовать в виде таблицы. Такая таблица будет включать три столбца и использоваться для вычисления относительной частоты. Столбцы обозначьте следующим образом:[2]
Реклама



-
1
Найдите количество чисел в наборе данных. Относительная частота характеризует, сколько раз конкретное число содержится в имеющемся наборе данных по отношению к общему количеству чисел. Чтобы найти относительную частоту, нужно посчитать общее количество чисел в наборе данных. Общее количество чисел станет знаменателем дроби, с помощью которой будет вычислена относительная частота.[3]
- В нашем примере набор данных содержит 16 чисел.
-
2
Найдите количество определенного числа. То есть посчитайте, сколько раз конкретное число встречается в наборе данных. Это можно сделать как для одного числа, так и для всех чисел из набора данных.[4]
- Например, в нашем примере число встречается в наборе данных три раза.
- Например, в нашем примере число
-
3
Разделите количество конкретного числа на общее количество чисел. Так вы найдете относительную частоту для определенного числа. Вычисление можно представить в виде дроби или воспользоваться калькулятором или электронной таблицей, чтобы разделить два числа.[5]
Реклама



-
1
Результаты вычислений запишите в созданную ранее таблицу. Она позволит представить результаты в наглядной форме. По мере вычисления относительной частоты результаты записывайте в таблицу напротив соответствующего числа. Как правило, значение относительной частоты можно округлить до второго знака после десятичной запятой, но это на ваше усмотрение (в зависимости от требований задачи или исследования). Помните, что округленный результат не равен точному ответу.[6]
- В нашем примере таблица относительных частот будет выглядеть следующим образом:
- x : n(x) : P(x)
- 1 : 3 : 0,19
- 2 : 1 : 0,06
- 3 : 2 : 0,13
- 4 : 3 : 0,19
- 5 : 4 : 0,25
- 6 : 2 : 0,13
- 7 : 1 : 0,06
- Итого : 16 : 1,01
-
2
Представьте числа (элементы), которых нет в наборе данных. Иногда представление чисел с нулевой частотой так же важно, как и представление чисел с ненулевой частотой. Обратите внимание на собранные данные; если между данными имеются пробелы, их нужно заполнить нулями.
- В нашем примере набор данных включает все числа от 1 до 7. Но предположим, что числа 3 нет в наборе. Возможно, это немаловажный факт, поэтому нужно записать, что относительная частота числа 3 равна 0.
-
3
Выразите результаты в процентах. Иногда результаты вычислений нужно преобразовать из десятичных дробей в проценты. Это общепринятая практика, потому что относительная частота характеризует процент случаев появления определенного числа в наборе данных. Чтобы преобразовать десятичную дробь в проценты, нужно десятичную запятую передвинуть на две позиции вправо и приписать символ процента.
- Например, десятичная дробь 0,13 равна 13%.
- Десятичная дробь 0,06 равна 6% (обратите внимание, что перед 6 стоит 0).
Реклама



Советы
- Относительная частота характеризует наличие или возникновение определенного события в наборе событий.
- Если сложить относительные частоты всех чисел из набора данных, вы получите единицу. Помните, что при сложении округленных результатов сумма не будет равна 1,0.
- Если набор данных слишком большой, чтобы обработать его вручную, воспользуйтесь программой MS Excel или MATLAB; это позволит избежать ошибок в процессе вычисления.
Реклама
Источники
Об этой статье
Эту страницу просматривали 145 917 раз.
Была ли эта статья полезной?
Мода и медиана
Модой ряда чисел называется число, наиболее часто встречающееся в данном ряду.
Обратимся снова к нашему примеру со сборной по футболу:
Чему в данном примере равна мода? Какое число наиболее часто встречается в этой выборке?
Все верно, это число ( displaystyle 181), так как два игрока имеют рост ( displaystyle 181) см; рост же остальных игроков не повторяется.
Тут все должно быть ясно и понятно, да и слово знакомое, правда?
Перейдем к медиане, ты ее должен знать из курса геометрии. Но мне не сложно напомнить, что в геометрии медиана (в переводе с латинского- «средняя») — отрезок внутри треугольника, соединяющий вершину треугольника с серединой противоположной стороны.
Ключевое слово – СЕРЕДИНА. Если ты знал это определение, то тебе легко будет запомнить, что такое медиана в статистике.
Медианой ряда чисел с нечетным числом членов называется число, которое окажется посередине, если этот ряд упорядочить (проранжировать, т.е. расположить значения в порядке убывания или возрастания).
Медианой ряда чисел с четным числом членов называется среднее арифметическое двух чисел, записанных посередине, если этот ряд упорядочить.
Ну что, вернемся к нашей выборке футболистов?
Ты заметил в определении медианы важный момент, который нам еще здесь не встречался? Конечно, «если этот ряд упорядочить»!
Для того, чтобы в ряду чисел был порядок, можно расположить значения роста футболистов как в порядке убывания, так и в порядке возрастания. Мне удобней выстроить этот ряд в порядке возрастания (от самого маленького к самому большому).
Вот, что у меня получилось:
Так, ряд упорядочили, какой еще есть важный момент в определении медианы? Правильно, четное и нечетное количество членов в выборке.
Заметил, что для четного и нечетного количества даже определения отличаются? Да, ты прав, не заметить – сложно. А раз так, то нам надо определиться, четное у нас количество игроков в нашей выборке или нечетное?
Все верно – игроков ( displaystyle 11), значит, количество нечетное! Теперь можем применять к нашей выборке менее заковыристое определение медианы для нечетного количества членов в выборке.
Ищем число, которое оказалось посередине в нашем упорядоченном ряду:
Ну вот, чисел у нас ( displaystyle 11), значит, по краям остается по пять чисел, а рост ( displaystyle 183) см будет медианой в нашей выборке.
Не так уж и сложно, правда?
Частота и относительная частота
Частота представляет собой число повторений, сколько раз за какой-то период происходило некоторое событие, проявлялось определенное свойство объекта либо наблюдаемый параметр достигал данной величины.
То есть частота определяет то, как часто повторяется та или иная величина в выборке.
Разберемся на нашем примере с футболистами. Перед нами вот такой вот упорядоченный ряд:
![]()
Частота – это число повторений какой-либо величины параметра. В нашем случае, это можно считать вот так. Сколько игроков имеет рост ( 176)?
Все верно, один игрок. Таким образом, частота встречи игрока с ростом ( 176) в нашей выборке равна ( 1).
Сколько игроков имеет рост ( 178)? Да, опять же один игрок. Частота встречи игрока с ростом ( 178) в нашей выборке равна ( 1).
Задавая такие вопросы и отвечая на них, можно составить вот такую табличку:
Ну вот, все довольно просто. Помни, что сумма частот должна равняться количеству элементов в выборке (объему выборки).
То есть в нашем примере: ( 1+1+1+2+1+1+1+1+1+1=11)
Перейдем к следующей характеристике – относительная частота.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Обратимся опять к нашему примеру с футболистами. Частоты для каждого значения мы рассчитали, общее количество данных в ряду мы тоже знаем ( left( n=11 right)) .
Рассчитываем относительную частоту для каждого значения роста и получаем вот такую табличку:
А теперь сам составь таблицы частот и относительных частот для примера с 9-классниками, решающими задачи.
Поможем решить контрольную, написать реферат, курсовую и диплом от 800р
Узнать стоимость
Статистическое распределение выборки
Содержание:
- Примеры использования формул и таблиц для решения практических задач
- Статистический интервальный ряд распределения
Предположим случай, когда из генеральной совокупности извлекается некоторая выборка, при этом каждому значению соответствует некоторый параметр, означающий количество раз, когда появлялось данное значение. Здесь $x_1$ было зафиксировано $n_1$ раз, $x_2$ было обнаружено $n_2$$x_k$ выявлено $n_k$. При этом
$sum_{i=1}^{k}n_i=n$
Где n — объём рассматриваемой выборки.
Определение 1
Используется следующая терминология: $x_k$ носят наименование вариантов, а последовательность таких вариантов, зафиксированный по возрастанию именуется вариационным рядом. Количество наблюдений каждого из вариантов носят название частот. При этом частное частот и выборки называют относительными частотами.
Определение 2
Статистическое распределение —это название всего набора вариантов и частот, которые с ними соотносятся. Чаще всего задаётся с помощью специальной таблицы, где представлены частоты, а также интервалы им соответствующие.
| $x_1$ | $x_2$ | … | $x_k$ |
| $n_1$ | $n_2$ | … | $n_k$ |
| $frac{n_1}{n}$ | $frac{n_2}{n}$ | $frac{n_k}{n}$ |
Здесь в первой строке представлены варианты, во второй частоты, в третьеq взяты относительные частоты.
Для определения размера интервала используется следующее выражение:
$d=frac{x_{max}- x_{min}}{1+3,332cdot lg n}$
Здесь $x_{max}$, $x_{min}$ наибольшее и наименьшее значения ряда вариантов, а n характеризуем объём выборки.
Примеры использования формул и таблиц для решения практических задач
Пример 1
В ходе проведения измерений в однородных группах, были определены следующие значения выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74. Необходимо использовать данные значения, что определить ряд распределения частот и ряд распределения относительных частот.
Решение.
1) Составим статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Рассчитаем суммарный размер выборки: n=2+4+8+2+4=20. Определим относительные частоты, для этого используем формулы: ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Теперь зафиксируем в таблице распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контрольная сумма должна равняться единице: 0,1+0,2+0,4+0,1+0,2=1.
Полигон частот
Название «полигоном частот» применяют для обозначения ломаной линии, каждый отрезок, которой соединяют точки $(х_1,n_1),(х_2,n_2),…,(х_k,n_k)$. Для построения на графике полигона частот по оси абсцисс отмечают варианты $х_2$, при этом на оси ординат отсчитывают– соответствующие частоты $n_i$. Когда полученные точки $(х_i,n_i)$ соединяются с помощью отрезков, то автоматически получают полигон частот.
Статистический интервальный ряд распределения.
Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются, если число различающихся вариант в полученной выборке не слишком большое. Также применение возможно, когда дискретность имеет важное значение для экспериментатора. В тех случаях, когда важный для задачи признак генеральной совокупности Х распределяется непрерывным образом, либо его дискретность нет возможности учесть, то варианты предпочтительнее всего группировать, чтобы получить интервалы.
Статистическое распределение допустимо задавать в том числе в качестве последовательности интервалов и частот, соответствующих этим интервалам. При это за частоту какого-либо интервала принимается сумма всех частот, вошедших в данный интервал.
Особенно следует отметить ,что $h_i-h_{i-1}=h$ при всех i, т.е. группировка проводится с равным шагом h. Также в вопросе группировки можно ориентироваться на ряд полученных опытным путём рекомендацийу, касающихся таких параметров, как а, k и $h_i$:
1. $Rраз_{мах}=X_{max}-X_{min}$
2. $h=R/k$; k-число групп
3.$ kgeq 1+3.321lgn$ (формула Стерджеса)
4. $a=x_{min}, b=x_{max}$
5.$ h=a+h_i, i=0,1…k$
Определённую в ходе решения задачи группировку удобнее всего скомпоновать и перевести в вид специальной таблицы, которая также может именоваться — «статистический интервальный ряд распределения»:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Таблицу подобного вида можно сделать, поменяв частоты $n_i$ на относительные частоты:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |

236
проверенных автора готовы помочь в написании работы любой сложности
Мы помогли уже 4 430 ученикам и студентам сдать работы от решения задач до дипломных на отлично! Узнай стоимость своей работы за 15 минут!
Пример 2
На склад пришла крупная партия деталей. Из них методом случайного отбора взято 50 экземпляров. Рассматривая изделия по одному, особенно интересующему признаку — размеру, определённому с точностью до 1 см, получим следующий вариационный ряд: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Требуется произвести расчёт и определить статистический интервальный ряд распределения.
Решение
Найдём параметры выборки используя сведения из условия задачи.
$k geq1+3,321cdot lg50=1+3.32lg(5cdot10)=1+3.32(lg5+lg10)=6.6$
Получили a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн. частоты | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Не получается написать работу самому?
Доверь это кандидату наук!
План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.
Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример использования функции ЧАСТОТА в Excel
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
Внесем данные в таблицу:
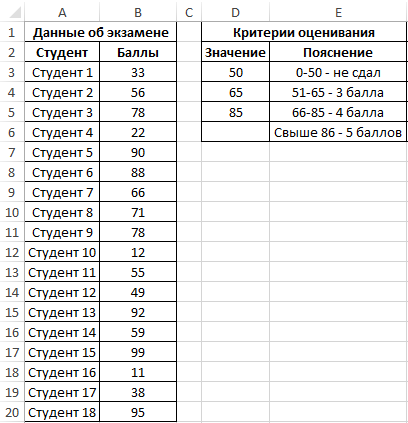
Для решения выделим области из 4 ячеек и введем следующую функцию:
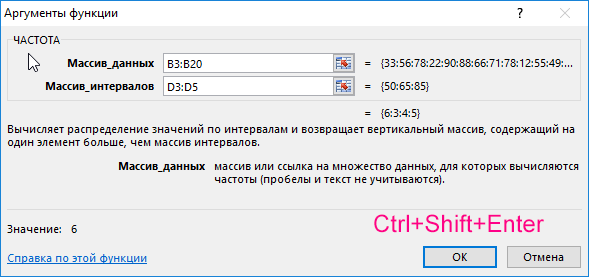
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
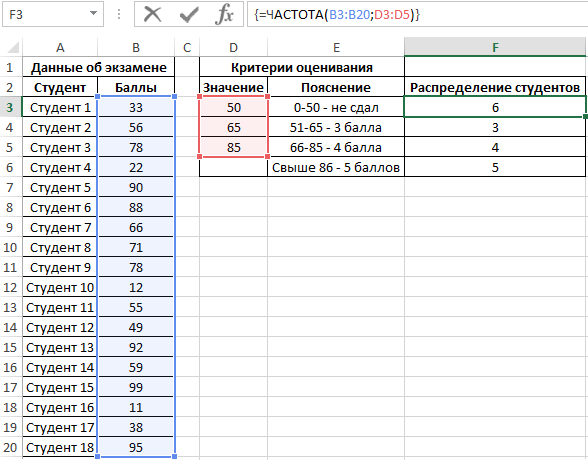
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
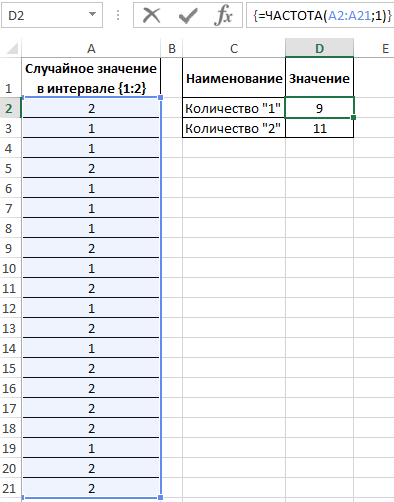
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
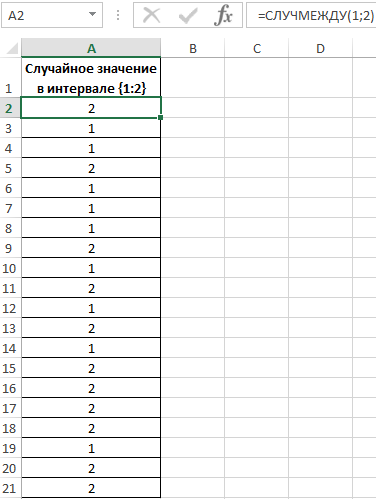
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
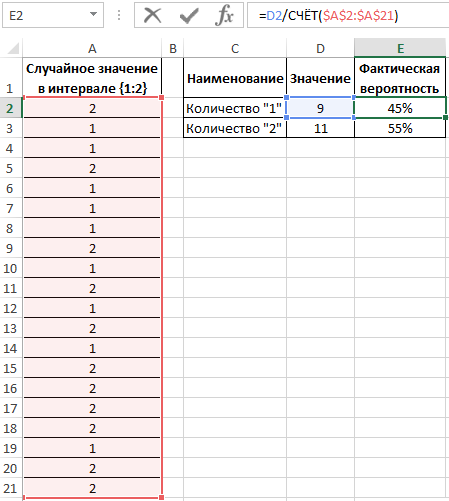
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» — 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
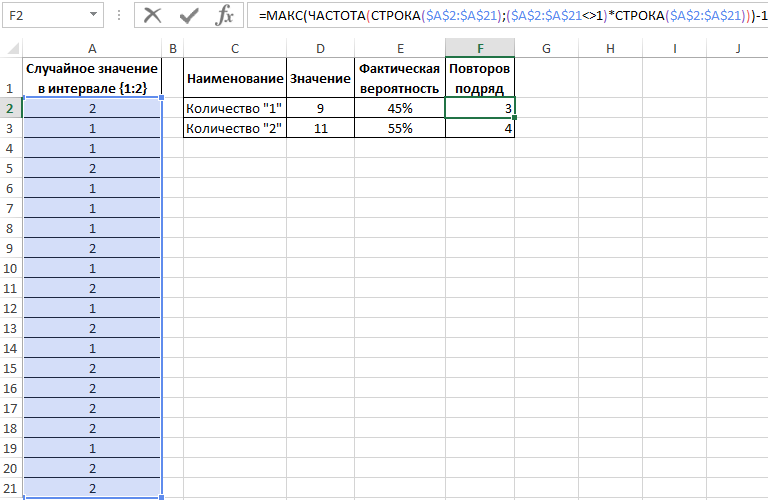
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: <>1 и <>2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
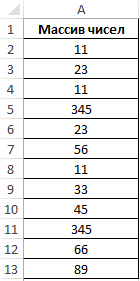
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
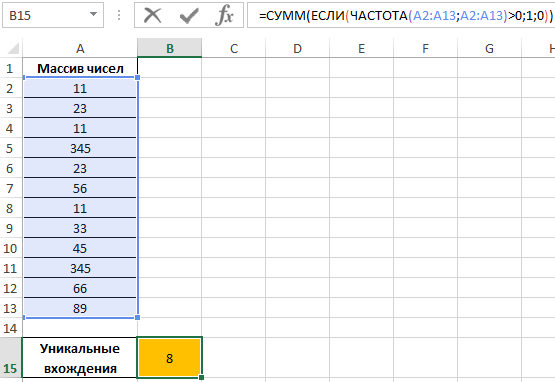
То есть, в указанном массиве содержится 8 уникальных значений.
Скачать пример функции ЧАСТОТА в Excel
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов — данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
=ЧАСТОТА(массив_данных;массив_интервалов)