Нажмита ‘Старт’ и скажите какую нибудь фразу в микрофон. Например: Съешь ещё этих мягких французских булок, да выпей же чаю!



Результат анализа голоса: % !
Автор вопроса: Александр Соловьёв
Опубликовано: 01/04/2023
Можно ли пробить человека по голосу?
У нас есть 22 ответов на вопрос Можно ли пробить человека по голосу? Скорее всего, этого будет достаточно, чтобы вы получили ответ на ваш вопрос.
- Можно ли представить внешность человека по голосу?
- Как найти человека в интернете по голосу?
- Как работает распознавание по голосу?
- Как называется анализ голоса?
- Можно ли пробить человека по голосу? Ответы пользователей
- Можно ли пробить человека по голосу? Видео-ответы
Отвечает Рамиль Корольков
У каждого человека есть свои вокальные характеристики — темп, громкость и интонация голоса,— … Но можно ли научить этому компьютер?
Можно ли представить внешность человека по голосу?
Учёные: По голосу практически безошибочно можно определить внешность человека Люди всегда делают определенные выводы о другом человеке, впервые увидев его или услышав голос. Например, разговаривая по телефону с незнакомцем, собеседник всегда представляет себе, как тот выглядит. Об этом сообщили британские ученые.
Как найти человека в интернете по голосу?
Для использования голосового поиска необходимо в веб-браузере Google Chrome 11 или более поздней версии перейти по адресу Google.com (выбрать в настройках поиска родной язык английский). Напротив строки для ввода запроса появится пиктограмма микрофона.
Как работает распознавание по голосу?
Как работает технология Сначала устройство записывает голосовой запрос, а нейросеть анализирует поток речи. Волна звука делится на фрагменты — фонемы. Затем нейросеть обращается к своим шаблонам и сопоставляет фонемы с буквой, слогом или словом.
Как называется анализ голоса?
Установление принадлежности записанного голоса и звучащей речи конкретному лицу (идентификация говорящего) – это одна из разновидностей фоноскопической экспертизы, которая, в свою очередь, представляет собой комплекс исследований относительно голоса и звучащей речи.
Отвечает Александр Качковский
Система идентификации человека по его голосу, созданная в России, … идентифицировать по голосу конкретного человека точно так же, как по …
Отвечает Лилия Шарибзянова
Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать …
Отвечает Вячеслав Биктагиров
Как найти клиентов по голосу … Если вам нужно открыть вклад, получить кредит или перевести деньги, необязательно идти в банк. Можно сделать это …
Отвечает Вячеслав Мутовкин
Возможно, данная функция доступна пока только пользователям, … как с помощью Search by Image можно узнать название здания или любой другой …
Отвечает Вячеслав Кудрявцев
Тщательно проверьте и идентифицируйте говорящих, используя уникальные характеристики голоса, связанные с конкретным пользователем.
Отвечает Пётр Линберг
Исследователи сосредоточились на прогнозировании таких параметров, как пол, возраст и национальность. И если первый и третий параметры система …
Отвечает Зураб Агапычев
Можно доказать принадлежность голоса, в случае поимки. Прокуратура, как и органы следствия и дознания, денег не берет, это взятка. Но и …
Отвечает Ната Суворова
С помощью данного вида исследования можно определить, чей голос звучит на аудиозаписи. … Также звучание голоса зависит от физического состояния человека …
Отвечает Андрей Плуготаренко
По голосу человека можно с разной точностью определить некоторые его особенности: легко можно определить пол, чуть сложнее (но все равно …
КАК ПОНЯТЬ ЧТО ТЕБЕ ЛГУТ ПО ГОЛОСУ
Сегодня вы узнаете о том, как по голосу собеседника можно определить, лжет ли он тебе! Детектор лжи!

Какие секреты раскроет ваш голос
А вы когда-нибудь задумывались, как воспринимается ваш голос другими людьми? Ваши друзья и семья, скорее всего, …

Как тон голоса влияет на окружающих? ВОН ИЗ МОЕГО КВАДРАТА!
Школа ораторского мастерства Я ГОВОРЮ! Прокачайте свою речь с опытным тренером https://i-say.ru/

Что можно узнать о человеке по звучанию его голоса
Человеческий голос — это способность, которой человек наделен с самого рождения, и люди частенько относятся к нему …

КАК ПОНЯТЬ ЧТО ТЕБЕ ЛГУТ ПО ГОЛОСУ
Сегодня вы узнаете о том, как по голосу собеседника можно определить, лжет ли он тебе! Детектор лжи!
Какие секреты раскроет ваш голос
А вы когда-нибудь задумывались, как воспринимается ваш голос другими людьми? Ваши друзья и семья, скорее всего, …
Как тон голоса влияет на окружающих? ВОН ИЗ МОЕГО КВАДРАТА!
Школа ораторского мастерства Я ГОВОРЮ! Прокачайте свою речь с опытным тренером https://i-say.ru/
Что можно узнать о человеке по звучанию его голоса
Человеческий голос — это способность, которой человек наделен с самого рождения, и люди частенько относятся к нему …
Кто там? — Идентификация человека по голосу
Время на прочтение
6 мин
Количество просмотров 56K

Здравствуй, дорогой читатель!
Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на статью о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется импульсно-кодовой модуляцией aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
double[] readAmplitudeValues(bool isBigEndian)
{
int MSB, LSB; // старший и младший байты
byte[] buffer = ReadDataFromExternalSource(); // читаем данные откуда-нибудь
double[] data = new double[buffer.length / 2];
for (int i = 0; i < buffer.length; i += 2)
{
if(isBigEndian) // задает порядок байтов во входном сигнале
{
// первым байтом будет MSB
MSB = buffer[2 * i];
// вторым байтом будет LSB
LSB = buffer[2 * i + 1];
}
else
{
// наоборот
LSB = buffer[2 * i];
MSB = buffer[2 * i + 1];
}
// склеиваем два байта, чтобы получить 16-битное вещественное число
// все значения делятся на максимально возможное - 2^15
data[i] = ((MSB << 8) || LSB) / 32768;
}
return data;
}
Освежить знания про порядок байтов можно на википедии.
Обработка звука
Полученные значения амплитуд могут не совпадать даже для двух одинаковых записей из-за внешнего шума, разных громкостей входного сигнала и других факторов. Для приведения звуков к «общему знаменателю» используется нормализация. Идея пиковой нормализации проста: разделить все значения амплитуд на максимальную (в рамках данного звукового файла). Таким образом мы уравняли образцы речи, записанные с разной громкостью, уложив все в шкалу от -1 до 1. Важно, что после такой трансформации любой звук полностью заполняет заданный промежуток.
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.
Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации.
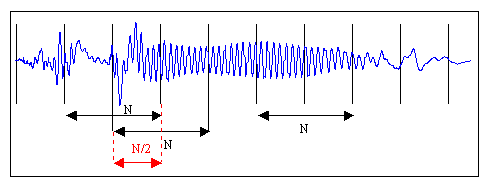
На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.
Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Мы же будем использовать окно Хэмминга.
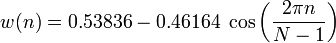
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
Дискретное преобразование Фурье
Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье.

N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал
Кроме этого, возведем каждое значение Xk в квадрат для дальнейшего логарифмирования.
Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом есть и на Хабре. Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок.

Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью.

m — частота в мелах
f — частота в герцах
Получение вектора признаков
Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2]
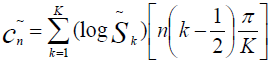
cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]
Как правило, число K выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент c0 несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
Так кто же все-таки говорил?
Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов.

Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода k-средних.
Итоги
Таким образом, я рассказал о простой но эффективной системе идентификации человека по голосу. Резюмируя, процесс распознавания построен следующим образом:
- Собираем несколько тренировочных образцов речи, чем больше — тем лучше.
- Находим для каждого из них характеристический вектор признаков.
- Для образцов с известным автором проводим кластеризацию с одним центром (усреднение) или несколькими. Приемлемые результаты начинаются уже с использованием 4-х центров для каждого диктора. [2]
- В режиме опознавания находим расстояние от пробного вектора до изученных во время тренировки центров кластеров. К какому кластеру пробная речь окажется ближе — к такому диктору и относим образец.
- Можно экспериментально установить даже некоторый доверительный интервал — максимальное расстояние, на котором может находиться пробный образец от центра кластера. В случае превышения этого значения — классифицировать образец как неизвестный.
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.
Литература:
- Modular Audio Recognition Framework v.0.3.0.6 (0.3.0 final) and its Applications
- Speaker identification using mel frequency cepstral coefficients
Концепция программного обеспечения для распознавания голоса ни в коем случае не является новой технологией. Вы уже познакомились с ним через Microsoft Cortana, Amazon Alexa и Siri. Это виртуальный ИИ, который позволяет вам использовать голосовые команды для управления вашим компьютером и мобильными телефонами. Но сегодня мы рассмотрим не только основные голосовые команды. Потому что с современными технологиями вы можете делать гораздо больше с помощью голоса. Я говорю о преобразовании аудио в текст.
Независимо от того, что вы делаете на своем компьютере, всегда будет какой-то аспект, связанный с набором текста. Отвечать на электронные письма, просматривать веб-страницы, печатать документы и многое другое. А если вы работаете на административной должности или зарабатываете себе на жизнь писательством, то вы будете делать это в еще большем масштабе. Это одна из причин, по которой вам следует подумать о программе для диктовки. Другой вариант использования, когда программное обеспечение для распознавания речи может быть критичным, — это если по какой-то причине вы не можете использовать пальцы. Джон Морроу — один из самых успешных блоггеров, но из-за спинальной мышечной атрофии он не может двигать мышцами рук. Как он это делает? Вы угадали. С помощью программного обеспечения для распознавания голоса.
Раньше было довольно сложно реализовать концепцию голоса в текст из-за большого разрыва, существовавшего между тем, что вы диктовали, и выводом текста. Это означало, что после редактирования документов приходилось тратить долгие часы. Но новые технологии привели к более точному диктату. Мы перечислим 5 лучших программ для распознавания голоса, которые будут для вас неоценимы.
Многие люди хвалят Dragon как программу распознавания речи номер один, и мне придется согласиться с ними по очевидным причинам. Он удивительно точен с первого дня использования и становится еще более точным, когда вы продолжаете его использовать, благодаря технологии глубокого обучения. Это функция, которая позволяет ему адаптироваться к вашему голосу, чем дольше вы его используете, и будет особенно полезна, если у вас иностранный акцент.
Естественно говорящий дракон
Dragon v15 создан для ОС Windows и позволит вам напрямую диктовать текст практически во всех приложениях Windows с помощью голоса. Это включает Microsoft Office и веб-браузеры. Если вы пользователь Mac, не волнуйтесь, вы можете получить точно такой же пакет с Dragon Professional Individual для Mac.
Еще одна вещь, которая вам обязательно понравится в этом программном обеспечении, — это его гибкость. Dragon v15 предлагает бесплатное приложение для записи, которое вы можете использовать для записи качественного звука, когда у вас нет доступа к компьютеру. Затем вы можете преобразовать звук в текст позже благодаря потрясающим возможностям транскрипции Dragon. Как будто это еще не все, у них также есть бесплатное приложение для микрофона, которое можно связать с настольным приложением через Wi-Fi, что дает вам больше свободы передвижения.
Дракон Профессиональный Индивидуальный v12
Помимо диктовки, Dragon также можно использовать в качестве виртуального помощника, выполняя ваши голосовые команды, такие как открытие приложений, отправка электронных писем, просмотр сети и планирование встреч. Это программное обеспечение содержит обучающие модули на экране в каждом из своих пакетов, которые дают четкие рекомендации о том, как в полной мере использовать возможности Dragon.
Dragon Professional v12, возможно, не самый дешевый, но я могу гарантировать, что благодаря тому, что он предлагает, вы получите полную отдачу от своих денег.
Braina, созданная на основе Brain искусственного интеллекта, — еще одно отличное программное обеспечение, которое также будет служить виртуальным помощником поверх диктовки. Вы можете использовать Braina для установки будильника, чтения онлайн-книг, поиска чего-либо в Интернете или даже воспроизведения мультимедиа на вашем компьютере.
Braina
Braina позволяет диктовать текст различным приложениям на вашем компьютере и поддерживает более 100 различных языков. Это программное обеспечение также достаточно эффективно для расшифровки акцентов, и, в довершение всего, вы можете настроить его для точного распознавания слов, которые могут отсутствовать в его базе данных. Кстати, у Braina довольно обширная база данных, охватывающая различные профессии, такие как юриспруденция, медицина и наука. Подобно Дракону, Braina позволяет вам озвучивать команды / текст по беспроводной сети с помощью приложения, доступного как для устройств Android, так и для iOS.
Braina доступна как в бесплатной, так и в платной версиях. Если вы используете бесплатную версию, вам, возможно, придется пойти на компромисс с некоторыми функциями. Например, он поддерживает распознавание голоса только для английского языка.
Пользователям Windows, которые ищут быстрый способ преобразовать свою речь в текст, не нужно далеко ходить. В ОС Windows есть собственный инструмент распознавания голоса, который можно легко настроить. Для пользователей Windows 10 все, что вам нужно сделать, это выполнить поиск по распознаванию речи на панели поиска, расположенной в левой части панели задач, и это запустит процесс установки.
Распознавание речи Windows
Этот инструмент позволяет не только преобразовывать голос в текст, но и управлять вашим компьютером. Это означает, что вы сможете открывать программы и перемещаться по меню, просто используя свой голос. Кроме того, вы сможете управлять каждым приложением из их определенного интерфейса. Будь то электронное письмо или текстовый документ.
Однако для использования распознавания речи Windows вам понадобится специальный микрофон. Он предлагает поддержку микрофона гарнитуры, настольного микрофона и различных других типов, таких как массивные микрофоны. Некоторые пользователи также могут использовать микрофон по умолчанию на своих компьютерах, но в большинстве случаев это может быть проблемой.
Windows Speech Recognition может не иметь возможностей адаптивного обучения Dragon Naturally Speaking, но в нем есть функция обучения распознаванию речи, с помощью которой вы можете научить свой компьютер лучше распознавать вашу речь. Вы также можете предоставить ему доступ к вашим документам, где он определит ваш наиболее часто используемый словарный запас и, следовательно, будет способствовать более точному диктованию. Распознавание Windows доступно на английском, французском, китайском, японском и испанском языках.
Хорошо, в Windows есть встроенный инструмент для диктовки, и поэтому, естественно, Apple должна иметь собственное программное обеспечение для распознавания речи, не так ли? Вы не ошиблись, пользователи iOS и MacOS также имеют доступ к бесплатному программному обеспечению для распознавания голоса под названием Apple Dictation. Если вы используете iOS, вы можете быстро активировать его, нажав микрофон на клавиатуре устройства. Для пользователей MacOS просто перейдите в Системные настройки, нажмите на клавиатуре, а затем на диктовку.
Яблочный диктант
К сожалению, если вы используете любую версию OS X старше 10.9, у вас будет доступ только к стандартной версии этого программного обеспечения, которая имеет свои ограничения. Например, вы не можете использовать его в автономном режиме, и даже тогда вы не можете разговаривать более 40 секунд за один раз. Вероятно, это связано с тем, что ваш звук должен быть сначала отправлен в Apple, прежде чем преобразовываться в текст. Однако с расширенной версией вам не нужно подключаться к Интернету и нет ограничений по времени.
Расширенная версия диктовки также имеет набор из более чем 70 команд, которые облегчают редактирование и форматирование вашего текста. Для простоты использования эти команды видны на небольшом экране дисплея вашего устройства. И что еще лучше, программа Apple Dictation позволяет создавать свои собственные команды. В отличие от распознавания речи Windows, это программное обеспечение поддерживает 20 различных языков.
Если вы часто используете Google Docs и G-Suite в целом, вы будете рады узнать, что в нем есть встроенная функция распознавания голоса, которая позволяет вам легко диктовать текст. И если вы не являетесь пользователем, возможно, вам пора подумать о том, чтобы попробовать его.
Голосовой ввод Google Документов
Чтобы использовать голосовой набор в Google docs, все, что вам нужно, это учетная запись Google. Как только вы войдете в свою учетную запись, откройте документы Google и перейдите к голосовому вводу. Во время первоначальной настройки вам будет предложено разрешить доступ к микрофону вашего компьютера. Вы также можете подключить внешний микрофон для более точного распознавания голоса. Обратите внимание: для доступа к этой функции вам нужно будет использовать Google Chrome.
Голосовая речь в Google docs содержит ряд команд, которые упрощают редактирование и форматирование текста. Например, чтобы выделить любой текст, все, что вам нужно сказать, — это «выбрать слово». С другой стороны, этот инструмент работает только с документами Google, поэтому вы не сможете диктовать им электронное письмо или вводить документ в текстовом процессоре вашего компьютера. Однако вы вряд ли найдете какой-либо другой бесплатный инструмент, который предлагает такой широкий выбор команд редактирования и форматирования. И не говоря уже о голосовом вводе в Google docs, который поддерживает 62 разных языка и еще лучше распознает акцент.
Shazam
Пожалуй, самое популярное приложение для поиска музыки. С его помощью вы быстро узнаете, кто поёт песню и как она называется. Пользоваться им очень просто: откройте Shazam и нажмите кнопку прослушивания на главном экране. Чтобы приложение лучше распознало композицию, поднесите смартфон поближе к источнику звука или увеличьте громкость.


SoundHound
Похожее на Shazam приложение, которое позволяет распознать проигрываемый трек. Работает оно аналогичным образом: подносим смартфон к источнику звука, например к колонке, и нажимаем кнопку на главном экране.
Кстати, в SoundHound есть ещё одна полезная опция. Приложение показывает не только, что за песня играет и кто исполняет её, но и текст — можно слушать и подпевать.

Голосовой ассистент Google
Опция распознавания мелодии встроена в голосовой ассистент Google. Чтобы найти нужный вам трек:
- Откройте голосовой помощник.
- Произнесите Ok, Google.
- Дайте голосовую команду: «Что за трек играет?»

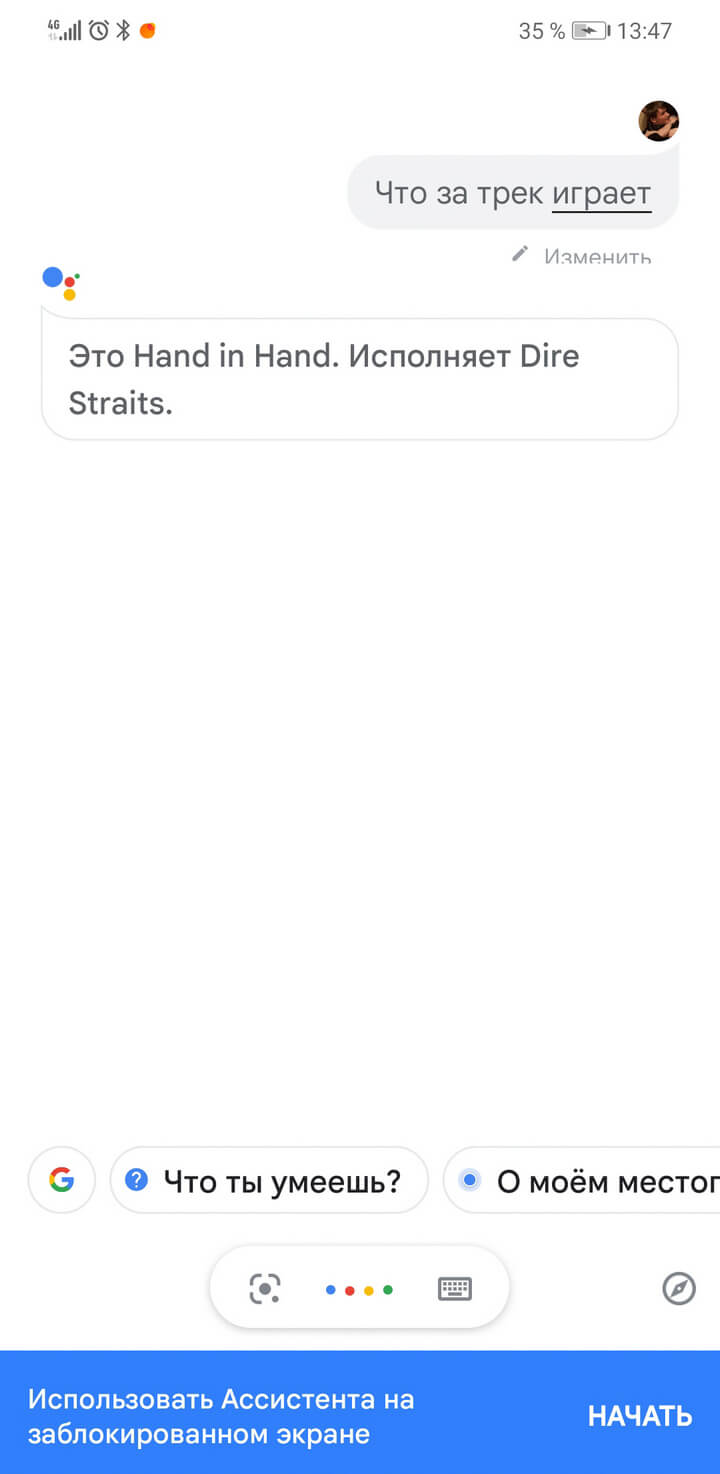
Через несколько секунд ассистент выдаст результат.
Нашли нужный трек? Слушайте его, а также миллионы других отличных композиций, музыкальные подборки и подкасты в МТС Music. Для новых пользователей — первые 30 дней бесплатно.