17 авг. 2022 г.
читать 1 мин
Вы можете использовать следующие методы для подсчета различных значений в определенном поле в MongoDB:
Метод 1: найти список различных значений
db.collection.distinct( 'field_name' )
Метод 2: найти количество различных значений
db.collection.distinct( 'field_name' ).length
В следующих примерах показано, как использовать каждый метод с набором команд со следующими документами:
db.teams.insertOne({team: " Mavs", position: " Guard", points: 31 })
db.teams.insertOne({team: " Mavs", position: " Guard", points: 22 })
db.teams.insertOne({team: " Rockets", position: " Center", points: 19 })
db.teams.insertOne({team: " Rockets", position: " Forward", points: 26 })
db.teams.insertOne({team: " Cavs", position: " Guard", points: 33 })
Пример 1: поиск списка различных значений
Мы можем использовать следующий код, чтобы найти список различных значений в поле «команда»:
db.teams.distinct( 'team' )
Этот запрос возвращает следующий результат:
[ 'Cavs', 'Mavs', 'Rockets' ]
В выходных данных показаны три различных названия команд из всех документов.
Мы также можем использовать следующий код, чтобы найти список различных значений в поле «позиция»:
db.teams.distinct( 'position' )
Этот запрос возвращает следующий результат:
[ 'Center', 'Forward', 'Guard' ]
Примечание.По умолчанию MongoDB сортирует отдельные значения в алфавитном порядке.
Пример 2: найти количество уникальных значений
Мы можем использовать следующий код для подсчета количества различных значений в поле «команда»:
db.teams.distinct( 'team' ).length
Этот запрос возвращает следующий результат:
3
Это говорит нам о том, что в поле «команда» есть 3 различных значения.
Мы также можем использовать следующий код для подсчета количества уникальных значений в поле «баллы»:
db.teams.distinct( 'points' ).length
Этот запрос возвращает следующий результат:
5
Это говорит нам о том, что в поле «точки» есть 5 различных значений.
Примечание.Полную документацию по отдельной функции можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в MongoDB:
MongoDB: как группировать и считать
MongoDB: как сгруппировать по нескольким полям
MongoDB: как найти максимальное значение в коллекции
I can select all the distinct values in a column in the following ways:
SELECT DISTINCT column_name FROM table_name;SELECT column_name FROM table_name GROUP BY column_name;
But how do I get the row count from that query? Is a subquery required?
asked Sep 26, 2008 at 19:52
![]()
Christian OudardChristian Oudard
47.7k25 gold badges65 silver badges69 bronze badges
1
You can use the DISTINCT keyword within the COUNT aggregate function:
SELECT COUNT(DISTINCT column_name) AS some_alias FROM table_name
This will count only the distinct values for that column.
![]()
answered Sep 26, 2008 at 19:54
![]()
Noah GoodrichNoah Goodrich
24.8k13 gold badges66 silver badges96 bronze badges
3
This will give you BOTH the distinct column values and the count of each value. I usually find that I want to know both pieces of information.
SELECT [columnName], count([columnName]) AS CountOf
FROM [tableName]
GROUP BY [columnName]
![]()
Crayons
1,8381 gold badge13 silver badges33 bronze badges
answered Oct 27, 2012 at 15:45
![]()
Paul JamesPaul James
2,4091 gold badge12 silver badges2 bronze badges
0
An sql sum of column_name’s unique values and sorted by the frequency:
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name ORDER BY 2 DESC;
answered May 20, 2015 at 0:04
![]()
xchiltonxxchiltonx
1,8963 gold badges20 silver badges18 bronze badges
0
Be aware that Count() ignores null values, so if you need to allow for null as its own distinct value you can do something tricky like:
select count(distinct my_col)
+ count(distinct Case when my_col is null then 1 else null end)
from my_table
/
answered Sep 26, 2008 at 21:32
![]()
David AldridgeDavid Aldridge
51.3k8 gold badges68 silver badges95 bronze badges
4
SELECT COUNT(DISTINCT column_name) FROM table as column_name_count;
you’ve got to count that distinct col, then give it an alias.
answered Sep 26, 2008 at 19:55
![]()
Pete Karl IIPete Karl II
4,0403 gold badges21 silver badges27 bronze badges
select count(*) from
(
SELECT distinct column1,column2,column3,column4 FROM abcd
) T
This will give count of distinct group of columns.
![]()
gipinani
13.9k12 gold badges56 silver badges85 bronze badges
answered Nov 4, 2008 at 9:37
select Count(distinct columnName) as columnNameCount from tableName
![]()
gipinani
13.9k12 gold badges56 silver badges85 bronze badges
answered Sep 26, 2008 at 19:54
![]()
WayneWayne
38.3k4 gold badges37 silver badges49 bronze badges
0
Using following SQL we can get the distinct column value count in Oracle 11g.
select count(distinct(Column_Name)) from TableName
![]()
Asclepius
56.4k17 gold badges164 silver badges142 bronze badges
answered Dec 26, 2018 at 2:07
![]()
After MS SQL Server 2012, you can use window function too.
SELECT column_name, COUNT(column_name) OVER (PARTITION BY column_name)
FROM table_name
GROUP BY column_name
![]()
Asclepius
56.4k17 gold badges164 silver badges142 bronze badges
answered Feb 19, 2020 at 5:57
![]()
AlperAlper
512 silver badges5 bronze badges
To do this in Presto using OVER:
SELECT DISTINCT my_col,
count(*) OVER (PARTITION BY my_col
ORDER BY my_col) AS num_rows
FROM my_tbl
Using this OVER based approach is of course optional. In the above SQL, I found specifying DISTINCT and ORDER BY to be necessary.
Caution: As per the docs, using GROUP BY may be more efficient.
answered Jun 3, 2021 at 20:38
![]()
AsclepiusAsclepius
56.4k17 gold badges164 silver badges142 bronze badges
select count(distinct(column_name)) AS columndatacount from table_name where somecondition=true
You can use this query, to count different/distinct data.
![]()
Asclepius
56.4k17 gold badges164 silver badges142 bronze badges
answered Jun 5, 2019 at 10:51
![]()
Without using DISTINCT this is how we could do it-
SELECT COUNT(C)
FROM (SELECT COUNT(column_name) as C
FROM table_name
GROUP BY column_name)
answered Jul 13, 2022 at 13:16
![]()
Deva44Deva44
831 silver badge9 bronze badges
You can do this.
Select distinct PRODUCT_NAME_X
,count (Product_name) products_#
from TableX
Group by PRODUCT_NAME
It will return
PRODUCT_NAME products
XXXXXXXXXX 4760
![]()
Fildor
14.1k4 gold badges34 silver badges66 bronze badges
answered Apr 10 at 19:08
![]()
Count(distinct({fieldname})) is redundant
Simply Count({fieldname}) gives you all the distinct values in that table. It will not (as many presume) just give you the Count of the table [i.e. NOT the same as Count(*) from table]
answered Dec 18, 2014 at 2:13
![]()
1
@lDrakonl До вашего исправления текста вопроса, просматривался именно такой смысл. По крайней мере я так его понимал. После вашего исправления, конечно такое уже не просматривается, но вы подогнали текст вопроса под тот смысл как вы его поняли, чего делать конечно не следовало. Лучше дождаться реакции задавшего вопрос. И если он подтвердит, что ваше толкование верно, от закрыть вопрос как дубль, так как таких вопросов с ответами уже масса.
– Mike
26 ноя 2017 в 8:22
На чтение 8 мин. Просмотров 49.7k.
Сводные таблицы Excel удивительны (я знаю, что упоминаю об этом каждый раз, когда пишу о сводных таблицах, но это правда).
Обладая базовым пониманием, вы можете выполнить свою работу за несколько секунд.
Большинство задач можно сделать с помощью нескольких щелчков в сводных таблицах, но некоторые потребуют дополнительных шагов или подготовительной работы.
Одной из таких задач является подсчет разных значений в сводной таблице.
В этой статье я покажу вам, как подсчитывать разные значения, а также уникальные значения в сводной таблице Excel.
Прежде чем приступить к работе, важно понять разницу между «Подсчетом разных значений» и «подсчетом уникальным значений»
Содержание
- Разные значения против уникальных значений
- Подсчет разных значений в сводной таблице Excel
- Добавление вспомогательного столбца в набор данных
- Недостатки использования вспомогательного столбца
- Добавить данные в модель данных и суммировать, используя «Число различных элементов»
- Что если вы хотите посчитать уникальные значения (а не разные значения)?
Разные значения против уникальных значений
Кажется, что это одно и то же, но это не так.
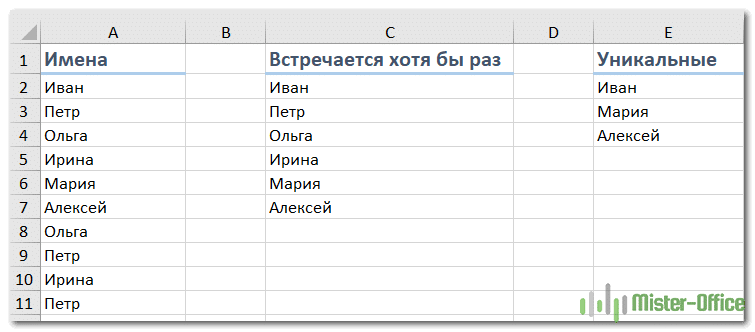
Ниже приведен пример со списком имен, в столбцах отдельно выделены уникальные и разные имена.

Уникальные значения / имена — это те, которые встречаются только один раз. Это означает, что все имена, которые повторяются и имеют дубликаты, не являются уникальными. Уникальные имена перечислены в столбце D вышеупомянутого набора данных.
Разными значениями / именами являются те, которые встречаются хотя бы один раз в наборе данных. Поэтому, если имя появляется три раза, оно все равно считается разным значением. Такой список можно получить путем удаления повторяющихся значений / имен и сохранения всех разных значений. Разные имена перечислены в столбце C приведенного выше набора данных.
В большинстве случаев, когда люди говорят, что хотят получить уникальные значения в сводной таблице, когда на самом деле имеют в виду разные.
Подсчет разных значений в сводной таблице Excel
Предположим, у вас есть данные о продажах:

Нажмите здесь, чтобы загрузить файл примера и делать все вместе со мной:
С этим набором данных вам нужно найти ответ на следующие вопросы:
- Сколько сотрудников в каждом регионе (а это не что иное, как количество разных сотрудников в каждом регионе)?
- Сколько сотрудников продали принтер в 2019 году?
Находить сумму сводные таблицы могут мгновенно, чтобы получить количество разных значений, вам нужно будет сделать еще несколько шагов.
Если вы используете Excel 2013 или более поздние версии, в сводной таблице есть встроенная функция, которая быстро подсчитывает количество.
А если вы используете Excel 2010 или ранние версии, вам придется изменить исходные данные, добавив вспомогательный столбец.
В этой статье рассматриваются следующие методы:
- Добавление вспомогательного столбца в исходный набор данных для подсчета разных значений (работает во всех версиях).
- Добавление данных в модель данных и использование параметра «Число различных элементов» (доступно в Excel 2013 и последующих версиях).
Существует третий метод, он называет метод сводной таблицы в сводной таблице.
Давайте начнем!
Добавление вспомогательного столбца в набор данных
Примечание. Если вы используете Excel 2013 и более поздние версии, пропустите этот метод и перейдите к следующему (вам доступна встроенная функция).
Это простой способ подсчета разных значений в сводной таблице, поскольку вам нужно только добавить вспомогательный столбец к исходным данным. После добавления вспомогательного столбца вы легко ответите на вопросы задачи.
Хотя это простой обходной путь, у него есть некоторые недостатки (которые будут рассмотрены далее).
Позвольте мне сначала показать вам, как добавить вспомогательный столбец и посчитать разные значения.
Предположим, у меня есть набор данных, как показано ниже:
Добавьте следующую формулу в столбец F и примените ее ко всем ячейкам, в которых есть данные в соседних столбцах.
= ЕСЛИ (СЧЁТЕСЛИМН ($C$2:C2; C2; $B$2:B2; B2) > 1;0;1)
Приведенная выше формула использует функцию СЧЁТЕСЛИМН для подсчета количества раз, когда имя появляется в данном регионе. Также обратите внимание на диапазоны критериев: $C$2:C2 и $B$2:B2. Это означает, что они продолжают расширяться, когда вы идете вниз по столбцу.
Например, в ячейке F2 диапазон критериев составляет $C$2:C2 и $B$2:B2, а в ячейке F3 эти диапазоны расширяются до $C$3:C3 и $B$3:B3.
Это гарантирует, что функция СЧЁТЕСЛИМН считает первый экземпляр имени как 1, второй экземпляр имени как 2 и так далее.
Поскольку мы хотим получить только разные имена, используется функция ЕСЛИ, которая возвращает 1, когда имя появляется для региона в первый раз, и возвращает 0, когда оно появляется снова. Это гарантирует, что учитываются только разные имена, а не повторы.
Ниже показано, как будет выглядеть таблица, когда вы добавите вспомогательный столбец.

Теперь, когда мы изменили исходные данные, мы можем использовать их для создания сводной таблицы. Подключив вспомогательный столбец, получим количество различных сотрудников в каждом регионе.
Ниже приведены шаги, как сделать это:
- Выберите любую ячейку в таблице.
- Нажмите вкладку «Вставка».

- Нажмите на кнопку Сводная таблица.

- В диалоговом окне «Создание сводной таблицы» убедитесь, что таблица / диапазон указаны правильно (и включает вспомогательный столбец), и выбран «На новый лист» в качестве места размещения.

- Нажмите ОК.
Вышеуказанные шаги вставят новый лист со сводной таблицей.
Перетащите поле «Регион» в область «Строки» и поле «Помощник» в область «Значения».

Вы получите вот такую сводную таблицу:

Теперь вы можете изменить заголовок столбца с «Сумма по полю Помощник» на «Количество сотрудников».
Недостатки использования вспомогательного столбца
Хотя этот метод довольно прост, я должен выделить несколько недостатков, связанных с изменением исходных данных в сводной таблице:
- Источник данных со вспомогательным столбцом не такой динамичный, как сводная таблица. Если изменится поставленная задача, вам придется вернуться к исходным данным и изменить формулу вспомогательного столбца (или добавить новый вспомогательный столбец).
- Поскольку вы добавляете больше данных в источник сводной таблицы (который также добавляется в сводный кэш), это может привести к увеличению размера файла Excel.
- Так как мы используем формулу Excel, это может замедлить работу вашей книги Excel, если в данных тысячи строк.
Добавить данные в модель данных и суммировать, используя «Число различных элементов»
В сводную таблицу добавлены новые функции в Excel 2013, которые позволяют получать количество различных значений.
В случае, если вы используете предыдущую версию, вы не сможете использовать этот метод (используйте метод, описанный выше).
Напомню, что у нас есть таблица данных, и мы хотим получить количество разных сотрудников в каждом регионе.

Ниже приведены шаги для получения количества разных сотрудников в сводной таблице:
- Выберите любую ячейку в таблице.
- Нажмите вкладку «Вставка».

- Нажмите на кнопку Сводная таблица.

- В диалоговом окне «Создание сводной таблицы» убедитесь, что таблица / диапазон указаны правильно и выбран новый рабочий лист.
- Установите флажок «Добавить эти данные в модель данных».

- Нажмите ОК.
Приведенные выше шаги вставят новый лист с новой сводной таблицей.
Перетащите регион в область «Строки» и «Сотрудник» в область «Значения». Вы получите такую сводную таблицу:

В этой сводной таблице приводится общее количество сотрудников в каждом регионе (а не количество разных).
Чтобы получить подсчет разных значений в сводной таблице, выполните следующие действия:
- Щелкните правой кнопкой мыши по любой ячейке в «Число элементов в столбце Сотрудник»
- Нажмите на «Параметры полей значений».

- В диалоговом окне «Параметры поля значений» выберите «Число различных элементов» в качестве операции (вам может потребоваться прокрутить список вниз, чтобы найти его).

- Нажмите ОК.
Обратите внимание, что название столбца изменится с «Число элементов в столбце Сотрудник» на «Число разных элементов в столбце Сотрудник». Вы можете изменить его.

Некоторые вещи, которые нужно знать, добавляя свои данные в модель данных:
- Если вы сохраните свои данные в модели данных, а затем откроете в более старой версии Excel, появится предупреждение: «Некоторые функции сводной таблицы не будут сохранены».
- Когда вы добавляете свои данные в модель данных и создаете сводную таблицу, в ней не отображаются параметры добавления вычисляемых полей и вычисляемых столбцов.
Что если вы хотите посчитать уникальные значения (а не разные значения)?
Если вы хотите посчитать уникальные значения, то встроенные функции вам не помогут, придется полагаться только на вспомогательные столбцы.
Помните — уникальные значения и разные значения не одно и то же. Нажмите здесь, чтобы узнать разницу.
Рассмотрим пример, когда нам нужно определить количество уникальных сотрудников для каждого региона. Это означает, что они работают только в одном конкретном регионе, а не в других.
В таких случаях вам нужно создать один или несколько вспомогательных столбцов.
Вот формула для этого случая:
= ЕСЛИ (ЕСЛИ (СЧЁТЕСЛИМН ($C$2:$C$1001; С2; $B$2:$B$1001; В2) / СЧЁТЕСЛИ ($C$2:$C$1001; С2) <1;0;1); ЕСЛИ (СЧЁТЕСЛИ ($С2:С$22; С2) > 1;0;1);0)
Приведенная выше формула проверяет, встречается ли имя сотрудника только в одном регионе или в нескольких регионах. Это делается путем подсчета количества появлений имени в регионе и деления его на общее количество появлений имени. Если значение меньше 1, это означает, что имя встречается в двух или более двух регионах.
Если имя встречается в нескольких регионах, формула возвращает 0, в противном случае возвращает единицу.
Формула также проверяет, повторяется ли имя в том же регионе или нет. Если имя повторяется, только первый экземпляр имени возвращает значение 1, а все остальные экземпляры возвращают 0.
Это может показаться немного сложным, но это опять-таки зависит от того, чего вы пытаетесь достичь.
Таким образом, если вы хотите подсчитать уникальные значения в сводной таблице, используйте вспомогательные столбцы, а если вы хотите подсчитать различные значения, вы можете использовать встроенную функцию (в Excel 2013 и более поздних версиях) или использовать вспомогательный столбец.
В этом руководстве вы узнаете, как подсчитывать уникальные значения в Excel с помощью формул и как это делать в сводной таблице. Мы также рассмотрим несколько примеров подсчета уникальных текстовых и числовых значений, в том числе с учетом регистра.
При работе с большим набором данных в Excel вам часто может потребоваться знать, сколько повторяющихся записей находится в таблице и сколько уникальных записей.
Если вы регулярно посещаете этот блог, вы уже знаете формулу Excel для подсчета дубликатов. Сегодня мы собираемся изучить различные способы подсчета уникальных значений в Excel. Но для ясности давайте сначала определим термины.
- Уникальные значения — это те, которые появляются в списке только один раз.
- Различные — это все, что есть в списке без учета повторений, т.е уникальные плюс первое появление повторяющихся.
Следующий рисунок иллюстрирует эту разницу:
Теперь давайте посмотрим, как их вычислить с помощью формул и функций сводной таблицы.
Ниже вы найдете несколько примеров для подсчета уникальных данных разных типов.
Считаем уникальные значения в столбце.
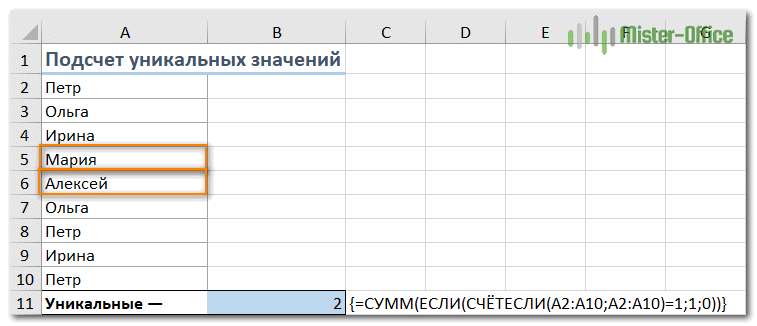
Предположим, у вас есть столбец имен на листе Excel, и вам нужно подсчитать, сколько их не дубликатов. Самое простое решение — использовать функцию СУММ в сочетании с ЕСЛИ и СЧЁТЕСЛИ :
= СУММ (ЕСЛИ (СЧЁТЕСЛИ (диапазон; диапазон) = 1,1,0))
Примечание. Это формула массива, поэтому обязательно нажмите Ctrl + Shift + Enter, чтобы ввести ее правильно. Как только это будет сделано, Excel автоматически заключит все выражение в {фигурные скобки}, как показано на снимке экрана ниже. Фигурные скобки ни в коем случае нельзя вводить вручную, не получится.
В этом примере мы подсчитываем уникальные имена в диапазоне A2: A10, поэтому наше выражение выглядит так:
{= СУММ (ЕСЛИ (СЧЁТЕСЛИ (A2: A10; A2: A10) = 1, 1, 0))}
Этот метод подходит как для текстовых, так и для цифровых данных. Обратной стороной является то, что, будучи уникальным, он будет пересчитывать любой контент, включая ошибки.
Позже в этом руководстве мы обсудим несколько других подходов для подсчета уникальных значений разных типов. И поскольку в основном это вариации этой базовой формулы, имеет смысл присмотреться к ней поближе. Если вы понимаете, как это работает, вы можете настроить его для своих данных. Если кого-то не интересуют технические детали, можете сразу перейти к следующему примеру.
Как работает формула подсчета уникальных значений?
Как видите, здесь используются 3 разные функции: СУММ, ЕСЛИ и СЧЁТЕСЛИ. Посмотрим, что делает каждый из них:
- Функция СЧЁТЕСЛИ подсчитывает, сколько раз каждое отдельное значение появляется в анализируемом диапазоне.
В этом примере СЧЁТЕСЛИ (A2: A10; A2: A10) возвращает матрицу {3: 2: 2: 1: 1: 2: 3: 2: 3}.
- Функция ЕСЛИ оценивает каждый элемент в этом массиве, сохраняет все единицы (то есть уникальные) и заменяет все остальные цифры нулями.
Затем функция ЕСЛИ (СЧЁТЕСЛИ (A2: A10; A2: A10) = 1; 1; 0) преобразуется в ЕСЛИ ({3: 2: 2: 1: 1: 2: 3: 2: 3}) = 1,1, 0).
А затем он превращается в массив чисел {0: 0: 0: 1: 1: 0: 0: 0: 0}. Здесь 1 означает уникальное значение, а 0 означает, что оно встречается более 1 раза.
- Наконец, функция СУММ складывает числа в этот последний массив и возвращает общее количество уникальных значений. Что нам нужно.
Совет. Чтобы увидеть, как определенная часть выражения дает результаты, выберите эту часть в строке формул и нажмите функциональную клавишу F9.
Подсчет уникальных текстовых значений.
Если ваш список содержит как числа, так и текст, и вы хотите подсчитывать только уникальные текстовые строки, добавьте функцию ETEXT () к приведенной выше формуле массива:
{= СУММ (ЕСЛИ (ETEXT (A2: A10) * СЧЁТЕСЛИ (A2: A10; A2: A10) = 1; 1; 0))}
Функция ETEXT возвращает TRUE, если исследуемая ячейка является текстовой, и FALSE в противном случае. Поскольку звездочка (*) в формулах массива работает как оператор И, функция ЕСЛИ возвращает 1 только в том случае, если она считается как текстовой, так и уникальной, в противном случае мы получаем 0. И после того, как функция СУММ сложит все числа, вы получите количество уникальные текстовые значения в указанном диапазоне.
Не забудьте нажать Ctrl + Shift + Enter, чтобы правильно ввести формулу массива, и вы получите следующий результат:

Как вы можете видеть на скриншоте выше, мы получили общее количество уникальных текстовых значений, исключая пустые ячейки, числа, логические выражения и ошибки ИСТИНА и ЛОЖЬ.
Как сосчитать уникальные числовые значения.
Чтобы подсчитать уникальные числа в списке данных, используйте формулу массива, как мы только что сделали для подсчета текстовых данных. Разница в том, что вы используете ISNUMBER вместо ETEXT:
{= СУММ (ЕСЛИ (ЕЧИСЛО (A2: A10) * СЧЁТЕСЛИ (A2: A10; A2: A10) = 1; 1; 0))}
Вы можете увидеть пример и результат на скриншоте чуть выше.
Примечание. Поскольку Microsoft Excel хранит дату и время в виде чисел, они также участвуют в вычислениях.
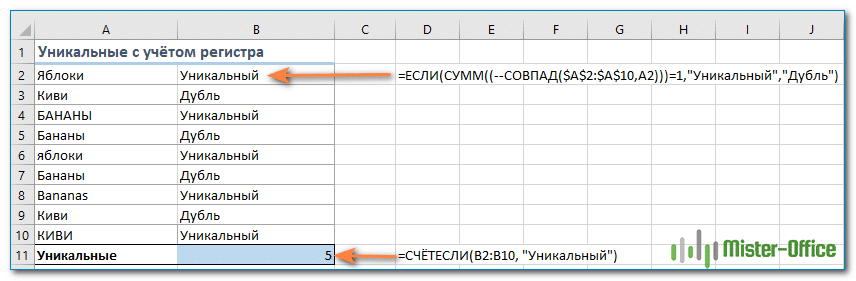
Уникальные значения с учетом регистра.
Если разница между прописными и строчными буквами критична для вас, самый простой способ подсчета — создать вспомогательный столбец со следующей формулой массива для определения повторяющихся и уникальных элементов:
{= ЕСЛИ (СУММ ((- ТОЧНЫЙ ($ A $ 2: $ A $ 10, A2))) = 1; «Уникальный»; «Двойной»)}
А затем используйте простую функцию СЧЁТЕСЛИ для подсчета уникальных значений:
= СЧЁТЕСЛИ (B2: B10; «Уникальный»)
Теперь посмотрим, как можно подсчитать количество значений, которые появляются хотя бы один раз, то есть так называемых разных значений.
Подсчет различных значений.
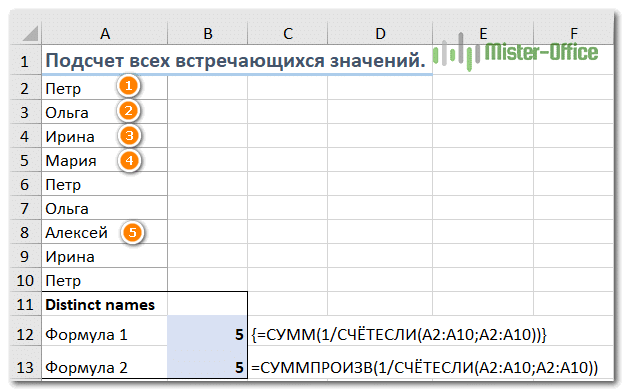
Используйте следующее общее выражение:
{= СУММ (1 / СЧЁТЕСЛИ (диапазон; диапазон))}
Помните, что это формула массива, поэтому вам следует нажать Ctrl + Shift + Enter вместо обычного Enter.
В качестве альтернативы вы можете использовать функцию СУММПРОИЗВ и написать формулу обычным способом:
= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (интервал; интервал))
Например, чтобы подсчитать различные значения в диапазоне A2: A10, вы можете использовать выражение:
{= СУММ (1 / СЧЁТЕСЛИ (A2: A10; A2: A10))}
или
= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (A2: A10; A2: A10))
Этот метод подходит не только для подсчета в столбце, но и для диапазона данных. Например, у нас есть два столбца для имен. Итак, давайте сделаем это:
{= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (A2: B10; A2: B10))}
Этот способ подходит для текста, чисел, дат.
Единственное ограничение — диапазон должен быть непрерывным и не содержать пустых ячеек или ошибок.
Если у вас есть пустые ячейки в диапазоне данных, вы можете изменить:
{= СУММПРОИЗВ (1 / СЧЁТЕСЛИ (A2: A10; A2: A10&»»))}
Тогда пустая ячейка будет включена в расчет и будет засчитана.
Как это работает?
Как вы уже знаете, мы используем функцию СЧЁТЕСЛИ, чтобы узнать, сколько раз каждый отдельный элемент встречается в указанном диапазоне. В приведенном выше примере результатом функции СЧЁТЕСЛИ является числовой массив: {3: 2: 2: 1: 3: 2: 1: 2: 3}.
Затем выполняется серия операций деления, в которых одна делится на каждую цифру этой матрицы. Это преобразует все неуникальные значения в дробные числа, соответствующие количеству повторений. Например, если число или текст появляется в списке 2 раза, в массиве создаются 2 элемента, равных 0,5 (1/2 = 0,5). А если он встречается 3 раза, то в массиве создаются 3 элемента из 0,333333.
В нашем примере результатом вычисления выражения 1 / COUNTIF (A2: A10; A2: A10) является массив {0,3333333333333333: 0,5: 0,5: 1: 0,333333333333333: 0,5: 1: 0,5: 0,333333333333333}.
Все еще не совсем ясно? Это потому, что мы еще не применили функцию СУММ / СУММПРОИЗВ. Когда одна из этих функций добавляет числа в массив, сумма всех дробных чисел для любого отдельного элемента всегда дает 1, независимо от того, сколько раз оно встречается. И поскольку все уникальные элементы отображаются в массиве как единицы (1/1 = 1), конечный результат — это сумма всех значений, которые встречаются.
Как и в случае с подсчетом уникальных значений в Excel, вы можете использовать универсальные параметры формулы для обработки чисел, текста или чувствительности к регистру.
Помните, что все следующие выражения являются формулами массива и требуют нажатия Ctrl + Shift + Enter.
Подсчет различных значений без учета пустых ячеек
Если столбец, который вы хотите подсчитать, может содержать пустые ячейки, вам следует добавить функцию ЕСЛИ к уже знакомой формуле массива. Он проверит ячейки на наличие пробелов (в этом случае базовая формула Excel, описанная выше, вернет ошибку # DIV / 0):
= СУММ (ЕСЛИ (диапазон «»; 1 / СЧЁТЕСЛИ (диапазон; диапазон); 0))
Вот как, например, можно подсчитать количество отдельных значений, игнорируя пустые ячейки:
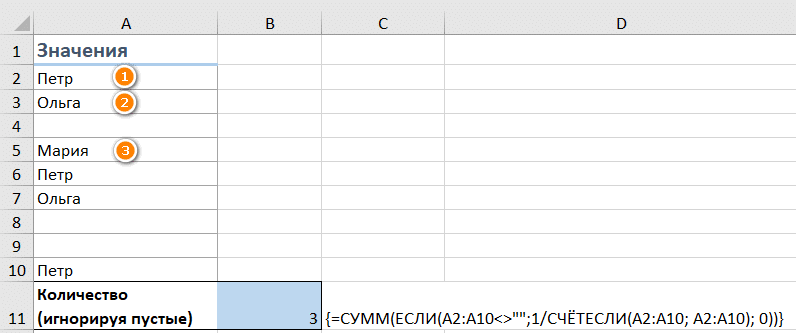
Мы используем:
{= СУММ (ЕСЛИ (A2: A10 «»; 1 / СЧЁТЕСЛИ (A2: A10; A2: A10), 0))}
Как видите, наш список состоит из трех имен.
Подсчет различных чисел.
Чтобы подсчитать несколько числовых значений (числа, даты и время), используйте функцию ЕЧИСЛО:
= СУММ (ЕСЛИ (ЕЧИСЛО (диапазон); 1 / СЧЁТЕСЛИ (диапазон; диапазон); «»))
Посчитаем, сколько разных чисел находится в диапазоне A2: A10:
{= СУММ (ЕСЛИ (ЕЧИСЛО (A2: A10), 1 / СЧЁТЕСЛИ (A2: A10, A2: A10);»»))}
Вы можете увидеть результат ниже.

Это довольно простое и элегантное решение, но оно намного медленнее, чем выражения, использующие функцию ЧАСТОТА для подсчета уникальных значений. Если у вас большие наборы данных, мы рекомендуем перейти на частотную формулу.
А вот еще один способ считать числа:
= СУММ (- (ЧАСТОТА (диапазон; диапазон)> 0))
Применяется к следующему примеру:
= СУММ (- (ЧАСТОТА (A2: A10; A2: A10)> 0))
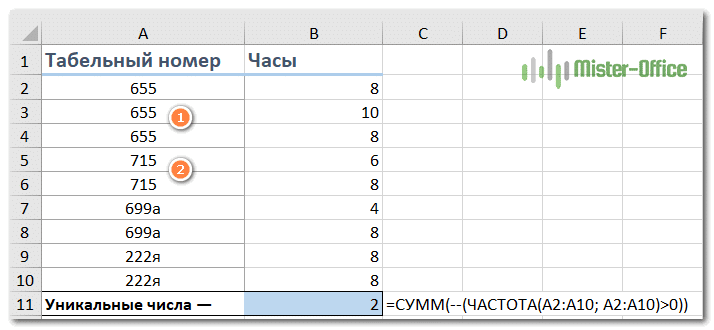
Как видите, записи, содержащие буквы, здесь игнорируются.
Посмотрим, как это работает пошагово.
Функция ЧАСТОТА возвращает массив цифр, которые соответствуют диапазонам, указанным доступными числами. В этом случае мы сравниваем один и тот же набор чисел для массива данных и для массива диапазонов.
В результате FREQUENCY () возвращает массив, который является счетчиком для каждого числового значения в массиве данных.
Это работает, потому что FREQUENCY () возвращает ноль для всех чисел, которые ранее появлялись в списке. Ноль также возвращается для текстовых данных. Таким образом, получившийся массив выглядит так:
{3: 0: 0: 2: 0: 0}
Как видите, обрабатываются только числа. Ячейки A7: A10 игнорируются, поскольку в них есть текст. А функция ЧАСТОТА () работает только с числами.
Теперь давайте проверим каждое из этих чисел на наличие условия «больше нуля».
У нас есть:
{ИСТИНА: ЛОЖЬ: ЛОЖЬ: ИСТИНА: ЛОЖЬ: ЛОЖЬ}
Теперь установите TRUE и FALSE соответственно на 1 и 0. Мы делаем это с двойным отрицанием. Проще говоря, это двойной минус, который не меняет величину числа, но позволяет по возможности получать действительные числа:
{1: 0: 0: 1: 0: 0}
А теперь функция СУММ складывает все, и мы получаем результат: 2.
Примечание. Вы можете легко использовать СУММПРОИЗВ вместо функции СУММ.
Различные текстовые значения.
Чтобы подсчитать отдельные текстовые записи в столбце, мы будем использовать тот же подход, что и для исключения пустых ячеек.
Как нетрудно догадаться, мы просто добавим функцию ETEXT и проверку состояния:
= СУММ (ЕСЛИ (ETEXT (диапазон); 1 / СЧЁТЕСЛИ (диапазон; диапазон); «»))
Рассчитываем количество отдельных символьных значений следующим образом:
{= СУММ (ЕСЛИ (ETEXT (A2: A10), 1 / СЧЁТЕСЛИ (A2: A10, A2: A10);»»))}
Не забывайте, что это формула массива.
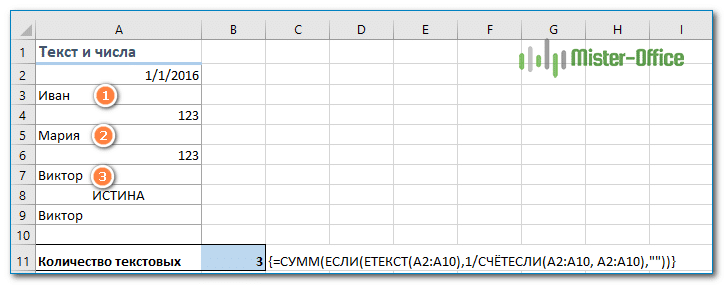
Если в вашей таблице нет пустых ячеек и ошибок, вы можете применить формулу, которая использует несколько функций: ЧАСТОТА, ПОИСК, СТРОКА и СУММПРОИЗВ.
В целом это выглядит так:
= СУММПРОИЗВ (- (ЧАСТОТА (ПОИСК (диапазон; диапазон; 0); СТРОКА (диапазон) — СТРОКА (диапазон_первый_ячейка) +1)> 0))
Предположим, у вас есть список имен сотрудников с указанием часов, в течение которых они работали над проектом, и вы хотите знать, сколько людей было задействовано. Глядя на данные, можно увидеть, что названия повторяются. И вы хотите посчитать всех, кто хоть раз попадал в этот список.
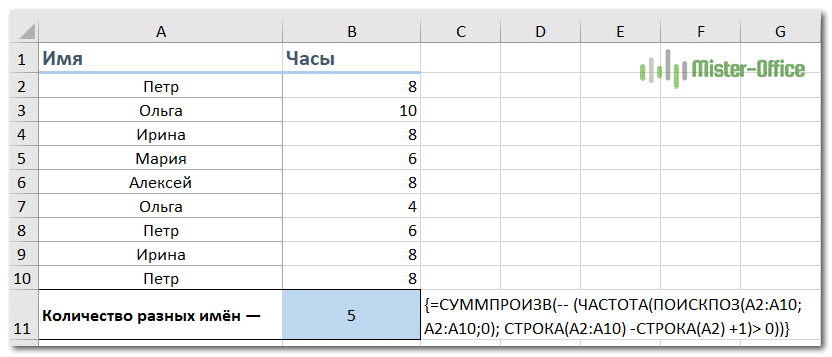
Применяем формулу массива:
{= СУММПРОИЗВ (- (ЧАСТОТА (ПОИСК (A2: A10; A2: A10,0); СТРОКА (A2: A10) -ЛИНИЯ (A2) +1)> 0))}
это сложнее, чем использование функции ЧАСТОТА () для подсчета разных чисел. Это потому, что FREQUENCY () не работает с текстом. Следовательно, MATCH преобразует имена в номера элементов, которые FREQUENCY () может обрабатывать().
Если какая-либо из ячеек в диапазоне пуста, вам нужно использовать более сложную формулу массива, которая включает функцию ЕСЛИ:
{= SUM (IF (FREQUENCY (IF (data «»; SEARCH (data; data; 0))); STRING (data) -LINE (data_first_cell) +1); 1))}
Примечание. Поскольку логический элемент управления в операторе IF содержит массив, наше выражение немедленно становится формулой массива, которая требует ввода с помощью Ctrl + Shift + Enter. Поэтому SUMPRODUCT был заменен на SUM.
В нашем примере это выглядит так:
{= СУММ (ЕСЛИ (ЧАСТОТА (ЕСЛИ (A2: A10 «», ПОИСК (A2: A10; A2: A10,0)), СТРОКА (A2: A10) -ЛИНИЯ (A2) +1), 1))}
Теперь этот расчет может быть «нарушен» только наличием ячеек с ошибками в исследуемом диапазоне.
Различные текстовые значения с условием.
Предположим, мы хотим пересчитать, сколько товаров заказал конкретный клиент.
В решении этой проблемы вам может помочь этот вариант:
{= СУММПРОИЗВ ((($ A $ 2: $ A $ 18 = E2)) / COUNTIF ($ A $ 2: $ A $ 18; $ A $ 2: $ A $ 18 & «»; $ B $ 2: $ B $ 18; $ B $ 2: $ B $ 18&»»))}
Введите его в пустую ячейку, куда вы хотите вставить результат, например F2. Затем нажмите одновременно Shift + Ctrl + Enter, чтобы получить правильный результат.
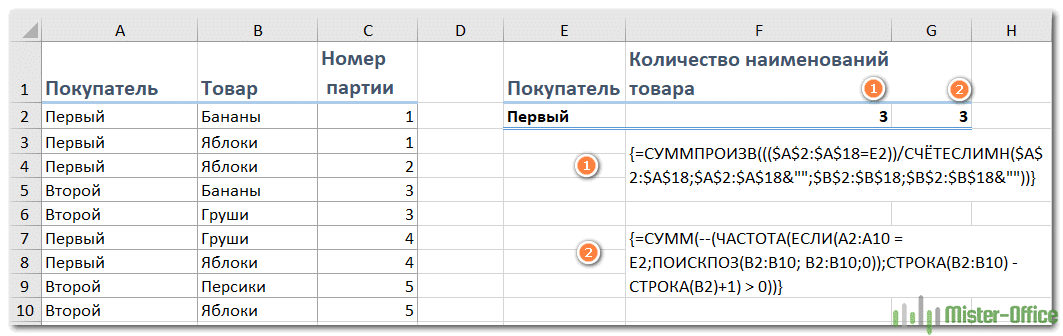
Поясним: здесь A2: A18 — это список покупателей с учетом того, какая область расчетов ограничена, B2: B18 — это список товаров, в которых вы хотите посчитать уникальные значения, E2 содержит критерий, на основании которого расчет ограничен только конкретным клиентом.
Второй способ.
Для уникальных значений в диапазоне с критериями можно использовать формулу массива, основанную на функции ЧАСТОТА.
{= СУММ (- (FREQUENCY (IF (критерий; MATCH (диапазон; диапазон; 0)); STRING (диапазон) -STRING (диапазон_первый_ячейка) +1)> 0))}
Применительно к нашему примеру:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (LA2: A10 = E2; ПОИСК (B2: B10; B2: B10,0)); СТРОКА (B2: B10) — СТРОКА (B2) +1)> 0))}
На основе ограничений IF () функция ПОИСКПОЗ определяет порядковый номер только для строк, которые соответствуют критериям.
Если какая-либо из ячеек в диапазоне критериев пуста, вам необходимо изменить расчет, добавив дополнительный SE для обработки пустых ячеек. В противном случае они будут переданы функции ПОИСКПОЗ, которая в ответ сгенерирует сообщение об ошибке.
Вот что произошло после корректировки:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (B2: B10 «»; ЕСЛИ (A2: A10 = E2; ПОИСК (B2: B10; B2: B10,0))); СТРОКА (B2: B10) -СТРОКА (B2) +1)> 0))}
То есть мы выполняем все действия и вычисления, если мы встретили непустую ячейку в столбце B: IF (B2: B10 «»….
Если у вас есть два критерия, вы можете расширить логику формулы, добавив еще один вложенный SE.
Мы объясняем. Определяем, сколько единиц товара было в первой партии покупателя.
Отметим критерии в G2 и G3.
В целом это выглядит так:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (критерий1, ЕСЛИ (критерий2, ПОИСКПОЗ (диапазон, диапазон, 0)))), СТРОКА (диапазон) — СТРОКА (диапазон_первый_элемент) +1)> 0))}
Подставляем сюда реальные данные и получаем результат:
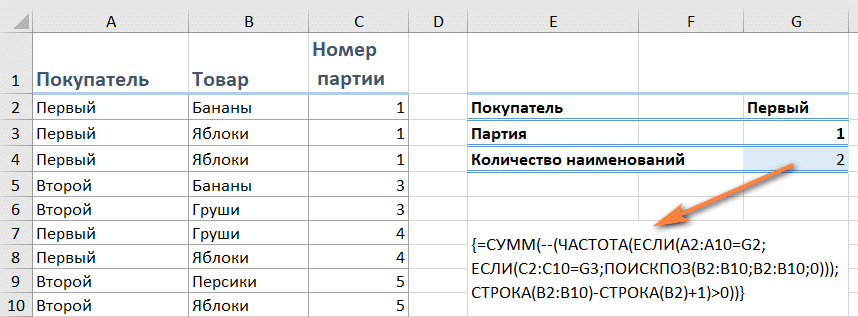
{= СУММ (- (ЧАСТОТА (ЕСЛИ (LA2: A10 = G2; ЕСЛИ (C2: C10 = G3; ПОИСК (B2: B10; B2: B10,0))); СТРОКА (B2: B10) -СТРОКА (B2) +1)> 0))}
У первого лота 2 товарных наименования, хотя есть 3 локации.
Различные числа с условием.
Если вам нужно пересчитать уникальные числа (с учетом первого вхождения) в диапазоне, с учетом некоторых ограничений, вы можете использовать формулу, основанную на СУММ и ЧАСТОТА, и одновременно применять критерии.
{= СУММ (- (ЧАСТОТА (ЕСЛИ (критерий, диапазон), диапазон)> 0))}
Предположим, у нас есть список сотрудников и количество отработанных часов в день. Необходимо посчитать, сколько человек проработали хотя бы один раз менее 8 часов, то есть неполную смену.
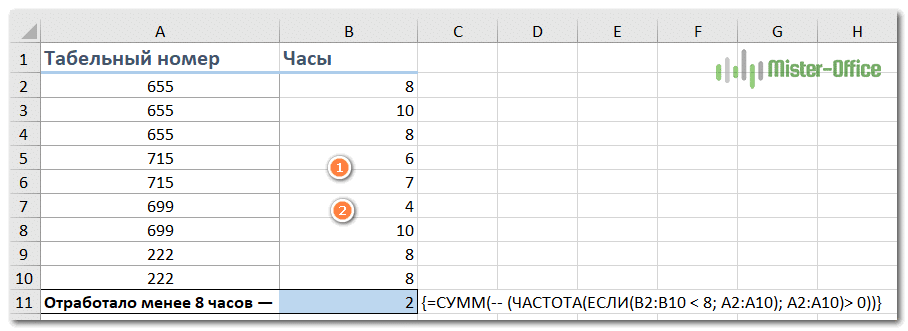
Вот наша матричная формула:
{= СУММ (- (ЧАСТОТА (ЕСЛИ (B2: B10 0))}
Как видите, таких случаев 3, но они связаны с двумя сотрудниками.
Различные значения с учетом регистра.
Подобно подсчету уникальных значений, самый простой способ подсчета различных значений с учетом регистра — это добавить вспомогательный столбец формулы массива, который идентифицирует нужные элементы, включая повторяющиеся первые вхождения.
Подход в основном такой же, как тот, который мы использовали для подсчета уникальных значений с учетом регистра, с одним небольшим изменением:
{= ЕСЛИ (СУММ ((- ТОЧНЫЙ ($ A $ 2: $ A2, $ A2))) = 1; «Уникальный»;»»)}
Как вы помните, все формулы массива в Excel требуют нажатия Ctrl + Shift + Enter.
Заметив это выражение, вы можете подсчитать «различные» значения, используя обычную функцию СЧЁТЕСЛИ, например:
= СЧЁТЕСЛИ (B2: B10; «Уникальный»)
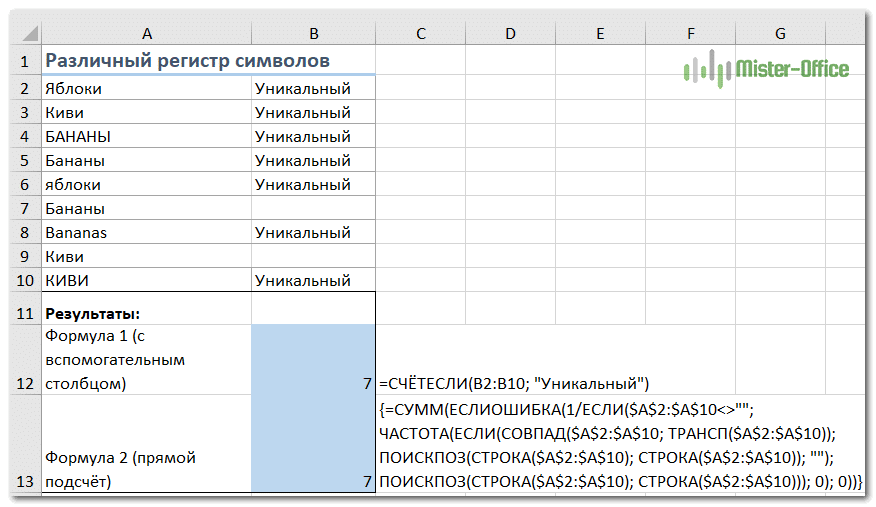
Если вы не можете добавить вспомогательный столбец на свой рабочий лист, вы можете использовать следующую более сложную формулу массива для подсчета различных значений с учетом регистра без создания дополнительного столбца:
{= СУММ (ЕСЛИОШИБКА (1 / IF ($ A $ 2: $ A $ 10 «»; FREQUENCY (IF (MATCH ($ A $ 2: $ A $ 10; TRANSPOSE ($ A $ 2: $ A $ 10)); ПОИСК (СТРОКА ($ A $ 2: $ A $ 10); СТРОКА ($ A $ 2: $ A $ 10)); «»); ПОИСК (СТРОКА ($ A $ 2: $ A $ 10)); LINE ($ A $ 2: $ A $ 10))); 0); 0))}
Как видите, обе формулы дают одинаковые результаты.
Подсчет уникальных строк в таблице.
Подсчет уникальных / различных строк в Excel аналогичен пересчету уникальных и различных значений. Единственное отличие состоит в том, что вы используете функцию СЧЁТЕСЛИ вместо СЧЁТЕСЛИ, которая позволяет вам указывать сразу несколько столбцов для проверки их уникальности.
Например, чтобы подсчитать уникальные строки на основе столбцов A (Имя) и B (Фамилия), используйте один из следующих вариантов:
Для уникальных строк:
{= СУММ (ЕСЛИ (СЧЁТЕСЛИМН (A3: A11; A3: A11; B3: B11; B3: B11) = 1; 1; 0))}
Для разных строк:
{= СУММ (1 / СЧЁТЕСЛИ (A3: A11; A3: A11; B3: B11; B3: B11))}
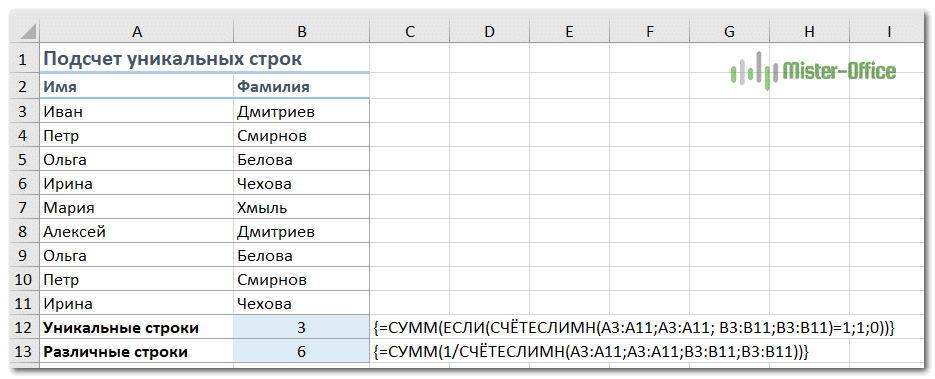
Конечно, вы не ограничены двумя столбцами. Функция СЧЁТЕСЛИ может обрабатывать до 127 пар диапазон / критерий.
Как можно использовать сводную таблицу.
Вот общая задача, которую все пользователи Excel должны время от времени выполнять. У вас есть список данных (например, названия продуктов), и вам нужно узнать количество уникальных позиций в этом списке. Как это сделать? Проще, чем вы думаете