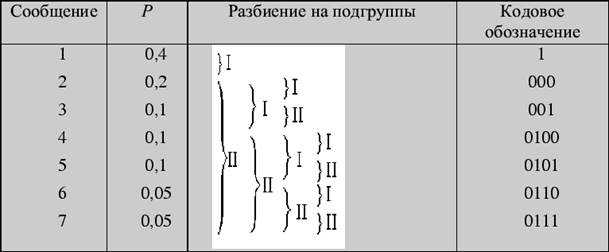
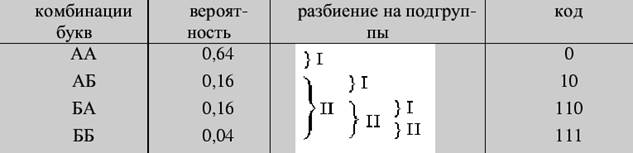
Решение 2 (табличный способ)
Цена кодирования (средняя длина кодового слова 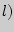 является критерием степени оптимальности кодирования. Вычислим ее в нашем случае.
является критерием степени оптимальности кодирования. Вычислим ее в нашем случае.
Для того чтобы закодировать сообщения по Хаффману, предварительно преобразуется таблица, задающая вероятности сообщений. Исходные данные записываются в столбец, две последние (наименьшие) вероятности в котором складываются, а полученная сумма становится новым элементом таблицы, занимающим соответствующее место в списке убывающих по величине вероятностей. Эта процедура продолжается до тех пор, пока в столбце не останутся всего два элемента.
Пример 2. Закодировать сообщения из предыдущего примера по методу Хаффмана.
Решение 1. Первый шаг

Вторым шагом производим кодирование, «проходя» по таблице справа налево (обычно это проделывается в одной таблице):
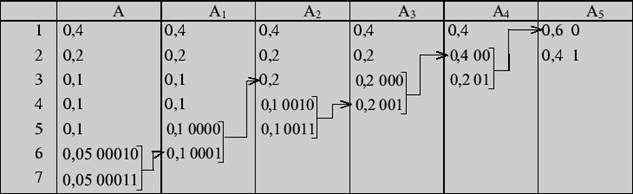
Решение 2. Построение кодового дерева начинается с корня. Двум исходящим из него ребрам приписывается в качестве весов вероятности 0,6 и 0,4, стоящие в последнем столбце. Образовавшимся при этом вершинам дерева приписываются кодовые символы 0 и 1. Далее «идем» по таблице справа налево. Поскольку вероятность 0,6 является результатом сложения двух вероятностей 0,4 и 0,2, из вершины 0 исходят два ребра с весами 0,4 и 0,2 соответственно, что приводит к образованию двух новых вершин с кодовыми символами 00 и 01. Процедура продолжается до тех пор, пока в таблице остаются вероятности, получившиеся в результате суммирования. Построение кодового дерева заканчивается образованием семи листьев, соответствующих данным сообщениям с присвоенными им кодами. Дерево, полученное в результате кодирования по Хаффману, имеет следующий вид:
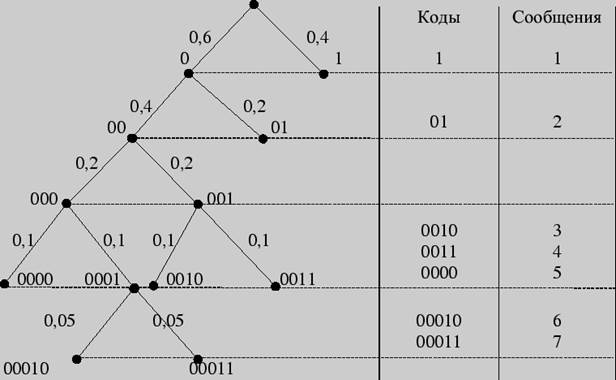
Рис. 2
Листья кодового дерева представляют собой кодируемые сообщения с присвоенными им кодовыми словами. Таблица кодов имеет вид:
| сообщение | |||||||
| код |
Цена кодирования здесь будет равна
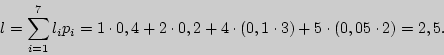
Для передачи данных сообщений можно перейти от побуквенного (поцифрового) кодирования к кодированию «блоков», состоящих из фиксированного числа последовательных «букв».
Пример 3. Провести кодирование по методу Фано двухбуквенных комбинаций, когда алфавит состоит из двух букв 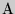 и
и 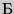 , имеющих вероятности
, имеющих вероятности  = 0,8 и
= 0,8 и  = 0,2.
= 0,2.
Решение.
Цена кода 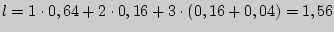 , и на одну букву алфавита приходится 0,78 бита информации. При побуквенном кодировании на каждую букву приходится следующее количество информации:
, и на одну букву алфавита приходится 0,78 бита информации. При побуквенном кодировании на каждую букву приходится следующее количество информации:
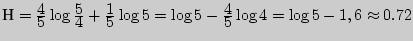 (бит).
(бит).
Пример 4. Провести кодирование по Хаффману трехбуквенных комбинаций для алфавита из предыдущего примера.

Построим кодовое дерево.
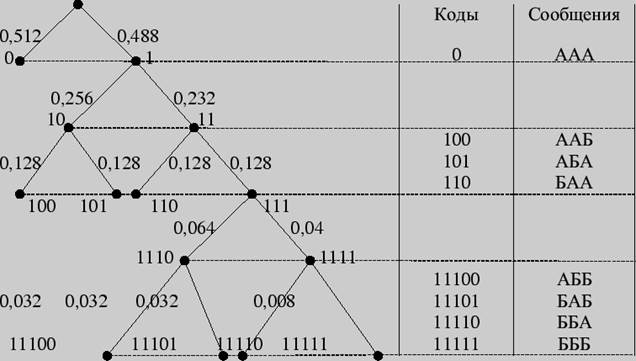
Рис. 3
Найдем цену кодирования
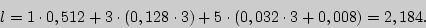
На каждую букву алфавита приходится в среднем 0,728 бита, в то время как при побуквенном кодировании — 0,72 бита.
Большей оптимизации кодирования можно достичь еще и использованием трех символов — 0, 1, 2 — вместо двух. Тринарное дерево Хаффмана получается, если суммируются не две наименьшие вероятности, а три, и приписываются каждому левому ребру 0, правому — 2, а серединному — 1.
Пример 5. Построить тринарное дерево Хаффмана для кодирования трехбуквенных комбинаций из примера 4.
Решение. Составим таблицу тройного «сжатия» по методу Хаффмана

Тогда тринарное дерево выглядит следующим образом:
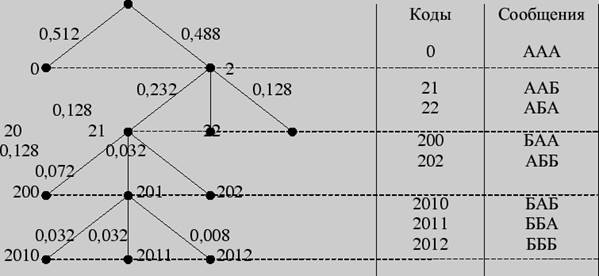
Рис. 4
Задачи
I1. Проведите кодирование по методу Фано алфавита из четырех букв, вероятности которых равны 0,4; 0,3; 0,2 и 0,1.
2. Алфавит содержит 7 букв, которые встречаются с вероятностями 0,4; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05. Осуществите кодирование по методу Фано.
3. Алфавит состоит из двух букв,  и , встречающихся с вероятностями
и , встречающихся с вероятностями  = 0,8 и
= 0,8 и 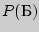 = 0,2. Примените метод Фано к кодированию всевозмож-ных двухбуквенных и трехбуквенных комбинаций.
= 0,2. Примените метод Фано к кодированию всевозмож-ных двухбуквенных и трехбуквенных комбинаций.
4. Проведите кодирование по методу Хаффмана трехбуквенных слов из предыдущей задачи.
5. Проведите кодирование 7 букв из задачи 302 по методу Хаффмана.
6. Проведите кодирование по методам Фано и Хаффмана пяти букв, равновероятно встречающихся.
II 7. Осуществите кодирование двухбуквенных комбинаций четырех букв из задачи 301.
8. Проведите кодирование всевозможных четырехбуквенных слов из задачи 303.
III 9. Сравните эффективность кодов Фано и Хаффмана при кодировании алфавита из десяти букв, которые встречаются с вероятностями 0,3; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05; 0,04; 0,03; 0,03.
10. Сравните эффективность двоичного кода Фано и кода Хаффмана при кодировании алфавита из 16 букв, которые встречаются с вероятностями 0,25; 0,2; 0,1; 0,1; 0,05; 0,04; 0,04; 0,04; 0,03; 0,03; 0,03; 0,03; 0,02; 0,02; 0,01; 0,01.
![]()
При l 1 c1 k, где k – число букв в алфавите B , следовательно, для префиксного кода можно выбрать c1 однобуквенных кодовых слов.
|
При l |
2 c |
k 2 |
l k |
k k c . |
|
2 |
1 |
1 |
||
|
Пусть c1 |
буква выбрана как однобуквенное кодовое слово, тогда |
для построения двухбуквенного кодового слова, обладающего
|
свойством префикса, у первой буквы остается k |
c1 возможность, у |
|
второй буквы k возможностей, то есть всего k k |
c1 возможностей, |
а c2 , число двухбуквенных кодовых слов в исходном коде, не
превосходит этого числа.
Пусть выбраны c1 кодовое слово длины 1, c2 слова длины два, и так далее вплоть до cl 1 слова длины l 1, обладающих свойством
префикса.
Покажем, что можно выбрать cl кодовых слов длины l , также обладающих свойством префикса.
В алфавите B слов длины l и k l . Найдем количество запрещенных слов, начинающихся с уже выбранных кодовых слов. Если какая-то буква выбрана в качестве однобуквенного кодового слова, то запрещены все слова длины l , начинающиеся с этой буквы, таких слов kl 1 .
Учитывая, что однобуквенных кодовых слов c1 , запрещено c1kl 1 слово. Запрещены все слова длины l , начинающиеся с c2 выбранных двухбуквенных слов, их c2kl 2 .
Таким образом число возможностей для выбора кодовых слов длины l , обладающих свойством префикса равно
|
kl |
c kl 1 |
c kl 2 |
c kl 3… |
c k , а |
c |
– число слов длины l в |
|
1 |
2 |
3 |
l 1 |
l |
исходном алфавите не превосходит этого числа. Следовательно, можно построить префиксный код с тем же набором длин кодовых слов, как в исходном взаимно однозначном коде .
13

3. Оптимальный код.
В русском алфавите 32 буквы, е и ё можно считать за одну букву, предположим их надо закодировать равномерным кодом в алфавите B {0, 1} . Тогда длина каждого кодового слова должна быть равна 5, любое сообщение становится длиннее в 5 раз. С другой стороны, такие буквы как щ; ч; ы; ъ; ь и так далее встречаются редко, их можно было бы закодировать более длинными кодовыми словами, а встречающиеся часто – более короткими. Так возникает идея оптимальных кодов, которая связана с частотной (вероятностной) характеристикой букв кодируемого алфавита.
|
Каждая |
буква |
ai |
кодируемого |
алфавита A обладает своей |
||||||||
|
частотой |
(вероятностью) использования в языке, |
обозначим |
ее |
|||||||||
|
m |
||||||||||||
|
pi , pi |
0, |
pi 1. |
Пусть |
задано |
алфавитное |
кодирование: |
||||||
|
i 1 |
||||||||||||
|
ai |
Bi , |
длина |
Bi |
равна li . Посмотрим, |
как |
меняется |
при |
|||||
|
кодировании длина |
N слова |
A1 , |
A1 |
ɱ A , то есть найдем длину |
||||||||
|
слова |
A1 . |
|||||||||||
|
Буква ai |
входит в слово A1 |
pi N раз, при кодировании она даст |
||||||||||
|
длину pi Nli , следовательно, длина слова |
A1 будет равна |
|||||||||||
|
m |
m |
|||||||||||
|
pi Nli |
N |
pili . |
||||||||||
|
i 1 |
i 1 |
|||||||||||
|
Определение. Ценой кодирования называется число c , где |
||||||||||||
|
m |
||||||||||||
|
c |
pili . |
|||||||||||
|
i |
1 |
|||||||||||
|
Цена |
кодирования |
показывает, во |
сколько |
раз |
увеличивается |
длина любого слова при кодировании, и является средней длиной кодового слова (математическим ожиданием кодового слова).
При фиксированных алфавитах A и B рассмотрим множество
|
взаимно однозначных кодов |
, цена кодирования каждого c . |
|||
|
Найдем min c |
на |
множестве |
, он очевидно, |
будет |
|
характеристикой кодируемого алфавита A: |
||||
|
min c |
c |
p1, p2, …pm |
(8) |
|
|
14 |

|
Определение. Код ,такой что c |
c p1, p2, …pm , называется |
оптимальным кодом или кодом с минимальной избыточностью. Пусть – оптимальный код, заданный набором кодовых слов
{B1,…Bm} с длинами l1, l2 ,…lm . Можно построить префиксный код ( по
теореме о существовании префиксного кода) с тем же набором длин кодовых слов, следовательно, с той же ценой кодирования.
Замечание. Среди оптимальных кодов всегда есть префиксный
|
код. |
||||||||
|
Пример 7. Пусть даны алфавиты |
A |
{a1, a2 , a3 , a4} |
с |
|||||
|
вероятностями |
p1 0,4, |
p2 |
0,25, |
p3 0,2 |
и |
p4 |
0,15 |
и |
|
кодирующий алфавит B {0, 1}. |
||||||||
|
Рассмотрим два кода K1 |
{00, 01,10,11} и K2 |
{1, 01, 000, 001}. |
||||||
|
Код K1 – равномерный, |
K2 |
– |
префиксный, |
оба |
однозначно |
декодируемые. Найдем для каждого цену кодирования.
|
c |
K1 |
0, 4 |
2 |
0, 25 2 |
0, 2 2 |
0,15 2 |
2 |
|
c |
K2 |
0, 4 1 |
0, 25 2 |
0, 2 3 |
0,15 3 |
1,95. |
Рассмотрим свойства оптимальных префиксных кодов.
1.Упорядоченность вероятностей кодового дерева по ярусам.
|
Пусть даны алфавит |
A |
{a1, a2 ,.. am} с набором вероятностей |
||||||
|
P {p1, p2 ,…pm}, |
алфавит |
B |
{0, 1}, оптимальный префиксный код |
|||||
|
K {B1, B2 ,…Bm}, где Bi |
ai |
, длина кодового слова Bi |
равна li . |
|||||
|
Тогда |
||||||||
|
а) если pi |
p j то li |
l j ; |
||||||
|
б) если lk |
max{l1, l2 ,…lm} и кодовое |
слово Bk |
B |
, где |
||||
|
{0, 1}, то существует кодовое слово B |
, |
входящее в K , |
то есть |
|||||
кодовые слова максимальной длины в оптимальный двоичный префиксный код входят попарно.
Замечание. Код называется q -ичным, если кодирующий алфавит B содержит q символов.
15

|
Доказательство. |
||||||||||||||
|
а) Пусть pi |
pj |
и li |
l j . Построим код K1 , переставив в коде K |
|||||||||||
|
два кодовых слова: |
ai |
Bj , |
aj |
Bi . |
||||||||||
|
Рассмотрим |
||||||||||||||
|
c(K ) |
c K1 |
p1l1 |
… |
pili … |
p jl j |
…pmlm |
||||||||
|
( p1l1 … |
pil j … |
pjli … |
pmlm ) |
|||||||||||
|
pili |
pjl j |
pil j |
pjli |
pi |
li |
l j |
pj li |
l j |
||||||
|
li |
l j pi |
pj |
0, |
|||||||||||
|
откуда следует c K1 |
c K , |
то есть код |
K не оптимальный, что |
|||||||||||
|
противоречит условию. |
||||||||||||||
|
б) Пусть кодовое слово Bk |
B |
и имеет максимальную длину |
||||||||||||
|
lmax , а кодового слова |
B |
нет. Рассмотрим |
фрагмент кодового |
|||||||||||
|
дерева, построенного для этого кода (рис. 8). |
||||||||||||||
|
Построим код K1 , |
заменив в коде K |
ak |
B , в |
|||||||||||
|
этом случае вершина B |
станет висячей, получим |
|||||||||||||
|
кодовое |
дерево |
для |
префиксного |
кода |
K1 . |
|||||||||
|
Рассмотрим |
||||||||||||||
|
c(K) |
c K1 |
p1l1 |
… |
pk lmax |
… pmlm |
|||||||||
|
Рис. 8 |
( p1l1 |
… |
pk |
lmax |
1 |
…pmlm ) pk |
0 . |
|||||||
|
Вновь пришли к противоречию, получив взаимно однозначный |
||||||||||||||
|
код K1 с ценой меньшей, чем оптимальный код. |
||||||||||||||
|
Следствие. |
В кодовом дереве для оптимального префиксного |
кода вероятности, приписанные вершинам предыдущего яруса, не меньше, чем вероятности, приписанные концевым вершинам следующего яруса.
|
2. Возможность построения упорядоченного оптимального |
||||||
|
кода. |
||||||
|
Пусть K |
B1, B2 ,…, Bm – оптимальный префиксный двоичный |
|||||
|
код |
для |
набора |
вероятностей |
P |
p1, p2 ,…pm , причем |
|
|
p1 |
p2 … |
pm . Тогда, переставив слова в коде K , |
можно получить |
|||
|
код |
K1 |
B1 , B2 ,…, Bm |
с длинами кодовых слов |
l1 ,l2 ,…,lm , для |
которого будут выполняться три условия:
16

|
а) код K1 – оптимальный, то есть c K1 |
c K , |
|
|
б) l1 l2 … |
lm , |
|
|
в) кодовые |
слова Bm 1 и Bm будут |
отличаться только в |
|
последнем разряде. |
||||||||||||||
|
Доказательство. Пусть li |
li 1 |
для какого-нибудь i . |
Тогда по |
|||||||||||
|
предыдущему свойству |
pi |
pi 1 , но по условию |
pi pi |
1 , |
отсюда |
|||||||||
|
pi |
pi 1 . Построим код K1 |
, |
переставив два кодовых слова в коде K , |
|||||||||||
|
то есть положим |
ai |
Bi |
1, |
ai 1 |
Bi . |
|||||||||
|
Рассмотрим |
||||||||||||||
|
c(K ) |
c K1 |
p1l1 … |
pili |
pi 1li 1 |
… |
pmlm |
||||||||
|
( p1l1 |
… |
pili 1. |
pi |
1li … |
pmlm ) |
|||||||||
|
pili |
pi 1li 1 |
pili 1 |
pi 1li |
|||||||||||
|
li |
pi |
pi 1 |
li 1 pi 1 |
pi |
0 |
|||||||||
|
c K1 |
c K , |
K1 |
– оптимальный код. Переставив так все кодовые |
|||||||||||
|
слова, |
для |
которых |
l j |
l j 1 , получим |
код K1 |
B1 , B2 |
,…, Bm |
, |
||||||
|
c K1 |
c K |
и |
длины |
кодовых |
слов будут |
расположены |
по |
|||||||
|
неубыванию, |
длина |
Bm |
lmax . |
Но |
возможно, |
кодовые |
слова |
максимальной длины, отличающиеся только в последнем разряде не будут стоять рядом. Пусть Bm B , Bm 2 B , но тогда длина Bm 1 также равна lmax . Переставив местами кодовые слова Bm 1 и Bm 2 ,
|
получим код K1 , рассмотрим c K1 |
c K1 |
= |
|||
|
pm 2lm 2 |
pm 1lm 1 |
pm 2lm 1 |
pm 1lm 2 |
||
|
pm 2lmax |
pm 1lmax |
pm 2lmax |
pm 1lmax |
0, цена кодирования не |
|
|
изменилась, |
K1 – оптимальный код. |
17

Лемма о префиксных кодах.
Пусть даны два двоичных кода K1 и K2 . Код
K1 {B1,…Bm , B 0, B 1}с набором вероятностей P {p1,…pm , p , p }, длина кодового слова Bi равна li , длина слова B равна l , тогда длины кодовых слов B 0 и B 1 равны l 1. Код K2 {B1,…Bm , B } с набором
|
вероятностей p1,…pm , p |
p p . |
|
|
Тогда утверждается: |
||
|
а) если K1 |
префиксный код, то K2 тоже префиксный код, и |
|
|
наоборот; |
||
|
б) c K1 |
c K2 |
p . |
Доказательство
а) Пусть K1 – префиксный код, тогда для него существует
кодовое дерево, висячим вершинам которого соответствуют кодовые слова. Рассмотрим фрагмент этого дерева (рис.9).
|
Если убрать |
вершины |
B 0 и |
B 1 |
вместе |
|
|
инцидентными |
ребрами, |
вершина |
B станет |
||
|
висячей, мы получим кодовое дерево для кода K2 , в |
|||||
|
котором кодовым словам соответствуют только |
|||||
|
висячие вершины, следовательно, |
код |
K2 – |
|||
|
Рис.9 |
префиксный. |
Наоборот, если K2 – префиксный, то вершина, соответствующая кодовому слову B , висячая. Добавив к этой вершине два ребра, получим две висячие вершины B 0 и B 1, а слово B в код K1 не входит, вновь получим кодовое дерево для префиксного кода.
|
б) Найдем цену кодирования кода K1 . |
|||||||
|
c K1 |
p1l1 |
… pmlm |
p |
l |
1 |
p |
l 1 |
|
p1l1 … |
pmlm |
p |
p |
l |
p |
p |
|
|
p1l1 … |
pmlm |
pl |
p |
c K2 |
p . |
18

|
Теорема редукции |
|||||||
|
Пусть K1 |
{B1,…Bm , B 0, B 1} |
двоичный |
код для |
вероятностей |
|||
|
кодируемого |
алфавита |
p1, p2 ,…pm , p , p , |
а |
K2 |
{B1,…Bm B } |
||
|
двоичный код для вероятностей p1, p2 ,…pm , p |
p |
p . |
|||||
|
Тогда |
|||||||
|
а) если K1 –оптимальный префиксный код, то K2 также |
|||||||
|
оптимальный префиксный код; |
|||||||
|
б) |
если |
K2 –оптимальный префиксный |
код |
и |
вероятности |
||
|
упорядочены |
p1 p2 … |
pm p |
p , то |
K1 |
тоже оптимальный |
||
|
префиксный код. |
|||||||
|
Доказательство |
|||||||
|
а) |
Пусть |
K1 – оптимальный префиксный код, |
K2 –префиксный |
код (по лемме), но пусть он не оптимальный. Тогда существует
|
оптимальный код K2 , такой что c K2 |
c K2 . Среди оптимальных |
|||||
|
кодов можно |
найти |
префиксный |
код K2 , |
такой |
что |
|
|
c K2 |
c K2 |
c K2 . |
||||
|
Пусть |
K2 {B1, B2 ,…Bm , B }. |
Построим |
код |
|||
|
K1 |
{B1, B2 ,…Bm , B 0 B 1}, |
он префиксный, цена кодирования |
его |
|||
|
c K1 |
c K2 |
p c K2 |
p c K1 , то |
есть код K1 |
имеет |
цену |
|
меньше, чем код K1 , что невозможно, так как K1 –оптимальный код. |
||||||
|
б) Пусть K2 – оптимальный префиксный код, K1 –префиксный |
||||||
|
код, |
но пусть он не оптимальный, тогда существует оптимальный |
префиксный код K1 и c K1 c K1 .
Пусть K1 {B1, B2 ,…Bm , Bm 1, Bm 2}. Так как вероятности
упорядочены по невозрастанию, по теореме о возможности построения упорядоченного оптимального кода, можно перестроить код K1 и получить код K1 , в котором кодовые слова расположены в
порядке неубывания длин и два последних слова отличаются только в последнем разряде:
|
K1 {B1, B2 ,…Bm , B , B |
}, c K1 c K1 |
c K1 . |
|
|
По коду K1 можно построить код K2 |
{B1, B2 ,…Bm , B }, |
19

c K2 c K1 p c K1 p c K2 , то есть мы нашли код, цена кодирования которого меньше, чем у оптимального кода – противоречие.
Следствие. Теорема редукции дает алгоритм построения оптимального кода, который называется кодом Хаффмена.
Пример 8. Построить оптимальный двоичный префиксный код
|
для упорядоченного набора вероятностей |
||||||||||||||
|
P 0,3, 0,3, 0, 2, 0,1, 0,05, 0,05 |
. Процедура Хаффмена выглядит |
|||||||||||||
|
следующим образом: |
||||||||||||||
|
Таблица 1 |
||||||||||||||
|
p |
1 |
2 |
3 |
4 |
||||||||||
|
00 |
0,3 |
0,3 |
0,3 |
0, 4 |
0, 6 |
0 |
||||||||
|
01 |
0,3 |
0,3 |
0,3 |
0,3 |
0, 4 |
1 |
||||||||
|
10 |
0,2 |
0,2 |
||||||||||||
|
0, 2 |
0,3 |
|||||||||||||
|
110 |
0,1 |
0,1 |
||||||||||||
|
0, 2 |
||||||||||||||
|
1110 |
0,05 |
|||||||||||||
|
0,1 |
||||||||||||||
|
1111 |
||||||||||||||
|
0,05 |
||||||||||||||
|
Для |
набора вероятностей |
0, 6;0, 4 , |
то есть для |
двух |
букв, |
|||||||||
|
оптимальным будет код 0,1 . |
Он играет роль кода K2 |
из теоремы |
||||||||||||
|
редукции, |
тогда код, |
построенный из K2 |
для набора вероятностей |
0, 4; 0, 3; 0, 3 , играет роль кода K1 и будет оптимальным. Повторяя
этот процесс, мы получим оптимальный код для исходного набора вероятностей. Для этих «обратных» шагов удобнее строить кодовое дерево (рис. 10).
Рис. 10
20

На этом примере видно, что хотя шаги 1-4 стандартны, оптимальный код не будет единственным, например, для вероятности 0,6 можно было взять кодовое слово 1, для 0,4 взять 0. На рис. 11 показано другое кодовое дерево для этого же набора вероятностей и соответствующий ему набор кодовых слов
K 11, 10, 01, 000, 0010, 0011
Рис. 11
4. Самокорректирующийся код
При передаче сообщения в канале связи может действовать источник помех или шумов. Ясно, что при произвольных помехах невозможно восстановить исходное сообщение. Код, позволяющий восстановить исходное сообщение при некоторых ограничениях на шумы, так называющий самокорректирующий код, был предложен Ричардом Хэммингом в 1950 году.
Рассмотрим равномерное кодирование, при котором длина каждого кодового слова равна l , а алфавит B 0,1 . Будем
предполагать, что помехи, во первых, не меняют длину кодовых слов, во-вторых, в каждом кодовом слове происходит не более p ошибок
p l типа замещение, то есть 0 меняется на 1, а 1 меняется на 0. Определение. Код называется корректирующим p ошибок типа
замещения, если при замене не более чем p символов в любом кодовом слове, можно восстановит это кодовое слово.
Хэмминг подробно описал код, корректирующий одну ошибку,
|
именно его мы и рассмотрим. |
|||
|
Пусть кодовое слово Bs |
1 2 |
l , где каждое i 0,1 , и k – |
|
|
минимальное натуральное число, такое что l 2k |
1. |
21

|
Тогда все числа от 1 до l можно закодировать k -разрядными |
||||||||||
|
двоичными числами, если t |
1,l , то его можно записать |
|||||||||
|
t |
tk 1,tk 2 , |
,t2 ,t1 |
,t0 |
2 |
. |
|||||
|
В |
множестве чисел |
1, 2, |
, l |
введем |
подмножества |
|||||
|
wi |
t : ti |
1 , тогда |
||||||||
|
w0 |
t : t0 |
1 |
1,3,5,7, |
, |
||||||
|
w1 |
t : t1 |
1 |
2, 4,6,7, |
, |
||||||
|
w2 |
t : t2 |
1 |
4,5,6,7, |
, |
||||||
|
wk |
1 |
t : tk 1 |
1 . |
Эти подмножества пересекаются, но не совпадают, причем среди чисел 1,2, ,l есть такие, которые попадают ровно в одно
подмножество. Такими числами будут степени числа два: 20 ,21,22 и так далее, так как в их двоичном представлении присутствует всего одна 1.
|
Определение. |
Кодом Хэмминга длины l называется множество |
|||||||||||
|
слов |
1 2 |
l , |
i |
0,1 |
, |
удовлетворяющих |
следующим |
|||||
|
условиям: |
||||||||||||
|
t |
0, |
t |
0, |
t |
0, |
(9) |
||||||
|
t w0 |
t w1 |
t |
wk 1 |
|||||||||
|
где |
означает сумму по модулю 2. |
|||||||||||
|
Теорема о коде Хэмминга. |
||||||||||||
|
1. |
Код Хэмминга длины l |
содержит 2l |
k |
кодовых слов. |
||||||||
|
2. |
k – целая часть сверху log2 |
l |
1 : |
k |
log2 (l 1) . |
|||||||
|
3. |
Код корректирует одну ошибку типа замещения. |
22
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Привет, сегодня поговорим про методы кодирования физических сигналов в компьютерных сетях , обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое
методы кодирования физических сигналов в компьютерных сетях , настоятельно рекомендую прочитать все из категории Теория информации и кодирования.
Тема10. Методы кодирования физических сигналов в компьютерных сетях.
Лекция16.
16.1Кодированиенафизическомуровне.
Отметим, что в этой лекции мы рассмотрим кодирование сигналов а не информации. Целью кодирования является кодирование или преобразование «0» и «1» поступающего кода в уровни электрических сигналов в линиях связи.
Прогресс последних лет в области повышения пропускной способности цифровых каналов связан с развитием технологии передачи цифровых данных. Здесь нужно решить проблемы синхронизации, эффективного кодирования и надежной передачи.
Проблема синхронизации состоит в том, что при генерации сигнала длительность элементарной позиции сигнала и такт их поступления на передающей стороне строго заданы и определяются тактовой частотой системы передачи.. На приемном конце для правильного восстановления сигнала необходимо иметь строго такие же параметры тактовой частоты и более того, необходима синхронизация до отдельного такта тактовой частоты.
Для решенияпроблемы синхронизации существует два метода передачи данных: синхронныйиасинхронный. Асинхронный метод используется для относительно низкоскоростных каналов передачи и автономного оборудования. Синхронный метод применяется в скоростных каналах и базируется на пересылке синхронизующего тактового сигнала по отдельному каналу или путем совмещения его с передаваемыми данными. При наличии синхронизации приемника и передатчика можно передавать более длинные последовательности нулей или единиц, без сбоев при их приеме.
Типичный кадр данных в асинхронном канале начинается со стартового бита, за которым следует 8 битов данных. Завершается такой кадр одним или двумя стоп-битами. Стартовый бит имеет полярность противоположную пассивному состоянию линии и переводит приемник в активное состояние. Пример передачи такого кадра показан на рис. 16.1
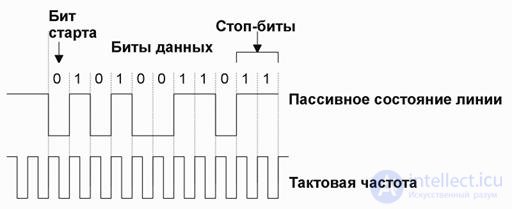
Рис. 16.1 Пример передачи кадра в асинхронном режиме
Начальный и стоп-биты на каждый байт данных снижают пропускную способность канала и по этой причине используются только для низких скоростей обмена. Увеличение же длины блока данных приводит к ужесточению требований к точности синхронизации. При использовании синхронного метода передачи необходимы специальные меры для выделения синхронизации из общего потока данных. Для решения этой задачи обычно используется особые свойства передаваемого кода, из которого извлекаются синхроимпульсы.
Рассмотримразличные методы кодирования сигналов для передачи сигналов по оптической, либопроводной линии связи. .
В основном рассмотрим методы кодирования для компьютерных сетей – или как их называют Ethernet – стандарты 10Base-T и 100 Base-TX и 1GB Ethernet.
16.2Самосихронхронизирующиесякоды — кодыRZиМанчестер—II.
Код RZ
RZ — это трехуровневый код, обеспечивающий возврат к нулевому уровню после передачи каждого бита информации. Его так и называют — «кодирование с возвратом к нулю» (Return to Zero). Логическому нулю соответствует положительный импульс, логической единице — отрицательный.
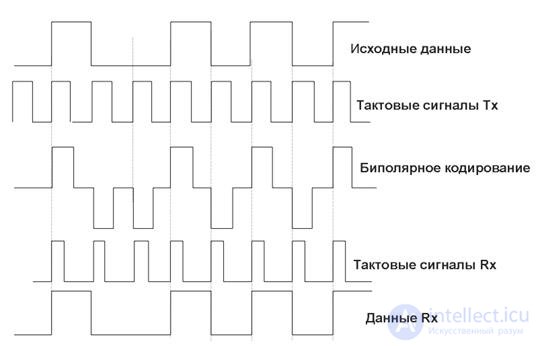
Рис. 16.2. Пример биполярного кодирования сигнала (схема RZ – return-to-zero)
Информационный переход осуществляется в начале бита, возврат к нулевому уровню — в середине бита. Особенностью кода RZ является то, что в центре бита всегда есть переход (положительный или отрицательный). Следовательно, каждый бит обозначен. Приемник может выделить синхроимпульс (строб), имеющий частоту следования импульсов, из самого сигнала. Привязка производится к каждому биту, что обеспечивает синхронизацию приемника с передатчиком. Такие коды, несущие в себе строб, называются самосинхронизирующимися.
Недостаток кода RZ состоит в том, что он не дает выигрыша в скорости передачи данных. Для передачи со скоростью 10 Мбит/с требуется частота несущей 10 МГц. Кроме того, для различения трех уровней (+1, 0, -1)необходимо лучшее соотношение сигнал / шум на входе в приемник, чем для двухуровневых кодов.
Наиболее часто код RZ используется в оптоволоконных сетях . Об этом говорит сайт https://intellect.icu . При передаче света не существует положительных и отрицательных сигналов, поэтому используют три уровня мощности световых импульсов. (Р=»1″, 0.5Р=»0″, 0Р=»-1″)
Код Манчестер-II
Код Манчестер-II или манчестерский код получил наибольшее распространение в локальных сетях. Он также относится к самосинхронизирующимся кодам, но в отличие от кода RZ имеет не три, а только два уровня, что обеспечивает лучшую помехозащищенность.
При низкой скорости обмена (10 Мбит/с) используется манчестерский код, при котором логическая единица кодируется переходом сигнала с низкого уровня на высокий (рис.2 и рис. 11.3), а логический ноль — переходом с высокого уровня на низкий. Недостатком манчестерского кода является широкая полоса частотного спектра, связанная с необходимостью переключения уровней сигнала при поступлении каждой двоичной цифры
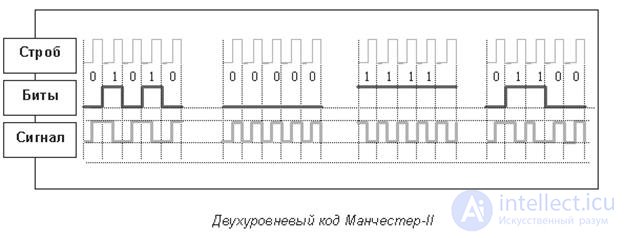
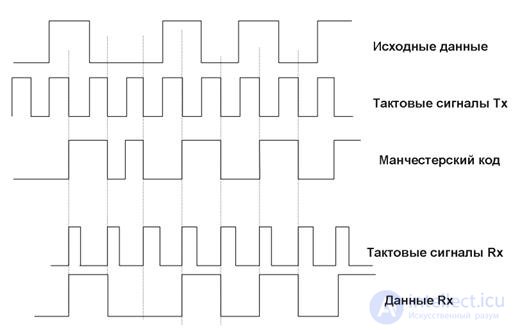
Рис. 16.3. Кодирование сигнала с использованием манчестерского кода.
Большое достоинство манчестерского кода — отсутствие постоянной составляющей при передаче длинной последовательности единиц или нулей. Благодаря этому гальваническая развязка сигналов выполняется простейшими способами, например, с помощью импульсных трансформаторов.
Код Манчестер-II нашел применение в медных и оптоволоконных исетях передачи данных. Самый распространенный протокол локальных сетей Ethernet 10 Мбит/с использует именно этот код.
16.3Несамосинхронизирующиесякоды. — кодNRZ.
Код NRZ (Non Return to Zero) — без возврата к нулю — это простейший двухуровневый код. Нулю соответствует нижний уровень, единице — верхний. Информационные переходы происходят на границе битов.
Несомненное достоинство кода — простота. Сигнал не надо кодировать и декодировать.
Кроме того, скорость передачи данных вдвое превышает тактовую частоту. Наибольшая частота будет фиксироваться при чередовании единиц и нулей. При частоте 1 Гц обеспечивается передача двух битов. Для других комбинаций частота будет меньше. При передаче последовательности одинаковых битов частота изменения сигнала равна нулю.
Код NRZI — Non Return to Zero Invert to ones метод без возврата к нулю с инвертированием для единиц. Этот метод представляет собой модификацию (NRZ), В методе NRZI также используется два уровня потенциала сигнала, но потенциал, используемый для кодирования текущего бита зависит от потенциала, который использовался для кодирования предыдущего бита (так называемое дифференциальное кодирование). Если текущий бит имеет значение 1, то текущий потенциал представляет собой инверсию значения предыдущего бита, независимо от его значения. Если же текущий бит имеет значение 0, то текущий потенциал повторяет предыдущий.
Код NRZ и NRZI не имеет синхронизации. Это является самым большим его недостатком. Если тактовая частота приемника отличается от частоты передатчика, теряется синхронизация, биты искажаются, данные теряются.
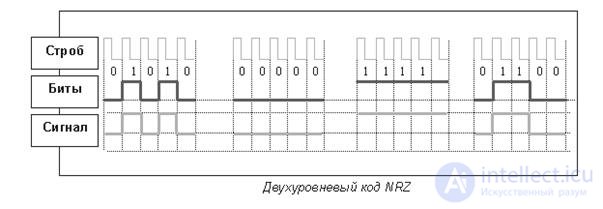
 |
Рис. 16.4.Коды NRZ, NRZI и MLT3
Для синхронизации начала приема пакета используется стартовый служебный бит, например, единица.
Наиболее известное применение кода NRZIпротокол USB –в USB 2.0 скорость передачи до 480 Мбит., кроме того он применяется в очень широкополосных каналах передачи данных — стандарт ATM155 скорость передачи 155Мб.
Самый распространенный протокол RS232, применяемый для соединений через последовательный порт ПК, также использует код NRZ. Передача информации ведется байтами по 8 бит, сопровождаемыми стартовыми и стоповыми битами.
16.4 Высокоскоростные коды— код MLT—3иPAM5.
Код трехуровневой передачи MLT-3 (Multi Level Transmission — 3) имеет много общего с кодом NRZ. Важнейшее отличие — три уровня сигнала.
Единице соответствует переход с одного уровня сигнала на другой. Изменение уровня сигнала происходит последовательно с учетом предыдущего перехода. Максимальной частоте сигнала соответствует передача последовательности единиц. При передаче нулей сигнал не меняется. Информационные переходы фиксируются на границе битов. Один цикл сигнала вмещает четыре бита.
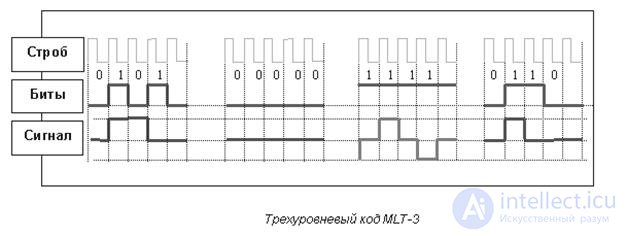
Рис 16.5. Трехуровневый код MLT-3
Недостаток кода MLT-3, как и кода NRZ — отсутствие синхронизации. Эту проблему решают с помощью преобразования данных, которое исключаетв коде длинные последовательности нулей и исключает возможность рассинхронизации.
Дополнительное преобразование данных производится при помощи метода предварительного перекодирования данных 4B5B
Протоколы, использующие код NRZ, чаще всего дополняют кодированием данных 4B5B. В отличие от кодирования сигналов, которое использует тактовую частоту и обеспечивает переход от импульсов к битам и наоборот, кодирование данных преобразует одну последовательность битов в другую.
В коде 4B5B используется пяти-битовая основа для передачи четырех-битовых информационных сигналов. Пяти-битовая схема дает 32 (два в пятой степени) двухразрядных буквенно-цифровых символа, имеющих значение в десятичном коде от 00 до 31. Для данных отводится четыре бита или 16 (два в четвертой степени) символов.
Четырех-битовый информационный сигнал перекодируется в пяти-битовый сигнал в кодере передатчика. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере приемника пять битов расшифровываются как информационные и служебные сигналы. Для служебных сигналов отведены девять символов, семь символов — исключены.
Исключены комбинации, имеющие более трех нулей (01 — 00001, 02 — 00010, 03 — 00011, 08 — 01000, 16 — 10000). Такие сигналы интерпретируются символом V и командой приемника VIOLATION — сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная комбинация из пяти нулей (00 — 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET — отсутствие сигнала в линии.
Кодирование данных решает две задачи — синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения последовательности более трех нулей. Высокая помехоустойчивость достигается контролем принимаемых данных на пяти-битовом интервале.
Цена кодирования данных — снижение скорости передачи полезной информации. В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы частот в протоколах с кодом MLT-3 и кодированием данных 4B5B уменьшается соответственно на 25%.
При совместном использовании кодирования сигналов MLT-3 и данных 4В5В скорость передачи- 3 бита информации на 1 герц несущей частоты сигнала. Такая схема используется в протоколе TP-PMD.
Еще более высокоскоростной код- кодPAM 5
Рассмотренные выше схемы кодирования сигналов были битовыми. При битовом кодировании каждому биту соответствует значение сигнала, определяемое логикой протокола.
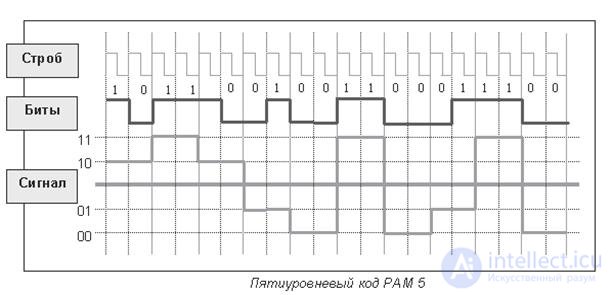
Рис 16.6. Пятиуровневый код RAM 5
Прикодировании уровень сигнала задают блоки из двух бит.
В пятиуровневом коде PAM 5 используется 5 уровней амплитуды и двухбитовое кодирование. Для каждой комбинации задается уровень напряжения. При двухбитовом кодировании для передачи информации необходимо четыре уровня (два во второй степени — 00, 01, 10, 11). Передача двух битов одновременно обеспечивает уменьшение в два раза частоты изменения сигнала.
Пятый уровень добавлен для создания избыточности кода, используемого для исправления ошибок. Это дает дополнительный резерв соотношения сигнал / шум 6 дБ.
Код PAM 5 используется в протоколе 1000 Base T Gigabit Ethernet . Данный протокол обеспечивает передачу данных со скоростью 1000 Мбит/с при ширине спектра сигнала всего 125 МГц.
16.5 Требуемаяполосачастотдляпередачиданныхиширинаспектрасигнала.
Кодирование сигналов — это способ на один период тактовой частоты повесить более 1-го бита передаваемой информации. С какой целью выполняют преобразование? Для того, чтобы увеличить скорость без изменения частотного диапазона канала связи. Кодирование требует использования более сложной приемо-передающей аппаратуры. Это минус. Зато при переходе к более скоростным протоколам можно использовать те же кабели. А это уже большой плюс.
Например, протокол Fast Ethernet 100 Base T4 обеспечивает работу сети со скоростью 100 Мбит/с на кабелях категории 3 (16 МГц) при кодировании методомNRZI. Gigabit Ethernet 1000BaseT реализован таким образом, чтобы на базе кабелякатегории 5 (полоса 100 Мгц), имеющий некоторый резерв, передавать 1000 Мбит/с.
Ширина спектра сигнала
Спектральная ширина сигнала зависит от тактовой частоты, метода кодирования и характеристик фильтра передатчика.
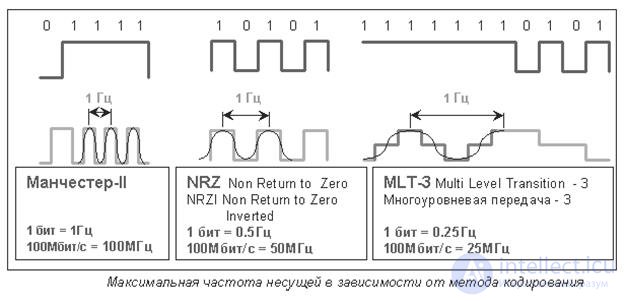
Рис.16.7 Максимальная частота несущей в зависимости от метода кодирования.
Рисунок 16.7 иллюстрирует, как метод кодирования позволяет уменьшить частоту несущей. Для трех методов кодирования приведены ситуации, требующие максимальную частоту несущей. Один период несущей передает один бит (1) при манчестерском кодировании, два бита (01) кода NRZ и четыре бита (1111) кода MLT-3. Фактор кодирования (передача) составляет соответственно один, два и четыре.
Другие комбинации битов требуют меньшей частоты. Например, при чередовании нулей и единиц частота спектра кода MLT-3 уменьшается еще в два раза, длительная последовательность нулей уменьшает частоту несущей до нуля.
Спектральную ширину сигнала не следует путать с тактовой частотой.
Тактовая частота — это метроном, задающий темп мелодии. На рисунке 6 тактовой частоте соответствует частота чередования битов входной информационной последовательности.. Спектральная ширина сигнала в данной аналогии это огибающая сигнала при условии, что она позволяет восстановить исходный импульсный сигнал.
16.6 Контрольныевопросы.
1. Назовите цели кодирования сигналов на физическом уровне.
2. В чем отличие самосинхронозирующихся и несамосинхронозирующихся кодов?
3. Какой из кодов потенциально более производителен: двухуровневый или многоуровневый?
4. Какой код применяется для передачи в интерфейсе USB 2.0?
Я хотел бы услышать твое мнение про методы кодирования физических сигналов в компьютерных сетях Надеюсь, что теперь ты понял что такое методы кодирования физических сигналов в компьютерных сетях
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Теория информации и кодирования
Ответы на вопросы для самопроверки пишите в комментариях,
мы проверим, или же задавайте свой вопрос по данной теме.