Кому может быть полезна эта статья?
Извращенцам делающим NLP на Java? Или может быть для обучения?
Хотя зачем эти оправдания? Весь код был написан because we can.Под катом мы рассмотрим как превращать числа вида «Двенадцать тысяч шестьсот пятьдесят девять целых четыре миллионных» в форму вроде 12 659, 000 004.
Русский язык обладает встроенными алиасами для некоторых чисел. Их мы будем с переводить в последовательность обычных чисел. Для этого составим словарь псевдонимов:
0 ноль нуль
1 один
2 два
3 три
4 четыре
5 пять
6 шесть
7 семь
8 восемь
9 девять
11 одиннадцать
12 двенадцать дюжина
13 тринадцать
14 четырнадцать
15 пятнадцать
16 шестнадцать
17 семнадцать
18 восемнадцать
19 девятнадцать
20 двадцать
30 тридцать
40 сорок
50 пятьдесят
60 шестьдесят
70 семьдесят
80 восемьдесят
90 девяносто
200 двести
300 триста
400 четыреста
500 пятьсот
600 шестьсот
700 семьсот
800 восемьсот
900 девятьсот
0.00000000001 стомиллиардный
0.0000000001 десятимиллиардный
0.000000001 миллиардный
0.00000001 стомиллионный
0.0000001 десятимиллионный
0.000001 миллионный
0.00001 стотысячный
0.0001 десятитысячный
0.001 тысячный
0.01 сотый
0.1 десятый
10 десять
100 сто
1000 тысяча
1000000 миллион
1000000000 миллиард
1000000000000 триллион
1000000000000000 квадриллион
1000000000000000000 квинтиллион
1000000000000000000000 секстиллион
1000000000000000000000000 септиллион
1000000000000000000000000000 октиллионЧтобы прочитать словарь из ресурсов в память, нам потребуется такой код на Kotlin:
{}.javaClass.getResourceAsStream("/dictionary")!!
.bufferedReader()
.readLines()
.flatMap { line ->
val aliases = line.split(' ')
val number = aliases.first().toDouble()
aliases.drop(1).map { Pair(it, number) }
}.toMap()Некоторая сложность этого кода обусловлена теоретической возможностью наличия двух и более псеводонимов для одного числа.
Теперь настало время выхода на сцену токенайзера и морфологического словаря.
Подключив их, мы можем вытащить из любой строки последовательность наших чисел в любых разрешенных русским языком склонениях:
val integerPart = mutableListOf<Double>()
val fractionalPart = mutableListOf<Double>()
var currentPart = integerPart
for (token in words) {
if (integerPart.isNotEmpty() && token.lowercase() in separators) {
currentPart = fractionalPart
continue
}
val number =
lookupForMeanings(token)
.run {
firstOrNull { it.partOfSpeech == Numeral || it.partOfSpeech == OrdinalNumber }
?: getOrNull(0)
}
?.lemma
?.toString()
?.let(numbers::get)
if (number != null) {
currentPart += number
continue
}
if (currentPart.isNotEmpty()) {
break
}
}Код ужасно мутабельный, но как сделать лучше пока не придумал. После этого нам остается только склеить последовательность обычных чисел в одно. Это самое простое, пока число в последовательности меньше следующего, то умножаем, а когда следующее становится меньше предыдущего, то складываем островки умножений.
private fun List<Double>.join(): Double {
var tokensSum = 0.0
var previousToken = first()
for (currToken in drop(1)) {
if (currToken > previousToken) {
previousToken *= currToken
} else {
tokensSum += previousToken
previousToken = currToken
}
}
return tokensSum + previousToken
}Пришло время тестов нашей чудо-библиотеки!
@Test
fun parseRussianDouble() {
assertThat("Двенадцать тысяч шестьсот пятьдесят девять целых четыре миллионных".parseRussianDouble())
.isEqualTo(12659.000004)
assertThat("Десять тысяч четыреста тридцать четыре".parseRussianDouble())
.isEqualTo(10434.0)
assertThat("Двенадцать целых шестьсот пятьдесят девять тысячных".parseRussianDouble())
.isEqualTo(12.659)
assertThat("Ноль целых пятьдесят восемь сотых".parseRussianDouble())
.isEqualTo(0.58)
assertThat("Сто тридцать пять".parseRussianDouble())
.isEqualTo(135.0)
}Если вам интересно, как сделать, чтобы метод .parseToRussianDouble появился для всех строк в вашем Kotlin (или Java) проекте, то вам нужно просто подключить пару строчек в вашей системе сборки:
https://jitpack.io/#demidko/chisla/2021.10.30
В качестве демонстрации еще одной возможности библиотеки приведу кусочек кода:
"Я хотел передать ему сто тридцать пять яблок".parseRussianDouble()
// 135Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Полезно?
50%
Да, может заиспользую в своем проекте
13
50%
Нет, буду пользоваться ICU / другим велосипедом
13
Проголосовали 26 пользователей.
Воздержались 20 пользователей.
- Формула для определения цифр в ячейке
- Макрос “Обнаружить цифры” в !SEMTools
- Как в Excel из всех цифр найти только определённые нужные цифры
- Найти нужные цифры с помощью регулярных выражений в !SEMTools
- Найти нужные цифры формулой
- Найти определённые отдельные слова-числа в тексте
- Преобразовать числа в текст
- Заключение
Периодически возникает ситуация, когда нужно найти в диапазоне ячеек числа, но они могут быть вперемешку с текстом, что сильно затрудняет такой поиск.
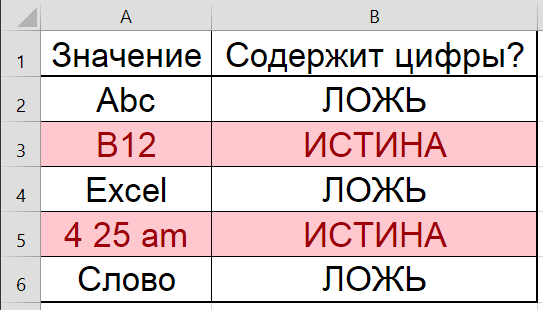
Прежде всего, определимся с понятиями. Обнаружить в общем случае это выявить, существует или не существует искомое значение в ячейке. Результатом срабатывания такой функции будет булевое значение — ИСТИНА или ЛОЖЬ.
Если же мы захотим не только обнаружить в ячейке цифры, но и произвести дополнительные действия, об этом можно почитать в других разделах:
- извлечь цифры из текста в Excel;
- удалить цифры из ячеек.
Цифры – это собирательное понятие, включающее в себя целый десяток символов. Чтобы обнаружить, содержит ли ячейка цифры, нужно сделать 10 проверок — по 1 на каждую цифру — 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
Один из примеров такого “подхода в лоб” использован в описании функции ЕСЛИ на этом сайте.
Но есть ли способ заменить 10 проверок 1 проверкой, которая включала бы их все?
К сожалению, простой функции в Excel нет, но можно комбинировать несколько формул, в том числе формулу массива, чтобы получить необходимый результат.
Формула для определения цифр в ячейке
Формула ниже вернёт ИСТИНА или ЛОЖЬ, не самый простой и запоминающийся синтаксис, однако отлично справляется с задачей.
=СЧЁТ(ПОИСК({1:2:3:4:5:6:7:8:9:0};A1))>0
Синтаксис функции тот же, что и для поиска кириллицы или латиницы в тексте.
Пожалуй, наиболее простое решение, доступное после подключения !SEMTools к Excel. Копируем исходный столбец, применяем макрос и получаем результат на месте.

Как в Excel из всех цифр найти только определённые нужные цифры
Чтобы найти только нужные цифры, например, только чётные или только нечётные, есть два способа — с помощью регулярных выражений и с помощью адаптации формулы выше.
Найти нужные цифры с помощью регулярных выражений в !SEMTools
Пользователям надстройки !SEMTools доступны возможности использования функций регулярных выражений. Синтаксис довольно прост — перечисляем в квадратных скобках любые нужные вам цифры и жмем ОК. С его же помощью можно найти латиницу или обнаружить заглавные буквы.

Найти нужные цифры формулой
Можно адаптировать под задачу сложную формулу массива, описанную выше, использующую функции СЧЁТ и ПОИСК, выглядеть будет так:
=СЧЁТ(ПОИСК({2:4:6:8:0};A1))>0
Она же позволяет находить не только цифры, но и числовые последовательности любой длины.
=СЧЁТ(ПОИСК({01:02:03:911:112};A1))>0
Найти определённые отдельные слова-числа в тексте
Иногда поиск чисел осложняется тем, что важно найти их не по вхождению в ячейку, а по точному совпадению конкретного числа. По сути в таком случае число будет считаться словом и нужно найти слово в ячейке, а если таких чисел несколько — найти слова из списка. Соответствующие процедуры !SEMTools позволяют это сделать.
На примере ниже мы ищем 1 как отдельное слово, при этом пропуская числа, содержащие его (например, 10).

Преобразовать числа в текст
Иногда нужно не только найти числа в тексте, но преобразовать числа в текст, а возможно, и изменить морфологию полученного текста. Смотрите, как это сделать, в соответствующих разделах:
- Число прописью в Excel;
- Склонение чисел в Excel.
Заключение
Надеюсь, этот раздел помог вам решить задачу поиска нужных цифр и чисел в ячейках. Если нет — смело обращайтесь к автору надстройки и этого сайта. Наверняка после обнаружения необходимых данных вам потребуется их извлечь, удалить или как-то изменить — обращайтесь к соответствующим разделам сайта, чтобы выяснить, как это сделать.
Столкнулись с необходимостью найти цифры в ячейках Excel?
Скачайте !SEMTools и решите эту и сотни других задач за пару кликов!
Если в тексте ячейки встречаются нечисловые знаки, то приходится извлекать текст числа (для примера из ячейки A1) специальной формулой, рассматривающей текст ячейки как массив, поэтому вводить формулы надо как формулу массива.
=ПСТР(A1;НачЧисла;ДлинаЧисла)
НачЧисла = ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0)
Окончание числа определяем как индекс пробела в исходной строке после начала числа (которого может и не быть, поэтому добавляем пробел)
ДлинаЧисла = НАЙТИ(» «; A1&» «;НачЧисла)-НачЧисла
после подстановки получаем:
ДлинаЧисла = НАЙТИ(» «; A1&» «;ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0))- ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0)
Формула для текста извлечённого числа:
=ПСТР(A1; ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0); НАЙТИ(» «; A1&» «;ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0))-ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0))
Формула для значения извлечённого числа:
=ЗНАЧЕН(ПСТР(A1; ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0); НАЙТИ(» «; A1&» «;ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0))-ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0)))
Эти формулы не учитывают, что на разных компьютерах могут быть разные настройки для десятичного разделителя (или запятая или пробел), а в случае отсутствия цифр в строке эти формулы дают ошибку.
Заменим десятичный разделитель в числе на правильный десятичный разделитель и обработаем ошибку если в ячейке вообще нет цифр:
Формула для значения извлечённого числа:
=ЕСЛИОШИБКА( ЗНАЧЕН( ПСТР( ЕСЛИ( ПСТР(1/3; 2; 1)=»,»; ПОДСТАВИТЬ(A1; «.»; «,»); ПОДСТАВИТЬ(A1; «,»; «.»)); ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР( A1 ))); 1))); 0); НАЙТИ(» «; A1&» «; ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0))-ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР(A1; СТРОКА( ДВССЫЛ(«1:»&ДЛСТР( A1 ))); 1))); 0))); «—-«)
Формула для текста извлечённого числа:
=ЕСЛИОШИБКА( ПСТР( ЕСЛИ( ПСТР(1/3; 2; 1)=»,»; ПОДСТАВИТЬ(A1; «.»; «,»); ПОДСТАВИТЬ(A1; «,»; «.»)); ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР( A1 ))); 1))); 0); НАЙТИ(» «; A1&» «; ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР( A1; СТРОКА( ДВССЫЛ( «1:»&ДЛСТР(A1) )); 1))); 0))-ПОИСКПОЗ( ИСТИНА; ЕЧИСЛО( ЗНАЧЕН( ПСТР(A1; СТРОКА( ДВССЫЛ(«1:»&ДЛСТР( A1 ))); 1))); 0)); «—-«)
Пример использования формул, позволяющих извлекать первое число из текстовой строки, независимо от установленного на компьютере десятичного разделителя.

Решение достаточно простое и ошибка, как указывалось в комментариях от того, что вы пытаетесь разделить по остатку переменную с типом данных string. Все что необходимо вам так это проверить: «Является, ли, элемент списка числом?». Для этого можно применить метод isdisgit(). Примерно будет выглядеть так:
>>> text = "jdføso 780 hsafp9 934 7384 iukdf" # тестовая строка
>>> words = text.split()
>>> mass = set()
>>> for elem in words:
>>> if elem.isdigit():
>>> print(f"Какой же тип данных у {elem}. Ответ {type(elem)}") # посмотрим на тип данных здесь
>>> if int(elem) % 2 == 0:
>>> mass.add(elem)
>>> print('Цифры:', mass)
Какой же тип данных у 780. Ответ <class 'str'>
Какой же тип данных у 934. Ответ <class 'str'>
Какой же тип данных у 7384. Ответ <class 'str'>
Цифры: {'780', '934', '7384'}
mass — переменную я определил тип данных как set, что дает нам уникальные значения для конечного результата. Проверим:
>>> text = "jdføso 780 hsafp9 934 7384 iukdf 934" # тестовая строка
...
...
>>> Цифры: {'934', '7384', '780'}
Это исправление вашего решения, но я вчитался еще раз в задание и понимаю, что вам надо найти все четные цифры, а не числа. В том числе и которые содержатся в словах. Можно решить вот так:
>>> import re
>>>
>>> text = "jdføso 780 hsafp9 934 7384 iukdf 934"
>>> mass = set()
>>> pattern = r"d"
>>> all_digits = set(re.findall(pattern, text))
>>> for item in all_digits:
>>> if int(item) % 2 == 0:
>>> mass.add(item)
>>> print(f"Цифры: {mass}")
Цифры: {'8', '0', '4'}
def get_digits(str1):
c = ""
for i in str1:
if i.isdigit():
c += i
return c
Above is the code that I used and the problem is that it only returns only the first digit of strings. For this, I have to keep both for loop and return statement. Anyone knows how to fix?
Thanks.
![]()
asked Aug 17, 2012 at 12:12
![]()
2
As the others said, you have a semantic problem on your indentation, but you don’t have to write such function to do that, a more pythonic way to do that is:
def get_digits(text):
return filter(str.isdigit, text)
On the interpreter:
>>> filter(str.isdigit, "lol123")
'123'
Some advice
Always test things yourself when people shows ‘faster’ methods:
from timeit import Timer
def get_digits1(text):
c = ""
for i in text:
if i.isdigit():
c += i
return c
def get_digits2(text):
return filter(str.isdigit, text)
def get_digits3(text):
return ''.join(c for c in text if c.isdigit())
if __name__ == '__main__':
count = 5000000
t = Timer("get_digits1('abcdef123456789ghijklmnopq123456789')", "from __main__ import get_digits1")
print t.timeit(number=count)
t = Timer("get_digits2('abcdef123456789ghijklmnopq123456789')", "from __main__ import get_digits2")
print t.timeit(number=count)
t = Timer("get_digits3('abcdef123456789ghijklmnopq123456789')", "from __main__ import get_digits3")
print t.timeit(number=count)
~# python tit.py
19.990989106 # Your original solution
16.7035926379 # My solution
24.8638381019 # Accepted solution
answered Aug 17, 2012 at 12:19
![]()
TarantulaTarantula
18.8k12 gold badges54 silver badges71 bronze badges
2
Your indentation is a bit borked (indentation in Python is quite important). Better:
def get_digits(str1):
c = ""
for i in str1:
if i.isdigit():
c += i
return c
A shorter and faster solution using generator expressions:
''.join(c for c in my_string if c.isdigit())
![]()
lvc
34k9 gold badges72 silver badges98 bronze badges
answered Aug 17, 2012 at 12:16
![]()
Benjamin WohlwendBenjamin Wohlwend
30.6k11 gold badges90 silver badges100 bronze badges
5
it’s because your return statement is inside the for loop, so it returns after the first true if condition and stops.
def get_digits(str1):
c = ""
for i in str1:
if i.isdigit():
c += i
return c
answered Aug 17, 2012 at 12:15
![]()
Ashwini ChaudharyAshwini Chaudhary
243k58 gold badges460 silver badges503 bronze badges
Of course it returns only the first digit, you explicitly tell Python to return as soon as you have a digit.
Change the indentation of the return statement and it should work:
def get_digits(str1):
c = ""
for i in str1:
if i.isdigit():
c += i
# Note the indentation here
return c
answered Aug 17, 2012 at 12:16
![]()
there is an indentation problem which returns when it finds the first digit, as with current indentation, it is intepreted as a statement inside if statement,
it needs to be parallel to the for statement
to be considered outside for statement.
def get_digits(str1):
c = ""
for i in str1:
if i.isdigit():
c += i
return c
digits = get_digits("abd1m4m3m22mmmbb4")
print(digits)
A curly braces equivalent of your incorrect code is :
def get_digits(str1){
c = ""
for i in str1 {
if i.isdigit(){
c += i
return c # Notice the error here
}
}
}
And when the code is corrected to move the return statement in alignment with for, the equivalent is :
def get_digits(str1){
c = ""
for i in str1 {
if i.isdigit(){
c += i
}
}
return c # Correct as required
}
answered Aug 17, 2012 at 12:15
![]()
DhruvPathakDhruvPathak
41.8k16 gold badges116 silver badges174 bronze badges
Your code was almost ok, except the return statement needed to be moved to the level of your for-loop.
def get_digits(str1):
c = ""
for i in str1:
if i.isdigit():
c += i
return c ## <--- moved to correct level
so, now:
get_digits('this35ad77asd5')
yields:
'35775'
Explanation:
Previously, your function was returning only the first digit because when it found one the if statement was executed, as was the return (causing you to return from the function which meant you didn’t continue looking through the string).
Whitespace/indentation really matters in Python as you can see (unlike many other languages).
answered Aug 17, 2012 at 12:15
![]()
LevonLevon
137k33 gold badges199 silver badges189 bronze badges