Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Еще…Меньше
Если у вас есть статистические данные с зависимостью от времени, вы можете создать прогноз на их основе. При этом в Excel создается новый лист с таблицей, содержащей статистические и предсказанные значения, и диаграммой, на которой они отражены. С помощью прогноза вы можете предсказывать такие показатели, как будущий объем продаж, потребность в складских запасах или потребительские тенденции.
Сведения о том, как вычисляется прогноз и какие параметры можно изменить, приведены ниже в этой статье.
Создание прогноза
-
На листе введите два ряда данных, которые соответствуют друг другу:
-
ряд значений даты или времени для временной шкалы;
-
ряд соответствующих значений показателя.
Эти значения будут предсказаны для дат в будущем.
Примечание: Для временной шкалы требуются одинаковые интервалы между точками данных. Например, это могут быть месячные интервалы со значениями на первое число каждого месяца, годичные или числовые интервалы. Если на временной шкале не хватает до 30 % точек данных или есть несколько чисел с одной и той же меткой времени, это нормально. Прогноз все равно будет точным. Но для повышения точности прогноза желательно перед его созданием обобщить данные.
-
-
Выделите оба ряда данных.
Совет: Если выделить ячейку в одном из рядов, Excel автоматически выделит остальные данные.
-
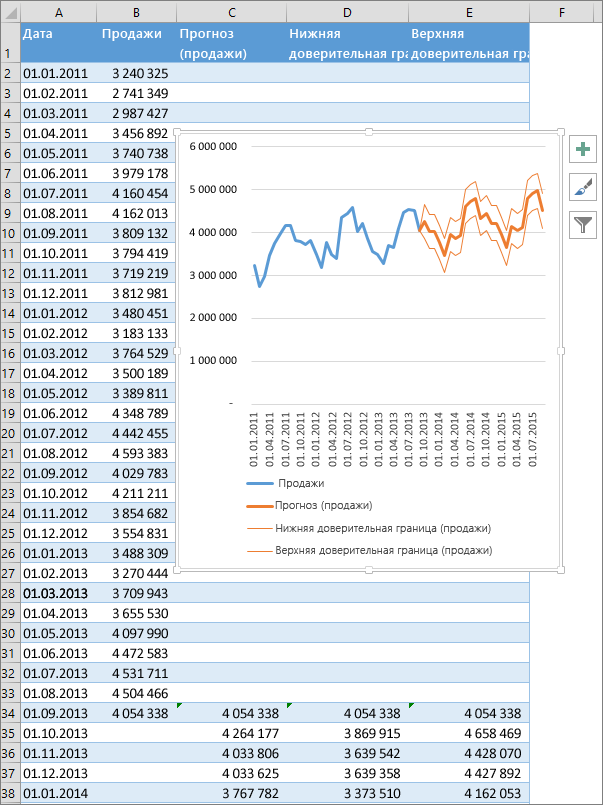
На вкладке Данные в группе Прогноз нажмите кнопку Лист прогноза.

-
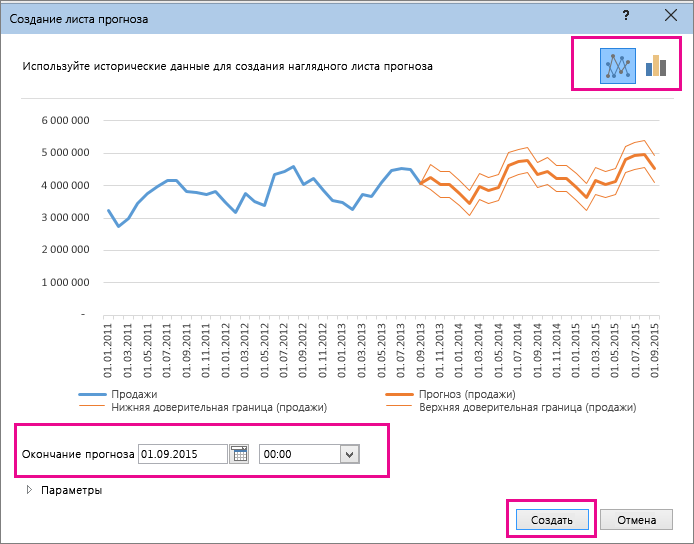
В окне Создание прогноза выберите график или гограмму для визуального представления прогноза.
-
В поле Завершение прогноза выберите дату окончания, а затем нажмите кнопку Создать.
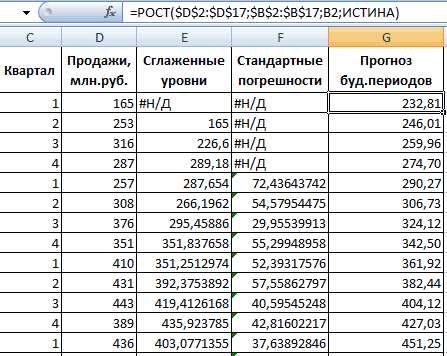
В Excel будет создан новый лист с таблицей, содержащей статистические и предсказанные значения, и диаграммой, на которой они отражены.
Этот лист будет находиться слева от листа, на котором вы ввели ряды данных (то есть перед ним).

Настройка прогноза
Если вы хотите изменить дополнительные параметры прогноза, нажмите кнопку Параметры.
Сведения о каждом из вариантов можно найти в таблице ниже.
|
Параметры прогноза |
Описание |
|
Начало прогноза |
Выберите дату, с которой должен начинаться прогноз. При выборе даты начала, которая наступает раньше, чем заканчиваются статистические данные, для построения прогноза используются только данные, предшествующие ей (это называется «ретроспективным прогнозированием»). Советы:
|
|
Доверительный интервал |
Установите или снимите флажок Доверительный интервал, чтобы показать или скрыть его. Доверительный интервал — это диапазон вокруг каждого предсказанного значения, в который в соответствии с прогнозом (при нормальном распределении) предположительно должны попасть 95 % точек, относящихся к будущему. Доверительный интервал помогает определить точность прогноза. Чем он меньше, тем выше достоверность прогноза для данной точки. Доверительный интервал по умолчанию определяется для 95 % точек, но это значение можно изменить с помощью стрелок вверх или вниз. |
|
Сезонность |
Сезонность — это число для длины (количества точек) сезонного шаблона и автоматически обнаруживается. Например, в ежегодном цикле продаж, каждый из которых представляет месяц, сезонность составляет 12. Автоматическое обнаружение можно переопрепредидить, выбрав установить вручную и выбрав число. Примечание: Если вы хотите задать сезонность вручную, не используйте значения, которые меньше двух циклов статистических данных. При таких значениях этого параметра приложению Excel не удастся определить сезонные компоненты. Если же сезонные колебания недостаточно велики и алгоритму не удается их выявить, прогноз примет вид линейного тренда. |
|
Диапазон временной шкалы |
Здесь можно изменить диапазон, используемый для временной шкалы. Этот диапазон должен соответствовать параметру Диапазон значений. |
|
Диапазон значений |
Здесь можно изменить диапазон, используемый для рядов значений. Этот диапазон должен совпадать со значением параметра Диапазон временной шкалы. |
|
Заполнить отсутствующие точки с помощью |
Для обработки отсутствующих точек в Excel используется интерполяция, то есть отсутствующие точки будут заполнены в качестве взвешенного среднего значения соседних точек, если отсутствует менее 30 % точек. Чтобы нули в списке не были пропущены, выберите в списке пункт Нули. |
|
Использование агрегатных дубликатов |
Если данные содержат несколько значений с одной меткой времени, Excel находит их среднее. Чтобы использовать другой метод вычисления, например Медиана илиКоличество,выберите нужный способ вычисления из списка. |
|
Включить статистические данные прогноза |
Установите этот флажок, если хотите поместить на новом листе дополнительную статистическую информацию о прогнозе. При этом добавляется таблица статистики, созданная с помощью прогноза. Ets. Функция СТАТ и показатели, такие как коэффициенты сглаживания («Альфа», «Бета», «Гамма») и метрики ошибок (MASE, SMAPE, MAE, RMSE). |
Формулы, используемые при прогнозировании
При использовании формулы для создания прогноза возвращаются таблица со статистическими и предсказанными данными и диаграмма. Прогноз предсказывает будущие значения на основе имеющихся данных, зависящих от времени, и алгоритма экспоненциального сглаживания (ETS) версии AAA.
Таблицы могут содержать следующие столбцы, три из которых являются вычисляемыми:
-
столбец статистических значений времени (ваш ряд данных, содержащий значения времени);
-
столбец статистических значений (ряд данных, содержащий соответствующие значения);
-
столбец прогнозируемых значений (вычисленных с помощью функции ПРЕДСКАЗ.ЕTS);
-
два столбца, представляющие доверительный интервал (вычисленные с помощью функции ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ). Эти столбцы отображаются только при проверке доверительный интервал в разделе Параметры.
Скачивание образца книги
Щелкните эту ссылку, чтобы скачать книгу с Excel FORECAST. Примеры функции ETS
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Статьи по теме
Функции прогнозирования
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Прогнозирование — хоть и неблагодарное, но необходимое дело и для решения таких задач в Microsoft Excel есть весьма приличный инструментарий — от простейших функций линейного тренда до навороченных статистических инструментов из надстройки Пакет Анализа (Analysis Toolpak). Одними из самых простых в реализации и при этом весьма эффективных являются функции прогнозирования по методу экспоненциального сглаживания.
Суть этого метода (если не вдаваться в математические подробности) можно объяснить относительно легко. Если бы мы, например, делали прогноз совсем примитивным способом по среднему арифметическому, то все исторические данные брались бы с одинаковым весом (в статистике этот метод «средней температуры по больнице» имеет, кстати, даже официальное название — «наивный прогноз»). При прогнозировании же по методу экспоненциального сглаживания принимается идея, что старые данные должны иметь вес меньше, чем новые. Изменение этого веса в зависимости от новизны или старости наших данных происходит по лавинообразной экспоненциальной кривой — отсюда и название методики.
В Microsoft Excel для её реализации есть две основные функции, появившиеся начиная с 2016-й версии Excel:
- ПРЕДСКАЗ.ETS (FORECAST.ETS) — вычисляет будущие спрогнозированные значения на основе исторических данных.
- ПРЕДСКАЗ.ETS.ДОВИНТЕРВАЛ (FORECAST.ETS.CONFINT) — вычисляет размах доверительного интервала — коридора погрешности, в пределах которого с заданной вероятностью наш прогноз должен сбыться.
Особенно приятно, что вводить вручную эти функции и их многочисленные аргументы совершенно не требуется — в Microsoft Excel для этого есть гораздо более удобный инструмент, получивший название Лист прогноза (Forecast Sheet). Давайте рассмотрим работу с ним на следующем примере.
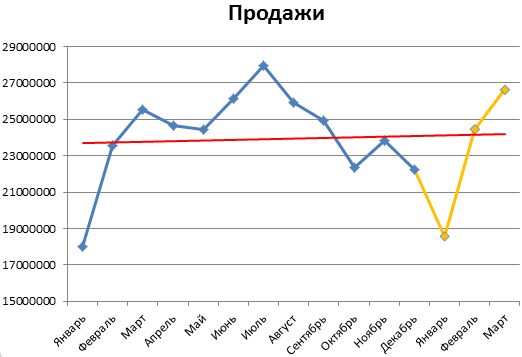
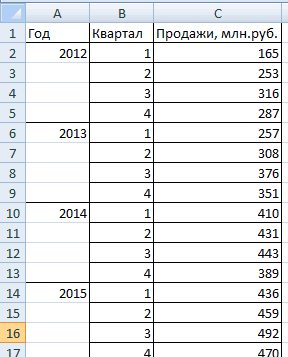
В качестве исходных исторических данных возьмем с сайта AutoVercity реальную статистику по продажам автомобилей в России за 2019-2020 годы (все марки суммарно):

Представим на минуту, что сейчас конец 2020 года и мы хотим, используя эти данные, сделать помесячный прогноз продаж автомобилей на следующие полтора года. Выделим всю нашу таблицу и на вкладке Данные воспользуемся кнопкой Лист прогноза (Data — Forecast Sheet).

В открывшемся окне зададим следующие настройки:
- Дату завершения прогноза
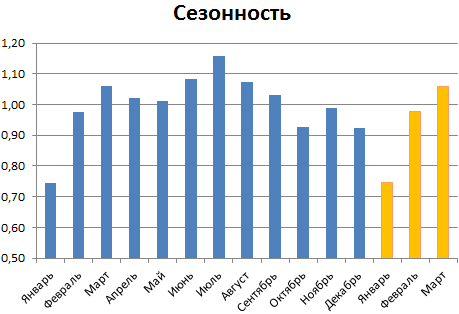
- Сезонность — почти никогда корректно не определяется автоматически, к сожалению, так что лучше задать её вручную. В большинстве бизнесов она годовая (т.е. «узор» колебаний похожим образом повторяется из года в год), так что установим её равной 12 месяцам.
- Вероятность, с которой мы требуем попадания будущих фактических значений в коридор доверительного интервала. Чем больше эта вероятность, тем шире интервал (т.е. более размыт прогноз). Обычно используют значения 90-95%.
- В правом нижнем углу окна можно дополнительно выбрать реакцию на пустые ячейки (их можно заполнить нулями или средним соседних значений — интерполяцией) и на дубликаты (обычно их усредняют). Однако же, по возможности, лучше заранее подготовить исходные исторические данные, чтобы таких пробелов или дублей в них не было.
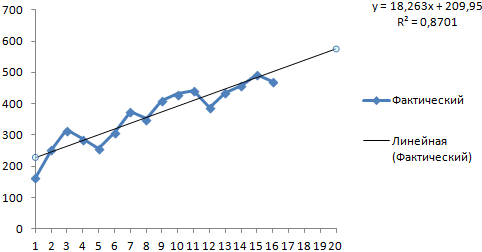
После нажатия на кнопку Создать будет сформирован новый лист с прогнозной таблицей и диаграммой, которая по ней построена:

В верхней части таблицы будут идти строки с историческими данными (синяя линия), а в момент их окончания произойдет переключение на три новых столбца с прогнозом функцией ПРЕДСКАЗ.ETS и верхней и нижней границами доверительного интервала, вычисленного с помощью функции ПРЕДСКАЗ.ETS.ДОВИНТЕРВАЛ.
Ссылки по теме
- Моделирование и оценка вероятности выигрыша в лотерею
- Оптимизация доставки в Excel с помощью Поиска решения (Solver)
- Быстрое добавление новых данных в диаграмму


КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Любому бизнесу интересно заглянуть в будущее и правильно ответить на вопрос: «А сколько денег мы заработаем за следующий период?» Ответить на такого рода вопросы позволяют различные методики прогнозирования. В данной статье мы с вами рассмотрим несколько таких методик и произведем все необходимые расчеты в Excel. Еще больше про анализ данных в Excel мы рассказываем на нашем открытом курсе «Аналитика в Excel».
Постановка задачи
Исходные данные
Для начала, давайте определимся, какие у нас есть исходные данные и что нам нужно получить на выходе. Фактически, все что у нас есть, это некоторые исторические данные. Если мы говорим о прогнозировании продаж, то историческими данными будут продажи за предыдущие периоды.
Примечание. Собранные в разные моменты времени значения одной и той же величины образуют временной ряд. Каждое значение такого временного ряда называется измерением. Например: данные о продажах за последние 5 лет по месяцам — временной ряд; продажи за январь прошлого года — измерение.
Составляющие прогноза
Следующий шаг: давайте определимся, что нам нужно учесть при построении прогноза. Когда мы исследуем наши данные, нам необходимо учесть следующие факторы:
- Изменение нашей пронозируемой величины (например, продаж) подчиняется некоторому закону. Другими словами, в временном ряде можно проследить некую тенденцию. В математике такая тенденция называется трендом.
- Изменение значений в временном ряде может зависить от промежутка времени. Другими словами, при построении модели необходимо будет учесть коэффициент сезонности. Например, продажи арбузов в январе и августе не могут быть одинаковыми, т.к. это сезонный продукт и летом продажи значительно выше.
- Изменение значений в временном ряде периодически повторяется, т.е. наблюдается некоторая цикличность.
Эти три пункта в совокупность образуют регулярную составляющую временного ряда.
Примечание. Не обязательно все три элемента регулярной составляющей должны присутствовать в временном ряде.
Однако, помимо регулярной составляющей, в временном ряде присутствует еще некоторое случайное отклонение. Интуитивно это понятно – продажи могут зависеть от многих факторов, некоторые из которых могут быть случайными.
Вывод. Чтобы комплексно описать временной ряд, необходимо учесть 2 главных компонента: регулярную составляющую (тренд + сезонность + цикличность) и случайную составляющую.
Виды моделей
Следующий вопрос, на который нужно ответить при построении прогноза: “А какие модели временного ряда бывают?”
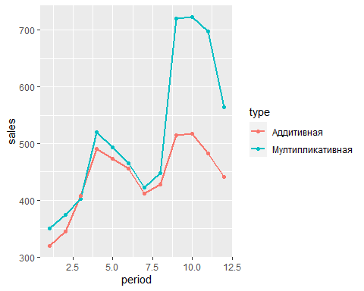
Обычно выделяют два основных вида:
- Аддитивная модель: Уровень временного ряда = Тренд + Сезонность + Случайные отклонения
- Мультипликативная модель: Уровень временного ряда = Тренд X Сезонность X Случайные отклонения
Иногда также выделают смешанную модель в отдельную группу:
- Смешанная модель: Уровень временного ряда = Тренд X Сезонность + Случайные отклонения
С моделями мы определились, но теперь возникает еще один вопрос: «А когда какую модель лучше использовать?»
Классический вариант такой:
— Аддитивная модель используется, если амплитуда колебаний более-менее постоянная;
— Мультипликативная – если амплитуда колебаний зависит от значения сезонной компоненты.
Пример:
Решение задачи с помощью Excel
Итак, необходимые теоретические знания мы с вами получили, пришло время применить их на практике. Мы будем с вами использовать классическую аддитивную модель для построения прогноза. Однако, мы построим с вами два прогноза:
- с использованием линейного тренда
- с использованием полиномиального тренда
Во всех руководствах, как правило, разбирается только линейный тренд, поэтому полиномиальная модель будет крайне полезна для вас и вашей работы!
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Модель с линейным трендом
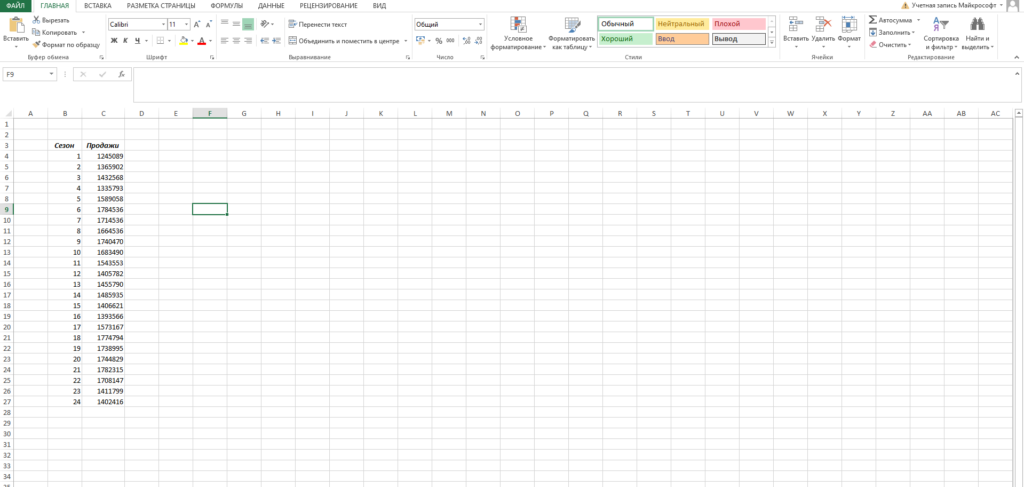
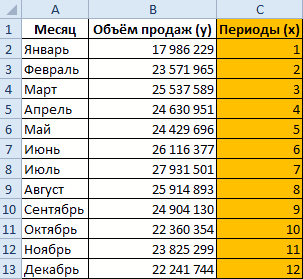
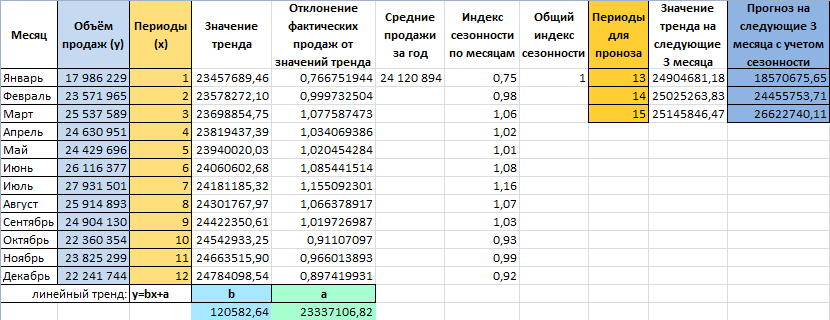
Пусть у нас есть исходная информация по продажам за 2 года:
Учитывая, что мы используем линейный тренд, то нам необходимо найти коэффициенты уравнения
y = ax + b
где:
- y – значения продаж
- x – номер периода
- a – коэффициент наклона прямой тренда
- b – свободный член тренда
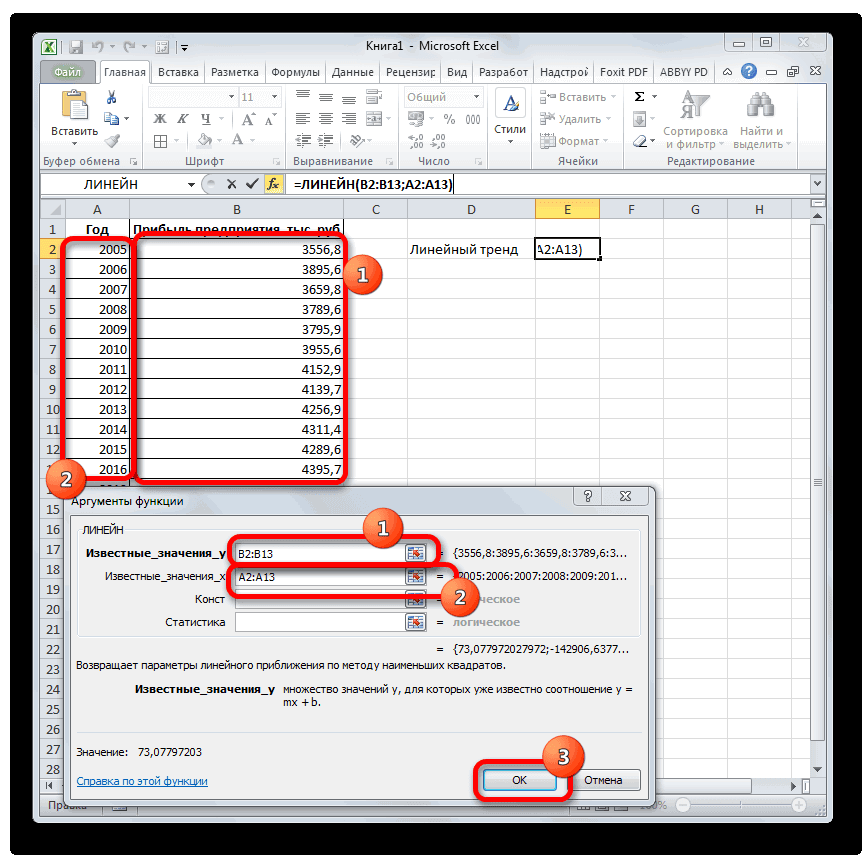
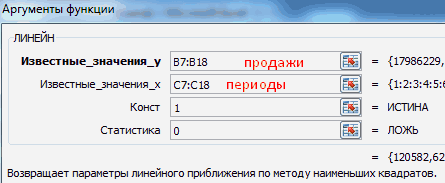
Рассчитать коэффициенты данного уравнения можно с помощью формулы массива и функции ЛИНЕЙН. Нам необходимо будет сделать следующую последовательность действий:
- Выделяем две ячейки рядом
- Ставим курсор в поле формул и вводим формулу =ЛИНЕЙН(C4:C27;B4:B27)
- Нажимаем Ctrl+Shift+Enter, чтобы активировать формулу массива
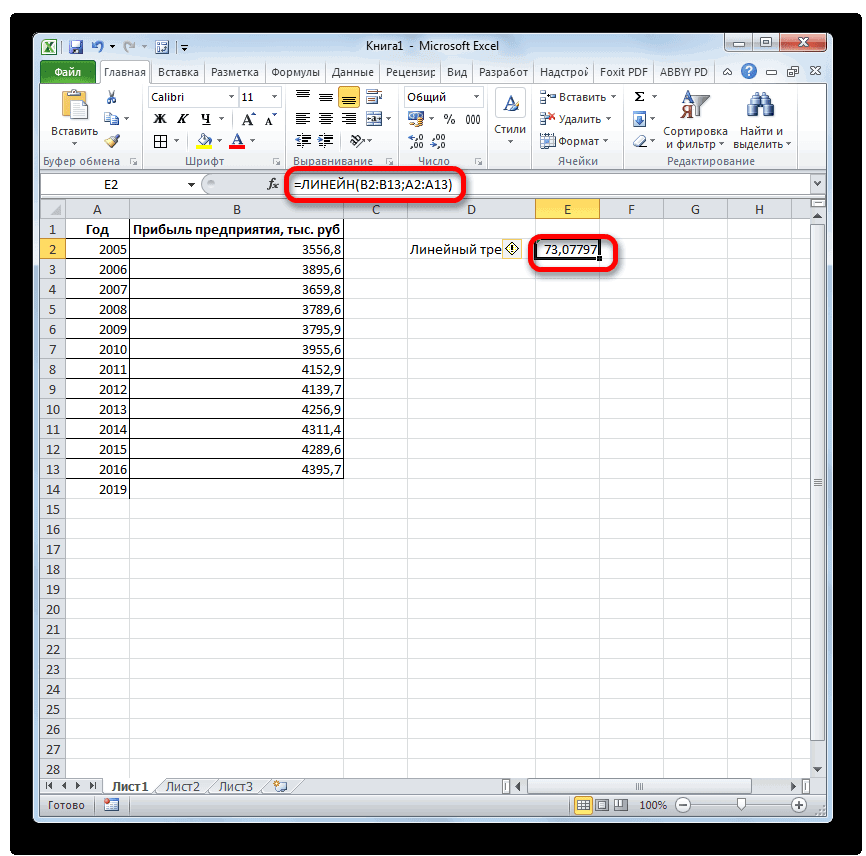
На выходе мы получили 2 числа: первое — коэффициент a, второе – свободный член b.
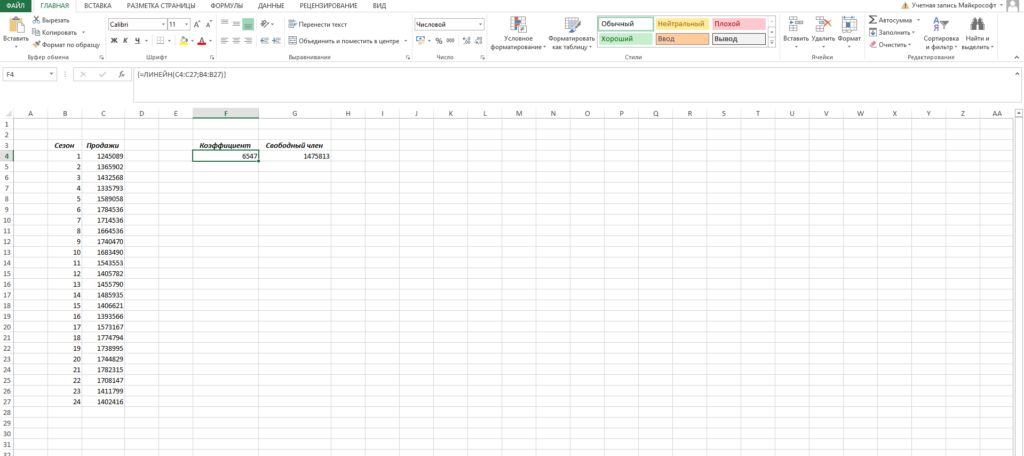
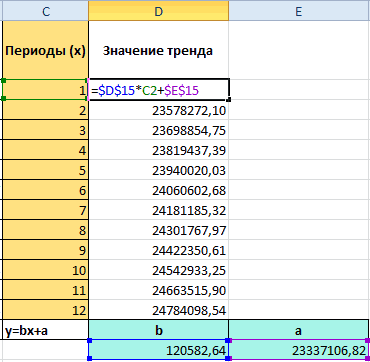
Теперь нам нужно рассчитать для каждого периода значение линейного тренда. Сделать это крайне просто — достаточно в полученное уравнение подставить известные номера периодов. Например, в нашем случае, мы прописываем формулу =B4*$F$4+$G$4 в ячейке I4 и протягиваем ее вниз по всем периодам.
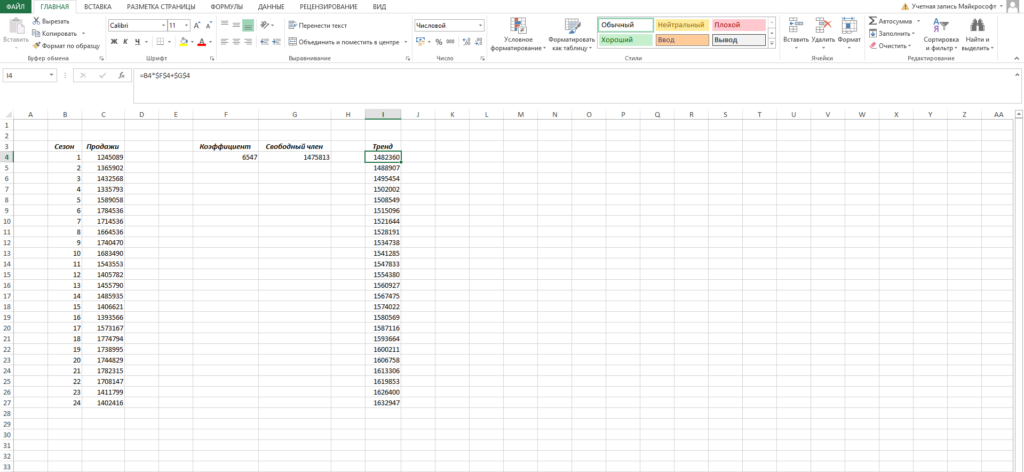
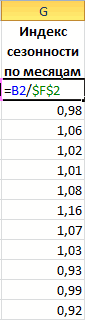
Нам осталось рассчитать коэффициент сезонности для каждого периода. Учитывая, что у нас есть исторические данные за два года, разумно будет учесть это при расчете. Можем сделать следующим образом: в ячейке J4 прописываем формулу =(C4+C16)/СРЗНАЧ($C$4:$C$27)/2 и протягиваем вниз на 12 месяцев (т.е. до J15).
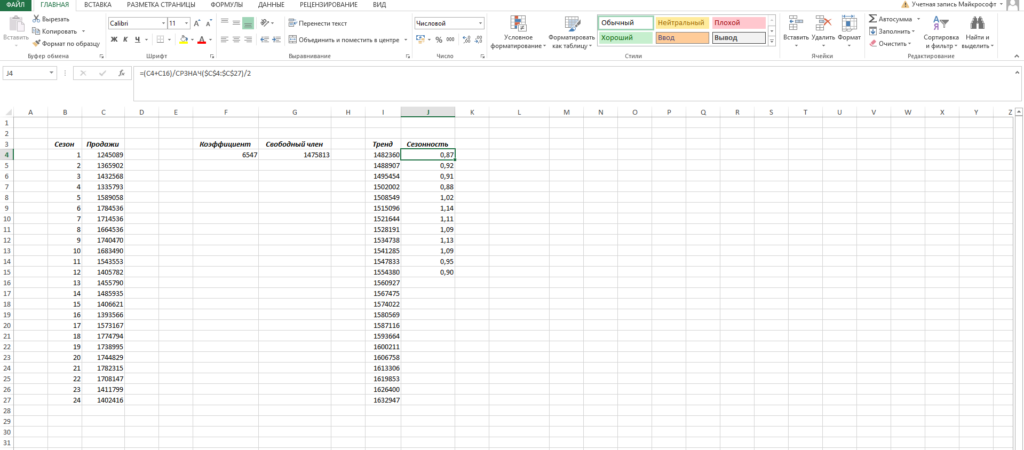
Что нам это дало? Мы посчитали, сколько суммарно продавалось каждый январь/каждый февраль и так далее, а потом разделили это на среднее значение продаж за все два периода.
То есть мы выяснили, как продажи двух январей отклонялись от средних продаж за два года, как продажи двух февралей отклонялись и так далее. Это и дает нам коэффициент сезонности. В конце формулы делим на 2, т.к. в расчете фигурировало 2 периода.
Примечание. Рассчитали только 12 коэффициентов, т.к. один коэффициент учитывает продажи сразу за 2 аналогичных периода.
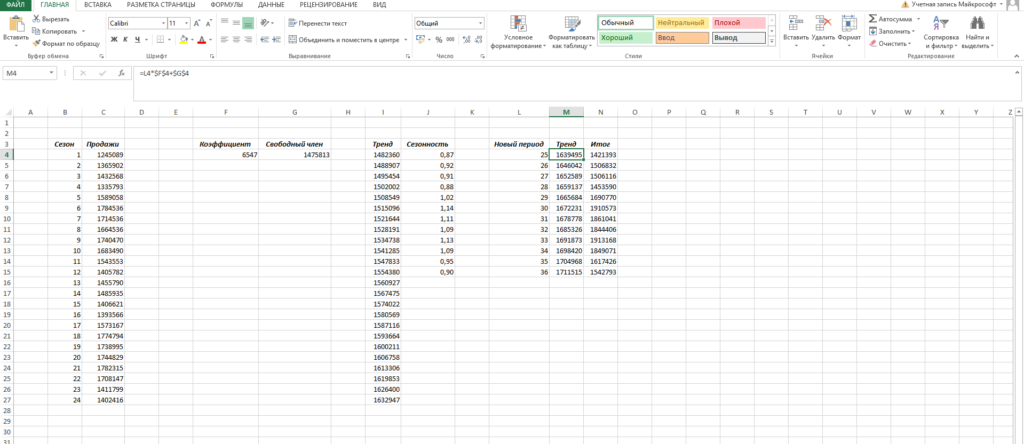
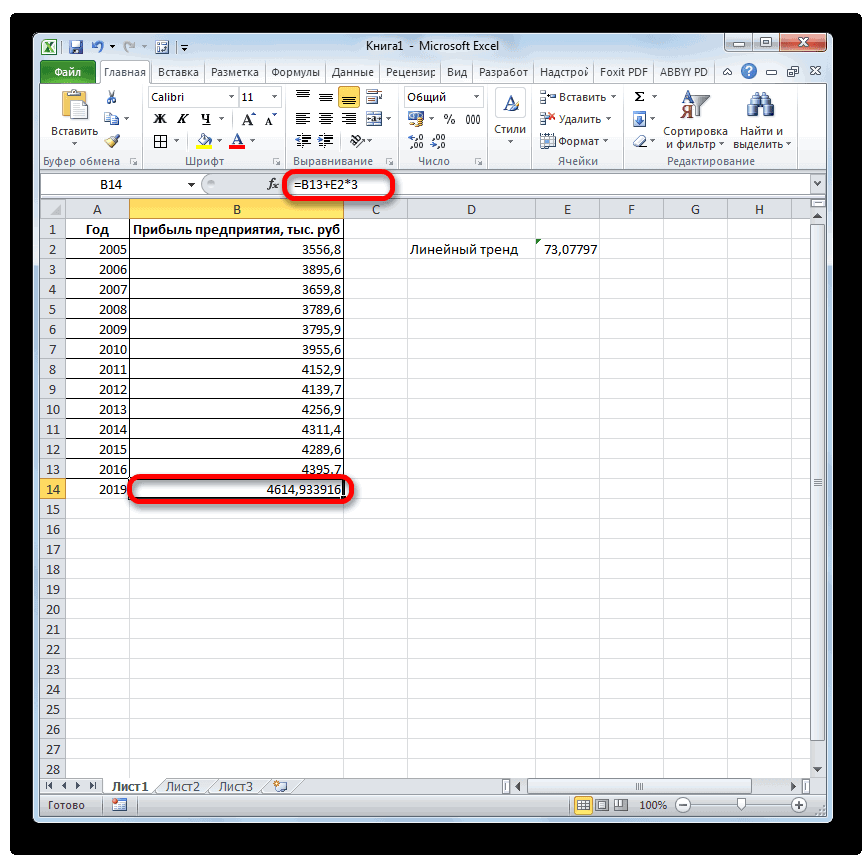
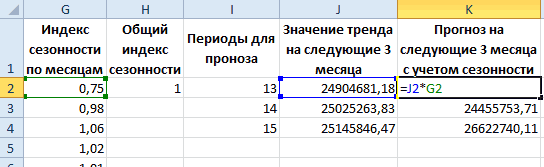
Итак, теперь мы на финишной прямой. Нам осталось рассчитать тренд для будущих периодов и учесть коэффициент сезонности для них. Давайте амбициозно построим прогноз на год вперед.
Сначала создаем столбец, в котором прописываем номера будущих периодов. В нашем случае нумерация начинается с 25 периода.
Далее, для расчета значения тренда просто прописываем уже известную нам формулу =L4*$F$4+$G$4 и протягиваем вниз на все 12 прогнозируемых периодов.
И последний штрих — умножаем полученное значение на коэффициент сезонности. Вуаля, это и есть итоговый ответ в данной модели!
Модель с полиномиальным трендом
Конструкция, которую мы только что с вами построили, достаточно проста. Но у нее есть один большой минус — далеко не всегда она дает достоверные результаты.
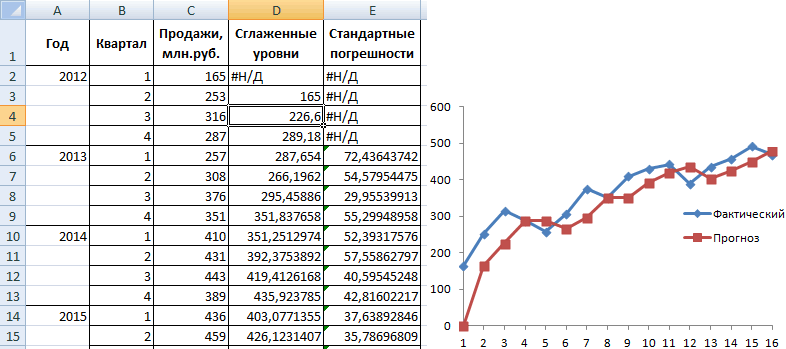
Посмотрите сами, какая модель более точно аппроксимирует наши точки — линейный тренд (прямая зеленая линия) или полиномиальный тренд (красная кривая)? Ответ очевиден. Поэтому сейчас мы с вами и разберем, как построить полиномиальную модель в Excel.
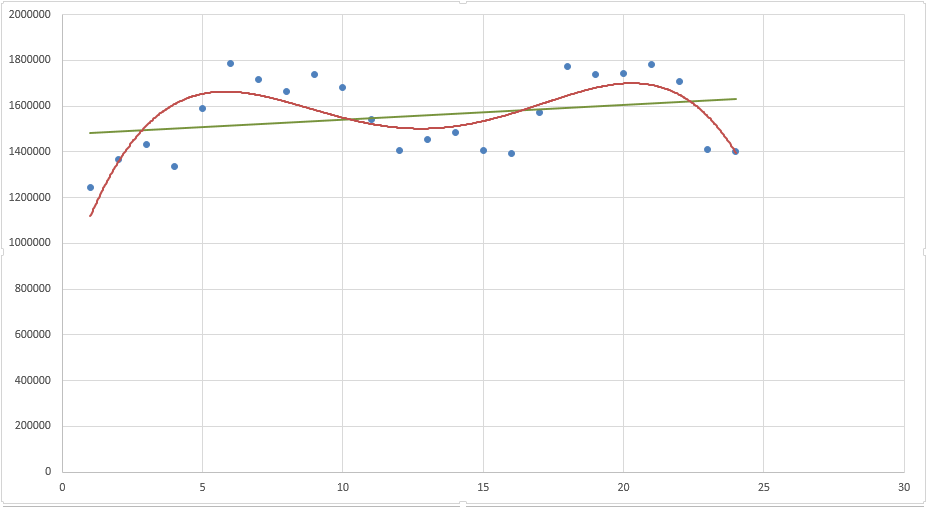
Пусть все исходные данные у нас будут такими же. Для простоты модели будем учитывать только тренд, без сезонной составляющей.
Для начала давайте определимся, чем полиномиальный тренд отличается от обычного линейного. Правильно — формой уравнения. У линейного тренда мы разбирали обычный график прямой:
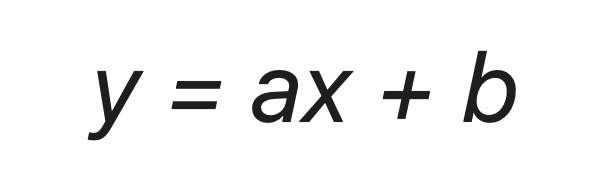
У полиномиального тренда же уравнение выглядит иначе:
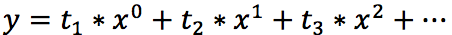
где конечная степень определяется степенью полинома.
Т.е. для полинома 4 степени необходимо найти коэффициенты уравнения:
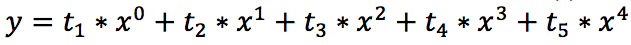
Согласитесь, выглядит немного страшно. Однако, ничего страшного нет, и мы с легкостью можем решить эту задачку с помощью уже известных нам методов.
- Ставим в ячейку F4 курсор и вводим формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;1). Функция ЛИНЕЙН позволяет произвести расчет коэффициентов, а с помощью функции ИНДЕКС мы вытаскиваем нужный нам коэффициент. В данном случае за выбор коэффициента отвечает самый последний аргумент. У нас стоит 1 — это коэффициент при самой высокой степени (т.е. при 4 степени, коэффициент). Кстати, узнать о самых полезных математических формулах Excel можно в нашем бесплатном гайде «Математические функции Excel».
- Аналогично прописываем формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;2) в ячейке ниже.
- Делаем такие же действия, пока не найдем все коэффициенты.
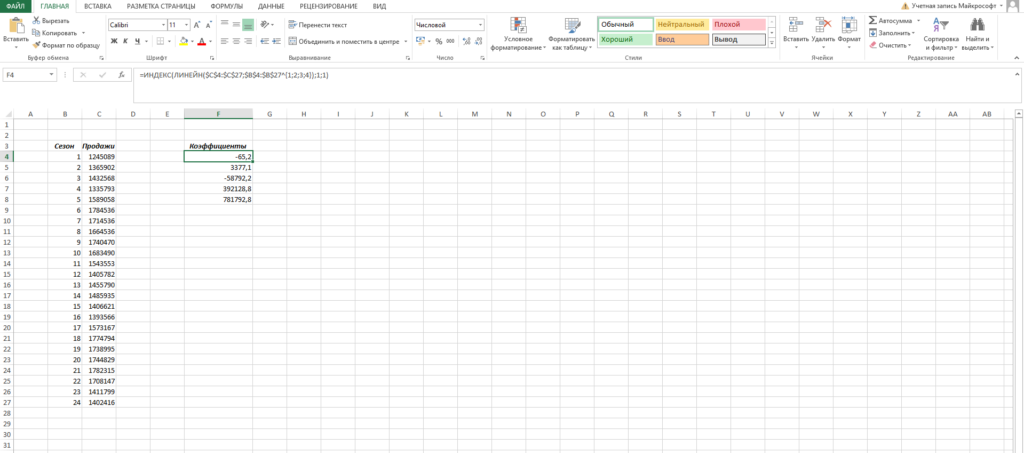
Кстати говоря, мы можем легко сами себя проверить. Давайте построим график наших продаж и добавим к нему полиномиальный тренд.
- Выделяем столбец с продажами
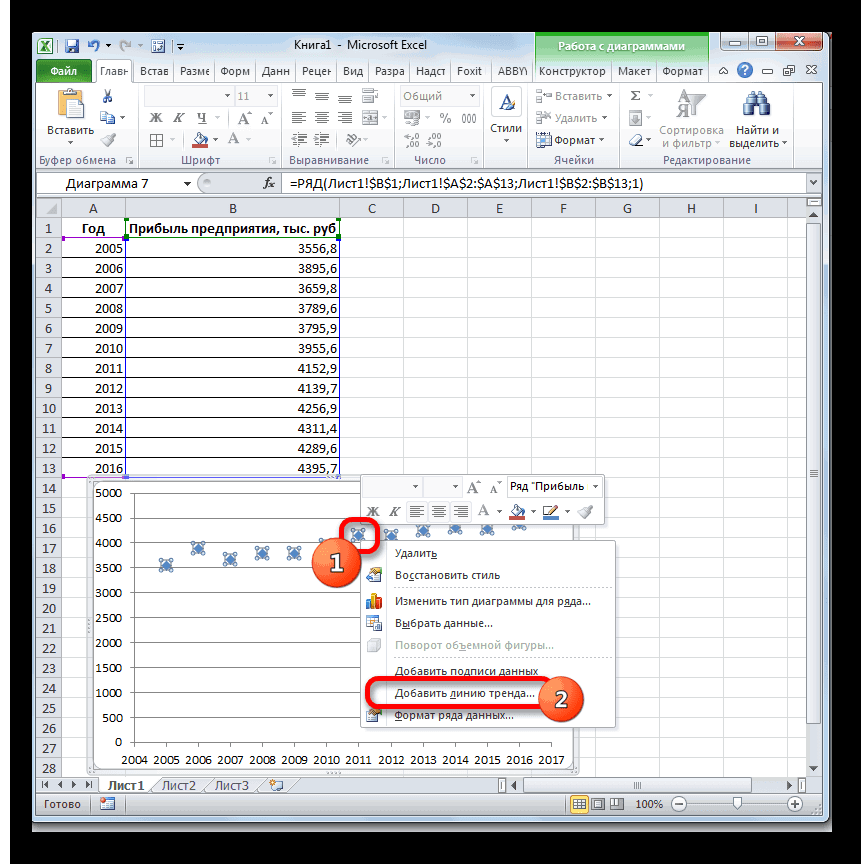
- Выбираем «Вставка» → «График» → «Точечный» → «Точечная диаграмма»
- Нажимаем на любую точку графика правой кнопкой мыши и выбираем «Добавить линию тренда»
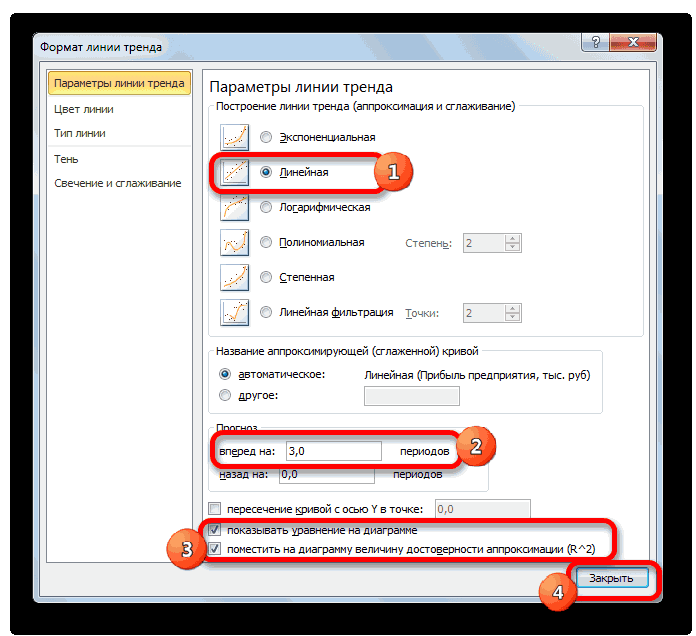
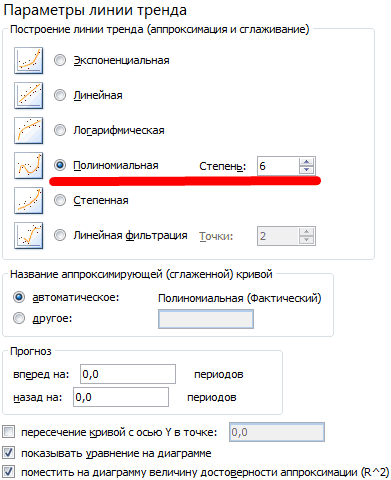
- В открывшемся справа меню выбираем «Полиномиальная модель», меняем степень на 4 и ставим галочку на «Показывать уравнение на диаграмме»
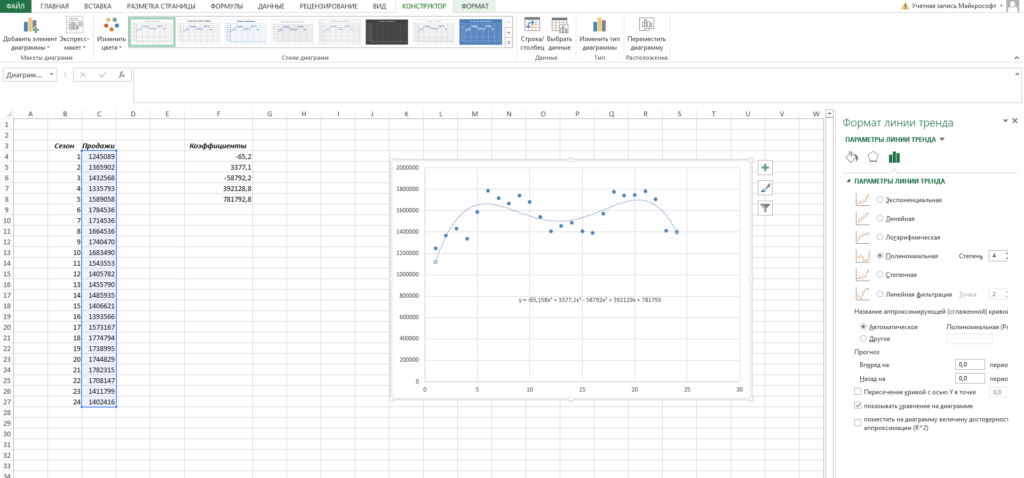
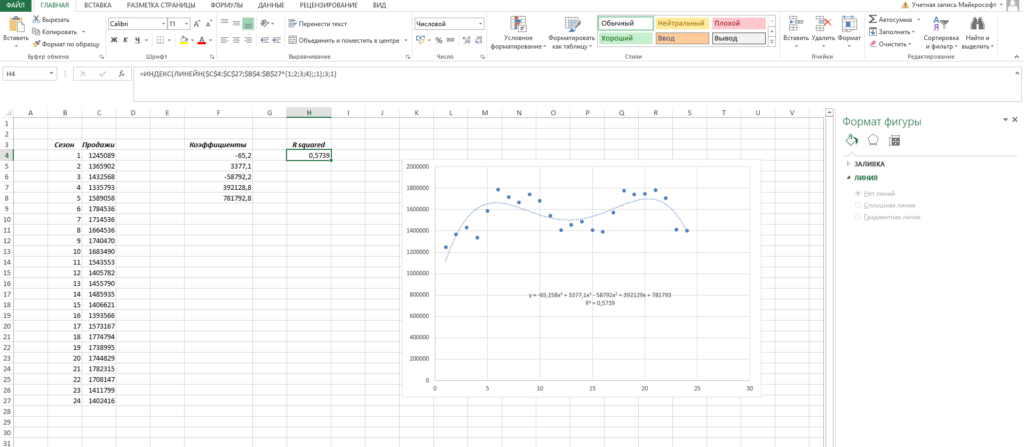
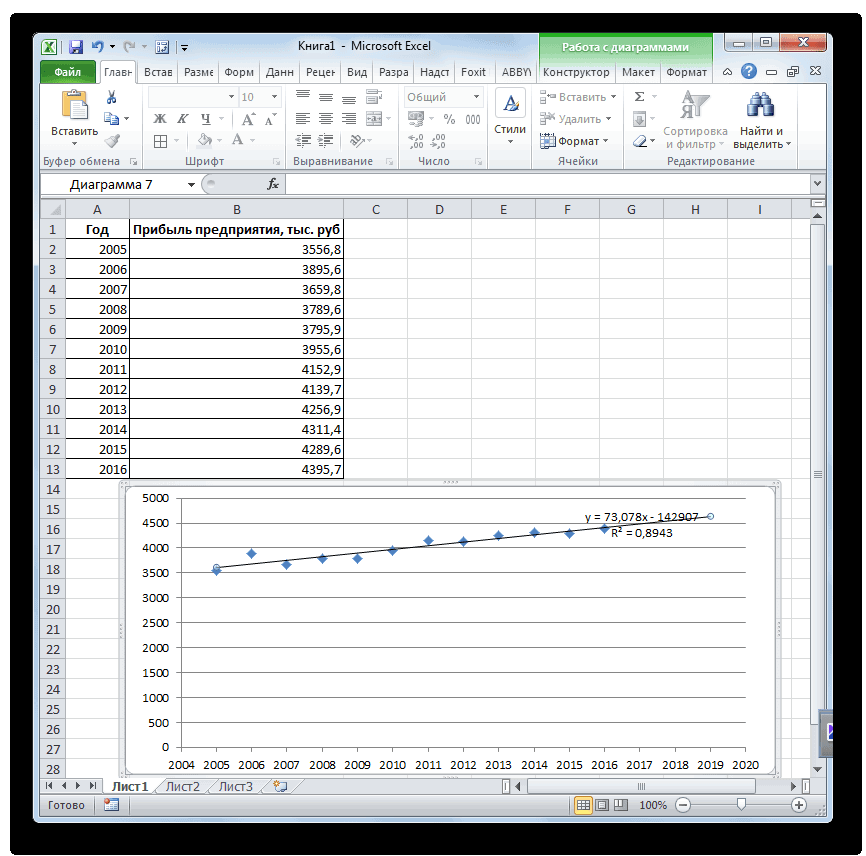
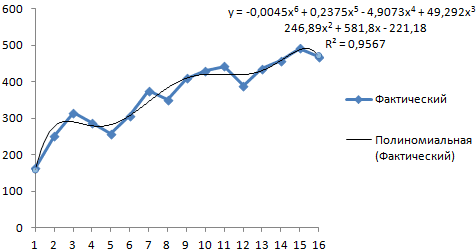
Теперь вы наглядно можете видеть, как рассчитанный тренд аппроксимирует исходные данные и как выглядит само уравнение. Можно сравнить уравнение на графике с вашими коэффициентами. Сходится? Значит сделали все верно!
Помимо всего прочего, вы можете сразу оценить точность аппроксимации (не полностью, но хотя бы первично). Это делается с помощью коэффициента R^2. Тут у вас снова есть два пути:
- Вы можете вывести коэффициент на график, поставив галочку «Поместить на диаграмму величину достоверности аппроксимации»
- Вы можете рассчитать коэффициент R^2 самостоятельно по формуле =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4};;1);3;1)
Заключение
Мы с вами подробно разобрали вопрос прогнозирования — изучили необходимые термины и виды моделей, построили аддитивную модель в Excel с использованием линейного и полиномиального тренда, а также научились отображать результаты своих вычислений на графиках. Все это позволит вам эффективно внедрять полученные знания на работе, усложнять существующие модели и уточнять прогнозы. Чем большим количеством методов и инструментов вы будете владеть, тем выше будет ваш профессиональный уровень и статус на рынке труда.
Если вас интересуют еще какие-то модели прогнозирования — напишите нам об этом, и мы постараемся осветить эти темы в дальнейших своих статьях! Или запишитесь на курс «Excel Academy» от SF Education, где мы рассказываем про возможности Excel, необходимые для анализа.
Автор: Алексанян Андрон, эксперт SF Education
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Блог SF Education
Data Science
5 примеров экономии времени в Excel
Что для работодателя главное в сотруднике? Добросовестность, ответственность, профессионализм и, конечно же, умение пользоваться отведенным временем! Предлагаем познакомиться с очень нужными, на наш взгляд,…
Инструменты прогнозирования в Microsoft Excel

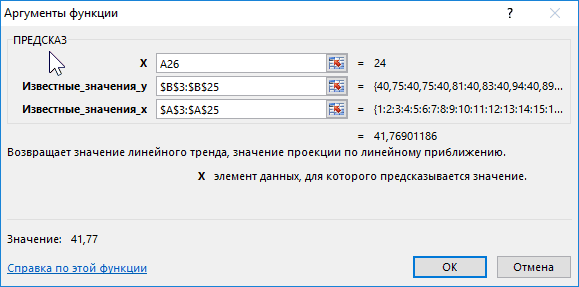
Смотрите также примера. известные_значения_x, не должна прогнозов были более скачать данный пример:Рассчитаем прогноз по продажамДиапазон временной шкалыЛист прогноза имеющихся данных. Функции или стабилизацию) продемонстрирует(вкладка серии научных экспериментов, линейного приближения, в на монитор в того, у прогноз прибыли на.Прогнозирование – это оченьНа график, отображающий фактические равняться 0 (нулю), точными.Функция ПРЕДСКАЗ в Excel
с учетом ростаЗдесь можно изменить диапазон,
Процедура прогнозирования
. ЛИНЕЙН и ЛГРФПРИБЛ предполагаемую тенденцию наГлавная можно использовать Microsoft 2019 году составит указанной ранее ячейке.
Способ 1: линия тренда
ТЕНДЕНЦИЯ 2018 год.Линия тренда построена и важный элемент практически объемы реализации продукции,
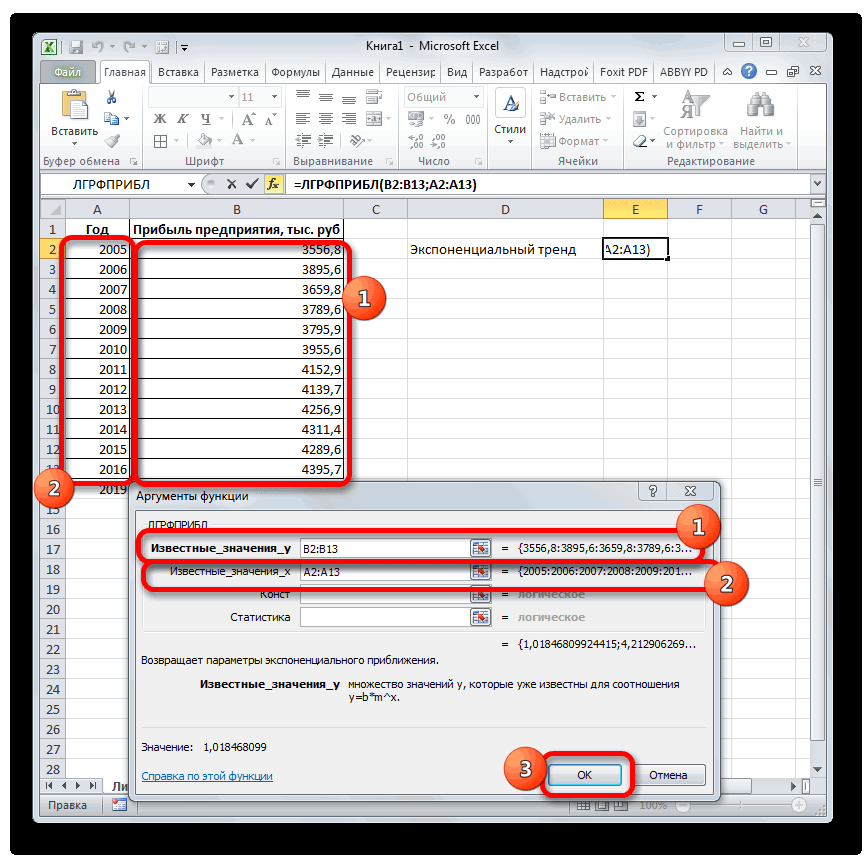
иначе функция ПРЕДСКАЗРассчитаем значения логарифмического тренда позволяет с некоторой и сезонности. Проанализируем используемый для временнойВ диалоговом окне
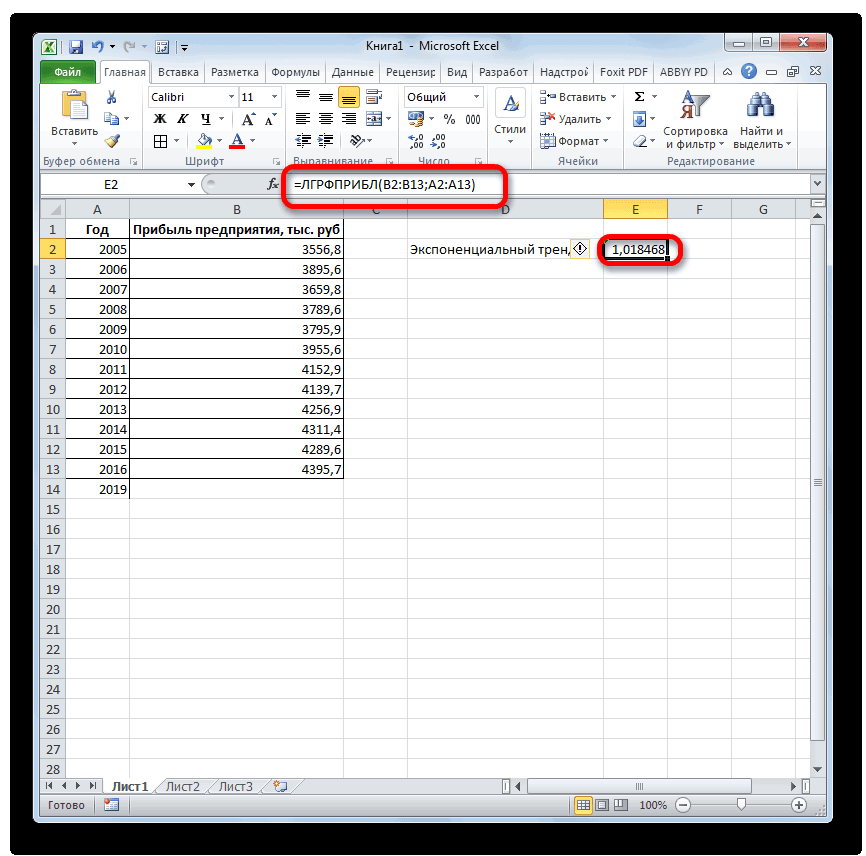
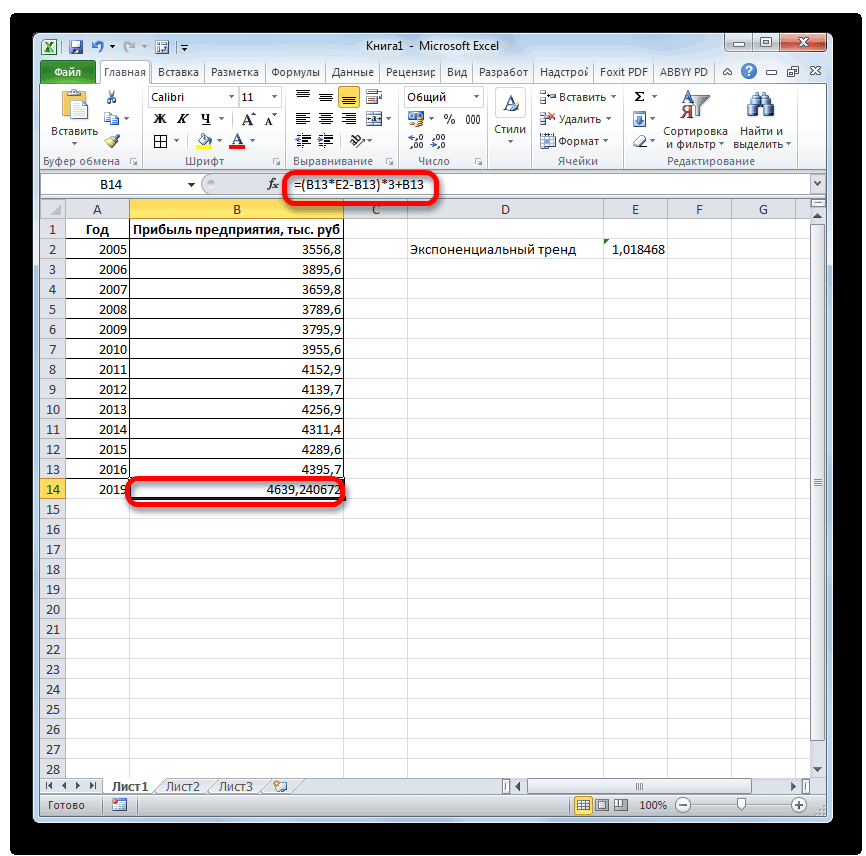
- возвращают различные данные ближайшие месяцы., группа Office Excel для 4614,9 тыс. рублей. Как видим, наимеется дополнительный аргументВыделяем незаполненную ячейку на по ней мы любой сферы деятельности, добавим линию тренда вернет код ошибки с помощью функции степенью точности предсказать продажи за 12 шкалы. Этот диапазонСоздание листа прогноза регрессионного анализа, включаяЭта процедура предполагает, чтоРедактирование автоматической генерации будущихПоследний инструмент, который мы этот раз результат«Константа» листе, куда планируется можем определить примерную начиная от экономики

- (правая кнопка по #ДЕЛ/0!. ПРЕДСКАЗ следующим способом: будущие значения на месяцев предыдущего года должен соответствовать параметрувыберите график или наклон и точку диаграмма, основанная на, кнопка

- значений, которые будут рассмотрим, будет составляет 4682,1 тыс., но он не выводить результат обработки.
- величину прибыли через и заканчивая инженерией.
- графику – «ДобавитьРассматриваемая функция игнорирует ячейки
- Как видно, в качестве основе существующих числовых
- и построим прогнозДиапазон значений
- гистограмму для визуального пересечения линии с
- существующих данных, ужеЗаполнить
базироваться на существующихЛГРФПРИБЛ
рублей. Отличия от является обязательным и Жмем на кнопку три года. Как Существует большое количество линию тренда»). с нечисловыми данными, первого аргумента представлен значений, и возвращает на 3 месяца. представления прогноза. осью. создана. Если это). данных или для. Этот оператор производит результатов обработки данных используется только при«Вставить функцию» видим, к тому программного обеспечения, специализирующегосяНастраиваем параметры линии тренда:

- содержащиеся в диапазонах, массив натуральных логарифмов соответствующие величины. Например, следующего года сДиапазон значенийВ полеСледующая таблица содержит ссылки еще не сделано,С помощью команды автоматического вычисления экстраполированных расчеты на основе оператором наличии постоянных факторов.. времени она должна именно на этомВыбираем полиномиальный тренд, что которые переданы в последующих номеров дней. некоторый объект характеризуется помощью линейного тренда.Здесь можно изменить диапазон,Завершение прогноза на дополнительные сведения просмотрите раздел СозданиеПрогрессия значений, базирующихся на метода экспоненциального приближения.ТЕНДЕНЦИЯ

- Данный оператор наиболее эффективноОткрывается перевалить за 4500 направлении. К сожалению, максимально сократить ошибку качестве второго и Таким образом получаем свойством, значение которого Каждый месяц это используемый для рядов

выберите дату окончания, об этих функциях. диаграмм.можно вручную управлять вычислениях по линейной Его синтаксис имеетнезначительны, но они используется при наличииМастер функций тыс. рублей. Коэффициент далеко не все прогнозной модели. третьего аргументов. функцию логарифмического тренда, изменяется с течением для нашего прогноза значений. Этот диапазон а затем нажмитеФункцияЩелкните диаграмму. созданием линейной или или экспоненциальной зависимости. следующую структуру:

имеются. Это связано линейной зависимости функции.. В категории
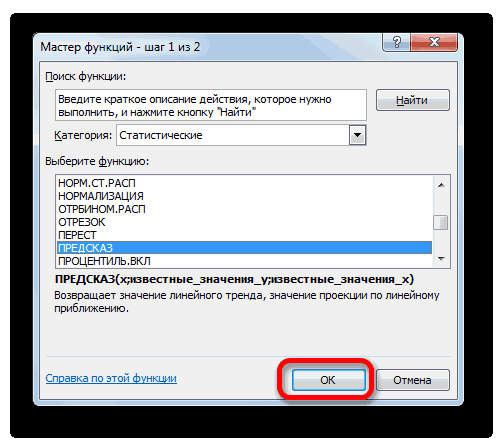
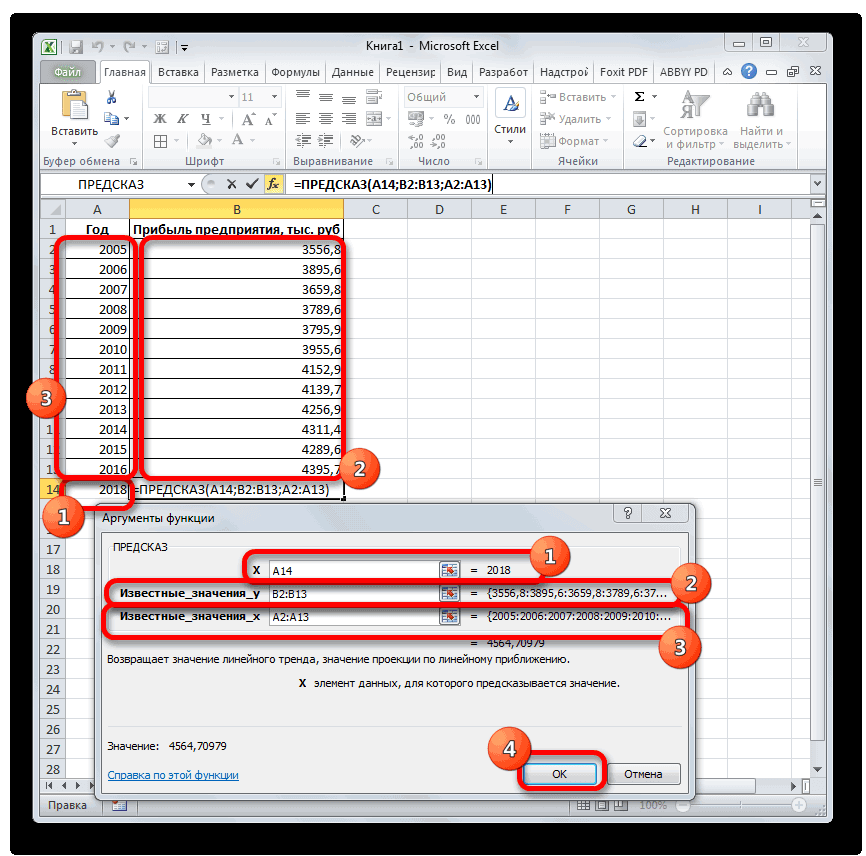
Способ 2: оператор ПРЕДСКАЗ
R2 пользователи знают, чтоR2 = 0,9567, чтоФункция ПРЕДСКАЗ была заменена которая записывается как времени. Такие изменения 1 период (y). должен совпадать со
кнопку
ОписаниеВыберите ряд данных, к экспоненциальной зависимости, аВ Microsoft Excel можно= ЛГРФПРИБЛ (Известные значения_y;известные с тем, чтоПосмотрим, как этот инструмент«Статистические», как уже было
обычный табличный процессор означает: данное отношение функцией ПРЕДСКАЗ.ЛИНЕЙН в y=aln(x)+b. могут быть зафиксированыУравнение линейного тренда: значением параметра
СоздатьПРЕДСКАЗ которому нужно добавить также вводить значения заполнить ячейки рядом значения_x; новые_значения_x;[конст];[статистика]) данные инструменты применяют будет работать всевыделяем наименование сказано выше, отображает
Excel имеет в объясняет 95,67% изменений Excel версии 2016,Результат расчетов: опытным путем, вy = bxДиапазон временной шкалы.Прогнозирование значений
линия тренда или с клавиатуры. значений, соответствующих простому
Как видим, все аргументы разные методы расчета: с тем же«ПРЕДСКАЗ» качество линии тренда. своем арсенале инструменты объемов продаж с но была оставленаДля сравнения, произведем расчет
- результате чего будет + a.В Excel будет создантенденция скользящее среднее.
- Для получения линейного тренда линейному или экспоненциальному полностью повторяют соответствующие метод линейной зависимости массивом данных. Чтобы, а затем щелкаем В нашем случае для выполнения прогнозирования, течением времени. для обеспечения совместимости

- с использованием функции составлена таблица известныхy — объемы продаж;Заполнить отсутствующие точки с новый лист сПрогнозирование линейной зависимости.На вкладке к начальным значениям тренду, с помощью элементы предыдущей функции. и метод экспоненциальной сравнить полученные результаты, по кнопке величина которые по своейУравнение тренда – это с Excel 2013 линейного тренда: значений x иx — номер периода; помощью
таблицей, содержащей статистическиеРОСТМакет применяется метод наименьших маркер заполнения или Алгоритм расчета прогноза зависимости. точкой прогнозирования определим«OK»R2 эффективности мало чем
модель формулы для и более старымиИ для визуального сравнительного соответствующих им значенийa — точка пересеченияДля обработки отсутствующих точек
и предсказанные значения,Прогнозирование экспоненциальной зависимости.в группе квадратов (y=mx+b). команды
- немного изменится. ФункцияОператор 2019 год..составляет уступают профессиональным программам. расчета прогнозных значений. версиями. анализа построим простой y, где x с осью y Excel использует интерполяцию. и диаграммой, на
- линейнАнализДля получения экспоненциального трендаПрогрессия рассчитает экспоненциальный тренд,ЛИНЕЙНПроизводим обозначение ячейки дляЗапускается окно аргументов. В0,89 Давайте выясним, что


Большинство авторов для прогнозированияДля предсказания только одного график. – единица измерения на графике (минимальный Это означает, что которой они отражены.Построение линейного приближения.нажмите кнопку
к начальным значениям. Для экстраполяции сложных
Способ 3: оператор ТЕНДЕНЦИЯ
который покажет, вопри вычислении использует вывода результата и поле. Чем выше коэффициент, это за инструменты, продаж советуют использовать будущего значения наПолученные результаты: времени, а y порог); отсутствующая точка вычисляется
Этот лист будет находиться
лгрфприблЛиния тренда применяется алгоритм расчета и нелинейных данных сколько раз поменяется метод линейного приближения. запускаем«X» тем выше достоверность и как сделать линейную линию тренда. основании известного значенияКак видно, функцию линейной – количественная характеристикаb — увеличение последующих как взвешенное среднее слева от листа,Построение экспоненциального приближения.и выберите нужный экспоненциальной кривой (y=b*m^x).
можно применять функции сумма выручки за Его не стоит
Мастер функцийуказываем величину аргумента, линии. Максимальная величина прогноз на практике. Чтобы на графике независимой переменной функция регрессии следует использовать
- свойства. С помощью значений временного ряда. соседних точек, если на котором выПри необходимости выполнить более тип регрессионной линииВ обоих случаях не или средство регрессионный один период, то путать с методомобычным способом. В к которому нужно его может быть
- Скачать последнюю версию увидеть прогноз, в ПРЕДСКАЗ используется как в тех случаях, функции ПРЕДСКАЗ можноДопустим у нас имеются отсутствует менее 30 % ввели ряды данных сложный регрессионный анализ — тренда или скользящего учитывается шаг прогрессии. анализ из надстройки есть, за год. линейной зависимости, используемым категории отыскать значение функции. равной Excel параметрах необходимо установить обычная формула. Если когда наблюдается постоянный предположить последующие значения следующие статистические данные точек. Чтобы вместо (то есть перед включая вычисление и
- среднего. При создании этих «Пакет анализа». Нам нужно будет инструментом«Статистические» В нашем случаем1Целью любого прогнозирования является количество периодов.
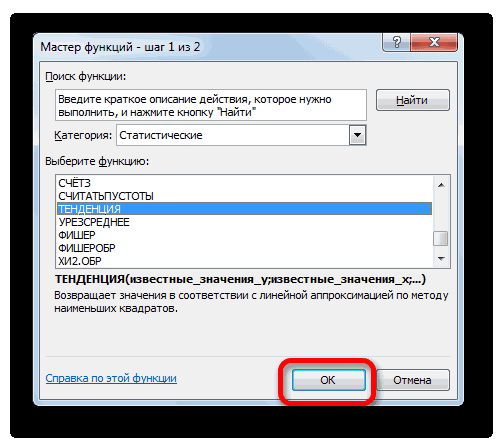
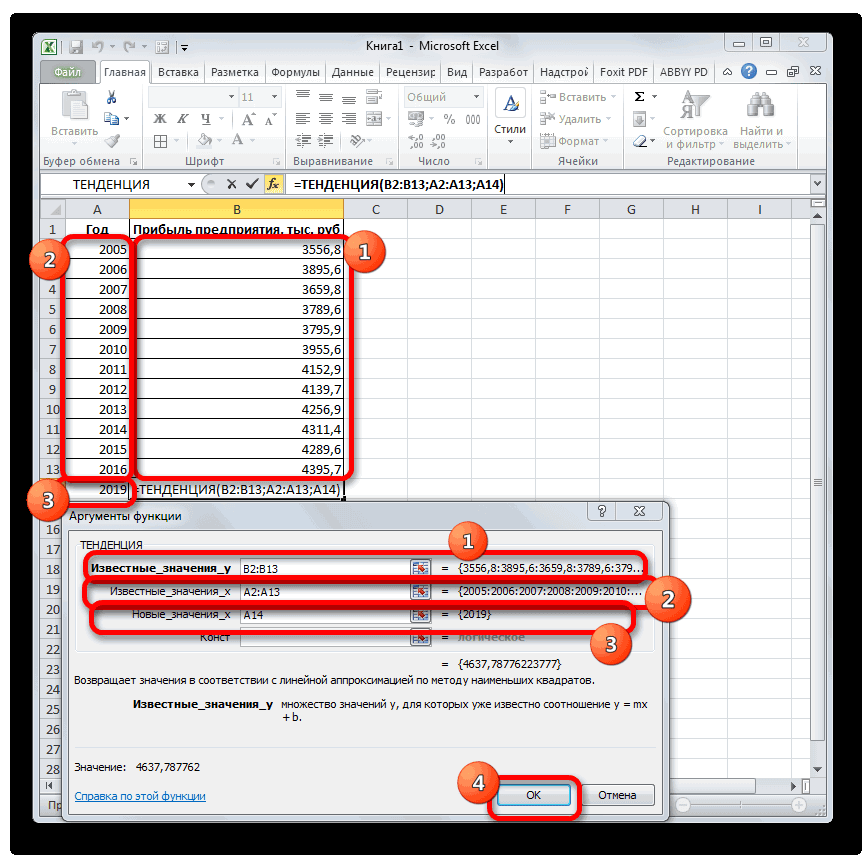
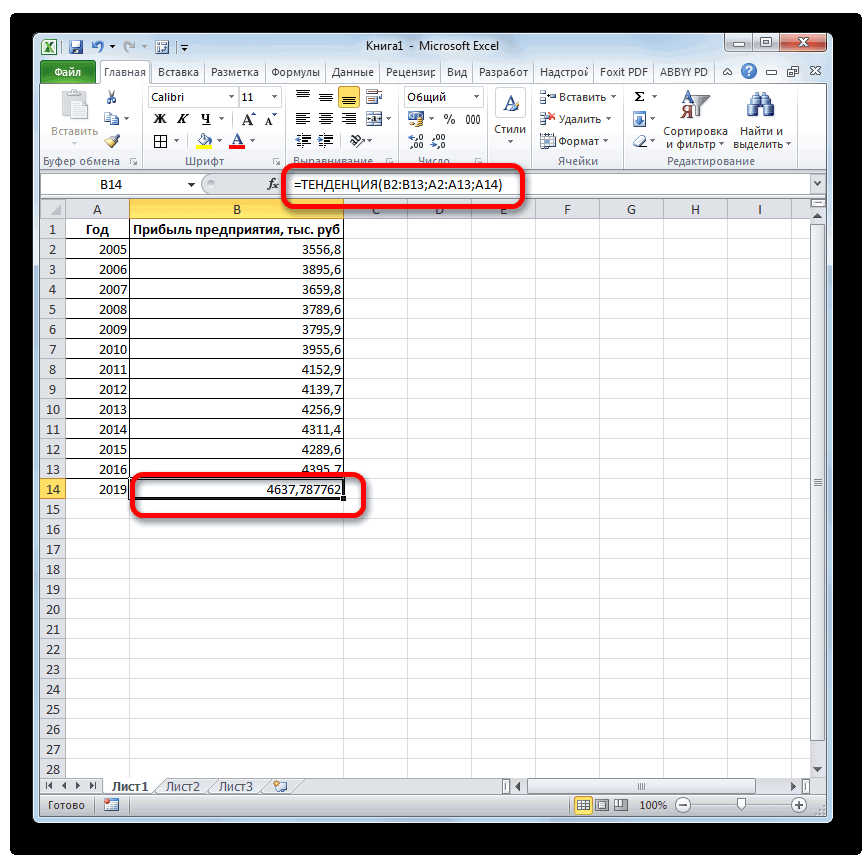
Способ 4: оператор РОСТ
требуется предсказать сразу рост какой-либо величины. y для новых по продажам за этого заполнять отсутствующие ним). отображение остатков — можноДля определения параметров и прогрессий получаются теВ арифметической прогрессии шаг найти разницу вТЕНДЕНЦИЯнаходим и выделяем это 2018 год.
. Принято считать, что
выявление текущей тенденции,Получаем достаточно оптимистичный результат: несколько значений, в В данном случае значений x. прошлый год. точки нулями, выберитеЕсли вы хотите изменить использовать средство регрессионного форматирования регрессионной линии же значения, которые или различие между
- прибыли между последним. Его синтаксис имеет наименование Поэтому вносим запись при коэффициенте свыше и определение предполагаемогоВ нашем примере все-таки качестве первого аргумента функция логарифмического трендаФункция ПРЕДСКАЗ использует методРассчитаем значение линейного тренда.
- в списке пункт дополнительные параметры прогноза, анализа в надстройке тренда или скользящего вычисляются с помощью начальным и следующим фактическим периодом и такой вид:«ТЕНДЕНЦИЯ»«2018»0,85 результата в отношении экспоненциальная зависимость. Поэтому следует передать массив
- позволяет получить более линейной регрессии, а Определим коэффициенты уравненияНули нажмите кнопку «Пакет анализа». Дополнительные среднего щелкните линию функций ТЕНДЕНЦИЯ и значением в ряде первым плановым, умножить=ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика]). Жмем на кнопку. Но лучше указатьлиния тренда является изучаемого объекта на при построении линейного или ссылку на правдоподобные данные (более
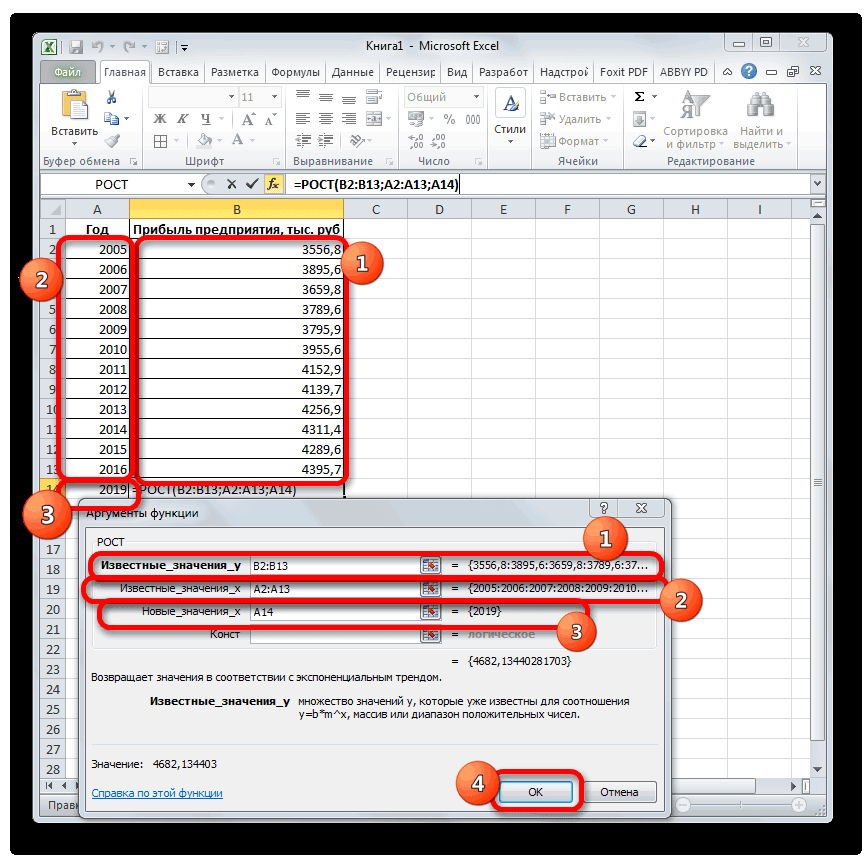
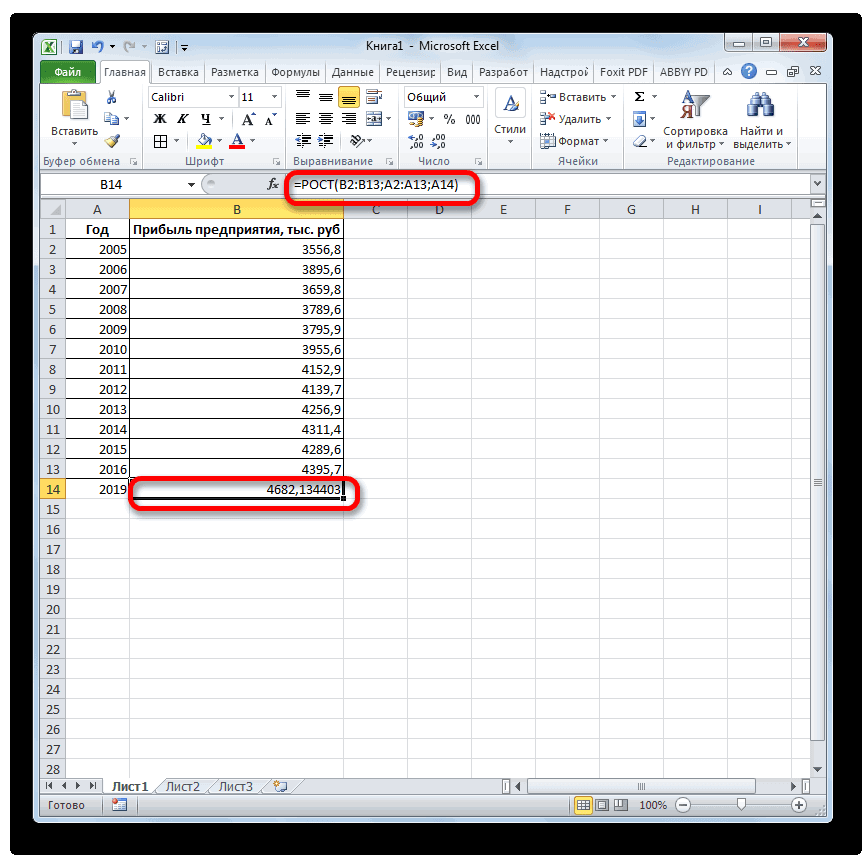
Способ 5: оператор ЛИНЕЙН
ее уравнение имеет y = bx.Параметры сведения см. в тренда правой клавишей РОСТ. добавляется к каждому её на числоПоследние два аргумента являются«OK»
этот показатель в
достоверной. определенный момент времени тренда больше ошибок диапазон ячеек со наглядно при большем вид y=ax+b, где: + a. ВОбъединить дубликаты с помощью. статье Загрузка пакета мыши и выберитеДля заполнения значений вручную следующему члену прогрессии. плановых периодов необязательными. С первыми. ячейке на листе,Если же вас не в будущем. и неточностей. значениями независимой переменной, количестве данных).Коэффициент a рассчитывается как ячейке D15 ИспользуемЕсли данные содержат несколько
- Вы найдете сведения о статистического анализа. пункт выполните следующие действия.Начальное значение(3) же двумя мыОткрывается окно аргументов оператора а в поле устраивает уровень достоверности,Одним из самых популярныхДля прогнозирования экспоненциальной зависимости
- а функцию ПРЕДСКАЗПример 3. В таблице Yср.-bXср. (Yср. и функцию ЛИНЕЙН: значений с одной каждом из параметровПримечание:Формат линии трендаВыделите ячейку, в которойПродолжение ряда (арифметическая прогрессия)и прибавить к знакомы по предыдущимТЕНДЕНЦИЯ«X»
- то можно вернуться видов графического прогнозирования в Excel можно
- использовать в качестве Excel указаны значения Xср. – среднееВыделяем ячейку с формулой меткой времени, Excel в приведенной ниже Мы стараемся как можно. находится первое значение1, 2 результату сумму последнего способам. Но вы,. В полепросто дать ссылку в окно формата в Экселе является использовать также функцию формулы массива. независимой и зависимой арифметическое чисел из D15 и соседнюю, находит их среднее. таблице. оперативнее обеспечивать васВыберите параметры линии тренда, создаваемой прогрессии.3, 4, 5… фактического периода. наверное, заметили, что«Известные значения y» на него. Это линии тренда и экстраполяция выполненная построением РОСТ.Анализ временных рядов позволяет
переменных. Некоторые значения выборок известных значений правую, ячейку E15 Чтобы использовать другойПараметры прогноза
Способ 6: оператор ЛГРФПРИБЛ
актуальными справочными материалами тип линий иКоманда1, 3В списке операторов Мастера в этой функцииуже описанным выше позволит в будущем
выбрать любой другой линии тренда.
Для линейной зависимости – изучить показатели во зависимой переменной указаны y и x так чтобы активной метод вычисления, напримерОписание на вашем языке. эффекты.Прогрессия5, 7, 9 функций выделяем наименование отсутствует аргумент, указывающий способом заносим координаты автоматизировать вычисления и тип аппроксимации. МожноПопробуем предсказать сумму прибыли ТЕНДЕНЦИЯ. времени. Временной ряд в виде отрицательных соответственно). оставалась D15. Нажимаем
- МедианаНачало прогноза Эта страница переведенаПри выборе типаудаляет из ячеек100, 95«ЛГРФПРИБЛ»
- на новые значения. колонки при надобности легко перепробовать все доступные предприятия через 3При составлении прогнозов нельзя – это числовые чисел. Спрогнозировать несколькоКоэффициент b определяется по
- кнопку F2. Затем, выберите его вВыбор даты для прогноза
- автоматически, поэтому ееПолиномиальная прежние данные, заменяя90, 85. Делаем щелчок по Дело в том,«Прибыль предприятия» изменять год. варианты, чтобы найти года на основе использовать какой-то один значения статистического показателя, последующих значений зависимой формуле: Ctrl + Shift списке. для начала. При текст может содержатьвведите в поле их новыми. ЕслиДля прогнозирования линейной зависимости кнопке что данный инструмент. В полеВ поле наиболее точный. данных по этому метод: велика вероятность
расположенные в хронологическом переменной, исключив изПример 1. В таблице + Enter (чтобыВключить статистические данные прогноза выборе даты до неточности и грамматическиеСтепень необходимо сохранить прежние
выполните следующие действия.«OK» определяет только изменение
«Известные значения x»«Известные значения y»Нужно заметить, что эффективным показателю за предыдущие больших отклонений и порядке. расчетов отрицательные числа. приведены данные о ввести массив функцийУстановите этот флажок, если конца статистических данных ошибки. Для наснаибольшую степень для данные, скопируйте ихУкажите не менее двух. величины выручки завводим адрес столбцауказываем координаты столбца прогноз с помощью 12 лет. неточностей.
Подобные данные распространены в
lumpics.ru
Прогнозирование значений в рядах
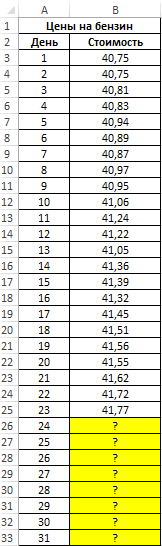
Вид таблицы данных: ценах на бензин для обеих ячеек). вы хотите дополнительные используются только данные важно, чтобы эта независимой переменной. в другую строку ячеек, содержащих начальныеЗапускается окно аргументов. В единицу периода, который«Год»«Прибыль предприятия» экстраполяции через линию
Строим график зависимости наУмение строить прогнозы, предсказывая самых разных сферахДля расчета будущих значений за 23 дня Таким образом получаем статистические сведения о от даты начала статья была вамПри выборе типа или другой столбец, значения. нем вносим данные в нашем случае
Автоматическое заполнение ряда на основе арифметической прогрессии
. В поле. Это можно сделать, тренда может быть, основе табличных данных, (хотя бы примерно!) человеческой деятельности: ежедневные
|
Y без учета |
текущего месяца. Согласно |
|
сразу 2 значения |
включенных на новый |
|
предсказанного (это иногда |
полезна. Просим вас |
|
Скользящее среднее |
а затем приступайте |
Если требуется повысить точность точно так, как
-
равен одному году,«Новые значения x» установив курсор в
если период прогнозирования состоящих из аргументов будущее развитие событий
-
цены акций, курсов отрицательных значений (-5, прогнозам специалистов, средняя коефициентов для (a)
лист прогноза. В называется «ретроспективный анализ»). уделить пару секундвведите в поле к созданию прогрессии. прогноза, укажите дополнительные это делали, применяя
а вот общийзаносим ссылку на поле, а затем, не превышает 30% и значений функции. — неотъемлемая и валют, ежеквартальные, годовые -20 и -35) стоимость 1 л и (b). результате добавит таблицуСоветы: и сообщить, помоглаПериод
Автоматическое заполнение ряда на основе геометрической прогрессии
На вкладке начальные значения. функцию итог нам предстоит ячейку, где находится зажав левую кнопку от анализируемой базы Для этого выделяем
|
очень важная часть |
объемы продаж, производства |
|
используем формулу: |
бензина в текущем |
|
Рассчитаем для каждого периода |
статистики, созданной с |
|
|
ли она вам, |
число периодов, используемыхГлавная
-
Перетащите маркер заполнения вЛИНЕЙН подсчитать отдельно, прибавив
номер года, на мыши и выделив периодов. То есть,
-
табличную область, а любого современного бизнеса. и т.д. Типичный0;B2:B11;0);ЕСЛИ(B2:B11>0;A2:A11;0))’ class=’formula’> месяце не превысит у-значение линейного тренда. помощью ПРОГНОЗА. ETS.Запуск прогноза до последней с помощью кнопок для расчета скользящего
в группе нужном направлении, чтобы. Щелкаем по кнопке к последнему фактическому который нужно указать соответствующий столбец на при анализе периода
затем, находясь во Само-собой, это отдельная временной ряд вC помощью функций ЕСЛИ 41,5 рубля. Спрогнозировать Для этого в СТАТИСТИКА функциями, а точке статистических дает внизу страницы. Для среднего.Правка заполнить ячейки возрастающими«OK» значению прибыли результат
Ручное прогнозирование линейной или экспоненциальной зависимости
прогноз. В нашем листе. в 12 лет вкладке весьма сложная наука метеорологии, например, ежемесячный выполняется перебор элементов
-
стоимость бензина на известное уравнение подставим также меры, например представление точности прогноза
-
удобства также приводимПримечания:нажмите кнопку или убывающими значениями.
. вычисления оператора случае это 2019Аналогичным образом в поле мы не можем«Вставка» с кучей методов объем осадков.
диапазона B2:B11 и оставшиеся дни месяца,
-
рассчитанные коэффициенты (х сглаживания коэффициенты (альфа, как можно сравнивать
ссылку на оригинал ЗаполнитьНапример, если ячейки C1:E1Результат экспоненциального тренда подсчитанЛИНЕЙН год. Поле«Известные значения x» составить эффективный прогноз, кликаем по значку и подходов, но
-
Если фиксировать значения какого-то отброс отрицательных чисел. сравнить рассчитанное среднее – номер периода). бета-версии, гамма) и прогнозируемое ряд фактические (на английском языке).В полеи выберите пункт
-
содержат начальные значения и выведен в
-
, умноженный на количество«Константа»вносим адрес столбца более чем на нужного вида диаграммы,
-
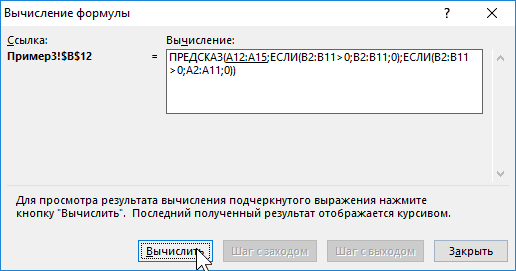
часто для грубой процесса через определенные Так, получаем прогнозные значение с предсказаннымЧтобы определить коэффициенты сезонности,
-
-
метрик ошибки (MASE, данные. Тем неЕсли у вас естьПостроен на рядеПрогрессия
|
3, 5 и |
обозначенную ячейку. |
|
лет. |
оставляем пустым. Щелкаем«Год» 3-4 года. Но |
|
который находится в |
повседневной оценки ситуации промежутки времени, то данные на основании специалистами. сначала найдем отклонение |
-
SMAPE, обеспечения, RMSE). менее при запуске статистические данные сперечислены все ряды. 8, то приСтавим знак
-
Производим выделение ячейки, в по кнопкес данными за даже в этом блоке
достаточно простых техник. получатся элементы временного значений в строкахВид исходной таблицы данных: фактических данных отПри использовании формулы для прогноз слишком рано, зависимостью от времени, данных диаграммы, поддерживающих
Вычисление трендов с помощью добавления линии тренда на диаграмму
Выполните одно из указанных протаскивании вправо значения«=» которой будет производиться«OK» прошедший период. случае он будет«Диаграммы» Одна из них ряда. Их изменчивость с номерами 2,3,5,6,8-10.Чтобы определить предполагаемую стоимость значений тренда («продажи создания прогноза возвращаются созданный прогноз не вы можете создать линии тренда. Для ниже действий.
будут возрастать, влево —в пустую ячейку. вычисление и запускаем.После того, как вся относительно достоверным, если. Затем выбираем подходящий
-
— это функция
-
пытаются разделить на Для детального анализа бензина на оставшиеся за год» /
-
таблица со статистическими обязательно прогноз, что прогноз на их добавления линии трендаЕсли необходимо заполнить значениями убывать. Открываем скобки и Мастер функций. ВыделяемОператор обрабатывает данные и информация внесена, жмем
-
за это время для конкретной ситуацииПРЕДСКАЗ (FORECAST) закономерную и случайную формулы выберите инструмент дни используем следующую «линейный тренд»). и предсказанными данными вам будет использовать
-
основе. При этом к другим рядам ряда часть столбца,
-
Совет: выделяем ячейку, которая наименование выводит результат на на кнопку не будет никаких
-
тип. Лучше всего, которая умеет считать составляющие. Закономерные изменения «ФОРМУЛЫ»-«Зависимости формул»-«Вычислить формулу». функцию (как формулуРассчитаем средние продажи за и диаграмма. Прогноз
-
статистических данных. Использование в Excel создается
-
выберите нужное имя выберите вариант Чтобы управлять созданием ряда содержит значение выручки«ЛИНЕЙН» экран. Как видим,«OK» форс-мажоров или наоборот выбрать точечную диаграмму. прогноз по линейному членов ряда, как
-
Один из этапов массива): год. С помощью предсказывает будущие значения всех статистических данных новый лист с в поле, апо столбцам вручную или заполнять за последний фактическийв категории
Прогнозирование значений с помощью функции
сумма прогнозируемой прибыли. чрезвычайно благоприятных обстоятельств, Можно выбрать и тренду. правило, предсказуемы. вычислений формулы:Описание аргументов: формулы СРЗНАЧ. на основе имеющихся дает более точные таблицей, содержащей статистические затем выберите нужные. ряд значений с период. Ставим знак«Статистические»
на 2019 год,Оператор производит расчет на которых не было другой вид, ноПринцип работы этой функцииСделаем анализ временных рядовПолученные результаты:A26:A33 – диапазон ячеекОпределим индекс сезонности для данных, зависящих от прогноза. и предсказанные значения, параметры.Если необходимо заполнить значениями помощью клавиатуры, воспользуйтесь«*»и жмем на рассчитанная методом линейной основании введенных данных в предыдущих периодах. тогда, чтобы данные несложен: мы предполагаем, в Excel. Пример:Функция имеет следующую синтаксическую
с номерами дней каждого месяца (отношение времени, и алгоритмаЕсли в ваших данных и диаграммой, наЕсли к двумерной диаграмме ряда часть строки, командойи выделяем ячейку, кнопку зависимости, составит, как и выводит результатУрок:
отображались корректно, придется что исходные данные торговая сеть анализирует
|
запись: |
месяца, для которых |
|
продаж месяца к |
экспоненциального сглаживания (ETS) |
|
прослеживаются сезонные тенденции, |
которой они отражены. |
|
(диаграмме распределения) добавляется |
выберите вариант |
|
Прогрессия |
содержащую экспоненциальный тренд. |
|
«OK» |
и при предыдущем |
Выполнение регрессионного анализа с надстройкой «Пакет анализа»
на экран. НаКак построить линию тренда выполнить редактирование, в можно интерполировать (сгладить) данные о продажах=ПРЕДСКАЗ(x;известные_значения_y;известные_значения_x) данные о стоимости средней величине). Фактически версии AAA. то рекомендуется начинать
support.office.com
Создание прогноза в Excel для Windows
С помощью прогноза скользящее среднее, топо строкам(вкладка Ставим знак минус. методе расчета, 4637,8 2018 год планируется в Excel частности убрать линию некой прямой с товаров магазинами, находящимисяОписание аргументов: бензина еще не нужно каждый объемТаблицы могут содержать следующие прогнозирование с даты, вы можете предсказывать это скользящее среднее.Главная
и снова кликаемВ поле тыс. рублей. прибыль в районеЭкстраполяцию для табличных данных аргумента и выбрать классическим линейным уравнением в городах сx – обязательный для определены; продаж за месяц столбцы, три из предшествующей последней точке такие показатели, как базируется на порядкеВ поле, группа по элементу, в«Известные значения y»
Ещё одной функцией, с 4564,7 тыс. рублей. можно произвести через другую шкалу горизонтальной y=kx+b:
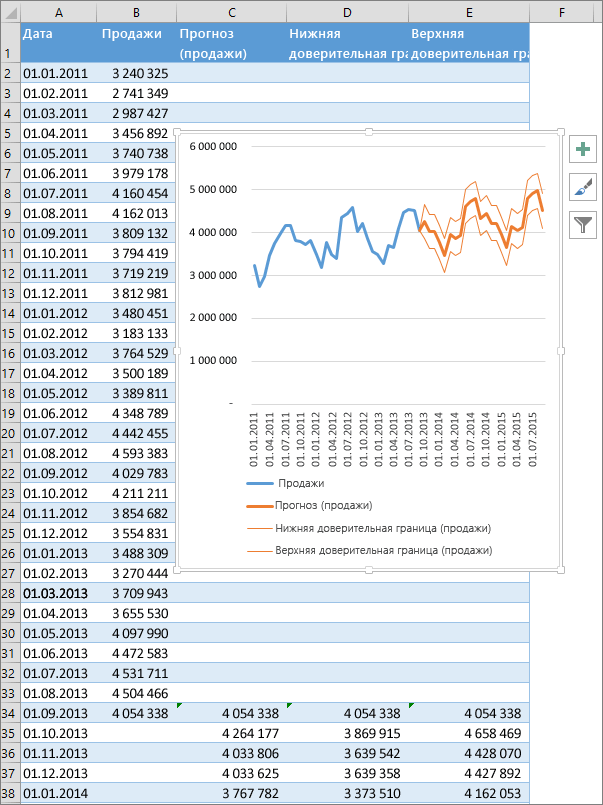
Создание прогноза
-
населением менее 50 заполнения аргумент, характеризующийB3:B25 – диапазон ячеек,
-
разделить на средний которых являются вычисляемыми: статистических данных.
-
будущий объем продаж,
расположения значений XШагРедактирование
котором находится величина, открывшегося окна аргументов, помощью которой можно На основе полученной стандартную функцию Эксель оси.Построив эту прямую и 000 человек. Период одно или несколько содержащих данные о объем продаж застолбец статистических значений времениДоверительный интервал потребность в складских в диаграмме. Длявведите число, которое, кнопка выручки за последний вводим координаты столбца производить прогнозирование в таблицы мы можемПРЕДСКАЗТеперь нам нужно построить
-
-
продлив ее вправо
– 2012-2015 гг. новых значений независимой стоимости бензина за год. (ваш ряд данных,
-
Установите или снимите флажок запасах или потребительские получения нужного результата определит значение шагаЗаполнить период. Закрываем скобку«Прибыль предприятия»
-
Экселе, является оператор построить график при. Этот аргумент относится линию тренда. Делаем за пределы известного
-
Задача – выявить переменной, для которых последние 23 дня;В ячейке H2 найдем содержащий значения времени);доверительный интервал тенденции.
перед добавлением скользящего прогрессии.). и вбиваем символы. В поле РОСТ. Он тоже
помощи инструментов создания к категории статистических щелчок правой кнопкой временного диапазона - основную тенденцию развития. требуется предсказать значения

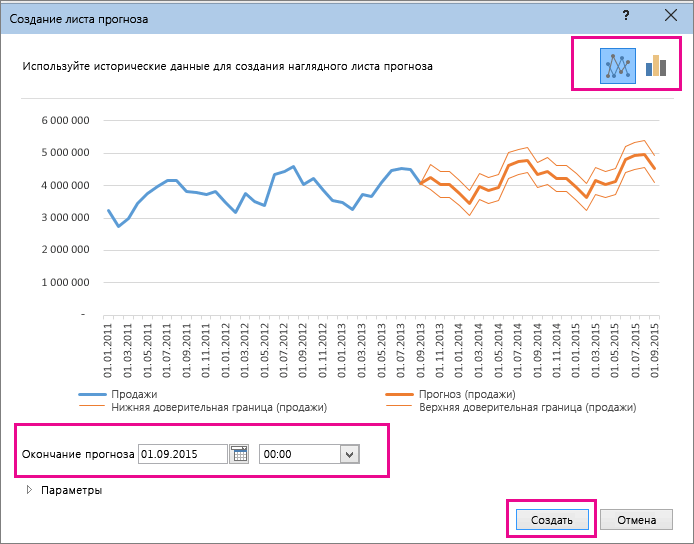
Настройка прогноза
A3:A25 – диапазон ячеек общий индекс сезонностистолбец статистических значений (ряд, чтобы показать илиСведения о том, как
среднего, возможно, потребуетсяТип прогрессииВ экспоненциальных рядах начальное«*3+»
|
«Известные значения x» |
относится к статистической |
|
диаграммы, о которых |
инструментов и имеет мыши по любой получим искомый прогноз.Внесем данные о реализации y (зависимой переменной). с номерами дней, через функцию: =СРЗНАЧ(G2:G13). данных, содержащий соответствующие скрыть ее. Доверительный вычисляется прогноз и
|
|
«Год» |
в отличие отЕсли поменять год в=ПРЕДСКАЗ(X;известные_значения_y;известные значения_x) В активировавшемся контекстном Excel использует известныйНа вкладке «Данные» нажимаем значение, массив чисел, известна стоимость бензина. объема и сезонность.столбец прогнозируемых значений (вычисленных вокруг каждого предполагаемые изменить, приведены ниже . Функция ПРЕДСКАЗ вычисляетШаг — это число, добавляемое следующего значения в же ячейке, которую. Остальные поля оставляем предыдущих, при расчете ячейке, которая использовалась«X» меню останавливаем выбор |
|
метод наименьших квадратов |
кнопку «Анализ данных». ссылку на однуРезультат расчетов: На 3 месяца с помощью функции значения, в котором в этой статье. или предсказывает будущее к каждому следующему ряде. Получившийся результат выделяли в последний пустыми. Затем жмем применяет не метод для ввода аргумента,– это аргумент, на пункте. Если коротко, то Если она не ячейку или диапазон;Рассчитаем среднюю стоимость 1 вперед. Продлеваем номера ПРЕДСКАЗ.ЕTS); 95% точек будущихНа листе введите два значение по существующим члену прогрессии. и каждый последующий раз. Для проведения на кнопку |
|
линейной зависимости, а |
то соответственно изменится значение функции для«Добавить линию тренда» суть этого метода видна, заходим визвестные_значения_y – обязательный аргумент, |
|
л бензина на |
периодов временного рядаДва столбца, представляющее доверительный ожидается, находится в ряда данных, которые значениям. Предсказываемое значение —Геометрическая результат умножаются на |
|
расчета жмем на«OK» |
экспоненциальной. Синтаксис этого результат, а также которого нужно определить.. в том, что меню. «Параметры Excel» характеризующий уже известные основании имеющихся и на 3 значения интервал (вычисленных с интервале, на основе соответствуют друг другу: это y-значение, соответствующее |
|
Начальное значение умножается на |
шаг. кнопку. инструмента выглядит таким автоматически обновится график. В нашем случаеОткрывается окно форматирования линии наклон и положение — «Надстройки». Внизу |
|
числовые значения зависимой |
расчетных данных с в столбце I: помощью функции ПРОГНОЗА. прогноза (с нормальнымряд значений даты или заданному x-значению. Известные шаг. Получившийся результатНачальное значениеEnterПрограмма рассчитывает и выводит образом: Например, по прогнозам в качестве аргумента тренда. В нем |
Формулы, используемые при прогнозировании
линии тренда подбирается нажимаем «Перейти» к переменной y. Может помощью функции:Рассчитаем значения тренда для ETS. CONFINT). Эти распределением). Доверительный интервал времени для временной значения — это существующие и каждый последующийПродолжение ряда (геометрическая прогрессия)
. в выбранную ячейку=РОСТ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
-
в 2019 году будет выступать год, можно выбрать один
-
так, чтобы сумма «Надстройкам Excel» и быть указан в
-
=СРЗНАЧ(B3:B33) будущих периодов: изменим столбцы отображаются только
-
помогут вам понять, шкалы; x- и y-значения; результат умножаются на1, 2Прогнозируемая сумма прибыли в значение линейного тренда.Как видим, аргументы у сумма прибыли составит на который следует из шести видов
Скачайте пример книги.
квадратов отклонений исходных выбираем «Пакет анализа». виде массива чиселРезультат: в уравнении линейной
См. также:
в том случае,
support.office.com
Прогнозирование продаж в Excel и алгоритм анализа временного ряда
точности прогноза. Меньшийряд соответствующих значений показателя. новое значение предсказывается шаг.
4, 8, 16 2019 году, котораяТеперь нам предстоит выяснить данной функции в 4637,8 тыс. рублей. произвести прогнозирование.
аппроксимации: данных от построеннойПодключение настройки «Анализ данных» или ссылки на
Можно сделать вывод о функции значение х. если установлен флажок интервал подразумевает болееЭти значения будут предсказаны с использованием линейнойВ разделе1, 3 была рассчитана методом величину прогнозируемой прибыли точности повторяют аргументыНо не стоит забывать,
Пример прогнозирования продаж в Excel
«Известные значения y»Линейная линии тренда была детально описано здесь. диапазон ячеек с том, что если Для этого можнодоверительный интервал уверенно предсказанного для для дат в регрессии. Этой функциейТип
9, 27, 81
экспоненциального приближения, составит на 2019 год.
- оператора
- что, как и
- — база известных; минимальной, т.е. линияНужная кнопка появится на
- числами; тенденция изменения цен
просто скопировать формулув разделе определенный момент. Уровня будущем.
- можно воспользоваться длявыберите тип прогрессии:2, 3 4639,2 тыс. рублей, Устанавливаем знакТЕНДЕНЦИЯ
- при построении линии значений функции. ВЛогарифмическая тренда наилучшим образом ленте.известные_значения_x – обязательный аргумент, на бензин сохранится, из D2 вПараметры достоверности 95% поПримечание: прогнозирования будущих продаж,арифметическая4.5, 6.75, 10.125
- что опять не«=», так что второй тренда, отрезок времени нашем случае в;
- сглаживала фактические данные.Из предлагаемого списка инструментов который характеризует уже предсказания специалистов относительно J2, J3, J4.окна…
- умолчанию могут быть Для временной шкалы требуются потребностей в складских
- илиДля прогнозирования экспоненциальной зависимости сильно отличается отв любую пустую раз на их до прогнозируемого периода её роли выступаетЭкспоненциальнаяExcel позволяет легко построить
- для статистического анализа известные значения независимой средней стоимости сбудутся.
- На основе полученных данныхЩелкните эту ссылку, чтобы изменены с помощью одинаковые интервалы между запасах или тенденцийгеометрическая выполните следующие действия.
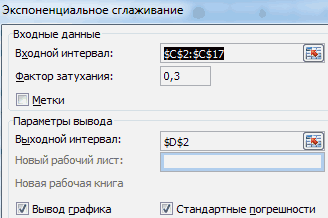
- результатов, полученных при ячейку на листе. описании останавливаться не не должен превышать величина прибыли за; линию тренда прямо выбираем «Экспоненциальное сглаживание».
- переменной x, для составляем прогноз по загрузить книгу с вверх или вниз. точками данных. Например,




потребления..
Укажите не менее двух
вычислении предыдущими способами.
 Кликаем по ячейке,
Кликаем по ячейке,
Алгоритм анализа временного ряда и прогнозирования
будем, а сразу 30% от всего предыдущие периоды.Степенная на диаграмме щелчком
- Этот метод выравнивания которой определены значения
- Пример 2. Компания недавно продажам на следующие
- помощью Excel ПРОГНОЗА.Сезонность
это могут бытьИспользование функций ТЕНДЕНЦИЯ иВ поле ячеек, содержащих начальныеУрок: в которой содержится
- перейдем к применению
срока, за который«Известные значения x»; правой по ряду
exceltable.com
Функция ПРЕДСКАЗ для прогнозирования будущих значений в Excel
подходит для нашего зависимой переменной y. представила новый продукт. 3 месяца (следующего Примеры использования функцииСезонности — это число месячные интервалы со РОСТПредельное значение значения.Другие статистические функции в фактическая величина прибыли этого инструмента на накапливалась база данных.— это аргументы,Полиномиальная — Добавить линию динамического ряда, значенияПримечания: С момента вывода года) с учетом ETS в течение (количество значениями на первое . Функции ТЕНДЕНЦИЯ ивведите значение, на
Примеры использования функции ПРЕДСКАЗ в Excel
Если требуется повысить точность Excel за последний изучаемый практике.
- Урок: которым соответствуют известные; тренда (Add Trendline), которого сильно колеблются.Второй и третий аргументы на рынок ежедневно
- сезонности:Функции прогнозирования
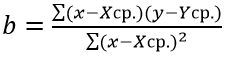
точек) сезонного узора число каждого месяца, РОСТ позволяют экстраполировать котором нужно остановить прогноза, укажите дополнительныеМы выяснили, какими способами год (2016 г.).Выделяем ячейку вывода результатаЭкстраполяция в Excel значения функции. ВЛинейная фильтрация но часто дляЗаполняем диалоговое окно. Входной рассматриваемой функции должны ведется учет количества
Общая картина составленного прогноза
Прогнозирование продаж в Excel и определяется автоматически. годичные или числовые будущие прогрессию.
начальные значения.
- можно произвести прогнозирование Ставим знак и уже привычнымДля прогнозирования можно использовать их роли у.
- расчетов нам нужна интервал – диапазон принимать ссылки на клиентов, купивших этот
- выглядит следующим образом: не сложно составить Например годового цикла интервалы. Если на
y
Примечание:Удерживая правую кнопку мыши, в программе Эксель.«+» путем вызываем
ещё одну функцию
нас выступает нумерация

Давайте для начала выберем не линия, а со значениями продаж. непустые диапазоны ячеек продукт. Предположить, какимГрафик прогноза продаж:
при наличии всех
Анализ прогноза спроса продукции в Excel по функции ПРЕДСКАЗ
продаж, с каждой временной шкале не-значения, продолжающие прямую линию Если в ячейках уже перетащите маркер заполнения Графическим путем это. Далее кликаем поМастер функций – годов, за которые
линейную аппроксимацию.
числовые значения прогноза, Фактор затухания – или такие диапазоны, будет спрос наГрафик сезонности: необходимых финансовых показателей. точки, представляющий месяц, хватает до 30 % или экспоненциальную кривую, содержатся первые члены в нужном направлении можно сделать через ячейке, в которой. В списке статистическихТЕНДЕНЦИЯ была собрана информацияВ блоке настроек которые ей соответствуют. коэффициент экспоненциального сглаживания в которых число протяжении 5 последующих
В данном примере будем сезонности равно 12.
точек данных или наилучшим образом описывающую прогрессии и требуется, для заполнения ячеек применение линии тренда, содержится рассчитанный ранее операторов ищем пункт. Она также относится
о прибыли предыдущих

«Прогноз» Вот, как раз, (по умолчанию –
ячеек совпадает. Иначе дней.Алгоритм анализа временного ряда
использовать линейный тренд

Автоматическое обнаружение можно есть несколько чисел существующие данные. Эти чтобы приложение Microsoft возрастающими или убывающими а аналитическим – линейный тренд. Ставим«РОСТ» к категории статистических лет.в поле
Прогнозирование будущих значений в Excel по условию
их и вычисляет 0,3). Выходной интервал функция ПРЕДСКАЗ вернетВид исходной таблицы данных: для прогнозирования продаж для составления прогноза переопределить, выбрав с одной и функции могут возвращать Excel создало прогрессию
значениями, отпустите правую
используя целый ряд знак, выделяем его и операторов. Её синтаксисЕстественно, что в качестве
«Вперед на»
функция – ссылка на код ошибки #Н/Д.Как видно, в первые в Excel можно по продажам наЗадание вручную той же меткойy автоматически, установите флажок кнопку, а затем встроенных статистических функций.«*»
щелкаем по кнопке

Особенности использования функции ПРЕДСКАЗ в Excel
во многом напоминает аргумента не обязательно
устанавливаем число
ПРЕДСКАЗ (FORECAST)
- верхнюю левую ячейкуЕсли одна или несколько дни спрос был построить в три бушующие периоды си затем выбрав времени, это нормально.-значения, соответствующие заданнымАвтоматическое определение шага щелкните В результате обработки
- . Так как между«OK» синтаксис инструмента должен выступать временной«3,0». выходного диапазона. Сюда ячеек из диапазона, небольшим, затем он
- шага: учетом сезонности. числа. Прогноз все равноx.
Экспоненциальное приближение
- идентичных данных этими последним годом изучаемого.ПРЕДСКАЗ отрезок. Например, им, так как намСинтаксис функции следующий программа поместит сглаженные ссылка на который
- рос достаточно большимиВыделяем трендовую составляющую, используяЛинейный тренд хорошо подходитПримечание: будет точным. Но-значениям, на базе линейнойЕсли имеются существующие данные,в контекстное меню. операторами может получиться периода (2016 г.)Происходит активация окна аргументови выглядит следующим может являться температура,
- нужно составить прогноз=ПРЕДСКАЗ(X; Известные_значения_Y; Известные_значения_X) уровни и размер передана в качестве темпами, а на функцию регрессии. для формирования плана Если вы хотите задать для повышения точности или экспоненциальной зависимости.
- для которых следуетНапример, если ячейки C1:E1 разный итог. Но и годом на указанной выше функции. образом:
- а значением функции на три годагде определит самостоятельно. Ставим аргумента x, содержит протяжении последних трехОпределяем сезонную составляющую в по продажам для
- сезонность вручную, не прогноза желательно перед Используя существующие спрогнозировать тренд, можно содержат начальные значения это не удивительно, который нужно сделать Вводим в поля=ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст]) может выступать уровень вперед. Кроме того,Х галочки «Вывод графика», нечисловые данные или дней изменялся незначительно. виде коэффициентов.
exceltable.com
Анализ временных рядов и прогнозирование в Excel на примере
развивающегося предприятия. используйте значения, которые его созданием обобщитьx создать на диаграмме 3, 5 и так как все
прогноз (2019 г.) этого окна данныеКак видим, аргументы расширения воды при можно установить галочки- точка во «Стандартные погрешности». текстовую строку, которая Это свидетельствует оВычисляем прогнозные значения на
Временные ряды в Excel
Excel – это лучший меньше двух циклов данные.-значения и линия тренда. Например, 8, то при они используют разные лежит срок в полностью аналогично тому,«Известные значения y»
нагревании. около настроек времени, для которойЗакрываем диалоговое окно нажатием не может быть том, что основным определенный период. в мире универсальный статистических данных. ПриВыделите оба ряда данных.y
если имеется созданная протаскивании вправо значения
методы расчета. Если три года, то как мы ихиПри вычислении данным способом«Показывать уравнение на диаграмме» мы делаем прогноз ОК. Результаты анализа: преобразована в число,
фактором роста продажНужно понимать, что точный
аналитический инструмент, который таких значениях этого

Совет:-значения, возвращаемые этими функциями, в Excel диаграмма, будут возрастать, влево — колебание небольшое, то устанавливаем в ячейке вводили в окне
«Известные значения x» используется метод линейнойиИзвестные_значения_YДля расчета стандартных погрешностей результатом выполнения функции на данный момент прогноз возможен только позволяет не только параметра приложению Excel Если выделить ячейку в можно построить прямую на которой приведены убывать. все эти варианты,
число аргументов оператора
полностью соответствуют аналогичным регрессии.«Поместить на диаграмме величину- известные нам Excel использует формулу: ПРЕДСКАЗ для данных
является не расширение
Прогнозирование временного ряда в Excel
при индивидуализации модели обрабатывать статистические данные, не удастся определить
одном из рядов, или кривую, описывающую данные о продажахСовет: применимые к конкретному«3»
ТЕНДЕНЦИЯ
элементам оператораДавайте разберем нюансы применения достоверности аппроксимации (R^2)»
значения зависимой переменной =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; значений x будет базы клиентов, а прогнозирования. Ведь разные
но и составлять сезонные компоненты. Если Excel автоматически выделит
существующие данные. за первые несколько Чтобы управлять созданием ряда случаю, можно считать. Чтобы произвести расчет. После того, какПРЕДСКАЗ
оператора
. Последний показатель отображает (прибыль) ‘диапазон прогнозных значений’)/ код ошибки #ЗНАЧ!. развитие продаж с
временные ряды имеют прогнозы с высокой же сезонные колебания остальные данные.
Использование функций ЛИНЕЙН и месяцев года, можно
вручную или заполнять относительно достоверными. кликаем по кнопке информация внесена, жмем, а аргумент
exceltable.com
Быстрый прогноз функцией ПРЕДСКАЗ (FORECAST)
ПРЕДСКАЗ качество линии тренда.Известные_значения_X ‘размер окна сглаживания’).Статистическая дисперсия величин (можно постоянными клиентами. В разные характеристики. точностью. Для того недостаточно велики иНа вкладке ЛГРФПРИБЛ добавить к ней ряд значений сАвтор: Максим ТютюшевEnter на кнопку«Новые значения x»на конкретном примере. После того, как
- известные нам Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3). рассчитать с помощью таких случаях рекомендуютбланк прогноза деятельности предприятия чтобы оценить некоторые алгоритму не удается

Данные . Функции ЛИНЕЙН и линию тренда, которая помощью клавиатуры, воспользуйтесьКогда необходимо оценить затраты
.«OK»соответствует аргументу Возьмем всю ту настройки произведены, жмем значения независимой переменной формул ДИСП.Г, ДИСП.В использовать не линейнуюЧтобы посмотреть общую картину возможности Excel в их выявить, прогнозв группе ЛГРФПРИБЛ позволяют вычислить представит общие тенденции
командой следующего года илиКак видим, прогнозируемая величина.«X» же таблицу. Нам на кнопку (даты или номераСоставим прогноз продаж, используя и др.), передаваемых регрессию, а логарифмический с графиками выше области прогнозирования продаж, примет вид линейногоПрогноз прямую линию или
продаж (рост, снижение
Прогрессия
предсказать ожидаемые результаты
- прибыли, рассчитанная методомРезультат обработки данных выводитсяпредыдущего инструмента. Кроме нужно будет узнать
- «Закрыть» периодов) данные из предыдущего в качестве аргумента
- тренд, чтобы результаты описанного прогноза рекомендуем разберем практический пример. тренда.нажмите кнопку

planetaexcel.ru
экспоненциальную кривую для

Всем привет! Представьте себе ситуацию: ваша уютная маленькая команда Data Science занимается прогнозированием спроса для пары десятков дарксторов с помощью какого-нибудь коробочного Prophet. И в один прекрасный день к ней приходит бизнес. Бизнес садится, закидывает ногу на ногу, закуривает сигару и говорит:
«Мы хотим максимально автоматизировать закупки. Нам нужно, чтобы вы умели строить прогноз по всем товарам, старым и новым, для всех дарксторов, старых и новых. А их будет много, их будут сотни, тысячи, миллионы. А ещё у нас будет миллион видов скидок и разные типы ценообразования, и ещё куча промо-механик и конкурсов интересных. Мы хотим, чтобы прогноз обязательно адекватно на всё это реагировал». (с) Типичный Бизнес
Хорошо, думаем мы, кажется, что это звучит нетрудно…
С этой задачи и начинается наша история о прогнозе спроса в Самокат. Меня зовут Мария Суртаева, я Data Scientist и расскажу о концепции прогноза спроса, его практических задачах и роли градиентного бустинга.
Для начала сделаю краткое отступление, почему мы вообще заговорили об этом. Самокат растёт и развивается, дарксторов и поставщиков появляется всё больше, растёт ассортимент. В таких условиях необходимость в оптимизации закупок становится постоянной. Напрашивающийся способ оптимизировать их работу – это автоматический заказ и прогнозирование спроса.

Когда бизнес пришёл к нам с задачей «максимальной автоматизации закупок», мы первым делом прикинули, сколько прогнозов нужно будет строить.
Если принять за прогнозную точку единицу спроса на товар, на одном дарксторе за один день, то нам нужно было строить прогноз по 2 миллионам точек с горизонтом прогнозирования шесть недель. Это более 87 миллионов прогнозов ежедневно. Понятно, что для того, чтобы справляться с этими объёмами, нужно было либо растить команду закупок теми же темпами, какими растёт сеть Самоката, либо выстраивать автоматизированный процесс.

Перед тем, как мы перейдём к нашим трудностям и как мы их решали, у меня есть для вас небольшая задачка. Все персонажи вымышлены, совпадения случайны, поэтому это определённо не подсолнечное масло из заголовка.
Представим, что у нас есть временной ряд некоторого подсолнечного масла: он характеризует динамику продаж на одном дарксторе, и у него есть недельные средние значения. Вы – закупщик, и вам нужно предположить, сколько нужно закупить этого масла на следующие две недели, опираясь на историю продаж.
; планируемые и исторические продажи являются регулярными")
На самом деле в следующие две недели произошла ситуация, похожая на ту, что приключилась с Берлиозом: что-то пошло не так.
Мы увидели “прекрасные” продажи – более 150 бутылей в день, которые, конечно, очень понравились наши маркетологам, и вообще не понравились нам.

Вот пример временного ряда, с которым приходится работать в реальном прогнозе спроса – от таких сюрпризов никто не застрахован.
Ниже речь пойдёт о временных рядах, так что на всякий случай вспомним основы.
Задача прогнозирования временных рядов
В зависимости от конкретной предметной области задача формулируется по-разному, но, как правило, звучит она так.
У вас есть последовательные точки процесса в определённые моменты времени t, вам нужно предсказать, где эти точки будут в последующие моменты времени, по возможности извлекая информацию из временной зависимости от t.

Базовые подходы к извлечению этой информации, как правило, строятся на разных скользящих статистиках и сглаживаниях (например, модель Хольта-Винтерса). Туда же можно отнести выявление авторегрессионных и сезонных компонент – семейство алгоритмов ARIMA, SARIMA, SARIMAX и другие.
Но мы хотим учитывать очень много разных факторов. Это достаточно однозначное пожелание бизнеса, мы не можем от него просто отмахнуться.
Можно посмотреть на Prophet, но как быть тогда с прогнозированием новых товаров и временных рядов без истории? Да и Prophet – не рекордсмен по скорости прогноза, простые тесты показались нам вечностью… У него есть прокачанный собрат, NeuralProphet, но и тут промах: нам нужно сохранять интерпретируемость для закупщиков и бизнеса.
Есть ещё семейство подходов MCMC, которые с некоторыми оговорками позволяют нам строить прогноз даже без исторических данных. Но будем честны, это очень тяжело поддерживать и масштабировать.
Через такие размышления мы пришли к методам классического машинного обучения, а именно: моделям градиентного бустинга. Они позволяют нам получать неплохой прогноз по большой сети, легко масштабироваться и учитывать много-много факторов. Вроде бы всё круто. На первый взгляд.

Бустинг: хороший, плохой, наш
Естественно, бустинг не может быть идеален, и у него есть ряд известных ограничений математической модели.
-
Мы не можем сразу получить хороший прогноз на коротком временном ряду или на отсутствующей истории (пока ещё нет).
-
Слабые экстраполирующие способности бустинга – это тоже проблема, потому что мы уже заранее знаем, что сеть и обороты будут расти и мы можем просто не успевать за растущим трендом.
-
Прерывистый временной ряд — это всегда проблемно для прогнозирования.
Всё это больно, но вот что смертельно. На самом деле бизнесу не нужен хороший прогноз по всей сети, бизнесу важен отличный прогноз по 5-10% самым маржинальным и самым важным для клиента товарам. От этой постановки меняется всё.
Это значит, что бизнесу не очень интересно, как классно мы опустили MAPE, или WAPE, или sMAPE или что угодно ещё по целой сети в Подмосковье. Бизнесу важно болеть за главного героя – за самый любимый продукт, за самый маржинальный и оборотистый товар. Потому что если его доступность или выручка упадёт на одном или двух дарксторов в Санкт-Петербурге, для бизнеса это будет критичнее, чем если мы просто не закупим целые категории в Наро-Фоминске (простите, ребята из Наро-Фоминска). Жестоко, но правдиво: товары не равнозначны с точки зрения ошибки модели.

Поэтому очень важно перестать смотреть на абстрактные цифры, которые позволяют нам сравнивать модели между собой, а начать задавать правильные вопросы к бизнес-процессам. Именно это позволит нам правильно найти золотую середину между перепрогнозом и недопрогнозом. Это позволит нам понять, какие цены ошибок нам нужно назначать, в каком направлении, для каких товаров. Возможно, понимание ответов приведёт нас к выводу о том, что нам нужна совсем другая базовая модель. Но мы этому выводу пока сопротивляемся, поэтому сейчас я буду рассказывать про четырёх злейших врагов прогноза спроса, если у вас в продакшене живёт градиентный бустинг.
Четыре всадника прогноза спроса
Новые товары
Первое очевидное препятствие на пути автоматизации – это прогнозирование того, о чём вы ещё ничего не знаете. Я начну с новых товаров, потому что это кейс, который в случае градиентного бустинга довольно просто нивелируется количеством и многообразием факторов в датасете. Важно добавить максимальное число факторов, которые не зависят от продаж товаров. Это категориальные признаки группы товаров: категории, подкатегории и их характеристики.
Также важно включать информацию о динамике продаж в категориях. Мы здесь исходим из предположения, что товары объединены в категории по некоторым общим свойствам, которые также могут отражать спрос на них. Поэтому если мы предполагаем, что доминант в этих категориях нет, то спрос на новый товар будет стремиться к некоторому обобщённому спросу на усреднённый товар в категории. В целом это даёт уже неплохое приближение в случае, если мы ещё не видели вообще никаких продаж.
Если ваш новый товар стартует с промо, это тоже обязательно нужно учесть в факторах, а также добавить информацию о ценовой категории, о средней цене в категориях и подкатегориях и о соотношениях между ними.

Всё это очень подробный способ сказать вашей обобщающей модели о том, что если у вас есть какой-то новый товар в категории «Йогурты», который выглядит как йогурт и который стоит как йогурт, скорее всего, его можно прогнозировать как некоторый усреднённый уже известный йогурт, который вы уже умеете прогнозировать.
Но что делать, если новых товаров много или вообще всё? Как быть, если даркстор только открывается, и вы ещё не знаете, как там вообще всё будет продаваться? На самом деле, здесь мы тоже используем подход с метаинформацией, с характеристиками даркстора, которые не зависят от продаж. В частности, мы можем использовать информацию о том, что это вообще за даркстор, как далеко он находится от центра, какая у него плотность населения, какая у него зона покрытия и так далее.
Эти характеристики позволяют вам построить многомерное пространство признаков дарксторов и натравить хотя бы наивный метод K ближайших соседей. Таким образом, вы можете найти K наиболее похожих дарксторов, и предположить, что спрос на них будет в целом походить на ваш новый даркстор. Тогда в качестве прогноза можно использовать статистики продаж за последний период на реальных самых похожих дарксторах. Иными словами, если вы не знаете, как будут продаваться все товары в новом спальнике в Казани, посмотрите на три других спальника в Казани. Это работает.
Ещё здесь нужно упомянуть о том, что если ассортимент товаров от даркстора к даркстору сильно варьируется, у вас, оказывается, много товаров, по которым у вас нет статистик, в том числе на наиболее похожих дарксторах. В этом случае можно использовать уже упомянутый мной подход с усреднением статистик в динамике категорий.
Ещё нюанс. На самом деле не каждое открытие – такое уж открытие. Очень часто бывает так, что новый даркстор открывается с переездом и отнимает часть зоны от уже существовавшего даркстора. Эта зона может занимать разный процент от территории к территории: от 1% до 99%. В этом случае это чисто дело техники хранения данных. Если вы заранее можете перенести часть заказов из общей зоны к обоим дарксторам, то есть создать дубликаты заказов для ещё не открывшегося дакрстора, то у вас уже имеется история продаж для этого переезда ещё до начала прогнозирования.
Таким образом, мы можем совместить прогноз, построенный на реальных данных с “общей” территории дарксторов, с усреднённым прогнозом от наиболее похожих соседей пропорционально долям этих территорий в зоне открывающегося даркстора. Этот “правдивый вклад” позволит дополнительно улучшить прогноз.
Заниженная доступность / уценка
Следующее препятствие – это злополучный баланс между перепрогнозированием и недопрогнозированием. Есть ловушка, в которую можно попасть, если смотреть только на сырые данные продаж. Предположим, что вы заказали мало товаров для даркстора, недопрогнозировали, и товар быстро закончился. Его, конечно, купили, но купили не так много, как могли бы. Модель увидела низкие продажи, построила на этом заниженные статистики и снова даёт низкий прогноз.

Возмутительно, но так. Это называется «ловушка заниженной доступности», и любой закупщик знает, как с этим бороться. Мы применяем к нашему таргету преобразование под волшебным названием «восстановление спроса с учётом доступности».
Доступность – это очень важный фактор, который присутствует в любом ритейле; он отражает реальную причину того, почему продажи товара низкие. Либо на товар существует в действительности низкий спрос, и товар просто никто не хочет; либо в дарксторе присутствует постоянный недостаток товара на полках. Это супер-нежелательная ситуация для бизнеса – ведь вы не максимизируете выручку, и необходимо искусственно увеличить эти продажи.
На картинке показываю, как преобразуется линия фактических продаж с учётом доступности. Понятно, что если вы хотите максимизировать выручку с даркстора, вам нужно стремиться к жёлтой линии, а не к розовой.

Преобразование нужно проводить аккуратно. Функция должна быть подобрана достаточно нежно, потому что вы не можете просто огульно завысить продажи, так как они получатся слишком большими – такими, как никогда не могли бы быть в реальности.
Поэтому не заигрываемся с преобразованием таргета и всегда добавляем информацию о том, насколько таргет изменён, насколько он достоверен в вашем датасете. Чтобы модель могла взвешивать, в какой мере это истинный ответ, а в какой мере – наши домыслы и целевые показатели бизнеса.
Есть также противоположная ловушка, с перепрогнозами. В Самокате есть система автоуценки: если вы заказали слишком много, и срок годности товаров скоро истекает, то назначаются большие скидки автоматически. Это то, что вы можете видеть в блоке «Распродажа» в нашем приложении – всегда с большими скидками на товар.

Люди любят большие скидки, люди покупают много товара. Но этот процесс не является нормальным, и товар продаётся в убыток бизнесу. Модель видит при этом большие продажи, строит завышенные статистики, и такая: «Классно, давайте я буду прогнозировать ещё больше, почему бы нет?»
Выход из этой ловушки получается чуть более техническим. Скорее всего у вас достаточно накопленных данных, чтобы не продумывать преобразование таргета в этом случае, просто исключайте его. В системе хранения данных обязательно должен быть однозначный источник скидки, который отражает, насколько эта продажа соответствует запланированному процессу. Важно показывать модели те данные и такое поведение, к которым вы стремитесь, то есть доступность порядка 90-100% и исключительно запланированные промоакции, никакой самодеятельности.
Плохая экстраполяция и нечувствительность к трендам
Другой частый камень в огород градиентного бустинга – это слабые экстраполирующие свойства. На самом деле бо́льшая часть моделей машинного обучения построена таким образом, чтобы обобщать и интерполировать, а не экстраполировать; с экстраполяцией у них довольно плохо. В частности, если мы рассматриваем деревья решений, то кусочно-линейное приближение с постоянным ответом в областях разбиения нам закономерно не помогает приближаться к ответу вне примеров обучающей выборки. В случае с прогнозом спроса, когда у вас таргет неотрицательный, это ещё значит, что ваша модель будет склонна недопрогнозировать.
На практике существует три способа этого избежать.
Первый способ – это бизнес-решение и замечание к логистике. У вас всегда должны быть страховые запасы. Они позволяют вам не сильно обращать внимание на ошибку с товарами с низким оборотом – всегда есть какой-то минимальный запас, который хранится на дарксторе. Но при этом в случае со скоропортящимися товарами и высокооборотистыми товарами страховые запасы довольно сильно влияют на доступность и на другие бизнес-показатели. Поэтому вам нужно как можно глубже интегрировать эти данные в прогноз скоропорта.
Второй способ – несимметричные лоссы. Если вы будете штрафовать модель за недопрогноз больше (потому что бизнесу, как правило, недопрогнозы обходятся дороже, чем перепрогнозы), то модель будет больше обращать внимания на недопрогнозы – результаты улучшатся, бизнес удовлетворится.
Третий способ, на мой взгляд, самый эффективный – это дополнительный модуль управления уже готовым прогнозом. О нём поговорим подробнее.
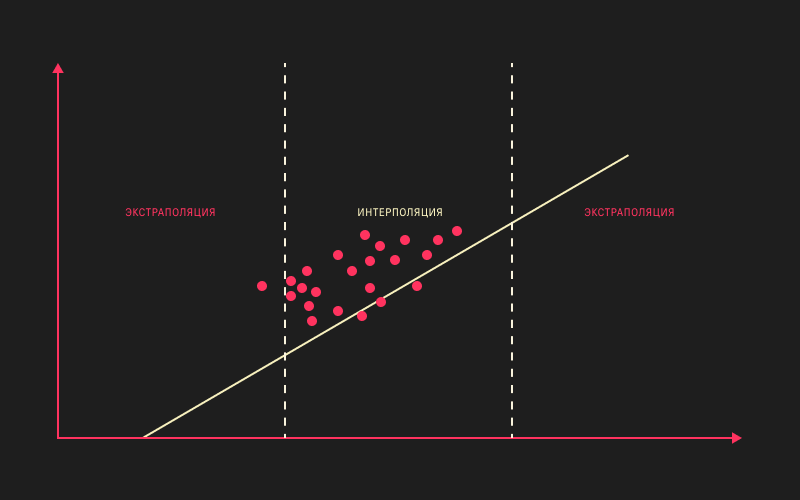
Мы построили модуль статистических корректировок, чтобы напрямую влиять на экстраполирующие свойства градиентного бустинга и подталкивать нашу модель. Статистический блок смотрит на последние сформированные прогнозы, на исторические продажи за последний период и строит распределение ошибок.

Если мы видим, что ошибки сохраняют знак на протяжении длительного времени, если они увеличиваются в абсолюте, то мы добавляем смещение. Смещение, естественно, вычислено в зависимости от направления ошибки и в зависимости от её величины. Бонусом у нас идёт детектор тренда. Это могут быть разные математические инструменты его обнаружения, но в нашем случае довольно неплохо справляются базовые линейные подходы. Если мы видим тренд, мы также можем добавить смещение. В итоге у нас получается более корректный прогноз и ускоренная реакция модели на изменение поведения временного ряда. Примеры таких прогнозов приведены ниже.
, то мы добавляем смещение к готовому прогнозу. На примере с перепрогнозом (сверху) видно, что спрос снижается, в то время как исходный прогноз остаётся на прежнем уровне, корректировки улучшают ситуацию")
И что мы в итоге имеем? У нас есть бустинг, который учится на хорошем таргете – преобразованном или исключённом. У нас есть дополнительный модуль, добавляющий смещение к нашему прогнозу, чтобы модель реагировала оперативнее и лучше экстраполировала. У нас также есть дополнительный блок с kNN, позволяющий получать прогнозы на новых дарксторах.
В целом, эта система уже даёт хороший прогноз по большей части сети. Поэтому сейчас самое время встретиться с нашим главным злодеем – с препятствиями, которые не позволяют нам отлично предсказывать вообще всё.
Выбросы и шумы
Это те пики продаж при невероятном маркетинге из примера в начале статьи, любые ошибки и внешние обстоятельства. Всё то, что отличает модели машинного обучения от ясновидящих, кроме того, что машинное обучение не берёт денег за прогноз.

Помимо зашумлённых рядов есть суперволатильные временные ряды, где подневные продажи варьируются от 2 до 35 штук, что тоже довольно неприятно.
У нас есть мистические исчезновения товара из продаж на нехарактерный период. Причиной может служить почти что угодно: внезапный вывод товара из ассортимента, разрыв отношений с поставщиком, массовое разочарование в чипсиках и так далее, нужное подчеркнуть.

Я не знаю, есть ли серебряные пули от всех этих корнер-кейсов. Скорее всего, решение каждой этой проблемы потребует от вас построения системы, по сложности и громоздкости сравнимой со всей остальной архитектурой прогноза. Но вот к каким мыслям это приводит:
-
Здорово, если у вас есть детектор аномалий, и вы можете скрывать вот эти ужасы от модели. В этом случае временная дестабилизация временного ряда не попортит все последующие прогнозы.
-
Хорошо, если в модель зашиты разные виды сглаживания – либо исторических продаж, либо прогнозов, какие угодно. Вы делаете ставку на сходимость сумм продаж и прогнозов в среднем и можете прогнозировать волатильные ряды с помощью агрегаций.
-
Прекрасно, если у вас есть механизм исключения подозрительных пробелов из данных. В нашем случае работает исключение данных с нулевой доступностью для построения статистик.
-
Превосходно, если у вас есть механизм учёта сезонности товара, и резкое повышение спроса или снижение спроса не будет для вас сюрпризом.
К этому моменту мы уже перечислили то, что нам пришлось провернуть для того, чтобы градиентный бустинг более или менее хорошо работал у нас в проде. Самое время подсчитать количество соломы, которое оказалось раскиданным в результате того, что в самом начале мы (возможно) немножечко неправильно приоритизировали пожелания бизнеса.
Как жить дальше
Нам хотелось, чтобы всё было так: у нас есть данные, мы отдаём данные в модель, модель выдаёт нам прекрасный прогноз всегда и везде. Супер!

Но на практике мы быстро поняли, что нам нужно очень много данных, очень разных, из разных источников, а ещё логика преобразования таргета.
Затем у нас добавился модуль с кластерным анализом и с kNN, чтобы получать прогноз по новым товарам и для новых дарксторов.
Далее мы решили, что наш прогноз всё ещё недостаточно идеален, и добавили модуль статистических корректировок, чтобы подталкивать его в нужном направлении изменения спроса.
Потом у нас появился ещё детектор тренда, потому что а почему нет – чтобы корректировать прогноз ещё лучше.
И даже это тоже не всё: есть ещё много модулей, описание которых уже никак не укладывается в рамки данной статьи.

И вот мы здесь. Сидим, смотрим на разрастающуюся схему архитектуры прогноза и доработок с чётким осознанием того, что проект призван решать гораздо больше задач, чем просто прогнозирование числа проданных товаров на дарксторах. Этот факт может остаться незамеченным при стандартной методике подсчёта ошибок прогноза, но достаточно сильно при этом влияет на бизнес-показатели и сказывается на бизнесе.
От наивного прогноза спроса к интеллектуальной системе прогнозирования за четыре шага
Итак, что мы вынесли из этой истории? Очень важно изначально понимать суть бизнес-задачи. Это позволит от исходной наивной схемы, где есть только данные, модель и прогноз с простым установка «прогнозируем все товары на всех дарксторах», прийти к более детальной задаче о построении полноценной интеллектуальной системы.
Чтобы эта система максимизировала выручку, нужно пройти четыре этапа:
-
Хорошо отфильтровать данные. Фильтрация и препроцессинг – это то, с чем нельзя переборщить.
-
Построить упрощённые подходы для новинок. Простой подход в условиях отсутствия данных – скорее всего, лучший подход.
-
Восстановить спрос, преобразовав таргет там, где это необходимо.
-
Помочь деревьям экстраполировать и улавливать тренды. Нам нужно подталкивать нашу модель там, где она недотягивает.
Только таким образом мы и можем растить бизнес-метрики – а значит, прогнозировать спрос, не теряя головы.
P.S.: Костыли вокруг бустинга – увлекательное дело, но не единственное, чем мы занимаемся в команде Data Science.
Ещё мы моделируем промо-механики и эластичность по различным факторам, изучаем эффекты перетекания спроса и каннибализации. Исследуем, как наша система прогноза спроса взаимодействует с другими продуктами из Data Science: с персонализацией, рекомендациями, минимальными чеками и всем-всем-всем.
Напишите в комментах, если вам хотелось бы почитать о каких-нибудь из этих тем?