Как найти дисперсию?
Понравилось? Добавьте в закладки
Дисперсия — это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая — значения сравнительно близки друг к другу, если большая — далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии — среднеквадратическое отклонение $sigma(X)=sqrt{D(X)}$, которое имеет ту же размерность, что и исходная величина и также описывает разброс.
Еще одно формальное определение дисперсии звучит так: «Дисперсия — это второй центральный момент случайной величины» (напомним, что первый начальный момент — это как раз математическое ожидание).
Нужна помощь? Решаем теорию вероятностей на отлично
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле:
$$
D(X)=M(X-M(X))^2,
$$
которую также часто записывают в более удобном для расчетов виде:
$$
D(X)=M(X^2)-(M(X))^2.
$$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2.
$$
Если же речь идет о непрерывной случайной величине (заданной плотностью вероятностей $f(x)$ в общем случае), формула дисперсии Х выглядит следующим образом:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения:
$$
x_i quad 1 quad 2 \
p_i quad 0.5 quad 0.5
$$
и
$$
y_i quad -10 quad 10 \
p_i quad 0.5 quad 0.5
$$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором — дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2 =\
= 1^2cdot 0.5 + 2^2 cdot 0.5 — (1cdot 0.5 + 2cdot 0.5)^2=2.5-1.5^2=0.25.
$$
$$
D(Y)=sum_{i=1}^{n}{y_i^2 cdot p_i}-left(sum_{i=1}^{n}{y_i cdot p_i} right)^2 =\
= (-10)^2cdot 0.5 + 10^2 cdot 0.5 — (-10cdot 0.5 + 10cdot 0.5)^2=100-0^2=100.
$$
Итак, значения случайных величин различались на 1 и 20 единиц, тогда как дисперсия показывает меру разброса в 0.25 и 100. Если перейти к среднеквадратическому отклонению, получим $sigma(X)=0.5$, $sigma(Y)=10$, то есть вполне ожидаемые величины: в первом случае значения отстоят в обе стороны на 0.5 от среднего 1.5, а во втором — на 10 единиц от среднего 0.
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Снова используем формулу для дисперсии дискретной случайной величины:
$$
D(X)=M(X^2)-(M(X))^2.
$$
В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Потом математическое ожидание квадрата случайной величины:
$$
M(X^2)=sum_{i=1}^{n}{x_i^2 cdot p_i}
= (-1)^2cdot 0.1 + 2^2 cdot 0.2 +5^2cdot 0.3 +10^2cdot 0.3+20^2cdot 0.1=78.4.
$$
А потом подставим все в формулу для дисперсии:
$$
D(X)=M(X^2)-(M(X))^2=78.4-6.8^2=32.16.
$$
Дисперсия равна 32.16 квадратных единиц.
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Вычислим сначала математическое ожидание:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{6} frac{x}{18} cdot x dx = int_{0}^{6} frac{x^2}{18} dx =
left.frac{x^3}{54} right|_0^6=frac{6^3}{54} = 4.
$$
Теперь вычислим
$$
M(X^2)=int_{-infty}^{+infty} f(x) cdot x^2 dx = int_{0}^{6} frac{x}{18} cdot x^2 dx = int_{0}^{6} frac{x^3}{18} dx = left.frac{x^4}{72} right|_0^6=frac{6^4}{72} = 18.
$$
Подставляем:
$$
D(X)=M(X^2)-(M(X))^2=18-4^2=2.
$$
Дисперсия равна 2.
Другие задачи с решениями по ТВ
Подробно решим ваши задачи на вычисление дисперсии
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку «Вычислить».
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Лучшее спасибо — порекомендовать эту страницу
Полезные ссылки
Не забывайте сначала прочитать том, как найти математическое ожидание. А тут можно вычислить также СКО: Калькулятор математического ожидания, дисперсии и среднего квадратического отклонения.
Что еще может пригодиться? Например, для изучения основ теории вероятностей — онлайн учебник по ТВ. Для закрепления материала — еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Расчет дисперсии и среднего квадратического отклонения по индивидуальным данным и в рядах распределения.
Основными
обобщающими показателями вариации в
статистике являются дисперсии и среднее
квадратическое отклонение.
Дисперсия
— это средняя арифметическая квадратов
отклонений каждого значения признака
от общей средней. Дисперсия обычно
называется средним квадратом отклонений
и обозначается
![]() .
.
В зависимости от исходных данных
дисперсия может вычисляться по средней
арифметической простой или взвешенной:
![]() —дисперсия
—дисперсия
невзвешенная (простая);
![]() —дисперсия
—дисперсия
взвешенная.
Среднее
квадратическое отклонение представляет
собой корень квадратный из дисперсии
и обозначается S:
![]() —среднее
—среднее
квадратическое отклонение невзвешенное;
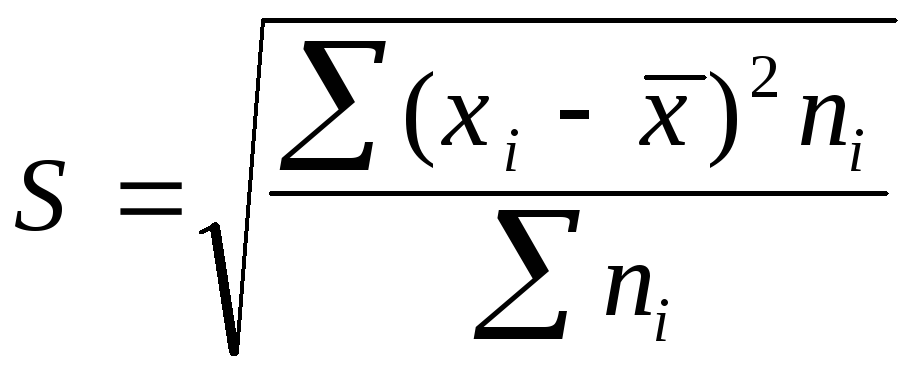 —среднее
—среднее
квадратическое отклонение взвешенное.
Среднее
квадратическое отклонение
— это обобщающая характеристика абсолютных
размеров вариации признака в совокупности.
Выражается оно в тех же единицах
измерения, что и признак (в метрах,
тоннах, процентах, гектарах и т.д.).
Среднее
квадратическое отклонение является
мерилом надежности средней. Чем меньше
среднее квадратическое отклонение, тем
лучше средняя арифметическая отражает
собой всю представляемую совокупность.
Вычислению
среднего квадратического отклонения
предшествует расчет дисперсии.
Порядок
расчета дисперсии взвешенную:
1)
определяют среднюю арифметическую
взвешенную
![]() ;
;
2)
определяются отклонения вариант от
средней
![]() ;
;
3)
возводят в квадрат отклонение каждой
варианты от средней
![]() ;
;
4)
умножают квадраты отклонений на веса
(частоты)
![]() ;
;
5)
суммируют полученные произведения
![]() ;
;
6)
Полученную сумму делят на сумму весов
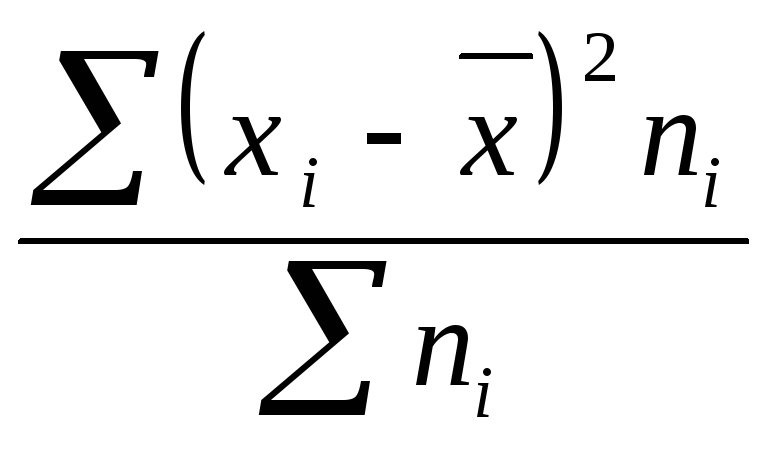 .
.
Пример
3.
Таблица
6.3.
|
Произведено ( |
Число |
|
|
|
|
|
8 |
7 |
56 |
-2 |
4 |
28 |
|
9 |
10 |
90 |
-1 |
1 |
10 |
|
10 |
15 |
150 |
0 |
0 |
0 |
|
11 |
12 |
132 |
1 |
1 |
12 |
|
12 |
6 |
72 |
2 |
4 |
24 |
|
ИТОГО |
50 |
500 |
74 |
Исчислим
среднюю арифметическую взвешенную:
![]() шт.
шт.
Значения
отклонений от средней и их квадратов
представлены в таблице 6.3. Определим
дисперсию:
![]() =1,48
=1,48
Среднее
квадратическое отклонение будет равно:
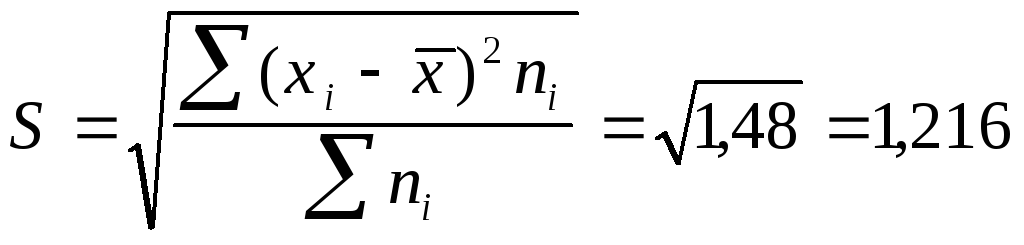 шт.
шт.
Если
исходные данные представлены в виде
интервального ряда распределения, то
сначала надо определить дискретное
значение признака, а далее применить
тот же метод, что изложен выше.
Пример
4.
Покажем
расчет дисперсии для интервального
ряда на данных о распределении посевной
площади колхоза по урожайности пшеницы:
Таблица
6.4
|
Урожайность |
Посевная |
|
|
|
|
|
|
14 |
100 |
15 |
1500 |
-3,4 |
11,56 |
1156 |
|
16 |
300 |
17 |
5100 |
-1,4 |
1,96 |
588 |
|
18 |
400 |
19 |
7600 |
0,6 |
0,36 |
144 |
|
20 |
200 |
21 |
4200 |
2,6 |
6,76 |
1352 |
|
ИТОГО |
1000 |
18400 |
3240 |
Средняя
арифметическая равна:
![]() ц с
ц с
1га.
Исчислим
дисперсию:
![]()
Расчет дисперсии по формуле по индивидуальным данным и в рядах распределения.
Техника
вычисления дисперсии сложна, а при
больших значениях вариант и частот
может быть громоздкой. Расчеты можно
упростить, используя свойства дисперсии.
Свойства
дисперсии.
-
Уменьшение
или увеличение весов (частот) варьирующего
признака в определенное число раз
дисперсии не изменяет. -
Уменьшение
или увеличение каждого значения признака
на одну и ту же постоянную величину А
дисперсии не изменяет. -
Уменьшение
или увеличение каждого значения признака
в какое-то число раз к соответственно
уменьшает или увеличивает дисперсию
в

раз, а среднее квадратическое отклонение
— в к раз. -
Дисперсия
признака относительно произвольной
величины всегда больше дисперсии
относительно средней арифметической
на квадрат разности между средней и
произвольной величиной:
 .
.
Если А равна нулю, то приходим к
следующему равенству:
 ,
,
т.е. дисперсия признака равна разности
между средним квадратом значений
признака и квадратом средней.
Каждое
свойство при расчете дисперсии может
быть применено самостоятельно или в
сочетании с другими.
Порядок
расчета дисперсии простой:
1)
определяют среднюю арифметическую
![]() ;
;
2)
возводят в квадрат среднюю арифметическую![]() ;
;
3)
возводят в квадрат каждую варианту ряда
![]() ;
;
4)
находим сумму квадратов вариант
![]() ;
;
5)
делят сумму квадратов вариант на их
число, т.е. определяют средний квадрат
![]() ;
;
6)
определяют разность между средним
квадратом признака и квадратом средней
![]() .
.
Пример
5.
Имеются
следующие данные о производительности
труда рабочих:
Таблица
6.4
|
Табельный |
Произведено |
|
|
1 |
8 |
64 |
|
2 |
9 |
81 |
|
3 |
10 |
100 |
|
4 |
11 |
121 |
|
5 |
12 |
144 |
|
ИТОГО |
50 |
510 |
Произведем
следующие расчеты:
![]() шт.
шт.
![]()
Пример
6.
Определить
дисперсию в дискретном ряду распределения,
используя табл. 6.5.
Таблица
6.5.
|
Произведено |
Число |
|
|
|
|
8 |
7 |
56 |
64 |
448 |
|
9 |
10 |
90 |
81 |
810 |
|
10 |
15 |
150 |
100 |
1500 |
|
11 |
12 |
132 |
121 |
1452 |
|
12 |
6 |
72 |
144 |
864 |
|
ИТОГО |
50 |
500 |
510 |
5074 |
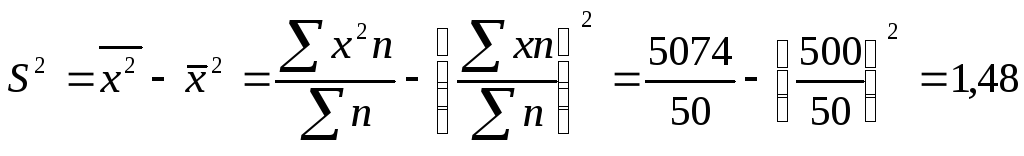
Получим
тот же результат, что в табл. 6.3.
Рассмотрим
расчет дисперсии в интервальном ряду
распределения.
Порядок
расчета дисперсии взвешенной (по формуле
![]() ):
):
-
определяют
среднюю арифметическую
 ;
; -
возводят
в квадрат полученную среднюю
 ;
; -
возводят
в квадрат каждую варианту ряда
 ;
; -
умножают
квадраты вариант на частоты
 ;
; -
суммируют
полученные произведения
 ;
; -
делят
полученную сумму на сумму весов и
получают средний квадрат признака
 ;
; -
определяют
разность между средним значением
квадратов и квадратом средней
арифметической, т.е. дисперсию
.
Пример
7.
Имеются
следующие данные о распределении
посевной площади колхоза по урожайности
пшеницы:
Таблица
6.6
|
Урожайность |
Посевная |
|
|
|
|
|
14 |
100 |
15 |
1500 |
225 |
22500 |
|
16 |
300 |
17 |
5100 |
289 |
36700 |
|
18 |
400 |
19 |
7600 |
361 |
144400 |
|
20 |
200 |
21 |
4200 |
441 |
88200 |
|
ИТОГО |
1000 |
18400 |
341200 |
В
подобных примерах прежде всего
определяется дискретное значение
признака в каждом интервале, а затем
применяется метод расчета, указанный
выше:
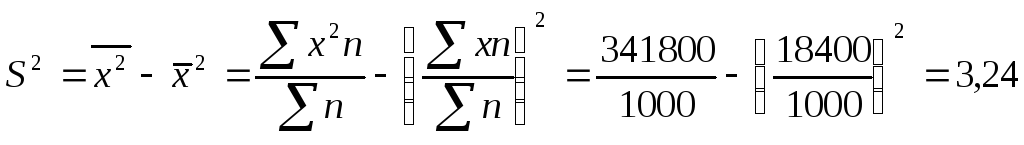
Средняя
величина отражает тенденцию развития,
т.е. действие главных причин. Среднее
квадратическое отклонение измеряет
силу воздействия прочих факторов.
Соседние файлы в папке statistica
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дисперсия, виды и свойства дисперсии
Понятие дисперсии
Дисперсия в статистике находится как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. В зависимости от исходных данных она определяется по формулам простой и взвешенной дисперсий:
1. Простая дисперсия (для несгруппированных данных) вычисляется по формуле:

2. Взвешенная дисперсия (для вариационного ряда):

где n — частота (повторяемость фактора Х)
Пример нахождения дисперсии
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
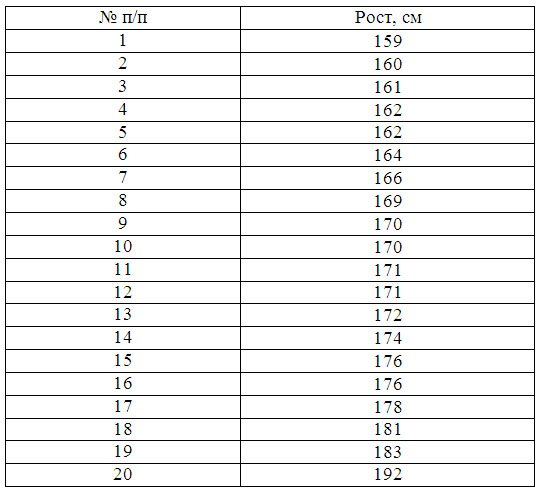
Пример 1. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию
Построим интервальную группировку. Определим размах интервала по формуле:

где X max– максимальное значение группировочного признака;
X min–минимальное значение группировочного признака;
n – количество интервалов:

Принимаем n=5. Шаг равен: h = (192 — 159)/ 5 = 6,6
Составим интервальную группировку

Для дальнейших расчетов построим вспомогательную таблицу:
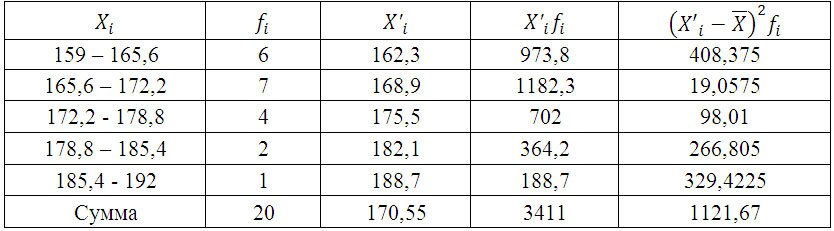
X’i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:
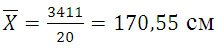
Определим дисперсию по формуле:
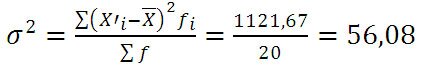
Пример 2. Определение групповой, средней из групповой, межгрупповой и общей дисперсии
Пример 3. Нахождение дисперсии и коэффициента вариации в группировочной таблице
Пример 4. Нахождение дисперсии в дискретном ряду
Формулу дисперсии можно преобразовать так:

Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии, вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i — величина интервала;
А — условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой;
m1 — квадрат момента первого порядка;
m2 — момент второго порядка
Дисперсия альтернативного признака (если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
Внутригрупповая дисперсия характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi — групповая средняя;
ni — число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Средняя из внутри групповых дисперсий отражает случайную вариацию, т. е. ту часть вариации, которая происходила под влиянием всех прочих факторов, за исключением фактора группировки. Она рассчитывается по формуле:

Межгрупповая дисперсия характеризует систематическую вариацию результативного признака, которая обусловлена влиянием признака-фактора, положенного в основание группировки. Она равняется среднему квадрату отклонений групповых средних от общей средней. Межгрупповая дисперсия рассчитывается по формуле:

Правило сложения дисперсии в статистике
Согласно правилу сложения дисперсий общая дисперсия равна сумме средней из внутригрупповых и межгрупповых дисперсий:

Смысл этого правила заключается в том, что общая дисперсия, которая возникает под влиянием всех факторов, равняется сумме дисперсий, которые возникают под влиянием всех прочих факторов, и дисперсии, возникающей за счет фактора группировки.
Пользуясь формулой сложения дисперсий, можно определить по двум известным дисперсиям третью неизвестную, а также судить о силе влияния группировочного признака.
Свойства дисперсии
1. Если все значения признака уменьшить (увеличить) на одну и ту же постоянную величину, то дисперсия от этого не изменится.
2. Если все значения признака уменьшить (увеличить) в одно и то же число раз n, то дисперсия соответственно уменьшится (увеличить) в n^2 раз.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Дискретный вариационный ряд и его характеристики
- Классификация рядов распределения
- Дискретный вариационный ряд, полигон частот и кумулята
- Выборочная средняя, мода и медиана
- Степень асимметрии вариационного ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования дискретного вариационного ряда
- Примеры
п.1. Классификация рядов распределения
Статистический ряд распределения – это количественное распределение единиц совокупности на однородные группы по некоторому варьирующему признаку.
В зависимости от природы признака различают атрибутивные и вариационные ряды.
Атрибутивный ряд распределения построен на качественном признаке.
Вариационный ряд распределения построен на количественном признаке.
Например:
Качественными признаками, которые не поддаются измерению, являются: профессия, пол, национальность и т.п.
Количественными признаками, которые можно подсчитать или измерить, являются: количество людей в группе, число повторений в опыте, возраст, вес, рост, скорость, температура и т.п.
По упорядоченности вариационные ряды делятся на упорядоченные (ранжированные) и неупорядоченные. Упорядочить ряд можно по возрастанию или убыванию исследуемого признака.
По характеру непрерывности признака вариационные ряды делятся на дискретные и интервальные.
Например:
Дискретными признаками, которые принимают отдельные значения, являются: количество людей в группе, число детей в семье, количество домов, число опытов и т.п.
Непрерывными признаками, которые могут принимать любые значения в интервале, являются: возраст, вес, рост, скорость, температура и т.п.
Варианты – это отдельные значения признака, которые он принимает в вариационном ряду.
Частоты – это численности отдельных вариант.
Например:
Распределение учеников по оценкам за контрольную работу
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
В данном ряду признак – это оценка, варианты признака (x_i) – это множество {2;3;4;5}, частоты (f_i) – это количество учеников, получивших каждую из оценок.
п.2. Дискретный вариационный ряд, полигон частот и кумулята
Дискретный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся прерывно и принимающему конечное множество значений.
Общий вид дискретного вариационного ряда
| Варианты, (x_i) | (x_1) | (x_2) | … | (x_k) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k — число вариант исследуемого признака.
Тогда общее количество исходов (число единиц в совокупности): (N=sum_{i=1}^k f_i)
Полигон частот – это ломаная, которая соединяет точки ((x_i,f_i)).
Например:
| Для распределения учеников по оценкам из нашего примера получаем такой полигон: |  |
Относительная частота варианты (x_i) — это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$ Относительная частота (w_i) является эмпирической оценкой вероятности варианты (x_i) в исследуемом ряду.
Полигон относительных частот – это ломаная, которая соединяет точки ((x_i,w_i)).
Полигон относительных частот является эмпирическим законом распределения исследуемого признака.
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)).
Ступенчатая кривая (F(x_i)), построенная по точкам ((x_i,S_i)), является эмпирической функцией распределения исследуемого признака.
Например:
Проведем необходимые расчеты и построим полигон относительных частот, кумуляту и эмпирическую функцию распределения учеников по оценкам.
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (w_i) | 0,0909 | 0,4545 | 0,3030 | 0,1515 | 1 |
| (S_i) | 0,0909 | 0,4545 | 0,8485 | 1 | — |
Полигон относительных частот (эмпирический закон распределения)
Кумулята (красная ломаная) и эмпирическая функция распределения (ступенчатая синяя кривая).
Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 2\ 0,0909, 2lt xleq 3\ 0,5455, 3lt xleq 4\ 0,8485, 4lt xleq 5\ 1, xgt 5 end{cases} $$
п.3. Выборочная средняя, мода и медиана
Выборочная средняя дискретного вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Мода дискретного вариационного ряда – это варианта с максимальной частотой: $$ M_o=x*, f(x*)=underset{i=overline{1,k}}{max}f_i $$ Мод может быть несколько. Тогда говорят, что ряд мультимодальный.
На полигоне частот мода – это абсцисса самой высокой точки.
Медиана дискретного вариационного ряда – это значение варианты посредине упорядоченного ряда.
Алгоритм:
1. Отсортировать ряд по возрастанию.
2а. Если общее количество измерений N нечётное, найти (m=lceilfrac N2rceil) и округлить в сторону увеличения. (M_e=x_m) — искомая медиана.
2б. Если общее количество измерений N чётное, найти (m=frac N2) и вычислить медиану как среднее (M_e=frac{x_m+x_{m+1}}{2}).
На графике кумуляты медиана – это абсцисса первой точки слева, ордината которой превысила 0,5.
Например:
1) Найдем выборочную среднюю для распределения учеников по оценкам:
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (x_if_i) | 6 | 45 | 40 | 25 | 116 |
$$ X_{cp}=frac{6+45+40+25}{33}=frac{116}{33}approx 3,5 $$ Средняя оценка за контрольную – 3,5.
2) Найдем моду. Максимальная частота – 15 человек – у троечников. Значит: (M_o=3).
3) Найдем медиану. Общее количество измерений N=33 — нечетное.
Находим: (m=lceilfrac N2rceil=17)
Смотрим на ряд слева направо. Сначала у нас идет 3 двоечника, затем 15 троечников.
Вместе их 18, и 17-й человек в ряду — троечник. Группа троечников является медианной: (M_e=3).
Также, медиану можно найти по графику кумуляты. (3;0,5455) – это первая слева точка, в которой ордината больше 0,5. Значит, медиана равна абсциссе этой точки, т.е. (M_e=3).
п.4. Степень асимметрии вариационного ряда
В рядах с асимметрией или выбросами выборочная средняя не отражает в полной мере особенности исследуемого признака. Типичный случай – значение среднего уровня доходов в странах с высоким индексом Джини, где 5% населения получает 95% доходов. Или анекдотичный случай со «средней температурой по больнице».
Поэтому, кроме средней, в статистическом исследовании всегда следует определять моду и медиану.
Мода, медиана и выборочная средняя совпадут, если вариационный ряд является симметричным: $$ X_{cp}=M_o=M_e $$ Если вершина распределения сдвинута влево и правая часть ветви длиннее левой (длинный правый хвост), такая асимметрия называется правосторонней. При правосторонней асимметрии: $$ M_olt M_elt X_{cp} $$ Если вершина распределения сдвинута вправо и левая часть ветви длиннее правой (длинный левый хвост), такая асимметрия называется левосторонней. При левосторонней асимметрии: $$ M_ogt M_egt X_{cp} $$ Для умеренно асимметричных рядов (по Пирсону) модуль разности между модой и средней не более 3 раз превышает модуль разности между медианой и средней: $$ frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}geq 3 $$
Например:
Для распределения учеников по оценкам мы получили (X_{cp}=3,5; M_o=3; M_e=3).
Т.к. средняя оказалась больше моды и медианы, наше распределение имеет правостороннюю асимметрию (что видно на полигоне частот – правый хвост длиннее).
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{0,5}{0,5}=1lt 3), т.е. распределение умеренно асимметрично.
п.5. Выборочная дисперсия и СКО
Выборочная дисперсия дискретного вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac{(x_1-X_{cp})^2 f_1+(x_2-X_{cp})^2 f_2+…+(x_k-X_{cp})^2 f_k}{N}=\ =frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
1) Найдем выборочную дисперсию для распределения учеников по оценкам:
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (x_i^2) | 4 | 9 | 16 | 25 | — |
| (x_i^2 f_i) | 12 | 135 | 160 | 125 | 432 |
$$ D=frac{12+135+160+125}{33}-3,5^2=frac{432}{33}-3,5^2approx 0,73 $$ 2) Значение СКО: (sigma=sqrt{D}approx 0,86)
п.6. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия дискретного вариационного ряда определяется как: begin{gather*} S^2=frac{1}{N-1}sum_{i=1}^k(x_i-X_{cp})^2 f_i=frac{N}{N-1}D end{gather*}
В теоретической статистике доказывается, что выборочная дисперсия D является смещенной оценкой дисперсии при распространении на генеральную совокупность.
А именно, выборочная дисперсия D всегда меньше математического ожидания для дисперсии генеральной совокупности.
Исправленная выборочная дисперсия S2 является несмещенной оценкой.
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Если показатель вариации V<33%, то выборка считается однородной, т.е. большинство полученных в ней вариант находятся недалеко от средней, и выборочная средняя хорошо характеризует среднюю генеральной совокупности.
В противном случае, выборка неоднородна. Варианты в выборке находятся далеко от средней, есть выбросы. А значит, и в генеральной совокупности они возможны. Т.е., распространять результаты выборки на генеральную совокупность нельзя.
Если исследуется не выборка, а вся генеральная совокупность, дисперсию «исправлять» не нужно.
Например:
Для распределения учеников по оценкам получаем:
1) Исправленная выборочная дисперсия $$ S^2=frac{N}{N-1}D=frac{33}{32}cdot 0,73approx 0,76 $$ 2) Стандартное отклонение $$ x=sqrt{S^2}approx 0,87 $$ 3) Коэффициент вариации: $$ V=frac{0,87}{3,5}cdot 100text{%}approx 24,8text{%}lt 33text{%} $$ Выборка является однородной.
Это означает, что согласно коэффициенту вариации полученные результаты контрольной работы можно рассматривать в качестве «типичных» и распространить их на генеральную совокупность, т.е. на всех школьников, которые будут писать эту работу.
п.7. Алгоритм исследования дискретного вариационного ряда
На входе: таблица с вариантами (x_i) и частотами (f_i, i=overline{1,k})
Шаг 1. Составить расчетную таблицу. Найти (w_i,S_i,x_if_i,x_i^2,x_i^2f_i)
Шаг 2. Построить полигон относительных частот (эмпирический закон распределения) и график кумуляты с эмпирической функцией распределения. Записать эмпирическую функцию распределения.
Шаг 3. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 4. Найти выборочную дисперсию и СКО.
Шаг 5. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.8. Примеры
Пример 1. На площадке фриланса была проведена выборка из 100 фрилансеров и подсчитано количество постоянных заказчиков, с которыми они работают.
В результате было получено следующее распределение:
| Число постоянных заказчиков | 0 | 1 | 2 | 3 | 4 | 5 |
| Число фрилансеров | 22 | 35 | 27 | 11 | 3 | 1 |
Исследуйте полученный вариационный ряд.
1) Вариационный ряд является дискретным.
Исследуемый признак – «число постоянных заказчиков».
Варианты признака (x_iinleft{0;1;..;5right}). Количество вариант k=6.
Составим расчетную таблицу:
| (x_i) | 0 | 1 | 2 | 3 | 4 | 5 | ∑ |
| (f_i) | 23 | 35 | 27 | 11 | 3 | 1 | 100 |
| (w_i) | 0,23 | 0,35 | 0,27 | 0,11 | 0,03 | 0,01 | — |
| (S_i) | 0,23 | 0,58 | 0,85 | 0,96 | 0,99 | 1 | — |
| (x_if_i) | 0 | 35 | 54 | 33 | 12 | 5 | 139 |
| (x_i^2) | 0 | 1 | 4 | 9 | 16 | 25 | — |
| (x_i^2f_i) | 0 | 35 | 108 | 99 | 48 | 25 | 315 |
2) Полигон относительных частот (эмпирический закон распределения):
Кумулята и эмпирическая функция распределения:
$$ F(x)= begin{cases} 0, xleq 0\ 0,23, 0lt xleq 1\ 0,58, 1lt xleq 2\ 0,85, 2lt xleq 3\ 0,96, 3lt xleq 4\ 0,99, 4lt xleq 5\ 1, xgt 5 end{cases} $$ 3) Выборочная средняя: $$ X_{cp}=frac1Nsum_{i=1}^k x_if_i= frac{1}{100}cdot 139=1,39 $$ Мода (абсцисса самой высокой точки на полигоне частот): (M_0=1).
Медиана (абсцисса первой слева точки на кумуляте, где значение превысило 0,5): точка (1;0,58), (M_e=1).
(X_{cp}gt M_e=M_0) – распределение асимметрично, с правосторонней асимметрией.
При этом (frac{|M_0-X_{cp}|}{|M_e-X_{cp}|}=frac{0,39}{0,39}=1lt 3), т.е. распределение умеренно асимметрично.
4) Выборочная дисперсия: $$ D=frac1Nsum_{i=1}^k x_i^2f_i-X_{cp}^2=frac{1}{100}cdot 315-1,39^2=1,2179approx 1,218 $$ CKO: $$ sigma=sqrt{D}approx 1,104 $$
5) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{100}{99}cdot 1,218approx 1,230 $$ Стандартное отклонение выборки: $$ s=sqrt{S^2}approx 1,109 $$ Коэффициент вариации: $$ V=frac{s}{X_{cp}}cdot 100text{%}=frac{1,109}{1,39}cdot 100text{%}approx 79,8text{%}gt 33text{%} $$ Представленная выборка неоднородна. Полученное значение средней (X_{cp}=1,39) не может быть распространено на генеральную совокупность всех фрилансеров.