В заметке рассмотрены основные свойства математического ожидания и дисперсии с доказательствами.
В статье приняты следующие обозначения:
(a ) — неслучайная величина (константа)
(X, Y ) — случайные величины
(M[X]) — Математическое ожидание X
(D[X]) — Дисперсия X
Математическое ожидание
Математическое ожидание неслучайной величины
[ M[a] = a]
Доказательство:
Доказать, это достаточно очевидное, свойство можно, рассматривая неслучайную величину как частный вид случайной, при одном возможном значении с вероятностью единица; тогда по общей формуле для математического ожидания:
[ M[a] = a * 1 = a ]
Математическое ожидание линейно
[ M[aX + bY] = aM[X] + bM[Y]]
Доказательство вынесения неслучайной величины за знак математического ожидания
[ M[aX] = a M[X] ]
Доказательство прямо следует из линейности суммы и интеграла.
Следует специально отметить, что теорема сложения математических ожиданий справедлива для любых случайных величин — как зависимых, так и независимых.
Теорема сложения математических ожиданий обобщается на произвольное число слагаемых.
Для дискретных величин
[ M[aX] = sum_{i} a x_i p _i = a sum_{i} x_i p_i = a M[X]]
Для непрерывных величин
[ M[aX] = intop_{ infty }^{infty} a x f(x) dx = a intop_{ infty }^{infty} x f(x) dx = a M[X]]
Доказательство математического ожидания суммы случайных величин
а) Пусть ((X, Y) ) — система дискретных случайных величин. Применим к сумме случайных величин общую формулу для математического ожидания функции двух аргументов:
[ M[X + Y] = sum_{i} sum_{j} (x_i + y_i) p_{ij} \
= sum_{i}sum_{j} x_i p_{ij} + sum_{i}sum_{j} y_i p_{ij} \
= sum_{i} x_isum_{j} p_{ij} + sum_{j} y_jsum_{i} p_{ij} ]
Но (sum_{j} p_{ij} ) представляет собой не что иное, как полную вероятность того, что величина (X ) примет значение (x_i ):
[ sum_{j} p_{ij} = P(X = x_i) = p_i ]
следовательно,
[ sum_{i} x_isum_{j} p_{ij} = sum_{i} x_i p_i = M[X] ]
Аналогично докажем, что
[ sum_{j} y_jsum_{i} p_{ij} = M[Y] ]
б) Пусть ((X, Y) ) — система непрерывных случайных величин.
[ M[X + Y] = int intop_{ infty }^{infty } (x+y) f(x,y) dx dy = int intop_{ infty }^{infty } x f(x,y) dx dy + int intop_{ infty }^{infty } y f(x,y) dx dy ]
Преобразуем первый из интегралов:
[ int intop_{ infty }^{infty } x f(x,y) dx dy = intop_{ infty }^{infty } x (intop_{ infty }^{infty } f(x,y)dy) dx = intop_{ infty }^{infty } x f_1(x) dx = M[X] ]
аналогично второй:
[ int intop_{ infty }^{infty } y f(x,y) dx dy = M[X] ]
Математическое ожидание произведения
Математическое ожидание произведения двух случайных величин равно произведению их математических ожиданий плюс корреляционный момент:
[ M[XY] = M[X] M[Y] + cov(XY)]
для независимых величин:
[ M[XY] = M[X] M[Y] ]
Доказательство
Будем исходить из определения корреляционного момента:
[ cov(X,Y) = M[ stackrel{ circ }{X} stackrel{ circ }{Y} ] = M[(X- M[X])(Y-M[Y])] ]
Преобразуем это выражение, пользуясь свойствами математического ожидания:
[ cov(X,Y) = M[(X- M[X])(Y-M[Y])] = \
M[XY] — M[X] M[Y] — M[Y]M[X] + M[X]M[Y] = \
M[X Y] — M[X] M[Y] ]
что, очевидно, равносильно доказываемому соотношению
Дисперсия
Дисперсия случайной величины есть характеристика рассеивания, разбросанности значений случайной величины около её математического ожидания.
[ D[X] = M[X^2] — (M[X])^2 ]
Дисперсия не зависит от знака
[ D[-X] = D[X] ]
Дисперсия суммы случайной и постоянной величин
[ D[X+b] = D[X] ]
Дисперсия неслучайной величины
[ D[a] = 0 ]
Доказательство:
По определению дисперсии:
[ D[a] = M[stackrel{ circ }{a^2}] = M[a — M[a]^2 ] = M[(a-a)^2] = M[0] = 0]
Дисперсия суммы случайных величин
[ D[X+Y] = D[X] + D[Y] + 2*cov(X,Y) ]
Доказательство:
Обозначим (XY = Z ).
По теореме сложения математических ожиданий:
[ M[Z] = M[X] + M[Y] ]
Перейдем от случайных величин (X, Y, Z ). к соответствующим центрированным величинам (stackrel{ circ }{X}, stackrel{ circ }{Y}, stackrel{ circ }{Z} ), имеем:
[ stackrel{ circ }{Z} = stackrel{ circ }{X} + stackrel{ circ }{Y} ]
По определению дисперсии
[ D[X+Y] = D[Z] = M[stackrel{ circ }{Z}^2] = M[stackrel{ circ }{X}^2] + 2M[stackrel{ circ }{X} stackrel{ circ }{Y}] + M[stackrel{ circ }{Y}^2] \
= D[X] + 2 cov(X,Y) + D[Y] ]
Дисперсия произведения неслучайной величины на случайную
[ D[aX] = a^2 D[X]]
Доказательство:
По определению дисперсии
[ D[aX] = M[(a X — M[a X])^2] = M[(a X — a M[X])^2] = a^2 M[(X — M[X])^2] = c^2 D[X] ]
Дисперсия произведения независимых величин
[ D[XY] = D[X] D[Y] + (M[X])^2 D[Y] + (M[Y])^2 D[X]]
Доказательство:
Обозначим (XY = Z ). По определению дисперсии
[ D[XY] = D[Z] = M[Z^2] = M[Z-M[Z]]^2]
Так как величины (XY) независимы, то (M[Z] = M[X]M[Y]) и
[ D[XY] = M[(XY — M[X]M[Y])^2] \
= M[X^2 Y^2] — 2M[X]M[Y]M[XY]+ M[X]^2M[Y]^2 ]
При независимых (XY) величины (X^2Y^2) также независимы, следовательно:
[ M[X^2 Y^2] = M[X^2] M[Y^2], M[XY] = M[X]M[Y]]
и
[ D[XY] = M[X^2]M[Y^2] — M[X]^2M[Y]^2 ]
но (M[X]^2) есть не что иное, как второй начальный момент величины (X) , и, следовательно, выражается через дисперсию:
[ M[X^2] = D[X]+M[X]^2 ]
аналогично
[ M[Y^2] = D[Y]+M[Y]^2 ]
Подставляя эти выражения и приводя подобные члены, приходим к формуле
[ D[XY] = D[X] D[Y] + (M[X])^2 D[Y] + (M[Y])^2 D[X]]
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product  is a product distribution.
is a product distribution.
Algebra of random variables[edit]
The product is one type of algebra for random variables: Related to the product distribution are the ratio distribution, sum distribution (see List of convolutions of probability distributions) and difference distribution. More generally, one may talk of combinations of sums, differences, products and ratios.
Many of these distributions are described in Melvin D. Springer’s book from 1979 The Algebra of Random Variables.[1]
Derivation for independent random variables[edit]
If  and
and  are two independent, continuous random variables, described by probability density functions
are two independent, continuous random variables, described by probability density functions  and
and  then the probability density function of is[2]
then the probability density function of is[2]

Proof[edit]
We first write the cumulative distribution function of  starting with its definition
starting with its definition

We find the desired probability density function by taking the derivative of both sides with respect to  . Since on the right hand side, appears only in the integration limits, the derivative is easily performed using the fundamental theorem of calculus and the chain rule. (Note the negative sign that is needed when the variable occurs in the lower limit of the integration.)
. Since on the right hand side, appears only in the integration limits, the derivative is easily performed using the fundamental theorem of calculus and the chain rule. (Note the negative sign that is needed when the variable occurs in the lower limit of the integration.)

where the absolute value is used to conveniently combine the two terms.[3]
Alternate proof[edit]
A faster more compact proof begins with the same step of writing the cumulative distribution of starting with its definition:

where  is the Heaviside step function and serves to limit the region of integration to values of
is the Heaviside step function and serves to limit the region of integration to values of  and
and  satisfying
satisfying  .
.
We find the desired probability density function by taking the derivative of both sides with respect to .
![{displaystyle {begin{aligned}f_{Z}(z)&=int _{-infty }^{infty }int _{-infty }^{infty }f_{X}(x)f_{Y}(y)delta (z-xy),dy,dx\&=int _{-infty }^{infty }f_{X}(x)f_{Y}(z/x)left[int _{-infty }^{infty }delta (z-xy),dyright],dx\&=int _{-infty }^{infty }f_{X}(x)f_{Y}(z/x){frac {1}{|x|}},dx.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fb5af9aa6708d3df7ca066a38aff758081dddffa)
where we utilize the translation and scaling properties of the Dirac delta function  .
.
A more intuitive description of the procedure is illustrated in the figure below. The joint pdf  exists in the — plane and an arc of constant value is shown as the shaded line. To find the marginal probability
exists in the — plane and an arc of constant value is shown as the shaded line. To find the marginal probability  on this arc, integrate over increments of area
on this arc, integrate over increments of area  on this contour.
on this contour.

Diagram to illustrate the product distribution of two variables.
Starting with  , we have
, we have  . So the probability increment is
. So the probability increment is  . Since
. Since  implies
implies  , we can relate the probability increment to the -increment, namely
, we can relate the probability increment to the -increment, namely  . Then integration over , yields
. Then integration over , yields  .
.
A Bayesian interpretation[edit]
Let  be a random sample drawn from probability distribution
be a random sample drawn from probability distribution  . Scaling by
. Scaling by  generates a sample from scaled distribution
generates a sample from scaled distribution  which can be written as a conditional distribution
which can be written as a conditional distribution  .
.
Letting be a random variable with pdf  , the distribution of the scaled sample becomes
, the distribution of the scaled sample becomes  and integrating out we get
and integrating out we get  so
so  is drawn from this distribution
is drawn from this distribution  . However, substituting the definition of
. However, substituting the definition of  we also have
we also have
 which has the same form as the product distribution above. Thus the Bayesian posterior distribution
which has the same form as the product distribution above. Thus the Bayesian posterior distribution  is the distribution of the product of the two independent random samples and .
is the distribution of the product of the two independent random samples and .
For the case of one variable being discrete, let have probability  at levels
at levels  with
with  . The conditional density is
. The conditional density is  . Therefore
. Therefore  .
.
Expectation of product of random variables[edit]
When two random variables are statistically independent, the expectation of their product is the product of their expectations. This can be proved from the law of total expectation:

In the inner expression, Y is a constant. Hence:
![{displaystyle operatorname {E} (XYmid Y)=Ycdot operatorname {E} [Xmid Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b64f770ca19f635f21bf6f431c027af335af078)
![{displaystyle operatorname {E} (XY)=operatorname {E} (Ycdot operatorname {E} [Xmid Y])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a07bbd79cef87f8515026b085405ab8f1d883fe2)
This is true even if X and Y are statistically dependent in which case ![{displaystyle operatorname {E} [Xmid Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65a2d84a7924d724ebb8f39eff47793edc858768) is a function of Y. In the special case in which X and Y are statistically
is a function of Y. In the special case in which X and Y are statistically
independent, it is a constant independent of Y. Hence:
![{displaystyle operatorname {E} (XY)=operatorname {E} (Ycdot operatorname {E} [X])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c18af9d5a6c414690cc675e3577b927c08da037a)

Variance of the product of independent random variables[edit]
Let  be uncorrelated random variables with means
be uncorrelated random variables with means  and variances
and variances  .
.
If, additionally, the random variables  and
and  are uncorrelated, then the variance of the product XY is
are uncorrelated, then the variance of the product XY is

In the case of the product of more than two variables, if  are statistically independent then[4] the variance of their product is
are statistically independent then[4] the variance of their product is

Characteristic function of product of random variables[edit]
Assume X, Y are independent random variables. The characteristic function of X is  , and the distribution of Y is known. Then from the law of total expectation, we have[5]
, and the distribution of Y is known. Then from the law of total expectation, we have[5]

If the characteristic functions and distributions of both X and Y are known, then alternatively,  also holds.
also holds.
Mellin transform[edit]
The Mellin transform of a distribution  with support only on
with support only on  and having a random sample is
and having a random sample is
![{displaystyle {mathcal {M}}f(x)=varphi (s)=int _{0}^{infty }x^{s-1}f(x),dx=operatorname {E} [X^{s-1}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/382eba02d8932ee7bdd16eb6bddcc73bf986ebaa)
The inverse transform is

if  are two independent random samples from different distributions, then the Mellin transform of their product is equal to the product of their Mellin transforms:
are two independent random samples from different distributions, then the Mellin transform of their product is equal to the product of their Mellin transforms:

If s is restricted to integer values, a simpler result is
![{displaystyle operatorname {E} [(XY)^{n}]=operatorname {E} [X^{n}];operatorname {E} [Y^{n}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/486d25ad89602cab980c5594f5edfb9c160168c4)
Thus the moments of the random product  are the product of the corresponding moments of and this extends to non-integer moments, for example
are the product of the corresponding moments of and this extends to non-integer moments, for example
![{displaystyle operatorname {E} [{(XY)^{1/p}}]=operatorname {E} [X^{1/p}];operatorname {E} [Y^{1/p}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/db6b88696ea4953d6ad9c5f8d58e08822d697d14)
The pdf of a function can be reconstructed from its moments using the saddlepoint approximation method.
A further result is that for independent X, Y
![{displaystyle operatorname {E} [X^{p}Y^{q}]=operatorname {E} [X^{p}]operatorname {E} [Y^{q}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f8d462736ca4b54e21855f47ac9f05120a4048fb)
Gamma distribution example To illustrate how the product of moments yields a much simpler result than finding the moments of the distribution of the product, let be sampled from two Gamma distributions,  with parameters
with parameters 
whose moments are
![{displaystyle operatorname {E} [X^{p}]=int _{0}^{infty }x^{p}Gamma (x,theta ),dx={frac {Gamma (theta +p)}{Gamma (theta )}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4a3636c4a322e793048dd9691d4c5f07c36388cf)
Multiplying the corresponding moments gives the Mellin transform result
![{displaystyle operatorname {E} [(XY)^{p}]=operatorname {E} [X^{p}];operatorname {E} [Y^{p}]={frac {Gamma (alpha +p)}{Gamma (alpha )}};{frac {Gamma (beta +p)}{Gamma (beta )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be12283230a2b1f28a6c1c49eb7b7b3ac063176e)
Independently, it is known that the product of two independent Gamma-distributed samples (~Gamma(α,1) and Gamma(β,1)) has a K-distribution:

To find the moments of this, make the change of variable  , simplifying similar integrals to:
, simplifying similar integrals to:

thus

The definite integral
 is well documented and we have finally
is well documented and we have finally

![{displaystyle {begin{aligned}E[Z^{p}]&={frac {2^{-(alpha +beta )-2p+1};2^{(alpha +beta )+2p-1}}{Gamma (alpha );Gamma (beta )}}Gamma left({frac {(alpha +beta +2p)+(alpha -beta )}{2}}right)Gamma left({frac {(alpha +beta +2p)-(alpha -beta )}{2}}right)\\&={frac {Gamma (alpha +p),Gamma (beta +p)}{Gamma (alpha ),Gamma (beta )}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f8ba4176159dde7c7d46487b9349aabc097806a2)
which, after some difficulty, has agreed with the moment product result above.
If X, Y are drawn independently from Gamma distributions with shape parameters  then
then
![{displaystyle operatorname {E} [X^{p}Y^{q}]=operatorname {E} [X^{p}];operatorname {E} [Y^{q}]={frac {Gamma (alpha +p)}{Gamma (alpha )}};{frac {Gamma (beta +q)}{Gamma (beta )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf9ef60853b09a18c307b89527eaad62aa6161bf)
This type of result is universally true, since for bivariate independent variables  thus
thus
![{displaystyle {begin{aligned}operatorname {E} [X^{p}Y^{q}]&=int _{x=-infty }^{infty }int _{y=-infty }^{infty }x^{p}y^{q}f_{X,Y}(x,y),dy,dx\&=int _{x=-infty }^{infty }x^{p}{Big [}int _{y=-infty }^{infty }y^{q}f_{Y}(y),dy{Big ]}f_{X}(x),dx\&=int _{x=-infty }^{infty }x^{p}f_{X}(x),dxint _{y=-infty }^{infty }y^{q}f_{Y}(y),dy\&=operatorname {E} [X^{p}];operatorname {E} [Y^{q}]end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fbb739a3e402eec9f126f79540a1f37b1ce69076)
or equivalently it is clear that  are independent variables.
are independent variables.
Special cases[edit]
Lognormal distributions[edit]
The distribution of the product of two random variables which have lognormal distributions is again lognormal. This is itself a special case of a more general set of results where the logarithm of the product can be written as the sum of the logarithms. Thus, in cases where a simple result can be found in the list of convolutions of probability distributions, where the distributions to be convolved are those of the logarithms of the components of the product, the result might be transformed to provide the distribution of the product. However this approach is only useful where the logarithms of the components of the product are in some standard families of distributions.
Uniformly distributed independent random variables[edit]
Let be the product of two independent variables  each uniformly distributed on the interval [0,1], possibly the outcome of a copula transformation. As noted in «Lognormal Distributions» above, PDF convolution operations in the Log domain correspond to the product of sample values in the original domain. Thus, making the transformation
each uniformly distributed on the interval [0,1], possibly the outcome of a copula transformation. As noted in «Lognormal Distributions» above, PDF convolution operations in the Log domain correspond to the product of sample values in the original domain. Thus, making the transformation  , such that
, such that  , each variate is distributed independently on u as
, each variate is distributed independently on u as
- .

and the convolution of the two distributions is the autoconvolution

Next retransform the variable to  yielding the distribution
yielding the distribution
- on the interval [0,1]

For the product of multiple (> 2) independent samples the characteristic function route is favorable. If we define  then
then  above is a Gamma distribution of shape 1 and scale factor 1,
above is a Gamma distribution of shape 1 and scale factor 1,  , and its known CF is
, and its known CF is  . Note that
. Note that  so the Jacobian of the transformation is unity.
so the Jacobian of the transformation is unity.
The convolution of  independent samples from
independent samples from  therefore has CF
therefore has CF  which is known to be the CF of a Gamma distribution of shape :
which is known to be the CF of a Gamma distribution of shape :
- .

Making the inverse transformation we get the PDF of the product of the n samples:

The following, more conventional, derivation from Stackexchange[6] is consistent with this result.
First of all, letting  its CDF is
its CDF is
![{displaystyle {begin{aligned}F_{Z_{2}}(z)=Pr {Big [}Z_{2}leq z{Big ]}&=int _{x=0}^{1}Pr {Big [}X_{2}leq {frac {z}{x}}{Big ]}f_{X_{1}}(x),dx\&=int _{x=0}^{z}1dx+int _{x=z}^{1}{frac {z}{x}},dx\&=z-zlog z,;;0<zleq 1end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0f37b1dc2347e73e5c2a569251d36ad73c9bf8a8)
The density of 
Multiplying by a third independent sample gives distribution function
![{displaystyle {begin{aligned}F_{Z_{3}}(z)=Pr {Big [}Z_{3}leq z{Big ]}&=int _{x=0}^{1}Pr {Big [}X_{3}leq {frac {z}{x}}{Big ]}f_{Z_{2}}(x),dx\&=-int _{x=0}^{z}log(x),dx-int _{x=z}^{1}{frac {z}{x}}log(x),dx\&=-z{Big (}log(z)-1{Big )}+{frac {1}{2}}zlog ^{2}(z)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/294db9eb5d2091d0d20404fb0df887a8731c6c62)
Taking the derivative yields

The author of the note conjectures that, in general,


The geometry of the product distribution of two random variables in the unit square.
The figure illustrates the nature of the integrals above. The shaded area within the unit square and below the line z = xy, represents the CDF of z. This divides into two parts. The first is for 0 < x < z where the increment of area in the vertical slot is just equal to dx. The second part lies below the xy line, has y-height z/x, and incremental area dx z/x.
Independent central-normal distributions[edit]
The product of two independent Normal samples follows a modified Bessel function. Let  be samples from a Normal(0,1) distribution and
be samples from a Normal(0,1) distribution and  .
.
Then

The variance of this distribution could be determined, in principle, by a definite integral from Gradsheyn and Ryzhik,[7]

thus

A much simpler result, stated in a section above, is that the variance of the product of zero-mean independent samples is equal to the product of their variances. Since the variance of each Normal sample is one, the variance of the product is also one.
[edit]
The product of correlated Normal samples case was recently addressed by Nadarajaha and Pogány.[8]
Let  be zero mean, unit variance, normally distributed variates with correlation coefficient
be zero mean, unit variance, normally distributed variates with correlation coefficient 
Then

Mean and variance: For the mean we have ![{displaystyle operatorname {E} [Z]=rho }](https://wikimedia.org/api/rest_v1/media/math/render/svg/bd9d809dfa1b01ef2e9deb73249e2a2313ef1230) from the definition of correlation coefficient. The variance can be found by transforming from two unit variance zero mean uncorrelated variables U, V. Let
from the definition of correlation coefficient. The variance can be found by transforming from two unit variance zero mean uncorrelated variables U, V. Let

Then X, Y are unit variance variables with correlation coefficient  and
and

Removing odd-power terms, whose expectations are obviously zero, we get
![{displaystyle operatorname {E} [(XY)^{2}]=rho ^{2}operatorname {E} [U^{4}]+(1-rho ^{2})operatorname {E} [U^{2}]operatorname {E} [V^{2}]=3rho ^{2}+(1-rho ^{2})=1+2rho ^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8b1224a6c79c0e85396501a5717819112398e232)
Since ![{displaystyle (operatorname {E} [Z])^{2}=rho ^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64599f5aeaebecefc6575c4abc64b0710328bb1e) we have
we have
![{displaystyle operatorname {Var} (Z)=operatorname {E} [Z^{2}]-(operatorname {E} [Z])^{2}=1+2rho ^{2}-rho ^{2}=1+rho ^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/441359c29ce6309ff257209df448e7a77a3185ef)
High correlation asymptote
In the highly correlated case,  the product converges on the square of one sample. In this case the
the product converges on the square of one sample. In this case the  asymptote is
asymptote is 
and

which is a Chi-squared distribution with one degree of freedom.
Multiple correlated samples. Nadarajaha et al. further show that if  iid random variables sampled from and
iid random variables sampled from and  is their mean then
is their mean then

where W is the Whittaker function while  .
.
Using the identity  , see for example the DLMF compilation. eqn(13.13.9),[9] this expression can be somewhat simplified to
, see for example the DLMF compilation. eqn(13.13.9),[9] this expression can be somewhat simplified to

The pdf gives the distribution of a sample covariance. The approximate distribution of a correlation coefficient can be found via the Fisher transformation.
Multiple non-central correlated samples. The distribution of the product of correlated non-central normal samples was derived by Cui et al.[10] and takes the form of an infinite series of modified Bessel functions of the first kind.
Moments of product of correlated central normal samples
For a central normal distribution N(0,1) the moments are
![{displaystyle operatorname {E} [X^{p}]={frac {1}{sigma {sqrt {2pi }}}}int _{-infty }^{infty }x^{p}exp(-{tfrac {x^{2}}{2sigma ^{2}}}),dx={begin{cases}0&{text{if }}p{text{ is odd,}}\sigma ^{p}(p-1)!!&{text{if }}p{text{ is even.}}end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b9035615a6e26e0630b830e5c800c17846f1cd3f)
where  denotes the double factorial.
denotes the double factorial.
If  are central correlated variables, the simplest bivariate case of the multivariate normal moment problem described by Kan,[11] then
are central correlated variables, the simplest bivariate case of the multivariate normal moment problem described by Kan,[11] then
![{displaystyle operatorname {E} [X^{p}Y^{q}]={begin{cases}0&{text{if }}p+q{text{ is odd,}}\{frac {p!q!}{2^{tfrac {p+q}{2}}}}sum _{k=0}^{t}{frac {(2rho )^{2k}}{{Big (}{frac {p}{2}}-k{Big )}!;{Big (}{frac {q}{2}}-k{Big )}!;(2k)!}}&{text{if }}p{text{ and }}q{text{ are even}}\{frac {p!q!}{2^{tfrac {p+q}{2}}}}sum _{k=0}^{t}{frac {(2rho )^{2k+1}}{{Big (}{frac {p-1}{2}}-k{Big )}!;{Big (}{frac {q-1}{2}}-k{Big )}!;(2k+1)!}}&{text{if }}p{text{ and }}q{text{ are odd}}end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a39155cfa9eb8ec8a69701c7a3d93061e8fcb6bb)
where
- is the correlation coefficient and
![{displaystyle t=min([p,q]/2)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bef305862a2f89c2b80e252b35465923e8e3cf16)
[needs checking]
[edit]
The distribution of the product of non-central correlated normal samples was derived by Cui et al.[10] and takes the form of an infinite series.
These product distributions are somewhat comparable to the Wishart distribution. The latter is the joint distribution of the four elements (actually only three independent elements) of a sample covariance matrix. If  are samples from a bivariate time series then the
are samples from a bivariate time series then the  is a Wishart matrix with K degrees of freedom. The product distributions above are the unconditional distribution of the aggregate of K > 1 samples of
is a Wishart matrix with K degrees of freedom. The product distributions above are the unconditional distribution of the aggregate of K > 1 samples of  .
.
Independent complex-valued central-normal distributions[edit]
Let  be independent samples from a normal(0,1) distribution.
be independent samples from a normal(0,1) distribution.
Setting
 are independent zero-mean complex normal samples with circular symmetry. Their complex variances are
are independent zero-mean complex normal samples with circular symmetry. Their complex variances are 
The density functions of
- are Rayleigh distributions defined as:


The variable  is clearly Chi-squared with two degrees of freedom and has PDF
is clearly Chi-squared with two degrees of freedom and has PDF

Wells et al.[12] show that the density function of  is
is

and the cumulative distribution function of  is
is
![{displaystyle P(a)=Pr[sleq a]=int _{s=0}^{a}sK_{0}(s)ds=1-aK_{1}(a)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f719a959f053aea19bfc3e96f29cac846f4e7711)
Thus the polar representation of the product of two uncorrelated complex Gaussian samples is
- .
![{displaystyle f_{s,theta }(s,theta )=f_{s}(s)p_{theta }(theta ){text{ where }}p(theta ){text{ is uniform on }}[0,2pi ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cdbc0a9dc29335ec6372c0206dfd86b7a83b43eb)
The first and second moments of this distribution can be found from the integral in Normal Distributions above


Thus its variance is  .
.
Further, the density of  corresponds to the product of two independent Chi-square samples
corresponds to the product of two independent Chi-square samples  each with two DoF. Writing these as scaled Gamma distributions
each with two DoF. Writing these as scaled Gamma distributions  then, from the Gamma products below, the density of the product is
then, from the Gamma products below, the density of the product is

Independent complex-valued noncentral normal distributions[edit]
The product of non-central independent complex Gaussians is described by O’Donoughue and Moura[13] and forms a double infinite series of modified Bessel functions of the first and second types.
Gamma distributions[edit]
The product of two independent Gamma samples,  , defining
, defining  , follows[14]
, follows[14]

Beta distributions[edit]
Nagar et al.[15] define a correlated bivariate beta distribution

where

Then the pdf of Z = XY is given by

where  is the Gauss hypergeometric function defined by the Euler integral
is the Gauss hypergeometric function defined by the Euler integral

Note that multivariate distributions are not generally unique, apart from the Gaussian case, and there may be alternatives.
Uniform and gamma distributions[edit]
The distribution of the product of a random variable having a uniform distribution on (0,1) with a random variable having a gamma distribution with shape parameter equal to 2, is an exponential distribution.[16] A more general case of this concerns the distribution of the product of a random variable having a beta distribution with a random variable having a gamma distribution: for some cases where the parameters of the two component distributions are related in a certain way, the result is again a gamma distribution but with a changed shape parameter.[16]
The K-distribution is an example of a non-standard distribution that can be defined as a product distribution (where both components have a gamma distribution).
Gamma and Pareto distributions[edit]
The product of n Gamma and m Pareto independent samples was derived by Nadarajah.[17]
See also[edit]
- Algebra of random variables
- Sum of independent random variables
Notes[edit]
- ^ Springer, Melvin Dale (1979). The Algebra of Random Variables. Wiley. ISBN 978-0-471-01406-5. Retrieved 24 September 2012.
- ^ Rohatgi, V. K. (1976). An Introduction to Probability Theory and Mathematical Statistics. Wiley Series in Probability and Statistics. New York: Wiley. doi:10.1002/9781118165676. ISBN 978-0-19-853185-2.
- ^ Grimmett, G. R.; Stirzaker, D.R. (2001). Probability and Random Processes. Oxford: Oxford University Press. ISBN 978-0-19-857222-0. Retrieved 4 October 2015.
- ^ Sarwate, Dilip (March 9, 2013). «Variance of product of multiple random variables». Stack Exchange.
- ^ «How to find characteristic function of product of random variables». Stack Exchange. January 3, 2013.
- ^ heropup (1 February 2014). «product distribution of two uniform distribution, what about 3 or more». Stack Exchange.
- ^ Gradsheyn, I S; Ryzhik, I M (1980). Tables of Integrals, Series and Products. Academic Press. pp. section 6.561.
- ^ Nadarajah, Saralees; Pogány, Tibor (2015). «On the distribution of the product of correlated normal random variables». Comptes Rendus de l’Académie des Sciences, Série I. 354 (2): 201–204. doi:10.1016/j.crma.2015.10.019.
- ^ Equ(13.18.9). «Digital Library of Mathematical Functions». NIST: National Institute of Standards and Technology.
- ^ a b Cui, Guolong (2016). «Exact Distribution for the Product of Two Correlated Gaussian Random Variables». IEEE Signal Processing Letters. 23 (11): 1662–1666. Bibcode:2016ISPL…23.1662C. doi:10.1109/LSP.2016.2614539.
- ^ Kan, Raymond (2008). «From moments of sum to moments of product». Journal of Multivariate Analysis. 99 (3): 542–554. doi:10.1016/j.jmva.2007.01.013.
- ^ Wells, R T; Anderson, R L; Cell, J W (1962). «The Distribution of the Product of Two Central or Non-Central Chi-Square Variates». The Annals of Mathematical Statistics. 33 (3): 1016–1020. doi:10.1214/aoms/1177704469.
- ^ O’Donoughue, N; Moura, J M F (March 2012). «On the Product of Independent Complex Gaussians». IEEE Transactions on Signal Processing. 60 (3): 1050–1063. Bibcode:2012ITSP…60.1050O. doi:10.1109/TSP.2011.2177264.
- ^ Wolfies (August 2017). «PDF of the product of two independent Gamma random variables». stackexchange.
- ^ Nagar, D K; Orozco-Castañeda, J M; Gupta, A K (2009). «Product and quotient of correlated beta variables». Applied Mathematics Letters. 22: 105–109. doi:10.1016/j.aml.2008.02.014.
- ^ a b
Johnson, Norman L.; Kotz, Samuel; Balakrishnan, N. (1995). Continuous Univariate Distributions Volume 2, Second edition. Wiley. p. 306. ISBN 978-0-471-58494-0. Retrieved 24 September 2012. - ^ Nadarajah, Saralees (June 2011). «Exact distribution of the product of n gamma and m Pareto random variables». Journal of Computational and Applied Mathematics. 235 (15): 4496–4512. doi:10.1016/j.cam.2011.04.018.
References[edit]
- Springer, Melvin Dale; Thompson, W. E. (1970). «The distribution of products of beta, gamma and Gaussian random variables». SIAM Journal on Applied Mathematics. 18 (4): 721–737. doi:10.1137/0118065. JSTOR 2099424.
- Springer, Melvin Dale; Thompson, W. E. (1966). «The distribution of products of independent random variables». SIAM Journal on Applied Mathematics. 14 (3): 511–526. doi:10.1137/0114046. JSTOR 2946226.
Функции случайных величин
Определение функции случайных величин. Функция дискретного случайного аргумента и ее числовые характеристики. Функция непрерывного случайного аргумента и ее числовые характеристики. Функции двух случайных аргументов. Определение функции распределения вероятностей и плотности для функции двух случайных аргументов.
Закон распределения вероятностей функции одной случайной величины
При решении задач, связанных с оценкой точности работы различных автоматических систем, точности производства отдельных элементов систем и др., часто приходится рассматривать функции одной или нескольких случайных величин. Такие функции также являются случайными величинами. Поэтому при решении задач необходимо знать законы распределения фигурирующих в задаче случайных величин. При этом обычно известны закон распределения системы случайных аргументов и функциональная зависимость.
Таким образом, возникает задача, которую можно сформулировать так.
Дана система случайных величин , закон распределения которой известен. Рассматривается некоторая случайная величина Y как функция данных случайных величин:
(6.1)
Требуется определить закон распределения случайной величины , зная вид функций (6.1) и закон совместного распределения ее аргументов.
Рассмотрим задачу о законе распределения функции одного случайного аргумента
Пусть — дискретная случайная величина, имеющая ряд распределения
Тогда также дискретная случайная величина с возможными значениями
. Если все значения
различны, то для каждого
события
и
тождественны. Следовательно,
и искомый ряд распределения имеет вид
Если же среди чисел есть одинаковые, то каждой группе одинаковых значений
нужно отвести в таблице один столбец и соответствующие вероятности сложить.
Для непрерывных случайных величин задача ставится так: зная плотность распределения случайной величины
, найти плотность распределения
случайной величины
. При решении поставленной задачи рассмотрим два случая.
Предположим сначала, что функция является монотонно возрастающей, непрерывной и дифференцируемой на интервале
, на котором лежат все возможные значения величины
. Тогда обратная функция
существует, при этом являясь также монотонно возрастающей, непрерывной и дифференцируемой. В этом случае получаем
(6.2)
Пример 1. Случайная величина распределена с плотностью
Найти закон распределения случайной величины , связанной с величиной
зависимостью
.
Решение. Так как функция монотонна на промежутке
, то можно применить формулу (6.2). Обратная функция по отношению к функции
есть
, ее производная
. Следовательно,
Рассмотрим случай немонотонной функции. Пусть функция такова, что обратная функция
неоднозначна, т. е. одному значению величины
соответствует несколько значений аргумента
, которые обозначим
, где
— число участков, на которых функция
изменяется монотонно. Тогда
(6.3)
Пример 2. В условиях примера 1 найти распределение случайной величины .
Решение. Обратная функция неоднозначна. Одному значению аргумента
соответствуют два значения функции
Применяя формулу (6.3), получаем:
Закон распределения функции двух случайных величин
Пусть случайная величина является функцией двух случайных величин, образующих систему
, т. е.
. Задача состоит в том, чтобы по известному распределению системы
найти распределение случайной величины
.
Пусть — плотность распределения системы случайных величин
. Введем в рассмотрение новую величину
, равную
, и рассмотрим систему уравнений
Будем полагать, что эта система однозначно разрешима относительно
и удовлетворяет условиям дифференцируемости.
Плотность распределения случайной величины
Заметим, что рассуждения не изменяются, если введенную новую величину положить равной
.
Математическое ожидание функции случайных величин
На практике часто встречаются случаи, когда нет особой надобности полностью определять закон распределения функции случайных величин, а достаточно только указать его числовые характеристики. Таким образом, возникает задача определения числовых характеристик функций случайных величин помимо законов распределения этих функций.
Пусть случайная величина является функцией случайного аргумента
с заданным законом распределения
Требуется, не находя закона распределения величины , определить ее математическое ожидание
Пусть — дискретная случайная величина, имеющая ряд распределения
Составим таблицу значений величины и вероятностей этих значений:
Эта таблица не является рядом распределения случайной величины , так как в общем случае некоторые из значений могут совпадать между собой и значения в верхней строке не обязательно идут в возрастающем порядке. Однако математическое ожидание случайной величины
можно определить по формуле
(6.4)
так как величина, определяемая формулой (6.4), не может измениться от того, что под знаком суммы некоторые члены будут заранее объединены, а порядок членов изменен.
Формула (6.4) не содержит в явном виде закон распределения самой функции , а содержит только закон распределения аргумента
. Таким образом, для определения математического ожидания функции
вовсе не требуется знать закон распределения функции
, а достаточно знать закон распределения аргумента
.
Для непрерывной случайной величины математическое ожидание вычисляется по формуле
где — плотность распределения вероятностей случайной величины
.
Рассмотрим случаи, когда для нахождения математического ожидания функции случайных аргументов не требуется знание даже законов распределения аргументов, а достаточно знать только некоторые их числовые характеристики. Сформулируем эти случаи в виде теорем.
Теорема 6.1. Математическое ожидание суммы как зависимых, так и независимых двух случайных величин равно сумме математических ожиданий этих величин:
Теорема 6.2. Математическое ожидание произведения двух случайных величин равно произведению их математических ожиданий плюс корреляционный момент:
Следствие 6.1. Математическое ожидание произведения двух некоррелированных случайных величин равно произведению их математических ожиданий.
Следствие 6.2. Математическое ожидание произведения двух независимых случайных величин равно произведению их математических ожиданий.
Дисперсия функции случайных величин
По определению дисперсии имеем . Следовательно,
, где
.
Приведем расчетные формулы только для случая непрерывных случайных аргументов. Для функции одного случайного аргумента дисперсия выражается формулой
(6.5)
где — математическое ожидание функции
;
— плотность распределения величины
.
Формулу (6.5) можно заменить на следующую:
Рассмотрим теоремы о дисперсиях, которые играют важную роль в теории вероятностей и ее приложениях.
Теорема 6.3. Дисперсия суммы случайных величин равна сумме дисперсий этих величин плюс удвоенная сумма корреляционных моментов каждой из слагаемых величин со всеми последующими:
Следствие 6.3. Дисперсия суммы некоррелированных случайных величин равна сумме дисперсий слагаемых:
Теорема 6.4. Дисперсия произведения двух независимых случайных величин вычисляется по формуле
Корреляционный момент функций случайных величин
Согласно определению корреляционного момента двух случайных величин и
, имеем
Раскрывая скобки и применяя свойства математического ожидания, получаем
(6.6)
Рассмотрим две функции случайной величины
Согласно формуле (6.6)
отсюда
т.е. корреляционный момент двух функций случайных величин равен математическому ожиданию произведения этих функций минус произведение из математических ожиданий.
Рассмотрим основные свойства корреляционного момента и коэффициента корреляции.
Свойство 1. От прибавления к случайным величинам постоянных величин корреляционный момент и коэффициент корреляции не изменяются.
Свойство 2. Для любых случайных величин и
абсолютная величина корреляционного момента не превосходит среднего геометрического дисперсий данных величин:
где — средние квадратические отклонения величин
и
.
Следствие 6.5. Для любых случайных величин и
абсолютная величина коэффициента корреляции не превосходит единицы:
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
Теорема 6.
Неслучайную величину можно выносить
за знак дисперсии, возводя ее в квадрат.
Если
с
—
неслучайная величина, а X
—
случайная, то
|
|
(7.2.1) |
Доказательство.
По определению дисперсии
|
|

Следствие
|
|
(7.2.2) |
т. е. неслучайную
величину можно выносить за знак
среднеквадратического отклонения ее
абсолютным значением. Доказательство
получим, извлекая корень квадратный из
формулы (7.2.1) и учитывая, что
среднеквадратическое положительная
величина.
Теорема 7.
Дисперсия неслучайной величины равна
нулю
Если с — неслучайная
величина, то
![]() ,
,
тогда
|
|
(7.2.3) |
Теорема 8.Дисперсия
суммы двух случайных величин равна
сумме их дисперсий плюс удвоенный
корреляционный момент:
|
|
(7.2.4) |
Доказательство.
Обозначим
|
|
(7.2.5) |
По теореме сложения
математических ожиданий
|
|
(7.2.6) |
Перейдем
от случайных величин X,Y,Z
к
соответствующим центрированным величинам
X,Y,Z.
Вычитая
почленно из равенства (7.2.5) равенство
(7.2.6), имеем:
|
|
По определению
дисперсии
|
|

что и требовалось
доказать.
Формула (7.2.4) для
дисперсии суммы может быть обобщена на
любое число слагаемых:
|
|
(7.2.7) |

где
Кij
—
корреляционный момент величин Xi
,
Xj,
знак
i<j
под суммой обозначает, что суммирование
распространяется на все возможные
попарные сочетания случайных величин
(X1
,Х2…..,Хn).
Доказательство
аналогично предыдущему и вытекает из
формулы для квадрата многочлена.
Формула (7.2.7) может
быть записана еще в другом виде:
|
|
(7.2.8) |

где
двойная сумма распространяется на все
элементы корреляционной матрицы системы
величин (Х1,Х2,….Хn),
содержащей
как корреляционные моменты, так и
дисперсии.
Если
все случайные величины (Х1,Х2,…,Хп),
входящие
в систему, некоррелированы (т. е. Кij
= 0 при
i![]() j).
j).
формула (7.2.7) принимает вид:
|
|
(7.2.9) |
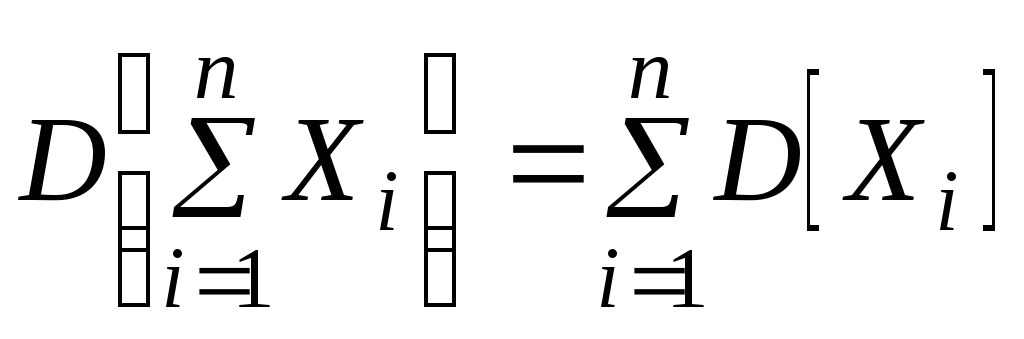
т.е.
дисперсия
суммы некоррелированных случайных
величин равна сумме дисперсий слагаемых.
Это
положение известно под названием теоремы
сложения дисперсий.
Теорема 9. Дисперсия
линейной конбинации случайных величин
определяется соотношением
|
|
(7.2.10) |

где
Кij—
корреляционный момент величин Xi,
Xj.
Доказательство.
Введем обозначение:
|
|
Тогда
|
|
(7.2.11) |
Применяя
к правой части выражения (7.2.11) формулу
(7.2.7) для дисперсии суммы и учитывая, что
D[b]
= 0, получим:
|
|
(7.2.12) |

где
![]() — корреляционный момент величинYi,
— корреляционный момент величинYi,
Yj.
|
|
Вычислим этот
момент. Имеем:
|
|
аналогично
|
|
Отсюда
|
|
Подставляя это
выражение в (7.2.12), приходим к формуле
(7.2.10).
В
частном случае, когда все величины
(Х1,Х2,…,Хn)
некоррелированные,
формула (7.2.10) принимает вид:
|
|
(7.2.13) |

т.е.
дисперсия
линейной функции некоррелированных
случайных величин равна сумме произведений
квадратов коэффициентов на дисперсии
соответствующих аргументов).
Теорема 10.
Дисперсия произведения независимых
случайных величин определяется
соотношением
|
|
(7.2.14) |
Доказательство.
Обозначим XY=Z.
По определению дисперсии
|
|
Так
как величины X,
Y
независимы,
mz
= mxmy
и
|
|
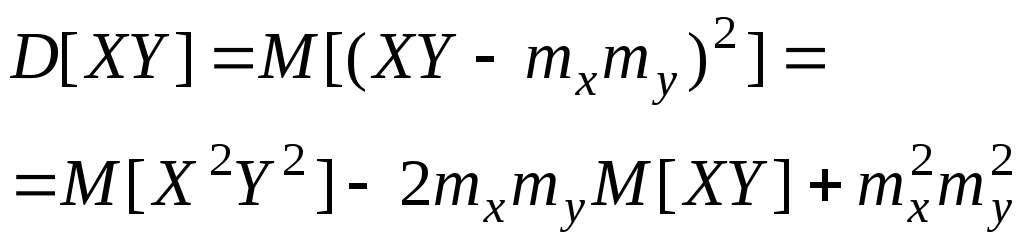
При
независимых X,
У величины
Х2,
Y2
тоже
независимы следовательно,
|
|
и
|
|
(7.2.15) |
Но
М[X2]
есть
не что иное, как второй начальный момент
величины X,
и,
следовательно, выражается через
дисперсию:
|
|
(7.2.16) |
аналогично
|
|
(7.2.17) |
Подставляя выражения
(7.2.16) и (7.2.17) в формулу (7.2.15) и приводя
подобные члены, приходим к формуле
(7.2.14).
В случае, когда
перемножаются центрированные случайные
величины (величины с математическими
ожиданиями, равными нулю), формула
(7.2.14) принимает вид:
|
|
(7.2.18) |
т.е.
дисперсия
произведения независимых центрированных
случайных величин равна произведению
их дисперсий.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Непрерывная случайная величина Х имеет Равномерный закон распределения на отрезке ![]() , если ее плотность вероятности Р(Х) постоянна на этом отрезке и равна нулю вне его, т. е.
, если ее плотность вероятности Р(Х) постоянна на этом отрезке и равна нулю вне его, т. е.

Функция распределения случайной величины Х, распределенной по равномерному закону, есть

Математическое ожидание ![]() дисперсия
дисперсия  а среднее квадратическое отклонение
а среднее квадратическое отклонение  .
.
Пример 8.14. Поезда метрополитена идут регулярно с интервалом 3 мин. Пассажир выходит на платформу в случайный момент времени. Какова вероятность того, что ждать пассажиру придется не больше минуты. Найти математическое ожидание и среднее квадратическое отклонение случайной величины Х — времени ожидания поезда.
Решение. Случайная величина Х — время ожидания поезда на временном (в минутах) отрезке ![]() имеет равномерный закон распределения
имеет равномерный закон распределения ![]() . Поэтому вероятность того, что пассажиру придется ждать не более минуты, равна
. Поэтому вероятность того, что пассажиру придется ждать не более минуты, равна ![]() От равной единице площади прямоугольника (рис. 8.11), т. е.
От равной единице площади прямоугольника (рис. 8.11), т. е.

![]() Мин,
Мин, ![]()
![]() мин.
мин.
 |
Рис. 8.11
Пример 8.15. Найти математическое ожидание и дисперсию произведения двух независимых случайных величин ξ и η с равномерными законами распределения: ξ в интервале ![]() , η — в интервале
, η — в интервале ![]() .
.
Решение. Так как математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий, то ![]() . Для нахождения дисперсии воспользуемся формулой
. Для нахождения дисперсии воспользуемся формулой
![]()
![]() найдем по формуле
найдем по формуле
 .
.
Аналогично рассчитаем
 .
.
Следовательно,
![]() .
.
Пример 8.16. Вычислить математическое ожидание и дисперсию определителя
 ,
,
Элементы которого ![]() — независимые случайные величины с
— независимые случайные величины с ![]() и
и ![]()
Решение. Вычислим математическое ожидание
![]()
Для нахождения дисперсии![]() докажем, что если ξ и η — независимые случайные величины, то
докажем, что если ξ и η — независимые случайные величины, то ![]()
Действительно,

Следовательно,

Замечание. Для определителя N-го порядка ![]() ;
; ![]()
Пример 8.17. Автоматический светофор работает в двух режимах: 1 мин. горит зеленый свет и 0,5 мин — красный и т. д. Водитель подъезжает к перекрестку в случайный момент времени. 1. Найти вероятность того, что он проедет перекресток без остановки. 2. Составить закон распределения и вычислить числовые характеристики времени ожидания у перекрестка.
Решение. 1. Момент проезда автомобиля T через перекресток распределен равномерно в интервале, равном периоду смены цветов светофора. Этот период равен 1 + 0,5 = 1,5 мин. Для того чтобы машина проехала через перекресток не останавливаясь, достаточно того, чтобы момент проезда пришелся на интервал времени ![]() . Тогда
. Тогда
 .
.
2. Время ожидания ![]() является смешанной случайной величиной: с вероятностью
является смешанной случайной величиной: с вероятностью ![]() она равна нулю, а с вероятностью
она равна нулю, а с вероятностью ![]() принимает с равномерной плотностью вероятностей любые значения между 0 и 0,5 мин; тогда график функции распределения случайной величины
принимает с равномерной плотностью вероятностей любые значения между 0 и 0,5 мин; тогда график функции распределения случайной величины ![]() имеет вид, изображенный на рис. 8.12:
имеет вид, изображенный на рис. 8.12:
 |
Рис. 8.12
То есть ![]() при
при ![]() ;
;  при
при ![]() ;
; ![]() при
при ![]() .
.
Среднее время ожидания у перекрестка
 Мин.
Мин.
Дисперсия времени ожидания
 Мин2;
Мин2;
![]() Мин.
Мин.
| < Предыдущая | Следующая > |
|---|