Метод сканирующей прямой (англ. scanline) заключается в сортировке точек на координатной прямой либо каких-то абстрактных «событий» по какому-то признаку и последующему проходу по ним.
Он часто используется для решения задач на структуры данных, когда все запросы известны заранее, а также в геометрии для нахождения объединений фигур.
#Точка, покрытая наибольшим количеством отрезков
Задача. Дан набор из $n$ отрезков на прямой, заданных координатами начал и концов $[l_i, r_i]$. Требуется найти любую точку на прямой, покрытую наибольшим количеством отрезков.
Рассмотрим функцию $f(x)$, равную числу отрезков, покрывающих точку $x$. Понятно, что каждую точку этой функции мы проверить не можем.
Назовем интересными те точки, в которых происходит смена количества отрезков, которыми она покрыта. Так как смена ответа может происходить только в интересной точке, то максимум достигается также в какой-то из интересных точек. Отсюда сразу следует решение за $O(n^2)$: просто перебрать все интересные точки (это будут концы заданных отрезков) и проверить для каждой по отдельности ответ.
Это решение можно улучшить. Отсортируем интересные точки по возрастанию координаты и пройдем по ним слева направо, поддерживая количество отрезков cnt, которые покрывают данную точку. Если в данной точке начинается отрезок, то надо увеличить cnt на единицу, а если заканчивается, то уменьшить. После этого пробуем обновить ответ на задачу текущим значением cnt.
Как такое писать: нужно представить интересные точки в виде структур с полями «координата» и «тип» (начало / конец) и отсортировать со своим компаратором. Удобно начало отрезка обозначать +1, а конец -1, чтобы просто прибавлять к cnt это значение и не разбивать на случаи.
Единственный нюанс — если координаты двух точек совпали, чтобы получить правильный ответ, сначала надо рассмотреть все начала отрезков, а только потом концы (чтобы при обновлении ответа в этой координате учлись и правые, и левые граничные отрезки).
struct event {
int x, type;
};
int scanline(vector<pair<int, int>> segments) {
vector<event> events;
for (auto [l, r] : segments) {
events.push_back({l, 1});
events.push_back({r, -1});
}
sort(events.begin(), events.end(), [](event a, event b) {
return (a.x < b.x || (a.x == b.x && a.type > b.type));
});
int cnt = 0, res = 0;
for (event e : events) {
cnt += e.type;
res = max(res, cnt);
}
return res;
}
Такое решение работает за $O(n log n)$ на сортировку. Если координаты небольшие, то от логарифма можно избавиться, если создать vector событий для каждой различной координаты и просто итерироваться по всем целочисленным координатам и событиям в них. Также всегда хорошей идеей будет сжать координаты.
Рассмотрим теперь несколько смежных задач.
#Длина объединения отрезков
Задача. Дан набор из $n$ отрезков на прямой, заданных координатами начал и концов $[l_i, r_i]$. Требуется найти суммарную длину их объединения.
Как и в прошлой задаче, отсортируем все интересные точки и при проходе будем поддерживать число отрезков, покрывающих текущую точку. Если оно больше 0, то отрезок, который мы прошли с прошлой рассмотренной точки, принадлежит объединению, и его длину нужно прибавить к ответу:
int cnt = 0, res = 0, prev = -inf;
for (event e : events) {
if (prev != -inf && cnt > 0)
res += e.x - prev; // весь отрезок [prev, e.x] покрыт cnt отрезками
cnt += e.type;
prev = e.x;
}
Время работы $O(n log n)$.
#Скольким отрезкам принадлежит точка
Пусть теперь надо для $q$ точек (не обязательно являющихся концами отрезков) ответить на вопрос: скольким отрезкам принадлежит данная точка?
Воспользуемся следующим приемом: сразу считаем все запросы и сохраним их, чтобы потом ответить на все сразу. Добавим точки запросов как события с новым типом 0, который будет означать, что в этой точке надо ответить на запрос, и отдельным полем для номера запроса.
Теперь аналогично отсортируем точки интереса и пройдем по ним слева направо, поддерживая cnt и отвечая на запросы, когда их встретим.
struct event {
int x, type, idx;
};
void scanline(vector<pair<int, int>> segments, vector<int> queries) {
int q = (int) queries.size();
vector<int> ans(q)
vector<event> events;
for (auto [l, r] : segments) {
events.push_back({l, 1});
events.push_back({r, -1});
}
for (int i = 0; i < q; i++)
events.push_back({queries[i], 0, i});
// при равенстве координат сначала идут добавления, потом запросы, потом удаления
sort(events.begin(), events.end(), [](event a, event b) {
return (a.x < b.x || (a.x == b.x && a.type > b.type));
});
int cnt = 0;
for (event e : events) {
cnt += e.type;
if (e.type == 0)
ans[e.idx] = cnt;
}
}
Асимптотика $O((n+q)log(n+q))$.
#Количество пересекающихся отрезков
Задача. Дан набор из $n$ отрезков на прямой, заданных координатами начал и концов $[l_i, r_i]$. Требуется для каждого отрезка сказать, с каким количеством отрезков он пересекается (в частности, он может иметь одну общую точку или быть вложенным).
Вместо того, чтобы для каждого отрезка считать количество отрезков, с которыми он пересекается, посчитаем количество отрезков, с которыми он не пересекается, и вычтем это число из $(n-1)$.
Отрезок $[l_1, r_1]$ не пересекается с другим отрезком $[l_2, r_2]$ только если $r_2 < l_1$ или $r_1 < l_2$. Посчитаем количество отрезков для каждого из этих случаев. Без ограничения общности, рассмотрим первый случай, то есть найдем для каждого отрезка количество отрезков, лежащих строго слева. Для этого нужно ввести два типа событий:
- Какой-то отрезок закончился в координате $r_i$.
- Какой-то отрезок с таким-то индексом начался в координате $l_j$.
Теперь нам достаточно пройтись по этим событиям слева направо, поддерживая количество встреченных событий первого типа и вычитая его из ячейки ответа для событий второго типа.
Аналогично пройдемся справа налево, находя отрезки, лежащие строго справа. Итоговое время работы будет $O(n log n)$ на сортировку.
#Сумма на прямоугольнике
Перейдем к двумерному сканлайну.
Задача. Даны $n$ точек на плоскости. Требуется ответить на $m$ запросов количества точек на прямоугольнике.
Во-первых, сожмем все координаты (и точек, и запросов): будем считать, что они все порядка $O(n + m)$.
Теперь разобьём каждый запрос на два запроса суммы на префиксах: сумма на прямоугольнике $[x_1, x_2] times [y_1, y_2]$ равна сумме на прямоугольнике $[0, x_2] times [y_1, y_2]$ минус сумме на прямоугольнике $[0, x_1] times [y_1, y_2]$.
Создадим дерево отрезков для суммы и массив ans для ответов на запросы. Теперь будем проходиться в порядке увеличения по всем интересным $x$ — координатам точек и правых границ префиксных запросов — и обрабатывать события трёх типов:
- Если мы встретили точку, то добавляем единицу к ячейке $y$ в дереве отрезков.
- Если мы встретили «левый» запрос префиксной суммы, то посчитаем через дерево отрезков сумму на отрезке $[y_1, y_2]$ и вычтем его из ячейки ответа.
- Если мы встретили «правый» запрос, то аналогично прибавим сумму на $[y_1, y_2]$ к ячейке ответа.
Таким образом, мы решим задачу в оффлайн за $O(n log n)$: сжатие координат / сортировка плюс $O(n)$ запросов к дереву отрезков (или любой другой структуре для динамической суммы).
Сумма на прямоугольнике как вспомогательная подзадача также часто используется в задачах на инверсии в перестановках и запросы на поддеревьях.
#Площадь объединения прямоугольников
Задача. Дано $n$ прямоугольников, требуется найти площадь их объединения.
Вдохновляясь предыдущим подходом, можно создать два типа событий:
- прямоугольник с $y$-координатами от $y_1$ до $y_2$ начинается в точке $x_1$;
- прямоугольник с $y$-координатами от $y_1$ до $y_2$ заканчивается в точке $x_2$;
и затем как-то пройтись по этим событиям в порядке увеличения $x$ и посчитать общую площадь подобно тому, как мы делали с одномерными отрезками.
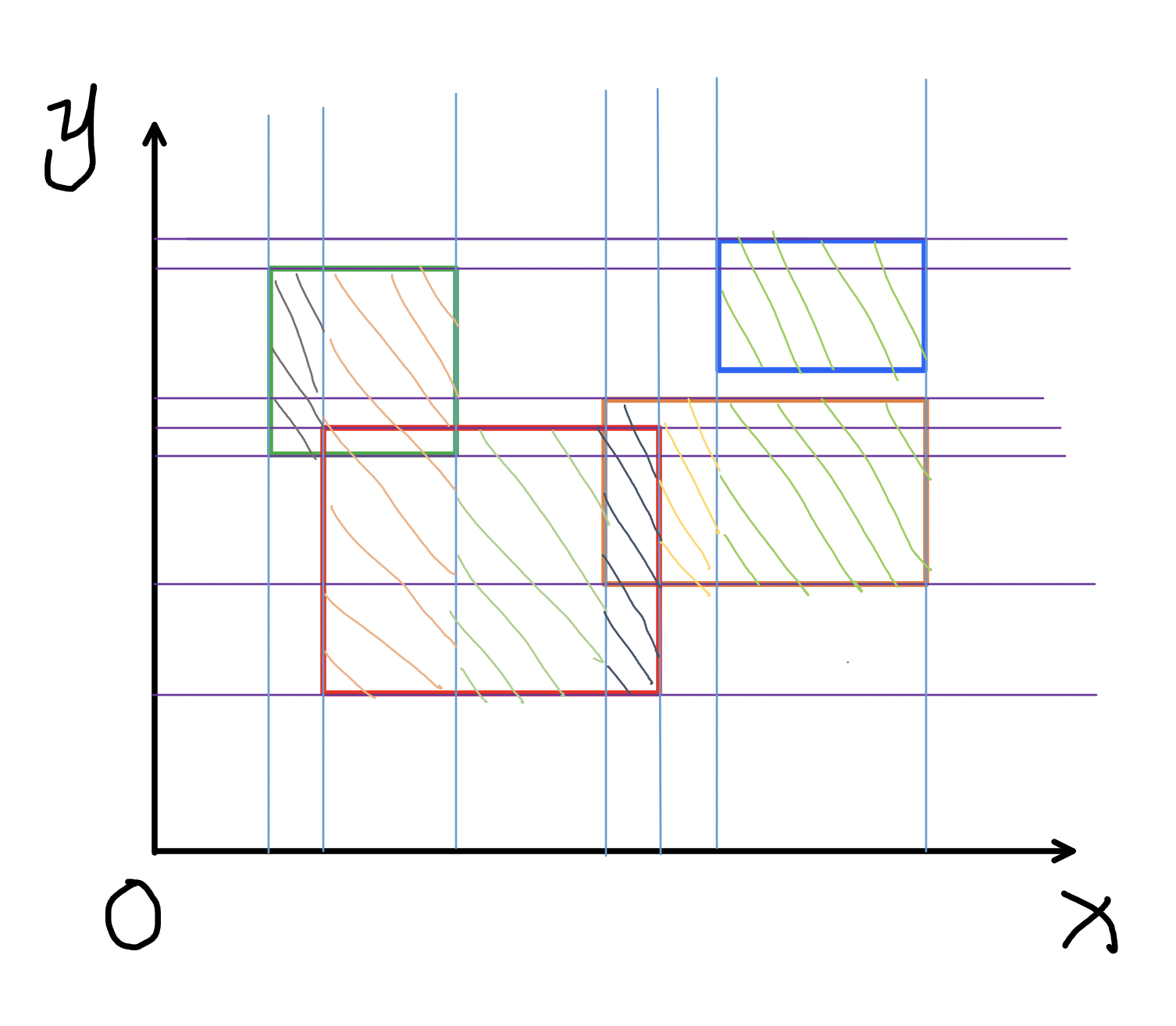
Если обобщать подход напрямую, то нам нужно завести массив размера $Y$ (максимальной $y$-координаты) и для каждой $y$-параллели поддерживать число прямоугольников, которые её покрывают, и каждый раз, когда $x$-координата события меняется, добавлять к ответу разницу $x$-координат старого и нового события, помноженную на число ненулевых элементов в массиве (точек на вертикальной сканирующей прямой, которые покрываются хотя бы одним прямоугольником).
Но это в худшем случае работает за $O(nY)$, что достаточно долго. Чтобы получить более приятную асимптотику, заменим массив деревом отрезков, в узлах которого будет храниться минимум и число элементов с таким минимумом (изначально минимум 0 и таких элементов на всём массиве $Y$).
Чтобы обновить ответ, нужно помножить разницу $x$-координат соседних событий на число ненулевых элементов, которое можно найти, вычтя из $Y$ количество минимумов-нулей на всём дереве. Одномерная задача пересчета этой информации при прибавлениях на отрезке остается упражнением читателю.
Такой алгоритм работает за $O(n log n)$, если аккуратно сжать координаты, и за $O(n log Y)$, если этого не делать. Этот метод также обобщается на задачу нахождения площадей и других геометрических фигур.
I have few bolded line segments on x-axis in form of their beginning and ending x-coordinates. Some line segments may be overlapping. How to find the union length of all the line segments.
Example, a line segment is 5,0 to 8,0 and other is 9,0 to 12,0. Both are non overlapping, so sum of length is 3 + 3 = 6.
a line segment is 5,0 to 8,0 and other is 7,0 to 12,0. But they are overlapping for range, 7,0 to 8,0. So union of length is 7.
But the x- coordinates may be floating points.
asked Feb 10, 2013 at 11:43
![]()
Shashwat KumarShashwat Kumar
5,1092 gold badges27 silver badges66 bronze badges
4
Represent a line segment as 2 EndPoint object. Each EndPoint object has the form <coordinate, isStartEndPoint>. Put all EndPoint objects of all the line segments together in a list endPointList.
The algorithm:
- Sort
endPointList, first by coordinate in ascending order, then place the start end points in front of the tail end points (regardless of which segment, since it doesn’t matter — all at the same coordinate). -
Loop through the sorted list according to this pseudocode:
prevCoordinate = -Inf numSegment = 0 unionLength = 0 for (endPoint in endPointList): if (numSegment > 0): unionLength += endPoint.coordinate - prevCoordinate prevCoordinate = endPoint.coordinate if (endPoint.isStartCoordinate): numSegment = numSegment + 1 else: numSegment = numSegment - 1
The numSegment variable will tell whether we are in a segment or not. When it is larger than 0, we are inside some segment, so we can include the distance to the previous end point. If it is 0, it means that the part before the current end point doesn’t contain any segment.
The complexity is dominated by the sorting part, since comparison-based sorting algorithm has lower bound of Omega(n log n), while the loop is clearly O(n) at best. So the complexity of the algorithm can be said to be O(n log n) if you choose an O(n log n) comparison-based sorting algorithm.
answered Feb 10, 2013 at 11:59
![]()
Use a range tree. A range tree is n log(n), just like the sorted begin/end points, but it has the additional advantage that overlapping ranges will reduce the number of elements (but maybe increase the cost of insertion) Snippet (untested)
struct segment {
struct segment *ll, *rr;
float lo, hi;
};
struct segment * newsegment(float lo, float hi) {
struct segment * ret;
ret = malloc (sizeof *ret);
ret->lo = lo; ret->hi = hi;
ret->ll= ret->rr = NULL;
return ret;
}
struct segment * insert_range(struct segment *root, float lo, float hi)
{
if (!root) return newsegment(lo, hi);
/* non-overlapping(or touching) ranges can be put into the {l,r} subtrees} */
if (hi < root->lo) {
root->ll = insert_range(root->ll, lo, hi);
return root;
}
if (lo > root->hi) {
root->rr = insert_range(root->rr, lo, hi);
return root;
}
/* when we get here, we must have overlap; we can extend the current node
** we also need to check if the broader range overlaps the child nodes
*/
if (lo < root->lo ) {
root->lo = lo;
while (root->ll && root->ll->hi >= root->lo) {
struct segment *tmp;
tmp = root->ll;
root->lo = tmp->lo;
root->ll = tmp->ll;
tmp->ll = NULL;
// freetree(tmp);
}
}
if (hi > root->hi ) {
root->hi = hi;
while (root->rr && root->rr->lo <= root->hi) {
struct segment *tmp;
tmp = root->rr;
root->hi = tmp->hi;
root->rr = tmp->rr;
tmp->rr = NULL;
// freetree(tmp);
}
}
return root;
}
float total_width(struct segment *ptr)
{
float ret;
if (!ptr) return 0.0;
ret = ptr->hi - ptr->lo;
ret += total_width(ptr->ll);
ret += total_width(ptr->rr);
return ret;
}
answered Feb 10, 2013 at 12:42
![]()
wildplasserwildplasser
42.8k8 gold badges64 silver badges108 bronze badges
2
Here is a solution I just wrote in Haskell and below it is an example of how it can be implemented in the interpreter command prompt. The segments must be presented in the form of a list of tuples [(a,a)]. I hope you can get a sense of the algorithm from the code.
import Data.List
unionSegments segments =
let (x:xs) = sort segments
one_segment = snd x - fst x
in if xs /= []
then if snd x > fst (head xs)
then one_segment - (snd x - fst (head xs)) + unionSegments xs
else one_segment + unionSegments xs
else one_segment
*Main> :load «unionSegments.hs»
[1 of 1] Compiling Main ( unionSegments.hs, interpreted )
Ok, modules loaded: Main.
*Main> unionSegments [(5,8), (7,12)]
7
answered Feb 10, 2013 at 13:17
![]()
גלעד ברקןגלעד ברקן
23.4k3 gold badges25 silver badges60 bronze badges
Java implementation
import java.util.*;
public class HelloWorld{
static void unionLength(int a[][],int sets)
{
TreeMap<Integer,Boolean> t=new TreeMap<>();
for(int i=0;i<sets;i++)
{
t.put(a[i][0],false);
t.put(a[i][1],true);
}
int count=0;
int res=0;
int one=1;
Set set = t.entrySet();
Iterator it = set.iterator();
int prev=0;
while(it.hasNext()) {
if(one==1){
Map.Entry me = (Map.Entry)it.next();
one=0;
prev=(int)me.getKey();
if((boolean)me.getValue()==false)
count++;
else
count--;
}
Map.Entry me = (Map.Entry)it.next();
if(count>0)
res=res+((int)me.getKey()-prev);
if((boolean)me.getValue()==false)
count++;
else
count--;
prev=(int)me.getKey();
}
System.out.println(res);
}
public static void main(String []args){
int a[][]={{0, 4}, {3, 6},{8,10}};
int b[][]={{5, 10}, {8, 12}};
unionLength(a,3);
unionLength(b,2);
}
}
answered Sep 9, 2020 at 16:50
![]()
luckylucky
212 bronze badges
1
На прямой заданы отрезки координатами левого и правого конца. Необходимо найти длину их объединения. Поместим все координаты в отдельный массив, при этом левому концу сопоставим -1, а правому +1. Все прямая разобъется на подотрезки, внутри которых нет других точек. Для каждого такого отрезка нужно определить надо ли добавлять его длину в общую сумму. Легко заметить что если количество левых концов слева от данной области равно количеству правых, то эта область не покрыта ни одним исходным отрезком, поэтому ее длину не надо добавлять. Для выяснения этого факта будем поддерживать переменную — баланс левых и правых концов.
template<typename T> T segments_union(vector<pair<T, T>> s) { vector<pair<T, int> > v; for (int i = 0; i < sz(s); ++i) { v.pb(mp(s[i].first, -1)); v.pb(mp(s[i].second, 1)); } sort(all(v)); T res = 0; for (int i = 0, sum = 0; i < sz(v); ++i) { if (sum) { res += v[i].first - v[i - 1].first; } sum += v[i].second; } return res; }

Программа должна вычислять длину объединения конечного
набора отрезков на координатной прямой, заданных целочисленными
координатами своих концов. Точка входит в объединение отрезков,
если она принадлежит хотя бы одному из них.
Входные данные.
Конечная последовательность отрезков на
координатной прямой, заданных целочисленными координатами
своих концов.
Выходные данные
. Общая длина объединения этих отрезков.
У меня есть код, но он выдает ошибки, я не понимаю, что не так. Помогите исправить, пожалуйста
| C++ | ||
|
Получить длину объединения |
Я |
28.06.12 — 11:57
В рамках 1С 8 тренировочная задачка на запросы
Есть таблица Т с двумя числовыми полями А и Б, А<Б всегда
Каждая запись таблицы интерпретируется как отрезок с координами концов А и Б на координатной прямой
Берется объединение всех отрезков таблицы
Требуется найти длину полученного объединения
1 — 28.06.12 — 11:58
мин(А) — макс(Б) не?
2 — 28.06.12 — 11:58
или пропуски тоже учитывать?
3 — 28.06.12 — 11:58
и решабельно ли это запросом?
4 — 28.06.12 — 12:00
(1)
1-4
2-6
итог 5 не равно 8
5 — 28.06.12 — 12:01
(2) конечно, иначе смысла нет
(3) запросом только
(4) правильный ответ в твоем примере 5
6 — 28.06.12 — 12:02
(5) ну дык, без учета пропусков max(Б) — min(А) )))
7 — 28.06.12 — 12:02
хм, щас посмотрим
8 — 28.06.12 — 12:04
(5) сам то написал запрос?
9 — 28.06.12 — 12:05
(6) 1 — 5, 10 — 20, длина = 5 + 10. не прет твоя формула)
10 — 28.06.12 — 12:05
а тупо посчитать длину отрезка в каждой строке и итог, не?
11 — 28.06.12 — 12:06
(9) у меня частное решение, что ты не заметил
12 — 28.06.12 — 12:06
(10) а если они пересекаются?
13 — 28.06.12 — 12:06
(12) да вот уже дошел до такого условия 
14 — 28.06.12 — 12:07
15 — 28.06.12 — 12:07
сумма всех длин — попарное пересечение всех отрезков
16 — 28.06.12 — 12:08
(0) Тест при приеме на работу?)
17 — 28.06.12 — 12:22
(8) да
(16) кстати, вполне может быть
18 — 28.06.12 — 12:22
(14) почему?
19 — 28.06.12 — 12:25
я б сделал, но работать надо
20 — 28.06.12 — 12:32
(19) Красиво отмазался)
21 — 28.06.12 — 12:43
(18) Вот, например для проверки резудьтата исходная таблица, должно 6 получится?
ВЫБРАТЬ
1 КАК А,
2 КАК Б
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
1,
3
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
3
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
1,
4
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
3,
5
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
9,
10
22 — 28.06.12 — 12:45
(21) должно 5 получиться
23 — 28.06.12 — 12:46
(22) тогда я не понял условие, почему 5?
24 — 28.06.12 — 12:47
(23) ну у тебя после объединения фактически два отрезка получатся 1-5 и 9-10, длина первого 4, второго 1
25 — 28.06.12 — 12:48
(24) ну да, 5 конечно, а не 6
26 — 28.06.12 — 12:50
(0)
если исходная выборка
1-4
2-6
9-12
10-20
45-46
как должна выглядеть результирующая выборка ?
27 — 28.06.12 — 12:51
(26) я вам что, калькулятор?
объединяем, получаем
1-6
9-20
45-46
5+11+1=17
28 — 28.06.12 — 12:53
(27) зачем калькулятор, у тебя же готовый запрос есть, подставляй))
29 — 28.06.12 — 12:54
Мне думается, что существует готовач формула для такой задачи и в запросе надо не изобретать велосипед, а воспользоваться ею
30 — 28.06.12 — 12:55
(28) дык в неудобном виде он данные дал ))
(29) выдай нам ее
31 — 28.06.12 — 12:56
(30) а последовательность отрезков в исходной таблице произвольная?
32 — 28.06.12 — 12:57
(31) а это на что может повлиять?
работая с таблицами БД надо абстрагироваться от понятия порядок
33 — 28.06.12 — 13:00
внутреннее соединение, не?
34 — 28.06.12 — 13:04
//
ВЫБРАТЬ
1 КАК Поле1,
5 КАК Поле2
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
5
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
3,
6
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
8,
10
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
мТаб.Поле1,
мТаб.Поле2 — мТаб.Поле1 КАК Раз,
мТаб.Поле2
ПОМЕСТИТЬ мТаб2
ИЗ
мТаб КАК мТаб
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
мТаб2.Поле1 КАК Поле1,
мТаб2.Раз КАК Раз,
мТаб2.Поле2 КАК Поле2
ПОМЕСТИТЬ мДва
ИЗ
мТаб2 КАК мТаб2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ мТаб2 КАК мТаб21
ПО мТаб2.Поле1 >= мТаб21.Поле1
И мТаб2.Поле2 > мТаб21.Поле2
СГРУППИРОВАТЬ ПО
мТаб2.Поле1,
мТаб2.Раз,
мТаб2.Поле2
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
МИНИМУМ(мТаб2.Поле1) КАК Поле1,
ВложенныйЗапрос.Поле1 КАК Поле11
ПОМЕСТИТЬ мОдин
ИЗ
мТаб2 КАК мТаб2,
(ВЫБРАТЬ ПЕРВЫЕ 1
мДва.Поле1 КАК Поле1
ИЗ
мДва КАК мДва) КАК ВложенныйЗапрос
СГРУППИРОВАТЬ ПО
ВложенныйЗапрос.Поле1
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
мрез2.Поле1,
мрез2.Раз КАК Раз,
мрез2.Поле2
ИЗ
(ВЫБРАТЬ
мОдин.Поле1 КАК Поле1,
мОдин.Поле11 — мОдин.Поле1 КАК Раз,
мОдин.Поле11 КАК Поле2
ИЗ
мОдин КАК мОдин
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
мДва.Поле1,
мДва.Раз,
мДва.Поле2
ИЗ
мДва КАК мДва) КАК мрез2
ИТОГИ
СУММА(Раз)
ПО
ОБЩИЕ
35 — 28.06.12 — 13:09
(34)пример не удачный, не работает
36 — 28.06.12 — 13:11
Создаем Таблицу (ТаблицаКоординат) количеством столбцов макс(Б)
Заполняем ее данными из исходной таблицы по принципу:
1 строка исходной Т -> 1 строка ТаблицыКоординат
в столбцы ТаблицыКоординат пишем 0 или 1 в зависимости от того попадает номер этого столбца в отрезок А-Б
Пример:
Исходня Т
А = 2 Б = 5
А = 3 Б = 4
ТаблицаКоординат:
0|1|1|1|1
0|0|1|1|0
ТаблицаКоординат сворачиваем, считаем количество столбцов где значение не равно 0.
ps во блин загнул -)
37 — 28.06.12 — 13:12
ВЫБРАТЬ
1 КАК Поле1,
5 КАК Поле2
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
5
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
3,
6
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
8,
10
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
8,
14
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
мТаб.Поле1,
мТаб.Поле2 — мТаб.Поле1 КАК Раз,
мТаб.Поле2
ПОМЕСТИТЬ мТаб2
ИЗ
мТаб КАК мТаб
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
мТаб2.Поле1 КАК Поле1,
мТаб2.Раз КАК Раз,
мТаб2.Поле2 КАК Поле2
ПОМЕСТИТЬ мДва
ИЗ
мТаб2 КАК мТаб2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ мТаб2 КАК мТаб21
ПО мТаб2.Поле1 >= мТаб21.Поле1
И мТаб2.Поле2 > мТаб21.Поле2
И мТаб2.Поле1 < мТаб21.Поле2
СГРУППИРОВАТЬ ПО
мТаб2.Поле1,
мТаб2.Раз,
мТаб2.Поле2
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
МИНИМУМ(мТаб2.Поле1) КАК Поле1,
ВложенныйЗапрос.Поле1 КАК Поле11
ПОМЕСТИТЬ мОдин
ИЗ
мТаб2 КАК мТаб2,
(ВЫБРАТЬ ПЕРВЫЕ 1
мДва.Поле1 КАК Поле1
ИЗ
мДва КАК мДва) КАК ВложенныйЗапрос
СГРУППИРОВАТЬ ПО
ВложенныйЗапрос.Поле1
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
мрез2.Поле1,
мрез2.Раз КАК Раз,
мрез2.Поле2
ИЗ
(ВЫБРАТЬ
мОдин.Поле1 КАК Поле1,
мОдин.Поле11 — мОдин.Поле1 КАК Раз,
мОдин.Поле11 КАК Поле2
ИЗ
мОдин КАК мОдин
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
мДва.Поле1,
мДва.Раз,
мДва.Поле2
ИЗ
мДва КАК мДва) КАК мрез2
ИТОГИ
СУММА(Раз)
ПО
ОБЩИЕ
38 — 28.06.12 — 13:12
(37) а так работает
39 — 28.06.12 — 13:13
(38) да вроде и (34) работало
40 — 28.06.12 — 13:14
(39) пример не удачный, (37) тоже не работает, опять же пример не удачный
41 — 28.06.12 — 13:15
(40) что значит «пример неудачный»? запрос должен работать на любых данных
42 — 28.06.12 — 13:16
вот в том то и дела беру другие данные и уже не работает
43 — 28.06.12 — 13:17
(41) сколько у тебя строк в запросе?
44 — 28.06.12 — 13:17
(42) + не считая формирования входных данных
45 — 28.06.12 — 13:18
боюсь, что если такое задание использовать в качестве теста при приеме на работу, то это сразу от 130 ))
46 — 28.06.12 — 13:18
(44) 52 вроде, с форматированием конструктором
47 — 28.06.12 — 13:19
(45) это же хорошо
48 — 28.06.12 — 13:20
у ненавижу работы нету, сам ставит себе задачи, решает их , а потом не дает работать остальным))
49 — 28.06.12 — 13:21
(48) завидовать не хорошо
50 — 28.06.12 — 13:22
я же белой завистью..)
51 — 28.06.12 — 13:22
(46) задай на вход таблицу
-5 -3
-10 -12
0 0
Работает?
52 — 28.06.12 — 13:23
А, пардон, 0-0 убрать, не подходит по условию
53 — 28.06.12 — 13:23
(18) ты мне мозг сломал )
54 — 28.06.12 — 13:24
(52) -10 -12 тоже нельзя
55 — 28.06.12 — 13:27
(54) хитер
56 — 28.06.12 — 13:37
фактически нужно посчитать количество «разрывов»
57 — 28.06.12 — 13:39
лень читать всю ветку, задача ещё актуальна?
58 — 28.06.12 — 13:40
59 — 28.06.12 — 13:41
(56) количество разрывов ничего не даст
(57) ждем твоего решения
60 — 28.06.12 — 13:42
(59) Количество и длина разрывов )
61 — 28.06.12 — 13:42
(59) 2. гы. да я только в ветку забрёл. щас буду думать.
на всякий: отрезки на положительной «части» оси, или могут быть и в минусе?
62 — 28.06.12 — 13:44
плохо что в полях выборки незя использовать подзапросы (
63 — 28.06.12 — 13:46
(61) это несущественно
64 — 28.06.12 — 13:55
Рекурсию можно использовать?
65 — 28.06.12 — 13:58
(64) в запросе? попробуй))
+(46) нашел проще — 30 строк
66 — 28.06.12 — 14:02
ВЫБРАТЬ
1 КАК А,
4 КАК Б
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
6
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
9,
12
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
10,
20
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
45,
46
;
////////////////////////////////////////////////////////////////////////////////
Выбрать
Минимум(Т1.А),
Т2.Б
Поместить ПредварительныеОтрезки
из мТаб как т1
Левое соединение мТаб как Т2
по т1.А < т2.А И т1.Б > т2.А
ГДЕ НЕ Т2.Б Есть NULL
Сгруппировать ПО
Т2.Б
;
Выбрать
Т1.А,
Т3.Б
Поместить ВозможныеИзмененияМаксимальнойГраницы
из мТаб как т1
Левое соединение мТаб как Т2
по т1.А < т2.А И т1.Б > т2.А
Левое Соединение мТаб как Т3
По Т1.А = Т3.А
ГДЕ
Т2.Б Есть NULL
;
Выбрать РАЗЛИЧНЫЕ
Т1.А,
ЕстьNULL(Т2.Б, Т1.Б) как Б
Поместить ОтрезкиСВнутреннимиОтрезками
Из
ПредварительныеОтрезки как Т1
Левое соединение ВозможныеИзмененияМаксимальнойГраницы как Т2
По Т1.А < Т2.А И Т2.А < Т1.Б И Т2.Б > Т1.Б
;
Выбрать
Т1.А,
Т1.Б
Поместить ОтрезкиБезВнутреннихОтрезков
Из ВозможныеИзмененияМаксимальнойГраницы как Т1
Левое соединение ОтрезкиСВнутреннимиОтрезками как Т2
ПО Т1.Б = Т2.Б
ГДЕ Т2.А Есть NULL
;
Выбрать
Сумма(Т1.Б — Т1.А) как Итог
Из
(Выбрать
Т1.А,
Т1.Б
ИЗ ОтрезкиСВнутреннимиОтрезками как Т1
Объединить все
Выбрать
Т1.А,
Т1.Б
ИЗ ОтрезкиБезВнутреннихОтрезков как Т1) как Т1
67 — 28.06.12 — 14:03
(66) вроде без промашек работает )
68 — 28.06.12 — 14:08
ВЫБРАТЬ
1 КАК А,
5 КАК Б
ПОМЕСТИТЬ _ВТ_АБ_
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
3,
7
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
10,
12
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
16,
18
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
_ВТ_АБ_.А,
ЕСТЬNULL(_ВТ_АБ_2.Б, _ВТ_АБ_.Б) КАК Б
ПОМЕСТИТЬ _ВТ_АБ_МаксБ
ИЗ
_ВТ_АБ_ КАК _ВТ_АБ_
ЛЕВОЕ СОЕДИНЕНИЕ _ВТ_АБ_ КАК _ВТ_АБ_2
ПО ((НЕ _ВТ_АБ_.А = _ВТ_АБ_2.А))
И (_ВТ_АБ_2.А < _ВТ_АБ_.Б)
И _ВТ_АБ_.А < _ВТ_АБ_2.Б
И _ВТ_АБ_.Б < _ВТ_АБ_2.Б
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
МИНИМУМ(_ВТ_АБ_МаксБ.А) КАК А,
_ВТ_АБ_МаксБ.Б
ПОМЕСТИТЬ _ВТ_Результат
ИЗ
_ВТ_АБ_МаксБ КАК _ВТ_АБ_МаксБ
СГРУППИРОВАТЬ ПО
_ВТ_АБ_МаксБ.Б
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
СУММА(_ВТ_Результат.Б - _ВТ_Результат.А) КАК Диапазон
ИЗ
_ВТ_Результат КАК _ВТ_Результат
вначале тестовые данные
69 — 28.06.12 — 14:09
(67) нифига
ВЫБРАТЬ
1 КАК А,
18 КАК Б
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
5,
8
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
7,
9
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
12,
15
;
70 — 28.06.12 — 14:09
+68 наверное не все учел, а то строк мало получается + мой запрос еще можно укоротить ))
71 — 28.06.12 — 14:10
+70 а, блин, мой только с одним пересечением работает, кажись (((
72 — 28.06.12 — 14:11
+71 на данных из (69) выдает 21 ((
73 — 28.06.12 — 14:12
(69) согласен)
74 — 28.06.12 — 14:15
+72 диапазон 5-9 левый цепляется ((
75 — 28.06.12 — 14:16
+74 надо отслеживать многократное пересечение
вот тут голова опухает — типа сколько же соединений надо
76 — 28.06.12 — 14:20
хорошо бы в таких веточках писать сразу код для mssms, готовящий таблицы с исходными данными. как принято на sql.ru например.
77 — 28.06.12 — 14:28
ВЫБРАТЬ
1 КАК А,
4 КАК Б
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
6
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
9,
12
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
10,
20
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
45,
46
;
////////////////////////////////////////////////////////////////////////////////
Выбрать
Минимум(Т1.А),
Т2.Б
Поместить ПредварительныеОтрезки
из мТаб как т1
Левое соединение мТаб как Т2
по т1.А < т2.А И т1.Б > т2.А
ГДЕ НЕ Т2.Б Есть NULL
Сгруппировать ПО
Т2.Б
;
Выбрать
Т1.А,
Т3.Б
Поместить ВозможныеИзмененияМаксимальнойГраницы
из мТаб как т1
Левое соединение мТаб как Т2
по т1.А < т2.А И т1.Б > т2.А
Левое Соединение мТаб как Т3
По Т1.А = Т3.А
ГДЕ
Т2.Б Есть NULL
Объединить все
Выбрать Различные
Т1.А,
Т2.Б
ИЗ ПредварительныеОтрезки как Т1
Внутреннее соединение мТаб как Т2
ПО т1.А = т2.А и Т1.Б < Т2.Б
;
Выбрать РАЗЛИЧНЫЕ
Т1.А,
Максимум(ЕстьNULL(Т2.Б, Т1.Б)) как Б
Поместить ОтрезкиСВнутреннимиОтрезками
Из
ПредварительныеОтрезки как Т1
Левое соединение ВозможныеИзмененияМаксимальнойГраницы как Т2
По Т1.А <= Т2.А И Т2.А < Т1.Б И Т2.Б > Т1.Б
Сгруппировать ПО т1.А
;
Выбрать
Т1.А,
Т1.Б
Поместить ОтрезкиБезВнутреннихОтрезков
Из ВозможныеИзмененияМаксимальнойГраницы как Т1
Левое соединение ОтрезкиСВнутреннимиОтрезками как Т2
ПО Т1.Б = Т2.Б
ГДЕ Т2.А Есть NULL
;
Выбрать
Сумма(Т1.Б — Т1.А) как Итог
Из
(Выбрать
Т1.А,
Т1.Б
ИЗ ОтрезкиСВнутреннимиОтрезками как Т1
Объединить все
Выбрать
Т1.А,
Т1.Б
ИЗ ОтрезкиБезВнутреннихОтрезков как Т1
Левое Соединение ОтрезкиСВнутреннимиОтрезками как Т2
По Т1.А> Т2.А И Т1.А < Т2.Б
ГДЕ Т2.А Есть NULL) как Т1
78 — 28.06.12 — 14:28
(77) теперь должно работать ))
79 — 28.06.12 — 14:30
+(78) не, не работает ) ща )
80 — 28.06.12 — 14:30
ВЫБРАТЬ
СУММА(ВТ.Б — ВТ.А) КАК ДлинаНепересекающихся
ПОМЕСТИТЬ НеПересекающиеся
ИЗ
ВТ КАК ВТ
ЛЕВОЕ СОЕДИНЕНИЕ ВТ КАК ВТ1
ПО (ВТ.А < ВТ1.Б
И ВТ.А > ВТ1.А
ИЛИ ВТ.Б < ВТ1.Б
И ВТ.Б > ВТ1.А)
ГДЕ
ВТ1.Ссылка ЕСТЬ NULL
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
МИНИМУМ(ВТ.А) КАК А,
МАКСИМУМ(ВТ.Б) КАК Б
ПОМЕСТИТЬ Пересекающиеся
ИЗ
ВТ КАК ВТ
ЛЕВОЕ СОЕДИНЕНИЕ ВТ КАК ВТ1
ПО (ВТ.А < ВТ1.Б
И ВТ.А > ВТ1.А
ИЛИ ВТ.Б < ВТ1.Б
И ВТ.Б > ВТ1.А)
ГДЕ
НЕ ВТ1.Ссылка ЕСТЬ NULL
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
НеПересекающиеся.ДлинаНепересекающихся + Пересекающиеся.Б — Пересекающиеся.А
ИЗ
НеПересекающиеся КАК НеПересекающиеся,
Пересекающиеся КАК Пересекающиеся
81 — 28.06.12 — 14:32
вот
ВЫБРАТЬ
1 КАК А,
20 КАК Б
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
6
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
9,
12
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
10,
19
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
18,
46
;
////////////////////////////////////////////////////////////////////////////////
Выбрать
Минимум(Т1.А),
Т2.Б
Поместить ПредварительныеОтрезки
из мТаб как т1
Левое соединение мТаб как Т2
по т1.А < т2.А И т1.Б > т2.А
ГДЕ НЕ Т2.Б Есть NULL
Сгруппировать ПО
Т2.Б
;
Выбрать
Т1.А,
Т3.Б
Поместить ВозможныеИзмененияМаксимальнойГраницы
из мТаб как т1
Левое соединение мТаб как Т2
по т1.А < т2.А И т1.Б > т2.А
Левое Соединение мТаб как Т3
По Т1.А = Т3.А
ГДЕ
Т2.Б Есть NULL
Объединить все
Выбрать Различные
Т1.А,
Т2.Б
ИЗ ПредварительныеОтрезки как Т1
Внутреннее соединение мТаб как Т2
ПО т1.А = т2.А и Т1.Б < Т2.Б
;
Выбрать РАЗЛИЧНЫЕ
Т1.А,
Максимум(ЕстьNULL(Т2.Б, Т1.Б)) как Б
Поместить ОтрезкиСВнутреннимиОтрезками
Из
ПредварительныеОтрезки как Т1
Левое соединение ВозможныеИзмененияМаксимальнойГраницы как Т2
По Т1.А <= Т2.А И Т2.А < Т1.Б И Т2.Б > Т1.Б
Сгруппировать ПО т1.А
;
Выбрать
Т1.А,
Т1.Б
Поместить ОтрезкиБезВнутреннихОтрезков
Из ВозможныеИзмененияМаксимальнойГраницы как Т1
Левое соединение ОтрезкиСВнутреннимиОтрезками как Т2
ПО Т1.Б = Т2.Б
ГДЕ Т2.А Есть NULL
;
Выбрать
Сумма(Т1.Б — Т1.А) как Итог
Из
(Выбрать
Т1.А,
Т1.Б
ИЗ ОтрезкиСВнутреннимиОтрезками как Т1
Объединить все
Выбрать
Т1.А,
Т1.Б
ИЗ ОтрезкиБезВнутреннихОтрезков как Т1
Левое Соединение ОтрезкиСВнутреннимиОтрезками как Т2
По Т1.А>= Т2.А И Т1.А <= Т2.Б
ГДЕ Т2.А Есть NULL) как Т1
82 — 28.06.12 — 14:33
(80) > ВТ1.Ссылка o_O
83 — 28.06.12 — 14:34
все, надоело думать )))
84 — 28.06.12 — 14:34
(80) а откуда ссылка взялась?)
85 — 28.06.12 — 14:34
в моем алгоритме где то небольшой косяк )))
86 — 28.06.12 — 14:35
(84) не работает
ВЫБРАТЬ
1 КАК А,
2 КАК Б
ПОМЕСТИТЬ мТаб
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
1,
3
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
3
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
1,
4
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
3,
5
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
4,
10
;
87 — 28.06.12 — 14:36
(81) Если подставить в конце
ВЫБРАТЬ
20,
46
то выдает 19 :))))
88 — 28.06.12 — 14:36
(76) ок, вот заготовочка
ВЫБРАТЬ
1 КАК А,
4 КАК Б
ПОМЕСТИТЬ Т
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
5
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
7,
9
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
9,
10
;
89 — 28.06.12 — 14:38
(87) гм, не предусмотрел, что в А и Б в разных отрезках будет одинаковое число )
ну эт фигня )
90 — 28.06.12 — 14:39
(88) проверь свой данными (86). работает?
91 — 28.06.12 — 14:40
(90) выдает 9
92 — 28.06.12 — 14:40
93 — 28.06.12 — 14:42
а у меня — 7 (
94 — 28.06.12 — 14:43
ВЫБРАТЬ
СУММА(ВТ.Б — ВТ.А) КАК ДлинаНепересекающихся
ПОМЕСТИТЬ НеПересекающиеся
ИЗ
ВТ КАК ВТ
ЛЕВОЕ СОЕДИНЕНИЕ ВТ КАК ВТ1
ПО (ВТ.А < ВТ1.Б
И ВТ.А > ВТ1.А
ИЛИ ВТ.Б < ВТ1.Б
И ВТ.Б > ВТ1.А)
ГДЕ
ВТ1.А ЕСТЬ NULL
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
МИНИМУМ(ВТ.А) КАК А,
МАКСИМУМ(ВТ.Б) КАК Б
ПОМЕСТИТЬ Пересекающиеся
ИЗ
ВТ КАК ВТ
ЛЕВОЕ СОЕДИНЕНИЕ ВТ КАК ВТ1
ПО (ВТ.А < ВТ1.Б
И ВТ.А > ВТ1.А
ИЛИ ВТ.Б < ВТ1.Б
И ВТ.Б > ВТ1.А)
ГДЕ
НЕ ВТ1.А ЕСТЬ NULL
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
НеПересекающиеся.ДлинаНепересекающихся + Пересекающиеся.Б — Пересекающиеся.А
ИЗ
НеПересекающиеся КАК НеПересекающиеся,
Пересекающиеся КАК Пересекающиеся
95 — 28.06.12 — 14:44
(91)
ВЫБРАТЬ
1 КАК А,
4 КАК Б
ПОМЕСТИТЬ Т
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
5
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
2,
9
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
9,
10
с такими данными что выдает?
96 — 28.06.12 — 14:45
+(95) у меня херню ))
97 — 28.06.12 — 14:45
(94) да, решение должно быть таким. красивым
98 — 28.06.12 — 14:45
(94) на (86) длига null :))
99 — 28.06.12 — 14:45
100 — 28.06.12 — 14:45
*длина