Обозначение кнопок мыши в таблице:
| ⠁ | ⠈ | ⠃ | ◠ |
| Левая кнопка | Правая кнопка | Двойной клик | Колесико |
 — Имеется дополнительная информация во всплывающей подсказке
— Имеется дополнительная информация во всплывающей подсказке
Управлять столбцами таблицы можно с помощью горячих клавиш:
Alt(1..5) — Скрыть/показать столбец 1 — 5; Alt0 — Показать все столбцы
Alt(1..5) — Изменить направление сортировки в столбце 1 — 5
Ctrl⠁ — Добавить сочетание в Редактор горячих клавиш
Подробнее об условных обозначениях и командах — в разделе О проекте
Работа по распознаванию изображений состоит из следующих этапов:
- Получить отсканированные изображения (сканы).
- Открыть их в OCR-программе (FineReader).
- Сделать разметку страниц на блоки. То есть, разбить страницу на области, в каждой из которых будет находиться или текст, или рисунки, или таблицы, или другое однородное содержимое.
- Собственно распознавание.
- Вычитка распознанного, сверка полученного текста и исходных сканов.
- Сохранение полученных результатов в одном из документальных форматов (DOC, RTF, PDF, HTML и т. д.).
При распознавании текстов возможны два варианта: или вы сканируете материал сами, или работаете с уже отсканированным текстом.
В первом случае этапы «Получить изображения» и «Открыть изображения» объединяются в одно — FineReader полученные сканы сразу же открывает в своем пакете. Во втором случае этап «Получить изображения» уже пройден, надо только открыть их в программе.
Рассмотрим оба варианта по очереди.
Отсканировать текст в FineReader
Сканирование запускается через «Файл → Сканировать страницы» или кнопкой меню «Сканировать», или Ctrl-K.
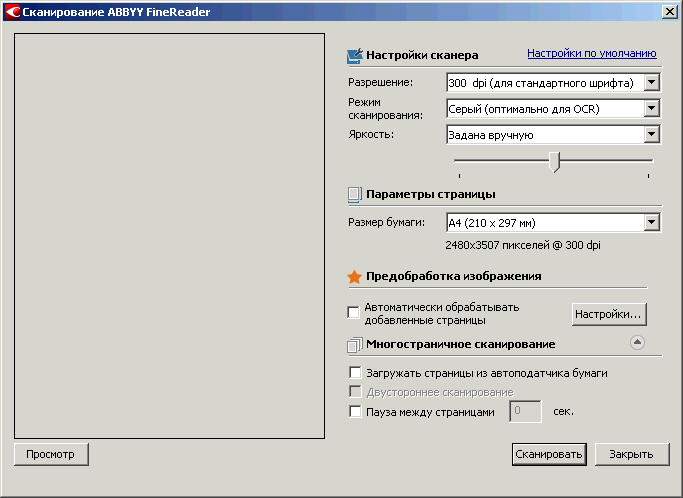
Рис. 1 Интерфейс сканирования
Однако, прежде чем начинать сканировать, неплохо бы разобраться, как получить сканы, наиболее оптимальные для распознавания. А для этого понять, чем «хороший» (с точки зрения FineReader) скан отличается от «не очень хорошего».
Для качественного распознавания программе требуется три вещи. Во-первых, возможность надежно отличить текст и иллюстрации от фона страницы. Во-вторых, чтобы буквы, цифры и прочее содержимое были четкими и разборчивыми, чтобы не возникало ситуаций «здесь и человеческий глаз не всегда поймет, что именно напечатано». В-третьих, строки текста на скане должны идти так же ровно, как они напечатаны на странице книги, без перекосов и искажений. Есть еще и другие требования к качественному скану, но эти можно считать ключевыми.
1. Для надежного различения «здесь текст, а здесь фон страницы» требуется, чтобы переход между тем и другим был резким, не размытым. Вот образцы страниц с плохой и с хорошей четкостью. Во первом случае, естественно, будет распознаваться хуже, с большим количеством ошибок.

Рис. 2. Размытые границы литер

Рис. 3. Четкие границы литер
Обычная причина размытых границ «текст-фон» — сканирование с нарушенной фокусировкой, то, что обычно называют «не в фокусе». Поэтому перед началом работы желательно проверить ваш сканер на этот момент.
Другая причина, которая может помешать различению текста и фона — слишком «плотный» фон страницы. В норме он должен быть или чисто белым, или белым с небольшой примесью какого-нибудь цвета. Если сканируются книги старых изданий, где бумага часто бывает пожелтевшей, то фон тоже может быть желтоватый (но умеренно).
Если же фон выглядит заметно перетемненным, то такие страницы опять же будут распознаваться хуже.
То, какой вид будет у фона, зависит от выставленной яркости сканирования. Ее можно регулировать через движок «Яркость». Для начала имеет смысл поставить 50%, проверить, что при этом будет, при необходимости поправить.
2. Разборчивость литер текста в основном зависит от яркости и от разрешения сканирования.
Если яркость слишком велика, линии букв будут будут рваными, они станут как бы рассыпаться на отдельные кусочки. Если яркость мала, то детали букв начинают сливаться между собой, возникают бесформенные пятна. И то, и другое для программ распознавания не очень-то съедобная «пища».
Яркость здесь настраивается так же, как и в предыдущем случае — ставим для начала в интерфейсе сканирования 50%, а дальше по ситуации.
Рис. 4. Страница со слишком большой яркостью

Рис. 5. Страница со слишком маленькой яркостью (перетемненный фон страницы)

Рис. 6. А вот эта же страница, но в нормальном виде
Разрешение сканирования определяет сколько пикселей в скане будет приходиться на каждую букву. Если этих пикселей достаточно для отрисовки контура буквы, то проблем при распознавании не будет. Если же недостаточно, то буквы могут стать плохо различимыми даже для человеческого глаза, не говоря уже о программах распознавания.

Рис. 7. Здесь отсканировано на 100 точек
Рисунки 7-9 также можно считать примерами несколько перетемненного фона.

Рис. 8. То же самое, но на 200 точек

Рис. 9. То же самое, но на 400 точек
При выборе разрешения обычно руководствуются следующими правилами:
- 300 точек выбирается для книг массовых изданий (страницы заполненные текстом обычного размера, почти без рисунков);
- 400 точек выбирается для книг и журналов с заметным объемом текста небольшими кеглями (примечания, подписи под рисунками, таблицы, врезки мелким текстом);
- 600 точек выбирается для книг, напечатанных совсем мелкими кеглями (многие справочники и энциклопедии, книги-миниатюры). Или же с мелкодеталированными рисунками, например, гравюрами. Сюда же надо отнести многие книги издания 1990-х годов — тогда издатели экономили на бумаге и часто печатали совсем крохотульными буквами.
Интерфейс сканирования в FineReader позволяет выбирать только 300 точек или 600 (строка «Разрешение»). Поэтому если у вас много материала, который желательно делать на 400 точек, то лучше сканировать не из-под FineReader, а из программы, идущей вместе со сканером.
Или же в настройках FineReader переключиться с собственного интерфейса программы на TWAIN-интерфейс вашего сканера («Сервис → Настройки → закладка «Сканировать/Открыть» → щелкнуть внизу по «Использовать интерфейс сканера»). Тогда вы сможете сканировать из FineReader, но работать будете в интерфейсе сканера (обычно там больший объем настроек и функций).
3. Ровные, аккуратно выглядящие строчки текста в основном обеспечиваются предобработкой изображения («пред-» в данном случае означает «выполняемое после сканирования, но перед распознаванием»). После правильно сделанной предобработки содержимое страниц будет распознаваться с более высоким качеством.
FineReader для этого имеет достаточно богатый набор функций, который можно увидеть в настройках программы, на закладке «Сканировать/Открыть». Также это окошко можно вызвать через кнопку «Настройки» в окошке интерфейса сканирования.
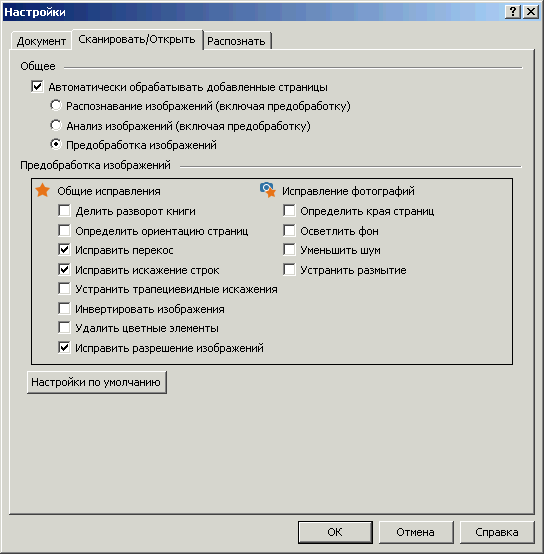
Рис. 10. Настройки предобработки
«Делить разворот книги» надо выбирать, когда книга сканировалась не постранично, а разворотами. Тогда для распознавания они будут нарезаны постранично.
«Определять ориентацию страниц» используется в том случае, если книга сканировалась повернутой набок. Тогда она будет развернута в свое нормальное положение. Но если в книге есть страницы, которые напечатаны повернутыми на 90 градусов относительно основной массы, то галочку здесь лучше снять. Иначе при выводе распознанного в PDF вы можете получить часть страниц в «книжной» ориентации, а часть — в «альбомной». Повернуть нужные страницы в этом случае лучше вручную, во встроенном редакторе изображений
«Исправить перекосы» устраняет перекосы страниц. Настройка однозначно необходимая, но надо иметь в виду, что PDF «Текст под изображением страницы», полученный из таких сканов, будет иметь не совсем аккуратный вид — сероватые клинья по краям страницы (там где делался поворот).
«Исправить искажения строк» выравнивает изгибы строк, которые при сканировании часто образуются около переплета (их еще называют «усы»).

Рис. 11. Пример страницы с изгибами строк
«Устранить трапециевидные искажения» исправляет деформации страниц, появляющиеся если книга не очень плотно прижата к стеклу сканера.
«Инвертировать изображения» необходима, если в сканируемом материале много текста «светлые буквы на темном фоне» и вы хотите преобразовать их в обычное «темные буквы на светлом фоне».
«Удалить цветные элементы» полезно, если на странице вида «черные буквы на белом фоне» надо убрать разные ненужности, вроде пометок ручкой на полях, подписей и печатей (офисная документация), а то и просто пятен. Но если на этой же странице есть какие-то сделанные в цвете «нужности» — графики, диаграммы или фотографии, то галочку ставить нельзя. Иначе будут удалены и они.
«Исправить разрешение изображений» — пункт, требующий более развернутого пояснения, чем предыдущие. Дело в том, что процесс распознавания в FineReader очень чувствителен к тому, какое разрешение выставлено в свойствах данного изображения. От этого существенно зависит то, насколько точно будут определены кегли букв текста, межбуквенные и межстрочные расстояния и прочее подобное. Поэтому галочка здесь необходима. Кроме того, не стоит удивляться, если по ходу распознавания вы будете постоянно получать сообщения FineReader «на странице такой-то неправильно выставлено разрешение и хорошо бы его исправить».
Кроме настроек предобработки на закладке «Сканировать/Открыть» есть блок настроек «Общее». Здесь задается набор основных действий, которые будут выполнены над открываемыми страницами. Варианты таких действий могут быть следующие:
- просто открыть отсканированные изображения, ничего с ними при этом не делая. Для этого надо снять галочку «Автоматически обрабатывать добавленные страницы».
Подобное имеет смысл только в том случае, если у вас сканы настолько высокого качества, что их уже ничем особенно не улучшишь. Можно сразу отправлять на распознавание. Бывает конечно и такое, но гораздо реже, чем хотелось бы :-), поэтому галочку лучше оставить. - открыть изображения, выполнить предобработку, но до вашей команды пока больше ничего не делать. Для этого надо выбрать пункт «Предобработка изображений».
Так обычно делают если надо не запускать сразу распознавание, а сначала посмотреть, что получилось в результате предобработки, насколько она хорошо отработала по данному набору изображений. - открыть изображения, выполнить предобработку, выполнить разметку на блоки, распознавание пока не запускать. Для этого надо выбрать пункт «Анализ изображений (включая предобработку)».
Наиболее часто выбираемый вариант. Сканы у вас вполне приличного качества, то, что с ними сделает предобработка вы хорошо представляете, проверять после нее нет необходимости. Значит соединяем в одно три описанных выше этапа работы с изображениями и начинаем смотреть насколько хорошо сделана разметка. - все этапы распознавания проходят автоматически, без какого-либо промежуточного контроля. Вы сразу получаете готовый результат и начинаете его вычитывать. Для этого надо выбрать пункт «Распознавание изображений (включая предобработку)». Так имеет смысл делать только если у вас сканы хорошего качества и с очень простым внешним видом — например сплошной текст на одном языке и ничего более. Во всех остальных случаях лучше выбирать вариант 2 или 3. Особенно если у вас страницы со сложным форматированием, таблицами, диаграммами, рисунками и т. д.

Рис. 12. Пример страницы со сложной версткой

Рис. 13. Пример страницы со сложной версткой
Открыть изображения в FineReader
Это второй вариант работы с изображениями: не сканировать их самому, а получить в уже готовом виде и открыть в FineReader. Делается через кнопку «Открыть» в меню основного окна или через «Файл → Открыть PDF или изображение», или через Ctrl-O.
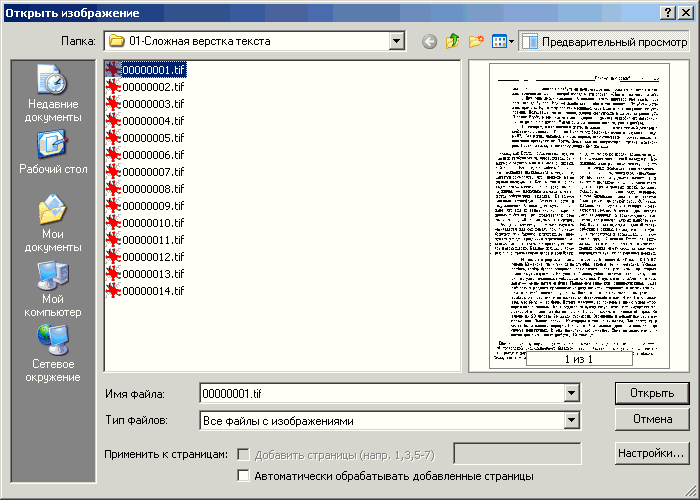
Рис. 14. Окно «Открыть изображение»
В открывшемся окошке Проводника выбираете изображения, задаёте необходимые настройки (кнопка «Настройки») и нажимаете «Открыть». Настройки здесь используются те же самые, что описаны для сканирования, работать с ними надо так же.
Когда страницы открыты в FineReader, то пакет по умолчанию создается безымянным («Документ без имени») и хранится в TMP-папке, только в пределах текущего сеанса работы. Чтобы случайно не потерять результаты работы, рекомендуется сразу же после создания сохранить пакет под каким-нибудь постоянным именем («Файл → Сохранить документ FineReader»).
Разметка страниц на блоки
После того, как вы открыли сканы, надо выполнить разметку страниц на блоки. Это делается через «Документ → Анализ документа» или через Ctrl-Shift-E.
Основных рабочих целей у разметки две.
Во-первых, отделить то, что на странице есть текст, от того, что текстом не является. «Текстом» в данном случае считается все, что FineReader в состоянии распознать. «Не-текстом» соответственно считается все, что он распознать не в состоянии. В основном это иллюстративная часть страницы — рисунки, чертежи, графики, диаграммы и прочее подобное. Формулы, рукописные записи и ноты с этой точки зрения тоже считаются не-текстом — распознавать их FineReader пока не умеет. А значит при разметке их надо пометить, как «картинка».
Во-вторых, еще надо то, что есть текст, разметить по категориям — просто текст, таблицы, примечания (сноски), колонтитулы, оглавления и тому подобное. Чтобы потом, когда вы будете читать распознанное в текстовом редакторе, все эти элементы выглядели бы именно так, как вы и привыкли (были бы отформатированы соответствующим образом).
Размеченная страница может иметь примерно следующий вид:

Рис. 15. Окно «Изображение» с размеченной страницей
Теперь надо просмотреть разметку, сделанную программой на каждой из страниц и при необходимости поправить ее.
Погрешности разметки обычно бывают следующих видов.
1. Какая-то часть содержимого страницы (текст, рисунок и т. д.) выделена правильно в смысле границ области, но ей присвоено не то содержимое. Например, фрагмент текста размечен, как рисунок или наоборот.
В этом случае надо щелкнуть мышью по такой области, открыть контекстное меню, выбрать в нем «Изменить тип области», в открывшейся подменюшке выбрать требуемый тип («Текст», «Таблица», «Картинка», «Фоновая картинка», «Штрих-код»).

Рис. 16. Контекстное меню «Изменить тип области»
Быстро посмотреть где какая область можно по цвету рамок. «Текст» выделяется рамками темно-зеленого цвета, «Таблица» — синего, «Картинка» — светло-красного, «Фоновая картинка» — темно-красного, «Штрих-код» — светло-зеленого.
2. В смысле содержимого область выделена правильно, но в смысле размеров (границ) выделено не все, что в данном случае требовалось. Или же наоборот — попал кусок от соседней области с другим содержимым.

Рис. 17. Страница с некорректно сделанной разметкой
К верхней области «картинка» прихвачены окружающие ее подписи (должны быть размечены, как «текст»).
В нижнюю область «картинка» при разметке не попала часть изображения.
Чтобы это поправить, надо сначала щелкнуть в окошке «Изображение» по кнопке «Стрелка».
![]()
А затем щелкать по каждой неправильно размеченной области и перемещать ее границы. Примерно таким же образом, как обычно перемещают границы окошек открытых программ.
3. Какая-то часть содержимого страницы разметкой вообще пропущена, не попала ни в одну из созданных областей.
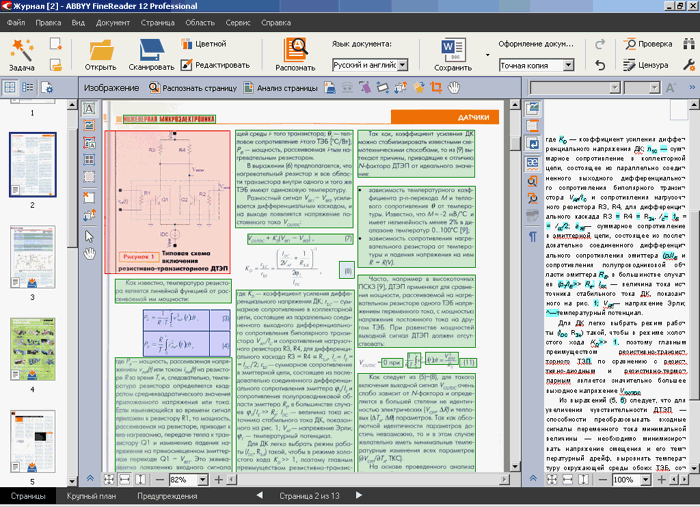
Рис. 18. Из разметки выпала формула (не попала ни в один из блоков)
Здесь надо будет создать на странице новую область (выделить пропущенную часть страницы рамкой), а затем присвоить созданной области нужный тип.
Для этого надо сначала щелкнуть в окошке «Изображение» по значку «Выделить зону распознавания»
![]()
После этого обвести нужный участок рамкой (как обычно в графическом редакторе выделяют часть рисунка) и наконец задать тип области. Последняя операция уже описана в пункте 1.
Если текстовая часть страницы вам нужна просто, как сплошной текст (что чаще всего и бывает), то этого вполне достаточно. Если же вы хотите, чтобы в Word различные элементы оформления распознанных страниц (примечания, колонтитулы) выглядели бы именно, как примечания и колонтитулы, то надо проверить и этот момент.
Регулируется он через контекстное меню. Щелкаете по нужной области «Текст» на проверяемой странице, в контекстном меню выбираете пункт «Назначение текста», внутри его подменюшки смотрите против какого пункта стоит галочка (обычно это «Автоопределение»). Если стоит не там, где надо, переключаетесь на нужный элемент.

Рис. 19. Контекстное меню «Назначение текста»
Распознавание
После того, как исправлены ошибки в разметке, можно запускать распознавание. Это делается через «Документ → Распознать документ» или через Ctrl-Shift-R. Перед этим не забудьте выставить язык распознавания и задать необходимые настройки.
Язык выставляется через окошко «Язык документа» в панели кнопок основного окна программы.
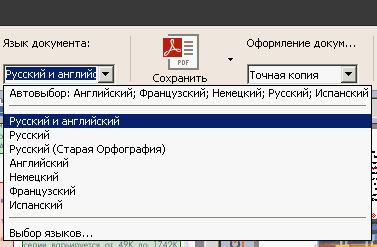
Рис. 20. Выбор языка через основное меню
Или в настройках («Сервис → Настройки → закладка «Документ»).
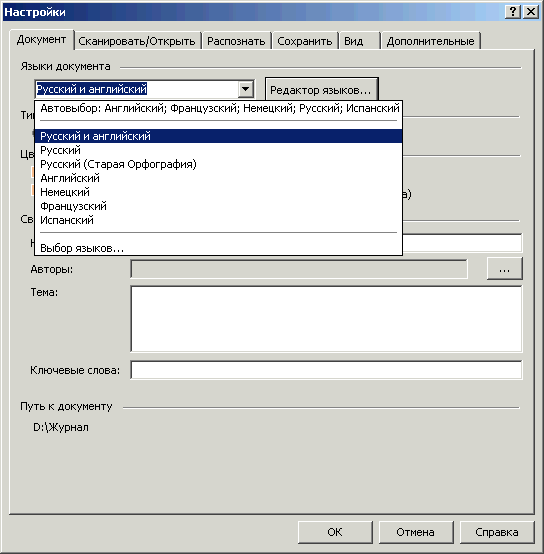
Рис. 21. Выбор языка через настройки FineReader
Если в открывшемся списке нет нужного вам языка, то нажмите «Выбор языков» в нижней части списка и в открывшемся окошке поставьте галочку против необходимого вам языка (набора языков). После этого он будет добавлен в список.
В настройках распознавания («Сервис → Настройки → закладка «Распознать») режим распознавания лучше оставить в умолчательном значении («Тщательное распознавание»). «Быстрое распознавание» имеет смысл ставить только если у вас что-то несложное по виду и с очень хорошим качеством сканирования. Например, отсканированная в черно-белом распечатка текстового документа без иллюстраций.
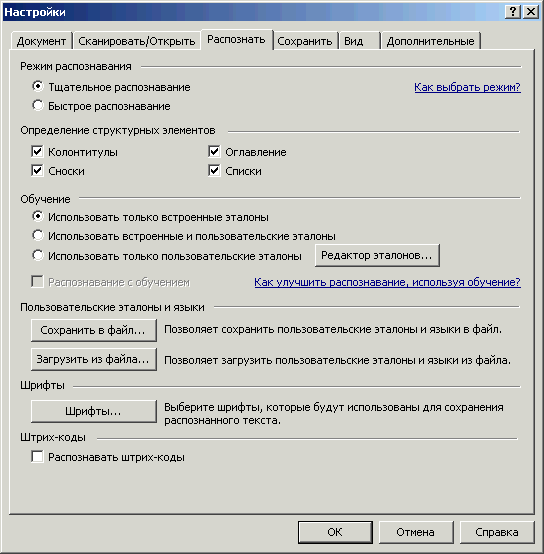
Рис. 22. Настройки, закладка «Распознать»
Из остальных настроек основное значение имеет группа «Определение структурных элементов». Здесь перечислены детали оформления страниц: сноски (примечания), колонтитулы, списки, оглавления. Когда против элемента поставлена галочка, он будет распознан и сохранен в DOC/RTF/DOCX не просто как часть текста на странице, а именно, как сноска, колонтитул, список или оглавление.
Только не забудьте при этом важный момент. Если вам приходится распознавать области с подобным содержимым, то одной галочки в настройках закладки «Распознать» может оказаться мало. Кроме этого еще требуется на этапе разметки правильно пометить эти области маркером «Назначение текста» из контекстного меню.
Вычитка
Вычитку распознанного текста в FineReader можно делать двумя способами. Или с помощью функции «Проверка», или обычным образом, просматривая страницы во встроенном редакторе FineReader. Через окно «Крупный план» сверяем со сканом, где есть ошибки — исправляем.
Функция «Проверка» запускается кнопкой в правом верхнем углу меню или через Ctrl-F7. Ее работа построена на том, что во время распознавания FineReader помечает символы и слова, которые были распознаны с недостаточно высоким уровнем достоверности. То есть, у программы по их поводу есть некоторое сомнение «может это действительно тот символ, который вам предъявлен, но может быть и что-то другое». Во время проверки такие сомнительные места по очереди показываются пользователю, чтобы он при необходимости их поправил.
Окно проверки устроено достаточно просто. В верхней его части показывается фрагмент страницы, в котором находится проверяемый символ. В нижней части выводится строка распознанного текста с этим символом, а также расположены несколько кнопок для несложного редактирования.
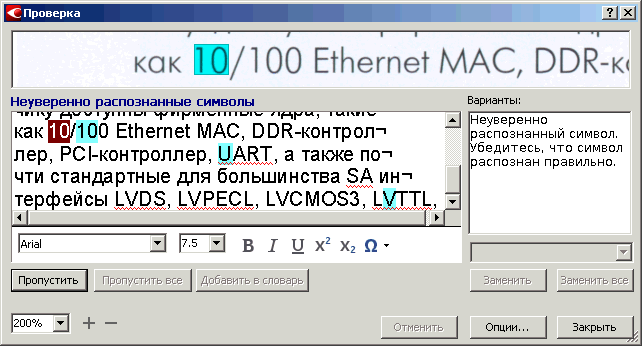
Рис. 23. Окно «Проверка»
Если все порядке, символ определен правильно, то нажимаем на «Пропустить». Если он определен неверно, то вводим правильное значение или с помощью клавиатуры, или если на клавиатуре такого нет, то с помощью кнопки «Вставить символ» (греческая буква «омега»). После чего нажимаем на «Подтвердить».
Аналогичным образом действуем если символ распознан верно, а вот его форматирование — неверно. Например в тексте книги в каком-то месте идет курсив, а распознался он, как обычный шрифт. Для переформатирования используем кнопки в нижней части окна.
Но возможности окна проверки все-таки достаточно ограничены. И по тому, какого размера кусочек страницы может быть показан в верхней части окна, и по возможностям редактирования, которые здесь имеются. Поэтому все перемещения по тексту, от одной точки проверки до другой, отслеживаются еще и в окнах «Текст» и «Крупный план». Все время, пока идет работа, курсоры в «Тексте» и «Крупном плане» перемещаются синхронно их положению в «Проверке».
Если в проверяемом фрагменте страницы (в его скане) вдруг потребовалось увидеть больше, чем несколько слов, показанных в «Проверке», то можно это сделать в «Крупном плане». Если для правки текущей ошибки требуются возможности редактора из «Текста», то можно на время переключиться в него (просто щелкнув по его окошку), сделать необходимую работу и вернуться обратно в «Проверку» (щелкнув по ее окошку). После возвращения в «Проверку», там будут отображены все изменения, которые вы сделали в «Тексте».

Рис. 24. Пример работы в одновременно открытых окнах «Проверка», «Текст» и «Крупный план»
Если вам окошко «Проверка» с его ограниченными возможностями не очень-то удобно (привыкли работать со всеми удобствами текстовых редакторов и привычки менять не собираетесь), то можно с самого начала делать эту работу в окне «Текст».
Места, требующие проверки, там отображаются в полном объеме — это символы и слова, выделенные светло-голубым. Возможность перемещаться от ошибки к ошибке, не просматривая всю страницу целиком, тоже имеется — кнопки «Следующая ошибка» и «Предыдущая ошибка» на панели кнопок с левой стороны окна.
Теоретически, по замыслу создателей FineReader, окна «Проверка» должно быть вполне достаточно для полноценной вычитки распознанного текста. Все сомнительные места отмечены, движемся вдоль них, правим ошибки, на выходе получаем полностью вычищенный текст.
Но, как это часто бывает, теория здесь расходится с повседневной практикой работы. В распознанных текстах систематически встречаются ошибочные места, которые, как ошибки, не помечены. То есть FineReader распознает какой-то символ/слово неверно, но при этом с полной уверенностью, что распознал правильно.
Поэтому для полноценной вычитки одного только окна «Проверка» обычно бывает недостаточно — в особенности если в тексте много научных или технических терминов, профессионального жаргона и тому подобной «несловарности». Надо еще пройтись по распознанному вручную — внимательно просмотреть его в окне «Текст» и проверить все мало-мальски сомнительные места.
Вычитка текста в окне «Текст» мало чем отличается от обычной корректорской работы. Настраиваете окна «Текст» и «Крупный план» так, чтобы они занимали большую часть рабочего окна программы, переходите к очередной проверяемой странице, просматриваете ее текст. Если обнаруживаете сомнительное или явно ошибочное место, то щелкаете по нему — при этом курсор в «Крупном плане» устанавливается точно в том же самом месте оригинала (скана). Сравниваете оригинал и распознанное, при необходимости правите, двигаетесь дальше.
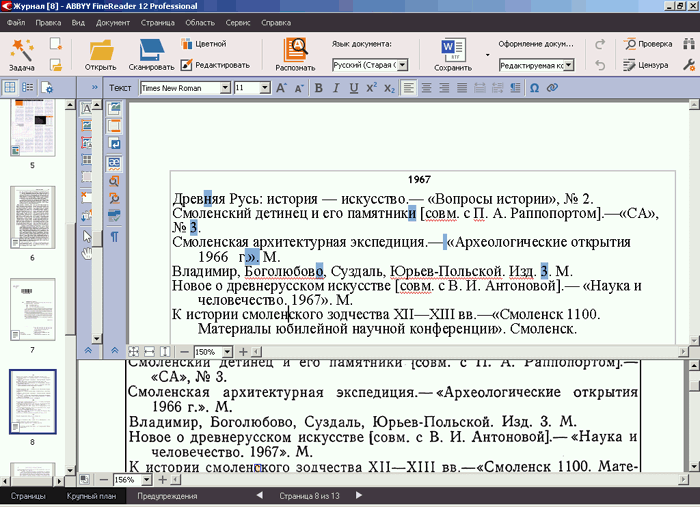
Рис. 25. Вычитка с помощью окон «Текст» и «Крупный план»
Функциональность редактора окна «Текст» ничем особо не отличается от функциональности любого текстового редактора средней степени сложности. Вид у кнопок в меню достаточно типовой, каких-либо проблем при работе с ними возникать не должно. Если надо поправить какой-то символ, который на клавиатуре отсутствует, то, как и в окошке «Проверка», надо нажать на кнопку с греческой «омегой» и в открывшейся таблице выбрать необходимое.
Сохранение результатов
Когда отсканированный материал распознан и вычитан, его надо сохранить в одном из документальных форматов — DOC, DOCX, RTF, PDF, HTML и т. д. Это делается через «Файл → Сохранить документ как → выбрать нужный формат» или через кнопку «Сохранить» в основном меню FineReader.
В открывшемся окошке Проводника выбираете формат, через кнопку «Настройки» задаете параметры сохранения, нажимаете «ОК». Если хотите сразу же посмотреть нет ли заметных ошибок во внешнем виде сохраненного текста, то кроме этого поставьте галочку в «Открыть документ после сохранения». Тогда он сразу же будет открыт в редакторе (браузере, программе просмотра).
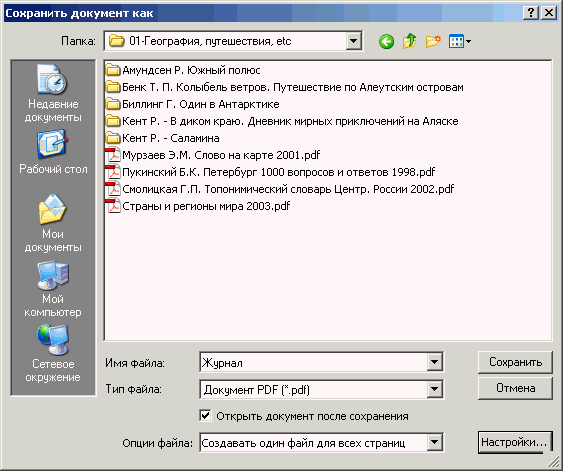
Рис. 26. Окно сохранения распознанного текста
Обычная практика распознавания — на вход поступает отсканированный текст книги или журнала, на выходе все его страницы сохраняются в файл с названием этой книги. Именно такая настройка «Создавать один файл для всех страниц» стоит по умолчанию в строке «Опции файла». Если же у вас распознается не какой-то цельный текст, а просто россыпь страниц (например офисная документация), то здесь надо будет выставить «Сохранять отдельный файл для каждой страницы».
Настройки сохранения в форматах DOC, DOCX, RTF
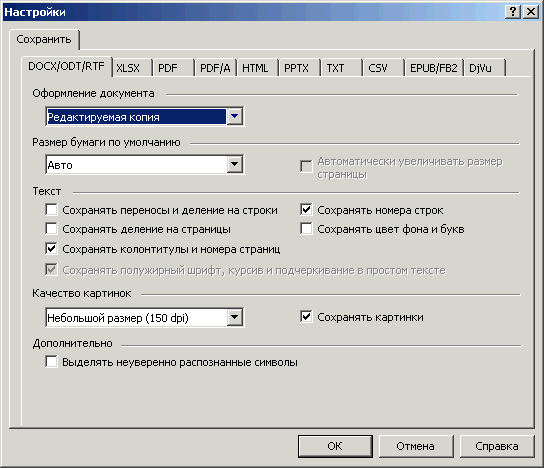
Рис. 27. Настройки сохранения в DOC/DOCX/RTF
Ключевое и основное, что здесь надо выбрать — это с какой степенью точности в сохраняемом документе будет отображен внешний вид оригинала (один из режимов сохранения в окошке «Оформление документа»). Все остальные настройки — не более, чем уточнение и деталировка этого пункта.
Вариантов выбора здесь четыре: «Точная копия», «Редактируемая копия», «Форматированный текст» и «Простой текст».
1. «Точная копия».
По замыслу разработчиков здесь должно было быть практически зеркальное подобие распознаваемой страницы. Именно потому так и названо. С точным воспроизведением шрифтов, размеров букв (кеглей), расстояний между буквами в словах, расстояний между словами, строками и абзацами и других деталей верстки. Идея, в общем-то, неплохая, но возможности реализовать ее в задуманном объеме у FineReader обычно не хватает.
Шрифты и их начертание (Normal, Italic, Bold) часто воспроизводятся по принципу «как выйдет, так и получится». Могут быть переданы точно. Может случиться так, что шрифт, использованный на распознаваемой странице, будет замещен другим шрифтом (сходным по виду, но другим). Может случиться так, что начертание Normal будет распознано как Bold или же наоборот. И так далее, и тому подобное.
С воспроизведение кеглей, расстояний и прочего форматирования ситуация не намного лучше — более или менее точно воспроизвести внешний вид (верстку) распознаваемой страницы обычно удается лишь в случаях чего-нибудь не очень сложного.
В результате получается не очень понятно что — Word-документ, который можно только читать (ну и копировать оттуда текст). Редактировать его за пределами «пару букв убрать, пару букв вставить» малореально. А редактировать таки требуется — он ведь дальше пойдет в какую-то работу, а значит надо будет переделывать форматирование под потребности будущего использования.
С одной стороны весь текст здесь раскидан по многочисленным фреймам, что изрядно осложняет работу с ним. С другой стороны во время распознавания программа генерирует кучу Word’овских стилей — все форматирование в тексте делается исключительно через стили. Вполне обычно, когда на текст книги среднего размера (300-400 страниц) генерируется несколько сотен различных стилей. Что еще больше усложняет редактирование.
Резюме — выбирать этот режим сохранения особого смысла не имеет, работать с сохраненным текстом здесь достаточно неудобно.
Если же вам требуется полное воспроизведение внешнего вида оригинала, то это и проще, и практичнее сделать в виде PDF «Текст под изображением страницы» или же PDF «Только текст и картинки» (об этих способах вывода немного ниже).
2. «Редактируемая копия».
По смыслу это облегченная версия «Точной копии». Внешний вид оригинала воспроизводится не с такой степенью дотошности, как в предыдущем случае, фреймов с текстом заметно поменьше (хотя периодически попадаются). Однако, хоть этот вариант и называется «редактируемым», работать с ним тоже, не сказать чтобы удобно.
Если Word-документ нужен, как есть, только для просмотреть его его содержимое и скопировать нужный фрагмент текста, то вполне можно использовать и этот вариант. Если же требуется много переделывать, переформатировывать и так далее, то лучше выбирать что-то другое.
Причина та же самая — слишком много возни по преобразованию текста из того вида, который выдаст «Редактируемая копия», в тот вид, который может потребоваться вам. Все еще осталось какое-то количество текста во фреймах, в форматировании все еще сохраняется тенденция точно воспроизводить внешний вид (верстку) оригинала. Да и привычка генерировать кучу стилей никуда не делась.
Резюме — работать с текстом здесь не так хлопотно, как в «Точной копии», но по прежнему оставляет желать лучшего.
3. «Форматированный текст».
Степень соответствия оригиналу здесь сведена к минимуму — воспроизведение шрифтов и кеглей, примерного расположения материала на страницах оригинала, общего вида текста и таблиц.
Работать с этим вариантом заметно проще, чем с предыдущими, однако все еще затруднительно из-за большого количества стилей. Впрочем это достаточно просто лечится — можно быстро пройтись по тексту и наложить на него ваш собственный комплект стилей.
4. «Простой текст».
Хотя он называется «Простой текст», но здесь можно сохранять как сам текст, так и текст с картинками. Форматирование в этом варианте сведено к минимуму — обычные Word’овские абзацы от одного края страницы до другого, плюс воткнутые между ними картинки. Привычная по предыдущим вариантам куча стилей тоже не генерируется.
Но при желании даже здесь можно оставить исходную разбивку на строки и на страницы. Плюс сохранять начертания шрифта — обычный, курсив, полужирный.
Обычно для сохранения выбирается или «Форматированный текст», или «Простой текст» — в зависимости от того, что вы собираетесь делать дальше и как использовать распознанное.
Теперь об остальных настройках этого окна.
- «Размер бумаги по умолчанию».
Здесь задается Word’овская настройка «Параметры страницы → Размер бумаги», то есть на бумаге какого формата вы будете делать распечатку. Обычно выставляется А4. Но надо иметь в виду, что в режимах «Точная копия» и «Редактируемая копия» один к одному сохраняется не только содержимое распознанной страницы, но и ее исходный размер. В результате если поставить здесь формат бумаги, больший, чем размер страницы, то при печати вокруг текста будут пустые поля. Если же поставить меньший формат, то часть материала страницы может быть потеряна (окажется за границами листа бумаги). - «Сохранять переносы и деление на строки».
Если галочка поставлена, то будет сохранена та разбивка на строки, которая имеется в оригинале. Переносы строк в этом случае делаются мягкими. Если галочки не ставить, то текст пойдет обычными Word-овскими абзацами, со строками от одного края страницы до другого. - «Сохранять деление на страницы».
Если галочка поставлена, то будет сохранена та разбивка на страницы, которая имеется в оригинале. Если галочки не ставить, то текст на страницы будет разбивать сам Word. - «Сохранять колонтитулы и номера страниц».
Если галочка поставлена, то текст, размеченный и распознанный, как колонтитулы и номера страниц, будет сохранен и размещен в соответствующих Word-овских полях. Если галочку не ставить, то эта часть текста вообще не выводится. - «Сохранять номера строк».
Если галочка поставлена, то в списках с пронумерованными строками будет сохранена нумерация этих строк. - «Сохранять цвет фона и букв».
Если галочка поставлена, то текст, напечатанный в цвете (или на цветном фоне), будет выведен, как в оригинале. Если галочки не ставить, то весь текст будет выводиться обычным образом — черным на белом фоне (или на белым на черном фоне). - «Сохранять полужирный шрифт, курсив и подчеркивание в простом тексте».
Вывод в «Простой текст» можно делать по принципу «все одним и тем же начертанием, Normal», а можно с сохранением начертания, которое было в оригинале. Здесь как раз этот момент и регулируется. - «Выделять неуверенно распознанные символы».
Эту галочку надо ставить если вы предпочитаете вычитывать распознанный текст не в FineReader, а в каком-нибудь текстовом редакторе. Тогда все пометки символов и слов, которые у вас были в окне «Текст», будут воспроизведены в сохраненном документе. - «Сохранять картинки».
Определяется будут ли кроме текста сохраняться еще и изображения. - «Качество картинок».
Здесь определяется степень сжатия изображений из оригинала. Оно может регулироваться по трем направлениям — через различные алгоритмы сжатия, через разрешение сохраняемого изображения и через глубину цвета в нем. Подробности можно посмотреть, если в строке «Качество картинок» выбрать вариант «Пользовательское». Наиболее практично пользоваться именно им, а не пресетами «Небольшой размер (150 dpi)» и «Высокое качество (разрешение исходного изображения)».
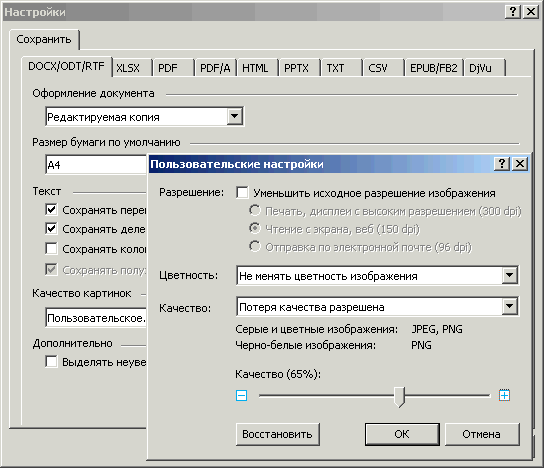
Рис. 28. Окно настройки качества изображения
Поскольку при уменьшении исходного разрешения и последующем сжатии возможны плохо предсказуемые искажения, то галочку «Уменьшать исходное разрешение изображения» лучше убрать.
Глубину цвета ставите по ситуации. Если изображения нужны, как есть, то выбираете «Не менять цветность изображения». Если достаточно просто общего вида, точное воспроизведение цветов не обязательно, то выбираете «Конвертировать цветные изображения в серые». Преобразование цветных и серых изображений в черно-белые лучше не выбирать, потому что бинаризация может давать много искажений (причем плохо предсказуемых). Пункт «Автоматически» тоже лучше не выбирать — не очень понятно какая логика работы там заложена и что вы при этом будете получать на выходе.
Движок «Качество» (цифры в нем) можно считать аналогом настройки «Quality» в JPEG-сжатии и регулировать здесь по опыту работы с JPEG-изображениями.
Настройки сохранения в форматах PDF и PDF/A

Рис. 29. Настройки сохранения в PDF
Режимов сохранения здесь тоже четыре: «Только текст и картинки», «Текст поверх изображения страницы», «Текст под изображением страницы», «Только изображение».
- «Только текст и картинки».
Здесь вы фактически получите PDF-вариант того, что выдается в «Точной копии» — распознанный текст и иллюстрации из окна «Текст» в виде, максимально приближенном к оригиналу. Качество воспроизведения оригинала здесь выше, чем в DOC/DOCX/RTF, поскольку PDF-формат имеет для этого заметно больше возможностей. - «Текст поверх изображения страницы».
Это PDF, состоящий из двух слоев — исходное изображение (нижний слой), на которое наложен распознанный текст (верхний слой). Такой вариант достаточно удобен, если PDF потом будет редактироваться - «Текст под изображением страницы».
Это PDF составленный из тех же двух слоев — исходное изображение и распознанный текст. Только они идут в обратном порядке — изображение верхним слоем, текст нижним (невидимым) слоем. Такой способ вывода еще называется «PDF с текстовой подложкой» и используется, когда надо получить с одной стороны точную копию внешнего вида оригинала, а с другой стороны возможность копировать текст этого оригинала. - «Только изображение».
Это PDF, собранный из исходных изображений. Кроме самих изображений там больше ничего нет.
Теперь об остальных настройках этого окошка.
1. «Размер бумаги по умолчанию».
В PDF-выводе смысл этой настройки такой же, как и в предыдущем случае — формат листа, на котором будет печататься страница.
В предыдущем случае говорилось о правиле «если страница меньше, чем заданный формат, то вокруг текста будут пустые поля, если больше — часть текста будет обрезана». В PDF оно соблюдается еще более жестко, поскольку здесь исходная страница в любом варианте воспроизводится один к одному. Поэтому наиболее разумно ставить здесь «Использовать размер оригинала».
2. «Сохранять цвет фона и букв».
3. «Сохранять колонтитулы».
Смысл этих двух настроек такой же, как и в предыдущем случае.
4. «Создать оглавление».
Если в настройках распознавания была поставлена галочка «Определение структурных элементов → Оглавление», то распознанное таким образом оглавление книги может быть использовано для автоматического создания оглавления в PDF-файле.
5. «Разрешить теги PDF».
В PDF теги — это функциональный аналог Word-вских стилей, способ структурной разметки содержимого PDF-файла. С их помощью сохраняется информация о разбивке текста на главы, о заголовках, оглавлении, иллюстрациях, таблицах, примечаниях, гиперссылках, математических формулах и прочем подобном.
Если вам надо будет часто копировать из PDF куски текста, то галочку здесь стоит поставить. Тогда скопированный текст будет гораздо больше соответствовать тому, как он выглядит на странице PDF.
Также теги полезны если PDF приходится просматривать на экранах различных размеров — от десктопов до смартфонов. В таких случаях PDF-читалкам приходится переформатировывать содержимое страниц под текущий размер экрана и с теговой разметкой это проходит значительно более аккуратно, без заметных искажений первоначального вида.
6. «Использовать смешанное растровое содержимое (MRC)».
MRC (Mixed Raster Content) — это название технологии сжатия, способной давать заметно большие кратности сжатия, чем известные всем JPEG и JPEG 2000. Многие знакомы с ней по формату DjVu — он построен именно на базе MRC. Выбор «надо ставить галочку или нет» здесь неоднозначный и определяется исходя из вашего расклада дел.
Основной плюс — размер получаемого PDF. Может быть в несколько раз меньше PDF, полученного с теми же настройками сжатия, но без MRC.
Какие могут быть минусы:
— MRC-сжатие так устроено, что при работе всегда дает плохо предсказуемое количество искажений. По причине того, что искажения здесь только частью зависят от настроек сжатия, а в изрядной мере от содержимого страницы. Текст, рисунки, графики, фотографии — при MRC-сжатии все они ведут себя заметно по разному и дают разное количество искажений.
— заметно большая ресурсоемкость при сжатии и просмотре таких PDF. Даже на сегодняшних компьютерах MRC-PDF может открываться и пролистываться не привычно-плавно, а скачками, когда очередная страница выводится на экран не вся сразу, а по частям.
7. «Сохранять картинки».
8. «Качество изображения».
Смысл этих настроек такой же, как и в предыдущем случае — надо или не надо при создании PDF сохранять изображения и с каким уровнем сжатия их сохранять. Рекомендации тоже аналогичные — убрать галочку из «Уменьшить исходное разрешение», цветность лучше не менять, движок «Качество» выставлять по аналогии со сжатием в JPEG 2000.
9. «Шрифты».
Если поставить «Использовать шрифты Windows», то для распознавания и последующего вывода будет использоваться тот набор шрифтов, который установлен у вас на компьютере. Если поставить «Использовать предопределенные шрифты», то только тот комплект шрифтов, который устанавливается при инсталляции FineReader.
Предпочтительнее выставлять первый вариант, поскольку при этом будет использоваться гораздо большее разнообразие шрифтов и программе будет легче подбирать соответствие шрифтам распознаваемых книг.
10. «Встраивать шрифты».
Если вам требуется, чтобы при просмотре PDF-файла на другом компьютере он был виден именно так, как вы его получили (именно в этих шрифтах), то надо поставить здесь галочку.
11. «Параметры защиты PDF».
Здесь можно выставить парольную защиту на просмотр PDF, печать, копирование из него текста и рисунков, редактирование.
Если у вас возникнут вопросы по работе FineReader, на которые вы не нашли ответа в тексте статьи, то их можно задать на форуме разработчиков программы.
Если пакет сохранялся, то он должен остаться на месте.
Если пакет не был сохранен, то попробуй посмотреть здесь:
C:Documents and Settings********Local SettingsTemp
Если осталась папка Untitled0, то там должны сохраниться все отсканированные документы.
Вместо ********* необходимо написать имя пользователя из-под которого производилось сканирование.
Для того, чтобы зайти в папку Local Settings необходимо в свойствах папки отметить «показывать скрытые файлы и папки»
Рассмотрение программы для сканирования и распознавания текста с изображения ABBYY FineReader 12 Professional, а также ее установка на операционную систему Windows 7.
Практически каждый пользователь компьютера сталкивался с такой задачей как сканирование, книги или журнала для последующего распознавания текста, или просто распознавание текста с изображения, например с фотографии. И, наверное, самой популярной (и, наверное, лучшей) из программ такого рода является продукт нашей Российской компании ABBYY, а именно программа FineReader.
На сегодняшний день последней версией этого продукта является FineReader 12, поэтому сегодня мы будем рассматривать особенности программы ABBYY FineReader 12 Professional, а также установим пробную версию этой программы на операционную систему Windows 7.
Построить нашу сегодняшнюю статью я хочу следующим образом, сначала мы поговорим об особенностях, преимуществах этой программы, затем разберем системные требования компьютера и ОС, на которую будет производиться установка данной программы, а также подробно рассмотрим установку FineReader 12 Professional и ограничения пробной версии. Так как программа популярная, поэтому ею практически каждый хоть раз, но пользовался, будь то у себя дома, будь то у знакомого или, например, у себя на работе, поэтому рассматривать, как именно можно сканировать и распознавать текст мы не будем, тем более что подробная инструкция есть на официальном сайте, да, кстати, скачать пробную версию можно также на официальном сайте, на данный момент страница программы следующая — https://www.abbyy.ru/download/finereader/
На этой странице можно скачать и инструкцию (Руководство пользователя) и пробную версию самой программы, для этого справа жмем скачать, затем нас попросят ввести адрес своей электронной почты, соответственно мы вводим (действующую) так как именно на нее придет ссылка для скачивания программы. После ввода email жмем «Отправить» потом выйдет сообщение «Спасибо за интерес к продуктам ABBYY, На указанный Вами e-mail был выслана ссылка для скачивания программы». И можете сразу проверять свой почтовый ящик, на который Вам придет сообщение со ссылкой на скачивание, Вы соответственно переходите по этой ссылке, и начинается скачивание продукта. Соответственно если Вам понравится это программа, то Вы ее можете приобрести здесь же сайте компании ABBYY. Теперь, где взять эту программу Вы знаете, давайте поговорим об ее особенностях и преимуществах.
Пакет ABBYY Finereader 12 — система оптического распознавания текстов (Optical Character Recognition — OCR). Предназначена как для автоматического ввода печатных документов в компьютер, так и для конвертирования PDF–документов и фотографий в редактируемые форматы(из руководства к программе)
Аббревиатура «OCR» применима для всех приложений для распознавания данных (а не только текста). Источником для извлечения данных может служить печатный или электронный документ. Когда-то не очень давно об OCR, в той или иной форме, мало кто знал, да и процесс перевода текста в электронный вид превращался в сущую рутину, вплоть до ручной перепечатки текста оригинала. Сегодня, обладая планшетным сканером (ручным в домашних условиях пользуются единицы) и finereader 12 — будьте уверены — никаких сложностей в сканировании и распознании не возникнет.
Начиная с шестой версии, FineReader поддерживает импорт и экспорт в формат PDF, запатентованный компанией Adobe. Многие читатели, вероятно, сталкивались с трудностями перевода из этого формата в любой иной (doc и т. п.), поскольку действительно полезных программ в этой области не так уж и много (внимания достоин разве что дочерний продукт компании ABBYY — PDF Transformer). Дело в том, что подобные программы проводят распознавание текста только единожды, вследствие чего «идентичность» результата вовсе невелика (в зависимости от сложности документа), плюс к тому изрядно теряется форматирование документа.
В случае с FineReader все обстоит по-иному. В девятую версию программы внедрена технология под названием Document OCR. В ее основе лежит принцип цельного распознавания документа: он анализируется и распознаётся как единое целое, а не постранично. При этом всевозможные колонки, колонтитулы, шрифты, стили, сноски и изображения остаются нетронутыми или заменяются близкими к оригиналу.
Достоинства и недостатки
Дальше давайте поговорим о положительных и отрицательных особенностях нашего офисного пакета. Список сильных и слабых сторон взломанной версии ABBYY FineReader 14 Business можно разделить на две части.
Плюсы:
- Огромное количество разных функций, позволяющих конвертировать офисные документы, распознавать текст, редактировать PDF и так далее.
- Программный интерфейс полностью переведен на русский язык.
- Серийный номер интегрирован.
- Множество положительных отзывов от людей, которые уже разобрались с этим приложением и используют его каждый день.
- Поддержка на любых версиях Windows.
- Наличие встроенного переводчика.
Минусы:
- Сама по себе программа очень тяжелая. Если вам нужно просто распознавать отсканированный текст, загружать огромный установочный дистрибутив с множеством ненужных функций нет никакого смысла.
- Кроме этого, рассматриваемое приложение очень требовательно к аппаратной части компьютера или ноутбука.

Если ни первый, не второй недостаток вас не пугают, мы можем переходить к практической части и рассматривать, как бесплатно скачать, а также установить данную программу для распознавания текста.
Установка пакета
Demo-версию Finereader 12 можно скачать на сайте Abbyy.ru, в разделе Download, полная лицензионная версия распространяется на CD-диске. О способах покупки можно узнать на этом же сайте в разделе «Купить».

ABBYY FineReader распространяется в нескольких версиях: Professional Edition, Corporate Edition, Site License Edition и др. Отличие версии Professional от остальных состоит в том, что предназначена для работы в корпоративной сети с возможностью совместной работы над распознаванием документов. В остальном разница незначительна и зависит от выбора условий лицензионного соглашения.
Сложно представить, что 12 лет назад существовал FineReader 2.0, занимавший около 10 Мб дискового пространство. Со временем пакет «вырос» десятикратно и сейчас в установленном виде занимает до 300 Мб. Много это или мало — судите сами. Новый FR поддерживает 179 языков распознавания, среди которых есть малоизвестные искусственные языки (идо, интерлингва, окциденталь и эсперанто), языки программирования, формул и т. п. Не будем забывать и о поддержке различных форматов, сценариев. Так что, если по какой-то причине вы захотите ограничить занимаемое пакетом место, при установке отметьте только те компоненты, которые будут востребованы при работе.
Выбор компонентов влияет на длительность установки, которая, впрочем, не должна занять много времени. В процессе инсталляции вас ознакомят с основными возможностями FR. После активации (по Интернету, через E-mail, с помощью полученного кода и др.) программа готова к полнофункциональной работе. В demo-режиме вы непременно столкнетесь с различными ограничениями, которые, к сожалению, не позволяют полноценно использовать пакет.
Скачать
Для того чтобы бесплатно загрузить полную русскую редакцию приложения для сканирования документов, просто прокрутите страничку ниже и нажмите кнопку, которую там найдете.
| Версия: | 14.0.107.232 |
| Разработчик: | ABBYY Software |
| Год выхода: | 2020 |
| Название: | ABBYY FineReader by KpoJIuK |
| Платформа: | Windows XP, 7, 8, 10 |
| Язык: | Русский |
| Лицензия: | RePack |
| Размер: | 493 Мб |
Интерфейс FineReader. Функциональные возможности
Доступ к возможностям программы доступен как с помощью сценариев, которые появятся в главном меню сразу после процесса инсталляции, так и, собственно, через основной интерфейс.

Внешний вид программы из версии к версии не претерпевает особых изменений: разработчики не видят смысла его кардинально менять. Значительное внимание уделяется эргономике, что заметно по всем продуктам компании ABBYY (Lingvo, PDF Transformer, FlexiCapture…). Другими словами, интерфейс Fine Reader 12 хорошо продуман и предрасположен ко всем пользователям, не исключая новичков. Принцип «Получить результат за одно нажатие» придется по вкусу тем, кто не привык что-то настраивать и изменять. С другой стороны, более опытные пользователи могут тщательно настроить FineReader через диалог настроек (Сервис -> Опции…). Единственный нюанс: для комфортной работы в приложении желательно установить разрешение экрана в 1280?800, чтобы все инструменты всегда были, что называется, под рукой.
После запуска программы Файн Ридер появится окно с кнопками быстрого доступа к функциям программы. Данное меню также доступно через меню Сервис -> ABBYY FineReader, кнопку «Основные сценарии» в крайнем правом углу программы или через сочетание клавиш Ctrl+N (по аналогии с Word, где данной комбинацией вызывается открытие нового документа).
Сканировать в Microsoft Word: в девятой версии FineReader появилась поддержка пока еще не успевшего стать популярным Microsoft Word 2007. В свою очередь, на панели инструментов в приложениях Microsoft Office, в разделе надстроек после установки FR появляется «фирменный» красный значок.


Помимо Microsoft Office, FR поддерживает интеграцию с Microsoft Outlook, обеспечивает экспорт результатов распознавания в те же Microsoft Word, Excel, Lotus Word Pro, Corel WordPerect и Adobe Acrobat. Эти возможности в некоторой мере облегчают и ускоряют работу с программой, в особенности, если вам приходится регулярно в ней работать.
PDF или изображения в Microsoft Word: распознать данные из PDF- или графического файла другого типа, поддерживаемого Finereader 12 версии. Следует отметить, что технология извлечения текста из PDF-файла в FR — это не просто «отслаивание» текстового наполнения (текстовый слой в PDF может и отсутствовать) от графического. На самом деле, технология распознавания достаточно непроста: проанализировав содержание документа, программа решает, что и как нужно делать с текстом: просто извлечь или распознать, — и так применительно к каждому текстовому фрагменту.
Сканировать в Microsoft Excel: сканирование в XLS (формат программы Microsoft Excel) может быть оправдано в том случае, если сканируемое изображение содержит таблицы.
Сканировать в PDF: поводов для сканирования в PDF может быть множество. Один из них — безопасность: это единственный формат, знакомый FR, в настройках которого можно установить блокировку паролем. Пароль устанавливается не только на открытие документа, но и на его печать и другие операции. Имеется возможность выбрать один из трёх уровней шифрования: 40-битный, 128-битный на основе стандарта RC4, 128-битный уровень, основанный на стандарте AES (Advanced Encryption Standard).
Конвертировать фотографию в Microsoft Word: перевод файла из графического формата (причем это может быть PDF или многостраничное изображение) в DOC/DOCX.
Сканировать и сохранить изображение: непосредственное сканирование аналогового графического формата в графический же, но электронный.
Открыть в Файн Ридер: открыть графический файл (PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG) для распознавания FineReader.
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.


Convertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
| Входные форматы | pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp, webp |
| Выходные форматы | Text Plain, PDF, Word , Excel, Pptx, Djvu, Epub, Fb2, Csv |
| Размер файла | ?, зависит от тарифа |
| Ограничения | 10 страниц бесплатно, дальше тарифы от 7 долларов. |
| Качество | Сложно оценить – файл с картинками (ИНН) не распознал совсем, отдельно вырезанный кусок текста распознал. Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе. |
Как пользоваться
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите капчу
- Щелкните “Преобразовать”
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.


Работа в FineReader
Сейчас — вкратце об особенностях работы программы. Весь процесс делится на сканирование, распознавание и сохранение результатов. После того как вы выбрали тип действия программы, указали файл или устройство для сканирования, FineReader поэтапно выполняет свою задачу, кстати, достаточно ресурсоемкую для центрального процессора.
Если вы — счастливый обладатель двухъядерного процессора, то, работая в пакете Fine Reader 12, можете оценить мощь быстродействия компьютера. Дело в том, что FR, обнаружив двухъядерный процессор, распознает не одну, а сразу две страницы документа параллельно. Мелочь — а приятно.
Вначале идет сканирование, затем — распознавание и экспорт временного документа в выбранный формат.

Сканирование. Никаких предварительных настроек в приложении FineReader (кроме выбора считывающего устройства) перед сканированием делать не нужно. Именно поэтому и были придуманы сценарии: они призваны упростить выполнение однотипных действий.
Распознавание. Упрощение коснулось и других мелочей. Так, если вспомнить прошлые версии программы, раньше нам приходилось вручную менять язык (языки, если их было несколько) документа. Сейчас это происходит автоматически, правда, тоже не всегда. В последнем случае FR ненавязчиво предлагает проверить язык документа.
Возвращаясь к технологии распознавания FR: почему программа вначале сканирует весь документ целиком, а не постранично? Как уже было сказано, текст распознается, исходя из всего содержания: подбираются аналогичные по размеру/гарнитуре шрифты, таблицы и границы, отступы и т. п.
Не удивляйтесь, если программа FineReader 12 выдаст сообщение, мол, страница не может быть распознана, поскольку не найдено ни одной области текста. Эксперимента ради, мы сфотографировали на мобильный телефон с экрана LCD-дисплея область текстового документа (впрочем, зная, результат уже заранее). Fine Reader 12не распознал текст изображения, поскольку оно было явно такого качества, которого для этого явно недостаточно. При втором заходе мы сфотографировали цифровым фотоаппаратом страницу с текстом при нормальном освещении.
FineReader без проблем распознал отрывок, сохранив форматирование и отметив маркерами некоторые сомнительные моменты или символы, у которых могут быть вариативное написание.
Как видно на изображении, преимущественно это точки, дефисы, запятые — в общем, мелкие символы. Кроме этого, хорошо видно, что программа учла неровности, изогнутости сфотографированной страницы и выровняла строки текста. Вывод — FR отлично справился со своей пусть и не очень сложной задачей.
Изредка могут оставаться незамеченными программой Файн Ридер кое-какие незначительные моменты, однако их легко откорректировать вручную. Благо, в пакете есть свой WYSIWYG-редактор, возможностей которого вполне достаточно для совершения окончательной правки документа. Проверка орфографии тоже имеется.
Как повысить точность распознавания, чтобы затем в меньшей степени заниматься правкой текста? Во-первых, вы можете подключить пользовательский словарь Microsoft Word. Правда, сложно судить о повышении точности, разве что о повышении словарного запаса спеллчекера (модуля, проверяющего орфографию и грамматику). Кроме всего прочего, для улучшения распознавания есть смысл ознакомиться с настройками программы (Сервис -> Опции) и выбрать один из двух режимов:
тщательное распознавание — его можно выбрать при распознавании документов любой «сложности»: с таблицами без линий сетки, текста, графиков, таблиц на цветном фоне и др. Также может помочь при некачественном источнике для распознавания
быстрое распознавание — данный режим рекомендуется для обработки больших объемов документов с простым оформлением или же в том случае, если время не позволяет проводить тщательное распознавание. В большинстве случаев, когда вы имеете с черным печатным текстом на белом фоне, можно остановиться на быстром распознавании.
Вообще, улучшение качества работы FineReader — это отдельная тема для разговора, о деталях которой вы можете узнать из официальной справки, а именно в разделе «Как улучшить полученные результаты».
Сохранение документа. Последний этап работы в программе Fine Reader 12 — сохранение итогового результата в определенный графический/текстовый формат. Предварительно настройки сохранения можно указать в опциях FR: Сервис ->Опции, вкладка «Сохранить». Для каждого формата предусмотрены свои настройки. При сохранении в DOCX-формате следует побеспокоится о совместимости форматов (Файлы DOCX-формата не распознаются в Word 2003 <). В txt-файлах не забудьте проверить правильность кодировки (особенно в случае с текстом в кириллице).
Системные требования
Для того чтобы данный инструмент работал правильно и не вызывал замедления компьютера, необходимо чтобы последний соответствовал приведенным в списке параметрам.
- Центральный процессор: двухъядерный 1.8 ГГц и выше.
- Оперативная память: 4 Гб и выше.
- Пространство на жестком диске: от 1 Гб.
- Платформа: Windows XP, 7, 8 и 10.
- Графический адаптер: не имеет значения.
- Разрешение экрана: 1280 x 720 и выше.

ABBYY Screenshot Reader
Во многие объемные пакеты очень часто разработчики любят добавлять мелкие сервисные утилиты. Скажем, в состав известного приложения для записи дисков Nero входит набор из 3 — 5 утилит, позволяющих то, чего не может даже сам Nero. Обзор Nero Express доступен здесь (здесь же можно скачать в составе Файн Ридер 12).
Что касается FineReader, то в его составе обнаруживается одно небольшое приложение Screenshot Reader. С его помощью вы можете сделать снимок экрана и быстро перевести его в желаемый формат посредством FR. Программа доступна через меню «Пуск» (Пуск -> Все программы -> ABBYY FineReader 12.0 -> ABBYY Screenshot Reader.).
Возможности Screenshot Reader несколько шире, чем может показаться на первый взгляд. (а иначе можно было бы обойтись простым нажатием клавиши «PrintScreen» на клавиатуре). В дополнение к тому, что Screenshot Reader делает снимок экрана (или, точнее, выбранной области экрана), программа тесно интегрирована с FR.
При нажатии на кнопку «Снимок» на панели Screenshot Reader курсор меняет форму и включается инструмент выделения области экрана. Выделенная область изображения заключается в рамку для дальнейшего распознавания текста (оно запускается автоматически).
В выпадающем списке вы можете выбрать желаемое действие: по сути, Screenshot Reader дублирует быстрые сценарии FR c той разницей, что вместо снимка со сканера «на вход» поступает снимок экрана.
Следует отметить, программа, наравне со всем пакетом, требует активации. При регистрации продукта ABBYY FineReader 12 Professional Edition Screenshot Reader предоставляется бесплатно, в качестве «бонуса».
Как сканировать и распознать документ:
Если программа на русском все достаточно просто и понятно, версия скачанная с нашего сайта бесплатна.
На верхней панели достаточно большие значки основных функций, на скрине ниже 11 версия но и в других все примерно одинаково изменены лишь сами значки.
Для того чтоб распознать нужно сначала сканировать со сканера документ либо загрузить картинку например с текстом, после нажать на кнопочку Распознать.

После распознания и корректировки можно сохранять документ в редактируемый а также желаемый формат например ПДФ (PDF).

Горячие клавиши FineReader 12
- Создать новый документ ABBYY FineReader — CTRL+N
- Открыть документ ABBYY FineReader 12 — CTRL+SHIFT+N
- Сохранить страницы — CTRL+S
- Сохранить изображение в файл — CTRL+ALT+S
- Распознать все страницы документа — CTRL+SHIFT+R
- Закрыть текущую страницу — CTRL+F4
- Распознать выделенные страницы документа ABBYY FineReader — CTRL+R
- Открыть Менеджер сценариев — CTRL+T
- Открыть диалог Опции «Файн Ридер»— CTRL+SHIFT+O
- Открыть справку — F1
- Перейти в окно Документ — ALT+1
- Перейти в окно Изображение — ALT+2
- Перейти в окно Текст — ALT+3
- Перейти в окно Крупный план — ALT+4
Горячие клавиши
Программа ABBYY FineReader имеет предустановленные горячие клавиши для выполнения команд, список которых находится
ниже. Помимо этого
программа позволяет настраивать горячие клавиши.
Как настроить клавиши для работы с программой:
- Откройте диалог Настройка панелей инструментов и горячих клавиш (меню
Сервис>Настройка…). - На закладке Сочетания клавиш
в поле Категории
выберите нужную категорию. - В поле Команды
выберите команду, для которой вы хотите задать или изменить клавиши. - Установите курсор в поле
Укажите новое сочетание, затем нажмите клавиши на клавиатуре, с
помощью которых будет вызываться выбранная команда. - Нажмите кнопку Назначить.
Указанные клавиши
будут добавлены в поле Текущее сочетание. - Нажмите кнопку
Ок, чтобы сохранить внесенные изменения. - Для приведения горячих клавиш к предустановленным значениям нажмите кнопку
Восстановить (для выбранной категории команд) или
Восстановить все (для всего набора горячих клавиш сразу).
- Меню Файл
- Меню Правка
- Меню Вид
- Меню
Документ - Меню
Страница - Меню
Области - Меню Сервис
- Меню Справка
- Общие
Меню Файл
| Команда | Сочетание клавиш |
|---|---|
| Сканировать страницы… | Ctrl+K |
| Открыть PDF/изображение… | Ctrl+O |
| Новый документ FineReader | Ctrl+N |
| Открыть документ FineReader… | Ctrl+Shift+N |
| Сохранить документ как | Ctrl+S |
| Сохранить изображения… | Ctrl+Alt+S |
| Отправить документ FineReader по электронной почте |
Ctrl+M |
| Отправить изображения страниц по электронной почте |
Ctrl+Alt+M |
| Печать изображения | Ctrl+Alt+P |
| Печать текста | Ctrl+P |

К началу
Меню Правка
| Команда | Сочетание клавиш |
|---|---|
| Отменить | Ctrl+Z |
| Восстановить | Ctrl+Enter |
| Вырезать | Ctrl+X |
| Копировать | Ctrl+C Ctrl+Insert |
| Вставить | Ctrl+V Shift+Insert |
| Удалить | Delete |
| Выделить всё | Ctrl+A |
| Найти… | Ctrl+F |
| Найти следующее | F3 |
| Заменить… | Ctrl+H |
К началу
Меню Вид
| Команда | Сочетание клавиш |
|---|---|
| Показать окно Страницы | F5 |
| Показать только окно Изображение | F6 |
| Показать окна Изображение и Текст | F7 |
| Показать только окно Текст | F8 |
| Показать | Ctrl+F5 |
| Следующее окно | Ctrl+Tab |
| Предыдущее окно | Ctrl+Shift+Tab |
| Свойства… | Alt+Enter |
К началу
Меню Документ
| Команда | Сочетание клавиш |
|---|---|
| Распознать | Ctrl+Shift+R |
| Анализ документа | Ctrl+Shift+E |
| Открыть следующую страницу | Alt+Down Arrow Page Up |
| Открыть предыдущую страницу | Alt+Up Arrow Page Down |
| Открыть страницу с номером… | Ctrl+G |
| Закрыть текущую страницу | Ctrl+F4 |
К началу
Меню Страница
| Команда | Сочетание клавиш |
|---|---|
| Распознать страницу | Ctrl+R |
| Анализ страницы | Ctrl+E |
| Редактировать изображение страницы… | Ctrl+Shift+C |
| Удалить все области и текст | Ctrl+Delete |
| Удалить текст | Ctrl+Shift+Delete |
| Свойства страницы… | Alt+Enter |
К началу
Меню Области
| Команда | Сочетание клавиш |
|---|---|
| Распознать область | Ctrl+Shift+B |
| Изменить тип области на тип Зона распознавания |
Ctrl+1 |
| Изменить тип области на тип Текст |
Ctrl+2 |
| Изменить тип области на тип Таблица |
Ctrl+3 |
| Изменить тип области на тип Картинка |
Ctrl+4 |
| Изменить тип области на тип Штрих-код |
Ctrl+5 |
К началу
Меню Сервис
| Команда | Сочетание клавиш |
|---|---|
| Менеджер сценариев… | Ctrl+T |
| Hot Folder… | Ctrl+Shift+H |
| Просмотр словарей… | Ctrl+Alt+D |
| Редактор языков… | Ctrl+Shift+L |
| Редактор эталонов… | Ctrl+Shift+A |
| Проверка… | Ctrl+F7 |
| Следующая ошибка | Shift+F4 |
| Предыдущая ошибка | Shift+F5 |
| Опции… | Ctrl+Shift+O |
К началу
Меню Справка
| Команда | Сочетание клавиш |
|---|---|
| Открыть справку | F1 |
К началу
Общие
| Команда | Сочетание клавиш |
|---|---|
| Отметить выделенный фрагмент текста как полужирный |
Ctrl+B |
| Отметить выделенный фрагмент текста как курсив |
Ctrl+I |
| Подчеркнуть выделенный фрагмент текста |
Ctrl+U |
| Перейти к ячейке таблицы | Стрелки влево, вправо, вниз и вверх |
|
Перейти в окно Страницы |
Alt+1 |
| Перейти в окно Изображение | Alt+2 |
| Перейти в окно Текст | Alt+3 |
| Перейти в окно Крупный план | Alt+4 |
К началу