begin;
create table user_links(id serial,year bigint, user_id bigint, sid bigint, cid bigint);
insert into user_links(year, user_id, sid, cid) values (null,null,null,null),
(null,null,null,null), (null,null,null,null),
(1,2,3,4), (1,2,3,4),
(1,2,3,4),(1,1,3,8),
(1,1,3,9),
(1,null,null,null),(1,null,null,null);
commit;
set operation with distinct and except.
(select id, year, user_id, sid, cid from user_links order by 1)
except
select distinct on (year, user_id, sid, cid) id, year, user_id, sid, cid
from user_links order by 1;
except all also works. Since id serial make all rows unique.
(select id, year, user_id, sid, cid from user_links order by 1)
except all
select distinct on (year, user_id, sid, cid)
id, year, user_id, sid, cid from user_links order by 1;
So far works nulls and non-nulls.
delete:
with a as(
(select id, year, user_id, sid, cid from user_links order by 1)
except all
select distinct on (year, user_id, sid, cid)
id, year, user_id, sid, cid from user_links order by 1)
delete from user_links using a where user_links.id = a.id returning *;
Here are seven ways to return duplicate rows in PostgreSQL when those rows have a primary key or other unique identifier column.
This means that the duplicate rows share exactly the same values across all columns with the exception of their primary key/unique ID column.
Sample Data
We’ll use the following data for our examples:
SELECT * FROM Dogs;Result:
dogid | firstname | lastname
-------+-----------+----------
1 | Bark | Smith
2 | Bark | Smith
3 | Woof | Jones
4 | Ruff | Robinson
5 | Wag | Johnson
6 | Wag | Johnson
7 | Wag | Johnson
The first two rows are duplicates (except for the DogId column, which is the table’s primary key, and contains a unique value across all rows). The last three rows are also duplicates (except for the DogId column).
The primary key column ensures that there are no duplicate rows, which is good practice in RDBMSs, because primary keys help to enforce data integrity. But because primary keys prevent duplicate rows, they have the potential to interfere with our ability to find duplicates.
In our table above, the primary key column is an incrementing number, and its value carries no meaning and is not significant. We therefore need to ignore that row if we want to find duplicates in the other columns.
Option 1
We can use the SQL GROUP BY clause to group the columns by their significant columns, then use the COUNT() function to return the number of identical rows:
SELECT
FirstName,
LastName,
COUNT(*) AS Count
FROM Dogs
GROUP BY FirstName, LastName;Result:
firstname | lastname | count -----------+----------+------- Ruff | Robinson | 1 Wag | Johnson | 3 Woof | Jones | 1 Bark | Smith | 2
Here we excluded the primary key column by omitting it from our query.
The result tells us that there are three rows containing Wag Johnson and two rows containing Bark Smith. These are duplicates (or triplicates in the case of Wag Johnson). The other two rows do not have any duplicates.
Option 2
We can exclude non-duplicates from the output with the HAVING clause:
SELECT
FirstName,
LastName,
COUNT(*) AS Count
FROM Dogs
GROUP BY FirstName, LastName
HAVING COUNT(*) > 1;Result:
firstname | lastname | count -----------+----------+------- Wag | Johnson | 3 Bark | Smith | 2
Option 3
Here’s an example of checking for duplicates on concatenated columns. In this case we use the CONCAT() function to concatenate our two columns, use the DISTINCT keyword to get distinct values, then use the COUNT() function to return the count:
SELECT
DISTINCT CONCAT(FirstName, ' ', LastName) AS DogName,
COUNT(*) AS Count
FROM Dogs
GROUP BY CONCAT(FirstName, ' ', LastName);Result:
dogname | count ---------------+------- Wag Johnson | 3 Ruff Robinson | 1 Woof Jones | 1 Bark Smith | 2
Option 4
We can alternatively use the ROW_NUMBER() window function:
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY FirstName, LastName
ORDER BY FirstName, LastName
) AS Row_Number
FROM Dogs;Result:
dogid | firstname | lastname | row_number
-------+-----------+----------+------------
1 | Bark | Smith | 1
2 | Bark | Smith | 2
4 | Ruff | Robinson | 1
5 | Wag | Johnson | 1
6 | Wag | Johnson | 2
7 | Wag | Johnson | 3
3 | Woof | Jones | 1
Using the PARTITION clause results in a new column being added, with a row number that increments each time there’s a duplicate, but resets again when there’s a unique row.
In this case we don’t group the results, which means we can see each duplicate row, including its unique identifier column.
Option 5
We can also use the previous example as a common table expression in a larger query:
WITH cte AS
(
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY FirstName, LastName
ORDER BY FirstName, LastName
) AS Row_Number
FROM Dogs
)
SELECT * FROM cte WHERE Row_Number <> 1;Result:
dogid | firstname | lastname | row_number
-------+-----------+----------+------------
2 | Bark | Smith | 2
6 | Wag | Johnson | 2
7 | Wag | Johnson | 3
This excludes non-duplicates from the output, and it excludes one row of each duplicate from the output. In other words, it only shows the excess rows from the duplicates. These rows are prime candidates for being deleted in a de-duping operation.
Option 6
Here’s a more concise way to get the same output as the previous example:
SELECT * FROM Dogs
WHERE DogId IN (
SELECT DogId FROM Dogs
EXCEPT SELECT MIN(DogId) FROM Dogs
GROUP BY FirstName, LastName
);Result:
dogid | firstname | lastname
-------+-----------+----------
6 | Wag | Johnson
2 | Bark | Smith
7 | Wag | Johnson
One difference between this example and the previous one is that this example doesn’t require generating our own separate row number.
Option 7
Here’s yet another option for returning duplicate rows in Postgres:
SELECT *
FROM Dogs d1, Dogs d2
WHERE d1.FirstName = d2.FirstName
AND d1.LastName = d2.LastName
AND d1.DogId <> d2.DogId
AND d1.DogId = (
SELECT MAX(DogId)
FROM Dogs d3
WHERE d3.FirstName = d1.FirstName
AND d3.LastName = d1.LastName
);Result:
dogid | firstname | lastname | dogid | firstname | lastname
-------+-----------+----------+-------+-----------+----------
2 | Bark | Smith | 1 | Bark | Smith
7 | Wag | Johnson | 5 | Wag | Johnson
7 | Wag | Johnson | 6 | Wag | Johnson
We have a table of photos with the following columns:
id, merchant_id, url
this table contains duplicate values for the combination merchant_id, url. so it’s possible that one row appears more several times.
234 some_merchant http://www.some-image-url.com/abscde1213
235 some_merchant http://www.some-image-url.com/abscde1213
236 some_merchant http://www.some-image-url.com/abscde1213
What is the best way to delete those duplications?
(I use PostgreSQL 9.2 and Rails 3.)
![]()
the Tin Man
158k42 gold badges214 silver badges303 bronze badges
asked Jan 23, 2013 at 1:47
![]()
3
Here is my take on it.
select * from (
SELECT id,
ROW_NUMBER() OVER(PARTITION BY merchant_Id, url ORDER BY id asc) AS Row
FROM Photos
) dups
where
dups.Row > 1
Feel free to play with the order by to tailor the records you want to delete to your specification.
SQL Fiddle => http://sqlfiddle.com/#!15/d6941/1/0
SQL Fiddle for Postgres 9.2 is no longer supported; updating SQL Fiddle to postgres 9.3
![]()
the Tin Man
158k42 gold badges214 silver badges303 bronze badges
answered Jan 23, 2013 at 3:21
![]()
MatthewJMatthewJ
3,1072 gold badges27 silver badges34 bronze badges
8
The second part of sgeddes’s answer doesn’t work on Postgres (the fiddle uses MySQL). Here is an updated version of his answer using Postgres: http://sqlfiddle.com/#!12/6b1a7/1
DELETE FROM Photos AS P1
USING Photos AS P2
WHERE P1.id > P2.id
AND P1.merchant_id = P2.merchant_id
AND P1.url = P2.url;
answered Mar 10, 2015 at 21:14
![]()
11101101b11101101b
7,6592 gold badges40 silver badges52 bronze badges
I see a couple of options for you.
For a quick way of doing it, use something like this (it assumes your ID column is not unique as you mention 234 multiple times above):
CREATE TABLE tmpPhotos AS SELECT DISTINCT * FROM Photos;
DROP TABLE Photos;
ALTER TABLE tmpPhotos RENAME TO Photos;
Here is the SQL Fiddle.
You will need to add your constraints back to the table if you have any.
If your ID column is unique, you could do something like to keep your lowest id:
DELETE FROM P1
USING Photos P1, Photos P2
WHERE P1.id > P2.id
AND P1.merchant_id = P2.merchant_id
AND P1.url = P2.url;
And the Fiddle.
![]()
the Tin Man
158k42 gold badges214 silver badges303 bronze badges
answered Jan 23, 2013 at 2:50
![]()
sgeddessgeddes
62.1k6 gold badges60 silver badges81 bronze badges
2
In this Tutorial we will see how to find duplicate rows in postgresql. Getting duplicate rows in postgresql table can be accomplished by using multiple methods each is explained with an example.
The table which we use for depiction is
ExamScore:

Method 1: Find Duplicate Rows in Postgresql:
select distinct * from ExamScore where studentid in ( select studentid from ( select studentid, count(*) from ExamScore group by studentid HAVING count(*) > 1) as foo);
We have chosen duplicate row by counting the number of rows for each studentid and chosen the rows having count > 1.
Resultant table:

Method 2: Find Duplicate Rows in Postgresql with partition by
We have chosen duplicate row by partition by and order by as shown below
select distinct * from ExamScore where studentid in ( select studentid from ( select studentid, ROW_NUMBER() OVER(PARTITION BY studentid ORDER BY studentid asc) AS Row FROM ExamScore ) as foo where foo.Row > 1);
Resultant table:
![]()
![]()
-
With close to 10 years on Experience in data science and machine learning Have extensively worked on programming languages like R, Python (Pandas), SAS, Pyspark.
View all posts
Deleting duplicate rows from a table is a little bit tricky. Finding and deleting duplicate rows is pretty easy if the table has a limited number of records. However, if the table has enormous data, then finding and deleting the duplicates can be challenging.
PostgreSQL provides multiple ways to find and delete duplicate rows in PostgreSQL. This post discusses the below-listed methods to find and delete duplicate rows in PostgreSQL:
● How to Find Duplicate Rows in PostgreSQL?
● How to Delete Duplicates in Postgres Using a DELETE USING Statement?
● How to Delete Duplicates Using Subquery?
● How to Delete Duplicates Using Immediate Tables in Postgres?
To illustrate this concept more clearly, let’s create a sample table.
Creating Sample Table
Let’s create a table named programming_languages and insert some duplicate rows in it:
CREATE TABLE programming_languages( id INT, language VARCHAR(100) NOT NULL );
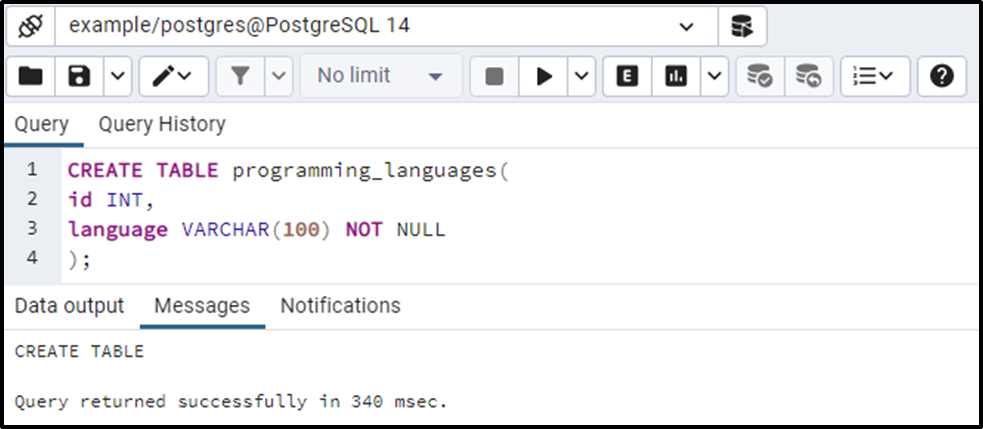
The programming_languages table has been created successfully. Let’s insert some data into it:
INSERT INTO programming_languages(id, language) values(1, 'C'), (2, 'C++'), (3, 'C'), (4, 'Java'), (5, 'Python'), (6, 'C++'), (7, 'C++'), (8, 'R'), (9, 'Java'), (10, 'JavaScript');
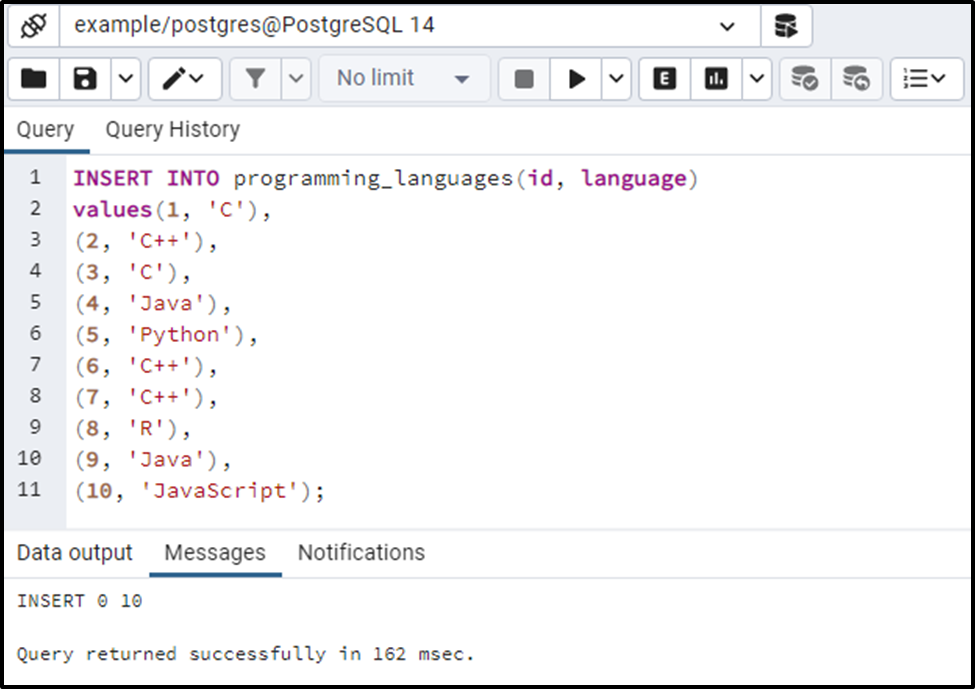
Let’s run the SELECT command to see the newly inserted data from the programming_languages table:
SELECT * FROM programming_languages;
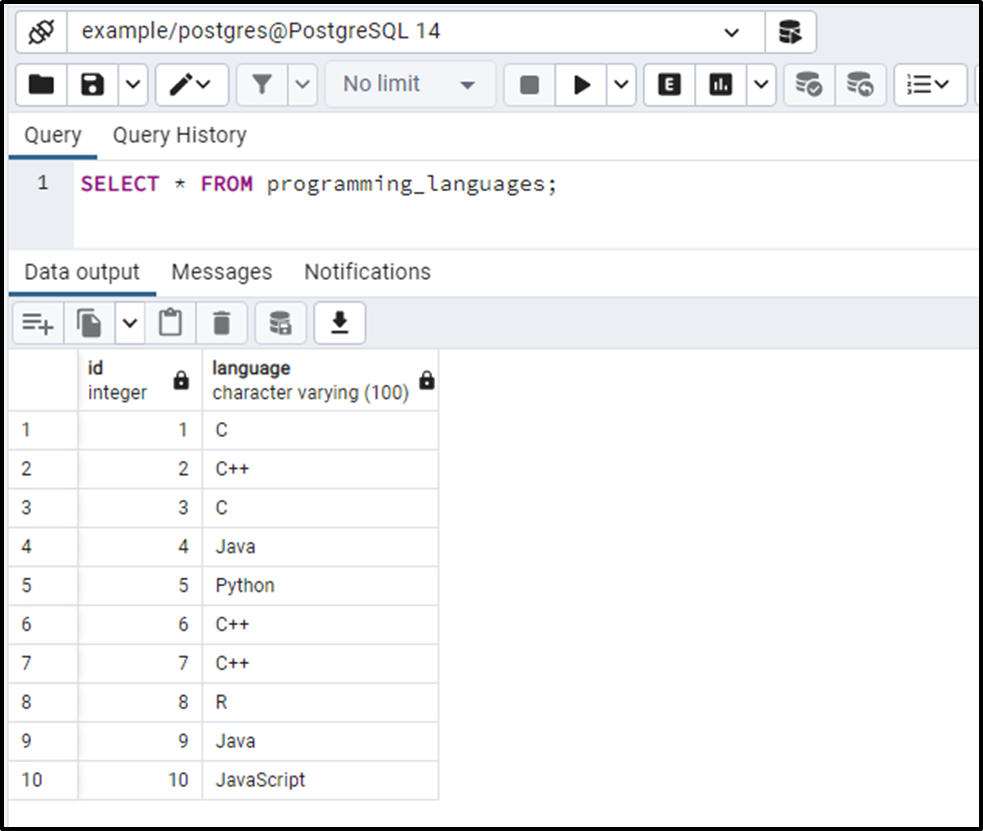
The output shows that the programming_languages table contains some duplicated records. Since the programming_languages table has limited records, so we can calculate the duplicates easily. However, counting the duplication of rows in large tables is challenging.
How to Find Duplicate Rows in PostgreSQL?
Use the COUNT() function to find the duplicate rows from a table. Execute the below code to find the duplicate rows in the programming_languages table:
SELECT language, COUNT(language) FROM programming_languages GROUP BY language HAVING COUNT(language)> 1;
From the programming_languages table, the SELECT statement will fetch the language column and number of occurrences of a language.
The GROUP BY clause will split the result set into groups based on the language column.
The HAVING clause will pick only those languages that occur more than once:
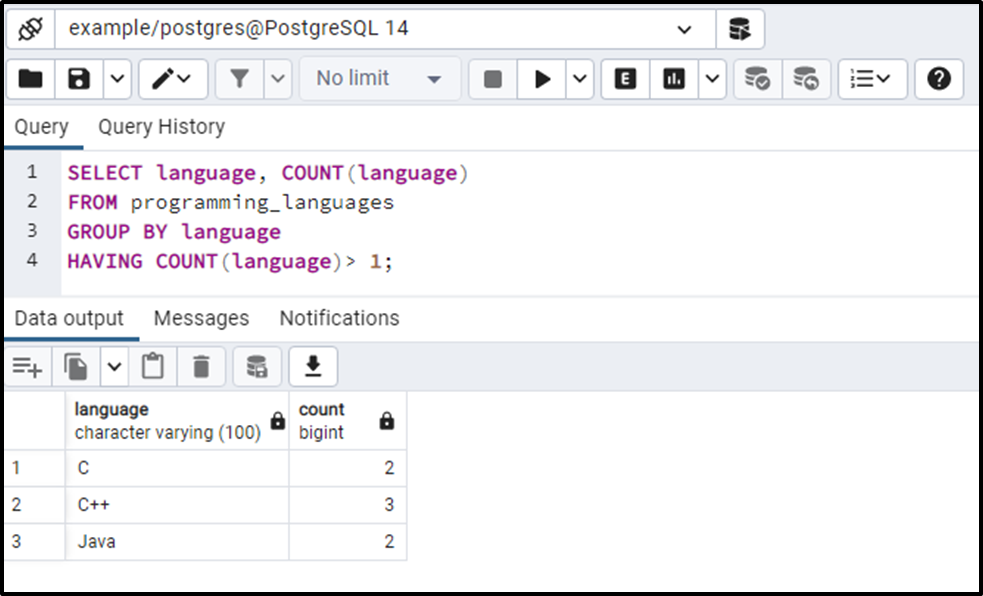
This way, you can find the duplicate rows using the COUNT() function.
How to Delete Duplicates in Postgres Using a DELETE USING Statement?
To delete duplicate rows from a table, use the below statement:
DELETE FROM programming_languages dup_lang USING programming_languages dist_lang WHERE dup_lang.id < dist_lang.id AND dup_lang.language = dist_lang.language;
The above snippet performs the following tasks:
— Joined the programming_languages table to itself.
— Checked if two records (dup_lan.id < dist_lang.id) have the same value in the language column.
— If yes, then the duplicated record will be deleted.
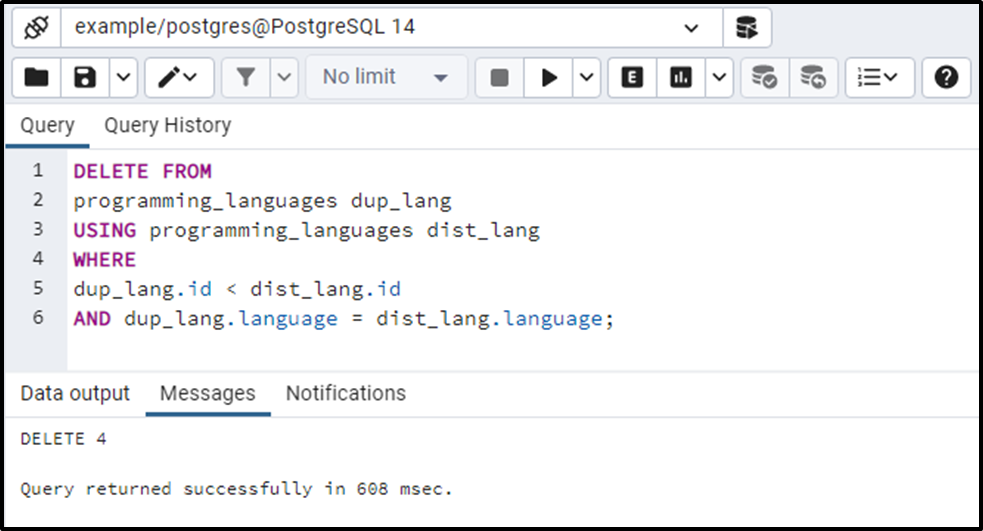
The output shows that four rows(duplicate) have been deleted from the programming_languages table. Let’s confirm the rows(duplicate) deletion using the below command:
SELECT * FROM programming_languages;
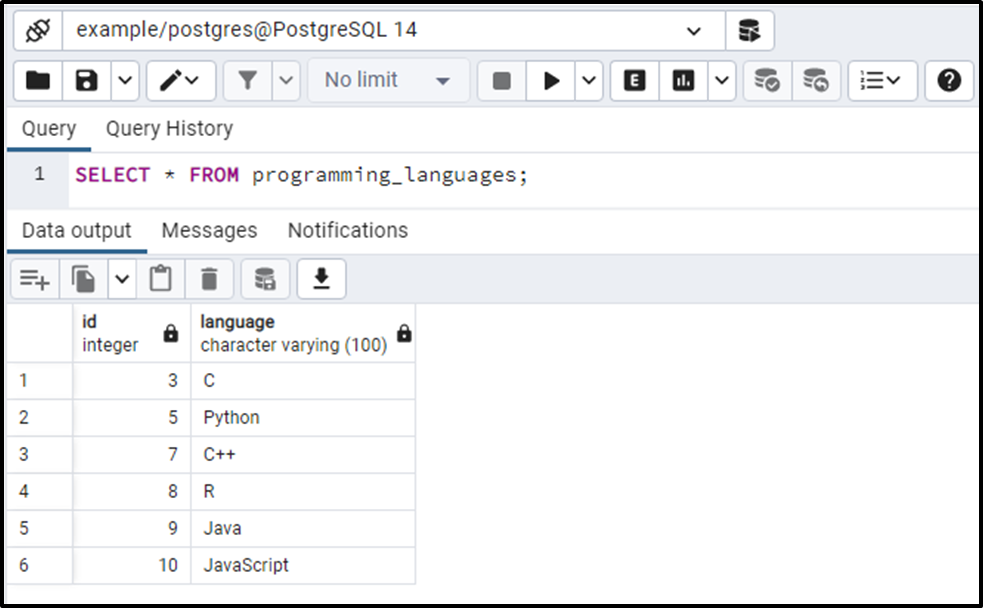
The output shows that the programming_languages table contains only unique languages. It proves that the duplicated rows have been deleted successfully.
As you can see from the output, the DELETE USING query deletes the languages with low IDs and retains the languages with high IDs. If you want the languages with high ids instead of low ids then use the “>” sign in the WHERE clause:
DELETE FROM programming_languages dup_lang USING programming_languages dist_lang WHERE dup_lang.id > dist_lang.id AND dup_lang.language = dist_lang.language;
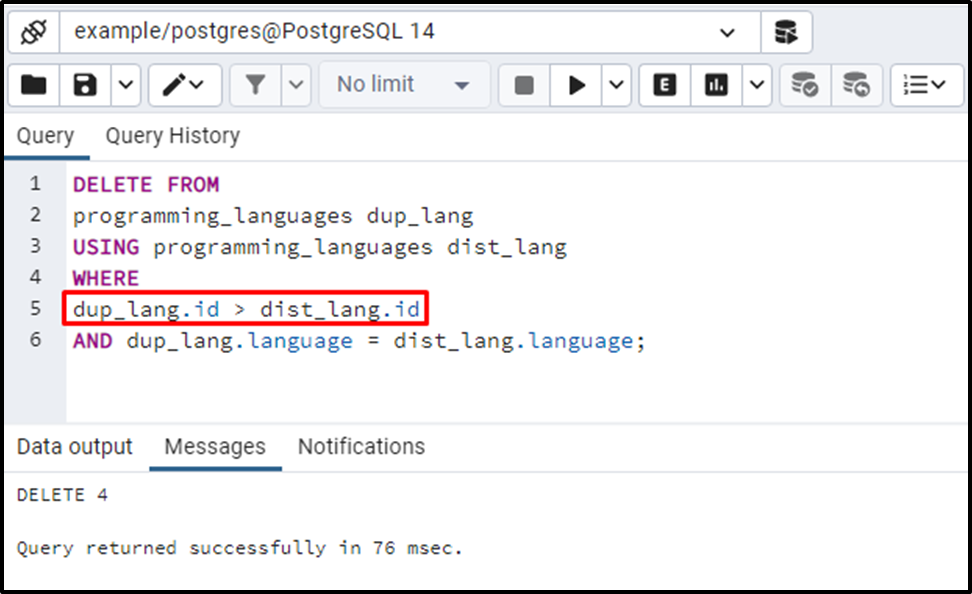
Let’s confirm the deletion of the rows using the below command:
SELECT * FROM programming_languages;
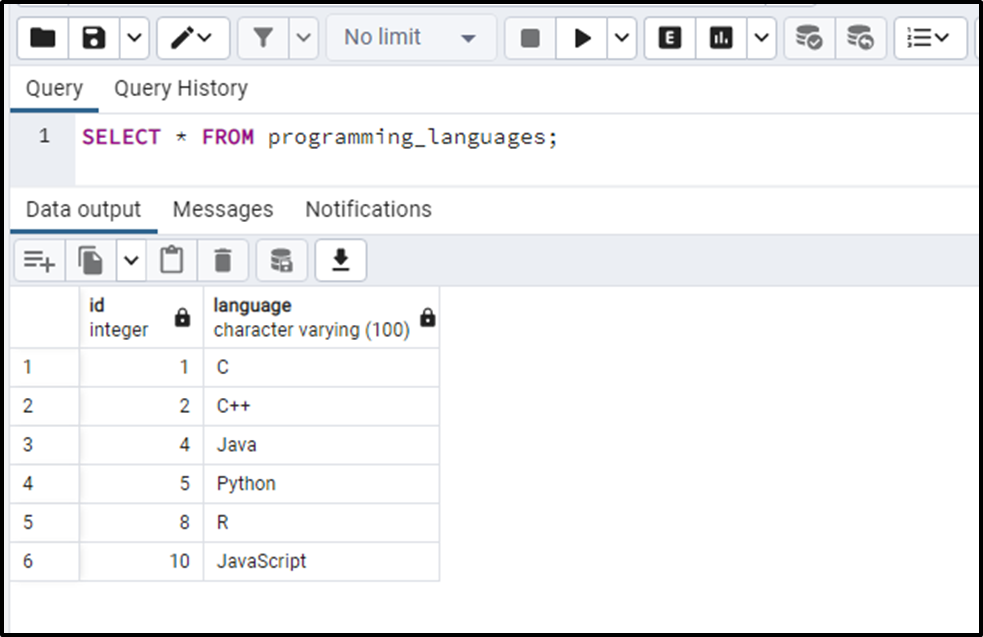
This time the DELETE USING statement deletes the duplicates with high ids.
How to Delete Duplicate Rows Using Subquery in PostgreSQL?
Run the following query for deleting duplicate rows from a table by employing a subquery:
DELETE FROM programming_languages WHERE id IN (SELECT id FROM (SELECT id, ROW_NUMBER() OVER(PARTITION BY language ORDER BY id ASC) AS row_num FROM programming_languages) lang WHERE lang.row_num > 1 );
The above-given query will perform the following functionalities:
— Use a subquery in the WHERE clause.
— Within the subquery, each row of a result set will have a unique integer value assigned by the ROW_NUMBER() function.
— Subquery will return the duplicate records except for the first row.
— The DELETE FROM query will delete the duplicates that are returned by the subquery.
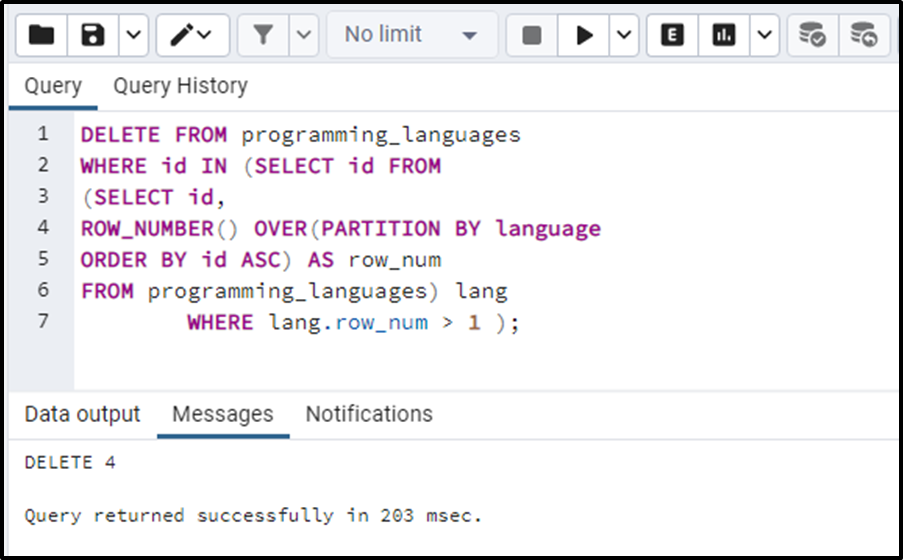
The above query will delete the duplicates with low ids. Let’s run the SELECT statement to confirm the working of the above query:
SELECT * FROM programming_languages;
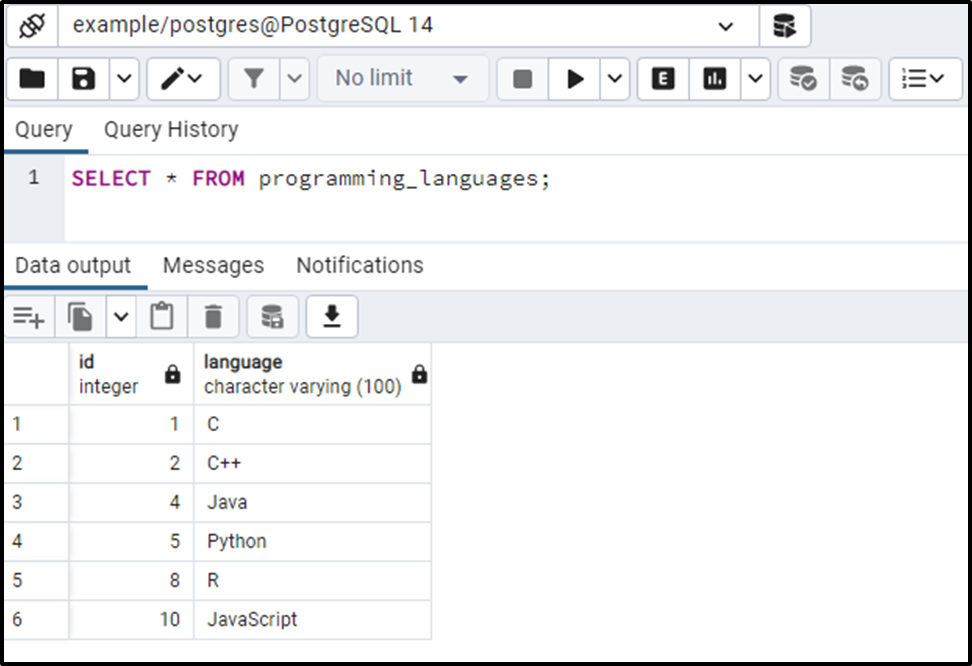
As you can see from the output, the result set does not contain any duplicate records. To retain records with the greatest ID, specify the DESC in the ORDER BY clause.
How to Delete Duplicate Rows Using Immediate Tables in PostgreSQL?
In Postgres, you can use the immediate tables to delete duplicate rows. For better understanding, follow the below-listed stepwise procedure:
Step 1: Create a Table
Firstly, you have to create a table having the same structure as the targeted table (programming_languages). To do this, run the below command:
CREATE TABLE temp_table (LIKE programming_languages);
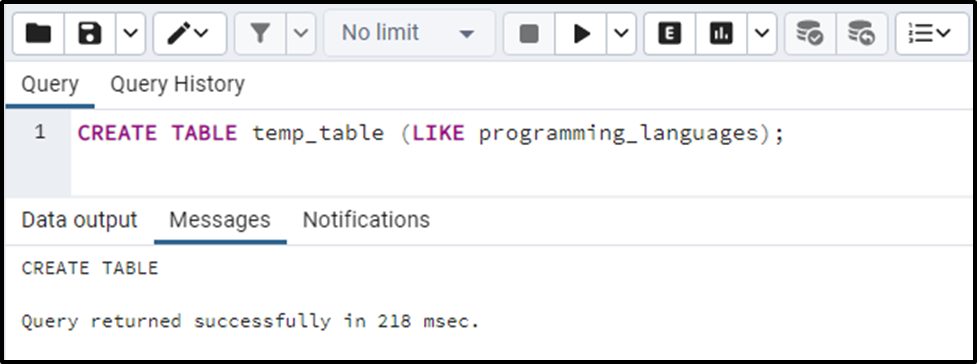
Let’s check the newly created table’s structure using the SELECT command:
SELECT * FROM temp_table;
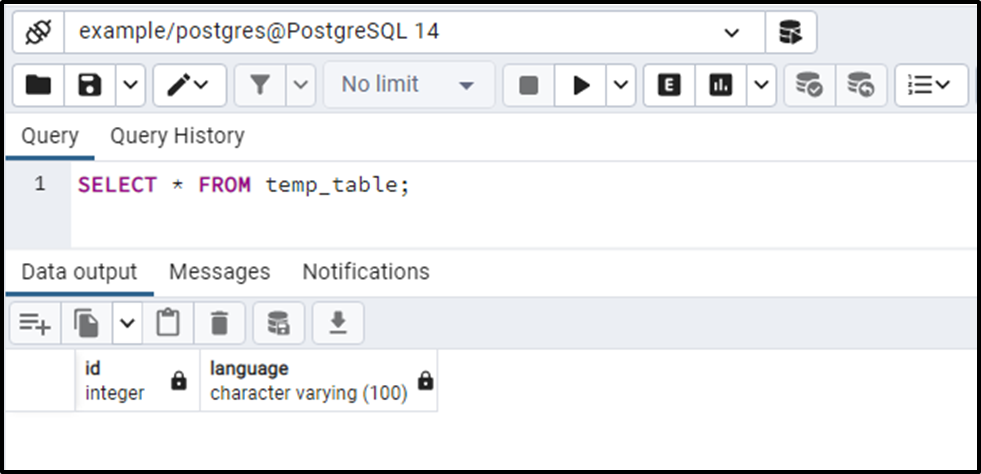
The output verifies that the temp_table has the same structure as the programming_languages table.
Step 2: Insert Distinct Records to the temp_table
Let’s insert the distinct rows from the programming_languages(source) table to the newly created table using the following command:
INSERT INTO temp_table(id, language) SELECT DISTINCT ON (language) id, language FROM programming_languages;
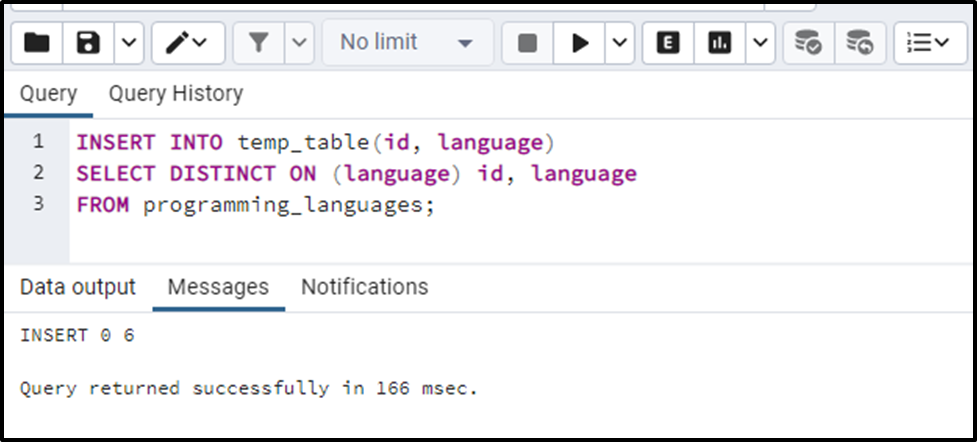
Let’s verify the table’s records using the below-given query:
SELECT * FROM temp_table;
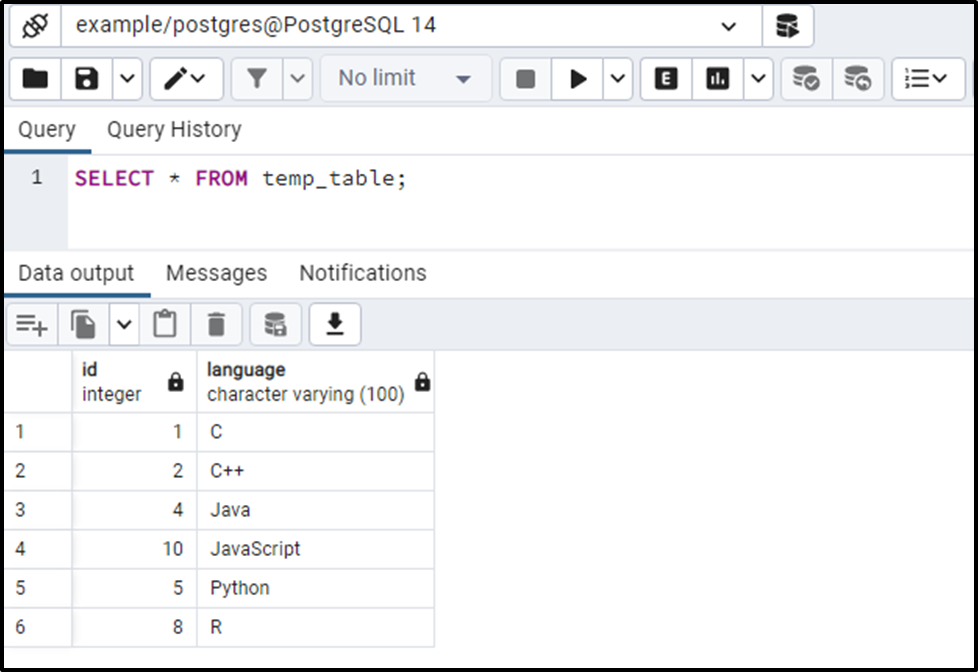
The output shows that the temp_table has only unique records.
Step 3: Drop the Source Table
Use the DROP TABLE command to drop the source table (i.e. programming_languages):
DROP TABLE programming_languages;
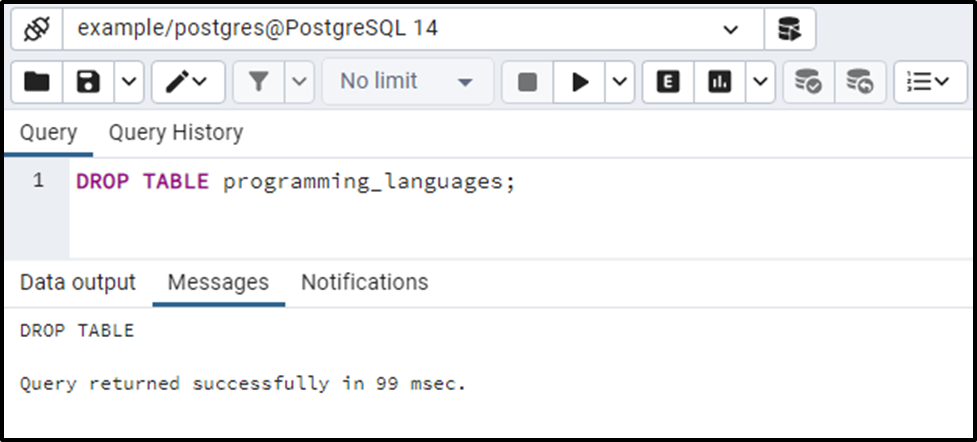
The source table has been dropped successfully.
Step 4: Rename the temp_table to the programming_languages
Utilize the ALTER TABLE statement for renaming the temp_table to the programming_languages:
ALTER TABLE temp_table RENAME TO programming_languages;
Let’s run the above statement to verify weather the temp_table has been renamed to programming_languages or not:
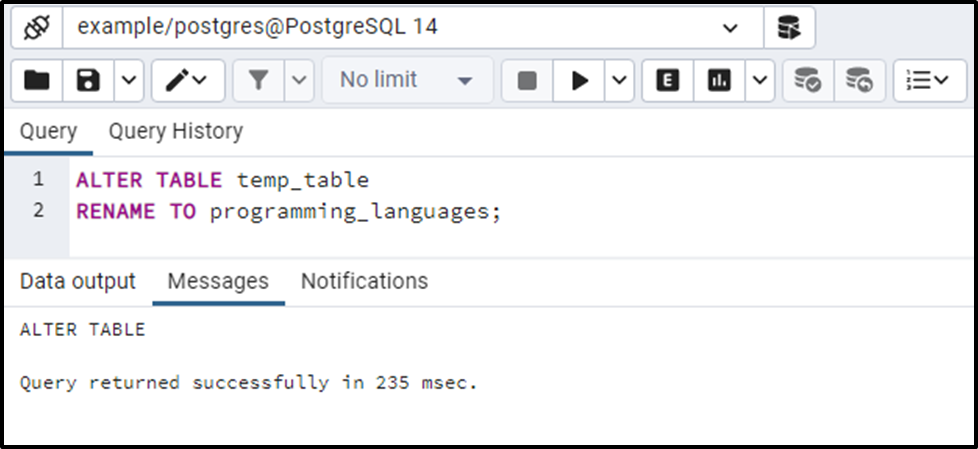
The temp_table has been altered successfully. Here are the details of programming_languages table:
SELECT * FROM programming_languages;
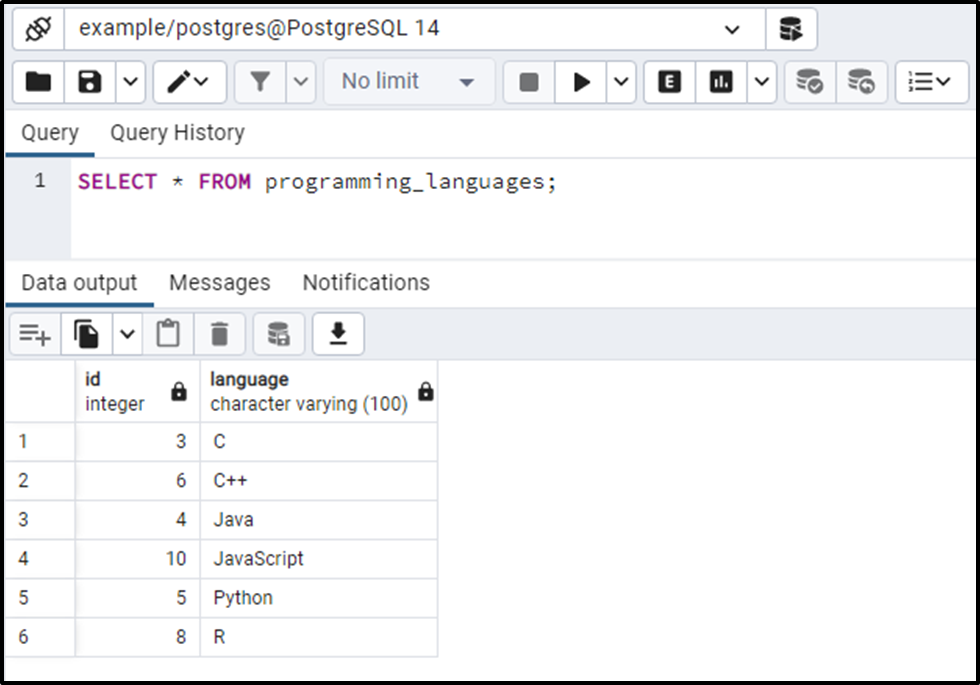
This way you can find and delete the duplicate rows from a table in PostgreSQL.
Conclusion
PostgreSQL offers multiple ways to find and delete duplicate rows. For finding the duplicates, we can utilize the Postgres COUNT() function. While to remove duplicate rows, we can use the “DELETE USING” Statement, subquery, or Postgres immediate Table. This write-up explained each method with practical examples.