Exponential smoothing is a rule of thumb technique for smoothing time series data using the exponential window function. Whereas in the simple moving average the past observations are weighted equally, exponential functions are used to assign exponentially decreasing weights over time. It is an easily learned and easily applied procedure for making some determination based on prior assumptions by the user, such as seasonality. Exponential smoothing is often used for analysis of time-series data.
Exponential smoothing is one of many window functions commonly applied to smooth data in signal processing, acting as low-pass filters to remove high-frequency noise. This method is preceded by Poisson’s use of recursive exponential window functions in convolutions from the 19th century, as well as Kolmogorov and Zurbenko’s use of recursive moving averages from their studies of turbulence in the 1940s.
The raw data sequence is often represented by  beginning at time
beginning at time  , and the output of the exponential smoothing algorithm is commonly written as
, and the output of the exponential smoothing algorithm is commonly written as  , which may be regarded as a best estimate of what the next value of
, which may be regarded as a best estimate of what the next value of  will be. When the sequence of observations begins at time , the simplest form of exponential smoothing is given by the formulas:[1]
will be. When the sequence of observations begins at time , the simplest form of exponential smoothing is given by the formulas:[1]

where  is the smoothing factor, and
is the smoothing factor, and  .
.
Basic (simple) exponential smoothing[edit]
The use of the exponential window function is first attributed to Poisson[2] as an extension of a numerical analysis technique from the 17th century, and later adopted by the signal processing community in the 1940s. Here, exponential smoothing is the application of the exponential, or Poisson, window function. Exponential smoothing was first suggested in the statistical literature without citation to previous work by Robert Goodell Brown in 1956,[3] and then expanded by Charles C. Holt in 1957.[4] The formulation below, which is the one commonly used, is attributed to Brown and is known as «Brown’s simple exponential smoothing».[5] All the methods of Holt, Winters and Brown may be seen as a simple application of recursive filtering, first found in the 1940s[2] to convert finite impulse response (FIR) filters to infinite impulse response filters.
The simplest form of exponential smoothing is given by the formula:

where is the smoothing factor, and  . In other words, the smoothed statistic
. In other words, the smoothed statistic  is a simple weighted average of the current observation
is a simple weighted average of the current observation  and the previous smoothed statistic
and the previous smoothed statistic  . Simple exponential smoothing is easily applied, and it produces a smoothed statistic as soon as two observations are available.
. Simple exponential smoothing is easily applied, and it produces a smoothed statistic as soon as two observations are available.
The term smoothing factor applied to here is something of a misnomer, as larger values of actually reduce the level of smoothing, and in the limiting case with = 1 the output series is just the current observation. Values of close to one have less of a smoothing effect and give greater weight to recent changes in the data, while values of closer to zero have a greater smoothing effect and are less responsive to recent changes.
There is no formally correct procedure for choosing . Sometimes the statistician’s judgment is used to choose an appropriate factor. Alternatively, a statistical technique may be used to optimize the value of . For example, the method of least squares might be used to determine the value of for which the sum of the quantities  is minimized.[6]
is minimized.[6]
Unlike some other smoothing methods, such as the simple moving average, this technique does not require any minimum number of observations to be made before it begins to produce results. In practice, however, a «good average» will not be achieved until several samples have been averaged together; for example, a constant signal will take approximately  stages to reach 95% of the actual value. To accurately reconstruct the original signal without information loss, all stages of the exponential moving average must also be available, because older samples decay in weight exponentially. This is in contrast to a simple moving average, in which some samples can be skipped without as much loss of information due to the constant weighting of samples within the average. If a known number of samples will be missed, one can adjust a weighted average for this as well, by giving equal weight to the new sample and all those to be skipped.
stages to reach 95% of the actual value. To accurately reconstruct the original signal without information loss, all stages of the exponential moving average must also be available, because older samples decay in weight exponentially. This is in contrast to a simple moving average, in which some samples can be skipped without as much loss of information due to the constant weighting of samples within the average. If a known number of samples will be missed, one can adjust a weighted average for this as well, by giving equal weight to the new sample and all those to be skipped.
This simple form of exponential smoothing is also known as an exponentially weighted moving average (EWMA). Technically it can also be classified as an autoregressive integrated moving average (ARIMA) (0,1,1) model with no constant term.[7]
Time constant[edit]
The time constant of an exponential moving average is the amount of time for the smoothed response of a unit step function to reach  of the original signal. The relationship between this time constant,
of the original signal. The relationship between this time constant,  , and the smoothing factor, , is given by the formula:
, and the smoothing factor, , is given by the formula:
 , thus
, thus


where  is the sampling time interval of the discrete time implementation. If the sampling time is fast compared to the time constant (
is the sampling time interval of the discrete time implementation. If the sampling time is fast compared to the time constant ( ) then
) then

Choosing the initial smoothed value[edit]
Note that in the definition above,  is being initialized to
is being initialized to  . Because exponential smoothing requires that at each stage we have the previous forecast, it is not obvious how to get the method started. We could assume that the initial forecast is equal to the initial value of demand; however, this approach has a serious drawback. Exponential smoothing puts substantial weight on past observations, so the initial value of demand will have an unreasonably large effect on early forecasts. This problem can be overcome by allowing the process to evolve for a reasonable number of periods (10 or more) and using the average of the demand during those periods as the initial forecast. There are many other ways of setting this initial value, but it is important to note that the smaller the value of , the more sensitive your forecast will be on the selection of this initial smoother value .[8][9]
. Because exponential smoothing requires that at each stage we have the previous forecast, it is not obvious how to get the method started. We could assume that the initial forecast is equal to the initial value of demand; however, this approach has a serious drawback. Exponential smoothing puts substantial weight on past observations, so the initial value of demand will have an unreasonably large effect on early forecasts. This problem can be overcome by allowing the process to evolve for a reasonable number of periods (10 or more) and using the average of the demand during those periods as the initial forecast. There are many other ways of setting this initial value, but it is important to note that the smaller the value of , the more sensitive your forecast will be on the selection of this initial smoother value .[8][9]
Optimization[edit]
For every exponential smoothing method we also need to choose the value for the smoothing parameters. For simple exponential smoothing, there is only one smoothing parameter (α), but for the methods that follow there is usually more than one smoothing parameter.
There are cases where the smoothing parameters may be chosen in a subjective manner – the forecaster specifies the value of the smoothing parameters based on previous experience. However, a more robust and objective way to obtain values for the unknown parameters included in any exponential smoothing method is to estimate them from the observed data.
The unknown parameters and the initial values for any exponential smoothing method can be estimated by minimizing the sum of squared errors (SSE). The errors are specified as  for
for  (the one-step-ahead within-sample forecast errors). Hence we find the values of the unknown parameters and the initial values that minimize
(the one-step-ahead within-sample forecast errors). Hence we find the values of the unknown parameters and the initial values that minimize
- [10]

Unlike the regression case (where we have formulae to directly compute the regression coefficients which minimize the SSE) this involves a non-linear minimization problem and we need to use an optimization tool to perform this.
«Exponential» naming[edit]
The name ‘exponential smoothing’ is attributed to the use of the exponential window function during convolution. It is no longer attributed to Holt, Winters & Brown.
By direct substitution of the defining equation for simple exponential smoothing back into itself we find that
![{displaystyle {begin{aligned}s_{t}&=alpha x_{t}+(1-alpha )s_{t-1}\[3pt]&=alpha x_{t}+alpha (1-alpha )x_{t-1}+(1-alpha )^{2}s_{t-2}\[3pt]&=alpha left[x_{t}+(1-alpha )x_{t-1}+(1-alpha )^{2}x_{t-2}+(1-alpha )^{3}x_{t-3}+cdots +(1-alpha )^{t-1}x_{1}right]+(1-alpha )^{t}x_{0}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/08e0741e7160744aaff5c671b60bc05f0be172fb)
In other words, as time passes the smoothed statistic becomes the weighted average of a greater and greater number of the past observations  , and the weights assigned to previous observations are proportional to the terms of the geometric progression
, and the weights assigned to previous observations are proportional to the terms of the geometric progression

A geometric progression is the discrete version of an exponential function, so this is where the name for this smoothing method originated according to Statistics lore.
Comparison with moving average[edit]
Exponential smoothing and moving average have similar defects of introducing a lag relative to the input data. While this can be corrected by shifting the result by half the window length for a symmetrical kernel, such as a moving average or gaussian, it is unclear how appropriate this would be for exponential smoothing. They also both have roughly the same distribution of forecast error when α = 2/(k + 1). They differ in that exponential smoothing takes into account all past data, whereas moving average only takes into account k past data points. Computationally speaking, they also differ in that moving average requires that the past k data points, or the data point at lag k + 1 plus the most recent forecast value, to be kept, whereas exponential smoothing only needs the most recent forecast value to be kept.[11]
In the signal processing literature, the use of non-causal (symmetric) filters is commonplace, and the exponential window function is broadly used in this fashion, but a different terminology is used: exponential smoothing is equivalent to a first-order infinite-impulse response (IIR) filter and moving average is equivalent to a finite impulse response filter with equal weighting factors.
Double exponential smoothing (Holt linear)[edit]
Simple exponential smoothing does not do well when there is a trend in the data. [1] In such situations, several methods were devised under the name «double exponential smoothing» or «second-order exponential smoothing,» which is the recursive application of an exponential filter twice, thus being termed «double exponential smoothing». This nomenclature is similar to quadruple exponential smoothing, which also references its recursion depth.[12]
The basic idea behind double exponential smoothing is to introduce a term to take into account the possibility of a series exhibiting some form of trend. This slope component is itself updated via exponential smoothing.
One method, works as follows:[13]
Again, the raw data sequence of observations is represented by , beginning at time . We use to represent the smoothed value for time  , and
, and  is our best estimate of the trend at time . The output of the algorithm is now written as
is our best estimate of the trend at time . The output of the algorithm is now written as  , an estimate of the value of
, an estimate of the value of  at time
at time  based on the raw data up to time . Double exponential smoothing is given by the formulas
based on the raw data up to time . Double exponential smoothing is given by the formulas

And for  by
by

where () is the data smoothing factor, and  (
( ) is the trend smoothing factor.
) is the trend smoothing factor.
To forecast beyond is given by the approximation:

Setting the initial value  is a matter of preference. An option other than the one listed above is
is a matter of preference. An option other than the one listed above is  for some
for some  .
.
Note that F0 is undefined (there is no estimation for time 0), and according to the definition F1=s0+b0, which is well defined, thus further values can be evaluated.
A second method, referred to as either Brown’s linear exponential smoothing (LES) or Brown’s double exponential smoothing works as follows.[14]

where at, the estimated level at time t and bt, the estimated trend at time t are:
![{displaystyle {begin{aligned}a_{t}&=2s'_{t}-s''_{t}\[5pt]b_{t}&={frac {alpha }{1-alpha }}(s'_{t}-s''_{t}).end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/496559e07c278001d2b3e1cf46743c3c4f9cae7c)
Triple exponential smoothing (Holt Winters)[edit]
Triple exponential smoothing applies exponential smoothing three times, which is commonly used when there are three high frequency signals to be removed from a time series under study. There are different types of seasonality: ‘multiplicative’ and ‘additive’ in nature, much like addition and multiplication are basic operations in mathematics.
If every month of December we sell 10,000 more apartments than we do in November the seasonality is additive in nature. However, if we sell 10% more apartments in the summer months than we do in the winter months the seasonality is multiplicative in nature. Multiplicative seasonality can be represented as a constant factor, not an absolute amount.
[15]
Triple exponential smoothing was first suggested by Holt’s student, Peter Winters, in 1960 after reading a signal processing book from the 1940s on exponential smoothing.[16] Holt’s novel idea was to repeat filtering an odd number of times greater than 1 and less than 5, which was popular with scholars of previous eras.[16] While recursive filtering had been used previously, it was applied twice and four times to coincide with the Hadamard conjecture, while triple application required more than double the operations of singular convolution. The use of a triple application is considered a rule of thumb technique, rather than one based on theoretical foundations and has often been over-emphasized by practitioners.
—
Suppose we have a sequence of observations , beginning at time with a cycle of seasonal change of length  .
.
The method calculates a trend line for the data as well as seasonal indices that weight the values in the trend line based on where that time point falls in the cycle of length .
Let represent the smoothed value of the constant part for time , is the sequence of best estimates of the linear trend that are superimposed on the seasonal changes, and  is the sequence of seasonal correction factors. We wish to estimate at every time mod in the cycle that the observations take on. As a rule of thumb, a minimum of two full seasons (or
is the sequence of seasonal correction factors. We wish to estimate at every time mod in the cycle that the observations take on. As a rule of thumb, a minimum of two full seasons (or  periods) of historical data is needed to initialize a set of seasonal factors.
periods) of historical data is needed to initialize a set of seasonal factors.
The output of the algorithm is again written as , an estimate of the value of at time  based on the raw data up to time . Triple exponential smoothing with multiplicative seasonality is given by the formulas[1]
based on the raw data up to time . Triple exponential smoothing with multiplicative seasonality is given by the formulas[1]
![{displaystyle {begin{aligned}s_{0}&=x_{0}\[5pt]s_{t}&=alpha {frac {x_{t}}{c_{t-L}}}+(1-alpha )(s_{t-1}+b_{t-1})\[5pt]b_{t}&=beta (s_{t}-s_{t-1})+(1-beta )b_{t-1}\[5pt]c_{t}&=gamma {frac {x_{t}}{s_{t}}}+(1-gamma )c_{t-L}\[5pt]F_{t+m}&=(s_{t}+mb_{t})c_{t-L+1+(m-1){bmod {L}}},end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cee3212f28cf23aad40563caab52147a225fd2a8)
where () is the data smoothing factor, () is the trend smoothing factor, and  (
( ) is the seasonal change smoothing factor.
) is the seasonal change smoothing factor.
The general formula for the initial trend estimate is:

Setting the initial estimates for the seasonal indices  for
for  is a bit more involved. If
is a bit more involved. If  is the number of complete cycles present in your data, then:
is the number of complete cycles present in your data, then:

where

Note that  is the average value of in the
is the average value of in the  cycle of your data.
cycle of your data.
Triple exponential smoothing with additive seasonality is given by:

Implementations in statistics packages[edit]
- R: the HoltWinters function in the stats package[17] and ets function in the forecast package[18] (a more complete implementation, generally resulting in a better performance[19]).
- Python: the holtwinters module of the statsmodels package allow for simple, double and triple exponential smoothing.
- IBM SPSS includes Simple, Simple Seasonal, Holt’s Linear Trend, Brown’s Linear Trend, Damped Trend, Winters’ Additive, and Winters’ Multiplicative in the Time-Series modeling procedure within its Statistics and Modeler statistical packages. The default Expert Modeler feature evaluates all seven exponential smoothing models and ARIMA models with a range of nonseasonal and seasonal p, d, and q values, and selects the model with the lowest Bayesian Information Criterion statistic.
- Stata: tssmooth command[20]
- LibreOffice 5.2[21]
- Microsoft Excel 2016[22]
See also[edit]
- Autoregressive moving average model (ARMA)
- Errors and residuals in statistics
- Moving average
- Continued fraction
Notes[edit]
- ^ a b c «NIST/SEMATECH e-Handbook of Statistical Methods». NIST. Retrieved 23 May 2010.
- ^ a b Oppenheim, Alan V.; Schafer, Ronald W. (1975). Digital Signal Processing. Prentice Hall. p. 5. ISBN 0-13-214635-5.
- ^ Brown, Robert G. (1956). Exponential Smoothing for Predicting Demand. Cambridge, Massachusetts: Arthur D. Little Inc. p. 15.
- ^ Holt, Charles C. (1957). «Forecasting Trends and Seasonal by Exponentially Weighted Averages». Office of Naval Research Memorandum. 52. reprinted in Holt, Charles C. (January–March 2004). «Forecasting Trends and Seasonal by Exponentially Weighted Averages». International Journal of Forecasting. 20 (1): 5–10. doi:10.1016/j.ijforecast.2003.09.015.
- ^ Brown, Robert Goodell (1963). Smoothing Forecasting and Prediction of Discrete Time Series. Englewood Cliffs, NJ: Prentice-Hall.
- ^ «NIST/SEMATECH e-Handbook of Statistical Methods, 6.4.3.1. Single Exponential Smoothing». NIST. Retrieved 5 July 2017.
- ^ Nau, Robert. «Averaging and Exponential Smoothing Models». Retrieved 26 July 2010.
- ^ «Production and Operations Analysis» Nahmias. 2009.
- ^ Čisar, P., & Čisar, S. M. (2011). «Optimization methods of EWMA statistics.» Acta Polytechnica Hungarica, 8(5), 73–87. Page 78.
- ^ 7.1 Simple exponential smoothing | Forecasting: Principles and Practice.
- ^ Nahmias, Steven (3 March 2008). Production and Operations Analysis (6th ed.). ISBN 978-0-07-337785-8.[page needed]
- ^ «Model: Second-Order Exponential Smoothing». SAP AG. Retrieved 23 January 2013.
- ^ «6.4.3.3. Double Exponential Smoothing». itl.nist.gov. Retrieved 25 September 2011.
- ^ «Averaging and Exponential Smoothing Models». duke.edu. Retrieved 25 September 2011.
- ^ Kalehar, Prajakta S. «Time series Forecasting using Holt–Winters Exponential Smoothing» (PDF). Retrieved 23 June 2014.
- ^ a b Winters, P. R. (April 1960). «Forecasting Sales by Exponentially Weighted Moving Averages». Management Science. 6 (3): 324–342. doi:10.1287/mnsc.6.3.324.
- ^ «R: Holt–Winters Filtering». stat.ethz.ch. Retrieved 5 June 2016.
- ^ «ets {forecast} | inside-R | A Community Site for R». inside-r.org. Archived from the original on 16 July 2016. Retrieved 5 June 2016.
- ^ «Comparing HoltWinters() and ets()». Hyndsight. 29 May 2011. Retrieved 5 June 2016.
- ^ tssmooth in Stata manual
- ^ «LibreOffice 5.2: Release Notes – the Document Foundation Wiki».
- ^ «Excel 2016 Forecasting Functions | Real Statistics Using Excel».
External links[edit]
- Lecture notes on exponential smoothing (Robert Nau, Duke University)
- Data Smoothing by Jon McLoone, The Wolfram Demonstrations Project
- The Holt–Winters Approach to Exponential Smoothing: 50 Years Old and Going Strong by Paul Goodwin (2010) Foresight: The International Journal of Applied Forecasting
- Algorithms for Unevenly Spaced Time Series: Moving Averages and Other Rolling Operators by Andreas Eckner
history 10 января 2021 г.
- Группы статей
Экспоненциальное сглаживание используется для сглаживания краткосрочных колебаний во временных рядах, чтобы облегчить определение долгосрочного тренда, а также для прогнозирования. Произведем экспоненциальное сглаживание с помощью надстройки MS EXCEL Пакет анализа и формулами. Рассмотрим двойное и тройное экспоненциальное сглаживание для прогнозирования рядов с трендом и сезонностью.
Экспоненциальное сглаживание один из наиболее распространённых методов для сглаживания временных рядов. В отличие от метода Скользящего среднего, где прошлые наблюдения имеют одинаковый вес, Экспоненциальное сглаживание присваивает им экспоненциально убывающие веса, по мере того как наблюдения становятся старше. Другими словами, последние наблюдения дают относительно больший вес при прогнозировании, чем старые наблюдения.
Примечание: Перед прочтением этой статьи рекомендуется прочитать про Скользящее среднее.
Примечание: В англоязычной литературе для экспоненциального сглаживания используется термин Single Exponential Smoothing или Simple Exponential Smoothing (SES).
Напомним, что при усреднении методом Скользящего среднего веса, присвоенные наблюдениям, одинаковы и равны 1/n, где n – количество периодов усреднения. Например, в случае усреднения за 3 периода скользящее среднее равно:
Yскол.i=(Yi+ Yi-1+ Yi-2)/3 = Yi/3+ Yi-1/3+ Yi-2/3
В случае Экспоненциального сглаживания формула выглядит следующим образом:
Yэксп.i=альфа*Yi-1+ (1-альфа)*Yэксп.i-1
или
Yэксп.i= Yэксп.i-1 + альфа*(Yi-1 — Yэксп.i-1)
где 0<альфа<1, i>2
Параметр альфа определяет степень сглаживания. При малых значениях альфа (0,1 – 0,2) имеет место сильное сглаживание. При значениях близких к 1, сглаженный ряд практически повторяет исходный ряд с задержкой (лагом) на один период. Для медленно меняющегося ряда часто берут небольшие значения альфа=0,1; а для быстро меняющегося 0,3-0,5.
Примечание: Формулы представляют собой рекуррентное соотношение – это когда последующий член ряда вычисляется на основе предыдущего.
Примечание: Существует альтернативный подход к Экспоненциальному сглаживанию: в нем в формуле вместо Yi-1 заменяют на Yi. Этот подход используется в контрольных картах экспоненциально взвешенного скользящего среднего (EWMA).
Надстройка Пакет анализа
Получить Экспоненциально сглаженный ряд можно с помощью надстройки Пакет анализа (Analysis ToolPak). Надстройка доступна из вкладки Данные, группа Анализ.
СОВЕТ: Подробнее о других инструментах надстройки Пакет анализа и ее подключении – читайте в статье.
Разместим исходный числовой ряд в диапазоне B7:B32.
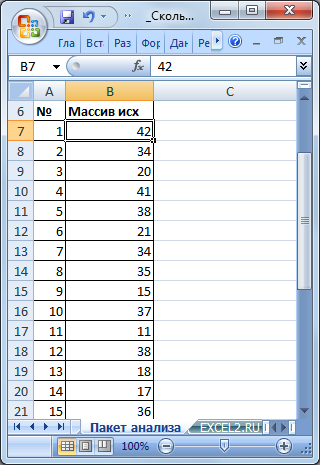
Для наглядности пронумеруем каждое значение ряда (столбец А).
Вызовем надстройку Пакет анализа, выберем инструмент Экспоненциальное сглаживание.
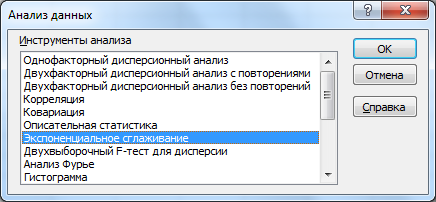
и нажмем ОК.
В появившемся диалоговом окне в поле Входной интервал введите ссылку на диапазон с данными ряда, т.е. на B7:B32.
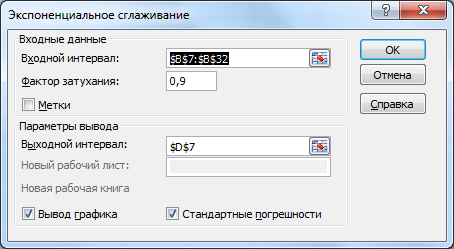
Если диапазон включает и заголовок, то нужно установить галочку в поле Метки. В нашем случае устанавливать галочку не требуется, т.к. заголовок столбца не входит в диапазон B7:B32.
Поле Фактор затухания, как и параметр альфа в вышеуказанной формуле, определяет степень сглаживания ряда. Фактор затухания равен (1- альфа). Чем больше Фактор затухания тем глаже получается ряд. Установим значение 0,8.
В поле Выходной интервал достаточно ввести ссылку на левую верхнюю ячейку диапазона с результатами (укажем ячейку D7).
Также поставим галочки в поле Вывод графика и Стандартные погрешности (будет выведен столбец с расчетами погрешностей, англ. Standard Errors).
Нажмем ОК.
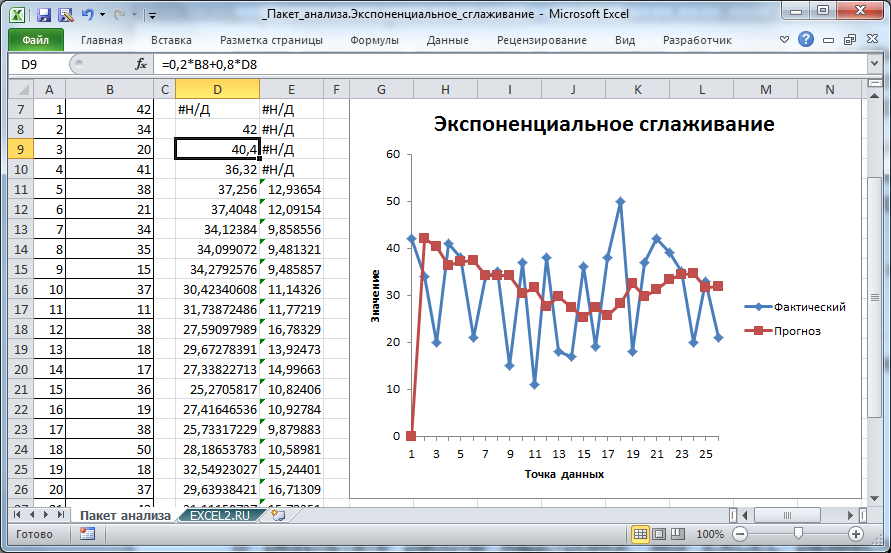
В результате работы надстройки, MS EXCEL разместил значения ряда, полученного методом Экспоненциального сглаживания, в столбце D (см. файл примера лист Пакет анализа).
В ячейке D7 содержится текстовое значение ошибки #Н/Д, т.к. для получения первого значения Экспоненциального сглаживания требуется значение исходного ряда за предыдущий период.
Первое значение сглаженного ряда, точнее формула =B7, содержится в ячейке D8. Второе значение вычисляется с помощью формулы =0,2*B8+0,8*D8.
Таким образом, Фактор затухания (0,8) определяет вес (вклад) предыдущего значения сглаженного ряда. Соответственно, (1-Фактор затухания)=альфа определяет вес предыдущего значения исходного ряда.
Диаграмма
Для отображения рядов MS EXCEL создал диаграмму типа график. Сглаженный ряд на диаграмме называется «Прогноз» (ряд красного цвета).
Первое значение сглаженного ряда, которое равно ошибке #Н/Д, отражаются как 0, и может ввести в заблуждение (особенно, если последующие значения ряда близки к 0). Поэтому его лучше удалить из ячейки D7.
Примечание: Значение #Н/Д в ячейке D7 является просто текстовым значением, что принципиально отличается от результата возвращаемого формулами, например, функцией НД(), хотя визуально они неразличимы. При построении диаграммы текстовые значения всегда отображаются как 0. Но, если ошибка #Н/Д является результатом формулы, то воспринимается диаграммой как пустая ячейка и на ней не отображается.
Диаграмма позволяет визуально определить «выбросы», т.е. значения исходного ряда, которые существенно отличаются от средних значений. Такие «выбросы» могут быть следствием ошибки, но они оказывают существенное влияние на вид сглаженного ряда.
Вычисление погрешности
В столбце E, начиная с ячейки Е11, MS EXCEL разместил формулы для вычисления погрешностей (англ. Standard Errors):
=КОРЕНЬ(СУММКВРАЗН(B8:B10;D8:D10)/3)
Т.е. данная погрешность вычисляется по формуле:
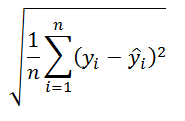
Значения y – это значения исходного ряда в период i. Значения «y с крышечкой» — значения ряда, полученного методом Экспоненциального сглаживания, в тот же в период i. Значение n для экспоненциального сглаживания всегда равно 3, т.е. ошибка вычисляется за 3 последних периода (последние 3 значения учитываются с макимальным весом при расчете текущего значения сглаженного ряда и, соответственно, вносят более 50% вклада в его значение. Величина вклада сильно зависит от альфа).
Подробнее об этой погрешности см. соответствующий раздел в статье про Скользящее среднее.
Почему сглаживание называется экспоненциальным?
Как было показано в статье про Взвешенное скользящее среднее веса значений исходного ряда берутся в зависимости от их удаленности от текущего периода. Например, для 3-х периодов усреднения для Взвешенного скользящего среднего можно использовать формулу:
Yскол.i=0,5*Yi+ 0,4*Yi-1+ 0,1*Yi-2
Экспоненциальное сглаживание по сути является модификацией Взвешенного скользящего среднего – при расчете значения сглаженного ряда используются ВСЕ предыдущие значения исходного ряда с весами уменьшающимися в геометрической прогрессии по мере удаления от текущего периода.
Чтобы это показать воспользуемся формулой
Yэксп.i=альфа*Yi-1+ (1-альфа)*Yэксп.i-1
и вычислим Yэксп.5, т.е. значения сглаженного ряда для 5-го периода. После очевидных преобразований получим:
Yэксп.5=альфа*[(1-альфа)0* Yэксп.4+ (1-альфа)1* Yэксп.3+(1-альфа)2* Yэксп.2] +(1-альфа)3* Y1
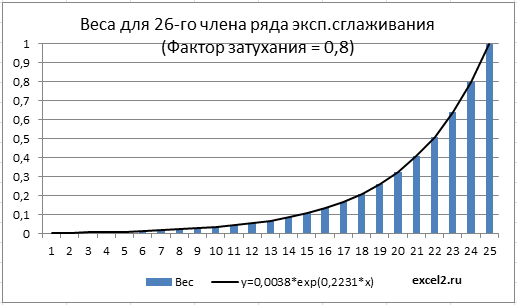
Таким образом, вес 4-го (предыдущего) члена ряда =(1-альфа)0, а вес 3-го =(1-альфа)1 и т.д. Пусть t – текущий период (в нашем случае =5). Вес (t-i)-го члена ряда =(1-альфа)t-1-i. Т.к. (1-альфа)<1, то с ростом i растет и вес, и для члена t-1 достигает максимума =1.
Как известно, экспоненциальный рост y=a*EXP(b*x) в случае дискретной области определения с равными интервалами x называют геометрическим ростом (значения экспоненциальной функции y=a*EXP(b*x) являются в этом случае членами геометрической прогрессии m^x).
В нашем случае, приравняв i-й вес (1-альфа)t-1-i соответствующему значению экспоненциальной функции a*EXP(b*i) получим уравнение, которое позволит вычислить коэффициенты a и b (понадобится еще одно уравнение, например, для i-1 веса).
Решив систему из 2-х уравнений получим, a= EXP((t-1)*LN(1-альфа)) и b= LN(1-альфа).
В файле примера для 26-го члена сглаженного ряда (t=26) вычислены веса всех предыдущих членов. На диаграмме ниже показано, что веса уменьшаются с ростом i в геометрической прогрессии, что соответствует экспоненциальной функции y=0,0038*exp(0,2231*x), где x=i. Вычисления параметров экспоненциальной кривой сделаны с помощью надстройки Поиск решения.
Экспоненциальное сглаживание с настраиваемым Фактором затухания
Недостатком формул, получаемых с помощью Пакета анализа, является то, что при изменении Фактора затухания (1-альфа) приходится перезапускать расчет. В файле примера на листе Формулы создана форма для быстрого пересчета Экспоненциального сглаживания в зависимости от значения Фактора затухания (полученный результат, естественно, полностью совпадает с расчетами надстройки Пакет анализа).
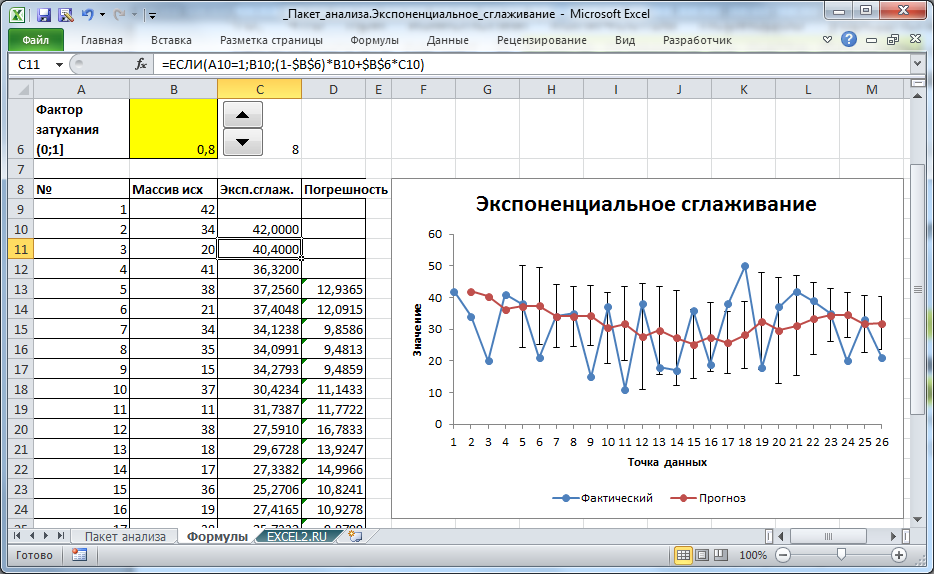
Значения ряда вычисляются с помощью формулы:
=ЕСЛИ(A10=1;B10;(1-$B$6)*B10+$B$6*C10)
в ячейке В6 содержится значение Фактора затухания.
Выбор значения Фактора затухания для удобства осуществляется с помощью элемента управления Счетчик с шагом 0,1.
17 авг. 2022 г.
читать 3 мин
Экспоненциальное сглаживание — это метод «сглаживания» данных временных рядов, который часто используется для краткосрочного прогнозирования.
Основная идея заключается в том, что данные временных рядов часто имеют связанный с ними «случайный шум», который приводит к пикам и впадинам в данных, но, применяя экспоненциальное сглаживание, мы можем сгладить эти пики и впадины, чтобы увидеть истинную основную тенденцию данных. .
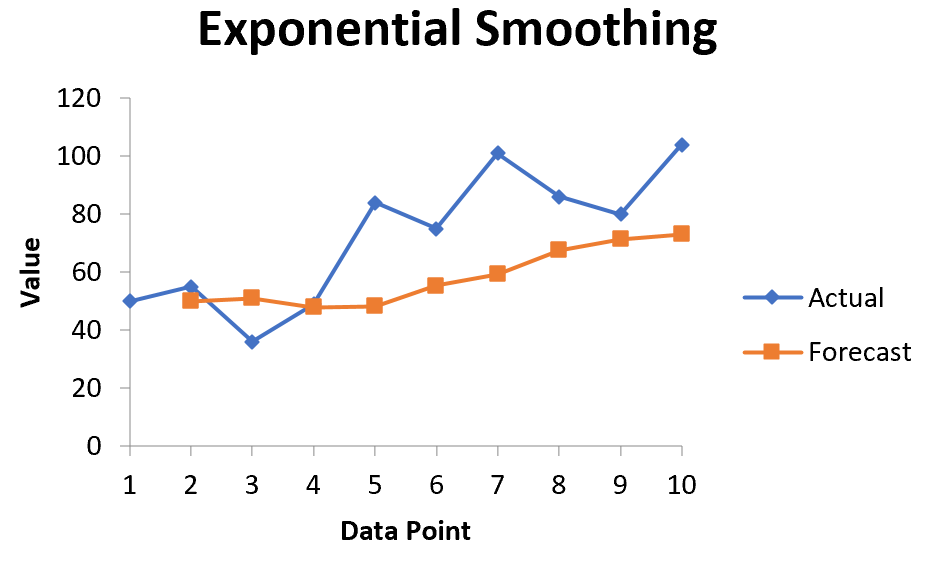
Основная формула для применения экспоненциального сглаживания выглядит следующим образом:
F t = αy t-1 + (1 – α) F t-1
куда:
F t = прогнозируемое значение для текущего периода времени t
α = значение константы сглаживания в диапазоне от 0 до 1.
y t-1 = Фактическое значение данных за предыдущий период времени
F t-1 = Прогнозируемое значение для предыдущего периода времени t-1
Чем меньше значение альфа, тем больше сглаживаются данные временного ряда.
В этом руководстве мы покажем, как выполнить экспоненциальное сглаживание данных временных рядов с помощью встроенной функции в Excel.
Пример: экспоненциальное сглаживание в Excel
Предположим, у нас есть следующий набор данных, который показывает продажи конкретной компании за 10 периодов продаж:
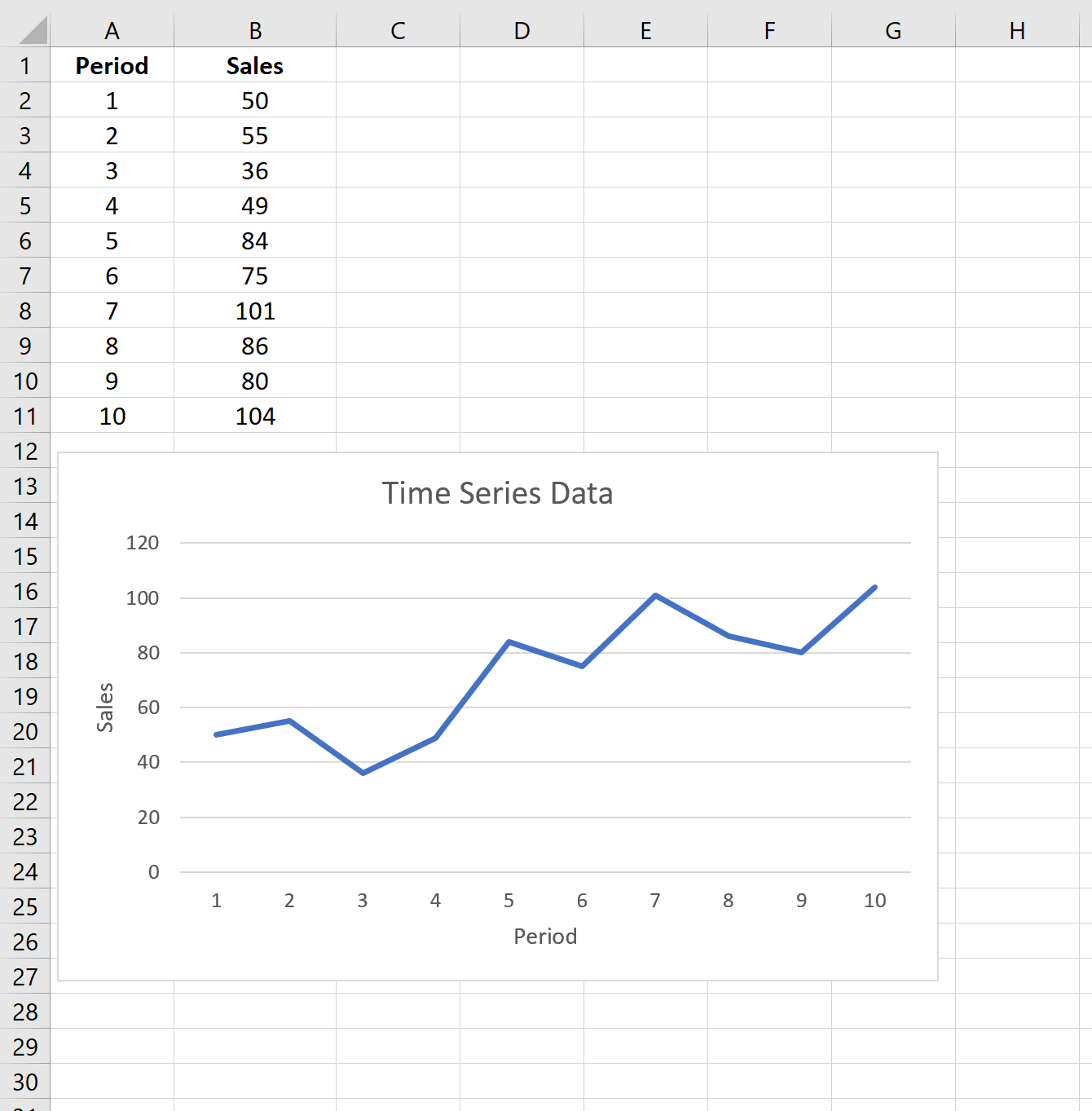
Выполните следующие шаги, чтобы применить экспоненциальное сглаживание к этим данным временного ряда.
Шаг 1: Нажмите кнопку «Анализ данных».
Перейдите на вкладку «Данные» на верхней ленте и нажмите кнопку «Анализ данных». Если вы не видите эту кнопку, вам нужно сначала загрузить Excel Analysis ToolPak , который можно использовать совершенно бесплатно.

Шаг 2: Выберите параметр «Экспоненциальное сглаживание» и нажмите «ОК».
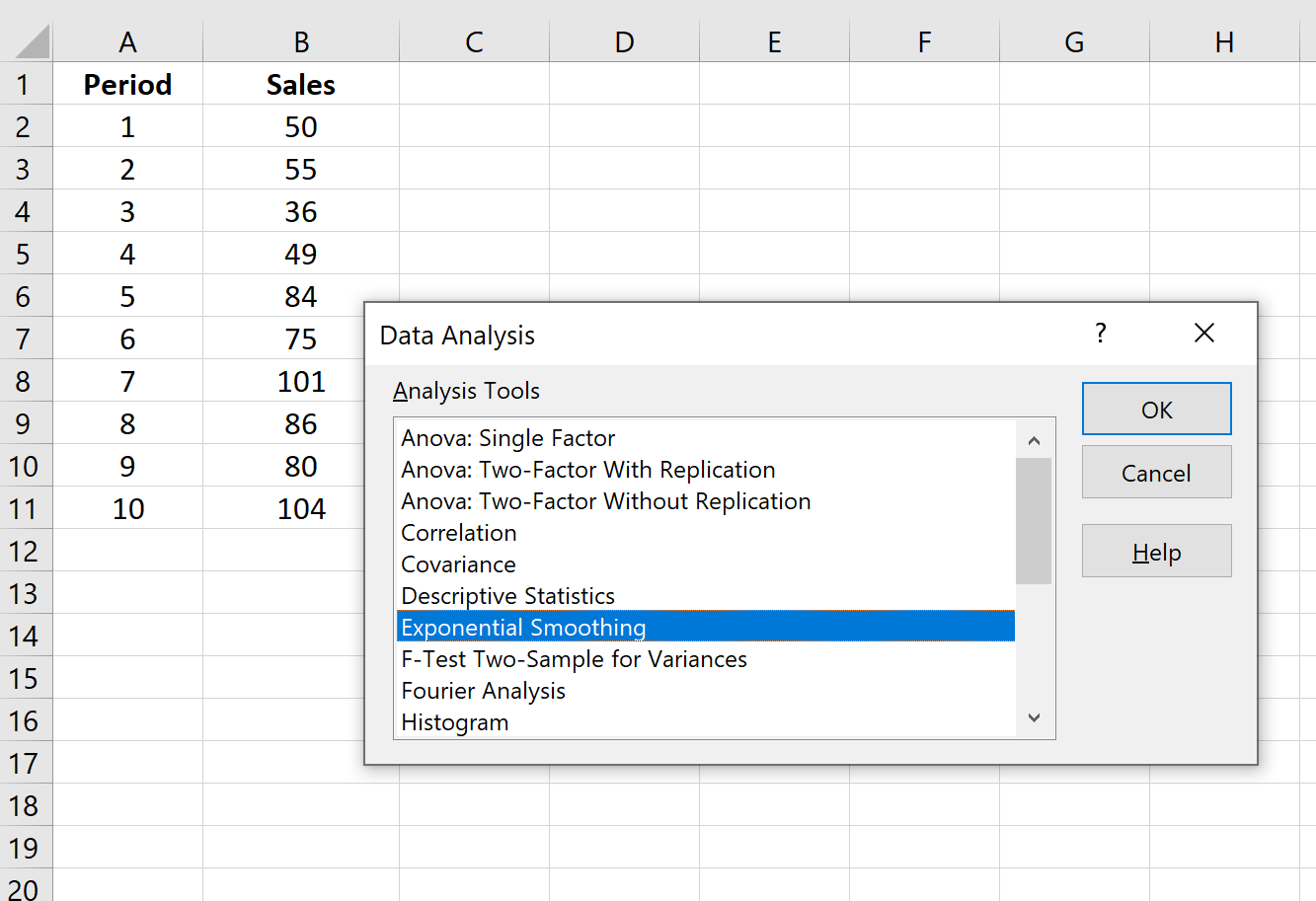
Шаг 3: Заполните необходимые значения.
- Заполните значения данных для Input Range .
- Выберите значение, которое вы хотели бы использовать для коэффициента затухания , которое равно 1-α. Если вы хотите использовать α = 0,2, то ваш коэффициент демпфирования будет 1-0,2 = 0,8.
- Выберите выходной диапазон , в котором должны отображаться прогнозируемые значения. Рекомендуется выбрать этот выходной диапазон рядом с вашими фактическими значениями данных, чтобы вы могли легко сравнивать фактические значения и прогнозируемые значения рядом друг с другом.
- Если вы хотите увидеть диаграмму с фактическими и прогнозируемыми значениями, установите флажок « Вывод диаграммы ».
Затем нажмите ОК.
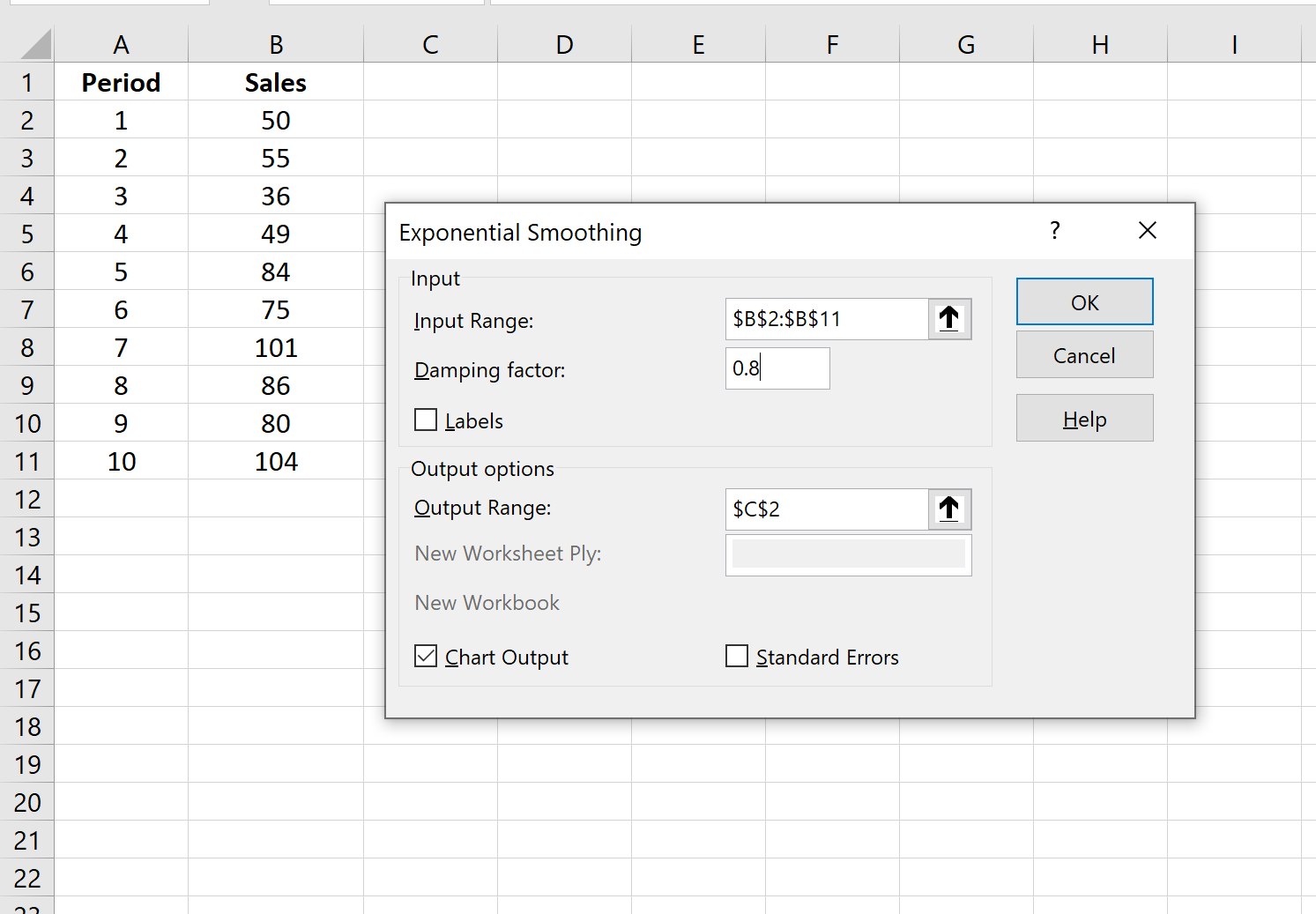
Автоматически появится список прогнозируемых значений и диаграмма:
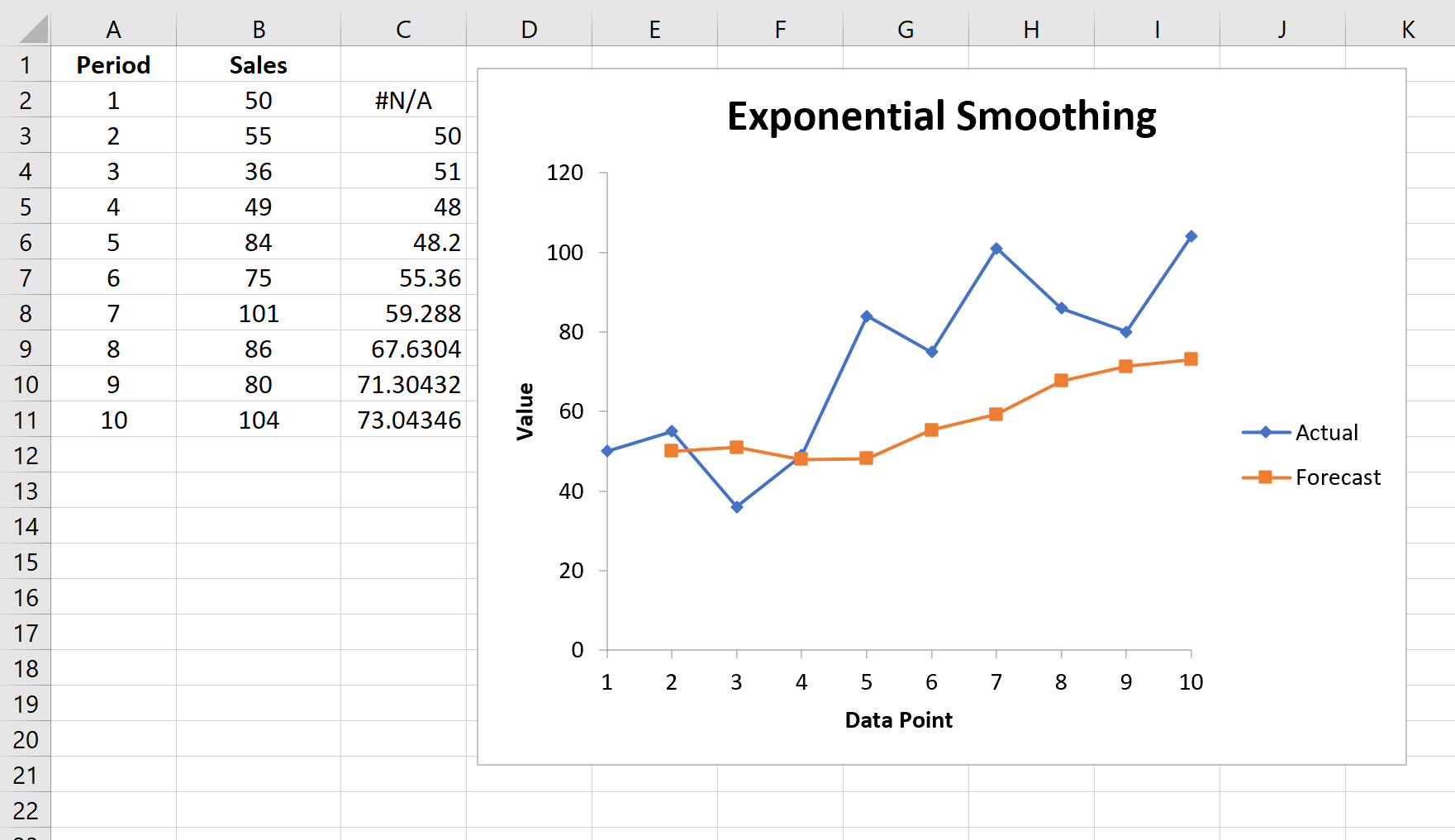
Обратите внимание, что первый период времени имеет значение #N/A, поскольку нет предыдущего периода времени, который можно было бы использовать для расчета прогнозируемого значения.
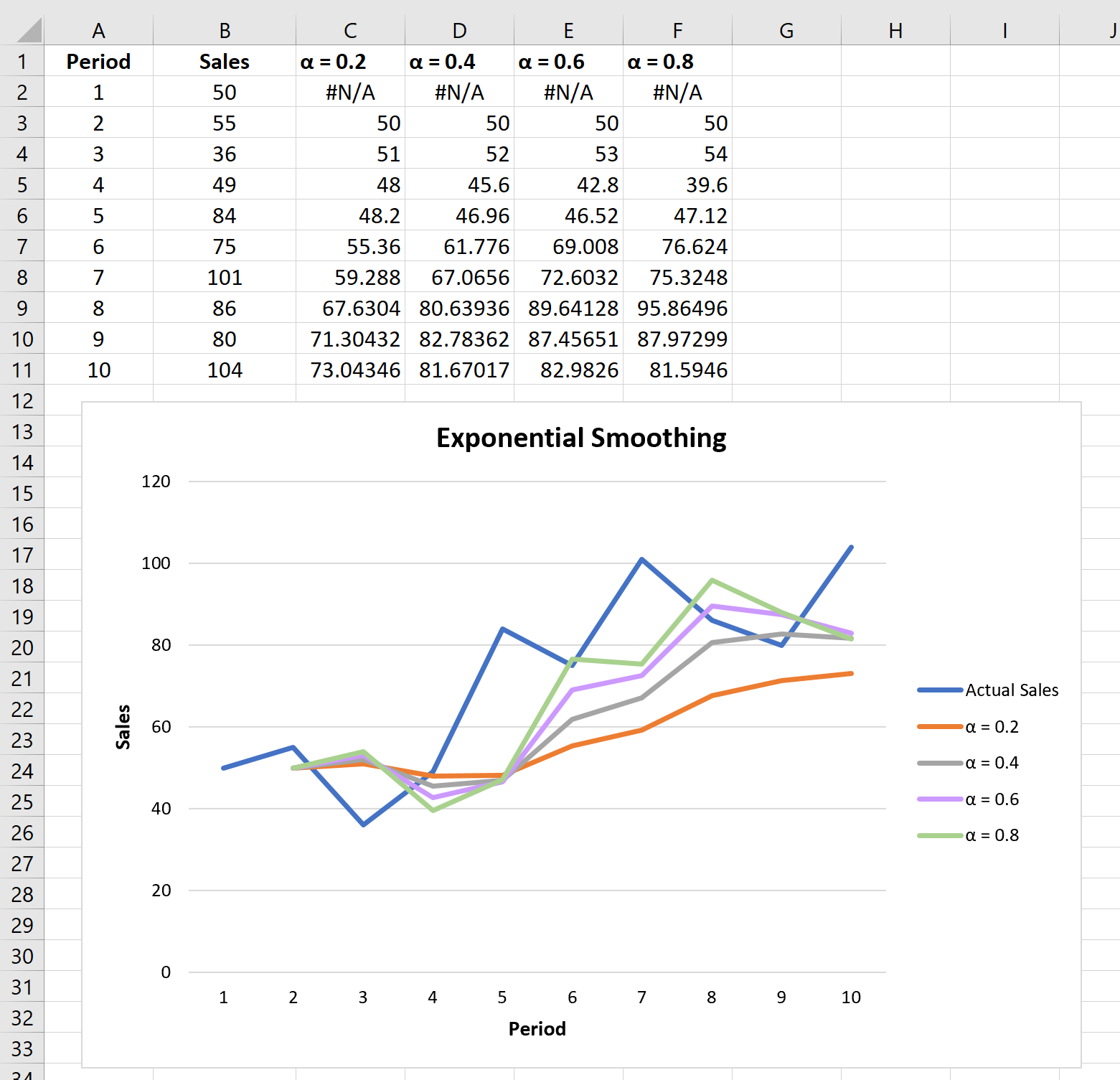
Эксперименты с коэффициентами сглаживания
Вы можете поэкспериментировать с различными значениями коэффициента сглаживания α и посмотреть, как он повлияет на прогнозируемые значения. Вы заметите, что чем меньше значение α (больше значение коэффициента затухания), тем более сглаженными будут прогнозируемые значения:
Для получения дополнительных руководств по Excel обязательно ознакомьтесь с нашим полным списком руководств по Excel .
Экспоненциальное сглаживание
Экспоненциальное сглаживание
является одним из наиболее распространенных приемов, используемых для
сглаживания временных рядов, а также для прогнозирования. В основе процедуры
сглаживания лежит расчёт экспоненциальных скользящих средних сглаживаемого
ряда.
Главное достоинство прогнозной модели, основанной на экспоненциальных
средних, состоит в том, что она способна последовательно адаптироваться
к новому уровню процесса без значительного реагирования на случайные отклонения.
Исторически метод независимо был разработан Брауном и Холтом. Холт также
разработал модели экспоненциального сглаживания для процессов с постоянным
уровнем, процессов с линейным ростом и процессов с сезонными эффектами.
Процедура простого экспоненциального сглаживания осуществляется по следующим
формулам:
![]()
![]()
где:
-
Xt-1. Фактическое
наблюдение в момент t-1; -
St.
Значение экспоненциального среднего в момент t; -
α.
Параметр сглаживания, α = const, α ϵ (0; 1].
Экспоненциальное среднее в момент t
здесь выражено как взвешенная сумма текущего наблюдения и экспоненциального
среднего прошлого наблюдения с весами α
и (1 — α) соответственно.
Если последовательно использовать данное рекуррентное соотношение, то
значение St
можно выразить через значения временного ряда X:
![]()
Таким образом, величина St оказывается
взвешенной суммой всех членов ряда. Причем значения весов уменьшаются
экспоненциально в зависимости от удаленности наблюдения относительно момента
t. Это и объясняет название «экспоненциальное
среднее».
Экспоненциальное сглаживание можно представить как фильтр, на вход которого
в виде потока последовательно поступают члены исходного ряда, а на выходе
формируются значения экспоненциальных средних. Причем, сглаженный ряд
St
имеет тоже математическое ожидание, что и ряд X,
но меньшую дисперсию.
При высоком значении α дисперсия
сглаженного ряда не значительно отличается от дисперсии ряда X.
Чем меньше α, тем в большей степени
сокращается дисперсия сглаженного ряда (то есть подавляются колебания
исходного ряда).
Далее экспоненциальное среднее можно использовать для построения краткосрочных
прогнозов. В этом случае предполагается, что исходный ряд описывается
моделью:
![]()
где:
-
at.
Изменяющийся во времени средний уровень ряда; -
errt.
Случайные неавтокоррелированные отклонения с нулевым математическим
ожиданием.
Прогнозная модель имеет вид:
![]()
где:
-
 . Прогноз, сделанный
. Прогноз, сделанный
в момент T на τ единиц времени
(шагов) вперед; -
 . Оценка aT.
. Оценка aT.
Оценкой параметра модели aT служит экспоненциальное
среднее ряда ST. Таким образом, все свойства экспоненциального
среднего распространяются на прогнозную модель. В частности, если привести
рекуррентную формулу к следующему виду:
![]()
и рассматривать St-1
как прогноз на один шаг вперед, то величина (Xt-1 — St-1) есть погрешность этого прогноза,
а новый прогноз St получается в результате корректировки
предыдущего прогноза с учетом его ошибки. В этом и состоит сущность адаптации.
На основе простого экспоненциального сглаживания были разработаны более
сложные модели сглаживания временных рядов, содержащих периодические сезонные
колебания и/или обладающих тенденцией роста.
Данная система позволяет строить наряду с простым экспоненциальным сглаживанием
модели, отражающие эффекты роста (линейного, экспоненциального или затухающего)
и сезонности (аддитивного или мультипликативного), которыми обладает исходный
ряд.
В общем виде рекуррентная формула экспоненциального сглаживания записывается
следующим образом:
![]()
где множители d1
и d2
определяются в зависимости от выбранной модели сглаживания. К примеру,
при простом экспоненциальном сглаживании, рассмотренном выше, d1 = Xt, d2 = St-1.
См. также:
Модель
с сезонными эффектами | Модели
роста | Метод наилучшей пробы
| Контейнер моделирования: модель «Экспоненциальное
сглаживание» | Анализ временных рядов: «Экспоненциальное
сглаживание» | IModelling.Expsmooth
| ISmExponentialSmoothing
Введение
В настоящее время известно большое количество различных методов прогнозирования, основывающихся только на анализе прошлых значений временной последовательности, то есть методов, использующих принципы, принятые в техническом анализе. Основным инструментом этих методов является схема экстраполяции, когда свойства последовательности, выявленные на рассматриваемом интервале времени распространяются за его пределы.
При этом предполагается, что свойства последовательности в будущем будут такими же, как в прошлом и настоящем. Реже в процессе прогнозирования используется более сложная схема экстраполяции, предполагающая исследование динамики изменения свойств последовательности и учет этой динамики на интервале прогноза.
Наверное, наиболее известными методами прогнозирования, основанными на экстраполяции, являются методы, использующие модель авторегрессии и скользящего среднего (ARIMA). Своей популярностью эти методы, в первую очередь, обязаны работам Бокса и Дженкинса (Boks Dzh., Dzhenkins G.), предложившим и развившим обобщенную модель ARIMA. Но кроме представленных Боксом и Дженкинсом
моделей, конечно, существуют и другие модели и методы прогнозирования.
В данной статье будут кратко рассмотрены более простые модели – модели экспоненциального сглаживания, которые были предложены Хольтом (Holt C.C) и Брауном (Brown R.G) еще до появления работ Бокса и Дженкинса.
Несмотря на более простой и доступный математический аппарат, прогнозирование при помощи моделей экспоненциального сглаживания часто дает результат, сопоставимый с результатом, полученным при использовании модели ARIMA. Это неудивительно, так как модели экспоненциального сглаживания являются частным случаем моделей ARIMA. Другими словами, каждая рассматриваемая в статье модель экспоненциального сглаживания имеет соответствующую эквивалентную модель ARIMA. Эти эквивалентные модели в статье рассматриваться не будут и приведены лишь для информации.
Известно, что процесс прогнозирования в каждом конкретном случае требует индивидуального подхода и обычно включает в себя целый ряд процедур.
Например:
- Анализ временной последовательности на предмет наличия пропущенных и выпадающих значений. Коррекция этих значений.
- Определение наличия тренда и его типа. Определение наличия периодичности в последовательности.
- Проверка последовательности на стационарность.
- Анализ последовательности на предмет необходимости предварительной обработки (логарифмирование, взятие разностей и так далее).
- Выбор модели.
- Определение параметров модели. Прогноз на основании выбранной модели.
- Оценка точности прогнозирования модели.
- Анализ характера ошибок выбранной модели.
- Определение адекватности выбранной модели и в случае необходимости ее замена и возвращение к предыдущим пунктам.
Здесь приведен далеко не полный список действий, необходимых для получения эффективного прогноза.
Следует подчеркнуть тот факт, что определение параметров модели и непосредственно получение прогноза являются лишь небольшой частью общей процедуры прогнозирования. Но рассмотреть в статье весь круг вопросов, так или иначе связанных с прогнозированием, не представляется возможным.
Поэтому в данной статье ограничимся только рассмотрением непосредственно самих моделей экспоненциального сглаживания, а в качестве тестовых последовательностей будем использовать котировки валют, без какой-либо их предварительной обработки. Конечно, совсем избежать в статье сопутствующих вопросов не удастся, но они будут затронуты лишь в объеме, необходимом для рассмотрения самих моделей.
1. Стационарность
Само понятие экстраполяции предполагает, что рассматриваемый процесс в будущем будет развиваться так же, как в прошлом и настоящем. Другими словами, речь идет о стационарности процесса. Стационарный процесс является наиболее привлекательным с точки зрения построения прогнозов, но, к сожалению, в природе таких процессов не существует, любой реальный процесс по мере своего развития подвержен изменениям.
У реальных процессов с течением времени могут заметно меняться математическое ожидание, дисперсия, закон распределения, но процессы, у которых эти характеристики изменяются очень медленно можно с той или иной вероятностью отнести к стационарным процессам. В данном случае понятие «очень медленно» означает, что изменение характеристик процесса на конечном интервале наблюдения оказывается настолько незначительным, что этими изменениями можно пренебречь.
Понятно, что чем короче доступный интервал наблюдения (короткая выборка), тем выше вероятность принятия ошибочного решения о стационарности процесса в целом. С другой стороны, если нас в большей степени интересует состояние процесса в более поздние моменты времени, и мы собираемся производить прогноз на очень короткий интервал, сокращение размера выборки в некоторых случаях может привести к увеличению точности такого прогноза.
Если процесс подвержен изменениям, то параметры последовательности, определенные на интервале наблюдения, за его пределами будут изменяться. Таким образом, чем длиннее интервал прогноза, тем большее влияние на погрешность прогноза будет оказывать изменчивость характеристик последовательности. Этот факт заставляет ограничиться лишь краткосрочным прогнозом, сильное сокращение интервала прогноза позволяет ожидать, что медленно изменяющиеся характеристики последовательности не внесут в прогноз существенных погрешностей.
Кроме того, изменчивость параметров последовательности приводит к тому, что при оценке по интервалу наблюдения мы получаем некоторое усредненное их значение, так как на этом интервале они не оставались постоянными. Поэтому найденные значения параметров не будут относиться к последнему моменту времени этого интервала, а будут отражать некоторое среднее их значение. Полностью устранить это неприятное явление, к сожалению, не представляется возможным, но его можно ослабить, если по возможности сокращать длительность интервала наблюдения, на котором производится оценка параметров модели (интервал обучения).
Укорачивать до бесконечности этот интервал тоже нельзя, так как при чрезмерном сокращении интервала обучения наверняка будет снижаться точность оценки параметров последовательности. Необходимо искать компромисс между влиянием ошибок, связанных с изменчивостью характеристик последовательности и возрастанием погрешностей, связанных с чрезмерным сокращением интервала обучения.
Все сказанное в полной мере относится к прогнозированию с использованием моделей экспоненциального сглаживания, так как эти модели построены исходя из предположения стационарности процессов, как впрочем, и модели ARIMA. Тем не менее, для упрощения в дальнейшем будем условно предполагать, что у всех рассматриваемых нами последовательностей их параметры на интервале наблюдения изменяются, но происходит это настолько медленно, что этими изменениями можно пренебречь.
Таким образом, в статье будут рассматриваться вопросы, связанные с краткосрочным прогнозированием последовательностей с медленно меняющимися характеристиками на базе моделей экспоненциального сглаживания. В данном случае понятие «краткосрочное прогнозирование» следует понимать как прогнозирование на один, два или несколько интервалов времени вперед, а не в смысле прогнозирования на период менее одного года, как это зачастую принято в экономике.
2. Тестовые последовательности
При написании статьи использовались предварительно сохраненные для периодов M1, M5, M30 и H1 котировки EURRUR, EURUSD, USDJPY и XAUUSD. Каждый из сохраненных файлов содержит по 1100 значений «open». Самое «старое» значение расположено в начале файла, а самое «новое» в конце. Самое последнее значение, записанное в файл, соответствует времени создания файла. Файлы с тестовыми последовательностями были созданы при помощи скрипта HistoryToCSV.mq5. Сами файлы с данными и скрипт, при помощи которого они были созданы, размещены в конце статьи в архиве Files.zip.
Как уже упоминалось, сохраненные котировки в данной статье используются без какой-либо предварительной обработки, несмотря на явные проблемы, на которые все же хочется обратить внимание. Например, котировки EURRUR_H1 в течение суток содержат то 12, то 13 бар, котировки XAUUSD по пятницам содержат на один бар меньше, чем в другие дни. Эти примеры показывают, что котировки представлены с неравномерным шагом дискретизации, и это совершенно неприемлемо для алгоритмов, рассчитанных на работу с корректными временными последовательностями, предполагающими равномерный шаг квантования.
Даже если при помощи интерполяции восстановить недостающие значения котировок, то открытым остается вопрос об отсутствии котировок в выходные дни. Можно предположить, что события, происходящие в мире в выходные дни, влияют на состояние мировой экономики не меньше, чем события, происходящие по будням. Революции, природные явления, громкие скандалы, смена правительства и другие более или менее крупные события подобного рода могут произойти когда угодно. Если такое событие произошло в субботу, то вряд ли оно окажет меньшее влияние на мировые рынки, чем в случае, если бы оно произошло в рабочий день.
Возможно, именно такие события приводят к тому, что мы часто наблюдаем разрывы котировок на границе рабочей недели. Скорее всего, мир продолжает существовать по своим законам даже тогда, когда FOREX не работает. Пока совершенно неясно, нужно ли в котировках, предназначенных для технического анализа восстанавливать значения, соответствующие выходным дням, даст ли это какую-либо выгоду?
Эти вопросы явно выходят за рамки данной статьи, но на первый взгляд, последовательность, не имеющая пропусков, представляется для анализа более привлекательной, хотя бы с точки зрения обнаружения циклических (сезонных) составляющих.
Значение предварительной подготовки данных для последующего анализа трудно переоценить, в данном случае это отдельная большая тема, так как котировки, в том виде, как они представлены в терминале, вообще малопригодны для технического анализа. К уже упомянутым проблемам с пропуском данных можно добавить еще целый ряд.
Например, при формировании котировок фиксированному моменту времени присваиваются значения «open» и «close» ему не принадлежащие, эти значения соответствуют времени формирования тика, а не фиксированному моменту выбранного таймфрейма графика, при этом тики, как известно иногда поступают очень редко.
Другой пример, это полное игнорирование теоремы Котельникова, ведь никто не дает гарантии, что хотя бы на минутном интервале частота дискретизации удовлетворяет упомянутой теореме (не говоря уже о других, более старших интервалах). Кроме всего прочего необходимо помнить и о наличии переменного спреда, который в некоторых случаях может наложиться на значения котировок.
Все же оставим все эти вопросы за рамками данной статьи и вернемся к ее непосредственной теме.
3. Экспоненциальное сглаживание
Для начала рассмотрим самую простую модель
![]() ,
,
где:
- X(t) – исследуемый (моделируемый) процесс,
- L(t) – изменяющийся уровень процесса,
- r(t)– случайная величина с нулевым средним значением.
Как видим, модель включает в себя сумму двух компонент, из которых нас интересует уровень процесса L(t), именно его мы и попытаемся выделить.
Хорошо известно, что при усреднении случайной последовательности можно добиться снижения ее дисперсии, то есть уменьшить размах ее отклонения от среднего значения. Поэтому можно предположить, что если процесс, описываемый нашей простейшей моделью подвергнуть усреднению (сглаживанию), то мы сможем если не совсем избавиться от случайной компоненты r(t), то хотя бы заметно ее ослабить, выделив тем самым интересующий нас уровень L(t).
Для этого обратимся к простому экспоненциальному сглаживанию (Simple Exponential Smoothing, SES).
![]()
В этом хорошо известном выражении степень сглаживания задается коэффициентом альфа, который можно установить в интервале от 0 до 1. При выборе значения альфа, равным нулю, вновь поступающие величины входной последовательности X не смогут оказать никакого влияния на результат сглаживания. Результатом сглаживания для любых моментов времени будет являться постоянная величина.
Таким образом, в этом крайнем случае мы полностью подавим мешающую случайную компоненту, но при этом и интересующий нас уровень процесса будет сглажен до состояния горизонтальной прямой линии. Если значение коэффициента альфа установить равным единице, то на входную последовательность процесс сглаживания вообще не будет оказывать никакого влияния. При этом интересующий нас уровень L(t) не будет искажен, но и случайная компонента подавлена не будет.
Интуитивно понятно, что при выборе величины альфа необходимо одновременно удовлетворять противоречивым требованиям. С одной стороны значение альфа должно быть близко к нулю, чтобы эффективно подавить случайную составляющую r(t). С другой, чтобы не исказить интересующую нас компоненту L(t), желательно выбирать значение альфа, близким к единице. Для нахождения оптимального значения альфа нам необходимо определить критерий, по которому это значение можно будет оптимизировать.
При определении такого критерия вспомним, что в данной статье речь идет о прогнозировании, а не просто о сглаживании последовательности.
В данном случае для простой модели экспоненциального сглаживания прогнозом на любое количество шагов вперед принято считать найденное в данный момент времени значение ![]() .
.
![]()
где ![]() – прогноз в момент времени t на m шагов вперед.
– прогноз в момент времени t на m шагов вперед.
Значит, прогнозом значения последовательности на момент времени t будет являться прогноз, сделанный на предыдущем шаге на один шаг вперед
![]()
В этом случае в качестве критерия для оптимизации значения коэффициента альфа можно использовать ошибку предсказания на один шаг
![]()
Таким образом, если минимизировать сумму квадратов этих ошибок по всей выборке, то можно будет определить оптимальное значение коэффициента альфа для данной последовательности. Естественно, наилучшим значением альфа будет такое, при котором величина суммы квадратов ошибок окажется минимальной.
На рисунке 1 приведен график зависимости суммы квадратов ошибок прогноза на один шаг вперед от величины коэффициента альфа для фрагмента тестовой последовательности USDJPY M1.

Рисунок 1. Простое экспоненциальное сглаживание
На полученном графике слабо различим минимум, примерно в районе значения альфа, равном 0,8. Но такую картину для простого экспоненциального сглаживания можно наблюдать далеко не всегда. При попытке определить оптимальное значение альфа для фрагментов тестовых последовательностей, используемых в статье, мы чаще всего будем получать непрерывно спадающий к единице график.
Столь высокие оптимальные значения коэффициента сглаживания говорят о том, что такая простейшая модель плохо подходит для описания наших тестовых последовательностей (котировок). Или уровень процесса L(t) изменяется слишком быстро, или в процессе присутствует тренд.
Несколько усложним нашу модель, добавив в нее ещё одну компоненту
![]() ,
,
где:
- X(t) — исследуемый (моделируемый) процесс;
- L(t) — изменяющийся уровень процесса;
- T(t) — линейный тренд;
- r(t) — случайная величина с нулевым средним значением.
Известно, что коэффициенты линейной регрессии можно определить, осуществив двойное сглаживание последовательности:
![]()
![]()
![]()
![]()
Для найденных таким образом коэффициентов a1 и a2 прогноз в момент времени t на m шагов вперед будет равен
![]()
Следует обратить внимание на тот факт, что в приведенных выражениях при первом и повторном сглаживании используется одинаковый коэффициент альфа. Такую модель называют аддитивной однопараметрической моделью линейного роста.
Продемонстрируем различие между простой моделью и моделью линейного роста.
Предположим, что на протяжении длительного времени исследуемый процесс представлял собой постоянную составляющую, то есть на графике выглядел как прямая горизонтальная линия и в какой-то момент времени начался линейный тренд. Прогноз такого процесса, сделанный упомянутыми моделями, показан на рисунке 2.

Рисунок 2. Сравнение моделей
Как видим, модель простого экспоненциального сглаживания заметно отстает от линейно изменяющейся входной последовательности, а прогноз, сделанный при помощи этой модели, еще больше от нее удаляется. При использовании модели линейного роста наблюдается иная картина. При возникновении тренда эта модель стремиться, как бы догнать линейно изменяющуюся последовательность, а ее прогноз лучше совпадает с направлением изменения входных значений.
Если бы в приведенном примере был выбран коэффициент сглаживания большей величины, то модель линейного роста за указанный промежуток времени вполне успела бы «догнать» входной сигнал, а ее прогноз практически совпал бы с входной последовательностью.
Несмотря на то, что в установившемся состоянии модель линейного роста при наличии линейного тренда показывает хороший результат, нетрудно заметить, что ей требуется определенное время для того чтобы «догнать» тренд. Поэтому, при частой смене направления тренда между моделью и входной последовательностью все время будет наблюдаться расхождение. Кроме того, если тренд нарастает не линейно, а по квадратичному закону, то модель линейного роста уже будет не в состоянии его «догнать». Но, несмотря на эти недостатки, при линейном тренде модель имеет преимущества перед моделью простого экспоненциального сглаживания.
Как уже упоминалось, мы использовали однопараметрическую модель линейного роста. Для поиска оптимального значения параметра альфа для фрагмента тестовой последовательности USDJPY M1 построим график зависимости суммы квадратов ошибок прогноза на один шаг вперед от величины этого параметра.
График такой зависимости показан на рисунке 3, при построении графика был использован тот же фрагмент последовательности, что и при построении графика, показанного на рисунке 1.

Рисунок 3. Модель линейного роста
По сравнению с результатом, показанным на рисунке 1, в данном случае величина оптимального значения для коэффициента альфа снизилась до значения, примерно равного 0,4. В данной модели для первого и второго сглаживания выбираются одинаковые коэффициенты, хотя теоретически они могут иметь разную величину. Модель линейного роста с двумя различными коэффициентами сглаживания будет представлена далее.
Обе рассмотренные модели экспоненциального сглаживания имеют свои аналоги в виде индикаторов, поставляемых в составе MetaTrader 5. Это хорошо известные EMA и DEMA, но предназначены они не для получения прогноза, а для сглаживания значений последовательности.
Следует учитывать, что при использовании индикатора DEMA на экран выводится значение соответствующее коэффициенту a1, а не значение прогноза на один шаг вперед. Коэффициент a2 (см. приведенные выше выражения для модели линейного роста) при этом не вычисляется и не используется. Кроме того, значение коэффициента сглаживания вычисляется через величину эквивалентного периода n
![]()
Для примера, значению альфа равному 0,8 будет соответствовать величина n примерно равная 2, а при значении альфа равным 0,4 величина n равна 4.
4. Начальные значения
Как уже упоминалось, при применении экспоненциального сглаживания необходимо тем или иным способом выбрать величину коэффициента сглаживания. Но этого оказывается недостаточно. Так как при экспоненциальном сглаживании текущее значение вычисляется на основе предыдущего, то для нулевого момента времени возникает ситуация, когда такое значение еще отсутствует. То есть, для нулевого момента времени, каким-то образом должны быть определенны начальное значение для S или для S1 и S2 в случае модели линейного роста.
Проблема выбора начальных значений не всегда легко разрешима. Если (как в случае использования котировок в MetaTrader 5) нам доступна очень длительная история, то даже при неточном определении начальных значений кривая экспоненциального сглаживания к текущему моменту времени успеет стабилизироваться, скорректировав нашу начальную ошибку. На это может понадобиться примерно от 10 до 200 (а иногда и больше) периодов в зависимости от величины коэффициента сглаживания.
В этой ситуации достаточно грубо оценить исходные значения и начать процесс экспоненциального сглаживания заранее, за 200-300 периодов до интересующего нас участка времени. Сложнее дело обстоит, когда в нашем распоряжении имеется выборка, содержащая, например, всего 100 значений.
В литературе можно встретить разные рекомендации по выбору начальных значений. Например, начальное значение для простого экспоненциального сглаживания может быть приравнено первому элементу последовательности или в надежде на сглаживание случайных выбросов может быть найдено как среднее значение трех-четырех начальных элементов последовательности. Для модели линейного роста начальные значения S1 и S2 могут быть определены исходя из предположения, что начальный уровень прогнозной кривой должен быть равен первому элементу последовательности, а наклон линейного тренда равен нулю.
В различных источниках можно найти еще целый ряд рекомендаций по выбору начальных значений, но все они не могут обеспечить отсутствие весьма чувствительных ошибок на начальных шагах алгоритма сглаживания. Особенно это заметно при использовании коэффициентов сглаживания с низкими значениями, когда для достижения стабильного состояния требуется большое количество периодов.
Поэтому чтобы свести к минимуму влияние проблем, связанных с выбором начальных значений (особенно для коротких последовательностей) иногда используют метод, предполагающий поиск таких значений, при которых ошибка прогноза окажется минимальной. Речь идет о вычислении ошибки прогноза по всей последовательности для изменяющихся с небольшим шагом величин исходных значений.
Наиболее удачный вариант можно выбрать после вычисления величины ошибки по сетке всех возможных комбинаций исходных значений. Но такой способ является очень трудоемким, требует большого количества вычислений и в прямом виде практически не используется.
Описанная задача является задачей оптимизации или поиска минимального значения функции многих переменных. Для решения подобного рода задач разработаны различные алгоритмы, позволяющие существенно сократить требуемые объемы вычислений. К вопросам оптимизации параметров сглаживания и начальных значений при прогнозировании вернемся несколько позже.
5. Оценка точности прогноза
В процессе прогнозирования и выбора начальных значений или параметров модели возникает задача оценки точности прогнозирования. Оценка точности важна и при сравнении между собой различных моделей или при определении состоятельности полученного прогноза. Известно большое количество оценок, определяющих точность прогнозирования, но для вычисления любой из них необходимо знать на каждом шаге ошибку прогнозирования.
Как уже упоминалось, ошибка прогнозирования на один шаг вперед в момент времени t равна
![]()
где:
Наверное, наиболее распространенной оценкой точности прогнозирования является среднее значение квадратов ошибок (Mean Squared Error):
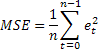
где n – количество элементов последовательности.
Иногда, в качестве недостатка оценки MSE указывают на ее чрезмерную чувствительность к редким одиночным ошибкам большой величины. Это объясняется тем, что значение ошибки при вычислении MSE возводится в квадрат. В этом случае в качестве альтернативы предлагается использовать среднее значение абсолютной ошибки (Mean Absolute Error)
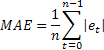
Здесь операция возведения значения ошибки в квадрат заменена на использование абсолютного ее значения. Предполагается, что при использовании MAE можно получить более устойчивые оценки.
Обе эти оценки хорошо подходят, например, для определения точности прогноза одной и той же последовательности при различных параметрах модели или при использовании различных моделей, но они оказываются малопригодными для сравнения между собой результатов прогнозирования, полученных на разных последовательностях.
Кроме того, непосредственно по величине этих оценок нельзя определить, насколько хорош результат прогнозирования. Например, получив значение MAE равное 0,03, или какое либо другое, мы не можем сказать хорошо это или плохо.
Для того чтобы иметь возможность сравнивать между собой точность
прогноза разных последовательностей можно использовать относительные оценки RelMSE и RelMAE:
![]()
При этом найденные оценки точности прогноза делятся на
соответствующие оценки, полученные при использовании тестового метода
прогнозирования. В качестве такого тестового метода удобно использовать так
называемый наивный метод, когда предполагается, что значение процесса в будущем
будет равно его значению в данный момент времени.
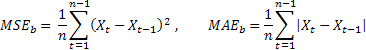
Если средняя величина ошибок прогнозирования равна
величине ошибок полученных при использовании наивного метода, то значение
относительных оценок будет равно единице. Если значение относительных оценок
меньше единицы, то это означает, что в среднем величина ошибок прогноза меньше,
чем при наивном методе. То есть, точность результатов прогноза превосходит
точность наивного метода. И наоборот, если значение относительных оценок больше
единицы, то точность результатов прогноза в среднем хуже, чем при наивном
методе прогнозирования.
Эти оценки так же пригодны для определения точности прогноза на два или более шагов вперед. Для этого нужно лишь вместо ошибки прогноза на один шаг при их расчете использовать значение ошибок прогноза на соответствующее количество шагов вперед.
Для примера в таблице приведены ошибки прогноза на один
шаг вперед RelMAE при использовании однопараметрической модели линейного
роста. Подсчет ошибок производился по 200 последним значениям каждой тестовой последовательности.
|
Таблица 1. Ошибки прогноза RelMAE на один шаг вперед.
Оценка RelMAE позволяет сравнить между собой эффективность
выбранного метода при прогнозировании разных последовательностей. Как видно из
результатов, приведенных в таблице 1, нам ни разу не удалось произвести прогноз
точнее, чем в случае использования наивного метода, все значения RelMAE больше единицы.
6. Аддитивные модели
Ранее в статье уже приводилась модель, которая включала в себя сумму уровня процесса, линейного тренда и случайной величины. В список рассматриваемых в статье моделей добавим еще и модель, которая в дополнение к перечисленным компонентам в виде суммы включает в себя циклическую, сезонную составляющую.
Модели экспоненциального сглаживания, в которых все компоненты входят в виде суммы, называют аддитивными моделями. Кроме таких моделей существуют мультипликативные модели, в которых одна, несколько или все компоненты входят в них в виде произведения. Перейдем к рассмотрению группы аддитивных моделей.
В прошлых разделах уже не раз упоминалось об ошибке прогноза, сделанного на один шаг вперед. Практически в любых приложениях, связанных с прогнозированием, на основе экспоненциального сглаживания приходится вычислять значение этой ошибки. Зная величину ошибки прогнозирования, выражения для представленных ранее моделей экспоненциального сглаживания можно записать в несколько иной форме (форма с коррекцией ошибки).
В данном случае будем использовать форму представления модели, когда в ее выражениях ошибка частично или полностью суммируется с ранее полученными значениями. Такое представление называют моделями с аддитивной ошибкой. Модели экспоненциального сглаживания также могут быть выражены и в форме с мультипликативной ошибкой, но в
данной статье такое представление моделей использовать не будем.
Рассмотрим аддитивные модели экспоненциального
сглаживания.
Простое экспоненциальное сглаживание:
![]()
![]()
Эквивалентная модель – ARIMA(0,1,1): ![]()
Аддитивная модель линейного роста:
![]()
![]()
![]()
В отличие от ранее представленной однопараметрической модели линейного роста, в данном случае используются два различных параметра сглаживания.
Эквивалентная модель – ARIMA(0,2,2): ![]()
Модель линейного роста с демпфированием:
![]()
![]()
![]()
Смысл такого демпфирования заключается в том, что на каждом последующем шаге прогнозирования крутизна тренда будет убывать в зависимости от величины значения коэффициента демпфирования. Этот эффект демонстрируется на рисунке 4.

Рисунок 4. Влияние коэффициента демпфирования
Как следует из приведенного рисунка, при построении прогноза, с уменьшением величины коэффициента демпфирования тренд все быстрее будет терять свою силу, таким образом, линейный рост оказывается все более демпфированным.
Эквивалентная модель — ARIMA(1,1,2): ![]()
К каждой из этих трех моделей можно в виде суммы добавить сезонную составляющую, при этом получим еще три модели.
Простая модель с аддитивной сезонностью:
![]()
![]()
![]()
Модель линейного роста с аддитивной сезонностью:
![]()
![]()
![]()
![]()
Модель линейного роста с демпфированием и аддитивной сезонностью:
![]()
![]()
![]()
![]()
Для моделей с сезонностью также существуют эквивалентные модели ARIMA, но они здесь не приводятся, так как вряд ли будут иметь какое-либо практическое значение.
В приведенных выражениях используются следующие обозначения:
Нетрудно заметить, что выражения для последней из приведенных моделей включают в себя все шесть рассматриваемых вариантов.
Если в
выражениях для модели линейного роста с демпфированием и аддитивной сезонностью
принять
![]() ,
,
то при вычислении прогноза сезонность учитываться не будет. Далее, при ![]() будет получена модель линейного роста, а при
будет получена модель линейного роста, а при ![]() получим модель линейного роста с демпфированием.
получим модель линейного роста с демпфированием.
Значениям ![]() будет соответствовать модель простого экспоненциального сглаживания.
будет соответствовать модель простого экспоненциального сглаживания.
При применении моделей, учитывающих сезонность, вначале необходимо каким-либо доступным методом определить наличие цикличности и период цикла, затем эти данные использовать для инициализации значения сезонных индексов.
В нашем случае, когда прогноз производится на коротких интервалах времени, обнаружить значительную устойчивую цикличность в используемых фрагментах тестовых последовательностей не удалось. Поэтому в статье не будем приводить примеры и подробно рассматривать особенности, связанные с учетом сезонности.
Для определения вероятностных пределов прогноза (prediction intervals) для рассматриваемых моделей воспользуемся аналитическим выводами, представленными в литературе [3]. В качестве оценки дисперсии ошибок прогноза на один шаг вперед будем использовать среднее значение суммы их квадратов, вычисленное по всей выборке размером n.
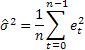
Тогда для определения величины дисперсии при прогнозе на 2 и более шагов вперед для рассматриваемых моделей будет справедливо выражение:
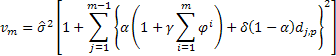
где ![]() равняется единице в случае, если j, взятое по модулю p равно нулю, в противном случае
равняется единице в случае, если j, взятое по модулю p равно нулю, в противном случае ![]() равно нулю.
равно нулю.
Вычислив значение дисперсии прогноза для каждого шага m, можно найти границы прогноза для 95% вероятностного интервала:
![]()
Далее такой вероятностный диапазон условимся называть доверительным интервалом прогноза.
Используя приведенные для моделей экспоненциального сглаживания выражения, реализуем их в виде класса написанного на MQL5.
7. Программная реализация класса AdditiveES
При реализации в виде класса использовались выражения для модели линейного роста с демпфированием и аддитивной сезонностью.
Как упоминалось ранее, остальные модели могут быть получены из нее путем соответствующего выбора параметров.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include <Object.mqh> class AdditiveES:public CObject { protected: double Alpha; double Gamma; double Phi; double Delta; int nSes; double S; double T; double Ises[]; int p_Ises; double F; public: AdditiveES(); double Init(double s,double t,double alpha=1,double gamma=0, double phi=1,double delta=0,int nses=1); double GetS() { return(S); } double GetT() { return(T); } double GetF() { return(F); } double GetIs(int m); void IniIs(int m,double is); double NewY(double y); double Fcast(int m); double VarCoefficient(int m); }; void AdditiveES::AdditiveES() { Alpha=0.5; Gamma=0; Delta=0; Phi=1; nSes=1; ArrayResize(Ises,nSes); ArrayInitialize(Ises,0); p_Ises=0; S=0; T=0; } double AdditiveES::Init(double s,double t,double alpha=1,double gamma=0, double phi=1,double delta=0,int nses=1) { S=s; T=t; Alpha=alpha; if(Alpha<0)Alpha=0; if(Alpha>1)Alpha=1; Gamma=gamma; if(Gamma<0)Gamma=0; if(Gamma>1)Gamma=1; Phi=phi; if(Phi<0)Phi=0; if(Phi>1)Phi=1; Delta=delta; if(Delta<0)Delta=0; if(Delta>1)Delta=1; nSes=nses; if(nSes<1)nSes=1; ArrayResize(Ises,nSes); ArrayInitialize(Ises,0); p_Ises=0; F=S+Phi*T; return(F); } double AdditiveES::NewY(double y) { double e; e=y-F; S=S+Phi*T+Alpha*e; T=Phi*T+Alpha*Gamma*e; Ises[p_Ises]=Ises[p_Ises]+Delta*(1-Alpha)*e; p_Ises++; if(p_Ises>=nSes)p_Ises=0; F=S+Phi*T+GetIs(0); return(F); } double AdditiveES::GetIs(int m) { if(m<0)m=0; int i=(int)MathMod(m+p_Ises,nSes); return(Ises[i]); } void AdditiveES::IniIs(int m,double is) { if(m<0)m=0; if(m<nSes) { int i=(int)MathMod(m+p_Ises,nSes); Ises[i]=is; } } double AdditiveES::Fcast(int m) { int i,h; double v,v1; if(m<1)h=1; else h=m; v1=1; v=0; for(i=0;i<h;i++){v1=v1*Phi; v+=v1;} return(S+v*T+GetIs(h)); } double AdditiveES::VarCoefficient(int m) { int i,h; double v,v1,a,sum,k; if(m<1)h=1; else h=m; if(h==1)return(1); v=0; v1=1; sum=0; for(i=1;i<h;i++) { v1=v1*Phi; v+=v1; if((int)MathMod(i,nSes)==0)k=1; else k=0; a=Alpha*(1+v*Gamma)+k*Delta*(1-Alpha); sum+=a*a; } return(1+sum); }
Кратко рассмотрим методы класса AdditiveES.
Метод Init
Входные параметры:
- double s — устанавливаемое начальное значение сглаженного уровня;
- double t — устанавливаемое начальное значение сглаженного тренда;
- double alpha=1 — устанавливаемый параметр сглаживания уровня последовательности;
- double gamma=0 — устанавливаемый параметр сглаживания тренда;
- double phi=1 — устанавливаемый параметр демпфирования;
- double delta=0 — устанавливаемый параметр сглаживания сезонных индексов;
- int nses=1 — устанавливаемое количество периодов в сезонном цикле.
Возвращаемое значение:
- Возвращает вычисленный на основании установленных начальных значений прогноз на один шаг вперед.
Обращение к методу Init необходимо производить в самую первую очередь. Это необходимо для установки параметров сглаживания и начальных значений. Следует отметить, что метод Init не предусматривает возможности инициализации сезонных индексов произвольными значениями, сезонные индексы при обращении к нему всегда будут установлены в нуль.
Метод IniIs
Входные параметры:
- Int m — номер сезонного индекса;
- double is — устанавливаемое значение сезонного индекса с номером m.
Возвращаемое значение:
- Нет
Обращение к методу IniIs(…) производится в случае необходимости присвоить сезонным индексам начальные значения отличные от нуля. Производить инициализацию сезонных индексов следует сразу после обращения к методу Init(…).
Метод NewY
Входные параметры:
- double y – новое значение входной последовательности
Возвращаемое значение:
- Возвращает вычисленный на основании нового поступившего значения последовательности прогноз на один шаг вперед
Метод, предназначенный для вычисления прогноза на один шаг вперед при поступлении каждого следующего значения входной последовательности. Обращаться к методу следует только после инициализации класса методами Init и при необходимости IniIs.
Метод Fcast
Входные параметры:
- int m – горизонт прогнозирования 1,2,3,… периода;
Возвращаемое значение:
- Возвращает значение прогноза, сделанного на m-шагов вперед.
Метод только рассчитывает значение прогноза, не влияя на состояние процесса сглаживания. Обычно обращение к нему должно производиться после обращения к методу NewY.
Метод VarCoefficient
Входные параметры:
- int m – горизонт прогнозирования 1,2,3,… периода;
Возвращаемое значение:
- Возвращает значение коэффициента для вычисления дисперсии прогноза.
Вычисляется значение коэффициента показывающего насколько возрастет величина дисперсии для прогноза на m-шагов по сравнению с дисперсией прогноза на один шаг вперед.
Методы GetS, GetT, GetF, GetIs
Методы служат для обеспечения доступа к защищенным переменным класса. GetS, GetT и GetF возвращают значения сглаженного уровня, сглаженного значения тренда и значение прогноза на один шаг соответственно. Метод GetIs обеспечивает доступ к сезонным индексам и требует в качестве входного аргумента указания номера индекса m.
Самой сложной из рассматриваемых нами моделей является модель линейного
роста с демпфированием и аддитивной сезонностью , на основе которой и создан класс AdditiveES. Совершенно резонно возникает вопрос, для чего тогда могут понадобиться остальные более простые модели?
Несмотря на то, что на первый взгляд более сложные модели должны иметь явное преимущество перед более простыми, на самом деле это далеко не всегда так. Более простые модели, имеющие меньшее число параметров в подавляющем большинстве случаев будут обеспечивать меньшую величину дисперсии ошибок прогнозирования, то есть будут работать более устойчиво. Этот факт используют при создании алгоритмов прогнозирования базирующихся на одновременной параллельной работе всех имеющихся в наличии моделей, от самых простых до самых сложных.
После того как последовательность полностью обработана, для прогнозирования выбирается модель, показавшая наименьшее значение ошибки с учетом числа ее параметров (то есть с учетом ее сложности). Для такого выбора разработан ряд критериев, например Akaike’s Information Criterion (AIC). В результате будет выбрана модель, от которой ожидается получение наиболее устойчивого прогноза.
Для демонстрации использования класса AdditiveES был создан несложный индикатор, в котором все параметры сглаживания задаются вручную.
Исходный код индикатора AdditiveES_Test.mq5 приводится ниже.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "PInterval+" #property indicator_type3 DRAW_LINE #property indicator_color3 clrCadetBlue #property indicator_style3 STYLE_SOLID #property indicator_width3 1 #property indicator_label4 "PInterval-" #property indicator_type4 DRAW_LINE #property indicator_color4 clrCadetBlue #property indicator_style4 STYLE_SOLID #property indicator_width4 1 double HIST[]; double FORE[]; double PINT1[]; double PINT2[]; input double Alpha=0.2; input double Gamma=0.2; input double Phi=0.8; input double Delta=0; input int nSes=1; input int nHist=250; input int nTest=150; input int nFore=12; #include "AdditiveES.mqh" AdditiveES fc; int NHist; int NFore; int NTest; double ALPH; double GAMM; double PHI; double DELT; int nSES; int OnInit() { NHist=nHist; if(NHist<100)NHist=100; NFore=nFore; if(NFore<2)NFore=2; NTest=nTest; if(NTest>NHist)NTest=NHist; if(NTest<50)NTest=50; ALPH=Alpha; if(ALPH<0)ALPH=0; if(ALPH>1)ALPH=1; GAMM=Gamma; if(GAMM<0)GAMM=0; if(GAMM>1)GAMM=1; PHI=Phi; if(PHI<0)PHI=0; if(PHI>1)PHI=1; DELT=Delta; if(DELT<0)DELT=0; if(DELT>1)DELT=1; nSES=nSes; if(nSES<1)nSES=1; MqlRates rates[]; CopyRates(NULL,0,0,NHist,rates); SetIndexBuffer(0,HIST,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,FORE,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFore); SetIndexBuffer(2,PINT1,INDICATOR_DATA); PlotIndexSetString(2,PLOT_LABEL,"Conf+"); PlotIndexSetInteger(2,PLOT_SHIFT,NFore); SetIndexBuffer(3,PINT2,INDICATOR_DATA); PlotIndexSetString(3,PLOT_LABEL,"Conf-"); PlotIndexSetInteger(3,PLOT_SHIFT,NFore); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,init,start; double v1,v2; if(rates_total<NHist){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated>rates_total||prev_calculated<=0||(rates_total-prev_calculated)>1) {init=1; start=rates_total-NHist;} else {init=0; start=prev_calculated;} if(start==rates_total)return(rates_total); if(init==1) { i=start; v2=(open[i+2]-open[i])/2; v1=(open[i]+open[i+1]+open[i+2])/3.0-v2; fc.Init(v1,v2,ALPH,GAMM,PHI,DELT,nSES); ArrayInitialize(HIST,EMPTY_VALUE); } PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFore); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFore); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFore); for(i=start;i<rates_total;i++) { HIST[i]=fc.NewY(open[i]); } v1=0; for(i=0;i<NTest;i++) { j=rates_total-NTest+i; v2=close[j]-HIST[j-1]; v1+=v2*v2; } v1/=NTest; j=1; for(i=rates_total-NFore;i<rates_total;i++) { v2=1.96*MathSqrt(v1*fc.VarCoefficient(j)); FORE[i]=fc.Fcast(j++); PINT1[i]=FORE[i]+v2; PINT2[i]=FORE[i]-v2; } return(rates_total); }
При запуске или повторной инициализации индикатора происходит установка начальных значений экспоненциального сглаживания
![]()
Для сезонных индексов в данном индикаторе начальных
установок не производится, поэтому их начальные значения всегда оказываются
равны нулю. При такой инициализации влияние сезонности на результат прогноза
при поступлении новых значений будет постепенно возрастать от нуля, до какой-то
установившейся величины.
Количество циклов, необходимых для достижения
установившегося режима, зависит от величины коэффициента сглаживания сезонных
индексов: чем ниже значение коэффициента сглаживания, тем больше времени на это
потребуется.
На рисунке 5 показан результат работы индикатора AdditiveES_Test.mq5 с установками по умолчанию.

Рисунок 5. Индикатор AdditiveES_Test.mq5
Кроме непосредственно прогноза индикатор дополнительно выводит линию, соответствующую прогнозу на один шаг для прошлых значений последовательности и границы 95% доверительного интервала прогноза.
Доверительный интервал строится на основе оценки дисперсии ошибки на один шаг вперед. Для того чтобы снизить влияние неточностей, допущенных при выборе начальных значений, эта оценка производится не по всей длине nHist, а только по последним барам, количество которых указывается во входном параметре nTest.
В конце статьи размещен архив Files.zip, включающий в себя файлы AdditiveES.mqh и AdditiveES_Test.mq5. При компиляции индикатора необходимо, чтобы включаемый файл AdditiveES.mqh был расположен в том же каталоге, что и AdditiveES_Test.mq5.
Если при построении индикатора AdditiveES_Test.mq5 проблема выбора начальных значений хоть как-то была решена, то проблема с выбором оптимальных значений параметров сглаживания так и осталась открытой.
8. Выбор оптимальных значений параметров
Простая модель экспоненциального сглаживания имеет единственный параметр сглаживания и для поиска его оптимального значения можно воспользоваться методом простого перебора. Произведя по всей последовательности расчет величины ошибок прогнозирования, изменим на небольшой шаг значение параметра и вновь произведем полный расчет. Будем повторять эту процедуру до тех пор, пока не переберем все возможные значения параметра. Далее
нам останется только выбрать значение параметра, при котором была получена
наименьшая величина ошибок.
Для того чтобы искать оптимальное значение коэффициента сглаживания в диапазоне от 0.1 до 0.9 с шагом 0.05, нам понадобиться семнадцать раз произвести полный расчет величины ошибок прогнозирования. Как видим, требуется не так уж много вычислений. Но для модели линейного роста с демпфированием оптимизировать необходимо уже три параметра сглаживания, и для того чтобы перебрать все их комбинации по сетке с тем же шагом 0.05, потребуется уже 4913 проходов.
Количество полных проходов, которое требуется для перебора всех возможных значений параметров, очень быстро возрастает с увеличением количества параметров, уменьшением шага их изменения и увеличением диапазона поиска. Если в дальнейшем возникнет необходимость кроме параметров сглаживания оптимизировать и начальные значения моделей, то методом простого перебора это сделать уже будет достаточно сложно.
Проблемы, связанные с поиском минимума функций многих переменных хорошо изучены и существует достаточно много различных алгоритмов такого рода. Описание и сравнение разных методов поиска минимума функции можно найти в литературе [7]. Все эти методы в первую очередь направлены на уменьшение количества обращений к целевой функции, то есть на снижение вычислительных затрат в процессе поиска минимума.
Часто в различной литературе можно встретить упоминание о так называемых квазиньютоновских методах оптимизации. Скорее всего, это связано с высокой их эффективностью, но для демонстрации подхода к оптимизации процесса прогнозирования достаточно будет реализовать какой-нибудь более простой метод. Остановим свой выбор на методе Пауэлла. Метод Пауэлла не требует вычисления производных целевой функции и относится к методам поиска.
Программно данный метод, впрочем, как и любой другой, может быть реализован по-разному. Окончание поиска может осуществляться при достижении определенной точности по значению целевой функции или по значению аргумента. Кроме того, конкретная реализация может включать в себя возможность использования ограничений на допустимый диапазон изменения параметров функции.
В нашем случае алгоритм безусловного поиска минимума методом Пауэлла реализован в виде класса PowellsMethod. Алгоритм прекращает поиск при достижении заданной точности по значению целевой функции. В качестве прототипа при реализации данного метода был использован алгоритм, приведенный в литературе [8].
Ниже приведен исходный код класса PowellsMethod.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include <Object.mqh> #define GOLD 1.618034 #define CGOLD 0.3819660 #define GLIMIT 100.0 #define SHFT(a,b,c,d) (a)=(b);(b)=(c);(c)=(d); #define SIGN(a,b) ((b) >= 0.0 ? fabs(a) : -fabs(a)) #define FMAX(a,b) (a>b?a:b) class PowellsMethod:public CObject { protected: double P[],Xi[]; double Pcom[],Xicom[],Xt[]; double Pt[],Ptt[],Xit[]; int N; double Fret; int Iter; int ItMaxPowell; double FtolPowell; int ItMaxBrent; double FtolBrent; int MaxIterFlag; public: void PowellsMethod(void); void SetItMaxPowell(int n) { ItMaxPowell=n; } void SetFtolPowell(double er) { FtolPowell=er; } void SetItMaxBrent(int n) { ItMaxBrent=n; } void SetFtolBrent(double er) { FtolBrent=er; } int Optimize(double &p[],int n=0); double GetFret(void) { return(Fret); } int GetIter(void) { return(Iter); } private: void powell(void); void linmin(void); void mnbrak(double &ax,double &bx,double &cx,double &fa,double &fb,double &fc); double brent(double ax,double bx,double cx,double &xmin); double f1dim(double x); virtual double func(const double &p[]) { return(0); } }; void PowellsMethod::PowellsMethod(void) { ItMaxPowell= 200; FtolPowell = 1e-6; ItMaxBrent = 200; FtolBrent = 1e-4; } void PowellsMethod::powell(void) { int i,j,m,n,ibig; double del,fp,fptt,t; n=N; Fret=func(P); for(j=0;j<n;j++)Pt[j]=P[j]; for(Iter=1;;Iter++) { fp=Fret; ibig=0; del=0.0; for(i=0;i<n;i++) { for(j=0;j<n;j++)Xit[j]=Xi[j+n*i]; fptt=Fret; linmin(); if(fabs(fptt-Fret)>del){del=fabs(fptt-Fret); ibig=i;} } if(2.0*fabs(fp-Fret)<=FtolPowell*(fabs(fp)+fabs(Fret)+1e-25))return; if(Iter>=ItMaxPowell) { Print("powell exceeding maximum iterations!"); MaxIterFlag=1; return; } for(j=0;j<n;j++){Ptt[j]=2.0*P[j]-Pt[j]; Xit[j]=P[j]-Pt[j]; Pt[j]=P[j];} fptt=func(Ptt); if(fptt<fp) { t=2.0*(fp-2.0*(Fret)+fptt)*(fp-Fret-del)*(fp-Fret-del)-del*(fp-fptt)*(fp-fptt); if(t<0.0) { linmin(); for(j=0;j<n;j++){m=j+n*(n-1); Xi[j+n*ibig]=Xi[m]; Xi[m]=Xit[j];} } } } } void PowellsMethod::linmin(void) { int j,n; double xx,xmin,fx,fb,fa,bx,ax; n=N; for(j=0;j<n;j++){Pcom[j]=P[j]; Xicom[j]=Xit[j];} ax=0.0; xx=1.0; mnbrak(ax,xx,bx,fa,fx,fb); Fret=brent(ax,xx,bx,xmin); for(j=0;j<n;j++){Xit[j]*=xmin; P[j]+=Xit[j];} } void PowellsMethod::mnbrak(double &ax,double &bx,double &cx, double &fa,double &fb,double &fc) { double ulim,u,r,q,fu,dum; fa=f1dim(ax); fb=f1dim(bx); if(fb>fa) { SHFT(dum,ax,bx,dum) SHFT(dum,fb,fa,dum) } cx=bx+GOLD*(bx-ax); fc=f1dim(cx); while(fb>fc) { r=(bx-ax)*(fb-fc); q=(bx-cx)*(fb-fa); u=bx-((bx-cx)*q-(bx-ax)*r)/(2.0*SIGN(FMAX(fabs(q-r),1e-20),q-r)); ulim=bx+GLIMIT*(cx-bx); if((bx-u)*(u-cx)>0.0) { fu=f1dim(u); if(fu<fc){ax=bx; bx=u; fa=fb; fb=fu; return;} else if(fu>fb){cx=u; fc=fu; return;} u=cx+GOLD*(cx-bx); fu=f1dim(u); } else if((cx-u)*(u-ulim)>0.0) { fu=f1dim(u); if(fu<fc) { SHFT(bx,cx,u,cx+GOLD*(cx-bx)) SHFT(fb,fc,fu,f1dim(u)) } } else if((u-ulim)*(ulim-cx)>=0.0){u=ulim; fu=f1dim(u);} else {u=cx+GOLD*(cx-bx); fu=f1dim(u);} SHFT(ax,bx,cx,u) SHFT(fa,fb,fc,fu) } } double PowellsMethod::brent(double ax,double bx,double cx,double &xmin) { int iter; double a,b,d,e,etemp,fu,fv,fw,fx,p,q,r,tol1,tol2,u,v,w,x,xm; a=(ax<cx?ax:cx); b=(ax>cx?ax:cx); d=0.0; e=0.0; x=w=v=bx; fw=fv=fx=f1dim(x); for(iter=1;iter<=ItMaxBrent;iter++) { xm=0.5*(a+b); tol2=2.0*(tol1=FtolBrent*fabs(x)+2e-19); if(fabs(x-xm)<=(tol2-0.5*(b-a))){xmin=x; return(fx);} if(fabs(e)>tol1) { r=(x-w)*(fx-fv); q=(x-v)*(fx-fw); p=(x-v)*q-(x-w)*r; q=2.0*(q-r); if(q>0.0)p=-p; q=fabs(q); etemp=e; e=d; if(fabs(p)>=fabs(0.5*q*etemp)||p<=q*(a-x)||p>=q*(b-x)) d=CGOLD*(e=(x>=xm?a-x:b-x)); else {d=p/q; u=x+d; if(u-a<tol2||b-u<tol2)d=SIGN(tol1,xm-x);} } else d=CGOLD*(e=(x>=xm?a-x:b-x)); u=(fabs(d)>=tol1?x+d:x+SIGN(tol1,d)); fu=f1dim(u); if(fu<=fx) { if(u>=x)a=x; else b=x; SHFT(v,w,x,u) SHFT(fv,fw,fx,fu) } else { if(u<x)a=u; else b=u; if(fu<=fw||w==x){v=w; w=u; fv=fw; fw=fu;} else if(fu<=fv||v==x||v==w){v=u; fv=fu;} } } Print("Too many iterations in brent"); MaxIterFlag=1; xmin=x; return(fx); } double PowellsMethod::f1dim(double x) { int j; double f; for(j=0;j<N;j++) Xt[j]=Pcom[j]+x*Xicom[j]; f=func(Xt); return(f); } int PowellsMethod::Optimize(double &p[],int n=0) { int i,j,k,ret; k=ArraySize(p); if(n==0)N=k; else N=n; if(N<1||N>k)return(0); ArrayResize(P,N); ArrayResize(Xi,N*N); ArrayResize(Pcom,N); ArrayResize(Xicom,N); ArrayResize(Xt,N); ArrayResize(Pt,N); ArrayResize(Ptt,N); ArrayResize(Xit,N); for(i=0;i<N;i++)for(j=0;j<N;j++)Xi[i+N*j]=(i==j?1.0:0.0); for(i=0;i<N;i++)P[i]=p[i]; MaxIterFlag=0; powell(); for(i=0;i<N;i++)p[i]=P[i]; if(MaxIterFlag==1)ret=-1; else ret=Iter; return(ret); }
Основным методом класса является метод Optimize.
Метод Optimize
Входные параметры :
- double &p[] — массив, содержащий на входе начальные величины параметров, оптимальное значение которых должно быть найдено, на выходе массив содержит найденные оптимальные значения этих параметров.
- int n=0 — количество аргументов в массиве p[]. При n=0 количество параметров считается равным размеру массива p[].
Возвращаемое значение:
- Возвращает количество итераций, которое потребовалось для работы алгоритма, или -1 если было достигнуто максимально
допустимое их количество.
В процессе поиска оптимальных значений параметров происходит итеративное приближение к точке минимума целевой функции. Метод Optimize возвращает количество итераций, понадобившихся для достижения минимума функции с заданной точностью. На каждой итерации происходит несколько обращений к целевой функции, то есть количество вызовов целевой функции может значительно (в десятки, а то и в сотни раз) превышать количество итераций, возвращаемое методом Optimize.
Другие методы класса.
Метод SetItMaxPowell
Входные параметры:
- Int n — максимально допустимое для метода Пауэлла количество итераций. Значение по умолчанию 200.
Возвращаемое значение:
- Нет.
Задается максимально допустимое количество итераций, при достижении которого поиск будет прекращен независимо от того, удалось или нет обнаружить с заданной точностью минимум целевой функции. При этом в журнал будет выведено соответствующее сообщение.
Метод SetFtolPowell
Входные параметры:
- double er — точность. Величина отклонения от значения минимума целевой функции, при достижении которой метод Пауэлла прекращает поиск. Значение по умолчанию 1e-6.
Возвращаемое значение:
- Нет.
Метод SetItMaxBrent
Входные параметры:
- Int n — максимально допустимое количество итераций для вспомогательного метода Брента. Значение по умолчанию 200.
Возвращаемое значение:
- Нет.
Задается максимально допустимое количество итераций. При его достижении вспомогательный метод Брента прекратит поиск и в журнал будет выведено соответствующее сообщение.
Метод SetFtolBrent
Входные параметры:
- double er – точность. Величина, определяющая точность при поиске минимума для вспомогательного метода Брента. Значение по умолчанию 1e-4.
Возвращаемое значение:
- Нет.
Метод GetFret
Входные параметры:
- Нет.
Возвращаемое значение:
- Возвращает найденное минимальное значение целевой функции.
Метод GetIter
Входные параметры:
- Нет.
Возвращаемое значение:
- Возвращает количество итераций, которое потребовалось для работы алгоритма.
Виртуальная функция func(const double &p[])
Входные параметры:
- const double &p[] – адрес массива содержащего
оптимизируемые параметры. Размер массива соответствует количеству параметров функции.
Возвращаемое значение:
- Возвращает значение функции
соответствующее переданным ей параметрам.
Виртуальначя
функция func() в каждом конкретном случае должна быть переопределена в
производном от PowellsMethod классе. Функция func()
является целевой функцией, для которой при обращении к алгоритму поиска будут
найдены ее аргументы, соответствующие минимальному возвращаемому функцией
значению.
В данной реализации метода Пауэлла для определения направления поиска по каждому из параметров используется одномерный метод параболической интерполяции Брента. Точность и максимально допустимое количество итераций для этих методов можно задавать раздельно при помощи обращения к SetItMaxPowell, SetFtolPowell, SetItMaxBrent и SetFtolBrent.
Таким образом можно изменить принятые по умолчанию характеристики алгоритма. Это может понадобиться в случае, если, например, для конкретной целевой функции, установленная по умолчанию точность оказалась завышенной и в процессе поиска алгоритму требуется слишком большое количество итераций. Изменением значения требуемой точности можно оптимизировать процедуру поиска для различных категорий целевых функций.
Несмотря на кажущуюся сложность алгоритма, реализующего метод Пауэлла, использовать его достаточно просто.
Приведем пример. Пусть у нас имеется функция
![]()
и нам необходимо найти величины параметров ![]() и
и ![]() , при которых функция будет иметь наименьшее значение.
, при которых функция будет иметь наименьшее значение.
Создадим скрипт, демонстрирующий способ решения этой задачи.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" class PM_Test:public PowellsMethod { public: void PM_Test(void) {} private: virtual double func(const double &p[]); }; double PM_Test::func(const double &p[]) { double f,r1,r2; r1=p[0]-0.5; r2=p[1]-6.0; f=r1*r1*4.0+r2*r2; return(f); } void OnStart() { int it; double p[2]; p[0]=8; p[1]=9; PM_Test *pm = new PM_Test; it=pm.Optimize(p); Print("Iter= ",it," Fret= ",pm.GetFret()); Print("p[0]= ",p[0]," p[1]= ",p[1]); delete pm; }
При написании скрипта в первую очередь была создана
как член класса PM_Test
функция func(), которая по переданным ей величинам параметров p[0] и p[1] вычисляет значение заданной тестовой функции. Далее в теле функции OnStart() искомым параметрам присваиваются начальные значения. С этих значений будет начат поиск.
Далее
создается экземпляр класса PM_Test и обращением к методу Optimize производится
запуск процесса поиска искомых величин p[0] и p[1], при этом методы родительского
класса PowellsMethod будут обращаться к переопределенной нами функции func(). По завершении поиска в журнал будет выведено количество произведенных итераций, значение функции в точке найденного минимума и найденные значения параметров p[0]=0.5 и p[1]=6.
Файл PowellsMethod.mqh и тестовый пример PM_Test.mq5 размещены в конце статьи в архиве Files.zip. Для того чтобы откомпилировать PM_Test.mq5, необходимо, чтобы он был расположен в том же каталоге, что и файл PowellsMethod.mqh.
9. Оптимизация значений параметров модели
В предыдущем разделе была представлена реализация метода поиска минимума функции и приведен простой пример ее использования. Теперь перейдем к рассмотрению вопросов, связанных с оптимизацией параметров непосредственно самой модели экспоненциального сглаживания.
Для начала максимально упростим представленный ранее класс AdditiveES, исключив из него все элементы, связанные с учетом сезонной компоненты, так как далее в статье все равно не предполагается рассматривать модели, учитывающие сезонность. Это позволит исходный код класса сделать более легким для восприятия и сократить количество вычислений. Кроме того, так же исключим все вычисления связанные с прогнозированием и расчетом доверительных интервалов прогноза, так легче продемонстрировать подход к оптимизации параметров используемой модели линейного роста с демпфированием.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" class OptimizeES:public PowellsMethod { protected: double Dat[]; int Dlen; double Par[5]; int NCalc; public: void OptimizeES(void) {} int Calc(string fname); private: int readCSV(string fnam,double &dat[]); virtual double func(const double &p[]); }; int OptimizeES::Calc(string fname) { int i,it; double relmae,naiv,s,t,alp,gam,phi,e,ae,pt; if(readCSV(fname,Dat)<0){Print("Error."); return(-1);} Dlen=ArraySize(Dat); NCalc=200; if(NCalc<0||NCalc>Dlen-1){Print("Error."); return(-1);} Par[0]=Dat[Dlen-NCalc]; Par[1]=0; Par[2]=0.5; Par[3]=0.5; Par[4]=0.5; it=Optimize(Par); s=Par[0]; t=Par[1]; alp=Par[2]; gam=Par[3]; phi=Par[4]; relmae=0; naiv=0; for(i=Dlen-NCalc;i<Dlen;i++) { e=Dat[i]-(s+phi*t); relmae+=MathAbs(e); naiv+=MathAbs(Dat[i]-Dat[i-1]); ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } relmae/=naiv; PrintFormat("%s: N=%i, RelMAE=%.3f",fname,NCalc,relmae); PrintFormat("Iter= %i, Fmin= %e",it,GetFret()); PrintFormat("p[0]= %.5f, p[1]= %.5f, p[2]= %.2f, p[3]= %.2f, p[4]= %.2f", Par[0],Par[1],Par[2],Par[3],Par[4]); return(0); } int OptimizeES::readCSV(string fnam,double &dat[]) { int n,asize,fhand; fhand=FileOpen(fnam,FILE_READ|FILE_CSV|FILE_ANSI); if(fhand==INVALID_HANDLE) { Print("FileOpen Error!"); return(-1); } asize=512; ArrayResize(dat,asize); n=0; while(FileIsEnding(fhand)!=true) { dat[n++]=FileReadNumber(fhand); if(n+128>asize) { asize+=128; ArrayResize(dat,asize); } } FileClose(fhand); ArrayResize(dat,n-1); return(0); } double OptimizeES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} sse=0; for(i=Dlen-NCalc;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(NCalc*MathLog(k1*k2*k3*sse)); }
Класс OptimizeES создан как производный от класса PowellsMethod и в него включено переопределение виртуальной функция func(). Как уже ранее упоминалось, на вход этой функции должны передаваться параметры, для которых вычисляется значение, величина которого будет минимизироваться в процессе оптимизации.
В соответствии с методом максимального правдоподобия в функции func() вычисляется логарифм суммы квадрата ошибок предсказания на один шаг вперед. Вычисление ошибок производится в цикле для NCalc последних значений последовательности.
Для сохранения устойчивости модели нам необходимо ввести ограничения на диапазон изменения ее параметров. Определим этот диапазон для параметров Alpha и Gamma от значения 0.05 до 0.95, а для параметра Phi от 0.05 до 1.0. Но в нашем случае для оптимизации используется метод безусловного поиска минимума, не предусматривающий использования ограничений на значения аргументов целевой функции.
Для того чтобы учесть налагаемые на параметры ограничения и при этом не изменять алгоритм поиска, попытаемся свести задачу поиска минимума функции многих переменных с ограничениями к задаче безусловного поиска минимума. Для этого воспользуемся так называемым методом штрафных функций. Этот метод легко продемонстрировать для одномерного случая.
Предположим, что у нас имеется функция одного аргумента (область определения которой лежит в диапазоне от 2.0 до 3.0) и алгоритм, который в процессе поиска может задавать любые значения параметру этой функции. В этом случае можно поступить следующим образом: если алгоритм поиска передал аргумент, превосходящий максимально допустимое значение, например 3.5, то можно вычислить функцию для аргумента равного 3.0, а затем полученный результат умножить на коэффициент, пропорциональный величине превышения максимального значения, например, k=1+(3.5-3)*200.
Если таким же образом поступить и со значениями аргумента, которые оказались ниже минимально возможного, то нам гарантировано возрастание результирующей целевой функции за пределами допустимого диапазона изменений ее аргумента. Такое искусственное увеличение возвращаемого значения целевой функции позволяет скрыть от алгоритма, осуществляющего поиск, тот факт, что передаваемый функции аргумент был каким-то образом ограничен, и гарантировать то, что минимум результирующей функции будет располагаться в заданных пределах аргумента. Такой подход легко переносится и на случай функции нескольких переменных.
Осовноым методом класса OptimizeES является метод Calc. При обращении к этому методу производится чтение данных из файла, поиск оптимальных величин параметров модели и для найденных значений параметров вычисляется оценка точности предсказания RelMAE. При этом количество обрабатываемых значений считанной из файла последовательности, задается в переменной NCalc.
Ниже приведен пример скрипта Optimization_Test.mq5, использующего класс OptimizeES.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "OptimizeES.mqh" OptimizeES es; void OnStart() { es.Calc("Dataset\USDJPY_M1_1100.TXT"); }
В результате исполнения этого скрипта мы должны получить следующий результат.

Рисунок 6. Результат исполнения скрипта Optimization_Test.mq5
Несмотря на то, что мы получили возможность находить оптимальные значения параметров и начальных значений модели, все же остается один параметр, оптимизировать который простыми средствами не удастся — это количество значений последовательности, по которым производится оптимизация. Производя оптимизацию по последовательности большой длинны, мы будем получать оптимальные значения параметров, в среднем обеспечивающих минимальную ошибку на всей ее длине.
Но если характер последовательности на протяжении этого интервала изменялся, то для отдельных ее фрагментов найденные значения уже не будут являться оптимальными. С другой стороны, если резко сократить длину последовательности, то мы получим оптимальные параметры для этого короткого отрезка, но в этом случае нет никакой гарантии, что эти значения будут оптимальными и на более продолжительном интервале времени.
Файлы OptimizeES.mqh и Optimization_Test.mq5 размещены в конце статьи в архиве Files.zip. При компиляции необходимо, чтобы файлы OptimizeES.mqh и PowellsMethod.mqh были размещены в том же каталоге, что и компилируемый файл Optimization_Test.mq5. В приведенном примере используется содержащий тестовую последовательность файл USDJPY_M1_1100.TXT, который должен находиться в каталоге MQL5FilesDataset.
В таблице 2 приведены значения оценки точности прогнозирования RelMAE, полученные при помощи этого скрипта. Прогнозирование производилось для восьми тестовых последовательностей, о которых говорилось в начале статьи. При построении прогноза использовались 100, 200 и 400 последних значений каждой из этих последовательностей.
| N=100 | N=200 | N=400 | |
|---|---|---|---|
| EURRUR M1 |
0.980 | 1.000 | 0.968 |
| EURRUR M30 |
0.959 | 0.992 | 0.981 |
| EURUSD M1 |
0.995 | 0.981 | 0.981 |
| EURUSD M30 |
1.023 | 0.985 | 0.999 |
| USDJPY M1 |
1.004 | 0.976 | 0.989 |
| USDJPY M30 |
0.993 | 0.987 | 0.988 |
| XAUUSD M1 |
0.976 | 0.993 | 0.970 |
| XAUUSD M30 |
0.973 | 0.985 | 0.999 |
Таблица 2. Ошибки прогнозирования RelMAE.
Как видим, оценки величины ошибок прогноза оказались близкими к единице, но в большинстве случаев точность прогноза используемой модели для заданных последовательностей превышает точность наивного метода.
10. Индикатор IndicatorES.mq5
Ранее при рассмотрении класса AdditiveES.mqh был приведен индикатор AdditiveES_Test.mq5, построенный на базе этого класса. В этом индикаторе все параметры сглаживания задавались вручную.
Теперь после рассмотрения метода, позволяющего производить оптимизацию параметров модели, можно создать такой же индикатор, оптимальные значения параметров и начальных значений которого будут определяться автоматически, задавать вручную нужно будет только длину обрабатываемой выборки. При этом исключим вычисления связанные с учетом сезонности.
Ниже приведен исходный код класса CIndiсatorES который используется при написании индикатора.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" class CIndicatorES:public PowellsMethod { protected: double Dat[]; int Dlen; double Par[5]; public: void CIndicatorES(void) { } void CalcPar(double &dat[]); double GetPar(int n) { if(n>=0||n<5)return(Par[n]); else return(0); } private: virtual double func(const double &p[]); }; void CIndicatorES::CalcPar(double &dat[]) { Dlen=ArraySize(dat); ArrayResize(Dat,Dlen); ArrayCopy(Dat,dat); Par[0]=Dat[0]; Par[1]=0; Par[2]=0.5; Par[3]=0.5; Par[4]=0.5; Optimize(Par); } double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
Данный класс содержит методы CalcPar и GetPar, первый из которых предназначен для вычисления оптимального значения параметров модели, а второй для доступа к этим значениям. Кроме того, класс CIndicatorES включает в себя переопределение виртуальной функции func().
Исходный код индикатора IndicatorES.mq5:
#property copyright "2011, victorg" #property link "https://www.mql5.com" #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; #include "CIndicatorES.mqh" #define NFORE 12 double Hist[],Fore[],Conf1[],Conf2[]; double Data[]; int NDat; CIndicatorES Es; int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); ArrayResize(Data,NDat); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,start; double s,t,alp,gam,phi,e,f,a,a1,a2,a3,var,ci; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); start=rates_total-NDat; PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; Es.CalcPar(Data); s=Es.GetPar(0); t=Es.GetPar(1); alp=Es.GetPar(2); gam=Es.GetPar(3); phi=Es.GetPar(4); f=(s+phi*t); var=0; for(i=0;i<NDat;i++) { e=Data[i]-f; var+=e*e; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; } var/=(NDat-1); a1=1; a2=0; a3=1; for(i=rates_total-NFORE;i<rates_total;i++) { a1=a1*phi; a2+=a1; Fore[i]=s+a2*t; ci=1.96*MathSqrt(var*a3); a=alp*(1+a2*gam); a3+=a*a; Conf1[i]=Fore[i]+ci; Conf2[i]=Fore[i]-ci; } return(rates_total); }
В индикаторе при поступлении каждого нового бара происходит поиск оптимальных значений параметров модели, модель просчитывается для заданного числа NHist баров и строится прогноз и доверительные границы прогноза.
Единственным параметром индикатора является длина обрабатываемой последовательности, минимальное значение которой ограничивается на уровне 24 баров. Все расчеты в индикаторе производятся на основании значений open[]. Горизонт прогнозирования составляет 12 баров. Код индикатора IndicatorES.mq5 и файл CIndicatorES.mqh размещены в конце статьи в архиве Files.zip.

Рисунок 7. Результат работы индикатора IndicatorES.mq5
На рисунке 7 приведен пример работы индикатора IndicatorES.mq5. При работе индикатора, 95% доверительный интервал прогноза будет принимать значения, соответствующие найденным оптимальным величинам параметров модели. Чем больше значения параметров сглаживания, тем быстрее при увеличении горизонта прогноза увеличивается доверительный интервал.
При несложной доработке индикатор IndicatorES.mq5 может быть использован не только для прогнозирования непосредственно котировок валют, но и для построения прогноза значений различного рода индикаторов или предварительно подготовленных данных.
Заключение
Основной целью статьи было знакомство читателя с используемыми для прогнозирования аддитивными моделями экспоненциального сглаживания. В процессе демонстрации их практического применения были затронуты и некоторые сопутствующие вопросы. Однако представленные в статье материалы можно рассматривать лишь как первое прикосновение к огромному пласту связанных с прогнозированием проблем и решений.
Хочется обратить внимание на то, что приведенные в статье классы, функции, скрипты и индикаторы были созданы в процессе написания статьи и предназначены в первую очередь для использования в качестве иллюстрации к материалам статьи. Поэтому серьезного тестирования на устойчивость и отсутствие ошибок не производилось. Кроме того, приведенные в статье индикаторы следует рассматривать только как демонстрацию программной реализации рассматриваемых в статье методов.
Скорее всего, точность прогнозирования приведенного в статье индикатора IndicatorES.mq5 можно несколько увеличить, если использовать модификации применяемой модели, которые будут лучше учитывать особенности рассматриваемых котировок. Так же можно дополнить индикатор другими моделями. Но эти вопросы уже выходят за рамки данной статьи.
В завершении следует отметить, что модели экспоненциального сглаживания в определенных случаях в состоянии давать прогнозы, не уступающие по точности прогнозам, полученным при использовании более сложных моделей, при этом лишний раз подтверждая тот факт, что самая сложная модель далеко не всегда является самой лучшей.
Ссылки
- Everette S. Gardner Jr. Exponential smoothing: The state of the art – Part II. June 3, 2005.
- Rob J Hyndman. Forecasting based on state space models for exponential smoothing. 29 August 2002.
- Rob J Hyndman et al. Prediction intervals for exponential smoothing using two new classes of state space models. 30 January 2003.
- Rob J Hyndman and Muhammad Akram. Some nonlinear exponential smoothing models are unstable. 17 January 2006.
- Rob J Hyndman and Anne B Koehler. Another look at measures of forecast accuracy. 2 November 2005.
- Лукашин Ю.П., Адаптивные методы краткосрочного прогнозирования временных рядов: Учебное пособие. — М.: Финансы и статистика, 2003.-416 с.
- Химмельблау Д., Прикладное нелинейное программирование. М.: Мир, 1975.
- Numerical Recipes in C. The Art of Scientific Computing. SecondEdition. Cambridge University Press.