Время на прочтение
7 мин
Количество просмотров 279K
Продолжение перевода неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
Содержание:
1. Установка
2. Первые Шаги
3. Навигация
4. Поиск Элементов
5. Ожидания
6. Объекты Страницы
7. WebDriver API
8. Приложение: Часто Задаваемые Вопросы
4. Поиск элементов
Существует ряд способов поиска элементов на странице. Вы вправе использовать наиболее уместные для конкретных задач. Selenium предоставляет следующие методы поиска элементов на странице:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
Чтобы найти все элементы, удовлетворяющие условию поиска, используйте следующие методы (возвращается список):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
[Как вы могли заметить, во втором списке отсутствует поиск по id. Это обуславливается особенностью свойства id для элементов HTML: идентификаторы элементов страницы всегда уникальны. — Прим. пер.]
Помимо общедоступных (public) методов, перечисленных выше, существует два приватных (private) метода, которые при знании указателей объектов страницы могут быть очень полезны: find_element and find_elements.
Пример использования:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
Для класса By доступны следующие атрибуты:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
4.1. Поиск по Id
Используйте этот способ, когда известен id элемента. Если ни один элемент не удовлетворяет заданному значению id, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
Элемент form может быть определен следующим образом:
login_form = driver.find_element_by_id('loginForm')
4.2. Поиск по Name
Используйте этот способ, когда известен атрибут name элемента. Результатом будет первый элемент с искомым значением атрибута name. Если ни один элемент не удовлетворяет заданному значению name, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
Элементы с именами username и password могут быть определены следующим образом:
username = driver.find_element_by_name('username')
password = driver.find_element_by_name('password')
Следующий код получит кнопку “Login”, находящуюся перед кнопкой “Clear”:
continue = driver.find_element_by_name('continue')
4.3. Поиск по XPath
XPath – это язык, использующийся для поиска узлов дерева XML-документа. Поскольку в основе HTML может лежать структура XML (XHTML), пользователям Selenium предоставляется возможность посредоством этого мощного языка отыскивать элементы в их веб-приложениях. XPath выходит за рамки простых методов поиска по атрибутам id или name (и в то же время поддерживает их), и открывает спектр новых возможностей, таких как поиск третьего чекбокса (checkbox) на странице, к примеру.
Одно из веских оснований использовать XPath заключено в наличии ситуаций, когда вы не можете похвастать пригодными в качестве указателей атрибутами, такими как id или name, для элемента, который вы хотите получить. Вы можете использовать XPath для поиска элемента как по абсолютному пути (не рекомендуется), так и по относительному (для элементов с заданными id или name). XPath указатели в том числе могут быть использованы для определения элементов с помощью атрибутов отличных от id и name.
Абсолютный путь XPath содержит в себе все узлы дерева от корня (html) до необходимого элемента, и, как следствие, подвержен ошибкам в результате малейших корректировок исходного кода страницы. Если найти ближайщий элемент с атрибутами id или name (в идеале один из элементов-родителей), можно определить искомый элемент, используя связь «родитель-подчиненный». Эти связи будут куда стабильнее и сделают ваши тесты устойчивыми к изменениям в исходном коде страницы.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
Элемент form может быть определен следующими способами:
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
- Абсолютный путь (поломается при малейшем изменении структуры HTML страницы)
- Первый элемент form в странице HTML
- Элемент form, для которого определен атрибут с именем id и значением loginForm
Элемент username может быть найден так:
username = driver.find_element_by_xpath("//form[input/@name='username']")
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
username = driver.find_element_by_xpath("//input[@name='username']")
- Первый элемент form с дочерним элементом input, для которого определен атрибут с именем name и значением username
- Первый дочерний элемент input элемента form, для которого определен атрибут с именем id и значением loginForm
- Первый элемент input, для которого определен атрибут с именем name и значением username
Кнопка “Clear” может быть найдена следующими способами:
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]")
- Элемент input, для которого заданы атрибут с именем name и значением continue и атрибут с именем type и значением button
- Четвертый дочерний элемент input элемента form, для которого задан атрибут с именем id и значением loginForm
Представленные примеры покрывают некоторые основы использования XPath, для более углубленного изучения рекомендую следующие материалы:
- W3Schools XPath Tutorial
- W3C XPath Recommendation
- XPath Tutorial — с интерактивными примерами
Существует также пара очень полезных дополнений (add-on), которые могут помочь в выяснении XPath элемента:
- XPath Checker — получает пути XPath и может использоваться для проверки результатов пути XPath
- Firebug — получение пути XPath — лишь одно из многих мощных средств, поддерживаемых этим очень полезным плагином
- XPath Helper — для Google Chrome
4.4. Поиск гиперссылок по тексту гиперссылки
Используйте этот способ, когда известен текст внутри анкер-тэга [anchor tag, анкер-тэг, тег «якорь» — тэг — Прим. пер.]. С помощью такого способа вы получите первый элемент с искомым значением текста тэга. Если никакой элемент не удовлетворяет искомому значению, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
Элемент-гиперссылка с адресом «continue.html» может быть получен следующим образом:
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
4.5. Поиск элементов по тэгу
Используйте этот способ, когда вы хотите найти элемент по его тэгу. Таким способом вы получите первый элемент с указанным именем тега. Если поиск не даст результатов, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
Элемент заголовка h1 может быть найден следующим образом:
heading1 = driver.find_element_by_tag_name('h1')
4.6. Поиск элементов по классу
Используйте этот способ в случаях, когда хотите найти элемент по значению атрибута class. Таким способом вы получите первый элемент с искомым именем класса. Если поиск не даст результата, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
Элемент “p” может быть найден следующим образом:
content = driver.find_element_by_class_name('content')
4.7. Поиск элементов по CSS-селектору
Используйте этот способ, когда хотите получить элемент с использованием синтаксиса CSS-селекторов [CSS-селектор — это формальное описание относительного пути до элемента/элементов HTML. Классически, селекторы используются для задания правил стиля. В случае с WebDriver, существование самих правил не обязательно, веб-драйвер использует синтаксис CSS только для поиска — Прим. пер.]. Этим способом вы получите первый элемент удовлетворяющий CSS-селектору. Если ни один элемент не удовлетворяют селектору CSS, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
Элемент “p” может быть определен следующим образом:
content = driver.find_element_by_css_selector('p.content')
На Sauce Labs есть хорошая документация по селекторам CSS.
От переводчика: советую также обратиться к следующим материалам:
- 31 CSS селектор — это будет полезно знать! — краткая выжимка по CSS-селекторам
- CSS селекторы, свойства, значения — отличный учебник параллельного изучения HTML и CSS
Перейти к следующей главе
Я пробовал этот код но он не работает:
jQuery(document).ready(function(){
var term = document.getElementById('input').value;
document.getElementById(term).style.display ='flex';
}
Error: cannot read property ‘style’ of null.
Я ввожу правильный id.
![]()
0xdb
51.4k194 золотых знака56 серебряных знаков232 бронзовых знака
задан 20 апр 2020 в 8:01
![]()
4
Раз в метках jquery, то вот моё решение задачи
ответ дан 20 апр 2020 в 8:59
![]()
De.MinovDe.Minov
22.9k4 золотых знака33 серебряных знака66 бронзовых знаков
1
Логика строится в том, чтобы добавить класс .active к элементу, который мы нашли
ответ дан 20 апр 2020 в 8:06
![]()
Михаил КамахинМихаил Камахин
8,5892 золотых знака14 серебряных знаков55 бронзовых знаков
Твой код читает инпут.value только один раз когда dom загружен полностью и jquery подключился(+0.1 сек от загрузки дома, не заморачивайся)
Определись, jQuery ты используешь или нативный js (document.getElementById)
Вот твой код без ожидания загрузки dom
const term = $('input').val();
$(`#${term}`).css('display', 'flex');
Самый универсальный ожидатель загрузки дома, для меня:
window.onload=()=>{
// code
};
А вообще рекомендую два экстета: этот(realtime) и вотэтот(page refresh)
ответ дан 20 апр 2020 в 9:43
![]()
VadimVadim
1,4972 золотых знака7 серебряных знаков18 бронзовых знаков
В этой статье рассмотрим одну из наиболее мощных и часто используемых возможностей функции jQuery: выбор элементов DOM посредством селектора.
Введение
Строительство полнофункциональных сайтов и веб-приложений невозможно без манипулирования элементами DOM из которых состоят страницы. Но, прежде чем ими манипулировать, их необходимо сначала получить.
К счастью, библиотека jQuery обеспечивает достаточно мощный способ выбора элементов, основанный на селекторах. Заключается он в том, что для получения набора элементов достаточно просто передать селектор в функцию jQuery:
// selector – это селектор
jQuery('selector');
// или с помощью псевдонима $
$('selector')Селектор – это шаблон для поиска элементов. Синтаксис селекторов в jQuery соответствует синтаксису CSS, который дополнен некоторыми нестандартными методами.
В качестве результата данная функция возвращает набор найденных элементов в формате объекта jQuery.
// $elements – переменная, в которой находится объект jQuery, содержащий все найденные элементы
var $elements = $('selector')Узнать количество выбранных элементов можно с помощью свойства length:
// $anchors - переменная, содержащая все найденные элементы <a> на странице
var $anchors = $('a');
// количество найденных элементов
var length = $anchors.length;Если length возвращает 0, то значит, что объект jQuery «пустой», т.е. он не содержит искомых элементов (они не были найдены).
При этом функция jQuery('selector') и «родные» JavaScript-методы для поиска элементов (querySelector, querySelectorAll и др.) возвращают совсем разные вещи.
«Родные» методы возвращают DOM-элемент или HTML-коллекцию элементов, а функция jQuery — объект jQuery.
Это означает, что вы не можете напрямую применить какие-либо «родные» свойства и методы JavaScript для работы с элементами к объекту jQuery. И наоборот, применить свойства и методы jQuery непосредственно к DOM-элементам.
Например, с помощью jQuery получим элемент <body> и изменим ему цвет фона:
// выберем элемент <body>
var $body = $('body');
// установим цвета фону элемента с помощью jQuery-метода css
$body.css('background-color', '#eee');На чистом JavaScript эти действия записываются так:
// выберем элемента <body>
var bodyElem = document.querySelector('body');
// установим стили элементу, используя нативные свойства JavaScript
bodyElem.style.backgroundColor = '#eee';Но, чтобы применить родные свойства и методы JavaScript к элементу, обёрнутому в объект jQuery, необходимо в этом случае обратиться непосредственно к этому элементу:
var $body = $('body');
// получим сам элемент
var bodyElem = $body[0];
if (bodyElem) {
// установим стили на чистом JavaScript
bodyElem.style.backgroundColor = '#eee';
}Также, если вы хотите использовать свойства и методы jQuery для DOM-элементов их следует обернуть в объект jQuery. Выполняется это следующим образом:
var bodyElem = document.querySelector('body');
// обернём $bodyElem в объект jQuery
var $body = $(bodyElem);
// установим стили с помощью jQuery-метода css
$body.css('background-color', '#eee');Базовые селекторы
Основные CSS селекторы, которые используются для выборки элементов в jQuery:
$('.class')– по классу;$('#id')– по id;$('tag')– по тегу;$('*')– все элементы;$('selector1,selector2,...')– по группе селекторов (выбирает все элементы, соответствующие хотя бы одному из указанных селекторов);$('selector1selector2...')– по комбинации селекторов (выбирает элементы, которые должны соответствовать всем указанным селекторам).
Примеры
1. Найдём все элементы с классом btn:
var elements = $('.btn');2. Выберем элемент с id="carousel":
var element = $('#carousel');3. Выполним поиск всех элементов с тегом <a>:
var elements = $('a');4. Выберем все элементы на странице:
var elements = $('*');5. Выполним поиск элементов с классом nav или menu:
var elements = $('.nav,.menu');6. Найдём элементы с тегом <nav> и классом menu:
// nav - селектор для выбора элементов по тегу <nav>
// .menu - селектор для выбора элементов с классом menu
var navs = $('nav.menu');Селекторы атрибутов
CSS селекторы для идентификации элементов по их атрибутам::
[attr]– по атрибуту независимо от его значения;[attr=value]– по атрибуту со значением, точно равным заданному;[attr^=value]– по атрибуту со значением, начинающимся точно с заданной строки;[attr|=value]– по атрибуту со значением, равным заданной строке или начинающимся с этой строки, за которой следует дефис (-);[attr$=value]– по атрибуту со значением, оканчивающимся точно на заданную строку (при сравнении учитывается регистр);[attr*=value]– по атрибуту со значением, содержащим заданную подстроку;[attr~=value]– по атрибуту со значением, содержащим заданное слово, отделённое пробелами;[attr!=value]– выбирает элементы, которые не содержат указанного атрибута, либо имеют указанный атрибут, но не с заданным значением.
Значение атрибута в выражении селектора должно быть заключено в кавычки. Осуществляется это одним из следующих способов:
$('a[rel="nofollow"]')— двойные кавычки внутри одинарных кавычек;$("[rel='nofollow']")— одинарные кавычки внутри двойных кавычек;$('a[rel='nofollow']')— экранированные одинарные кавычки внутри одинарных кавычек;$("a[rel="nofollow"]")— экранированные двойные кавычки внутри двойных кавычек;
Селектор [attr!="value"] не является стандартным CSS селектором. Это расширение jQuery. При его использовании снижается производительность, поэтому в выборке не рекомендуется его использовать. Вместо него предпочтительнее использовать следующую конструкцию:
$('selector').not('[attr="value"]')Примеры
1. Выберем изображения <img> с атрибутом alt:
<img src="photo-1.jpg" alt="">
<img src="photo-2.jpg" alt="Фото">
<img src="photo-3.jpg">
<script>
// используем селектор [attr]
var $elements = $('img[alt]');
</script>2. Найдём элементы с атрибутом type="button":
<input type="button" value="Рассчитать стоимость заказа">
<button type="button">Информация о заказе</button>
<input type="submit" value="Отправить заказ">
<script>
// используем селектор [attr=value]
var elements = $('[type="button"]');
</script>3. Выполним поиск <а> с классом btn и атрибутом href начинающимся со строки «http:».
<a class="btn btn-default" href="http://itchief.ru">...</a>
<a href="http://jquery.com/">...</a>
<a class="btn" href="my1.html">...</a>
<script>
// используем селектор [attr^=value]
var elements = $('a.btn[href^="http:"]');
</script>4. Выполним поиск всех <div> с атрибутом data-name, имеющим значение, равное alert или начинающимся с alert, за которым следует дефис:
<div data-name="alert">...</div>
<p data-name="alert">...</p>
<div data-name="alert-warning">...</div>
<div data-name="warning">...</div>
<script>
// используем селектор [attr|=value]
var elements = $('div[data-name|="alert"]');
</script>5. Найдём все элементы с атрибутом href, имеющие значения точно оканчивающиеся на строку «.zip»:
<a href="downloads/archive.zip">...</a>
<a href="#">...</a>
<div>...</div>
<script>
// используем селектор [attr$=value]
var elements = $('[href$=".zip"]');
</script>6. Найдём все элементы с атрибутом href, содержащим подстроку «youtube»:
<a href="http://www.youtube.com/">...</a>
<a href="#">...</a>
<div>...</div>
<script>
// используем селектор [attr*=value]
var elements = $('[href*="youtube"]');
</script>7. Выполним поиск <а> с атрибутом data-target, значение которого содержит «btn», отделённое от других пробелами:
<a href="#" data-target="btn btn-default">...</a><!-- да -->
<a href="#" data-target="btn" >...</a> <!-- да -->
<button type="submit" data-target="btn btn-default">Отправить</button> <!-- нет -->
<a href="#">...</a> <!-- нет -->
<a href="#" class="btn-default">...</a> <!-- нет -->
<script>
// используем селектор [attr~=value]
var elements = $('a[data-target~="btn"]');
</script>8. Выберем <a>, которые не содержат атрибут rel, либо имеют его, но не с значением nofollow:
<a href="#" rel="nofollow">...</a>
<a href="#" rel="nofollow next">...</a>
<a href="#">...</a>
<a href="#" rel="next">...</a>
<p>...</p>
<script>
// используем селектор [attr!=value]
var elements = $('a[rel!="nofollow"]');
// но лучше так
// $('a').not('[rel!="nofollow"]')
</script>9. Выберем <a>, имеющий следующие атрибуты: id, href, начинающий со строки «http:» и class, содержащим слово btn, отделённое пробелами:
<a id="intro" class="btn btn-default" href="http://getbootstrap.com/">...</a>
<a class="btn btn-success" href="http://itchief.ru/">...</a>
<a href="index.html">...</a>
<script>
// используем комбинацию селекторов $('selector1selector2...')
var elements = $('a[id][href^="http:"][class~="btn"]');
</script>Селекторы отношений
В документы каждый элемент связан определёнными отношениями с другими элементами.
В CSS имеется 4 селектора отношений (A и B – это селекторы):
A>B– выбирает элементыB, расположенные непосредственно вA;A B– выбирает элементыB, расположенные вA;A+B– выбирает элементыB, каждый из которых расположен сразу же послеA(при этом данные элементы должны являться детьми одного родителя, т.е. находиться на одном уровне вложенности);A~B– выбирает все элементыB, каждые из которых расположены послеA(при этом данные элементы должны являться детьми одного родителя, т.е. находиться на одном уровне вложенности).
Примеры
1. Найдём все <p>, расположенные в <article>:
<section>
<p>...</p>
<article>
<h1>...</h1>
<p>...</p> <!-- + -->
<div>
<p>...</p> <!-- + -->
</div>
</article>
<aside>
<p>...</p>
</aside>
</section>
<script>
var $elements = $('article p');
</script>2. Выберем все <li>, расположенные непосредственно в #nav:
<ul id="nav">
<li>...</li> <!-- + -->
<li> <!-- + -->
<ul>
<li>...</li>
<li>...</li>
</ul>
</li>
<li>...</li> <!-- + -->
</ul>
<script>
var $elements = $('#nav>li');
</script>3. Найдём все элементы .warning, расположенные сразу же после элементов .danger:
<section>
<div class="warning">...</div>
<div class="danger">...</div>
<div class="warning">...</div> <!-- + -->
<div class="danger">
<div class="warning">...</div>
</div>
<div class="warning">...</div> <!-- + -->
</section>
<script>
var $elements = $('.danger+.warning');
</script>4. Выберем все <input>, которые находятся сразу же за <label>. При этом <input> и <label> должны располагаться на одном уровне вложенности, т.е. иметь одного родителя:
var $elements = $('label + input');5. Найти все <div>, расположенные после .prev внутри одного родителя:
var $elements = $('.prev~div');Управление контекстом
По умолчанию поиск элементов осуществляется во всём документе. Но при необходимости вы можете его ограничить, определив контекст поиска.
Контекст представляет собой элемент, в рамках которого следует производить выборку элементов.
Контекст передаётся во второй аргумент функции jQuery. Задавать его можно с помощью селектора, DOM-элемента или набора jQuery.
Например, найдём элементы с классом active в контексте элемента с id="#list":
// #list – контекст
var active = $('.active', '#list');Задачи
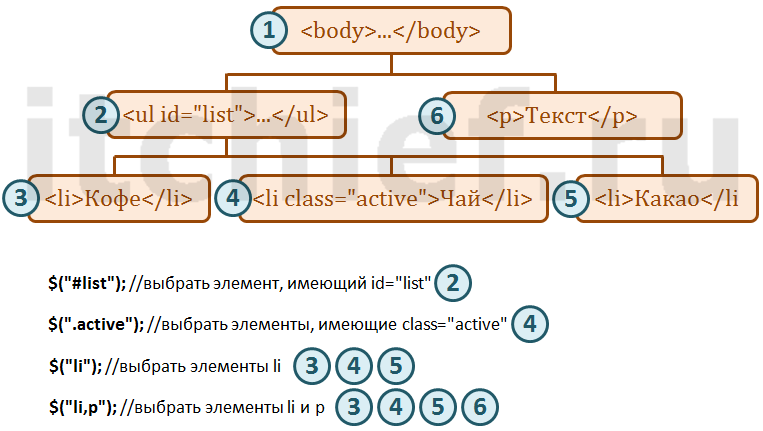
1. Задача:
...
<body>
<ul id="list"> <!-- 1 -->
<li>Кофе</li> <!-- 2 -->
<li class="active">Чай</li> <!-- 3 -->
<li>Какао</li> <!-- 4 -->
</ul>
<p>Текст</p> <!-- 5 -->
</body>
</html>$('#list')— 1;$('.active')— 3;$('li')— 2, 3, 4;$('ul,li,p')— 1, 2, 3, 4, 5;
Этой статьей я начинаю цикл публикаций, посвященных основам автоматизации тестирования веб-приложений с использованием инструмента Selenium WebDriver. Для того, чтобы овладеть столь необходимым навыком, нам потребуется сделать всего лишь 3 шага. Итак, приступим.
Шаг 1. Правильно определяем локаторы
Для чего же нужны локаторы и почему нужно правильно их определять? C помощью локатора мы говорим WebDriver какой именно элемент на странице ему нужно найти и выполнить определенные действия.
Если, для написания автоматизированных тестов, используется Selenium, то локатор указывается в поле target, если selenium WebDriver, то локатор передается в метод findElement. (WebElement element = driver.findElement(By.name(«q»)).
Если мы плохо (некачественно) определим локатор, то есть большая вероятность того, что при выполнении теста WebDriver не найдет нужный элемент и весь тест тут же завершиться ошибкой.
Теперь определимся с инструментарием. Для определения локаторов я буду использовать дополнения firebug и firepath для браузера Firefox, которые можно загрузить из меню Дополнения браузера. Firepath является дополнением Firebird и, помимо показа тэгов и атрибутов элементов, позволяет писать и проверять css и xpath выражения.

Для отображения атрибутов элемента веб-страницы, нужно активировать Firebug и кликнуть по элементу.
Каждый элемент на веб-странице представлен html-тэгом и набором атрибутов. Для определения локатора мы можем использовать все атрибуты элемента. Selenium использует следующие типы локаторов:
- Id
- name
- link
- css
- xpath
Разберем каждый из них по порядку:
ID
Определение локатора по идентификатору элемента (атрибут id) – является самым простым. Находим элемент на странице, кликаем по нему и в firebug смотрим его id. Например, на приведенном ниже на рисунке примере, id элемента будет равен «gs_htif0».
![]()
Главным минусом определения локатора по идентификатору является то, что очень часто элементы имеют динамичные id, которые изменяются при каждой новой загрузке страницы, вследствие чего ваши автотесты будут непригодны для использования.
Name
Определение локатора по атрибуту name элемента очень часто используется при работе уникальными полями для ввода, такими как поля для ввода логина и пароля. Принцип определения такой же, как и у id. Кликаем по элементу и среди набора атрибутов ищем атрибут name и его значение.
![]()
Часто бывает, что элементов с одинаковым атрибутом name на странице несколько. В таком случае, использовать локатор с типом name нельзя, так как он не позволит уникальным образом идентифицировать элемент.
Link или же LinkText.
Определение локатора по тексту ссылки, как следует из названия, необходимо использовать для ссылок. Локатором в этом случает будет являться текст ссылки.
![]()
В примере на рисунке локатор определим, как link = ”вспомнить пароль”.
Три вышеперечисленных типа локаторов относятся к простым. Что же делать, если при помощи этих типов нельзя уникально идентифицировать элемент на странице (id динамичный, а атрибут name одинаков для нескольких элементов)? Тут нам на помощь приходят следующие 2 типа локаторов, так называемая «высшая лига», css и xpath. При помощи этих типов, мы сможем идентифицировать элементы при помощи всех его атрибутов или же при помощи расположения элемента на странице относительно других элементов.
CSS
Сначала рассмотрим те CSS выражения, которые буду выполнять поиск элемента на странице по связке html тэг-атрибут. К элементу на странице мы можем обратиться по его идентификатору (id). Синтаксис будет следующий:
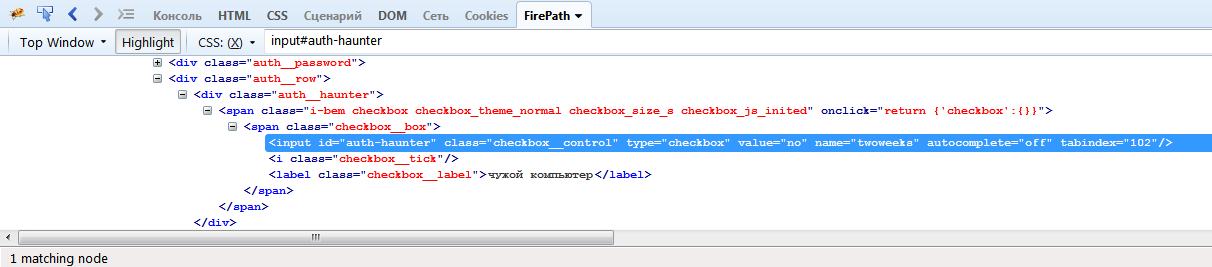
#id. Так, выражение #auth-haunter, найдет элемент(ы), у которых атрибут id=auth-haunter.

Можно найти элемент по наименованию класса:
.class – выражение .checkbox__control найдет все элементы, у которых атрибут class=checkbox__control

Можно обратиться к элементу напрямую, для этого достаточно просто указать html тэг элемента. Так, тэг button найдет все элементы button на странице.

При составлении СSS выражений, мы можем комбинировать тэги и атрибуты. Так, выражение input#auth-haunter найдет нам элемент input у которого id= auth-haunter, а выражение input.checkbox__control, найдет нам элемент input, у которого атрибут class = checkbox__control. Как видно из рисунка ниже, это будет один и тот же элемент 
Для того, чтобы найти элемент по любому другому атрибуту, используется следующая форма записи:
element[attribute] – так, выражение button[type] найдет на странице все элементы button, у которых есть атрибут type

При помощи CSS мы может строить выражения, которые будут находить элемент на странице при помощи его тэга, атрибута и значения атрибута.
element[attribute =”value”] – строгое совпадение по значению. Так, выражение input[title=”Search”] найдет нам элемент input, у которого значение атрибута title = Search

element[attribute^=”value”] – значение атрибута начинается со строки value
element[attribute$=”value”] – значение атрибута заканчивается строкой value
element[attribute*=”value”] – значение атрибута содержит строку value
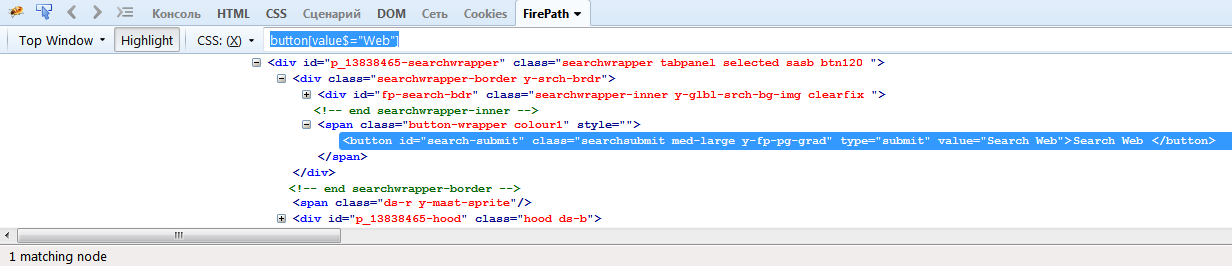
Например, button[value$=»Web»] найдет элемент button, у которого атрибут value заканчивается словом Web
Иногда необходимо найти элемент по его расположению относительно другого элемента (вторая ссылка в списке, третья запись в таблице). Нужно понимать, что структура элементов на странице представляет из себя дерево, где элементы находятся в отношении родитель – потомок.
Рассмотрим, как нам строить css выражения в таких случаях.
element1 element2 – ищет среди всех потомков element1 нужный element2. Например, div input найдет все элементы input, которые являются потомками элемента div

element1 > element2 – найдет нужный element2, который является непосредственным потомком element1. Так из примера выше, элементы input являются потомками div, но непосредственными потомками они являются дял элемента form. Поэтому для их поиска можно написать следующее выражение: form>input

element1 + element2 – ищет нужный element2, который располагается сразу за element1.
В нашем примере, input располагается сразу за элементом i. Найдем элемент input выражением: i+input
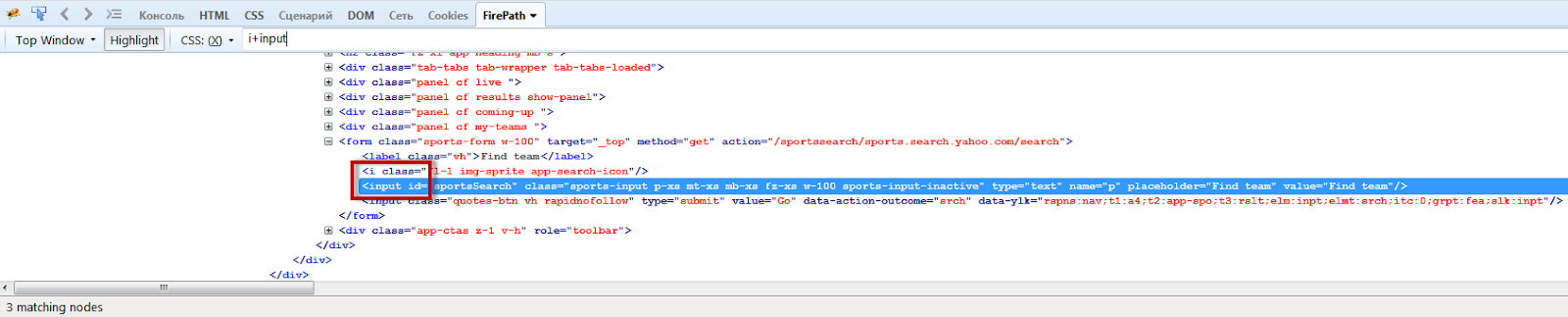
element:nth-of-type(n) – ищет элемент, который расположен n-ым по счету. Так, для того, чтобы найти второй input из нашего примера, можно написать следующее выражение: form>input:nth-of-type(2) (Среди прямых потомков элемента form найти элемент input, который будет располагаться 2-м по счету).

Итак, мы рассмотрели основные принципы построения css выражений. Комбинируя их, мы можем уникально идентифицировать практически любой элемент на странице.
Xpath
Xpath выражения осуществляют поиск по xml разметке веб-страницы. Любое xpath выражение начинается со знака «/», который обозначает корень дерева элементов на странице.
Рассмотрим синтаксис основных xpath выражений:
* — любые элементы
// — поиск по всем потомкам, так выражение //div произведет поиск по всем элементам, начиная от корня и найдет все элементы div
Xpath, как и css, позволяет искать элементы по связке тэг-атрибут. Для обращения к атрибуту используется символ «@». Синтаксис в этом случае будет следующий: //element[@attribute=”value”]. Например, выражение //input[@title=»Search»] говорит, что нужно искать среди всех элементов, начиная с корня, все элементы Input, у которых атрибут title = Search

Если элемент содержит какой-либо текст, мы может обратиться к нему используя функцию text()=”value” (//element[text()=”value”]).
//em[text()=»Mail»] – найдет на странице элемент em с текстом Mail.

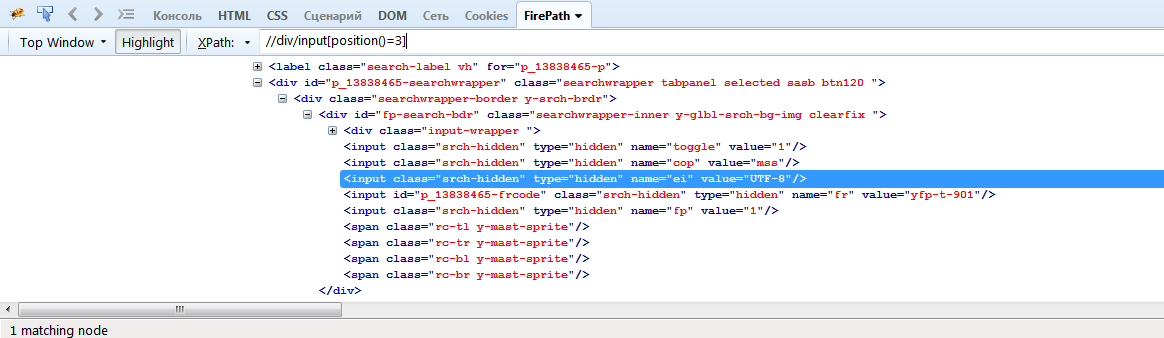
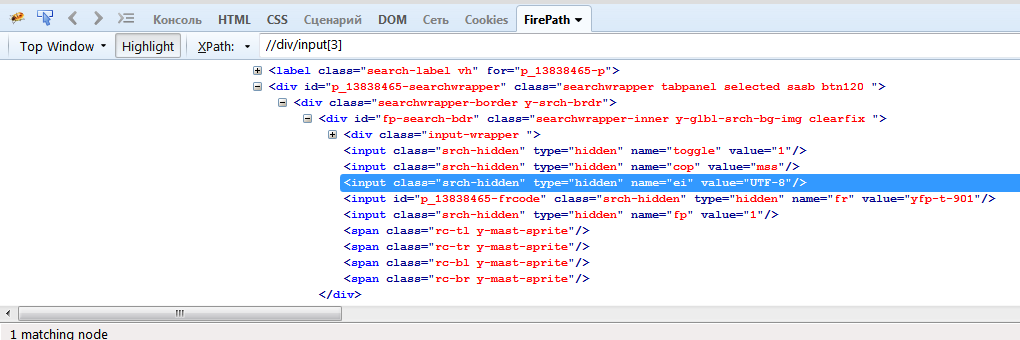
Если на странице идет несколько одинаковых элементов подряд, то при поиске можно указать позицию элемента функцией position()=value, или же [value]. Выражения //div/input[position()=3]) или //div/input[3] найдут элемент input, который является потомком элемента div и является 3-им по счету.
Xpath также поддерживает логические выражения «И» и «ИЛИ».
Для «ИЛИ» синтаксис следующий: //element[@attribute=”value” or @attribute=”value”]. Например //input[@type=»text» or @name=»cop»] найдет среди всех элементов страницы элементы input, у которых атрибут type=text или атрибут name=cop.
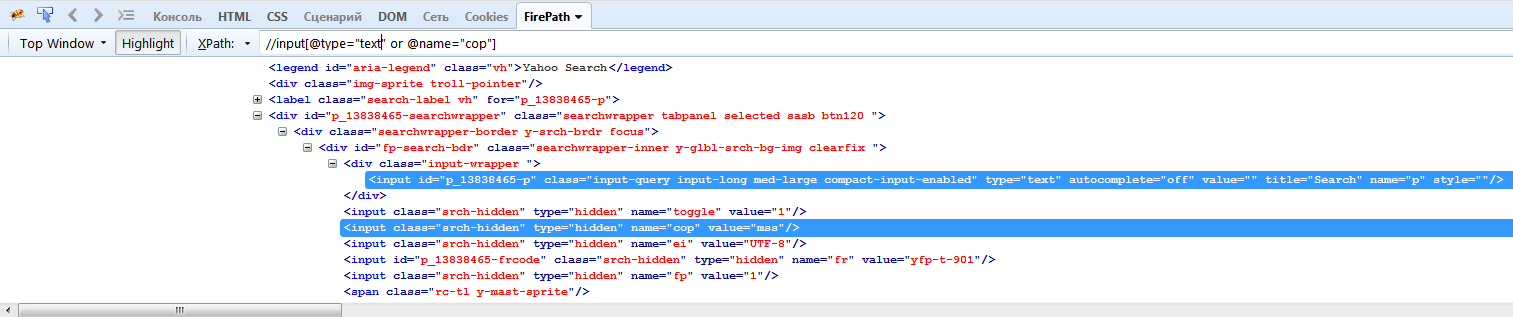
Для «И» выражение будет выглядеть следующим образом: //element[@attribute=”value” and @attribute=”value”]. //input[position()=2 and @value=»Go»] – среди всех элементом страницы найдет элемент input, который располагается вторым и у которого атрибут value = Go.

Мы рассмотрели наиболее часто употребляемые способы написания локаторов при помощи xpath. Есть еще одно правило, которое касается как xpath, так и css выражений – нужно избегать использования промежуточных локаторов (длинных выражений), так как такие локаторы очень чувствительны к изменениям. Т.е. чем меньше элементов мы задействуем в определении локатора, тем он будет надежней. Например, локатор //*[@id=’default-p_30345827-bd’]/div/div/ol/li[1]/a лучше преобразовать к виду //*[@id=’default-p_30345827-bd’]//li[1]/a, убрав промежуточную часть (/div/div/ol/). Как видим из примера, и в том, и в другом случае будет найдет один и тот же элемент.


И напоследок еще один совет: Всегда старайтесь при определении локатора следовать принципу от простого к сложному. Пытайтесь определять локаторы при помощи простых типов (id, name, link) и используйте сложные (css, xpath) только в случае необходимости.
На этом с локаторами все, следующий раз мы научимся писать и запускать автоматизированные тесты при помощи Selenuim Web-Driver.
Как вы, возможно, уже поняли, чтобы управлять элементами страницы, нам нужно сначала найти их. Selenium использует так называемые локаторы, чтобы находить элементы на веб-странице.
В Selenium есть 8 методов которые помогут в поиске HTML элементов:
| Цель поиска Используемый метод |
Пример | ||
| Поиск по ID find_element_by_id(«user») |
|
||
| Поиск по имени find_element_by_name(«username») |
|
||
| Поиск по тексту ссылки find_element_by_link_text(«Login») |
|
||
| Поиск по частичному тексту ссылки find_element_by_partial_link_text(«Next») |
|
||
| Поиск используя XPath find_element_by_xpath(‘//div[@id=»login»]/input’) |
|
||
| Поиск по названию тэга find_element_by_tag_name(«body») |
|||
| Поиск по классу элемента find_element_by_class_name(«table») |
|
||
| Поиск по CSS селектору find_element_by_css_selector(‘#login > input[type=»text»]’) |
|
Вы можете использовать любой из них, чтобы сузить поиск элемента, который вам нужен.
Запуск браузера
Тестирование веб-сайтов начинается с браузера. В приведенном ниже тестовом скрипте запускается окно браузера Firefox, и осуществляется переход на сайт.
|
from selenium import webdriver driver = webdriver.Firefox() driver.get(«http://testwisely.com/demo») |
Используйте webdriver.Chrome и webdriver.Ie() для тестирования в Chrome и IE соответственно. Новичкам рекомендуется закрыть окно браузера в конце тестового примера.
Поиск элемента по ID
Использование идентификаторов — самый простой и безопасный способ поиска элемента в HTML. Если страница соответствует W3C HTML, идентификаторы должны быть уникальными и идентифицироваться в веб-элементах управления. По сравнению с текстами тестовые сценарии, использующие идентификаторы, менее склонны к изменениям приложений (например, разработчики могут принять решение об изменении метки, но с меньшей вероятностью изменить идентификатор).
|
driver.find_element_by_id(«submit_btn»).click() # Клик по кнопке driver.find_element_by_id(«cancel_link»).click() # Клик по ссылке driver.find_element_by_id(«username»).send_keys(«agileway») # Ввод символов driver.find_element_by_id(«alert_div»).text # Получаем текст |
Поиск элемента по имени
Атрибут имени используются в элементах управления формой, такой как текстовые поля и переключатели (radio кнопки). Значения имени передаются на сервер при отправке формы. С точки зрения вероятности будущих изменений, атрибут name, второй по отношению к ID.
|
driver.find_element_by_name(«comment»).send_keys(«Selenium Cool») |
Поиск элемента по тексту ссылки
Только для гиперссылок. Использование текста ссылки — это, пожалуй, самый прямой способ щелкнуть ссылку, так как это то, что мы видим на странице.
|
driver.find_element_by_link_text(«Cancel»).click() |
HTML для которого будет работать
|
<a href=«/cancel»>Cancel</a> |
Поиск элемента по частичному тексту ссылки
Selenium позволяет идентифицировать элемент управления гиперссылкой с частичным текстом. Это может быть полезно, если текст генерируется динамически. Другими словами, текст на одной веб-странице может отличаться при следующем посещении. Мы могли бы использовать общий текст, общий для этих динамически создаваемых текстов ссылок, для их идентификации.
|
# Полный текст ссылки «Cancel Me» driver.find_element_by_partial_link_text(«ance»).click() |
HTML для которого будет работать
|
<a href=«/cancel»>Cancel me</a> |
Поиск элемента по XPath
XPath, XML Path Language, является языком запросов для выбора узлов из XML документа. Когда браузер отображает веб-страницу, он анализирует его в дереве DOM. XPath может использоваться для ссылки на определенный узел в дереве DOM. Если это звучит слишком сложно для вас, не волнуйтесь, просто помните, что XPath — это самый мощный способ найти определенный веб-элемент.
|
# Клик по флажку в контейнере с ID div2 driver.find_element_by_xpath(«//*[@id=’div2′]/input[@type=’checkbox’]»).click() |
HTML для которого будет работать
|
<form> <div id=«div2»> <input value=«rules» type=«checkbox»> </div> </form> |
Некоторые тестеры чувствуют себя «запуганными» сложностью XPath. Тем не менее, на практике существует только ограниченная область для использования XPath.
Избегайте XPath из Developer Tool
Избегайте использования скопированного XPath из инструмента Developer Tool.
Инструмент разработчика браузера (щелкните правой кнопкой мыши, чтобы выбрать «Проверить элемент», чтобы увидеть) очень полезен для определения веб-элемента на веб-странице. Вы можете получить XPath веб-элемента там, как показано ниже (в Chrome):
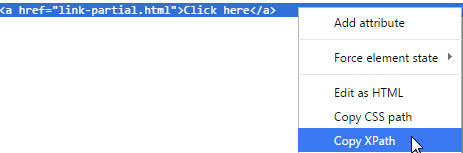
Скопированный XPath для второй ссылки «Нажмите здесь» в примере:
|
//*[@id=«container»]/div[3]/div[2]/a |
Этот метод работает. Тем не менее, этот подход не рекомендуется для постоянного применения, поскольку тестовый сценарий является довольно хрупким и изменчивым.
Попытайтесь использовать выражения XPath, которое менее уязвимо для структурных изменений вокруг веб-элемента.
Поиск элемента по имени тега
В HTML есть ограниченный набор имен тегов. Другими словами, многие элементы используют одни и те же имена тегов на веб-странице. Обычно мы не используем локатор tag_name для поиска элемента. Мы часто используем его с другими элементами в цепочке локаторах. Однако есть исключение.
|
driver.find_element_by_tag_name(«body»).text |
Вышеприведенная тестовая инструкция возвращает текстовое содержимое веб-страницы из тега body.
Поиск элемента по имени класса
Атрибут class элемента HTML используется для стилизации. Он также может использоваться для идентификации элементов. Как правило, атрибут класса элемента HTML имеет несколько значений, как показано ниже.
|
<a href=«back.html» class=«btn btn-default»>Cancel</a> <input type=«submit» class=«btn btn-deault btn-primary»> Submit </input> |
Вы можете использовать любой из них.
|
driver.find_element_by_class_name(«btn-primary»).click() # Клик по кнопки driver.find_element_by_class_name(«btn»).click() # Клик по ссылке # # |
Метод class_name удобен для тестирования библиотек JavaScript / CSS (таких как TinyMCE), которые обычно используют набор определенных имен классов.
|
driver.find_element_by_id(«client_notes»).click() time.sleep(0.5) driver.find_element_by_class_name(«editable-textarea»).send_keys(«inline notes») time.sleep(0.5) driver.find_element_by_class_name(«editable-submit»).click() |
Поиск элемента с помощью селектора CSS
Вы также можете использовать CSS селектор для поиска веб-элемента.
|
driver.find_element_by_css_selector(«#div2 > input[type=’checkbox’]»).click() |
Однако использование селектора CSS, как правило, более подвержено структурным изменениям веб-страницы.
Используем find_elements для поиска дочерних элементов
Для страницы, содержащей более одного элемента с такими же атрибутами, как приведенный ниже, мы могли бы использовать XPath селектор.
|
<div id=«div1»> <input type=«checkbox» name=«same» value=«on»> Same checkbox in Div 1 </div> <div id=«div2»> <input type=«checkbox» name=«same» value=«on»> Same checkbox in Div 2 </div> |
Есть еще один способ: цепочка из find_element чтобы найти дочерний элемент.
|
driver.find_element_by_id(«div2»).find_element_by_name(«same»).click() |
Поиск нескольких элементов
Как следует из названия, find_elements возвращает список найденных элементов. Его синтаксис точно такой же, как find_element, то есть он может использовать любой из 8 локаторов.
Пример HTML кода
|
<div id=«container»> <input type=«checkbox» name=«agree» value=«yes»> Yes <input type=«checkbox» name=«agree» value=«no»> No </div> |
Выполним клик по второму флажку.
|
checkbox_elems = driver.find_elements_by_xpath(«//div[@id=’container’]//input[@type=’checkbox’]») print(len(checkbox_elems)) # Результат: 2 checkbox_elems[1].click() |
Иногда find_element вылетает из-за нескольких совпадающих элементов на странице, о которых вы не знали. Метод find_elements пригодится, чтобы найти их.