Мы занимаемся закупкой трафика из Adwords (рекламная площадка от Google). Одна из регулярных задач в этой области – создание новых баннеров. Тесты показывают, что баннеры теряют эффективность с течением времени, так как пользователи привыкают к баннеру; меняются сезоны и тренды. Кроме того, у нас есть цель захватить разные ниши аудитории, а узко таргетированные баннеры работают лучше.
В связи с выходом в новые страны остро встал вопрос локализации баннеров. Для каждого баннера необходимо создавать версии на разных языках и с разными валютами. Можно просить это делать дизайнеров, но эта ручная работа добавит дополнительную нагрузку на и без того дефицитный ресурс.
Это выглядит как задача, которую несложно автоматизировать. Для этого достаточно сделать программу, которая будет накладывать на болванку баннера локализованную цену на «ценник» и call to action (фразу типа «купить сейчас») на кнопку. Если печать текста на картинке реализовать достаточно просто, то определение положения, куда нужно его поставить — не всегда тривиально. Перчинки добавляет то, что кнопка бывает разных цветов, и немного отличается по форме.
Этому и посвящена статья: как найти указанный объект на картинке? Будут разобраны популярные методы; приведены области применения, особенности, плюсы и минусы. Приведенные методы можно применять и для других целей: разработки программ для камер слежения, автоматизации тестирования UI, и подобных. Описанные трудности можно встретить и в других задачах, а использованные приёмы использовать и для других целей. Например, Canny Edge Detector часто используется для предобработки изображений, а количество ключевых точек (keypoints) можно использовать для оценки визуальной “сложности” изображения.
Надеюсь, что описанные решения пополнят ваш арсенал инструментов и трюков для решения проблем.
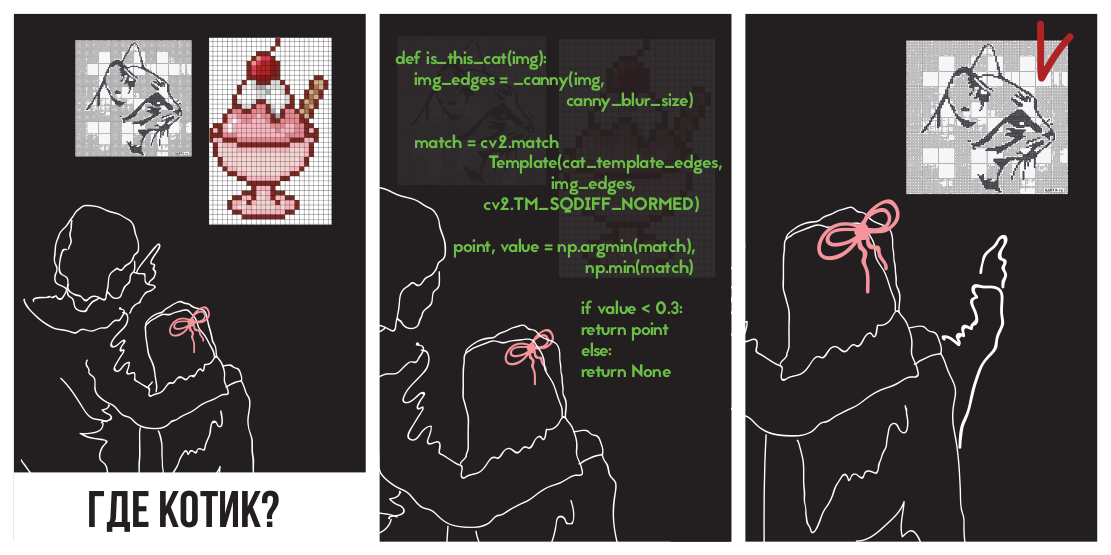
Код приведён на Python 3.6 (репозиторий); требуется библиотека OpenCV. От читателя ожидается понимание основ линейной алгебры и computer vision.
Фокусироваться будем на нахождении самой кнопки. Про нахождение ценников будем помнить (так как нахождение прямоугольника можно решить и более простыми способами), но опустим, так как решение будет выглядеть аналогичным образом.
Template matching
Первая же мысль, которая приходит в голову — почему бы просто не взять и найти на картинке регион, который наиболее похож на кнопку в терминах разницы цветов пикселей? Это и делает template matching — метод, основанный на нахождении места на изображении, наиболее похожем на шаблон. “Похожесть” изображения задается определенной метрикой. То есть, шаблон «накладывается» на изображение, и считается расхождение между изображением и и шаблоном. Положение шаблона, при котором это расхождение будет минимальным, и будет означать место искомого объекта.
В качестве метрики можно использовать разные варианты, например — сумма квадратов разниц между шаблоном и картинкой (sum of squared differences, SSD), или использовать кросс-корреляцию (cross-correlation, CCORR). Пусть f и g — изображение и шаблон размерами (k, l) и (m, n) соответственно (каналы цвета пока будем игнорировать); i,j — позиция на изображении, к которой мы «приложили» шаблон.


Попробуем применить разницу квадратов для нахождения котёнка

На картинке

(картинка взята с ресурса PETA Caring for Cats).
Левая картинка — значения метрики похожести места на картинке на шаблон (т.е. значения SSD для разных i,j). Темная область — это и есть место, где разница минимальна. Это и есть указатель на место, которое наиболее похоже на шаблон — на правой картинке это место обведено.

Кросс-корреляция на самом деле является сверткой двух изображений. Свёртки можно реализовать быстро, используя быстрое преобразование Фурье. Согласно теореме о свёртке, после преобразования Фурье свёртка превращается в простое поэлементное умножение:

Где  — оператор свёртки. Таким образом мы можем быстро посчитать кросс-корреляцию. Это даёт общую сложность O(kllog(kl)+mnlog(mn)), против O(klmn) при реализации «в лоб». Квадрат разницы также можно реализовать с помощью свёртки, так как после раскрытия скобок он превратится в разницу между суммой квадратов значений пикселей изображения и кросс-корреляции:
— оператор свёртки. Таким образом мы можем быстро посчитать кросс-корреляцию. Это даёт общую сложность O(kllog(kl)+mnlog(mn)), против O(klmn) при реализации «в лоб». Квадрат разницы также можно реализовать с помощью свёртки, так как после раскрытия скобок он превратится в разницу между суммой квадратов значений пикселей изображения и кросс-корреляции:



Детали можно посмотреть в этой презентации.
Перейдём к реализации. К счастью, коллеги из нижненовгородского отдела Intel позаботились о нас, создав библиотеку OpenCV, в ней уже реализован поиск шаблона с помощью метода matchTemplate (кстати используется именно реализация через FFT, хотя в документации это нигде не упоминается), использующий разные метрики расхождений:
- CV_TM_SQDIFF — сумма квадратов разниц значений пикселей
- CV_TM_SQDIFF_NORMED — сумма квадрат разниц цветов, отнормированная в диапазон 0..1.
- CV_TM_CCORR — сумма поэлементных произведений шаблона и сегмента картинки
- CV_TM_CCORR_NORMED — сумма поэлементных произведений, отнормированное в диапазон -1..1.
- CV_TM_CCOEFF — кросс-коррелация изображений без среднего
- CV_TM_CCOEFF_NORMED — кросс-корреляция между изображениями без среднего, отнормированная в -1..1 (корреляция Пирсона)
Применим их для поиска котёнка:

Видно, что только TM_CCORR не справился со своей задачей. Это вполне объяснимо: так как он представляет собой скалярное произведение, то наибольшее значение этой метрики будет при сравнении шаблона с белым прямоугольником.
Можно заметить, что эти метрики требуют попиксельного соответствия шаблона в искомом изображении. Любое отклонение гаммы, света или размера приведут к тому, что методы не будут работать. Напомню, что это именно наш случай: кнопки могут быть разного размера и разного цвета.
Проблему разного цвета и света можно решить применив фильтр нахождения граней (edge detection filter). Этот метод оставляет лишь информацию о том, в каком месте изображения находились резкие перепады цвета. Примененим Canny Edge Detector (его подробнее разберём чуть дальше) к кнопкам разного цвета и яркости. Слева приведены исходные баннеры, а справа — результат применения фильтра Canny.

В нашей случае, также существует проблема разных размеров, однако она уже была решена. Лог-полярная трансформация преобразует картинку в пространство, в котором изменение масштаба и поворот будут проявляться как смещение. Используя эту трансформацию, мы можем восстановить масштаб и угол. После этого, отмасштабировав и повернув шаблон, можно найти и позицию шаблона на исходной картинке. Во всей этой процедуре также можно использовать FFT, как описано в статье An FFT-Based Technique for Translation, Rotation, and Scale-Invariant Image Registration . В литературе рассматривается случай, когда по горизонтали и вертикали шаблон изменяется пропорционально, и при этом коэффициент масштаба варьируется в небольших пределах (2.0… 0.8). К сожалению, изменение размеров кнопки может быть бо́льшим и непропорциональным, что может привести к некорректному результату.
Применим полученную конструкцию (фильтр Canny, восстановление только масштаба через лог-полярную трансформацию, получение положения через нахождения места с минимальным квадратичным расхождением), для нахождения кнопки на трех картинках. В качестве шаблона будем использовать большую желтую кнопку:

При этом на баннерах кнопки будут разных типов, цветов и размеров:

В случае с изменением размера кнопки метод сработал некорректно. Это связано с тем, что метод предполагает изменение размеров кнопок в одинаковое количество раз и по горизонтали, и по вертикали. Однако, это не всегда так. На правой картинке размер кнопки по вертикали не изменился, а по горизонтали — уменьшился сильно. При слишком большом изменении размера искажения, вызванные логполярным преобразованием, делают поиск нестабильным. В связи с этим метод не смог обнаружить кнопку в третьем случае.
Keypoint detection
Можно попробовать другой подход: давайте вместо того, чтобы искать кнопку целиком, найдём её типичные части, например, углы кнопки, или элементы бордюра (по контуру кнопки есть декоративная обводка). Кажется, что найти углы и бордюр проще, так как это мелкие (а значит, простые) объекты. То, что лежит между четырёх углов и бордюра — и будет кнопкой. Класс методов нахождения ключевых точек называется “keypoint detection”, а алгоритмы сравнения и поиска картинок с помощью ключевых точек — “keypoint matching”. Поиск шаблона на картинке сводится к применению алгоритма обнаружения ключевых точек к шаблону и картинке, и сопоставлению ключевых точек шаблона и картинки.
Обычно “ключевые точки” находят автоматически, находя пиксели, окружение которых которых обладает определёнными свойствами. Было придумано множество способов и критериев их нахождения. Все эти алгоритмы являются эвристиками, которые находят какие-то характерные элементы изображения, как правило — углы или резкие перепады цвета. Хороший детектор должен работать быстро, и быть устойчивым к трансформациям картинки (при изменении картинки ключевые точки не должны переставать находиться/двигаться).
Harris corner detector
Одним из самых базовых алгоритмов считается Harris corner detector. Для картинки (тут и дальше мы считаем, что оперируем “интенсивностью” — изображением, переведенной в grayscale) он пытается найти точки, в окрестностях которых перепады интенсивности больше определенного порога. Алгоритм выглядит так:
-
От интенсивности
 находятся производные по оси X и Y ( и соответственно). Их можно найти, например, применив фильтр Собеля.
находятся производные по оси X и Y ( и соответственно). Их можно найти, например, применив фильтр Собеля. -
Для пикселя считаем квадрат
, квадрат и произведения и . Некоторые источники обозначают их как , и — что не добавляет понятности, так как можно подумать, что это вторые производные интенсивности (а это не так). -
Для каждого пикселя считаем суммы в некой окрестности (больше 1 пикселя) w следующие характеристики:
Как и в Template Detection, эту процедуру для больших окон можно провести эффективно, если использовать теорему о свертке.
-
Для каждого пикселя посчитать значение
эвристики R Значение
подбирается эмпирически в диапазоне [0.04, 0.06] Если у какого-то пикселя больше определенного порога, то окрестность этого пикселя содержит угол, и мы отмечаем его как ключевую точку.
-
Предыдущая формула может создавать кластеры лежащих рядом друг с другом ключевых точек, в таком случае стоит их убрать. Это можно сделать проверив для каждой точки является ли у неё значение
максимальным среди непосредственных соседей. Если нет — то ключевая точка отфильтровывается. Эта процедура называется non-maximum suppression.
 находятся производные по оси X и Y (
находятся производные по оси X и Y ( ,
,  и
и 


 эвристики R
эвристики R 
 подбирается эмпирически в диапазоне [0.04, 0.06] Если
подбирается эмпирически в диапазоне [0.04, 0.06] Если  этого пикселя содержит угол, и мы отмечаем его как ключевую точку.
этого пикселя содержит угол, и мы отмечаем его как ключевую точку.
 Формула
Формула  выбрана так неспроста.
выбрана так неспроста.  — компоненты структурного тензора — матрицы, описывающую поведение градиента в окрестности:
— компоненты структурного тензора — матрицы, описывающую поведение градиента в окрестности:

Эта матрица многими свойствами и формой похожа на матрицу ковариации. Например, они обе положительно полуопределённые матрицы, но этим сходство не ограничивается. Напомню, что у матрицы ковариации есть геометрическая интерпретация. Собственные вектора матрицы ковариации указывают на направления наибольшей дисперсии исходных данных (на которых ковариация была посчитана), а собственные числа — на разброс вдоль оси:

Картинка взята из http://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix/
Точно так же ведут себя и собственные числа структурного тензора: они описывают разброс градиентов. На ровной поверхности собственные числа структурного тензора будут маленькими (потому что разброс самих градиентов будет маленьким). Собственные числа структурного тензора, построенного на кусочке картинки с гранью, будут сильно различаться: одно число будет большим (и соответствовать собственному вектору, направленному перпендикулярно грани), а второе — маленьким. На тензоре угла оба собственных числа будут большие. Исходя из этого, мы можем построить эвристику ( — собственные числа структурного тензора).
— собственные числа структурного тензора).

Значение этой эвристики будет большое, когда оба собственных числа — большие.
Сумма собственных чисел — это след матрицы, который можно рассчитать как сумму элементов на диагонали (а если взглянуть на формулы A и B, то станет понятно, что это еще и сумма квадратов длин градиентов в области):

Произведение собственных чисел — определитель матрицы, который в случае 2×2 тоже легко выписать:

Таким образом, мы можем эффективно посчитать , выразив её в терминах компонентов структурного тензора.
FAST
Метод Харриса хорош, но существует множество альтернатив ему. Рассматривать так же подробно, как метод выше, все не будем, упомянем лишь несколько популярных, чтобы показать интересные приёмы и сравнить их в действии.

Пиксели, проверяемые алгоритмом FAST
Альтернатива методу Харриса — FAST. Как подсказывает название, FAST работает гораздо быстрее вышеописанного метода. Этот алгоритм пытается найти точки, которые лежат на краях и углах объектах, т.е. в местах перепада контраста. Их нахождение происходит следующим образом: FAST строит вокруг пикселя-кандидата окружность радиуса R, и проверяет, есть ли на ней непрерывный отрезок из пикселей длины t, который темнее (или светлее) пикселя-кандидата на K единиц. Если это условие выполняется, то пиксель считается “ключевой точкой”. При определённых t мы можем реализовать эту эвристику эффективно, добавив несколько предварительных проверок, которые будут отсекать пиксели гарантированно не являющиеся углами. Например, при  и
и  , достаточно проверить, есть ли среди 4 крайних пикселей 3 последовательных, которые строго темнее/светлее центра на K (на картинке — 1, 5, 9, 13). Это условие позволяет эффективно отсечь кандидатов, точно не являющихся ключевыми точками.
, достаточно проверить, есть ли среди 4 крайних пикселей 3 последовательных, которые строго темнее/светлее центра на K (на картинке — 1, 5, 9, 13). Это условие позволяет эффективно отсечь кандидатов, точно не являющихся ключевыми точками.
SIFT
Оба предыдущих алгоритма не устойчивы к изменениям размера картинки. Они не позволяют найти шаблон на картинке, если масштаб объекта был изменён. SIFT (Scale-invariant feature transform) предлагает решение этой проблемы. Возьмем изображение, из которого извлекаем ключевые точки, и начнём постепенно уменьшать его размер с каким-то небольшим шагом, и для каждого варианта масштаба будем находить ключевые точки. Масштабирование — тяжелая процедура, но уменьшение в 2/4/8/… раз можно провести эффективно, пропуская пиксели (в SIFT эти кратные масштабы называются “октавами”). Промежуточные масштабы можно аппроксимировать, применяя к картинке гауссовский блюр с разным размером ядра. Как мы уже описали выше, это можно сделать вычислительно эффективно. Результат будет похож на то, как если бы мы сначала уменьшили картинку, а потом увеличили ее до исходного размера — мелкие детали теряются, изображение становится “замыленным”.
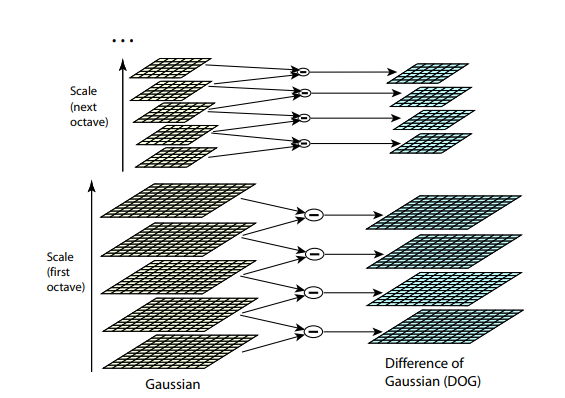
После этой процедуры посчитаем разницу между соседними масштабами. Большие (по модулю) значения в этой разнице получатся, если какая-то мелкая деталь перестает быть видна на следующем уровне масштаба, или, наоборот, следующий уровень масштаба начинает захватывает какую-то деталь, которая на предыдущем не была видна. Этот прием называется DoG, Difference of Gaussian. Можно считать, что большое значение в этой разнице уже является сигналом того, что в этом месте на изображении есть что-то интересное. Но нас интересует тот масштаб, для которого эта ключевая точка будет наиболее выразительной. Для этого будем считать ключевой точкой не только точку, которая отличается от своего окружения, но и отличается сильнее всего среди разных масштабов изображений. Другими словами, выбирать ключевую точку мы будем не только в пространстве X и Y, а в пространстве  . В SIFT это делается путём нахождения точек в DoG (Difference of Gaussians), которые являются локальными максимумами или минимумами в
. В SIFT это делается путём нахождения точек в DoG (Difference of Gaussians), которые являются локальными максимумами или минимумами в  кубе пространства вокруг неё:
кубе пространства вокруг неё:
Алгоритмы нахождения ключевых точек и построения дескрипторов SIFT и SURF запатентованы. То есть, для их коммерческого использования необходимо получать лицензию. Именно поэтому они недоступны из основного пакета opencv, а только из отдельного пакет opencv_contrib. Однако, пока что наше исследование носит исключительно академический характер, поэтому ничто не мешает поучаствовать SIFT в сравнении.
Дескрипторы
Попробуем применить какой-нибудь детектор (например, Харриса) к шаблону и картинке.


После нахождения ключевых точек на картинке и шаблоне надо как-то сопоставить их друг с другом. Напомню, что мы пока извлекли только положения ключевых точек. То, что обозначает эта точка (например, в какую сторону направлен найденный угол), мы пока не определили. А такое описание может помочь при сопоставлении точек изображения и шаблона друг с другом. Часть точек шаблона на картинке может быть сдвинута искажениями, закрыта другими объектами, поэтому опираться исключительно на положение точек относительно друг друга кажется ненадежным. Поэтому давайте для каждой ключевой точки возьмём её окрестность чтобы построить некое описание (дескриптор), которое потом позволит взять пару точек (одну точку из шаблона, одну из картинки), и сравнить их схожесть.
BRIEF
Если мы сделаем дескриптор в виде бинарного массива (т.е. массив из 0 и 1), то мы их сможем сравнивать крайне эффективно, сделав XOR двух дескрипторов, и посчитать количество единичек в результате. Как составить такой вектор? Например, мы можем выбрать N пар точек в окрестности ключевой точки. Затем, для i-й пары проверить, является ли первая точка ярче второй, и если да — то в i-ю позицию дескриптора записать 1. Таким образом мы можем составить массив длины N. Если мы будем выбирать в качестве одной из точек всех пар какую-то одну точку в окрестности (например, центр окрестности — саму ключевую точку), то такой дескриптор будет неустойчивым к шуму: достаточно немного поменяться яркости всего одного пикселя, чтобы весь дескриптор “поехал”. Исследователи обнаружили, что достаточно эффективно выбрать точки случайно (из нормального распределения с центром в ключевой точке). Это положено в основу алгоритма BRIEF.

Часть рассмотренных авторами методов генераций пар. Каждый отрезок символизирует пару сгенерированных точек. Авторы обнаружили, что вариант GII работает чуть лучше остальных вариантов.
После того, как мы выбрали пары, их стоит зафиксировать (т.е. пары генерировать не при каждом запуске расчёта дескриптора, а сгенерировать один раз, и запомнить). В реализации от OpenCV эти пары и вовсе сгенерированы заранее и захардкожены.
Дескриптор SIFT
SIFT также может эффективно считать дескрипторы, используя результаты применения гауссового размытия на разных октавах на картинке. Для расчёта дескриптора SIFT выбирает регион 16х16 вокруг ключевой точки, и разбивает его на блоки 4х4 пикселя. Для каждого пикселя считается градиент (мы оперируем в том же масштабе и октаве, в котором была найдена ключевая точка). Градиенты в каждом блоке распределяются на 8 групп по направлению (вверх, вверх-вправо, вправо, и т.д.). В каждой группе длины градиентов складываются — получается 8 чисел, которые можно представить как вектор, описывающий направление градиентов в блоке. Этот вектор нормируется для устойчивости к изменению яркости. Так, для каждого блока рассчитывается 8-мерный вектор единичной длины. Эти вектора конкатенируются в один большой дескриптор длины 128 (в окрестности 4*4 = 16 блоков, в каждом по 8 значений). Для сравнения дескрипторов используется Евклидово расстояние.
Сравнение
Находя пары наиболее подходящих друг к другу ключевых точек (например — жадно составляя пары, начиная с самых похожих по дескрипторам), мы наконец-таки сможем сравнить шаблон и картинку:

Котик нашелся — но тут у нас имеется попиксельное соответствие между шаблоном и фрагментом картинки. А что будет в случае кнопки?
Предположим, перед нами прямоугольная кнопка. Если ключевая точка расположена на углу, то три четверти локали точки будет именно то, что лежит за пределами кнопки. А то, что лежит за пределами кнопки, сильно меняется от картинки к картинке, в зависимости от того, поверх чего расположена кнопка. Какая доля дескриптора будет оставаться постоянной при изменении фона? В дескрипторе BRIEF, так как координаты пары выбираются в локали случайно и независимо, бит дескриптора будет оставаться постоянным только в случае, когда обе точки лежат на кнопке. Другими словами, в BRIEF всего 1/16 дескриптора не будет меняться. В SIFT ситуация чуть лучше — из-за блочной структуры 1/4 дескриптора меняться не будет.
В связи с этим дальше будем использовать дескриптор SIFT.
Сравнение детекторов
Теперь применим все полученные знания для решения нашей задачи. В нашем случае требования к детектору ключевых точек достаточно: инвариантность к изменению размера нам ни к чему, равно как и крайне высокая производительность. Сравним все три детектора.
| Harris corner detector | FAST | SIFT |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
SIFT нашел крайне мало ключевых точек на кнопке. Это объяснимо — кнопка представляет собой достаточно небольшой и плоский объект, и изменение масштаба не помогает найти ключевые точки.
Также, ни один детектор не справился с третьим случаем. Это объяснимо и ожидаемо. Обычно вышеописанные методы применяют для того, чтобы найти объект из шаблона на снимке, на котором он может быть частично скрыт, быть повернут, или немного искажен. В нашем случае мы хотим найти не точно такой же объект , а объект, достаточно похожий на шаблон (кнопку) . Это немного другая задача. Так, изменение самой формы кнопки (например, радиуса скругления углов, или толщины рамки точек) меняет ключевые точки в них, и их дескрипторы. Кроме того, ключевые точки будут находиться на углу кнопки. Из-за положения на краю точки будут неустойчивы: на их точное расположение и дескрипторы влияет то, что нарисовано рядом с кнопкой.
Вывод — метод хорош, и корректно отрабатывает ситуации, когда искомый объект повернут, его размер изменен, или объект частично скрыт (что хорошо для поиска сложных объектов, или ценника, например). Однако, если на объекте мало точек, за которые можно «зацепиться», или форма объекта меняется слишком сильно, то ключевые точки и их на шаблоне и изображении могут не совпасть. Также, фон с большим количеством мелких деталей может сместить «ключевые точки» или изменить их дескрипторы.
Мы можем придумать матчинг, который бы использовал координаты ключевых точек. Вместо того, чтобы искать пары точек на шаблоне и картинке, окрестность которых похожа, можно искать такие наборы точек, взаимоположение ключевых точек на шаблоне и картинке будут похожи. В общем случае это достаточно сложная (и вычислительно, и с точки зрения программирования) задача, особенно в ситуации, когда некоторые точки могут быть сдвинуты или отсутствовать. Но, учитывая, что у нас ключевые точки — углы, нам достаточно найти такие группы, которые будут примерно образовывать прямоугольник нужных пропорций, и внутри которого не будет ключевых точек. Постепенно мы подходим к следующему методу:
Contour detection
Обычно кнопка — это какой-то прямоугольный объект (иногда — со скруглёнными углами), стороны которого параллельны осям координат. Тогда давайте попробуем выделить зоны перепады контраста (грани/edges), и среди них найдем грани, очертания которых похожи на контур нужного нам объекта. Этот метод называется contour detection.
Edge detection
В отличии от keypoint detection, нам интересны не только ключевые точки-углы, но и рёбра. Однако, основные идеи мы можем взять оттуда. Сгладим изображение Гауссовым фильтром, и как в Harris corner detector. Затем посчитаем производные интенсивности  и
и  . Так как нам не нужно отличать углы от ребер, то не надо считать структурный тензор — достаточно посчитать силу градиента:
. Так как нам не нужно отличать углы от ребер, то не надо считать структурный тензор — достаточно посчитать силу градиента:  (кстати, это корень из
(кстати, это корень из  , или из суммы диагонали структурного тензора). После этого, оставим только пиксели, которые являются локальными максимумами в терминах
, или из суммы диагонали структурного тензора). После этого, оставим только пиксели, которые являются локальными максимумами в терминах  (используя уже расмотренный non-maximum suppression), но в качестве локали будем выбирать не 8 соседних пикселей, а те пиксели из этих 8, в сторону которого направлен I, и с противоположной стороны:
(используя уже расмотренный non-maximum suppression), но в качестве локали будем выбирать не 8 соседних пикселей, а те пиксели из этих 8, в сторону которого направлен I, и с противоположной стороны:
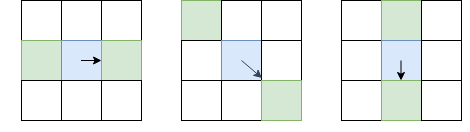
Синим отмечен рассматриваемый пиксель, стрелка — направление I. Зелёные пиксели — те, которые будут учитываться при non-maximum suppression.
Такой необычный выбор пикселей для сравнения обусловлен тем, что мы не хотим делать разрывы в границе. В левой картинке грань проходит сверху вниз, и так как non-maximum suppression не будет проводить сравнения интенсивности с пикселями выше и ниже синего, мы получим непрерывную грань.
Очевидно, одного non-maximum suppression недостаточно, и надо применить какую-то фильтрацию, чтобы убрать ребра со слишком низким Il. Для этого применим приём “double thresholding”: уберем все пиксели с Il, силой градиента, ниже порога Low, все пиксели выше порога High назначим “сильными ребрами”. Пиксели, у которых сила градиента лежит между Low и High, назовём “слабыми ребрами”, оставим только если они соединены с “сильными ребрами”:
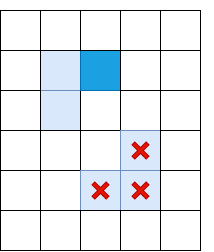
Светло-синим отмечены “слабые ребра”, тёмно-синим — сильные. Ребра в нижней части отсеиваются, так как они не соеденены ни с одним сильным ребром.
Мы только что описали Canny Edge Detector. Он крайне широко применяется и по сей день в качестве простой и быстрой процедуры, позволяющей найти контуры объектов.
Border tracking
Следующее действие — среди карты с найденными гранями выделить контуры. Найдем связанные компоненты (острова смежных пикселей, прошедших все проверки), и проверим каждый из них, насколько он похож на кнопку. После применения non-maximum suppression в Canny, у нас есть гарантии того, что ребра будут получаться толщиной в один пиксель, но давайте на будем на нее опираться. Для каждого пикселя, который был отнесен к грани, и рядом с которым есть пиксель не-грань, отнесем к “бордюру”. Перемещаясь от одного пикселя бордюра к другому, мы либо придём обратно в тот же пиксель (и тогда мы нашли контур), либо в тупик (тогда можно попробовать вернуться назад, если где-то по пути была развилка):

Полный алгоритм border tracking, учитывающий разные краевые случаи (например, когда объект с толстой гранью сгенерировал два контура, внутренний и внешний), описан тут. После применения этого алгоритма у нас останется набор контуров, которые потенциально могут быть кнопками.
Фильтрация контуров
Как узнать, что наш контур — кнопка? Для прямоугольников и многоугольников есть отличный > метод, основанный на упрощении контура. Достаточно постепенно “схлопывать” ребра, если они находятся почти на одной прямой, а затем посчитать количество оставшихся ребер, и проверить углы между ними. К сожалению, для нашего случая эти методы не подходят — наш прямоугольник имеет скругленные углы. Также, есть contour matching для фигур, имеющих сложную геометрию — но это тоже не про нас, так как у нас всего лишь прямоугольник (в статье приводятся примеры с контуром человека). Поэтому лучше сделать фильтр, основанный на свойства самой фигуры. Мы знаем, что:
- Кнопка достаточно большая (площадь больше 100 пикселей)
- Стороны параллельны осям координат
- Отношение площади фигуры к площади ограничивающего прямоугольника должна быть достаточно близка к единице. Мы устанавливаем порог в 0.8, так как кнопка — прямоугольник со сторонами параллельными осям координат, и недостающие 20% — это и есть скругленные углы.
Кроме того, по опыту применения детекторов ключевых точек мы помним, что могут быть проблемы с ситуациями, когда под кнопкой лежит контрастный объект. Поэтому после применения Canny размоем грани, чтобы закрыть мелкие дырки, которые могли возникнуть из-за таких объектов.
Применим получившийся подход:

Применение Canny filter (2 картинка) нашло нужные очертания, но из-за сложной формы кнопки и градиента нашлось сразу много контуров, и из-за non-max suppression некоторые из них не были замкнуты. Применение размытия (3 картинка) исправило проблему.
Тестирование подхода
Запустим в получившейся картинке поиск контуров. Покрасим контуры, прошедшие проверки, красным цветом. Если таких несколько, то нам нужно выбрать среди них наиболее удачный вариант. Выберем контур наибольшей площади, и покрасим его в зелёный цвет.
|  |
|  |
|  |
|
Получившаяся конструкция нашла кнопки на тестовых изображениях. Прогон на всех баннерах показал, что изредка (1 случай из ~20) она вместо кнопки выделяет прямоугольные плашки iOS Appstore и Google Apps, или другие прямоугольные объекты (чехлы телефонов). Поэтому добавив возможность ручного указания положения на тот редкий случай неверного определения, мы реализовали этот вариант в инструменте локализации.
Заключение
Подведем итоги. “Классический” CV без deep learning по-прежнему работает, и на его основе можно решить задачи. Они неприхотливы и не требуют большого количества размеченных данных, мощного железа, и их проще отлаживать. Однако, они вводят дополнительные предположения, и поэтому с их помощью не каждую задачу можно решить эффективно.
- Template Matching — самый простой способ, основывается на нахождении места в изображении, наиболее похожем (по какой-то простой метрике) на шаблон. Эффективен при попиксельном совпадении. Можно сделать устойчивым к поворотам и небольшим изменениям размеров, но при больших изменениях может работать некорректно.
- Keypoint detection/matching — находим ключевые точки, сопоставляем точки изображения и шаблона. Детекторы устойчивы к поворотам, изменениям масштаба (в зависимости от выбранного детектора и дескриптора), а сопоставление — к частичным перекрытиям. Но этот метод хорошо работает только если в объекте нашлось достаточно «ключевых точек», и локали точки шаблона и изображения совпадают достаточно хорошо (т.е. на шаблоне и картинке — один и тот же объект).
- Contour detection — нахождение контуров объектов, и поиске контура, похожего на контур искомого объекта. Это решение учитывает только форму объекта, и игнорирует его содержимое и цвет (что может быть как и плюсом, так и минусом).
Осведомленный читатель может заметить, что наша задача может быть решена и с помощью современных обучаемых методов computer vision. Например, сеть YOLO возвращает bounding box искомого объекта — а именно это нас и интересует. Да, мы успешно протестировали и запустили решение, основанные на глубоком обучении — но в качестве второй итерации (уже после того, как инструмент локализации был запущен и начал работать). Эти решения более устойчивы к изменениям параметров кнопок, и имеют много положительных свойств: например, вместо того, чтобы подбирать руками пороги и параметры, можно просто добавлять в тренировочное множество примеры баннеров, на которых сеть ошибается (Active Learning). Использование глубокого обучение для нашей задачи имеет свои проблемы и интересные моменты. Например — многие современные методы computer vision требуют большого количества размеченных картинок, а у нас разметки не было (как и во многих реальных случаях), а общее количество разных баннеров не превышает нескольких тысяч. Поэтому мы решили разметить небольшое количество изображений сами, и написать генератор, который будет на их основе создавать другие похожие баннеры. В этом направлении есть немало интересных приёмов. Есть много других подводных камней, да и сама задача определения положения объекта computer vision обширна, и имеет много способов решения. Поэтому было принято решение ограничить поле обзора статьи, и решения, основанные на глубоком обучении, не были рассмотрены.
Код с блокнотами, которые реализуют описанные методы и рисуют картинки статьи, можно найти в репозитории).
Распознать объекты на изображении онлайн бесплатно
Обнаруживает объекты на изображениях бесплатно на любом устройстве, с помощью современного браузера, такого как Chrome, Opera или Firefox
При поддержке aspose.com и aspose.cloud
Добавить метки
Добавить баллы
Порог: %
Цвет:
Допустимые метки:
Заблокированные метки:
Aspose.Imaging Распознавание позволяет легко обнаруживать и классифицировать объекты на растровых и векторных изображениях.
Распознавание — это бесплатное приложение, основанное на Aspose.Imaging, профессиональном .NET / Java API, предлагающее расширенные функции обработки изображений на месте и готовое для использования на стороне клиента и сервера.
Требуется облачное решение? Aspose.Imaging Cloud предоставляет SDK для популярных языков программирования, таких как C#, Python, PHP, Java, Android, Node.js, Ruby, которые созданы на основе Cloud REST API и постоянно развиваются.
Aspose.Imaging Распознавание
- Обнаруживает объекты на изображении с помощью метода Single Shot Detection(SSD)
- Обнаруженные объекты обводятся прямоугольниками и могут быть подписаны
- Полный список поддерживаемых объектов содержит более 180 элементов
Как распознать объекты на изображении
- Кликните внутри области перетаскивания файла, чтобы выбрать и загрузить файл изображения, или перетащите файл туда
- Нажмите кнопку Старт, чтобы начать процесс обнаружения объектов.
- После запуска процесса на странице появляется индикатор, отображающий ход его выполнения. После того, как все объекты будут обнаружены, изображение с результатами появится на странице.
- Обратите внимание, что исходные и получившиеся изображения не хранятся на наших серверах
Часто задаваемые вопросы
-
❓ Как я могу обнаружить объекты на изображении?
Во-первых, вам нужно добавить файл изображения: перетащить его на форму или по ней чтобы выбрать файл. Затем задайте настройки и нажмите кнопку «Старт». КАк только процесс распознавания будет завершен, полученное изображение будет отображено.
-
⏱️ Сколько времени требуется для распознавания объектов на изображении?
Это зависит от размера входного изображения. Обычно это занимает всего несколько секунд
-
❓ Какой метод обнаружения объектов вы используете?
В настоящее время мы используем только метод Single Show Detection (SSD)
-
❓ Какие объекты вы можете обнаружить на изображениях?
-
💻 Какие форматы изображений вы поддерживаете?
Мы поддерживаем изображения форматов JPG (JPEG), J2K (JPEG-2000), BMP, TIF (TIFF), TGA, WEBP, CDR, CMX, DICOM, DJVU, DNG, EMF, GIF, ODG, OTG, PNG, SVG и WMF.
-
🛡️ Безопасно ли обнаруживать объекты с помощью бесплатного приложения Aspose.Imaging Object Detection?
Да, мы удаляем загруженные файлы сразу после завершения операции обнаружения объектов. Никто не имеет доступа к вашим файлам. Обнаружение объектов абсолютно безопасно.
Когда пользователь загружает свои файлы из сторонних сервисов, они обрабатываются таким же образом.
Единственное исключение из вышеуказанных политик возможно, когда пользователь решает поделиться своими файлами через форум, запросив бесплатную поддержку, в этом случае только наши разработчики имеют доступ к ним для анализа и решения проблемы.
Как найти предмет по фото в яндексе
Содержание
- Когда это может быть полезно?
- Как найти первоисточник фотографии в интернете?
- Поиск Гугл по фото / картинке
- Видео
- Яндекс
- Как найти предмет по фото?
- TinEye
- Содержание
- Где скачать Алису с поиском по картинкам
- Как включить поиск по картинкам в Алисе
- Возможности Алисы по распознаванию изображений и список команд
- Узнать знаменитость по фото
- Распознать надпись или текст и перевести его
- Узнать марку и модель автомобиля
- Узнать породу животного
- Узнать вид растения
- Узнать автора и название картины
- Найти предмет в Яндекс.Маркет
- Распознать QR-код
- Поиск похожих картинок в тинай
- PhotoTracker Lite – поиск 4в1
- Когда это может понадобиться
- Как найти оригинал заданного изображения

Иногда нам нужно отыскать информацию в интернете не только по какому-то ключевому запросу, но и по изображению. В данной статье я расскажу про поиск Гугл по фото, картинке — как найти фотографию в интернете по фотографии. Также рассмотрим другие полезные сервисы.
Эта инструкция поможет отыскать не только нужные картинки и первоисточники, но даже предметы, которые отображены на картинке, и сайты, которые на них ссылаются.

Когда это может быть полезно?
Сферы использования технологии поиска по фото достаточно разные. Вы можете:
- Бороться с фейками. Допустим вы общаетесь с человеком в социальной сети. Но, посмотрев на его аватар, понимаете, что картинка не является подлинной. Поэтому вы можете проверить, является ли данный человек реальным, просто взяв несколько снимков из его профиля. Если в сети будет много совпадений, можно судить с вероятностью 99%, что вы имеете дело с каким-то мошенником, или злоумышленником.
- Отыскать неизвестные предметы. К примеру, Вы увидели красивую картинку с каким-то интересным интерьером, Вам понравился определённый предмет, но вы не знаете, как он называется и где его искать. Так вот поиск по изображениям поможет вам решить данную проблему.
- Можно «накопать» информацию о знаменитостях. Полезно, когда у вас есть только фото, но вы не знаете, как этого человека зовут.
Давайте приступим к рассмотрению простейших способов.
Как найти первоисточник фотографии в интернете?
Поскольку первоисточник индексируется поисковыми роботами намного раньше, чем уже скопированное изображение, можно за несколько кликов в кратчайшие сроки выполнить поиск файла в системах Google или Яндекс.
Где бы ни находился файл: в социальных сетях, на форумах и других сайтах, Google отлично справляется с задачей и выдаёт перечень ресурсов в ранжированного порядке. Несмотря на то, что существует множество различных «умных» приложений для поиска по фото, самые точные алгоритмы присутствуют только у Гугла и Яндекса (и с недавних пор на Facebook). Они способны находить требуемые объекты не только в своей базе, но и на сторонних ресурсах, которые не присутствуют в индексе.
Поиск Гугл по фото / картинке
- Достаточно перейти на сайт и кликнуть на значок камеры:

- Затем выбрать один из вариантов – либо указать ссылку (если фото расположено в интернете), или же переходим на вкладку «Загрузить файл» и открываем файл, расположенный на Вашем компьютере:

- Нажимаем на кнопку «Поиск» и видим результаты:

Нам выдает не только похожие изображения, но и текстовое описание со ссылками на упоминания в сети. Если подгрузить фото реального человека, то можно увидеть всю информацию о нем.
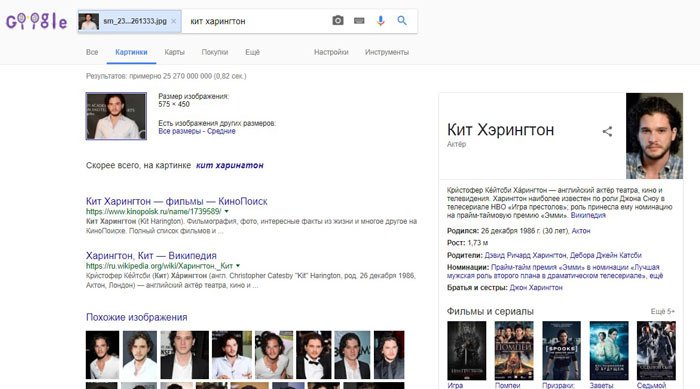
Если в выдаче присутствует очень много результатов, реально их отфильтровать, нажав на кнопку «Инструменты» под строкой ввода. Доступен выбор периода упоминания, размера (расширения) файла и т.д.
Рекомендуем:
Видео
Для лучшего понимания темы рекомендую посмотреть следующий ролик:

Яндекс
- Заходим на сайт и кликаем по значку камеры справа от поля ввода:

- Указываем путь к изображению, которое хранится на ПК или же вставляем в соответствующую строку ссылку на картинку:

- В результатах поиска видим такое же фото, но с другими размерами, похожие объекты и сайты, где использовался этот графический элемент.
Как найти предмет по фото?
В сети Интернет мы частенько видим изображения различных интересных вещей, гаджетов, но не всегда можем вспомнить как называется данный предмет, какая это модель. С помощью современных алгоритмов искусственного интеллекта можно легко отыскать данные предметы и их описания.
Ниже показан наглядный пример, как это работает в Гугле:

Система легко определила, что мы пытаемся найти заварник для чая, и сразу нам предложила несколько сайтов.
Автор советует:
TinEye
Помимо перечисленных способов есть еще один очень интересный инструмент, который называется TinEye . Он чуть отличается от описанных выше решений внешним видом и английским интерфейсом:

Результаты программа выдает более структурировано и сжато. Но в общем – «то же пальто, только другого цвета».
Я поведал про поиск Гугл по фото или картинке, как найти фотографию в интернете по фотографии. Какой вариант использовать – зависит только от Вас.
Яндекс Алиса и другие приложения научились распознавать картинки и фото с камеры, и делать с ними различные полезные действия.
Сейчас уже существует довольно много мобильных приложений, которые распознают фотографии для получения некоторой полезной информации о людях или объёктах на нём. Одно из таких приложений – Facer, показывает на кого из знаменитостей вы похожи, используя алгоритмы на основе нейронных сетей.



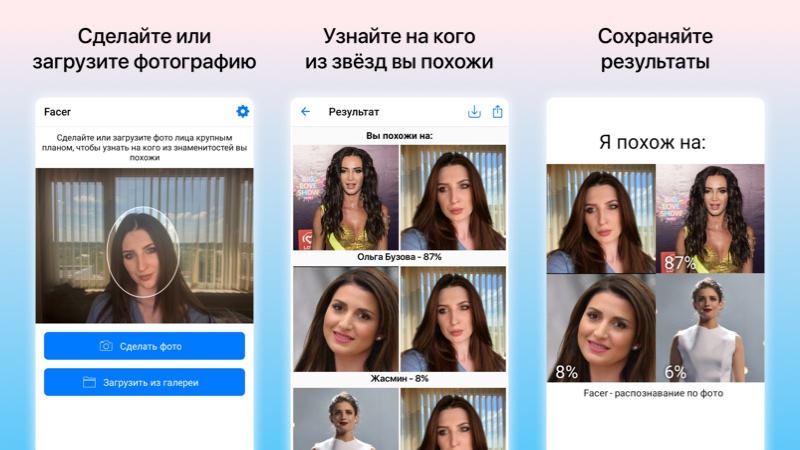
Загружаете фото лица крупным планом и через пару секунд вы видите трёх знаменитостей, на которых вы похожи, с указанием процента сходства. Среди похожих на себя звёзд можно встретить российских и зарубежных музыкантов, актёров, блогеров или спортсменов. Приложение Facer можно скачать по ссылкам: на Android и iOS.
У компании Яндекс тоже есть функции распознавания изображений, они встроены в их голосового помощника. Алиса научилась искать информацию по фотографиям с камеры или любым другим картинкам, которые вы ей отправите. На основе загруженного изображения помощник может сделать некоторые полезные действия. Эти новыми функциями можно воспользоваться в приложении Яндекс и Яндекс.Браузер.
Содержание
Где скачать Алису с поиском по картинкам
Голосовой ассистент Алиса встроен в приложение под названием «Яндекс». Скачать приложение для Android и iOS можно по этим ссылкам:




Как включить поиск по картинкам в Алисе
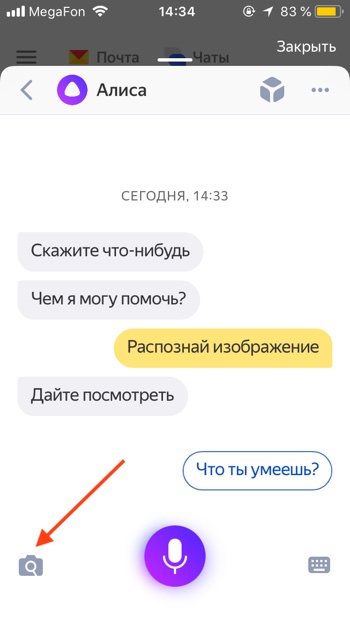
- Чтобы открыть Алису нажимаем на красный значок приложения «Яндекс».
- Первый способ открыть функцию распознавания изображений: нажимаем на серый значок фотоаппарата с лупой в поисковой строке и переходим к шагу 4. Второй способ: нажимаем на фиолетовый значок Алисы или говорим «Привет, Алиса!» если у вас включена голосовая активация.
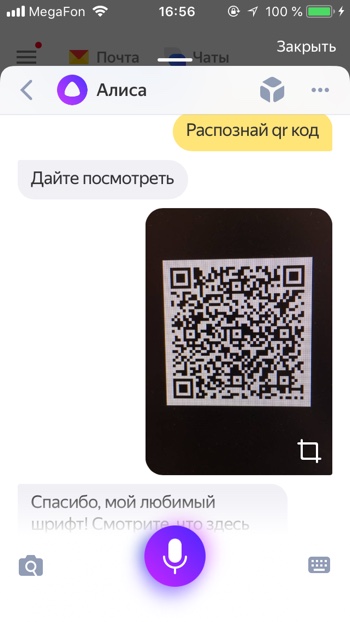
- Откроется диалог (чат) с Алисой. Нужно дать команду Алисе «Распознай изображение» или «Сделай фото». Также вы можете нажать на серый значок фотоаппарата с лупой.
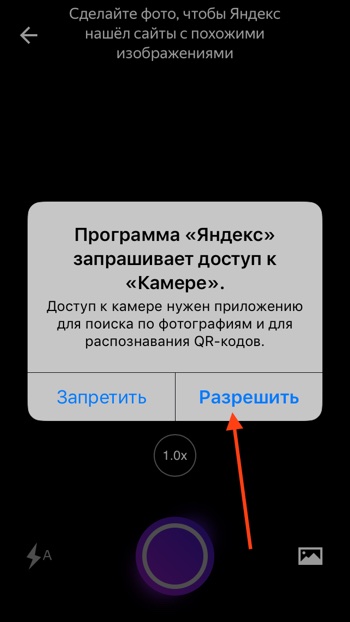
- Приложение попросит доступ к камере вашего мобильного устройства. Нажимаем «Разрешить».
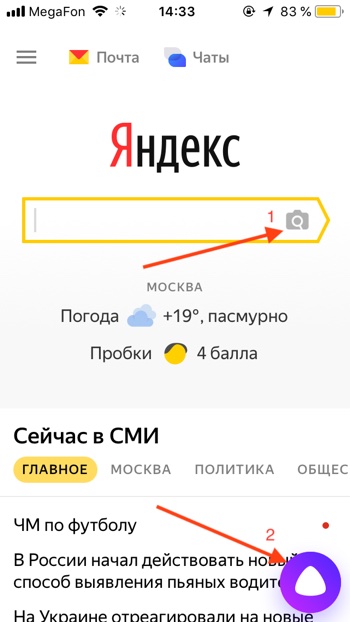
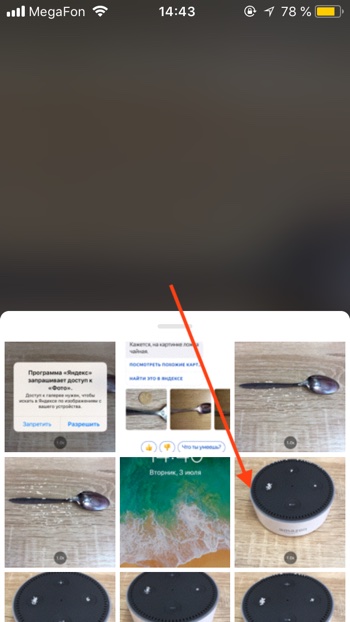
- Откроется режим съёмки. Здесь вы можете загрузить изображение из вашей галлереи или сделать новый снимок прямо сейчас. Нажмите на фиолетовый круг, чтобы сделать снимок.
- Алиса распознает объект на изображении.
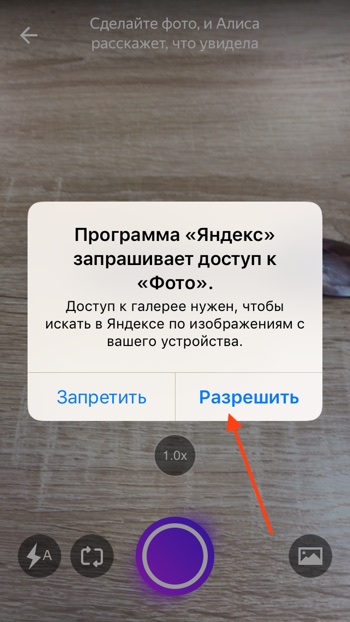
- Давайте попробуем загрузить фотографию из памяти, т.е. галереи вашего iPhone или Android. Нажимаем на иконку с фотографией.
- Алиса попросит доступ к вашим фотографиям. Нажимаем «Разрешить».
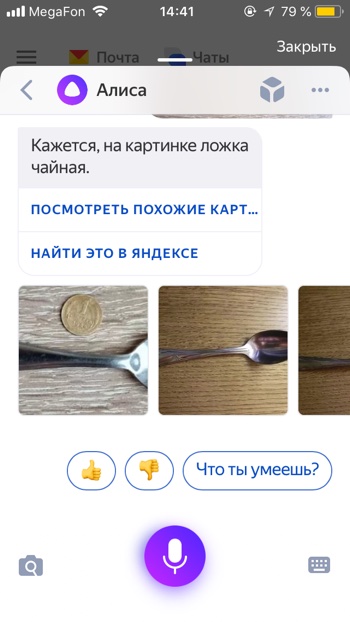
- Выбираем фотографию.
- Через некоторое время фотография загрузится на сервера Яндекса и Алиса вам скажет, на что похоже загруженное изображение. В нашем случае мы загрузили фотографию умной колонки Amazon Echo Dot, и Алиса её успешно распознала.



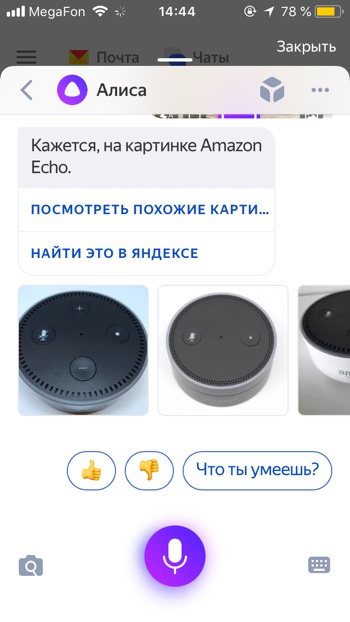
Возможности Алисы по распознаванию изображений и список команд
Помимо общей команды «сделай фото», Алисе можно дать более точную команду по распознаванию объекта. Алиса умеет делать следующие операции с изображениями по соответствующим командам:
Узнать знаменитость по фото
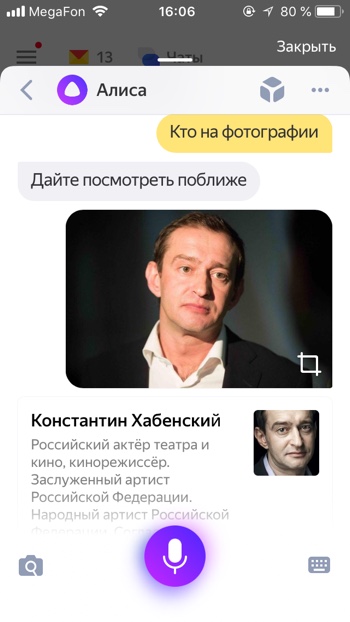
- Кто на фотографии?
- Что за знаменитость на фотографии?
Алиса распознаёт фото знаменитых людей. Мы загрузили изображение актёра Константина Хабенского и Алиса успешно распознала его.
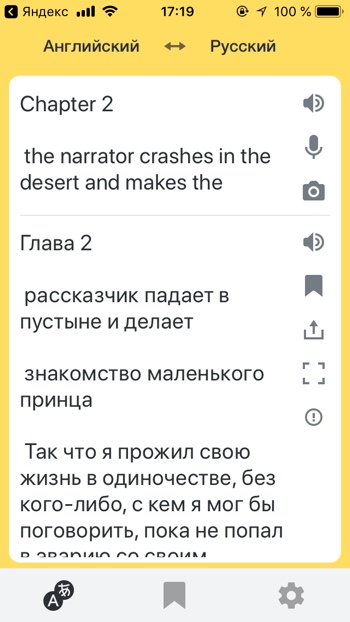
Распознать надпись или текст и перевести его
- Распознай текст
- Распознай и переведи надпись
Вы можете загрузить фотографию с текстом и Алиса распознает его и даже поможет его перевести. Для того, чтобы распознать и перевести текст с помощью Алисы необходимо:
— Загрузить фото с текстом.
— Прокрутить вниз.
— Нажать «Найти и перевести текст».
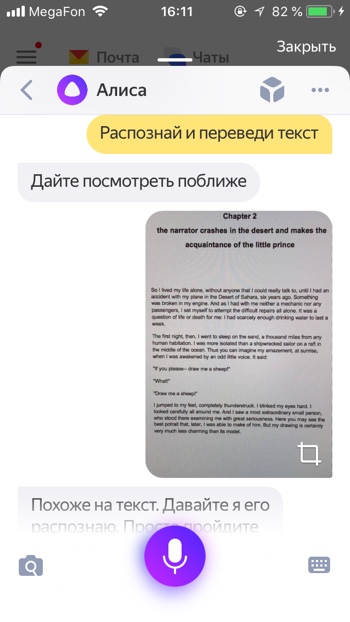
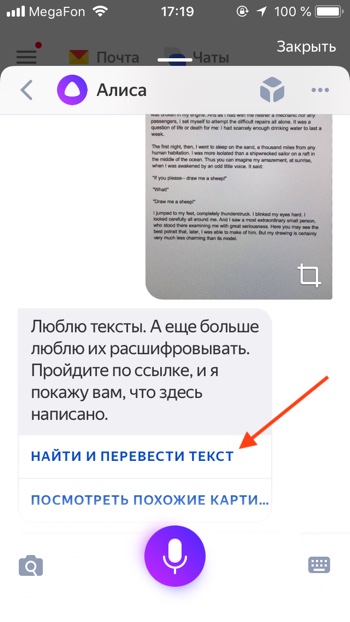
— Откроется распознанный текст. Нажимаем «Перевести».
— Откроется Яндекс.Переводчик с переведённым текстом.

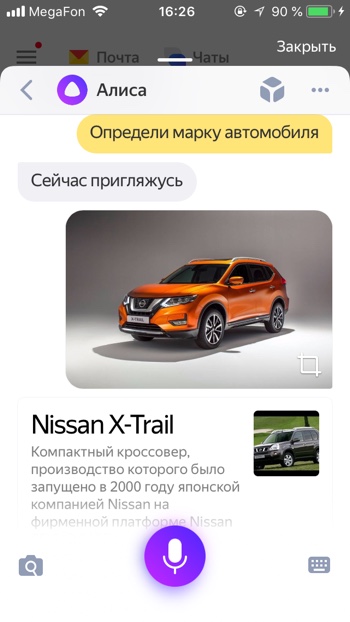
Узнать марку и модель автомобиля
- Определи марку автомобиля
- Распознай модель автомобиля
Алиса умеет определять марки автомобилей. Например, она без труда распознаёт новый автомобиль Nissan X-Trail, в который встроена мультимедийная система Яндекс.Авто с Алисой и Яндекс.Навигатором.
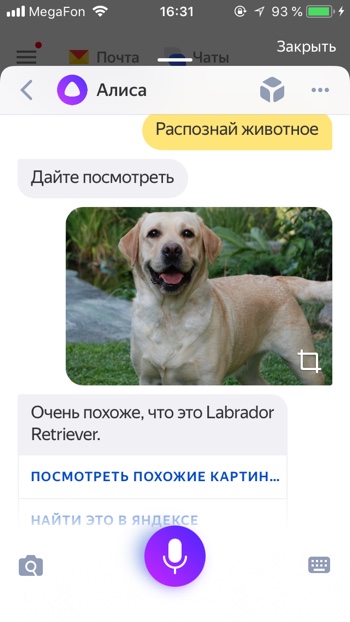
Узнать породу животного
- Распознай животное
- Определи породу собаки
Алиса умеет распознавать животных. Например, Алиса распознала не только, что на фото собака, но и точно определила породу Лабрадор по фото.
Узнать вид растения
- Определи вид растения
- Распознай растение
Если вы встретили экзотическое растение, Алиса поможет вам узнать его название.
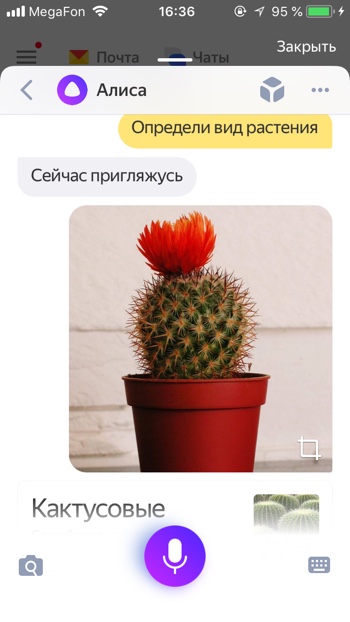
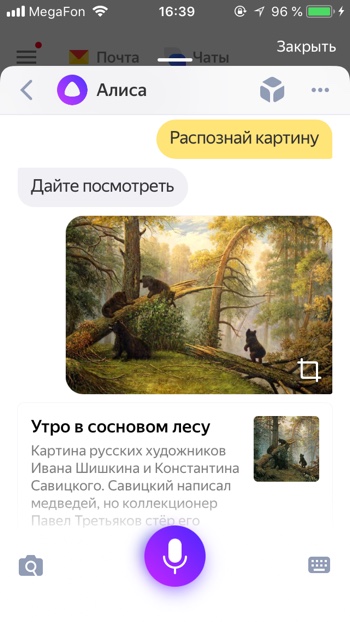
Узнать автора и название картины
- Распознай картину
- Определи что за картина
Если вы увидели картину и хотите узнать её название, автора и описание, просто попросите Алису вам помочь. Картину «Утро в сосновом лесу» художника Ивана Ивановича Шишкина Алиса определяет моментально.
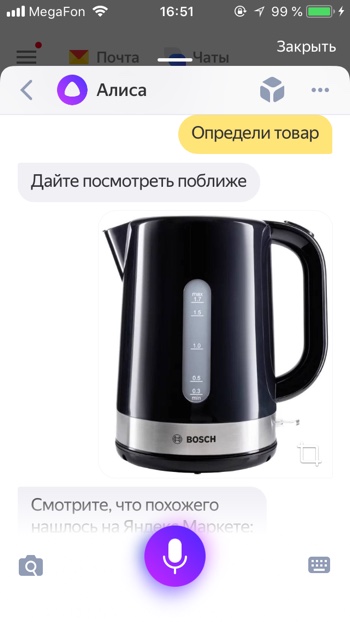
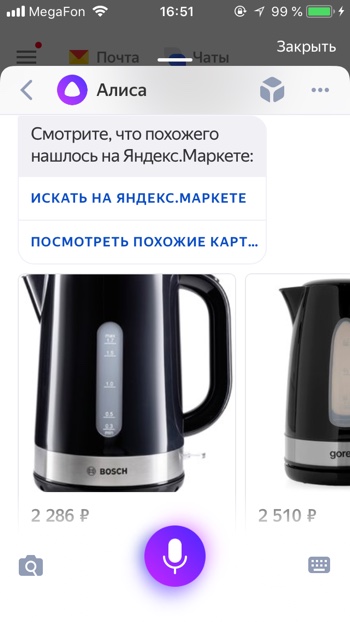
Найти предмет в Яндекс.Маркет
- Определи товар
- Найди товар
Если вы увидите интересный предмет, который вы не прочь были бы приобрести – вы можете попросить Алису найти похожие на него товары. Найденный товар вы можете открыть на Яндекс Маркете и там прочитать его характеристики, или сразу заказать.
Распознать QR-код
- Определи Кью Эр код
- Распознай Кью Эр код
Алиса пока не так быстро и качественно распознаёт QR коды, нам потребовалось несколько попыток, чтобы успешно распознать QR код.


Попробуйте распознать с помощью Алисы какое-нибудь изображение и напишите о своём опыте и впечатлениях в комментариях.
Яндекс постоянно добавляет новые команды для Алисы. Мы сделали приложение со справкой по командам , которое регулярно обновляем. Установив это приложение, у вас всегда будет под рукой самый актуальный список команд:
Допустим у Вас есть какое-то изображение (рисунок, картинка, фотография), и Вы хотите найти такое же (дубликат) или похожее в интернет. Это можно сделать при помощи специальных инструментов поисковиков Google и Яндекс, сервиса TinEye, а также потрясающего браузерного расширения PhotoTracker Lite, который объединяет все эти способы. Рассмотрим каждый из них.

Укажите адрес картинки в сети интернет либо загрузите её с компьютера (можно простым перетаскиванием в специальную области в верхней части окна браузера):

Результат поиска выглядит таким образом:
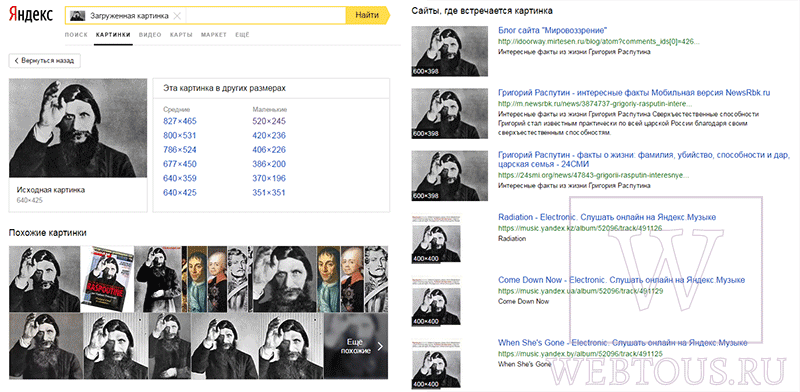
Вы мгновенно получаете доступ к следующей информации:
- Какие в сети есть размеры изображения, которое Вы загрузили в качестве образца для поиска
- Список сайтов, на которых оно встречается
- Похожие картинки (модифицированы на основе исходной либо по которым алгоритм принял решение об их смысловом сходстве)
Поиск похожих картинок в тинай
Многие наверняка уже слышали об онлайн сервисе TinEye, который русскоязычные пользователи часто называют Тинай. Он разработан экспертами в сфере машинного обучения и распознавания объектов. Как следствие всего этого, тинай отлично подходит не только для поиска похожих картинок и фотографий, но их составляющих.
Проиндексированная» база изображений TinEye составляет более 10 миллиардов позиций, и является крупнейших во всем Интернет. «Здесь найдется всё» — это фраза как нельзя лучше характеризует сервис.

Переходите по ссылке https://www.tineye.com/, и, как и в случае Яндекс и Google, загрузите файл-образец для поиска либо ссылку на него в интернет.

На открывшейся страничке Вы получите точные данные о том, сколько раз картинка встречается в интернет, и ссылки на странички, где она была найдена.
PhotoTracker Lite – поиск 4в1
Расширение для браузера PhotoTracker Lite (работает в Google Chrome, Opera с версии 36, Яндекс.Браузере, Vivaldi) позволяет в один клик искать похожие фото не только в указанных выше источниках, но и по базе поисковика Bing (Bing Images)!
В настройках приложения укажите источники поиска, после чего кликайте правой кнопкой мыши на любое изображение в браузере и выбирайте опцию «Искать это изображение» PhotoTracker Lite:
![]()
Есть еще один способ поиска в один клик. По умолчанию в настройках приложения активирован пункт «Показывать иконку быстрого поиска». Когда Вы наводите на какое-то фото или картинку, всплывает круглая зеленая иконка, нажатие на которую запускает поиск похожих изображений – в новых вкладках автоматически откроются результаты поиска по Гугл, Яндекс, Тинай и Бинг.

Расширение создано нашим соотечественником, который по роду увлечений тесно связан с фотографией. Первоначально он создал этот инструмент, чтобы быстро находить свои фото на чужих сайтах.
Когда это может понадобиться
- Вы являетесь фотографом, выкладываете свои фото в интернет и хотите посмотреть на каких сайтах они используются и где возможно нарушаются Ваши авторские права.
- Вы являетесь блогером или копирайтером, пишите статьи и хотите подобрать к своему материалу «незаезженное» изображение.
- А вдруг кто-то использует Ваше фото из профиля Вконтакте или Фейсбук в качестве аватарки на форуме или фальшивой учетной записи в какой-либо социальной сети? А ведь такое более чем возможно!
- Вы нашли фотографию знакомого актера и хотите вспомнить как его зовут.
На самом деле, случаев, когда может пригодиться поиск по фотографии, огромное множество. Можно еще привести и такой пример…
Как найти оригинал заданного изображения
Например, у Вас есть какая-то фотография, возможно кадрированная, пожатая, либо отфотошопленная, а Вы хотите найти её оригинал, или вариант в лучшем качестве. Как это сделать? Проводите поиск в Яндекс и Гугл, как описано выше, либо средствами PhotoTracker Lite и получаете список всех найденных изображений. Далее руководствуетесь следующим:
-
Оригинальное изображение, как правило имеет больший размер и лучшее качество по сравнению с измененной копией, полученной в результате кадрирования. Конечно можно в фотошопе выставить картинке любой размер, но при его увеличении относительно оригинала, всегда будут наблюдаться артефакты. Их можно легко заметить даже при беглом визуальном осмотре.
Уважаемые читатели, порекомендуйте данный материал своим друзьям в социальных сетях, а также задавайте свои вопросы в комментариях и делитесь своим мнением!
>
Задача нахождения объектов на изображении — задача машинного обучения, в рамках которой выполняется определение наличия или отсутствия объекта определённого домена на изображении, нахождение границ этого объекта в системе координат пикселей исходного изображения. В зависимости от алгоритма обучения, объект может характеризоваться координатами ограничивающей рамки, ключевыми точками, контуром объекта.
Содержание
- 1 Постановка задачи
- 1.1 Метрики
- 2 Наборы данных
- 3 Подходы к решению задачи детекции объектов
- 3.1 Двухэтапные методы
- 3.1.1 R-CNN
- 3.1.2 Fast R-CNN
- 3.1.3 Faster R-CNN
- 3.1.4 Mask R-CNN
- 3.2 Одноэтапные методы
- 3.2.1 YOLO
- 3.2.2 YOLOv2, YOLOv3
- 3.2.3 SSD
- 3.3 Anchor boxes
- 3.3.1 Генерация ключевых рамок
- 3.3.2 Процесс обучения
- 3.3.3 Процесс предсказаний
- 3.1 Двухэтапные методы
- 4 См.также
- 5 Примечания
- 6 Источники информации
Постановка задачи
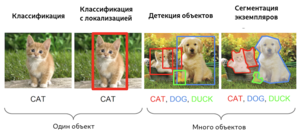
Различие между задачами классификации изображения, классификации с локализацией, детекции объектов и сегментации экземпляров
Задача нахождения объектов на изображении может быть поставлена различным образом и включает в себя класс других задач, помогающих определить, какие объекты находятся на изображении и где они расположены в сетке пикселей исходного изображения.
Задача семантической сегментации (англ. semantic segmentation) — задача, в которой на вход модели подаётся изображение, а на выходе для каждого пикселя является метка принадлежности этого пикселя к определённой категории. Например, если в исходном изображении человек переходит дорогу, то для каждого пикселя необходимо вывести, является ли этот пиксель частью человеческого тела, профиля дороги, знака дорожного движения, неба, или какого-то другого типа. Существенный недостаток применения одной лишь семантической сегментации относительно задач, связанных с распознаванием объектов — маркировка пикселей по принадлежности только к типу объекта, что не создаёт различия между объектами как таковыми. Например, если назвать «объектом» связную область пикселей, характеризующих одинаковый тип, то два объекта, перегораживающих друг друга на исходном изображении, будут определены как один объект, что в корне неверно. Задача семантической сегментации изображения с дифференцированием объектов называется задачей сегментации экземпляров (англ. instance segmentation). Модели, решающие задачу сегментации экземпляров, применяются, в том числе, для подсчёта людей в массовых скоплениях, для автомобилей с автоматическим управлением.
Задача классификации с локализацией (англ. classification and localization) — задача, в которой в дополнение к предсказанию метки категории класса определяется рамка, ограничивающая местоположение экземпляра одиночного объекта на картинке. Как правило, рамка имеет прямоугольную форму, её стороны ориентированы параллельно осям исходного изображения, а площадь является минимальной при условии полного нахождения экземпляра объекта внутри этой рамки. Такую прямоугольную рамку называют термином «ограничивающая рамка» (англ. bounding box). Ограничивающую рамку можно задать как при помощи центра, ширины и высоты, так и при помощи четырёх сторон. Модель в данном случается одновременно обучается как верной классификации, так и максимально точному определению границ рамки.
Задача детекции объектов (англ. object detection) — задача, в рамках которой необходимо выделить несколько объектов на изображении посредством нахождения координат их ограничивающих рамок и классификации этих ограничивающих рамок из множества заранее известных классов. В отличие от классификации с локализацией, число объектов, которые находятся на изображении, заведомо неизвестно.
Метрики
В задачах классификации с локализацией и детекции объектов для определения достоверности местоположения ограничивающей рамки в качестве метрики чаще всего используется отношение площадей ограничивающих рамок (англ. Intersection over Union):
$IoU = frac{S(A cap B)}{S(A cup B)}$,
где $A$ и $B$ — предсказанная ограничивающая рамка и настоящиая ограничивающая рамка соответственно. $IoU$ равно нулю в случае непересекающихся ограничивающих рамок и равно единице в случае идеального наложения.
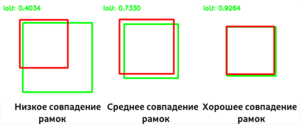
Примеры влияния взаимного положения ограничивающих рамок на метрику IoU
В задачах детекции объектов в качестве метрики зачастую используется $mAP$ (англ. mean average precision) — усреднённая по всем категориям величина средней точности (англ. average precision, AP)
$AP = int_{0}^{1} p(r) dr$,
где $p$ — точность, $r$ — полнота из предположения, что ограничивающая рамка определена верно, если $IoU geq 0.5$. Поскольку точность и полнота находятся в промежутке от $0$ до $1$, то $AP$, а следовательно, и $mAP$ также находится в пределах от $0$ до $1$. На практике, $AP$ часто считают по точкам, значения полноты которых равномерно распределены в промежутке $[0;1]$:
$AP_c = frac{1}{11} cdot (AP_c(0) + AP_c(0.1) + ldots + AP_c(1))$
$mAP = overline{AP_c}$
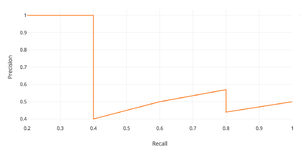
Зависимость точности от полноты, необходимая для вычисления average presicion (AP)
Наборы данных
Наборы данных в задачах детекции объектов на изображениях размечаются вручную асессорами. Зачастую изображения могут различаться в разрешении и качестве, что может вносить коррективы в работу моделей.
- PASCAL VOC 2012[1] (Pattern Analysis, Statistical Modelling and Computational Learning: Visual Object Classes ) — содержит 11530 изображений 20 классов с 27450 регионами предложений и 6929 сегментациями
- MS COCO 2017[2] (Microsoft Common Objects in Context) — 118000 изображений в тренировочной выборке, 5000 изображений в валидационной выборке, 41000 изображений в тестовой выборке. Набор данных содержит 80 классов, на которых можно определить вложенность
- ImageNet[3] — 400000 изображений 200 классов с 350000 размеченными ограничивающими рамками
- Google Open Images[4] — в шестой версии февраля 2020 года содержит свыше 1743000 изображений в тестовой выборке, свыше 41000 изображений в валидационной выборке и свыше 125000 изображений в тестовой выборке. Суммарно на изображениях размечено около 16000000 ограничивающих рамок
Подходы к решению задачи детекции объектов
Одним из наивных подходов на основе свёрточных нейронных сетей может быть использование в качестве ядра каноничных изображений классов, которые необходимо найти на изображении, и дальнейшее использование скользящего окна для вычисления свёртки. Такой подход называется сопоставлением с шаблоном (англ. template matching). В случае, когда вместо шаблона используется натренированный классификатор, для достижения наилучшего результата необходимо осуществить полный перебор ограничивающих рамок с порогом уверенности в правдивости классификации за счёт того, что объекты могут быть разных масштабов и находиться в разных местах изображений. Однако, на изображении разрешения $W times H$ суммарное число ограничивающих рамок равно $sum_{i=0}^{W} sum_{j=0}^{H} (W-i)cdot(H-j) = frac{1}{4} m cdot n cdot (m + 1) cdot (n +1) = O(m^2n^2)$, что делает полный перебор неэффективным методом, занимающим очень большое количество времени. Для уменьшения количества рассматриваемых ограничивающих рамок выделяют два основных параллельно развивающихся подхода:
- Двухэтапные методы (англ. two-stage methods), они же «методы, основанные на регионах» (англ. region-based methods) — подход, разделённый на два этапа. На первом этапе селективным поиском или с помощью специального слоя нейронной сети выделяются регионы интереса (англ. regions of interest, RoI) — области , с высокой вероятностью содержащие внутри себя объекты. На втором этапе выбранные регионы рассматриваются классификатором для определения принадлежности исходным классам и регрессором, уточняющим местоположение ограничивающих рамок.
- Одноэтапные методы (англ. one-stage methods) — подход, не использующий отдельный алгоритм для генерации регионов, вместо этого предсказывая координаты определённого количества ограничивающих рамок с различными характеристиками, такими, как результаты классификации и степень уверенности и в дальнейшем корректируя местоположение рамок.
Двухэтапные методы
R-CNN
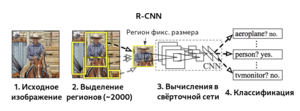
Region-CNN[5] (R-CNN, Region-based Convolutional Network) — алгоритм, основанный на свёрточных нейронных сетях. Вместо того, чтобы использовать для поиска изображений скользящие окна фиксированного размера, на первом шаге алгоритм пытается найти селективным поиском «регионы» — прямоугольные рамки разных размеров, которые, предположительно, содержат объект. Это обеспечивает более быстрое и эффективное нахождение объектов независимо от размера объекта, расстояния до камеры, угла зрения. Суммарное количество регионов для каждого изображения, сгенерированных на первом шаге, примерно равно двум тысячам. Найденные регионы при помощи аффинных преобразований приобретают размер, который нужно подать на вход CNN. Также вместо аффинных преобразований можно использовать паддинги, либо расширять ограничивающие рамки до размеров, необходимых для входа CNN. В качестве CNN зачастую используется архитектура CaffeNet[6], извлекающая для каждого региона порядка 4096 признаков. На последнем этапе вектора признаков регионов обрабатываются SVM, проводящими классификацию объектов, по одной SVM на каждый домен.
Селективный поиск, в свою очередь, тоже можно обучать с помощью линейной регрессии параметров региона — ширины, высоты, центра. Этот метод, названный bounding-box regression, позволяет более точно выделить объект. В качестве данных для регрессии используются признаки, полученные в результате работы CNN.
Fast R-CNN
За счёт того, что в R-CNN для каждого из 2000 регионов классификация производится отдельно, обучение сети занимает большой объём времени. Оригинальной версии алгоритма R-CNN для обработки каждого тестового изображения требовалось порядка 47 секунд, поэтому его авторы предложили алгоритм, улучшающий производительность — Fast R-CNN[7]. Его характерной особенностью является подача на вход CNN не отдельных регионов, а всего изображения сразу для получения общей карты признаков. Предложенные регионы накладываются на общую карту признаков, и в результате количество операций свёртки существенно уменьшается. Поскольку регионы имеют разный размер, необходимо привести признаки к фиксированному размеру при помощи операции RoIPooling (Region of interest pooling). В рамках RoIPooling регион делится на сетку, размерность ячеек которой совпадает с размерностью выхода, после чего по ячейкам сетки проводится выбор максимального значения. Полученные регионы фиксированного размера далее являются входом для полносвязного слоя, который и осуществляет как классификацию, так и линейную регрессию для сдвига границ его рамок. Стоит отметить, что в Fast R-CNN используется совместное обучение SVM для классификации, CNN и bounding box регрессора вместо независимого их обучения —для этого используется совместная функция потерь.
Faster R-CNN
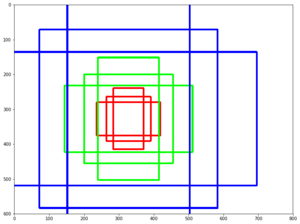
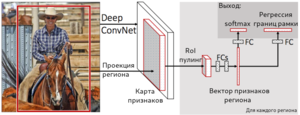
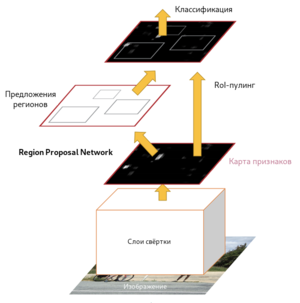
Ключевые рамки различных масштабов и ориентации
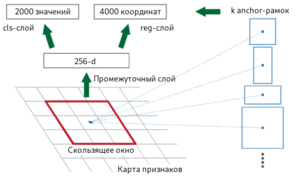
Fast R-CNN, как и оригинальный алгоритм R-CNN, использует для нахождения регионов селективный поиск. Несмотря на то, что за счёт единоразовой свёртки время обучения на одном тестовом изображении алгоритмом снизилось с 49 до 2.3 секунд, селективный поиск, который выполняет предложения регионов, является узким местом в производительности Fast R-CNN. Авторы алгоритма Faster R-CNN[8], призванного решить эту проблему, предложили вычислять регионы с помощью отдельного модуля Region Proposal Network (RPN). RPN является свёрточной сетью, выполняющей роль генератора регионов по признакам исходного изображения. Сгенерированные регионы передаются в два полносвязных слоя — box-regression-layer (сокр. reg layer), прогнозирующий значения смещения для ограничивающих рамок, и box-classification-layer (сокр. cls layer), классифицирующий изображения в пределах предлагаемой области. Также важную роль играют ключевые рамки (англ. anchor boxes) — рамки с различными положениями и размерами для скользящего окна. Ключевые рамки имеют зафиксированное положение и различную форму и масштаб. Для одного и того же масштаба выбирается, как правило, три ключевые рамки — квадратной формы; прямоугольной формы, ориентированной горизонтально; прямоугольной формы, ориентированной вертикально. Учитывая масштаб ключевой рамки, производится его перемещение скользящим окном для генерации регионов. Для сгенерированных таким образом регионов рассчитываются вероятности нахождения объекта внутри рамки cls-слоем, а за сдвиг местоположения отвечает reg-слой. После прохождения слоя RPN следует RoIPooling, как и в алгоритме Fast R-CNN — для преобразования регионов к одному размеру и дальнейшей классификации и смещения границ ограничивающих рамок. Поскольку классификацией и регрессией границ занимается как сеть в целом, так и RPN, предлагающая регионы, функция потерь учитывает как финальное решение по классификации и регрессии координат, так и классификацию и регрессию координат, проведённую RPN.
|
Схема работы Faster R-CNN |
Ключевые рамки в Faster R-CNN |
Mask R-CNN
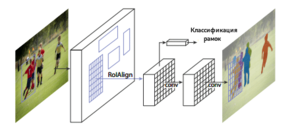
Mask R-CNN[9] — улучшение алгоритма Faster R-CNN, предложенное в 2017 году и обеспечивающее осуществлять возможность сегментации экземпляров объектов, а не только составление ограничивающих рамок с классификацией. В Mask R-CNN к традиционным для алгоритмов семейства R-CNN метке класса и координатам ограничивающей рамки добавляется также маска объекта — прямоугольная матрица принадлежности пикселя текущему объекту. Маски предсказываются для каждого класса с помощью классификации без наличия информации о том, что изображено в регионе, что выдяеляет отдельный классификатор на последнем уровне сети. Потребность предсказания маски обусловила несколько архитектурных изменений относительно Faster R-CNN: ключевым является использование RoIAlign вместо RoIPooling. RoIPooling хорошо подходит для масштабирования ограничивающих рамок, однако, для маски такой метод оказывается недостаточно точным. RoIAlign не использует округлений сдвигов для пулинга, а сохраняет значения с плавающей точкой, используя билинейную интерполяцию. Это обеспечило более точное выделение маски объекта.
Модель Mask R-CNN совершила прорыв в задачах сегментации экземпляров, детекции объектов и определения поз людей на фотографии (англ. human pose estimation). Функция потерь является общей и включает три компонента — классификация, регрессия границ рамки и регрессия значений маски. Это позволило обеспечить взаимопомощь определения сдвигов границ объектов и более точного определения маски.
|
|
Пример семантической сегментации объектов посредством Mask R-CNN |

Одноэтапные методы
Семейство алгоритмов R-CNN использует предсказания регионов, что позволяет обеспечивать хорошую точность, но может быть очень медленным для некоторых сфер, таких, как беспилотное управление автомобилем. Можно выделить ещё одно семейство параллельно развивающихся алгоритмов для детекции изображений, которое не использует регионы — семейство алгоритмов быстрой детекции.
YOLO
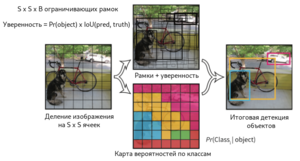
Алгоритм YOLO[10] (You Look Only Once), предложенный в 2016 году, был первой попыткой сделать возможной детекцию объектов в реальном времени. В рамках алгоритма YOLO исходное изображение сначала разбивается на сетку из $N times N$ ячеек. Если центр объекта попадает внутрь координат ячейки, то эта ячейка считается ответственной за определение параметров местонахождения объекта. Каждая ячейка описывает несколько вариантов местоположения ограничивающих рамок для одного и того же объекта. Каждый из этих вариантов характеризуется пятью значениями — координатами центра ограничивающей рамки, его шириной и высотой, а также степени уверенности в том, что ограничивающая рамка содержит в себе объект. Также необходимо для каждой пары класса объектов и ячейки определить вероятность того, что ячейка содержит в себе объект этого класса. Таким образом, последний слой сети, принимающий конечное решение об ограничивающих рамках и классификации объектов работает с тензором размерности $N times N times (5B + C)$, где $B$ — количество предсказываемых ограничивающих рамок для ячейки, $C$ — количество классов объектов, определённых изначально.
Алгоритм YOLO работает быстрее алгоритмов семейства R-CNN за счёт того, что поддерживает дробление на константное количество ячеек вместо того, чтобы предлагать регионы и рассчитывать решение для каждого региона отдельно, однако, в качестве проблем YOLO указывается плохое качество распознавания объектов сложной формы или группы небольших объектов из-за ограниченного числа кандидатов для ограничивающих рамок.
|
Схема работы алгоритма YOLO |
Архитектура нейронной сети для алгоритма YOLO |
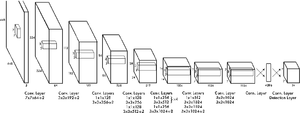
YOLOv2, YOLOv3
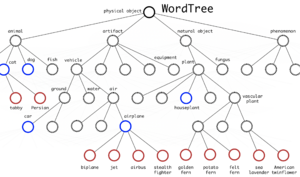
Древовидная структура классов в YOLO9000
Улучшенная версия модели YOLOv2[11] отличается от предшественницы использованием батчевой нормализации на свёрточных слоях, обучением модели на изображениях с повышенным разрешением, использованием ключевых рамок для предсказания местонахождения объектов, использованием кластеризации алгоримтом $k$-средних для обучения более эффективного выбора размеров ограничивающих рамок на тренировочной выборке с использованием функции расстояния на основе IoU:
$dist(x, c_i) = 1 — IoU(x, c_i)$
где $x$ — настоящая ограничивающая рамка, $c_i$ — центроид кластера. Количество ограничивающих рамок-центроидов выбирается при помощи «метода локтя» (англ. elbow method). Также в YOLOv2 используется предположение, что ограничивающиеся рамки не слишком отклоняются от местоположения центра, что обеспечивает стабильность на фоне менее эффективного равномерного выбора рамок-кандидатов по всему исходному изображению. YOLO9000, представленный в той же статье и названный согласно использованию 9000 лучших классов ImageNet, использует древовидную структуру классов, учитывая их вложенность. Например, если среди классов есть метка «Персидская кошка», это будет означать, что найденный объект будет подклассом метки «Кошка». Таким образом, не возникает взаимной исключительности классов, и softmax ко всем классам не применяется. Чтобы предсказать вероятность узла класса, мы можем следовать по пути от узла к корню:
$p($persian cat$|$object$) = p($persian cat$|$cat$) cdot p($cat$|$animal$) cdot p($animal$|$object$) cdot p($object$)$
$p($object$)$ — вероятность обнаружения объекта, вычисленная на этапе генерации ограничительных рамок. Путь прогнозирования условной вероятности может остановиться на любом этапе, в зависимости от того, какие метки доступны.
YOLOv3[12], в свою очередь, является небольшим улучшением YOLOv2 — используется логистическая регрессия для оценок достоверностей ограничивающих рамок вместо суммы квадратов ошибок для условий классификации в YOLO и YOLOv2; использование нескольких независимых логистических классификаторов для каждого класса вместо одного слоя softmax; добавление межуровневых соединений между уровнями прогнозирования ограничивающих рамок; использование архитектур DarkNet и ResNet для свёрточных сетей.
SSD
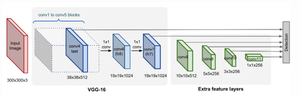
Архитектура нейронной сети для алгоритма SSD
Модель Single Shot Detector[13] (SSD) использует идею использования пирамидальной иерархии выходов свёрточной сети для эффективного обнаружения объектов различных размеров. Изображение последовательно передаётся на слои свёрточной сети, которые уменьшаются в размерах. Выход из последнего слоя каждой размерности участвует в принятии решения по детекции объектов, таким образом, складывается «пирамидальная характеристика» изображения. Это позволяет обнаруживать объекты различных масштабов, так как размерность выходов первых слоёв сильно коррелирует с ограничивающими рамками для маленьких объектов, а последних — для крупных. В отличие от YOLO, SSD не разбивает изображение на сетку произвольного размера, а предсказывает смещение ключевых рамок. Ключевые рамки на разных уровнях масштабируются так, что одна размерность выходного слоя отвечает за объекты своего масштаба. В результате, большие объекты могут быть обнаружены только на более высоком уровне, а маленькие объекты — на низких уровнях. Как и в других алгоритмах, функция потерь обеспечивает совместный вклад как потерь локализации, так и потерь классификации.
Anchor boxes
Anchor boxes — алгоритм нахождения объектов, основанный на предсказании категории объекта и отступа от истинной ограничивающей рамки для большого количества сгенерированных ключевых рамок с последующей их фильтрацией.
Генерация ключевых рамок
Пусть входное изображение имеет высоту $h$ и ширину $w$. Генерируем ключевые рамки с различными формами и размерами, центрированные на каждом пикселе изображения. Предположим, что размер $s∈(0, 1]$, соотношение сторон $r>0$, тогда ширина и высота ключевой рамки равны $wssqrt{r}$ и $hs/sqrt{r}$. Затем определяем набор размеров $s_1,ldots, s_n$ и набор соотношений $r_1,ldots, r_m$. Если использовать комбинацию всех размеров и пропорций, то входное изображение будет иметь $whnm$ ключевых рамок, что может привести к большой вычислительной сложности. Поэтому обычно выбираются только комбинации, содержащие размеры $s_1$ и пропорции $r_1$:
$(s_1, r_1), (s_1, r_2), ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), ldots, (s_n, r_1).$
При таком подходе число рамок для входного изображения сокращается до $wh(n+m-1)$.
Процесс обучения
Пусть набор ключевых рамок входного изображения это $A_1, A_2, ldots, A_{n_a}$, а набор истинных ограничивающих рамок это $B_1, B_2, ldots, B_{n_b}$, и $n_a geq n_b$. Определяем матрицу $mathbf{X} in mathbb{R}^{n_a times n_b}$, где элемент $x_{ij}$ — это $IoU$ ключевой рамки $A_i$ с истинной рамкой $B_j$. Затем находим наибольший элемент в матрице $mathbf{X}$ и сохраняем индекс строки и колонки элемента как $i_1,j_1$. Так мы обозначили ограничивающую рамку $B_{j_1}$ для ключевой рамки $A_{i_1}$. Далее исключаем все элементы в строке с индексом $i_1$ и колонке с индексом $j_1$ в матрице $mathbf{X}$ для последующих поисков максимального элемента. Теперь ищем наибольший элемент среди оставшихся элементов матрицы $mathbf{X}$ и сохраняем его индексы как элемент $i_2, j_2$, и также исключаем элементы из соответствующих колонок и строк.
Повторяем данные действия пока все $n_b$ колонки матрицы $mathbf{X}$ не будут исключены. Затем, для оставшихся $n_a — n_b$ ключевых рамок $A_i$ находим лучшую истинную рамку $B_j$ с наибольшим IoU в строке матрицы $mathbf{X}$ с индексом $i$. Присваиваем ключевой рамке $A_i$ ограничивающую рамку $B_j$ только если IoU больше предустановленного порогового значения.
Теперь мы можем определить категорию и отступ для каждой ключевой рамки. Если ключевой рамке $mathbf{A}$ назначена $mathbf{B}$, то тогда ее категория такая же как и у $mathbf{B}$. А смещение ключевой рамки $mathbf{A}$ устанавливается в соответствии с относительным положением центральных координат $mathbf{B}$ и $mathbf{A}$ и относительными размерами двух рамок. Поскольку положения и размеры различных рамок в наборе данных могут различаться, эти относительные положения и относительные размеры обычно требуют некоторых специальных преобразований, чтобы сделать распределение смещений более равномерным и более простым для подгонки. Предположим, что центр ключевой рамки $mathbf{A}$ это $(x_a, y_a)$, высота и ширина это $h_a$ и $w_a$; для $mathbf{B}$ — $(x_b, y_b)$, $h_b$ и $w_b$ соответственно. В таком случае отступ для A рассчитывается следующим образом:
$left( frac{ frac{x_b — x_a}{w_a} — mu_x }{sigma_x},
frac{ frac{y_b — y_a}{h_a} — mu_y }{sigma_y},
frac{ log frac{w_b}{w_a} — mu_w }{sigma_w},
frac{ log frac{h_b}{h_a} — mu_h }{sigma_h}right)$
Дефолтные значения констант $mu_x = mu_y = mu_w = mu_h = 0$, $sigma_x=sigma_y=0.1$, и $sigma_w=sigma_h=0.2$.
Если ключевой рамке не назначен ограничивающий прямоугольник, то устанавливаем категорию background.
Процесс предсказаний
На этапе прогнозирования сначала генерируется несколько ключевых рамок для изображения, а затем прогнозируются их категории и смещения. Затем на основе ключевых блоков и их прогнозируемых смещений получаются ограничивающие рамки прогнозирования. Когда имеется много ключевых рамок или много одинаковых ограничивающих рамок предсказания могут выводиться несколько раз для одного и того же объекта. Чтобы упростить результаты, можно удалить аналогичные ограничивающие рамки прогнозирования. Обычно используется метод, который называется не максимальное подавление (NMS).
См.также
- Глубокое обучение
- Сверточные нейронные сети
- Модель алгоритма и ее выбор
Примечания
- ↑ PASCAL VOC 2012
- ↑ MS COCO 2017
- ↑ ImageNet
- ↑ Google Open Images
- ↑ Region-CNN
- ↑ CaffeNet
- ↑ Fast R-CNN
- ↑ Faster R-CNN
- ↑ Mask R-CNN
- ↑ YOLO
- ↑ YOLOv2
- ↑ YOLOv3
- ↑ Single Shot Detector
Источники информации
- Stanford CS231n: Detection and Segmentation
- Stepik.org: Deep Learning School
- Habr: обзор Deep Learning в Computer Vision
- Список статей о детекции объектов методами глубокого обучения
- R-CNN, Fast R-CNN, Faster R-CNN, YOLO — Object Detection Algorithms
- Dive into deep lerning — Computer vision — Anchor Boxes
Что на картинке: три простых шага, чтобы это узнать
Мы привыкли пользоваться поисковыми системами для того, чтобы найти информацию об интересующем нас предмете по ключевым словам. Но есть и функция для других случаев: когда у вас есть только фото объекта и вам нужно определить, что на нем изображено. Достаточно сделать три простых шага, чтобы понять, что именно изображено на фото. Рассмотрим эту функцию более подробно.
- Когда может понадобиться определить, что на картинке?
- Как воспользоваться функцией?
- Голосовой помощник «Алиса»: ещё проще, ещё удобнее
Случаев, когда может понадобиться определить предмет по его изображению очень много.
- В туристических поездках – узнать название достопримечательности и информацию о ней.
- Определить сорта и виды различных цветов, деревьев и растений.
- Найти понравившуюся мебель, предмет интерьера. Узнать название, производителя, примерную стоимость, а также то, где именно можно купить понравившуюся вещь.
- Определить, что это за животное, птица, рыба.
- Получить развернутую информацию о фильме или клипе по кадру из него.
- Найти схему вязания понравившегося свитера.
- Понять, что за часы на руке у случайного попутчика в метро.
- Распознать текст на фотографии.
- И ещё примерно миллион других поводов воспользоваться функцией определения того, что же именно изображено на фото.
Определить по фото или картинке, что именно на ней изображено, можно одинаково просто и в Google, и в Яндекс. Для каждой из этих поисковых систем можно выделить три основных шага:
- Открыть страницу «Картинки». В Google эта вкладка находится в верхнем правом углу окна браузера. В Яндексе – прямо над окошком поиска.
- Навести курсор на значок фотоаппарата.
- Выбрать файл или указать ссылку на изображение. В Яндекс.Браузере можно просто перетащить фотографию с помощью курсора мыши.
Система сама предложит вам похожие варианты. Например, допустим, что нужно определить сорт розы, изображённой на приведенном ниже фото.

Роза. Сорт неизвестен, а хотелось бы узнать.
Выбираем файл и смотрим, что предлагают поисковые системы.

Скриншот из поисковой системы Google
Google определяет, что именно изображено на картинке – роза. Предоставляет несколько ссылок, которые могут быть связаны с данным изображением и предлагает похожие. Если во всемирной паутине уже есть такие же картинки, Google указывает их размеры.
Теперь посмотрим, что скажет по этому поводу Яндекс.

Скриншот из Яндекс.Картинок
Яндекс также предлагает другие размеры этой картинки. Внизу можно увидеть похожие картинки, а вот информация справа уже интереснее. Здесь не только предполагаемые названия сортов, но и похожие товары на Яндекс.Маркет с актуальными ценами. Очень удобно: сразу можно узнать название, и найти магазин с этим товаром. Если кликнуть по ссылке с названием сорта, то можно попытаться визуально определить, похожи цветы этого сорта на тот, что изображён на исходном фото или нет.
Также есть возможность выбрать фрагмент картинки. Это может пригодиться в тех случаях, когда на фото продемонстрировано сразу несколько объектов, а информация необходима только про один из них.
С помощью голосового помощника «Алиса» от Яндекса можно не только определить, что изображено на уже сохранённой картинке, но и сделать фото того, что вы видите перед собой в данный момент. Для того чтобы воспользоваться функцией поиска по фото, необходимо сделать следующее:
- Открыть голосовой помощник.
- Попросить «Алису» сделать фото и определить, что на нём изображено.
После этого откроется меню камеры и галерея фото. Можно будет либо сделать новое фото объекта, либо выбрать из уже имеющихся.

«Алиса» просит предоставить исходную картинку…
Важно: Убедитесь в том, что голосовому помощнику «Алиса» разрешён доступ к вашей камере и файлам!
- Просмотрите предложенные «Алисой» варианты и выберите то, что вам подходит.

… и предлагает варианты.

Здесь – не только различные сорта роз, но и другие предметы с похожими изображениями. Например, постеры или схемы для вышивания
«Алиса» не только найдёт похожие изображения, но и предложит воспользоваться поиском по картинке. Дальше голосовой помощник перенаправит вас в браузер и выдаст всю имеющуюся в сети информацию о данном изображении.
Если у пользователя нет возможности общаться с «Алисой» голосом, то можно нажать на значок фотоаппарата – он располагается справа от фиолетового микрофона. В результате будут проделаны те же шаги, что и при поиске в браузере.
Функция определения того, что изображено на картинке, ускоряет поиск необходимой информации об объекте. Можно перебирать тысячи похожих картинок в браузере. А можно просто воспользоваться этим удобным изобретением с помощью поисковой системы или голосового помощника «Алиса».