Locating the elements based on the provided locator values.
One of the most fundamental aspects of using Selenium is obtaining element references to work with.
Selenium offers a number of built-in locator strategies to uniquely identify an element.
There are many ways to use the locators in very advanced scenarios. For the purposes of this documentation,
let’s consider this HTML snippet:
<ol id="vegetables">
<li class="potatoes">…
<li class="onions">…
<li class="tomatoes"><span>Tomato is a Vegetable</span>…
</ol>
<ul id="fruits">
<li class="bananas">…
<li class="apples">…
<li class="tomatoes"><span>Tomato is a Fruit</span>…
</ul>
First matching element
Many locators will match multiple elements on the page. The singular find element method will return a reference to the
first element found within a given context.
Evaluating entire DOM
When the find element method is called on the driver instance, it
returns a reference to the first element in the DOM that matches with the provided locator.
This value can be stored and used for future element actions. In our example HTML above, there are
two elements that have a class name of “tomatoes” so this method will return the element in the “vegetables” list.
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
WebElement vegetable = driver.findElement(By.className("tomatoes"));
vegetable = driver.find_element(By.CLASS_NAME, "tomatoes")
var vegetable = driver.FindElement(By.ClassName("tomatoes"));
vegetable = driver.find_element(class: 'tomatoes')
const vegetable = await driver.findElement(By.className('tomatoes'));
val vegetable: WebElement = driver.findElement(By.className("tomatoes"))
Evaluating a subset of the DOM
Rather than finding a unique locator in the entire DOM, it is often useful to narrow the search to the scope
of another located element. In the above example there are two elements with a class name of “tomatoes” and
it is a little more challenging to get the reference for the second one.
One solution is to locate an element with a unique attribute that is an ancestor of the desired element and not an
ancestor of the undesired element, then call find element on that object:
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
WebElement fruits = driver.findElement(By.id("fruits"));
WebElement fruit = fruits.findElement(By.className("tomatoes"));
fruits = driver.find_element(By.ID, "fruits")
fruit = fruits.find_element(By.CLASS_NAME,"tomatoes")
IWebElement fruits = driver.FindElement(By.Id("fruits"));
IWebElement fruit = fruits.FindElement(By.ClassName("tomatoes"));
fruits = driver.find_element(id: 'fruits')
fruit = fruits.find_element(class: 'tomatoes')
const fruits = await driver.findElement(By.id('fruits'));
const fruit = fruits.findElement(By.className('tomatoes'));
val fruits = driver.findElement(By.id("fruits"))
val fruit = fruits.findElement(By.className("tomatoes"))
Java and C#WebDriver, WebElement and ShadowRoot classes all implement a SearchContext interface, which is
considered a role-based interface. Role-based interfaces allow you to determine whether a particular
driver implementation supports a given feature. These interfaces are clearly defined and try
to adhere to having only a single role of responsibility.
Optimized locator
A nested lookup might not be the most effective location strategy since it requires two
separate commands to be issued to the browser.
To improve the performance slightly, we can use either CSS or XPath to find this element in a single command.
See the Locator strategy suggestions in our
Encouraged test practices section.
For this example, we’ll use a CSS Selector:
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
WebElement fruit = driver.findElement(By.cssSelector("#fruits .tomatoes"));
fruit = driver.find_element(By.CSS_SELECTOR,"#fruits .tomatoes")
var fruit = driver.FindElement(By.CssSelector("#fruits .tomatoes"));
fruit = driver.find_element(css: '#fruits .tomatoes')
const fruit = await driver.findElement(By.css('#fruits .tomatoes'));
val fruit = driver.findElement(By.cssSelector("#fruits .tomatoes"))
All matching elements
There are several use cases for needing to get references to all elements that match a locator, rather
than just the first one. The plural find elements methods return a collection of element references.
If there are no matches, an empty list is returned. In this case,
references to all fruits and vegetable list items will be returned in a collection.
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
List<WebElement> plants = driver.findElements(By.tagName("li"));
plants = driver.find_elements(By.TAG_NAME, "li")
IReadOnlyList<IWebElement> plants = driver.FindElements(By.TagName("li"));
plants = driver.find_elements(tag_name: 'li')
const plants = await driver.findElements(By.tagName('li'));
val plants: List<WebElement> = driver.findElements(By.tagName("li"))
Get element
Often you get a collection of elements but want to work with a specific element, which means you
need to iterate over the collection and identify the one you want.
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
List<WebElement> elements = driver.findElements(By.tagName("li"));
for (WebElement element : elements) {
System.out.println("Paragraph text:" + element.getText());
}
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
# Navigate to Url
driver.get("https://www.example.com")
# Get all the elements available with tag name 'p'
elements = driver.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)
using OpenQA.Selenium;
using OpenQA.Selenium.Firefox;
using System.Collections.Generic;
namespace FindElementsExample {
class FindElementsExample {
public static void Main(string[] args) {
IWebDriver driver = new FirefoxDriver();
try {
// Navigate to Url
driver.Navigate().GoToUrl("https://example.com");
// Get all the elements available with tag name 'p'
IList < IWebElement > elements = driver.FindElements(By.TagName("p"));
foreach(IWebElement e in elements) {
System.Console.WriteLine(e.Text);
}
} finally {
driver.Quit();
}
}
}
}
require 'selenium-webdriver'
driver = Selenium::WebDriver.for :firefox
begin
# Navigate to URL
driver.get 'https://www.example.com'
# Get all the elements available with tag name 'p'
elements = driver.find_elements(:tag_name,'p')
elements.each { |e|
puts e.text
}
ensure
driver.quit
end
const {Builder, By} = require('selenium-webdriver');
(async function example() {
let driver = await new Builder().forBrowser('firefox').build();
try {
// Navigate to Url
await driver.get('https://www.example.com');
// Get all the elements available with tag 'p'
let elements = await driver.findElements(By.css('p'));
for(let e of elements) {
console.log(await e.getText());
}
}
finally {
await driver.quit();
}
})();
import org.openqa.selenium.By
import org.openqa.selenium.firefox.FirefoxDriver
fun main() {
val driver = FirefoxDriver()
try {
driver.get("https://example.com")
// Get all the elements available with tag name 'p'
val elements = driver.findElements(By.tagName("p"))
for (element in elements) {
println("Paragraph text:" + element.text)
}
} finally {
driver.quit()
}
}
Find Elements From Element
It is used to find the list of matching child WebElements within the context of parent element.
To achieve this, the parent WebElement is chained with ‘findElements’ to access child elements
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class findElementsFromElement {
public static void main(String[] args) {
WebDriver driver = new ChromeDriver();
try {
driver.get("https://example.com");
// Get element with tag name 'div'
WebElement element = driver.findElement(By.tagName("div"));
// Get all the elements available with tag name 'p'
List<WebElement> elements = element.findElements(By.tagName("p"));
for (WebElement e : elements) {
System.out.println(e.getText());
}
} finally {
driver.quit();
}
}
}
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.example.com")
# Get element with tag name 'div'
element = driver.find_element(By.TAG_NAME, 'div')
# Get all the elements available with tag name 'p'
elements = element.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.Collections.Generic;
namespace FindElementsFromElement {
class FindElementsFromElement {
public static void Main(string[] args) {
IWebDriver driver = new ChromeDriver();
try {
driver.Navigate().GoToUrl("https://example.com");
// Get element with tag name 'div'
IWebElement element = driver.FindElement(By.TagName("div"));
// Get all the elements available with tag name 'p'
IList < IWebElement > elements = element.FindElements(By.TagName("p"));
foreach(IWebElement e in elements) {
System.Console.WriteLine(e.Text);
}
} finally {
driver.Quit();
}
}
}
}
require 'selenium-webdriver'
driver = Selenium::WebDriver.for :chrome
begin
# Navigate to URL
driver.get 'https://www.example.com'
# Get element with tag name 'div'
element = driver.find_element(:tag_name,'div')
# Get all the elements available with tag name 'p'
elements = element.find_elements(:tag_name,'p')
elements.each { |e|
puts e.text
}
ensure
driver.quit
end
const {Builder, By} = require('selenium-webdriver');
(async function example() {
let driver = new Builder()
.forBrowser('chrome')
.build();
await driver.get('https://www.example.com');
// Get element with tag name 'div'
let element = driver.findElement(By.css("div"));
// Get all the elements available with tag name 'p'
let elements = await element.findElements(By.css("p"));
for(let e of elements) {
console.log(await e.getText());
}
})();
import org.openqa.selenium.By
import org.openqa.selenium.chrome.ChromeDriver
fun main() {
val driver = ChromeDriver()
try {
driver.get("https://example.com")
// Get element with tag name 'div'
val element = driver.findElement(By.tagName("div"))
// Get all the elements available with tag name 'p'
val elements = element.findElements(By.tagName("p"))
for (e in elements) {
println(e.text)
}
} finally {
driver.quit()
}
}
Get Active Element
It is used to track (or) find DOM element which has the focus in the current browsing context.
- Java
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
public class activeElementTest {
public static void main(String[] args) {
WebDriver driver = new ChromeDriver();
try {
driver.get("http://www.google.com");
driver.findElement(By.cssSelector("[name='q']")).sendKeys("webElement");
// Get attribute of current active element
String attr = driver.switchTo().activeElement().getAttribute("title");
System.out.println(attr);
} finally {
driver.quit();
}
}
}
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.com")
driver.find_element(By.CSS_SELECTOR, '[name="q"]').send_keys("webElement")
# Get attribute of current active element
attr = driver.switch_to.active_element.get_attribute("title")
print(attr)
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace ActiveElement {
class ActiveElement {
public static void Main(string[] args) {
IWebDriver driver = new ChromeDriver();
try {
// Navigate to Url
driver.Navigate().GoToUrl("https://www.google.com");
driver.FindElement(By.CssSelector("[name='q']")).SendKeys("webElement");
// Get attribute of current active element
string attr = driver.SwitchTo().ActiveElement().GetAttribute("title");
System.Console.WriteLine(attr);
} finally {
driver.Quit();
}
}
}
}
require 'selenium-webdriver'
driver = Selenium::WebDriver.for :chrome
begin
driver.get 'https://www.google.com'
driver.find_element(css: '[name="q"]').send_keys('webElement')
# Get attribute of current active element
attr = driver.switch_to.active_element.attribute('title')
puts attr
ensure
driver.quit
end
const {Builder, By} = require('selenium-webdriver');
(async function example() {
let driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://www.google.com');
await driver.findElement(By.css('[name="q"]')).sendKeys("webElement");
// Get attribute of current active element
let attr = await driver.switchTo().activeElement().getAttribute("title");
console.log(`${attr}`)
})();
import org.openqa.selenium.By
import org.openqa.selenium.chrome.ChromeDriver
fun main() {
val driver = ChromeDriver()
try {
driver.get("https://www.google.com")
driver.findElement(By.cssSelector("[name='q']")).sendKeys("webElement")
// Get attribute of current active element
val attr = driver.switchTo().activeElement().getAttribute("title")
print(attr)
} finally {
driver.quit()
}
}
Support the Selenium Project
Want to support the Selenium project? Learn more or view the full list of sponsors.
Как вы, возможно, уже поняли, чтобы управлять элементами страницы, нам нужно сначала найти их. Selenium использует так называемые локаторы, чтобы находить элементы на веб-странице.
В Selenium есть 8 методов которые помогут в поиске HTML элементов:
| Цель поиска Используемый метод |
Пример | ||
| Поиск по ID find_element_by_id(«user») |
|
||
| Поиск по имени find_element_by_name(«username») |
|
||
| Поиск по тексту ссылки find_element_by_link_text(«Login») |
|
||
| Поиск по частичному тексту ссылки find_element_by_partial_link_text(«Next») |
|
||
| Поиск используя XPath find_element_by_xpath(‘//div[@id=»login»]/input’) |
|
||
| Поиск по названию тэга find_element_by_tag_name(«body») |
|||
| Поиск по классу элемента find_element_by_class_name(«table») |
|
||
| Поиск по CSS селектору find_element_by_css_selector(‘#login > input[type=»text»]’) |
|
Вы можете использовать любой из них, чтобы сузить поиск элемента, который вам нужен.
Запуск браузера
Тестирование веб-сайтов начинается с браузера. В приведенном ниже тестовом скрипте запускается окно браузера Firefox, и осуществляется переход на сайт.
|
from selenium import webdriver driver = webdriver.Firefox() driver.get(«http://testwisely.com/demo») |
Используйте webdriver.Chrome и webdriver.Ie() для тестирования в Chrome и IE соответственно. Новичкам рекомендуется закрыть окно браузера в конце тестового примера.
Поиск элемента по ID
Использование идентификаторов — самый простой и безопасный способ поиска элемента в HTML. Если страница соответствует W3C HTML, идентификаторы должны быть уникальными и идентифицироваться в веб-элементах управления. По сравнению с текстами тестовые сценарии, использующие идентификаторы, менее склонны к изменениям приложений (например, разработчики могут принять решение об изменении метки, но с меньшей вероятностью изменить идентификатор).
|
driver.find_element_by_id(«submit_btn»).click() # Клик по кнопке driver.find_element_by_id(«cancel_link»).click() # Клик по ссылке driver.find_element_by_id(«username»).send_keys(«agileway») # Ввод символов driver.find_element_by_id(«alert_div»).text # Получаем текст |
Поиск элемента по имени
Атрибут имени используются в элементах управления формой, такой как текстовые поля и переключатели (radio кнопки). Значения имени передаются на сервер при отправке формы. С точки зрения вероятности будущих изменений, атрибут name, второй по отношению к ID.
|
driver.find_element_by_name(«comment»).send_keys(«Selenium Cool») |
Поиск элемента по тексту ссылки
Только для гиперссылок. Использование текста ссылки — это, пожалуй, самый прямой способ щелкнуть ссылку, так как это то, что мы видим на странице.
|
driver.find_element_by_link_text(«Cancel»).click() |
HTML для которого будет работать
|
<a href=«/cancel»>Cancel</a> |
Поиск элемента по частичному тексту ссылки
Selenium позволяет идентифицировать элемент управления гиперссылкой с частичным текстом. Это может быть полезно, если текст генерируется динамически. Другими словами, текст на одной веб-странице может отличаться при следующем посещении. Мы могли бы использовать общий текст, общий для этих динамически создаваемых текстов ссылок, для их идентификации.
|
# Полный текст ссылки «Cancel Me» driver.find_element_by_partial_link_text(«ance»).click() |
HTML для которого будет работать
|
<a href=«/cancel»>Cancel me</a> |
Поиск элемента по XPath
XPath, XML Path Language, является языком запросов для выбора узлов из XML документа. Когда браузер отображает веб-страницу, он анализирует его в дереве DOM. XPath может использоваться для ссылки на определенный узел в дереве DOM. Если это звучит слишком сложно для вас, не волнуйтесь, просто помните, что XPath — это самый мощный способ найти определенный веб-элемент.
|
# Клик по флажку в контейнере с ID div2 driver.find_element_by_xpath(«//*[@id=’div2′]/input[@type=’checkbox’]»).click() |
HTML для которого будет работать
|
<form> <div id=«div2»> <input value=«rules» type=«checkbox»> </div> </form> |
Некоторые тестеры чувствуют себя «запуганными» сложностью XPath. Тем не менее, на практике существует только ограниченная область для использования XPath.
Избегайте XPath из Developer Tool
Избегайте использования скопированного XPath из инструмента Developer Tool.
Инструмент разработчика браузера (щелкните правой кнопкой мыши, чтобы выбрать «Проверить элемент», чтобы увидеть) очень полезен для определения веб-элемента на веб-странице. Вы можете получить XPath веб-элемента там, как показано ниже (в Chrome):
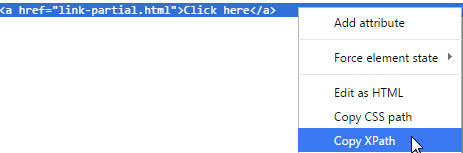
Скопированный XPath для второй ссылки «Нажмите здесь» в примере:
|
//*[@id=«container»]/div[3]/div[2]/a |
Этот метод работает. Тем не менее, этот подход не рекомендуется для постоянного применения, поскольку тестовый сценарий является довольно хрупким и изменчивым.
Попытайтесь использовать выражения XPath, которое менее уязвимо для структурных изменений вокруг веб-элемента.
Поиск элемента по имени тега
В HTML есть ограниченный набор имен тегов. Другими словами, многие элементы используют одни и те же имена тегов на веб-странице. Обычно мы не используем локатор tag_name для поиска элемента. Мы часто используем его с другими элементами в цепочке локаторах. Однако есть исключение.
|
driver.find_element_by_tag_name(«body»).text |
Вышеприведенная тестовая инструкция возвращает текстовое содержимое веб-страницы из тега body.
Поиск элемента по имени класса
Атрибут class элемента HTML используется для стилизации. Он также может использоваться для идентификации элементов. Как правило, атрибут класса элемента HTML имеет несколько значений, как показано ниже.
|
<a href=«back.html» class=«btn btn-default»>Cancel</a> <input type=«submit» class=«btn btn-deault btn-primary»> Submit </input> |
Вы можете использовать любой из них.
|
driver.find_element_by_class_name(«btn-primary»).click() # Клик по кнопки driver.find_element_by_class_name(«btn»).click() # Клик по ссылке # # |
Метод class_name удобен для тестирования библиотек JavaScript / CSS (таких как TinyMCE), которые обычно используют набор определенных имен классов.
|
driver.find_element_by_id(«client_notes»).click() time.sleep(0.5) driver.find_element_by_class_name(«editable-textarea»).send_keys(«inline notes») time.sleep(0.5) driver.find_element_by_class_name(«editable-submit»).click() |
Поиск элемента с помощью селектора CSS
Вы также можете использовать CSS селектор для поиска веб-элемента.
|
driver.find_element_by_css_selector(«#div2 > input[type=’checkbox’]»).click() |
Однако использование селектора CSS, как правило, более подвержено структурным изменениям веб-страницы.
Используем find_elements для поиска дочерних элементов
Для страницы, содержащей более одного элемента с такими же атрибутами, как приведенный ниже, мы могли бы использовать XPath селектор.
|
<div id=«div1»> <input type=«checkbox» name=«same» value=«on»> Same checkbox in Div 1 </div> <div id=«div2»> <input type=«checkbox» name=«same» value=«on»> Same checkbox in Div 2 </div> |
Есть еще один способ: цепочка из find_element чтобы найти дочерний элемент.
|
driver.find_element_by_id(«div2»).find_element_by_name(«same»).click() |
Поиск нескольких элементов
Как следует из названия, find_elements возвращает список найденных элементов. Его синтаксис точно такой же, как find_element, то есть он может использовать любой из 8 локаторов.
Пример HTML кода
|
<div id=«container»> <input type=«checkbox» name=«agree» value=«yes»> Yes <input type=«checkbox» name=«agree» value=«no»> No </div> |
Выполним клик по второму флажку.
|
checkbox_elems = driver.find_elements_by_xpath(«//div[@id=’container’]//input[@type=’checkbox’]») print(len(checkbox_elems)) # Результат: 2 checkbox_elems[1].click() |
Иногда find_element вылетает из-за нескольких совпадающих элементов на странице, о которых вы не знали. Метод find_elements пригодится, чтобы найти их.
В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
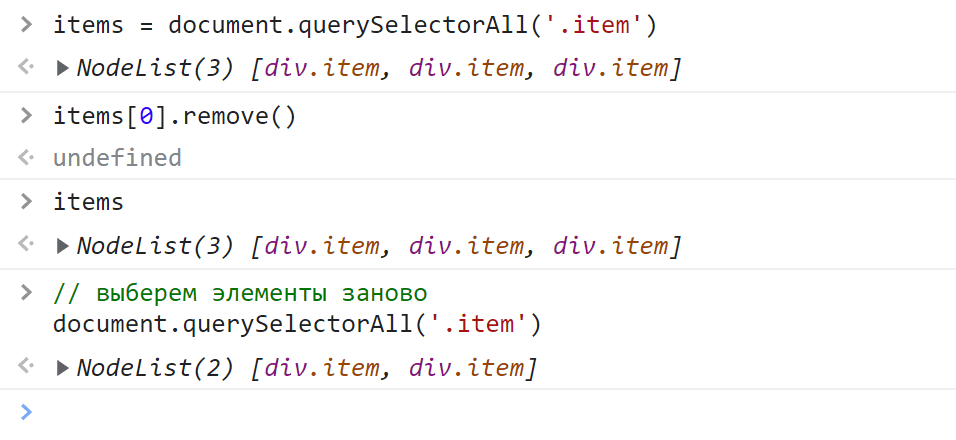
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
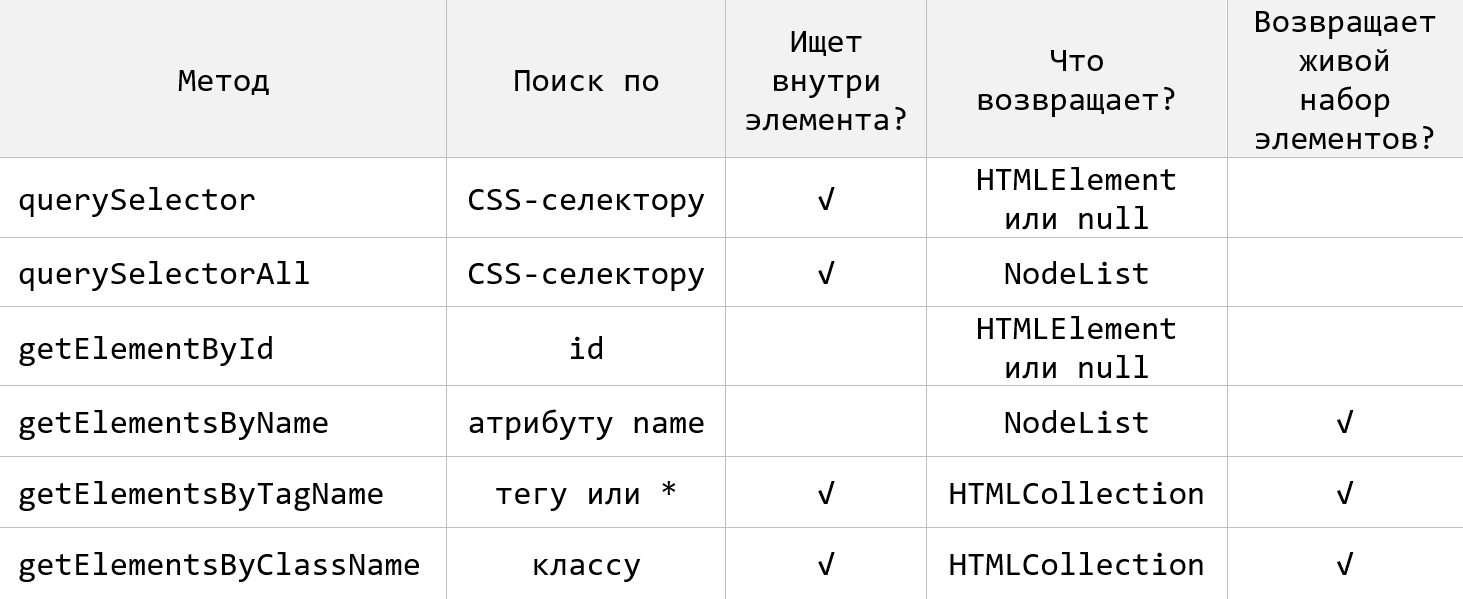
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>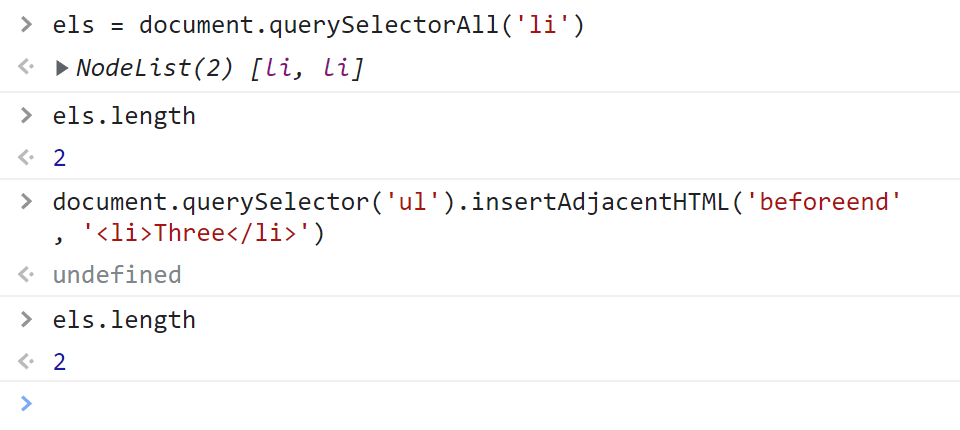
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
Время на прочтение
7 мин
Количество просмотров 279K
Продолжение перевода неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
Содержание:
1. Установка
2. Первые Шаги
3. Навигация
4. Поиск Элементов
5. Ожидания
6. Объекты Страницы
7. WebDriver API
8. Приложение: Часто Задаваемые Вопросы
4. Поиск элементов
Существует ряд способов поиска элементов на странице. Вы вправе использовать наиболее уместные для конкретных задач. Selenium предоставляет следующие методы поиска элементов на странице:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
Чтобы найти все элементы, удовлетворяющие условию поиска, используйте следующие методы (возвращается список):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
[Как вы могли заметить, во втором списке отсутствует поиск по id. Это обуславливается особенностью свойства id для элементов HTML: идентификаторы элементов страницы всегда уникальны. — Прим. пер.]
Помимо общедоступных (public) методов, перечисленных выше, существует два приватных (private) метода, которые при знании указателей объектов страницы могут быть очень полезны: find_element and find_elements.
Пример использования:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
Для класса By доступны следующие атрибуты:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
4.1. Поиск по Id
Используйте этот способ, когда известен id элемента. Если ни один элемент не удовлетворяет заданному значению id, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
Элемент form может быть определен следующим образом:
login_form = driver.find_element_by_id('loginForm')
4.2. Поиск по Name
Используйте этот способ, когда известен атрибут name элемента. Результатом будет первый элемент с искомым значением атрибута name. Если ни один элемент не удовлетворяет заданному значению name, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
Элементы с именами username и password могут быть определены следующим образом:
username = driver.find_element_by_name('username')
password = driver.find_element_by_name('password')
Следующий код получит кнопку “Login”, находящуюся перед кнопкой “Clear”:
continue = driver.find_element_by_name('continue')
4.3. Поиск по XPath
XPath – это язык, использующийся для поиска узлов дерева XML-документа. Поскольку в основе HTML может лежать структура XML (XHTML), пользователям Selenium предоставляется возможность посредоством этого мощного языка отыскивать элементы в их веб-приложениях. XPath выходит за рамки простых методов поиска по атрибутам id или name (и в то же время поддерживает их), и открывает спектр новых возможностей, таких как поиск третьего чекбокса (checkbox) на странице, к примеру.
Одно из веских оснований использовать XPath заключено в наличии ситуаций, когда вы не можете похвастать пригодными в качестве указателей атрибутами, такими как id или name, для элемента, который вы хотите получить. Вы можете использовать XPath для поиска элемента как по абсолютному пути (не рекомендуется), так и по относительному (для элементов с заданными id или name). XPath указатели в том числе могут быть использованы для определения элементов с помощью атрибутов отличных от id и name.
Абсолютный путь XPath содержит в себе все узлы дерева от корня (html) до необходимого элемента, и, как следствие, подвержен ошибкам в результате малейших корректировок исходного кода страницы. Если найти ближайщий элемент с атрибутами id или name (в идеале один из элементов-родителей), можно определить искомый элемент, используя связь «родитель-подчиненный». Эти связи будут куда стабильнее и сделают ваши тесты устойчивыми к изменениям в исходном коде страницы.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
Элемент form может быть определен следующими способами:
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
- Абсолютный путь (поломается при малейшем изменении структуры HTML страницы)
- Первый элемент form в странице HTML
- Элемент form, для которого определен атрибут с именем id и значением loginForm
Элемент username может быть найден так:
username = driver.find_element_by_xpath("//form[input/@name='username']")
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
username = driver.find_element_by_xpath("//input[@name='username']")
- Первый элемент form с дочерним элементом input, для которого определен атрибут с именем name и значением username
- Первый дочерний элемент input элемента form, для которого определен атрибут с именем id и значением loginForm
- Первый элемент input, для которого определен атрибут с именем name и значением username
Кнопка “Clear” может быть найдена следующими способами:
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]")
- Элемент input, для которого заданы атрибут с именем name и значением continue и атрибут с именем type и значением button
- Четвертый дочерний элемент input элемента form, для которого задан атрибут с именем id и значением loginForm
Представленные примеры покрывают некоторые основы использования XPath, для более углубленного изучения рекомендую следующие материалы:
- W3Schools XPath Tutorial
- W3C XPath Recommendation
- XPath Tutorial — с интерактивными примерами
Существует также пара очень полезных дополнений (add-on), которые могут помочь в выяснении XPath элемента:
- XPath Checker — получает пути XPath и может использоваться для проверки результатов пути XPath
- Firebug — получение пути XPath — лишь одно из многих мощных средств, поддерживаемых этим очень полезным плагином
- XPath Helper — для Google Chrome
4.4. Поиск гиперссылок по тексту гиперссылки
Используйте этот способ, когда известен текст внутри анкер-тэга [anchor tag, анкер-тэг, тег «якорь» — тэг — Прим. пер.]. С помощью такого способа вы получите первый элемент с искомым значением текста тэга. Если никакой элемент не удовлетворяет искомому значению, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
Элемент-гиперссылка с адресом «continue.html» может быть получен следующим образом:
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
4.5. Поиск элементов по тэгу
Используйте этот способ, когда вы хотите найти элемент по его тэгу. Таким способом вы получите первый элемент с указанным именем тега. Если поиск не даст результатов, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
Элемент заголовка h1 может быть найден следующим образом:
heading1 = driver.find_element_by_tag_name('h1')
4.6. Поиск элементов по классу
Используйте этот способ в случаях, когда хотите найти элемент по значению атрибута class. Таким способом вы получите первый элемент с искомым именем класса. Если поиск не даст результата, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
Элемент “p” может быть найден следующим образом:
content = driver.find_element_by_class_name('content')
4.7. Поиск элементов по CSS-селектору
Используйте этот способ, когда хотите получить элемент с использованием синтаксиса CSS-селекторов [CSS-селектор — это формальное описание относительного пути до элемента/элементов HTML. Классически, селекторы используются для задания правил стиля. В случае с WebDriver, существование самих правил не обязательно, веб-драйвер использует синтаксис CSS только для поиска — Прим. пер.]. Этим способом вы получите первый элемент удовлетворяющий CSS-селектору. Если ни один элемент не удовлетворяют селектору CSS, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
Элемент “p” может быть определен следующим образом:
content = driver.find_element_by_css_selector('p.content')
На Sauce Labs есть хорошая документация по селекторам CSS.
От переводчика: советую также обратиться к следующим материалам:
- 31 CSS селектор — это будет полезно знать! — краткая выжимка по CSS-селекторам
- CSS селекторы, свойства, значения — отличный учебник параллельного изучения HTML и CSS
Перейти к следующей главе
There are various strategies to locate elements in a page. You can use the most
appropriate one for your case. Selenium provides the following method to
locate elements in a page:
- find_element
To find multiple elements (these methods will return a list):
- find_elements
Example usage:
from selenium.webdriver.common.by import By driver.find_element(By.XPATH, '//button[text()="Some text"]') driver.find_elements(By.XPATH, '//button')
The attributes available for the By class are used to locate elements on a page.
These are the attributes available for By class:
ID = "id" NAME = "name" XPATH = "xpath" LINK_TEXT = "link text" PARTIAL_LINK_TEXT = "partial link text" TAG_NAME = "tag name" CLASS_NAME = "class name" CSS_SELECTOR = "css selector"
The ‘By’ class is used to specify which attribute is used to locate elements on a page.
These are the various ways the attributes are used to locate elements on a page:
find_element(By.ID, "id") find_element(By.NAME, "name") find_element(By.XPATH, "xpath") find_element(By.LINK_TEXT, "link text") find_element(By.PARTIAL_LINK_TEXT, "partial link text") find_element(By.TAG_NAME, "tag name") find_element(By.CLASS_NAME, "class name") find_element(By.CSS_SELECTOR, "css selector")
If you want to locate several elements with the same attribute replace find_element with find_elements.
4.1. Locating by Id¶
Use this when you know the id attribute of an element. With this strategy,
the first element with a matching id attribute will be returned. If no
element has a matching id attribute, a NoSuchElementException will be
raised.
For instance, consider this page source:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> </form> </body> </html>
The form element can be located like this:
login_form = driver.find_element(By.ID, 'loginForm')
4.2. Locating by Name¶
Use this when you know the name attribute of an element. With this strategy,
the first element with a matching name attribute will be returned. If no
element has a matching name attribute, a NoSuchElementException will be
raised.
For instance, consider this page source:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
The username & password elements can be located like this:
username = driver.find_element(By.NAME, 'username') password = driver.find_element(By.NAME, 'password')
This will give the “Login” button as it occurs before the “Clear” button:
continue = driver.find_element(By.NAME, 'continue')
4.3. Locating by XPath¶
XPath is the language used for locating nodes in an XML document. As HTML can
be an implementation of XML (XHTML), Selenium users can leverage this powerful
language to target elements in their web applications. XPath supports the
simple methods of locating by id or name attributes and extends them by opening
up all sorts of new possibilities such as locating the third checkbox on the
page.
One of the main reasons for using XPath is when you don’t have a suitable id or
name attribute for the element you wish to locate. You can use XPath to either
locate the element in absolute terms (not advised), or relative to an element
that does have an id or name attribute. XPath locators can also be used to
specify elements via attributes other than id and name.
Absolute XPaths contain the location of all elements from the root (html) and as
a result are likely to fail with only the slightest adjustment to the
application. By finding a nearby element with an id or name attribute (ideally
a parent element) you can locate your target element based on the relationship.
This is much less likely to change and can make your tests more robust.
For instance, consider this page source:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
The form elements can be located like this:
login_form = driver.find_element(By.XPATH, "/html/body/form[1]") login_form = driver.find_element(By.XPATH, "//form[1]") login_form = driver.find_element(By.XPATH, "//form[@id='loginForm']")
- Absolute path (would break if the HTML was changed only slightly)
- First form element in the HTML
- The form element with attribute id set to loginForm
The username element can be located like this:
username = driver.find_element(By.XPATH, "//form[input/@name='username']") username = driver.find_element(By.XPATH, "//form[@id='loginForm']/input[1]") username = driver.find_element(By.XPATH, "//input[@name='username']")
- First form element with an input child element with name set to username
- First input child element of the form element with attribute id set to
loginForm - First input element with attribute name set to username
The “Clear” button element can be located like this:
clear_button = driver.find_element(By.XPATH, "//input[@name='continue'][@type='button']") clear_button = driver.find_element(By.XPATH, "//form[@id='loginForm']/input[4]")
- Input with attribute name set to continue and attribute type set to
button - Fourth input child element of the form element with attribute id set to
loginForm
These examples cover some basics, but in order to learn more, the following
references are recommended:
- W3Schools XPath Tutorial
- W3C XPath Recommendation
- XPath Tutorial
— with interactive examples.
Here is a couple of very useful Add-ons that can assist in discovering the XPath
of an element:
- xPath Finder —
Plugin to get the elements xPath. - XPath Helper —
for Google Chrome
4.4. Locating Hyperlinks by Link Text¶
Use this when you know the link text used within an anchor tag. With this
strategy, the first element with the link text matching the provided value will
be returned. If no element has a matching link text attribute, a
NoSuchElementException will be raised.
For instance, consider this page source:
<html> <body> <p>Are you sure you want to do this?</p> <a href="continue.html">Continue</a> <a href="cancel.html">Cancel</a> </body> </html>
The continue.html link can be located like this:
continue_link = driver.find_element(By.LINK_TEXT, 'Continue') continue_link = driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti')
4.5. Locating Elements by Tag Name¶
Use this when you want to locate an element by tag name. With this strategy,
the first element with the given tag name will be returned. If no element has a
matching tag name, a NoSuchElementException will be raised.
For instance, consider this page source:
<html> <body> <h1>Welcome</h1> <p>Site content goes here.</p> </body> </html>
The heading (h1) element can be located like this:
heading1 = driver.find_element(By.TAG_NAME, 'h1')
4.6. Locating Elements by Class Name¶
Use this when you want to locate an element by class name. With this strategy,
the first element with the matching class name attribute will be returned. If
no element has a matching class name attribute, a NoSuchElementException
will be raised.
For instance, consider this page source:
<html> <body> <p class="content">Site content goes here.</p> </body> </html>
The “p” element can be located like this:
content = driver.find_element(By.CLASS_NAME, 'content')
4.7. Locating Elements by CSS Selectors¶
Use this when you want to locate an element using CSS selector
syntax. With this strategy, the first element matching the given CSS selector
will be returned. If no element matches the provided CSS selector, a
NoSuchElementException will be raised.
For instance, consider this page source:
<html> <body> <p class="content">Site content goes here.</p> </body> </html>
The “p” element can be located like this:
content = driver.find_element(By.CSS_SELECTOR, 'p.content')
Sauce Labs has good documentation on CSS
selectors.