
Привет! Меня зовут Иван, я руковожу горизонталью автоматизации тестирования в Skyeng. Часть моей работы — обучать ручных тестировщиков ремеслу автоматизации. И тема с поиском локаторов, по моему опыту, самая тяжкая для изучения. Здесь куча нюансов, которые надо учитывать. Но стоит разобраться, и локаторы начинают бросаться в глаза сами. Хороший автоматизатор должен идеально уметь находить читабельные и краткие локаторы на странице. Об этом и пойдет речь ниже.
Наливаем чай-кофе и погнали!
Что такое локатор
Локатор — обычный текст, которой идентифицирует себя как элемент DOM’а страницы. Простым языком: с помощью локатора на странице можно найти элементы. В случае CSS — локатор включает в себя набор уникальных атрибутов элемента, а в случае XPath — это путь по DOM’у к элементу.
Если вы изучали CSS ранее, то в конструкции ниже p будет являться локатором элемента, также и атрибут color: red может являться его локатором. Атрибут элемента это всё, что идёт после тега. Например, в теге <p class=”element” id=”value”> атрибутами являются class и id.
p: {
color: red;
}Сразу оговорка по терминологии, локатор = селектор.
Локатор — это название селектора на русском. Иногда встречаю в интернете, что селектор относится только к CSS, но это не совсем так. XPath-локатор тоже может быть, просто означает он путь к элементу в DOM’е. Давайте похоливарим в комментах, чем же всё-таки локатор отличается от селектора 
DOM страницы — это HTML-код, написанный человеком или сгенерированный фреймворком, который преобразуется браузером в DOM. То есть набор объектов, где каждый объект — это HTML-тег.

Есть очень много видов локаторов, но чаще всего в работе применяется лишь часть из них. Их можно искать по следующим видам:
-
имя элемента
-
id
-
классы
-
кастомные атрибуты
-
родители и дети элементов
-
ссылки
-
и так далее.
Полное строение элемента
Элемент состоит из имени, то есть самого HTML-тега. Например, div, span, input, button и другие. Внутри него перечислены атрибуты, которые отвечают за все возможные свойства элемента. Например, цвет, размер, действие, которое будет происходить по клику на элемент.

У элемента может быть родитель и ребёнок. Родитель может быть один, а детей может быть несколько. Если детей несколько, то они являются соседями и каждый из них образует свою ось. 1 ребёнок = 1 ось со своими особенностями и своими вложенными элементами. А — родитель, B D E F W X Y — дети A. У каждого элемента есть свои дети, свои дальнейшие ветки, это и называется оси.

Поиск локаторов в браузере
Для поиска элементов в DOM’е страницы нужны средства разработчиков в браузере. Рассмотрим их на примере Chrome. Они же называются DevTools (F12). Нас интересует вкладка Elements, именно там находятся все элементы. Чтобы найти локатор в поле Elements, нужно нажать Ctrl+F. Внизу появится небольшое поле поиска, с ним мы будем работать всё время.
Давайте попробуем найти элемент по названию HTML-тега. Искать просто: в строке поиска вводим название тега. Скорее всего этот локатор элемента будет не уникальным и по его значению найдутся много элементов. Для тестов важно, чтобы был только один элемент для взаимодействия. Если одному локатору будут соответствовать несколько элементов, то тест или будет взаимодействовать с первым из них, или просто упадёт с ошибкой. Элементы можно искать не только с помощью тегов (p, span, div и т.д.), но и с помощью атрибутов тега. Например, color=”red” и class=”button”. Подробнее об этом чуть ниже.

Микро-задание: попробуй открыть DevTools на этой страничке (F12) и найти (Ctrl + F) количество элементов с тегом button.
P.S. поздравляю, ты уже написал свой первый локатор! Дальше — больше 
Уникальные локаторы
Где будем практиковаться? https://eu.battle.net/login/ru/ — простая и понятная форма авторизации.


Рассмотрим поиск на примере формы авторизации и регистрации. В коде страницы есть 2 поля («Почта» и «Пароль») и кнопка «Авторизация». Сравним, по каким атрибутам можно найти локатор и определим уникальные атрибуты.

Подробно разберём, как можно найти локатор поля Почта:

Разберём, как можно найти локатор поля Пароль:

Разберём, как можно найти локатор поля Авторизация:

Начнём с разбора не уникальных локаторов. Если по локатору находятся 2 и более элементов на HTML-странице, такой локатор можно назвать неуникальным. Тест при обнаружении большого количества элементов по данному локатору упадёт или возьмёт первый. Ненадежно, точно не наш бро.
Уникальный, но non-suitable локатор. Если мы в DevTools введем вышеуказанные названия, то найдется элемент. И здесь мы опускаемся до следующего уровня написания локаторов — уровня понятности, читаемости и надёжности локатора.
-
title=»Электронная почта или телефон» — считается плохим паттерном писать локаторы с русским текстом. Тем более в примере текст в title еще и длинный, это визуально громоздко. На текст завязываться можно в крайнем случае, но нужно быть готовым к тому, что тексты часто меняются, любая правка может сломать автотесты.
-
title=»Пароль» — аналогично ^
-
type=»text» — представь, ты открываешь среду разработки и видишь локатор “тип=текст”. Совсем не ясно, к какому элементу относится локатор. Со смысловой точки зрения, это неудачный локатор, потому что он не передаёт смысл локатора.
-
type=»password» — этот атрибут говорит о том, что у поля тип «password» и все символы, которые мы вводим заменяются на звёздочки/точки. При добавлении еще одного поля с type=”password” (например, поле «Подтвердите пароль») локатор сразу станет неактуальным. Стараемся думать наперёд.
Уникальные локаторы. Они найдут только один элемент, они осмысленные, иногда читабельные и краткие. Как раз уникальные атрибуты — это class, id, name и подобные. Они точно наши бро!
Небольшой итог
Хороший локатор — краткий, читабельный и осмысленный. Например, у поля «Пароль» хорошо иметь в локаторе слово password.
Возникает вопрос, почему class=»btn-block btn btn-primary submit-button btn-block» был вынесен в категорию уникальных? Такие локаторы встречаются повсеместно, и именно их мы берём за основу и приводим к красивому виду.
Поиск элементов с помощью CSS
id и class — самые важные атрибуты, с помощью которых мы будем искать бóльшую часть элементов на странице. Есть очень много тонкостей по работе с ними, постараемся рассмотреть все из них.
Кнопка «Авторизация» имеет несколько классов в одном:
-
btn-block
-
btn
-
btn-primary
-
submit-button
-
btn-block
Каждый из этих классов определяет свой визуал кнопки. Например, btn-primary определяет цвет кнопки, submit-button увеличивает её размер (это лишь догадки, основное значение знают только Blizzard). Несколько классов внутри атрибута class разделяются пробелом.
Наличие более одного класса внутри атрибута говорит о том, что он комбинированный. Бывают и комбинированные атрибуты кроме классов. Но классы необязательно будут уникальны для одного элемента. В данном случае у кнопки «Авторизация» такие атрибуты:
class="btn-block btn btn-primary submit-button btn-block"
Но если добавить туда кнопку «Регистрация», то может отличаться лишь один класс. Например, он будет выглядеть следующим образом:
class="btn-block btn btn-primary registration-button btn-block"
Сразу заметно, что отличается всего лишь один класс — submit-button сменился на registration-button. Остальные свойства могут иметь и другие кнопки.
Читабельность локатора
Допустим, мы ищем элемент по полному классу. Это хороший и действенный способ. Почти всегда элемент будет уникальным, но очень нечитабельным и громоздким, как в случае с кнопкой «Авторизация».
class с помощью CSS можно записать следующим образом:
-
.locator (точка — сокращенная запись class’а)
-
или выделяем название и значение класса в квадратные скобочки: [class=”value”]
Полный класс элемента кнопки «Авторизация» состоит из 5 классов: btn-block btn btn-primary submit-button btn-block, а выглядеть полный локатор будет так:
[class=”btn-block btn btn-primary submit-button btn-block”]
Разделение происходит с помощью пробела внутри. Для класса его сокращенной формой является точка, поэтому можно записать локатор так:
btn-block.btn.btn-primary.submit-button.btn-block
Да, стало короче, но всё равно есть смысловая перегрузка. Сокращаем дальше.
Отдельно здесь стоит добавить про поиск по подстроке. Запись [class=”локатор”] ищет только всю строку класса элемента. Если мы напишем [class=”btn-block”] или любой другой класс, то кнопка «Авторизация» не будет найдена. Но если мы запишем локатор полностью [class=”btn-block btn btn-primary submit-button btn-block”], то кнопка найдётся.
Из данной ситуации помогает найти выход символ звёздочки. Он ищет ПОДстроку в строке, то есть часть локатора может найти элемент.
Краткость локатора
Про подстроку
Можно почитать на википедии, там приведён доступный пример для общего понимания поиска по подстроке. Также поиск по подстроке можно сравнить с методом includes из JS
Локатор кнопки«Авторизация» [class=”btn-block btn btn-primary submit-button btn-block”] можно записать следующим образом:
-
[class*=”btn-block”]
-
[class*=”submit-button”]
-
[class*=”btn-block btn”]
-
[class*=”btn btn-primary”]
-
[class*=”primary submit”] (конец одного класса и начала другого, но только в том случае, если они написаны подряд, друг за другом)
-
можно даже сократить название подкласса: не длинное submit-button, а просто submit, например, [class*=”submit”]. Можно даже сократить слово submit — [class*=”sub”].
Важно понимать, это будет работать, если классы идут только последовательно. Если мы укажем [class*=”btn-block submit-button”], то локатор работать не будет, потому что между btn-block и submit-button идут несколько классов: btn и btn-primary. Но это можно обойти, разделив локатор на 2 разных. Например, 2 класса слитно — [class*=”btn-block”][class*=”submit-button”]. Это работает и часто пригождается, когда нужно уточнить, в каком именно элементе мы ищем определенный класс.
Также можно комбинировать краткую запись с помощью точки и тега элемента:
-
.submit-button = [class*=”submit-button”]
-
.btn = [class*=”btn”]
-
.btn-block = [class*=”btn-block”]
-
button[class*=”submit-button”] = button.submit-button
-
button[class*=”btn”] = button.btn
-
button[class*=”btn”][class*=“submit-button”] = button.btn.submit-button
-
button[class*=”submit”]
Краткую запись (через точку) предпочтительнее использовать, чем полную (в квадратных скобках).
Лаконичность локатора
Мы можем определить кнопку «Авторизация» по классу submit-button. Это не самый лаконичный локатор, но дословно означает действие отправки данных на сервер с формы авторизации. Но что делать, если у кнопки нет контекста? Например, классы кнопки Авторизации будут выглядеть так: [class=”btn-block btn btn-primary btn-block”]. Если нет контекста из слова submit (отправка), то можно очень быстро потеряться и сразу не ясно, к какому элементу относится этот локатор. В данном случае нам поможет название текущего элемента или его родителя.
Для наглядности рассмотрим весь блок с кнопкой «Авторизация».
Как вариант — к локатору можно добавить сам тег button. Например, button[class*=”btn”] (сократил класс для наглядности). В таком случае можно взять тег или класс родителя за основу, а именно div или [class=»control-group submit no-cancel»]. Если нужно указать родителя, то эта связь пишется через пробел. Через пробел можно обращаться на любой уровень вложенности, например, из form сразу прыгнуть к button. Полный путь будет выглядеть так: form div button.
С полученными знаниями можно расширить пул локаторов:
-
form button
-
form [type=”submit”]
-
#password-form #submit (решётка — сокращённая форма id, точка — сокращённая форма class)
-
и еще много-много локаторов, которые можно найти комбинаторикой, главное, чтобы по итогу локатор выглядел кратко и лаконично, передавал суть элемента
А как с ID
С ID работает всё точно также, только краткая запись ID — это решётка, например, <form id=”password-form”> можно записать как form#password-form, по такому же принципу, как и с классом
Поиск по кастомным атрибутам
Кастомные атрибуты тоже заслуживают упоминания. У элемента могут быть не только классы и айдишники, но и еще бесконечно множество атрибутов. В исключительных случаях можно искать элементы по этим атрибутам, но только в случае их приличного вида. Например, в случае кнопки «Авторизация» указаны несколько необычных атрибутов, которые вряд ли можно использовать за основу для её поиска:
-
data-loading-text
-
tabindex=»0″
Очень хорошей практикой на проекте является обвешивание интерактивных элементов кастомным атрибутом data-qa или data-qa-id. Например, <button id=”css-1232” data-qa=”login-button”>. Если поменяют локатор, то этот атрибут останется и тесты будут стабильными долгое время. Добавлять эти атрибуты могут фронтенд-разработчики или автоматизаторы, если имеют доступ к коду фронтенда и возможность пушить в него правки.
Локаторы можно и нужно комбинировать! Элементы, состоящие из нескольких классов, айди и других атрибутов, можно объединять в один локатор. Например, возьмем элемент формы, который находится выше кнопки «Авторизация»: form#password-form[method=”post”][class*=”username”]
Итоги поиска локаторов с помощью CSS
-
классы и id можно писать сокращенно с помощью точки и решетки
-
<button class=”login”>: .login = [class=”login”] = [class*=”log”] = button.login = button[class=”login”]
-
<button id=”size”>: #size = [id=”size”] = [id*=”ze”] = button#size = button[id=”size”]
-
всё, что не class, и не id в сокращённом виде пишем в [] (квадратных скобках), например, [name=”phone”], [data-qa-id=”regButton”]
-
если тег лежит внутри другого тега, то переходим к нему через пробел (независимо от степени вложенности), например, <span> -> <button> -> <a> = span a = button a = span button a
Поиск элементов с помощью XPath
XPath в корне отличается от CSS как идеей, так и реализацией. XPath — это полноценный язык для поиска элементов в дереве, причём неважно каком, будь это XML или XHTML. Можно использовать XPath в веб-страницах, нативной мобильной вёрстке и других инструментах.
Я изучал XPath больше месяца с нуля. Проблема была в том, что я никак не понимал принцип его работы — мы ходим от элемента к элементу, но не ясно, как это происходит, как писать красивые пути, какие преимущества у такого подхода. Неделями изучал документацию, статьи на блогах (к сожалению, тогда еще не было человекопонятных статей на Хабре) и видео в ютубе. Мне очень помогло одно видео, где автор объяснял базовые принципы XPath, после чего меня осенило и в голове сложилась картинка. Поэтому хочу поделиться с вами этой информацией, чтобы сократить время на изучение тонны материала. Изучение XPath самостоятельно полезно, но я бы с огромным удовольствием потратил полтора месяца на вещи поважнее.
Предположим, у нас есть следующая структура документа:
<div class="popup">
<div id="payment-popup">
<button name="regButton">
<span href="/doReg">Кнопка</span>
</button>
</div>
</div>XPath — это путь от элемента к элементу. Можно представить, что структура тегов — это дерево каталогов, как в любой ОС. Например, в данном случае теги можно представить в виде папок: div -> div -> button -> span. В терминале по ним можно переключаться через команду cd, а именно: cd div/div/button/span
div/div/button/span — это и есть путь к элементу с помощью XPath, только первый элемент ищут по всему дереву элементов, поэтому пишут // в начале строки. В данном случае это будет выглядеть так: //div/div/button/span. 2 слэша можно использовать не только в начале — они обозначают то, что мы ищем элемент где-то внутри. Например, //div//span — элемент будет найден, мы пропустили второй div и button.
Главная отличительная особенность XPath — возможность проходить не только от родителя к детям, но и от детей к родителям. Например, есть структура:
<div class=”popup”>
<div id=”payment-popup”>
<button name=”regButton”>
<span href=”/doReg” />
</button>
<button name=”loginButton”>
<span href=”/doLogin” />
</button>
</div>
</div>
Мы можем перейти от кнопки doLogin в кнопку doReg вот так:
//*[@href=”/doLogin”]/../..//*[@href=”/doReg”]
Чтобы перейти на уровень выше, как и терминале ОС, нужно написать 2 точки, как показано в примере. С помощью 2 точек мы поднимаемся с уровня span сначала до button, а с button до общего div.
Главный вопрос, который может возникнуть, а где это может пригодиться? Практически всюду, где есть одинаковые блоки, которые отличаются по какому-то одному признаку. Возьмем страницу RDR2 в Epic Games. На середине страницы сейчас перечислены 3 издания:

В DevTools отчётливо видно, что блоки идентичные. Отличия только в названии издания, описании и цене.

Есть задача: нажмите на кнопку «Купить сейчас» у издания Red Dead Online. Для этого надо завязаться на текст издания, подняться до первого общего элемента у названия издания и кнопки и опуститься до кнопки «Купить сейчас».
//*[contains(text(), “Red Dead Online”)]/ancestor::*[contains(@data-component, "OfferCard")]//*[contains(@data-component, "Purchase")]
Лайфхак: как найти первый общий элемент у двух элементов?
Нажимаем на любом элементе ПКМ -> Посмотреть код, открывается вкладка Elements. Наводим курсором на текущий элемент и он выделяется синим цветом. Просто тащим курсор наверх, пока визуально не найдём элемент, который объединяет 2 элемента — в нашем случае текст и кнопку «Купить сейчас».

В XPath, как и в CSS, можно искать по элементам и по атрибутам в элементе. Например:
<div class=”popup”>
<div id=”payment-popup”>
<button name=”regButton”>
<span href=”/doReg” />
</button>
<button name=”loginButton”>
<span href=”/doLogin” />
</button>
</div>
</div>Можно найти кнопку регистрации:
-
//*[@href=”/doReg”] или //span[@href=”/doReg”] -
//*[@name=”regButton”] или //button[@name=”regButton”]
Как мы можем заметить — звёздочка заменяет название элемента. Где стоит звёздочка, означает, что элемент может называться как угодно. Главное, чтобы внутри него был заданный атрибут. Если мы хотим указать конкретный элемент, то подставляем его вместо звёздочки. Например, путь //span[@href=”/doReg”] — сразу говорит нам, что в элементе span мы ищем @href=”/doReg”, но если нам не важен элемент, то тогда span заменяем на звёздочку //*[@href=”/doReg”].
Атрибуты всегда пишутся со знаком @ в начале, это тоже особенность языка.
Еще следует упомянуть переходы по смежным осям. В примере выше есть 2 разные оси — 2 button: элементы одинаковые, но отвечают за разные кнопки. Это можно сделать с помощью зарезервированных слов: following-sibling и preceding-sibling.
Например, нам нужно достать кнопку Войти, зная кнопку Регистрация: //*[@name=”regButton”]/following-sibling::*[@name=”loginButton”]. Если нужно найти кнопку Регистрации зная кнопку Войти, то делается это точно также, только ищем в осях, идущих до кнопки Регистрации: //*[@name=”loginButton”]/preceding-sibling::*[@name=”regButton”]. Переходы между осями или дереву (вверх-вниз) всегда происходит через 2 точки, если мы пишем полное название направления, например, following-sibling::, ancestor::
Не всегда есть возможность искать элементы по полному названию класса, так как оно может являться достаточно большим и нечитабельным. В CSS мы это делали с помощью символа звёздочки. Здесь звёздочку заменяет слово contains и работает точно также, как и в CSS. Например, ищем кнопку Войти: //*[contains(@name, “Login”)]. Как мы видим, contains — это что-то вроде функции в XPath. 1 параметр — атрибут, в котором ищем часть текста, 2 — сам текст.
Последней функцией, которую мы рассмотрим, будет text(). Она позволяет искать элемент по тексту, который в нём находится. Например, есть HTML-разметка:
<button>
<span>Кнопка Войти</span>
</button>
<button>
<span>Кнопка Регистрация</span>
</button>Чтобы найти текст по точному совпадению, нужно писать следующий путь: //*[text()=”Кнопка Войти”]. Но если мы захотим искать по 1 слову, то на помощь приходит комбинация со словом contains, а именно: //*[contains(text(), “Войти”)].
Коротко про «Гибкие локаторы»
Термин «гибкий локатор» применяется к поиску локаторов через CSS и с XPath. Называется он гибким, потому что независимо от текста внутри — локатор не изменится. Для примера снова возьмём страничку с игрой RDR2. На ней есть 3 издания. Сами локаторы не меняются, меняется только текст (название, описание, цена). Общий шаблон локатора будет выглядеть так: //*[contains(text(), “Название издания”)]/ancestor::*[contains(@data-component, «OfferCard»)]//*[contains(@data-component, «Purchase»)]. Текст уже можем в него передавать любой, какой захотим. Так вот именно этот локатор будет называться гибким — его тело остаётся неизменным, а меняются лишь параметры внутри него. В автоматизации мы очень часто пользуемся гибкими локаторами.
Выводы
Мы разобрали 2 основных способа поиска элементов на странице, с помощью CSS и XPath. Небольшое сравнение этих методов:
|
Плюсы CSS |
Минусы CSS |
|
— краткий — читабельный — простой для освоения и полностью граничит с изучением базового CSS — что-то вроде мифа — он работает быстрее, то есть быстрее ищет элемент на странице, но на фоне мощности современных процессоров эта разница во времени неощутима и составляет пару миллисекунд |
— может переходить только от родителя к ребёнку, но не наоборот — вверх подниматься нельзя — более ограниченный набор функций для поиска элементов, например, нельзя искать элемент по тексту, который в нём находится — CSS заточен только под веб-страницы |
|
Плюсы XPath |
Минусы XPath |
|
— полноценный язык для поиска элементов не только в вебе, но и в других средах и документах — позволяет перемещаться по дереву вниз и вверх — гибко работает с осями элементов — есть очень много функций, которые помогают в поиске локаторов, например, поиску по тексту в элементе или аналог normalize-space, который убирает пробелы у строки по бокам |
— громоздкий — нечитабельный — сложен в освоении — работает дольше, чем поиск по CSS, хоть и незначительно |
В тестах лучше использовать CSS, но это не всегда реально. Именно поэтому в таких случаях приходит на помощь XPath.
Полезные ссылки
CSS:
-
https://flukeout.github.io/ — практика в поиске локаторов.
-
https://code.tutsplus.com/ru/tutorials/the-30-css-selectors-you-must-memorize—net-16048 — полезно узнать про различные виды селекторов. Мы используем не все, но всегда бывает ситуация, когда раз в жизни придётся использовать тот или иной локатор.
-
https://appletree.or.kr/quick_reference_cards/CSS/CSS%20selectors%20cheatsheet.pdf — локаторы наглядно.
-
https://learn.javascript.ru/css-selectors — оформление в виде документации.
XPath:
-
https://topswagcode.com/xpath/ — практика в поиске локаторов.
-
https://www.w3schools.com/xml/xpath_nodes.asp — подробнее про ноды.
-
https://www.w3schools.com/xml/xpath_syntax.asp — синтаксис.
-
https://www.w3schools.com/xml/xpath_axes.asp — оси.
-
https://soltau.ru/index.php/themes/dev/item/413-kratkoe-rukovodstvo-po-xpath — более подробная информация с примерами на русском.
What’s the easiest way to find Dom elements with a css selector, without using a library?
function select( selector ) {
return [ /* some magic here please :) */ ]
};
select('body')[0] // body;
select('.foo' ) // [div,td,div,a]
select('a[rel=ajax]') // [a,a,a,a]
This question is purely academical. I’m interested in learning how this is implemented and what the ‘snags’ are. What would the expected behavior of this function be? ( return array, or return first Dom element, etc ).
asked May 20, 2009 at 8:40
![]()
StefanStefan
9,2187 gold badges38 silver badges46 bronze badges
1
These days, doing this kind of stuff without a library is madness. However, I assume you want to learn how this stuff works. I would suggest you look into the source of jQuery or one of the other javascript libraries.
With that in mind, the selector function has to include a lot of if/else/else if or switch case statements in order to handle all the different selectors. Example:
function select( selector ) {
if(selector.indexOf('.') > 0) //this might be a css class
return document.getElementsByClassName(selector);
else if(selector.indexOf('#') > 0) // this might be an id
return document.getElementById(selector);
else //this might be a tag name
return document.getElementsByTagName(selector);
//this is not taking all the different cases into account, but you get the idea.
};
answered May 20, 2009 at 8:45
![]()
Jose BasilioJose Basilio
50.6k13 gold badges120 silver badges117 bronze badges
2
Creating a selector engine is no easy task. I would suggest learning from what already exists:
- Sizzle (Created by Resig, used in jQuery)
- Peppy (Created by James Donaghue)
- Sly (Created by Harald Kirschner)
answered May 20, 2009 at 8:50
![]()
JamesJames
109k31 gold badges162 silver badges175 bronze badges
1
Here is a nice snippet i’ve used some times. Its really small and neat. It has support for the all common css selectors.
http://www.openjs.com/scripts/dom/css_selector/
answered May 20, 2009 at 8:51
![]()
alexnalexn
57.4k14 gold badges111 silver badges145 bronze badges
No there’s no built in way. Essentially, if you decide to go without jQuery, you’ll be replicating a buggy version of it in your code.
answered May 20, 2009 at 8:42
![]()
Mehrdad AfshariMehrdad Afshari
413k90 gold badges850 silver badges788 bronze badges
2
Как вы, возможно, уже поняли, чтобы управлять элементами страницы, нам нужно сначала найти их. Selenium использует так называемые локаторы, чтобы находить элементы на веб-странице.
В Selenium есть 8 методов которые помогут в поиске HTML элементов:
| Цель поиска Используемый метод |
Пример | ||
| Поиск по ID find_element_by_id(«user») |
|
||
| Поиск по имени find_element_by_name(«username») |
|
||
| Поиск по тексту ссылки find_element_by_link_text(«Login») |
|
||
| Поиск по частичному тексту ссылки find_element_by_partial_link_text(«Next») |
|
||
| Поиск используя XPath find_element_by_xpath(‘//div[@id=»login»]/input’) |
|
||
| Поиск по названию тэга find_element_by_tag_name(«body») |
|||
| Поиск по классу элемента find_element_by_class_name(«table») |
|
||
| Поиск по CSS селектору find_element_by_css_selector(‘#login > input[type=»text»]’) |
|
Вы можете использовать любой из них, чтобы сузить поиск элемента, который вам нужен.
Запуск браузера
Тестирование веб-сайтов начинается с браузера. В приведенном ниже тестовом скрипте запускается окно браузера Firefox, и осуществляется переход на сайт.
|
from selenium import webdriver driver = webdriver.Firefox() driver.get(«http://testwisely.com/demo») |
Используйте webdriver.Chrome и webdriver.Ie() для тестирования в Chrome и IE соответственно. Новичкам рекомендуется закрыть окно браузера в конце тестового примера.
Поиск элемента по ID
Использование идентификаторов — самый простой и безопасный способ поиска элемента в HTML. Если страница соответствует W3C HTML, идентификаторы должны быть уникальными и идентифицироваться в веб-элементах управления. По сравнению с текстами тестовые сценарии, использующие идентификаторы, менее склонны к изменениям приложений (например, разработчики могут принять решение об изменении метки, но с меньшей вероятностью изменить идентификатор).
|
driver.find_element_by_id(«submit_btn»).click() # Клик по кнопке driver.find_element_by_id(«cancel_link»).click() # Клик по ссылке driver.find_element_by_id(«username»).send_keys(«agileway») # Ввод символов driver.find_element_by_id(«alert_div»).text # Получаем текст |
Поиск элемента по имени
Атрибут имени используются в элементах управления формой, такой как текстовые поля и переключатели (radio кнопки). Значения имени передаются на сервер при отправке формы. С точки зрения вероятности будущих изменений, атрибут name, второй по отношению к ID.
|
driver.find_element_by_name(«comment»).send_keys(«Selenium Cool») |
Поиск элемента по тексту ссылки
Только для гиперссылок. Использование текста ссылки — это, пожалуй, самый прямой способ щелкнуть ссылку, так как это то, что мы видим на странице.
|
driver.find_element_by_link_text(«Cancel»).click() |
HTML для которого будет работать
|
<a href=«/cancel»>Cancel</a> |
Поиск элемента по частичному тексту ссылки
Selenium позволяет идентифицировать элемент управления гиперссылкой с частичным текстом. Это может быть полезно, если текст генерируется динамически. Другими словами, текст на одной веб-странице может отличаться при следующем посещении. Мы могли бы использовать общий текст, общий для этих динамически создаваемых текстов ссылок, для их идентификации.
|
# Полный текст ссылки «Cancel Me» driver.find_element_by_partial_link_text(«ance»).click() |
HTML для которого будет работать
|
<a href=«/cancel»>Cancel me</a> |
Поиск элемента по XPath
XPath, XML Path Language, является языком запросов для выбора узлов из XML документа. Когда браузер отображает веб-страницу, он анализирует его в дереве DOM. XPath может использоваться для ссылки на определенный узел в дереве DOM. Если это звучит слишком сложно для вас, не волнуйтесь, просто помните, что XPath — это самый мощный способ найти определенный веб-элемент.
|
# Клик по флажку в контейнере с ID div2 driver.find_element_by_xpath(«//*[@id=’div2′]/input[@type=’checkbox’]»).click() |
HTML для которого будет работать
|
<form> <div id=«div2»> <input value=«rules» type=«checkbox»> </div> </form> |
Некоторые тестеры чувствуют себя «запуганными» сложностью XPath. Тем не менее, на практике существует только ограниченная область для использования XPath.
Избегайте XPath из Developer Tool
Избегайте использования скопированного XPath из инструмента Developer Tool.
Инструмент разработчика браузера (щелкните правой кнопкой мыши, чтобы выбрать «Проверить элемент», чтобы увидеть) очень полезен для определения веб-элемента на веб-странице. Вы можете получить XPath веб-элемента там, как показано ниже (в Chrome):
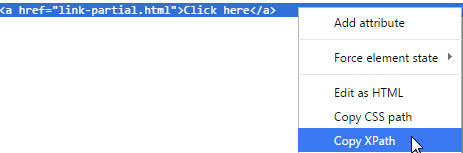
Скопированный XPath для второй ссылки «Нажмите здесь» в примере:
|
//*[@id=«container»]/div[3]/div[2]/a |
Этот метод работает. Тем не менее, этот подход не рекомендуется для постоянного применения, поскольку тестовый сценарий является довольно хрупким и изменчивым.
Попытайтесь использовать выражения XPath, которое менее уязвимо для структурных изменений вокруг веб-элемента.
Поиск элемента по имени тега
В HTML есть ограниченный набор имен тегов. Другими словами, многие элементы используют одни и те же имена тегов на веб-странице. Обычно мы не используем локатор tag_name для поиска элемента. Мы часто используем его с другими элементами в цепочке локаторах. Однако есть исключение.
|
driver.find_element_by_tag_name(«body»).text |
Вышеприведенная тестовая инструкция возвращает текстовое содержимое веб-страницы из тега body.
Поиск элемента по имени класса
Атрибут class элемента HTML используется для стилизации. Он также может использоваться для идентификации элементов. Как правило, атрибут класса элемента HTML имеет несколько значений, как показано ниже.
|
<a href=«back.html» class=«btn btn-default»>Cancel</a> <input type=«submit» class=«btn btn-deault btn-primary»> Submit </input> |
Вы можете использовать любой из них.
|
driver.find_element_by_class_name(«btn-primary»).click() # Клик по кнопки driver.find_element_by_class_name(«btn»).click() # Клик по ссылке # # |
Метод class_name удобен для тестирования библиотек JavaScript / CSS (таких как TinyMCE), которые обычно используют набор определенных имен классов.
|
driver.find_element_by_id(«client_notes»).click() time.sleep(0.5) driver.find_element_by_class_name(«editable-textarea»).send_keys(«inline notes») time.sleep(0.5) driver.find_element_by_class_name(«editable-submit»).click() |
Поиск элемента с помощью селектора CSS
Вы также можете использовать CSS селектор для поиска веб-элемента.
|
driver.find_element_by_css_selector(«#div2 > input[type=’checkbox’]»).click() |
Однако использование селектора CSS, как правило, более подвержено структурным изменениям веб-страницы.
Используем find_elements для поиска дочерних элементов
Для страницы, содержащей более одного элемента с такими же атрибутами, как приведенный ниже, мы могли бы использовать XPath селектор.
|
<div id=«div1»> <input type=«checkbox» name=«same» value=«on»> Same checkbox in Div 1 </div> <div id=«div2»> <input type=«checkbox» name=«same» value=«on»> Same checkbox in Div 2 </div> |
Есть еще один способ: цепочка из find_element чтобы найти дочерний элемент.
|
driver.find_element_by_id(«div2»).find_element_by_name(«same»).click() |
Поиск нескольких элементов
Как следует из названия, find_elements возвращает список найденных элементов. Его синтаксис точно такой же, как find_element, то есть он может использовать любой из 8 локаторов.
Пример HTML кода
|
<div id=«container»> <input type=«checkbox» name=«agree» value=«yes»> Yes <input type=«checkbox» name=«agree» value=«no»> No </div> |
Выполним клик по второму флажку.
|
checkbox_elems = driver.find_elements_by_xpath(«//div[@id=’container’]//input[@type=’checkbox’]») print(len(checkbox_elems)) # Результат: 2 checkbox_elems[1].click() |
Иногда find_element вылетает из-за нескольких совпадающих элементов на странице, о которых вы не знали. Метод find_elements пригодится, чтобы найти их.
dom
Введение
Когда-то давным давно, когда js был совсем молод и еще ходили Netscape-динозавры, то все думали,
что мощь-js заканчивается следующими сценариями:
- создание мигающих ссылок;
- скрытие/расскрытие элементов;
- …
Метеориты падали и падали, многие динозавры вымерли, и JS начал изменяться под потребности работадателей и
других ‘зверей’:
- Исполнения кода не только в браузере;
- Запуск js на сервере;
- Firefox Os;
- Phonegap;
- …
Но все ‘мутации’, которым подвергся js, не изменили его главную цель, а именно, создание динамических страниц
в браузере. Конечно со времен динозавров много воды утекло и потребности изменились:
- Календари;
- Частичное заполнение форм;
- Саггесты(подсказки при вводе);
- Динамическая отрисовка страниц;
- И многое другое…
В этой лекции мы поговорим о том, что делает фронтенд разработчика — фронтенд разработчиком.
P.S. Все примеры, который написаны в данной главе работают в относительно современных браузерах.
Так как лекции готовятся с расчетом на смерть ie10 <=
Запуск кода в браузере
Запустить js в браузере можно множеством способов:
- Через консоль разработки
- Через сервисы-песочницы
- Через html документ
Давай-те рассмотрим каждый из вариантов:
Запуск кода через консоль
- Запускаем Яндекс.Браузер
- Идем в Settings
- Идем в Advanced
- Идем в More Tools
- Идем в Developer Tools
- Затем идем в таб Console
- Пишем в строке код 2+2
- Жмем enter // 4
P.S. Для запуска Developer Tools есть хоткей
Запуск кода через песочницу
- идем на сайт jsfiddle.net
- во вкладке js пишем: console.log(2+2)
- жмем кнопку run
- идем в Developer tools
Запуск кода через html документ
- Создадим простую html-страницу
<html> <head></head> <body> <h1>Hello world!</h1> </boby> </html>
- Вставляем тэг-script
<html> <head></head> <body> <h1>Hello world!</h1> <script> console.log(2+2); </script> </boby> </html>
- Открываем ваш документ в браузере
- открываем Developer Tools
DOM
Что такое DOM
Что такое DOM для разработчика
DOM — это API, которое предоставляет браузер js-интерпретатору для взаимодействия с html-документов:
- чтение данных из документа;
- изменение документа;
- реакция на действия пользователя;
Очень важно понимать, что DOM — это API, которое удоволетворяет стандарту, то есть
каждый браузер старается реализовать стандарт, но бывает возникают некоторые ‘проблемы’.
Стандарт можно почитать здесь: http://www.w3.org/DOM/
Что такое DOM для интерпретатора
<html> <body> <form> <input type='text' placeholder='Имя'/> <input type='text' placeholder='Фамилия'/> <button type='submit'>Отправить</button> </form> </body> </html>
DOM — это Document Object Model, то есть браузер предоставляет интерпретатору
не html страницу ввиде строки, а некоторый object, который связан с документом,
отображаемым в браузере. То есть при изменении модели меняется документ, а при
изменении документа меняется модель.
Грубо говоря модель — это граф, который состоит из узлов(Node).
Что такое узел?
Node — это, объект со следующими полями:
- тип узла;
- набор атрибутов;
- ссылка на левого/правого соседа;
- ссылка на родительский узел;
- ссылка на массив ‘детей’;
Каждый узел имеет тип. Типов очень много, но не все из них одинакого полезные,
поэтому укажу только важные:
- ELEMENT_NODE=1 — элемент;
- TEXT_NODE=3 — текст;
- COMMENT_NODE=8 — комментарий
- DOCUMENT_NODE=9 — документ(ссылка на тэг-html)
- DOCUMENT_TYPE_NODE=10 — DOCTYPE
- DOCUMENT_FRAGMENT_NODE=11 — фрагмент
Из списка типов элементов можно понять следующее:
- DOM сохраняет информацию о тексте;
- DOM сохраняет информацию о комментарии;
- DOM содержит особый элемент DOCUMENT_NODE, то есть на корень графа;
Пока оставим за сценой, что такое DOCUMENT_FRAGMENT_NODE, но в конце лекции мы вернемся к нему.
DOCUMENT_NODE — в документе ровно один. Для получение ссылки
на DOCUMENT_NODE нужно обратиться к переменную document.
document.nodeType === document.DOCUMENT_NODE;
Давай-те вернемся к нашему основному примеру:
<html> <body> <form> <input type='text' placeholder='Имя'/> <input type='text' placeholder='Фамилия'/> <button type='submit'>Отправить</button> </form> </body> </html>
Сколько узлов будет в DOM?
- 6 — элементарных узлов;
- 1 — элемент текста;
Но не все так просто мы забыли посчитать пробельные символы между элементами:
- 6 — элементарных узлов;
- 9 — текстовых узлов;
То есть соседний элемент у ‘Фамилия’ — не ‘Имя’, а некоторый текстовый элемент.
Поэтому многие разработчики ‘минифицируют’ свой html перед отправкой его клиенту,
удаляя все лишние пробелы и переводы строк.
Как искать что-то по DOM
<html> <body> <form> <input type='text' placeholder='Имя'/> <input type='text' placeholder='Фамилия'/> <button type='submit'>Отправить</button> </form> </body> </html>
Прежде чем перейти к чему-то сложному, нужно научиться находить какие-то узлы.
Поставим для себя следующие задачи:
- Найти форму
- Найти текстовые поля
Поиск по id
Давай-те разметим наш документ id-ми:
<html> <body> <form id='form'> <input id='name' type='text' placeholder='Имя'/> <input id='surname' type='text' placeholder='Фамилия'/> <button id='submit' type='submit'>Отправить</button> </form> </body> </html>
Для поиска по id нужно воспользоваться методом getElementById, который есть только у
document.
var form = document.getElementById('form'); var name = document.getElementById('name');
- Подходит для поиска уникальных элементов;
- Очень быстрый;
- Поведение не гарантированно при наличии дупликатов;
Поиск по тэгам
Возьмем наш html.
<html> <body> <form> <input type='text' placeholder='Имя'/> <input type='text' placeholder='Фамилия'/> <button type='submit'>Отправить</button> </form> </body> </html>
Для поиска по тэгу необходимо воспользоваться методом getElementsByTagName.
var forms = document.getElementsByTagName('form'); var input = document.getElementByTagName('input');
Метод возвращает не массив элементов, а некоторый array-like объект NodeList.
NodeList — это живая-коллекция, то есть она меняется при изменении DOM
Из-за своей особенности(живучести), NodeList очень сильно не любят =>
от него очень часто избавляются по средством превращения array-like объекта в массив:
var inputs = document.getElementByTagName('input'); inputs = [].slice.call(inputs);
Но если вы готовы:
- Помнить, что коллекция может неожиданно измениться
- Кэш коллекции сбрасывается при изменении DOM
- Вы не сможете пользоваться методами массива
Метод getElementsByTagName есть не только у document, но и у всех других элементов,
если вы вызываете этот метод не у document, то метод ищет в контексте элемента.
- вы можете найти все тэги за один запрос;
- можно искать в контексте определенного элемента;
- редко нужно искать по тэгам, так как такой код сложно поддерживать
Поиск по классу
Возьмем наш html и добавим все элементам классы.
<html> <body> <form class='b-form'> <input class='b-form__name' type='text' placeholder='Имя'/> <input class='b-form__surname' type='text' placeholder='Фамилия'/> <button class='b-form__submmit' type='submit'>Отправить</button> </form> </body> </html>
Для поиска элементов по классам можно воспользоваться методом
getElementsByClassName, который есть так же у всех узлов.
var form = document.getElementsByClassName('b-form')[0]; var name = form.getElementsByClassName('form__name')[0];
- Можно искать сразу много элементов удоволетворяющих одному css селектору;
- Можно гибко размечать нужные элементы;
- Метод не такой быстрый, как getElementById, но не критично.
Поиск элемента по css-селектору:
Для поиска по DOM интерпретатор предоставляет два очень удобных метода:
- querySelector — поиск первого элемента по css-селектору
- querySelectorAll — поиск всех элементов удоволетворяющих css-селектору
var form = document.querySelector('.b-form'); var items = form.querySelectorAll('input');
- метод очень удобный
- метод помедленне всех остальных, но не критично
Мы рекомендуем вам пользоваться им.
Как искать что-то рядом
Поиск родительского элемента
Для поиска родительского элемента нужно воспользоваться свойствами:
- parentNode
- parentElement
parentNode — ищет родительский Node узел произвольного типа, а parentElement
ищет родительский узел типа отличного от комментарий, текст или DOCTYPE.
Лучше использовать всегда parentElement, или обфуцировать свой html и использовать
parentNode.
var formsName = document.querySelector('.b-form__name'); var form = formsName.parentElement;
Поиск определенного родительского элемента
Метод closest, который есть у всех элементов, позволяет найти ближайшего родителя
или самого себя, удоволетворяющего css-селектору.
Если нет отца/самого_себя удоволетворяющего условию, то вернется null
<div class='b-page'> <div class='controller'></div> </div> <div class='b-page'> <div class='another-controller'></div> </div>
var controller = document.querySelector('.controller'); var page = controller.closest('.b-page');
Поиск соседей
Для поиска соседей существует 4ре свойства:
- nextSibling
- nextElementSibling
- previousSibling
- previousElementSibling
next — ищет правого соседа, а previous — левого.
var formsName = document.querySelector('.b-form__name'); var formsSurName = formsName.nextSibling; formsName === formsSurName.previousSibling;
Поиск детей
Для поиска детей есть следующие свойства:
- firstChild — возвращает ссылку на первого ребенка
- firstElementChild
- lastChild — возвращает ссылку на последнего ребенка
- lastElementChild
- childNodes — возвращает live-array со списком детей
- children
var form = document.querySelector('.b-form__name'); var name = form.firsElementChild; var submit = form.lastElemenChild;
Matches
Метод, который есть у всех элементов, проверяет что dom-element подходит под
css-селектор.
<div class='b-page'> <div class='controller current'></div> </div> <div class='b-page'> <div class='another-controller'></div> </div>
var controller = document.querySelector('.controller'); controller.matches('.controller.current')
Работа с атрибутами
атрибуты нужны для двух вещей:
- для настройки нативной работы некоторых html элементов(таких как ссылки)
- для передачи данных на клиент и работы с ними
Чтение из атрибутов
<html> <body> <form class='b-form'> <input class='b-form__name' type='text' placeholder='Имя'/> <input class='b-form__surname' type='text' placeholder='Фамилия'/> <button class='b-form__submmit' type='submit'>Отправить</button> </form> </body> </html>
Для чтения из атрибутов нужно воспользоваться методом getAttribute()
var name = document.querySelector('.b-form__name'); name.getAttribute('placeholder');
Изменение атрибутов
Для чтения из атрибутов нужно воспользоваться методом setAttribute()
var name = document.querySelector('.b-form__name'); name.setAttribute('placeholder', 'Имя вашего соседа');
Для удаления атрибутов
Для чтения из атрибутов нужно воспользоваться методом removeAttribute()
var name = document.querySelector('.b-form__name'); name.removeAttribute('placeholder');
свойства vs атрибуты
Многие атрибуты отражены в свойствах Node, например:
var name = document.querySelector('.b-form__name'); name.placeholder; name.className; name.id;
НО:
- Не у всех атрибутов совпадает имя со свойством. Например, class и className
- значение, находящиеся в атрибуте, может не совпадать со свойством
- при изменении атрибута/свойства синхронизация не всегда гарантирована
важные cвойства и атрибуты
- id —
Идентификатор объекта, который используется для поиска уникальных элементов. - className —
В js ‘class’ зарезервированное имя, поэтому разработчики стандарта
решили использовать имя className
style —
Это свойство используется для задания стилей конкретным элементам.
Обычно используется для динамического изменения: width, height, left, right…
Если у вас есть какой-то конечный(разумный) набор состояний у html элемента, то лучше
менять класс, а style использовать только в крайнем случаи.
4.
и другие
Пользовательские атрибуты
Веб-стандарты выделелили под бизнес-лапшу namespace атрибутов.
Все атрибуты с префиксом ‘data-‘ считаются пользовательскими => веб-стандарты
никогда не выпустят атрибут, который начинается с ‘data-‘ => их можно безопасно использовать
для своих нужд.
<div class='page' data-server-time='01/09/2007'> </div>
var page = document.querySearch('page'); page.getAttribute('data-search-time');
Более того, веб-стандарты создали для нас специальное свойство
dataset, которое содержит все пользовательские атрибуты.
Если бы пользовательские атрибуты в словаре dataset именовались так же
как в html-разметке, то тогда ими было бы не удобно пользоваться:
var domElement = document.querySelector('.element'); domElement.dataset['data-track-id'];
Поэтому разработчики стандарта решили нам упростить жизнь, и создали
отображение html-атрибутов в js-свойства и обратно.
Отображение html-атрибута в js-свойство:
- Берем имя атрибута
- Откусываем префикс ‘data-‘
- Преобразовываем к верхнему регистру символы следующие за ‘-‘
- Удаляем символы ‘-‘
Отображение js-свойства в html
- Берем имя свойства
- Ищем все символы в верхнем регистре (*с 1ой позиции)
- Вставляем перед ним ‘-‘
- Опускаем строку в нижний регистр и прибавляем префикс ‘data-
<div class="track-list"> <div class="track-list__item" data-duration="2m30s">...</div> </div>
var trackList = document.querySelector('.track-list'); var tracks = [].slice.apply(trackList.querySelectorAll('.trackList__item')); tracks.forEach(function (track) { console.log(track.dataset.duration); });
Между data-атрибутами и dataset существует ‘связь’, то есть при
изменении атрибута меняется свойство, а при изменении свойства изменяется
атрибут.
var item = document.querySelector('.track-list__item'); item.dataset.url = 'https://music.yandex.ru/album/2754/track/21168' item.getAttribute('data-url') === item.dataset.url; item.setAttribute('data-artist') = 'Marilyn Manson' item.getAttribute('data-artist') === item.dataset.artist;
Изменение class
При разработке интерфейсов многие компоненты имеют визуальные состояния:
- Модальное окно открыто/закрыто
- Элемент когда-то нажимали или нет
- Любимый трэк пользователя или нет
Для изменение визуального состояния страницы можно поступать следующими способами:
- Отправить на другую страницу с измененным отображением(старая школа)
- Удалить часть элементов из html
- Изменить style у нужных элементов
- Изменить class
Способы 1-3 хороши, но давай-те поговорим о 4.
Изменение атрибута
class — это тоже атрибут, для его изменения вы можете изменить этот атрибут:
var track = document.querySelector('.track'); track.setAttribute('class', 'track track_lovely_yes');
Тут нужно обратить внимание, что при изменении class через атрибут вы работаете
со строкой => вам все операции по работе с классами нужно писать самим:
- удаление класса
- замена класса
- добавление класса
В качестве домашнего упражнения можете написать мальнькие функции, которые это делают.
Изменение свойства
Так же менять класс можно через свойство className
var track = document.querySelector('.track'); track.className = 'track track_lovely_yes';
Тут такая же ситуация, как и с setAttribute.
Работа со свойством classList
После такой работы с классами кажется, что веб очень-очень странный, но
функции для изменения класса пишутся довольно легко.
Шли годы и разработчики стандарта решили уделить время созданию более удобному
интерфейсу для работы с классами, так как пользовательский сценарий по
изменению класса довольно частый.
classList — это свойство, которое есть у всех dom-element.
Для добавления нового класса у элемента нужно воспользоваться методом add:
var track = document.querySelector('.track'); track.classList.add('track_lovely_yes'); track.className;
Для удаления класса из элемента нужно воспользоваться методом remove:
var track = document.querySelector('.track'); track.classList.remove('track_lovely_yes'); track.className;
Для замены класса из элемента нужно воспользоваться методом toggle:
var track = document.querySelector('.track'); track.classList.toggle('hidden', 'shown'); track.className;
Для проверки на наличия класса нужно воспользоваться методом contain:
var track = document.querySelector('.track'); track.classList.contain('track');
Изменение DOM
Когда-то давным давно чтобы изменить страницу нужно было перейти по url
с измененной страницей.
Но темные времена прошли и веб стал очень динамичным. При работе с сайтом dom частенько меняется:
- открытие модальных окон
- создание таблиц
- бесконечные ленты
- обновление страниц без перезагрузки данных
Поэтому очень важно уметь менять dom.
Создание новых dom-элементов.
У объекта страницы есть метод createElement, который принимает название tag нового элемента и создает новый element с вашим тэгом.
var track = document.createElement('div'); track.className = 'track'
Когда вы создаете новый элемент, то он создается в «вакууме» и нигде не отображается.
Чтобы он стал виден на странице его нужно добавить к одному из элементу, который уже отображен на странице.
Создание текста
Для создание текста нужно воспользоваться методом createTextNode
var text = document.createTextNode('Ваша любимая песня');
Добавление элемента
Мало создать элемент, но нужно его еще добавить к существующему dom, иначе
от него мало толку.
Для этого существует несколько способоов.
Способ первый
Находим какой-то элемент и добавляем справа к его детям новый элемент.
var track = document.createElement('div'); var label = document.createElement('div'); track.appendChild(label);
Способ второй
Находим элемент и вставляем перед ним.
var track = document.createElement('div'); var label = document.createElement('div') var duration = document.createElement('div') track.appendChild(duration); track.insertBefore(label, duration);
Способ третий — заменить существующий элемент
Находим старый элемент, заменяем на новый
var track = document.createElement('div'); var label = document.createElement('div'); track.appendChild(track); // какой-то код track.replaceChild(document.createTextNode('Ваша любимая песня'), label);
Способ пять
Все способы до этого кажутся очень кропотливыми и если нам предстоит задача
по json нарисовать страничку на клиенте, то такая задача кажется непосильной.
Поэтому есть свойство innerHTML, которое позволяет создавать новые элементы проще.
Это свойство позволяет получить html детей в виде строки.
var html = document.innerHTML;
Так же в свойство innerHTML можно присваивать новый html:
var track = document.createElement('div'); track.innerHTML = "<div class='label'>Marilyn Manson</div><div class='star'>5</div>"
Но innerHTML опасное свойство, так как это свойство не экранирует html, что очень даже логично,
но это является уязвимостью. Например, XSS.
Способ шесть
DOM элементы содержат в себе некоторый аналог innerHTML, а именно, innerText.
innerText — это свойство, которое позволяет заменить все содержимое элемента на заэкранированный текст,
то есть если вы вставить некий html-код, то вы на странице увидете код, а не html-элементы.
var track = document.createElement('div'); track.innerText = 'Пользовательский ввод';
Способ семь
Все предыдущие способы по генерации нового html содержимого кажутся ‘неприятными’.
И я с вами полностью согласен. Поэтому умные js разработчики написали кучу шаблонизаторов,
которые позволяют создавать html ввиде строки значительно приятнее, а затем
вы можете вставить этот html 5 способом.
https://garann.github.io/template-chooser/
Маленькое домашнее задание придумать свой шаблонизатор! Больше шаблонизаторов!
Удаление элементов
Для удаления html элементов надо воспользоваться функцией removeChild
var track = document.querySelector('.track'); var label = track.querySelector('.label'); track.removeChild(label);
Добавление нескольких элементов
Бывает, нам нужно добавить не одного ребенка, а сразу N
Способ 1
Берем метод appendChild и цикл for
var track = document.querySelector('.track'); for(var i = 0; i < 10; i++) { var label = document.createElement('div'); track.appendChild(label) }
Но важно помнить, что каждый раз когда вы изменяете dom у вас запускаются
внутренние механихмы браузера по обновлению страницы. Следовательно, есть
правило хорошего тона: ‘Трогать дом можно, но чуть-чуть’;
Второй способ
Создаем какой-то dom-элемент, вставляем в него новые элементы и, вставляем в dom.
var track = document.querySelector('.track'); var container = document.createElement('div'); for(var i = 0; i < 10; i++) { var label = document.createElement('div'); container.appendChild(label); } track.appendChild(container);
Этот способ хорош с точки зрения вставки пачки элементов в DOM, но
у вас создается лишний элемент, а мусор в доме держать плохо.
Третий способ
Для решение этой проблемы есть специальный тип Node — DOCUMENT_FRAGMENT.
DocumentFragment — растворяется в DOM при присоединении его к отображаемым элементамю.
Для создание DocumentFragment нам нужно воспользоваться методом createDocumentFragment у document
var track = document.querySelector('.track'); var container = document.createDocumentElement(); for(var i = 0; i < 10; i++) { var label = document.createElement('div'); container.appendChild(label); } track.appendChild(container);
События
Когда-то давным давно люди думали, что html-страницы нужны только для
публикации научных статей, но время шло и людям захотелось не только
смотреть на текст + картинки, но и как-то взаимодействовать со страницей.
Для этого браузер оснастили механизмом событий, а именно, способностью
сообщать клиентскому коду, что на странице что-то произошло. Например:
- пользователь тыкнул на кнопку
- страница загрузилась
- пользователь начал скролить и так далее.
Сам механизм события довольно сложный, поэтому мы о нем поговорим позже.
Как подписаться на событие
Как обычно в js существует несколько способов
Способ первый
Подписать на событие можно с помощью html-атрибута. Для всех основных
событий имя атрибута: on + имя событие(onclick, onblur, …) .Обработчик события
записываем в виде строки в разметку или записываем имя глобальной функции
<button onclick='onClickByButton()'>First</button> <button onclick='(function(){alert(2);})()'>Second</button>
function onClickByButton() { alert(1); }
- Можно добавить только один обработчик;
- Смешиваем отображение с реализацией;
- Глобальные функции;
- Самый простой вариант;
Способ второй
В js у всех dom-element есть свойства on + имя событие. Чтобы подписаться на
событие через js нужно присвоить функцию обработчик в атрибут.
Чтобы отписаться от события нужно присвоить в атрибут null.
var button = document.querySelector('button'); button.onclick = function () { console.log('Click!!!'); }
- Можно добавить только один обработчик;
- Самый простой вариант;
способ третий
Разработчики веб стандарта предлагают пользоваться методом addEventListener, который есть у всех dom-element.
Метод принимает три аргумента:
- eventName имя событие
- listener — ваш обработчик
- useCapture — стадия активации обработчика, о которой мы поговорим позже.
var button = document.querySelector('button'); var callback = function (event) { alert('Click') } button.addEventListener('click', callback, false);
Объект event
Обработчик событий принимает объект event, который в себе содержит всю информацию о произошедшем событии.
- target — на каком элементе сработало событие
- currentTarget — на каком элементе в данный момент обрабатывается событие
- type — название события
- и другие свойства, которые специфичны для различных событий
Отписка от событий
У метода addEventListener есть напарник removeEventListener(), который имеет такую же сигнатуру.
var button = document.querySelector('button'); var callback = function () { alert('Click') }; button.addEventListener('click', callback, false); button.removeEventListener('click', callback, false);
Важно обратить внимание, что при отписке от события нужно передать туже функцию.
Следующий код не будет работать:
var button = document.querySelector('button'); button.addEventListener('click', function () { alert('Click') }, false); button.removeEventListener('click', function () { alert('Click') }, false);
Зачем может понадобиться отписываться:
- при изменении состояния приложения(например, контрол заблокирован)
Механизм работы обработки событий
Вот и настал момент, когда мы примерно представляем интерфейс и мы можем поговорить, о том как устроен механизм обработки событий.
Когда событие возникает на dom елементе, то события вовзникает не только
на нем но и на всех родителях причем. Но обо все по порядку.
Механизм:
- Кто-то создал событие (например, тыкнул мышкой по кнопке)
- Берем спискок родителей
- Начинаем стадию захвата
- Бежим в цикле по родителям начиная с самого дальнего
-
- Вызываем обработчики, которые подписаны на стадию захвата
- Начинаем стадию цели
- Вызываем все обработчики, которые подписаны не важно на какую стадию
- Начинаем стадию всплытия
- Бежим в цикле по родителям начиная с самого ближнего
-
- Вызываем обработчики, которые подписаны на стадию всплытия
Что мы узнали из механизма:
- addEventListener — последним параметром принимает стадию захвата/всплытие
- Список элементов на которых будут вызваны обработчики фиксируется при возникновении события
- Событие на стадии захвата происходят чуть быстрее(но по историческим причинам все используют стадию всплытия)
- На цели обработчики вызываются в произвольном порядке.
10 — пунктов в алгоритме очень тяжело поэтому давайте рассмотрим пример
Пример с квадратами:
http://jsfiddle.net/851kwgnv/1/
Так давай-те тыкнем по ‘красному квадрату’:
- target=red
- parents = [html, body, container]
- Вызываем обработчики захвата на html -> body -> container
- Вызываем обработчики цели на red
- Вызываем обработчики стадии всплытия container -> body -> html
Затем давай-те тыкнем по ‘синему квадрату’:
- target=blue
- parents = [html, body, container, red]
- Вызываем обработчики захвата на html -> body -> container->red
- Вызываем все обработчики на blue
- Вызываем обработчики стадии всплытия red -> container -> body -> html
Затем давай-те тыкнем по ‘зеленому квадрату’:
- target=green
- parents = [html, body, container, red, blue]
- Вызываем обработчики захвата на html -> body -> container->red-> blue
- Вызываем все обработчики на blue
- Вызываем обработчики стадии всплытия blue -> red -> container -> body -> html
Делегирование событий
Механизм событий позволяет делегировать обработку событий родителю. Для этого
нам нужно сделать следующее:
- Найти родителя;
- подписаться на нужное событие в родителе на стадию всплытия;
- в обработчике отсеять не нужные элементы;
Как будем отсеивать. Все обработчики события вызывают с параметром event.
Параметр event — это объект в котором есть куча полезных вещей:
- currentTarget — dom-elem на котором вызван обработчик (совпадает с this)
- target — элемент, по которому реально тыкнули
- и другие полезные параметры
Тогда делегирование событий может быть реализованно как-то так:
<form> <button data-number=1>Первый</button> <button data-number=2>Второй</button> <button data-number=3>Третий</button> </form>
var button = document.querySelector('form'); button.addEventListener('click', function (event) { if (event.target.tagName !== 'BUTTON') { return; } console.log(event.target.dataset.number); }, false);
Но возникаем проблема, когда в элементе с которого мы хотим делигировать событие
есть вложенные элементы
<form> <button data-number=1><span>Первый</span></button> <button data-number=2><span>Второй</span></button> <button data-number=3><span>Третий</span></button> </form>
var button = document.querySelector('form'); button.addEventListener('click', function (event) { if (event.target.tagName !== 'BUTTON') { return; } console.log(event.target.dataset.number); }, false);
Проблема в том, что target будет указывать на кликнутый элемент, то есть
на самый вложенные, в нашем случае span. Чтобы эту проблему решить нужно
маленько ‘прокачать’ наш обработчик:
<form> <button data-number=1><span>Первый</span></button> <button data-number=2><span>Второй</span></button> <button data-number=3><span>Третий</span></button> </form>
var button = document.querySelector('form'); button.addEventListener('click', function (event) { var ourTarget = event.target.closest('button'); if (!ourTarget) { return; } console.log(ourTarget.dataset.number); }, false);
Что мы сделали:
- взяли элемент по которому тыкнули (event.target)
- нашли от него ближайший родитель/самого себя, нашей реальной цели
- если реальная цель не нашлась, то беда и тыкнули по чему-то другому
- иначе мы нашли что надо.
Ясное дело, что постоянно писать такие обработчики накладно, поэтому
рекондую вам написать функцию delegate, которая принимает:
-
parentTarget — элемент на который делегируют ответственность за обработку событий
-
selector — селектор детей с которых делегируется ответственность
-
listener — обработчик
-
Не нужно подписывать на каждый элемент при добавлении.
-
Не нужно отписываться от событий при удалении элементов.
-
Один обработчик вместо N.
-
Обработчик становится чуть сложнее.
-
Обработчик будет срабатывать, когда мог бы не срабатывать.
Я рекомендую иметь на вооружении этот инструмент, так как он помогает избавиться
от кучи проблем.
Так же вам может показаться, что было бы не плохо повешать delegate на body,
чтобы иметь минимальное количество обработчиков или вообще один. Но
при таком подходе обработчик будет срабатывать очень часто и это может
повлиять на производитьльность. Но такой подход используют некоторые framework.
stopPropagation
Бывает в одном из обработчиков мы понимаем, что мы все обработали и вызов дальнейших обработчиков не нужен.
Тогда нам на помощь приходитм метод stopPropagation, который есть у объекта event.
<div class='container'> <div class='block'></div> </div>
var container = document.querySelector('.container'); var block = document.querySelector('.block'); block.addEventListener('click', function (event) { console.log(1); event.stopPropagation(); }, false); container.addEventListener('click', function (event) { console.log('этот текст никогда не распечатается'); }, false);
!!!stopPropagation полность останавливает обработку события.
preventDefault
Некоторые html-элементы имеют некоторое действие по умолчанию, при возникновении
определенных событий. Например, ссылка при клике осуществляет переход по ссылке.
Чтобы этого избежать у объекта event есть метод preventDefault.
<a class='link' href='yadnex.ru'> какая классная ссылка </a>
var link = document.querySelector('.link'); link.addEventListener('click', function (event) { event.preventDefault(); }, false);
В этой статье подробно разберем, как найти CSS селекторы, которые необходимы для сбора данных с сайта
Важно! Не переживайте, если ранее не были знакомы с html и CSS, здесь не потребуется специальных знаний в программировании
CSS селекторы показывают путь, в каком именно теге содержится нужная нам информация. Для их поиска можно воспользоваться специальными программами для браузера, например, SelectorGadget, но они не гарантируют того, что найденные селекторы будут соответствовать вашим задачам.
Поиск нужного элемента
Для начала откройте html код страницы вашего сайта. Сделать это можно кликнув правой кнопкой мыши и выбрав «Показать код элемента»/Inspect (здесь и далее рассматривается работа в браузере Chrome).
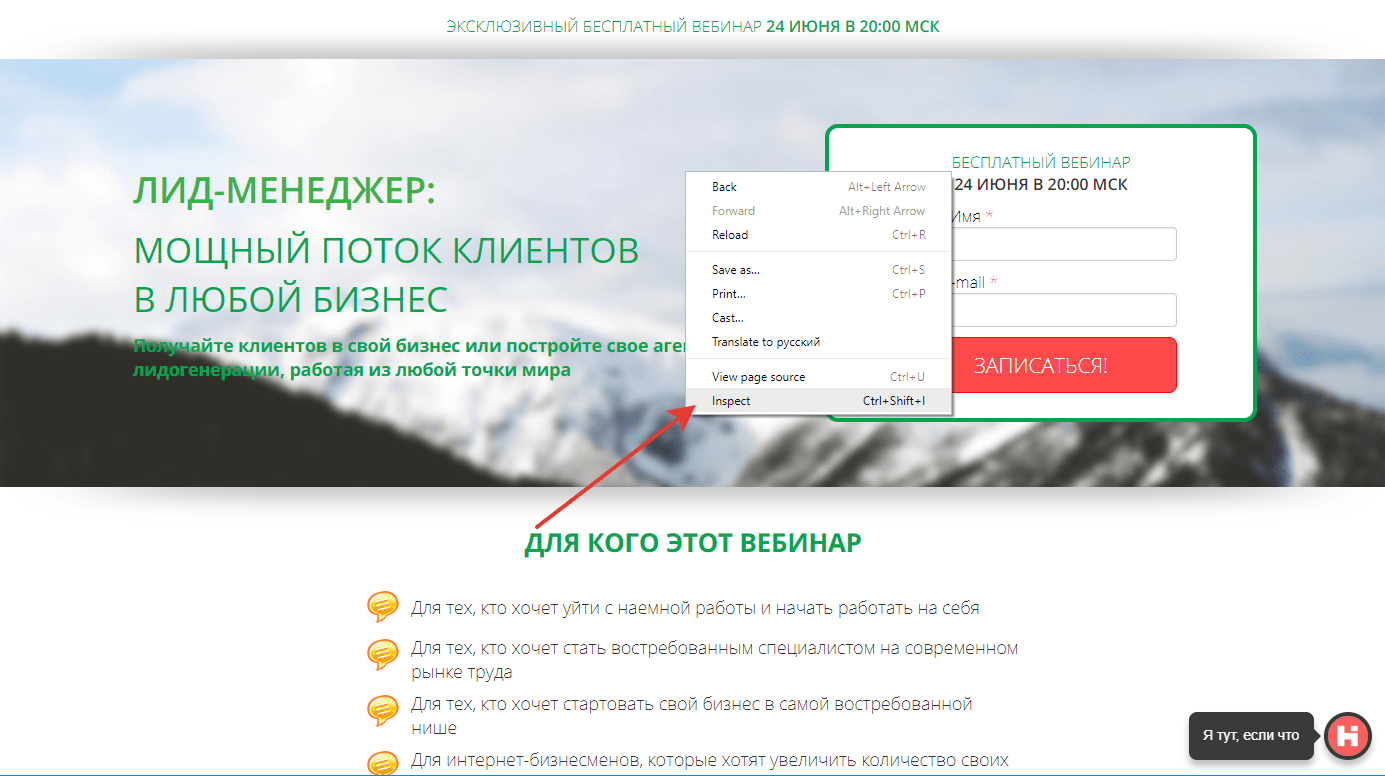
Откроется дополнительная панель браузера, где во вкладке Elements отобразится весь html код страницы, загруженный в данный момент. На скриншоте примера выделен тег, на который как раз был клик правой кнопкой мыши.
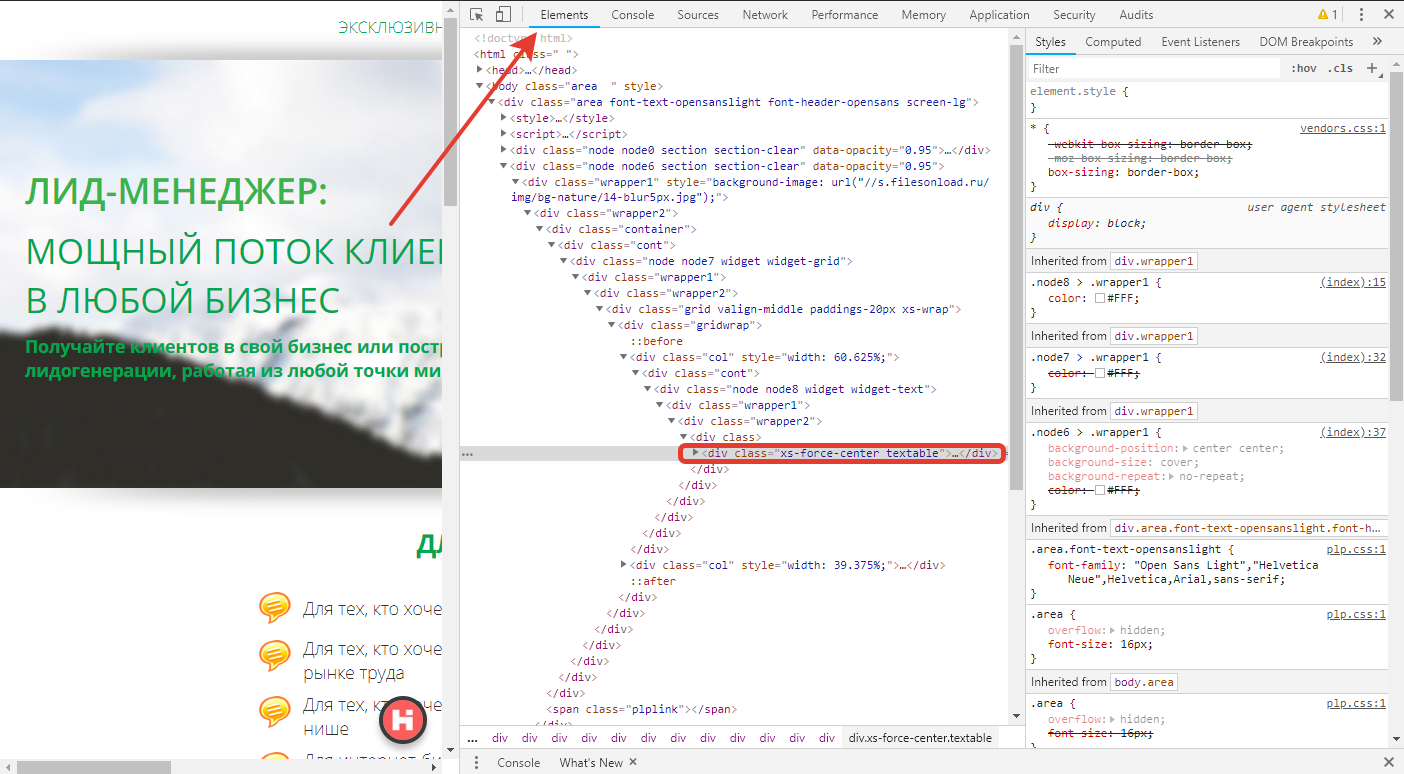
Следующий этап работы — определить тег, который нам нужен. Сделать это можно несколькими способами:
- кликнуть на конкретную область, нажать на правую кнопку мыши и еще раз выбрать «Показать код элемента»/Inspect;
- переключиться на выбор элемента на странице из консоли, нажав на соответствующую кнопку в консоли браузера;
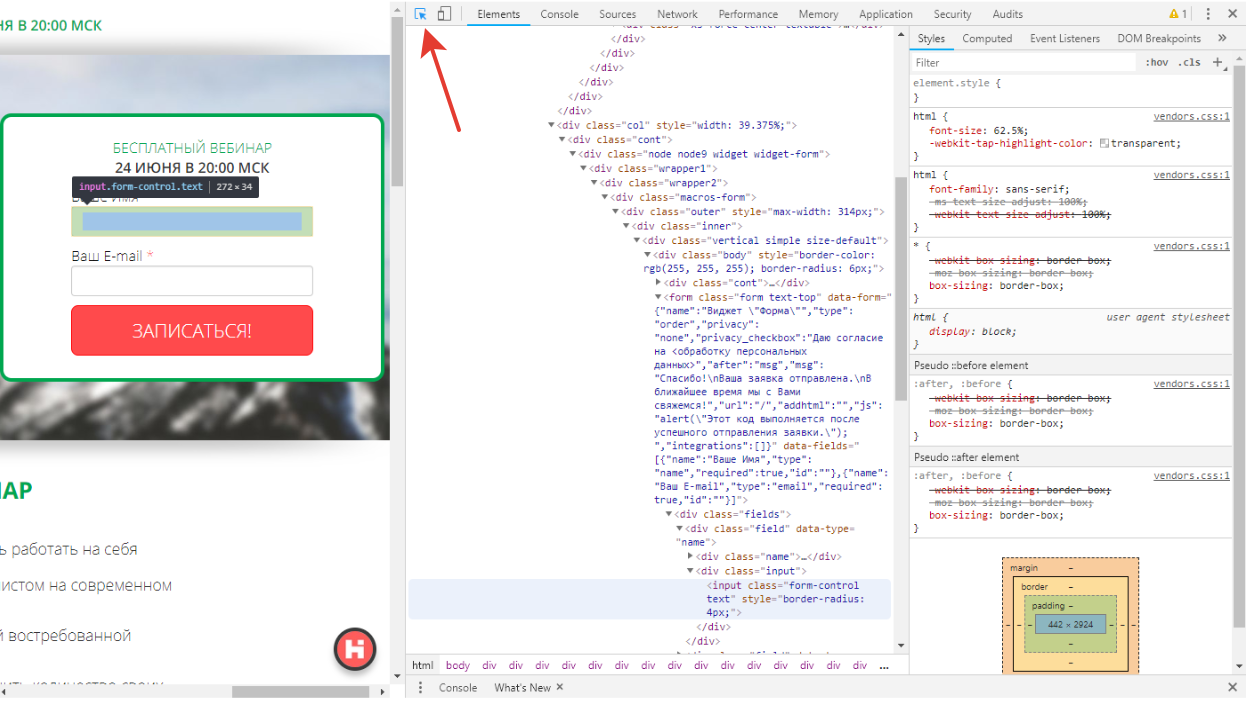
- через поиск найти тег прямо в html коде. Для этого кликните на любой тег, нажмите сочетание клавиш Ctrl + F и в появившейся строке поиска введите любой текст с сайта. Браузер сам подсветит элемент и рядом напишет количество совпадений на странице. В нашем примере видно, что «записаться» повторяется на странице дважды. При нажатии Enter в строке поиска, браузер переключает к следующему элементу на странице (этот момент поможет вам проверять уникальность селектора на странице либо уточнять, все ли найденные элементы соответствуют вашим задачам, когда их должно быть несколько).
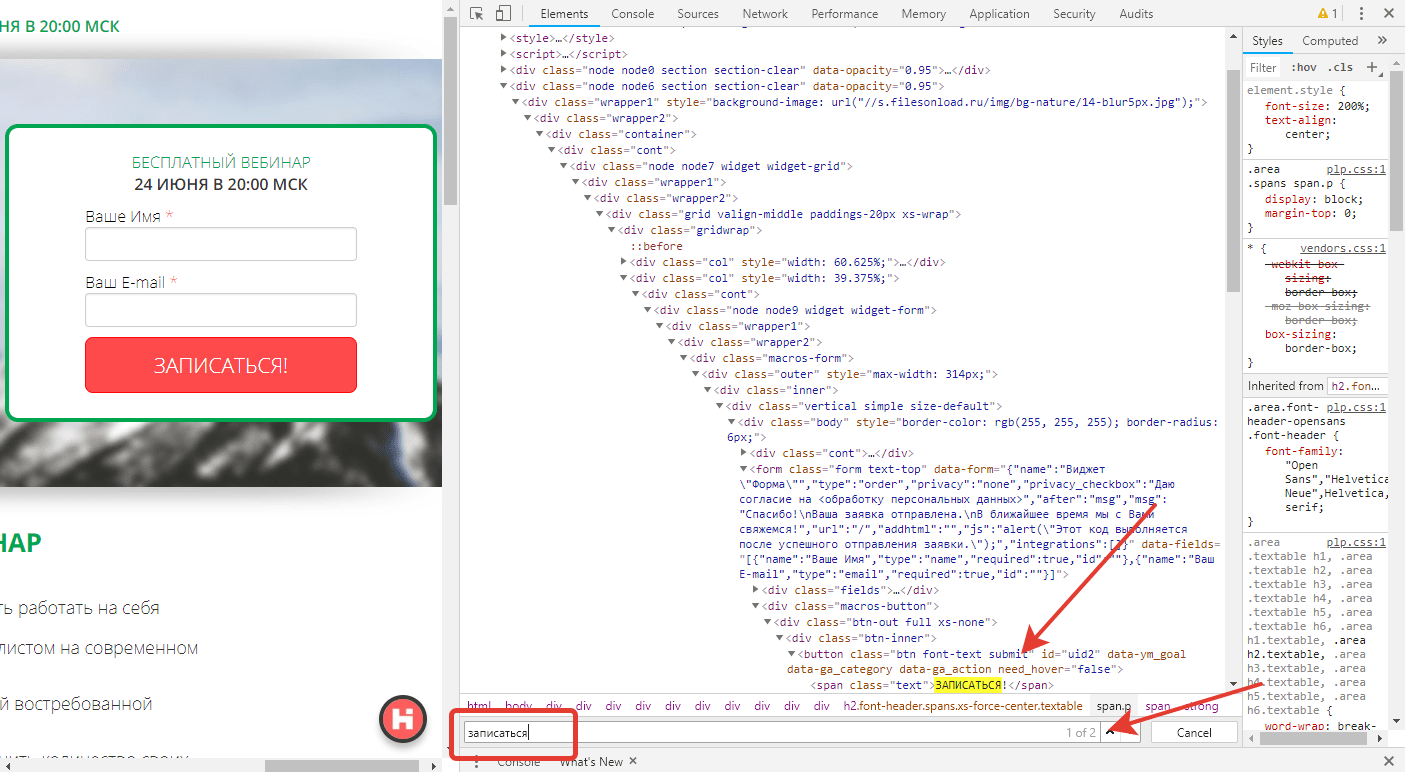
Основные понятия в html коде
Далее разберем, что можно увидеть в html коде и что из этого необходимо знать для сбора данных.
Тег — это элемент, который может состоять из начального и конечного, и содержать внутри себя текст (span в примере — название тега), а может быть одиночным, например <br> (перенос текста на новую строку).

Атрибут тега — дополнительные параметры тега, которые влияют на содержимое тега, например текст. Например, 
— здесь style=»font-size: 200%; text-align: center;» является атрибутом и в нашем примере он сделает размер текста Записаться в два раза крупнее и разместит его по центру.
У одного тега может быть несколько атрибутов, которые будут разделены пробелами, например, так:
здесь два атрибута у одного тега — class и style.
Значение атрибута — атрибут тега состоит из двух элементов: названия и значения.
Цифрой 1 отмечены названия атрибутов, цифрой 2 — их значения. Значений, как и самих атрибутов в теге, может быть несколько, разделяются они также пробелом.

Расположение тегов — в html коде все теги должны располагаться по четким правилам, как матрешки, один в другом либо рядом. У всех тегов есть родители (теги, внутри которых они находятся) и у многих дети. Например, тег <strong></strong> ребенок и тега <h2></h2>, и тега <div></div>, а они соответственно его родители:
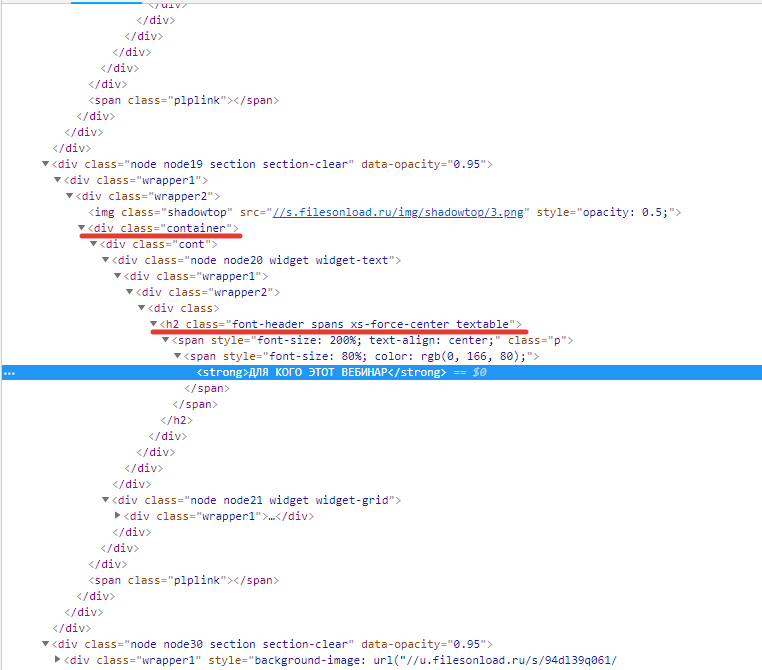
Правила обозначения CSS селекторов
Использовать для указания на конкретный тег или его содержимое можно практически все элементы html. Далее рассмотрим несколько самых простых вариантов.
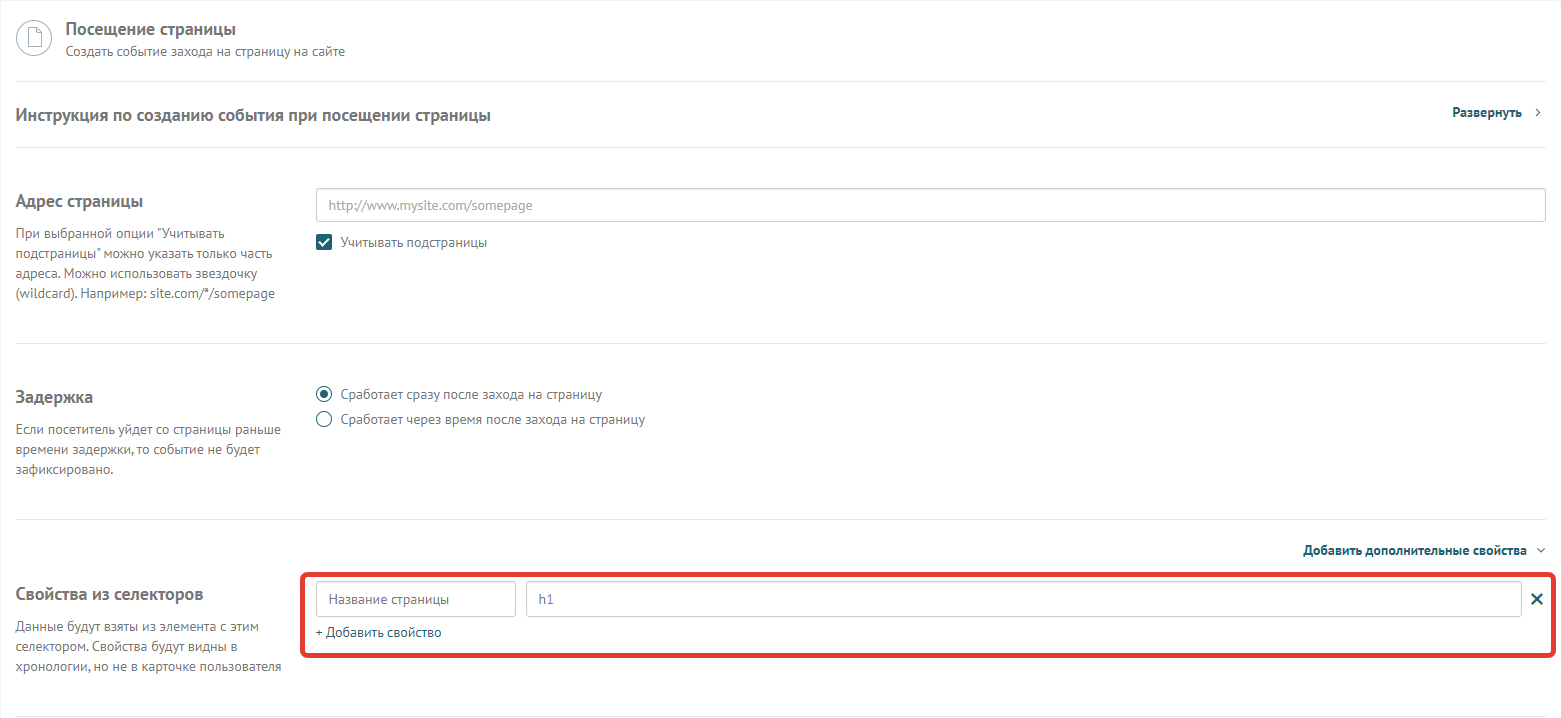
Название тега — достаточно просто указать span, div, img, h2 в месте, где нужно прописать селектор, и такой селектор будет учитывать все теги с таким названием на странице. Обычно этого хватает для записи названия страницы, так как обычно оно присутствует в теге h1, который не повторяется. Например, так будет выглядеть настройка записи в свойство события «Посещение страницы» названия страницы:
Атрибуты class и id — это уникальные в нашем случае атрибуты, которые обозначаются не так, как все остальные. Пример:

Здесь селектор class мы запишем как .text или .wrapper2, то есть просто добавим точку перед значением. Если мы хотим указать, что нам нужен тег, где в обязательном порядке присутствуют оба значения, то пропишем так .text.wrapper2 (без пробела).
Значение id должно являться уникальным по правилам html и иметь только одно значение внутри этого тега. Про примеру оно будет обозначаться так #section24.
Вам повезло, если в нужном вам элементе есть id, так как этого как раз будет достаточно для большинства настроек сбора данных.
Другие атрибуты — все остальные атрибуты записываются по единому правилу: название тега[атрибут и его значение]. Например, укажем CSS селектор для тега с конкретной картинкой, используя атрибут scr (ссылку на картинку):
img[src=»//s.filesonload.ru/img/shadowbottom/1.png»]

Использования элементов нескольких тегов — иногда атрибуты у нужного тега не уникальны или вовсе отсутствуют. В этих случаях можно использовать атрибуты родителей для определения селектора. Например, мы хотим использовать для сбора данных информацию из тега <strong>:

Сначала пробуем ближайшего родителя, то есть тег <span>. Селектор будет выглядеть так: span strong, то есть нам достаточно написать названия тегов в нужном порядке и такой селектор выберет все теги <strong>, которые находятся в теге <span>. Аналогично будет выглядеть и с родителей <h2>: h2 strong.
Мы можем задать и более четкое условие, что нам нужно все теги <strong>, которые находятся непосредственно в теге <span>. Для этого используем символ >: span > strong.
Можно использовать цепочку из названий тегов и их атрибутов, которые в конечном итоге укажут на нужный тег: h2.font-header span span strong.
Несколько CSS селекторов для одной задачи — бывает, что необходимо указать сразу несколько селекторов для сбора одного события или свойства. Для этого необязательно добавлять несколько отдельных настроек в Мастере сбора данных, достаточно прописать через запятую все нужные селекторы. Например, так выглядит настройка клика по элементу, если по факту несколько кнопок на странице обозначают одно и то же, но имеют разные селекторы:
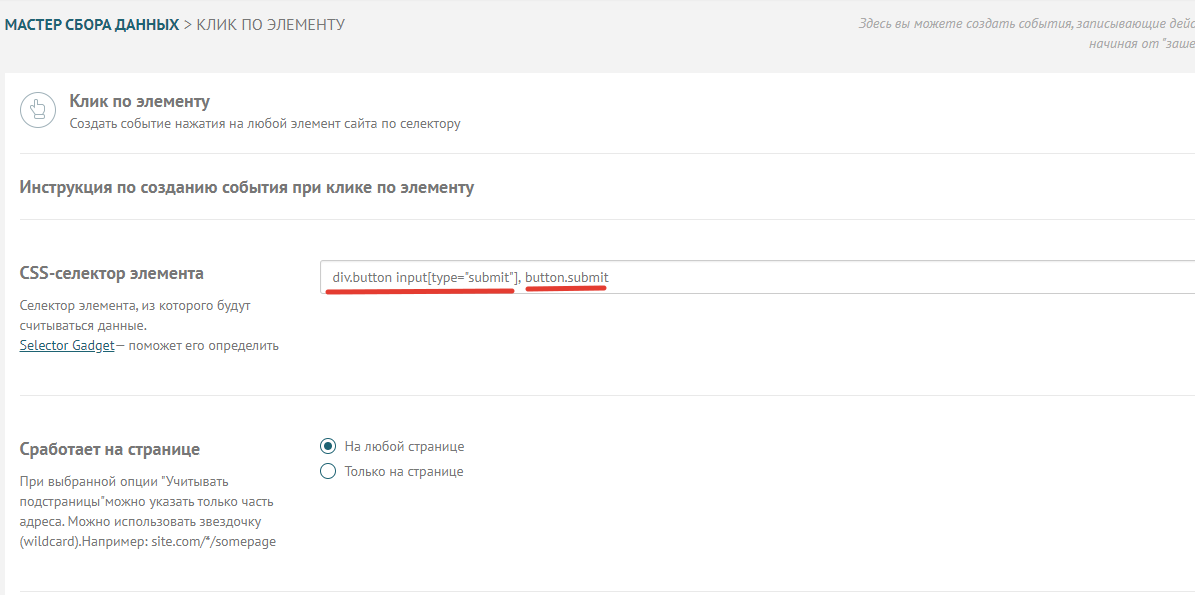
В этом примере все просто: мы имеем ввиду 2 тега, клик на которые будут записываться в хронологию пользователя, как отдельное событие. Первый селектор div.button input[type=»submit»] обозначает, что нам нужны все теги <input>, в которых есть атрибут type=»submit» и они должны являться детьми тега <div>, в котором есть атрибут class=»button». В упрощенном варианте это будет выглядеть так в html (на самом сайте, конечно, будет больше всего вокруг):
<div class=»button»>
<input type=»submit»></input>
</div>
Тут же, через запятую, прописан еще один селектор: все теги <button> с атрибутом class=»submit».
Проверка уникальности CSS селектора
Уникальность CSS селектора для нас очень важна. Если селектор прописан неверно и он не является уникальным, то сбор данных будет не точным, а значит — бесполезным.
Проверить уникальность можно прямо в браузере через поиск в панеле Elements. Нажмите сочетание клавиш Ctrl + F, и введите в строке поиска найденный вами ранее CSS селектор. Браузер сам подсветит тег, путь к которому вы указали и напишет количество таких совпадений на странице.
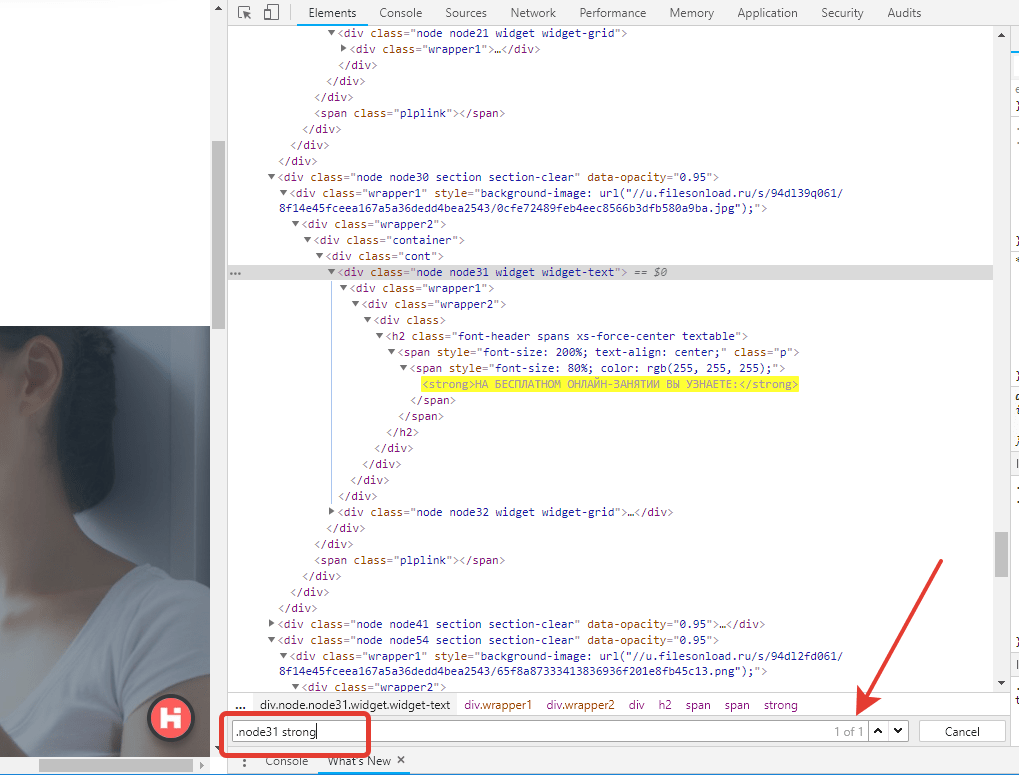
В большинстве случаев, совпадение должно быть только одно (будет написано — 1/1). Иногда требуется, чтобы совпадений было несколько, но все они указывали на нужные вам теги, например, свойство «Товары в корзине» подтягивает названия товаров из списка товаров в самой корзине. При настройке такого свойства количество совпадений по селекторам должно равняться реальному количеству товаров в корзине на данный момент.
Как проверить, правильно вы настроили сбор данных в Carrot quest, можно посмотреть в этой статье. При любых сложностях — пишите нам в чат, будем рады помочь.