Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».

- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть
as pd, Jupyter Notebook понимает, что в будущем, при вводеpdподразумевается именно библиотека pandas.


Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.

DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.

В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv().
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need
elephant,1001,500
elephant,1002,600
elephant,1003,550
tiger,1004,300
tiger,1005,320
tiger,1006,330
tiger,1007,290
tiger,1008,310
zebra,1009,200
zebra,1010,220
zebra,1011,240
zebra,1012,230
zebra,1013,220
zebra,1014,100
zebra,1015,80
lion,1016,420
lion,1017,600
lion,1018,500
lion,1019,390
kangaroo,1020,410
kangaroo,1021,430
kangaroo,1022,410
Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…

затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…

…и назовем его zoo.csv!

Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',')

Готово! Это файл zoo.csv, перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:

Если кликнуть на него…

…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';')
Данные загружены в pandas!

Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';',
names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])

Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл
.csvчерез URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv(
'https://pythonru.com/downloads/pandas_tutorial_read.csv',
delimiter=';',
names=['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!

Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head()

Или последние 5 строк:
article_read.tail()

Или 5 случайных строк:
article_read.sample(5)

Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']]

Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]

Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO']
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли 'SEO' значением колонки article_read.source? Результат всегда будет булевым значением (True или False).

Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read.

Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']]
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head()
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']
)[['country', 'user_id']].head()
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2. Выведите первые 5 строк!
Вперед!
.
.
.
.
.
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head()
Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2']
ar_filtered_cols = ar_filtered[['user_id','topic', 'country']]
ar_filtered_cols.head()
В любом случае, логика не отличается. Сначала берется оригинальный dataframe (article_read), затем отфильтровываются строки со значением для колонки country — country_2 ([article_read.country == 'country_2']). Потому берутся три нужные колонки ([['user_id', 'topic', 'country']]) и в конечном итоге выбираются только первые пять строк (.head()).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
Я пытаюсь загрузить .csv файл, используя pd.read_csv() когда я получаю ошибку, несмотря на правильность пути к файлу и использование необработанных строк.
import pandas as pd
df = pd.read_csv('C:\Users\user\Desktop\datafile.csv')
df = pd.read_csv(r'C:UsersuserDesktopdatafile.csv')
df = pd.read_csv('C:/Users/user/Desktop/datafile.csv')
все дает ошибку ниже:
FileNotFoundError: Файл b ‘ xe2x80xaaC: /Users/user/Desktop/tutorial.csv’ (или соответствующий путь) не существует.
Только когда я копирую файл в рабочий каталог, он будет загружен правильно.
Кто-нибудь знает, что может вызвать ошибку?
Я ранее загружал другие наборы данных с полными файловыми путями без каких-либо проблем, и в настоящее время я только сталкиваюсь с проблемами, так как я заново установил свой python (через установщик пакетов Anaconda).
Изменить:
Я нашел проблему, которая вызывала проблему.
Когда я копировал путь к файлу из окна свойств файла, я невольно копировал другой символ, который кажется невидимым.
Присвоение этой скопированной string также дает ошибку unicode.
Удаление этого невидимого персонажа сделало любой из вышеперечисленных кодов.
17 авг. 2022 г.
читать 2 мин
Чтобы прочитать текстовый файл с пандами в Python, вы можете использовать следующий базовый синтаксис:
df = pd.read_csv (" data.txt", sep=" ")
В этом руководстве представлено несколько примеров использования этой функции на практике.
Чтение текстового файла с заголовком
Предположим, у нас есть следующий текстовый файл с именем data.txt и заголовком:
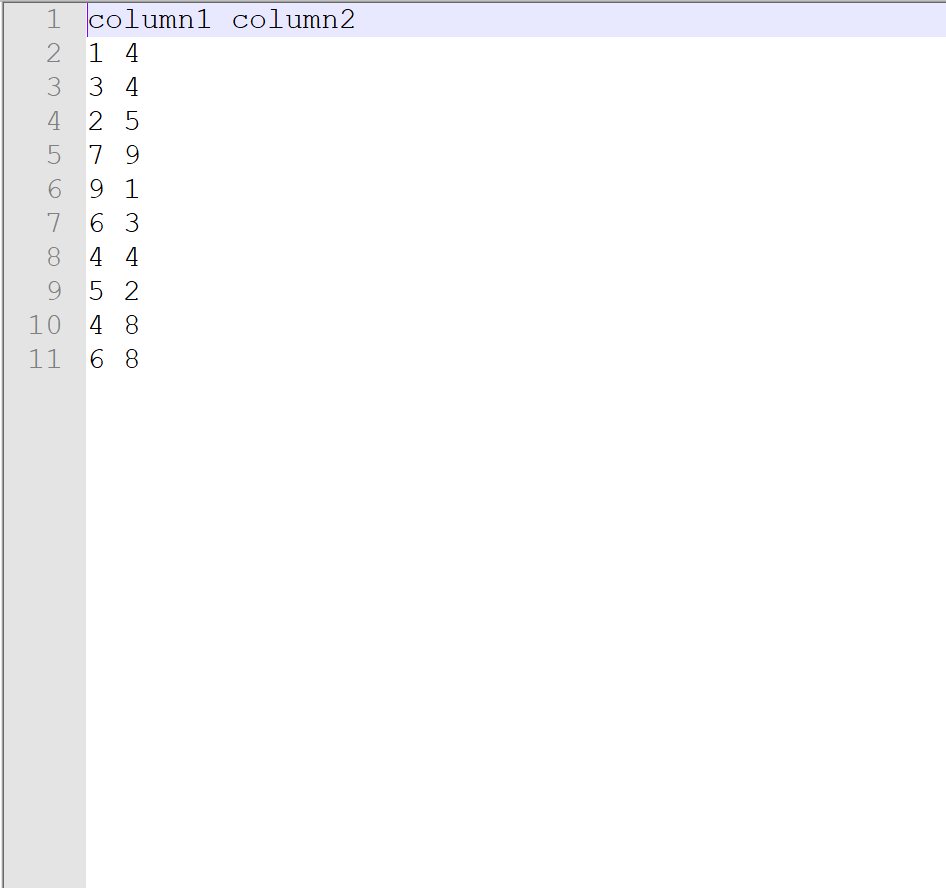
Чтобы прочитать этот файл в DataFrame pandas, мы можем использовать следующий синтаксис:
import pandas as pd
#read text file into pandas DataFrame
df = pd.read_csv (" data.txt", sep=" ")
#display DataFrame
print(df)
column1 column2
0 1 4
1 3 4
2 2 5
3 7 9
4 9 1
5 6 3
6 4 4
7 5 2
8 4 8
9 6 8
Мы можем распечатать класс DataFrame и найти количество строк и столбцов, используя следующий синтаксис:
#display class of DataFrame
print(type(df))
<class 'pandas.core.frame.DataFrame'>
#display number of rows and columns in DataFrame
df.shape
(10, 2)
Мы видим, что df — это DataFrame pandas с 10 строками и 2 столбцами.
Чтение текстового файла без заголовка
Предположим, у нас есть следующий текстовый файл с именем data.txt без заголовков:
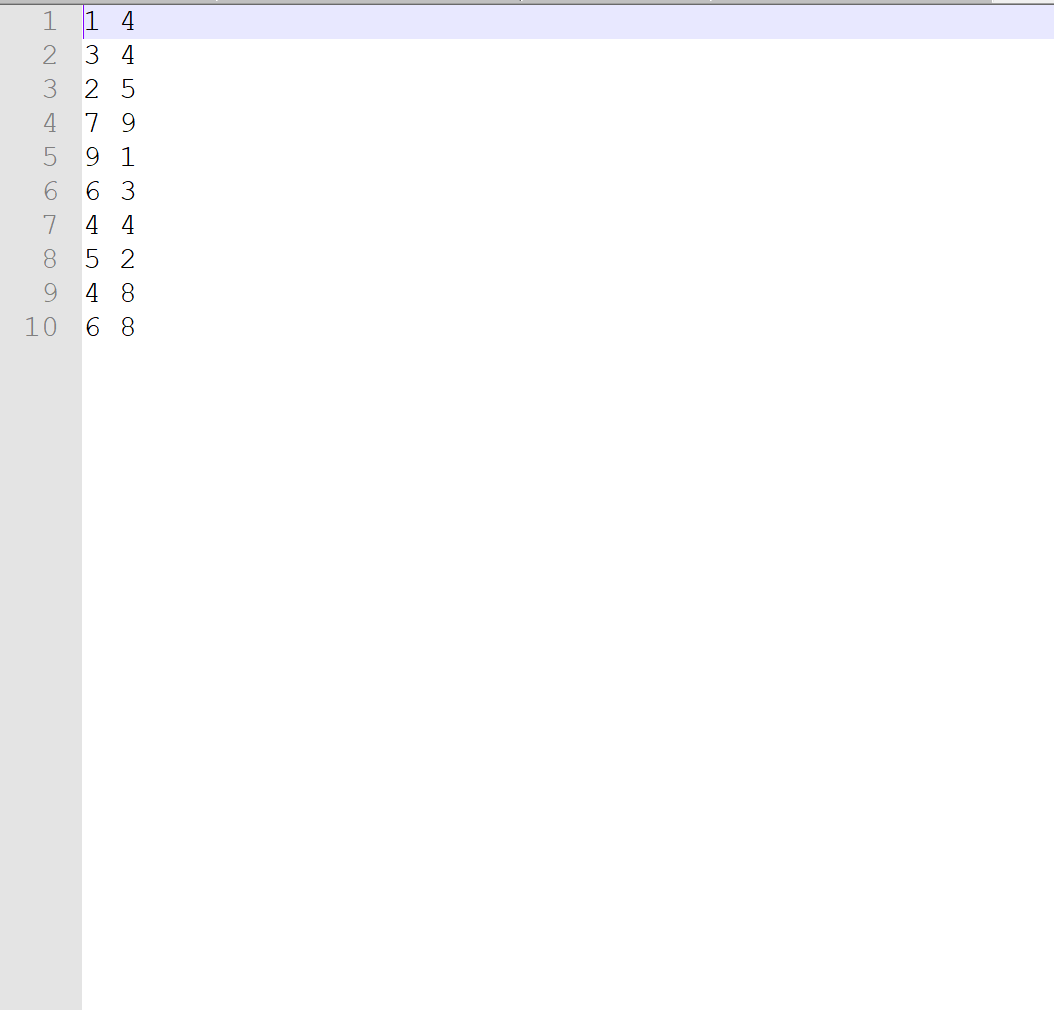
Чтобы прочитать этот файл в DataFrame pandas, мы можем использовать следующий синтаксис:
#read text file into pandas DataFrame
df = pd.read_csv (" data.txt", sep="", header= None )
#display DataFrame
print(df)
0 1
0 1 4
1 3 4
2 2 5
3 7 9
4 9 1
5 6 3
6 4 4
7 5 2
8 4 8
9 6 8
Поскольку в текстовом файле не было заголовков, Pandas просто назвали столбцы 0 и 1 .
Прочитайте текстовый файл без заголовка и укажите имена столбцов
При желании мы можем присвоить имена столбцам при импорте текстового файла с помощью аргумента имен :
#read text file into pandas DataFrame and specify column names
df = pd.read_csv (" data.txt", sep="", header= None, names=[" A", " B "] )
#display DataFrame
print(df)
A B
0 1 4
1 3 4
2 2 5
3 7 9
4 9 1
5 6 3
6 4 4
7 5 2
8 4 8
9 6 8
Дополнительные ресурсы
Как читать файлы CSV с помощью Pandas
Как читать файлы Excel с помощью Pandas
Как прочитать файл JSON с помощью Pandas
Хотя вы можете читать и писать файлы CSV в Python, используя встроенную
open() или специальный модуль
csv, вы также можете
использовать Pandas.
В этой статье вы увидите, как использовать
библиотеку Python Pandas для чтения и
записи файлов CSV.
Что такое файл CSV?
Давайте быстро напомним, что такое файл CSV — не что иное, как простой
текстовый файл с соблюдением нескольких соглашений о форматировании.
Однако это наиболее распространенный, простой и легкий способ хранения
табличных данных. Этот формат упорядочивает таблицы в соответствии с
определенной структурой, разделенной на строки и столбцы. Именно в этих
строках и столбцах содержатся ваши данные.
Новая строка завершает каждую строку, чтобы начать следующую строку.
Точно так же разделитель, обычно запятая, разделяет столбцы в каждой
строке.
Например, у нас может быть таблица, которая выглядит так:
| City | State | Capital | Population |
| ------------ | ------------ | ------- | ------------- |
| Philadelphia | Pennsylvania | No | 1.581 Million |
| Sacramento | California | Yes | 0.5 Million |
| New York | New York | No | 8.623 Million |
| Austin | Texas | Yes | 0.95 Million |
| Miami | Florida | No | 0.463 Million |
Если бы мы преобразовали его в формат CSV, это выглядело бы так:
City,State,Capital,Population
Philadelphia,Pennsylvania,No,1.581 Million
Sacramento,California,Yes,0.5 Million
New York,New York,No,8.623 Million
Austin,Texas,Yes,0.95 Million
Miami,Florida,No,0.463 Million
Хотя имя (значения, разделенные запятыми) по своей сути использует
запятую в качестве разделителя, вы также можете использовать другие
разделители (разделители), такие как точка с запятой ( ; ). Каждая
строка таблицы — это новая строка файла CSV, и это очень компактный и
лаконичный способ представления табличных данных.
Теперь давайте посмотрим на read_csv() .
Чтение и запись файлов CSV с помощью Pandas
Pandas — очень мощный и популярный фреймворк для анализа и обработки
данных. Одной из самых ярких особенностей Pandas является его
способность читать и записывать различные типы файлов, включая CSV и
Excel. Вы можете эффективно и легко управлять CSV-файлами в Pandas,
используя такие функции, как read_csv() и to_csv() .
Установка Pandas
Мы должны установить Pandas перед его использованием. Давайте
использовать pip :
$ pip install pandas
Чтение файлов CSV с помощью read_csv ()
Давайте импортируем Titanic Dataset, который можно получить на
GitHub
:
import pandas as pd
titanic_data = pd.read_csv('titanic.csv')
Pandas будет искать этот файл в каталоге сценария, естественно, и мы
просто указываем путь к файлу, который хотим проанализировать, как
единственный обязательный аргумент этого метода.
Давайте посмотрим на head() этого набора данных, чтобы убедиться, что
он импортирован правильно:
titanic_data.head()
Это приводит к:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
Кроме того, вы также можете читать файлы CSV с сетевых ресурсов, таких
как GitHub, просто передав URL-адрес ресурса в read_csv() . Давайте
прочитаем этот же CSV-файл из репозитория GitHub, не загружая его
сначала на локальный компьютер:
import pandas as pd
titanic_data = pd.read_csv(r'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
print(titanic_data.head())
Это также приводит к:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns]
По умолчанию метод read_csv() использует первую строку файла CSV в
качестве заголовков столбцов. Иногда у этих заголовков могут быть
странные имена, и вы можете использовать свои собственные заголовки. Вы
можете установить заголовки либо после чтения файла, просто присвоив
columns области в DataFrame экземпляре другого список, или вы можете
установить заголовки при чтении CSV в первую очередь.
Давайте определим список имен столбцов и будем использовать эти имена
вместо имен из CSV-файла:
import pandas as pd
col_names = ['Id',
'Survived',
'Passenger Class',
'Full Name',
'Gender',
'Age',
'SibSp',
'Parch',
'Ticket Number',
'Price', 'Cabin',
'Station']
titanic_data = pd.read_csv(r'E:Datasetstitanic.csv', names=col_names)
print(titanic_data.head())
Запустим этот код:
Id Survived Passenger Class ... Price Cabin Station
0 PassengerId Survived Pclass ... Fare Cabin Embarked
1 1 0 3 ... 7.25 NaN S
2 2 1 1 ... 71.2833 C85 C
3 3 1 3 ... 7.925 NaN S
4 4 1 1 ... 53.1 C123 S
Хм, теперь у нас есть собственные заголовки, но первая строка файла
CSV, которая изначально использовалась для установки имен столбцов,
также включена в DataFrame . Мы хотим пропустить эту строку, поскольку
она больше не представляет для нас никакой ценности.
Пропуск строк при чтении CSV
skiprows эту проблему, используя аргумент skiprows:
import pandas as pd
col_names = ['Id',
'Survived',
'Passenger Class',
'Full Name',
'Gender',
'Age',
'SibSp',
'Parch',
'Ticket Number',
'Price', 'Cabin',
'Station']
titanic_data = pd.read_csv(r'E:Datasetstitanic.csv', names=col_names, skiprows=[0])
print(titanic_data.head())
Теперь давайте запустим этот код:
Id Survived Passenger Class ... Price Cabin Station
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
Работает как шарм! skiprows принимает список строк, которые вы хотите
пропустить. Вы можете пропустить, например, 0, 4, 7 если хотите:
titanic_data = pd.read_csv(r'E:Datasetstitanic.csv', names=col_names, skiprows=[0, 4, 7])
print(titanic_data.head(10))
В результате DataFrame , в котором нет некоторых из строк, которые мы
видели раньше:
Id Survived Passenger Class ... Price Cabin Station
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 5 0 3 ... 8.0500 NaN S
4 6 0 3 ... 8.4583 NaN Q
5 8 0 3 ... 21.0750 NaN S
6 9 1 3 ... 11.1333 NaN S
7 10 1 2 ... 30.0708 NaN C
8 11 1 3 ... 16.7000 G6 S
9 12 1 1 ... 26.5500 C103 S
Имейте в виду, что пропуск строк происходит до того, как DataFrame
будет полностью сформирован, поэтому вы не пропустите никаких индексов
самого DataFrame , хотя в этом случае вы можете увидеть, что Id
(импортированное из файла CSV) отсутствует ID 4 и 7 .
Вы также можете решить полностью удалить заголовок, что приведет к
DataFrame который просто имеет 0...n столбцов заголовка, установив
для аргумента header None :
titanic_data = pd.read_csv(r'E:Datasetstitanic.csv', header=None, skiprows=[0])
Вы также захотите пропустить здесь первую строку, поскольку в противном
случае значения из первой строки будут фактически включены в первую
строку:
0 1 2 3 4 ... 7 8 9
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500
Указание разделителей
Как было сказано ранее, вы, вероятно, столкнетесь с CSV-файлом, в
котором для разделения данных на самом деле не используются запятые. В
таких случаях вы можете использовать sep для указания других
разделителей:
titanic_data = pd.read_csv(r'E:Datasetstitanic.csv', sep=';')
Запись файлов CSV с помощью to_csv ()
Опять же, DataFrame являются табличными. Превратить DataFrame в файл
CSV так же просто, как преобразовать файл CSV в DataFrame — мы
вызываем write_csv() в экземпляре DataFrame
При записи DataFrame в файл CSV вы также можете изменить имена
столбцов с помощью columns или указать разделитель с помощью аргумента
sep Если вы не укажете ни один из них, вы получите стандартный файл
значений, разделенных запятыми.
Давайте поиграемся с этим:
import pandas as pd
cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida']], columns=['City', 'State'])
cities.to_csv('cities.csv')
Здесь мы создали простой DataFrame с двумя городами и их
соответствующими состояниями. Затем мы сохранили эти данные в файл CSV,
используя to_csv() и указав имя файла.
В результате в рабочем каталоге выполняемого вами скрипта создается
новый файл, который содержит:
,City,State
0,Sacramento,California
1,Miami,Florida
Хотя это не совсем хорошо отформатировано. У нас все еще есть индексы из
DataFrame , который также ставит странное пропущенное место перед
именами столбцов. Если мы повторно импортируем этот CSV- DataFrame
обратно в DataFrame, это будет беспорядок:
df = pd.read_csv('cities.csv')
print(df)
Это приводит к:
Unnamed: 0 City State
0 0 Sacramento California
1 1 Miami Florida
Индексы из DataFrame превратились в новый столбец, который теперь
называется Unnamed .
При сохранении файла, давайте удостоверимся , что уронить индекс
DataFrame :
import pandas as pd
cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida']], columns=['City', 'State'])
cities.to_csv('cities.csv', index=False)
Теперь это приводит к файлу, который содержит:
City,State
Sacramento,California
Miami,Florida
Работает как шарм! Если мы повторно импортируем его и распечатаем
содержимое, DataFrame будет построен правильно:
df = pd.read_csv('cities.csv')
print(df)
Это приводит к:
City State
0 Sacramento California
1 Miami Florida
Давайте изменим заголовки столбцов с заголовков по умолчанию:
import pandas as pd
cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida']], columns=['City', 'State'])
new_column_names = ['City_Name', 'State_Name']
cities.to_csv('cities.csv', index=False, header=new_column_names)
Мы new_header список new_header, который содержит разные значения для
наших столбцов. Затем, используя header , мы установили их вместо
исходных имен столбцов. Будет создан cities.csv с таким содержимым:
City_Name,State_Name
Sacramento,California
Miami,Florida
Washington DC,Unknown
Настройка разделителя
Давайте изменим разделитель со значения по умолчанию ( , ) на новый:
import pandas as pd
cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida']], columns=['City', 'State'])
cities.to_csv('cities.csv', index=False, sep=';')
В результате cities.csv файл cities.csv, содержащий:
City;State
Sacramento;California
Miami;Florida
Обработка отсутствующих значений
Иногда в DataFrame отсутствуют значения, которые мы оставили как NaN
или NA . В таких случаях вы можете отформатировать их при записи в
файл CSV. Вы можете использовать na_rep и установить значение, которое
будет помещено вместо отсутствующего значения:
import pandas as pd
cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida'], ['Washington DC', pd.NA]], columns=['City', 'State'])
cities.to_csv('cities.csv', index=False, na_rep='Unknown')
Здесь у нас есть две допустимые пары город-государство, но
Washington DC имеет своего штата. Если мы запустим этот код, это
приведет к созданию cities.csv следующего содержания:
City,State
Sacramento,California
Miami,Florida
Washington DC,Unknown
Заключение
В статье показано, как читать и записывать файлы CSV с помощью
библиотеки Python Pandas. Для чтения файла CSV используется метод
read_csv() библиотеки Pandas. Вы также можете передать
пользовательские имена заголовков при чтении CSV файлов через names
атрибута read_csv() метод. Наконец, для записи в файл CSV с помощью
панд, вы должны сначала создать объект Панды DataFrame , а затем вызвать
to_csv метод на DataFrame.
Если вы планируете получать приложения IPA файлы из Panda Helper, вы должны пройти облегченную версию Panda Helper чтобы получить их. Здесь мы расскажем, как вы загружаете файлы IPA приложений из Panda Helper.
Зачем людям нужны приложения и файлы IPA? У вас могут быть сомнения. Иногда вы не можете использовать бесплатно Panda Helper или облегченный Panda Helper устанавливать приложения напрямую, когда его общий сертификат отозван, и люди могут использовать приложения, которые они хотят, самостоятельно подписывая его файлы IPA.
С Panda Helper предоставил огромное количество взломанных приложений, измененных приложений и платных приложений, а также часто обновлял приложения, такие как Coin Master, Last Day on Earth мотыга, Tap Titans 2 Взлом, Dragon Ball Legends мотыга, Clash of Clans — AI, что привлекает многих людей к его использованию. Когда сертификат работает, вы можете устанавливать приложения из Panda Helper; когда он будет отозван, мы приложим все усилия, чтобы исправить это, и вы также можете использовать lite Panda Helper чтобы получить файлы IPA приложения.
Вы можете получить файлы Panda IPA с ПК, iPhone или iPad. Поэтому мы делимся способами получения файлов IPA с разных устройств.
Способ 1: скачать файлы IPA на ПК
Теперь люди могут получать файлы .ipa из Panda Helper Веб-сайт на M1 Mac после того, как Apple заблокировала неопубликованную загрузку с iPhone и iPad с помощью стороннего инструмента, такого как iMaze. См. более подробную информацию ниже, чтобы получить файлы .iPA из Panda Helper Веб-сайт.
Apple официально заблокировала загрузку приложений iPhone или iPad для пользователей M1 Mac. Больше не нужно использовать такие инструменты, как iMazing, чтобы получить файл .ipa приложения с iPhone или iPad и установить его на M1 Mac.
Это изменение не влияет на установленные приложения или загруженные файлы .ipa на вашем M1 Mac; вы по-прежнему можете установить или наслаждаться ими на своем M1 Mac. Но вы больше не можете получить новые файлы .ipa, как обычно.
Во-первых, открыть Panda Helper облегченная. И введите приложение, которое вы хотите.
Затем нажмите кнопку с тремя линиями в правом нижнем углу. Нажмите «Загрузите файл .IPA для установки с Altsigner».
Наконец, у вас есть файл ipa приложения на вашем M1 Mac. Наслаждайся этим!
Способ 2: загрузка файлов IPA на iPhone или iPad
Во-первых, открыть Panda Helperофициальный сайт и нажмите «Загрузить iOS», чтобы установить Бесплатная веб-версия.
Далее откройте Panda Helper с главного экрана и найдите нужные приложения.
Уведомление: Пожалуйста, не нажимайте «Установить» справа, а в другом месте, чтобы перейти на страницу приложения.
Нажмите кнопку с тремя линиями в правом нижнем углу. И нажмите «Загрузить файл .IPA для установки с Altsigner».
Кроме того, вы можете узнать самое безопасное место для IPA.
Способ 3: загрузка файлов IPA по электронной почте с помощью Panda Helper
1. Войдите в электронную почту на iPhone и проверьте письмо, отправленное Panda Helper VIP.
2. Загрузите установочный пакет IPA по электронной почте.