Плотность распределения вероятностей непрерывной случайной величины
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
Краткая теория
Ранее
непрерывная случайная величина задавалась с помощью функции распределения. Этот
способ задания не является единственным. Непрерывную случайную величину можно
также задать, используя другую функцию, которую называют плотностью
распределения или плотностью вероятности (иногда ее называют дифференциальной
функцией).
Плотностью распределения вероятностей непрерывной случайной величины
называют функцию
– первую производную от функции распределения
:
Из этого определения следует, что
функция распределения является первообразной для плотности распределения.
Заметим, что для описания
распределения вероятностей дискретной случайной величины плотность
распределения неприменима.
Зная плотность распределения, можно
вычислить вероятность того, что непрерывная случайная величина примет значение,
принадлежащее заданному интервалу.
Вероятность того, что непрерывная
случайная величина
примет
значение, принадлежащее интервалу
равна
определенному интегралу от плотности распределения, взятому в пределах от
до
:
Геометрически полученный результат
можно истолковать так: вероятность того, что непрерывная случайная величина
примет значение, принадлежащее интервалу
, равна площади криволинейной трапеции, ограниченной
осью
, кривой распределения
и прямыми
и
.
В частности, если
– четная
функция и концы интервала симметричны относительно начала координат, то:
Зная плотность распределения
можно найти
функцию распределения
по формуле:
Свойства плотности распределения
Свойство 1.
Плотность
распределения – неотрицательная функция:
Свойство 2.
Несобственный
интеграл от плотности распределения в пределах от
до
равен единице:
Смежные темы решебника:
- Дискретная случайная величина
- Непрерывная случайная величина
- Интегральная функция распределения вероятностей
Примеры решения задач
Пример 1
Задана
плотность распределения вероятностей f(x) непрерывной случайной
величины X. Требуется:
1)
определить коэффициент A;
2) найти
функцию распределения F(x);
3)
схематично построить графики F(x) и f(x);
4) найти
математическое ожидание и дисперсию X;
5) найти
вероятность того, что X примет значение из
интервала (α,β):
α=1; β=1.7
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
1)
Постоянный параметр
найдем из
свойства плотности вероятности:
В
нашем случае эта формула имеет вид:
Получаем:
2)
Функцию распределения
найдем из
формулы:
Учитывая
свойства
, сразу можем
отметить, что:
Остается
найти выражение для
, когда
принадлежит
интервалу
.
Получаем:
3) Построим графики
и
:
График плотности распределения
График функции распределения
4)
Математическое ожидание находим по формуле:
Для
нашего примера:
Дисперсию
можно найти по формуле:
5)
Вероятность того, что случайная величина примет значение из интервала
:
Пример 2
Плотность
распределения вероятности непрерывной случайной величины равна
, x∈(0,∞). Найти нормировочный множитель C,
математическое ожидание M(X) и дисперсию D(X).
Решение
Нормировочный множитель
найдем из
свойства плотности вероятности:
В
нашем случае эта формула имеет вид:
Плотность
вероятности:
Математическое
ожидание находим по формуле:
Для
нашего примера:
Дисперсию
можно найти по формуле:
Пример 3
Непрерывная
случайная величина
имеет плотность распределения:
Найти
величину a, вероятность P(X<0) и математическое
ожидание X.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Постоянный
параметр
найдем из
свойства плотности вероятности:
В
нашем случае эта формула имеет вид:
Плотность
вероятности имеет вид:
Вероятность:
Математическое
ожидание находим по формуле:
Для
нашего примера:
Задачи контрольных и самостоятельных работ
Задача 1
Плотность
распределения непрерывной случайной величины X имеет вид:
Найти:
а)
параметр a;
б)
функцию распределения F(x);
в)
вероятность попадания случайной величины X в интервал (6.5; 11);
г)
математическое ожидание M(X) и дисперсию D(X);
Построить
график функций f(x) и F(x).
Задача 2
Задана
функция распределения непрерывной случайной величины:
Найти и
построить график функции плотности распределения вероятностей.
Задача 3
Случайная
величина X задана функцией распределения F(x).
Найти плотность распределения вероятностей, математическое ожидание и дисперсию
случайной величины. Построить график функции
F(x).
Задача 4
Задана
плотность вероятности f(x) или функции распределения
непрерывной случайной величины X. Найти a, M[X], D[X], P(α<x<β).
α=1,β=2
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 5
Непрерывная
случайная величина
задана плотностью распределения вероятностей.
Требуется
найти:
— функцию
распределения вероятностей;
—
математическое ожидание;
—
дисперсию;
— среднее
квадратическое отклонение;
— вероятность
того, что случайная величина отклонится от своего математического ожидания не
более, чем на одну четвертую длины всего интервала возможных значений этой
величины;
—
построить графики функции распределения и плотности распределения вероятностей.
Задача 6
Случайная
величина X равномерно распределена на интервале (2;7).
Составить f(x),F(x), построить графики. Найти
M(X),D(X).
Задача 7
Случайная
величина X~N(a,σ)
a=25;
σ=4; α=13; β=30; δ=0.1.
Требуется:
—
составить функцию плотности распределения и построить ее график;
— найти
вероятность того, что случайная величина в результате испытания примет
значение, принадлежащее интервалу (α; β);
— найти
вероятность того, что абсолютная величина отклонения значений случайной
величины от ее математического ожидания не превысит δ.
Задача 8
Плотность
вероятности непрерывной случайной величины ξ задана следующим выражением:
Найти
постоянную C, функцию распределения Fξ (x), математическое
ожидание и дисперсию Dξ случайной величины ξ.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 9
Случайная
величина X задана функцией распределения вероятностей F(x).
Требуется:
1. Найти
функцию плотности распределения f(x).
2. Найти M(X).
3. Найти
вероятность P(α<X<β)
4.
Построить графики f(x) и F(x).
α=2, β=4.5
Задача 10
Найти
функцию плотности нормально распределенной случайной величины X и
постройте ее график, зная M(X) и D(X).
M(X)=-1; D(X)=8
Задача 11
Случайная
величина X задана интегральной F(x) или дифференциальной f(x)
функцией. Требуется:
а) найти
параметр C;
б) при
заданной интегральной функции F(x) найти дифференциальную функцию f(x), а при
заданной дифференциальной функции f(x) найти интегральную функцию F(x);
в)
построить графики функций F(x) и f(x);
г) найти
математическое ожидание M(X), дисперсию D(X) и
среднее квадратическое отклонение σ(x);
д)
вычислить вероятность попадания в интервал P(a≤x≤b)
е)
определить, квантилем какого порядка является точка xp;
ж)
вычислить квантиль порядка p
a=π/4; b=π/3; xp=π/2; p=0.75
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
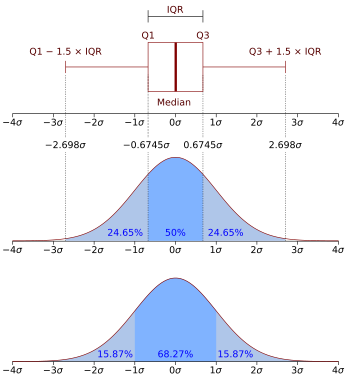

Geometric visualisation of the mode, median and mean of an arbitrary unimodal probability density function.[1]
In probability theory, a probability density function (PDF), or density of an absolutely continuous random variable, is a function whose value at any given sample (or point) in the sample space (the set of possible values taken by the random variable) can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample.[2][3] Probability density is the probability per unit length, in other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0 (since there is an infinite set of possible values to begin with), the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.
In a more precise sense, the PDF is used to specify the probability of the random variable falling within a particular range of values, as opposed to taking on any one value. This probability is given by the integral of this variable’s PDF over that range—that is, it is given by the area under the density function but above the horizontal axis and between the lowest and greatest values of the range. The probability density function is nonnegative everywhere, and the area under the entire curve is equal to 1.
The terms probability distribution function and probability function have also sometimes been used to denote the probability density function. However, this use is not standard among probabilists and statisticians. In other sources, «probability distribution function» may be used when the probability distribution is defined as a function over general sets of values or it may refer to the cumulative distribution function, or it may be a probability mass function (PMF) rather than the density. «Density function» itself is also used for the probability mass function, leading to further confusion.[4] In general though, the PMF is used in the context of discrete random variables (random variables that take values on a countable set), while the PDF is used in the context of continuous random variables.
Example[edit]
Suppose bacteria of a certain species typically live 4 to 6 hours. The probability that a bacterium lives exactly 5 hours is equal to zero. A lot of bacteria live for approximately 5 hours, but there is no chance that any given bacterium dies at exactly 5.00… hours. However, the probability that the bacterium dies between 5 hours and 5.01 hours is quantifiable. Suppose the answer is 0.02 (i.e., 2%). Then, the probability that the bacterium dies between 5 hours and 5.001 hours should be about 0.002, since this time interval is one-tenth as long as the previous. The probability that the bacterium dies between 5 hours and 5.0001 hours should be about 0.0002, and so on.
In this example, the ratio (probability of dying during an interval) / (duration of the interval) is approximately constant, and equal to 2 per hour (or 2 hour−1). For example, there is 0.02 probability of dying in the 0.01-hour interval between 5 and 5.01 hours, and (0.02 probability / 0.01 hours) = 2 hour−1. This quantity 2 hour−1 is called the probability density for dying at around 5 hours. Therefore, the probability that the bacterium dies at 5 hours can be written as (2 hour−1) dt. This is the probability that the bacterium dies within an infinitesimal window of time around 5 hours, where dt is the duration of this window. For example, the probability that it lives longer than 5 hours, but shorter than (5 hours + 1 nanosecond), is (2 hour−1)×(1 nanosecond) ≈ 6×10−13 (using the unit conversion 3.6×1012 nanoseconds = 1 hour).
There is a probability density function f with f(5 hours) = 2 hour−1. The integral of f over any window of time (not only infinitesimal windows but also large windows) is the probability that the bacterium dies in that window.
Absolutely continuous univariate distributions[edit]
A probability density function is most commonly associated with absolutely continuous univariate distributions. A random variable  has density
has density  , where is a non-negative Lebesgue-integrable function, if:
, where is a non-negative Lebesgue-integrable function, if:
![{displaystyle Pr[aleq Xleq b]=int _{a}^{b}f_{X}(x),dx.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/45fd7691b5fbd323f64834d8e5b8d4f54c73a6f8)
Hence, if  is the cumulative distribution function of , then:
is the cumulative distribution function of , then:

and (if is continuous at  )
)

Intuitively, one can think of  as being the probability of falling within the infinitesimal interval
as being the probability of falling within the infinitesimal interval ![[x,x+dx]](https://wikimedia.org/api/rest_v1/media/math/render/svg/f07271dbe3f8967834a2eaf143decd7e41c61d7a) .
.
Formal definition[edit]
(This definition may be extended to any probability distribution using the measure-theoretic definition of probability.)
A random variable with values in a measurable space  (usually
(usually  with the Borel sets as measurable subsets) has as probability distribution the measure X∗P on : the density of with respect to a reference measure
with the Borel sets as measurable subsets) has as probability distribution the measure X∗P on : the density of with respect to a reference measure  on is the Radon–Nikodym derivative:
on is the Radon–Nikodym derivative:

That is, f is any measurable function with the property that:
![{displaystyle Pr[Xin A]=int _{X^{-1}A},dP=int _{A}f,dmu }](https://wikimedia.org/api/rest_v1/media/math/render/svg/591b4a96fefea18b28fe8eb36d3469ad6b33a9db)
for any measurable set 
Discussion[edit]
In the continuous univariate case above, the reference measure is the Lebesgue measure. The probability mass function of a discrete random variable is the density with respect to the counting measure over the sample space (usually the set of integers, or some subset thereof).
It is not possible to define a density with reference to an arbitrary measure (e.g. one can’t choose the counting measure as a reference for a continuous random variable). Furthermore, when it does exist, the density is almost unique, meaning that any two such densities coincide almost everywhere.
Further details[edit]
Unlike a probability, a probability density function can take on values greater than one; for example, the uniform distribution on the interval [0, 1/2] has probability density f(x) = 2 for 0 ≤ x ≤ 1/2 and f(x) = 0 elsewhere.
The standard normal distribution has probability density

If a random variable X is given and its distribution admits a probability density function f, then the expected value of X (if the expected value exists) can be calculated as
![{displaystyle operatorname {E} [X]=int _{-infty }^{infty }x,f(x),dx.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/00ce7a00fac378eafc98afb88de88d619e15e996)
Not every probability distribution has a density function: the distributions of discrete random variables do not; nor does the Cantor distribution, even though it has no discrete component, i.e., does not assign positive probability to any individual point.
A distribution has a density function if and only if its cumulative distribution function F(x) is absolutely continuous. In this case: F is almost everywhere differentiable, and its derivative can be used as probability density:

If a probability distribution admits a density, then the probability of every one-point set {a} is zero; the same holds for finite and countable sets.
Two probability densities f and g represent the same probability distribution precisely if they differ only on a set of Lebesgue measure zero.
In the field of statistical physics, a non-formal reformulation of the relation above between the derivative of the cumulative distribution function and the probability density function is generally used as the definition of the probability density function. This alternate definition is the following:
If dt is an infinitely small number, the probability that X is included within the interval (t, t + dt) is equal to f(t) dt, or:

Link between discrete and continuous distributions[edit]
It is possible to represent certain discrete random variables as well as random variables involving both a continuous and a discrete part with a generalized probability density function using the Dirac delta function. (This is not possible with a probability density function in the sense defined above, it may be done with a distribution.) For example, consider a binary discrete random variable having the Rademacher distribution—that is, taking −1 or 1 for values, with probability 1⁄2 each. The density of probability associated with this variable is:

More generally, if a discrete variable can take n different values among real numbers, then the associated probability density function is:

where  are the discrete values accessible to the variable and
are the discrete values accessible to the variable and  are the probabilities associated with these values.
are the probabilities associated with these values.
This substantially unifies the treatment of discrete and continuous probability distributions. The above expression allows for determining statistical characteristics of such a discrete variable (such as the mean, variance, and kurtosis), starting from the formulas given for a continuous distribution of the probability.
Families of densities[edit]
It is common for probability density functions (and probability mass functions) to be parametrized—that is, to be characterized by unspecified parameters. For example, the normal distribution is parametrized in terms of the mean and the variance, denoted by and  respectively, giving the family of densities
respectively, giving the family of densities

Different values of the parameters describe different distributions of different random variables on the same sample space (the same set of all possible values of the variable); this sample space is the domain of the family of random variables that this family of distributions describes. A given set of parameters describes a single distribution within the family sharing the functional form of the density. From the perspective of a given distribution, the parameters are constants, and terms in a density function that contain only parameters, but not variables, are part of the normalization factor of a distribution (the multiplicative factor that ensures that the area under the density—the probability of something in the domain occurring— equals 1). This normalization factor is outside the kernel of the distribution.
Since the parameters are constants, reparametrizing a density in terms of different parameters to give a characterization of a different random variable in the family, means simply substituting the new parameter values into the formula in place of the old ones.
Densities associated with multiple variables[edit]
For continuous random variables X1, …, Xn, it is also possible to define a probability density function associated to the set as a whole, often called joint probability density function. This density function is defined as a function of the n variables, such that, for any domain D in the n-dimensional space of the values of the variables X1, …, Xn, the probability that a realisation of the set variables falls inside the domain D is

If F(x1, …, xn) = Pr(X1 ≤ x1, …, Xn ≤ xn) is the cumulative distribution function of the vector (X1, …, Xn), then the joint probability density function can be computed as a partial derivative

Marginal densities[edit]
For i = 1, 2, …, n, let fXi(xi) be the probability density function associated with variable Xi alone. This is called the marginal density function, and can be deduced from the probability density associated with the random variables X1, …, Xn by integrating over all values of the other n − 1 variables:

Independence[edit]
Continuous random variables X1, …, Xn admitting a joint density are all independent from each other if and only if

Corollary[edit]
If the joint probability density function of a vector of n random variables can be factored into a product of n functions of one variable

(where each fi is not necessarily a density) then the n variables in the set are all independent from each other, and the marginal probability density function of each of them is given by

Example[edit]
This elementary example illustrates the above definition of multidimensional probability density functions in the simple case of a function of a set of two variables. Let us call  a 2-dimensional random vector of coordinates (X, Y): the probability to obtain in the quarter plane of positive x and y is
a 2-dimensional random vector of coordinates (X, Y): the probability to obtain in the quarter plane of positive x and y is

Function of random variables and change of variables in the probability density function[edit]
If the probability density function of a random variable (or vector) X is given as fX(x), it is possible (but often not necessary; see below) to calculate the probability density function of some variable Y = g(X). This is also called a “change of variable” and is in practice used to generate a random variable of arbitrary shape fg(X) = fY using a known (for instance, uniform) random number generator.
It is tempting to think that in order to find the expected value E(g(X)), one must first find the probability density fg(X) of the new random variable Y = g(X). However, rather than computing

one may find instead

The values of the two integrals are the same in all cases in which both X and g(X) actually have probability density functions. It is not necessary that g be a one-to-one function. In some cases the latter integral is computed much more easily than the former. See Law of the unconscious statistician.
Scalar to scalar[edit]
Let  be a monotonic function, then the resulting density function is
be a monotonic function, then the resulting density function is

Here g−1 denotes the inverse function.
This follows from the fact that the probability contained in a differential area must be invariant under change of variables. That is,

or

For functions that are not monotonic, the probability density function for y is

where n(y) is the number of solutions in x for the equation  , and
, and  are these solutions.
are these solutions.
Vector to vector[edit]
Suppose x is an n-dimensional random variable with joint density f. If y = H(x), where H is a bijective, differentiable function, then y has density g:
![{displaystyle g(mathbf {y} )=f{Bigl (}H^{-1}(mathbf {y} ){Bigr )}left|det left[left.{frac {dH^{-1}(mathbf {z} )}{dmathbf {z} }}right|_{mathbf {z} =mathbf {y} }right]right|}](https://wikimedia.org/api/rest_v1/media/math/render/svg/732bd3920089d7177a63016ab1717b6e0a56b654)
with the differential regarded as the Jacobian of the inverse of H(⋅), evaluated at y.[5]
For example, in the 2-dimensional case x = (x1, x2), suppose the transform H is given as y1 = H1(x1, x2), y2 = H2(x1, x2) with inverses x1 = H1−1(y1, y2), x2 = H2−1(y1, y2). The joint distribution for y = (y1, y2) has density[6]

Vector to scalar[edit]
Let  be a differentiable function and be a random vector taking values in , be the probability density function of and
be a differentiable function and be a random vector taking values in , be the probability density function of and  be the Dirac delta function. It is possible to use the formulas above to determine
be the Dirac delta function. It is possible to use the formulas above to determine  , the probability density function of
, the probability density function of  , which will be given by
, which will be given by

This result leads to the law of the unconscious statistician:
![{displaystyle operatorname {E} _{Y}[Y]=int _{mathbb {R} }yf_{Y}(y),dy=int _{mathbb {R} }yint _{mathbb {R} ^{n}}f_{X}(mathbf {x} )delta {big (}y-V(mathbf {x} ){big )},dmathbf {x} ,dy=int _{{mathbb {R} }^{n}}int _{mathbb {R} }yf_{X}(mathbf {x} )delta {big (}y-V(mathbf {x} ){big )},dy,dmathbf {x} =int _{mathbb {R} ^{n}}V(mathbf {x} )f_{X}(mathbf {x} ),dmathbf {x} =operatorname {E} _{X}[V(X)].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ad5325e96f2d76c533cb1a21d2095e8cf16e6fc7)
Proof:
Let  be a collapsed random variable with probability density function
be a collapsed random variable with probability density function  (i.e., a constant equal to zero). Let the random vector
(i.e., a constant equal to zero). Let the random vector  and the transform
and the transform  be defined as
be defined as

It is clear that is a bijective mapping, and the Jacobian of  is given by:
is given by:

which is an upper triangular matrix with ones on the main diagonal, therefore its determinant is 1. Applying the change of variable theorem from the previous section we obtain that

which if marginalized over leads to the desired probability density function.
Sums of independent random variables[edit]
The probability density function of the sum of two independent random variables U and V, each of which has a probability density function, is the convolution of their separate density functions:

It is possible to generalize the previous relation to a sum of N independent random variables, with densities U1, …, UN:

This can be derived from a two-way change of variables involving Y = U + V and Z = V, similarly to the example below for the quotient of independent random variables.
Products and quotients of independent random variables[edit]
Given two independent random variables U and V, each of which has a probability density function, the density of the product Y = UV and quotient Y = U/V can be computed by a change of variables.
Example: Quotient distribution[edit]
To compute the quotient Y = U/V of two independent random variables U and V, define the following transformation:


Then, the joint density p(y,z) can be computed by a change of variables from U,V to Y,Z, and Y can be derived by marginalizing out Z from the joint density.
The inverse transformation is


The absolute value of the Jacobian matrix determinant  of this transformation is:
of this transformation is:

Thus:

And the distribution of Y can be computed by marginalizing out Z:

This method crucially requires that the transformation from U,V to Y,Z be bijective. The above transformation meets this because Z can be mapped directly back to V, and for a given V the quotient U/V is monotonic. This is similarly the case for the sum U + V, difference U − V and product UV.
Exactly the same method can be used to compute the distribution of other functions of multiple independent random variables.
Example: Quotient of two standard normals[edit]
Given two standard normal variables U and V, the quotient can be computed as follows. First, the variables have the following density functions:


We transform as described above:
This leads to:
![{displaystyle {begin{aligned}p(y)&=int _{-infty }^{infty }p_{U}(yz),p_{V}(z),|z|,dz\[5pt]&=int _{-infty }^{infty }{frac {1}{sqrt {2pi }}}e^{-{frac {1}{2}}y^{2}z^{2}}{frac {1}{sqrt {2pi }}}e^{-{frac {1}{2}}z^{2}}|z|,dz\[5pt]&=int _{-infty }^{infty }{frac {1}{2pi }}e^{-{frac {1}{2}}left(y^{2}+1right)z^{2}}|z|,dz\[5pt]&=2int _{0}^{infty }{frac {1}{2pi }}e^{-{frac {1}{2}}left(y^{2}+1right)z^{2}}z,dz\[5pt]&=int _{0}^{infty }{frac {1}{pi }}e^{-left(y^{2}+1right)u},du&&u={tfrac {1}{2}}z^{2}\[5pt]&=left.-{frac {1}{pi left(y^{2}+1right)}}e^{-left(y^{2}+1right)u}right|_{u=0}^{infty }\[5pt]&={frac {1}{pi left(y^{2}+1right)}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/63983efb2501c35f094487a9c6473a30e9405551)
This is the density of a standard Cauchy distribution.
See also[edit]
- Density estimation
- Kernel density estimation
- Likelihood function
- List of probability distributions
- Probability amplitude
- Probability mass function
- Secondary measure
- Uses as position probability density:
- Atomic orbital
- Home range
References[edit]
- ^ «AP Statistics Review — Density Curves and the Normal Distributions». Archived from the original on 2 April 2015. Retrieved 16 March 2015.
- ^ Grinstead, Charles M.; Snell, J. Laurie (2009). «Conditional Probability — Discrete Conditional» (PDF). Grinstead & Snell’s Introduction to Probability. Orange Grove Texts. ISBN 978-1616100469. Archived (PDF) from the original on 2003-04-25. Retrieved 2019-07-25.
- ^ «probability — Is a uniformly random number over the real line a valid distribution?». Cross Validated. Retrieved 2021-10-06.
- ^ Ord, J.K. (1972) Families of Frequency Distributions, Griffin. ISBN 0-85264-137-0 (for example, Table 5.1 and Example 5.4)
- ^ Devore, Jay L.; Berk, Kenneth N. (2007). Modern Mathematical Statistics with Applications. Cengage. p. 263. ISBN 978-0-534-40473-4.
- ^ David, Stirzaker (2007-01-01). Elementary Probability. Cambridge University Press. ISBN 978-0521534284. OCLC 851313783.
Further reading[edit]
- Billingsley, Patrick (1979). Probability and Measure. New York, Toronto, London: John Wiley and Sons. ISBN 0-471-00710-2.
- Casella, George; Berger, Roger L. (2002). Statistical Inference (Second ed.). Thomson Learning. pp. 34–37. ISBN 0-534-24312-6.
- Stirzaker, David (2003). Elementary Probability. ISBN 0-521-42028-8. Chapters 7 to 9 are about continuous variables.
External links[edit]
- Ushakov, N.G. (2001) [1994], «Density of a probability distribution», Encyclopedia of Mathematics, EMS Press
- Weisstein, Eric W. «Probability density function». MathWorld.
2.4.3. Функция ПЛОТНОСТИ распределения вероятностей
или дифференциальная функция распределения. Она представляет собой производную функции распределения: ![]() .
.
Примечание: для дискретной случайной величины такой функции не существует
В нашем примере:
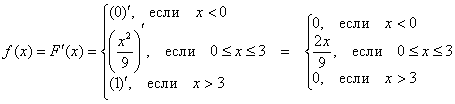
то есть, всё очень просто – берём производную от каждого куска, и порядок.
Но настоящий порядок состоит в том, что несобственный интеграл от ![]() с пределами интегрирования от «минус» до «плюс» бесконечности:
с пределами интегрирования от «минус» до «плюс» бесконечности:
![]() – равен единице, и строго единице. В противном случае перед нами не функция плотности, и если эта функция была найдена как производная, то
– равен единице, и строго единице. В противном случае перед нами не функция плотности, и если эта функция была найдена как производная, то ![]() – не является функцией распределения (несмотря на какие бы то ни было другие признаки).
– не является функцией распределения (несмотря на какие бы то ни было другие признаки).
Проверим «подлинность» наших функций. Если случайная величина ![]() принимает значения из конечного промежутка, то всё дело сводится к вычислению определённого интеграла. В силу свойства аддитивности, делим интеграл на 3 части:
принимает значения из конечного промежутка, то всё дело сводится к вычислению определённого интеграла. В силу свойства аддитивности, делим интеграл на 3 части:

Совершенно понятно, что левый и правый интегралы равны нулю и нам осталось вычислить средний интеграл:
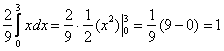 , что и требовалось проверить.
, что и требовалось проверить.
С вероятностной точки зрения это означает, что случайная величина ![]() достоверно примет одно из значений отрезка
достоверно примет одно из значений отрезка ![]() . Геометрически же это значит, что площадь между осью
. Геометрически же это значит, что площадь между осью ![]() и графиком
и графиком ![]() равна единице, и в данном случае речь идёт о площади треугольника
равна единице, и в данном случае речь идёт о площади треугольника ![]() . Сторона
. Сторона ![]() является фрагментом прямой
является фрагментом прямой ![]() и для её построения достаточно найти точку
и для её построения достаточно найти точку ![]() :
:
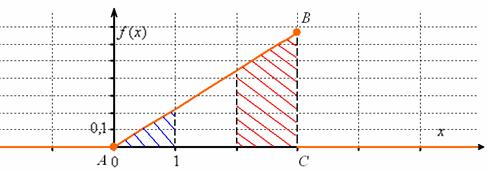
Ну вот, теперь всё наглядно – где бОльшая площадь, там и сконцентрированы более вероятные значения.
Так как функция плотности «собирает под собой» вероятности, то она неотрицательна ![]() и её график не может располагаться ниже оси
и её график не может располагаться ниже оси ![]() . В общем случае функция разрывна (смотрим, где «жирные» оранжевые точки!).
. В общем случае функция разрывна (смотрим, где «жирные» оранжевые точки!).
Теперь разберём весьма любопытный факт: поскольку действительных чисел несчётно много, то вероятность того, что случайная величина ![]() примет какое-то конкретное значение стремится к нулю. И поэтому вероятности рассчитывают не для отдельно взятых точек, а для целых промежутков (пусть даже очень малых). Как вы правильно догадываетесь:
примет какое-то конкретное значение стремится к нулю. И поэтому вероятности рассчитывают не для отдельно взятых точек, а для целых промежутков (пусть даже очень малых). Как вы правильно догадываетесь:
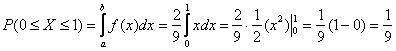 (синяя площадь на чертеже) – вероятность того, что случайная величина примет значение из отрезка
(синяя площадь на чертеже) – вероятность того, что случайная величина примет значение из отрезка ![]() ;
;
![]() (красная площадь) – вероятность того, что случайная величина примет значение из отрезка
(красная площадь) – вероятность того, что случайная величина примет значение из отрезка ![]() .
.
По той причине, что отдельно взятые значения можно не принимать во внимание, с помощью этих же интегралов рассчитываются и вероятности по интервалам и полуинтервалам, в частности:

Этим же объяснятся аналогичная «вольность» с функцией ![]() .
.
Возможно, кто-то спросит: а зачем считать интегралы, если есть функция ![]() ?
?
А дело в том, что во многих задачах непрерывная случайная величина ИЗНАЧАЛЬНО задана функцией ![]() плотности распределения, которая ТОЖЕ однозначно определяет случайную величину. Но, как вариант, можно сначала найти функцию
плотности распределения, которая ТОЖЕ однозначно определяет случайную величину. Но, как вариант, можно сначала найти функцию ![]() (с помощью тех же интегралов), после чего использовать «лёгкий способ» бросить курить отыскания вероятностей. Впрочем, об этом чуть позже:
(с помощью тех же интегралов), после чего использовать «лёгкий способ» бросить курить отыскания вероятностей. Впрочем, об этом чуть позже:
Задача 105
Непрерывная случайная величина ![]() задана своей функцией распределения:
задана своей функцией распределения:
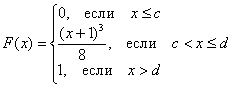
Найти значения ![]() и функцию
и функцию ![]() . Проверить, что
. Проверить, что ![]() действительно является функцией плотности распределения. Вычислить вероятности
действительно является функцией плотности распределения. Вычислить вероятности ![]() . Построить графики
. Построить графики ![]() .
.
Тренируемся самостоятельно! Если возникнут затруднения, то внимательно перечитайте вышеизложенный материал. Краткое решение и ответ в конце книги.
Вообще, типовые задачи на непрерывную случайную величину можно разделить на 2 большие группы:
1) когда дана функция ![]() , 2) когда дана функция
, 2) когда дана функция ![]() .
.
В первом случае не составляет особых трудностей отыскать функцию плотности распределения – почти всегда производные не то что простЫ, а примитивны (в чём мы только что убедились). Но вот когда НСВ задана функцией ![]() , то нахождение функции распределения – есть более кропотливый процесс:
, то нахождение функции распределения – есть более кропотливый процесс:
Задача 106
Непрерывная случайная величина ![]() задана функцией плотности распределения:
задана функцией плотности распределения:
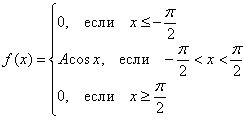
Найти значение ![]() и составить функцию распределения вероятностей
и составить функцию распределения вероятностей ![]() . Вычислить
. Вычислить ![]() .
.
Построить графики ![]() .
.
Решение: найдём константу ![]() . Это классика (в подавляющем большинстве задач вам не предложат готовую функцию плотности). Используем свойство
. Это классика (в подавляющем большинстве задач вам не предложат готовую функцию плотности). Используем свойство ![]() .
.
В данном случае:

На практике нулевые интегралы можно опускать, а константу сразу выносить за знак интеграла:
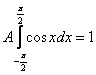 (*)
(*)
Пользуясь чётностью подынтегральной функции, вычислим интеграл:
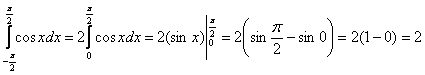 и подставим результат в уравнение (*):
и подставим результат в уравнение (*):
![]() , откуда выразим
, откуда выразим ![]()
Таким образом, функция плотности распределения:
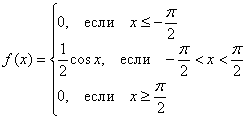
Выполним проверку, а именно, вычислим тот же самый интеграл, но уже с известной константой. Для разнообразия я не буду пользоваться чётностью:
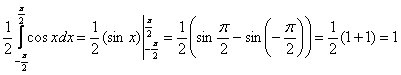 , отлично.
, отлично.
Обратите внимание, что только при ![]() и только при этом значении предложенная в условии функция является функцией плотности распределения. Ну и тут не лишним будет проконтролировать, что на интервале
и только при этом значении предложенная в условии функция является функцией плотности распределения. Ну и тут не лишним будет проконтролировать, что на интервале ![]() , т.е. условие неотрицательности действительно выполнено. Доверяй условию, да проверяй
, т.е. условие неотрицательности действительно выполнено. Доверяй условию, да проверяй  Не раз и не два мне встречались функции, которые в принципе не могли быть плотностью, что говорило об опечатках или о невнимательности авторов задач.
Не раз и не два мне встречались функции, которые в принципе не могли быть плотностью, что говорило об опечатках или о невнимательности авторов задач.
Теперь начинается самое интересное. Функции распределения вероятностей – есть интеграл:
![]()
Так как ![]() состоит из трёх кусков, то решение разобьётся на 3 шага:
состоит из трёх кусков, то решение разобьётся на 3 шага:
1) На промежутке ![]() , поэтому:
, поэтому: ![]()
2) На интервале ![]() , и мы прицепляем следующий вагончик:
, и мы прицепляем следующий вагончик:
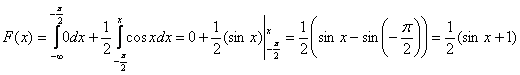
При подстановке верхнего предела интегрирования можно считать, что вместо «икс» мы подставляем «икс». Если же возник вопрос с пределом нижним, то вспоминаем график синуса либо его нечётность: ![]() .
.
3) И, наконец, на ![]() , и детский паровозик отправляется в путь:
, и детский паровозик отправляется в путь:

Внимание! А вот в этом задании нулевые интегралы пропускать НЕ НАДО. Чтобы показать своё понимание функции распределения К тому же, они могут оказаться вовсе не нулевыми, и тогда придётся иметь дело с интегралами несобственными. И такой пример я обязательно разберу ниже.
Записываем наши достижения под единую скобку:
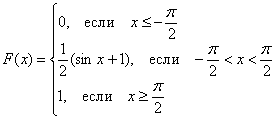
С высокой вероятностью всё правильно, но, тем не менее, устно возьмём производную: 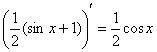 , а также «прозвоним» точки «стыка»:
, а также «прозвоним» точки «стыка»:
![]()
Правильность решения можно проконтролировать и в ходе построения графика, но, во-первых, он не всегда требуется, а во-вторых, до сего момента можно успеть «наломать дров». Ибо вероятности попадания чаще находят с помощью функции распределения:
![]()
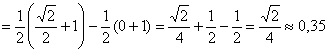 – вероятность того, что случайная величина
– вероятность того, что случайная величина ![]() примет значение из промежутка
примет значение из промежутка ![]()
Второй способ состоит в вычислении интеграла:
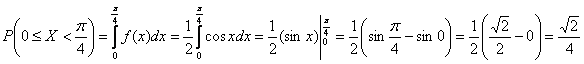 что, кстати, не труднее. И проверочка заодно получилась.
что, кстати, не труднее. И проверочка заодно получилась.
Выполним чертежи. График ![]() представляет собой
представляет собой косинусоиду, сжатую вдоль ординат в 2 раза. Тот редкий случай, когда функция плотности непрерывна:
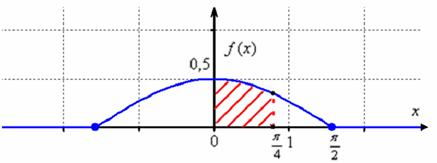
Значение ![]() численно равно заштрихованной площади – это я специально нарисовал, чтобы напомнить вероятностный смысл плотности функции распределения. И вся площадь под «дугой» равна единице, то есть, достоверным является тот факт, что случайная величина примет значение из интервала
численно равно заштрихованной площади – это я специально нарисовал, чтобы напомнить вероятностный смысл плотности функции распределения. И вся площадь под «дугой» равна единице, то есть, достоверным является тот факт, что случайная величина примет значение из интервала ![]() . Заметьте, что значения
. Заметьте, что значения ![]() по условию, невозможны.
по условию, невозможны.
Осталось изобразить функцию распределения. График ![]() представляет собой синусоиду, сжатую в 2 раза вдоль оси ординат и сдвинутую на
представляет собой синусоиду, сжатую в 2 раза вдоль оси ординат и сдвинутую на ![]() вверх:
вверх:
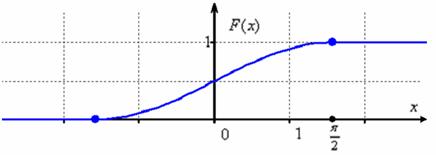
В принципе, тут можно было не заморачиваться преобразованием графиков, а найти несколько опорных точек и догадаться, как выглядит кривая (тригонометрическая таблица в помощь). Но «любительский» подход чреват тем, что график получится принципиально не точным. Так, в нашем примере в точке ![]() существует перегиб графика функции
существует перегиб графика функции ![]() , и велик риск неверно отобразить его выпуклость / вогнутость.
, и велик риск неверно отобразить его выпуклость / вогнутость.
Чертежи желательно расположить так, чтобы оси ординат (вертикальные оси) лежали ровненько одна под другой. Это будет хорошим тоном.
И я так чувствую, вам уже не терпится проверить свои силы. Как водится, пример попроще:
Задача 107
Задана плотность распределения вероятностей непрерывной случайной величины ![]() :
:
![]()
Требуется:
1) определить коэффициент ![]() ;
;
2) найти функцию распределения ![]() ;
;
3) построить графики ![]() ;
;
4) найти вероятность того, что ![]() примет значение из промежутка
примет значение из промежутка ![]()
и задачка поинтереснее:
Задача 108
Непрерывная случайная величина ![]() задана плотностью распределения вероятностей:
задана плотностью распределения вероятностей:
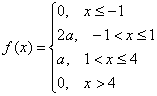
Найти значение ![]() и построить график плотности распределения. Найти функцию распределения вероятностей
и построить график плотности распределения. Найти функцию распределения вероятностей ![]() и построить её график. Вычислить вероятность
и построить её график. Вычислить вероятность ![]() .
.
Дерзайте! Свериться с решением можно внизу книги.
Следует отметить, что все эти задачи реально предлагают студентам-заочникам, и поэтому я не предлагаю вам ничего необычного.
И в заключение параграфа обещанные случаи с несобственными интегралами:
Задача 109
Непрерывная случайная величина ![]() задана своей плотностью распределения:
задана своей плотностью распределения:
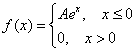
Найти коэффициент ![]() и функцию распределения
и функцию распределения ![]() . Построить графики.
. Построить графики.
Решение: по свойству функции плотности распределения:
![]()
В данной задаче ![]() состоит из 2 частей, поэтому:
состоит из 2 частей, поэтому:
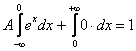
Правый интеграл равен нулю, а вот левый – есть «живой» несобственный интеграл с бесконечным нижним пределом:
![]()
Таким образом, наше уравнение превратилось в готовый результат:
![]()
и функция плотности:
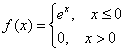
Функция ![]() , как нетрудно понять, отыскивается в 2 шага:
, как нетрудно понять, отыскивается в 2 шага:
1) На промежутке ![]() , следовательно:
, следовательно:
![]() – вот такая вот у нас замечательная экспонента. Как птица Феникс.
– вот такая вот у нас замечательная экспонента. Как птица Феникс.
2) На интервале ![]() и:
и:
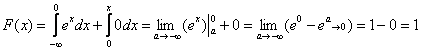 , что и должно получиться.
, что и должно получиться.
Для построения графиков найдём пару опорных точек: ![]() и аккуратно прочертим кусочки экспонент с причитающимися дополнениями:
и аккуратно прочертим кусочки экспонент с причитающимися дополнениями:

Заметьте, что теоретически случайная величина ![]() может принять сколь угодно большое по модулю отрицательное значение, и ось абсцисс является горизонтальной асимптотой для обоих графиков при
может принять сколь угодно большое по модулю отрицательное значение, и ось абсцисс является горизонтальной асимптотой для обоих графиков при ![]() .
.
В соответствующей статье сайта я рассмотрел ещё более интересный пример с функцией ![]() , где случайная величина теоретически принимает вообще ВСЕ действительные значения. Но это уже несколько повышенный уровень сложности.
, где случайная величина теоретически принимает вообще ВСЕ действительные значения. Но это уже несколько повышенный уровень сложности.
 2.4.4. Как вычислить математическое ожидание и дисперсию НСВ?
2.4.4. Как вычислить математическое ожидание и дисперсию НСВ?
 2.4.2. Вероятность попадания в промежуток
2.4.2. Вероятность попадания в промежуток
| Оглавление |
Полную и свежую версию этой книги в pdf-формате,
а также курсы по другим темам можно найти здесь.
Также вы можете изучить эту тему подробнее – просто, доступно, весело и бесплатно!
С наилучшими пожеланиями, Александр Емелин