Шифр гаммирования.
Гаммирование.В
этом способе шифрование выполняется
путем сложения символов исходного
текста и ключа по модулю, равному числу
букв в алфавите. Если в исходном алфавите,
например, 33 символа, то сложение
производится по модулю 33. Такой процесс
сложения исходного текста и ключа
называется в криптографии наложением
гаммы.
Пусть
символам исходного алфавита соответствуют
числа от 0
(А) до 32
(Я).
Если обозначить число, соответствующее
исходному символу, x,
а символу ключа – k,
то можно записать правило гаммирования
следующим образом:
z
= x + k (mod N),
где z –
закодированный символ, N —
количество символов в алфавите, а
сложение по модулю N —
операция, аналогичная обычному сложению,
с тем отличием, что если обычное
суммирование дает результат, больший
или равный N,
то значением суммы считается остаток
от деления его на N.
Например, пусть сложим по модулю 33
символы Г
(3) и Ю
(31):
3
+ 31 (mod 33) = 1,
то
есть в результате получаем символ Б,
соответствующий числу 1.
Наиболее
часто на практике встречается двоичное
гаммирование. При этом используется двоичный
алфавит,
а сложение производится по модулю два.
Операция сложения по модулю 2 часто
обозначается ![]() ,
,
то есть можно записать:
![]()
Операция
сложения по модулю два в алгебре
логики называется
также «исключающее
ИЛИ» или
по-английски XOR.
Пример:
Предположим, нам необходимо зашифровать
десятичное число 14 методом
гаммирования с использованием ключа 12.
Для этого вначале необходимо преобразовать
исходное число и ключ (гамму) в двоичную
форму:14(10)=1110(2),
12(10)=1100(2).
Затем надо записать полученные двоичные
числа друг под другом и каждую пару
символов сложить по модулю два. При
сложении двух двоичных знаков получается 0,
если исходные двоичные цифры одинаковы,
и 1,
если цифры разные:
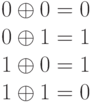
Сложим
по модулю два двоичные числа 1110 и 1100:
Исходное
число 1 1 1 0
Гамма
1 1 0 0
Результат
0 0 1 0
В
результате сложения получили двоичное
число 0010.
Если перевести его в десятичную форму,
получим 2.
Таким образом, в результате применения
к числу 14 операции
гаммирования с ключом 12 получаем
в результате число 2.
Каким
же образом выполняется расшифрование?
Зашифрованное число 2 представляется
в двоичном виде и снова производится
сложение по модулю 2 с
ключом:
Зашифрованное
число 0 0 1 0
Гамма
1 1 0 0
Результат
1 1 1 0
Переведем
полученное двоичное значение 1110 в
десятичный вид и получим 14,
то есть исходное число.
Комбинированные (составные) шифры.
Два
самых известных полевых шифра в истории
криптографии — ADFGX и ADFGVX. Таблица шифрозамен
ADFGX представляет собой матрицу 5 х 5, а
для ADFGVX – 6 х 6. Строки и столбцы обозначаются
буквами, входящими в название шифра.
Пример таблицы шифрозамен для шифра
ADFGVX применительно к русскому алфавиту
показан на следующем рисунке.
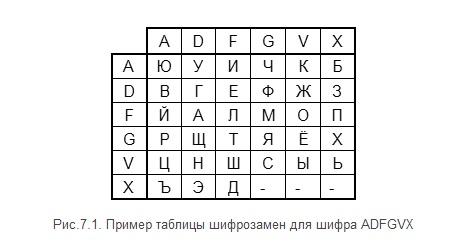
Шифрозамена
для буквы исходного текста состоит из
букв, обозначающих строку и столбец, на
пересечении которых она находится.
Пример:
Оригинальный
текст:
АБРАМОВ
Шифрованный
текст:
FD
AX GA FD FG FV DA
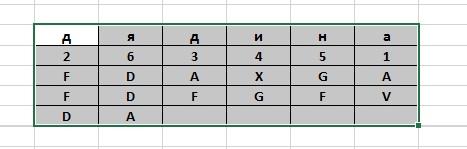
На
втором этапе для выполнения перестановки
полученный набор шифрозамен вписывается
построчно сверху-вниз в таблицу,
количество столбцов в которой строго
определено (ADFGX) или соответствует
количеству букв в ключевом слове
(ADFGVX). Нумерация столбов либо оговаривается
сторонами (ADFGX) либо соответствует
положению букв ключевого слова в
алфавите, как в шифре вертикальной
перестановки (ADFGVX). Например, для
полученного выше набора шифрозамен
перестановочная таблица с ключевым
словом «ДЯДИНА» показана на следующем
рисунке.
На
третьем этапе буквы выписываются из
столбцов в соответствии с их нумерацией,
при этом считывание происходит по
столбцам, а буквы объединяются в
пятибуквенные группы.
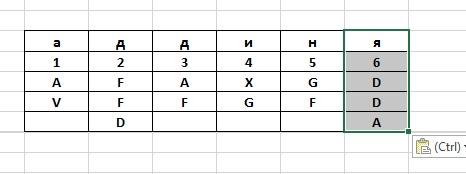
Таким
образом, окончательная шифрограмма для
рассматриваемого примера будет выглядеть
«AVFFD AFXGG FDDA».
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В аддитивных шифрах используется сложение по модулю (mod) исходного сообщения с гаммой, представленных в числовом виде. Напомним, что результатом сложения двух целых чисел по модулю является остаток от деления (например, 5+10 mod 4 = 15 mod 4 = 3).
В литературе шифры этого класса часто называют потоковыми, хотя к потоковым относятся и другие разновидности шифров. Стойкость закрытия этими шифрами определяется, главным образом, качеством гаммы, которое зависит от длины периода и случайности распределения по периоду. При этом символы в пределах периода гаммы являются ключом шифра.
Длиною периода гаммы называется минимальное количество символов, после которого последовательность цифр в гамме начинает повторяться. Случайность распределения символов по периоду означает отсутствие закономерностей между появлением различных символов в пределах периода.
По длине периода различаются гаммы с конечным и бесконечным периодом. Если длина периода гаммы превышает длину шифруемого текста, гамма является истинно случайной и не используется для шифрования других сообщений, то такое преобразование является абсолютно стойким (совершенный шифр).
Сложение по модулю N. В 1888 г. француз маркиз де Виари в одной из своих научных статей, посвященных криптографии, доказал, что при замене букв исходного сообщения и ключа на числа справедливы формулы
Ci = (Pi + Ki) mod N, (6.1)
Pi = (Ci + N — Ki) mod N, (6.2)
где Pi, Ci — i-ый символ открытого и шифрованного сообщения;
N — количество символов в алфавите;
Кi — i-ый символ гаммы (ключа). Если длина гаммы меньше, чем длина сообщения, то она используется повторно.
Данные формулы позволяют выполнить зашифрование / расшифрование по Виженеру при замене букв алфавита числами согласно следующей таблице (применительно к русскому алфавиту):

Таблица кодирования символов
Например, для шифрования используется русский алфавит (N = 33), открытое сообщение – «АБРАМОВ», гамма – «ЖУРИХИН». При замене символов на числа буква А будет представлена как 0, Б – 1, …, Я – 32. Результат шифрования показан в следующей таблице.
Таблица 6.1. Пример аддитивного шифрования по модулю N

Сложение по модулю 2. Значительный успех в криптографии связан с именем американца Гильберто Вернамом. В 1917 г. он, будучи сотрудником телеграфной компании AT&T, совместно с Мейджором Джозефом Моборном предложил идею автоматического шифрования телеграфных сообщений. Речь шла о своеобразном наложении гаммы на знаки алфавита, представленные в соответствии с телетайпным кодом Бодо пятизначными «импульсными комбинациями». Например, буква A представлялась комбинацией («– – – + +»), а комбинация («+ + – + +») представляла символ перехода от букв к цифрам. На бумажной ленте, используемой при работе телетайпа, знаку «+» отвечало наличие отверстия, а знаку «–» — его отсутствие. При считывании с ленты металлические щупы проходили через отверстия, замыкали электрическую цепь и, тем самым, посылали в линию импульс тока.
Вернам предложил электромеханически покоординатно складывать «импульсы» знаков открытого текста с «импульсами» гаммы, предварительно нанесенными на ленту. Сложение проводилось «по модулю 2». Имеется в виду, что если «+» отождествить с 1, а «–» с 0, то сложение определяется двоичной арифметикой:
 |
0 | 1 |
| 0 | 0 | 1 |
| 1 | 1 | 0 |
Т.о., при данном способе шифрования символы текста и гаммы представляются в двоичных кодах, а затем каждая пара двоичных разрядов складывается по модулю 2 (, для булевых величин аналог этой операции – XOR, «Исключающее ИЛИ»). Процедуры шифрования и дешифрования выполняются по следующим формулам
Ci = Pi Ki, (6.3)
Pi = Ci Ki. (6.4)
Вернам сконструировал и устройство для такого сложения. Замечательно то, что процесс шифрования оказывался полностью автоматизированным, в предложенной схеме исключался шифровальщик. Кроме того, оказывались слитыми воедино процессы зашифрования / расшифрования и передачи по каналу связи.
В 1918 г. два комплекта соответствующей аппаратуры были изготовлены и испытаны. Испытания дали положительные результаты. Единственное неудовлетворение специалистов — криптографов было связано с гаммой. Дело в том, что первоначально гамма была нанесена на ленту, склеенную в кольцо. Несмотря на то, что знаки гаммы на ленте выбирались случайно, при зашифровании длинных сообщений гамма регулярно повторялась. Этот недостаток так же отчетливо осознавался, как и для шифра Виженера. Уже тогда хорошо понимали, что повторное использование гаммы недопустимо даже в пределах одного сообщения. Попытки удлинить гамму приводили к неудобствам в работе с длинным кольцом. Тогда был предложен вариант с двумя лентами, одна из которых шифровала другую, в результате чего получалась гамма, имеющая длину периода, равную произведению длин исходных периодов.
Шифры гаммирования стали использоваться немцами в своих дипломатических представительствах в начале 20-х гг., англичанами и американцами – во время Второй мировой войны. Разведчики-нелегалы ряда государств использовали шифрблокноты1. Шифр Вернама (сложение по модулю 2) применялся на правительственной «горячей линии» между Вашингтоном и Москвой, где ключевые материалы представляли собой перфорированные бумажные ленты, производившиеся в двух экземплярах .
Перед иллюстрацией использования шифра приведем таблицу кодов символов Windows 1251 и их двоичное представление.
Коды символов Windows 1251 и их двоичное представление

Примечание. Dec-код – десятичный код символа, Bin-код – двоичный код символа.
Пример шифрования сообщения «ВОВА» с помощью гаммы «ЮЛЯ» показан в следующей таблице.
Пример аддитивного шифрования по модулю 2

Шифрование по модулю два обладает замечательным свойством, вместо истинной гаммы противнику можно сообщить ложную гамму, которая при наложении на шифрограмму даст осмысленное выражение.
Пример использования ложной гаммы

В 2013 г. ученые Корнельского университета предложили использовать для генерации ключей (шифроблокнотов) куски полупрозрачного стекла [42]. Кратко принцип нового метода шифрования заключается в том, что отправитель и получатель (Алиса и Боб) во время встречи формируют общий ключ, облучая кусочки стекла изображением-паттерном с IDi (внешне он напоминает QR-код). В результате отражения и преломления, характер которого индивидуален для каждого куска стекла, у Алисы и Боба получаются собственные случайные изображения, которые затем оцифровываются (получаются ключи keyAi и keyBi). Из этих изображений и составляется общий ключ (keyABi = keyAi keyBi).
Схема генерации одного общего ключа показана на следующем рисунке.

Схема генерации одного общего ключа
Как и в классической системе Вернама, каждый случайный паттерн (ключи keyAi, keyВi и keyAВi) можно использовать лишь однажды. В связи с этим Алиса и Боб должны сформировать достаточное количество ключей, облучая свои куски стекла разными паттернами. После генерации общие ключи keyAВi помещаются в общедоступное хранилище.
Процедура обмена шифрограммами выглядит следующим образом .
1) Алиса выбирает паттерн с IDi, облучает свой кусочек стекла и оцифровывает полученное изображение, получая ключ keyAi.
2) Исходное сообщение Pi Алиса складывает по модулю 2 с ключом keyAi (Ci = Pi keyAi) и отсылает шифрограмму Ci с идентификатором паттерна IDi Бобу.
3) Боб по полученному идентификатору IDi из общедоступного хранилища считывает общий ключ keyABi и, облучая паттерн с IDi и свой кусочек стекла, генерирует собственный ключ keyBi.
4) Складывая по модулю 2 ключи keyABi и keyBi, Боб получает ключ keyAi (keyAi = keyABi keyBi).
5) Для прочтения исходного сообщения Pi Боб складывает по модулю 2 шифрограмму Ci и ключ keyAi (Pi = Ci keyAi).

Схема зашифрования и дешифрования сообщения
По утверждению авторов схемы, взломать шифр Вернама можно только украв сами кусочки полупрозрачного стекла. Однако даже в этом случае у Алисы и Боба будет около 24 часов на определение факта кражи, поскольку злоумышленнику потребуется определить структуру стеклянного образца.
Представляю вам очередную вылазку в мир криптографии. На этот раз в роли жертвы выступает шифр гаммирования. Он не из легких, но поддался явно легче, чем перестановочный. Хотя идея самого шифра мне кажется гораздо проще — всего одна операция и никаких премудростей. Шифровать данные этим алгоритмом очень просто, но давайте посмотрим, просто ли будет его взломать?
Прежде чем продолжить чтение, обратите внимание на реализации других шифров
- Реализация и взлом шифра Цезаря;
- Реализация и взлом шифра простой перестановки;
- Реализация и взлом шифра гаммирования;
- Реализация и взлом шифра простой замены.
Шифр гаммирования
Вся суть шифра описывается красивым схематичным изображением, которое я позаимствовал у википедии.
Для того, чтобы получить зашифрованный текст достаточно сложить каждый символ открытого текста с символом гаммы. В качестве гаммы будет выступать символьная последовательность произвольной длины. В случае, если ее длина меньше длины текста, мы просто повторим последовательность нужное количество раз, чтобы хватило на зашифровку всего текста.
Расшифровка выполняется аналогичным образом. Складываем символы зашифрованного текста с символами гаммы и получаем открытый текст.
Реализация шифра гаммирования на Python
В качестве языка программирования по прежнему выступает скриптовый Python. Так как мы будем шифровать не двоичную последовательность, а текст на английском языке, то и сложение будем выполнять не по модулю 2, как на схеме, а по модулю 26.
Функция шифрования
На вход поступает открытый текст без пробелов, в виде массива символов, и ключ — гамму. Анализируем длину текста, «растягиваем» гамму до нужного размера и выполняем посимвольное сложение.
def encrypt(text, gamma): textLen = len(text) gammaLen = len(gamma) #Формируем ключевое слово(растягиваем гамму на длину текста) keyText = [] for i in range(textLen // gammaLen): for symb in gamma: keyText.append(symb) for i in range(textLen % gammaLen): keyText.append(gamma[i]) #Шифрование code = [] for i in range(textLen): code.append(alphabeth[(alphabeth.index(text[i]) + alphabeth.index(keyText[i])) % 26]) return code
Функция расшифрования
Работает аналогично. «Растягиваем» гамму и выполняем посимвольное вычитание ее из текста.
def decrypt(code, gamma): codeLen = len(code) gammaLen = len(gamma) #Формируем ключевое слово(растягиваем гамму на длину текста) keyText = [] for i in range(codeLen // gammaLen): for symb in gamma: keyText.append(symb) for i in range(codeLen % gammaLen): keyText.append(gamma[i]) #Расшифровка text = [] for i in range(codeLen): text.append(alphabeth[(alphabeth.index(code[i]) - alphabeth.index(keyText[i]) + 26) % 26]) return text
Реализация взлома шифра гаммирования
С шифрованием и дешифровкой быстро разобрались, там нет ничего сложного и необычного, самое время начать криптоанализ шифра гаммирования.
По традиции можно выделить два основных этапа.
- получение длины гаммы.
- получение значения гаммы.
Первая часть задачи решается с помощью параметра, называемого индексом совпадений. Он определяется как вероятность совпадения двух произвольных символов в строке. Считается по этой формуле.

Где n — длина текста, f_i — количество появлений в тексте i-го символа алфавита.
Мы будем перебирать длину гаммы и разбивать шифр на столбцы до тех пор, пока индекс совпадений первого столбца не будет максимально близок к 0.066 — это табличное значение индекса совпадений для литературного текста на английском языке.
На практике я заметил, что если длина подходящая, то индекс первого столбца будет гарантированно превышать значение 0.053. А когда длина плохая, он будет колебаться от 0.03 до 0.044.
На втором этапе будет использоваться уже взаимный индекс совпадений двух столбцов. Он считается по такой формуле.

Где f_i — количество появлений i-го символа в первом столбце, g_i — во втором, n — длина первого столбца, n - длина второго. В нашем случае n = n`, столбцы одинаковой длины.
Мы разбиваем код на столбцы по длине гаммы, которую нашли на прошлом этапе, и перебираем все их пары, начиная с первого. У второго столбца в паре перебираем все сдвиги(от 1 до 26) и считаем для каждого взаимный индекс совпадений. В тот момент, когда индекс будет близок к 0.066, запоминаем смещение и переходим к следующей паре столбцов.
После этой процедуры мы получим относительные сдвиги второго столбца относительно первого, третьего относительно второго, четвертого относительно третьего и так далее для всех столбиков.
Следующим шагом будет вычисление правильного сдвига для первого столбца, чтобы затем применить все относительные сдвиги и получить наконец открытый текст. Сдвиг будем искать с помощью частотного анализа, в точности как в шифре Цезаря. Подробнее об этой процедуре я написал в комментариях к коду. После того, как мы нашли сдвиг первого столбика, сдвигаем все столбцы относительно своих соседей и получаем значение гаммы.
На этом описание алгоритма взлома завершено, я постарался максимально подробно его описать, но как всегда, лучше один раз глянуть код, чем сотню раз прочитать алгоритм. Комментарии писал везде, где только можно.
Исходный код функции взлома на Python
#Функция взлома шифра гаммирования
def hack(code):
codeLen = len(code)
#Подобрать длину гаммы
gammaLen = -1
for n in range(2, codeLen // 2):
#Формируем столбец
col = []
for i in range(0, codeLen, n):
col.append(code[i])
#Посчитать индекс Фридмана для каждого нулевого столбика для всех длин,
#взять за эталонную первую, при которой индекс будет максимально близок к 0.066
symbolsCount = [0 for i in range(26)]
for symb in col:
symbolsCount[alphabeth.index(symb)] += 1
FriedmanIndex = 0
for i in range(len(symbolsCount)):
FriedmanIndex += (symbolsCount[i] * (symbolsCount[i] - 1)) / (len(col) * (len(col) - 1))
#Проверить индекс на попадание в диапазон
#if abs(FriedmanIndex - 0.066) < 0.006:
if FriedmanIndex > 0.053:
#Если попал, берем n за эталон и уходим
gammaLen = n
break
print('gamma len = ', gammaLen)
#Теперь можно определить саму гамму
#Разбиваем текст на столбцы по этой длине гаммы
#формируем подстроки
rows = [] #блоки(строки)
for i in range(0, codeLen - gammaLen, gammaLen): #без последнего блока
row = [ code[i + j] for j in range(gammaLen)]
rows.append(row)
#формируем столбцы
collumns = []
for k in range(n): #выбираем номер столбца
collumn = []
for i in range(len(rows)): #выбираем строку
collumn.append(rows[i][k])
collumns.append(collumn)
#Находим относительные сдвиги столбцов с помощью взаимного индекса Фридмана(совпадений)
slides = []
for n in range(1, gammaLen):
#Находим встречаемость каждого символа в первом столбике
firstSymbolsCount = [0 for i in range(26)]
for symb in collumns[n - 1]:
firstSymbolsCount[alphabeth.index(symb)] += 1
#Ищем сдвиг для второго столбца такой, чтобы взаимный индекс Фридмана был близок к 0.066
for m in range(26):
#сдвинуть второй столбец
slideSecondCol = []
for symb in collumns[n]:
slideSecondCol.append(alphabeth[(alphabeth.index(symb) + m) % 26])
#Находим встречаемость каждого символа во втором столбике
secondSymbolsCount = [0 for i in range(26)]
for symb in slideSecondCol:
secondSymbolsCount[alphabeth.index(symb)] += 1
#Находим взаимный индекс Фридмана
FriedmanIndex = 0
for i in range(len(firstSymbolsCount)):
FriedmanIndex = FriedmanIndex + ((firstSymbolsCount[i] * secondSymbolsCount[i]) / (len(collumns[n])**2))
#Проверяем диапазон
#if abs(FriedmanIndex - 0.066) < 0.006:
if FriedmanIndex > 0.053:
#Если попали, запоминаем это смещение и останавливаем перебор
slides.append((26 - m) % 26)
break
#У нас есть взаимные сдвиги всех столбцов, теперь нужно найти сдвиг первого
#искать будем с помощью частотного анализа символов(как в шифре Цезаря)
currentSymbolsFreq = [0 for i in range(26)]
for symb in collumns[0]:
currentSymbolsFreq[alphabeth.index(symb)] += 1
for i in range(len(currentSymbolsFreq)):
currentSymbolsFreq[i] = currentSymbolsFreq[i] / len(collumns[0]) * 100
#Находим все возможные сдвиги для первого столбца
slidesOfFirstCol = []
for i in range(len(currentSymbolsFreq)):
for j in range(len(symbolsFreq)):
if abs(currentSymbolsFreq[i] - symbolsFreq[j]) < 0.12: #0.25
slidesOfFirstCol.append(i - j)
#Берем за эталонное такое смещение, которое встречалось чаще всего
finalSlide = slidesOfFirstCol[0]
maximum = slidesOfFirstCol.count(slidesOfFirstCol[0])
for slide in slidesOfFirstCol:
if slidesOfFirstCol.count(slide) > maximum:
maximum = slidesOfFirstCol.count(slide)
finalSlide = slide
#Посчитать сдвиги для столбиков, зная сдвиг первого
finalSlides = []
finalSlides.append(finalSlide)
for slide in slides:
finalSlides.append(slide)
#считаем сдвиги столбиков
for i in range(1, len(finalSlides)):
finalSlides[i] = (finalSlides[i-1] + finalSlides[i]) % 26
#Мы нашли гамму в виде сдвигов, осталось преобразовать ее в слово
gamma = []
for slide in finalSlides:
gamma.append(alphabeth[slide])
return ''.join(gamma)
Заключение
Вот уже четыре взломанных шифра на моем счету. На очереди стоит шифр простой замены, этот экспонат уже совсем непрост, но мне все равно придется его взломать, чтобы получить зачет по предмету. Так что статья про его взлом обязательно появится! А на сегодня все, спасибо за внимание!

В данной работе рассматриваются шифры замены и табличного гаммирования. Читателю предлагается поучаствовать в процессе решения несколько задач из области защиты информации.
Допустим, что устройства читателя подвергаются атаке со стороны неизвестного хакера.
Нарушитель, хакер, злоумышленник не ограничивается выводом из строя устройств. Он их перепрограммирует с целью принудить владельца выполнять какие-то требования либо банального вымогательства у владельца устройств некоторой денежной суммы. Объявляет о требованиях, например, звонком по сотовому телефону и диктует условия (цену) за восстановление работоспособного состояния устройства. Информационная подсистема приборов защищена шифрами разной сложности. Нарушитель использует свои параметры этих разных шифров для затруднения владельцу самостоятельно восстановить работоспособность устройств.
Некоторые положения теории криптологии
Математическая модель произвольного шифра замены SА = (Х, К, Y, E, D), где
X – символ (фрагмент) открытого текста в алфавите А, |A| = n;
Y– символ шифртекста в алфавите В, |B| = m;
K – ключ шифра k =1(1)K; Ek – преобразование зашифрования с ключом kз;
Dk – преобразование расшифрования с ключом kp.
Правило зашифрования произвольного шифра замены yj ∊ фk(хj), j = 1(1)J , j = 1(1)J.
Требования к криптографической системе (КГС)
-
реализуемость и неизменность шифралгоритма программная и аппаратная;
-
преобразования, используемые в шифралгоритме должны быть обратимыми;
-
владение шифралгоритмом не должно способствовать вскрытию ключ;
-
совпадение объемов (длина шифрованного равна длине исходного) текстов;
-
любой возможный ключ должен обеспечивать равновероятную защиту;
-
отсутствие просто устанавливаемых зависимостей между ключами в сеансах связи;
-
прочтение шифртекста только с соответствующим ключом;
-
малые изменения ключа должны существенно менять шифртекст прежнего исходного;
-
малые изменения исходного текста при одном ключе существенно меняют шифртекст;
-
дополнительные символы к исходному тексту надежно скрываются в шифтексте;
-
число операций в атаке перебором ключей ограничивается возможностями компьютера;
-
число операций при атаке на ключ должно быть не меньше числа возможных ключей.
Требования к криптографическим примитивам [8]
-
биективность (при n=m), регулярность или (n,m,k)-эластичность векторного отображения;
-
высокая степень корреляционной иммунности;
-
большая алгебраическая степень и высокая нелинейность;
-
низкие автокорреляционные показатели, обеспечение строгого лавинного критерия.
Классификация шифров. Признак — тип преобразования зашифрования открытого текста порождает при замене символа (фрагмента) Х на эквивалентный символ Y шифртекста: шифр замены; получение шифртекста перестановкой символов открытого текста порождает шифр перестановки; зашифрование последовательно открытого текста двумя или более разными шифрами порождает композиционный шифр.
При совпадении ключей зашифрования и расшифрования kз= kр в шифрах замены возникает симметричный шифр; при несовпадении ключей kз≠ kр асимметричный шифр. Если в преобразованиях используются неоднозначные функции возникает шифр многозначной замены (пропорциональной замены, омофоны); шифр однозначной замены (шифр гаммирования) возникает в случае использования однозначных функций. Правило зашифрования для шифра однозначной замены yj = ф(хj), j = 1(1)J , j = 1(1)J.
Шифр равнозначной замены возникает при выборе шифрующего символа yi из алфавита В, |B| = m, yi ∊ Вq, i =1(1)N; иначе возникает шифр разнозначной замены. Для шифров замены часто используют V∊Ар, для некоторого р∊N. При р = 1 возникают поточные шифры; при р>1 возникают блочные шифры замены.
При использовании в процессе шифрования единственного алфавита шифр замены называют одноалфавитным шифром замены или шифром простой замены. В других случаях — многоалфавитным шифром замены. С шифрами перестановки ситуация более простая. Открытый текст размещают перед шифрованием в таблицу, например, a×b =4×7. Шифрованный текст пишем по столбцам пнотртйаиупнмреоешрвррекмаси. Это шифр маршрутной перестановки.

Аналогично формируются столбцовые (строчные) перестановки.Усложнение возможно путем введения ключа k = <3,5,7,1,4,2,6>, указывающего порядок чтения столбцов, или «хитрого» обхода ячеек таблицы, например, таблицу a×b =8×8 обходом шахматного коня.
Для защиты информационной подсистемы «умного» устройства используется простая криптографической система, использующая алфавит естественного языка (русского). В сценарии участвуют два субъекта: владелец устройства и хакер. Владелец знает, что алфавит естественного языка (ЕЯ) предварительно подвергается преобразованию путем умножения на известную ему перестановку 32 степени. Буквы е и ё считаются одной буквой поэтому размерность алфавита не 33, а 32 буквы. Тексты пишутся без пробелов.
Задача читателя, который получил доступ к смешанному алфавиту, состоит в полном восстановлении работоспособности умного устройством (текстов команд), получении возможности замены смешанного алфавита другим (собственным) и зашифровании на его основе текстов (команд управления), которые появляются на экране устройства.
Отметим, что при работе с шифрами учитываются законы естественных языков (ЕЯ):
-
закон избыточности текстов,
-
закон частоты встречаемости элементов (букв, слов, n-грамм ) текста,
-
закон Ципфа-Мандельброта.
Простая одноалфавитная замена (без ключа)
Задача №1
Устройство перестало подчиняться командам (отказало), подверглось атаке нарушителя. После простейших проверок наличия внешних дефектов, энергоинтерфейсов, запаха горелой проводки изоляции не чувствуется, а на экранчике дисплея появилось (см. ниже

Зашифрованное сообщение №1
ъ ы п т к ю з г ю я ъ ы п ч к с ы э
Это набор из 18 символов {ъыпткюзгюяъыпчксыэ}, кажущийся бессмысленным. Но на самом деле нарушитель что-то сообщает владельцу на экране и исключает возможность использования устройства по назначению. Попробуем расшифровать оставленное злоумышленником сообщение. Для этого сформируем в таблице 1 перестановку, т.е. последовательность символов (букв) смешанного алфавита (четвертая строка).
 естественного алфавита (третья строка), последняя (четвертая строка) содержит переставленные перестановкой Р 32 степени буквы ЕЯ")
Шифрование текста нарушителем. В регистр загружается открытый текст и заменяем каждую его букву символом из 4-й строки (табл. 1), этот символ появляется на экране устройства (вторая строка таблицы 2)

Частоты встречаемости символов каждой пары «хи» → «уш» в этом шифре совпадают, но так как шифртекст имеет малый объем, то частоты его символов накапливаются по многим шифртекстам. Здесь обозначены «хи» — символ исходного, а «уш» – символ шифрованного текстов.
Расшифрование текста с экрана. С каждым символом хакерского шифртекста экрана последовательно входим в таблицу 1 (нижняя строка) и в третьей ее строке находим соответствующий символ исходного (не шифрованного, открытого) текста хакера. Пройдя все 18 символов удается восстановить текст от хакера, его пожелание владельцу устройства «прочитайте про шифры».
Одноалфавитная замена с ключом
Задача №2
Для увеличения стойкости шифра к атакам, использующим частотный закон ЕЯ, в этом шифре используется не только смешанный алфавит, но вводится новый элемент в алгоритм шифрования, называемый ключом.
Определение. Ключом называется секретная последовательность символов алфавита (слово) фиксированной длины, возможно осмысленная, что совсем не обязательно, используемая при преобразовании открытого текста в шифрованный и обратно.
Таким образом, к характеристикам ключа относятся:
-
доступность – закрытый, открытый (в двухключевых шифрах),
-
алфавит – языка страны,
-
длина – число букв (символов),
-
состав – названия всех букв ключа,
-
порядок – следование букв состава ключа (осмысленный или нет),
-
срок – длительность использования.
Введение в алгоритм шифрования нового элемента «ключа» способствует при замене символа «х» открытого текста символом «у» шифрованного текста при очередном повторном появлении символа «х» заменить его не символом «у», как первый раз, а каким-то другим, на который укажет символ ключа. Подсчет нарушителем встречаемости символов открытого и шифрованного текста, не позволяет ему правильно сопоставлять пары таких символов, так как частота символов шифртекста стала отличной от прежней. Действительно, одному символу открытого текста стали соответствовать несколько разных символов шифртекста. Наглядно это увидим на конкретном примере.
Пусть, как и раньше, на экране устройства хакер написал свой текст (он изменился):

Зашифрованное сообщение №2
ю я и ю ю я и ю ю я и ю ю я и ю ю я
Этот текст возник иначе, чем в задаче 1, т.е. другим путем (с использованием ключа) отличным от способа шифрования в задаче 1. В качестве ключа используется короткое 4-х буквенное слово «ТЕСТ».
Шифрование. В таблице 3 верхняя строка заполнена открытым текстом хакера, а под ней выписан многократно без пробелов ключ ТЕСТ. В третью строку вписываются символы шифрованного текста, взятые из последней строки таблицы 1

Шифртекст получился «не очень» впечатляющим, так сработал усовершенствованный новый алгоритм шифра. Действительно одной букве шифртекста стали соответствовать разные буквы открытого текста и наоборот — букве открытого несколько букв шифртекста.
Расшифрование текста с экрана. В тексте легко выделяются повторяющиеся части (юяию -4 символа). Это наводит на мысль, что породил такие части не исходный текст, а именно ключ. Этот ключ содержит 4 символа, причем 1-й и 4-й символы, по-видимому, совпадают. Частоты символов позволяют установить состав букв ключа. Легко в ключе определяется только его длина. Состав символов и их порядок определится путем рассмотрения допустимых сочетаний по 4 символа из алфавита ЕЯ.
Задача №3
Шифрование. Для увеличения стойкости шифра к атакам, использующим частотный закон ЕЯ, в этом шифре используется не только смешанный алфавит, но вводится новый элемент в алгоритм шифрования, называемый ключом. Как влияет длина ключа на шифртекст? Изменим (увеличим на 1 символ) длину ключа. В таблице 4 верхняя строка заполнена открытым текстом хакера, а под ней выписан многократно без пробелов ключ ТЕКСТ. В третью строку вписываются символы смешанного алфавита, взятые из последней строки таблицы 1
Пусть, как и раньше, на экране устройства хакер (нарушитель) написал свой текст:

Зашифрованное сообщение №3 (текст опять изменился)
ю я л и ю ю я л и и ю ю я л и ю ю я л

Получилась очень похожая на предыдущую картинка, просто повторов стало меньше, а длина ключа возросла на 1 символ.
Расшифрование текста с экрана. В тексте легко выделяются повторяющиеся части (юялию — 5 символов). Это наводит на мысль, что породил такие части не сам исходный текст, а именно новый ключ. Этот ключ содержит 5 символов, причем 1-й и 5-й символы, по-видимому, совпадают. Частоты символов позволяют установить состав букв ключа. О новом ключе можно сказать практически то же самое. Ключ имеет длину 5-символов, и его 1-й и 5-й символы совпадают. Состав подбирается путем допустимых сочетаний по 5 символов из алфавита ЕЯ.
Многоалфавитная замена с ключом, гаммирование
Рассмотрение проблемы с атакой на шифры, которая использует частотные зависимости ЕЯ, привело к мысли использовать в алгоритме шифрования не только ключ, что как мы видели в задачах 2,3 оказалось не очень удачным решением (легко определяется длина ключа, повторяющиеся символы), но и более чем один (множество) смешанных алфавитов.
Ниже мы подробно рассмотрим схему шифрования с этими нововведениями и некоторые факторы, влияющие на стойкость шифра к атакам
Задача №4
В этой задаче используется множество смешанных алфавитов, организованных в квадрат Виженера, а ключи используются прежние.
Для увеличения стойкости шифра к атакам, использующим частотный закон ЕЯ, в этом шифре используется не единственный смешанный алфавит, а их множество с применением циклического сдвига каждого последующего на один символ относительно предыдущего. Вытолкнутый циклическим сдвигом символ из начала алфавита помещается в конец списка букв алфавита так, что полная длина алфавите не меняется.
При одноалфавитной замене без ключа всегда символ «х» (буква) исходного (открытого) текста заменялась одной и той же буквой «у» смешанного алфавита, и частота использования х и у была одинаковой, совпадающей с частотой встречаемости символа «х» в ЕЯ. При многоалфавитной замене нарушитель понимает, что символ «х» при каждом очередном появлении в открытом тексте заменяется разными буквами из разных смешанных алфавитов. Этот факт не дает возможности нарушителю напрямую воспользоваться частотным законом ЕЯ, так как частота встречаемости символов открытого текста осталась прежней, но частота встречаемости символов шифрованного текста стала совершенно другой.

Зашифрованное сообщение №4 (текст опять изменился)
у и р г а т н э ь л з ш з ц ч ж ш з
Что же такое нарушитель желает сообщить владельцу «умного» устройства? Стремление разобраться в шифрованном сообщении приводит к необходимости детального анализа ситуации с шифрами и текстами открытыми и шифрованными. Прежде всего, необходимо уяснить как будет использоваться множество смешанных алфавитов, какое их количество задействуется в алгоритме и как эти алфавиты соотносятся друг с другом. Ответ на эти вопросы помогает найти новая таблица 5, названная квадратом 32×32 (таблицей) Виженера. Сколько смешанных алфавитов следует привлекать в алгоритме шифра? Как выбрать ключ шифра?
Строкам таблицы Виженера соответствуют символы (буквы) ключа. Из этого следует, что при шифровании используются столько строк квадрата Виженера, сколько букв содержит ключ шифра (при условии отсутствия повторов). Так как ключом может быть произвольная последовательность букв, то строкам квадрата соответствует полный алфавит. Колонкам квадрата соответствуют символы исходного текста – также полный алфавит.
Таким образом, в этом квадрате размещаются 32 смешанных алфавита (см таблица 1) по горизонтали и по вертикали. Каждый алфавит в этих линиях сдвигается (изменяется) на один символ относительно предыдущей линии, и этот символ вписывается после последнего символа в конце списка. Верхняя строка и вторая колонка – это алфавит ЕЯ с исходным упорядочением букв, т.е. каждая строка и столбец помечены буквой стандартного алфавита.

Из множества возможных перемешиваний алфавита Б. Виженер предложил использовать только n = 32. Способ их получения из первого путем циклического сдвига на каждом шаге на одну позицию.
Процесс шифрования. Исходный текст без пробелов вписывается в линейный регистр. Каждой букве отводится своя ячейка регистра. Ниже этого регистра помещается другой регистр, в который вписывается ключ ТЕСТ шифра. Если ключ шифра короче текста, то ключ вписывается многократно один за другим без пробелов. Таким образом, каждая буква исходного текста соответствует некоторой букве ключа. Это можно отобразить так «хи» → «хk».
Шифртекст представленный на экране (у и р г а т н э ь л з ш з ц ч ж ш з) устройства — это 3-я строка таблицы 6.

Первой букве открытого (столбец) текста соответствует первая буква ключа (строка)
«хи =П»→«хk=т». Переходим в квадрат Виженера. Строка квадрата обозначена буквой «т» ключа, а столбец квадрата определяется буквой открытого текста «П». В клетке пересечения выбранных линий (строки, столбца) находится буква шифртекста «уш = у». Формально эти действия описываются цепочкой «хk = т» → «хи = П» → «уш = у» из трех символов: тПу.
Дальше все повторяется до исчерпания открытого текста. Результатом такого шифрования является третья строчка таблицы 6. Именно она появляется на экране дисплея умного устройства.
Анализ текста с экрана. Из примера для ключа «ТЕСТ» видим, что первая буква ИТ П заменяется на У, которая взята в строке квадрата, помеченной буквой Т ключа, и в колонке квадрата, соответствующей (помеченной) букве П.
Второй раз, когда буква П встречается в ИТ замена (буква 3) для нее берется в строке, ключа, помеченной буквой С (не как раньше буквой т), и в той же самой колонке для буквы П. Уже отсюда видим, что подсчет частот встречаемости буквы П в исходном тексте и символов замены для этой буквы в шифрованном тексте не совпадают, что не позволяет напрямую воспользоваться законом частоты повторяемости букв при вскрытии шифртекста.
Здесь же укажем, что при использовании ключа происходит многоалфавитная замена. Количество используемых при шифровании алфавитов в общем случае соответствует числу различных букв в ключе, но, понятно, что не более n = 32. Отсюда, как казалось-бы, напрашивается вывод — больше длина ключа — надежнее шифр. К сожалению, это не всегда так.
Во-первых, в ключе могут быть повторяющиеся буквы и для них используется одна и та же строка квадрата Виженера:
Во-вторых, не исключается возможность совпадений (наложений) одинаковых непрерывных участков ИТ на одинаковые непрерывные участки ключа.
К чему это может привести будет рассмотрено на примере оцифровки для второго более длинного ключа «ТЕКСТ».
Анализ исходного текста и шифртекста с ключом ТЕСТ показывает следующее: в ИТ имеются две повторяющиеся триграммы «ПРО», в скобках за буквами пишем какими буквами они заменились в шифртексте: Р(И, Ш, Ш) встречается три раза; буквы П (У, З), О(Р З), Т(Т, Ь), И(А, Б) – по два раза; Ч(Г), А(Н),Й(Э),Е(Л),Ш(Ц),Ф(Ж),Ы(З).
Наш ограниченного объема пример позволил продемонстрировать все возможности замен. Хотя ключ ТЕСТ содержит четыре буквы, но различных среди них только три. Следовательно, при шифровании будут использованы только три различных смешанных алфавита.
Задача №5
Процесс шифрования. В этой задаче также используется множество смешанных алфавитов, организованных в квадрат Виженера. Используется более длинный ключ ТЕКСТ.
Первой букве открытого текста соответствует первая буква ключа «хи =П»→«хk=т».
Переходим в квадрат Виженера. Строка квадрата обозначена буквой «т» ключа, а столбец квадрата определяется буквой открытого текста «П». В клетке пересечения выбранных строки и столбца находится буква шифртекста «уш = у». Формально эти действия описываются цепочкой «хk = т» → «хи = П» → «ущ = у» из трех символов: тПу.
Дальше все повторяется до исчерпания открытого текста. Результатом такого шифрования является третья строчка таблицы 7. Именно она появляется на экране дисплея умного устройства.

Зашифрованное сообщение №5
у и ч к а ь я о в т у и ч г а ж и я
Будем пытаться прочесть это сообщение в ходе анализа шифртекста.
Анализ и дешифрование текста с экрана. Ключ ТЕКСТ содержит пять букв, из них различных только четыре, и с этим ключом будут использованы четыре различных смешанных алфавита. Какой же из ключей обеспечивает большую устойчивость к взлому (расшифрованию)?
Казалось-бы, тот шифр, который использует большее число различных алфавитов, что приводит к замене одной и той же буквы ИТ большим числом других букв, и лучше ее маскирует. Но, увы, это не общее правило. Наш пример призван это подтвердить.
Криптоаналитики стремятся использовать разнообразные и всесторонние подходы к задачам вскрытия шифровок. Так, например, они выявляют в ШТ повторяющиеся отрезки текста даже если шифрование было многоалфавитным. Эти отрезки могут быть однобуквенными — монограммы, двухбуквенными — биграммы, трехбуквенными — триграммы и т. д. Подсчитываем число повторяющихся отрезков и интервалы (в числе символов) между ними. Что это дает? Очень даже много.
В ШТ встречаются буквы У(П,П), Ч(О,О), А(И,И), Я(А, Ы) – по два раза, И(РРР) — 3 раза. 18 позиций сообщения представлены 12 буквами ИТ и 12 буквами ШТ, но состав этих 12 букв различен. Совпадение количества букв, конечно, случайное.
Все ситуации замены при шифровании могут быть описаны следующим перечнем:
-
одинаковые буквы ИТ (П(УУ), Р(ИИИ), О(ЧЧ), И(АА),) заменяются одинаковыми в ШТ (У, И, Ч, А);
-
одинаковые буквы ИТ (Т) заменяются разными в ШТ (Ь, В);
-
разные буквы ИТ(Ч, А, Й, Е, Ш, Ф, Ы) заменяются разными в ШТ(К, Я, О, Т, Г, Ж, Я);
-
разные буквы ИТ (А, Ы) заменяются одинаковыми в ШТ (Я).
Определение длины ключа. Причиной появления одной и той же буквы Y в ШТ может быть либо совпадение буквы X в ИТ и буквы ключа под ней; либо на Y была заменена другая буква из ИТ при использовании сдвинутого смешанного алфавита.
В первом случае интервалы между повторениями буквы Y в ШТ будут совпадать с числовыми значениями кратными длине ключа; во-втором, — понятно, совпадения ожидать не приходится. Аналогичная ситуация может иметь место и для других повторяющихся в ШТ букв.

Действительно, в исходном тексте буква Р попадает трижды на букву Е ключа ТЕКСТ во 2-й, 12-й и 17-й позициях и заменяется буквой И из одного и того же смешанного циклически сдвинутого алфавита. Этот алфавит в квадрате Виженера соответствует строке, помеченной буквой Е ключа. Интервалы между повторениями буквы И кратны числу 5. Все три интервала кратны 5.
17 – 12 = 5, 17 – 2 = 15, 12 – 2 = 10.
Аналогично с буквой У в 1 и 11— й позициях ШТ, интервал 11 – 1=10 кратен 5; с буквой Ч в 3-й и в 13-й позициях ШТ; интервал равен 13 – 3 = 10, что также кратно 5. Буква Я в позициях 7-й и 18-й ШТ не удовлетворяет общему правилу 18 – 7=11, что не кратно 5, а вот буква А в ШТ в позициях 5-й и 15-й опять подчинена правилу, интервал 15 – 5 = 10 кратен 5.
Повторение буквы Я в ШТ можно считать случайностью, тем более, что мы это знаем. Правильнее было бы сказать, что это норма. Именно это и требуется для нарушения закона частоты. Для такого маленького примера многовато совпадений, но ведь он и подобран специально. Каким же может быть объяснение подобных совпадений? При таком числе совпадений на ШТ из 18 букв следует однозначный вывод — длина ключа равна 5 символам.
Как только решен этот вопрос сразу же становится возможным определение списков букв ШТ, которые были зашифрованы одним и тем же смешанным алфавитом. Не зная самого ключа, мы должны полагать, что используются пять различных алфавитов (по числу букв в ключе), т.е. пять строк квадрата Виженера.
Множество всех букв ШТ теперь можно расчленить на L = 5 групп, таким образом, что в каждой группе соберутся буквы из одной строки квадрата Виженера, т. е. из одного смешанного алфавита. Таким образом удается свести задачу к нескольким последовательным, но одноалфавитной замены для каждого. А это уже задача из числа успешно решаемых. Как же осуществить разбиение букв?
Очень просто. Первая буква Т ключа ТЕКСТ соответствует некоторой строке квадрата. С другой стороны, в примере эта буква стоит в позициях 1-й, 6— й, 11-й, 16-й. Все буквы ШТ в этих позициях заменялись буквами из одной и той же строки. Обозначим длину ключа символом L, тогда в каждую m-ю группу, (m соответствует порядковому номеру буквы в ключе) попадают все буквы ШТ из позиций с номерами m + L*i, i = 0(1)4, m = 1(1) L, где переменная i — порядковый номер буквы в списке букв выбираемом из одной строки квадрата Виженера. Эту часть анализа удобно представить таблицей.

Данная таблица содержит две колонки, помеченные одинаковой буквой Т ключа. Это означает, что размещенные в этих колонках буквы выбирались из одной строки квадрата Виженера. Для продолжения криптоанализа эти колонки необходимо слить вместе. Далее для всех колонок подсчитывается количество одинаковых букв в каждой — кратность ее использования в ШТ. Таблица 4 после слияния колонок для буквы Т примет следующий вид.

На этом этапе вскрытия шифрограммы перед нами встает задача выбора дальнейшего пути исследования. Если бы выборки в каждой группе были значительными (более 700 букв), то используя закон частоты встречаемости буквы, сопоставив частоту появления букв в русском языке и в каждой группе, а также учитывая семантику вскрываемого текста можно было бы и завершить решение задачи, но при малых выборках ожидать успеха на этом пути не приходится.
Что еще кроме длины можно установить по ШТ о ключе? Конечно, интерес представляет само слово или выражение, но подступы к таким данным пока не просматриваются. Имеется информация о том, что интервалы между буквами ключа в стандартном алфавите связаны со сдвигами смешанных алфавитов в квадрате Виженера. Да это так. Каждая буква стандартного алфавита имеет свой порядковый номер. Интервалы между буквами ключа могут быть вычислены. Для нашего примера эти интервалы удобно представить в виде квадратных матриц. Шапка и боковик таблиц заполняются буквами ключа, а значения в клетках -разности номеров букв в стандартном алфавите. Эти матрицы описывают величины сдвигов между используемыми смешанными.

Можно ли каким-то образом получить такие матрицы, не располагая данными о ключе?
Эта информация может явиться той основой, которая позволит выявить сам ключ, т.е. слово. Ясно, что, зная величину сдвигов между алфавитами, можно пытаться подобрать слово из букв стандартного алфавита по маске, которая учитывает структуру самих сдвигов. Поиск может выполняться с использованием словарей или с визуальным контролем. Надо полагать, что ключ будет осмысленным словом или даже фразой. Это и должно использоваться при контроле в процессе поиска ключа.
Покажем на нашем примере как такой поиск выполняется. Построим (гребенку (Рис. 1 которая будет играть роль движка или шаблона (маски). Разность между крайними отметками на гребенке равна модулю наибольшего сдвига между алфавитами. Отметим крайние положения (зубцы) гребенки номерами наиболее раздвинутых алфавитов (в примере наиболее удаленных друг от друга букв Т и Е ключа) как 1 и 2. Все другие положения на гребенке определяются относительными расстояниями (сдвигами) алфавитов, занимающих промежуточное положение между выявленными крайними.
Снабдим их соответствующей нумерацией 3, 4, 5. Теперь, если перемещать движок- гребенку вдоль стандартного алфавита, помещенного на полоске, склеенной в кольцо, и считывать буквы напротив зубцов, то оказывается, что различных положений у такого движка всего 32 по числу букв в алфавите. Соответственно и буквенных наборов, потенциально образующих ключ такое же число. Остается выяснить путем перебора какая совокупность букв с точки зрения семантики наиболее подходит в качестве ключа. Считаем, что лента с алфавитом склеена в кольцо и движок перемещается по окружности.

На самом деле вопрос о построении гребенки не так прост. В нашем примере мы знаем ключ и соответственно ему нумеровали рабочие алфавиты из квадрата Виженера. При неизвестном ключе мы можем построить гребенку, но нумерация зубцов остается невыясненной. Порядок букв в ключе (относительный) будет определен так. В примере мы крайний правый зубец гребенки снабдили номером 1, а крайний левый номером 2, что соответствует буквам Т и Е стандартного алфавита. Но, не зная ключа, можно было поместить зубцы и наоборот (зубцы на Рис.1 для второй возможности представлены в виде (“-^-“)
Вскрытие ключа. Приведем те совокупности букв, которые выявляются движком — гребенкой по первому варианту:
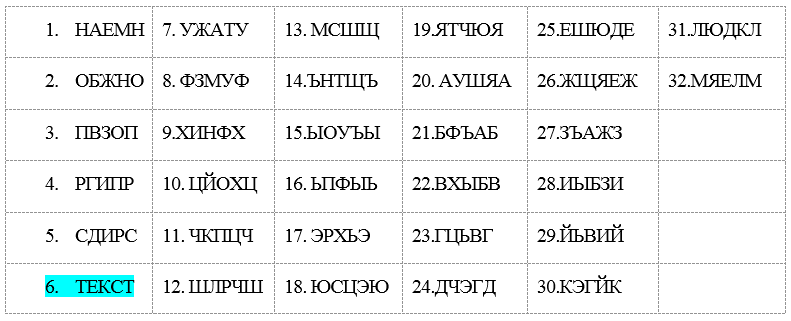
Беглый анализ этих совокупностей после прочтения показывает, что совсем непросто получить осмысленный текст при произвольном выборе гребенки. Даже похожих на осмысленные слова совокупностей практически нет. Первая совокупность могла бы быть подозрительной на ключ с учетом того, что допущена ошибка в длине ключа и ключом является слово НАЕМНИК.
Но среди всей этой абракадабры имеется одно единственное вполне осмысленное слово ТЕКСТ (выделено заливкой) и, конечно, только оно может быть принято в качестве ключа.
Заключение
Материал приведенный в публикации знакомит с простыми шифрами алфавитной замены, которые известны с прошлого столетия или еще раньше, но для тех читателей, которые раньше не были знакомы с проблемами информационной безопасности, текст может быть интересен.
Подробно рассмотрено влияние ключа (его длины и состава) на шифртекст. Упоминание о законах естественного языка, которые всегда учитываются в науке криптология может заинтересовать читателей по разным причинам. Так, например, совсем слабо освещена в науке проблема избыточности ЕЯ. Как от нее избавляться или как ее использовать, где эта избыточность размещается в текстах мало что известно.
Архиваторы, сжимающие тексты, существуют давно, но их теория на сформулированные вопросы не отвечает. Более того, часто архиваторы проектируются так, чтобы тексты восстанавливались без потерь, т.е. исходная избыточность текстов восстанавливается.
С другой стороны, например, хорошо известно как используется организованная избыточность для поддержания целостности информационного сообщения — это коды обнаруживающие и исправляющие ошибки о чем я уже писал раньше.
Литература
1.Алферов А.П. и др. Основы криптографии.- М.:Гелиос АРВ, 2001.- 480с.
2. Маховенко Е.Б. Теоретико-числовые методы в криптографии. -М.: Гелиос АРВ, 2006. — 320 с.
3. Ростовцев А.Г. Алгебраические основы криптографии.- СПб.: Мир и семья, 2000. — 354 с.
4. Ростовцев А.Г., Маховенко Е.Б. Введение в криптографию с открытым ключом. -СПб.: Мир и семья, 2001. — 336 с.
5. Ростовцев А.Г., Маховенко Е.Б. Введение в теорию итерированных шифров.- СПб.:Мир и семья,2003. — 302 с.
6. Жельников В. Криптография от папируса до компьютера.- М.: АBF, 1996.-
7 . Уэзерелл Ч. Этюды для программистов. — М.: Мир, 1982. — 288 с.
8. Молдовян А.А. и др. Криптография: скоростные шифры. -СПб.: БХВ, 2002. — 496 с.
Шифрование методом гаммирования
В аддитивных шифрах символы исходного сообщения заменяются числами, которые складываются по модулю с числами гаммы. Ключом шифра является гамма, символы которой последовательно повторяются.
Перед шифрованием символы сообщения и гаммы заменяются их номерами в алфавите и само кодирование выполняется по формуле
Ci = (Ti+Gi) mod N
Примечания:
а) mod — операция целочисленного деления, вычисляющая остаток от деления. Например, 18 mod 5 = 3
или 48 mod 44 = 4. Данная операция доступна в Windows-калькуляторе в режиме «Инженерный».
б) N равен количеству символов применяемого алфавита.
в) Ci, Ti и Gi — номера i-х символов, соответственно, шифрограммы, шифруемого текста и гаммы
г) если Ci будет равно нулю, то его следует приравнять N.
Создание шифрограммы завершается заменой полученных чисел Ci на соответствующие буквы алфавита.
В рассмотренном ниже примере исходное сообщение — «КАФЕДРА СИСТЕМ ИНФОРМАТИКИ», используемая гамма — «СИМВОЛ».
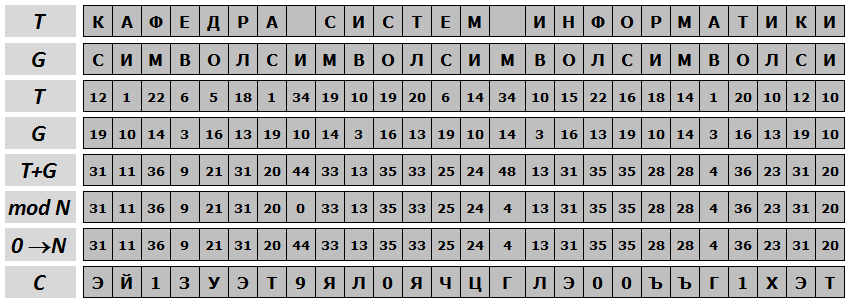
Рис. 3.1. Схема шифрования гаммированием по модулю N
В данной теме используется алфавит, состоящий из 44 символов (N=44).
Примечание: Если в строке T+G значение меньше чем N, то значение в строке mod N должно быть таким же как в T+G, противном случае значение строки T+G убавляйте на N.
Таблица 3.1. Алфавит «Русские буквы, цифры и пробел» (44 символа)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| А | Б | В | Г | Д | Е | Ё | Ж | З | И | Й | К | Л | М | Н | О | П | Р | С | Т | У | Ф | Х |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 7 | 38 | 39 | 40 | 41 | 42 | 43 | 44 |
| Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я | пробел | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Ниже Вам предлагается сдать тест на знание алгоритма шифрования сообщения методом гаммирования
Тест 3.1. Кодирование текста шифром гаммирования
Для того, чтобы увидеть форму, вам необходимо
установить Java плагин для вашего браузера и разрешить выполнение Java-апплетов.
Как установить Java плагин в браузере?
Как включить Java в браузере?
Если Вы пользуетесь браузером IE9 с установленным Java плагином и апплет тем не менее не работает, то
возможно, что Java-апплет фильтруется ActiveX Filtering, новой функцией в IE9. Для ее отключения выберите
Сервис/Безопасность и снимите галочку с Фильтрация ActiveX.
В отчет вставьте скрин формы с результатами теста.
Дешифрирование выполняется по формуле
Ti = (Ci-Gi+N) mod N ,
где Ti – это символы исходного сообщения, Ci – символы зашифрованного сообщения, Gi – символы гаммы.
Примечание:
если Ti=0, то его следует взять равным N.
В примере ниже зашифрованное выше сообщение вновь приводится к исходному виду
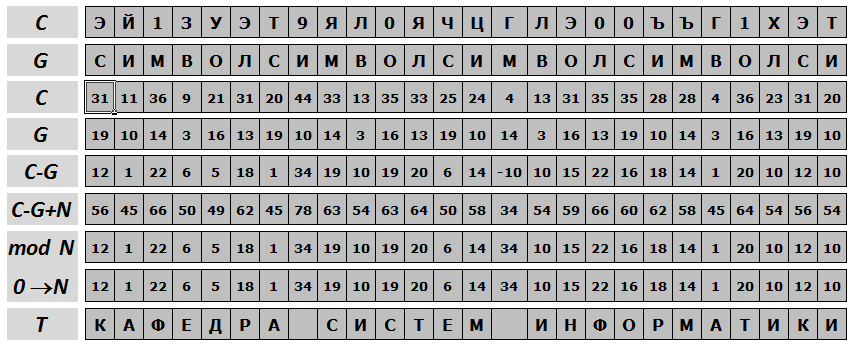
Рис. 3.2. Схема дешифрирования гаммированием по модулю N
Тест 3.2. Декодирование текста, зашифрованного методом гаммирования
В отчет вставьте скрин формы с результатами теста.