There are several methods to find indexes on a table. The methods include using system stored procedure sp_helpindex, system catalog views like sys.indexes or sys.index_columns. We will see these methods one by one.
1. Find Indexes on a Table Using SP_HELPINDEX
sp_helpindex is a system stored procedure which lists the information of all the indexes on a table or view. This is the easiest method to find the indexes in a table. sp_helpindex returns the name of the index, description of the index and the name of the column on which the index was created.
Syntax
EXEC sp_helpindex '[[[SCHEMA-NAME.TABLE-NAME]]]' GO
Example
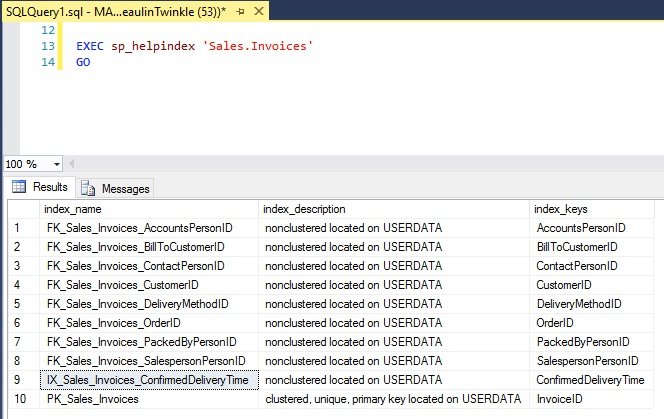
2. Using SYS.INDEXES
The sys.indexes system catalog view returns all the indexes of the table or view or table valued function. If you want to list down the indexes on a table alone, then you can filter the view using the object_id of the table. Here is the syntax for using the sys.indexes view to list the indexes of a table. In this example, I’ve filtered out the hypothetical index using the WHERE clause condition is_hypothetical = 0. If you think you need to see the hypothetical index, then ignore this condition
Syntax
SELECT
name AS Index_Name,
type_desc As Index_Type,
is_unique,
OBJECT_NAME(object_id) As Table_Name
FROM
sys.indexes
WHERE
is_hypothetical = 0 AND
index_id != 0 AND
object_id = OBJECT_ID('[[[SCHEMA-NAME.TABLE-NAME]]]');
GO
Example
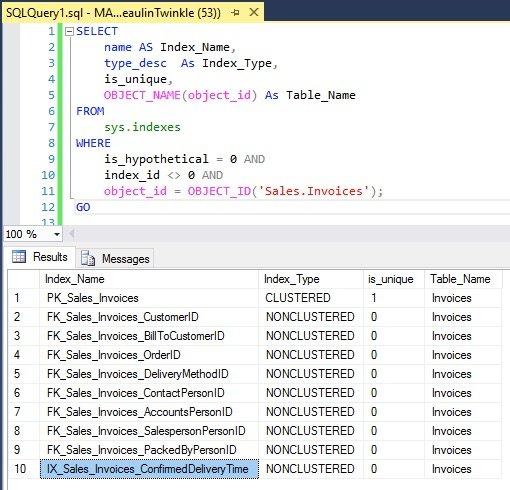
3. Using SYS.INDEX_COLUMNS
This method is an extension of the earlier sys.indexes method. Here we are joining another system catalog view, sys.index_columns to get the name of the column or columns the index was created or included. This will be helpful to see the column names along with the index name.
Syntax
SELECT
a.name AS Index_Name,
OBJECT_NAME(a.object_id),
COL_NAME(b.object_id,b.column_id) AS Column_Name,
b.index_column_id,
b.key_ordinal,
b.is_included_column
FROM
sys.indexes AS a
INNER JOIN
sys.index_columns AS b
ON a.object_id = b.object_id AND a.index_id = b.index_id
WHERE
a.is_hypothetical = 0 AND
a.object_id = OBJECT_ID('[[[SCHEMA-NAME.TABLE-NAME]]]');
Example
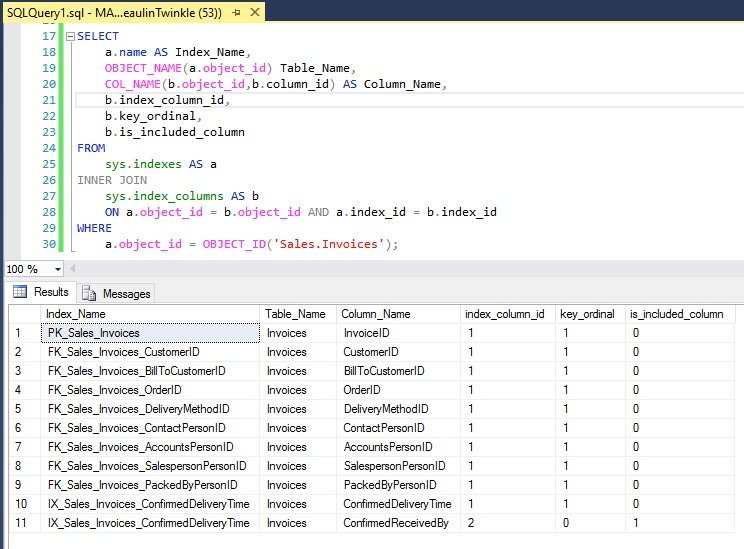
Related Articles
- Article on finding the row count of all the tables In a database.
Reference
- Querying the SQL Server system catalog FAQ at MSDN.
I need a query to see if a table already has any indexes on it.
![]()
asked Nov 25, 2009 at 23:37
![]()
2
On SQL Server, this will list all the indexes for a specified table:
select * from sys.indexes
where object_id = (select object_id from sys.objects where name = 'MYTABLE')
This query will list all tables without an index:
SELECT name
FROM sys.tables
WHERE OBJECTPROPERTY(object_id,'IsIndexed') = 0
And this is an interesting MSDN FAQ on a related subject:
Querying the SQL Server System Catalog FAQ
answered Nov 26, 2009 at 12:12
![]()
gkrogersgkrogers
8,0663 gold badges29 silver badges36 bronze badges
3
If you’re using MySQL you can run SHOW KEYS FROM table or SHOW INDEXES FROM table
answered Nov 25, 2009 at 23:38
![]()
nickfnickf
535k198 gold badges648 silver badges721 bronze badges
1
If you just need the indexed columns
EXEC sp_helpindex ‘TABLE_NAME’
answered Aug 4, 2015 at 13:00
![]()
Sam SalimSam Salim
2,08522 silver badges18 bronze badges
Simply you can find index name and column names of a particular table using below command
SP_HELPINDEX 'tablename'
It works for me
![]()
codersl
2,2224 gold badges30 silver badges33 bronze badges
answered Jun 3, 2020 at 9:15
![]()
1
Most modern RDBMSs support the INFORMATION_SCHEMA schema. If yours supports that, then you want either INFORMATION_SCHEMA.TABLE_CONSTRAINTS or INFORMATION_SCHEMA.KEY_COLUMN_USAGE, or maybe both.
To see if yours supports it is as simple as running
select count(*) from INFORMATION_SCHEMA.TABLE_CONSTRAINTS
EDIT: SQL Server does have INFORMATION_SCHEMA, and it’s easier to use than their vendor-specific tables, so just go with it.
answered Nov 26, 2009 at 0:04
![]()
DonnieDonnie
45.4k10 gold badges64 silver badges86 bronze badges
1
Here is what I used for TSQL which took care of the problem that my table name could contain the schema name and possibly the database name:
DECLARE @THETABLE varchar(100);
SET @THETABLE = 'theschema.thetable';
select i.*
from sys.indexes i
where i.object_id = OBJECT_ID(@THETABLE)
and i.name is not NULL;
The use case for this is that I wanted the list of indexes for a named table so I could write a procedure that would dynamically compress all indexes on a table.
answered Apr 19, 2016 at 1:43
![]()
On Oracle:
-
Determine all indexes on table:
SELECT index_name FROM user_indexes WHERE table_name = :table -
Determine columns indexes and columns on index:
SELECT index_name , column_position , column_name FROM user_ind_columns WHERE table_name = :table ORDER BY index_name, column_order
References:
- ALL_IND_COLUMNS
- ALL_INDEXES
![]()
Sнаđошƒаӽ
16.6k12 gold badges72 silver badges89 bronze badges
answered Nov 25, 2009 at 23:39
![]()
FerranBFerranB
35.4k18 gold badges66 silver badges85 bronze badges
First you check your table id (aka object_id)
SELECT * FROM sys.objects WHERE type = 'U' ORDER BY name
then you can get the column’s names. For example assuming you obtained from previous query the number 4 as object_id
SELECT c.name
FROM sys.index_columns ic
INNER JOIN sys.columns c ON c.column_id = ic.column_id
WHERE ic.object_id = 4
AND c.object_id = 4
answered Jan 4, 2017 at 17:46
![]()
Ed_Ed_
95511 silver badges25 bronze badges
Created a stored procedure to list indexes for a table in database in SQL Server
create procedure _ListIndexes(@tableName nvarchar(200))
as
begin
/*
exec _ListIndexes '<YOUR TABLE NAME>'
*/
SELECT DB_NAME(DB_ID()) as DBName,SCH.name + '.' + TBL.name AS TableName,IDX.name as IndexName, IDX.type_desc AS IndexType,COL.Name as ColumnName,IC.*
FROM sys.tables AS TBL
INNER JOIN sys.schemas AS SCH ON TBL.schema_id = SCH.schema_id
INNER JOIN sys.indexes AS IDX ON TBL.object_id = IDX.object_id
INNER JOIN sys.index_columns IC ON IDX.object_id = IC.object_id and IDX.index_id = IC.index_id
INNER JOIN sys.columns COL ON ic.object_id = COL.object_id and IC.column_id = COL.column_id
where TBL.name = @tableName
ORDER BY TableName,IDX.name
end
answered Apr 24, 2017 at 12:51
![]()
check this as well
This gives an overview of associated constraints across a database.
Please also include facilitating where condition with table name of interest so gives information faster.
select
a.TABLE_CATALOG as DB_name,a.TABLE_SCHEMA as tbl_schema, a.TABLE_NAME as tbl_name,a. CONSTRAINT_NAME as constraint_name,b.CONSTRAINT_TYPE
from INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE a
join INFORMATION_SCHEMA.TABLE_CONSTRAINTS b on
a.CONSTRAINT_NAME=b.CONSTRAINT_NAME
![]()
answered Jan 7, 2017 at 1:31
![]()
for smss — mssql, one can refer the create script
answered Jul 4, 2022 at 9:49
![]()
kj3kj3
691 silver badge4 bronze badges
Индексы таблиц сильно влияют на работу с базой данных. Так, отсутствие необходимого индекса может приводить к:
-
- чтению большего количества строк данных
- увеличению времени выполнения запроса
- появлению избыточных блокировок
- и другим негативным последствиям
В данной статье мы рассмотрим как можно найти недостающие индексы с помощью динамических административных функций MS SQL Server.
Информация о динамических функциях
Динамические административные представления и функции возвращают информацию о состоянии сервера, которую можно применить для наблюдения за работой и анализа проблем.
В данной статье мы воспользуемся тремя динамическими административными функциями (DMF): dm_db_missing_index_group_stats, dm_db_missing_index_groups, dm_db_missing_index_details
| Функция | Описание |
|---|---|
| dm_db_missing_index_group_stats | Возвращает сведения о группах отсутствующих индексов. Содержит информацию о количествах операций поиска, которые могли бы быть выполнены по отсутствующему индексу, среднем проценте выигрыша и средней стоимости запросов, которая могла бы быть уменьшена при использовании индекса |
| dm_db_missing_index_groups | Возвращает сведения об отсутствующих индексах, содержащихся в конкретной группе отсутствующих индексов. Далее используется для связи отсутствующих индексов и групп индексов |
| dm_db_missing_index_details | Возвращает подробные сведения об отсутствующих индексах. Содержит информацию о столбцах соответствующих предикатам равенства и неравенства, а так же о столбцах необходимых для запроса |
Запрос поиска недостающих индексов и анализ его результата
Следующий запрос выведет всю необходимую в дальнейшем информацию:
|
SELECT TOP 10 DB_NAME(database_id), mid.*, migs.*, avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) as Perf FROM sys.dm_db_missing_index_group_stats as migs INNER JOIN sys.dm_db_missing_index_groups AS mig ON (migs.group_handle = mig.index_group_handle) INNER JOIN sys.dm_db_missing_index_details AS mid ON (mig.index_handle = mid.index_handle) ORDER BY avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) DESC |
Выражение avg_total_user_cost * avg_user_impact * (user_seeks + user_scans), использованное в запросе, соответствует оценке выигрыша при добавлении отсутствующего индекса. Файл запроса можно скачать во вложениях к статье.
Выполним запрос и проанализируем его результаты на простом примере.

Как видно, отсутствует индекс в таблице AccumRg23573, при этом запрос, для которого необходим индекс, выполняется с предикатом равенства по полю Fld23580RRef. В поле user_seeks указано что этот индекс мог бы быть использован 750 раз в целях поиска по индексу, avg_user_impact говорит о том что средний процент выигрыша равен 99,99%. Так же имеет смысл обратить внимание на поле last_user_seek, оно указывает на дату и время последнего пользовательского запроса, который мог бы использовать отсутствующий индекс для поиска. Если последний раз подходящий запрос был давно, возможно, индекс будет использовать редко и необходимости в нем нет — необходимо оценить перед добавлением индекса. Теперь воспользуемся обработкой выводящей структуру хранения базы данных в терминах 1С:Предприятия (из статьи «Получение информации о структуре хранения базы данных в терминах 1С:Предприятие и СУБД»).
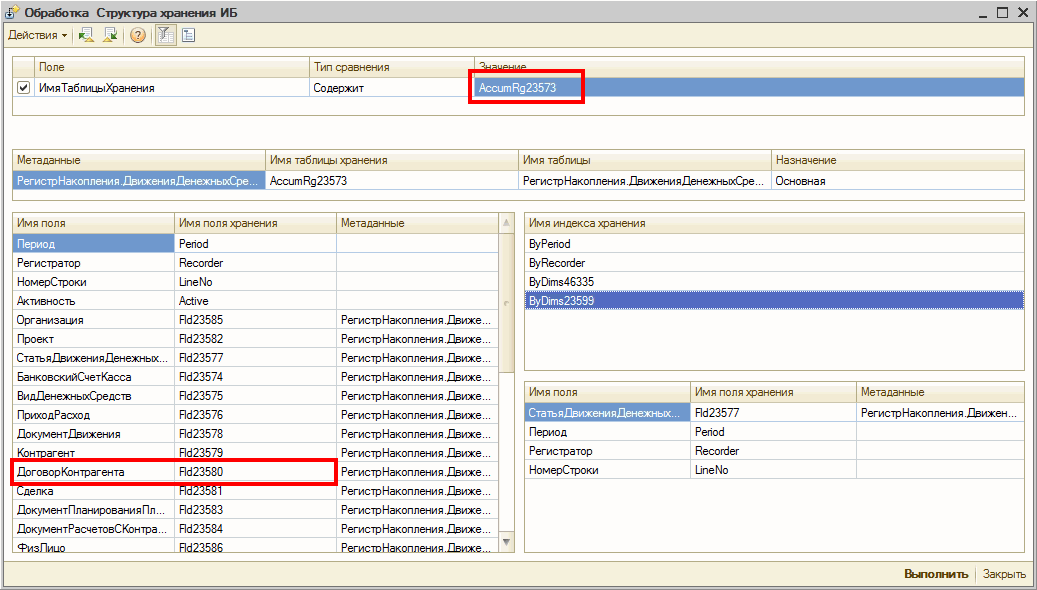
С помощью обработки мы видим что индекса не хватает в основной таблице регистра накопления ДДС, а также видим что условие на равенство используется по полю ДоговорКонтрагента. При этом в таблице существуют индексы по Периоду, Регистратору, СтатьеДДС, Проекту. Индекса по полю ДоговорКонтрагента нет, хотя условие запроса именно на равенство по этому полю, а это значит что системе необходимо будет сканировать всю таблицу при выполнении запроса. Давайте добавим отсутствующий индекс.
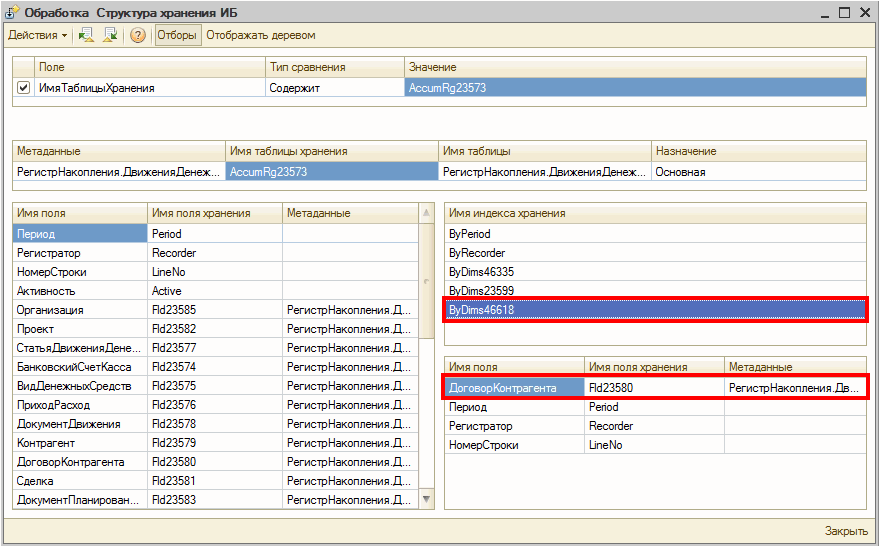
Статистика использования индекса
И так, индекс добавлен, но теперь нам необходимо оценить результат своих действий. Для этих целей воспользуемся еще одним запросом с динамическими административными функциями, о которых будет рассказано в следующей статье. Стоит упомянуть что выполнять его стоит не сразу же, а через некоторое время работы пользователей в базе данных для того чтобы накопилась статистика.
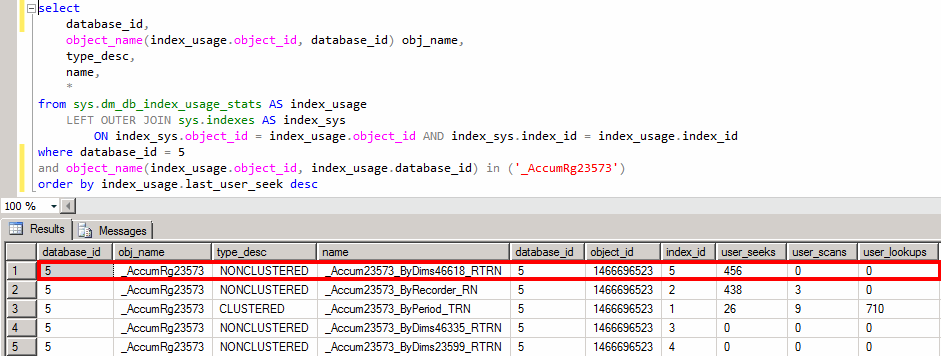
Оценив значения в колонке user_seeks можно сделать вывод что в данной системе этот индекс используется достаточно часто, а эффективность от его использования высока (была оценена первым запросом).
Во время анализа состояния базы данных, и возможного анализа ее производительности, стоит обратить внимание на состояние ее индексов и их количества.
Получить список индексов базы данных MS SQL
Для получения полного списка индексов базы данных, можно использовать System View sys.indexes, которое — покажет список всех индексов в выбранной базе данных. Результат запроса вида: select * from sys.indexes выглядит не очень читаемо, но если добавить информацию из других предствлений (View), то можно получить список с наглядной информацией. Например, запрос:
USE <Имя БД>
select i.[name] as index_name,
substring(column_names, 1, len(column_names)-1) as [columns],
case when i.[type] = 1 then 'Clustered index'
when i.[type] = 2 then 'Nonclustered unique index'
when i.[type] = 3 then 'XML index'
when i.[type] = 4 then 'Spatial index'
when i.[type] = 5 then 'Clustered columnstore index'
when i.[type] = 6 then 'Nonclustered columnstore index'
when i.[type] = 7 then 'Nonclustered hash index'
end as index_type,
case when i.is_unique = 1 then 'Unique'
else 'Not unique' end as [unique],
schema_name(t.schema_id) + '.' + t.[name] as table_view,
case when t.[type] = 'U' then 'Table'
when t.[type] = 'V' then 'View'
end as [object_type]
from sys.objects t
inner join sys.indexes i
on t.object_id = i.object_id
cross apply (select col.[name] + ', '
from sys.index_columns ic
inner join sys.columns col
on ic.object_id = col.object_id
and ic.column_id = col.column_id
where ic.object_id = t.object_id
and ic.index_id = i.index_id
order by key_ordinal
for xml path ('') ) D (column_names)
where t.is_ms_shipped <> 1
and index_id > 0
order by i.[name]Вернет результат подобный тому что показан ниже: а при необходимости этот запрос успешно редактируется, добавлением необходимых полей.
а при необходимости этот запрос успешно редактируется, добавлением необходимых полей.
Получить состояние фрагментации индексов базы данных MS SQL
При работе с данными (при вставке, обновлении или удалении), также происходит изменение информации хранящейся в индексах. С точки зрения SQL, фрагментация выглядит как несоответствие логического порядка индекса, физическому порядку размещения данных, и чем больший процент фрагментации в индексе, тем существеннее это отражается на производительности. В целом, это нормальный рабочий момент, за которым надо следить, настраивая планы обслуживания. Но иногда бывает полезно в целом узнать «среднюю темпиратуру по больнице», чтобы создать новые или отредактировать старые планы обслуживания.
Если выполнялось сжатие (shrink) базы данных или отдельных файлов БД, то после этого, с высокой долей вероятности, потребуется выполнение операции перестроения индексов. Иначе, можно получить существенную деградацию производительности базы данных.
Ниже, приведен пример скрипта, которые отображает список всех индексов БД в порядке по убыванию уровня фрагментации:
declare @DB sysname = <Имя БД>;
select s.name schema_name, t.name TableName, i.name IndexName, d.avg_fragmentation_in_percent Fragmentation
from sys.dm_db_index_physical_stats( DB_ID(@DB), null, null, null, null) d
inner join sys.tables t on d.object_id = t.object_id
inner join sys.schemas s on t.schema_id = s.schema_id
inner join sys.indexes i on d.object_id = i.object_id AND d.index_id = i.index_id
where d.index_id > 0 and d.page_count > 8
order by fragmentation descРезультат: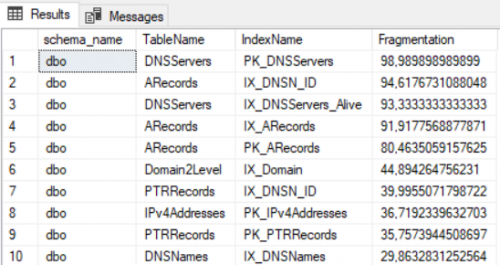
Перестроить (Rebuild) все индексы в базе данных
Для перестроения всех индексов базы данных, можно использовать чуть более сложный скрипт, ниже
begin
declare @databaseName sysname = N'IPScan';
declare @rebuildFloor float = 40;
declare @schemaName sysname;
declare @tableName sysname;
declare @indexName sysname;
declare @fragmentation float;
declare @command nvarchar(500);
print N'Начало перестроения индекса: ' + convert( nvarchar(100), SYSDATETIME(), 20 );
print N'-------------------------------------------------------------------------';
declare indexCursor cursor fast_forward local for
select s.name schema_name, t.name table_name, i.name index_name, d.avg_fragmentation_in_percent fragmentation
from sys.dm_db_index_physical_stats( DB_ID(@databaseName), null, null, null, null) d
inner join sys.tables t on d.object_id = t.object_id
inner join sys.schemas s on t.schema_id = s.schema_id
inner join sys.indexes i on d.object_id = i.object_id AND d.index_id = i.index_id
where d.index_id > 0
and d.avg_fragmentation_in_percent > 10
and d.page_count > 8
open indexCursor;
while( 1=1 )
begin
fetch next from indexCursor into @schemaName, @tableName, @indexName, @fragmentation;
if @@FETCH_STATUS <> 0 break;
begin try
set @command = N'ALTER INDEX ' + @indexName + N' ON ' + @databaseName + N'.' + @schemaName + N'.' + @tableName;
if @fragmentation < @rebuildFloor
begin
set @command = @command + N' REORGANIZE;';
set @command = @command + N' UPDATE STATISTICS ' + @databaseName + N'.' + @schemaName + N'.' + @tableName + N' ' + @indexName + N';';
end
else
begin
set @command = @command + N' REBUILD WITH (ONLINE = ON); ';
end;
--print @command;
exec (@command);
print N'INDEX ' + @indexName + N'ON ' + @databaseName + N'.' + @schemaName + N'.' + @tableName + N' Обработан';
end try
begin catch
print N'ERROR REBUILD INDEX ' + @indexName;
print N'ERROR MESSAGE: ' + ERROR_MESSAGE();
end catch
end;
print N'-------------------------------------------------------------------------';
print N'Перестроение индексов завершено: ' + convert( nvarchar(100), SYSDATETIME(), 20 );
close indexCursor;
deallocate indexCursor;
end;
Результат выполнения скрипта: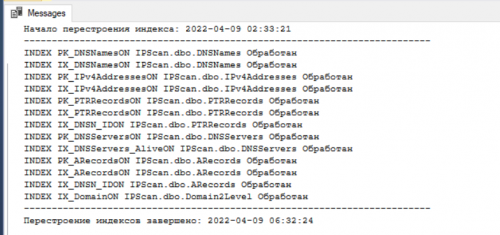
Скрипт можно скопивать из текста выше или скачать файлом по ссылке:
Иногда возникают задачи по массовой обработке индексов, например, переносу индексов на другую базу. В этой статье рассмотрим как можно получить список всех индексов, получить SQL индекса и массово перестроить индексы.
Как получить все индексы базы данных SQL Server с их определением
declare @dbTablePrefix nvarchar(256) = ''
SELECT
'if not exists( SELECT * FROM sys.indexes WHERE name='''+I.name+''' ) begin ' + CHAR(13) + CHAR(10) + --AND object_id = OBJECT_ID('Schema.YourTableName')
' CREATE ' +
CASE
WHEN I.is_unique = 1 THEN ' UNIQUE '
ELSE ''
END +
I.type_desc COLLATE DATABASE_DEFAULT + ' INDEX ' +
I.name + ' ON ' +
SCHEMA_NAME(T.schema_id) + '.' + T.name + ' ( ' +
KeyColumns + ' ) ' +
ISNULL(' INCLUDE (' + IncludedColumns + ' ) ', '') +
ISNULL(' WHERE ' + I.filter_definition, '') + ' WITH ( ' +
CASE
WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON '
ELSE ' PAD_INDEX = OFF '
END + ',' +
'FILLFACTOR = ' + CONVERT(
CHAR(5),
CASE
WHEN I.fill_factor = 0 THEN 100
ELSE I.fill_factor
END
) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE
WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON '
ELSE ' IGNORE_DUP_KEY = OFF '
END + ',' +
CASE
WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF '
ELSE ' STATISTICS_NORECOMPUTE = ON '
END + ',' +
' ONLINE = OFF ' + ',' +
-- ' drop_existing = on ' + ',' +
CASE
WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON '
ELSE ' ALLOW_ROW_LOCKS = OFF '
END + ',' +
CASE
WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON '
ELSE ' ALLOW_PAGE_LOCKS = OFF '
END + ' ) ON [' +
DS.name + ' ] ' + CHAR(13) + CHAR(10) +
' print ''Create index '+ I.name +'''' + CHAR(13) + CHAR(10) +
'end -- if exists' + CHAR(13) + CHAR(10) + 'GO ' [CreateIndexScript],
schema_name(t.schema_id) + '.' + t.[name] as table_view,
i.[name] as index_name,
KeyColumns,
IncludedColumns,
-- substring(column_names, 1, len(column_names)-1) as [columns],
case when i.[type] = 1 then 'Clustered index'
when i.[type] = 2 then 'Nonclustered unique index'
when i.[type] = 3 then 'XML index'
when i.[type] = 4 then 'Spatial index'
when i.[type] = 5 then 'Clustered columnstore index'
when i.[type] = 6 then 'Nonclustered columnstore index'
when i.[type] = 7 then 'Nonclustered hash index'
end as index_type,
case when i.is_unique = 1 then 'Unique'
else 'Not unique' end as [unique],
case when t.[type] = 'U' then 'Table'
when t.[type] = 'V' then 'View'
end as [object_type]
FROM sys.indexes I
JOIN sys.tables T
ON T.object_id = I.object_id
JOIN sys.sysindexes SI
ON I.object_id = SI.id
AND I.index_id = SI.indid
JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']' + CASE
WHEN MAX(CONVERT(INT, IC1.is_descending_key))
= 1 THEN
' DESC '
ELSE
' ASC '
END
FROM sys.index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
ORDER BY
MAX(IC1.key_ordinal)
FOR XML PATH('')
),
1,
2,
''
) KeyColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp3
)tmp4
ON I.object_id = tmp4.object_id
AND I.Index_id = tmp4.index_id
JOIN sys.stats ST
ON ST.object_id = I.object_id
AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS
ON I.data_space_id = DS.data_space_id
JOIN sys.filegroups FG
ON I.data_space_id = FG.data_space_id
LEFT JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']'
FROM sys.index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
FOR XML PATH('')
),
1,
2,
''
) IncludedColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp1
WHERE IncludedColumns IS NOT NULL
) tmp2
ON tmp2.object_id = I.object_id
AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0
AND I.is_unique_constraint = 0
AND (@dbTablePrefix = '' or t.[name] like @dbTablePrefix + '%') --Comment for all tables I.Object_id = object_id(@dbTable)
--AND I.name = 'IX_Address_PostalCode' --comment for all indexes
and t.is_ms_shipped <> 1
order by table_view
Если указать @dbTablePrefix, то мы получим только индексы на таблицы, начинающиеся с заданного префикса.
В результате выполнения скрипта мы получим скрипты вида:
if not exists( SELECT * FROM sys.indexes WHERE name='ind_apiActions_code' ) begin
CREATE NONCLUSTERED INDEX ind_apiActions_code ON dbo.as_api_actions ( [code] ASC )
WITH ( PAD_INDEX = OFF ,FILLFACTOR = 100 ,SORT_IN_TEMPDB = OFF ,
IGNORE_DUP_KEY = OFF , STATISTICS_NORECOMPUTE = OFF , ONLINE = OFF ,
ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY ]
print 'Create index ind_apiActions_code'
end
GO Копируем определения индексов и выполняем массово на другой базе. Если такой индекс был, то он пропускается. Если нет какого-то столбца или таблицы, то будет просто ошибка, но другие индексы создадутся.
Поиск дубликатов индексов SQL Server
При массовом добавлении индексов может возникнуть такая ситуация, что какие-то индексы будут дублироваться — называются они по разному, но имеют одинаковые настройки. Выявить их можно через такой скрипт:
-- Ищем дубликаты индексов (создает нагрузку на процессор)
select t1.tablename,t1.indexname,t1.columnlist,t2.indexname,t2.columnlist from
(select distinct object_name(i.object_id) tablename,i.name indexname,
(select distinct stuff((select ', ' + c.name
from sys.index_columns ic1 inner join
sys.columns c on ic1.object_id=c.object_id and
ic1.column_id=c.column_id
where ic1.index_id = ic.index_id and
ic1.object_id=i.object_id and
ic1.index_id=i.index_id
order by index_column_id FOR XML PATH('')),1,2,'')
from sys.index_columns ic
where object_id=i.object_id and index_id=i.index_id) as columnlist
from sys.indexes i inner join
sys.index_columns ic on i.object_id=ic.object_id and
i.index_id=ic.index_id inner join
sys.objects o on i.object_id=o.object_id
where o.is_ms_shipped=0) t1 inner join
(select distinct object_name(i.object_id) tablename,i.name indexname,
(select distinct stuff((select ', ' + c.name
from sys.index_columns ic1 inner join
sys.columns c on ic1.object_id=c.object_id and
ic1.column_id=c.column_id
where ic1.index_id = ic.index_id and
ic1.object_id=i.object_id and
ic1.index_id=i.index_id
order by index_column_id FOR XML PATH('')),1,2,'')
from sys.index_columns ic
where object_id=i.object_id and index_id=i.index_id) as columnlist
from sys.indexes i inner join
sys.index_columns ic on i.object_id=ic.object_id and
i.index_id=ic.index_id inner join
sys.objects o on i.object_id=o.object_id
where o.is_ms_shipped=0) t2 on t1.tablename=t2.tablename and
substring(t2.columnlist,1,len(t1.columnlist))=t1.columnlist and
(t1.columnlist<>t2.columnlist or
(t1.columnlist=t2.columnlist and t1.indexname<>t2.indexname))Далее можно ручками удалить ненужные индексы в базе.
Реорганизация или перестройка индексов в базе SQL Server
Вы можете сделать либо reorganize либо rebuild для всех индексов в базе.
Для этого можно использовать следующий скрипт:
-- Скрипт реорганизует индексы по всем таблицам
IF OBJECT_ID(N'tempdb..#RowCounts') IS NOT NULL
BEGIN
DROP TABLE #RowCounts
END
GO
declare @minRows int =400 -- перестройка индекса выполняется только для таблиц где больше N строк
CREATE TABLE #RowCounts(NumberOfRows BIGINT,TableName VARCHAR(128))
EXEC sp_MSForEachTable 'INSERT INTO #RowCounts
SELECT COUNT_BIG(*) AS NumberOfRows,
''?'' as TableName FROM ?'
select TableName, NumberOfRows from #RowCounts where NumberOfRows>@minRows
---SELECT TableName,NumberOfRows FROM #RowCounts ORDER BY NumberOfRows DESC,TableName
declare @TableName nvarchar(256)
declare @NumberOfRows int
declare cur CURSOR LOCAL for
select TableName, NumberOfRows from #RowCounts where NumberOfRows>@minRows
open cur
fetch next from cur into @TableName, @NumberOfRows
while @@FETCH_STATUS = 0 BEGIN
print @TableName
-- Rebuild (блочит таблицу, но быстрее идет) или REORGANIZE (дольше. но не блочит таблицу)
EXEC ('ALTER INDEX ALL ON ' +@TableName + ' Rebuild ;')
fetch next from cur into @TableName, @NumberOfRows
END
close cur
deallocate cur
DROP TABLE #RowCountsrebuild выполняется быстрее, но блокирует таблицу. Есть режим with ONLINE,но он работает только для Enterprise версии SQL Server. Фактически это пересоздание индекса.
reorganize выполняется дольше, но не блокирует таблицу базы данных.
В скрипте есть настройка @minRows — минимальное количество строк в таблицах, для которых будет перестроен индекс.
Где нужно ставить индексы в SQL Server, какие индексы можно удалить из базы данных SQL Server
Вы можете периодически запускать эти скрипты для поиска мест оптимизации индексов. Первый запрос покажет, какие индексы можно добавить. Второй запрос показывает какие индексы не используются эффективно (происходит больше записей, нежели чтения).
Данные запросы работают на основе внутренней статистики SQL Server, т.е. данные в них будут менять по мере использования базы.
--Поиск, где можно установить индексы:
select d.name AS DatabaseName, mid.*
from sys.dm_db_missing_index_details mid
join sys.databases d ON mid.database_id=d.database_id
--Убрать лишние индексы:
--там где user_updates больше чем user_lookup - можно удалить индексы
SELECT d.name, t.name, i.name, ius.*
FROM sys.dm_db_index_usage_stats ius
JOIN sys.databases d ON d.database_id = ius.database_id
JOIN sys.tables t ON t.object_id = ius.object_id
JOIN sys.indexes i ON i.object_id = ius.object_id AND i.index_id =
ius.index_id
ORDER BY user_updates DESC