Изучая программирование на Python, вы практически в самом начале знакомитесь со списками и различными операциями, которые можете выполнять над ними. В этой статье мы бы хотели рассказать об одной из таких операций над списками.
Представьте, что у вас есть список, состоящий из каких-то элементов, и вам нужно определить индекс элемента со значением x. Сегодня мы рассмотрим, как узнать индекс определенного элемента списка в Python.
Но сначала давайте убедимся, что все понимают, что представляет из себя список.
Список в Python — это встроенный тип данных, который позволяет нам хранить множество различных значений, таких как числа, строки, объекты datetime и так далее.
Важно отметить, что списки упорядочены. Это означает, что последовательность, в которой мы храним значения, важна.
Индексирование списка начинаются с нуля и заканчивается на длине списка минус один. Для получения более подробной информации о списках вы можете обратиться к статье «Списки в Python: полное руководство для начинающих».
Итак, давайте посмотрим на пример списка:
fruits = ["apple", "orange","grapes","guava"] print(type(fruits)) print(fruits[0]) print(fruits[1]) print(fruits[2]) # Результат: # <class 'list'> # apple # orange # grapes
Мы создали список из 4 элементов. Первый элемент в списке имеет нулевой индекс, второй элемент — индекс 1, третий элемент — индекс 2, а последний — 3.
Для списка получившихся фруктов fruits допустимыми индексами являются 0, 1, 2 и 3. При этом длина списка равна 4 (в списке 4 элемента). Индекс последнего элемента равен длине списка (4) минус один, то есть как раз 3.
[python_ad_block]
Как определить индекс элемента списка в Python
Итак, как же определить индекс элемента в Python? Давайте представим, что у нас есть элемент списка и нам нужно узнать индекс или позицию этого элемента. Сделать это можно следующим образом:
print(fruits.index('orange'))
# 1
print(fruits.index('guava'))
# 3
print(fruits.index('banana'))
# А здесь выскочит ValueError, потому что в списке нет значения banana
Списки Python предоставляют нам метод index(), с помощью которого можно получить индекс первого вхождения элемента в список, как это показано выше.
Познакомиться с другими методами списков можно в статье «Методы списков Python».
Мы также можем заметить, что метод index() вызовет ошибку VauleError, если мы попытаемся определить индекс элемента, которого нет в исходном списке.
Для получения более подробной информации о методе index() загляните в официальную документацию.
Базовый синтаксис метода index() выглядит так:
list_var.index(item),
где list_var — это исходный список, item — искомый элемент.
Мы также можем указать подсписок для поиска, и синтаксис для этого будет выглядеть следующим образом:
list_var.index(item, start_index_of_sublist, end_index_of_sublist)
Здесь добавляются два аргумента: start_index_of_sublist и end_index_of_sublist. Тут всё просто. start_index_of_sublist обозначает, с какого элемента списка мы хотим начать поиск, а end_index_of_sublist, соответственно, на каком элементе (не включительно) мы хотим закончить.
Чтобы проиллюстрировать это для лучшего понимания, давайте рассмотрим следующий пример.
Предположим, у нас есть список book_shelf_genres, где индекс означает номер полки (индексация начинается с нуля). У нас много полок, среди них есть и полки с учебниками по математике.
Мы хотим узнать, где стоят учебники по математике, но не вообще, а после четвертой полки. Для этого напишем следующую программу:
book_shelf_genres = ["Fiction", "Math", "Non-fiction", "History", "Math", "Coding", "Cooking", "Math"]
print(book_shelf_genres.index("Math"))
# Результат:
# 1
Здесь мы видим проблему. Использование просто метода index() без дополнительных аргументов выдаст первое вхождение элемента в список, но мы хотим знать индекс значения «Math» после полки 4.
Для этого мы используем метод index() и указываем подсписок для поиска. Подсписок начинается с индекса 5 до конца списка book_shelf_genres, как это показано во фрагменте кода ниже:
print(book_shelf_genres.index("Math", 5))
# Результат:
# 7
Обратите внимание, что указывать конечный индекс подсписка необязательно.
Чтобы вывести индекс элемента «Math» после полки номер 1 и перед полкой номер 5, мы просто напишем следующее:
print(book_shelf_genres.index("Math", 2, 5))
# Результат:
# 4
Как найти индексы всех вхождений элемента в списке
А что, если искомое значение встречается в списке несколько раз и мы хотим узнать индексы всех этих элементов? Метод index() выдаст нам индекс только первого вхождения.
В этом случае мы можем использовать генератор списков:
book_shelf_genres = ["Fiction", "Math", "Non-fiction", "History", "Math", "Coding",
"Cooking", "Math"]
indices = [i for i in range(0, len(book_shelf_genres)) if book_shelf_genres[i]=="Math"]
print(indices)
# Результат:
# [1, 4, 7]
В этом фрагменте кода мы перебираем индексы списка в цикле for и при помощи range(). Далее мы проверяем значение элемента под каждым индексом на равенство «Math«. Если значение элемента — «Math«, мы сохраняем значение индекса в списке.
Все это делается при помощи генератора списка, который позволяет нам перебирать список и выполнять некоторые операции с его элементами. В нашем случае мы принимаем решения на основе значения элемента списка, а в итоге создаем новый список.
Подробнее про генераторы списков можно почитать в статье «Генераторы списков в Python для начинающих».
Благодаря генератору мы получили все номера полок, на которых стоят книги по математике.
Как найти индекс элемента в списке списков
Теперь представьте ситуацию, что у вас есть вложенный список, то есть список, состоящий из других списков. И ваша задача — определить индекс искомого элемента для каждого из подсписков. Сделать это можно следующим образом:
programming_languages = [["C","C++","Java"],
["Python","Rust","R"],
["JavaScript","Prolog","Python"]]
indices = [(i, x.index("Python")) for i, x in enumerate(programming_languages) if "Python" in x]
print(indices)
# Результат:
# [(1, 0), (2, 2)]
Здесь мы используем генератор списков и метод index(), чтобы найти индексы элементов со значением «Python» в каждом из имеющихся подсписков. Что же делает этот код?
Мы передаем список programming_languages методу enumerate(), который просматривает каждый элемент в списке и возвращает кортеж, содержащий индекс и значение элемента списка.
Каждый элемент в списке programming_languages также является списком. Оператор in проверяет, присутствует ли элемент «Python» в этом списке. Если да — мы сохраняем индекс подсписка и индекс элемента «Python» внутри подсписка в виде кортежа.
Результатом программы, как вы можете видеть, является список кортежей. Первый элемент кортежа — индекс подсписка, а второй — индекс искомого элемента в этом подсписке.
Таким образом, (1,0) означает, что подсписок с индексом 1 списка programming_languages имеет элемент «Python», который расположен по индексу 0. То есть, говоря простыми словами, второй подсписок содержит искомый элемент и этот элемент стоит на первом месте. Не забываем, что в Python индексация идет с нуля.
Как искать индекс элемента, которого, возможно, нет в списке
Бывает, нужно получить индекс элемента, но мы не уверены, есть ли он в списке.
Если попытаться получить индекс элемента, которого нет в списке, метод index() вызовет ошибку ValueError. При отсутствии обработки исключений ValueError вызовет аварийное завершение программы. Такой исход явно не является хорошим и с ним нужно что-то сделать.
Вот два способа, с помощью которых мы можем избежать такой ситуации:
books = ["Cracking the Coding Interview", "Clean Code", "The Pragmatic Programmer"]
ind = books.index("The Pragmatic Programmer") if "The Pragmatic Programmer" in books else -1
print(ind)
# Результат:
# 2
Один из способов — проверить с помощью оператора in, есть ли элемент в списке. Оператор in имеет следующий синтаксис:
var in iterable
Итерируемый объект — iterable — может быть списком, кортежем, множеством, строкой или словарем. Если var существует как элемент в iterable, оператор in возвращает значение True. В противном случае он возвращает False.
Это идеально подходит для решения нашей проблемы. Мы просто проверим, есть ли элемент в списке, и вызовем метод index() только если элемент существует. Это гарантирует, что метод index() не вызовет нам ошибку ValueError.
Но если мы не хотим тратить время на проверку наличия элемента в списке (это особенно актуально для больших списков), мы можем обработать ValueError следующим образом:
books = ["Cracking the Coding Interview", "Clean Code", "The Pragmatic Programmer"]
try:
ind = books.index("Design Patterns")
except ValueError:
ind = -1
print(ind)
# Результат:
# -1
Здесь мы применили конструкцию try-except для обработки ошибок. Программа попытается выполнить блок, стоящий после слова try. Если это приведет к ошибке ValueError, то она выполнит блок после ключевого слова except. Подробнее про обработку исключений с помощью try-except можно почитать в статье «Обрабатываем исключения в Python: try и except».
Заключение
Итак, мы разобрали как определить индекс элемента списка в Python. Теперь вы знаете, как это сделать с помощью метода index() и генератора списков.
Мы также разобрали, как использовать метод index() для вложенных списков и как найти каждое вхождение элемента в списке. Кроме того, мы рассмотрели ситуацию, когда нужно найти индекс элемента, которого, возможно, нет в списке.
Мы надеемся, что данная статья была для вас полезной. Успехов в написании кода!
Больше 50 задач по Python c решением и дискуссией между подписчиками можно посмотреть тут
Перевод статьи «Python Index – How to Find the Index of an Element in a List».
Метод index() возвращает индекс указанного элемента в списке.
Синтаксис метода в Python:
list.index(element, start, end)
Список параметров
Метод в Python может принимать не более трех аргументов:
- element – элемент для поиска;
- start (необязательно) – начать поиск с этого индекса;
- end (необязательно) – искать элемент до этого индекса.
Возвращаемое значение из списка
- Метод возвращает индекс данного элемента в списке.
- Если элемент не найден, возникает исключение ValueError.
Примечание: Команда возвращает только первое вхождение соответствующего элемента.
Пример 1: Найти индекс элемента
# vowels list
vowels = ['a', 'e', 'i', 'o', 'i', 'u']
# index of 'e' in vowels
index = vowels.index('e')
print('The index of e:', index)
# element 'i' is searched
# index of the first 'i' is returned
index = vowels.index('i')
print('The index of i:', index)
Выход
The index of e: 1 The index of i: 2
Пример 2: Указатель элемента, отсутствующего в списке
# vowels list
vowels = ['a', 'e', 'i', 'o', 'u']
# index of'p' is vowels
index = vowels.index('p')
print('The index of p:', index)
Выход
ValueError: 'p' is not in list
Пример 3: Работа с параметрами начала и конца
# alphabets list
alphabets = ['a', 'e', 'i', 'o', 'g', 'l', 'i', 'u']
# index of 'i' in alphabets
index = alphabets.index('e') # 2
print('The index of e:', index)
# 'i' after the 4th index is searched
index = alphabets.index('i', 4) # 6
print('The index of i:', index)
# 'i' between 3rd and 5th index is searched
index = alphabets.index('i', 3, 5) # Error!
print('The index of i:', index)
Выход
The index of e: 1 The index of i: 6 Traceback (most recent call last): File "*lt;string>", line 13, in ValueError: 'i' is not in list
336-559cookie-checkФункция index() в Python
Время на прочтение
10 мин
Количество просмотров 148K
| Часть 1 | Часть 2 | Часть 3 | Часть 4 |
|---|
 Данная статья является продолжением моей статьи «Python: коллекции, часть 1: классификация, общие подходы и методы, конвертация».
Данная статья является продолжением моей статьи «Python: коллекции, часть 1: классификация, общие подходы и методы, конвертация».
В данной статье мы продолжим изучать общие принципы работы со стандартными коллекциями (модуль collections в ней не рассматривается) Python.
Для кого: для изучающих Python и уже имеющих начальное представление о коллекциях и работе с ними, желающих систематизировать и углубить свои знания, сложить их в целостную картину.
ОГЛАВЛЕНИЕ:
- Индексирование
- Срезы
- Сортировка
1. Индексирование
1.1 Индексированные коллекции
Рассмотрим индексированные коллекции (их еще называют последовательности — sequences) — список (list), кортеж (tuple), строку (string).
Под индексированностью имеется ввиду, что элементы коллекции располагаются в определённом порядке, каждый элемент имеет свой индекс от 0 (то есть первый по счёту элемент имеет индекс не 1, а 0) до индекса на единицу меньшего длины коллекции (т.е. len(mycollection)-1).
1.2 Получение значения по индексу
Для всех индексированных коллекций можно получить значение элемента по его индексу в квадратных скобках. Причем, можно задавать отрицательный индекс, это значит, что будем находить элемент с конца считая обратном порядке.
При задании отрицательного индекса, последний элемент имеет индекс -1, предпоследний -2 и так далее до первого элемента индекс которого равен значению длины коллекции с отрицательным знаком, то есть (-len(mycollection).
| элементы | a | b | c | d | e |
|---|---|---|---|---|---|
| индексы | 0 (-5) | 1 (-4) | 2 (-3) | 3 (-2) | 4 (-1) |
my_str = "abcde"
print(my_str[0]) # a - первый элемент
print(my_str[-1]) # e - последний элемент
print(my_str[len(my_str)-1]) # e - так тоже можно взять последний элемент
print(my_str[-2]) # d - предпоследний элемент
Наши коллекции могут иметь несколько уровней вложенности, как список списков в примере ниже. Для перехода на уровень глубже ставится вторая пара квадратных скобок и так далее.
my_2lvl_list = [[1, 2, 3], ['a', 'b', 'c']]
print(my_2lvl_list[0]) # [1, 2, 3] - первый элемент — первый вложенный список
print(my_2lvl_list[0][0]) # 1 — первый элемент первого вложенного списка
print(my_2lvl_list[1][-1]) # с — последний элемент второго вложенного списка
1.3 Изменение элемента списка по индексу
Поскольку кортежи и строки у нас неизменяемые коллекции, то по индексу мы можем только брать элементы, но не менять их:
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[0]) # 1
my_tuple[0] = 100 # TypeError: 'tuple' object does not support item assignment
А вот для списка, если взятие элемента по индексу располагается в левой части выражения, а далее идёт оператор присваивания =, то мы задаём новое значение элементу с этим индексом.
my_list = [1, 2, 3, [4, 5]]
my_list[0] = 10
my_list[-1][0] = 40
print(my_list) # [10, 2, 3, [40, 5]]
UPD: Примечание: Для такого присвоения, элемент уже должен существовать в списке, нельзя таким образом добавить элемент на несуществующий индекс.
my_list = [1, 2, 3, 4, 5]
my_list[5] = 6 # IndexError: list assignment index out of range
2 Срезы
2.1 Синтаксис среза
Очень часто, надо получить не один какой-то элемент, а некоторый их набор ограниченный определенными простыми правилами — например первые 5 или последние три, или каждый второй элемент — в таких задачах, вместо перебора в цикле намного удобнее использовать так называемый срез (slice, slicing).
Следует помнить, что взяв элемент по индексу или срезом (slice) мы не как не меняем исходную коллекцию, мы просто скопировали ее часть для дальнейшего использования (например добавления в другую коллекцию, вывода на печать, каких-то вычислений). Поскольку сама коллекция не меняется — это применимо как к изменяемым (список) так и к неизменяемым (строка, кортеж) последовательностям.
Синтаксис среза похож на таковой для индексации, но в квадратных скобках вместо одного значения указывается 2-3 через двоеточие:
my_collection[start:stop:step] # старт, стоп и шагОсобенности среза:
- Отрицательные значения старта и стопа означают, что считать надо не с начала, а с конца коллекции.
- Отрицательное значение шага — перебор ведём в обратном порядке справа налево.
- Если не указан старт [:stop:step]— начинаем с самого края коллекции, то есть с первого элемента (включая его), если шаг положительный или с последнего (включая его), если шаг отрицательный (и соответственно перебор идет от конца к началу).
- Если не указан стоп [start:: step] — идем до самого края коллекции, то есть до последнего элемента (включая его), если шаг положительный или до первого элемента (включая его), если шаг отрицательный (и соответственно перебор идет от конца к началу).
- step = 1, то есть последовательный перебор слева направо указывать не обязательно — это значение шага по умолчанию. В таком случае достаточно указать [start:stop]
- Можно сделать даже так [:] — это значит взять коллекцию целиком
- ВАЖНО: При срезе, первый индекс входит в выборку, а второй нет!
То есть от старта включительно, до стопа, где стоп не включается в результат. Математически это можно было бы записать как [start, stop) или пояснить вот таким правилом:[ <первый включаемый> : <первый НЕ включаемый> : <шаг> ]Поэтому, например, mylist[::-1] не идентично mylist[:0:-1], так как в первом случае мы включим все элементы, а во втором дойдем до 0 индекса, но не включим его!
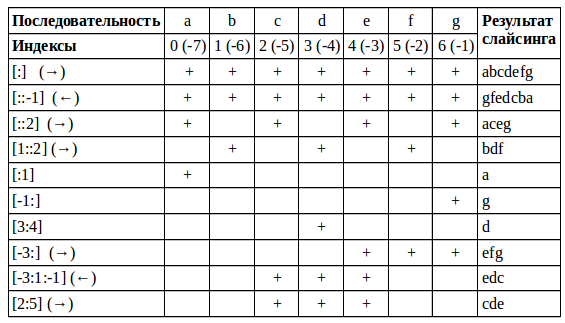
Примеры срезов в виде таблицы:
Код примеров из таблицы
col = 'abcdefg'
print(col[:]) # abcdefg
print(col[::-1]) # gfedcba
print(col[::2]) # aceg
print(col[1::2]) # bdf
print(col[:1]) # a
print(col[-1:]) # g
print(col[3:4]) # d
print(col[-3:]) # efg
print(col[-3:1:-1]) # edc
print(col[2:5]) # cde2.2. Именованные срезы
Чтобы избавится от «магических констант», особенно в случае, когда один и тот же срез надо применять многократно, можно задать константы с именованными срезами с пользованием специальной функции slice()()
Примечание: Nonе соответствует опущенному значению по-умолчанию. То есть [:2] становится slice(None, 2), а [1::2] становится slice(1, None, 2).
person = ('Alex', 'Smith', "May", 10, 1980)
NAME, BIRTHDAY = slice(None, 2), slice(2, None)
# задаем константам именованные срезы
# данные константы в квадратных скобках заменятся соответствующими срезами
print(person[NAME]) # ('Alex', 'Smith')
print(person[BIRTHDAY]) # ('May', 10, 1980)
my_list = [1, 2, 3, 4, 5, 6, 7]
EVEN = slice(1, None, 2)
print(my_list[EVEN]) # [2, 4, 6]
2.3 Изменение списка срезом
Важный момент, на котором не всегда заостряется внимание — с помощью среза можно не только получать копию коллекции, но в случае списка можно также менять значения элементов, удалять и добавлять новые.
Проиллюстрируем это на примерах ниже:
- Даже если хотим добавить один элемент, необходимо передавать итерируемый объект, иначе будет ошибка TypeError: can only assign an iterable
my_list = [1, 2, 3, 4, 5] # my_list[1:2] = 20 # TypeError: can only assign an iterable my_list[1:2] = [20] # Вот теперь все работает print(my_list) # [1, 20, 3, 4, 5] - Для вставки одиночных элементов можно использовать срез, код примеров есть ниже, но делать так не рекомендую, так как такой синтаксис хуже читать. Лучше использовать методы списка .append() и .insert():
Срез аналоги .append() и insert()
my_list = [1, 2, 3, 4, 5] my_list[5:] = [6] # вставляем в конец — лучше использовать .append(6) print(my_list) # [1, 2, 3, 4, 5, 6] my_list[0:0] = [0] # вставляем в начало — лучше использовать .insert(0, 0) print(my_list) # [0, 1, 2, 3, 4, 5, 6] my_list[3:3] = [25] # вставляем между элементами — лучше использовать .insert(3, 25) print(my_list) # [0, 1, 2, 25, 3, 4, 5, 6] - Можно менять части последовательности — это применение выглядит наиболее интересным, так как решает задачу просто и наглядно.
my_list = [1, 2, 3, 4, 5] my_list[1:3] = [20, 30] print(my_list) # [1, 20, 30, 4, 5] my_list[1:3] = [0] # нет проблем заменить два элемента на один print(my_list) # [1, 0, 4, 5] my_list[2:] = [40, 50, 60] # или два элемента на три print(my_list) # [1, 0, 40, 50, 60] - Можно просто удалить часть последовательности
my_list = [1, 2, 3, 4, 5] my_list[:2] = [] # или del my_list[:2] print(my_list) # [3, 4, 5]
2.4 Выход за границы индекса
Обращение по индексу по сути является частным случаем среза, когда мы обращаемся только к одному элементу, а не диапазону. Но есть очень важное отличие в обработке ситуации с отсутствующим элементом с искомым индексом.
Обращение к несуществующему индексу коллекции вызывает ошибку:
my_list = [1, 2, 3, 4, 5]
print(my_list[-10]) # IndexError: list index out of range
print(my_list[10]) # IndexError: list index out of range
А в случае выхода границ среза за границы коллекции никакой ошибки не происходит:
my_list = [1, 2, 3, 4, 5]
print(my_list[0:10]) # [1, 2, 3, 4, 5] — отработали в пределах коллекции
print(my_list[10:100]) # [] - таких элементов нет — вернули пустую коллекцию
print(my_list[10:11]) # [] - проверяем 1 отсутствующий элемент - пустая коллекция, без ошибки
Примечание: Для тех случаев, когда функционала срезов недостаточно и требуются более сложные выборки, можно воспользоваться синтаксисом выражений-генераторов, рассмотрению которых посвещена 4 статья цикла.
3 Сортировка элементов коллекции
Сортировка элементов коллекции важная и востребованная функция, постоянно встречающаяся в обычных задачах. Тут есть несколько особенностей, на которых не всегда заостряется внимание, но которые очень важны.
3.1 Функция sorted()
Мы может использовать функцию sorted() для вывода списка сортированных элементов любой коллекции для последующее обработки или вывода.
- функция не меняет исходную коллекцию, а возвращает новый список из ее элементов;
- не зависимо от типа исходной коллекции, вернётся список (list) ее элементов;
- поскольку она не меняет исходную коллекцию, ее можно применять к неизменяемым коллекциям;
- Поскольку при сортировке возвращаемых элементов нам не важно, был ли у элемента некий индекс в исходной коллекции, можно применять к неиндексированным коллекциям;
- Имеет дополнительные не обязательные аргументы:
reverse=True — сортировка в обратном порядке
key=funcname (начиная с Python 2.4) — сортировка с помощью специальной функции funcname, она может быть как стандартной функцией Python, так и специально написанной вами для данной задачи функцией и лямбдой.
my_list = [2, 5, 1, 7, 3]
my_list_sorted = sorted(my_list)
print(my_list_sorted) # [1, 2, 3, 5, 7]
my_set = {2, 5, 1, 7, 3}
my_set_sorted = sorted(my_set, reverse=True)
print(my_set_sorted) # [7, 5, 3, 2, 1]
Пример сортировки списка строк по длине len() каждого элемента:
my_files = ['somecat.jpg', 'pc.png', 'apple.bmp', 'mydog.gif']
my_files_sorted = sorted(my_files, key=len)
print(my_files_sorted) # ['pc.png', 'apple.bmp', 'mydog.gif', 'somecat.jpg']
3.2 Функция reversed()
Функция reversed() применяется для последовательностей и работает по другому:
- возвращает генератор списка, а не сам список;
- если нужно получить не генератор, а готовый список, результат можно обернуть в list() или же вместо reversed() воспользоваться срезом [: :-1];
- она не сортирует элементы, а возвращает их в обратном порядке, то есть читает с конца списка;
- из предыдущего пункта понятно, что если у нас коллекция неиндексированная — мы не можем вывести её элементы в обратном порядке и эта функция к таким коллекциям не применима — получим «TypeError: argument to reversed() must be a sequence»;
- не позволяет использовать дополнительные аргументы — будет ошибка «TypeError: reversed() does not take keyword arguments».
my_list = [2, 5, 1, 7, 3]
my_list_sorted = reversed(my_list)
print(my_list_sorted) # <listreverseiterator object at 0x7f8982121450>
print(list(my_list_sorted)) # [3, 7, 1, 5, 2]
print(my_list[::-1]) # [3, 7, 1, 5, 2] - тот же результат с помощью среза3.3 Методы списка .sort() и .reverse()
У списка (и только у него) есть особые методы .sort() и .reverse() которые делают тоже самое, что соответствующие функции sorted() и reversed(), но при этом:
- Меняют сам исходный список, а не генерируют новый;
- Возвращают None, а не новый список;
- поддерживают те же дополнительные аргументы;
- в них не надо передавать сам список первым параметром, более того, если это сделать — будет ошибка — не верное количество аргументов.
my_list = [2, 5, 1, 7, 3]
my_list.sort()
print(my_list) # [1, 2, 3, 5, 7]
Обратите внимание: Частая ошибка начинающих, которая не является ошибкой для интерпретатора, но приводит не к тому результату, который хотят получить.
my_list = [2, 5, 1, 7, 3]
my_list = my_list.sort()
print(my_list) # None
3.4 Особенности сортировки словаря
В сортировке словаря есть свои особенности, вызванные тем, что элемент словаря — это пара ключ: значение.
UPD: Так же, не забываем, что говоря о сортировке словаря, мы имеем ввиду сортировку полученных из словаря данных для вывода или сохранения в индексированную коллекцию. Сохранить данные сортированными в самом стандартном словаре не получится, они в нем, как и других неиндексированных коллекциях находятся в произвольном порядке.
- sorted(my_dict) — когда мы передаем в функцию сортировки словарь без вызова его дополнительных методов — идёт перебор только ключей, сортированный список ключей нам и возвращается;
- sorted(my_dict.keys()) — тот же результат, что в предыдущем примере, но прописанный более явно;
- sorted(my_dict.items()) — возвращается сортированный список кортежей (ключ, значение), сортированных по ключу;
- sorted(my_dict.values()) — возвращается сортированный список значений
my_dict = {'a': 1, 'c': 3, 'e': 5, 'f': 6, 'b': 2, 'd': 4}
mysorted = sorted(my_dict)
print(mysorted) # ['a', 'b', 'c', 'd', 'e', 'f']
mysorted = sorted(my_dict.items())
print(mysorted) # [('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5), ('f', 6)]
mysorted = sorted(my_dict.values())
print(mysorted) # [1, 2, 3, 4, 5, 6]
Отдельные сложности может вызвать сортировка словаря не по ключам, а по значениям, если нам не просто нужен список значений, и именно выводить пары в порядке сортировки по значению.
Для решения этой задачи можно в качестве специальной функции сортировки передавать lambda-функцию lambda x: x[1] которая из получаемых на каждом этапе кортежей (ключ, значение) будет брать для сортировки второй элемент кортежа.
population = {"Shanghai": 24256800, "Karachi": 23500000, "Beijing": 21516000, "Delhi": 16787941}
# отсортируем по возрастанию населения:
population_sorted = sorted(population.items(), key=lambda x: x[1])
print(population_sorted)
# [('Delhi', 16787941), ('Beijing', 21516000), ('Karachi', 23500000), ('Shanghai', 24256800)]
UPD от ShashkovS: 3.5 Дополнительная информация по использованию параметра key при сортировке
Допустим, у нас есть список кортежей названий деталей и их стоимостей.
Нам нужно отсортировать его сначала по названию деталей, а одинаковые детали по убыванию цены.
shop = [('каретка', 1200), ('шатун', 1000), ('седло', 300),
('педаль', 100), ('седло', 1500), ('рама', 12000),
('обод', 2000), ('шатун', 200), ('седло', 2700)]
def prepare_item(item):
return (item[0], -item[1])
shop.sort(key=prepare_item)
Результат сортировки
for det, price in shop:
print('{:<10} цена: {:>5}р.'.format(det, price))
# каретка цена: 1200р.
# обод цена: 2000р.
# педаль цена: 100р.
# рама цена: 12000р.
# седло цена: 2700р.
# седло цена: 1500р.
# седло цена: 300р.
# шатун цена: 1000р.
# шатун цена: 200р.
Перед тем, как сравнивать два элемента списка к ним применялась функция prepare_item, которая меняла знак у стоимости (функция применяется ровно по одному разу к каждому элементу. В результате при одинаковом первом значении сортировка по второму происходила в обратном порядке.
Чтобы не плодить утилитарные функции, вместо использования сторонней функции, того же эффекта можно добиться с использованием лямбда-функции.
# Данные скопировать из примера выше
shop.sort(key=lambda x: (x[0], -x[1]))Дополнительные детали и примеры использования параметра key:
- wiki.python.org/moin/HowTo/Sorting#Key_Functions (на английском).
- habrahabr.ru/post/319200/#comment_10011882 — еще один комментарий с детальным примером ShashkovS к данной статье
UPD от ShashkovS: 3.6 Устойчивость сортировки
Допустим данные нужно отсортировать сначала по столбцу А по возрастанию, затем по столбцу B по убыванию, и наконец по столбцу C снова по возрастанию.
Если данные в столбце B числовые, то при помощи подходящей функции в key можно поменять знак у элементов B, что приведёт к необходимому результату.
А если все данные текстовые? Тут есть такая возможность.
Дело в том, что сортировка sort в Python устойчивая (начиная с Python 2.2), то есть она не меняет порядок «одинаковых» элементов.
Поэтому можно просто отсортировать три раза по разным ключам:
data.sort(key=lambda x: x['C'])
data.sort(key=lambda x: x['B'], reverse=True)
data.sort(key=lambda x: x['А'])
Дополнительная информация по устойчивости сортировки и примеры: wiki.python.org/moin/HowTo/Sorting#Sort_Stability_and_Complex_Sorts (на наглийском).
| Часть 1 | Часть 2 | Часть 3 | Часть 4 |
|---|
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
Перейти к содержанию
На чтение 2 мин Просмотров 366 Опубликовано 17.03.2023
Содержание
- Введение
- Метод index()
- Вывод всех вхождений элемента в список
- Заключение
Введение
Довольно часто бывает такая ситуация, что нужно определить индекс элемента в списке. В статье ответим на вопрос, как найти индекс элемента списка в Python.
Метод index()
Самый простой способ определения индекса элемента в списке – это использование метода index().
x = ['a', 'b', 'c', 'd', 'e']
print(x.index('c'))
# Вывод: 2Проблема только в том, что сама функция index() возвращает индекс первого вхождения заданного элемента в списке. Т.е. в списке может быть несколько элементов “a”, метод index() выведет индекс первого из них.
Пример:
x = ['a', 'b', 'c', 'a', 'e']
print(x.index('a'))
# Вывод: 0Вывод всех вхождений элемента в список
Для вывода всех вхождений элемента в список используем генератор списка с условием, где пройдёмся по всем элементам и их индексам при помощи функции enumerate(). В условии проверим совпадение итерабельного элемента с искомым:
x = ['a', 'b', 'c', 'a', 'e']
result = [i for i, x in enumerate(x) if x == 'a']
print(f"Элемент {'a'} присутствует по индекс(у/ам) {result}")
# Вывод: Элемент a присутствует по индекс(у/ам) [0, 3]Заключение
В ходе статьи мы с Вами научились находить индекс элемента списка в языке программирования Python. Надеюсь Вам понравилась статья, желаю удачи и успехов! 🙂
![]()
На чтение 3 мин Просмотров 1.2к. Опубликовано
В Python списки (list) — это структуры данных, которые представляют собой упорядоченные коллекции элементов. Каждый элемент в списке имеет свой индекс, который указывает на его положение в списке. Иногда возникает необходимость узнать индекс определенного элемента в списке. Например, если мы хотим удалить элемент из списка или изменить его значение. В этой статье мы рассмотрим несколько способов, как узнать индекс элемента в списке Python.
Содержание
- Методы для нахождения индекса элемента
- Использование метода index()
- Использование цикла for и функции enumerate()
- Обработка исключений при поиске индекса
Методы для нахождения индекса элемента
Использование метода index()
Метод index() является встроенным методом для списков в Python, который возвращает индекс первого вхождения элемента в списке. Метод принимает один аргумент, который является элементом, индекс которого мы хотим найти. Метод index() возвращает индекс первого вхождения указанного элемента в список. Если элемент не найден, будет сгенерировано исключение ValueError.
Пример использования метода index():
fruits = ['apple', 'banana', 'cherry', 'apple', 'banana']
index_of_cherry = fruits.index('cherry')
print(index_of_cherry) # Будет выведено: 2В данном примере мы создали список fruits, который содержит несколько элементов. Затем мы вызываем метод index() и передаем ему строку 'cherry' в качестве аргумента. Метод находит индекс первого вхождения элемента 'cherry' в списке и возвращает его. Результат выполнения кода будет равен 2, так как 'cherry' является третьим элементом списка, и индексация в Python начинается с 0.
Использование цикла for и функции enumerate()
Другой способ для нахождения индексов элементов в списке — использование цикла for и функции enumerate(). Функция enumerate() пронумеровывает элементы списка и возвращает кортежи из двух значений: индекс элемента и сам элемент.
Пример использования enumerate() для нахождения индексов элементов списка:
fruits = ['apple', 'banana', 'orange', 'kiwi', 'orange']
for index, fruit in enumerate(fruits):
if fruit == 'orange':
print(f"'orange' найден на позиции {index}")Этот код выведет следующий результат:
'orange' найден на позиции 2
'orange' найден на позиции 4В этом примере мы использовали цикл for для перебора всех элементов списка fruits. Функция enumerate() возвращает кортеж (index, fruit) на каждой итерации цикла, и мы проверяем, является ли fruit равным 'orange'. Если это так, мы выводим сообщение с позицией элемента.
Также обратите внимание, что список fruits содержит два элемента со значением 'orange'. Функция enumerate() возвращает индексы обоих элементов, потому что они различаются в списке. Если бы мы использовали метод index(), он вернул бы только первый индекс, который соответствует первому элементу со значением 'orange'.
Обработка исключений при поиске индекса
При поиске индекса элемента в списке Python необходимо учитывать возможность того, что элемент может не находиться в списке. В таком случае, при использовании метода index(), Python выдаст ошибку ValueError: <элемент> не найден в списке. Это приведёт к остановке выполнения программы.
Чтобы избежать ошибки при поиске элемента, можно обернуть операцию поиска в блок try-except, чтобы обработать возможное исключение. Если элемент не найден, в блоке except можно выполнить определенные действия, например, вывести сообщение об ошибке или вернуть значение по умолчанию.
Пример использования обработки исключений при поиске индекса элемента:
my_list = [1, 2, 3, 4, 5]
try:
index = my_list.index(6)
print(f"Индекс элемента: {index}")
except ValueError:
print("Элемент не найден в списке")В этом примере мы пытаемся найти индекс элемента 6 в списке my_list. Так как элемент не найден в списке, возникает исключение ValueError. Мы обрабатываем это исключение с помощью блока try-except и выводим сообщение об ошибке.
Если мы попробуем найти индекс элемента, который присутствует в списке, то мы получим корректный результат.