1. Найди информационный объём следующего сообщения, если известно, что один символ кодируется одним байтом.
Кто владеет информацией, тот владеет миром.
Решение: посчитаем количество символов в сообщении, будем учитывать буквы, знаки препинания и пробелы.
Всего (43) символа. Каждый символ кодируется (1) байтом.
(I = К · i), (43 · 1) байт (= 43) байта.
Ответ: (43) байта.
2. Найди информационный объём слова из (12) символов в кодировке Unicode (каждый символ кодируется двумя байтами). Ответ дайте в битах.
Решение.
Мы знаем из условия задачи, что каждый символ кодируется двумя байтами. Найдём сколько это бит.
(2) байта (· 8 = 16) бит;
Слово состоит из (12) символов, поэтому
(16) бит (· 12) символов (= 192) бита.
Ответ: (192) бита.
3. Найди информационный вес книги, которая состоит из (700) страниц, на каждой странице (70) строк и в каждой строке (95) символов . Мощность алфавита — (256) символов. Ответ дать в Мб.
Решение: если мощность алфавита (256) символов, то информационный объём одного символа (8) бит.
Найдём количество символов в книге: (700·70·95 = 4655000) символов.
Информационный вес сообщения: (4655000·8=37240000) бит.
Ответ нужно дать в Мб, поэтому переведём биты в Мб
(37240000:8:1024:1024 = 4,44) Мб
Ответ: (4,44) Мб.
Задачи на определение информационного объема текста
Проверяется умение оценивать количественные параметры информационных объектов.
Теоретический материал:
N = 2i , где N – мощность алфавита (количество символов в используемом
алфавите),
i – информационный объем одного символа (информационный
вес символа), бит
I = K*i, где I – информационный объем текстового документа (файла),
K – количество символов в тексте
Задача 1.

Считаем количество символов в заданном тексте (перед и после тире – пробел, после знаков препинания, кроме последнего – пробел, пробел – это тоже символ). В результате получаем – 52 символа в тексте.
Дано:
i = 16 бит
K = 52
I — ?
Решение:
I = K*i
I = 52*16бит = 832бит (такой ответ есть — 2)
Ответ: 2
Задача 2.

Дано:
K = 16*35*64 – количество символов в статье
i = 8 бит
I — ?
Решение: Чтобы перевести ответ в Кбайты нужно разделить результат на 8 и на 1024 (8=23, 1024=210)
I=16*35*64*8 бит= =35Кбайт Ответ: 4
=35Кбайт Ответ: 4
Задача 3.

Пусть x – это количество строк на каждой странице, тогда K=10*x*64 – количество символов в тексте рассказа.
Дано:
I = 15 Кбайт
K =10*x*64
i = 2 байта
x — ?
Решение:
Переведем информационный объем текста из Кбайт в байты.
I = 15 Кбайт = 15*1024 байт (не перемножаем)
Подставим все данные в формулу для измерения количества информации в тексте.
I = K*i
15*1024 = 10*x*64*2
Выразим из полученного выражения x
x =  – количество строк на каждой странице – 4
– количество строк на каждой странице – 4
Ответ: 4
Задачи для самостоятельного решения:
Задача 1.

Задача 2.

Задача 3.

Задача 4.

Задача 5.

Задача 6.

Задача 7.

Задачи взяты с сайта fipi.ru из открытого банка заданий (с.1-7)
1. Информационный объём текстового
сообщения
Расчёт
информационного объёма текстового сообщения (количества информации,
содержащейся в информационном сообщении) основан на подсчёте количества
символов в этом сообщении, включая пробелы, и на определении
информационного веса одного символа, который зависит от кодировки, используемой
при передаче и хранении данного сообщения.
Для расчёта
информационного объёма текстового сообщения используется формула
I=K*i, где
I – это информационный объём текстового сообщения,
измеряющийся в байтах, килобайтах, мегабайтах;
K – количество символов в
сообщении,
i – информационный вес одного символа, который
измеряется в битах на один символ.
Информационный
объём одного символа связан с количеством символов в алфавите формулой
N=2i, где
N — это количество символов в алфавите (мощность
алфавита),
i — информационный
вес одного символа в битах на один символ.
2. Информационный объём растрового
графического изображения
Расчёт
информационного объёма растрового графического изображения (количества
информации, содержащейся в графическом изображении) основан на подсчёте количества
пикселей в этом изображении и на определении глубины
цвета (информационного веса одного пикселя).
Для расчёта
информационного объёма растрового графического изображения используется
формула
I=K*i, где
I – это информационный объём растрового графического
изображения, измеряющийся в байтах, килобайтах, мегабайтах;
K – количество пикселей (точек) в
изображении, определяющееся разрешающей способностью носителя информации
(экрана монитора, сканера, принтера);
i – глубина цвета, которая
измеряется в битах на один пиксель.
Глубина цвета связана с
количеством отображаемых цветов формулой
N=2i, где
N – это количество цветов в палитре,
i – глубина цвета в битах на
один пиксель.
Информатика
7 класс
Урок № 6
Единицы измерения информации
Перечень вопросов, рассматриваемых в теме:
- Алфавитный подход к измерению информации.
- Наименьшая единица измерения информации.
- Информационный вес одного символа алфавита и информационный объём всего сообщения.
- Единицы измерения информации.
- Задачи по теме урока.
Тезаурус:
Каждый символ информационного сообщения несёт фиксированное количество информации.
Единицей измерения количества информации является бит – это наименьшаяединица.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
Информационный объём сообщения определяется по формуле:
I = К · i,
I – объём информации в сообщении;
К – количество символов в сообщении;
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Любое сообщение несёт некоторое количество информации. Как же его измерить?
Одним из способов измерения информации является алфавитный подход, который говорит о том, что каждый символ любого сообщения имеет определённый информационный вес, то есть несёт фиксированное количество информации.
Сегодня на уроке мы узнаем, чему равен информационный вес одного символа и научимся определять информационный объём сообщения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2i.
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
Дано:
N=16, i = ?
Решение:
N = 2i
16 = 2i, 24 = 2i, т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Сообщение состоит из множества символов, каждый из которых имеет свой информационный вес. Поэтому, чтобы вычислить объём информации всего сообщения, нужно количество символов, имеющихся в сообщении, умножить на информационный вес одного символа.
Математически это произведение записывается так: I = К · i.
Например: сообщение, записанное буквами 32-символьного алфавита, содержит 180 символов. Какое количество информации оно несёт?
Дано:
N = 32,
K = 180,
I= ?
Решение:
I = К · i,
N = 2i
32 = 2i, 25 = 2 i, т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
Итак, информационный вес всего сообщения равен 900 бит.
В алфавитном подходе не учитывается содержание самого сообщения. Чтобы вычислить объём содержания в сообщении, нужно знать количество символов в сообщении, информационный вес одного символа и мощность алфавита. То есть, чтобы определить информационный вес сообщения: «сегодня хорошая погода», нужно сосчитать количество символов в этом сообщении и умножить это число на восемь.
I = 23 · 8 = 184 бита.
Значит, сообщение весит 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Итак, сегодня мы узнали, что собой представляет алфавитный подход к измерению информации, выяснили, в каких единицах измеряется информация и научились определять информационный вес одного символа и информационный объём сообщения.
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Сейчас используют целых пять систем кодировок русского алфавита (КОИ8-Р, Windows, MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид. Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере.
Разбор решения заданий тренировочного модуля
№1. Определите информационный вес символа в сообщении, если мощность алфавита равна 32?
Варианты ответов:
3
5
7
9
Решение:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
32 = 2i, 32 – это 25, следовательно, i =5 битов.
Ответ: 5 битов.
№2. Выразите в килобайтах 216 байтов.
Решение:
216 можно представить как 26 · 210.
26 = 64, а 210 байт – это 1 Кб. Значит, 64 · 1 = 64 Кб.
Ответ: 64 Кб.
№3. Тип задания: выделение цветом
8х = 32 Кб, найдите х.
Варианты ответов:
3
4
5
6
Решение:
8 можно представить как 23. А 32 Кб переведём в биты.
Получаем 23х=32 · 1024 ·8.
Или 23х = 25 · 210 · 23.
23х = 218.
3х = 18, значит, х=6.
Ответ: 6.
Информационный объем текста складывается из информационных весов составляющих его символов.
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется всего два символа 0 и 1. Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц — машинным языком.
Какой длины должен быть двоичный код, чтобы с его помощью можно было закодировать васе символы клавиатуры компьютера?
Достаточный алфавит
В алфавит мощностью 256 символов можно поместить практически все символы, которые есть на клавиатуре. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице в 8 бит присвоили свое название — байт.
1 байт = 8 бит.
Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Для измерения больших информационных объемов используются более крупные единицы измерения информации:
Единицы измерения количества информации:
1 килобайт = 1 Кб = 1024 байта
1 мегабайт = 1 Мб = 1024 Кб
1 гигабайт = 1 Гб = 1024 Гб
Информационный объем текста
Книга содержит 150 страниц.
На каждой странице — 40 строк.
В каждой строке 60 символов (включая пробелы).
Найти информационный объем текста.
1. Количество символов в книге:
60 * 40 * 150 = 360 000 символов.
2. Т.к. 1 символ весит 1 байт, информационный объем книги равен
3. Переведем байты в более крупные единицы:
360 000 / 1024 = 351,56 Кб
351,56 / 1024 = 0,34 Мб
Ответ: Информационный объем текста 0,34 Мб.
Задача:
Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Кб. Сколько символов содержит этот текст?
Информационный объем текста 3,5 Мб. Найти количество символов в тексте.
1. Переведем объем из Мб в байты:
3,5 Мб * 1024 = 3584 Кб
3584 Кб * 1024 = 3 670 016 байт
2. Т.к. 1 символ весит 1 байт, количество символов в тексте равно


SEO-анализ текста от Text.ru — это уникальный сервис, не имеющий аналогов. Возможность подсветки «воды», заспамленности и ключей в тексте позволяет сделать анализ текста интерактивным и легким для восприятия.
SEO-анализ текста включает в себя:
С помощью данного онлайн-сервиса можно определить число слов в тексте, а также количество символов с пробелами и без них.
Возможность нахождения поисковых ключей в тексте и определения их количества полезна как для написания нового текста, так и для оптимизации уже существующего. Расположение ключевых слов по группам и по частоте сделает навигацию по ключам удобной и быстрой. Сервис также найдет и морфологические варианты ключей, которые выделятся в тексте при нажатии на нужное ключевое слово.
Данный параметр отображает процент наличия в тексте стоп-слов, фразеологизмов, а также словесных оборотов, фраз, соединительных слов, являющихся не значимыми и не несущими смысловой нагрузки. Небольшое содержание «воды» в тексте является естественным показателем, при этом:
- до 15% — естественное содержание «воды» в тексте;
- от 15% до 30% — превышенное содержание «воды» в тексте;
- от 30% — высокое содержание «воды» в тексте.
Процент заспамленности текста отражает количество поисковых ключевых слов в тексте. Чем больше в тексте ключевых слов, тем выше его заспамленность:
- до 30% — отсутствие или естественное содержание ключевых слов в тексте;
- от 30% до 60% — SEO-оптимизированный текст. В большинстве случаев поисковые системы считают данный текст релевантным ключевым словам, которые указаны в тексте.
- от 60% — сильно оптимизированный или заспамленный ключевыми словами текст.
Данный параметр показывает количество слов, состоящих из букв различных алфавитов. Часто это буквы русского и английского языка, например, слово «стол», где «о» — буква английского алфавита. Некоторые копирайтеры заменяют в русских словах часть букв на английские, чтобы обманным путем повысить уникальность текста. SEO-анализ текста от Text.ru успешно выявляет такие слова.
SEO-анализ текста доступен через API. Подробнее в API-проверке.

К огда человек только начинает учиться копирайтингу, автор испытывает уйму сложностей даже в таких простых вещах, как определение объёма текста. Кажется: сущая мелочь, но и с ней надо уметь справиться.
Как узнать объём текста? Предлагаю вашему вниманию несколько удобных вариантов.
Редактор Word (или другая программа для работы с текстом). Когда вы набираете символы в Office, внизу страницы ведётся подсчёт слов и символов с пробелами.
- Чтобы посчитать объём текста частично, выделите нужный фрагмент мышкой и снова посмотрите на параметры внизу листа. Удобно, правда?
Чтоб увидеть всю статистику, кликните на надпись внизу, и перед глазами появится табличка, как на картинке (изображение увеличивается).
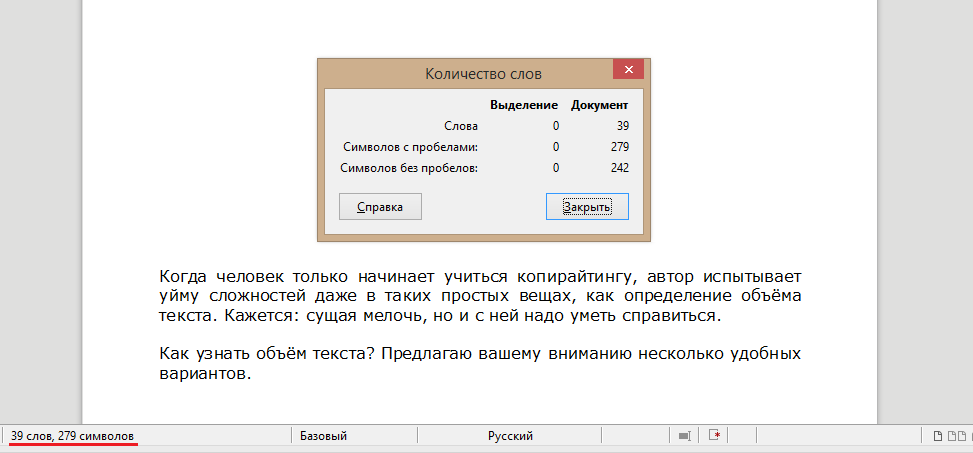
Подсчёт объёма текста в Word
TextAnalyzer. Об этом сервисе для вебмастеров я уже писала. Онлайн-инструмент выручает меня в работе над SEO-статьями. Закиньте контент в редактор, кликните на кнопку, и всего через две секунды вы сможете узнать объём текста (с пробелами и без).
Также посчитать объём текста легко в Istio.com, Content Watch, 1y.ru, text.ru или других сервисах для «сеошников», копирайтеров, журналистов.
Как видите, узнать объём текста не составляет никакого труда. В следующий раз расскажу в блоге о том, как определить объём текста с учётом ключевых слов. Этот материал будет полезен тем, кто осваивает SEO-копирайтинг. Удачи начинающим авторам!