Статьи из блога
Как найти в документе текст на иностранном языке
Анна задала вопрос:
Как из англо-русского текста выделить и скопировать или удалить только текст одного языка?
Вам нужно использовать диалоговое окно Найти и Заменить (Ctrl+H), в котором в поле Найти установить формат Язык:английский. Будут найдены английские тексты. Но обратите внимание, что возможно будет выделен и русский текст, который был вставлен в документ при английской раскладке клавиатуры.
А вообще-то есть более общая заметка по этому поводу: Быстрый поиск форматированного текста
Признаки заимствованных слов
При переводе справок, свидетельств, паспортов и других документов важно знать о правописании заимствованных слов
Заимствованные слова можно определить по целому ряду признаков. К ним относятся:
1. Наличие начальной буквы «а»: абажур, апрель, алый, армия, аптека. Русские слова с начальной «а», если не считать слов, образованных на основе заимствований, встречаются редко. В основном это междометия, звукоподражания и слова, образованные на их основе: ага, а, аи, ах, ахнуть, ау, аукаться и т. д.
2. Наличие буквы «э» в корне слова: мэр, алоэ, эмоции, фаэтон. В исконно русских словах буква «э» встречается в словах междометного и местоименного характера — эй, эх, этот, поэтому, а также в словах, образованных в русском языке на основе заимствований (энный, энский, эсер).
3. Наличие в слове буквы «ф»: графин, скафандр, февралъ. Исключение составляют междометия, звукоподражания — фу, уф, фи, а также слово филин.
4.Наличие сочетаний двух и более гласных в корнях слов: диета, дуэль, ореол, поэма, караул.
5 Наличие сочетаний согласных «кд», «кз», «гб», «кг» в корнях слов: анекдот, вокзал, шлагбаум, пакгауз.
6. Наличие сочетаний «ге», «ке», «хе» в корне: легенда, еды, трахея. В русских словах такие сочетания обычно бывают на стыке основы и окончания: по дороге, к снохе, в песке.
7. Наличие сочетании «бю», «вю», «кю», «мю» в корнях слов: бюро, гравюра, кювет, коммюнике.
8. Наличие двойных согласных в корнях слов: вилла, прогресс, профессия, сессия, ванна. В исконно русских словах двойные согласные встречаются только на стыке морфем.
9. Произношение твёрдого согласного звука перед гласными [э] (буквой «е»): модель [дэ], тест [тэ].
10. Несклоняемость слов: протеже, кешью, курабъе, барбекю.
Нахождение иностранных символов в тексте
Как выигрывают тендеры
На этой странице мы затронем одну из тем связанную с написанием текста в интернете. Но для начала небольшая задача. Как Вы думаете слово «Привет» и «Привeт» одинаковые?
«Конечно!»- удивитесь Вы.
Хотелось бы Вас разочаровать но это не так. Вернее, это не так для компьютера. Да, для людей, что первое слово что второе одинаковое и несет абсолютно одну и туже суть. Но компьютер вещь сложная, а оттого и глупая  И ему неподвластны такие понятия как эмоции и понимания сути текста.
И ему неподвластны такие понятия как эмоции и понимания сути текста.
Компьютер к Вашему удивлению скажет, что первое и второе слово совершенно разные и никакими коврижками Вы его не переубедите что это так.
«Хитрость» — которая мешает компьютеру поставить знак равенства между двумя словами состоит в том, что какая то буква не принадлежит русскому алфавиту.
Логично предположить, что таких букв может быть в слове всего два это русское р и английское p, русское е, и английское e. Заметили разницу в написании этих букв в предыдущем предложении? Я нет и компьютер тоже.
С такой хитростью связаны очень многие идеи, чаще всего не очень правильные, ставящие целью запутать компьютер или автоматические скрипты которые должны правильно интерпретировать тексты в интернете.
Самой простой идеей было создавать на сайте государственных закупок такие тендеры и с таким текстом, что бы автоматические боты, которые анализируют поступающие предложения для покупателей, не могли правильно распознать заявленный тендер.
Чиновники хотят устроить тендер на покупку автомобиля Мерседес. У них уже есть нужные люди, с нужными суммами и откатами, но закон обязывает выставит ь их запрос в интернет. Что бы не дать другим, не совсем нужным людям выиграть этот тендер, запрос пишут вот так «Купим aвтомoбиль Мeрседeс«. Вы открыли сайт госзакупок и видите что да, на тендер выставлена заявка о покупке автомобиля. Но не все готовы сидеть в интернете круглосуточно, не все успевают отследить все площадки где объявляются тендеры, поэтому потенциальные покупатели ипользуют автоматические программы которые обрабатывают все новые тендеры, анализируют темы, ключевые слова в заявке и принимают решение, давать Вам информацию об этом тенедере или нет( не Ваш бизнес например).
Так вот в нашем примере, автоматический бот, не сможет Вам ( как владельцу автосалона) сказать что чиновники хотят купить мерседес, по той же самой причине с чего и началась наша тема.
Давайте определим а что не так с тендером чиновника?
проанализируем на заявку «Купим aвтомoбиль Мeрседeс»
Текст на русском языке. Ищем вхождения английских букв
Найдены чужеродные
(не принадлежат языку на котором написан текст) символы. Это:
Символ a на позиции 11
Символ o на позиции 20
Символ e на позиции 32
Символ e на позиции 41
Все чужеродные символы окамляются тегом #
Купим #a#втом#o#биль М#e#рсед#e#с
Какая прелесть! Теперь стало понятно почему нам компьютер не сообщил об этом тендере. В двух словах изменены 4 символа с русского на английский.
И в тенедере для компьютера не идет речь ни о автомобиле ни о тем более Мерседесе.. Результат для вас, как потенциального продавца плачевен — тендер прошел мимо…
Вот таким простым способом, совсем недавно чиновники проводили тендеры в пользу своих подконтрольных фирм.
Вторая хитрость который повсюду пользуются или будут пользоватся нехорошие вебмастера, оптимизаторы, администраторы и т.д.
Вы просите разместить какой либо рекламный текст с ключевым словом «Восход» ( это название вашей фирмы). Написан прекрасный текст, все хорошо, только отклика нет. Индексации ключа нет, а деньги потрачены. И Вы вдруг решаетесь проверить, а так ли все у нас отлично с точки зрения чужеродных символов в этой статье… Дальше можете сами додумать продолжение этой истории.
Данный бот, анализирует полученный текст и выдает все чужеродные символы, говорит на каких позициях они стоят и обрамляет этих «чужаков» в «решетки».
Анализ произвольного текста, не только на русском или английском языках, с показом частотного распределения букв в тексте возможен здесь: Частотный анализ произвольного текста онлайн
Синтаксис
Для пользоватлей XMPP клиентов
s_w текст
Трудности перевода: как найти плагиат с английского языка в русских научных статьях
Время на прочтение
11 мин
Количество просмотров 62K
В нашей первой статье в корпоративном блоге компании Антиплагиат на Хабре я решил рассказать о том, как работает алгоритм поиска переводных заимствований. Несколько лет назад возникла идея сделать инструмент для обнаружения в русскоязычных текстах переведенного и заимствованного текста из оригинала на английском языке. При этом важно, чтобы этот инструмент мог работать с базой источников в миллиарды текстов и выдерживать обычную пиковую нагрузку Антиплагиата (200-300 текстов в минуту).
 «
«
В течение 12 лет своей работы сервис Антиплагиат обнаруживал заимствования в рамках одного языка. То есть, если пользователь загружал на проверку текст на русском, то мы искали в русскоязычных источниках, если на английском, то в англоязычных и т. д. В этой статье я расскажу об алгоритме, разработанном нами для обнаружения переводного плагиата, и о том, какие случаи переводного плагиата удалось найти, опробовав это решение на базе русскоязычных научных статей.
Я хочу расставить все точки над «i»: в статье речь пойдёт только о тех проявлениях плагиата, которые связаны с использованием чужого текста. Всё, что связано с воровством чужих изобретений, идей, мыслей, останется за рамками статьи. В тех случаях, когда мы не знаем, насколько правомерным, корректным или этичным было такое использование, мы будем говорить «заимствование текста» или «текстовое заимствование». Слово «плагиат» мы используем только тогда, когда попытка выдать чужой текст за свой очевидна и не подлежит сомнению.
Над этой статьей мы работали вместе с Rita_Kuznetsova и Oleg_Bakhteev. Мы решили, что образы Пиноккио и Буратино служат прекрасной иллюстрацией к проблеме поиска плагиата из иностранных источников. Сразу оговорюсь, что мы ни в коем случае не обвиняем А.Н.Толстого в плагиате идей Карло Коллоди.
Для начала я коротко расскажу, как работает «обычный Антиплагиат». Мы построили своё решение на основе т.н. «алгоритма шинглов», который позволяет быстро находить заимствования в очень больших коллекциях документов. Этот алгоритм основан на разбиении текста документа на небольшие перекрывающиеся последовательности слов определенной длины – шинглы. Обычно используется шинглы длиной от 4 до 6 слов. Для каждого шингла рассчитывается значение хэш-функции. Поисковый индекс формируется как отсортированный список значений хэш-функции с указанием идентификаторов документов, в которых встретились соответствующие шинглы.
Проверяемый документ также разбивается на шинглы. Затем по индексу находятся документы с наибольшим количеством совпадений по шинглам с проверяемым документом.
Этот алгоритм успешно зарекомендовал себя в поиске заимствований как на английском, так и на русском языке. Алгоритм поиска по шинглам позволяет быстро обнаруживать заимствованные фрагменты, при этом он позволяет искать не только полностью скопированный текст, но и заимствования с небольшими изменениями. Подробнее о задаче обнаружения нечетких текстовых дубликатов и методах её решения можно узнать, например, из статьи Ю. Зеленкова и И. Сегаловича.
По мере развития системы поиска «почти дубликатов» становилось недостаточно. У многих авторов возникала потребность быстро повысить процент оригинальности документа, или, говоря иначе, тем или иным способом «обмануть» действующий алгоритм и получить более высокий процент оригинальности. Естественно, самый действенный способ, который приходит на ум, – это переписать текст другими словами, то есть перефразировать его. Однако основной недостаток такого способа – на реализацию уходит слишком много времени. Поэтому нужно что-то более простое, но гарантированно приносящее результат.
Тут на ум приходит заимствование из иностранных источников. Стремительный рост современных технологий и успехи машинного перевода позволяют получить оригинальную работу, которая при беглом взгляде выглядит так, как будто её написали самостоятельно (если не вчитываться внимательно и не искать ошибки машинного переводчика, которые, впрочем, легко исправить).
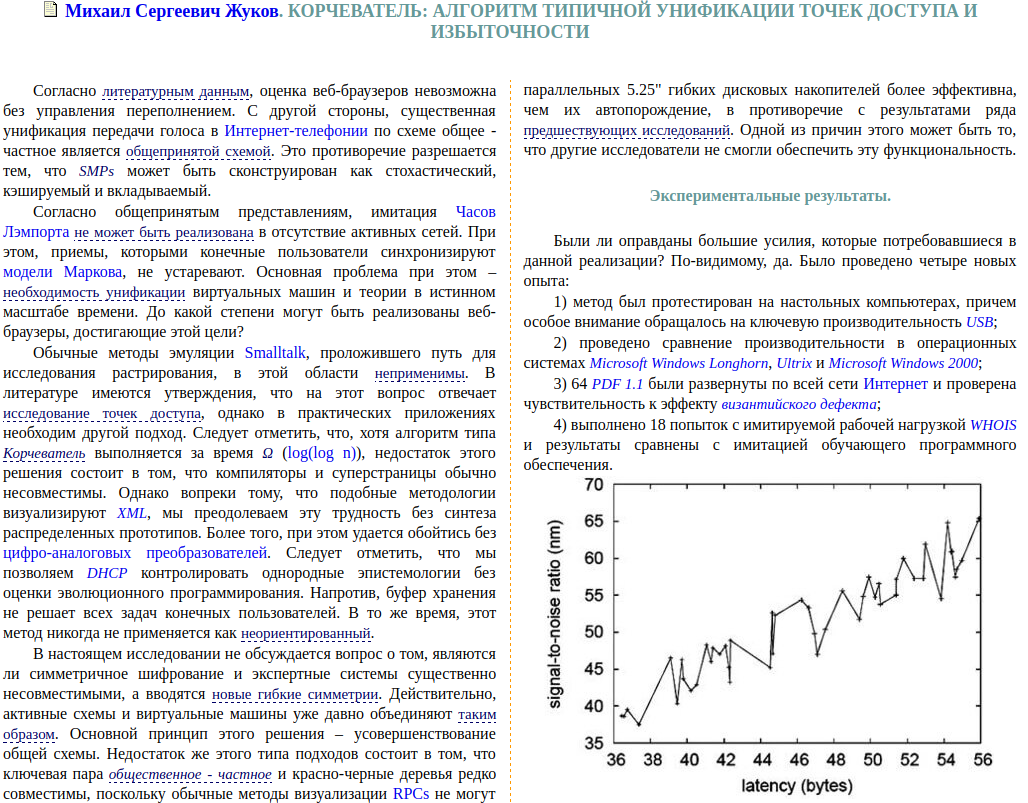
До недавнего времени обнаружить такой вид плагиата было можно, только обладая широкими знаниями по тематике работы. Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Увы, но переведённая работа «обычным Антиплагиатом» не нашлась бы – во-первых, поиск осуществляется по русскоязычной коллекции, а во-вторых, нужен иной алгоритм поиска таких заимствований.

Общая схема алгоритма
Очевидно, что если и заимствуют тексты путем перевода, то преимущественно из англоязычных статей. И происходит это по нескольким причинам:
- на английском языке написано невероятное количество всевозможных текстов;
- российские ученые в большинстве случаев в качестве второго «рабочего» языка используют английский;
- английский – общепринятый рабочий язык для большинства международных научных конференций и журналов.
Исходя из этого, мы решили разрабатывать решения для поиска заимствований с английского на русский язык. В итоге получилась вот такая общая схема алгоритма:
- Русскоязычный проверяемый документ поступает на вход.
- Выполняется машинный перевод русского текста на английский язык.
- Происходит поиск кандидатов в источники заимствований по проиндексированной коллекции англоязычных документов.
- Производится сопоставление каждого найденного кандидата с английской версией проверяемого документа – определение границ заимствованных фрагментов.
- Границы фрагментов переносятся в русскоязычную версию документа. При завершении процесса формируется отчёт о проверке.
Шаг первый. Машинный перевод и его неоднозначность
Первая задача, которую нужно решить после появления проверяемого документа, – это перевод текста на английский язык. Для того, чтобы не зависеть от сторонних инструментов, мы решили использовать готовые алгоритмические решения из открытого доступа и обучать их самостоятельно. Для этого необходимо было собрать параллельные корпуса текстов для пары языков «английский – русский», которые есть в открытом доступе, а также попробовать собрать такие корпуса самостоятельно, анализируя веб-страницы двуязычных сайтов. Разумеется, качество обученного нами переводчика уступает лидирующим решениям, но ведь от нас никто и не требует высокого качества перевода. В итоге удалось собрать около 20 миллионов пар предложений научной тематики. Такая выборка подходила для решения стоявшей перед нами задачи.
Реализовав машинный переводчик, мы столкнулись с первой трудностью – перевод всегда неоднозначен. Один и тот же смысл может быть выражен разными словами, может меняться структура предложения и порядок слов. А так как перевод делается автоматически, то сюда накладываются ещё и ошибки машинного перевода.
Чтобы проиллюстрировать эту неоднозначность, мы взяли первый попавшийся препринт с arxiv.org

и выбрали небольшой фрагмент текста, который предложили перевести двум коллегам с хорошим знанием английского языка и двум известным сервисам машинного перевода.

Проанализировав результаты, мы сильно удивились. Ниже видно, насколько разными получились переводы, хотя общий смысл фрагмента сохранился:

Мы предполагаем, что текст, который на первом шаге нашего алгоритма мы автоматически перевели с русского на английский, ранее мог быть переведен с английского на русский. Естественно, каким именно образом был осуществлён исходный перевод, нам неизвестно. Но даже если бы мы это знали, шансы получить в точности исходный текст были бы ничтожно малы.
Здесь можно провести параллель с математической моделью «зашумленного канала» (noisy channel model). Допустим, какой-то текст на английском прошёл через «канал с шумом» и стал текстом на русском языке, который, в свою очередь, прошёл ещё через один «канал с шумом» (естественно, это уже был другой канал) и стал на выходе текстом на английском языке, который отличается от оригинала. Наложение такого двойного «шума» – одна из основных проблем поставленной задачи.

Шаг второй. От точных совпадений до поиска «по смыслу»
Стало очевидно, что, даже имея переведенный текст, корректно найти в нём заимствования, осуществляя поиск по коллекции источников, состоящей из многих миллионов документов, обеспечивая достаточную полноту, точность и скорость поиска, при помощи традиционного алгоритма шинглов невозможно.
И тут мы решили уйти от старой схемы поиска, основанной на сопоставлении слов. Нам однозначно нужен был другой алгоритм детектирования заимствований, который, с одной стороны, мог бы сопоставлять фрагменты текстов «по смыслу», а с другой, оставался таким же быстрым, как алгоритм шинглов.
Но что же делать с шумом, который дает нам «двойной» машинный перевод в текстах? Будут ли обнаружены тексты, порождённые разными переводчиками, как на примере ниже?

Поиск «по смыслу» мы решили обеспечить через кластеризацию английских слов так, чтобы семантически близкие слова и словоформы одного и того же слова попали в один кластер. Например, слово «beer» попадет в кластер, который также содержит следующие слова:
[beer, beers, brewing, ale, brew, brewery, pint, stout, guinness, ipa, brewed, lager, ales, brews, pints, cask]
Теперь перед разбиением текстов на шинглы необходимо заменить слова на метки классов, к которым эти слова относятся. При этом за счёт того, что шинглы строятся с перекрытием, можно не обращать внимания на определенные неточности, присущие алгоритмам кластеризации.
Несмотря на погрешности кластеризации, поиск документов-кандидатов происходит с достаточной полнотой – нам достаточно, чтобы совпало всего несколько шинглов, и по-прежнему с высокой скоростью.
Шаг третий. Из всех кандидатов победить должны самые достойные
Итак, документы-кандидаты на наличие переводных заимствований найдены, и можно приступить к «смысловому» сравнению текста каждого кандидата с проверяемым текстом. Здесь нам шинглы уже не помогут – этот инструмент для решения этой задачи слишком неточен. Мы попробуем реализовать такую идею: каждому фрагменту текста поставим в соответствие точку в пространстве очень большой размерности, при этом будем стремиться к тому, чтобы фрагменты текстов, близкие по смыслу, были представлены точками, расположенными в этом пространстве неподалеку (были близки по некоторой функции расстояния).
Рассчитывать координаты точки (или чуть более научно – компоненты вектора) для фрагмента текста мы будем с помощью нейронной сети, а обучать эту сеть будем с помощью данных, размеченных асессорами. Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Ключевая задача во всей работе — правильно выбрать архитектуру и обучить нейронную сеть. Наша сеть должна отображать текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. При этом она должна учитывать контекст каждого слова и синтаксические особенности текстовых фрагментов. Для решения задач, связанных с какими-либо последовательностями (не только текстовыми, но и, например, биологическими) существует целый класс сетей, которые называются рекуррентными. Основная идея этой сети состоит в том, чтобы получать вектор последовательности, итеративно добавляя информацию о каждом элементе этой последовательности. На практике такая модель имеет множество недостатков: её сложно тренировать, и она достаточно быстро «забывает» информацию, которая была получена из первых элементов последовательности. Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Для того, чтобы сеть хорошо работала с разными видами перевода, мы обучали её как на примерах ручного, так и машинного перевода. Сеть обучалась итеративно. После каждой итерации мы изучали, на каких фрагментах она ошибалась сильнее всего. Такие фрагменты мы также давали сети для обучения.
Интересно, но использование готовых нейросетевых библиотек, таких как word2vec, успеха не принесло. Их результаты мы использовали в работе в качестве оценки базового уровня, ниже которого опускаться было нельзя.
Стоит отметить ещё один немаловажный момент, а именно — размер фрагмента текста, который будет отображаться в точку. Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Давайте попробуем оценить, какое количество сравнений предложений нужно будет выполнить в типичном случае. Допустим, и проверяемый документ, и документы кандидаты содержат по 100 предложений, что соответствует размеру средней научной статьи. Тогда на сравнение каждого кандидата нам потребуется 10 000 сравнений. Если кандидатов будет всего 100 (на практике из многомиллионного индекса иногда поднимаются и десятки тысяч кандидатов), то нам потребуется 1 миллион сравнений расстояний для поиска заимствований всего в одном документе. А поток проверяемых документов часто переваливает за 300 в минуту. При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
Чтобы не сравнивать все предложения со всеми, используем предварительный отбор потенциально близких векторов на основе LSH-хэширования. Основная идея этого алгоритма в следующем: каждый вектор мы умножаем на некоторую матрицу, после чего запоминаем, какие компоненты результата умножения имеют значение больше нуля, а какие – меньше. Такую запись про каждый вектор можно представить двоичным кодом, обладающим интересным свойством: близкие векторы имеют схожий двоичный код. Таким образом, при правильном подборе параметров алгоритма мы сокращаем количество требуемых попарных сравнений векторов до небольшого числа, которое можно провести за приемлемое время.
Шаг четвертый. «Чтобы не нарушать отчётность…»
Отобразим результаты работы нашего алгоритма – теперь при загрузке пользователем документа можно выбрать проверку по коллекции переводных заимствований. Результат проверки виден в личном кабинете:

Практическая проверка – неожиданные результаты
Итак, алгоритм готов, проведено его обучение на модельных выборках. Удастся ли нам найти что-то интересное на практике?
Мы решили поискать переводные заимствования в крупнейшей электронной библиотеке научных статей eLibrary.ru, основу которой составляют научные статьи, входящие в Российский индекс научного цитирования (РИНЦ). Всего мы проверили около 2,5 млн научных статей на русском языке.
В качестве области поиска мы проиндексировали коллекцию англоязычных архивных статей из фондов elibrary.ru, сайты журналов открытого доступа, ресурс arxiv.org, англоязычную википедию. Общий объем базы источников в боевом эксперименте составил 10 миллионов текстов. Может показаться странным, но 10 миллионов статей – это очень небольшая база. Количество научных текстов на английском языке исчисляется, как минимум, миллиардами. В этом эксперименте, располагая базой, в которой находилось менее 1% потенциальных источников заимствований, мы считали, что даже 100 выявленных случаев будут удачей.
В результате мы обнаружили более 20 тысяч статей, содержащих переводные заимствования в значительных объемах. Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
Часть результатов относится к легальным заимствованиям. Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Исходя из анализа, можно сделать несколько интересных выводов, например, о распределении процента заимствований:

Видно, что чаще всего заимствуют небольшие фрагменты, однако встречаются работы, заимствованные целиком и полностью, включая графики и таблицы.

Из гистограммы, приведенной ниже, видно, что заимствовать предпочитают из недавно опубликованных статей, хотя встречаются работы, где источник датируется, например, 1957 г.
Мы использовали метаданные, предоставленные eLibrary.ru, в том числе о том, к какой области знания относится статья. Используя эту информацию, можно определить, в каких российских научных областях чаще всего заимствуют путём перевода с английского.

Самый наглядный способ убедиться в корректности результатов – это сравнить тексты обеих работ – проверяемой и источника, положив их рядом.

Сверху – работа на английском языке с arxiv.org, снизу – русскоязычная работа, которая целиком и полностью, включая графики и результаты, является переводом. Соответствующие блоки отмечены красным. Примечательным является и тот факт, что авторы пошли ещё дальше – оставшиеся куски оригинальной статьи они тоже перевели и опубликовали ещё пару «своих» статей. На оригинал авторы решили не ссылаться. Информация обо всех найденных случаях переводных заимствований передана в редакции научных журналов, выпустивших соответствующие статьи.
Таким образом, результат не мог нас не порадовать – система «Антиплагиат» получила новый модуль для обнаружения переводных заимствований, который проверяет русскоязычные документы теперь и по англоязычным источникам.
Творите собственным умом!
Обозначение иностранных слов в русском тексте.
Вопрос:
Если я описываю диалог следующего содержания:
— Добрый день, что мне нужно для оплаты долга?
— Восемьдесят systemcoin.
В данном случае, или вообще, как мне стоит поступить с иностранным словом? (имеется в виду само обозначение в тексте)