Интервальные оценки для генеральной средней.
Правила построения
доверительного интервала для
математического ожидания зависят от
того, известна или не известна дисперсия
генеральной случайной величины.
1) Пусть из генеральной
совокупности Х с нормальным законом
распределения
![]() и известной дисперсии
и известной дисперсии![]() взята
взята
случайная выборка объёмомn
и вычислено средняя арифметическая
![]() .
.
Требуется найти интервальную оценку
математического ожидания генеральной
случайной величины![]() .
.
Поскольку![]() имеет нормальное распределение с
имеет нормальное распределение с
параметрами![]() ,
,
то статистика![]() имеет нормированное нормальное
имеет нормированное нормальное
распределение с параметрами![]() .
.
Тогда по интегральной теореме Лапласа
имеем:
![]() .
.
Значение
![]() при заданной доверительной вероятности
при заданной доверительной вероятности
найдём по таблице функции Лапласа из
уравнения
![]() .
.
Обозначим решение
этого уравнения через
![]() ,
,
а искомый интервал найдём из неравенства
![]() ,
,
![]() (5)
(5)
Точность оценки
равна
![]() (6)
(6)
Границы доверительного
интервала равны:
![]()
Из формулы (6) можно
при заданной точности
![]() найти
найти
необходимый объём выборки, а при заданном
объёме и точности – доверительную
вероятность.
2) Предположим
теперь, что
![]() в генеральной совокупности неизвестно,
в генеральной совокупности неизвестно,
и вычислена выборочная дисперсия![]() .
.
В этом случае для
построения интервальной оценки
используется статистика
![]() ,
,
имеющая распределение
Стьюдента с числом степеней свободы
![]() .
.
По таблице
t-распределения
для
![]() степеней свободы, при заданном уровне
степеней свободы, при заданном уровне
значимости![]() ,
,
находим значение![]() ,
,
для которого справедливо равенство
![]() ,
,
(7)
где точность оценки
генеральной средней равна
![]() (8)
(8)
При достаточно
большём объёме выборки различие в
доверительных интервалах (5) и (7) мало,
так как при неограниченном увеличении
числа n
распределение Стьюдента стремится к
нормальному распределению.
3) Приближённая
интервальная оценка.
Пусть требуется
найти интервальную оценку для
математического ожидания в случае,
когда закон распределения генеральной
совокупности неизвестен. При достаточно
большом объёме выборки средняя
арифметическая, согласно центральной
теореме Ляпунова, имеет распределение
близкое к нормальному.
Поэтому доверительную
вероятность можно вычислять по формуле:
![]() (8)
(8)
где
![]() —
—
средняя квадратическая ошибка при
замене![]() на приближённое выборочное значение.
на приближённое выборочное значение.
В зависимости от цели образования
выборки и способа отбора в неё элементов
генеральной совокупности, получены
следующие формулы средних квадратических
ошибок:
-
Выборка
Повторная
Бесповторная
Цель
выборкиДля
средней


Здесь N—
объём генеральной совокупности, n—
объём выборки.
Минимальный объём
выборки, гарантирующий попадание с
надёжностью
![]() параметра
параметра![]() в интервал
в интервал![]() при фиксированной предельной ошибке
при фиксированной предельной ошибке![]() ,
,
вычисляется по одной из формул:
-
Выборка
Повторная
Бесповторная
Цель
выборкиДля
средней

Здесь
![]() находится с помощью таблицы из уравнения
находится с помощью таблицы из уравнения
![]() .
.
(9)
Рассмотрим решение
некоторых типовых задач:
Задача 1.
В условии примера 1. (Лекция 1.) найти:
1) Вероятность
того, что среднее значение диаметра
ствола сосен во всём массиве отличается
от среднего диаметра в выборке не более
чем на 0,5 см.
2) Границы, в которых
с вероятностью 0,9544 заключён средний
диаметр сосен всего массива.
3) Объём выборки,
для которой доверительные границы с
предельной ошибкой
![]() см. имели бы место с доверительной
см. имели бы место с доверительной
вероятностью![]() .
.
Решение:
1) В примере 1 были
подсчитаны выборочная средняя и
дисперсия:
![]() .
.
Подсчитаем среднюю
квадратическую ошибку выборочной
средней, учитывая, что объём генеральной
совокупности (весь лесной массив) очень
велик и формулы повторной и бесповторной
выборок совпадают.
![]() .
.
Тогда из формулы
(8) находим
![]() .
.
2) По формуле (9)
найдем такое значение t
при котором
![]()
Из таблицы легко
найти
![]() .
.
Тогда предельная
ошибка выборки
![]() .
.
Доверительные границы будут равны:
![]() (см.)
(см.)
![]() (см.)
(см.)
3) Для ответа на
третий вопрос задачи применим формулу
объёма выборки как повторной при
определении средней:
![]() (сосен)
(сосен)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда нам нужно получить одно число в качестве оценки параметра совокупности, мы используем точечную оценку. Тем не менее, из-за ошибки выборки, точечная оценка не будет в точности равняться параметру совокупности при любом размере данной выборки.
Часто, вместо точечной оценки, более полезным подходом будет найти диапазон значений, в рамках которого, как мы ожидаем, может находится значение искомого параметра с заданным уровнем вероятности.
Этот подход называется интервальной оценкой параметра (англ. ‘interval estimate of parameter’), а доверительный интервал выполняет роль этого диапазона значений.
Определение доверительного интервала.
Доверительный интервал (англ. ‘confidence interval’) представляет собой диапазон, для которого можно утверждать, с заданной вероятностью (1 — alpha ), называемой степенью доверия (или степенью уверенности, англ. ‘degree of confidence’), что он будет содержать оцениваемый параметр.
Этот интервал часто упоминается как (100 (1 — alpha)% ) доверительный интервал для параметра.
Конечные значения доверительного интервала называются нижним и верхним доверительными пределами (или доверительными границами или предельной погрешностью, англ. ‘lower/upper confidence limits’).
В этом чтении, мы имеем дело только с двусторонними доверительными интервалами — доверительные интервалами, для которых мы вычисляем и нижние и верхние пределы.
Кроме того, можно определить два типа односторонних доверительных интервалов для параметра совокупности.
Нижний односторонний доверительный интервал устанавливает только нижний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности равен или превышает нижний предел.
Верхний односторонний доверительный интервал устанавливает только верхний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности меньше или равен верхнему пределу.
Инвестиционные аналитики редко используют односторонние доверительные интервалы.
Доверительные интервалы часто дают либо вероятностную интерпретацию, либо практическую интерпретацию.
При вероятностной интерпретации, мы интерпретируем 95%-ный доверительный интервал для среднего значения совокупности следующим образом.
При повторяющейся выборке, 95% таких доверительных интервалов будут, в конечном счете, включать в себя среднее значение совокупности.
Например, предположим, что мы делаем выборку из совокупности 1000 раз, и на основании каждой выборки мы построим 95%-ный доверительный интервал, используя вычисленное выборочное среднее.
Из-за случайного характера выборок, эти доверительные интервалы отличаются друг от друга, но мы ожидаем, что 95% (или 950) этих интервалов включают неизвестное значение среднего по совокупности.
На практике мы обычно не делаем такие повторяющиеся выборки. Поэтому в практической интерпретации, мы утверждаем, что мы 95% уверены в том, что один 95%-ный доверительный интервал содержит среднее по совокупности.
Мы вправе сделать это заявление, потому что мы знаем, что 95% всех возможных доверительных интервалов, построенных аналогичным образом, будут содержать среднее по совокупности.
Доверительные интервалы, которые мы обсудим в этом чтении, имеют структуры, подобные описанной ниже базовой структуре.
Построение доверительных интервалов.
Доверительный интервал (100 (1 — alpha)% ) для параметра имеет следующую структуру.
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка
где
- Точечная оценка = точечная оценка параметра (значение выборочной статистики).
- Фактор надежности (англ. ‘reliability factor’) = коэффициент, основанный на предполагаемом распределении точечной оценки и степени доверия ((1 — alpha)) для доверительного интервала.
- Стандартная ошибка = стандартная ошибка выборочной статистики, значение которой получено с помощью точечной оценки.
Величину (Фактор надежности) (times) (Cтандартная ошибка) иногда называют точностью оценки (англ. ‘precision of estimator’). Большие значения этой величины подразумевают более низкую точность оценки параметра совокупности.
Самый базовый доверительный интервал для среднего значения по совокупности появляется тогда, когда мы делаем выборку из нормального распределения с известной дисперсией. Фактор надежности в данном случае на основан стандартном нормальном распределении, которое имеет среднее значение, равное 0 и дисперсию 1.
Стандартная нормальная случайная величина обычно обозначается как (Z). Обозначение (z_alpha ) обозначает такую точку стандартного нормального распределения, в которой (alpha) вероятности остается в правом хвосте.
Например, 0.05 или 5% возможных значений стандартной нормальной случайной величины больше, чем ( z_{0.05} = 1.65 ).
Предположим, что мы хотим построить 95%-ный доверительный интервал для среднего по совокупности, и для этой цели, мы сделали выборку размером 100 из нормально распределенной совокупности с известной дисперсией (sigma^2) = 400 (значит, (sigma) = 20).
Мы рассчитываем выборочное среднее как ( overline X = 25 ). Наша точечная оценка среднего по совокупности, таким образом, 25.
Если мы перемещаем 1.96 стандартных отклонений выше среднего значения нормального распределения, то 0.025 или 2.5% вероятности остается в правом хвосте. В силу симметрии нормального распределения, если мы перемещаем 1.96 стандартных отклонений ниже среднего, то 0.025 или 2.5% вероятности остается в левом хвосте.
В общей сложности, 0.05 или 5% вероятности лежит в двух хвостах и 0.95 или 95% вероятности лежит между ними.
Таким образом, ( z_{0.025} = 1.96) является фактором надежности для этого 95%-ного доверительного интервала. Обратите внимание на связь (100 (1 — alpha)% ) для доверительного интервала и (z_{alpha/2}) для фактора надежности.
Стандартная ошибка среднего значения выборки, заданная Формулой 1, равна:
( sigma_{overline X} = 20 Big / sqrt{100} = 2 )
Доверительный интервал, таким образом, имеет нижний предел:
( overline X — 1.96 sigma_{overline X} ) = 25 — 1.96(2) = 25 — 3.92 = 21.08.
Верхний предел доверительного интервала равен:
( overline X + 1.96sigma_{overline X} ) = 25 + 1.96(2) = 25 + 3.92 = 28.92
95%-ный доверительный интервал для среднего по совокупности охватывает значения от 21.08 до 28.92.
Доверительные интервалы для среднего по совокупности (нормально распределенная совокупность с известной дисперсией).
Доверительный интервал (100 (1 — alpha)% ) для среднего по совокупности ( mu ), когда мы делаем выборку из нормального распределения с известной дисперсией ( sigma^2 ) задается формулой:
( Large dst overline X pm z_{alpha /2}{sigma over sqrt n} ) (Формула 4)
Факторы надежности для наиболее часто используемых доверительных интервалов приведены ниже.
Факторы надежности для доверительных интервалов на основе стандартного нормального распределения.
Мы используем следующие факторы надежности при построении доверительных интервалов на основе стандартного нормального распределения:
- 90%-ные доверительные интервалы: используется (z_{0.05}) = 1.65
- 95%-ные доверительные интервалы: используется (z_{0.025}) = 1.96
- 99%-ные доверительные интервалы: используется (z_{0.005}) = 2.58
На практике, большинство финансовых аналитиков используют значения для (z_{0.05}) и (z_{0.005}), округленные до двух знаков после запятой.
Для справки, более точными значениями для (z_{0.05}) и (z_{0.005}) являются 1.645 и 2.575, соответственно.
Для быстрого расчета 95%-ного доверительного интервала (z_{0.025}) иногда округляют 1.96 до 2.
Эти факторы надежности подчеркивают важный факт о всех доверительных интервалах. По мере того, как мы повышаем степень доверия, доверительный интервал становится все шире и дает нам менее точную информацию о величине, которую мы хотим оценить.
«Чем уверенней мы хотим быть, тем меньше мы должны быть уверены»
см. Freund и Williams (1977), стр. 266.
На практике, допущение о том, что выборочное распределение выборочного среднего, по меньшей мере, приблизительно нормальное, часто является обоснованным, либо потому, что исходное распределение приблизительно нормальное, либо потому что мы имеем большую выборку и поэтому к ней применима центральная предельная теорема.
Однако, на практике, мы редко знаем дисперсию совокупности. Когда дисперсия генеральной совокупности неизвестна, но выборочное среднее, по меньшей мере, приблизительно нормально распределено, у нас есть два приемлемых пути чтобы вычислить доверительные интервалы для среднего значения совокупности.
Вскоре мы обсудим более консервативный подход, который основан на t-распределении Стьюдента (t-распределение, для краткости).
Распределение статистики (t) называется t-распределением Стьюдента (англ. «Student’s t-distribution») из-за псевдонима «Студент» (Student), использованного британским математиком Уильямом Сили Госсеттом, который опубликовал свою работу в 1908 году.
В финансовой литературе, это наиболее часто используемый подход для статистической оценки и проверки статистических гипотез, касающихся среднего значения, когда дисперсия генеральной совокупности не известна, как для малого, так и для большого размер выборки.
Второй подход к доверительным интервалам для среднего по совокупности, основанного на стандартном нормальном распределении, — это z-альтернатива (англ. ‘z-alternative’). Он может быть использован только тогда, когда размер выборки является большим (в общем случае, размер выборки 30 или больше, можно считать большим).
В отличии от доверительного интервала, приведенного в Формуле 4, этот доверительный интервал использует стандартное отклонение выборки (s) при вычислении стандартной ошибки выборочного среднего (по Формуле 2).
Доверительные интервалы для среднего по совокупности — z-альтернатива (большая выборка, дисперсия совокупности неизвестна).
Доверительный интервал (100 (1 — alpha)% ) для среднего по совокупности ( mu ) при выборке из любого распределения с неизвестной дисперсией, когда размер выборки большой, задается формулой:
( Large dst overline X pm z_{alpha /2}{s over sqrt n} ) (Формула 5)
Поскольку этот тип доверительного интервала применяется довольно часто, мы проиллюстрируем его вычисление в Примере 4.
Пример (4) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием z-статистики.
Предположим, что инвестиционный аналитик делает случайную выборку акций взаимных фондов США и рассчитывает средний коэффициент Шарпа.
[см. также: CFA — Коэффициент Шарпа]
Размер выборки равен 100, а средний коэффициент Шарпа составляет 0.45. Выборка имеет стандартное отклонение 0.30.
Рассчитайте и интерпретируйте 90-процентный доверительный интервал для среднего по совокупности всех акций взаимных фондов США с использованием фактора надежности на основе стандартного нормального распределения.
Фактор надежности для 90-процентного доверительного интервала, как указано ранее, составляет ( z_{0.05} = 1.65 ).
Доверительный интервал будет равен:
( begin{aligned} & overline X pm z_{0.05}{s over sqrt n } \ &= 0.45 pm 1.65{0.30 over sqrt {100}} \ &= 0.45 pm 1.65(0.03) = 0.45 pm 0.0495 end{aligned} )
Доверительный интервал охватывает значения 0.4005 до 0.4995, или от 0.40 до 0.50, с округлением до двух знаков после запятой. Аналитик может сказать с 90-процентной уверенностью, что интервал включает среднее по совокупности.
В этом примере аналитик не делает никаких конкретных предположений о распределении вероятностей, характеризующем совокупность. Скорее всего, аналитик опирается на центральную предельную теорему для получения приближенного нормального распределения для выборочного среднего.
Как показывает Пример 4, даже если мы не уверены в характере распределения совокупности, мы все еще можем построить доверительные интервалы для среднего по совокупности, если размер выборки достаточно большой, поскольку можем применить центральную предельную теорему.
Концепция степеней свободы.
Обратимся теперь к консервативной альтернативе и используем t-распределение Стьюдента, чтобы построить доверительные интервалы для среднего по совокупности, когда дисперсия генеральной совокупности не известна.
Для доверительных интервалов на основе выборок из нормально распределенных совокупностей с неизвестной дисперсией, теоретически правильный фактор надежности основан на t-распределении. Использование фактора надежности, основанного на t-распределении, имеет важное значение для выборок небольшого размера.
Применение фактора надежности (t) уместно, когда дисперсия генеральной совокупности неизвестна, даже если у нас есть большая выборка и мы можем использовать центральную предельную теорему для обоснования использования фактора надежности (z). В этом случае большой выборки, t-распределение обеспечивает более консервативные (широкие) доверительные интервалы.
t-распределение является симметричным распределением вероятностей и определяется одним параметром, известным как степени свободы (DF, от англ. ‘degrees of freedom’). Каждое значение для числа степеней свободы определяет одно распределение в этом семействе распределений.
Далее мы сравним t-распределения со стандартным нормальным распределением, но сначала мы должны понять концепцию степеней свободы. Мы можем сделать это путем изучения расчета выборочной дисперсии.
Формула 3 дает несмещенную оценку выборочной дисперсии, которую мы используем. Выражение в знаменателе, ( n — 1 ), означающее размер выборки минус 1, это число степеней свободы при расчете дисперсии совокупности с использованием Формулы 3.
Мы также используем ( n — 1 ) как число степеней свободы для определения факторов надежности на основе распределения Стьюдента. Термин «степени свободы» используются, так как мы предполагаем, что в случайной выборке наблюдения отобраны независимо друг от друга. Числитель выборочной дисперсии, однако, использует выборочное среднее.
Каким образом использование выборочного среднего влияет на количество наблюдений, отобранных независимо, для формулы выборочной дисперсии?
При выборке размера 10 и среднем значении в 10%, к примеру, мы можем свободно отобрать только 9 наблюдений. Независимо от отобранных 9 наблюдений, мы всегда можем найти значение для 10-го наблюдения, которое дает среднее значение, равное 10%. С точки зрения формулы выборочной дисперсии, здесь есть 9 степеней свободы.
Учитывая, что мы должны сначала вычислить выборочное среднее от общего числа (n) независимых наблюдений, только (n — 1) наблюдений могут быть отобраны независимо друг от друга для расчета выборочной дисперсии.
Концепция степеней свободы часто применяется в финансовой статистике, и вы встретите ее в последующих чтениях.
t-распределение Стьюдента.
Предположим, что мы делаем выборку из нормального распределения.
Коэффициент (z = (overline X — mu) Big / (sigma big / sqrt n) ) нормально распределен со средним значением 0 и стандартным отклонением 1, однако, коэффициент (t = (overline X — mu) Big / (s big / sqrt n) ) следует t-распределению со средним 0 и (n — 1) степеней свободы.
Коэффициент (t) не является нормальным, поскольку представляет собой отношение двух случайных величин, выборочного среднего и стандартного отклонения выборки.
Определение стандартной нормальной случайной величины включает в себя только одну случайную величину, выборочное среднее. По мере увеличения степеней свободы, однако, t-распределение приближается к стандартному нормальному распределению.
На Рисунке 1 показано стандартное нормальное распределение и два t-распределения, одно с DF = 2 и одно с DF = 8.
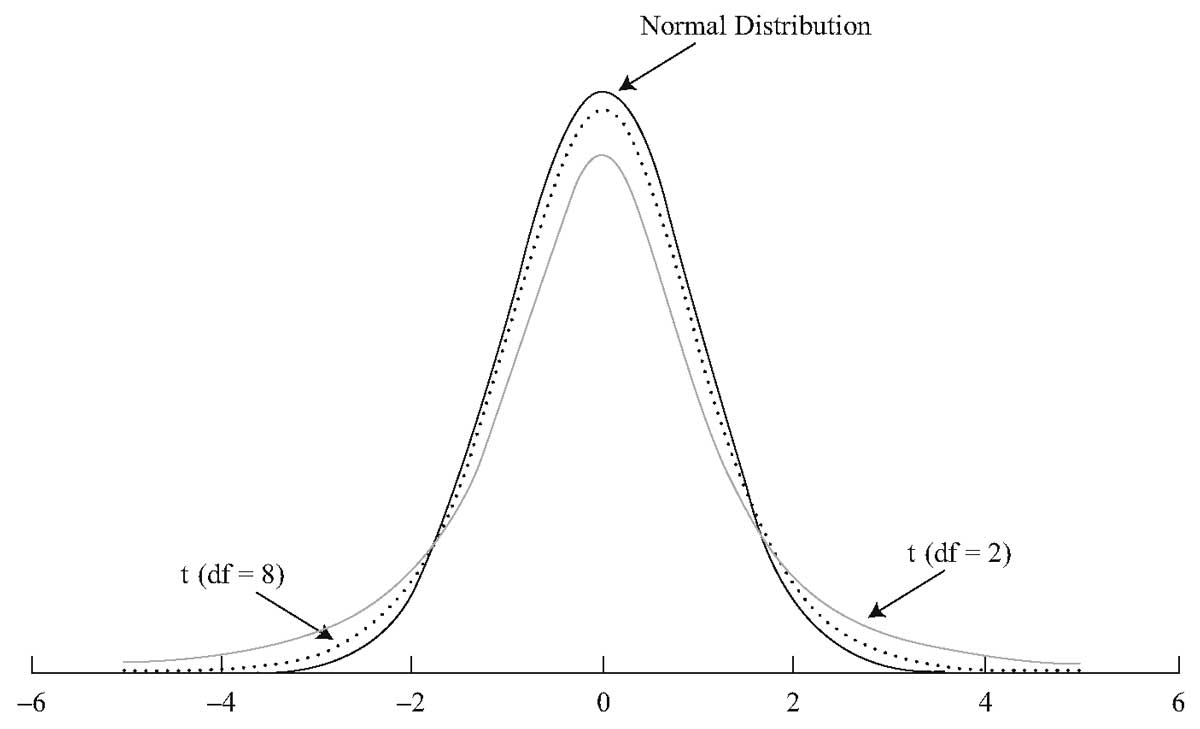 Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Из трех распределений, показанных на Рисунке 1, стандартное нормальное распределение имеет хвосты, которые стремятся к нулю быстрее, чем хвосты двух t-распределений. t-распределение симметрично распределено вокруг среднего нулевого значения, так же как и нормальное распределение.
По мере увеличения степеней свободы, t-распределение приближается к стандартному нормальному распределению. t-распределение с DF = 8 ближе к стандартному нормальному, чем t-распределение с DF = 2.
Помимо области плюс и минус четырех стандартных отклонений от среднего значения, остальная область под стандартным нормальным распределением, как представляется, близка к 0. Однако, оба t-распределения содержать некоторую площадь под каждой кривой за пределом четырех стандартных отклонений.
t-распределения имеют более толстые хвосты, но хвосты t-распределения Стьюдента с DF = 8 сильнее напоминают хвосты нормального распределения. По мере увеличения степеней свободы, хвосты распределения Стьюдента становятся менее толстыми.
Для часто используемых значений распределения Стьюдента составлены таблицы. Например, для каждой степени свободы (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) значения будут такими, что соответственно, 0.10, 0.05, 0.025, 0.01 и 0.005 вероятности останется в правом хвосте для заданного числа степеней свободы.
Значения (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) также называют односторонними критическими значениями t на значимых уровнях 0.10, 0.05, 0.025, 0.01 и 0.005, для указанного числа степеней свободы.
Например,
для DF = 30,
(t_{0.10}) = 1.310,
(t_{0.05}) = 1.697,
(t_{0.025}) = 2.042,
(t_{0.01}) = 2.457,
(t_{0.005}) = 2.750.
Приведем форму доверительных интервалов для среднего по совокупности, используя распределение Стьюдента.
Доверительные интервалы для среднего по совокупности (дисперсия совокупности неизвестна) — t-распределение.
Если мы делаем выборку из генеральной совокупности с неизвестной дисперсией и соблюдается одно из перечисленных ниже условий:
- выборка является большой, или
- выборка небольшая, но совокупность имеет нормальное распределение, или приблизительно нормально распределена,
то доверительный интервал (100 (1 — alpha)% ) для среднего совокупности ( mu ) задается формулой:
( Large dst overline X pm t_{alpha /2}{s over sqrt n} ) (Формула 6)
где число степеней свободы для ( t_{alpha /2}) равно ( n-1 ), а ( n ) — это размер выборки.
Пример 5 использует данные Примера 4, но применяет t-статистику, а не z-статистику, чтобы рассчитать доверительный интервал для среднего значения совокупности коэффициентов Шарпа.
Пример (5) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием t-статистики.
Как и в Примере 4, инвестиционный аналитик стремится вычислить 90-процентный доверительный интервал для среднего по совокупности коэффициентов Шарпа, основанных на случайной выборке из 100 взаимных фондов США.
Выборочное среднее коэффициентов Шарпа составляет 0.45, а выборочное стандартное отклонение — 0.30.
Теперь, признав, что дисперсия генеральной совокупности распределения коэффициентов Шарпа неизвестна, аналитик решает вычислить доверительный интервал, используя теоретически правильную t-статистику.
Поскольку размер выборки равен 100, DF = 99. Используя таблицу степеней свободы, мы находим, что (t_{0.05}) = 1.66.
Этот фактор надежности немного больше, чем фактор надежности (z_{0.05}) = 1.65, который был использован в Примере 4.
Доверительный интервал будет:
( begin{aligned} & overline X pm t_{0.05}{s over sqrt n } \ &= 0.45 pm 1.66{0.30 over sqrt {100}} \ &= 0.45 pm 1.66(0.03) = 0.45 pm 0.0498 end{aligned} )
Доверительный интервал охватывает значения 0.4002 до 0.4998, или 0.40 до 0.50, с двумя знаками после запятой. При округлении до двух знаков после запятой, доверительный интервал не изменился по сравнению с Примером 4.
В Таблице 3 приведены различные факторы надежности, которые мы использовали.
|
Выборка из: |
Статистика для выборки малого размера |
Статистика для выборки большого размера |
|---|---|---|
|
Нормальное распределение с известной дисперсией |
(z) |
(z) |
|
Нормальное распределение с неизвестной дисперсией |
(t) |
(t)* |
|
Ненормальное распределение с известной дисперсией |
недоступно |
(z) |
|
Ненормальное распределение с неизвестной дисперсией |
недоступно |
(t)* |
* Использование (z) также приемлемо.
Построим в MS EXCEL доверительный интервал для оценки среднего значения распределения в случае известного значения дисперсии.
В статье
Статистики, выборочное распределение и точечные оценки в MS EXCEL
дано определение
точечной оценки
параметра распределения (point estimator). Однако, в силу случайности выборки,
точечная оценка
не совпадает с оцениваемым параметром и более разумно было бы указывать интервал, в котором может находиться неизвестный параметр при наблюденной выборке х
1
, x
2
, …, х
n
. Поэтому цель использования
доверительных интервалов
состоит в том, чтобы по возможности избавиться от неопределенности и сделать как можно более полезный
статистический вывод
.
Примечание
: Процесс обобщения данных
выборки
, который приводит к
вероятностным
утверждениям обо всей
генеральной совокупности
, называют
статистическим выводом
(statistical inference).
СОВЕТ
: Для построения
Доверительного интервала
нам потребуется знание следующих понятий:
-
дисперсия и стандартное отклонение
,
-
выборочное распределение статистики
,
-
уровень доверия/ уровень значимости
,
-
стандартное нормальное распределение
и
его квантили
.
К сожалению, интервал, в котором
может
находиться неизвестный параметр, совпадает со всей возможной областью изменения этого параметра, поскольку соответствующую
выборку
, а значит и
оценку параметра
, можно получить с ненулевой вероятностью. Поэтому приходится ограничиваться нахождением границ изменения неизвестного параметра с некоторой заданной наперед вероятностью.
Определение
:
Доверительным интервалом
называют такой интервал изменения случайной величины
,
которыйс заданной вероятностью
,
накроет истинное значение оцениваемого параметра распределения.
Эту заданную вероятность называют
уровнем доверия
(или
доверительной вероятностью
).
Обычно используют значения
уровня доверия
90%; 95%; 99%, реже 99,9% и т.д. Например,
уровень
доверия
95% означает, что дополнительное событие, вероятность которого 1-0,95=5%, исследователь считает маловероятным или невозможным.
Примечание
:
Вероятность этого дополнительного события называется
уровень значимости
или
ошибка первого рода
. Подробнее см. статью
Уровень значимости и уровень надежности в MS EXCEL
.
Разумеется, выбор
уровня доверия
полностью зависит от решаемой задачи. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание
:
Построение
доверительного интервала
в случае, когда
стандартное отклонение
неизвестно, приведено в статье
Доверительный интервал для оценки среднего (дисперсия неизвестна) в MS EXCEL
. О построении других
доверительных интервалов
см. статью
Доверительные интервалы в MS EXCEL
.
Формулировка задачи
Предположим, что из
генеральной совокупности
имеющей
нормальное распределение
взята
выборка
размера n. Предполагается, что
стандартное отклонение
этого распределения известно. Необходимо на основании этой
выборки
оценить неизвестное
среднее значение распределения
(μ,
математическое ожидание
) и построить соответствующий
двухсторонний
доверительный интервал
.
Точечная оценка
Как известно из
Центральной предельной теоремы
,
статистика
![]()
(обозначим ее
Х
ср
) является
несмещенной оценкой среднего
этой
генеральной совокупности
и имеет распределение N(μ;σ
2
/n).
Примечание
:
Что делать, если требуется построить
доверительный интервал
в случае распределения, которое
не является
нормальным?
В этом случае на помощь приходит
Центральная предельная теорема
, которая гласит, что при достаточно большом размере
выборки
n из распределения
не являющемся
нормальным
,
выборочное распределение статистики Х
ср
будет
приблизительно
соответствовать
нормальному распределению
с параметрами N(μ;σ
2
/n).
Итак,
точечная оценка
среднего
значения распределения
у нас есть – это
среднее значение выборки
, т.е.
Х
ср
. Теперь займемся
доверительным интервалом.
Построение доверительного интервала
Обычно, зная распределение и его параметры, мы можем вычислить вероятность того, что случайная величина примет значение из заданного нами интервала. Сейчас поступим наоборот: найдем интервал, в который случайная величина попадет с заданной вероятностью. Например, из свойств
нормального распределения
известно, что с вероятностью 95%, случайная величина, распределенная по
нормальному закону
, попадет в интервал примерно +/- 2
стандартных отклонения
от
среднего значения
(см. статью про
нормальное распределение
). Этот интервал, послужит нам прототипом для
доверительного интервала
.
Теперь разберемся,знаем ли мы распределение
,
чтобы вычислить этот интервал? Для ответа на вопрос мы должны указать форму распределения и его параметры.
Форму распределения мы знаем – это
нормальное распределение
(напомним, что речь идет о
выборочном распределении
статистики
Х
ср
).
Параметр μ нам неизвестен (его как раз нужно оценить с помощью
доверительного интервала
), но у нас есть его оценка
Х
ср
,
вычисленная на основе
выборки,
которую можно использовать.
Второй параметр –
стандартное отклонение выборочного среднего
будем считать известным
, он равен σ/√n.
Т.к. мы не знаем μ, то будем строить интервал +/- 2
стандартных отклонения
не от
среднего значения
, а от известной его оценки
Х
ср
. Т.е. при расчете
доверительного интервала
мы НЕ будем считать, что
Х
ср
попадет в интервал +/- 2
стандартных отклонения
от μ с вероятностью 95%, а будем считать, что интервал +/- 2
стандартных отклонения
от
Х
ср
с вероятностью 95% накроет μ
– среднее генеральной совокупности,
из которого взята
выборка
. Эти два утверждения эквивалентны, но второе утверждение нам позволяет построить
доверительный интервал
.
Кроме того, уточним интервал: случайная величина, распределенная по
нормальному закону
, с вероятностью 95% попадает в интервал +/- 1,960
стандартных отклонений,
а не+/- 2
стандартных отклонения
. Это можно рассчитать с помощью формулы
=НОРМ.СТ.ОБР((1+0,95)/2)
, см.
файл примера Лист Интервал
.
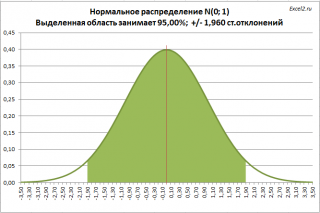
Теперь мы можем сформулировать вероятностное утверждение, которое послужит нам для формирования
доверительного интервала
: «Вероятность того, что
среднее генеральной совокупности
находится от
среднего выборки
в пределах 1,960 «
стандартных отклонений выборочного среднего»
, равна 95%».
Значение вероятности, упомянутое в утверждении, имеет специальное название
уровень доверия
, который связан с
уровнем значимости α (альфа) простым выражением
уровень доверия
=
1
-α
.
В нашем случае
уровень значимости
α
=1-0,95=0,05
.
Теперь на основе этого вероятностного утверждения запишем выражение для вычисления
доверительного интервала
:
![]()
где Z
α/2
–
верхний α/2-квантиль
стандартного
нормального распределения
(такое значение случайной величины
z
,
что
P
(
z
>=
Z
α/2
)=α/2
).
Примечание
:
Верхний α/2-квантиль
определяет ширину
доверительного интервала
в
стандартных отклонениях
выборочного среднего.
Верхний α/2-квантиль
стандартного
нормального распределения
всегда больше 0, что очень удобно.
В нашем случае при α=0,05,
верхний α/2-квантиль
равен 1,960. Для других уровней значимости α (10%; 1%)
верхний α/2-квантиль
Z
α/2
можно вычислить с помощью формулы
=НОРМ.СТ.ОБР(1-α/2)
или, если известен
уровень доверия
,
=НОРМ.СТ.ОБР((1+ур.доверия)/2)
.
Обычно при построении
доверительных интервалов для оценки среднего
используют только
верхний α
/2-
квантиль
и не используют
нижний α
/2-
квантиль
. Это возможно потому, что
стандартное
нормальное распределение
симметрично относительно оси х (
плотность его распределения
симметрична относительно
среднего, т.е. 0
)
.
Поэтому, нет нужды вычислять
нижний α/2-квантиль
(его называют просто α
/2-квантиль
), т.к. он равен
верхнему α
/2-
квантилю
со знаком минус.
Напомним, что, не смотря на форму распределения величины х, соответствующая случайная величина
Х
ср
распределена
приблизительно
нормально
N(μ;σ
2
/n) (см. статью про
ЦПТ
). Следовательно, в общем случае, вышеуказанное выражение для
доверительного интервала
является лишь приближенным. Если величина х распределена по
нормальному закону
N(μ;σ
2
/n), то выражение для
доверительного интервала
является точным.
Расчет доверительного интервала в MS EXCEL
Решим задачу.
Время отклика электронного компонента на входной сигнал является важной характеристикой устройства. Инженер хочет построить доверительный интервал для среднего времени отклика при уровне доверия 95%. Из предыдущего опыта инженер знает, что стандартное отклонение время отклика составляет 8 мсек. Известно, что для оценки времени отклика инженер сделал 25 измерений, среднее значение составило 78 мсек.
Решение
: Инженер хочет знать время отклика электронного устройства, но он понимает, что время отклика является не фиксированной, а случайной величиной, которая имеет свое распределение. Так что, лучшее, на что он может рассчитывать, это определить параметры и форму этого распределения.
К сожалению, из условия задачи форма распределения времени отклика нам не известна (оно не обязательно должно быть
нормальным
).
Среднее, т.е. математическое ожидание
, этого распределения также неизвестно. Известно только его
стандартное отклонение
σ=8. Поэтому, пока мы не можем посчитать вероятности и построить
доверительный интервал
.
Однако, не смотря на то, что мы не знаем распределение
времени
отдельного отклика
, мы знаем, что согласно
ЦПТ
,
выборочное распределение
среднего времени отклика
является приблизительно
нормальным
(будем считать, что условия
ЦПТ
выполняются, т.к. размер
выборки
достаточно велик (n=25))
.
Более того,
среднее
этого распределения равно
среднему значению
распределения единичного отклика, т.е. μ. А
стандартное отклонение
этого распределения (σ/√n) можно вычислить по формуле
=8/КОРЕНЬ(25)
.
Также известно, что инженером была получена
точечная оценка
параметра μ равная 78 мсек (Х
ср
). Поэтому, теперь мы можем вычислять вероятности, т.к. нам известна форма распределения (
нормальное
) и его параметры (Х
ср
и σ/√n).
Инженер хочет знать
математическое ожидание
μ распределения времени отклика. Как было сказано выше, это μ равно
математическому ожиданию выборочного распределения среднего времени отклика
. Если мы воспользуемся
нормальным распределением
N(Х
ср
; σ/√n), то искомое μ будет находиться в интервале +/-2*σ/√n с вероятностью примерно 95%.
Уровень значимости
равен 1-0,95=0,05.
Наконец, найдем левую и правую границу
доверительного интервала
. Левая граница:
=78-НОРМ.СТ.ОБР(1-0,05/2)*8/КОРЕНЬ(25)
=
74,864
Правая граница:
=78+НОРМ.СТ.ОБР(1-0,05/2)*8/КОРЕНЬ(25)=81,136
или так
Левая граница:
=НОРМ.ОБР(0,05/2; 78; 8/КОРЕНЬ(25))
Правая граница:
=НОРМ.ОБР(1-0,05/2; 78; 8/КОРЕНЬ(25))
Ответ
:
доверительный интервал
при
уровне доверия 95% и σ
=8
мсек
равен
78+/-3,136 мсек.
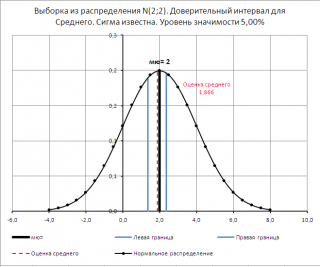
В
файле примера на листе Сигма
известна создана форма для расчета и построения
двухстороннего
доверительного интервала
для произвольных
выборок
с заданным σ и
уровнем значимости
.
Функция
ДОВЕРИТ.НОРМ()
Если значения
выборки
находятся в диапазоне
B20:B79
, а
уровень значимости
равен 0,05; то формула MS EXCEL:
=СРЗНАЧ(B20:B79)-ДОВЕРИТ.НОРМ(0,05;σ; СЧЁТ(B20:B79))
вернет левую границу
доверительного интервала
.
Эту же границу можно вычислить с помощью формулы:
=СРЗНАЧ(B20:B79)-НОРМ.СТ.ОБР(1-0,05/2)*σ/КОРЕНЬ(СЧЁТ(B20:B79))
Примечание
: Функция
ДОВЕРИТ.НОРМ()
появилась в MS EXCEL 2010. В более ранних версиях MS EXCEL использовалась функция
ДОВЕРИТ()
.
Доверительный интервал для среднего
17 авг. 2022 г.
читать 2 мин
Доверительный интервал для среднего значения — это диапазон значений, который может содержать среднее значение генеральной совокупности с определенным уровнем достоверности.
В этом руководстве объясняется следующее:
- Мотивация создания доверительного интервала для среднего значения.
- Формула для создания доверительного интервала для среднего значения.
- Пример расчета доверительного интервала для среднего значения.
- Как интерпретировать доверительный интервал для среднего.
Доверительный интервал для среднего значения: мотивация
Причина, по которой мы даже хотели бы создать доверительный интервал для среднего значения, заключается в том, что мы хотим зафиксировать нашу неопределенность при оценке среднего значения генеральной совокупности.
Например, предположим, что мы хотим оценить средний вес определенного вида черепах во Флориде. Поскольку во Флориде тысячи черепах, было бы очень много времени и денег, чтобы обойти и взвесить каждую отдельную черепаху.
Вместо этого мы могли бы взять простую случайную выборку из 50 черепах и использовать средний вес черепах в этой выборке для оценки истинного среднего значения популяции:
Проблема в том, что средний вес в выборке не обязательно точно соответствует среднему весу всего населения. Итак, чтобы зафиксировать эту неопределенность, мы можем создать доверительный интервал, содержащий диапазон значений, которые, вероятно, содержат истинный средний вес черепах в популяции.
Доверительный интервал для среднего: формула
Мы используем следующую формулу для расчета доверительного интервала для среднего значения:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: выбранное значение z
- s: стандартное отклонение выборки
- n: размер выборки
Z-значение, которое вы будете использовать, зависит от выбранного вами уровня достоверности. В следующей таблице показано значение z, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Обратите внимание, что более высокие уровни достоверности соответствуют большим значениям z, что приводит к более широким доверительным интервалам. Это означает, что, например, 99-процентный доверительный интервал будет шире, чем 95-процентный доверительный интервал для того же набора данных.
Доверительный интервал для среднего значения: пример
Предположим, мы собираем случайную выборку черепах со следующей информацией:
- Размер выборки n = 25
- Средний вес выборки x = 300
- Стандартное отклонение выборки s = 18,5
Вот как найти различные доверительные интервалы для истинного среднего веса населения:
90% доверительный интервал: 300 +/- 1,645*(18,5/√ 25 ) = [293,91, 306,09]
95% доверительный интервал: 300 +/- 1,96*(18,5/ √25 ) = [292,75, 307,25]
99% доверительный интервал: 300 +/- 2,58*(18,5/√ 25 ) = [ 290,47 , 309,53]
Примечание. Вы также можете найти эти доверительные интервалы с помощью калькулятора доверительных интервалов Statology .
Доверительный интервал для среднего: интерпретация
То, как мы интерпретируем доверительный интервал, выглядит следующим образом:
Вероятность того, что доверительный интервал [292,75, 307,25] содержит истинный средний вес популяции черепах, составляет 95%.
Другой способ сказать то же самое состоит в том, что существует только 5%-ная вероятность того, что истинное среднее значение генеральной совокупности лежит за пределами 95%-го доверительного интервала. То есть существует только 5% вероятность того, что истинный средний вес черепах в популяции больше 307,25 фунтов или меньше 292,75 фунтов.
Доверительный интервал для математического ожидания нормальной случайной
величины при неизвестной дисперсии
Пусть
, причем
и
неизвестны. Необходимо построить доверительный интервал,
накрывающий с надежностью
истинное значение параметра
.
Для этого из генеральной
совокупности СВ
извлекается
выборка объема
:
.
1) В качестве точечной
оценки математического ожидания
используется
выборочное среднее
, а в
качестве оценки дисперсии
–
исправленная выборочная дисперсия
которой соответствует стандартное отклонение
.
2) Для нахождения
доверительного интервала строится статистика
имеющая в этом случае распределение Стьюдента с
числом степеней свободы
независимо
от значений параметров
и
.
3) Задается требуемый
уровень значимости
.
4) Применяется следующая
формула расчета вероятности:
где
–
критическая точка распределения Стьюдента, которая находится по таблице критических точек распределения Стьюдента (односторонняя критическая область).
Тогда:
Это означает, что
интервал:
накрывает неизвестный
параметр
с
надежностью
Доверительный интервал для математического ожидания
нормальной случайной величины при известной дисперсии
Пусть количественный
признак
генеральной
совокупности имеет нормальное распределение
с
заданной дисперсией
и
неизвестным математическим ожиданием
. Построим
доверительный интервал для
.
1) Пусть для оценки
извлечена
выборка
объема
. Тогда
2) Составим случайную
величину:
Нетрудно показать, что случайная величина
имеет стандартизированное нормальное распределение, то есть:
3) Зададим уровень
значимости
.
4) Применяя формулу нахождения
вероятности отклонения нормальной величины от математического ожидания, имеем:
Это означает, что
доверительный интервал
накрывает неизвестный
параметр
с надежностью
. Точность оценки определяется величиной:
Число
определяется
по таблице значений функции Лапласа из равенства
Окончательно получаем:
Доверительный интервал для
дисперсии нормальной случайной величины при неизвестном математическом ожидании
Пусть
, причем
и
–
неизвестны. Пусть для оценки
извлечена выборка объема
:
.
1) В качестве точечной оценки дисперсии
используется
исправленная выборочная дисперсия
:
которой соответствует стандартное отклонение
.
2) При нахождении
доверительного интервала для дисперсии в этом случае вводится статистика
имеющая
–
распределение с числом степеней свободы
независимо
от значения параметра
.
3) Задается требуемый
уровень значимости
.
4) Тогда, используя таблицу критических точек хи-квадрат распределения, нетрудно указать критические
точки
, для которых будет выполняться следующее
равенство:
Подставив вместо
соответствующее значение, получим:
Получаем доверительный
интервал для неизвестной дисперсии:
Доверительный интервал для
дисперсии нормальной случайной величины при известном математическом ожидании
Пусть
, причем
–
известна, а
–
неизвестна. Пусть для оценки
извлечена выборка объема
:
.
1) В качестве точечной оценки дисперсии
используется выборочная дисперсия:
2) При нахождении
доверительного интервала для дисперсии в этом случае вводится статистика
имеющая
–
распределение с числом степеней свободы
независимо
от значения параметра
.
3) Задается требуемый
уровень значимости
.
4) Тогда, используя таблицу критических точек хи-квадрат распределения,
нетрудно указать критические точки
, для которых будет выполняться следующее
равенство:
Подставив вместо
соответствующее значение, получим:
Получаем доверительный
интервал для неизвестной дисперсии:
Доверительный интервал для
среднего квадратического отклонения
Извлекая квадратный корень:
Положив:
Получим следующий
доверительный интервал для среднего квадратического
отклонения:
Для отыскания
по заданным
и
пользуются специальными таблицами.
Для проверки на нормальность заданного распределения случайной величины можно использовать
правило трех сигм.
Задача
Имеется
три независимых реализации нормальной случайной величины: 0.8, 3.2, 2.0.
Построить
доверительные интервалы для среднего и дисперсии с надежностью
Указание:
воспользоваться таблицами Стьюдента и хи-квадрат.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычисление средней и дисперсии
Вычислим среднее и
исправленную дисперсию
:
Нахождение доверительных интервалов для средней и дисперсии
Найдем доверительный интервал для оценки
неизвестного среднего. Он считается по формуле:
По таблице критических точек t-критерия Стьюдента, для уровня значимости
(односторонняя критическая область):
Искомый
доверительный интервал для среднего:
Найдем доверительный интервал для оценки дисперсии.
Он считается по формуле:
Для уровня значимости
и
получаем по таблице значений хи-квадрат:
Искомый доверительный интервал для дисперсии:
Ответ
Кроме этой задачи на другой странице сайта есть
пример расчета доверительного интервала математического ожидания и среднего квадратического отклонения для интервального вариационного ряда
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Для помощи во время экзамена/зачета в онлайн режиме необходимо договариваться заранее.