Время на прочтение
9 мин
Количество просмотров 6.7K
NLP — natural language processing
Большая часть данных в мире не структурирована – это просто тексты на русском или на любом другом языке. Извлеченные факты из таких текстов могут представлять особый интерес для бизнеса, поэтому подобные задачи возникают сплошь и рядом. Этим вопросом занимается отдельное направление искусственного интеллекта: обработка естественного языка, тот самый NLP (Natural Language Processing).

Существует много способов выделить факты из текста и у всех свои плюсы и минусы:
-
Регулярные выражения
Высокая скорость работы и стабильность нивелируется сложностью синтаксиса и низким покрытием.
-
Нейронные сети
Модно, хорошее качество при обучении на большой выборке, однако для работы требуется много разметки, при этом каждая новая задача требует новой разметки.
-
КС-грамматики
Предсказуемость результата, легко писать правила, но сложно запускать в ПРОМе
В этой статье мы поговорим о последних, а именно о Томита – парсере, инструменте с открытым исходным кодом, разработанном в Яндексе, а также в рамках статьи, разберемся как это работает на конкретном примере. Итак, возьмем для примера абстрактные неструктурированные данные в виде наименований платежных поручений, и постараемся извлечь из них некоторые факты, например, назначение платежа, адрес и период:
Исходный текст
|
Оплата за аренду торгового места №2 по адресу ул Маршала Жукова,15 за июнь 2020г., в сумме 5400,00 р |
|
Перечисление денежных средств на Шустрик У.С. в субаренду автомобиля в сумме 15299,00 руб, без НДС |
|
Оплата за найм общежития №575 по адресу пр Обуховской обороны, 145 от 17.09.2020 за февраль 2020 года, с ндс 18% — 5300 рублей. |
|
Оплата за аренду нежилого помещения по адресу Малая Садовая ул, 23, договор 51 от 01.09.2020 — 7500 рублей. |
|
Частичная оплата по Договору аренды №1-03а от 01.07.2020 за аренду помещения по проспекту Дальневосточный 211 в октябре 2020 Сумма 23000 в т.ч.НДС(18%) |
Что такое Томита-парсер?
Томита-парсер – это инструмент для извлечения структурированных данных (фактов) из русского текста, позволяющий создавать и быстро прототипировать систему извлечения фактов с помощью шаблонов (контекстно-свободных грамматик) и словарей ключевых слов. Исходный код проекта открыт и размещен на GitHub, собственно отсюда мы скачиваем проект и проводим сборку для дальнейшей работы.
Где можно использовать Томита-парсер?
-
Обработка транзакций – аренда, покупка
-
Обработка транскрипций звонков – выставление задач
-
Новостной мониторинг – оценка состояния кредитующейся компании
-
Парсинг текста резюме – автоматизация выделения навыка и опытов кандидата
-
Парсинг текста судебных дел
Как работает Томита-парсер?
Томита-парсер распространяется в виде консольной утилиты, получает на вход текст на естественном языке и далее с помощью словарей и грамматик, составленных пользователем, преобразует этот текст в набор структурированных данных. Сразу отметим, что у Яндекса есть очень подробная документация, а также видеокурс, который позволяет осуществить быстрый старт в Томитный мир.
Для запуска необходима сама программа tomitaparser.exe (рекомендации по сборке см. здесь) и следующие файлы:
-
config.proto — конфигурационный файл парсера. Сообщает парсеру всю информацию о том, где искать все остальные файлы и как их интерпретировать. Этот файл обязательный и выступает в роли единственного аргумента для tomitaparser.exe;
-
dic.gzt – корневой словарь. Содержит перечень всех используемых в проекте словарей и грамматик. Другими словами, это некий агрегатор, который собирает все, что создается в рамках проекта. Без этого файла парсер работать не будет;
-
mygram.cxx – грамматика. Содержит набор правил, которые описывают текстовые цепочки. Таких файлов может быть несколько. Взаимодействует с парсером через корневой словарь;
-
facttypes.proto – описание типов фактов;
-
kwtypes.proto – описание типов ключевых слов. Нужен, если в проекте создаются новые типы ключевых слов.
Все эти файлы необходимо начинать с явного указания кодировки utf8 везде, где планируется использовать кириллические символы (русский текст).
Корневой словарь
Начинаем с создания корневого словаря «dic.gzt», где выполняем импорт служебных файлов и грамматики, которую мы создадим чуть позже.
encoding "utf8"; // явно указываем кодировку
// импортируем зашитые в парсер файлы с базовыми типами, используемыми в словарях и грамматиках
import "base.proto";
import "articles_base.proto";
// оставляем ссылку на нашу грамматику
TAuxDicArticle "payment" {
key = { "tomita:mygram.cxx" type=CUSTOM }
};Грамматика
Для создания своей грамматики разберемся с простейшими правилами и понятиями. Томитные грамматики работают с цепочками, где грамматика — это набор правил, которые описывают цепочки слов в тексте. Грамматика пишется на специальном формальном языке. Структурно правило разделяется символом «->» на левую и правую части. В левой части указывается один терминал, в правой – последовательность терминалов и нетерминалов. Нетерминал строится из терминалов и должен хотя бы один раз встретиться в правой части правила. Если нетерминал встречается только в левой части это означает вершину грамматики. В роли терминалов выступают названия частей речи (Noun, Verb, Adj), символы (Comma, Punct, Ampersand, PlusSign) и леммы. Полный перечень терминалов см. по ссылке.
Правая часть правила может сопровождаться операторами. Например, оператор «+»после (не)терминала означает, что символ повторяется один или более раз. Этот и другие операторы подробно описаны в документации.
Для наложения ограничений на (не)терминал используются специальные пометы, которые уточняют свойства (не)терминала, например, определение регистра символов или связей по роду и падежу между словами. Записываются пометы после (не)терминала в угловых скобках «< >» через запятую. С полным перечнем ограничений-помет можно ознакомится по ссылке. Теперь, когда мы обладаем необходимым теоретическим минимумом создадим в папке с парсером файл формата «cxx», где мы будем описывать свою грамматику – «mygram.cxx». Ссылку на этот файл мы уже оставили в корневом словаре. Для начала создадим правило для выделения назначения платежа. В нашем случае наименование оплаченного объекта — это существительное, перед которым может стоять прилагательное, стоящее за словами «аренда», «субаренда», «найм».
#encoding "utf8" // явно указываем кодировку
// оператор "|" работает аналогично оператору "или"
Rent -> 'аренда' | 'субаренда' | 'найм';
// оператор "" означает, что символ может встречаться в тексте 0 или более раз
// помета <gnc-agr[1]> говорит о том, что прилагательное должно быть согласовано с существительным по роду, числу и падежу
Purpose -> Rent Adj<gnc-agr[1]> Noun<gnc-agr[1]>;Далее нам нужен нетерминал для распознавания адреса. Как правило, название улиц состоит из прилагательного согласованного с дескриптором улицы, например, Московский проспект. Или это может быть именная группа, например,улица Красных зорь.
// в нетерминале StreetW указываем названия дескрипторов улицы, а в StreetAbbr - перечисляем известные сокращения
StreetW -> 'улица' | 'проспект' | 'шоссе' | 'линия';
StreetAbbr -> 'ул' | 'пр' | 'просп' | 'пр-т' | 'ш';
// объединяем два нетерминала в один нетерминал StreetDescr, который будет обозначать либо полнозначную лемму StreetW либо сокращение StreetAbbr
StreetDescr -> StreetW | StreetAbbr;
StreetNameNoun -> (Adj<gnc-agr[1]>) Word<gnc-agr[1], rt> (Word<gram="род">);
StreetNameAdj -> Adj<h-reg1> Adj*;Нетерминалом «StreetNameNoun» мы описали названия улиц, выраженных существительным. Основным элементом в данной цепочке выступает слово, для этого, обозначаем его пометой «<rt>». Перед ним опционально может стоять или не стоять прилагательное, согласованное по роду, числу и падежу. После основного слова может стоять или не стоять слово в родительном падеже, например, пр. Обуховской обороны. Чтобы указать на то, что прилагательное и слово в родительном падеже слева и справа от основного текста являются опциональными, т.е. не обязательными, используем оператор «()». Нетерминал «StreetNameAdj» описывает названия улиц, выраженных прилагательным. Первое прилагательное в такой цепочке начинается с большой буквы. Добиваемся этого результата благодаря помете «<h-reg1>». Далее может встречаться еще некоторое количество прилагательных, для этого применяем оператор «*». Переходим к описанию правил, определяющих адрес.
Address -> StreetDescr StreetNameNoun<gram="род", h-reg1>;
Address -> StreetDescr StreetNameNoun<gram="им", h-reg1>;
Address -> StreetNameAdj<gnc-agr[1]> StreetW<gnc-agr[1]>;
Address -> StreetNameAdj StreetAbbr;Первая цепочка начинается с дескриптора улицы и далее в родительном падеже с большой буквы идет название улицы. Второе правило аналогично первому с той лишь разницей, что название улицы после дескриптора идет в именительном падеже. Третье и четвертое правила для названий улиц, выраженных прилагательным. Теперь нам нужен нетерминал для выделения периода. Период состоит из месяца и года, поэтому нам понадобиться список месяцев. Добавляем в корневой словарь соответствующую статью:
// добавляем список месяцев в корневой словарь «dic.gzt»
TAuxDicArticle "month" {
key = { "январь" | "февраль" | "март" | "апрель" | "май" | "июнь" | "июль" | "август" | "сентябрь" | "октябрь" | "ноябрь" | "декабрь" }
};В файл с грамматикой добавляем следующее:
Month -> Noun<kwtype="month">;
Year -> AnyWord<wff=/[1-2]?[0-9]{1,3}г?.?/>;
Period -> Month Year;Пометка «kwtype» означает, что существительное ограничено статьей «month» в корневом словаре, а благодаря регулярным выражениям мы выделяем год как число от 0 до 2999 с возможными «г» или «г.» в конце. Переходим к определению корневого нетерминала, который соберет вместе все созданные ранее правила. Корневой нетерминал назовем «Result» и составим несколько возможных вариантов:
Result -> Purpose AnyWord* Address AnyWord* Period;
Result -> Purpose AnyWord* Address;
Result -> Purpose;Терминал «AnyWord» с оператором «*» означает, что между соседними нетерминалами может встречаться любая последовательность символов 0 или более раз. В первой цепочке встречаются все выделенные нами атрибуты: назначение, адрес и период. Во второй: назначение и адрес, а в третьей только назначение.
Факты
На данном этапе мы научили парсер выделять цепочки слов в тексте. Для извлечения фактов из полученных цепочек создаем отдельный файл – «facttypes.proto» и сразу же добавляем в корневой словарь «dic.gzt» строчку с импортом (помним, что корневой словарь- это агрегатор всего, что создается в проекте).
import "facttypes.proto"; // импортируем в словарь «dic.gzt» фактыВ файле «facttypes.proto» определяем новый факт «Payment» и добавляем три атрибута (поля): назначение, адрес и период платежа. Запишем в файл следующее:
// импорт базовых типов
import "base.proto";
import "facttypes_base.proto";
message Payment: NFactType.TFact {
required string Purpose = 1;
optional string Address = 2;
optional string Period = 3;
};Факт «Payment» наследуется от базового типа «NFactType.TFact», а «required» и «optional» означает, что атрибут является обязательными или опциональным соответственно. Для того, чтобы интерпретировать подцепочку в факт, необходимо написать слово «interp» и после него в скобках указать имя факта и имя поля, в которое должна попасть подцепочка. Теперь внесем изменения в корневые правила грамматики, добавив процедуру интерпретации.
// подцепочка «Purpose» интерпретируется в поле «Purpose» факта «Payment»
// подцепочка «Address» интерпретируется в поле «Address» факта «Payment»
// подцепочка «Period» интерпретируется в поле «Period» факта «Payment»
Result -> Purpose interp(Payment.Purpose) AnyWord* Address interp(Payment.Address) AnyWord* Period interp(Payment.Period);
Result -> Purpose interp(Payment.Purpose) AnyWord* Address interp(Payment.Address);
Result -> Purpose interp(Payment.Purpose);Конфигурационный файл
Далее создаем конфигурационный файл и сообщаем парсеру, где искать исходный текст, куда записывать результат, какие грамматики использовать и какие факты извлекать.
encoding "utf8"; // явно указываем кодировку
TTextMinerConfig {
// указываем корневой словарь
Dictionary = "dic.gzt";
// входные данные
Input = {File = "input.txt"}
// указываем куда записывать результат работы парсера
Output = {File = "output.txt"
Format = text}
// грамматики, которые будут использоваться при парсинге
Articles = [
{ Name = "payment" }
]
// факты, которые извлекаем
Facts = [
{ Name = "Payment" }
]
// показать отладочный вывод с результатами работы грамматики
PrettyOutput = "pretty.html"
}Запуск парсера
Запускается парсер из командной строки:
> tomitaparser.exe config.protoВ файл «input.txt» мы поместили исходный текст, размещенный в самом начале статьи. После работы парсер записал результат в файл «output.txt»:
Оплата за аренду торгового места № 2 по адресу ул Маршала Жукова , 15 за июнь 2020г . , в сумме 5400,00 р
Payment
{
Purpose = аренда торгового места
Address = ул Маршала Жукова
Period = июнь 2020г
}
Перечисление денежных средств на Шустрик У. С. в субаренду автомобиля в сумме 15299,00 руб , без НДС
Payment
{
Purpose = субаренда автомобиля
}
Оплата за найм общежития № 575 по адресу пр Обуховской обороны , 145 от 17.09.2020 за февраль 2020 года , с ндс 18% - 5300 рублей .
Payment
{
Purpose = найм общежития
Address = пр Обуховской обороны
Period = февраль 2020
}
Оплата за аренду нежилого помещения по адресу Малая Садовая ул , 23 , договор 51 от 01.09.2020 - 7500 рублей .
Payment
{
Purpose = аренда нежилого помещения
Address = Садовая ул
}
Частичная оплата по Договору аренды № 1-03а от 01.07.2020 за аренду помещения по проспекту Дальневосточный 211 в октябре 2020 Сумма 23000 в т.ч.НДС ( 18% )
Payment
{
Purpose = аренда помещения
Address = проспект Дальневосточный
Period = октябрь 2020
}Извлечение фактов из естественного языка довольно нетривиальная задача в IT мире по сей день. Теперь в наших руках появился еще один доступный инструмент. Как видите, создать свою первую грамматику можно довольно легко, потратив при этом немного времени на изучение, т.к. по Томите приведена подробная и исчерпывающая документация. Тем не менее, качество выделенных фактов сильно зависит от самого разработчика и его знаний в экспертной области.
Вы часами пытались найти строку кода на своем сайте WordPress? Это может быть неприятно, если после тщательного ручного поиска вы не добьетесь успеха. Попробуйте некоторые из бесплатных инструментов, которые сделают задачу проще и точнее.
Иногда случается, что вы добавили код настройки и теперь не можете его отследить. Другая возможность заключается в том, что вы внесли много изменений на свой сайт. Это может включать в себя фрагмент кода с ошибками, который не является ошибочным, но может давать нежелательный результат. После нескольких дней добавления этого кода, когда вы поймете, что результат не такой, как ожидалось, вы можете захотеть его изменить. Затем вам нужно будет отследить источник и исправить его. Теперь вы не можете найти строку кода на своем веб-сайте. Ручной поиск может работать, а может и не работать постоянно. В этой статье, здесь Templatetoaster WordPress сайте застройщика, мы рассмотрим несколько простых в использовании методов для автоматизации процесса, чтобы найти строку кода в веб – сайте.
Ручные методы поиска строк кода
1. Найдите строку кода на веб-сайте с помощью PHP / текстового редактора.
Вы можете использовать любой текстовый редактор, например Notepad ++, чтобы использовать расширенные функции поиска. Notepad ++ – лучший и самый популярный редактор файлов PHP, работающий как для Windows, так и для Mac. После того, как вы скачали файлы PHP WordPress, вы можете использовать Notepad ++, чтобы найти строку кода в файле веб-сайта.
Если вам известен файл, в котором отображается ошибка, вы можете просто загрузить этот файл и найти в нем код. Вы также можете искать строки кода в своем каталоге WordPress, используя расширенные функции поиска редактора.
2. Найдите строку кода на веб-сайте в системах Unix / Linux / MacOS
Команда grep позволяет искать текстовые шаблоны в файле. Используйте вариант использования приведенной ниже команды, чтобы найти строку кода в файлах вашего веб-сайта для сервера Linux / Unix. Прежде всего, вам необходимо войти на сервер через терминал с помощью Putty или Bitvise. Перейдите в каталог установки WordPress и выполните команду ниже:
grep $search-term file.phpПримечание: вам может потребоваться ssh-доступ к веб-серверу, если вы не являетесь администратором.
3. Поиск по строке кода на веб-сайте на компьютерах с Windows
В Windows вы можете установить Cygwin, а затем использовать grep для поиска определенного текста или текста, соответствующего регулярным выражениям. Вы также можете использовать команду findstr для поиска файлов, содержащих строки кода, которые точно соответствуют указанной строке или соответствуют регулярному выражению.
Автоматические инструменты для поиска строк кода
Утилиты и инструменты, такие как Agent Ransack, позволяют найти строку кода в файлах веб-сайта. Сначала вам нужно загрузить файлы кода веб-сайта на локальный компьютер, а затем запустить инструмент для загруженных файлов.
Агент Рэнсак
Agent Ransack – это инструмент для быстрого и эффективного поиска файлов с определенным текстом. Это позволяет искать в содержимом файлов код или текст. Агент Ransack отображает текстовые результаты, и вы можете просматривать результаты, не открывая каждый файл. Agent Ransack также предоставляет мастер для построения регулярных выражений, которые создают более сложные поисковые запросы.
С помощью Agent Ransack вы можете указать выражение имени файла для поиска, строку кода для поиска и каталог для поиска. Вы также можете искать двоичные файлы, но не файлы .zip или другие архивы.
Agent Ransack или FileLocator Lite (для корпоративных сред) – это «облегченная» версия инструмента FileLocator Pro, которая хорошо работает для новичков. Для опытных программистов, которым требуется расширенный поиск большего количества файлов, FileLocator Pro предоставляет дополнительные функции.
Альтернативные варианты для Agent Ransack
Давайте теперь рассмотрим некоторые другие популярные и бесплатные альтернативы Agent Ransack для Windows, Linux, Mac, BSD, Self-Hosted и других сред. Вы можете попробовать эти утилиты для поиска строк кода в файлах вашего сайта.
1. DocFetcher
Портативное настольное приложение для поиска с открытым исходным кодом. Вы можете использовать этот инструмент для поиска содержимого файлов, чтобы найти строку кода на веб-сайте, который вы ищете.
2. FileSearchy
Это служебная программа для поиска файлов, обеспечивающая эффективный поиск по содержимому файла. Он выделяет найденный текст в содержимом файла.
3. Восстановить
Позволяет искать содержимое ваших файлов, как поисковая система. Вы можете быстро искать в больших объемах данных с помощью поискового индекса. Regain незаметно просматривает файлы или веб-страницы, извлекая весь текст и добавляя его в индекс интеллектуального поиска. Вы можете сразу же получить результаты поиска по своей неотслеживаемой строке кода.
4. AstroGrep
Утилита поиска файлов с графическим интерфейсом пользователя Microsoft Windows, которую можно использовать для поиска совпадений регулярного выражения в исходном коде. Вы можете использовать это, чтобы найти совпадающие строки кода в файлах вашего веб-сайта.
5. SearchMonkey
Это поисковая система в реальном времени для отображения совпадений регулярных выражений в содержимом файлов и в нескольких каталогах.
6. SearchMyFiles
Это точный вариант поиска Windows, который позволяет легко искать файлы по содержимому файла, которое может быть текстовым или двоичным.
Строки поиска на HTML-сайтах
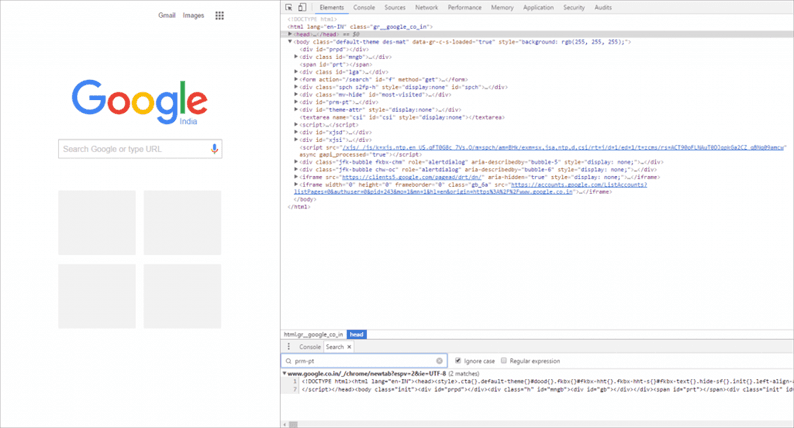
Веб-сайт может содержать код HTML, Javascript и CSS. Возможно, вы захотите найти строку кода в исходном коде своего веб-сайта. Каждый браузер позволяет вам просматривать источник просматриваемого веб-сайта. Вы можете щелкнуть правой кнопкой мыши «Просмотр источника страницы», чтобы открыть исходный код страницы. Вы можете найти строку кода в исходном коде с помощью инструментов, предоставляемых браузером.
Вы также можете выполнять поиск по всем ресурсам веб-сайта, таким как HTML, CSS, JavaScript и т.д. В случае браузера Chrome вы можете использовать инструменты разработчика для выполнения поиска. На любой панели откройте панель поиска (Win: Ctrl + Shift + f, Mac: Cmd + Opt + f). Введите строку кода или имя класса для поиска на текущей HTML-странице. Все результаты поиска с номерами строк будут отображены на панели.
Плагины WordPress для поиска строки кода на веб-сайте
Иногда при создании веб-сайта вы можете застрять, пытаясь выяснить, какой шаблон используется на конкретной странице. Вы можете поискать строки кода на страницах своего веб-сайта. Могут быть фрагменты неотслеживаемого текста, исходный код которых невозможно. Есть несколько доступных плагинов WordPress, которые помогут вам с этими проблемами.
1. Что за файл
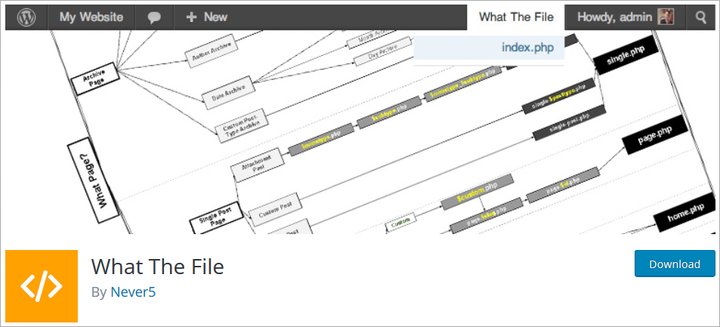
Плагин «What The File» позволяет добавить на панель инструментов параметр, отображающий файл и шаблоны, используемые для отображения просматриваемой в данный момент страницы. Вы можете напрямую просматривать, находить строку кода на веб-сайте и редактировать файл через редактор темы. Затем вы можете искать строки кода внутри этих файлов.
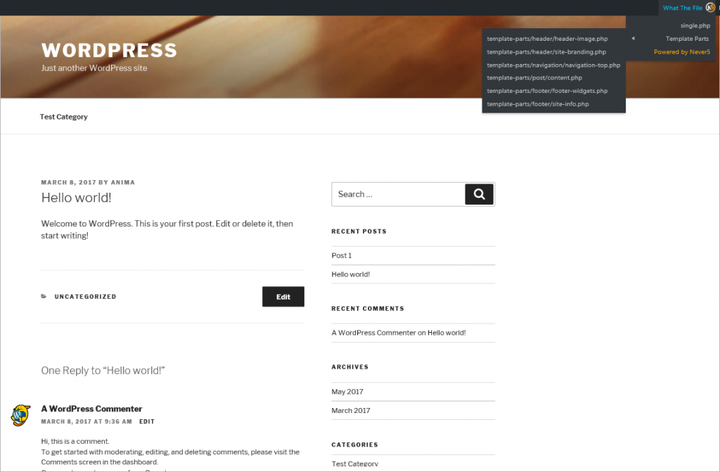
2. Локатор строк

При работе с темами и плагинами вы можете увидеть фрагмент текста, который выглядит так, как будто он жестко закодирован в файлах. Возможно, вам придется изменить его, но вы не можете найти строку кода в файлах темы. С помощью плагина «String Locator» вы можете искать темы, плагины или основные файлы WordPress. Плагин представляет результаты в виде списка файлов, совпадающего текста и строки файла, который соответствовал поиску.
Вывод
Поиск, ручной или автоматический, не всегда может дать вам наилучшие результаты. Вы можете бесконечно пытаться найти строку кода на веб-сайте вручную, но это приведет к разочарованию только в том случае, если поисковый контент большой. Автоматические инструменты, утилиты и плагины WordPress помогут значительно сократить усилия, но при этом будут более точными. Инструмент TemplateToaster для создания веб-сайтов также прост в использовании. TemplateToaster, программа для веб-дизайна, поддерживает все плагины WordPress и помогает создавать расширенные темы и шаблоны страниц. Он не требует кодирования и автоматически генерирует код. С помощью конструктора веб- сайтов TemplateToaster и конструктора тем WordPress вам больше не нужно будет самостоятельно создавать, искать и устранять неполадки любого кода настройки.
Источник записи: https://blog.templatetoaster.com
Часто возникают ситуации, когда необходимо проанализировать содержимое веб-страницы: посмотреть description, узнать размер какого-то элемента или просто выяснить, какой используется шрифт. С помощью опции «Просмотреть код» можно узнать не только это, но и многое другое – практически всю подноготную сайта.
Для каких целей нужен навык чтения кода и как в несколько кликов посмотреть содержимое сайта? Об этом и многом другом поговорим в сегодняшней статье.
Зачем мне нужен исходный код сайта?
Думаете, если вы не программист или верстальщик, то код вам вряд ли понадобится? На самом деле, он может помочь в разных ситуациях. Код может быть полезен:
- SEO-специалистам. Не всегда есть возможность проанализировать страницу и узнать, есть ли с ней какие-либо проблемы. Например, чтобы узнать Description страницы, можно не пользоваться специальными плагинами и прочими средствами – достаточно открыть исходный код, и описание будет перед глазами. Аналогичным образом можно посмотреть заголовок страницы, узнать, подключена ли Яндекс.Метрика и другие скрипты.
- Для более глубокого анализа конкурентов. Посмотреть, какими способами продвигается сайт, мы можем через код: ключевые слова, мета-теги и прочее – все это доступно для обычного пользователя.
- Веб-дизайнерам. Речь снова идет о конкуренции, но и не только. Когда дизайнер создает свой сайт, он часто обращается к различным ресурсам, чтобы посмотреть, как расположены те или иные элементы. Все это мы можем узнать на любом сайте: какой отступ у этой кнопки, какого она размера, сколько пикселей та фотография и так далее.
- Для лучшего понимания кода. Изучив основы HTML-кода и CSS-стилей, вы сможете понять, как работает ваш верстальщик и какие элементы следует оптимизировать.
Еще несколько возможностей при просмотре кода страницы: выгрузка картинок с исходным размером, просмотр сайта в адаптивном режиме, возможность изменять содержимое веб-страницы. Последнее работает в локальном режиме – изменения будут применены только на текущем ПК до тех пор, пока страница не будет обновлена.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Как узнать код сайта
Прежде чем переходить к просмотру кода сайта, давайте сначала разберемся, что же включает в себя код любого веб-ресурса. Как правило, это список пронумерованных строк с информацией о том или ином элементе сайта. Если открыть код главной страницы Timeweb, то мы увидим, что в четвертой строке установлен заголовок документа:
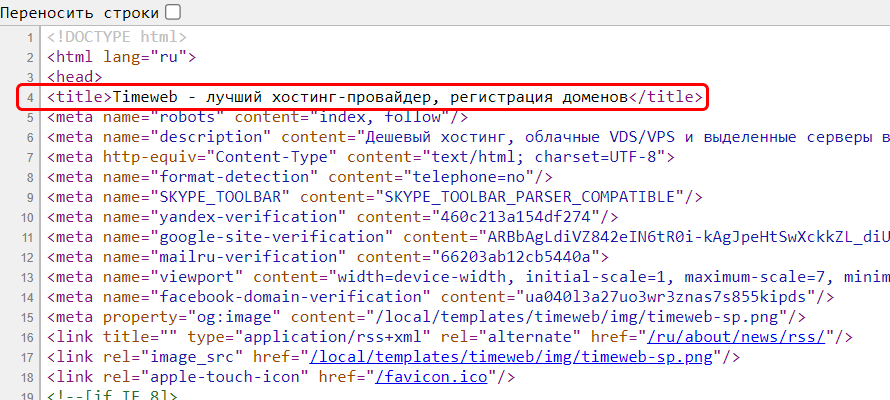
Как видите, здесь все логично и понятно.
Подробнее о том, что представляет собой код сайта, мы поговорим в следующем разделе, а пока давайте рассмотрим основные способы его просмотра.
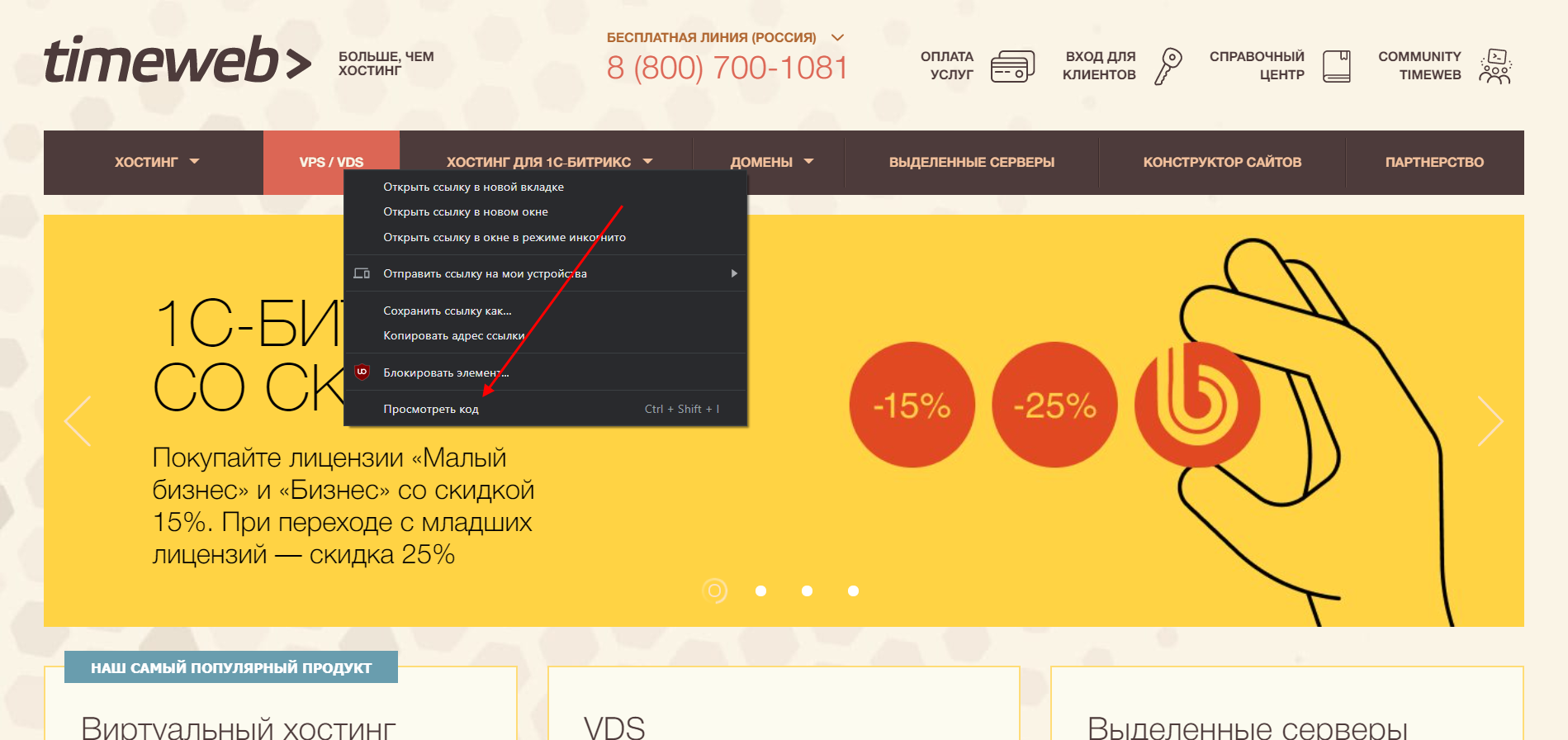
Способ 1: Функция «Посмотреть код»
Открываем страницу, код которой нужно просмотреть, и кликаем по любой области правой кнопкой мыши. В отобразившемся меню выбираем «Посмотреть код». Также вы можете воспользоваться комбинацией клавиш «CTRL+SHIFT+I».
В результате мы попадаем в инспектор браузера – на экране появляется дополнительное окно, где сверху находится код страницы, а снизу – CSS-стили.
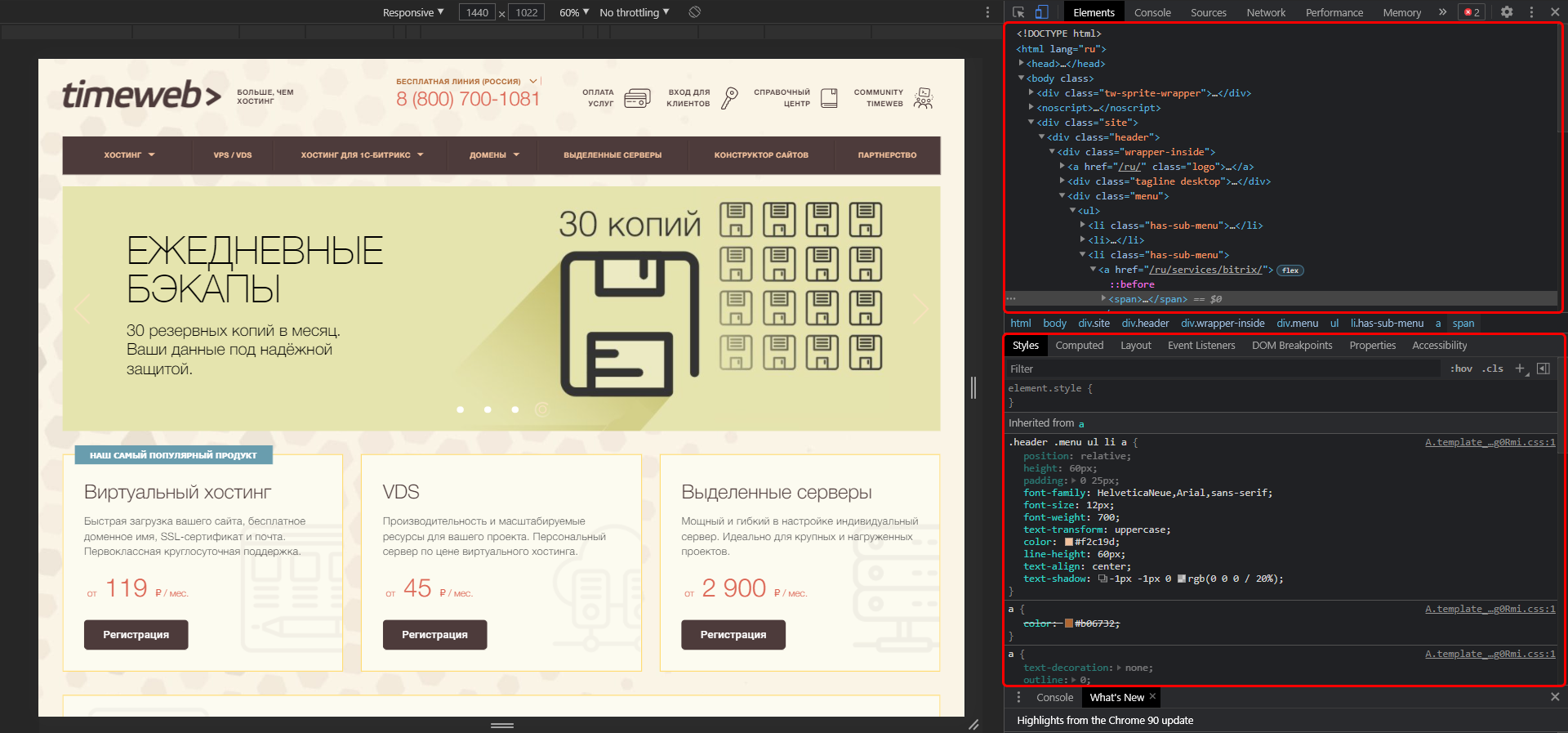
Обратите внимание на то, что запуск инструмента разработчика выполнялся в Google Chrome. В другом браузере название кнопки запуска может отличаться.
Способ 2: «Просмотр кода страницы»
Если в предыдущем случае мы могли открыть всю подноготную сайта, то сейчас нам будет доступен лишь HTML-код. Чтобы его посмотреть, находим на сайте пустое поле и кликаем по нему правой кнопкой мыши, затем выбираем «Просмотр кода страницы» (можно воспользоваться комбинацией клавиш «CTRL+U»). Если вы кликните правой кнопкой по элементу сайта, то кнопка «Просмотр кода страницы» будет отсутствовать.

После этого нас перенаправит на новую страницу со всем исходным кодом:
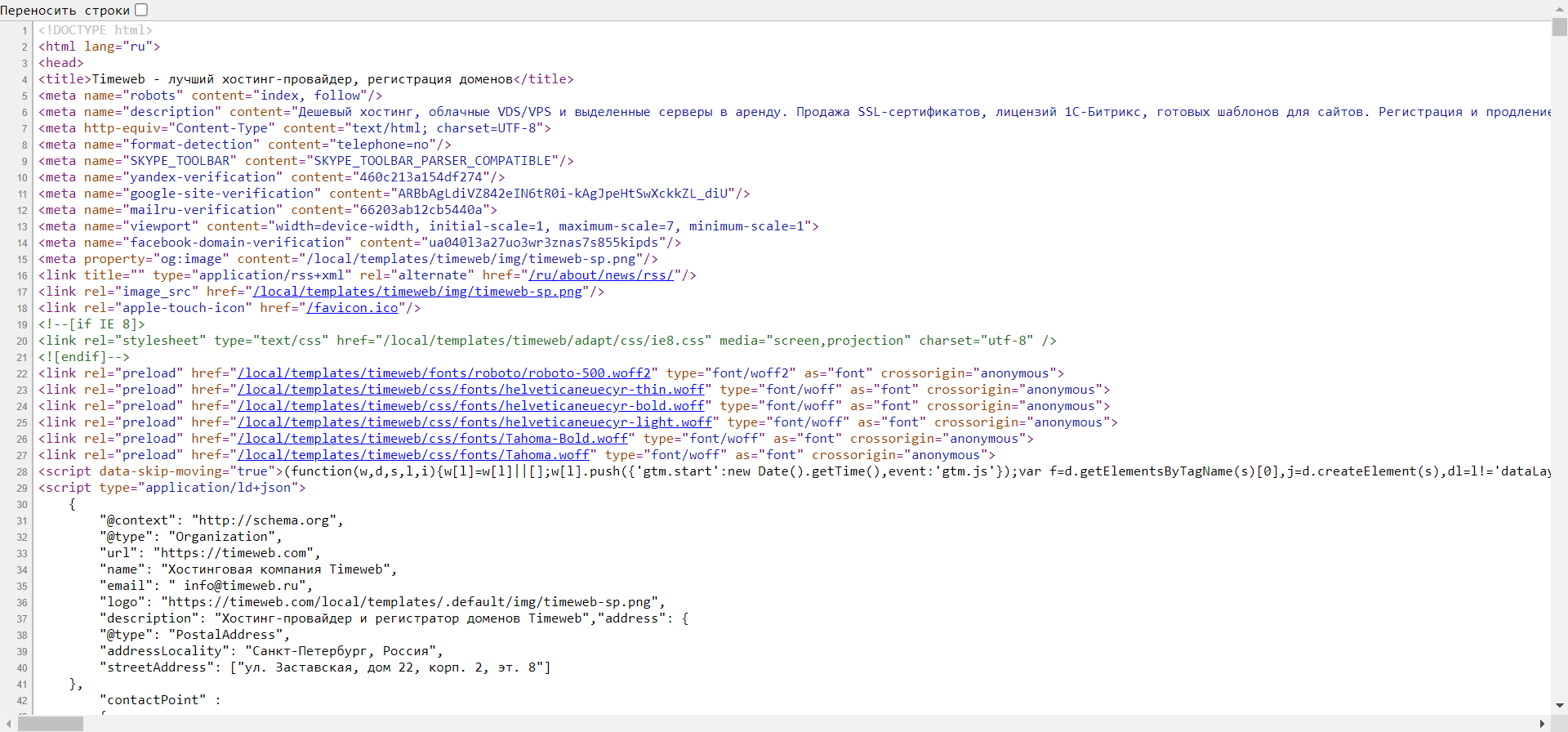
Здесь мы также можем посмотреть все содержимое страницы, однако узнать CSS и изменить данные у нас не получится.
Что такое HTML и CSS
HTML – это язык гипертекстовой разметки, выступающий в качестве строительного материала страницы. С его помощью создается основной контент – текстовая часть, изображения, различные блоки и прочее. Все это заполняется с помощью тегов, специальных команд для браузера, которые вводятся пользователем в специальном файле с расширением .html. Синтаксис выглядит следующим образом:
<tag> … </tag> <! Вводится открывающий тег, прописывается содержимое, а затем тег закрывается >
Например, часто используется такая конструкция: <h1> Это мой первый сайт! </h1>, где h1 – тег, обозначающий заголовок первого уровня, внутри которого находится текст, отображаемый на странице.
Подобных тегов более сотни, для их изучения рекомендую обратиться к справочнику.
CSS – это помощник HTML, который позволяет преображать страницу как угодно: можно настраивать цвета элементов, изменять их положение, размер и форму, добавлять адаптивность и многое другое. Подключение CSS выполняется непосредственно в HTML-файле с помощью специального тега.
Рассмотрим на небольшом примере, как работают стили:
- Допустим, у нас есть HTML-тег <body> с текстом «Привет! Это мой первый сайт»:

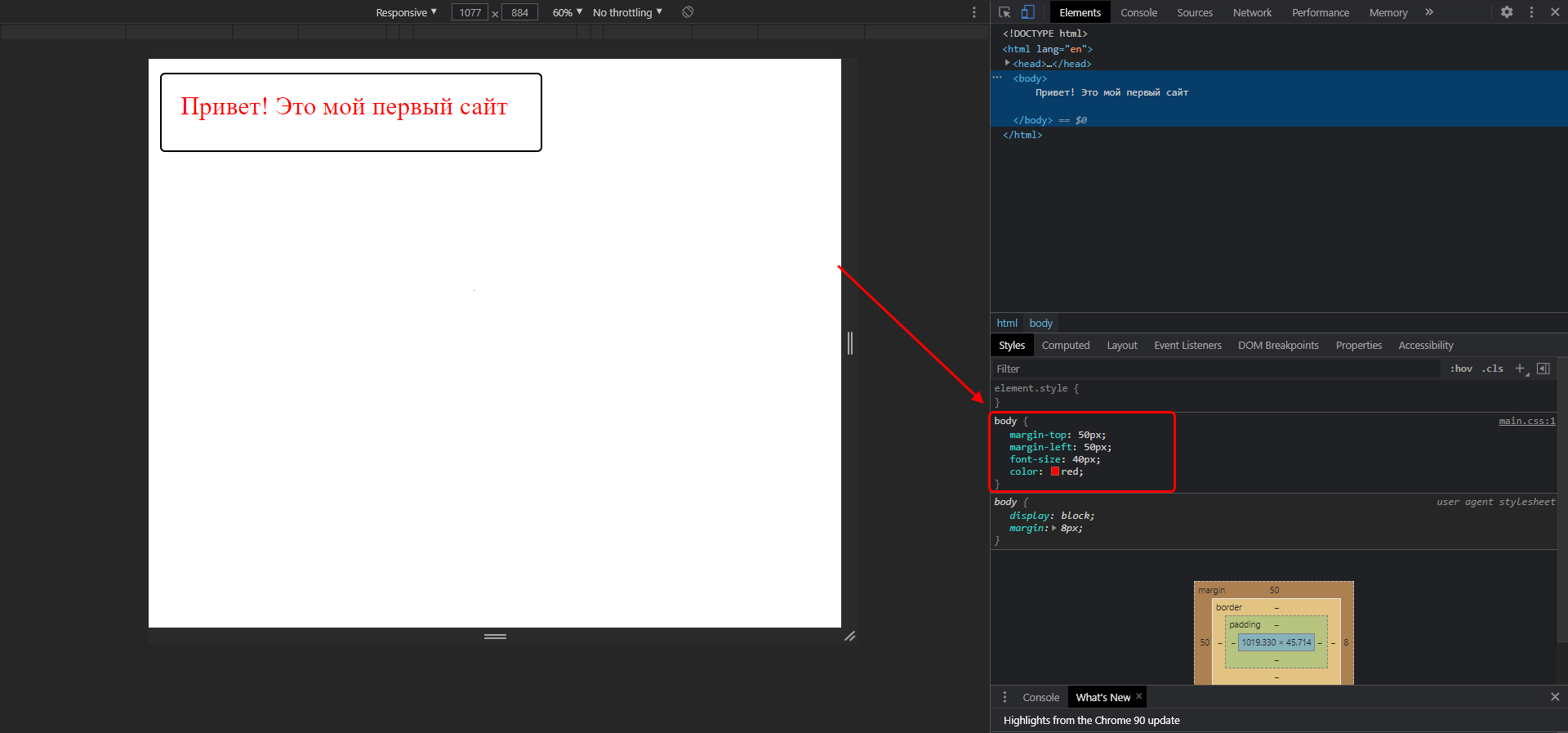
- Мы хотим, чтобы текст стал другого цвета. Давайте сделаем его красным! Для этого используются каскадные стили (CSS), в данном случае достаточно для тега body прописать стиль «color: red;». В результате текстовый элемент преобразится, а информацию о его стилях мы можем посмотреть в инспекторе браузера:
Каждый сайт, который вы встречаете, использует связку HTML и CSS. Стоит упомянуть, что еще есть язык программирования JavaScript, который позволяет оживлять страницу. Например, он может активировать формы обратной связи, создать сложную анимацию, установить всплывающие окна и многое другое. Обычным пользователям разбираться в нем не нужно от слова совсем. Если вы собираетесь вести аналитику сайта или просто интересуетесь его содержимым, то в знаниях JavaScript нет никакой необходимости.
Как я могу использовать код
Выше мы рассмотрели лишь основные моменты, связанные с кодом сайта – научились просматривать его и узнали, что такое HTML и CSS. Теперь давайте применим полученные знания на практике – посмотрим, как всем этим пользоваться.
Вариант 1: Редактирование контента
Как мы уже говорили ранее, можно поменять контент страницы внутри своего браузера. Изменения будем видеть лишь мы, но это дает нам возможность посмотреть альтернативный вариант размещения элементов.
Например, доступна возможность изменять содержимое текста – для этого достаточно выбрать нужный текст, кликнуть по нему правой кнопкой мыши и перейти в «Посмотреть код». После этого перед нами отобразится инспектор с выделенным текстом.
В среде разработчика мы можем заменить текст, расположенный в данном теге. Чтобы это сделать, находим его в коде, кликаем по нему двойным щелчком мыши и заменяем на другой. Ниже пример: мы поменяли «Виртуальный хостинг» на «Классное решение».
Чтобы отменить внесенные изменения, достаточно воспользоваться клавишей «F5» – страница будет обновлена, а весь контент станет исходным.
Аналогичным образом мы можем поменять CSS-стили через нижнее окно, но для этого потребуются некоторые знания. Подробную информацию рекомендую посмотреть в CSS-справочнике.
Вариант 2: Скачивание картинок
Сейчас мы можем напрямую загружать картинки с сайта, но по некоторым причинам это получается далеко не всегда. В таких случаях остается только один способ – выгрузить картинку через код. Сделать это довольно просто:
- Выбираем картинку, которую нужно скачать, кликаем по ней правой кнопкой мыши и переходим в «Посмотреть код». После это перед нами откроется инспектор браузера с выделенным тегом – в нем нас интересует значение «src». Там содержится ссылка на картинку, которую нужно скопировать и вставить в браузер.
- Мы попадаем в окно с необходимым изображением в полном размере. Чтобы его скачать, достаточно кликнуть правой кнопкой мыши и выбрать «Сохранить картинку как…».
Аналогичным образом мы можем выгрузить и фоновое изображение, но его стоит искать через CSS-стили в атрибуте background.
Вариант 3: Просмотр SEO-элементов
С помощью кода можно посмотреть основные SEO-теги. Сделать это можно следующим образом:
- Открываем страницу, которую нужно проанализировать, и кликаем по пустой области правой кнопкой мыши. Затем выбираем «Просмотр кода страницы».
- Далее нас перенаправляет на страницу с кодом – здесь мы можем найти такие элементы, как H1, Description, Title и другие. Для удобства рекомендую использовать поиск по странице, который запускается с помощью комбинации клавиш «CTRL+F».

Подобные элементы можно посмотреть и через инспектор кода.
Как посмотреть исходный код на телефоне
Функционал мобильных браузеров сильно ограничен – посмотреть код сайт через инспектор мы не можем. Доступен только вариант с отображением всего HTML-кода страницы. Чтобы им воспользоваться, необходимо перед ссылкой прописать «view-source:». Например, для https://timeweb.com/ru это будет выглядеть так:
view-source:https://timeweb.com/ru
Если нужны расширенные возможности для устройства на Android, то можно поискать специальные приложения, например, VT View Source.
Заключение
Подведем итоги:
- Просматривать и читать исходный код страницы может каждый, и для этого не нужно обладать навыками программирования.
- Код страницы состоит из HTML-элементов и CSS-стилей, изучить которые может любой пользователь.
- Базовые знания позволят изучить SEO-элементы сайта, выгрузить из него картинки, посмотреть используемые элементы и узнать много другой полезной информации.
Как найти текст по отрывку
Когда вам необходимо найти текст по отрывку, состоящему из нескольких предложений, а то и слов, то на помощь может прийти только интернет. Все тексты литературных произведений, технических документов, научных трудов, которые были выложены во всемирную паутину, индексируются. Поэтому уникальный порядок слов в отрывке – тот код, по которому можно будет найти весь текст, в котором он встречается.

Инструкция
Вы можете воспользоваться возможностями любой поисковой системы: Google, Mail.ru, Yandex, Rumbler и т.п. Введите в строке поиска часть отрывка, и на экране монитора появится список сайтов, на страницах которых размещены тексты, содержащие те же слова, которые встречаются в нем. В верхней части списка будут расположены ссылки, в которых эти слова встречаются в том же порядке, что и в приведенном отрывке. Просмотрите их, убедитесь, что отрывок не используется в тексте как цитата, и вы узнаете название первоисточника и его автора, которые будут указаны в заголовке.
Специальный сервис Google «Книги» позволит вам существенно снизить границы поиска. Для этого введите отрывок или его часть в поле «Расширенный поиск книг» и кликните кнопку «Поиск». Для удобства, водите отрывок без знаков препинания. Система предоставит вам список книг, текст которых содержит этот отрывок. Их следует просмотреть, чтобы найти первоисточник с именем автора и названием произведения.
Найти текст по отрывку можно с помощью известных сервисов – антиплагиаторов, таких, например, как Advego Plagiatus. Это бесплатная система, которую можно установить, посетив сайт Advego.ru. Она позволяет искать в интернете частичные или полные копии текстового документа. Интуитивный интерфейс системы позволяет с высокой степенью точности идентифицировать искомый текст, даже если отрывок не совсем точен и слова поменяны местами. Система покажет не только процент уникальности данного отрывка, но и даст ссылку на тот документ, часть содержания которого наиболее релевантна ему. Перейдите по этой ссылке, и вы сможете увидеть полный искомый текст.
Полезный совет
Неважно, каким способом вы будете искать первоисточник. Чем точнее будет текст отрывка, указанный в качестве поискового запроса, тем быстрее вы найдете правильный ответ. Поэтому старайтесь соблюдать не только порядок слов в отрывке, но и избегать орфографических ошибок.
Источники:
- Сайт Advego Plagiatus
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Содержание статьи
- Панели поиска в браузерах
- Поиск текста в Google Chrome
- Поиск текста в Mozilla Firefox
- Поиск текста в Яндекс Браузере
Каждому юзеру приходится искать-либо на страницах сайтов. Это может быть не статья или новость целиком, а конкретный абзац или отрывок текста, где находится ключевое слово или фраза. Если на странице много текста, а нужен только кусок с искомым описанием, то юзаем поиск слов в браузере. Это функция, идентичная с поиском в Ворде, Экселе или PDF-редакторах.
Панели поиска в браузерах
В каждом браузере есть своя панель поиска. Чтобы вызвать ее, следует нажать Ctrl+F. Рассмотрим панели поиска таких браузеров как Хром, Firefox и Яндекс Браузер.
Поиск текста в Google Chrome
Открыть панель в Хроме можно другим способом, нажав на меню и выбрав функцию «Найти…».

Находясь на любой странице, набираем интересующее слово или фразу и нажимаем enter. Как видно на скриншоте, найденное слово подсвечено оранжевым. На панели указано количество найденных слов. С помощью стрелок осуществляется переход от одного результата к другому.

Поиск текста в Mozilla Firefox
В Firefox панель поиска более продвинутая и удобная. Обладает следующими опциями:
- подсветить все;
- с учетом регистра;
- только слова целиком.

«Подсветить все», как вы догадались, позволяет увидеть все нужные слова в документе.

Функция «С учетом регистра» придает поиску чувствительность к большим и маленьким буквам. Например, если вы напечатали слово «нефть», то есть слово с маленькой буквы, то в качестве совпадений варианты «Нефть» или «НЕФТЬ» учитываться не будут.

Поиск при помощи опции «Только слова целиком» отсеивает слова со склонениями и окончаниями. Вобъем персидское слово «нефт», чтобы проверить результат.

Поиск текста в Яндекс Браузере
Браузер Яндекса имеет аналогичную с Хромом панель поиска текста, однако обладает крутой лингвистической системой. Известно, что Яндекс как поисковик лучше любой другой системы понимает русский язык. Именно это преимущество дает пользователю возможность находить среди текста на странице нужный фрагмент или отдельные предложения с максимальным количеством вариантов. Алгоритм поиска текста учитывает падежи, склонения, число, род, часть речи.
