Содержание
- Смотрим, как выглядела страница раньше
- Способ 1: Поиск Google
- Способ 2: Internet Archive
- Способ 3: Web Archive
- Вопросы и ответы

Пользовательские страницы ВКонтакте, включая и ваш персональный профиль, часто меняются под влиянием тех или иных факторов. В связи с этим становится актуальной тема просмотра раннего внешнего вида страницы, и для этого необходимо использовать сторонние средства.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Подробнее: Как открыть стену ВК
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
Примечание: Нами будет затронут только поиск Google, но аналогичные веб-сервисы требуют тех же действий.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Подробнее: Поиск без регистрации ВК
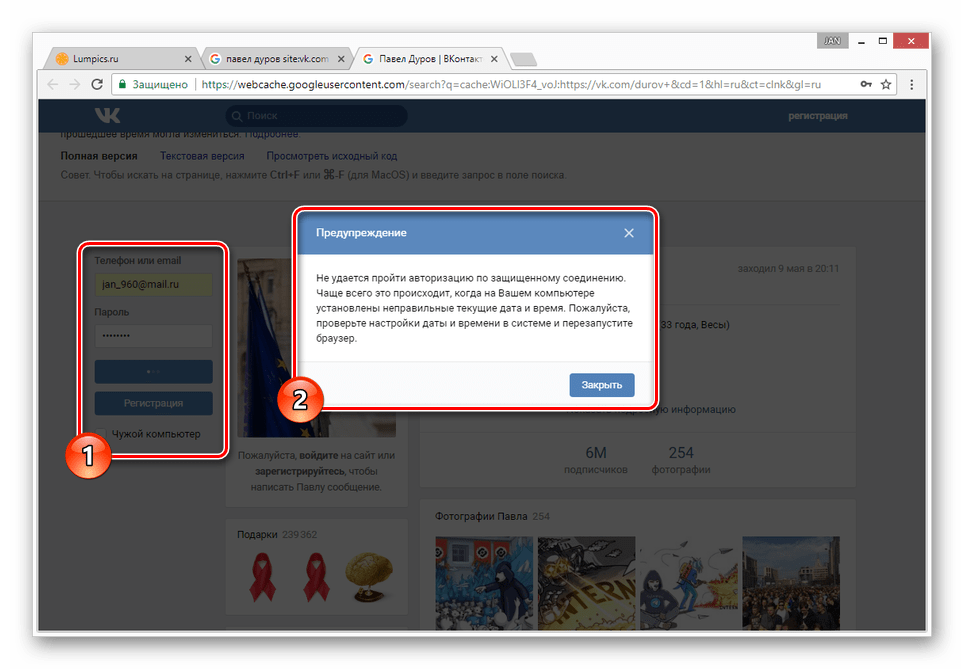
- Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
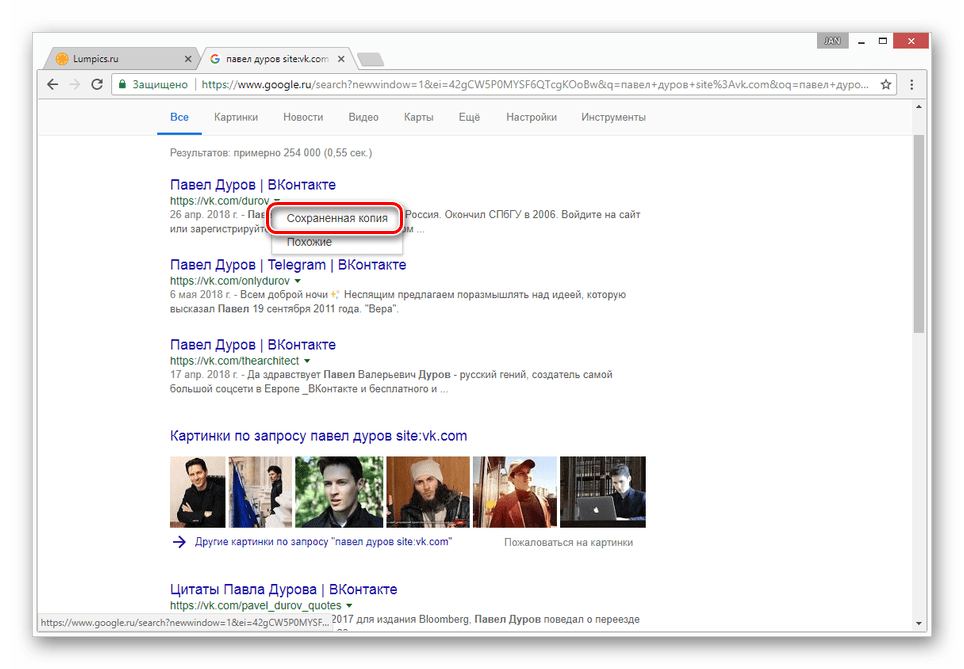
- Из раскрывшегося списка выберите пункт «Сохраненная копия».
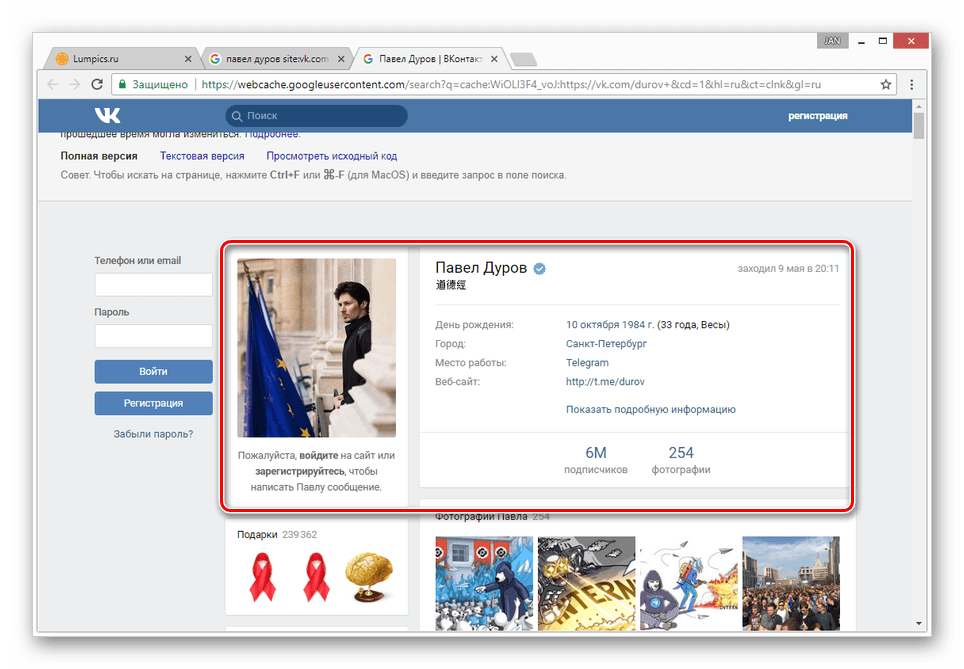
- После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.

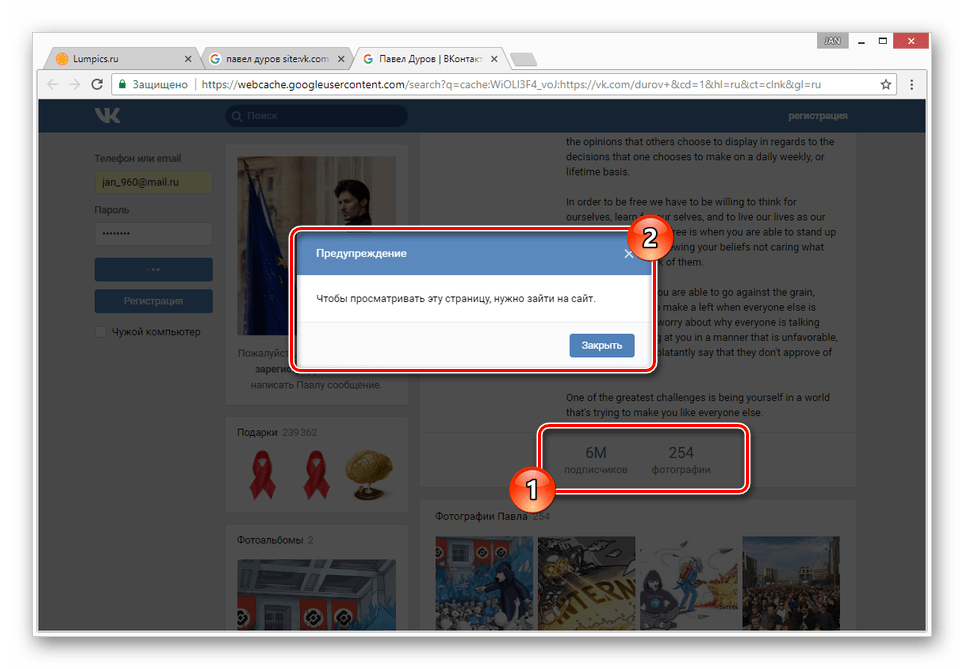
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
Перейти к официальному сайту Internet Archive
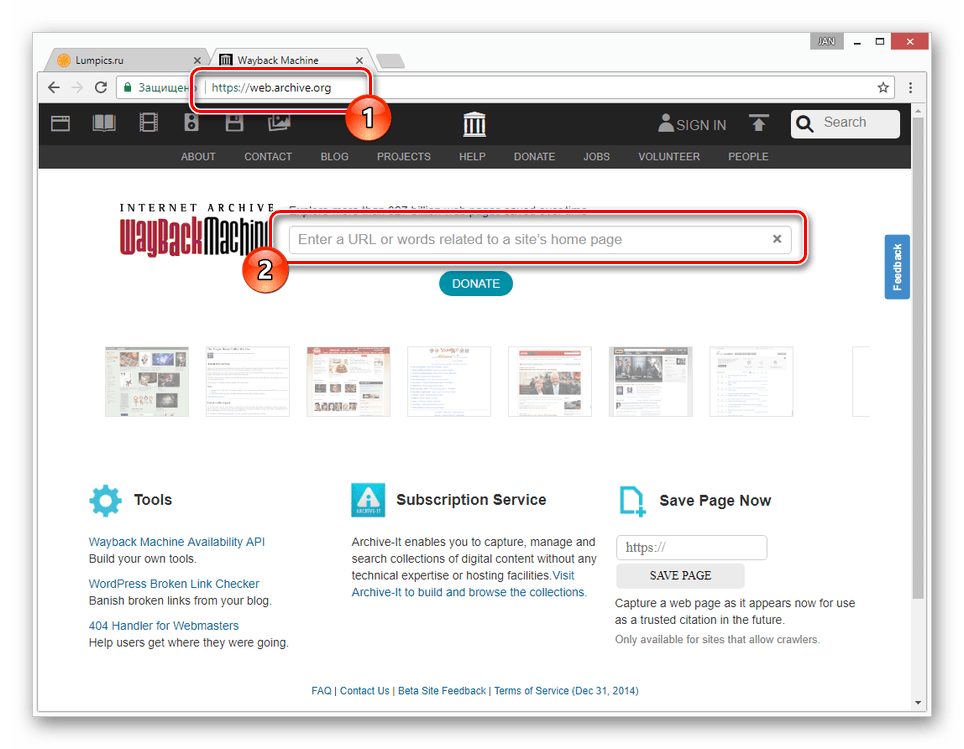
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
- В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
Примечание: Чем меньшей популярностью пользуется владелец профиля, тем ниже будет количество найденных копий.
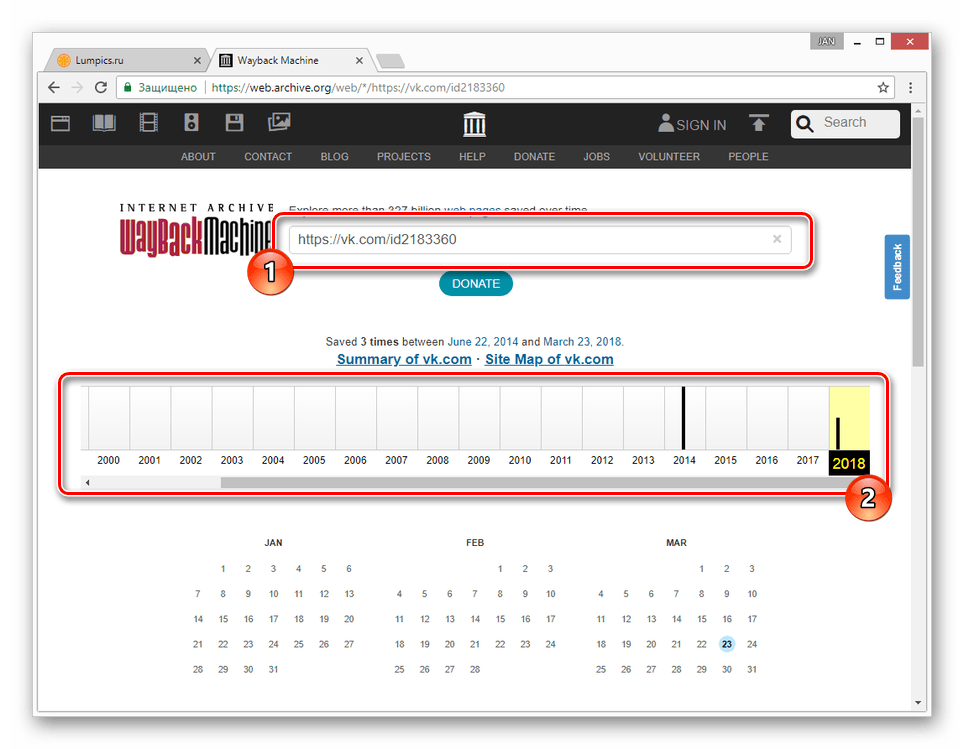
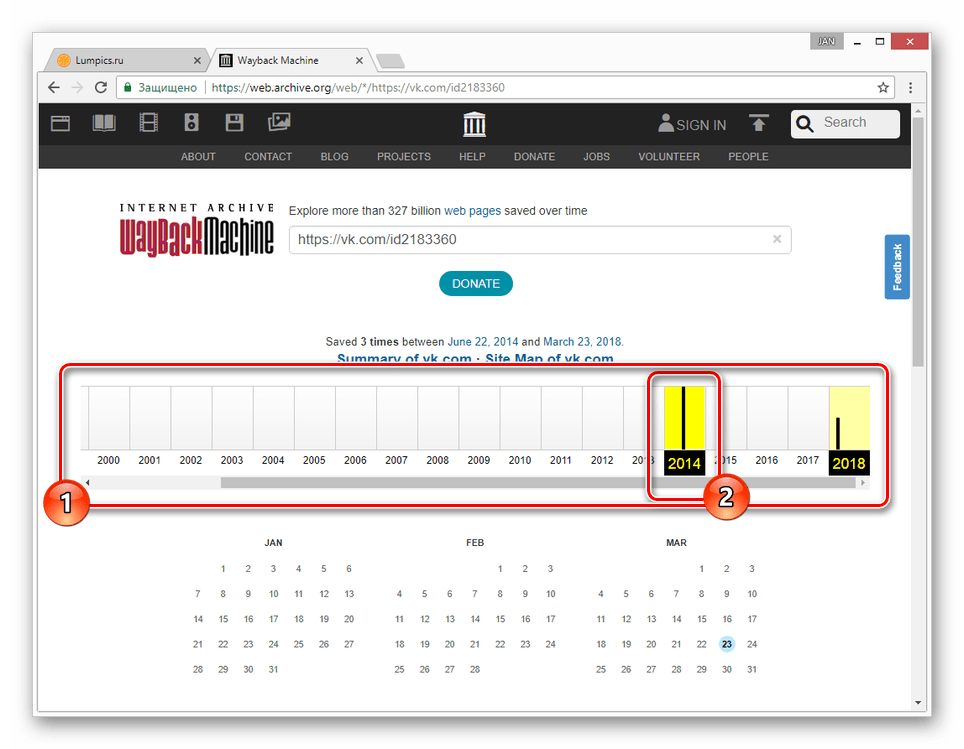
- Переключитесь к нужной временной зоне, кликнув по соответствующему году.
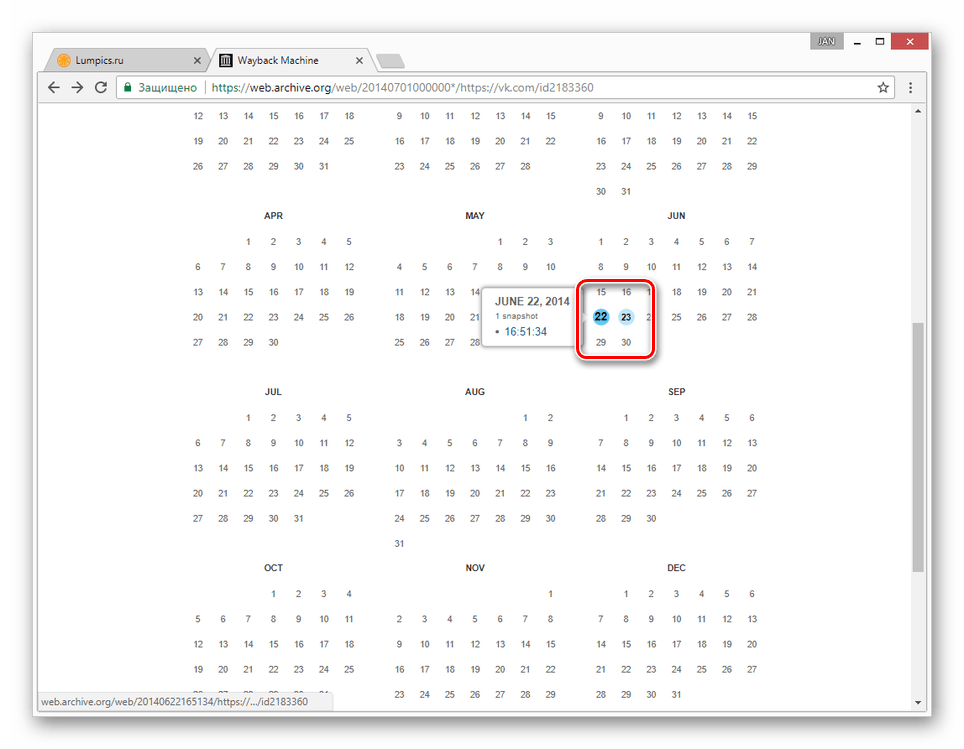
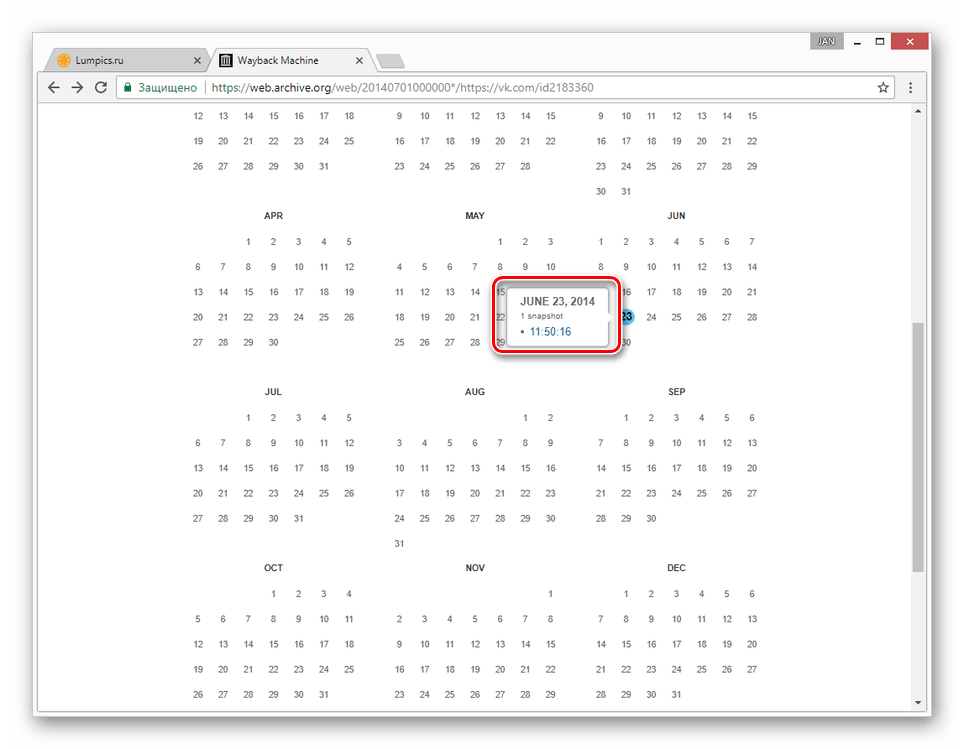
- С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
- Из списка «Snapshot» выберите нужное время, кликнув по ссылке с ним.
- Теперь вам будет представлена страница пользователя, но лишь на английском языке.

Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
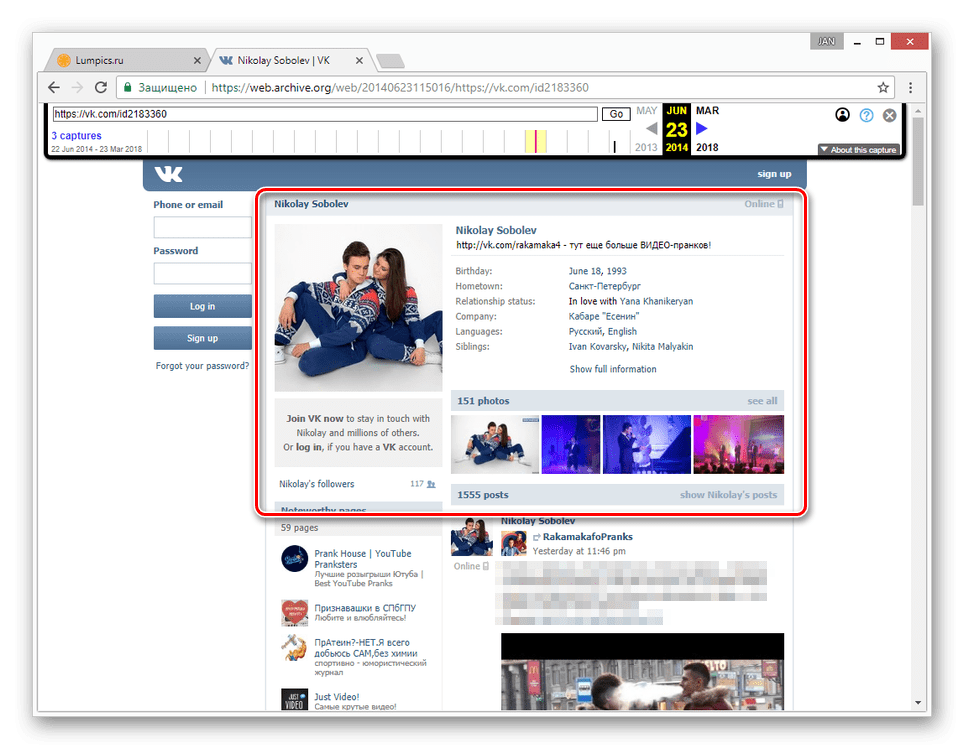
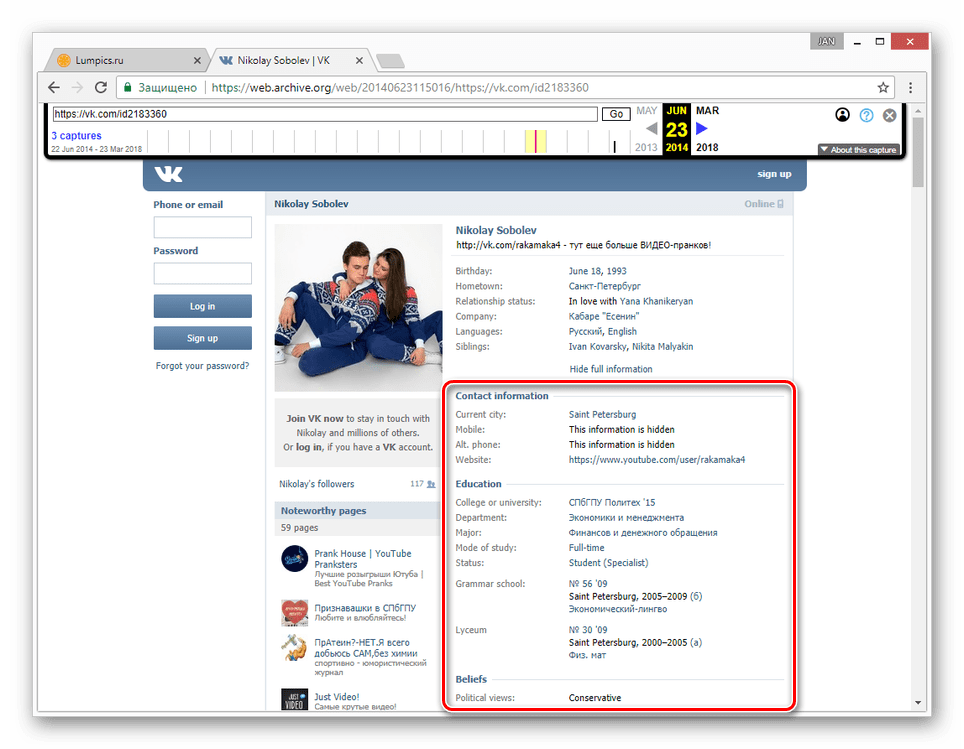
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
Перейти к официальному сайту Web Archive
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти».
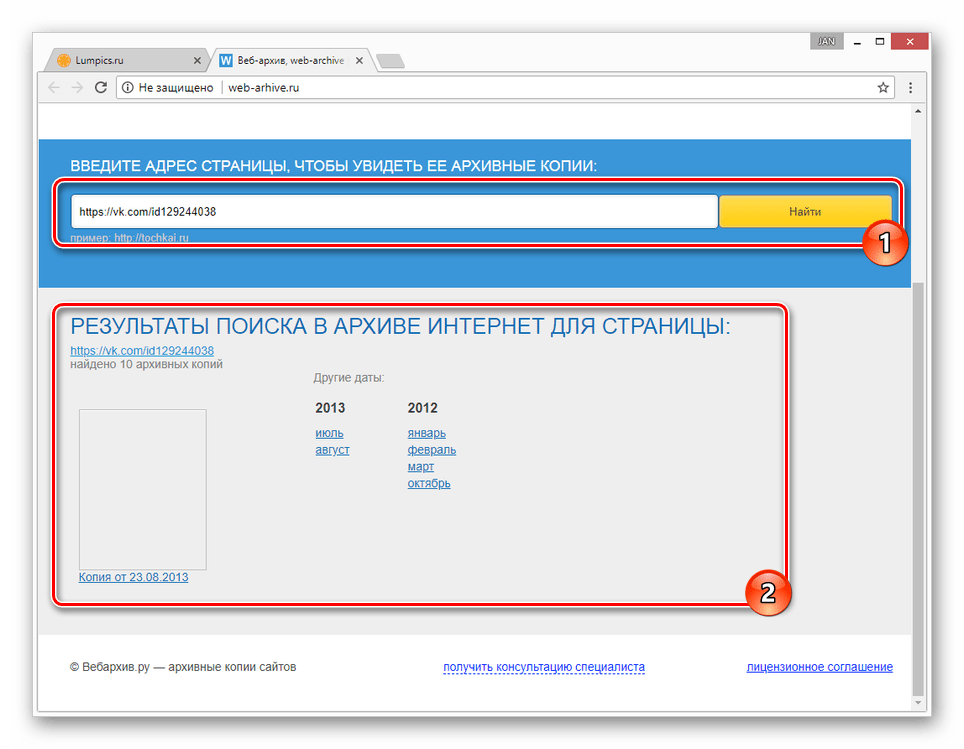
- После этого под формой поиска появится поле «Результаты», где будут представлены все найденные копии страницы.
- В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
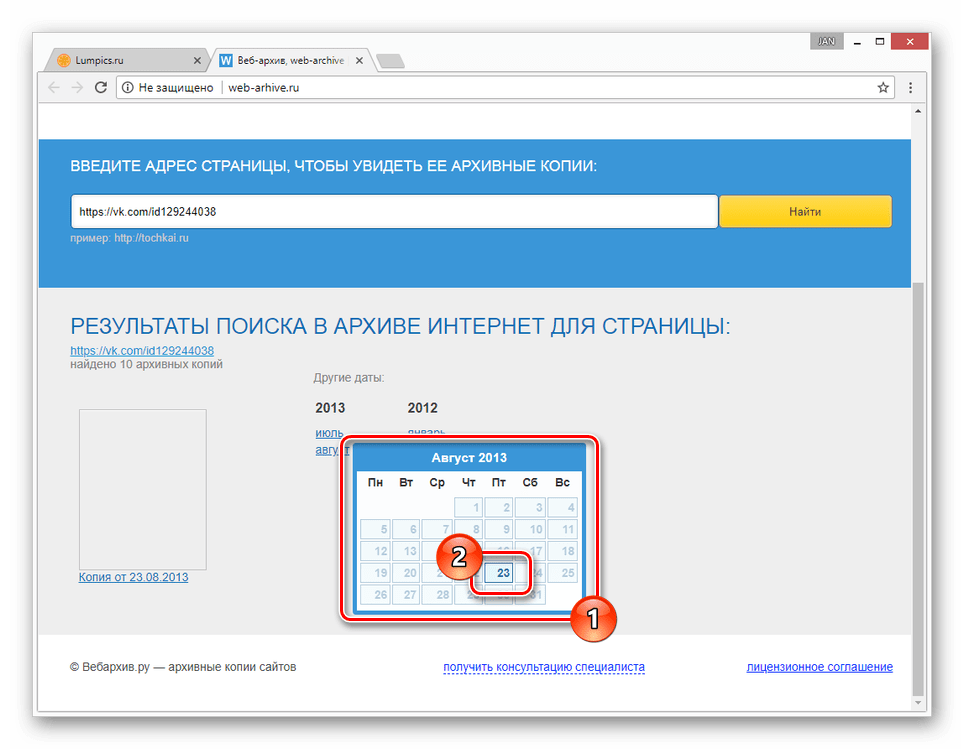
- С помощью календаря кликните по одному из найденных чисел.
- По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
- Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.
Примечание: В сети присутствует много похожих сервисов, адаптированных под разные языки.

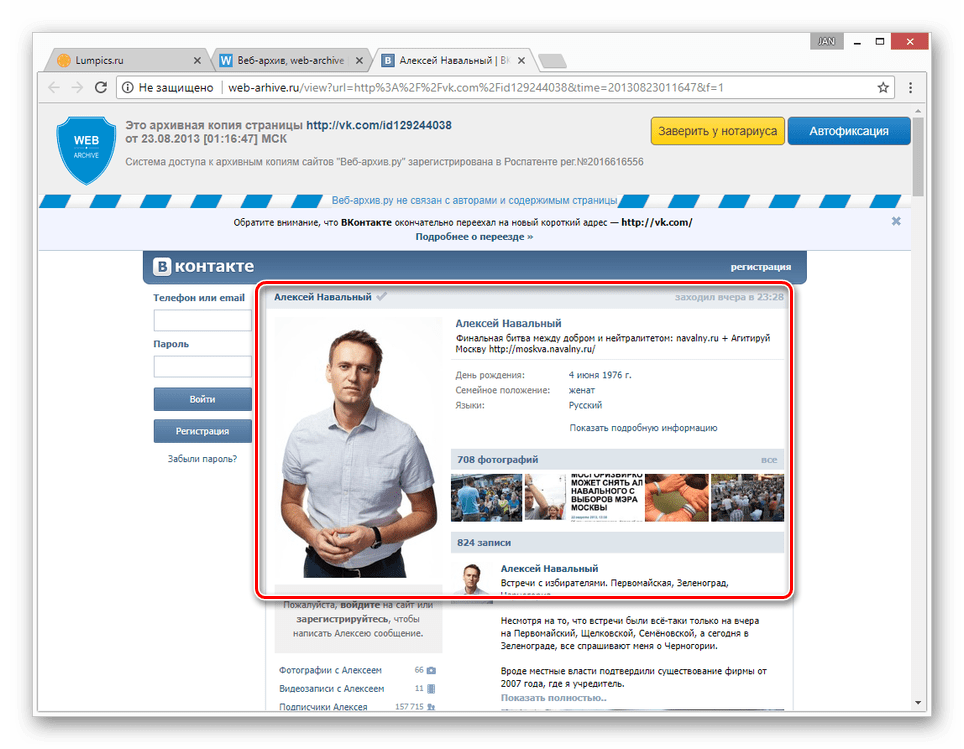
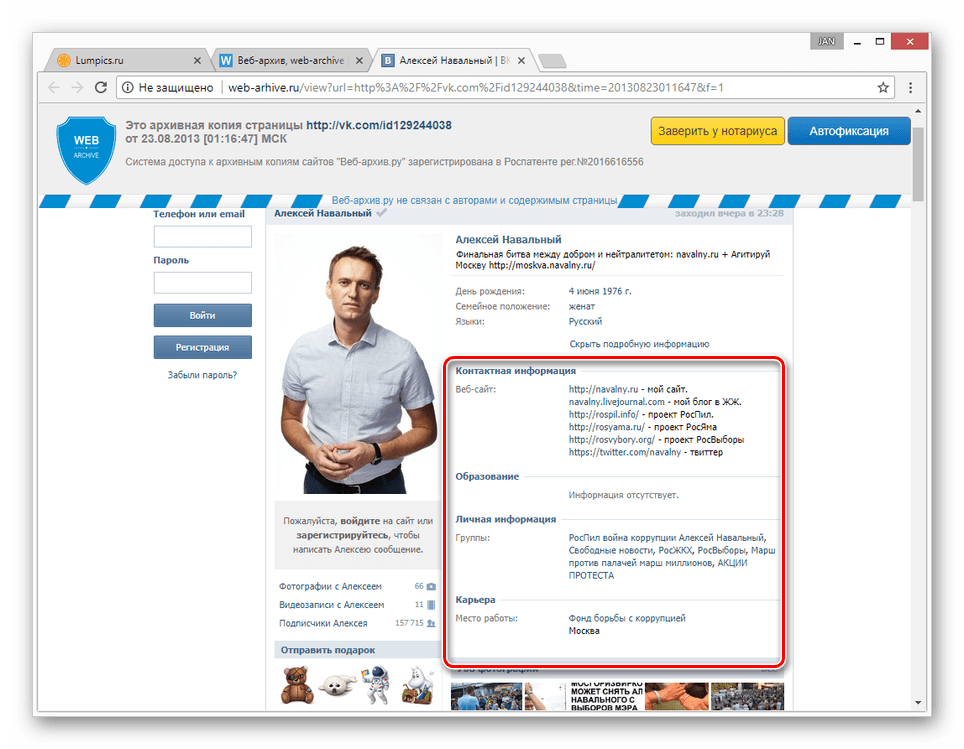
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц. Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Еще статьи по данной теме:
Помогла ли Вам статья?
Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
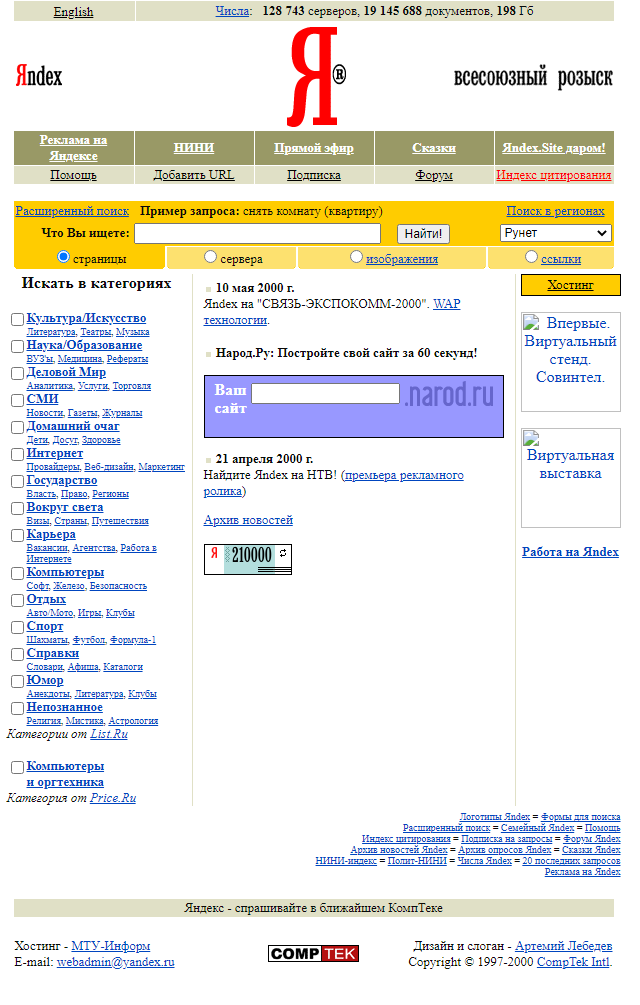
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
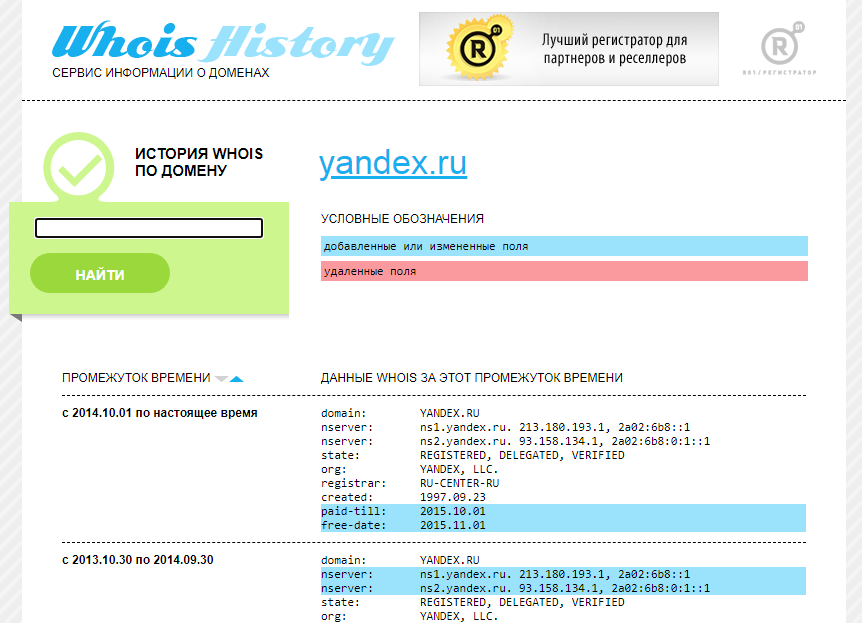
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
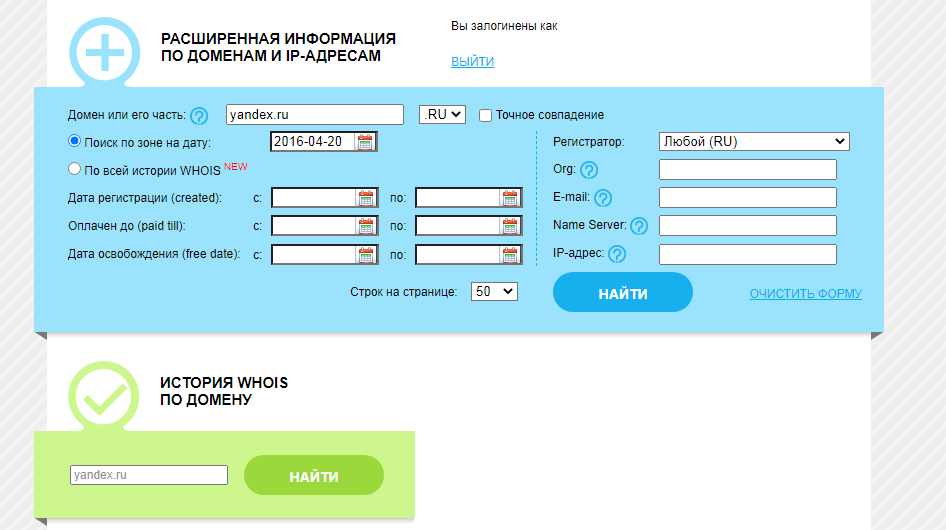
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
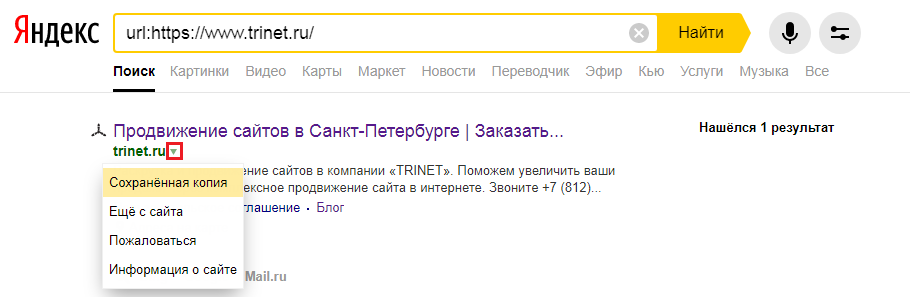
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.

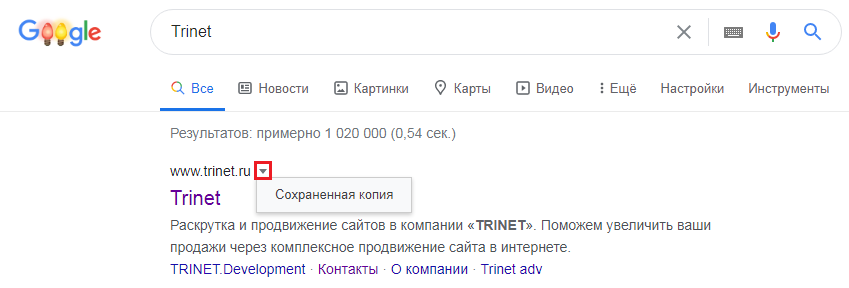
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:

Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.

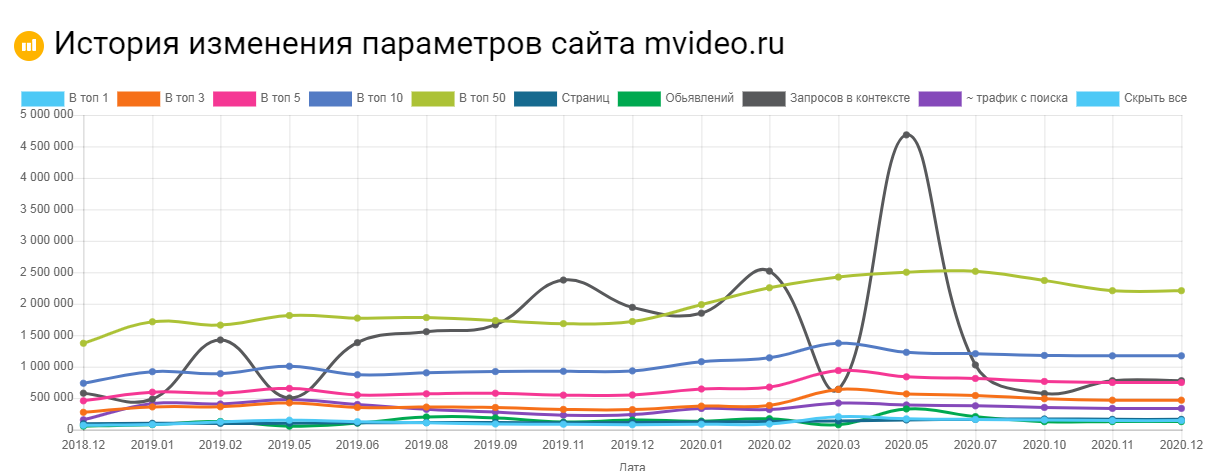
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
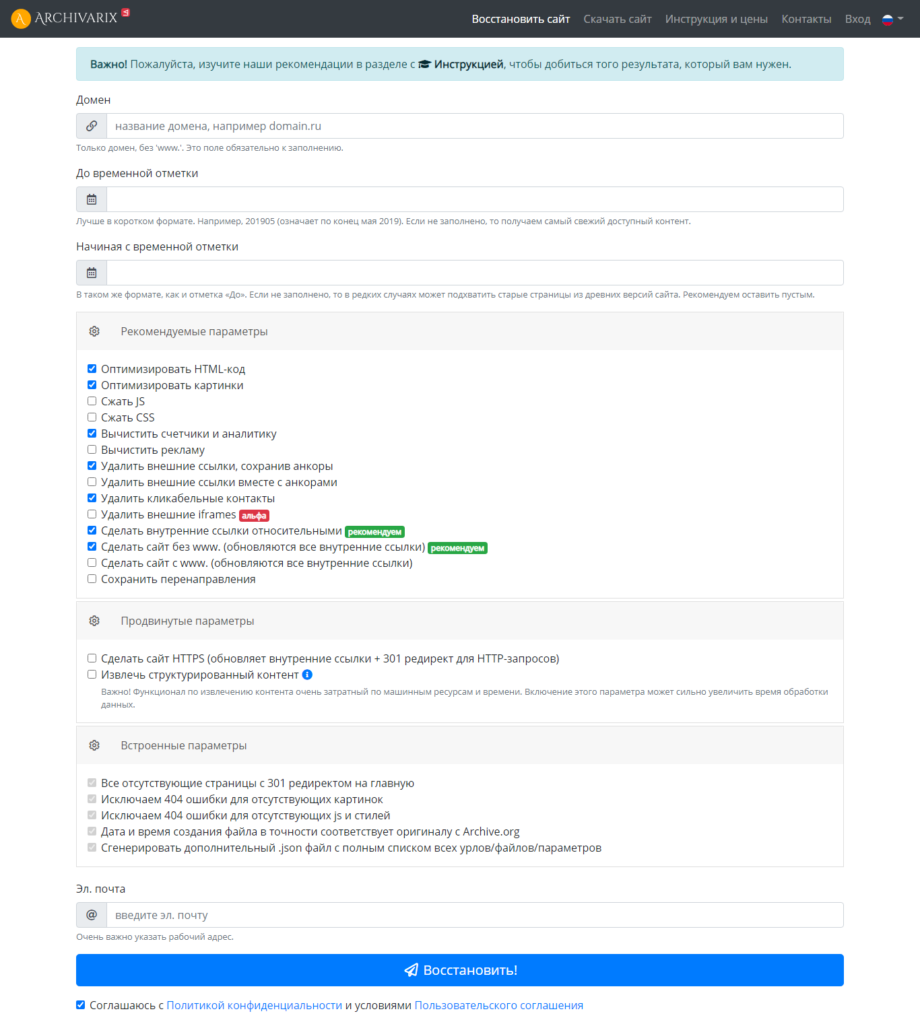
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Ссылка на сервис https://www.rush-analytics.ru/land/skachivanie-kopiy-saytov-iz-wayback-machine
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
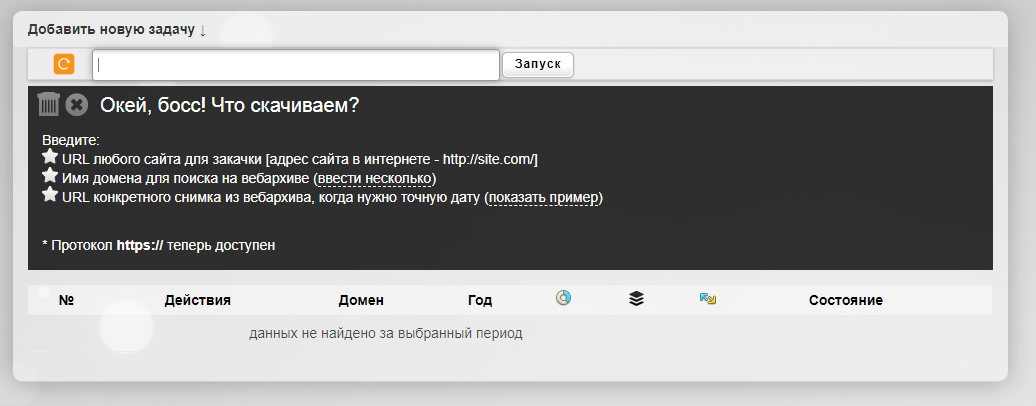
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.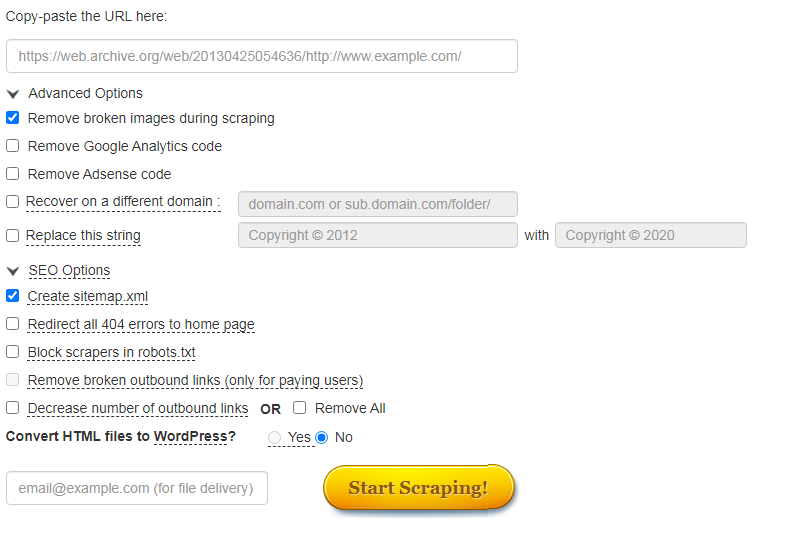
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
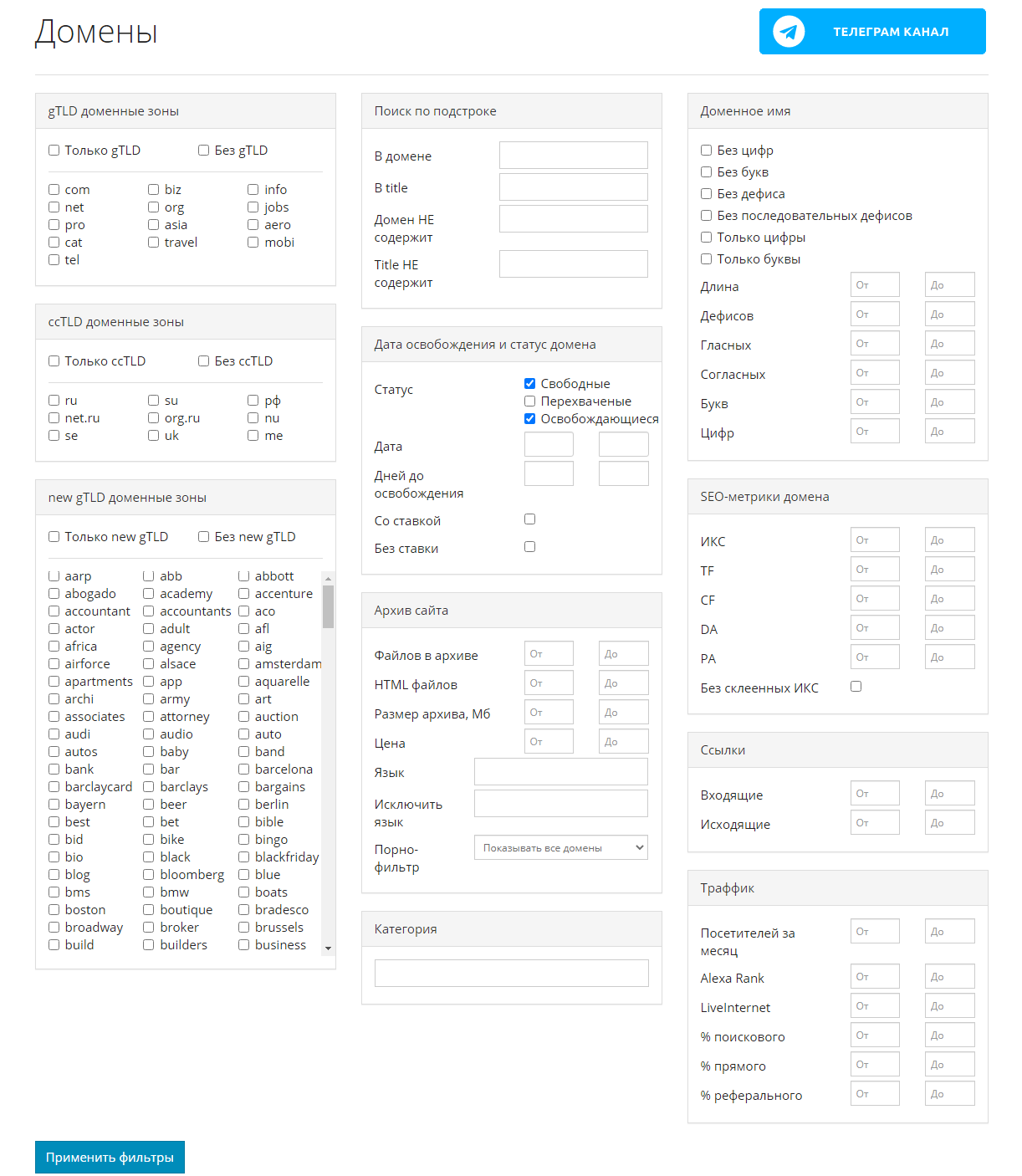
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента или комплексные услуги по продвижению и созданию сайтов, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
Сервис, который может показать, как выглядели сайты в прошлом, напоминает своеобразную машину времени в интернете. С его помощью можно перенестись на год, два или двадцать лет назад и увидеть, какими ресурсы были тогда. Зачем может понадобиться эта информация и как воспользоваться данным сервисом?
Содержание
- 1 Для чего нужно искать старые версии сайтов
- 2 Как узнать прошлое веб-ресурса с помощью archive.org
- 2.1 Если это страница Вконтакте
- 3 Как выглядели культовые сайты раньше
- 3.1 Поисковик Яндекс
- 3.2 Поисковик Google
- 3.3 YouTube
- 3.4 Википедия
- 3.5 ВКонтакте
- 4 Можно ли восстановить сайт из вебархива?
- 5 Выводы
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
- Отслеживание истории изменений. Такая потребность может возникать у копирайтеров или журналистов для подготовки нового контента. Также это может быть нужно для анализа конкурентов: можно проследить путь их развития и увидеть допущенные ошибки.
- Восстановление ресурса. Если пользователь забыл продлить домен или не сделал бэкап, веб-архив будет отличным вариантом восстановления.
- Поиск уникального контента. Если площадка больше не доступна, её контент становится уникальным. Можно использовать его полностью или частично, предварительно проверив уникальность.
- Увидеть необходимый контент, если страница уже недоступна. Например, пользователь добавил площадку в закладки, а через время оказалось, что её больше нет. Тогда посмотреть её содержимое можно только с помощью веб-архива.
Как узнать прошлое веб-ресурса с помощью archive.org
Чтобы узнать, как выглядел конкретный веб-ресурс ранее, можно воспользоваться сайтом для просмотра страниц в прошлом – archive.org. Для этого нужно выполнить следующее:
- Пройти по ссылке https://archive.org/.
- Ввести URL-адрес и нажать кнопку «Go».

- Выбрать интересующий период времени. Затем с помощью календаря найти нужную дату, навести на нее курсор мыши и выбрать время сохранения копии (в списке может быть как одна, так и несколько ссылок).

После этого откроется главная страница в том виде, какой она была в выбранный период.

Учитывайте, что кликабельными в календаре являются только дни, помеченные синим или зеленым цветом. Посмотреть, как выглядел сайт в даты без подсветки, не получится.
Если это страница Вконтакте
Аналогичным образом можно узнать содержимое страницы ВКонтакте. Достаточно указать на нее ссылку в соответствующем поле.
По сравнению с новостными или другими веб-ресурсами здесь будет меньше подсвеченных дат с сохранённым содержимым. Количество дат зависит от популярности страницы: у обычных пользователей их будет немного, в то время как у известных медиа-личностей – на порядок больше.

Дальнейшие действия такие же: надо выбрать любую из подсвеченных дат и перейти по кликабельной ссылке. В этой же вкладке откроется страница в ВКонтакте с актуальным на тот момент содержимым.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.

На тот момент выглядел Яндекс вот так:

Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:

YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видеохостингом:

Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:

ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.

Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
- ввести URL-адрес;
- выбрать нужный год, месяц и число;
- нажать кнопку «Восстановить сайт».

Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Выводы
С помощью веб-архива можно посмотреть, какой дизайн и контент были у сайтов раньше, что может быть необходимо для восстановления данных, анализа конкурентов, поиска интересного контента с исчезнувших ресурсов или просто ради интереса.

Как узнать, как сайт выглядел раньше?
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine – Internet Archive. Работает с 1996 года, за это время собрал в базе данных более 279 миллиардов веб-страниц.
Переходим по ссылке: http://archive.org/web/web.php В строку вводим: адрес интересующего сайта и нажимаем «Browse History». Система выдаст всю историю по конкретному порталу.
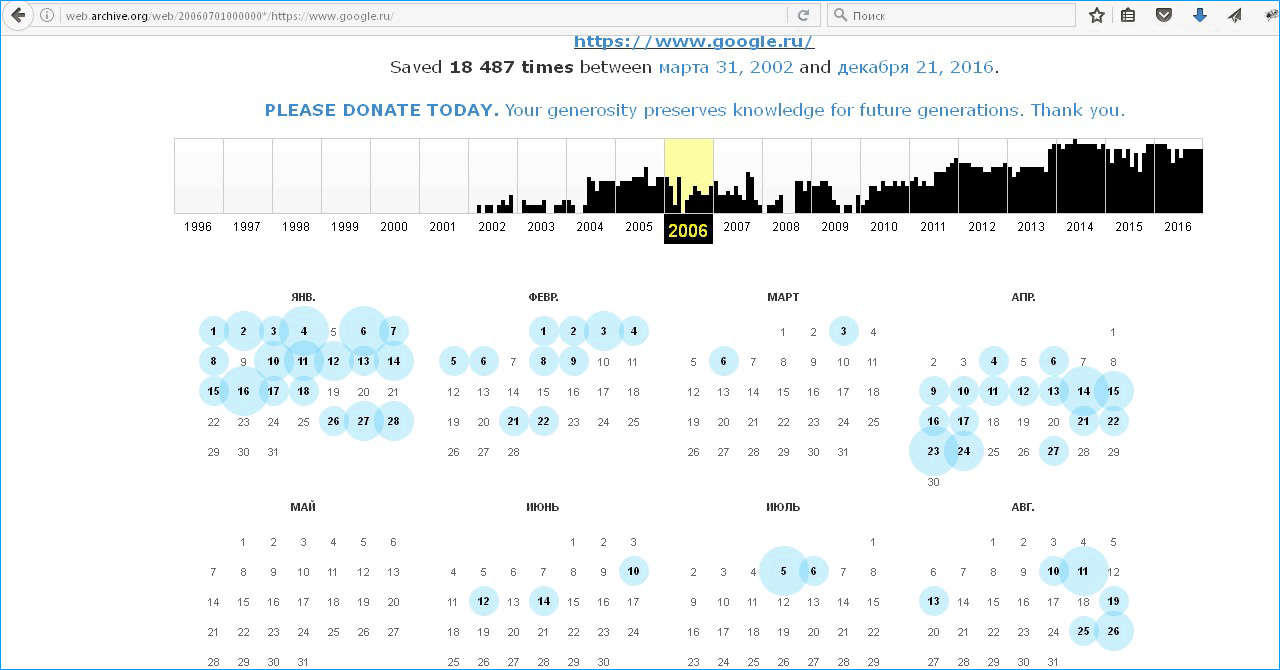
Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Где посмотреть, как выглядели страницы сайтов в разные годы
Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари». А майл.ру начали использовать поисковик на своем портале. Через год Яндекс купит разработчика мобильного софта «Смартком» и соц. сеть «Мой круг». Запустит «Календари», блого-сервис Я.ру, портал Яндекс.Mirror и откроет школу анализа данных — бесплатный образовательный курс.
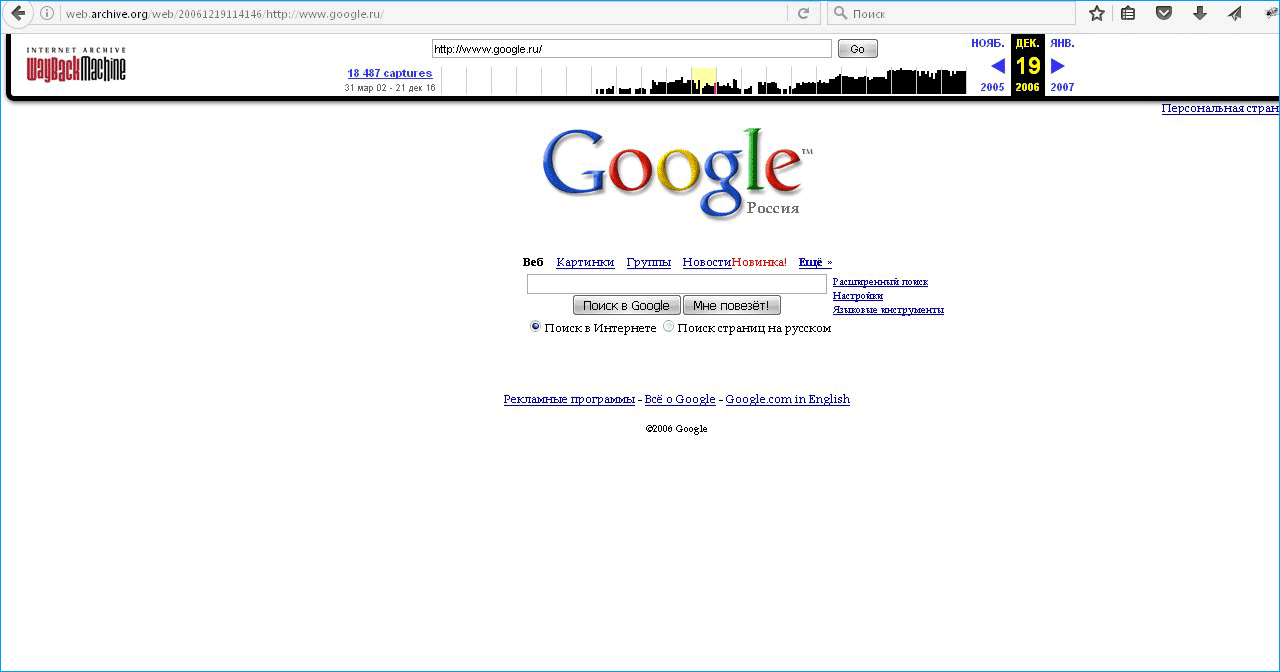
Google запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 компания установит крупнейшую систему солнечных батарей (Сейчас она обеспечивает энергией 30% офисов) и объявит о появлении Android. А сотрудники начинают ездить по офисам на велосипедах gBikes.
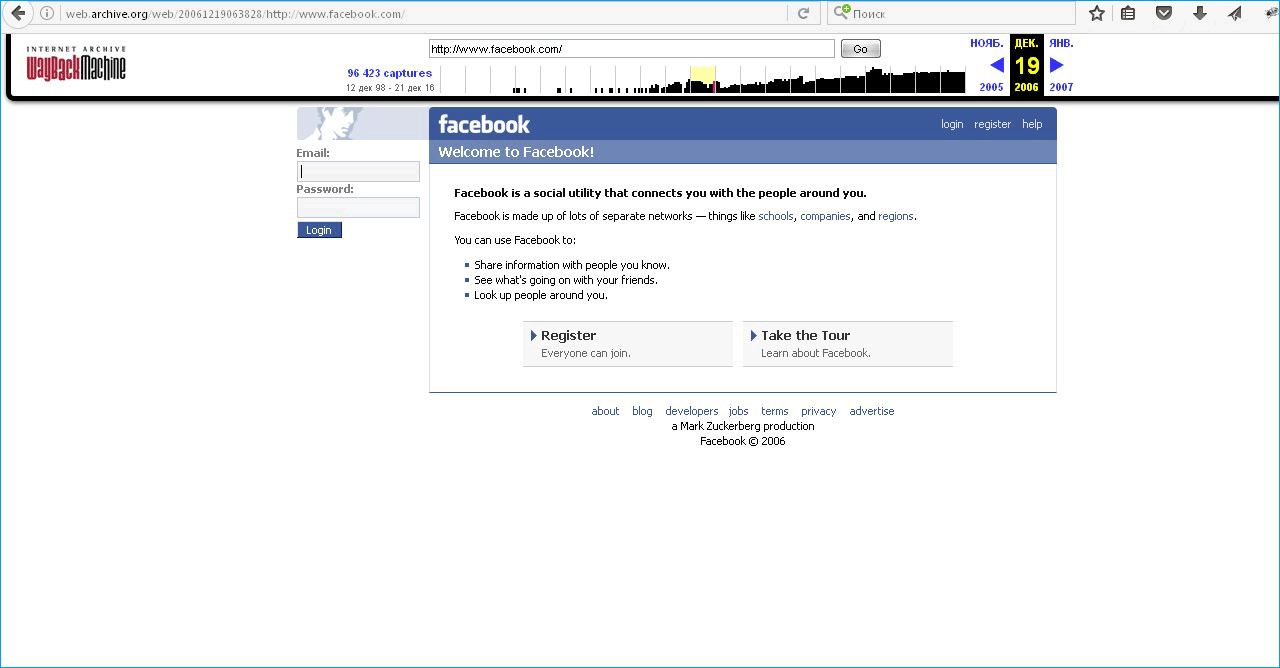
История Facebook уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
Как раньше выглядел наш сайт
А вот так менялся наш сайт с 2006 года:

iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
- Виртуальные серверы с NVMe SSD дисками от 299 руб/мес
- Безлимитный хостинг на SSD дисках от 142 руб/мес
- Выделенные серверы в наличии и под заказ
- Регистрацию доменов в более 350 зонах