Для каждого трейдера важно понимать, что мы работаем с торговыми инструментами, состоящими из пары валют. В отличие от фондового рынка, где, как правило, каждый торговый инструмент это всего лишь одна индивидуальная единица, на Форекс используется измерение стоимости одной валюты в единицах другой. При этом мы не редко можем наблюдать, визуальную схожесть в движении нескольких валютных пар. Это может быть связано с тем, что обе пары могут содержать одну и ту же валюту в обоих случаях. Например, можно говорить о корреляции валютных пар EUR/USD и USD — CHF с отрицательным значением К.
Одним из способов использования корреляции пар в торговле является устранение расхождения инструментов. Например, трейдер выбрал для своей работы две валютные пары, которые коррелируют с К = 0.8. В этом случае, при наблюдении за движением подопытных, человек заметит, что К время от времени меняется, то несколько увеличиваясь, то несколько уменьшаясь. Тем не менее, средние значения коэффициента все равно находятся в диапазоне 0.7<К<0.8.
Как только на рынке наступит ситуация, что К<0.4, например, то это будет означать наличие лишь частичного соответствия в движении обоих инструментов. То есть, при росте одной пары рост другой окажется весьма ограничен. Но, помня о том, что в целом эти инструменты коррелируют с К=0.7 или 0.8, мы можем использовать данный разрыв себе на пользу, открыв позиции в сторону сближения пар.
Нахождение подобных ситуаций и дальнейшее их использование затрудняется непостоянностью значения К. Мы можем не верно толковать новые значения коэффициента, принимая из за ожидаемый нами разрыв, но позже может оказаться, что это новое значение данного коэффициента, которое теперь станет постоянным на определенное время. Существуют специальные корреляционные индикаторы, помогающие трейдерам наблюдать за схождением и расхождением инструментов, а другими словами, за изменениями текущих значений К.
Сложно переоценить значимость коэффициента корреляции в рыночной торговле. Его использование позволяет смотреть на трейдинг более глобально, учитывая движения пар, относительно друг друга. Еще одной областью применения коэффициента стало хеджирование. Желая снизить риски в своей торговле, спекулянты могут проводить хеджирование не только на разных рынках, но и с помощью коррелирующих инструментов. Таким образом, происходит частичное хеджирование.
Для начала разберемся в самой сути такого понятия, как арбитраж. Это несколько логически связанных сделок, направленных на извлечение прибыли из разницы в ценах на одинаковые или связанные активы в одно и то же время на разных рынках (пространственный арбитраж), либо на одном и том же рынке в разные моменты времени (временно́й арбитраж, обычная биржевая спекуляция). Выделяют эквивалентный арбитраж — операции с комбинацией составных или производных активов (опционов, биржевых индексов) и обычных контрактов, когда между теоретически эквивалентными комбинациями на практике возникает разница цен.
Упрощенно арбитраж выглядит следующим образом: торгуются пары или группы инструментов, суммарная стоимость которых должна быть равна определенной величине, исходя из природы инструментов. Например: акции одной и той же компании на различных торговых площадках, группа инструментов входящих в индекс и фьючерс на индекс. При отклонении стоимости корзины от расчетной величины, совершается сделка. Трейдеры-арбитражеры сглаживают дисбаланс цен на родственных» инструментах.
Коэффициент корреляции (Correlation coefficient) — это
В первоначальном виде арбитраж возник на заре развития вторичных (региональных) бирж, когда один итот же актив торговался на разных площадках по разным ценам и с 44 каждым годом разрыв этой цены стремительно сокращался, а вместе с ним скорость арбитражных стратегий и их объем.
Сегодня существует в качестве межбиржевого варианта, когда актив торгуется на биржах разных стран, например на токийской и нью-йоркской, лондонской и франкфуртской. А также на NYSE и NASDAQ в качестве арбитража разных активов, например двух-трех акций из одного сектора.

В основе арбитража лежит такое понятие, как корреляция. корреляция, если простыми словами — это взаимосвязь двух или более событий, т.е. когда происходит одно, то вероятно (статистически подтверждено) и другое. Когда-то корреляции на рынке были невыраженными в моменте, они были растянуты во времени. Вот к примеру, как рассуждают экономисты/аналитики: «Если индекс доллара упадет, цена на нефть должна расти…» или «Если индекс SNP упадет, цена на золото должна вырасти или наоборот…», ну это как бы простые причинно-следственные связи. Однако совершенно очевидно, что если все так просто, то все бы с легкостью зарабатывали, чего, как мы все прекрасно знаем, не происходит. Пример самой жесткой корреляции — это пары типа Евро/Доллар. Они намертво связаны между собой. Малейшее изменение цены одного приводит к мгновенному изменению цены другого. Тут, понятно, корреляция обратная и речь идет о торгуемых инструментах, например, на СМЕ. И данная корреляция действительна в обе стороны. Есть же, например, бумаги, которые сами «ничего не решают», но есть у них «старший», который и скажет, куда им «идти». А есть ситуации, в которых таких «старших» два и более, вот тут совсем все интересно становится.
Когда речь заходит о корреляциях, в том смысле, в каком я их понимаю, неизбежно возникает вопрос: «а кто главный (ведущий)?». Для этого введем понятие «Поводырь» — это будет любой торгуемый инструмент, изменение цены которого приведет к какой-либо реакции того, за которым мы наблюдаем (торгуем).

Основные поводыри для Американского фондового рынка следующие (в порядке убывания силы глобального влияния):
1. Фьючерсный контракт на индекс SNP 500 — главный поводырь, самый влиятельный, нет ни одного ликвидного инструмента, на который бы не оказало влияние изменение цены фьючерсного контракта хотя бы на тик, реакция есть всегда. Вопрос о первичности (кто за кем «ходит»), индекс или фьючерс, всегда рождает много споров, но нас, спекулянтов, скальперов, волнует только одно — кто из них быстрее. Я могу ответственно заявить, что фьючерсный контракт — быстрее, изменчивее (в разы) и главнее в данном контексте.

2. Фьючерс на нефть марки Light Sweet — углеводороды, что тут еще сказать. Сильное влияние оказывает на некоторые сектора, на отдельные индустрии, связанные с нефтедобычей и нефтепереработкой, а также на те отрасли, где существенная статья издержек — топливо и ГСМ, например авиакомпании. Сам актив несколько зависим от Индекса доллара.

3. Фьючерсный контракт на золото (и другие драг. металлы) — Au рулит по-прежнему, ибо мировое «золотое плечо» уже вылезло за все допустимые рамки, не дам источник, но цитату приведу: «В мире обещания продать золото, больше в 100 раз, чем самого золота», как-то так. Т.е. это и мерило ценности некоторых валют, и надежный (однако!) для многих актив, и инструмент хеджирования рисков и еще много чего полезного делает. Также как и нефть, оказывает серьезное влияние на компании, занимающиеся золотодобычей, переработкой, реализацией и прочим. Сам по себе поводырь зависим (в моменте) от Индекса доллара.

4. Индекс доллара — с появлением евро все сильнее стал подвержен колебаниям, связанным с проблемами в Еврозоне, также изменчив за счет спекулятивных действий в торгуемой валютной паре евро/доллар. Сам зависим от макроэкономической статистики, стоимости облигаций (и наоборот тоже, тут уже сложный аналитический расклад, который данной статьи никак не касается, тем более, я не аналитик и тем более, не экономист, а спекулянт. Оказывает влияние на многие товарные фьючерсы, расчет по которым ведется в долларах Соединенных Штатов.

Поводырем вторичным (а иногда и первичным) может также являться акция, которая в данный момент самая сильная/слабая в секторе/индустрии, которая сама по себе является более весомой в индексе из всего сектора. Например, если $C (Citigroup) измениться резко в цене на полпроцента, это мгновенно скажется на остальных акциях, связанных с банковской деятельностью и с финансами, не так сильно отразиться на $JPM и $BAC, но точно «дернет» $BBT и $PNC, к примеру, а уж $FAZ и $FAS отреагируют как следует, по взрослому, с резким изменением котировок и объемом. А вот обратное не будет иметь такого влияния. Если $PNC или какой-нибудь банк Испании или Ирландии не обрушиться на пару процентов, то никто из «толстых» не заметит, однако по цепочке может привести к некоей корректировке на графике. Скажем так, $PNC также входит в состав портфеля, торгуемого в виде ETF $FAZ ($FAS), так вот сильное его ($PNC) изменение приведет к неминуемому (но небольшому) изменению цены индекса, что, закономерно, приведет к корректировке даже $C и $BAC, первого на несколько центов, а второго, возможно, ни на сколько, разве стакан уплотниться в «сильную» сторону. Это один из вариантов, комбинаций может быть очень много. На графике видно, как акции вторичные стоят в рэйндже, пока сильнейшие представители сектора «смотрят» в разные стороны, и как послушно они «идут» за всеми, если направление сильных совпадает:

На графике изображены: SPY — SPDR S&P 500 (белая линия), C — Citigroup, Inc., JPM — JP Morganand Co., BAC — Bank of America Corp Corporation, GS — The Goldman Sachs Group, Inc., BBT — BB&T Corporation, PNC — PNC Financial Services Group Inc.
Теперь давайте рассмотрим какой-нибудь самый необычный пример. Вот Авиакомпании. Например $UAL или $DAL или $LCC, не входят в состав индекса SNP 500 и тем более DJIA, однако довольно объемны, имеют высокую капитализацию, в целом привязаны к рынку, как таковому, но главное — зависят от цен на топливо. И не нужно рассказывать, что у них все поставки фьючерсные, с фиксированной ценой на пару лет вперед и прочее, это все так, но откройте их график минутный и понаблюдайте, что происходит, когда нефть очень резко изменяется в цене. А теперь добавьте сюда индекс доллара, который влияет на них самих, т.к. Цены их услуг — они в долларахи сама нефть зависит от него (доллара), ну и SNP 500, который частенько идет в противоход нефти… Вот их (акции авиакомпаний) разрывает в разные стороны. А еще помню день был, когда у $LCC отчет случился и нефть с рынком в разные стороны… Вот остальных трепало! График выглядел интересно. Вот пример за эту неделю, $LCC валится на растущей черного золота и растущем фьючерсе, и отрастает на падающей черного золота (тикер $USO):

На графике изображены: SPY — SPDR S&P 500 (белая линия), USO — United States Oil, UAL — United Continental Holdings, Inc., LCC — US Airways Group, Inc., DAL — Delta Air Lines Inc.
Также, для дальнейшего понимания написанного мною, потребуется ввести еще один термин — «Драйвер», под которым понимается некое событие, которое сильно влияет на поведение торгуемого актива, либо, что немаловажно, поводыря, за которым мы также наблюдаем, это может быть новость в компании, отчет, понижение/повышение рейтинга или новость, касающаяся сектора в целом, макроэкономическая статистика, изменение ставки вложения инвистиций и другие. Т.е. драйверы глобальные влияют на фьючерсные контракты (поводыри, описанные выше), а те, в свою очередь, на торгуемые инструменты и т.д.

Теперь вопрос: почему акции так одинаково ходят и кто за всем этим стоит? Да все, особенно скальперы, роботы-скальперы, люди-скальперы. Роботы-арбитражеры в первую очередь, а также алгоритмы, котирующие акцию (читай маркетмейеры). Ведь иначе невозможно было бы такую массу акций заставить двигаться более менее одинаково, речь, понятно, внутри дня. Потому что, если мы взглянем на большие таймфреймы, то выясниться, что многие сектора живут своей отдельной жизнью. Вот например, график месячный, с 2000 года:

На нем изображены: XLK — Technology Select Sector SPDR, XLF — Financial Select Sector SPDR, XLP — customer Staples Select Sector SPDR, XLE — energy Select Sector SPDR, XLV — Health Care Select Sector SPDR, XLI — Industrial Select Sector SPDR, XLB — Materials Select Sector SPDR, XLU — Utilities Select Sector SPDR, XLY — customer Discret Select Sector SPDR, SPY — SPDR S&P 500 (белая линия).
Ютилитис какие слабенькие. Интересно, они рванут вверх, за ростом фьючерсного контракта или на малейшем его откате шлёпнутся еще ниже? Разброс относительно $SPY приличный. А вот, что на меньших масштабах времени, дневка, за 2012 год:

Действующие лица те же. В общем есть некое понимание, что графики похожи, но одни сильнее рынка в целом, а другие слабее, в абсолютном выражении, при расчете на начало года. Это все глобально, на год, а вот на месяц:

Действующие лица те же. Меня же в торговле интересует арбитраж внутридневной, график — от пятиминутного до минутного:

Или, например, технологический сектор в пятницу (14.09.2012), смотрите, как на откатах фьючерсного контракта вниз они «валяться» и «стоят» на его росте, между прочим — это и есть входы в шорт:

На графике изображены: SPY — SPDR S&P 500 (белая линия), T — AT&T, Inc., VZ — Verizon Communications Inc., XLK — Technology Select Sector SPDR.
Это, что касательно фьючерсного контракта SNP 500 (на графиках, для моего удобства показан не сам фьючерс, а ETF на индекс SNP 500, учитывая, что график — линия, различий нет совсем). А вот пример акций нефтяной индустрии, в сравнении с черным золотом:

На графике изображены: USO — United States Oil, XOM — Exxon Mobil Corporation, SLB — Schlumberger Limited, CVX — Chevron. Или, например, «золотые» акции, в сравнении, понятно, с золотом:

На графике изображены: GLD — SPDR gold Shares, NEM — Newmont mining industry Corp., KGC — Kinross gold Corporation, ABX — Barrick gold Corporation.
Однако, график — одно, а стакан с лентой (LEVEL II + Time & sales) — совсем другое дело (кстати, именно это и позволяет торговать $SPY, опираясь на фьючерс). Показать в картинках, что происходит и какая реакция — сложно, потому распишу немного словами. Что можем видеть на ведомых, если на ведущих есть большое движение? В первую очередь — изменение котировки без сделок, оно и понятно, акции скоррелированы, а торговать-то некому, ибо акции не первого эшелона, но машинки-котировщики будут исправно двигать биды с оферами, в след за «старшим» братом, держа при этом некий спред, обычно больше 3-4 ц. Если же движение общее, не только на сильных акциях, а на всем рынке в целом, то может произойти сильное движение, с объемом, и с еще большим расширением спреда в противоположную от него (движения) сторону. Например, нефть ($USO) улетела вверх на полпроцента за секунду, в $SLB будет расширен спред в сторону оферов (ASK), чтобы продать повыше, а потом закрыться пониже, поднимая биды (BID). Это один из десятков сценариев, понятно, что всегда есть вариации, но уловить общее можно, если тщательно понаблюдать и проанализировать поведение акций и их поводырей.

Стиль торговли таким образом называется «арбитраж», торгуется, как правило, минимум два инструмента, причем часто в разные стороны, но можно торговать один, рассматривая другие инструменты, как поводырей. Стиль сегодня очень роботизирован, но и для «мануальных скальперов» еще есть место.
Сложим все варианты арбитража в одну табличку и определим четыре варианта действий (простым языком, не пинайте, но так понятно всем будет): что отросло и главное — продавать, а что недоросло — покупать; что упало и главное — покупать, а что недоупало — продавать; что отросло и главное — не трогать, а что недоросло — продавать; что упало и главное — не трогать, а что недоупало — покупать.

Имея ввиду торговлю одного инструмента, чаще поступают так, торгуя по тренду сектора (индустрии): что не главное и отросло сильно — продавать, в случае, когда главное — «стоит и смотрит» вниз (было на вебинаре, кто помнит, $TCK); что не главное и упало сильно — покупать, в случае, когда главное — «стоит и смотрит» вверх.
Еще более кратко сам процесс можно описать так: определяем глобально (по секторам), кто сильный, кто слабый — по дневке; смотрим внутри сектора (на дневках) между акциями тоже самое; смотрим внутри дня на акции (по тренду сектора), опираясь на фьючерсный контракт (+ другие поводыри).
Коэффициент корреляции (Correlation coefficient) — это
Теперь, как определить «главного» в секторе/индустрии. Те, кто первый в столбце, те и рулят, как правило. НО!!! В случае, если нет глобальных новостей по сектору или если нет отчетов у разных акций из этого сектора. Т.е. их главенство имеет место быть в самый скучный понедельник, а не в день статистики, запасов газа, безработицы да еще с отчетом старших акций.

Вычисление коэффициента корреляции портфеля
Итак, перейдем к вычислению средней доходности, дисперсии и стандартного отклонения для портфеля акций, состоящего на 60% из акций А и на 40% из акций В. Мы предполагаем, что доходность по каждой из акций А и В — это случайные величины Rа и Rв. Среднее значение доходности акции А равно 10%, со стандартным отклонением 8,66%. Среднее значение доходности акции В равно 15%, со стандартным отклонением 12%.
Коэффициент корреляции (Correlation coefficient) — это
Теперь нас интересует, каково будет среднее значение доходности портфеля и стандартное отклонение для портфеля. Вопрос средней доходности портфеля решается просто. А вот стандартное отклонение — показатель уровня изменчивости доходности портфеля, не отражает средней изменчивости доходности его компонентов (акций). Причина в том, что диверсификация снижает изменчивость, так как цены различных акций изменяются неодинаково. Во многих случаях снижение стоимости одной акции компенсируется ростом цены на другую.
Ожидаемая доходность нашего портфеля равна средневзвешенной ожидаемых значений доходностей отдельных акций:

Для того, чтобы найти дисперсию и стандартное отклонение доходности портфеля, мы должны знать значения ковариации акций А и В. Ковариация служит для измерения степени совместной изменчивости двух акций. Общая формула вычисления ковариации:

Из формулы видно, что ковариация любой акции с ней самой равна ее дисперсии. В задачах, значение ковариации двух активов будет дано. Или, вместо нее будет дано значение коэффициента корреляции — безразмерной величины, которая стандартизует ковариацию для облегчения сравнения, и принимает значения от -1 до 1. Пусть нам дано, что коэффициент корреляции акций А и В равен 0,7. Формула коэффициента корреляции:

В большинстве случаев, изменение акций происходит в одном направлении. В этом случае коэффициент корреляции и, соответственно, ковариация, положительны. Если акции изменяются соверженно не связанно, тогда коэффициент корреляции и ковариация равны нулю. Если акции изменяются в противоположных направляения — коэффициент корреляции и ковариация отрицательны. Для нахождения дисперсии портфеля, нам надо заполнить матрицу:

Эта матрица очень похожа на матрицу ковариаций. Заполнив матрицу, надо просто сложить полученные в ней величины и найдем дисперсию портфеля:

Вычислим дисперсию портфеля:

Стандартное отклонение равно квадратному корню из дисперсии, то есть:

Легко подсчитать, что только в том случае, если коэффициент корреляции двух акций равен +1, то стандартное отклонение портфеля равно средневзвешенному стандартных отклонений доходности отдельных акций:

Если же коэффициент корреляции равен -1, то стандартное отклонение портфеля равно:

и можно было бы добиться, изменяя пропорции X1 и X2 акций в портфеле, чтобы стандартное отклонение портфеля было равно нулю. К сожалению, в реальности, отрицательная корреляция акций практически не встречается.
Коэффициент корреляции (Correlation coefficient) — это
Применение линейного коэффициента корреляции в трейдинге
Коллеги, добрый день! В настоящей статье я хочу предложить вашему вниманию небольшое исследование, посвященное одному из статистических показателей — линейному коэффициенту корреляции. А также поделюсь некоторыми соображениями по его применению в трейдинге на примере акций Лукойла.
Коэффициент корреляции (Correlation coefficient) — это
Для начала позвольте небольшой экскурс в историю возникновения показателя корреляции (да возблагодарим Википедию!): Корреляция (корреляционная зависимость) — статистическая взаимосвязь двух или нескольких случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом изменения значений одной или нескольких из этих величин сопутствуют систематическому изменению значений другой или других величин. Математической мерой корреляции двух случайных величин служит корреляционное отношение либо коэффициент корреляции. В случае, если изменение одной случайной величины не ведёт к закономерному изменению другой случайной величины, но приводит к изменению другой статистической характеристики данной случайной величины, то подобная связь не считается корреляционной, хотя и является статистической.

Впервые в научный оборот термин «корреляция» ввёл французский палеонтолог Жорж Кювье в XVIII веке. Он разработал «закон корреляции» частей и органов живых существ, с помощью которого можно восстановить облик ископаемого животного, имея в распоряжении лишь часть его останков. В статистике слово «корреляция» первым стал использовать английский биолог и статистик Фрэнсис Гальтон в конце XIX века.

Некоторые виды коэффициентов корреляции могут быть положительными или отрицательными. В первом случае предполагается, что мы можем определить только наличие или отсутствие связи, а во втором — также и ее направление. Если предполагается, что на значениях переменных задано отношение строгого порядка, то отрицательная корреляция — корреляция, при которой увеличение одной переменной связано с уменьшением другой. При этом коэффициент корреляции будет отрицательным. Положительная корреляция в таких условиях — это такая связь, при которой увеличение одной переменной связано с увеличением другой переменной. Возможна также ситуация отсутствия статистической взаимосвязи — например, для независимых случайных величин.
Линейный коэффициент корреляции (далее ЛКК) (коэффициент корреляции Пирсона), который разработали Карл Пирсон, Фрэнсис Эджуорт и Рафаэль Уэлдон в 90-х годах XIX века. Коэффициент корреляции рассчитывается по формуле:

Коэффициент корреляции изменяется в пределах [-1…+1]. Данный метод обработки статистических данных весьма популярен в экономике и социальных науках (в частности в психологии и социологии), хотя сфера применения коэффициентов корреляции обширна: контроль качества промышленной продукции, металловедение, агрохимия, гидробиология, биометрия и прочие. В различных прикладных отраслях приняты разные границы интервалов для оценки тесноты и значимости связи.
Популярность метода обусловлена двумя моментами: коэффициенты корреляции относительно просты в подсчете, их применение не требует специальной математической подготовки. В сочетании с простотой интерпретации, простота применения коэффициента привела к его широкому распространению в сфере анализа статистических данных.

Итак, коллеги, ЛКК определяет: во-первых, наличие связи между двумя потоками данных, во-вторых, силу этой связи (сила связи определяется приближением абсолютного значения ЛКК к единице), в-третьих, направление этой связи (прямая — ЛКК больше единицы или обратная — ЛКК меньше единицы). Важным и необходимым условием для расчета ЛКК является наличие двух одинаковых по количеству данных потоков данных. Так же в общем случае считается, что значения ЛКК можно считать достоверным, если в расчете участвует поток из более, чем 30 пар данных.
Коэффициент корреляции (Correlation coefficient) — это
В Excel расчет значения ЛКК реализован через функцию «КОРРЕЛ()». Пример наличия корреляции: Положительная корреляция: температура окружающего воздуха и продажи летней одежды. Чем теплее на улице, тем больше покупаем летних вещей. Рост температуры — рост продаж. Отрицательная корреляция: та же самая температура окружающего воздуха, но продажи уже зимней одежды. Чем холоднее на улице, тем больше покупаем зимних теплых вещей. Снижение температуры — рост продаж.

Примеры применения ЛКК в трейдинге. Области применения ЛКК в трейдинге достаточно широки. Например, долго считалось, что при падении фондовых рынков в целом растет спрос на золото. То есть между динамикой фондовых рынков и динамикой цен на золото существует обратная корреляционная зависимость. Другой пример. Рост котировок нефти и рост рынков, вес «нефтянки» в которых высок и является значимым. К таким рынкам относится и фондовый рынок России. Но в последние несколько лет, а именно в основном начиная с 2007 года, такие зависимости явно изменились. И либо сильно ослабли, либо исчезли совсем.

У приведенных выше примеров есть одна общая особенность: они построены строго на двух потоках данных, как того и требует формула расчета ЛКК. Тем не менее, в одной из книг, посвященных теории управления капиталом (а именно, Р.Винс «Математика управления капиталом») я нашел интересный подход к построению ЛКК на массиве, состоящем только из одного потока данных. Это может быть, например, непрерывный поток исходов в системных сделках или поток цен какой-то одной акции. О таком методе построения ЛКК ниже.
Коэффициент корреляции (Correlation coefficient) — это
Торговая стратегия, построенная на коэффициенте корреляции
Итак, давайте исследуем, например, поток цен на акции Лукойла (LKOH). Составим поток из недельных свечей. Мне удалось найти архив, начиная с 01.01.2001 и по сей день, то есть поток из почти 600 недельных свечей за десять с половиной лет. Исследовать будем не свечи в целом, а, например, максимальные цены в каждой свечей. Таким образом, перед нами непрерывный поток из 600 данных — максимальные цены в каждой торговой неделе, начиная с 01 января 2001 года. Кроме этих данных, пока никакие другие данные нам не нужны.

На рисунке показана динамика максимальных недельных цен в акциях LKOH. Расчет ЛКК должен дать ответы на вопросы: Есть ли зависимость между максимальными ценами двух любых соседних недель. Если зависимость есть, то какова ее направленность? Коллеги, если упростить, то вопрос можно сформулировать так: Если на истекшей неделе Лукойл обновил свой недельный максимум по сравнению с предыдущей неделей, то можем ли мы ожидать продолжения роста и на будущей неделе? Для расчета ЛКК поток данных требует некоторой трансформации. Составим таблицу:

В таблице на рисунке в последнем столбце, построенном на основе данных столбца «High цена», логика расчета следующая: если максимум текущей недели выше, чем максимум предыдущей недели, то в ячейке стоит значение 1. В противном случае значение равно 0. Таким образом, поток цен преобразован в поток единиц и нулей. Далее произведем расчет ЛКК на основе данных столбца «Обновление High цены». Поскольку для расчета ЛКК необходимо два потока данных, то сделаем следующее:

Как видно из рисунка, поток 2 «сдвинут» относительно потока 1 на один период. Таким образом, из одного потока данных получено два. И теперь смысл расчета ЛКК заключается в выяснении связи между двумя соседними значениями выборки. В нашем случае — максимальными ценами соседних недель (текущей и предыдущей). Теперь собственно по расчету ЛКК. Расчет произведем двумя способами: Охватим весь период выборки (600 недель).
Начиная с 30й недели выборки (август 2001 года) для каждой недели рассчитаем значение ЛКК по последним 30 неделям. То есть для каждой недели рассчитаем т.н. «скользящее» значение ЛКК с периодом n=30 (по аналогии со скользящей средней), поскольку при n>30 в общем случае значение ЛКК считается значимым. Результаты расчетов отражены на рисунке:

Выводы по рисунка: На протяжении всего периода выборки у акций Лукойла наблюдается неярко выраженная положительная корреляция между максимальными ценами соседних недель (красная линия графика с ЛКК = +0,1). То есть факт обновления максимальной цены на текущей неделе по сравнению с предыдущей позволяет сделать предположение о том, что на следующей неделе в сравнении с текущей вероятность обновления максимума выше вероятности НЕобновления максимума.
Коэффициент корреляции (Correlation coefficient) — это
ЛКК, построенное по последним 30 неделям (синяя линия на графике), изменяется в диапазоне от -0,35 (сильная отрицательная корреляция) до +0,6 (очень сильная положительная корреляция). Самый продолжительный период, в течение которого корреляция между недельными максимумами была положительная — это период с мая 2004 года до августа 2007 года. В этот период обновление максимумов на прошлой неделе в большинстве случаев приводило к обновлению максимумов в течение текущей недели. Именно в этот период акции Лукойла агрессивно росли.

Самый продолжительный период, в течение которого корреляция между недельными максимумами была отрицательная — это период с августа 2007 года по июль 2011 года. В этот период недельной обновление максимумов на прошлой неделе в большинстве случаев не приводило к обновлению максимумов в течение текущей недели. И наоборот, НЕобновление недельных максимумов в течение текущей недели в большинстве случае приводило к росту на следующей неделе. В этот период акции Лукойла «запилило» от максимумов весной 2008 года до низов в июле 2009 года.

В точках, где синяя линия находится выше красной, корреляция между недельными максимумами выше средней за период и имеет прямую направленность. В таких точках при обновлении недельных максимумов на текущей неделе наиболее вероятно обновление максимумов в течение следующей недели. В точках, где синяя линия находится ниже красной, корреляция между недельными максимумами ниже средней за период и имеет в основном обратную направленность. В таких точках, в отличие от ситуации п.5, наиболее вероятно обновление максимумов в течение следующей недели при НЕобновлении недельных максимумов текущей недели.
Коллеги, на основании последних двух выводов у меня сформировалась идея тестирования стратегии, построенной на принципах такого парного корреляционного эффекта.
Коэффициент корреляции (Correlation coefficient) — это
Торговля ациями по коэффициенту корреляции
Стратегия, построенная на принципах автокорреляции. Общее описание стратегии. Принципы стратегии: тестируемый инструмент — акции Лукойла (LKOH) на недельном ТФ за период с 01.01.2001 по 31.07.2012; типы совершаемых сделок — исключительно Long; время удержания позиции — вход на Open недельной свечи, выход на Close этой же свечи. Таким образом, удержание позиции строго в течение торговой недели без ухода в бумагах на выходные; внешние факторы — цены на нефть, мировые новости, динамика западных рынков и проч. — не учитываются; внутренние факторы — внутрикорпоративные новости, дивидендные отсечки и проч. — не учитываются.

Принципы формирования сигналов: Методом тестирования определяется некое критическое скользящее значение линейного коэффициента корреляции (далее — ЛККкр) по 30 периодам. Покупка Вариант 1. Если текущее значение ЛКК ВЫШЕ критического значения и на текущей неделе ПРОИЗОШЛО обновление максимума по сравнению с прошлой неделей, то на Open следующей недели происходит покупка. Срок удержания позиции — не позднее Close недели открытия позиции.

Покупка Вариант 2. Если текущее значение ЛКК НИЖЕ критического значения и на текущей неделе НЕ ПРОИЗОШЛО обновление максимума по сравнению с прошлой неделей, то на Open следующей недели происходит покупка. Срок удержания позиции — не позднее Close недели открытия позиции. Во всех остальных случаях — вне позиции (cash). Таким образом, для принятия решения о входе/невходе в позицию необходима информация о максимальных ценах последних 30ти недель. И ничего более сверх этого.
Коэффициент корреляции (Correlation coefficient) — это
Само решение принимается в промежутке между закрытием торговой недели и открытием следующей торговой недели. В случае формирования торгового сигнала трейдеру необходимо находиться в рынке утром первого дня торговой недели для открытия позиции и вечером последнего дня торговой недели для выхода из бумаг. Для тестирования такой стратегии вполне хватило возможностей Excel. У недельного Лукойла критическим значением ЛКК оказалось значение 0,15. Приведу пару примеров для иллюстрации:
Пример 1.

Сигнал от 25.06.12. В данном случае выполнены оба условия покупки: ЛККкр=0,1855 (>0,15) и обновлен максимум предыдущей недели (1805 руб. > 1765 руб.). На основании этого на Open свечи 02.07.12 совершена покупка по 1804 руб. Позиция закрыта на Close свечи 02.07.12, то есть 06.07.12, по цене 1825 руб. Рентабельность сделки составила +1,2% при периоде удержания позиции 5 сессий.
Сигнал от 02.07.12. В данном случае так же выполнены оба условия покупки: ЛККкр=0,2472 (>0,15) и обновлен максимум предыдущей недели (1857 руб. > 1805 руб.). На основании этого на Open свечи 09.07.12 совершена покупка по 1826 руб. Позиция закрыта на Close свечи 09.07.12, то есть 13.07.12, по цене 1818 руб. Рентабельность сделки составила -0,4% при периоде удержания позиции 5 сессий.
Пример 2.

Сигнал от 07.05.12. В данном случае выполнены оба условия покупки: ЛККкр=0,1098 (<0,15) и НЕ обновлен максимум предыдущей недели (1700 руб. < 1802 руб.). На основании этого на Open свечи 14.05.12 совершена покупка по 1684 руб. Позиция закрыта на Close свечи 14.05.12, то есть 18.05.12, по цене 1594 руб. Рентабельность сделки составила -5,4% при периоде удержания позиции 5 сессий.
Сигнал от 14.05.12. В данном случае выполнены оба условия покупки: ЛККкр=0,1258 (<0,15) и НЕ обновлен максимум предыдущей недели (1684 руб. < 1700 руб.). На основании этого на Open свечи 21.05.12 совершена покупка по 1602 руб. Позиция закрыта на Close свечи 21.05.12, то есть 25.05.12, по цене 1639 руб. Рентабельность сделки составила +2,3% при периоде удержания позиции 5 сессий.
Коэффициент корреляции (Correlation coefficient) — это
Сигнал от 21.05.12. В данном случае выполнены оба условия покупки: ЛККкр=0,1336 (<0,15) и НЕ обновлен максимум предыдущей недели (1602 руб. < 1684 руб.). На основании этого на Open свечи 28.05.12 совершена покупка по 1647 руб. Позиция закрыта на Close свечи 28.05.12, то есть 01.06.12, по цене 1742 руб. Рентабельность сделки составила +5,8% при периоде удержания позиции 5 сессий.
Back-testing стратегии. В данном разделе приведу результаты тестирования стратегии в сравнении со стратегией «Buy&Hold» (B&H).

На рисунке показана динамика дохода тестируемой стратегии в сравнении с принципом B&H. За точку отчета (0%) принята цена акций Лукойла в начале января 2001 года (270 руб.). Как видно, принцип B&H опережал стратегию в течение 2001-2008 гг. Падение ранка в 2008 году сравняло результаты обоих стратегий до уровня примерно +200% к старту. Затем, начиная с 2009 года, обе стратегии показали примерно одинаковые результаты и на сегодня корреляционная стратегия незначительно опережает по доходности принцип B&H.
Как видно из профилей графиков, волатильность (риск) принципа B&H гораздо выше волатильности тестируемой стратегии. Размер среднегодовой доходности тестируемой стратегии составляет 20% годовых на всем периоде тестирования.
Риск-менеджмент, основанный на коэффициенте корреляции
Покупка по Варианту 1 (ЛККкр >0,15 + новый максимум)
")
Из 600 недель тестового периода сигналы по Варианту 1 возникли в 109 случаях (19% потока или каждая пятая неделя). Из 109 сигналов 74 отработали в плюс (68%, или два из трех сигналов). Средний результат положительного исхода равен по модулю среднему результату отрицательного исхода (38 руб./акция) Общий положительный результат потока сигналов сформирован за счет превышения в 2 раза количества положительных исходов над отрицательными исходами.
Коэффициент корреляции (Correlation coefficient) — это
С учетом частоты распределения положительных и отрицательных исходов расчет математического ожидания выглядит следующим образом: Размер ожидаемого успеха +26 руб./акция, Размер ожидаемого убытка -13 руб./акция, Общий ожидаемый результат +13 руб./акция, Размер среднеквадратичного отклонения исходов сигналов составляет 24 руб./акция. Диапазон колебаний исходов сигналов находится в пределах [-11 руб.;+38 руб.], Максимальная серия подряд убыточных сигналов составила 2 сигнала с максимальным риском не более 178 руб./акция. В нынешних ценах это около 9% торгового депозита.
Покупка по Варианту 2 (ЛККкр <0,15 + нет нового максимума)
")
Фактически покупки по варианту 2 — это покупки против падения рынка. Поэтому показатели риска и волатильности выше, нежели по варианту 1. Из 600 недель тестового периода сигналы по Варианту 2 возникли в 190 случаях (33% потокаили каждая третья неделя). Из 190 сигналов 91 отработали в плюс (48% или половина сигналов). Средний результат положительного исхода равен +66 руб./акция, а отрицательного исхода -50 руб./акция. Общий положительный результат потока сигналов сформирован за счет превышения размера средней прибыли над средним убытком.
Коэффициент корреляции (Correlation coefficient) — это
С учетом частоты распределения положительных и отрицательных исходов расчет математического ожидания выглядит следующим образом: Размер ожидаемого успеха +32 руб./акция, Размер ожидаемого убытка -26 руб./акция, Общий ожидаемый результат +6 руб./акция, Размер среднеквадратичного отклонения исходов сигналов составляет 49 руб./акция. Диапазон колебаний исходов сигналов находится в пределах [-44 руб.;+55 руб.], Максимальная серия подряд убыточных сигналов составила 6 сигналов с максимальным риском 187 руб./акция. В нынешних ценах это около 10% торгового депозита. Стратегия в целом:

Из 600 недель тестового периода сигналы по стратегии в целом возникли в 299 случаях (53% потока или каждая вторая неделя). Из 299 сигналов 165 отработали в плюс (55% или более половины сигналов). Средний результат положительного исхода равен +53 руб./акция, а отрицательного исхода -47 руб./акция. Общий положительный результат потока сигналов сформирован как за счет превышения количества положительных исходов над отрицательными исходами, так и за счет превышения размера средней прибыли над средним убытком.

С учетом частоты распределения положительных и отрицательных исходов расчет математического ожидания выглядит следующим образом: Размер ожидаемого успеха +29 руб./акция, Размер ожидаемого убытка -21 руб./акция, Общий ожидаемый результат +8 руб./акция, Размер среднеквадратичного отклонения исходов сигналов составляет 55 руб./акция. Диапазон колебаний исходов сигналов находится в пределах [-47 руб.;+63 руб.], Максимальная серия подряд убыточных сигналов составила 6 сигналов с максимальным риском 187 руб./акция. В нынешних ценах это около 10% торгового депозита при доходности 20% годовых.
В целом стратегия показала неплохой тренд-следящий результат, а так же оказалась достаточно устойчива в условиях падения 2008 года. Особенно, если учесть усилия трейдера по следованию сигналам. Коллеги, за сим пока все по описанию линейной корреляции и ее применении в трейдинге.

Коэффициент корреляции валютных пар
Рассмотрим такое явление, как межвалютная корреляция на Форексе. Данная методика может существенно повысить понимание рыночных процессов, а также улучшить качество ваших краткосрочных и среднесрочных прогнозов. Существует две разновидности межвалютной корреляции, которые могут помочь в работе трейдера. Рассмотрим подробнее.
Коэффициент корреляции (Correlation coefficient) — это
Корреляция — это статистический термин, означающий наличие взаимосвязанных тенденций изменений между двумя рядами данных. В нашем случае Валютная корреляция — это взаимосвязь между историческими данными курсов одной валютной пары. Или изменения курса одной пары могут быть взаимосвязанными с изменениями другой пары. Данная взаимосвязь чаще всего имеет фундаментальное экономическое обоснование и уходит корнями в особенности всемирного хозяйства. Проще говоря, есть две валютных пары: A/B и C/D. Если между ними есть корреляция, при росте курса A/B может стабильно наблюдаться или рост кусра C/D (тогда это прямая корреляция) или его падение (тогда корреляция буде обратной).

Выше мы говорили о двух разновидностях. Это скользящая и прямая корреляция. Прямая корреляция валютных пар — явление, полезное для повышения точности прогнозов. Даже торгуя на одном инструменте, вы можете повысить точность прогнозирования, применяя анализ нескольких валютных пар. Вернемся к нашим A/B и C/D, допустим, вы торгуете инструментом A/B. Известно, что эти валютные пары в прямой корреляции, то есть вверх и вниз идут синхронно. Ваш технический анализ показал, что пара A/B должна падать. Соответственно, если теханализ пары C/D говорит об обратном, есть повод усомниться в достоверности сигнала. Если же всё совпало, — вы можете с большей уверенностью открывать позицию. Получается, зная взаимосвязи, можно уменьшить количество случайных сигналов. Однако нужно помнить, что корреляционный анализ работает на относительно больших масштабах (в лучшем случае на часовых или получасовых графиках). Если ваша торговая стратегия базируется на «минутках», эти данные могут только помешать.

Следующий вид корреляции — скользящая. Суть в том, что взаимосвязь проявляется на сдвинутом по временной шкале наборе данных. То есть изменение курса пары A/B сейчас является предвестником изменения пары C/D в будущем. Если собрать информацию, достаточно детальную для формирования торговой стратегии, наличие таких корреляций может очень существенно повысить точность. Фактически, у вас появляется инструмент базового прогнозирования курса.
Как анализировать корреляцию?

Чтобы отыскать корреляционную связь, можно пользоваться существующими утилитами из Интернета (которые не сложно найти в Гугле по запросу «корреляция валют форекс») или делать всё руками, в старом добром экселе. Там есть такая замечательная функция КОРРЕЛ, которая показывает корреляцию двух выбранных множеств данных. Берем курсы нескольких инструментов, копируем исторические данные в Эксель и ищем корреляцию. Чтобы искать прямую корреляцию, необходимо выделять два совпадающих по временному промежутку набора данных. Чтобы искать скользящую взаимосвязь, сдвигаем множество вправо или влево на несколько периодов. Корреляция более 0.5 свидетельствует о прямой взаимосвязи, менее 0.5 — об обратной взаимосвязи, в пределах от -0.5 до 0.5 — об отсутствии взаимосвязи. Эти границы более чем условны, следует проверять их на практике…
Коэффициент корреляции (Correlation coefficient) — это
Для того чтобы легче было понять взаимосвязи и соотношение с числом коэффициента корреляции я подготовил рисунки, которые наглядно показывают коэффициент и визуальное сходство двух рядов. В качестве примера взяты рад косинуса и зашумлённый ряд косинусоиды, от амплитуды зашумления зависит коэффициент корреляции:

А здесь пример обратной корреляции валют. Как видим когда одна расчёт другая падает! Как EUR/USD и USD — CHF:

Текущая корреляция наиболее популярных валютных пар. Нужно понимать, что корреляция между валютами не является постоянной, рынок постоянно меняется. Приведенные здесь данные являются примерными, точную информацию нужно рассчитывать самостоятельно. Рассмотрим, как коррелирует с другими инструментами наиболее популярный среди трейдеров инструмент EUR/USD: прямая корреляция с: AUD — USD, BP/USD, NZD — USD; обратная корреляция с: USD-JPY, USD / CHF, USD — CAD.
Еще один любимый нашими трейдерами инструмент — «йенадоллар», USD/JPY. Взгялем на него: прямая: Доллар / Франк, USD / CAD; обратная: EUR/USD, AUS/USD,GBP/USD,NZD/USD. Что касается скользящей корреляции, ловить ее довольно сложно. К примеру, часто цена на золото опережает или немного отстает от GBP — USD. Но такую взаимосвязь нужно рассчитывать чуть ли не для каждого отдельного торгового дня.

Изменение коэффициента корреляции ценовых графиков
В качестве примера корреляции двух пар с положительным К, можно вспомнить о EUR/USD и EUR / JPY. В обоих случаях мы покупаем EUR и продаем вторую валюту. Некоторые пары движутся относительно друг друга, но со временем К может меняться. Например, чтобы определить для своей работы две коррелирующие между собой валютные пары, достаточно найти такую из всего ассортимента, предоставляемого ДЦ, которая бы имела очень низкую волатильность. В 2012 году в качестве такого инструмента вполне могла бы выступать EUR/CHF. Не каждый день ширина ее движения на рынке превышала бы 30 пунктов, что можно считать малой величиной, относительно аналогичных показателей других пар.

Данную валютную пару можно без труда разложить на две пары, используя для этого ту валюту, которая “разбавит” выбранный нами инструмент. Для этого мы берем USD, который позволит представить нам EUR/CHF, как EUR/USD*USD/CHF. Действительно, если перемножить две новых долларовых пары, то в результате мы вновь получаем исследуемую нами EUR/CHF. Данное преобразование говорит о том, что обе пары будут коррелировать между собой, так как их произведение будет демонстрировать значения пары EUR/CHF, а они относительно малы, о чем говорили в самом начале примера.
Коэффициент корреляции (Correlation coefficient) — это
Для уверенной торговли необходимо иметь четкое представление не только об особенностях отдельных инструментов торговли, но и об их взаимодействии друг с другом. Существуют целые торговые стратегии, построенные с использованием К. Могут применяться даже наложения одного ценового графика на другой, для выявления аналогий в движениях цены. Коэффициент может периодически рассчитываться заново, учитывая последние изменения в поведении ценовых графиков.

Коэффициент корреляции в анализе инвестиционного портфеля
Согласно Марковицу, любой инвестор должен основывать свой выбор исключительно на ожидаемой доходности и стандартном отклонении при выборе портфеля. Таким образом, осуществив оценку различных комбинаций портфелей, ондолжен выбрать «лучший», исходя из соотношения ожидаемой доходности и стандартного отклонения этих портфелей. При этом соотношение доходность-риск портфеля остается обычным: чем выше доходность, тем выше риск.

Также, прежде чем приступить к формированию портфеля, необходимо дать определение термину «эффективный портфель». Эффективный портфель — это портфель, который обеспечивает: максимальную ожидаемую доходность для некоторого уровня риска, или минимальный уровень риска для некоторой ожидаемой доходности.
В дальнейшем будем находить эффективные портфели в среде Excel в соответствии со вторым принципом — с минимальным уровнем риска для любой ожидаемой доходности. Для нахождения оптимального портфеля необходимо определить допустимое множество соотношений «риск-доход» для инвестора, которое достигается путем построения минимально-дисперсионной границы портфелей, т.е. границы, на которой лежат портфели с минимальным риском при заданной доходности.
граница src=»/pictures/investments/img1996892_Minimalno_dispersionnaya_granitsa.gif» style=»width: 600px; height: 373px;» title=»Минимально — дисперсионная граница» />
На рисунке выше жирной линией отображена «эффективная граница», а большими точками отмечены возможные комбинации портфелей.
Эффективная граница — это граница, которая определяет эффективное множество портфелей. Портфели, лежащие слева от эффективной границы применить нельзя, т.к. они не принадлежат допустимому множеству. Портфели, находящиеся справа (внутренние портфели) и ниже эффективной границы являются неэффективными, т.к. существуют портфели, которые при данном уровне риска обеспечивают более высокую доходность, либо более низкий риск для данного уровня доходности.
Коэффициент корреляции (Correlation coefficient) — это
Для построения минимально-дисперсионной границы и определения «эффективной границы» нам будут необходимы значения ожидаемых доходностей, рисков (стандартных отклонений) и ковариации активов. Имея эти данные можно приступить к нахождению «эффективных портфелей».
Начнем с расчета ожидаемой доходности портфеля по формуле:

где Хi — доля i-ой бумаги в портфеле, E(ri) — ожидаемая доходность i-ой бумаги. А затем определим дисперсию портфеля, в формуле которой используется двойное суммирование:


И как следствие найдем стандартное отклонение портфеля, которое является квадратным корнем из дисперсии. Для наглядности приведем пример построения эффективной границы при помощи Microsoft Excel, а точнее при помощи встроенного в него компонента Поиск решения.
Зададим долю каждого актива в нашем первоначальном портфеле пропорционально их количеству. Следовательно, доля каждого актива в портфеле составит 1/3, т.е. 33%. Общая доля должна равняться 1, как для портфелей,в которых разрешены «короткие» позиции, так и для тех, в которых запрещены. Сам Марковиц запрещает открывать «короткие» позиции по активам, входящим в портфель, однако современная портфельная это разрешает. Если «короткие» позиции разрешены, то доля по активу будет отображена как -0.33 и средства, вырученные от его продажи, должны быть вложены в другой актив, таким образом, доля активов в портфеле в любом случае будет равняться 1.
Рассчитаем ожидаемую доходность, дисперсию и стандартное отклонение средневзвешенного портфеля:

Как видно из таблицы, для определения дисперсии портфеля нужно просто просуммировать данные в ячейках B19-D19, а квадратный корень из значения ячейки C21 даст нам стандартное отклонение портфеля в ячейке C22. Произведение долей бумаг на их ожидаемую доходность даст нам ожидаемую доходность нашего портфеля, которая отражена в ячейке C23. Окончательный результат средневзвешенного портфеля представлен ниже.

Средняя (ожидаемая) месячная доходность средневзвешенного портфеля 0,28% при риске 6,94%. Теперь можноприменить тот самый второй принцип, о котором было написано выше, т.е. обеспечить минимальный риск при заданном уровне доходности. Для этого воспользуемся функцией «Поиск Решений» из меню «Сервис». Если нет, значит надо открыть «Сервис» выбрать «Надстройки» и установить «Поиск решений». Запускаем «Поиск решений», в пункте «Установить указанную ячейку» указываем ячейку С22, которую будем минимизировать за счет изменения долей бумаг в портфеле, т.е. варьированием значений в ячейках A16-A18. Далее надо добавить два условия, а именно:

— сумма долей должна равняться 1, т.е. ячейка A19 = 1;
— задать доходность, которая нас интересует, к примеру, доходность 0.28% (ячейка С23), которая получилась при расчете средневзвешенного портфеля.
Так как мы запрещаем наличие «коротких» позиций по бумагам в меню «Параметры» надо установить галочку «Неотрицательные значения». Вот так должно выглядеть:


В результате мы получаем:

Итак, задав «Поиск решений» найти минимальное стандартное отклонение при заданной ожидаемой доходности в 0,33% мы получили оптимальный портфель, состоящий на 83% из РАО ЕЭС, на 17% из Лукойла и на 0% из Ростелекома. Несмотря на то, что уровень доходности тот же, что и при средневзвешенном портфеле, риск снизился.
Парный трейдинг и коэффициент корреляции
Понятие корреляция лежит в основе многих прибыльных торговых стратегий валютного рынка. В качестве примера можно привести парный трейдинг, основанный на корреляции валютных пар, позволяющий получить стабильную высокую прибыль на разных коррелирующих инструментах (об этом мы писали в предыдущих статьях) и торгового робота Octopus Arbitrage, его реализующего. В этой статье мы попытаемся просто и доступно объяснить суть корреляции и показать, как это можно применить на практике для парного трейдинга.
Почему было решено посвятить этой теме отдельную статью? Дело вот в чем. Несмотря на то, что корреляция нашла широкое практическое применение, доступное объяснение найти весьма трудно.

Как говорил Альберт Эйнштейн «если ты не можешь объяснить шестилетнему ребенку, чем ты занимаешься, значит, ты шарлатан». К сожалению, математики, пишущие учебные материалы этого принципа не придерживаются. Как только открываешь их талмуды, желая понять достаточно простые вещи, например, корреляция, так на тебя злобно смотрят четырехэтажные формулы, тройные интегралы и двухстраничные доказательства с применением огромного количества матерных слов незнакомых терминов. Самые стойкие засыпают через три минуты прочтения. Менее стойкие — через пять секунд созерцания этой «математической гармонии» создают облако пыли от захлопывающегося талмуда или нажимают крестик в правом верхнем углу экрана.

Корреляция — величина, характеризующая взаимную зависимость двух случайных величин, X и Y, безразлично, определяется ли она некоторой причинной связью или просто случайным совпадением… Итак, что такое корреляция? По сути, корреляция показывает, насколько сильно связаны между собой величины. Если взять две произвольные величины, они могут быть сильно связаны между собой, никак не связаны, или слабо связаны.
Рассмотрим пример. Насколько связаны между собой количество прибыли, которую заработал трейдер за торговую сессию от количества выпитых им чашек кофе за тот же период? Т.е. имеем две величины: количество кружек кофе и прибыль.

Простой и наглядный способ анализа корреляции — загнать эти данные в Microsoft Excel и построить график. Стандартными средствами Excel можно вывести линию тренда, а также коэффициент корреляции R2. Как определяется коэффициент корреляции, поговорим чуть позже, пока лишь скажем, что эта величина изменяется от 0 до 1. При этом 0 — показывает, что связи нет вообще, а 1 — самая сильная связь, какая может быть. Линия тренда при отсутствии связи будет направлена параллельно оси X, при максимально сильной связи — под углом 45 градусов.

Ну что ж, похоже количество выпитого кофе на получение прибыли трейдером не влияет никак. Коэфициент корреляции R2 всего лишь 0,0289, линия тренда почти горизонтальна. Почему так? Возможно, помимо выпитого кофе существует множество факторов, оказывающих куда более существенное влияния на получение прибыли: факторы рынка, работа ДЦ, особенности выбранной торговой стратегии, личные качества трейдера и т.д.
Теперь разберем другой пример. Рассмотрим связь между валютными парами EUR/USD и GBP / USD. Были взяты скользящие средние дневных цен с 2 по 5 декабря 2013 года. Было взято четыре точки для простоты дальнейшего объяснения расчетов. Как правило, для подобных расчетов, точек нужно брать больше.

Теперь, аналогично, предыдущему примеру на основании этих данных построим график в Excel.

Так, здесь видно, что зависимость гораздо сильнее, так как R2 близко к единице, а линия тренда расположена почти под 45о. Можно сказать, что величины здесь коррелируют. Теперь рассмотрим, как рассчитывается коэффициент R. Здесь, к сожалению, без формул не обойтись. Однако, на самом деле, все заумные формулы можно свести к уровню седьмого класса средней школы. Для начала определимся, что у нас есть две «случайные» величины. Обозначим EURUSD как X, а GBPUSD как Y.
Далее хочу отметить, что большинство понятий, математической статистики базируются на среднем значении выборки. Проще говоря, на среднем арифметическом, т.е. сумма всех элементов, поделенная на их число. Вычислим среднее для величин X и Y.

Далее, приведем формулу расчета R2. В ней нет ничего сложного, как может показаться на первый взгляд. Здесь просто используются вычисленные нами средние арифметические:


Подставив выделенное в формулу получаем:

Таким образом, мы получили, посчитав «вручную», то, что автоматически делает Excel. Коэффициент R2 называется еще «коэффициентом Пирсона». Корреляция по EURUSD и GBPUSD, на самом деле, достаточно сильная, на это конечно есть фундаментальные причины, рассмотрение которых находится за рамками этой статьи.

Как корреляцию можно использовать для получения прибыли? Ярким примером может послужить стратегия парного трейдинга. Стратегия подразумевает, что большую часть времени выбранные валютные пары двигаются в рынке синхронно, но расхождения в поведении курсов происходят достаточно часто и каждое значительное рассогласование можно использовать для извлечения прибыли. Когда валютные пары расходятся на определенное количество пунктов: открываются две сделки, на одной паре — продажа, на другой — покупка. Когда пары возвращаются «друг к другу», позиции закрываются и прибыль фиксируется на одной или обеих позициях.
При расхождении инструментов открываются встречные позиции, при возвращении корреляции в исходное положение, встречные ордера закрываются, прибыль фиксируется на одной или обеих позициях

Безусловно, в нашей статье, описаны только основные принципы корреляции и парного трейдинга, поняв которые можно четко уяснить суть. Однако, для того, чтобы получать прибыль на FOREX, одних этих знаний недостаточно. Необходимо использовать специальные индикаторы, понимать расхождение каждой из пар и многое другое. Сколько трейдеров уже набили себе шишек на этом пути!
Коэффициент корреляции (Correlation coefficient) — это
Кроме того, необходимо постоянно быть «в рынке», двадцать четыре часа в сутки, семь дней в неделю, чтобы «не проспать», когда разойдется или же наоборот сойдется корреляция. При этом для устойчивого получения прибыли необходимо использовать не две валютные пары, а больше. Трейдер просто физически не сможет этого сделать. Как же здесь быть?
К счастью, есть уникальный торговый советник Octopus Arbitrage. Правильно настроив его и установив на нескольких парах, от трейдера, как правило, больше ничего не требуется. Все остальное сделает робот. Уникальный алгоритм позволит получать достойную прибыль при минимальных просадках, трейдер просто наблюдает за ростом депозита. Как говорится: «Вкалывают роботы — счастлив человек».

Коэффициент корреляции в психологических исследованиях
Коэффициент корреляции является одним из самых востребованых методов математической статистики в психологических и педагогических исследованиях. Формально простой, этот метод позволяет получить массу информации и сделать такое же количество ошибок. В этой статье мы рассмотрим сущность коэффициента корреляции, его свойства и виды. Слово correlation (корреляция) состоит из приставки «co-», которая обозначает совместность происходящего (по аналогии с «координация») и корня «relation», переводится как «отношение» или «связь» (вспомним public relations — связи с общественностью). Дословно correlation переводится как взаимосвязь.

Коэффициент корреляции — это мера взаимосвязи измеренных явлений. Коэффициент корреляции (обозначается «r») рассчитывается по специальной формуле и изменяется от -1 до +1. Показатели близкие к +1 говорят о том, что при увеличении значения одной переменной увеличивается значение другой переменной. Показатели близкие к -1 свидетельствуют об обратной связи, т.е. При увеличении значений одной переменной, значения другой уменьшаются.
Пример. На большой выборке был проведён тест FPI. Проанализируем взаимосвязи шкал Общительность, Застенчивость, Депрессивность. Начнем с Застенчивости и Депрессивности. Для наглядности, задаём систему координат, на которой по X будет застенчивость, а по Y — депрессивность. Таким образом, каждый человек из выборки исследования может быть изображен точкой на этой системе координат. В результате расчетов, коэффициент корреляции между ними r=0,6992.

Как видим, точки (испытуемые) расположены не хаотично, а выстраиваются вокруг одной линии, причём, глядя на эту линию можно сказать, что чем выше у человека выражена застенчивость, тем больше депрессивность, т. е. эти явления взаимосвязаны. Построим аналогичный график для Застенчивости и Общительности.

Мы видим, что с увеличением застенчивости общительность уменьшается. Их коэффициент корреляции -0,43. Таким образом, коэффициент корреляции больший от 0 до 1 говорит о прямопропорциональной связи (чем больше… тем больше…), а коэффициент от -1 до 0 о обратнопропорциональной (чем больше… тем меньше…). Если бы точки были расположены хаотично, коэффициент корреляции приближался бы к 0.
Коэффициент корреляции отражает степень приближенности точек на графике к прямой. Приведём примеры графиков, отражающих различную степень взаимосвязи (корреляции) переменных исследования. Сильная положительная корреляция:

Слабая положительная корреляция:

Нулевая корреляция:

В подписи у каждого графика кроме значения r есть значение p. p — это вероятность ошибки, о которой будет рассказано отдельно.
Источники и ссылки
ru.wikipedia.org — свободная энциклопедия Википедия
ru.math.wikia.com — математическая энциклопедия
vocabulary.ru — национальная психологическая энциклопедия
basegroup.ru — технологии анализа данных
investpark.ru — портал инвестора ИнвестПарк
megafx.ru — сайт для начинающих на рынке Форекс
psyfactor.org — центр практической психологии
learnspss.ru — сайт профессиональной обработки даных
exceltip.ru — блог о программе Microsoft Excel
economyreview.ru — информационные системы и технологии в экономике
aup.ru — аминистративно-управленческий портал
math-pr.com — решение задач и примеров по высшей математике
neerc.ifmo.ru — Викиконспекты
exponenta.ru — образовательный математический сайт
edu.jobsmarket.ru — курсы повышения квалификации в России и за рубежом
quans.ru — анализ и исследование рынка
![]()
Download Article
Calculate correlation by hand, online, or with a graphing calculator
![]()
Download Article
- By Hand
- Online Calculators
- Graphing Calculators
- Reviewing the Fundamentals
- Q&A
|
|
|
|
The correlation coefficient, denoted as r or ρ, is the measure of linear correlation (the relationship, in terms of both strength and direction) between two variables. It ranges from -1 to +1, with plus and minus signs used to represent positive and negative correlation. If the correlation coefficient is exactly -1, then the relationship between the two variables is a perfect negative fit; if the correlation coefficient is exactly +1, then the relationship is a perfect positive fit. Otherwise, two variables may have a positive correlation, a negative correlation, or no correlation at all. You can calculate correlation by hand, by using some free correlation calculators available online, or by using the statistical functions of a good graphing calculator.
-

1
Assemble your data. To begin calculating a correlation efficient, first examine your data pairs. It is helpful to put them in a table, either vertically or horizontally. Label each row or column x and y.[1]
- For example, suppose you have four data pairs for x and y. Your table may look like this:
- x || y
- 1 || 1
- 2 || 3
- 4 || 5
- 5 || 7
- For example, suppose you have four data pairs for x and y. Your table may look like this:
-
2
Calculate the mean of x. In order to calculate the mean, you must add all the values of x, then divide by the number of values.[2]
Advertisement
-
3
Find the mean of y. To find the mean of y, follow the same steps, adding all the values of y together, then dividing by the number of values.[3]
-
4
Determine the standard deviation of x. Once you have your means, you can calculate standard deviation. To do so, use the formula:[4]
-
5
Calculate the standard deviation of y. Using the same basic steps, find the standard deviation of y. You will use the same formula, using the y data points.[5]
-
6
Review the basic formula for finding a correlation coefficient. The formula for calculating a correlation coefficient uses means, standard deviations, and the number of pairs in your data set (represented by n). The correlation coefficient itself is represented by the lower-case letter r or the lower-case Greek letter rho, ρ. For this article, you will use the formula known as the Pearson correlation coefficient, shown below:[6]
- You may notice slight variations in the formula, here or in other texts. For example, some will use the Greek notation with rho and sigma, while others will use r and s. Some texts may show slightly different formulas; but they will be mathematically equivalent to this one.
-
7
Find the correlation coefficient. You now have the means and standard deviations for your variables, so you can proceed to use the correlation coefficient formula. Remember that n represents the number of values you have. You have already worked out the other relevant information in the steps above.[7]
-
8
Interpret your result. For this data set, the correlation coefficient is 0.988. This number tells you two things about the data. Look at the sign of the number and the size of the number.[8]
- Because the correlation coefficient is positive, you can say there is a positive correlation between the x-data and the y-data. This means that as the x values increase, you expect the y values to increase also.
- Because the correlation coefficient is very close to +1, the x-data and y-data are very closely connected. If you were to graph these points, you would see that they form a very good approximation of a straight line.









Advertisement
-
1
Search the Internet for correlation calculators. Measuring correlation is a fairly standard calculation for statisticians. The calculation can become very tedious if done by hand for large data sets. As a result, many sources have made correlation calculators available online. Use any search engine and enter the search term “correlation calculator.”
-
2
Enter your data. Carefully review the instructions on the website so you will enter your data properly. It is important that your data pairs are kept in order, or you will generate an incorrect correlation result. Different websites use different formats to enter data.
- For example, at the website http://ncalculators.com/statistics/correlation-coefficient-calculator.htm, you will find one horizontal box for entering x-values and a second horizontal box for entering y-values. You enter your terms, separated only by commas. Thus, the x-data set that was calculated earlier in this article should be entered as 1,2,4,5. The y-data set should be 1,3,5,7.
- At another site, http://www.alcula.com/calculators/statistics/correlation-coefficient/, you can enter data either horizontally or vertically, as long as you keep the data points in order.
-
3
Calculate your results. These calculation sites are popular because, after you enter your data, you generally need only to click on the button that says “Calculate,” and the result will appear automatically.



Advertisement
-
1
Enter your data. Using a handheld graphing calculator, enter your calculator’s statistics function and then select the “Edit” command.[9]
- Each calculator will have slightly different key commands. This article will give the specific instructions for the Texas Instruments TI-86.
- Enter the Stat function by pressing [2nd]-Stat (above the + key), then hit F2-Edit.
-
2
Clear any old stored data. Most calculators will keep statistical data until cleared. To make sure that you do not confuse old data with new data, you should first clear any previously stored information.[10]
- Use the arrow keys to move the cursor to highlight the heading “xStat.” Then press Clear and Enter. This should clear all values in the xStat column.
- Use the arrow keys to highlight the yStat heading. Press Clear and Enter to empty the data from that column as well.
-
3
Enter your data values. Using the arrow keys, move the cursor to the first space under the xStat heading. Type in your first data value and then hit Enter. You should see the space at the bottom of the screen display “xStat(1)=__,” with your value filling the blank space. When you hit Enter, the data will fill the table, the cursor will move to the next line, and the line at the bottom of the screen should now read “xStat(2)=__.”[11]
- Continue entering all the x-data values.
- When you complete the x-data, use the arrow keys to move to the yStat column and enter the y-data values.
- After all the data has been entered, hit Exit to clear the screen and leave the Stat menu.
-
4
Calculate the linear regression statistics. The correlation coefficient is a measure of how well the data approximates a straight line. A statistical graphing calculator can very quickly calculate the best-fit line and the correlation coefficient.[12]
- Enter the Stat function and then hit the Calc button. On the TI-86, this is [2nd][Stat][F1].
- Choose the Linear Regression calculations. On the TI-86, this is [F3], which is labeled “LinR.” The graphic screen should then display the line “LinR _,” with a blinking cursor.
- You now need to enter the names of the two variables that you want to calculate. These are xStat and yStat.
- On the TI-86, select the Names list by hitting [2nd][List][F3].
- The bottom line of your screen should now show the available variables. Choose [xStat] (this is probably button F1 or F2), then enter a comma, then [yStat].
- Hit Enter to calculate the data.
-
5
Interpret your results. When you hit Enter, the calculator will instantly calculate the following information for the data that you entered:[13]





Advertisement
-
1
Understand the concept of correlation. Correlation refers to the statistical relationship between two quantities. The correlation coefficient is a single number that you can calculate for any two sets of data points. The number will always be something between -1 and +1, and it indicates how closely connected the two data sets tend to be.[14]
- For example, if you were to measure the heights and ages of children up to the age of about 12, you would expect to find a strong positive correlation. As children get older, they tend to get taller.
- An example of negative correlation would be data comparing a person’s time spent practicing golf shots and that person’s golf score. As the practice increases, the score should decrease.
- Finally, you would expect very little correlation, either positive or negative, between a person’s shoe size, for example, and SAT scores.
-
2
Know how to find a mean. The arithmetic mean, or “average,” of a set of data is calculated by adding all of the values of the data together, then dividing by the number of values in the set. When you find the correlation coefficient for your data, you will need to calculate the mean of each set of data.[15]
- The mean of a variable is denoted by the variable with a horizontal line above it. This is often referred to as “x-bar” or “y-bar” for the x and y data sets. Alternatively, the mean may be signified by the lower-case Greek letter mu, μ. To indicate the mean of x-data points, for example, you could write μx or μ(x).
- As an example, if you have a set of x-data points (1,2,5,6,9,10), then the mean of this data is calculated as follows:
-
3
Note the importance of standard deviation. In statistics, standard deviation measures variation, showing how numbers are spread out in relationship to the mean. A group of numbers with a low standard deviation are fairly tightly collected. A group of numbers with a high standard deviation are widely scattered.[16]
- Symbolically, standard deviation is expressed with either the lower-case letter s or the lower-case Greek letter sigma, σ. Thus, the standard deviation of the x-data is written as either sx or σx.
-
4
Recognize summation notation. The summation operator is one of the most common operators in mathematics, indicating a sum of values. It is represented by the upper-case Greek letter, sigma, or ∑.[17]
- As an example, if you have a set of x-data points (1,2,5,6,9,10), then ∑x means:
- 1+2+5+6+9+10 = 33.
- As an example, if you have a set of x-data points (1,2,5,6,9,10), then ∑x means:




Advertisement
Add New Question
-
Question
You are given the following information about two variables x and y: Mean(x)= 315 and Mean(y)=1,103. Variance(x)=59 and Variance(y)=156. Covariance(x,y)= -54. Calculate the coefficient of correlation between X and Y. Calculate your answer to two decimal places.

This question raises a higher level of statistics than is addressed in this article. It is possible to calculate the correlation coefficient from the means, variance and covariance, without actually having the original data points to begin with. The relationship is Correlation Coefficient = Covariance / ((Std. Dev. (x) * (Std. Dev. (y)). The standard deviation is the square root of the variance. So, with your data, this simplifies to Corr.Coeff.=-54/sqrt(59)sqrt(156) = -0.56.
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
In general, a correlation coefficient higher than 0.8 (either positive or negative) represents a strong correlation; a correlation coefficient lower than 0.5 (again, either positive or negative) represents a weak one.
-
The correlation coefficient is sometimes called the “Pearson product-moment correlation coefficient” in honor of its developer, Karl Pearson.
Thanks for submitting a tip for review!
Advertisement
-
Correlation shows that the two sets of data are connected in some way. However, be careful not to interpret this as causation. For example, if you compare people’s shoe sizes and their height, you will probably find a strong positive correlation. Taller people generally have larger feet. However, this does not mean that growing tall causes your feet to grow, or that large feet cause you to grow tall. They just happen together.
Advertisement
References
About This Article
Article SummaryX
To find the correlation coefficient by hand, first put your data pairs into a table with one row labeled “X” and the other “Y.” Then calculate the mean of X by adding all the X values and dividing by the number of values. Calculate the mean for Y in the same way. Next, use the formula for standard deviation to calculate it for both X and Y. Finally, use the means and standard deviations and the number of pairs in your data set as inputs to the correlation coefficient formula, and solve the resulting equation. To learn how to find the correlation coefficient with an online calculator or your own graphing calculator, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 204,279 times.
Did this article help you?
Термин «корреляция» активно используется в гуманитарных науках, медицине; часто мелькает в СМИ. Ключевую роль корреляции играют в психологии. В частности, расчет корреляций выступает важным этапом реализации эмпирического исследования при написании ВКР по психологии.
Материалы по корреляциям в сети слишком научны. Неспециалисту трудно разобраться в формулах. В то же время понимание смысла корреляций необходимо маркетологу, социологу, медику, психологу – всем, кто проводит исследования на людях.
В этой статье мы простым языком объясним суть корреляционной связи, виды корреляций, способы расчета, особенности использования корреляции в психологических исследованиях, а также при написании дипломных работ по психологии.
Содержание
Что такое корреляция
Численное выражение корреляционной связи
- Прямая и обратная корреляция
- Сильная и слабая корреляция
Корреляционный анализ в психологии
Коэффициенты корреляции Пирсона и Спирмена
Как рассчитать коэффициент корреляции
- Расчет корреляций с помощью электронных таблиц Microsoft Excel
- Как вычислить значение корреляции с помощью статистической программы STATISTICA
Использование корреляционного анализа в дипломных работах по психологии
Что такое корреляция
Корреляция – это связь. Но не любая. В чем же ее особенность? Рассмотрим на примере.
Представьте, что вы едете на автомобиле. Вы нажимаете педаль газа – машина едет быстрее. Вы сбавляете газ – авто замедляет ход. Даже не знакомый с устройством автомобиля человек скажет: «Между педалью газа и скоростью машины есть прямая связь: чем сильнее нажата педаль, тем скорость выше».
Это зависимость функциональная – скорость выступает прямой функцией педали газа. Специалист объяснит, что педаль управляет подачей топлива в цилиндры, где происходит сжигание смеси, что ведет к повышению мощности на вал и т.д. Это связь жесткая, детерминированная, не допускающая исключений (при условии, что машина исправна).
Теперь представьте, что вы директор фирмы, сотрудники которой продают товары. Вы решаете повысить продажи за счет повышения окладов работников. Вы повышаете зарплату на 10%, и продажи в среднем по фирме растут. Через время повышаете еще на 10%, и опять рост. Затем еще на 5%, и опять есть эффект. Напрашивается вывод – между продажами фирмы и окладом сотрудников есть прямая зависимость – чем выше оклады, тем выше продажи организации. Такая же это связь, как между педалью газа и скоростью авто? В чем ключевое отличие?
Правильно, между окладом и продажами заисимость не жесткая. Это значит, что у кого-то из сотрудников продажи могли даже снизиться, невзирая на рост оклада. У кого-то остаться неизменными. Но в среднем по фирме продажи выросли, и мы говорим – связь продаж и оклада сотрудников есть, и она корреляционная.
В основе функциональной связи (педаль газа – скорость) лежит физический закон. В основе корреляционной связи (продажи – оклад) находится простая согласованность изменения двух показателей. Никакого закона (в физическом понимании этого слова) за корреляцией нет. Есть лишь вероятностная (стохастическая) закономерность.
Численное выражение корреляционной зависимости
Итак, корреляционная связь отражает зависимость между явлениями. Если эти явления можно измерить, то она получает численное выражение.
Например, изучается роль чтения в жизни людей. Исследователи взяли группу из 40 человек и измерили у каждого испытуемого два показателя: 1) сколько времени он читает в неделю; 2) в какой мере он считает себя благополучным (по шкале от 1 до 10). Ученые занесли эти данные в два столбика и с помощью статистической программы рассчитали корреляцию между чтением и благополучием. Предположим, они получили следующий результат -0,76. Но что значит это число? Как его проинтерпретировать? Давайте разбираться.
Полученное число называется коэффициентом корреляции. Для его правильной интерпретации важно учитывать следующее:
- Знак «+» или «-» отражает направление зависимости.
- Величина коэффициента отражает силу зависимости.
Прямая и обратная
Знак плюс перед коэффициентом указывает на то, что связь между явлениями или показателями прямая. То есть, чем больше один показатель, тем больше и другой. Выше оклад — выше продажи. Такая корреляция называется прямой, или положительной.
Если коэффициент имеет знак минус, значит, корреляция обратная, или отрицательная. В этом случае чем выше один показатель, тем ниже другой. В примере с чтением и благополучием мы получили -0,76, и это значит, что, чем больше люди читают, тем ниже уровень их благополучия.
Сильная и слабая
Корреляционная связь в численном выражении – это число в диапазоне от -1 до +1. Обозначается буквой «r». Чем выше число (без учета знака), тем корреляционная связь сильнее.
Чем ниже численное значение коэффициента, тем взаимосвязь между явлениями и показателями меньше.
Максимально возможная сила зависимости – это 1 или -1. Как это понять и представить?
Рассмотрим пример. Взяли 10 студентов и измерили у них уровень интеллекта (IQ) и успеваемость за семестр. Расположили эти данные в виде двух столбцов.
|
Испытуемый |
IQ |
Успеваемость (баллы) |
|
1 |
90 |
4,0 |
|
2 |
91 |
4,1 |
|
3 |
92 |
4,2 |
|
4 |
93 |
4,3 |
|
5 |
94 |
4,4 |
|
6 |
95 |
4,5 |
|
7 |
96 |
4,6 |
|
8 |
97 |
4,7 |
|
9 |
98 |
4,8 |
|
10 |
99 |
4,9 |
Посмотрите внимательно на данные в таблице. От 1 до 10 испытуемого растет уровень IQ. Но также растет и уровень успеваемости. Из любых двух студентов успеваемость будет выше у того, у кого выше IQ. И никаких исключений из этого правила не будет.
Перед нами пример полного, 100%-но согласованного изменения двух показателей в группе. И это пример максимально возможной положительной взаимосвязи. То есть, корреляционная зависимость между интеллектом и успеваемостью равна 1.
Рассмотрим другой пример. У этих же 10-ти студентов с помощью опроса оценили, в какой мере они ощущают себя успешными в общении с противоположным полом (по шкале от 1 до 10).
|
Испытуемый |
IQ |
Успех в общении с противоположным полом (баллы) |
|
1 |
90 |
10 |
|
2 |
91 |
9 |
|
3 |
92 |
8 |
|
4 |
93 |
7 |
|
5 |
94 |
6 |
|
6 |
95 |
5 |
|
7 |
96 |
4 |
|
8 |
97 |
3 |
|
9 |
98 |
2 |
|
10 |
99 |
1 |
Смотрим внимательно на данные в таблице. От 1 до 10 испытуемого растет уровень IQ. При этом в последнем столбце последовательно снижается уровень успешности общения с противоположным полом. Из любых двух студентов успех общения с противоположным полом будет выше у того, у кого IQ ниже. И никаких исключений из этого правила не будет.
Это пример полной согласованности изменения двух показателей в группе — максимально возможная отрицательная взаимосвязь. Корреляционная связь между IQ и успешностью общения с противоположным полом равна -1.
А как понять смысл корреляции равной нулю (0)? Это значит, связи между показателями нет. Еще раз вернемся к нашим студентам и рассмотрим еще один измеренный у них показатель – длину прыжка с места.
|
Испытуемый |
IQ |
Длина прыжка с места (м) |
|
1 |
90 |
2,5 |
|
2 |
91 |
1,2 |
|
3 |
92 |
2,0 |
|
4 |
93 |
1,7 |
|
5 |
94 |
1,9 |
|
6 |
95 |
1,3 |
|
7 |
96 |
1,7 |
|
8 |
97 |
2,3 |
|
9 |
98 |
1,1 |
|
10 |
99 |
2,6 |
Не наблюдается никакой согласованности между изменением IQ от человека к человеку и длинной прыжка. Это и свидетельствует об отсутствии корреляции. Коэффициент корреляции IQ и длины прыжка с места у студентов равен 0.
Мы рассмотрели крайние случаи. В реальных измерениях коэффициенты редко бывают равны точно 1 или 0. При этом принята следующая шкала:
- если коэффициент больше 0,70 – связь между показателями сильная;
- от 0,30 до 0,70 – связь умеренная,
- меньше 0,30 – связь слабая.
Если оценить по этой шкале полученную нами выше корреляцию между чтением и благополучием, то окажется, что эта зависимость сильная и отрицательная -0,76. То есть, наблюдается сильная отрицательная связь между начитанностью и благополучием. Что еще раз подтверждает библейскую мудрость о соотношении мудрости и печали.
Приведенная градация дает очень приблизительные оценки и в таком виде редко используются в исследованиях.
Чаще используются градации коэффициентов по уровням значимости. В этом случае реально полученный коэффициент может быть значимым или не значимым. Определить это можно, сравнив его значение с критическим значением коэффициента корреляции, взятым из специальной таблицы. Причем эти критические значения зависят от численности выборки (чем больше объем, тем ниже критическое значение).
Корреляционный анализ в психологии
Корреляционный метод выступает одним из основных в психологических исследованиях. И это не случайно, ведь психология стремится быть точной наукой. Получается ли?
В чем особенность законов в точных науках. Например, закон тяготения в физике действует без исключений: чем больше масса тела, тем сильнее оно притягивает другие тела. Этот физический закон отражает связь массы тела и силы притяжения.
В психологии иная ситуация. Например, психологи публикуют данные о связи теплых отношений в детстве с родителями и уровня креативности во взрослом возрасте. Означает ли это, что любой из испытуемых с очень теплыми отношениями с родителями в детстве будет иметь очень высокие творческие способности? Ответ однозначный – нет. Здесь нет закона, подобного физическому. Нет механизма влияния детского опыта на креативность взрослых. Это наши фантазии! Есть согласованность данных (отношения – креативность), но за ними нет закона. А есть лишь корреляционная связь. Психологи часто называют выявляемые взаимосвязи психологическими закономерностями, подчеркивая их вероятностный характер — не жесткость.
Пример исследования на студентах из предыдущего раздела хорошо иллюстрирует использование корреляций в психологии:
- Анализ взаимосвязи между психологическими показателями. В нашем примере IQ и успешность общения с противоположным полом – это психологические параметры. Выявление корреляции между ними расширяет представления о психической организации человека, о взаимосвязях между различными сторонами его личности – в данном случае между интеллектом и сферой общения.
- Анализ взаимосвязей IQ с успеваемостью и прыжками – пример связи психологического параметра с непсихологическими. Полученные результаты раскрывают особенности влияния интеллекта на учебную и спортивную деятельность.
Вот как могли выглядеть краткие выводы по результатам придуманного исследования на студентах:
- Выявлена значимая положительная зависимость интеллекта студентов и их успеваемости.
- Существует отрицательная значимая взаимосвязь IQ с успешностью общения с противоположным полом.
- Не выявлено связи IQ студентов с умением прыгать с места.
Таким образом, уровень интеллекта студентов выступает позитивным фактором их академической успеваемости, в то же время негативно сказываясь на отношениях с противоположным полом и не оказывая значимого влияния на спортивные успехи, в частности, способность к прыгать с места.
Как видим, интеллект помогает студентам учиться, но мешает строить отношения с противоположным полом. При этом не влияет на их спортивные успехи.
Неоднозначное влияние интеллекта на личность и деятельность студентов отражает сложность этого феномена в структуре личностных особенностей и важность продолжения исследований в этом направлении. В частности, представляется важным провести анализ взаимосвязей интеллекта с психологическими особенностями и деятельностью студентов с учетом их пола.
Коэффициенты Пирсона и Спирмена
Рассмотрим два метода расчета.
Коэффициент Пирсона – это особый метод расчета взаимосвязи показателей между выраженностью численных значений в одной группе. Очень упрощенно он сводится к следующему:
- Берутся значения двух параметров в группе испытуемых (например, агрессии и перфекционизма).
- Находятся средние значения каждого параметра в группе.
- Находятся разности параметров каждого испытуемого и среднего значения.
- Эти разности подставляются в специальную форму для расчета коэффициента Пирсона.
Коэффициент ранговой корреляции Спирмена рассчитывается похожим образом:
- Берутся значения двух индикаторов в группе испытуемых.
- Находятся ранги каждого фактора в группе, то есть место в списке по возрастанию.
- Находятся разности рангов, возводятся в квадрат и суммируются.
- Далее разности рангов подставляются в специальную форму для вычисления коэффициента Спирмена.
В случае Пирсона расчет шел с использованием среднего значения. Следовательно, случайные выбросы данных (существенное отличие от среднего), например, из-за ошибки обработки или недостоверных ответов могут существенно исказить результат.
В случае Спирмена абсолютные значения данных не играют роли, так как учитывается только их взаимное расположение по отношению друг к другу (ранги). То есть, выбросы данных или другие неточности не окажут серьезного влияния на конечный результат.
Если результаты тестирования корректны, то различия коэффициентов Пирсона и Спирмена незначительны, при этом коэффициент Пирсона показывает более точное значение взаимосвязи данных.
Как рассчитать коэффициент корреляции
Коэффициенты Пирсона и Спирмена можно рассчитать вручную. Это может понадобиться при углубленном изучении статистических методов.
Однако в большинстве случаев при решении прикладных задач, в том числе и в психологии, можно проводить расчеты с помощью специальных программ.
Расчет с помощью электронных таблиц Microsoft Excel
Вернемся опять к примеру со студентами и рассмотрим данные об уровне их интеллекта и длине прыжка с места. Занесем эти данные (два столбца) в таблицу Excel.
Переместив курсор в пустую ячейку, нажмем опцию «Вставить функцию» и выберем «КОРРЕЛ» из раздела «Статистические».
Формат этой функции предполагает выделение двух массивов данных: КОРРЕЛ (массив 1; массив»). Выделяем соответственно столбик с IQ и длиной прыжков.

Далее нажимаем галочку (то есть, рассчитать) и получаем значение , в нашем случае 0,038. Как видим, коэффициент не равен нулю, хотя и очень близок к нему.
В таблицах Excel реализована формула расчета только коэффициента Пирсона.
Расчет с помощью программы STATISTICA
Заносим данные по интеллекту и длине прыжка в поле исходных данных. Далее выбираем опцию «Непараметрические критерии», «Спирмена». Выделяем параметры для расчета и получаем следующий результат.

Как видно, расчет дал результат 0,024, что отличается от результата по Пирсону – 0,038, полученной выше с помощью Excel. Однако различия незначительны.
Использование корреляционного анализа в дипломных работах по психологии (пример)
Большинство тем выпускных квалификационных работ по психологии (дипломов, курсовых, магистерских) предполагают проведение корреляционного исследования (остальные связаны с выявлением различий психологических показателей в разных группах).
Сам термин «корреляция» в названиях тем звучит редко – он скрывается за следующими формулировками:
- «Взаимосвязь субъективного ощущения одиночества и самоактуализации у женщин зрелого возраста»;
- «Особенности влияния жизнестойкости менеджеров на успешность их взаимодействия с клиентами в конфликтных ситуациях»;
- «Личностные факторы стрессоустойчивости сотрудников МЧС».
Таким образом, слова «взаимосвязь», «влияние» и «факторы» — верные признаки того, что методом анализа данных в эмпирическом исследовании должен быть корреляционный анализ.
Рассмотрим кратко этапы его проведения при написании дипломной работы по психологии на тему: «Взаимосвязь личностной тревожности и агрессивности у подростков».
1. Для расчета необходимы сырые данные, в качестве которых обычно выступают результаты тестирования испытуемых. Они заносятся в сводную таблицу и помещаются в приложение. Эта таблица устроена следующим образом:
- каждая строка содержит данные на одного испытуемого;
- каждый столбец содержит показатели по одной шкале для всех испытуемых.
|
№ испытуемого |
Личностная тревожность |
Агрессивность |
|
1 |
12 |
24 |
|
2 |
14 |
25 |
|
3 |
11 |
13 |
|
4 |
17 |
19 |
|
5 |
21 |
29 |
|
6 |
26 |
29 |
|
7 |
13 |
16 |
|
8 |
16 |
20 |
|
8 |
13 |
24 |
|
9 |
18 |
21 |
|
10 |
23 |
31 |
2. Необходимо решить, какой из двух типов коэффициентов — Пирсона или Спирмена — будет использоваться. Напоминаем, что Пирсон дает более точный результат, но он чувствителен к выбросам в данных Коэффициенты Спирмена могут использоваться с любыми данными (кроме номинативной шкалы), поэтому именно они чаще всего используют в дипломах по психологии.
3. Заносим таблицу сырых данных в статистическую программу.

4. Рассчитываем значение.

5. На следующем этапе важно определить, значима ли взаимосвязь. Статистическая программа подсветила результаты красным, что означает, что корреляция статистически значимы при уровне значимости 0,05 (указано выше).
Однако полезно знать, как определить значимость вручную. Для этого понадобится таблица критических значений Спирмена.
Таблица критических значений коэффициентов Спирмена
|
Уровень статистической значимости |
|||
|
Число испытуемых |
р=0,05 |
р=0,01 |
р=0,001 |
|
5 |
0,88 |
0,96 |
0,99 |
|
6 |
0,81 |
0,92 |
0,97 |
|
7 |
0,75 |
0,88 |
0,95 |
|
8 |
0,71 |
0,83 |
0,93 |
|
9 |
0,67 |
0,8 |
0,9 |
|
10 |
0,63 |
0,77 |
0,87 |
|
11 |
0,6 |
0,74 |
0,85 |
|
12 |
0,58 |
0,71 |
0,82 |
|
13 |
0,55 |
0,68 |
0,8 |
|
14 |
0,53 |
0,66 |
0,78 |
|
15 |
0,51 |
0,64 |
0,76 |
Нас интересует уровень значимости 0,05 и объем нашей выборки 10 человек. На пересечении этих данных находим значение критического Спирмена: Rкр=0,63.
Правило такое: если полученное эмпирическое значение Спирмена больше либо равно критическому, то он статистически значим. В нашем случае: Rэмп (0,66) > Rкр (0,63), следовательно, взаимосвязь между агрессивностью и тревожностью в группе подростков статистически значима.
5. В текст дипломной нужно вставлять данные в таблице формата word, а не таблицу из статистической программы. Под таблицей описываем полученный результат и интерпретируем его.
Таблица 1
Коэффициенты Спирмена агрессивности и тревожности в группе подростков
|
Агрессивность |
|
|
Личностная тревожность |
0,665* |
* — статистически достоверна (р≤0,05)
Анализ данных, приведенных в таблице 1, показывает, что существует статистически значимая положительная связьмежду агрессивностью и тревожностью подростков. Это означает, что чем выше личностная тревожность подростков, тем выше уровень их агрессивности. Такой результат дает основание предположить, что агрессия для подростков выступает одним из способов купирования тревожности. Испытывая неуверенность в себе, тревогу в связи с угрозами самооценке, особенно чувствительной в подростковом возрасте, подросток часто использует агрессивное поведение, таким непродуктивным способом снижая тревогу.
6. Можно ли при интерпретации связей говорить о влиянии? Можно ли сказать, что тревожность влияет на агрессивность? Строго говоря, нет. Выше мы показали, что корреляционная связь между явлениями носит вероятностный характер и отражает лишь согласованность изменений признаков в группе. При этом мы не можем сказать, что эта согласованность вызвана тем, что одно из явлений является причиной другого, влияет на него. То есть, наличие корреляции между психологическими параметрами не дает оснований говорить о существовании между ними причинно-следственной связи. Однако практика показывает, что термин «влияние» часто используется при анализе результатов корреляционного анализа.
© СтудентуПсихологу.рф
Содержание:
Корреляционный анализ:
Связи между различными явлениями в природе сложны и многообразны, однако их можно определённым образом классифицировать. В технике и естествознании часто речь идёт о функциональной зависимости между переменными x и у, когда каждому возможному значению х поставлено в однозначное соответствие определённое значение у. Это может быть, например, зависимость между давлением и объёмом газа (закон Бойля—Мариотта).
В реальном мире многие явления природы происходят в обстановке действия многочисленных факторов, влияния каждого из которых ничтожно, а число их велико. В этом случае связь теряет свою однозначность и изучаемая физическая система переходит не в определённое состояние, а в одно из возможных для неё состояний. Здесь речь может идти лишь о так называемой статистической связи. Статистическая связь состоит в том, что одна случайная переменная реагирует на изменение другой изменением своего закона распределения. Следовательно, для изучения статистической зависимости нужно знать аналитический вид двумерного распределения. Однако нахождение аналитического вида двумерного распределения по выборке ограниченного объёма, во-первых, громоздко, во-вторых, может привести к значительным ошибкам. Поэтому на практике при исследовании зависимостей между случайными переменными X и У обычно ограничиваются изучением зависимости между одной из них и условным математическим ожиданием другой, т.е. 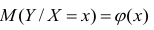
Вопрос о том, что принять за зависимую переменную, а что — за независимую, следует решать применительно к каждому конкретному случаю.
Знание статистической зависимости между случайными переменными имеет большое практическое значение: с её помощью можно прогнозировать значение зависимой случайной переменной в предположении, что независимая переменная примет определенное значение. Однако, поскольку понятие статистической зависимости относится к осредненным условиям, прогнозы не могут быть безошибочными. Применяя некоторые вероятностные методы, как будет показано далее, можно вычислить вероятность того, что ошибка прогноза не выйдет за определенные границы.
Введение в корреляционный анализ
Связь, которая существует между случайными величинами разной природы, например, между величиной X и величиной Y, не обязательно является следствием прямой зависимости одной величины от другой (так называемая функциональная связь).
В некоторых случаях обе величины зависят от целой совокупности разных факторов, общих для обеих величин, в результате чего и формируется связанные друг с другом закономерности. Когда связь между случайными величинами обнаружена с помощью статистики, мы не можем утверждать, что обнаружили причину происходящего изменения параметров, скорее мы лишь увидели два взаимосвязанных следствия.
Например, дети, которые чаще смотрят по телевизору американские боевики, меньше читают. Дети, которые больше читают, лучше учатся. Не так-то просто решить, где тут причины, а где следствия, но это и не является задачей статистики.
Статистика может лишь, выдвинув гипотезу о наличии связи, подкрепить ее цифрами. Если связь действительно имеется, говорят, что между двумя случайными величинами есть корреляция. Если увеличение одной случайной величины связано с увеличением второй случайной величины, корреляция называется прямой.
Например, количество прочитанных страниц за год и средний балл (успеваемость). Если, напротив рост одной величины связано с уменьшением другой, говорят об обратной корреляции. Например, количество боевиков и количество прочитанных страниц. Взаимная связь двух случайных величин называется корреляцией, корреляционный анализ позволяет определить наличие такой связи, оценить, насколько тесна и существенна эта связь. Все это выражается количественно.
Как определить, есть ли корреляция между величинами? В большинстве случаев, это можно увидеть на обычном графике. Например, по каждому ребенку из нашей выборки можно определить величину  (число страниц) и
(число страниц) и 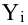 (средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси X и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (,) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.
(средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси X и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (,) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.
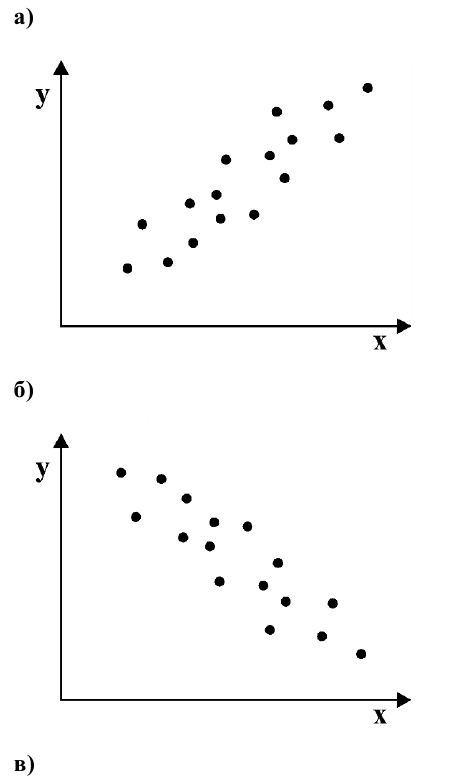
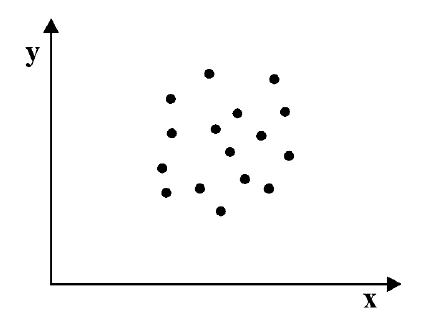
Если график имеет вид а), то это говорит о наличии прямой корреляции, в случае, если он имеет вид б) — корреляция обратная. Отсутствие корреляции тоже можно приблизительно определить по виду графика — это случай в).
С помощью коэффициента корреляции можно посчитать насколько тесная связь существует между величинами.
Пусть, существует корреляция между ценой и спросом на товар. Количество купленных единиц товара в зависимости от цены у разных продавцов показано в таблице:  Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции:
Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции: 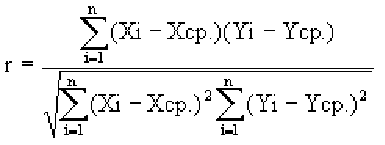
Коэффициент r мы считаем в Excel, с помощью функции 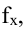 далее статистические функции, функция KOPPEЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (X и Y). В нашем случае коэффициент корреляции получился r = -0,988.
далее статистические функции, функция KOPPEЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (X и Y). В нашем случае коэффициент корреляции получился r = -0,988.
Надо отметить, что чем ближе к 0 коэффициент корреляции, тем слабее связь между величинами. Наиболее тесная связь при прямой корреляции соответствует коэффициенту r, близкому к +1. В нашем случае, корреляция обратная, но тоже очень тесная, и коэффициент близок к -1.
Что можно сказать о случайных величинах, у которых коэффициент имеет промежуточное значение? Например, если бы мы получили r = 0,65. В этом случае, статистика позволяет сказать, что две случайные величины частично связаны друг с другом. Скажем на 65% влияние на количество покупок оказывала цена, а на 35% — другие обстоятельства. И еще одно важное обстоятельство надо упомянуть.
Поскольку мы говорим о случайных величинах, всегда существует вероятность, что замеченная нами связь — случайное обстоятельство. Причем вероятность найти связь там, где ее нет, особенно велика тогда, когда точек в выборке мало, а при оценке Вы не построили график, а просто посчитали значение коэффициента корреляции на компьютере. Так, если мы оставим всего две разные точки в любой произвольной выборке, коэффициент корреляции будет равен или +1 или -1. Из школьного курса геометрии мы знаем, что через две точки можно всегда провести прямую линию. Для оценки статистической достоверности факта обнаруженной Вами связи полезно использовать так называемую корреляционную поправку: 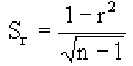
Связь нельзя считать случайной, если: 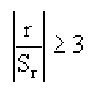
В то время как задача корреляционного анализа — установить, являются ли данные случайные величины взаимосвязанными, цель регрессионного анализа — описать эту связь аналитической зависимостью, т.е. с помощью уравнения. Мы рассмотрим самый несложный случай, когда связь между точками на графике может быть представлена прямой линией. Уравнение этой прямой линии 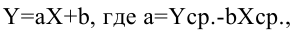
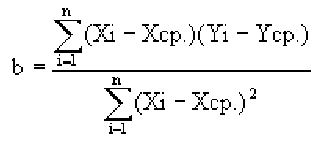
Зная уравнение прямой, мы можем находить значение функции по значению аргумента в тех точках, где значение X известно, a Y — нет. Эти оценки бывают очень нужны, но они должны использоваться осторожно, особенно, если связь между величинами не слишком тесная. Отметим также, что из сопоставления формул для b и r видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.
Определение формы связи. Понятие регрессии
Определить форму связи — значит выявить механизм получения зависимой случайной переменной. При изучении статистических зависимостей форму связи можно характеризовать функцией регрессии (линейной, квадратной, показательной и т.д.).
Условное математическое ожидание  случайной переменной К, рассматриваемое как функция х, т.е.
случайной переменной К, рассматриваемое как функция х, т.е. 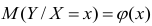 , называется
, называется
функцией регрессии случайной переменной Y относительно X (или функцией регрессии Y по X). Точно так же условное математическое ожидание
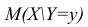 случайной переменной X, т.е.
случайной переменной X, т.е. 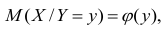 называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
На примере, дискретного распределения найдём функцию регрессии.
Функция регрессии имеет важное значение при статистическом анализе зависимостей между переменными и может быть использована для прогнозирования одной из случайных переменных, если известно значение другой случайной переменной. Точность такого прогноза определяется дисперсией условного распределения.
Несмотря на важность понятия функции регрессии, возможности её практического применения весьма ограничены. Для оценки функции регрессии необходимо знать аналитический вид двумерного распределения (X, Y). Только в этом случае можно точно определить вид функции регрессии, а затем оценить параметры двумерного распределения. Однако для подобной оценки мы чаще всего располагаем лишь выборкой ограниченного объема, по которой нужно найти вид двумерного распределения (X, Y), а затем вид функции регрессии. Это может привести к значительным ошибкам, так как одну и ту же совокупность точек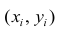 на плоскости можно одинаково успешно описать с помощью различных функций. Именно поэтому возможности практического применения функции регрессии ограничены. Для характеристики формы связи при изучении зависимости используют понятие кривой регрессии.
на плоскости можно одинаково успешно описать с помощью различных функций. Именно поэтому возможности практического применения функции регрессии ограничены. Для характеристики формы связи при изучении зависимости используют понятие кривой регрессии.
Кривой регрессии Y по X (или Y на А) называют условное среднее значение случайной переменной У, рассматриваемое как функция определенного класса, параметры которой находят методом наименьших квадратов по наблюдённым значениям двумерной случайной величины (х, у), т.е.
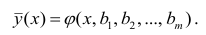
Аналогично определяется кривая регрессии X по Y (X на Y):
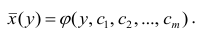
Кривую регрессии называют также эмпирическим уравнением регрессии или просто уравнением регрессии. Уравнение регрессии является оценкой соответствующей функции регрессии.
Возникает вопрос: почему для определения кривой регрессии
используют именно условное среднее Функция у(х) обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза. Предположим, что кривая регрессии — произвольная функция. Средняя погрешность прогноза по кривой регрессии определяется математическим ожиданием квадрата разности между измеренной величиной и вычисленной по формуле кривой регрессии, т.е.
Функция у(х) обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза. Предположим, что кривая регрессии — произвольная функция. Средняя погрешность прогноза по кривой регрессии определяется математическим ожиданием квадрата разности между измеренной величиной и вычисленной по формуле кривой регрессии, т.е.  . Естественно потребовать вычисления такой кривой регрессии, средняя погрешность прогноза по которой была бы наименьшей. Таковой является
. Естественно потребовать вычисления такой кривой регрессии, средняя погрешность прогноза по которой была бы наименьшей. Таковой является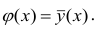 Это следует из свойств минимальности рассеивания около центра распределения
Это следует из свойств минимальности рассеивания около центра распределения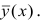
Если рассеивание вычисляется относительно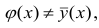 то средний квадрат отклонения увеличивается. Поэтому можно сказать, что кривая регрессии, выражаемая как
то средний квадрат отклонения увеличивается. Поэтому можно сказать, что кривая регрессии, выражаемая как 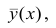 минимизирует среднеквадратическую погрешность прогноза величины Y по X.
минимизирует среднеквадратическую погрешность прогноза величины Y по X.
Основные положения корреляционного анализа
Статистические связи между переменными можно изучать методом корреляционного и регрессионного анализа. С помощью этих методов решают разные задачи; требования, предъявляемые к исследуемым переменным, в каждом методе различны.
Основная задача корреляционного анализа — выявление связи между случайными переменными путём точечной и интервальной оценки парных коэффициентов корреляции, вычисления и проверки значимости множественных коэффициентов корреляции и детерминации, оценки частных коэффициентов корреляции. Корреляционный анализ позволяет также оценить функцию регрессии одной случайной переменной на другую.
Предпосылки корреляционного анализа следующие:
- 1) переменные величины должны быть случайными;
- 2) случайные величины должны иметь совместное нормальное распределение.
Рассмотрим простейший случай корреляционного анализа — двумерную модель. Введём основные понятия и опишем принцип проведения корреляционного анализа. Пусть X и Y — случайные переменные, имеющие совместное нормальное распределение. В этом случае связь между X и Y можно описать коэффициентом корреляции p;. Этот коэффициент определяется как ковариация между X и Y, отнесённая к их среднеквадратическим отклонениям:
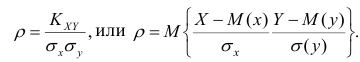 (1.1)
(1.1)
Оценкой коэффициента корреляции является выборочный коэффициент корреляции r. Для его нахождения необходимо знать оценки следующих параметров: 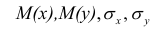 . Наилучшей оценкой
. Наилучшей оценкой
математического ожидания является среднее арифметическое, т.е.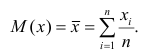
Оценкой дисперсии служит выборочная дисперсия, т.е.
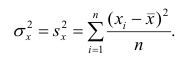
Тогда выборочный коэффициент корреляции
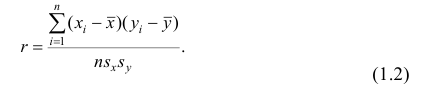
Коэффициент р называют также парным коэффициентом корреляции, а r— выборочным парным коэффициентом корреляции.
При совместном нормальном законе распределения случайных величин X и Y, используя рассмотренные выше параметры распределения и коэффициент корреляции, можно получить выражение для условного математического ожидания, т. е, записать выражение для функции регрессии одной случайной величины на другую. Так, функция регрессии Y на X имеет вид:
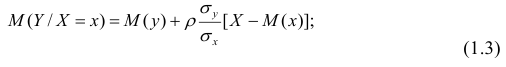
функция регрессии X на Y — следующий вид:
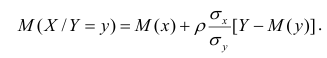
Выражения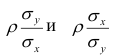 — называют коэффициентами регрессии.
— называют коэффициентами регрессии.
Подставив в (1.3) соответствующие оценки параметров, получим уравнения регрессии, график которых — прямая линия, проходящая через точку 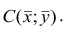 Запишем уравнение регрессии у на х и х на у:
Запишем уравнение регрессии у на х и х на у:
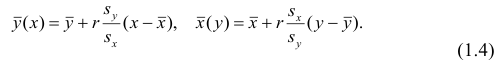
Таким образом, в корреляционном анализе на основе оценок параметров двумерной нормальной совокупности получаем оценки тесноты связи между случайными переменными и можем оценить регрессию одной переменной на другую. Особенностью корреляционного анализа является строго линейная зависимость между переменными. Это обусловливается исходными предпосылками. На практике корреляционный анализ можно применять для обработки наблюдений, сделанных на предприятиях при нормальных условиях работы, если случайные изменения свойства сырья или других факторов вызывают случайные изменения свойств продукции.
Свойства коэффициента корреляции
Коэффициент корреляции является одним из самых распространенных способов измерения связи между случайными переменными. Рассмотрим некоторые свойства этого коэффициента.
Теорема 1. Коэффициент корреляции принимает значения на интервале (-1, +1).
Доказательство. Докажем справедливость утверждения для случая дискретных переменных. Запишем явно неотрицательное выражение:
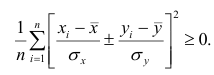
Возведём выражение под знаком суммы в квадрат:
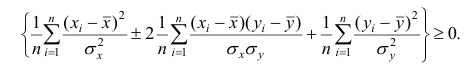
Первое и третье из слагаемых равны единице, поскольку из определения дисперсии следует, что 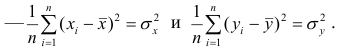
Таким образом, окончательно получаем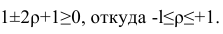
Если коэффициент корреляции положителен, то связь между переменными также положительна и значения переменных увеличиваются или уменьшаются одновременно. Если коэффициент корреляции имеет отрицательное значение, то при увеличении одной переменной уменьшается другая.
Приведём следующее важное свойство коэффициента корреляции: коэффициент корреляции не зависит от выбора начала отсчёта и единицы измерения, т. е. от любых постоянных  таких, что
таких, что т.е.
т.е.
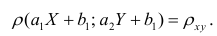
Таким образом, переменные X и У можно уменьшать или увеличивать в а раз, а также вычитать или прибавлять к значениям X и У одно и то же число b. В результате величина коэффициента корреляции не изменится.
Если коэффициент корреляции  то случайные переменные некоррелированы. Понятие некоррелированности не следует смешивать с понятием независимости, независимые величины всегда некоррелированы. Однако обратное утверждение невероятно: некоррелированные величины могут быть зависимы и даже функционально, однако эта связь не линейная.
то случайные переменные некоррелированы. Понятие некоррелированности не следует смешивать с понятием независимости, независимые величины всегда некоррелированы. Однако обратное утверждение невероятно: некоррелированные величины могут быть зависимы и даже функционально, однако эта связь не линейная.
Выборочный коэффициент корреляции вычисляют по формуле (1.2). Имеется несколько модификаций этой формулы, которые удобно использовать при той или иной форме представления исходной информации. Так, при малом числе наблюдений выборочный коэффициент корреляции удобно вычислять по формуле
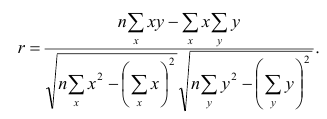
Если информация имеет вид корреляционной таблицы (см. п 1.5), то удобно пользоваться формулой
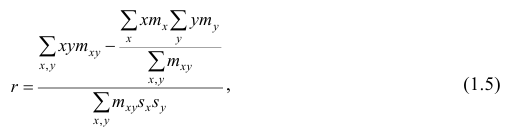
где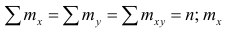 — суммарная частота наблюдаемого значенияпризнака х при всех значениях
— суммарная частота наблюдаемого значенияпризнака х при всех значениях 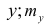 — суммарная частота наблюдаемого значения признака упри всех значениях х;
— суммарная частота наблюдаемого значения признака упри всех значениях х; 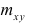 — частота появления пары признаков (x, у).
— частота появления пары признаков (x, у).
Из формулы (1.2) очевидно, что 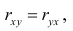 т.е. величина выборочного коэффициента корреляции не зависит от порядка следования переменных, поэтому обычно пишут просто r.
т.е. величина выборочного коэффициента корреляции не зависит от порядка следования переменных, поэтому обычно пишут просто r.
Поле корреляции. Вычисление оценок параметров двумерной модели
На практике для вычисления оценок параметров двумерной модели удобно использовать корреляционную таблицу и поле корреляции. Пусть, например, изучается зависимость между объёмом выполненных работ (у) и накладными расходами (x). Имеем выборку из генеральной совокупности, состоящую из 150 пар переменных  Считаем, что предпосылки корреляционного анализа выполнены.
Считаем, что предпосылки корреляционного анализа выполнены.
Пару случайных чисел  можно изобразить графически в виде точки с координатами
можно изобразить графически в виде точки с координатами . Аналогично можно изобразить весь набор пар случайных чисел (всю выборку). Однако при большом объёме выборки это затруднительно. Задача упрощается, если выборку упорядочить, т.е. переменные сгруппировать. Сгруппированные ряды могут быть как дискретными, так и интервальными.
. Аналогично можно изобразить весь набор пар случайных чисел (всю выборку). Однако при большом объёме выборки это затруднительно. Задача упрощается, если выборку упорядочить, т.е. переменные сгруппировать. Сгруппированные ряды могут быть как дискретными, так и интервальными.
По осям координат откладывают или дискретные значения переменных, или интервалы их изменения. Для интервального ряда наносят координатную сетку. Каждую пару переменных из данной выборки изображают в виде точки с соответствующими координатами для дискретного ряда или в виде точки в соответствующей клетке для интервального ряда. Такое изображение корреляционной зависимости называют полем корреляции. На рис. 1.1 изображено поле корреляции для выборки, состоящей из 150 пар переменных (ряд интервальный).
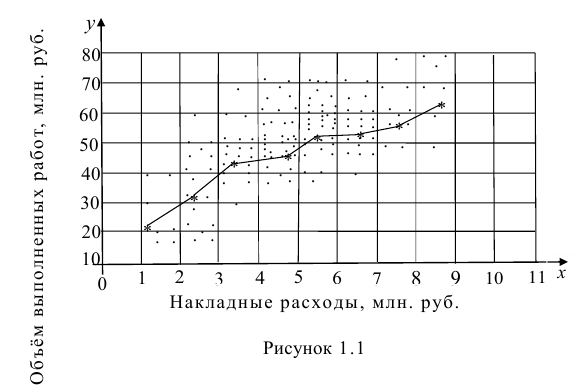
Если вычислить средние значения у в каждом интервале изменения х [обозначим их  )], нанести эти точки на рис. 1.1 и соединить между собой, то получим ломаную линию, по виду которой можно судить, как в среднем меняются у в зависимости от изменения х. По виду этой линии можно также сделать предположение о форме связи между переменными. В данном случае ломаную линию можно аппроксимировать прямой линией, так как она достаточно хорошо приближается к ней. По выборочным данным можно построить также корреляционную табл. 1.1.
)], нанести эти точки на рис. 1.1 и соединить между собой, то получим ломаную линию, по виду которой можно судить, как в среднем меняются у в зависимости от изменения х. По виду этой линии можно также сделать предположение о форме связи между переменными. В данном случае ломаную линию можно аппроксимировать прямой линией, так как она достаточно хорошо приближается к ней. По выборочным данным можно построить также корреляционную табл. 1.1.
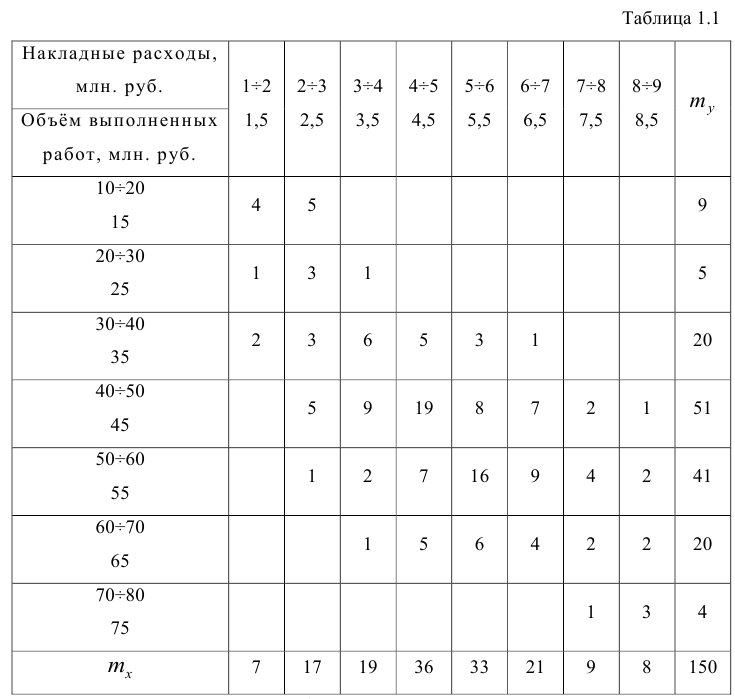
Корреляционную таблицу, как и поле корреляции, строят по
сгруппированному ряду (дискретному или интервальному). Табл. 1.1 построена на основе интервального ряда. В первой строке и первом столбце таблицы помещают интервалы изменения х и у и значения середин интервалов. Так, например, 1,5 — середина интервала изменения *=1-2,15— середина интервала изменения у= 10-20. В ячейки, образованные пересечением строк и столбцов, заносят частоты попадания пар значений (л у) в соответствующие интервалы по х и у. Например, частота 4 означает, что в интервал изменения у от 10 до 20 попало 4 пары наблюдавшихся значений. Эти частоты обозначают  В 9-й строке и 10-м столбце находятся значения
В 9-й строке и 10-м столбце находятся значения  — суммы
— суммы 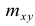 по соответствующим столбцу и строке.
по соответствующим столбцу и строке.
Как будет показано в дальнейшем, корреляционно таблицей удобно пользоваться при вычислении коэффициентов корреляций и параметров уравнений регрессии.
Корреляционная таблица построена на основе интервального ряда, поэтому для оценок параметров воспользуемся формулами гл. 1 для вычисления средней арифметической и дисперсии. Имеем:
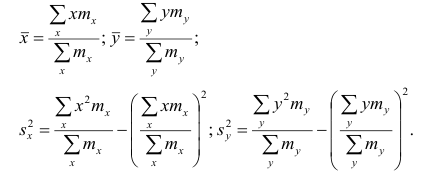 (1.6)
(1.6)
Проверка гипотезы о значимости коэффициента корреляции
На практике коэффициент корреляции р обычно неизвестен. По результатам выборки может быть найдена его точечная оценка — выборочный коэффициент корреляции r.
Равенство нулю выборочного коэффициента корреляции ещё не свидетельствует о равенстве нулю самого коэффициента корреляции, а следовательно, о некоррелированности случайных величин X и Y. Чтобы выяснить, находятся ли случайные величины в корреляционной зависимости, нужно проверить значимость выборочного коэффициента корреляции г, т.е. установить, достаточна ли его величина для обоснованного вывода о наличии корреляционной связи. Для этого проверяют нулевую гипотезу 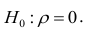 . Предполагается наличие двумерного нормального распределения случайных переменных; объём выборки может быть любым. Вычисляют
. Предполагается наличие двумерного нормального распределения случайных переменных; объём выборки может быть любым. Вычисляют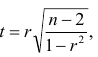
которая имеет распределение Стьюдента с k=n-2
степенями свободы. Для проверки нулевой гипотезы по уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (t-распределение; см. табл. 1 приложения) критическое значение 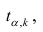 удовлетворяющее условию
удовлетворяющее условию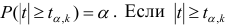 , то нулевую гипотезу об отсутствии корреляционной связи между переменными X и Y следует отвергнуть. Переменные считают зависимыми. При
, то нулевую гипотезу об отсутствии корреляционной связи между переменными X и Y следует отвергнуть. Переменные считают зависимыми. При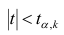 нет оснований отвергать нулевую гипотезу.
нет оснований отвергать нулевую гипотезу.
В случае значимого выборочного коэффициента, корреляции есть смысл построить доверительный интервал для коэффициента корреляций р. Однако для этого нужно знать закон распределения выборочного коэффициента корреляции r.
Плотность вероятности выборочного коэффициента корреляции имеет сложный вид, поэтому прибегают к специально подобранным функциям от выборочного коэффициента корреляции, которые сводятся к хорошо изученным распределениям, например нормальному или Стьюдента. Чаще всего для подбора функции применяют преобразование Фишера. Вычисляют статистику:
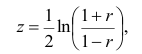
где r=thz — гиперболический тангенс от z.
Распределение статистики z хорошо аппроксимируется нормальным распределением с параметрами
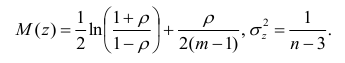
В этом, случае доверительный интервал для римеетвид Величины
Величины  находят по таблицам по следующим значениям:
находят по таблицам по следующим значениям:
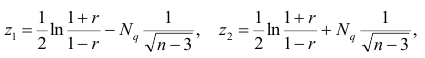
где 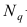 — нормированная функция Лапласа для q % доверительного интервала (см. табл. 2 приложений значение функции
— нормированная функция Лапласа для q % доверительного интервала (см. табл. 2 приложений значение функции 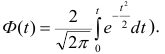
Если коэффициент корреляции значим, то коэффициенты регрессии также значимо отличаются от нуля, а интервальные оценки для них можно получить по следующим формулам:
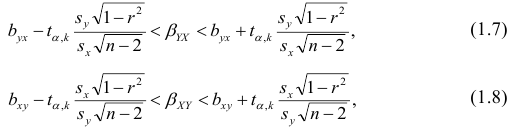
где 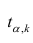 имеет распределение Стьюдента с k=n—2 степенями свободы.
имеет распределение Стьюдента с k=n—2 степенями свободы.
Корреляционное отношение
На практике часто предпосылки корреляционного анализа нарушаются: один из признаков оказывается величиной не случайной, или признаки не имеют совместного нормального распределения. Однако статистическая зависимость между ними существует. Для изучения связи между признаками в этом случае существует общий показатель зависимости признаков, основанный на показателе изменчивости — общей (или полной) дисперсии.
Полной называется дисперсия признака относительно его математического ожидания. Так, для признака Y это 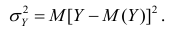 Дисперсию
Дисперсию 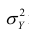 можно разложить на две составляющие, одна из которых характеризует влияние фактора X на Y, другая — влияние прочих факторов.
можно разложить на две составляющие, одна из которых характеризует влияние фактора X на Y, другая — влияние прочих факторов.
Очевидно, чем меньше влияние прочих факторов, тем теснее связь, тем более приближается она к функциональной. Представим 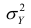 в следующем виде:
в следующем виде:
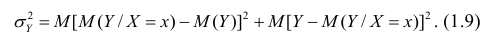
Первое слагаемое обозначим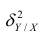 Это дисперсия функции регрессии относительно математического ожидания признака (в данном случае признака У);.она измеряет влияние признака X на Y. Второе слагаемое обозначим
Это дисперсия функции регрессии относительно математического ожидания признака (в данном случае признака У);.она измеряет влияние признака X на Y. Второе слагаемое обозначим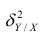 . Это дисперсия признака Y относительно функции регрессии. Её называют также средней из условных дисперсий или остаточной дисперсией
. Это дисперсия признака Y относительно функции регрессии. Её называют также средней из условных дисперсий или остаточной дисперсией 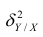 измеряет влияние на Y прочих факторов.
измеряет влияние на Y прочих факторов.
Покажем, что 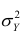 действительно можно разложить на два таких слагаемых:
действительно можно разложить на два таких слагаемых:
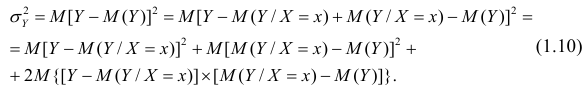
Для простоты полагаем распределение дискретным. Имеем 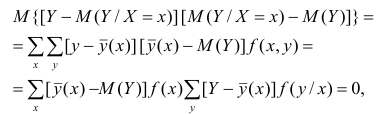
так как при любом х справедливо равенство
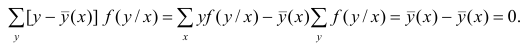
Третье слагаемое в равенстве (1.10) равно нулю, поэтому равенство (1.9) справедливо. Поскольку второе слагаемое в равенстве (1.9) оценивает влияние признака X на Y, то его можно использовать для оценки тесноты связи между X и Y. Тесноту связи удобно оценивать в единицах общей дисперсии 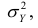 т.е. рассматривать отношение
т.е. рассматривать отношение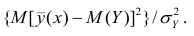 . Эту величину обозначают
. Эту величину обозначают 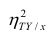 и называют теоретическим корреляционным отношением. Таким образом,
и называют теоретическим корреляционным отношением. Таким образом,
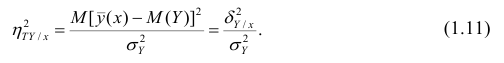
Разделив обе части равенства (1.9) на 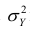 получим
получим
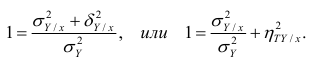
Из последней формулы имеем

Поскольку 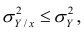 так как
так как 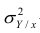 — составная часть
— составная часть 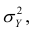 то из равенства (1.12) следует, что значение
то из равенства (1.12) следует, что значение 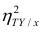 всегда заключено между нулем и единицей.
всегда заключено между нулем и единицей.
Все сделанные выводы справедливы и для 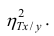 Из равенства (1.12)
Из равенства (1.12)
следует, что 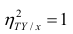 только тогда, когда
только тогда, когда 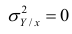 , т.е. отсутствует влияние прочих факторов и всё распределение сконцентрировано на кривой регрессии
, т.е. отсутствует влияние прочих факторов и всё распределение сконцентрировано на кривой регрессии  . В этом случае между Y и X существует функциональная зависимость.
. В этом случае между Y и X существует функциональная зависимость.
Далее, из равенства (1.12) следует, что  тогда и только тогда, когда
тогда и только тогда, когда
 = const, т.е. линия регрессии У по X — горизонтальная прямая, проходящая через центр распределения. В этом случае можно сказать, что переменная У не коррелирована с X (рис. 1.2,а, б, в).
= const, т.е. линия регрессии У по X — горизонтальная прямая, проходящая через центр распределения. В этом случае можно сказать, что переменная У не коррелирована с X (рис. 1.2,а, б, в).
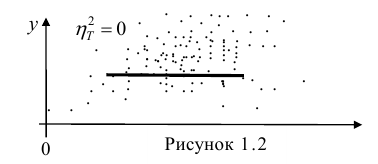
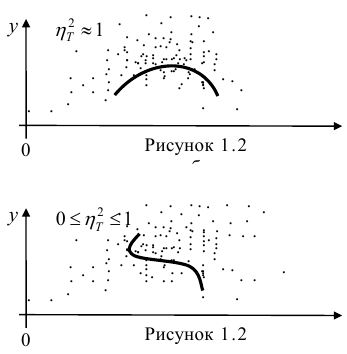
Аналогичными свойствами обладает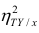 — показатель тесноты связи между X и У.
— показатель тесноты связи между X и У.
Часто используют величину

Считают, что она не может быть отрицательной. Значения величины  также могут находиться лишь в пределах от нуля до единицы. Это очевидно из формулы (1.13).
также могут находиться лишь в пределах от нуля до единицы. Это очевидно из формулы (1.13).
Значения лежащие в интервале
лежащие в интервале являются показателями тесноты группировки точек около кривой регрессии независимо от её вида (формы связи). Корреляционное отношение
являются показателями тесноты группировки точек около кривой регрессии независимо от её вида (формы связи). Корреляционное отношение  связано
связано 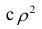 следующим образом:
следующим образом: 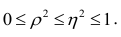 В случае линейной зависимости между переменными
В случае линейной зависимости между переменными 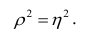
Разность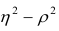 может быть использована как показатель нелинейности связи между переменными.
может быть использована как показатель нелинейности связи между переменными.
При вычислении 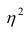 по выборочным данным получаем выборочное корреляционное отношение. Обозначим его
по выборочным данным получаем выборочное корреляционное отношение. Обозначим его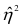 . Вместо дисперсий в этом случае используются их оценки. Тогда формула (1.12) принимает вид
. Вместо дисперсий в этом случае используются их оценки. Тогда формула (1.12) принимает вид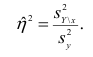
Понятие о многомерном корреляционном анализе
Частный коэффициент корреляции. Основные понятия корреляционного анализа, введенные для двумерной модели, можно распространить на многомерный случай. Задачи и предпосылки корреляционного анализа были сформулированы в п. 1.3. Однако если при изучении взаимосвязи переменных по двумерной модели мы ограничивались рассмотрением парных коэффициентов корреляции, то для многомерной модели этого недостаточно. Многообразие связей между переменными находит отражение в частных и множественных коэффициентах корреляции.
Пусть имеется многомерная нормальная совокупность с m признаками 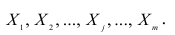 В этом случае взаимозависимость между признаками
В этом случае взаимозависимость между признаками
можно описать корреляционной матрицей. Под корреляционной матрицей будем понимать, матрицу, составленную из парных коэффициентов корреляции (вычисляются по формуле (1,1)):
где 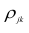 — парные коэффициенты корреляции; m — порядок матрицы.
— парные коэффициенты корреляции; m — порядок матрицы.
Оценкой парного коэффициента корреляции является выборочный парный коэффициент корреляции, определяемый по формуле (1.2), однако для m признаков формула (9.2) принимает вид
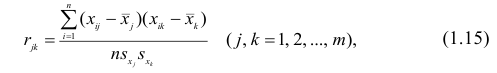
где 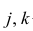 — порядковые номера признаков.
— порядковые номера признаков.
Как и в двумерном случае, для оценки коэффициента корреляции необходимо оценить математические ожидания и дисперсии. В многомерном корреляционном анализе имеем т математических ожиданий и m дисперсий, а также m(m—1)/2 парных коэффициентов корреляции. Таким образом, нужно произвести оценку 2m+m(m—1)/2 параметров.
В случае многомерной корреляции зависимости между признаками более многообразны и сложны, чем в двумерном случае. Одной корреляционной матрицей нельзя полностью описать зависимости между признаками. Введём понятие частного коэффициента корреляции l-го порядка.
Пусть исходная совокупность состоит из т признаков. Можно изучать зависимости между двумя из них при фиксированном значении l признаков из m-2 оставшихся. Рассмотрим, например, систему из 5 признаков. Изучим зависимости между 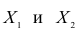 при фиксированном значении признака
при фиксированном значении признака 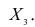 В этом случае имеем частный коэффициент корреляции первого порядка, так как фиксируем только один признак.
В этом случае имеем частный коэффициент корреляции первого порядка, так как фиксируем только один признак.
Рассмотрим более подробно структуру частных коэффициентов корреляции на примере системы из трёх признаков 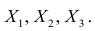 . Эта система позволяет изучить частные коэффициенты корреляции только первого порядка, так как нельзя фиксировать больше одного признака. Частный коэффициент корреляции первого порядка для признаков
. Эта система позволяет изучить частные коэффициенты корреляции только первого порядка, так как нельзя фиксировать больше одного признака. Частный коэффициент корреляции первого порядка для признаков при фиксированном значении
при фиксированном значении  выражается через парные коэффициенты
выражается через парные коэффициенты
корреляции и имеет вид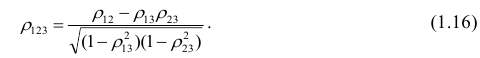
Частный коэффициент корреляции, так же как и парный коэффициент корреляции, изменяется от —1 до +1, В общем виде, когда система состоит из m признаков, частный коэффициент корреляции l-го порядка может быть найден из корреляционной матрицы. Если 1=m—2, то рассматривается матрица порядка m, при — подматрица порядкаl+2, составленная из элементов матрицы
— подматрица порядкаl+2, составленная из элементов матрицы  , которые отвечают индексам коэффициента частной
, которые отвечают индексам коэффициента частной
корреляции. Например, корреляционная матрица системы из пяти признаков имеет вид
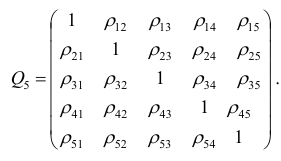
Для определения частного коэффициента корреляции второго порядка, например следует использовать подматрицу четвертого порядка,
следует использовать подматрицу четвертого порядка,
вычеркнув из исходной матрицы  третью строку и третий столбец, так как признак
третью строку и третий столбец, так как признак 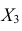 не рассматривают.
не рассматривают.
В общем виде формулу частного коэффициента корреляции l-го порядка (1=m—2) можно записать в виде
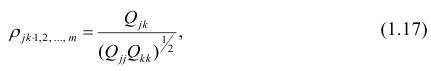
где 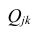 — алгебраические дополнения к элементу
— алгебраические дополнения к элементу 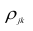 корреляционной
корреляционной
матрицы 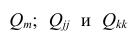 — алгебраические дополнения к элементам
— алгебраические дополнения к элементам 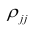 и ркк корреляционной матрицы
и ркк корреляционной матрицы 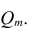
Очевидно, что выражение (1.16) является частым случаем выражения (1.17), в чём легко убедиться, рассмотрев корреляционную матрицу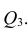
Оценкой частного коэффициента корреляции l-го порядка является выборочный частный коэффициент корреляции l-го порядка. Он вычисляется на основе корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции:
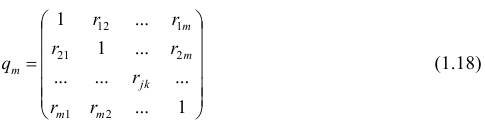
Формула выборочного частного коэффициента корреляции имеет вид

где 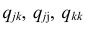 — алгебраические дополнения к соответствующим элементам матрицы (1.18).
— алгебраические дополнения к соответствующим элементам матрицы (1.18).
Частный коэффициент корреляции l-го порядка, вызволенный на основе п наблюдений над признаками, имеет такое же распределение, что и парный коэффициент корреляции, вычисленный  наблюдениям. Поэтому значимость частных коэффициентов корреляции оценивают так же, как и в п. 1.6.
наблюдениям. Поэтому значимость частных коэффициентов корреляции оценивают так же, как и в п. 1.6.
Множественный коэффициент корреляции
Часто представляет интерес оценить связь одного из признаков со всеми остальными. Это можно сделать с помощью множественного, или совокупного, коэффициента корреляции

где  —определитель корреляционной матрицы
—определитель корреляционной матрицы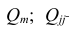 —алгебраическое
—алгебраическое
дополнение к элементу 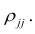
Квадрат коэффициента множественной корреляции 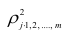 называется
называется
множественным коэффициентом детерминации. Коэффициенты множественной корреляции и детерминации — величины положительные, принимающие значения в интервале Оценками этих
Оценками этих
коэффициентов являются выборочные множественные коэффициенты корреляции и детерминации, которые обозначают соответственно 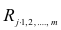 и
и
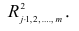 Формула для вычисления выборочного множественного коэффициента корреляции имеет вид
Формула для вычисления выборочного множественного коэффициента корреляции имеет вид

где 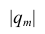 —определитель корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции;
—определитель корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции; 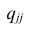 алгебраическое дополнение к элементу
алгебраическое дополнение к элементу 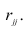
Многомерный корреляционный анализ позволяет получить оценку функции регрессии — уравнение регрессии. Коэффициенты в уравнении регрессии можно найти непосредственно через выборочные парные коэффициенты корреляции или воспользоваться методом многомерной регрессии, который мы рассмотрим в вопросе 2.7. В этом случае все предпосылки регрессионного анализа оказываются выполненными и, кроме того, связь между переменными строго линейна.
Ранговая корреляция
В некоторых случаях встречаются признаки, не поддающиеся количественной оценке (назовём такие признаки объектами). Попытаемся, например, оценить соотношение между математическими и музыкальными способностями группы учащихся. «Уровень способностей» является переменной величиной в том смысле; что он варьирует от одного индивидуума к другому. Его можно измерить, если выставлять каждому индивидууму отметки. Однако этот способ лишен объективности, так как разные экзаменаторы могут выставить одному и тому же учащемуся разные отметки. Элемент субъективизма можно исключить, если учащиеся будут ранжированы. Расположим учащихся по порядку, в соответствии со степенью способностей и присвоим каждому из них порядковый номер, который назовем рангом. Корреляция между рангами более точно отражает соотношение между способностями учащихся, чем корреляция между отметками.
Тесноту связи между рангами измеряют так же, как и между признаками. Рассмотрим уже известную формулу коэффициента корреляции
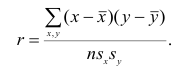
Пусть 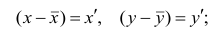 тогда, учитывая,
тогда, учитывая,
что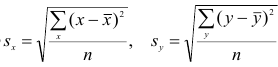 ,можно записать
,можно записать

В зависимости от того, что принять за меру различия между величинами  можно получить различные коэффициенты связи между рангами. Обычно используют коэффициент корреляции рангов Кэнделла
можно получить различные коэффициенты связи между рангами. Обычно используют коэффициент корреляции рангов Кэнделла 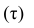 и коэффициент корреляции рангов Спирмэна р.
и коэффициент корреляции рангов Спирмэна р.
Введём следующую меру различия между объектами: будем считать 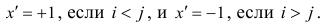 Поясним сказанное на примере. Имеем две последовательности:
Поясним сказанное на примере. Имеем две последовательности:
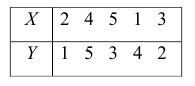
Рассмотрим отдельно каждую из них. В последовательности X первой паре элементов —2; 4 припишем значение +1, так как второй паре 2; 5 также припишем значение +1, третьей паре 2; 1 припишем значение —1, поскольку
второй паре 2; 5 также припишем значение +1, третьей паре 2; 1 припишем значение —1, поскольку 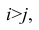 и т.д. Последовательно перебираем все пары, причём каждая пара должна быть учтена один раз. Так, если учтена пара 2; 1, то не следует учитывать пару 1; 2. Аналогичные действия проделаем с последовательностью У, причём порядок перебора пар должен в точности повторять порядок перебора пар в последовательности X. Результаты этих действий представим в виде табл. 1.3.
и т.д. Последовательно перебираем все пары, причём каждая пара должна быть учтена один раз. Так, если учтена пара 2; 1, то не следует учитывать пару 1; 2. Аналогичные действия проделаем с последовательностью У, причём порядок перебора пар должен в точности повторять порядок перебора пар в последовательности X. Результаты этих действий представим в виде табл. 1.3.
Рассмотрим формулу ( 1 .22). В нашем случае и равна
и равна
количеству пар, участвовавших в переборе. Каждая пара встречается только один раз, поэтому их общее количество равно числу сочетаний из n по 2, т.е. Обозначая
Обозначая 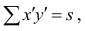 получаем формулу коэффициента корреляции рангов Кэнделла:
получаем формулу коэффициента корреляции рангов Кэнделла:
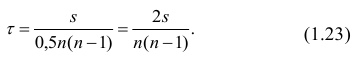
Теперь рассмотрим другую меру различия между объектами. Если обозначить через 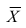 средний ранг последовательности X, через
средний ранг последовательности X, через 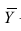 — средний ранг последовательности Т, то
— средний ранг последовательности Т, то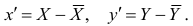 Поскольку ранги последовательности X и Y есть числа натурального ряда, то их сумма равна
Поскольку ранги последовательности X и Y есть числа натурального ряда, то их сумма равна 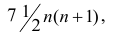 а средний ранг
а средний ранг 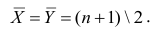
Тогда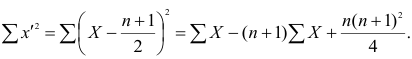 Сумма
Сумма
чисел натурального ряда равна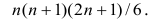
Тогда 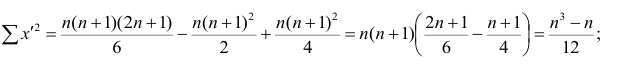
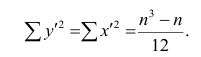
Введём новую величину d, равную разности между рангами: d=X—Y, и определим через неё величину . Имеем:
. Имеем: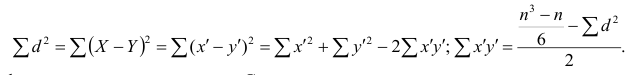
Коэффициент корреляции рангов Спирмэна

У коэффициентов  разные масштабы, они отличаются шкалами измерений. Поэтому на практике нельзя ожидать, что они совпадут. Чаще всего, если значения обоих коэффициентов не слишком, близки к 1, p; по абсолютной величине примерно на 50% превышает
разные масштабы, они отличаются шкалами измерений. Поэтому на практике нельзя ожидать, что они совпадут. Чаще всего, если значения обоих коэффициентов не слишком, близки к 1, p; по абсолютной величине примерно на 50% превышает Выведены неравенства, связывающие
Выведены неравенства, связывающие Например, при больших n можно пользоваться следующим приближённым соотношением:
Например, при больших n можно пользоваться следующим приближённым соотношением: 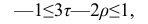 или
или
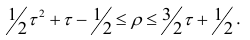 Коэффициент p легче рассчитать, однако с теоретической точки зрения больший интерес представляет коэффициент
Коэффициент p легче рассчитать, однако с теоретической точки зрения больший интерес представляет коэффициент
При вычислении коэффициента корреляций рангов Кэнделла для подсчёта s можно использовать следующий приём: одну из последовательностей упорядочивают так, чтобы её элементы были числами натурального ряда; соответственно изменяют и другую последовательность. Тогда сумму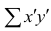 можно подсчитывать лишь по последовательности К, так как все
можно подсчитывать лишь по последовательности К, так как все 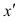 равны +1.
равны +1.
Если нельзя установить ранговое различие нескольких объектов, говорят, что такие объекты являются связанными. В этом случае объектам приписывается средний ранг. Например, если связанными являются объекты 4 и 5, то им приписывают ранг 4.5; если связанными являются объекты 1, 2, 3, 4 и 5, то их средний ранг (1+2+3+4+5)/5=3. Сумма рангов связанных объектов должна быть равна сумме рангов при ранжировании без связей. Формулы коэффициентов корреляции для 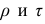 в этом случае также можно вывести из формулы обобщённого коэффициента корреляции, только знаменатель выражения (1.21) в этом случае не равен n(n—1)/2. Если / последовательных членов связаны, то все оценки, относящиеся к любой вобранной из них паре, равны нулю; число таких пар t(t—1), Следовательно,
в этом случае также можно вывести из формулы обобщённого коэффициента корреляции, только знаменатель выражения (1.21) в этом случае не равен n(n—1)/2. Если / последовательных членов связаны, то все оценки, относящиеся к любой вобранной из них паре, равны нулю; число таких пар t(t—1), Следовательно,
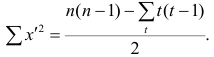 Соответственно для другой последовательности
Соответственно для другой последовательности
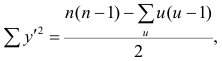
где t и u—число связанных пар в последовательностях.
Обозначая 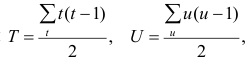 получаем
получаем
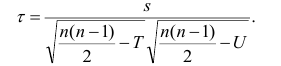
Аналогично находим выражение для р. Только в этом случае
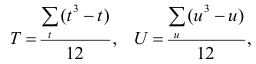 , где е и г — число связанных пар в
, где е и г — число связанных пар в
последовательностях, а
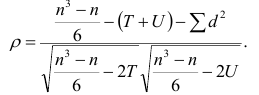
Если имеется несколько последовательностей, то возникает необходимость определить общую меру согласованности между ними. Такой мерой является коэффициент копкордации.
Пусть ь — число последовательностей, т — количество рангов в каждой последовательности. Тогда коэффициент конкордации

где d — фактически встречающееся отклонение от среднего значения суммы рангов одного объекта.
Коэффициент корреляции рангов может быть использован для быстрого оценивания взаимосвязи между признаками, не имеющими нормального распределения, и полезен в тех случаях, когда признаки поддаются ранжированию, но не могут быть точно измерены.
Пример:
Для данных табл. 13 найти выборочный коэффициент корреляции, проверить его значимость на уровне 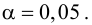
Решение. Для вычислений составим таблицу. Находим суммы
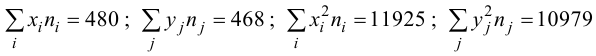 и заносим их в таблицу. Вычислим
и заносим их в таблицу. Вычислим
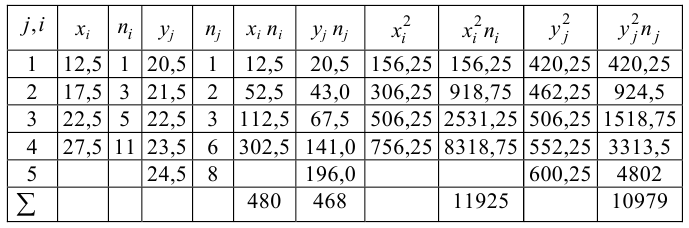
Подставляя полученные значения сумм в (8), найдем выборочный коэффициент корреляции
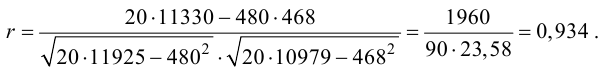
Проверим значимость  на уровне
на уровне  Для этого вычислим статистику
Для этого вычислим статистику
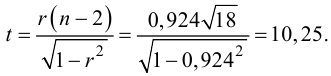
По таблице распределения П6 Стьюдента 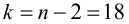 находим критическое значение
находим критическое значение 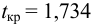 Так как
Так как 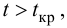 то считаем
то считаем  значимым.
значимым.
Пример:
Для данных табл. 13 найти корреляционное отношение 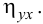
Для вычисления эмпирического корреляционного отношения найдем групповые средние 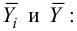
Тогда
Вычисляем корреляционное отношение
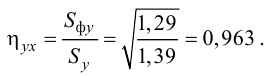
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Статистическая проверка гипотез
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
- Регрессионный анализ