Хеш-таблицы
Время на прочтение
9 мин
Количество просмотров 190K
Предисловие
Я много раз заглядывал на просторы интернета, нашел много интересных статей о хеш-таблицах, но вразумительного и полного описания того, как они реализованы, так и не нашел. В связи с этим мне просто нетерпелось написать пост на данную, столь интересную, тему.
Возможно, она не столь полезна для опытных программистов, но будет интересна для студентов технических ВУЗов и начинающих программистов-самоучек.

Мотивация использовать хеш-таблицы
Для наглядности рассмотрим стандартные контейнеры и асимптотику их наиболее часто используемых методов.
Все данные при условии хорошо выполненных контейнерах, хорошо подобранных хеш-функциях
Из этой таблицы очень хорошо понятно, почему же стоит использовать хеш-таблицы. Но тогда возникает противоположный вопрос: почему же тогда ими не пользуются постоянно?
Ответ очень прост: как и всегда, невозможно получить все сразу, а именно: и скорость, и память. Хеш-таблицы тяжеловесные, и, хоть они и быстро отвечают на вопросы основных операций, пользоваться ими все время очень затратно.
Понятие хеш-таблицы
Хеш-таблица — это контейнер, который используют, если хотят быстро выполнять операции вставки/удаления/нахождения. В языке C++ хеш-таблицы скрываются под флагом unoredered_set и unordered_map. В Python вы можете использовать стандартную коллекцию set — это тоже хеш-таблица.
Реализация у нее, возможно, и не очевидная, но довольно простая, а главное — как же круто использовать хеш-таблицы, а для этого лучше научиться, как они устроены.
Для начала объяснение в нескольких словах. Мы определяем функцию хеширования, которая по каждому входящему элементу будет определять натуральное число. А уже дальше по этому натуральному числу мы будем класть элемент в (допустим) массив. Тогда имея такую функцию мы можем за O(1) обработать элемент.
Теперь стало понятно, почему же это именно хеш-таблица.
Проблема коллизии
Естественно, возникает вопрос, почему невозможно такое, что мы попадем дважды в одну ячейку массива, ведь представить функцию, которая ставит в сравнение каждому элементу совершенно различные натуральные числа просто невозможно. Именно так возникает проблема коллизии, или проблемы, когда хеш-функция выдает одинаковое натуральное число для разных элементов.
Существует несколько решений данной проблемы: метод цепочек и метод двойного хеширования. В данной статье я постараюсь рассказать о втором методе, как о более красивом и, возможно, более сложном.
Решения проблемы коллизии методом двойного хеширования
Мы будем (как несложно догадаться из названия) использовать две хеш-функции, возвращающие взаимопростые натуральные числа.
Одна хеш-функция (при входе g) будет возвращать натуральное число s, которое будет для нас начальным. То есть первое, что мы сделаем, попробуем поставить элемент g на позицию s в нашем массиве. Но что, если это место уже занято? Именно здесь нам пригодится вторая хеш-функция, которая будет возвращать t — шаг, с которым мы будем в дальнейшем искать место, куда бы поставить элемент g.
Мы будем рассматривать сначала элемент s, потом s + t, затем s + 2*t и т.д. Естественно, чтобы не выйти за границы массива, мы обязаны смотреть на номер элемента по модулю (остатку от деления на размер массива).
Наконец мы объяснили все самые важные моменты, можно перейти к непосредственному написанию кода, где уже можно будет рассмотреть все оставшиеся нюансы. Ну а строгое математическое доказательство корректности использования двойного хеширования можно найти тут.
Реализация хеш-таблицы
Для наглядности будем реализовывать хеш-таблицу, хранящую строки.
Начнем с определения самих хеш-функций, реализуем их методом Горнера. Важным параметром корректности хеш-функции является то, что возвращаемое значение должно быть взаимопросто с размером таблицы. Для уменьшения дублирования кода, будем использовать две структуры, ссылающиеся на реализацию самой хеш-функции.
int HashFunctionHorner(const std::string& s, int table_size, const int key)
{
int hash_result = 0;
for (int i = 0; s[i] != s.size(); ++i)
hash_result = (key * hash_result + s[i]) % table_size;
hash_result = (hash_result * 2 + 1) % table_size;
return hash_result;
}
struct HashFunction1
{
int operator()(const std::string& s, int table_size) const
{
return HashFunctionHorner(s, table_size, table_size - 1); // ключи должны быть взаимопросты, используем числа <размер таблицы> плюс и минус один.
}
};
struct HashFunction2
{
int operator()(const std::string& s, int table_size) const
{
return HashFunctionHorner(s, table_size, table_size + 1);
}
};Чтобы идти дальше, нам необходимо разобраться с проблемой: что же будет, если мы удалим элемент из таблицы? Так вот, его нужно пометить флагом deleted, но просто удалять его безвозвратно нельзя. Ведь если мы так сделаем, то при попытке найти элемент (значение хеш-функции которого совпадет с ее значением у нашего удаленного элемента) мы сразу наткнемся на пустую ячейку. А это значит, что такого элемента и не было никогда, хотя, он лежит, просто где-то дальше в массиве. Это основная сложность использования данного метода решения коллизий.
Помня о данной проблеме построим наш класс.
template <class T, class THash1 = HashFunction1, class THash2 = HashFunction2>
class HashTable
{
static const int default_size = 8; // начальный размер нашей таблицы
constexpr static const double rehash_size = 0.75; // коэффициент, при котором произойдет увеличение таблицы
struct Node
{
T value;
bool state; // если значение флага state = false, значит элемент массива был удален (deleted)
Node(const T& value_) : value(value_), state(true) {}
};
Node** arr; // соответственно в массиве будут хранится структуры Node*
int size; // сколько элементов у нас сейчас в массиве (без учета deleted)
int buffer_size; // размер самого массива, сколько памяти выделено под хранение нашей таблицы
int size_all_non_nullptr; // сколько элементов у нас сейчас в массиве (с учетом deleted)
};На данном этапе мы уже более-менее поняли, что у нас будет храниться в таблице. Переходим к реализации служебных методов.
...
public:
HashTable()
{
buffer_size = default_size;
size = 0;
size_all_non_nullptr = 0;
arr = new Node*[buffer_size];
for (int i = 0; i < buffer_size; ++i)
arr[i] = nullptr; // заполняем nullptr - то есть если значение отсутствует, и никто раньше по этому адресу не обращался
}
~HashTable()
{
for (int i = 0; i < buffer_size; ++i)
if (arr[i])
delete arr[i];
delete[] arr;
}Из необходимых методов осталось еще реализовать динамическое увеличение, расширение массива — метод Resize.
Увеличиваем размер мы стандартно вдвое.
void Resize()
{
int past_buffer_size = buffer_size;
buffer_size *= 2;
size_all_non_nullptr = 0;
size = 0;
Node** arr2 = new Node * [buffer_size];
for (int i = 0; i < buffer_size; ++i)
arr2[i] = nullptr;
std::swap(arr, arr2);
for (int i = 0; i < past_buffer_size; ++i)
{
if (arr2[i] && arr2[i]->state)
Add(arr2[i]->value); // добавляем элементы в новый массив
}
// удаление предыдущего массива
for (int i = 0; i < past_buffer_size; ++i)
if (arr2[i])
delete arr2[i];
delete[] arr2;
}Немаловажным является поддержание асимптотики O(1) стандартных операций. Но что же может повлиять на скорость работы? Наши удаленные элементы (deleted). Ведь, как мы помним, мы ничего не можем с ними сделать, но и окончательно обнулить их не можем. Так что они тянутся за нами огромным балластом. Для ускорения работы нашей хеш-таблицы воспользуемся рехешом (как мы помним, мы уже выделяли под это очень странные переменные).
Теперь воспользуемся ими, если процент реальных элементов массива стал меньше 50, мы производим Rehash, а именно делаем то же самое, что и при увеличении таблицы (resize), но не увеличиваем. Возможно, это звучит глуповато, но попробую сейчас объяснить. Мы вызовем наши хеш-функции от всех элементов, переместим их в новых массив. Но с deleted-элементами это не произойдет, мы не будем их перемещать, и они удалятся вместе со старой таблицей.
Но к чему слова, код все разъяснит:
void Rehash()
{
size_all_non_nullptr = 0;
size = 0;
Node** arr2 = new Node * [buffer_size];
for (int i = 0; i < buffer_size; ++i)
arr2[i] = nullptr;
std::swap(arr, arr2);
for (int i = 0; i < buffer_size; ++i)
{
if (arr2[i] && arr2[i]->state)
Add(arr2[i]->value);
}
// удаление предыдущего массива
for (int i = 0; i < buffer_size; ++i)
if (arr2[i])
delete arr2[i];
delete[] arr2;
}Ну теперь мы уже точно на финальной, хоть и длинной, и полной колючих кустарников, прямой. Нам необходимо реализовать вставку (Add), удаление (Remove) и поиск (Find) элемента.
Начнем с самого простого — метод Find элемент по значению.
bool Find(const T& value, const THash1& hash1 = THash1(), const THash2& hash2 = THash2())
{
int h1 = hash1(value, buffer_size); // значение, отвечающее за начальную позицию
int h2 = hash2(value, buffer_size); // значение, ответственное за "шаг" по таблице
int i = 0;
while (arr[h1] != nullptr && i < buffer_size)
{
if (arr[h1]->value == value && arr[h1]->state)
return true; // такой элемент есть
h1 = (h1 + h2) % buffer_size;
++i; // если у нас i >= buffer_size, значит мы уже обошли абсолютно все ячейки, именно для этого мы считаем i, иначе мы могли бы зациклиться.
}
return false;
}Далее мы реализуем удаление элемента — Remove. Как мы это делаем? Находим элемент (как в методе Find), а затем удаляем, то есть просто меняем значение state на false, но сам Node мы не удаляем.
bool Remove(const T& value, const THash1& hash1 = THash1(), const THash2& hash2 = THash2())
{
int h1 = hash1(value, buffer_size);
int h2 = hash2(value, buffer_size);
int i = 0;
while (arr[h1] != nullptr && i < buffer_size)
{
if (arr[h1]->value == value && arr[h1]->state)
{
arr[h1]->state = false;
--size;
return true;
}
h1 = (h1 + h2) % buffer_size;
++i;
}
return false;
}Ну и последним мы реализуем метод Add. В нем есть несколько очень важных нюансов. Именно здесь мы будем проверять на необходимость рехеша.
Помимо этого в данном методе есть еще одна часть, поддерживающая правильную асимптотику. Это запоминание первого подходящего для вставки элемента (даже если он deleted). Именно туда мы вставим элемент, если в нашей хеш-таблицы нет такого же. Если ни одного deleted-элемента на нашем пути нет, мы создаем новый Node с нашим вставляемым значением.
bool Add(const T& value, const THash1& hash1 = THash1(),const THash2& hash2 = THash2())
{
if (size + 1 > int(rehash_size * buffer_size))
Resize();
else if (size_all_non_nullptr > 2 * size)
Rehash(); // происходит рехеш, так как слишком много deleted-элементов
int h1 = hash1(value, buffer_size);
int h2 = hash2(value, buffer_size);
int i = 0;
int first_deleted = -1; // запоминаем первый подходящий (удаленный) элемент
while (arr[h1] != nullptr && i < buffer_size)
{
if (arr[h1]->value == value && arr[h1]->state)
return false; // такой элемент уже есть, а значит его нельзя вставлять повторно
if (!arr[h1]->state && first_deleted == -1) // находим место для нового элемента
first_deleted = h1;
h1 = (h1 + h2) % buffer_size;
++i;
}
if (first_deleted == -1) // если не нашлось подходящего места, создаем новый Node
{
arr[h1] = new Node(value);
++size_all_non_nullptr; // так как мы заполнили один пробел, не забываем записать, что это место теперь занято
}
else
{
arr[first_deleted]->value = value;
arr[first_deleted]->state = true;
}
++size; // и в любом случае мы увеличили количество элементов
return true;
}В заключение приведу полную реализацию хеш-таблицы.
int HashFunctionHorner(const std::string& s, int table_size, const int key)
{
int hash_result = 0;
for (int i = 0; s[i] != s.size(); ++i)
{
hash_result = (key * hash_result + s[i]) % table_size;
}
hash_result = (hash_result * 2 + 1) % table_size;
return hash_result;
}
struct HashFunction1
{
int operator()(const std::string& s, int table_size) const
{
return HashFunctionHorner(s, table_size, table_size - 1);
}
};
struct HashFunction2
{
int operator()(const std::string& s, int table_size) const
{
return HashFunctionHorner(s, table_size, table_size + 1);
}
};
template <class T, class THash1 = HashFunction1, class THash2 = HashFunction2>
class HashTable
{
static const int default_size = 8;
constexpr static const double rehash_size = 0.75;
struct Node
{
T value;
bool state;
Node(const T& value_) : value(value_), state(true) {}
};
Node** arr;
int size;
int buffer_size;
int size_all_non_nullptr;
void Resize()
{
int past_buffer_size = buffer_size;
buffer_size *= 2;
size_all_non_nullptr = 0;
size = 0;
Node** arr2 = new Node * [buffer_size];
for (int i = 0; i < buffer_size; ++i)
arr2[i] = nullptr;
std::swap(arr, arr2);
for (int i = 0; i < past_buffer_size; ++i)
{
if (arr2[i] && arr2[i]->state)
Add(arr2[i]->value);
}
for (int i = 0; i < past_buffer_size; ++i)
if (arr2[i])
delete arr2[i];
delete[] arr2;
}
void Rehash()
{
size_all_non_nullptr = 0;
size = 0;
Node** arr2 = new Node * [buffer_size];
for (int i = 0; i < buffer_size; ++i)
arr2[i] = nullptr;
std::swap(arr, arr2);
for (int i = 0; i < buffer_size; ++i)
{
if (arr2[i] && arr2[i]->state)
Add(arr2[i]->value);
}
for (int i = 0; i < buffer_size; ++i)
if (arr2[i])
delete arr2[i];
delete[] arr2;
}
public:
HashTable()
{
buffer_size = default_size;
size = 0;
size_all_non_nullptr = 0;
arr = new Node*[buffer_size];
for (int i = 0; i < buffer_size; ++i)
arr[i] = nullptr;
}
~HashTable()
{
for (int i = 0; i < buffer_size; ++i)
if (arr[i])
delete arr[i];
delete[] arr;
}
bool Add(const T& value, const THash1& hash1 = THash1(),const THash2& hash2 = THash2())
{
if (size + 1 > int(rehash_size * buffer_size))
Resize();
else if (size_all_non_nullptr > 2 * size)
Rehash();
int h1 = hash1(value, buffer_size);
int h2 = hash2(value, buffer_size);
int i = 0;
int first_deleted = -1;
while (arr[h1] != nullptr && i < buffer_size)
{
if (arr[h1]->value == value && arr[h1]->state)
return false;
if (!arr[h1]->state && first_deleted == -1)
first_deleted = h1;
h1 = (h1 + h2) % buffer_size;
++i;
}
if (first_deleted == -1)
{
arr[h1] = new Node(value);
++size_all_non_nullptr;
}
else
{
arr[first_deleted]->value = value;
arr[first_deleted]->state = true;
}
++size;
return true;
}
bool Remove(const T& value, const THash1& hash1 = THash1(), const THash2& hash2 = THash2())
{
int h1 = hash1(value, buffer_size);
int h2 = hash2(value, buffer_size);
int i = 0;
while (arr[h1] != nullptr && i < buffer_size)
{
if (arr[h1]->value == value && arr[h1]->state)
{
arr[h1]->state = false;
--size;
return true;
}
h1 = (h1 + h2) % buffer_size;
++i;
}
return false;
}
bool Find(const T& value, const THash1& hash1 = THash1(), const THash2& hash2 = THash2())
{
int h1 = hash1(value, buffer_size);
int h2 = hash2(value, buffer_size);
int i = 0;
while (arr[h1] != nullptr && i < buffer_size)
{
if (arr[h1]->value == value && arr[h1]->state)
return true;
h1 = (h1 + h2) % buffer_size;
++i;
}
return false;
}
};Коллизия хеш—функции — это когда у двух разных входных элементов таблицы hash будет одинаковым. Коллизии встречаются в разнообразных алгоритмах хеширования, однако это не является нормой и в «правильных» алгоритмах их возникновение сведено к минимальному значению. Но в то же время, когда приходится работать с большими таблицами хеширования, то их возникновение неизбежно. А в некоторых алгоритмах хеширования, к примеру, в MD5, наличие коллизии вообще обязательно.
Коллизия криптографической хеш—функции
Любая криптографическая хеш—функция подтверждает неизменность исходящей информации. Поэтому наличие тут коллизий должно быть сведено к нулю. Ведь, к примеру, если использовать данную функцию, чтобы создавать оцифрованную подпись, то поиск ее коллизии практически приравнивается к подделке самой подписи. Поэтому к криптографическому алгоритму хеширования не должно быть возможным применение способа просто отыскать коллизию. Максимум — это полностью перебирать все хеш-значения в таблице. То есть этот вид хеш—функции считается самым защищенным, так как применяется для хранения засекреченных сведений.
Коллизия хеш—функции может быть использована для взлома
Можно разобрать простейшую форму для входа на какой-нибудь ресурс:
- когда новый пользователь регистрируется на каком-либо ресурсе, он придумывает логин/пароль для входа; эти значения записываются в таблицу хеширования хеш—функцией;
- когда пользователь повторно входит на ресурс и вводит свои логин и пароль, эти значения сравниваются с уже внесенными в базу данных той же технологией хеширования.
В целом, это распространенный и защищенный метод хеширования. При таком варианте, если вдруг взломщику откроется возможность доступа к БД, ему все равно будет недоступно восстановление исходных паролей юзеров ресурса. Но в то же время, если взломщик сможет найти коллизии для имеющейся хеш—функции, он легко сможет подделать пароль, у которого hash-сумма будет идентична с hash-суммой пароля взломанных пользователей.
Также злоумышленники часто используют коллизии хеш—функции, чтобы подделать различные элементы:
- оповещения о финансовых операциях; могут запрашивать секретные данные в сообщениях;
- оцифрованные подписи;
- дипломы и web-сертификаты и т.д.
Защита от применения коллизий хеш—функций
Как мы говорили чуть выше, поиск коллизии функции хеширования может привести к взлому и подделке важных аспектов. Однако можно использовать ряд методов, чтобы защититься от использования коллизий в злых умыслах:
- Метод «salt». «Подсаливание» хеширования дополнительными элементами, то есть добавляется последовательность каких-нибудь символов перед ним. В таком случае взломщику нужно будет разгадать еще алгоритм «salt», что усложнит задачу в несколько раз.
- Метод конкатенации hash. Это когда значения hash «смешиваются» от двух разных технологий хеширования. В таком случае взломщику нужно будет предугадать коллизии сразу 2-х хеш—функций.
Простые возможности поиска коллизии хеш—функции
Каких-то универсальных возможностей поиска коллизии хеш—функции не бывает. По одной причине, что самих алгоритмов хеширования большое разнообразие. Для некоторых вообще не существует способов поиска, для других он построен на решении сложных математических уравнений.
Для hash—функций с небольшой длиной хеша можно выделить несколько методов для поиска коллизии:
- Поиск методом «Парадокс дня рождения». Атака осуществляется при помощи подбора 2-х случайных наборов сообщений по формуле 2*n/2. Где n — битовая длина хеша. Предполагается, что в таком подборе есть вероятность найти пару сообщений с одинаковыми значениями, равная 1⁄2. заказать систему безопасности secoros
- Поиск методом «Атака расширения». При данном методе не атакуется само значение в hash-таблице, а лишь его hash-значения. И как только оно узнается, открывается возможность переписывать чужие сообщения.
А в целом подбирать метод поиска коллизии нужно в индивидуальном порядке. В сети есть разнообразные варианты и формулы. Потому что многие «общие» или простые возможности просто могут вам не подойти.
Разрешение коллизий (англ. collision resolution) в хеш-таблице, задача, решаемая несколькими способами: метод цепочек, открытая адресация и т.д. Очень важно сводить количество коллизий к минимуму, так как это увеличивает время работы с хеш-таблицами.
Содержание
- 1 Разрешение коллизий с помощью цепочек
- 2 Линейное разрешение коллизий
- 2.1 Стратегии поиска
- 2.2 Проверка наличия элемента в таблице
- 2.3 Проблемы данных стратегий
- 2.4 Удаление элемента без пометок
- 3 Двойное хеширование
- 3.1 Принцип двойного хеширования
- 3.2 Выбор хеш-функций
- 3.3 Пример
- 3.4 Простая реализация
- 3.5 Реализация с удалением
- 4 Альтернативная реализация метода цепочек
- 5 См. также
- 6 Источники информации
Разрешение коллизий с помощью цепочек
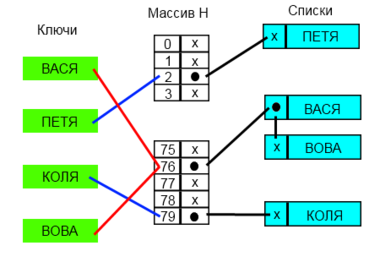
Разрешение коллизий при помощи цепочек.
Каждая ячейка массива содержит указатель на начало списка всех элементов, хеш-код которых равен , либо указывает на их отсутствие. Коллизии приводят к тому, что появляются списки размером больше одного элемента.
В зависимости от того нужна ли нам уникальность значений операции вставки у нас будет работать за разное время. Если не важна, то мы используем список, время вставки в который будет в худшем случае равна . Иначе мы проверяем есть ли в списке данный элемент, а потом в случае его отсутствия мы его добавляем. В таком случае вставка элемента в худшем случае будет выполнена за
Время работы поиска в наихудшем случае пропорционально длине списка, а если все ключей захешировались в одну и ту же ячейку (создав список длиной ) время поиска будет равно плюс время вычисления хеш-функции, что ничуть не лучше, чем использование связного списка для хранения всех элементов.
Удаления элемента может быть выполнено за , как и вставка, при использовании двухсвязного списка.
Линейное разрешение коллизий
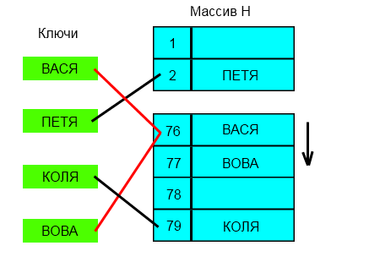
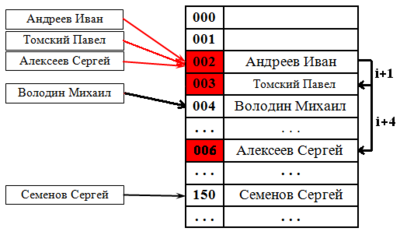
Пример хеш-таблицы с открытой адресацией и линейным пробированием.
Все элементы хранятся непосредственно в хеш-таблице, без использования связных списков. В отличие от хеширования с цепочками, при использовании этого метода может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, следовательно, будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Стратегии поиска
Последовательный поиск
При попытке добавить элемент в занятую ячейку начинаем последовательно просматривать ячейки и так далее, пока не найдём свободную ячейку. В неё и запишем элемент.
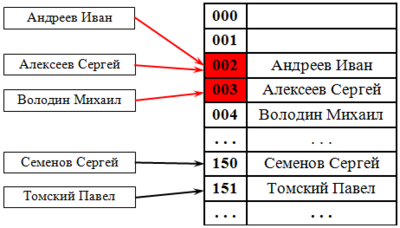
Линейный поиск
Выбираем шаг . При попытке добавить элемент в занятую ячейку начинаем последовательно просматривать ячейки и так далее, пока не найдём свободную ячейку. В неё и запишем элемент.
По сути последовательный поиск — частный случай линейного, где .
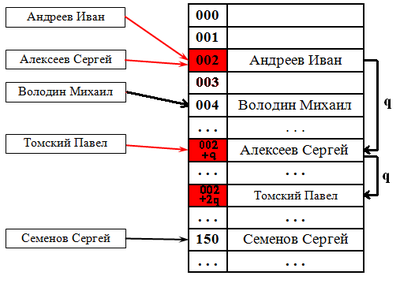
Квадратичный поиск
Шаг не фиксирован, а изменяется квадратично: . Соответственно при попытке добавить элемент в занятую ячейку начинаем последовательно просматривать ячейки и так далее, пока не найдём свободную ячейку.
Проверка наличия элемента в таблице
Проверка осуществляется аналогично добавлению: мы проверяем ячейку и другие, в соответствии с выбранной стратегией, пока не найдём искомый элемент или свободную ячейку.
При поиске элемента может получится так, что мы дойдём до конца таблицы. Обычно поиск продолжается, начиная с другого конца, пока мы не придём в ту ячейку, откуда начинался поиск.
Проблемы данных стратегий
Проблем две — крайне нетривиальное удаление элемента из таблицы и образование кластеров — последовательностей занятых ячеек.
Кластеризация замедляет все операции с хеш-таблицей: при добавлении требуется перебирать всё больше элементов, при проверке тоже. Чем больше в таблице элементов, тем больше в ней кластеры и тем выше вероятность того, что добавляемый элемент попадёт в кластер.
Для защиты от кластеризации используется двойное хеширование и хеширование кукушки.
Удаление элемента без пометок
Рассуждение будет описывать случай с линейным поиском хеша. Будем при удалении элемента сдвигать всё последующие на позиций назад. При этом:
- если в цепочке встречается элемент с другим хешем, то он должен остаться на своём месте (такая ситуация может возникнуть если оставшаяся часть цепочки была добавлена позже этого элемента)
- в цепочке не должно оставаться «дырок», тогда любой элемент с данным хешем будет доступен из начала цепи
Учитывая это будем действовать следующим образом: при поиске следующего элемента цепочки будем пропускать все ячейки с другим значением хеша, первый найденный элемент копировать в текущую ячейку, и затем рекурсивно его удалять. Если такой следующей ячейки нет, то текущий элемент можно просто удалить, сторонние цепочки при этом не разрушатся (чего нельзя сказать про случай квадратичного поиска).
Псевдокод
function delete(Item i):
j = i + q
while table[j] == null or table[j].key != table[i].key
if table[j] == null
table[i] = null
return
j += q
table[i] = table[j]
delete(j)
Хеш-таблицу считаем зацикленной
| Утверждение (о времени работы): |
|
Асимптотически время работы и совпадают |
| Заметим что указатель в каждой итерации перемещается вперёд на (с учётом рекурсивных вызовов ). То есть этот алгоритм последовательно пройдёт по цепочке от удаляемого элемента до последнего — с учётом вызова собственно для нахождения удаляемого элемента, мы посетим все ячейки цепи. |
Вариант с зацикливанием мы не рассматриваем, поскольку если взаимнопросто с размером хеш-таблицы, то для зацикливания в ней вообще не должно быть свободных позиций
Теперь докажем почему этот алгоритм работает. Собственно нам требуется сохранение трёх условий.
- В редактируемой цепи не остаётся дырок
Докажем по индукции. Если на данной итерации мы просто удаляем элемент (база), то после него ничего нет, всё верно. Если же нет, то вызванный в конце (см. псевдокод) заметёт созданную дыру (скопированный элемент), и сам, по предположению, новых не создаст.
- Элементы, которые уже на своих местах, не должны быть сдвинуты.
Это учтено.
- В других цепочках не появятся дыры
Противное возможно только в том случае, если какой-то элемент был действительно удалён. Удаляем мы только последнюю ячейку в цепи, и если бы на её месте возникла дыра для сторонней цепочки, это бы означало что элемент, стоящий на позиций назад, одновременно принадлежал нашей и другой цепочкам, что невозможно.
Двойное хеширование
Двойное хеширование (англ. double hashing) — метод борьбы с коллизиями, возникающими при открытой адресации, основанный на использовании двух хеш-функций для построения различных последовательностей исследования хеш-таблицы.
Принцип двойного хеширования
При двойном хешировании используются две независимые хеш-функции и . Пусть — это наш ключ, — размер нашей таблицы, — остаток от деления на , тогда сначала исследуется ячейка с адресом , если она уже занята, то рассматривается , затем и так далее. В общем случае идёт проверка последовательности ячеек где
Таким образом, операции вставки, удаления и поиска в лучшем случае выполняются за , в худшем — за , что не отличается от обычного линейного разрешения коллизий.
Однако в среднем, при грамотном выборе хеш-функций, двойное хеширование будет выдавать лучшие результаты, за счёт того, что вероятность совпадения значений сразу двух независимых хеш-функций ниже, чем одной.
Выбор хеш-функций
может быть обычной хеш-функцией. Однако чтобы последовательность исследования могла охватить всю таблицу, должна возвращать значения:
- не равные
- независимые от
- взаимно простые с величиной хеш-таблицы
Есть два удобных способа это сделать. Первый состоит в том, что в качестве размера таблицы используется простое число, а возвращает натуральные числа, меньшие . Второй — размер таблицы является степенью двойки, а возвращает нечетные значения.
Например, если размер таблицы равен , то в качестве можно использовать функцию вида
Вставка при двойном хешировании
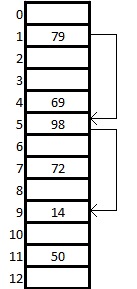
Пример
Показана хеш-таблица размером 13 ячеек, в которой используются вспомогательные функции:
Мы хотим вставить ключ 14. Изначально . Тогда . Но ячейка с индексом 1 занята, поэтому увеличиваем на 1 и пересчитываем значение хеш-функции. Делаем так, пока не дойдем до пустой ячейки. При получаем . Ячейка с номером 9 свободна, значит записываем туда наш ключ.
Таким образом, основная особенность двойного хеширования состоит в том, что при различных пара дает различные последовательности ячеек для исследования.
Простая реализация
Пусть у нас есть некоторый объект , в котором определено поле , от которого можно вычислить хеш-функции и
Так же у нас есть таблица величиной , состоящая из объектов типа .
Вставка
function add(Item item):
x = h1(item.key)
y = h2(item.key)
for (i = 0..m)
if table[x] == null
table[x] = item
return
x = (x + y) mod m
table.resize()// ошибка, требуется увеличить размер таблицы
Поиск
Item search(Item key):
x = h1(key)
y = h2(key)
for (i = 0..m)
if table[x] != null
if table[x].key == key
return table[x]
else
return null
x = (x + y) mod m
return null
Реализация с удалением
Чтобы наша хеш-таблица поддерживала удаление, требуется добавить массив типов , равный по величине массиву . Теперь при удалении мы просто будем помечать наш объект как удалённый, а при добавлении как не удалённый и замещать новым добавляемым объектом. При поиске, помимо равенства ключей, мы смотрим, удалён ли элемент, если да, то идём дальше.
Вставка
function add(Item item):
x = h1(item.key)
y = h2(item.key)
for (i = 0..m)
if table[x] == null or deleted[x]
table[x] = item
deleted[x] = false
return
x = (x + y) mod m
table.resize()// ошибка, требуется увеличить размер таблицы
Поиск
Item search(Item key):
x = h1(key)
y = h2(key)
for (i = 0..m)
if table[x] != null
if table[x].key == key and !deleted[x]
return table[x]
else
return null
x = (x + y) mod m
return null
Удаление
function remove(Item key):
x = h1(key)
y = h2(key)
for (i = 0..m)
if table[x] != null
if table[x].key == key
deleted[x] = true
else
return
x = (x + y) mod m
Альтернативная реализация метода цепочек
В Java 8 для разрешения коллизий используется модифицированный метод цепочек. Суть его заключается в том, что когда количество элементов в корзине превышает определенное значение, данная корзина переходит от использования связного списка к использованию сбалансированного дерева. Но данный метод имеет смысл лишь тогда, когда на элементах хеш-таблицы задан линейный порядок. То есть при использовании данныx типа или имеет смысл переходить к дереву поиска, а при использовании каких-нибудь ссылок на объекты не имеет, так как они не реализуют нужный интерфейс. Такой подход позволяет улучшить производительность с до . Данный способ используется в таких коллекциях как HashMap, LinkedHashMap и ConcurrentHashMap.
См. также
- Хеширование
- Хеширование кукушки
- Идеальное хеширование
Источники информации
- Бакнелл Дж. М. «Фундаментальные алгоритмы и структуры данных в Delphi», 2003
- Кормен, Томас Х., Лейзерсон, Чарльз И., Ривест, Рональд Л., Штайн Клиффорд «Алгоритмы: построение и анализ», 2-е издание. Пер. с англ. — М.:Издательский дом «Вильямс», 2010.— Парал. тит. англ. — ISBN 978-5-8459-0857-5 (рус.)
- Дональд Кнут. «Искусство программирования, том 3. Сортировка и поиск» — «Вильямс», 2007 г.— ISBN 0-201-89685-0
- Седжвик Р. «Фундаментальные алгоритмы на C. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск», 2003
- Handle Frequent HashMap Collisions with Balanced Trees
- Wikipedia — Double_hashing
- Разрешение коллизий
- Пример хеш таблицы
- Пример хеш таблицы с двойным хешированием
Коллизии хэш-функций
Стойкость современных хэш-функций часто основывается на предположении об их стойкости к нахождению коллизий.
Пусть H: {0,1}^* -> {0,1}^n функция, переводящая множество двоичных векторов произвольной длины
в множество векторов фиксированной длины n. n называется размеров выхода хэш-функции H.
Хэш-функция H называется стойкой к коллизиям второго рода, если вычислительно сложно найти такую пару (x,y) in {0,1}^* : x != y, H(x) = H(y).
Очевидно, что даже для «идеальной» хэш-функции (т.е. хэш-функции, на которую не существуют атак лучше перебора)
существуют коллизии, из-за разности мощностей множества прообразов и множества образов хэш-функции.
Атака на основе парадокса дней рождений
Рассмотрим атаку на основе так называемого парадокса дней рождений.
0. S <- пустое множество.
1. Выбрать произвольный элемент x из {0,1}^*
2. Вычислить значение h_x = H(x)
3. Проверить, есть ли в множестве S элемент (y, h_x). Если есть => goto DONE
4. Добавить элемент (x, h_x) в множество S
5. goto 1
DONE:
6. Вернуть пару (x, y) как коллизию хэш-функции.
Данная атака на некоторую стойкую к коллизиям хэш-функцию H: {0,1}^* -> {0,1}^n имеет вычислительную сложность O(2^(n/2)) и
требует O(2^(n/2)) памяти.
Объяснение «на пальцах» почему откуда взялся корень.
NB! Это только наглядное объяснение, а не доказательство! Доказательство вводится формально на лекции.
При выборе q-го элемента число пар составляет q(q-1) ~ q^2. При этом вероятность коллизии в каждой паре — 1/2^n (совпадение двух случайных векторов). Хотим вероятность коллизии порядка 1, следовательно q^2/2^n ~ 1, q=sqrt(n).
Атака на основе метода Полларда
Рассмотрим атаку на основе метода Полларда.
Основная идея — уменьшить требования к памяти, используя параллельные вычисления.
Пусть имеется m потоков выполнения программы. Пусть Pi : {0,1}^a -> {0,1}^(a+k) — инъективная функция: x |-> x || 0^k,
где 0^k — нулевой двоичный вектор длины k. q=b/2 - log_2(m). H: {0,1}^* -> {0,1}^b
Отличительной точкой (distinguished point) назовём такой вектор y, у которого первые q бит — нулевые.
Каждый поток инициализируется уникальным начальным значением y_0. Начальные значения сохранены в памяти.
Основная идея — каждый поток вычисляет последовательно цепочку хэшей, с применением поверх хэша инъективной функции.
y_i = Pi(H(y_{i-1})
Номер текущей итерации для каждого потока (i) также сохранён в памяти.
После чего производится проверка, является ли получено значение отличительной точкой. Если является — проверяем, встречали ли
мы такую точку ранее. Если нет — добавляем в множество найденных точек и продолжаем алгоритм.
Если данная точка уже встречалась — значит где-то в построенных цепочках встречались 2 различных прообраза.
Для найденной отличительной точки имеем 2 номера итерации i и j. Пусть i>j Находим разность между ними d=i-j.
Применяем d итераций к начальной точке y_0, соответствующей цепочке большей длины. Далее синхронно итерируем цепочки,
пока не найдём коллизию.
Сложность нахождения отличительной точки на одном потоке — O(2^{b/2}), на m потоках — O(2^{b/2}/m)
Потребление памяти порядка O(m)
0. S <- пустое множество. Общий доступ для всех потоков.
Каждый поток выполняет следующий алгоритм:
1. y_i = Pi(H(y_{i-1})
2. Если y_i != 0^q || yr_i: goto 1
3. Если (z_j, j) : z_j == y_i, для любого j находится в S: goto FOUND
4. Добавить (y_i, i) в S
5. goto 1
FOUND:
Имеем начальные точки для двух потоков (y_0, z_0); соответствующие итерации, на которых был получена коллизия (i, j).
6. Пусть i>j. Вычислить d = i-j
7. Вычислить y = ((Pi*H)^d)(y_0), z = z_0; (Pi*H)(u)=Pi(H(u))
8. Если H(y) = H(z): вернуть (y,z) как коллизию хэш-функции.
9. (y, z) = (Pi(H(y)), Pi(H(z)))
10. goto 8
Выполнение лабораторной
- Реализовать «усеченные» хэш функции sha-XX, путём взятия первый XX бит функции sha-256. XX = {15-20}
- Найти коллизию используя парадокс дней рождений для хэш функций sha-XX.
- Найти коллизию, используя Ро-метод Полладра для хэш функций sha-XX на двух потоках.
При реализации метода Полларда необходимо учесть, что коллизия может быть найдена как в различных, так и внутри одного потока.
Для пунктов 2 и 3 оценить используемую память для каждого метода. Для каждого из пунктов найти не менее 100 (больше — лучше) различных коллизий для каждой хэш-функциий. Замерить время выполнения. Построить график зависимости
среднего времени выполнения от размера выхода хэш-функции и средних затрат памяти памяти от размера выхода хэш-функции для обоих методов нахождения коллизий. Затраты по памяти можно для простоты оценить приблизительно как количество хранимых хэшей, умноженное на размер хэша + размер прочих хранимых данных в байтах.
При сложностях в реализации многопоточного метода Полларда можно реализовать в одном потоке, «симулируя» в цикле последовательное выполнение двух или более потоков.
Пример вывода алгоритма нахождения коллизии для двух-байтной хэш функции, где критерий особой точки — нулевой первый байт. Итерации потоков с префиксом Q — действия после перехода на метку FOUND:
Коллизия найдена на разных потоках: https://github.com/CryptoCourse/CryptoLabs/blob/master/Impl/collision_different_thread.txt
Коллизия найдена на одном потоке: https://github.com/CryptoCourse/CryptoLabs/blob/master/Impl/collision_one_thread.txt
Результат работы:
код, коллизии для хэш-функций (список hex значений), графики.
Проверка коллизий будет осуществляться через сайт https://emn178.github.io/online-tools/sha256.html (будут сравниваться первые байты полученных значений).
Доп литература:
https://github.com/CryptoCourse/CryptoLectures/blob/master/Lectures/HashFunctionsLite.pdf
https://iamaaditya.github.io/2012/07/the-birthday-paradox-proof/
https://crypto.stackexchange.com/questions/52231/what-is-the-best-and-fastest-algorithm-to-generate-a-hash-collision
https://cr.yp.to/hash/collisioncost-20090517.pdf (стр 9-10)
В этой статье вы познакомитесь с хэш-таблицами и увидите примеры их реализации в Cи, C++, Java и Python.
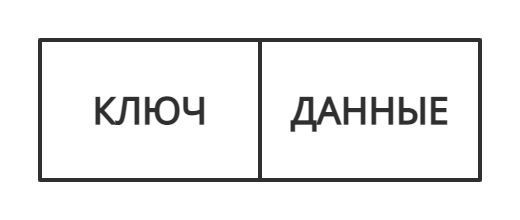
Хеш-таблица — это структура данных, в которой все элементы хранятся в виде пары ключ-значение, где:
- ключ — уникальное число, которое используется для индексации значений;
- значение — данные, которые с этим ключом связаны.
Хеширование (хеш-функция)
В хеш-таблице обработка новых индексов производится при помощи ключей. А элементы, связанные с этим ключом, сохраняются в индексе. Этот процесс называется хешированием.
Пусть k — ключ, а h(x) — хеш-функция.
Тогда h(k) в результате даст индекс, в котором мы будем хранить элемент, связанный с k.

Коллизии
Когда хеш-функция генерирует один индекс для нескольких ключей, возникает конфликт: неизвестно, какое значение нужно сохранить в этом индексе. Это называется коллизией хеш-таблицы.
Есть несколько методов борьбы с коллизиями:
- метод цепочек;
- метод открытой адресации: линейное и квадратичное зондирование.
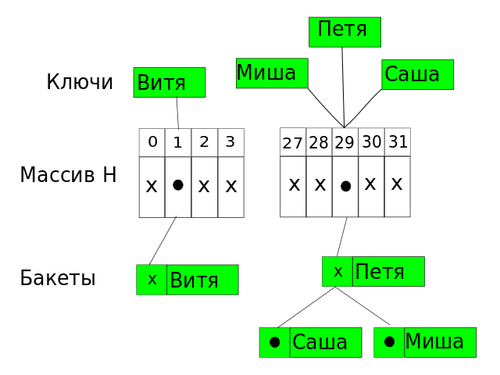
1. Метод цепочек
Суть этого метода проста: если хеш-функция выделяет один индекс сразу двум элементам, то храниться они будут в одном и том же индексе, но уже с помощью двусвязного списка.
Если j — ячейка для нескольких элементов, то она содержит указатель на первый элемент списка. Если же j пуста, то она содержит NIL.

Псевдокод операций
chainedHashSearch(T, k)
return T[h(k)]
chainedHashInsert(T, x)
T[h(x.key)] = x
chainedHashDelete(T, x)
T[h(x.key)] = NIL 2. Открытая адресация
В отличие от метода цепочек, в открытой адресации несколько элементов в одной ячейке храниться не могут. Суть этого метода заключается в том, что каждая ячейка либо содержит единственный ключ, либо NIL.
Существует несколько видов открытой адресации:
a) Линейное зондирование
Линейное зондирование решает проблему коллизий с помощью проверки следующей ячейки.
h(k, i) = (h′(k) + i) mod m,
где
i = {0, 1, ….}h'(k)— новая хеш-функция
Если коллизия происходит в h(k, 0), тогда проверяется h(k, 1). То есть значение i увеличивается линейно.
Проблема линейного зондирования заключается в том, что заполняется кластер соседних ячеек. Это приводит к тому, что при вставке нового элемента в хеш-таблицу необходимо проводить полный обход кластера. В результате время выполнения операций с хеш-таблицами увеличивается.
b) Квадратичное зондирование
Работает оно так же, как и линейное — но есть отличие. Оно заключается в том, что расстояние между соседними ячейками больше (больше одного). Это возможно благодаря следующему отношению:
h(k, i) = (h′(k) + c1i + c2i2) mod m,
где
c1иc2— положительные вспомогательные константы,i = {0, 1, ….}
c) Двойное хэширование
Если коллизия возникает после применения хеш-функции h(k), то для поиска следующей ячейки вычисляется другая хеш-функция.
h(k, i) = (h1(k) + ih2(k)) mod m
«Хорошие» хеш-функции
«Хорошие» хеш-функции не уберегут вас от коллизий, но, по крайней мере, сократят их количество.
Ниже мы рассмотрим различные методы определения «качества» хэш-функций.
1. Метод деления
Если k — ключ, а m — размер хеш-таблицы, то хеш-функция h() вычисляется следующим образом:
h(k) = k mod m
Например, если m = 10 и k = 112, то h(k) = 112 mod 10 = 2. То есть значение m не должно быть степенью 2. Это связано с тем, что степени двойки в двоичном формате — 10, 100, 1000… При вычислении k mod m мы всегда будем получать p-биты низшего порядка.
если m = 22, k = 17, тогда h(k) = 17 mod 22 = 10001 mod 100 = 01
если m = 23, k = 17, тогда h(k) = 17 mod 22 = 10001 mod 100 = 001
если m = 24, k = 17, тогда h(k) = 17 mod 22 = 10001 mod 100 = 0001
если m = 2p, тогда h(k) = p биты порядком ниже, чем m2. Метод умножения
h(k) = ⌊m(kA mod 1)⌋,
где
kA mod 1отделяет дробную частьkA;⌊ ⌋округляет значение;A— произвольная константа, значение которой должно находиться между 0 и 1. Оптимальный вариант ≈ (√5-1) / 2, его предложил Дональд Кнут.
3. Универсальное хеширование
В универсальном хешировании хеш-функция выбирается случайным образом и не зависит от ключей.
Где применяются
- Когда необходима постоянная скорость поиска и вставки.
- В криптографических приложениях.
- Когда необходима индексация данных.
Примеры реализации хеш-таблиц в Python, Java, Си и C++
Python
# Реализация хеш-таблицы в Python
hashTable = [[],] * 10
def checkPrime(n):
if n == 1 or n == 0:
return 0
for i in range(2, n//2):
if n % i == 0:
return 0
return 1
def getPrime(n):
if n % 2 == 0:
n = n + 1
while not checkPrime(n):
n += 2
return n
def hashFunction(key):
capacity = getPrime(10)
return key % capacity
def insertData(key, data):
index = hashFunction(key)
hashTable[index] = [key, data]
def removeData(key):
index = hashFunction(key)
hashTable[index] = 0
insertData(123, "apple")
insertData(432, "mango")
insertData(213, "banana")
insertData(654, "guava")
print(hashTable)
removeData(123)
print(hashTable)
Java
// Реализация хеш-таблицы в Java
import java.util.*;
class HashTable {
public static void main(String args[])
{
Hashtable<Integer, Integer>
ht = new Hashtable<Integer, Integer>();
ht.put(123, 432);
ht.put(12, 2345);
ht.put(15, 5643);
ht.put(3, 321);
ht.remove(12);
System.out.println(ht);
}
}
Cи
// Реализация хеш-таблицы в Cи
#include <stdio.h>
#include <stdlib.h>
struct set
{
int key;
int data;
};
struct set *array;
int capacity = 10;
int size = 0;
int hashFunction(int key)
{
return (key % capacity);
}
int checkPrime(int n)
{
int i;
if (n == 1 || n == 0)
{
return 0;
}
for (i = 2; i < n / 2; i++)
{
if (n % i == 0)
{
return 0;
}
}
return 1;
}
int getPrime(int n)
{
if (n % 2 == 0)
{
n++;
}
while (!checkPrime(n))
{
n += 2;
}
return n;
}
void init_array()
{
capacity = getPrime(capacity);
array = (struct set *)malloc(capacity * sizeof(struct set));
for (int i = 0; i < capacity; i++)
{
array[i].key = 0;
array[i].data = 0;
}
}
void insert(int key, int data)
{
int index = hashFunction(key);
if (array[index].data == 0)
{
array[index].key = key;
array[index].data = data;
size++;
printf("n Ключ (%d) вставлен n", key);
}
else if (array[index].key == key)
{
array[index].data = data;
}
else
{
printf("n Возникла коллизия n");
}
}
void remove_element(int key)
{
int index = hashFunction(key);
if (array[index].data == 0)
{
printf("n Данного ключа не существует n");
}
else
{
array[index].key = 0;
array[index].data = 0;
size--;
printf("n Ключ (%d) удален n", key);
}
}
void display()
{
int i;
for (i = 0; i < capacity; i++)
{
if (array[i].data == 0)
{
printf("n array[%d]: / ", i);
}
else
{
printf("n Ключ: %d array[%d]: %d t", array[i].key, i, array[i].data);
}
}
}
int size_of_hashtable()
{
return size;
}
int main()
{
int choice, key, data, n;
int c = 0;
init_array();
do
{
printf("1.Вставить элемент в хэш-таблицу"
"n2.Удалить элемент из хэш-таблицы"
"n3.Узнать размер хэш-таблицы"
"n4.Вывести хэш-таблицу"
"nn Пожалуйста, выберите нужный вариант: ");
scanf("%d", &choice);
switch (choice)
{
case 1:
printf("Введите ключ -:t");
scanf("%d", &key);
printf("Введите данные-:t");
scanf("%d", &data);
insert(key, data);
break;
case 2:
printf("Введите ключ, который хотите удалить-:");
scanf("%d", &key);
remove_element(key);
break;
case 3:
n = size_of_hashtable();
printf("Размер хеш-таблицы-:%dn", n);
break;
case 4:
display();
break;
default:
printf("Неверно введены данныеn");
}
printf("nПродолжить? (Нажмите 1, если да): ");
scanf("%d", &c);
} while (c == 1);
}
C++
// Реализация хеш-таблицы в C++
#include <iostream>
#include <list>
using namespace std;
class HashTable
{
int capacity;
list<int> *table;
public:
HashTable(int V);
void insertItem(int key, int data);
void deleteItem(int key);
int checkPrime(int n)
{
int i;
if (n == 1 || n == 0)
{
return 0;
}
for (i = 2; i < n / 2; i++)
{
if (n % i == 0)
{
return 0;
}
}
return 1;
}
int getPrime(int n)
{
if (n % 2 == 0)
{
n++;
}
while (!checkPrime(n))
{
n += 2;
}
return n;
}
int hashFunction(int key)
{
return (key % capacity);
}
void displayHash();
};
HashTable::HashTable(int c)
{
int size = getPrime(c);
this->capacity = size;
table = new list<int>[capacity];
}
void HashTable::insertItem(int key, int data)
{
int index = hashFunction(key);
table[index].push_back(data);
}
void HashTable::deleteItem(int key)
{
int index = hashFunction(key);
list<int>::iterator i;
for (i = table[index].begin();
i != table[index].end(); i++)
{
if (*i == key)
break;
}
if (i != table[index].end())
table[index].erase(i);
}
void HashTable::displayHash()
{
for (int i = 0; i < capacity; i++)
{
cout << "table[" << i << "]";
for (auto x : table[i])
cout << " --> " << x;
cout << endl;
}
}
int main()
{
int key[] = {231, 321, 212, 321, 433, 262};
int data[] = {123, 432, 523, 43, 423, 111};
int size = sizeof(key) / sizeof(key[0]);
HashTable h(size);
for (int i = 0; i < n; i++)
h.insertItem(key[i], data[i]);
h.deleteItem(12);
h.displayHash();
}