Непрерывная случайная величина
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
Краткая теория
Случайная величина называется непрерывной, если ее функция
распределения
непрерывно дифференцируема. В этом случае
имеет производную, которую обозначим через
– плотность распределения вероятностей.
Плотностью распределения вероятностей непрерывной случайной
величины
называются функцию
– первую производную от функции распределения
:
Из этого определения следует, что функция распределения является
первообразной для плотности распределения.
Заметим, что для описания распределения вероятностей дискретной
случайной величины плотность распределения неприменима.
Вероятность того, что непрерывная случайная величина
примет значение, принадлежащее интервалу
равна определенному интегралу от плотности
распределения, взятому в пределах от
до
.
Зная плотность распределения
,
можно найти функцию распределения
по формуле:
Числовые характеристики непрерывной случайной величины
Математическое ожидание непрерывной случайной величины
,
возможные значения которой принадлежат всей оси
,
определяется равенством:
где
– плотность распределения случайной величины
.
Предполагается, что интеграл сходится абсолютно.
В частности, если все возможные значения принадлежат интервалу
,
то:
Все свойства математического ожидания, указанные для
дискретных случайных величин, сохраняются и для непрерывных величин.
Дисперсия непрерывной случайной величины
,
возможные значения которой принадлежат всей оси
,
определяется равенством:
или равносильным равенством:
В частности, если все возможные значения
принадлежат интервалу
,
то
или
Все свойства дисперсии, указанные для дискретных случайных
величин, сохраняются и для непрерывных случайных величин.
Среднее квадратическое отклонение
непрерывной случайной величины определяется так же, как и для дискретной
величины:
При решении задач, которые выдвигает практика, приходится
сталкиваться с различными распределениями непрерывных случайных величин.
Основные законы распределения непрерывных случайных величин
- Нормальный закон распределения СВ
- Показательный закон распределения СВ
- Равномерный закон распределения СВ
Примеры решения задач
Пример 1
Дана
функция распределения F(х) непрерывной случайной величины
Х.
Найти плотность распределения вероятностей f(x), математическое ожидание M(X), дисперсию D(X) и вероятность попадания X на отрезок [a,b]. Построить графики функций F(x) и f(x).
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Плотность
распределения вероятностей:
Математическое
ожидание:
Дисперсию
можно найти по формуле:
Вероятность
попадания на отрезок:
Построим графики функций F(x) и f(x).
График плотности
распределения
График функции
распределения
Пример 2
Случайная величина Х задана плотностью вероятности
Определить константу c, математическое ожидание, дисперсию, функцию распределения величины X, а также вероятность ее попадания в интервал [0;0,25].
Решение
Константу
определим,
используя свойство плотности вероятности:
В нашем случае:
Найдем математическое
ожидание:
Найдем дисперсию:
Искомая дисперсия:
Найдем функцию
распределения:
для
:
для
:
для
:
Искомая функция
распределения:
Вероятность попадания
в интервал
:
Пример 3
Плотность
распределения непрерывной случайной величины
имеет вид:
Найти:
а)
параметр
;
б)
функцию распределения
;
в)
вероятность попадания случайной величины
в интервал
г)
математическое ожидание
и дисперсию
д)
построить графики функций
и
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
а)
Постоянный параметр
найдем из
свойства плотности вероятности:
В нашем
случае эта формула имеет вид:
б)
Функцию распределения
найдем из
формулы:
Учитывая
свойства
, сразу можем отметить,
что:
Остается
найти выражение для
, когда
принадлежит
интервалу
:
Получаем:
в)
Вероятность
попадания случайной величины
в интервал
:
г)
Математическое ожидание находим по формуле:
Для
нашего примера:
Дисперсию
можно найти по формуле:
Среднее
квадратическое отклонение равно квадратному корню из дисперсии:
д) Построим графики
и
:
График плотности вероятности f(x)
График функции распределения F(x)
Задачи контрольных и самостоятельных работ
Задача 1
НСВ на всей
числовой оси oX задана интегральной функцией:
Найти
вероятность, что в результате 2 испытаний случайная величина примет значение,
заключенное в интервале (0;4).
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 2
Дана
дифференциальная функция непрерывной СВ Х. Найти: постоянную С, интегральную
функцию F(x).
Задача 3
Случайная
величина Х задана функцией распределения F(x):
а) Найти
плотность вероятности СВ Х — f(x).
б) Построить графики
f(x), F(x).
в) Найти вероятность
попадания НСВ в интервал (0; 3).
Задача 4
Дифференциальная
функция НСВ Х задана на всей числовой оси ОХ:
Найти:
а) постоянный
параметр С=const;
б) функцию
распределения F(x);
в) вероятность
попадания в интервал -4<X<4;
г) построить
графики f(x), F(X).
Задача 5
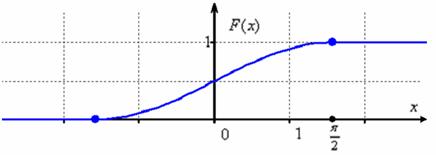
Случайная величина
Х задана функцией распределения F(x):
а) Найти
плотность вероятности СВ Х — f(x).
б) Построить
графики f(x), F(x).
в) Найти
вероятность попадания НСВ в интервал (0;π⁄2).
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 6
НСВ X имеет
плотность вероятности (закон Коши)
а) постоянный
параметр С=const;
б) функцию
распределения F(x);
в) вероятность
попадания в интервал -1<X<1;
г) построить
графики f(x), F(X).
Задача 7
Случайная
величина X задана интегральной F(x) или дифференциальной f(x)
функцией. Требуется:
а) найти
параметр C;
б) при
заданной интегральной функции F(x) найти дифференциальную
функцию f(x), а при заданной дифференциальной функции f(x) найти интегральную
функцию F(x);
в)
построить графики функций F(x) и f(x);
г) найти
математическое ожидание M(X), дисперсию D(X) и
среднее квадратическое отклонение σ(X);
д)
вычислить вероятность попадания в интервал P(a≤x≤b);
е)
определить, квантилем какого порядка является точка xp;
ж)
вычислить квантиль порядка p
Задание 8
Дана
интегральная функция распределения случайной величины X. Найти дифференциальную
функцию распределения, математическое ожидание M(X), дисперсию D(X) и
среднее квадратическое отклонение.
Задача 9
Случайная
величина X задана интегральной функцией распределения
Найти
дифференциальную функцию, математическое ожидание и дисперсию X.
Задача 10
СВ Х
задана функцией распределения F(x). Найдите вероятность
того, что в результате испытаний НСВ Х попадет в заданный интервал (0;0,5).
Постройте график функции распределения. Найдите плотность вероятности НСВ Х и
постройте ее график. Найдите числовые
характеристики НСВ Х, если
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
2.4.3. Функция ПЛОТНОСТИ распределения вероятностей
или дифференциальная функция распределения. Она представляет собой производную функции распределения: ![]() .
.
Примечание: для дискретной случайной величины такой функции не существует
В нашем примере:
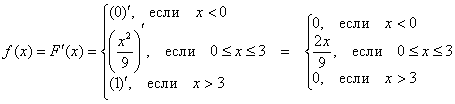
то есть, всё очень просто – берём производную от каждого куска, и порядок.
Но настоящий порядок состоит в том, что несобственный интеграл от ![]() с пределами интегрирования от «минус» до «плюс» бесконечности:
с пределами интегрирования от «минус» до «плюс» бесконечности:
![]() – равен единице, и строго единице. В противном случае перед нами не функция плотности, и если эта функция была найдена как производная, то
– равен единице, и строго единице. В противном случае перед нами не функция плотности, и если эта функция была найдена как производная, то ![]() – не является функцией распределения (несмотря на какие бы то ни было другие признаки).
– не является функцией распределения (несмотря на какие бы то ни было другие признаки).
Проверим «подлинность» наших функций. Если случайная величина ![]() принимает значения из конечного промежутка, то всё дело сводится к вычислению определённого интеграла. В силу свойства аддитивности, делим интеграл на 3 части:
принимает значения из конечного промежутка, то всё дело сводится к вычислению определённого интеграла. В силу свойства аддитивности, делим интеграл на 3 части:

Совершенно понятно, что левый и правый интегралы равны нулю и нам осталось вычислить средний интеграл:
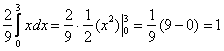 , что и требовалось проверить.
, что и требовалось проверить.
С вероятностной точки зрения это означает, что случайная величина ![]() достоверно примет одно из значений отрезка
достоверно примет одно из значений отрезка ![]() . Геометрически же это значит, что площадь между осью
. Геометрически же это значит, что площадь между осью ![]() и графиком
и графиком ![]() равна единице, и в данном случае речь идёт о площади треугольника
равна единице, и в данном случае речь идёт о площади треугольника ![]() . Сторона
. Сторона ![]() является фрагментом прямой
является фрагментом прямой ![]() и для её построения достаточно найти точку
и для её построения достаточно найти точку ![]() :
:
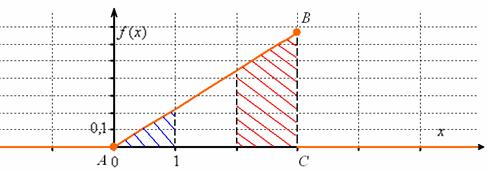
Ну вот, теперь всё наглядно – где бОльшая площадь, там и сконцентрированы более вероятные значения.
Так как функция плотности «собирает под собой» вероятности, то она неотрицательна ![]() и её график не может располагаться ниже оси
и её график не может располагаться ниже оси ![]() . В общем случае функция разрывна (смотрим, где «жирные» оранжевые точки!).
. В общем случае функция разрывна (смотрим, где «жирные» оранжевые точки!).
Теперь разберём весьма любопытный факт: поскольку действительных чисел несчётно много, то вероятность того, что случайная величина ![]() примет какое-то конкретное значение стремится к нулю. И поэтому вероятности рассчитывают не для отдельно взятых точек, а для целых промежутков (пусть даже очень малых). Как вы правильно догадываетесь:
примет какое-то конкретное значение стремится к нулю. И поэтому вероятности рассчитывают не для отдельно взятых точек, а для целых промежутков (пусть даже очень малых). Как вы правильно догадываетесь:
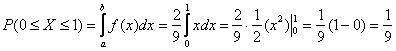 (синяя площадь на чертеже) – вероятность того, что случайная величина примет значение из отрезка
(синяя площадь на чертеже) – вероятность того, что случайная величина примет значение из отрезка ![]() ;
;
![]() (красная площадь) – вероятность того, что случайная величина примет значение из отрезка
(красная площадь) – вероятность того, что случайная величина примет значение из отрезка ![]() .
.
По той причине, что отдельно взятые значения можно не принимать во внимание, с помощью этих же интегралов рассчитываются и вероятности по интервалам и полуинтервалам, в частности:

Этим же объяснятся аналогичная «вольность» с функцией ![]() .
.
Возможно, кто-то спросит: а зачем считать интегралы, если есть функция ![]() ?
?
А дело в том, что во многих задачах непрерывная случайная величина ИЗНАЧАЛЬНО задана функцией ![]() плотности распределения, которая ТОЖЕ однозначно определяет случайную величину. Но, как вариант, можно сначала найти функцию
плотности распределения, которая ТОЖЕ однозначно определяет случайную величину. Но, как вариант, можно сначала найти функцию ![]() (с помощью тех же интегралов), после чего использовать «лёгкий способ» бросить курить отыскания вероятностей. Впрочем, об этом чуть позже:
(с помощью тех же интегралов), после чего использовать «лёгкий способ» бросить курить отыскания вероятностей. Впрочем, об этом чуть позже:
Задача 105
Непрерывная случайная величина ![]() задана своей функцией распределения:
задана своей функцией распределения:
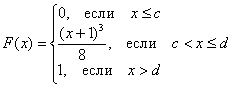
Найти значения ![]() и функцию
и функцию ![]() . Проверить, что
. Проверить, что ![]() действительно является функцией плотности распределения. Вычислить вероятности
действительно является функцией плотности распределения. Вычислить вероятности ![]() . Построить графики
. Построить графики ![]() .
.
Тренируемся самостоятельно! Если возникнут затруднения, то внимательно перечитайте вышеизложенный материал. Краткое решение и ответ в конце книги.
Вообще, типовые задачи на непрерывную случайную величину можно разделить на 2 большие группы:
1) когда дана функция ![]() , 2) когда дана функция
, 2) когда дана функция ![]() .
.
В первом случае не составляет особых трудностей отыскать функцию плотности распределения – почти всегда производные не то что простЫ, а примитивны (в чём мы только что убедились). Но вот когда НСВ задана функцией ![]() , то нахождение функции распределения – есть более кропотливый процесс:
, то нахождение функции распределения – есть более кропотливый процесс:
Задача 106
Непрерывная случайная величина ![]() задана функцией плотности распределения:
задана функцией плотности распределения:
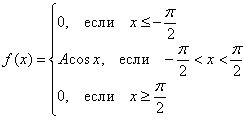
Найти значение ![]() и составить функцию распределения вероятностей
и составить функцию распределения вероятностей ![]() . Вычислить
. Вычислить ![]() .
.
Построить графики ![]() .
.
Решение: найдём константу ![]() . Это классика (в подавляющем большинстве задач вам не предложат готовую функцию плотности). Используем свойство
. Это классика (в подавляющем большинстве задач вам не предложат готовую функцию плотности). Используем свойство ![]() .
.
В данном случае:

На практике нулевые интегралы можно опускать, а константу сразу выносить за знак интеграла:
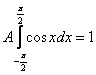 (*)
(*)
Пользуясь чётностью подынтегральной функции, вычислим интеграл:
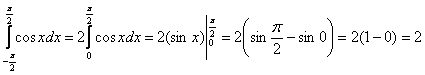 и подставим результат в уравнение (*):
и подставим результат в уравнение (*):
![]() , откуда выразим
, откуда выразим ![]()
Таким образом, функция плотности распределения:
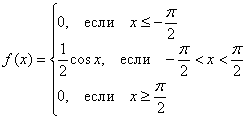
Выполним проверку, а именно, вычислим тот же самый интеграл, но уже с известной константой. Для разнообразия я не буду пользоваться чётностью:
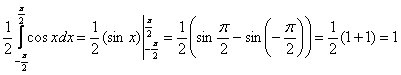 , отлично.
, отлично.
Обратите внимание, что только при ![]() и только при этом значении предложенная в условии функция является функцией плотности распределения. Ну и тут не лишним будет проконтролировать, что на интервале
и только при этом значении предложенная в условии функция является функцией плотности распределения. Ну и тут не лишним будет проконтролировать, что на интервале ![]() , т.е. условие неотрицательности действительно выполнено. Доверяй условию, да проверяй
, т.е. условие неотрицательности действительно выполнено. Доверяй условию, да проверяй  Не раз и не два мне встречались функции, которые в принципе не могли быть плотностью, что говорило об опечатках или о невнимательности авторов задач.
Не раз и не два мне встречались функции, которые в принципе не могли быть плотностью, что говорило об опечатках или о невнимательности авторов задач.
Теперь начинается самое интересное. Функции распределения вероятностей – есть интеграл:
![]()
Так как ![]() состоит из трёх кусков, то решение разобьётся на 3 шага:
состоит из трёх кусков, то решение разобьётся на 3 шага:
1) На промежутке ![]() , поэтому:
, поэтому: ![]()
2) На интервале ![]() , и мы прицепляем следующий вагончик:
, и мы прицепляем следующий вагончик:
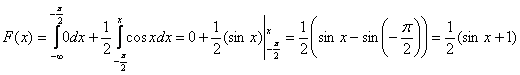
При подстановке верхнего предела интегрирования можно считать, что вместо «икс» мы подставляем «икс». Если же возник вопрос с пределом нижним, то вспоминаем график синуса либо его нечётность: ![]() .
.
3) И, наконец, на ![]() , и детский паровозик отправляется в путь:
, и детский паровозик отправляется в путь:

Внимание! А вот в этом задании нулевые интегралы пропускать НЕ НАДО. Чтобы показать своё понимание функции распределения К тому же, они могут оказаться вовсе не нулевыми, и тогда придётся иметь дело с интегралами несобственными. И такой пример я обязательно разберу ниже.
Записываем наши достижения под единую скобку:
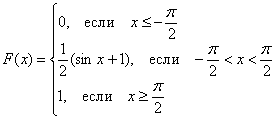
С высокой вероятностью всё правильно, но, тем не менее, устно возьмём производную: 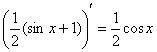 , а также «прозвоним» точки «стыка»:
, а также «прозвоним» точки «стыка»:
![]()
Правильность решения можно проконтролировать и в ходе построения графика, но, во-первых, он не всегда требуется, а во-вторых, до сего момента можно успеть «наломать дров». Ибо вероятности попадания чаще находят с помощью функции распределения:
![]()
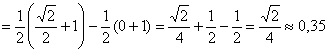 – вероятность того, что случайная величина
– вероятность того, что случайная величина ![]() примет значение из промежутка
примет значение из промежутка ![]()
Второй способ состоит в вычислении интеграла:
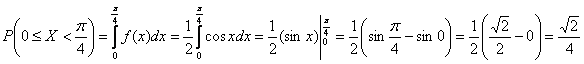 что, кстати, не труднее. И проверочка заодно получилась.
что, кстати, не труднее. И проверочка заодно получилась.
Выполним чертежи. График ![]() представляет собой
представляет собой косинусоиду, сжатую вдоль ординат в 2 раза. Тот редкий случай, когда функция плотности непрерывна:
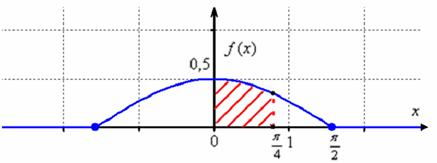
Значение ![]() численно равно заштрихованной площади – это я специально нарисовал, чтобы напомнить вероятностный смысл плотности функции распределения. И вся площадь под «дугой» равна единице, то есть, достоверным является тот факт, что случайная величина примет значение из интервала
численно равно заштрихованной площади – это я специально нарисовал, чтобы напомнить вероятностный смысл плотности функции распределения. И вся площадь под «дугой» равна единице, то есть, достоверным является тот факт, что случайная величина примет значение из интервала ![]() . Заметьте, что значения
. Заметьте, что значения ![]() по условию, невозможны.
по условию, невозможны.
Осталось изобразить функцию распределения. График ![]() представляет собой синусоиду, сжатую в 2 раза вдоль оси ординат и сдвинутую на
представляет собой синусоиду, сжатую в 2 раза вдоль оси ординат и сдвинутую на ![]() вверх:
вверх:
В принципе, тут можно было не заморачиваться преобразованием графиков, а найти несколько опорных точек и догадаться, как выглядит кривая (тригонометрическая таблица в помощь). Но «любительский» подход чреват тем, что график получится принципиально не точным. Так, в нашем примере в точке ![]() существует перегиб графика функции
существует перегиб графика функции ![]() , и велик риск неверно отобразить его выпуклость / вогнутость.
, и велик риск неверно отобразить его выпуклость / вогнутость.
Чертежи желательно расположить так, чтобы оси ординат (вертикальные оси) лежали ровненько одна под другой. Это будет хорошим тоном.
И я так чувствую, вам уже не терпится проверить свои силы. Как водится, пример попроще:
Задача 107
Задана плотность распределения вероятностей непрерывной случайной величины ![]() :
:
![]()
Требуется:
1) определить коэффициент ![]() ;
;
2) найти функцию распределения ![]() ;
;
3) построить графики ![]() ;
;
4) найти вероятность того, что ![]() примет значение из промежутка
примет значение из промежутка ![]()
и задачка поинтереснее:
Задача 108
Непрерывная случайная величина ![]() задана плотностью распределения вероятностей:
задана плотностью распределения вероятностей:
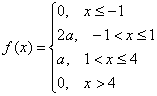
Найти значение ![]() и построить график плотности распределения. Найти функцию распределения вероятностей
и построить график плотности распределения. Найти функцию распределения вероятностей ![]() и построить её график. Вычислить вероятность
и построить её график. Вычислить вероятность ![]() .
.
Дерзайте! Свериться с решением можно внизу книги.
Следует отметить, что все эти задачи реально предлагают студентам-заочникам, и поэтому я не предлагаю вам ничего необычного.
И в заключение параграфа обещанные случаи с несобственными интегралами:
Задача 109
Непрерывная случайная величина ![]() задана своей плотностью распределения:
задана своей плотностью распределения:
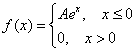
Найти коэффициент ![]() и функцию распределения
и функцию распределения ![]() . Построить графики.
. Построить графики.
Решение: по свойству функции плотности распределения:
![]()
В данной задаче ![]() состоит из 2 частей, поэтому:
состоит из 2 частей, поэтому:
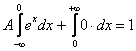
Правый интеграл равен нулю, а вот левый – есть «живой» несобственный интеграл с бесконечным нижним пределом:
![]()
Таким образом, наше уравнение превратилось в готовый результат:
![]()
и функция плотности:
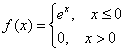
Функция ![]() , как нетрудно понять, отыскивается в 2 шага:
, как нетрудно понять, отыскивается в 2 шага:
1) На промежутке ![]() , следовательно:
, следовательно:
![]() – вот такая вот у нас замечательная экспонента. Как птица Феникс.
– вот такая вот у нас замечательная экспонента. Как птица Феникс.
2) На интервале ![]() и:
и:
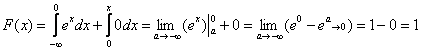 , что и должно получиться.
, что и должно получиться.
Для построения графиков найдём пару опорных точек: ![]() и аккуратно прочертим кусочки экспонент с причитающимися дополнениями:
и аккуратно прочертим кусочки экспонент с причитающимися дополнениями:

Заметьте, что теоретически случайная величина ![]() может принять сколь угодно большое по модулю отрицательное значение, и ось абсцисс является горизонтальной асимптотой для обоих графиков при
может принять сколь угодно большое по модулю отрицательное значение, и ось абсцисс является горизонтальной асимптотой для обоих графиков при ![]() .
.
В соответствующей статье сайта я рассмотрел ещё более интересный пример с функцией ![]() , где случайная величина теоретически принимает вообще ВСЕ действительные значения. Но это уже несколько повышенный уровень сложности.
, где случайная величина теоретически принимает вообще ВСЕ действительные значения. Но это уже несколько повышенный уровень сложности.
 2.4.4. Как вычислить математическое ожидание и дисперсию НСВ?
2.4.4. Как вычислить математическое ожидание и дисперсию НСВ?
 2.4.2. Вероятность попадания в промежуток
2.4.2. Вероятность попадания в промежуток
| Оглавление |
Полную и свежую версию этой книги в pdf-формате,
а также курсы по другим темам можно найти здесь.
Также вы можете изучить эту тему подробнее – просто, доступно, весело и бесплатно!
С наилучшими пожеланиями, Александр Емелин
Лекция
7.
Функция
распределения и плотность распределения
непрерывной случайной величины, их
взаимосвязь и свойства.
Определение
и свойства функции распределения
сохраняются и для непрерывной случайной
величины, для которой функцию распределения
можно считать одним из видов задания
закона распределения. Но для непрерывной
случайной величины вероятность каждого
отдельного ее значения равна 0. Это
следует из свойства 4 функции распределения:
р(Х
= а)
= F(a)
– F(a)
= 0. Поэтому для такой случайной величины
имеет смысл говорить только о вероятности
ее попадания в некоторый интервал.
Вторым
способом задания закона распределения
непрерывной случайной величины является
так называемая плотность распределения
(плотность вероятности, дифференциальная
функция).
Определение.
Функция
f(x),
называемая плотностью
распределения непрерывной
случайной величины, определяется по
формуле:
f
(x)
= F′(x),
то
есть является производной функции
распределения.
Свойства
плотности распределения.
-
f(x)
≥ 0, так как функция распределения
является неубывающей. -
 ,
,
что следует из определения плотности
распределения. -
Вероятность
попадания случайной величины в интервал
(а,
b)
определяется формулой
Действительно,
-
(условие
нормировки). Его справедливость следует
из того, что
а
-
так
как
при
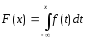 ,
,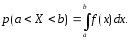

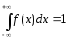
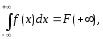
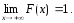


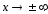
Таким
образом, график плотности распределения
представляет собой кривую, расположенную
выше оси Ох,
причем эта ось является ее горизонтальной
асимптотой при

(последнее справедливо только для
случайных величин, множеством возможных
значений которых является все множество
действительных чисел). Площадь
криволинейной трапеции, ограниченной
графиком этой функции, равна единице.
Замечание.
Если
все возможные значения непрерывной
случайной величины сосредоточе-ны на
интервале [a,
b],
то все интегралы вычисляются в этих
пределах, а вне интервала [a,
b]
f(x)
≡ 0.
Пример
1. Плотность распределения непрерывной
случайной величины задана формулой

Найти:
а) значение константы С;
б) вид функции распределения; в) p(-1
< x
< 1).
Решение.
а) значение константы С
найдем
из свойства 4:

откуда
 .
.
б)
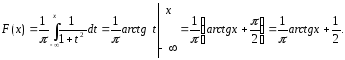
в)
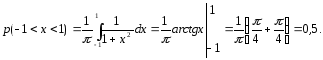
Пример
2. Функция распределения непрерывной
случайной величины имеет вид:
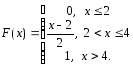
Найти
плотность распределения.
Решение.

Числовые
характеристики непрерывных случайных
величин.
Математическим
ожиданием
непрерывной случайной величины называют
интеграл
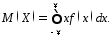
Дисперсией
непрерывной случайной величины называют
математическое ожидание квадрата ее
отклонения

Среднее
квадратическое отклонение
непрерывной случайной величины
определяется равенством

Замечание.
Можно доказать, что свойства математического
ожидания и дисперсии дискретной случайной
величины сохраняются для непрерывных
величин.
Равномерный
закон распределения.
Определение.
Закон
распределения непрерывной случайной
величины называется равномерным,
если на интервале, которому принадлежат
все возможные значения случайной
величины, плотность распределения
сохраняет постоянное значение (
f(x)
= const
при a
≤ x
≤ b,
f(x)
= 0 при x
< a,
x
> b.
Найдем
значение, которое принимает f(x)
при

Из условия нормировки следует, что
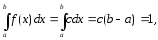
откуда
 .
.
Вероятность
попадания равномерно распределенной
случайной величины на интервал
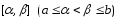
равна при этом
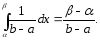
Вид
функции распределения для нормального
закона:
Пример.
Автобусы некоторого маршрута идут с
интервалом 5 минут. Найти вероятность
того, что пришедшему на остановку
пассажиру придется ожидать автобуса
не более 2 минут.
Решение.
Время ожидания является случайной
величиной, равномерно распределенной
в интервале [0, 5]. Тогда
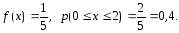
Нормальный
закон распределения
Определение.
Непрерывная
случайная величина называется
распределенной по нормальному
закону,
если ее плотность распределения имеет
вид:
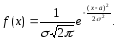
Замечание.
Таким
образом, нормальное распределение
определяется двумя параметрами: а
и σ.
График
плотности нормального распределения
называют нормальной
кривой (кривой Гаусса).
Выясним, какой вид имеет эта кривая, для
чего исследуем функцию f(x).
-
Область
определения этой функции: (-∞, +∞). -
f(x)
> 0 при любом х
(следовательно, весь график расположен
выше оси Ох). -
то
есть ось Ох
служит горизонтальной асимптотой
графика при
-
при
х
= а;
при x
> a,
при x
< a.
Следовательно,
— точка максимума. -
F(x
– a)
= f(a
– x),
то есть график симметричен относительно
прямой х
= а. -
при
,
то есть точки
являются точками перегиба.

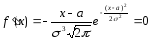
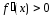
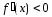


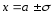 ,
,
Примерный
вид кривой Гаусса изображен на рис.1.
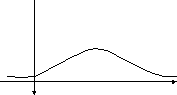 х
х
Рис.1.
Найдем
вид функции распределения для нормального
закона:
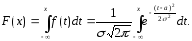
Перед
нами так называемый «неберущийся»
интеграл, который невозможно выразить
через элементарные функции. Поэтому
для вычисления значений F(x)
приходится пользоваться таблицами. Они
составлены для случая, когда а
= 0, а σ
= 1.
Определение.
Нормальное
распределение с параметрами а
= 0, σ
= 1
называется нормированным,
а его функция распределения

-
функцией
Лапласа.
Замечание.
Функцию
распределения для произвольных параметров
можно выразить через функцию Лапласа,
если сделать замену:
 ,
,
тогда
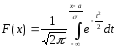 .
.
Найдем
вероятность попадания нормально
распределенной случайной величины на
заданный интервал:

Пример.
Случайная величина Х
имеет нормальное распределение с
параметрами а
= 3, σ = 2. Найти вероятность того, что она
примет значение из интервала (4, 8).
Решение.

Правило
«трех сигм».
Найдем
вероятность того, что нормально
распределенная случайная величина
примет значение из интервала (а
— 3σ,
а + 3σ):

Следовательно,
вероятность того, что значение случайной
величины окажется вне
этого интервала, равна 0,0027, то есть
составляет 0,27% и может считаться
пренебрежимо малой. Таким образом, на
практике можно считать, что все
возможные значения нормально распределенной
случайной величины лежат в интервале
(а
— 3σ,
а + 3σ).
Полученный
результат позволяет сформулировать
правило
«трех сигм»:
если
случайная величина распределена
нормально, то модуль ее отклонения от
х = а не превосходит 3σ.
Показательное
распределение.
Определение.
Показательным
(экспоненциальным) называют
распределение вероятностей непрерывной
случайной величины Х,
которое описывается плотностью

В
отличие от нормального распределения,
показательный закон определяется только
одним параметром λ.
В этом его преимущество, так как обычно
параметры распределения заранее не
известны и их приходится оценивать
приближенно. Понятно, что оценить один
параметр проще, чем несколько.
Найдем
функцию распределения показательного
закона:

Следовательно,

Теперь
можно найти вероятность попадания
показательно распределенной случайной
величины в интервал (а,
b):
 .
.
Значения
функции е-х
можно найти из таблиц.
Функция
надежности.
Пусть
элемент
(то
есть некоторое устройство) начинает
работать в момент времени t0
= 0
и должен проработать в течение периода
времени t.
Обозначим за Т
непрерывную случайную величину – время
безотказной работы элемента, тогда
функция F(t)
= p(T
< t)
определяет вероятность отказа за время
t.
Следовательно, вероятность безотказной
работы за это же время равна
R(t)
= p(T
> t)
= 1 – F(t).
Эта
функция называется функцией
надежности.
Показательный
закон надежности.
Часто
длительность безотказной работы элемента
имеет показательное распределение, то
есть
F(t)
= 1 – e—λt
.
Следовательно,
функция надежности в этом случае имеет
вид:
R(t)
= 1 – F(t)
= 1 – (1 – e-λt)
= e-λt
.
Определение.
Показательным
законом надежности
называют функцию надежности, определяемую
равенством
R(t)
= e—λt
, где λ
–
интенсивность отказов.
Пример.
Пусть время безотказной работы элемента
распределено по показательному закону
с плотностью распределения f(t)
= 0,1 e—0,1t
при
t
≥ 0. Найти вероятность того, что элемент
проработает безотказно в течение 10
часов.
Решение.
Так как λ
= 0,1, R(10)
= e-0,1·10
= e-1
= 0,368.
Соседние файлы в папке Лекции 2 курс
- #
- #
- #
- #
- #
- #
- #
- #
- #
Функция, интеграл которой по региону описывает вероятность события, происходящего в этом регионе 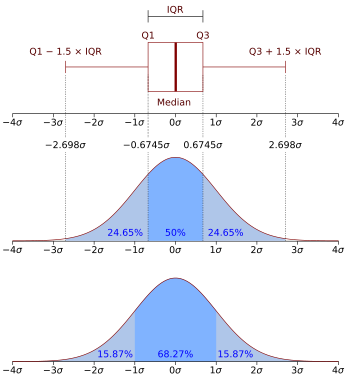 График и плотность вероятности функция нормального распределения N (0, σ).
График и плотность вероятности функция нормального распределения N (0, σ).  Геометрическая визуализация режима , медианы и среднего произвольная функция плотности вероятности.
Геометрическая визуализация режима , медианы и среднего произвольная функция плотности вероятности.
В теории вероятностей, функция плотности вероятности (PDF ) или плотность из непрерывная случайная величина, является функцией , значение которой в любой заданной выборке (или точке) в пространстве выборки (набор возможных значений, принимаемых случайной величиной) может интерпретироваться как обеспечение относительной вероятности того, что значение случайной величины будет равно этой выборке. Другими словами, хотя абсолютная вероятность того, что непрерывная случайная переменная примет какое-либо конкретное значение, равна 0 (поскольку существует бесконечный набор возможных значений для начала), значение PDF для двух разных выборок может использоваться для вывода, насколько более вероятно, что случайная величина будет равна одной выборке по сравнению с другой выборкой, при любом конкретном розыгрыше случайной величины.
В более точном смысле PDF используется для определения вероятности попадания случайной величины в конкретный диапазон значений, в отличие от принятия какого-либо одного значения. Эта вероятность дается интегралом PDF этой переменной в этом диапазоне, то есть она дается площадью под функцией плотности, но над горизонтальной осью и между наименьшим и наибольшим значениями диапазона. Функция плотности вероятности везде неотрицательна, и ее интеграл по всему пространству равен 1.
Термины «функция распределения вероятностей» и «функция вероятности» также иногда использовались для обозначения функции плотности вероятности. Однако такое использование не является стандартным среди специалистов по теории вероятностей и статистиков. В других источниках «функция распределения вероятностей» может использоваться, когда распределение вероятностей определяется как функция по общим наборам значений, или оно может относиться к кумулятивной функции распределения, или может быть функцией вероятности и массы (PMF), а не плотностью. Сама «функция плотности» также используется для функции массы вероятности, что ведет к дальнейшему недоразумению. Однако в целом PMF используется в контексте дискретных случайных величин (случайных величин, принимающих значения в счетном наборе), в то время как PDF используется в контексте непрерывных случайных величин.
Содержание
- 1 Пример
- 2 Абсолютно непрерывные одномерные распределения
- 3 Формальное определение
- 3.1 Обсуждение
- 4 Дополнительные сведения
- 5 Связь между дискретным и непрерывным распределениями
- 6 Семейства плотности
- 7 Плотности, связанные с несколькими переменными
- 7.1 Предельные плотности
- 7.2 Независимость
- 7.3 Следствие
- 7.4 Пример
- 8 Функция случайных величин и изменение переменных в функции плотности вероятности
- 8.1 Скаляр в скаляр
- 8.2 Вектор в вектор
- 8.3 Вектор в скаляр
- 9 Суммы независимых случайных величин
- 10 Произведения и частные независимых случайных величин
- 10.1 Пример: распределение частных
- 10.2 Пример: отношение двух стандартных норм
- 11 См. Также
- 12 Ссылки
- 13 Библиография
- 14 Внешние ссылки
Пример
Предположим, бактерии определенного вида обычно живут от 4 до 6 часов. Вероятность того, что бактерия живет ровно 5 часов, равна нулю. Многие бактерии живут приблизительно 5 часов, но нет никаких шансов, что какая-либо конкретная бактерия погибнет ровно в 5.0000000000… часов. Однако вероятность того, что бактерия погибнет в период от 5 часов до 5,01 часа, поддается количественной оценке. Предположим, ответ 0,02 (т.е. 2%). Тогда вероятность того, что бактерия погибнет в период от 5 часов до 5,001 часа, должна быть около 0,002, поскольку этот временной интервал в десять раз меньше предыдущего. Вероятность того, что бактерия погибнет в период от 5 часов до 5.0001 часа, должна быть около 0,0002 и так далее.
В этих трех примерах соотношение (вероятность смерти во время интервала) / (продолжительность интервала) приблизительно постоянное и равно 2 в час (или 2 часа). Например, вероятность смерти 0,02 в интервале 0,01 часа от 5 до 5,01 часа, а (вероятность 0,02 / 0,01 часа) = 2 часа. Это количество в 2 часа называется плотностью вероятности смерти примерно через 5 часов. Следовательно, вероятность того, что бактерия погибнет через 5 часов, может быть записана как (2 часа) dt. Это вероятность того, что бактерия погибнет в бесконечно малом временном окне около 5 часов, где dt — продолжительность этого окна. Например, вероятность того, что он живет дольше 5 часов, но меньше (5 часов + 1 наносекунда), составляет (2 часа) × (1 наносекунда) ≈ 6 × 10 (с использованием преобразования единиц измерения 3,6 × 10 наносекунд = 1 час).
Существует функция плотности вероятности f с f (5 часов) = 2 часа. интеграл от f для любого временного окна (не только бесконечно малых, но и больших окон) — это вероятность того, что бактерия погибнет в этом окне.
Абсолютно непрерывные одномерные распределения
Функция плотности вероятности чаще всего связана с абсолютно непрерывными одномерными распределениями. A случайная величина X { displaystyle X} имеет плотность f X { displaystyle f_ {X}}
имеет плотность f X { displaystyle f_ {X}} , где е Икс { displaystyle f_ {X}}— неотрицательная интегрируемая по Лебегу функция, если:
, где е Икс { displaystyle f_ {X}}— неотрицательная интегрируемая по Лебегу функция, если:
- Pr [a ≤ X ≤ b] = ∫ abf X ( х) dx. { displaystyle Pr [a leq X leq b] = int _ {a} ^ {b} f_ {X} (x) , dx.}
![Pr[aleq Xleq b]=int _{a}^{b}f_{X}(x),dx.](https://wikimedia.org/api/rest_v1/media/math/render/svg/45fd7691b5fbd323f64834d8e5b8d4f54c73a6f8)
Следовательно, если FX { displaystyle F_ {X}} — кумулятивная функция распределения для X { displaystyle X}, тогда:
— кумулятивная функция распределения для X { displaystyle X}, тогда:
- FX (x) = ∫ — ∞ xf X (u) du, { displaystyle F_ {X} (x) = int _ {- infty} ^ {x} f_ {X} (u) , du,}

и (если е Икс { displaystyle f_ {X}}непрерывно в x { displaystyle x} )
)
- f X (x) = ddx FX (x). { Displaystyle f_ {X} (x) = { frac {d} {dx}} F_ {X} (x).}

Интуитивно можно представить себе f X (x) dx { displaystyle f_ {X } (x) , dx} как вероятность попадания X { displaystyle X}в бесконечно малый интервал [x, x + dx] { displaystyle [x, x + dx]}
как вероятность попадания X { displaystyle X}в бесконечно малый интервал [x, x + dx] { displaystyle [x, x + dx]}![[x,x+dx]](https://wikimedia.org/api/rest_v1/media/math/render/svg/f07271dbe3f8967834a2eaf143decd7e41c61d7a) .
.
Формальное определение
(Это определение может быть расширено до любого распределения вероятностей с использованием теории меры определение вероятности.)
A случайная величина X { displaystyle X}со значениями в измеримое пространство (X, A) { displaystyle ({ mathcal {X}}, { mathcal {A}})} (обычно R n { displaystyle mathbb {R} ^ {n}}
(обычно R n { displaystyle mathbb {R} ^ {n}} с наборами Бореля в качестве измеримых подмножеств) имеет как распределение вероятностей меру X ∗ P на (X, A) { displaystyle ({ mathcal {X}}, { mathcal {A}})}: плотность из Икс { displaystyle X}относительно контрольной меры μ { displaystyle mu}
с наборами Бореля в качестве измеримых подмножеств) имеет как распределение вероятностей меру X ∗ P на (X, A) { displaystyle ({ mathcal {X}}, { mathcal {A}})}: плотность из Икс { displaystyle X}относительно контрольной меры μ { displaystyle mu} на (X, A) { displaystyle ({ mathcal {X}}, { mathcal {A}})}— производная Радона – Никодима :
на (X, A) { displaystyle ({ mathcal {X}}, { mathcal {A}})}— производная Радона – Никодима :
- f = d X ∗ P d μ. { displaystyle f = { frac {dX _ {*} P} {d mu}}.}

То есть f — это любая измеримая функция со следующим свойством:
- Pr [X ∈ A] = ∫ Икс — 1 A d п знак равно ∫ A fd μ { displaystyle Pr [X in A] = int _ {X ^ {- 1} A} , dP = int _ {A} f , d mu}
![Pr[Xin A]=int _{X^{-1}A},dP=int _{A}f,dmu](https://wikimedia.org/api/rest_v1/media/math/render/svg/591b4a96fefea18b28fe8eb36d3469ad6b33a9db)
для любого измеримого множества A ∈ A. { displaystyle A in { mathcal {A}}.}
Обсуждение
В непрерывном одномерном случае выше эталонной мерой является мера Лебега. Функция вероятности и массы дискретной случайной величины представляет собой плотность относительно счетной меры в пространстве выборки (обычно набор целых чисел или некоторые его подмножества).
Невозможно определить плотность со ссылкой на произвольную меру (например, нельзя выбрать счетную меру в качестве эталона для непрерывной случайной величины). Более того, когда он действительно существует, плотность почти везде уникальна.
Дополнительные сведения
В отличие от вероятности функция плотности вероятности может принимать значения больше единицы; например, равномерное распределение на интервале [0, ½] имеет плотность вероятности f (x) = 2 для 0 ≤ x ≤ ½ и f (x) = 0 в другом месте.
Стандартное нормальное распределение имеет плотность вероятности
- f (x) = 1 2 π e — x 2/2. { displaystyle f (x) = { frac {1} { sqrt {2 pi}}} ; e ^ {- x ^ {2} / 2}.}

Если задана случайная величина X и его распределение допускает функцию плотности вероятности f, то ожидаемое значение X (если ожидаемое значение существует) может быть вычислено как
- E [X] = ∫ — ∞ ∞ xf (x) dx. { displaystyle operatorname {E} [X] = int _ {- infty} ^ { infty} x , f (x) , dx.}
![operatorname {E} [X]=int _{-infty }^{infty }x,f(x),dx.](https://wikimedia.org/api/rest_v1/media/math/render/svg/00ce7a00fac378eafc98afb88de88d619e15e996)
Не каждое распределение вероятностей имеет функцию плотности: распределения дискретных случайных величин — нет; равно как и распределение Кантора, даже при том, что оно не имеет дискретной составляющей, т.е. не присваивает положительную вероятность какой-либо отдельной точке.
Распределение имеет функцию плотности тогда и только тогда, когда его кумулятивная функция распределения F (x) абсолютно непрерывна. В этом случае: F почти всюду дифференцируемо, и его производная может использоваться как плотность вероятности:
- d d x F (x) = f (x). { displaystyle { frac {d} {dx}} F (x) = f (x).}

Если распределение вероятностей допускает плотность, то вероятность каждого одноточечного набора {a} равна нулю; то же самое верно для конечных и счетных множеств.
Две плотности вероятности f и g представляют одно и то же распределение вероятностей, если они различаются только на наборе Лебега нулевой меры.
в поле в статистической физике, неформальная переформулировка приведенного выше отношения между производной кумулятивной функции распределения и функцией плотности вероятности обычно используется в качестве определения функции плотности вероятности. Это альтернативное определение выглядит следующим образом:
Если dt — бесконечно малое число, вероятность того, что X входит в интервал (t, t + dt), равна f (t) dt, или:
- Pr (t < X < t + d t) = f ( t) d t. {displaystyle Pr(t

Связь между дискретным и непрерывным распределениями
Можно представить определенные дискретные случайные величины, а также случайные величины, включающие как непрерывную, так и дискретную часть, с помощью обобщенного функция плотности вероятности с использованием дельта-функции Дирака. (Это невозможно с функцией плотности вероятности в смысле, определенном выше, это может быть выполнено с распределением.) Например,, рассмотрим двоичную дискретную случайную величину, имеющую распределение Радемахера, то есть принимающее -1 или 1 для значений с вероятностью 1/2 каждое. Плотность вероятности, связанная с этой переменной, равна:
- е (t) = 1 2 (δ (t + 1) + δ (t — 1)). { Displaystyle f (t) = { frac {1} {2}} ( delta (t + 1) + delta (t-1)).}

Более общие y, если дискретная переменная может принимать n различных значений среди действительных чисел, тогда соответствующая функция плотности вероятности имеет вид:
- f (t) = ∑ i = 1 npi δ (t — xi), { displaystyle f (t) = sum _ {i = 1} ^ {n} p_ {i} , delta (t-x_ {i}),}

где x 1…, xn { displaystyle x_ {1} ldots, x_ {n}} — дискретные значения, доступные для переменной, а p 1,…, pn { displaystyle p_ {1}, ldots, p_ {n}}
— дискретные значения, доступные для переменной, а p 1,…, pn { displaystyle p_ {1}, ldots, p_ {n}} — вероятности, связанные с этими значениями.
— вероятности, связанные с этими значениями.
Это существенно унифицирует обработку дискретных и непрерывных распределений вероятностей. Например, приведенное выше выражение позволяет определять статистические характеристики такой дискретной переменной (такие как ее среднее, ее дисперсия и ее эксцесс ), начиная с приведены формулы для непрерывного распределения вероятности.
Семейства плотностей
Обычно функции плотности вероятности (и функции массы вероятности ) параметризуются, то есть характеризуются неопределенными параметрами . Например, нормальное распределение параметризуется в терминах среднего и дисперсии, обозначенных μ { displaystyle mu}и σ 2 { displaystyle sigma ^ {2}} соответственно, что дает семейство плотностей
соответственно, что дает семейство плотностей
- f (x; μ, σ 2) = 1 σ 2 π e — 1 2 (х — μ σ) 2. { displaystyle f (x; mu, sigma ^ {2}) = { frac {1} { sigma { sqrt {2 pi}}}} e ^ {- { frac {1} {2 }} left ({ frac {x- mu} { sigma}} right) ^ {2}}.}

Важно помнить о различии между доменом семейства плотностей и параметров семейства. Разные значения параметров описывают разные распределения разных случайных величин на одном и том же пространстве выборки (один и тот же набор всех возможных значений переменной); это пространство выборки является областью семейства случайных величин, которое описывает это семейство распределений. Данный набор параметров описывает единичное распределение внутри семейства, разделяющее функциональную форму плотности. С точки зрения данного распределения параметры являются константами, а члены функции плотности, которые содержат только параметры, но не переменные, являются частью коэффициента нормализации распределения (мультипликативный коэффициент, который гарантирует, что площадь под плотностью — вероятность того, что что-то произойдет в области — равна 1). Этот коэффициент нормализации находится за пределами ядра распределения.
Поскольку параметры являются константами, повторная параметризация плотности в терминах различных параметров, чтобы дать характеристику другой случайной переменной в семействе, означает простую замену новых значений параметров в формулу вместо старых.. Однако изменение области определения плотности вероятности сложнее и требует дополнительных усилий: см. Раздел ниже, посвященный замене переменных.
Плотности, связанные с несколькими переменными
Для непрерывных случайных величин X1,…, X n также можно определить плотность вероятности функция, связанная с множеством в целом, часто называемая совместной функцией плотности вероятности . Эта функция плотности определяется как функция n переменных, так что для любой области D в n-мерном пространстве значений переменных X 1,…, X n, вероятность того, что реализация набора переменных попадет в область D, равна
- Pr (X 1,…, X n ∈ D) = ∫ D f X 1,…, X n (x 1,…, xn) dx 1 ⋯ dxn. { displaystyle Pr left (X_ {1}, ldots, X_ {n} in D right) = int _ {D} f_ {X_ {1}, ldots, X_ {n}} (x_ {1}, ldots, x_ {n}) , dx_ {1} cdots dx_ {n}.}

Если F (x 1,…, x n) = Pr (X 1 ≤ x 1,…, X n ≤ x n) — это кумулятивная функция распределения вектора (X 1,…, X n), тогда совместная функция плотности вероятности может быть вычислена как частная производная
- f (x) = ∂ n F ∂ x 1 ⋯ ∂ xn | х { displaystyle f (x) = { frac { partial ^ {n} F} { partial x_ {1} cdots partial x_ {n}}} { bigg |} _ {x}}

Предельные плотности
Для i = 1, 2,…, n пусть f Xi(xi) будет функцией плотности вероятности, связанной только с переменной X i. Это называется функцией предельной плотности, и ее можно вывести из плотности вероятности, связанной со случайными величинами X 1,…, X n, путем интегрирования по всем значениям других n — 1 переменная:
- f X i (xi) = ∫ f (x 1,…, xn) dx 1 ⋯ dxi — 1 dxi + 1 ⋯ dxn. { displaystyle f_ {X_ {i}} (x_ {i}) = int f (x_ {1}, ldots, x_ {n}) , dx_ {1} cdots dx_ {i-1} , dx_ {i + 1} cdots dx_ {n}.}

Независимость
Непрерывные случайные величины X 1,…, X n, допускающие плотность соединений все независимы друг от друга тогда и только тогда, когда
- f X 1,…, X n (x 1,…, xn) = f X 1 (x 1) ⋯ f X n ( xn). { displaystyle f_ {X_ {1}, ldots, X_ {n}} (x_ {1}, ldots, x_ {n}) = f_ {X_ {1}} (x_ {1}) cdots f_ { X_ {n}} (x_ {n}).}

Следствие
Если совместная функция плотности вероятности вектора из n случайных величин может быть разложена на произведение n функций одной переменной
- е Икс 1,…, Икс N (Икс 1,…, xn) = f 1 (x 1) ⋯ fn (xn), { displaystyle f_ {X_ {1}, ldots, X_ {n}} (x_ {1}, ldots, x_ {n}) = f_ {1} (x_ {1}) cdots f_ {n} (x_ {n}),}

(где каждое f i не обязательно является плотностью), то все n переменных в наборе независимы друг от друга, и функция предельной плотности вероятности каждой из них задается как
- f X i (xi) = fi (xi) ∫ fi (x) dx. { displaystyle f_ {X_ {i}} (x_ {i}) = { frac {f_ {i} (x_ {i})} { int f_ {i} (x) , dx}}.}

Пример
Этот элементарный пример иллюстрирует приведенное выше определение многомерных функций плотности вероятности в простом случае функции от набора двух переменных. Назовем R → { displaystyle { vec {R}}} двумерным случайным вектором координат (X, Y): вероятность получить R → { displaystyle { vec {R}}}в четверть плоскости положительных значений x и y равно
двумерным случайным вектором координат (X, Y): вероятность получить R → { displaystyle { vec {R}}}в четверть плоскости положительных значений x и y равно
- Pr (X>0, Y>0) = ∫ 0 ∞ ∫ 0 ∞ f X, Y ( х, у) dxdy. { displaystyle Pr left (X>0, Y>0 right) = int _ {0} ^ { infty} int _ {0} ^ { infty} f_ {X, Y} (x, y) , dx , dy.}

Функция случайных величин и изменение переменных в функции плотности вероятности
Если функция плотности вероятности случайной величины (или вектора) X задана как f X (x), можно (но часто не обязательно; см. Ниже) вычислить функцию плотности вероятности некоторой переменной Y = g (X). Это также называется «заменой переменной» и на практике используется для генерации случайной величины произвольной формы f g (X) = f Y с использованием известного (например, равномерного) генератора случайных чисел.
Заманчиво думать, что для того, чтобы найти математическое ожидание E (g (X)), нужно сначала найти плотность вероятности f g (X) новой случайной величины Y = g (X). Однако вместо вычисления
- E (g (X)) = ∫ — ∞ ∞ yfg (X) (y) dy, { displaystyle operatorname {E} { big (} g (X) { big)} = int _ {- infty} ^ { infty} yf_ {g (X)} (y) , dy,}

вместо этого можно найти
- E (g (X)) = ∫ — ∞ ∞ д (х) е х (х) дх. { displaystyle operatorname {E} { big (} g (X) { big)} = int _ {- infty} ^ { infty} g (x) f_ {X} (x) , dx.}

Значения двух интегралов одинаковы во всех случаях, когда и X, и g (X) фактически имеют функции плотности вероятности. Необязательно, чтобы g была однозначной функцией. В некоторых случаях последний интеграл вычисляется намного проще, чем первый. См. Закон бессознательного статистика.
От скаляра до скаляра
Пусть g: R → R { displaystyle g: { mathbb {R}} rightarrow { mathbb {R} }} быть монотонной функцией, тогда результирующая функция плотности будет
быть монотонной функцией, тогда результирующая функция плотности будет
- f Y (y) = f X (g — 1 (y)) | d d y (g — 1 (y)) |. { displaystyle f_ {Y} (y) = f_ {X} { big (} g ^ {- 1} (y) { big)} left | { frac {d} {dy}} { big (} g ^ {- 1} (y) { big)} right |.}

Здесь g обозначает обратную функцию.
Это следует из того факта, что вероятность, содержащаяся в дифференциальной области, должна быть инвариантным относительно замены переменных. То есть
- | f Y (y) d y | = | f X (x) d x |, { displaystyle left | f_ {Y} (y) , dy right | = left | f_ {X} (x) , dx right |,}

или
- f Y (y) = | д х д у | f X (x) = | d d y (x) | f X (x) = | d d y (g — 1 (y)) | f X (g — 1 (y)) = | (g — 1) ′ (y) | ⋅ е X (г — 1 (у)). { displaystyle f_ {Y} (y) = left | { frac {dx} {dy}} right | f_ {X} (x) = left | { frac {d} {dy}} (x) right | f_ {X} (x) = left | { frac {d} {dy}} { big (} g ^ {- 1} (y) { big)} right | f_ {X } { big (} g ^ {- 1} (y) { big)} = {{ big |} { big (} g ^ {- 1} { big)} ‘(y) { big |}} cdot f_ {X} { big (} g ^ {- 1} (y) { big)}.}

Для функций, которые не являются монотонными, функция плотности вероятности для y равна
- ∑ k = 1 n (y) | d d y g k — 1 (y) | ⋅ е Икс (gk — 1 (y)), { displaystyle sum _ {k = 1} ^ {n (y)} left | { frac {d} {dy}} g_ {k} ^ {- 1} (y) right | cdot f_ {X} { big (} g_ {k} ^ {- 1} (y) { big)},}

где n (y) — количество решения по x уравнения g (x) = y { displaystyle g (x) = y} и gk — 1 (y) { displaystyle g_ {k} ^ {-1} (y)}
и gk — 1 (y) { displaystyle g_ {k} ^ {-1} (y)} — вот эти решения.
— вот эти решения.
Вектор в вектор
Вышеупомянутые формулы могут быть обобщены для переменных (которые мы снова будем называть y) в зависимости от более чем одной другой переменной. f (x 1,…, x n) должно обозначать функцию плотности вероятности переменных, от которых зависит y, и зависимость должна быть y = g (x 1,…, x n). Тогда результирующая функция плотности будет
- ∫ y = g (x 1,…, xn) f (x 1,…, xn) ∑ j = 1 n ∂ g ∂ xj (x 1,…, xn) 2 d V, { displaystyle int limits _ {y = g (x_ {1}, ldots, x_ {n})} { frac {f (x_ {1}, ldots, x_ {n})} { sqrt { sum _ {j = 1} ^ {n} { frac { partial g} { partial x_ {j}}} (x_ {1}, ldots, x_ {n}) ^ {2} }}} , dV,}

где интеграл берется по всему (n — 1) -мерному решению уравнения с индексами, а символическое dV должно быть заменено параметризацией этого решения для конкретного вычисления; переменные x 1,…, x n в таком случае, конечно, являются функциями этой параметризации.
Это происходит из следующего, возможно, более интуитивного представления: Предположим, x — это n-мерная случайная величина с совместной плотностью f. Если y = H (x ), где H — биективная, дифференцируемая функция, то y имеет плотность g:
- g (y) = f (H — 1 (y)) | det [d H — 1 (z) d z | z = y] | { Displaystyle г ( mathbf {y}) = е { Big (} H ^ {- 1} ( mathbf {y}) { Big)} left vert det left [{ frac {dH ^ {- 1} ( mathbf {z})} {d mathbf {z}}} { Bigg vert} _ { mathbf {z} = mathbf {y}} right] right vert}
![{displaystyle g(mathbf {y})=f{Big (}H^{-1}(mathbf {y}){Big)}leftvert det left[{frac {dH^{-1}(mathbf {z})}{dmathbf {z} }}{Bigg vert }_{mathbf {z} =mathbf {y} }right]rightvert }](https://wikimedia.org/api/rest_v1/media/math/render/svg/c6d564757b3f48359e65d6c05fe801fa60aaa72d)
с дифференциалом, рассматриваемым как якобиан обратной величины H (.), Вычисляемой как y.
. Например, в двумерном случае x = (x 1, x 2), предположим, что преобразование H задано как y 1 = H 1(x1, x 2), y 2 = H 2(x1, x 2) с обратными x 1 = H 1(y1, y 2), x 2 = H 2(y1, y 2). Совместное распределение для y = (y 1, y 2) имеет плотность
- g (y 1, y 2) = f X 1, X 2 (H 1 — 1 (y 1, y 2), H 2 — 1 (y 1, y 2)) | ∂ H 1 — 1 ∂ y 1 ∂ H 2 — 1 ∂ y 2 — ∂ H 1 — 1 ∂ y 2 ∂ H 2 — 1 ∂ y 1 |. { displaystyle g (y_ {1}, y_ {2}) = f_ {X_ {1}, X_ {2}} { big (} H_ {1} ^ {- 1} (y_ {1}, y_ { 2}), H_ {2} ^ {- 1} (y_ {1}, y_ {2}) { big)} left vert { frac { partial H_ {1} ^ {- 1}} { partial y_ {1}}} { frac { partial H_ {2} ^ {- 1}} { partial y_ {2}}} — { frac { partial H_ {1} ^ {- 1}} { partial y_ {2}}} { frac { partial H_ {2} ^ {- 1}} { partial y_ {1}}} right vert.}

Вектор в скаляр
Пусть V: R n → R { displaystyle V: { mathbb {R}} ^ {n} rightarrow { mathbb {R}}} — дифференцируемая функция и X { displaystyle X}быть случайным вектором, принимающим значения в R n { displaystyle { mathbb {R}} ^ {n}}
— дифференцируемая функция и X { displaystyle X}быть случайным вектором, принимающим значения в R n { displaystyle { mathbb {R}} ^ {n}} , f X (⋅) { displaystyle f_ {X} ( cdot)}
, f X (⋅) { displaystyle f_ {X} ( cdot)} — функция плотности вероятности от X { displaystyle X}и δ (⋅) { displaystyle delta ( cdot)}
— функция плотности вероятности от X { displaystyle X}и δ (⋅) { displaystyle delta ( cdot)} быть дельта-функцией Дирака. Можно использовать приведенные выше формулы для определения f Y (⋅) { displaystyle f_ {Y} ( cdot)}
быть дельта-функцией Дирака. Можно использовать приведенные выше формулы для определения f Y (⋅) { displaystyle f_ {Y} ( cdot)} , функции плотности вероятности Y = V (X) { displaystyle Y = V (X)}
, функции плотности вероятности Y = V (X) { displaystyle Y = V (X)} , который будет задан как
, который будет задан как
- f Y (y) = ∫ R nf X (x) δ (y — V (x)) dx. { displaystyle f_ {Y} (y) = int _ {{ mathbb {R}} ^ {n}} f_ {X} ( mathbf {x}) delta { big (} yV ( mathbf { x}) { big)} , d mathbf {x}.}

Этот результат приводит к Закону бессознательного статистика :
- EY [Y] = ∫ R yf Y (y) dy = ∫ R y ∫ R nf X (x) δ (y — V (x)) dxdy = ∫ R n ∫ R yf X (x) δ (y — V (x)) dydx = ∫ R n V (x) f X (x) dx = EX [V (X)]. { displaystyle operatorname {E} _ {Y} [Y] = int _ { mathbb {R}} yf_ {Y} (y) dy = int _ { mathbb {R}} y int _ { { mathbb {R}} ^ {n}} f_ {X} ( mathbf {x}) delta { big (} yV ( mathbf {x}) { big)} , d mathbf {x } dy = int _ {{ mathbb {R}} ^ {n}} int _ { mathbb {R}} yf_ {X} ( mathbf {x}) delta { big (} yV ( mathbf {x}) { big)} , dyd mathbf {x} = int _ {{ mathbb {R}} ^ {n}} V ( mathbf {x}) f_ {X} ( mathbf {x}) d mathbf {x} = operatorname {E} _ {X} [V (X)].}
![{displaystyle operatorname {E} _{Y}[Y]=int _{mathbb {R} }yf_{Y}(y)dy=int _{mathbb {R} }yint _{{mathbb {R} }^{n}}f_{X}(mathbf {x})delta {big (}y-V(mathbf {x}){big)},dmathbf {x} dy=int _{{mathbb {R} }^{n}}int _{mathbb {R} }yf_{X}(mathbf {x})delta {big (}y-V(mathbf {x}){big)},dydmathbf {x} =int _{{mathbb {R} }^{n}}V(mathbf {x})f_{X}(mathbf {x})dmathbf {x} =operatorname {E} _{X}[V(X)].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0cd5acec96860375eea687a2904e06361df92c61)
Доказательство:
Пусть Z { displaystyle Z} быть свернутой случайной величиной с функцией плотности вероятности p Z (z) = δ (z) { displaystyle p_ {Z} (z) = delta (z)}
быть свернутой случайной величиной с функцией плотности вероятности p Z (z) = δ (z) { displaystyle p_ {Z} (z) = delta (z)} (т.е. константа, равная нулю). Пусть случайный вектор X ~ { displaystyle { tilde {X}}}
(т.е. константа, равная нулю). Пусть случайный вектор X ~ { displaystyle { tilde {X}}} и преобразование H { displaystyle H}
и преобразование H { displaystyle H} определены как
определены как
- ЧАС (Z, X) знак равно [Z + V (X) X] = [YX ~] { Displaystyle H (Z, X) = { begin {bmatrix} Z + V (X) \ X end {bmatrix }} = { begin {bmatrix} Y \ { tilde {X}} end {bmatrix}}}.
 .
.Ясно, что H { displaystyle H}является биективное отображение, и якобиан H — 1 { displaystyle H ^ {- 1}} задается следующим образом:
задается следующим образом:
- d H — 1 (y, x ~) dydx ~ = [ 1 — d V (x ~) dx ~ 0 n × 1 I n × n] { displaystyle { frac {dH ^ {- 1} (y, { tilde { mathbf {x}}})} {dy , d { tilde { mathbf {x}}}}} = { begin {bmatrix} 1 — { frac {dV ({ tilde { mathbf {x}}})} {d { tilde { mathbf {x}}}}} \ mathbf {0} _ {n times 1} mathbf {I} _ {n times n} end {bmatrix}}},
 ,
,который является верхним треугольная матрица с единицами на главной диагонали, поэтому ее определитель равен 1. Применяя теорему о замене переменной из предыдущего раздела, получаем, что
- f Y, X (y, x) = f X (x) δ (y -В (Икс)) { Displaystyle F_ {Y, X} (Y, X) = F_ {X} ( mathbf {x}) delta { big (} yV ( mathbf {x}) { big) }},
 ,
,который, если его маргинализировать более чем x { displaystyle x}приводит к желаемой функции плотности вероятности.
Суммы независимых случайных величин
Функция плотности вероятности суммы двух независимых случайных величин U и V, каждая из которых имеет функцию плотности вероятности, является свертка их отдельных функций плотности:
- f U + V (x) = ∫ — ∞ ∞ f U (y) f V (x — y) dy = (f U ∗ f V) ( х) { displaystyle f_ {U + V} (x) = int _ {- infty} ^ { infty} f_ {U} (y) f_ {V} (xy) , dy = left (f_ {U} * f_ {V} right) (x)}

Можно обобщить предыдущее соотношение на сумму N независимых случайных величин с плотностями U 1,…, U N:
- е U 1 + ⋯ + UN (x) = (е U 1 * ⋯ * f UN) (x) { displaystyle f_ {U_ {1} + cdots + U_ {N}} (x) = left (f_ {U_ {1}} * cdots * f_ {U_ {N}} right) (x)}

Это можно получить из двухсторонней замены переменных с участием Y = U + V и Z = V, аналогично приведенному ниже примеру для частного независимых случайных величин.
Произведения и частные независимых случайных величин
Даны две независимые случайные величины U и V, каждая из которых имеет функцию плотности вероятности, плотность произведения Y = UV и частное Y = U / V можно вычислить заменой переменных.
Пример: частное распределение
Чтобы вычислить частное Y = U / V двух независимых случайных величин U и V, определите следующее преобразование:
- Y = U / V { displaystyle Y = U / V}
- Z = V { displaystyle Z = V}


Тогда совместная плотность p (y, z) может быть вычислена заменой переменных с U, V на Y, Z, и Y может быть получен путем маргинализации Z из плотности соединения.
Обратное преобразование:
- U = YZ { displaystyle U = YZ}
- V = Z { displaystyle V = Z}


Матрица Якоби J (U, V ∣ Y, Z) { displaystyle J (U, V mid Y, Z)} этого преобразования равно
этого преобразования равно
- | ∂ u ∂ y ∂ u ∂ z ∂ v ∂ y ∂ v ∂ z | = | z y 0 1 | = | z |. { displaystyle { begin {vmatrix} { frac { partial u} { partial y}} { frac { partial u} { partial z}} \ { frac { partial v} { partial y}} { frac { partial v} { partial z}} end {vmatrix}} = { begin {vmatrix} z y \ 0 1 end {vmatrix}} = | z |.}

Таким образом:
- p (y, z) = p (u, v) J (u, v ∣ y, z) = p (u) p (v) J (u, v ∣ y, z) = p U (yz) p V (z) | z |. { Displaystyle п (Y, Z) знак равно п (и, v) , J (и, v середина у, г) = п (и) , р (v) , J (и, v середина у, z) = p_ {U} (yz) , p_ {V} (z) , | z |.}

И распределение Y может быть вычислено путем маргинализации Z:
- p (y) = ∫ — ∞ ∞ p U (yz) p V (z) | z | dz { displaystyle p (y) = int _ {- infty} ^ { infty} p_ {U} (yz) , p_ {V} (z) , | z | , dz}

Этот метод критически требует, чтобы преобразование из U, V в Y, Z было биективным. Вышеупомянутое преобразование соответствует этому, потому что Z может быть отображено непосредственно обратно в V, и для данного V отношение U / V является монотонным. То же самое и для суммы U + V, разности U — V и произведения UV.
Точно такой же метод можно использовать для вычисления распределения других функций от нескольких независимых случайных величин.
Пример: частное двух стандартных нормалей
Для двух стандартных нормальных переменных U и V, частное можно вычислить следующим образом. Во-первых, переменные имеют следующие функции плотности:
- p (u) = 1 2 π e — u 2 2 { displaystyle p (u) = { frac {1} { sqrt {2 pi}}} е ^ {- { гидроразрыва {u ^ {2}} {2}}}}
- p (v) = 1 2 π e — v 2 2 { displaystyle p (v) = { frac {1} { sqrt {2 pi}}} e ^ {- { frac {v ^ {2}} {2}}}}


Преобразуем, как описано выше:
- Y = U / V { displaystyle Y = U / V}
- Z = V { displaystyle Z = V}
Это приводит к:
- p (y) = ∫ — ∞ ∞ p U (yz) p V (z) | z | d z = ∫ — ∞ ∞ 1 2 π e — 1 2 y 2 z 2 1 2 π e — 1 2 z 2 | z | d z = ∫ — ∞ ∞ 1 2 π e — 1 2 (y 2 + 1) z 2 | z | dz = 2 ∫ 0 ∞ 1 2 π e — 1 2 (y 2 + 1) z 2 zdz = ∫ 0 ∞ 1 π e — (y 2 + 1) uduu = 1 2 z 2 = — 1 π (y 2 + 1) е — (Y 2 + 1) U] U знак равно 0 ∞ = 1 π (Y 2 + 1) { Displaystyle { begin {align} p (y) = int _ {- infty} ^ { infty} p_ {U} (yz) , p_ {V} (z) , | z | , dz \ [5pt] = int _ {- infty} ^ { infty} { frac {1} { sqrt {2 pi}}} e ^ {- { frac {1} {2}} y ^ {2} z ^ {2}} { frac {1} { sqrt {2 pi}}} e ^ {- { frac {1} {2}} z ^ {2}} | z | , dz \ [5pt] = int _ {- infty} ^ { infty} { frac {1} {2 pi}} e ^ {- { frac {1} {2}} (y ^ {2} +1) z ^ {2}} | z | , dz \ [ 5pt] = 2 int _ {0} ^ { infty} { frac {1} {2 pi}} e ^ {- { frac {1} {2}} (y ^ {2} +1) z ^ {2}} z , dz \ [5pt] = int _ {0} ^ { infty} { frac {1} { pi}} e ^ {- (y ^ {2} +1)u},duu={tfrac {1}{2}}z^{2}\[5pt]=left.-{frac {1}{pi (y^{2} +1)}}e^{-(y^{2}+1)u}right]_{u=0}^{infty }\[5pt]={frac {1}{pi (y^{2}+1)}}end{aligned}}}
![{displaystyle {begin{aligned}p(y)=int _{-infty }^{infty }p_{U}(yz),p_{V}(z),|z|,dz\[5pt]=int _{-infty }^{infty }{frac {1}{sqrt {2pi }}}e^{-{frac {1}{2}}y^{2}z^{2}}{frac {1}{sqrt {2pi }}}e^{-{frac {1}{2}}z^{2}}|z|,dz\[5pt]=int _{-infty }^{infty }{frac {1}{2pi }}e^{-{frac {1}{2}}(y^{2}+1)z^{2}}|z|,dz\[5pt]=2int _{0}^{infty }{frac {1}{2pi }}e^{-{frac {1}{2}}(y^{2}+1)z^{2}}z,dz\[5pt]=int _{0}^{infty }{frac {1}{pi }}e^{-(y^{2}+1)u},duu={tfrac {1}{2}}z^{2}\[5pt]=left.-{frac {1}{pi (y^{2}+1)}}e^{-(y^{2}+1)u}right]_{u=0}^{infty }\[5pt]={frac {1}{pi (y^{2}+1)}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/59d9a9e9626c22660b6e3e67169802d996cf0f1c)
This is the density of a standard Cauchy distribution.
See also
References
Bibliography
- Pierre Simon de Laplace (1812). Analytical Theory of Probability.
-
- The first major treatise blending calculus with probability theory, originally in French: Théorie Analytique des Probabilités.
-
- The modern measure-theoretic foundation of probability theory; the original German version (Grundbegriffe der Wahrscheinlichkeitsrechnung) appeared in 1933.
- Patrick Billingsley (1979). Вероятность и мера. New York, Toronto, London: John Wiley and Sons. ISBN 0-471-00710-2.
- David Stirzaker (2003). Elementary Probability. ISBN 0-521-42028-8.
-
- Chapters 7 to 9 are about continuous variables.