Работа с сохраненной копией страницы
Содержание:
- Зачем нужна сохраненная копия страницы и как её посмотреть
- Как посмотреть сохраненную копию в Google
- Как посмотреть сохраненную копию веб-страницы в Яндекс
- Почему сохраненной страницы может не быть
- Специализированные веб-архивы
- Wayback Machine
- Archive.Today
- Расширения для браузеров
- Cached Page
- Выводы
Чтобы пользователь нашел документ в поисковой выдаче, недостаточно добавления его на сервер. Контент должен быть проиндексирован (добавлен поисковыми роботами в индекс) поисковыми системами Яндекс и Google. Поэтому, наличие сохраненной копии — показатель что поисковый бот был на странице. Рассмотрим, что можно посмотреть и какие ошибки обнаружить с помощью сохраненной копии веб-страницы.
Роботы Яндекса и Google добавляют копии найденных веб-страниц в специальное место в облаке — кеш. При этом новая копия страницы перезаписывает старую. Поэтому в кеше отображаются свежие версии веб-страниц.
Сохраненная копия — это версия веб-страницы, которая сохранена в кэше поисковой системы. Условно это бесплатная резервная копия от поисковых систем.
На самом деле веб-страницы сохраняют:
- Поисковые системы. В них находится находится последняя проиндексированная версия страницы. Такие «снимки» используют SEO-специалисты, чтобы увидеть какие данные обнаружил на странице поисковый бот;
- Специализированные сервисы. Занимаются сохранением содержимого веб-страницы. Основная задача таких сервисов сохранить страницы в конкретный момент времени. С помощью них вы можете узнать как выглядел сайт или страница несколько лет назад.
Зачем нужна сохраненная копия страницы и как её посмотреть
На сайтах регулярно происходит добавление нового и редактирование существующего контента. Периодически изменяется его дизайн, добавляются и/или удаляются графические элементы. Это трудоемкая работа в процессе, которой могут возникнуть ошибки: потеряться контент, «съехать дизайн», удалиться блок или перестать индексироваться часть материала. Выявить, как выглядела страницы до определенного момента, поможет сохраненная копия.
Пример из практики:
Есть у нас технически сложный проект, который при заполнении объема памяти перестает, корректно работать. Если по простому, то вместо работающего сайта, мы видим ошибку базы данных.
Время от времени сайт отваливается по ночам, а утром разработчики все исправляют. И тут важный момент, сохраненные копии, позволяют понять успели ли поисковые системы проиндексировать сломанный сайт или нет. А также позволяют выявить, какие именно страницы успел переобойти бот.
Как посмотреть сохраненную копию в Google
Рассмотрим на примере страницы https://discript.ru/prodvizhenie-sajtov/kolomna/. Перед url адресом пропишите оператор «site:». В сниппете (блок информации о странице веб-сайта) результата, нажмите на иконку в виде треугольника, выберите соответствующий пункт.
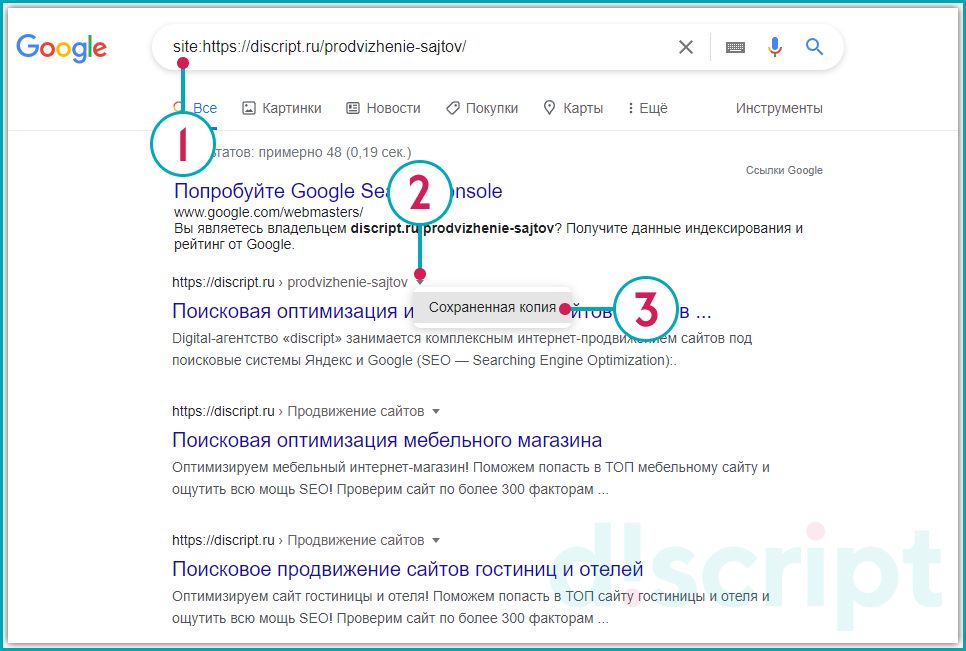
Сохраненная копия в Google
Откроется сохраненная копия веб-страницы. Google выведет окно с сообщением, что открылся «снимок» страницы.
Разберем представленную информацию:
- Дату фиксации. В данном параметре указано, когда был сделан слепок страницы. Поэтому сопоставив указанную дату с датой внесения правок, можно предположить успел ли поисковый бот обойти страницу или еще нет (Важно! данный метод не гарантирует 100% верную информацию, т.к. данные хранятся в кеше и могут отличаться в зависимости от вашего место нахождения) ;
- Полная версия. Отображается версия страница, как должен был ее увидеть пользователь.
- Текстовая версия. Позволяет просмотреть контент веб-страницы без применения стилей. Такой формат позволяет увидеть скрытые от пользователя элементы, но доступные для поисковых роботов Яндекса и Google;
- Исходный код. Выводит исходный код HTML-страницы. Это требуется для изучения тега Title и мета тегов, таких как Description. Данное представление позволяет изучить, как сверстана веб-страница, и нет ли на ней критических ошибок.
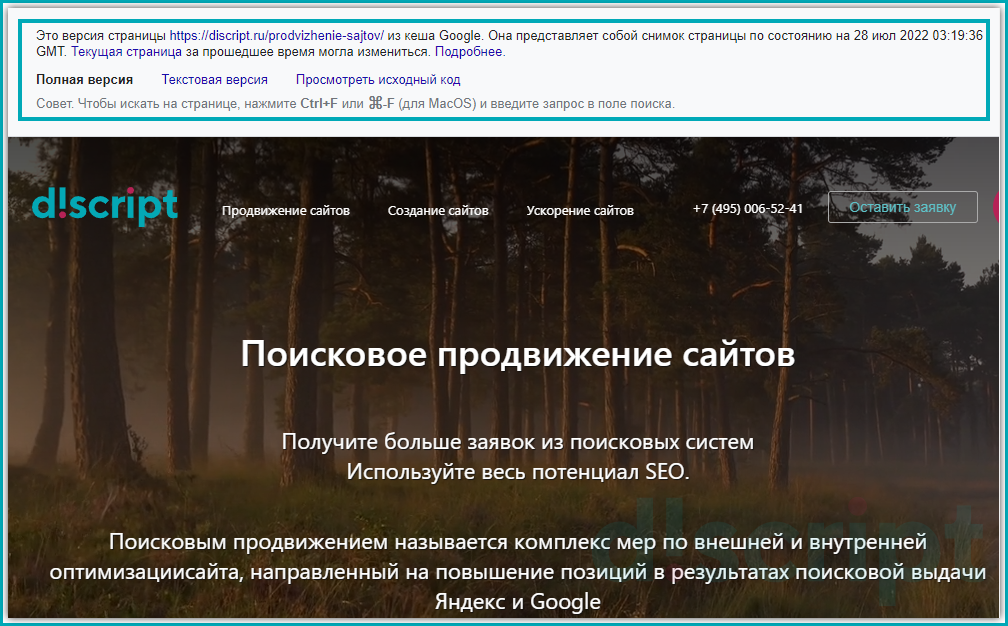
Просмотр версии страницы из кеша Google
Как посмотреть сохраненную копию веб-страницы в Яндекс
Рассмотрим на примере страницы https://discript.ru/site-development/. В строку поиска обязательно пропишите оператор «url:» перед url-адресом. нажмите на значок в виде трех горизонтальных точек, выберите «Сохраненная копия».
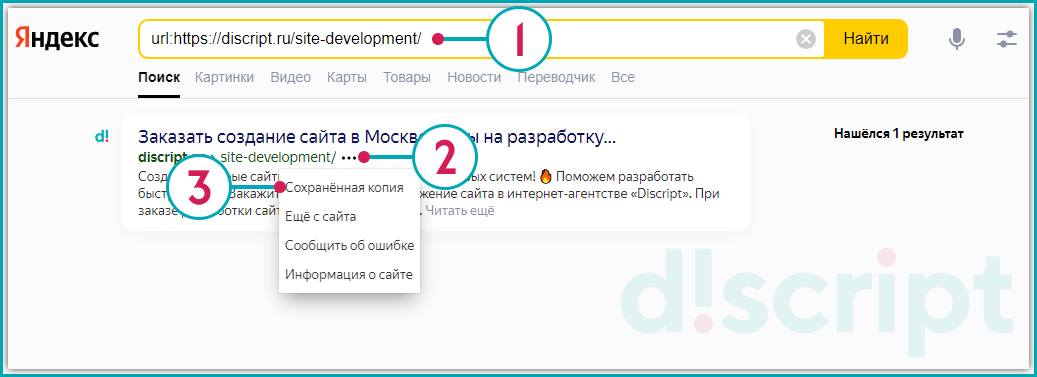
Пример поиска сохраненной страницы в Яндексе
Далее Яндекс предоставит следующие данные:
- Дата индексации. Данное значение информирует в какой момент выполнен слепок страницы.
- Полная версия страницы. Отображение страницы со всеми стилями.
- Текстовая версия страницы. Текстовая версия, аналогично позволяет изучить страницу без стилей и получить всю скрытую информацию. Часто именно при проверке текстовой копии обнаруживаются сквозные блоки текста на страницах. Т.к. при использовании стилей они скрыты.
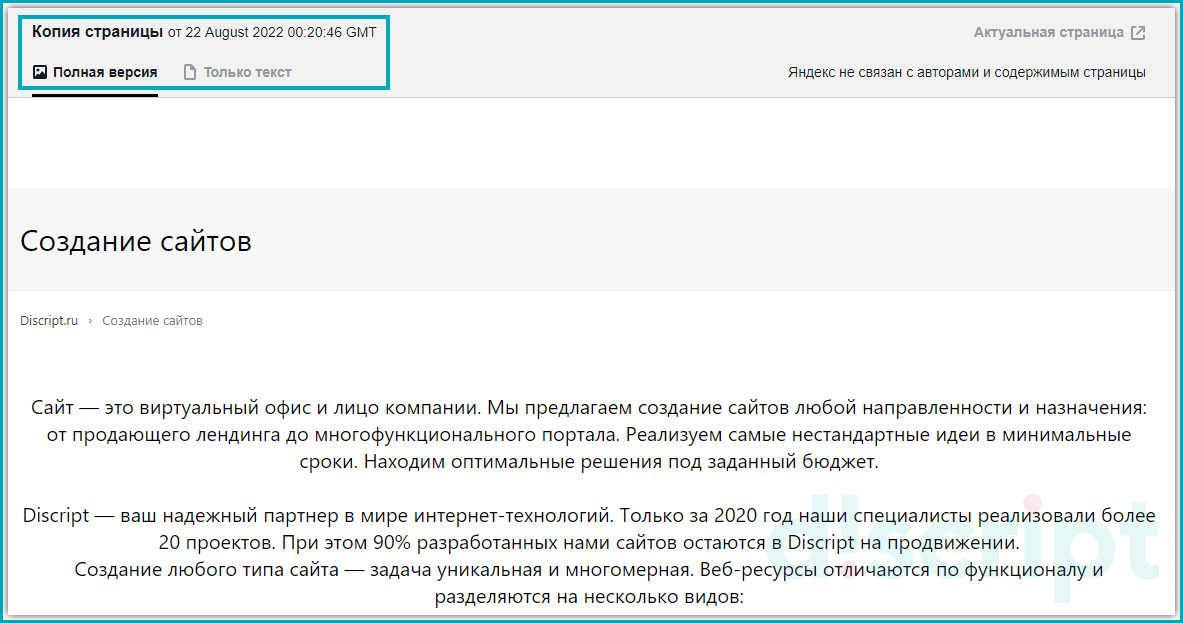
Предоставление данных о копии страницы в Яндексе
Почему сохраненной страницы может не быть
Это происходит в результате:
- Сбой работы поисковых систем. Разработчики Яндекса даже говорят, что нет стопроцентной гарантии, что страница сохранится. Конкретная причина не указывается.
- HTML-код содержит мета тег мета-тег «robots» со значением «noarchive», что означает запрет на кэширование (локальное сохранение данных для получения быстрого доступа к странице при следующих запросах).
Что предпринять если в ПС нет сохраненной копии, а посмотреть содержимое нужно? Попробуйте изучить специализированные площадки и расширения.
Рассмотренными выше способами можно посмотреть:
- Мобильную версию веб-сайта. Пропишите url мобильной версии в Яндексе или Google. Из выдачи перейдите на нее далее, как в примере рассмотренном выше.
- Адаптивную версию. Перейдя в сохраненную копию (так же как в примере выше). Открываем инструменты разработчика. Клавиша F12 в обозревателе. Или нажать ПКМ на пустом месте страницы, выбрать «Посмотреть код». Переходим в раздел мобильное отображение и перезагружаем веб-страницу.
Специализированные веб-архивы
Выше мы обсуждали, что существуют сервисы, задачи которых сохранять в истории страницы сайтов. Сейчас рассмотрим их подробнее и расскажем, как с ними работать.
И начнем с самого популярного и известно.
Wayback Machine
Сервис Wayback Machine — бесплатным онлайн-архивом, задача которого является сохранить и архивировать информацию размещенную в открытых интернет‑ресурсах. Wayback Machine является частью некоммерческого проекта Интернет Архива. На его серверах хранятся копии веб-сайтов, книг, аудио, фото, видео.
Чтобы открыть копию страницы перейдите на https://archive.org/, далее откроется поисковая форма, куда пропишите URL страницы. Нажмите кнопку «GO».

Онлайн-архив Wayback Machine
Сервис отобразит имеющиеся в архиве снимки.
Далее выберите в календаре нужную дату и откройте страницы. Результатом вывода будет открытие страницы, которую зафиксировали роботы за выбранную дату.
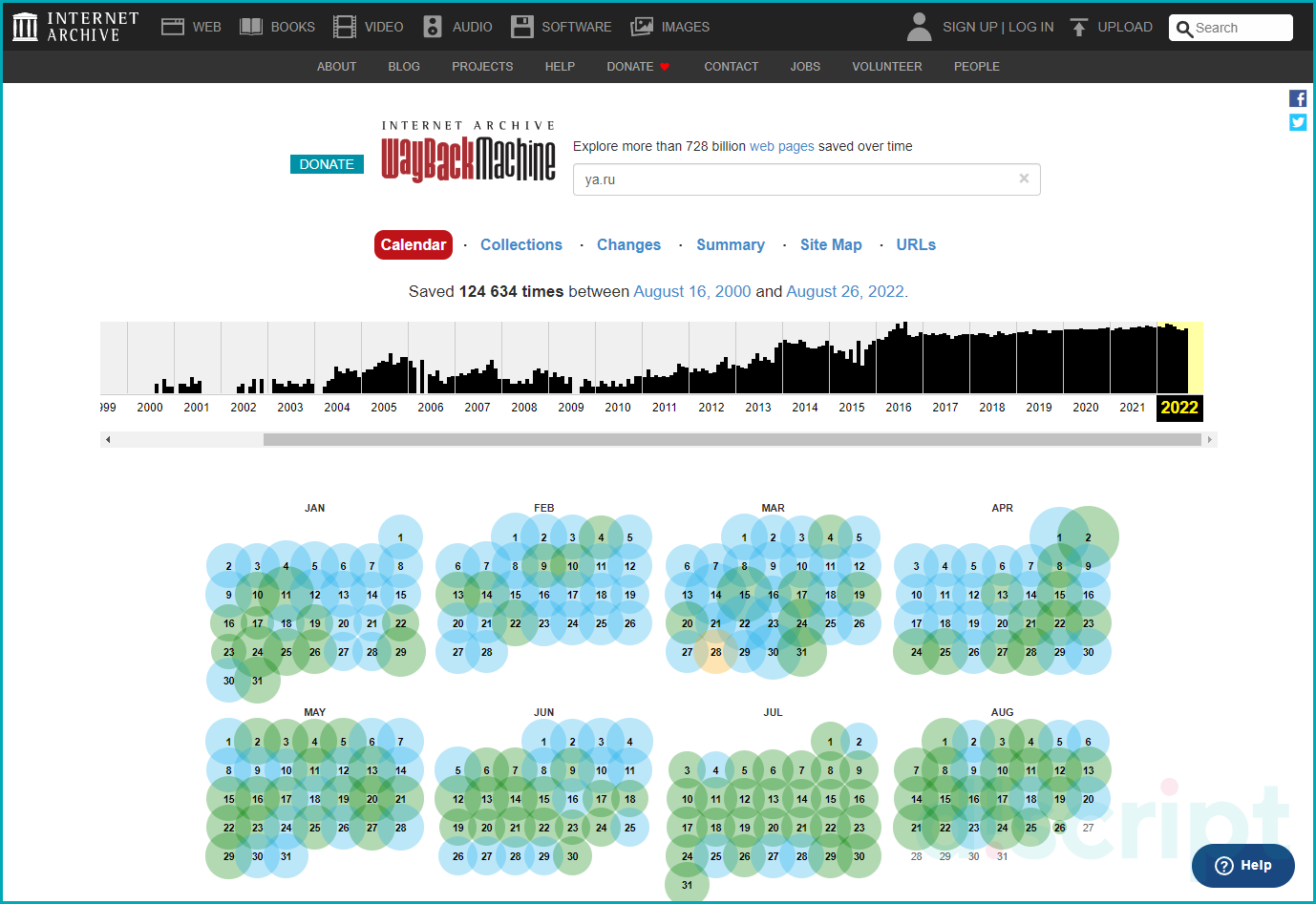
Календарь Wayback Machine
Кроме просмотра снимков страниц, сервис поможет:
- Проанализировать robots.txt. Сервис будет сканировать веб-сайты вне зависимости от настроек robots.txt;
- Узнать данные о домене. Актуально перед покупкой. Уточните какая информация размещалась на нем. Если вы купите «заспамленный» или домен под «санкциями» (например была размещена информация для взрослых) новый контент будет плохо ранжироваться. Если же ранее на нем размещалась информация, которая подходит по тематике и качеству для вашего будущего ресурса, тогда вы сможете использовать ее на этом же домене.
- Найти в архивных копиях пропавшую информацию.
- Если, например, на веб-сайте наблюдается спад трафика, откройте сохраненную версия сайта до момента уменьшения посещаемости. Проанализируйте, какие были сделаны изменения, чтобы разобраться в причине падения посещаемости.
Archive.Today
Archive.Today — бесплатный некоммерческий севрис сохраняющий веб-страницы в оналйн режиме. Особенность — сохраняет не только статические страницы, но и генерируемые Веб 2.0-проектами страницы. Например, карты Google.
Основное отличие от Wayback Machine, что Archive.Today сохраняет веб-страницы только по запросу пользователей. При этом сервер полностью сохраняет:
- HTML-страницы,
- CSS файлы,
- JS файлы,
- PDF,
- аудио файлы,
- пр.
Важно, помнить, что Archive.Today игнорирует файл robots.txt поэтому в нем можно сохранить страницы недоступные для Wayback Machine.
Обратите внимание, общий в Размер заархивированной страницы со всеми изображениями не должен превышать 50 МБ.
У Archive.Today есть собственное приложение для браузера Mozilla Firefox. Ссылка на ПО https://addons.mozilla.org/en-US/firefox/addon/archive-page/
Для начала работы с Archive.Today перейдите по адресу: https://archive.md/. Чтобы получить результат укажите в форму интересующий URL-адрес.
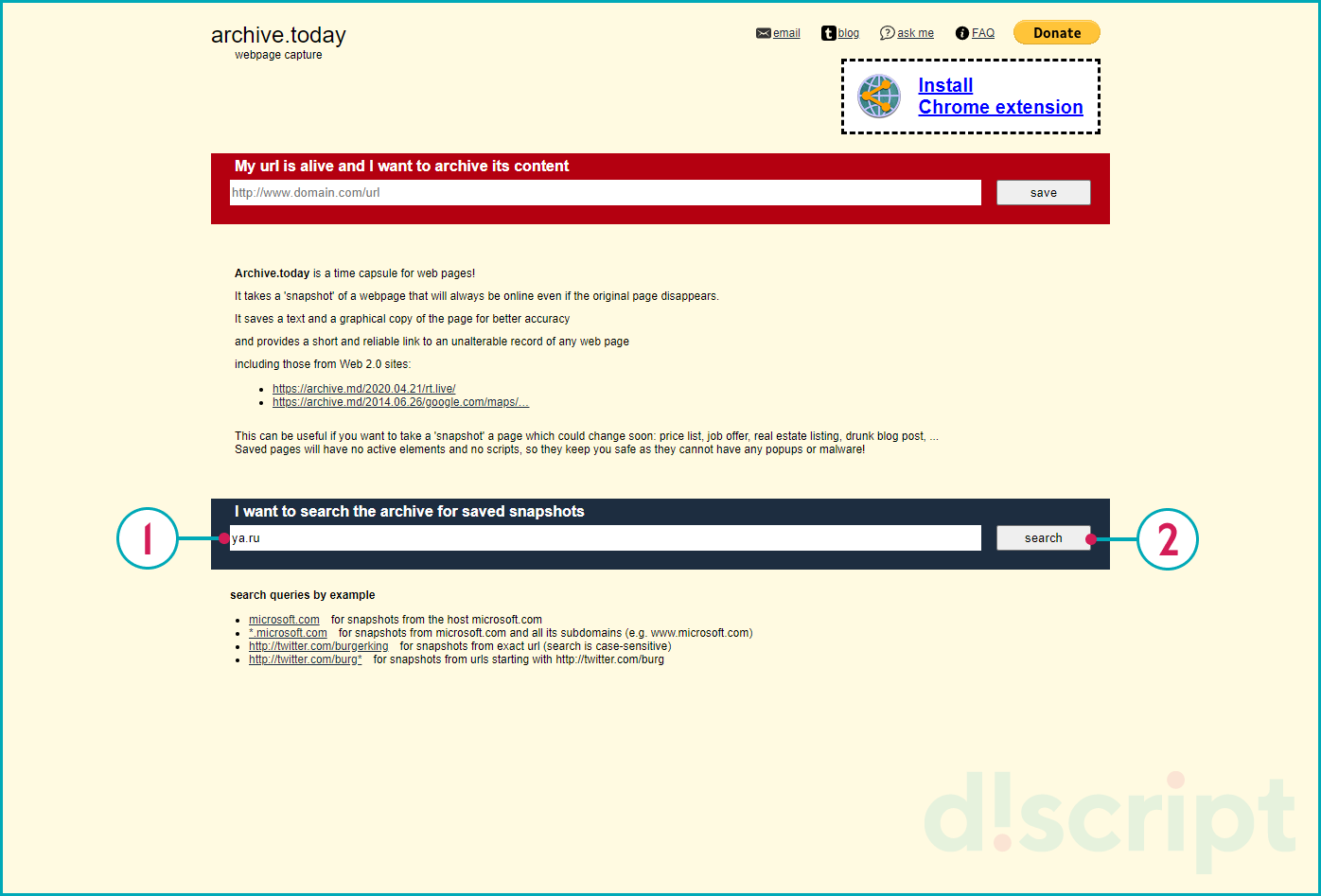
Сервис Archive.Today
Откроется страница с сохраненными снимками и информацией о дате создания копии.
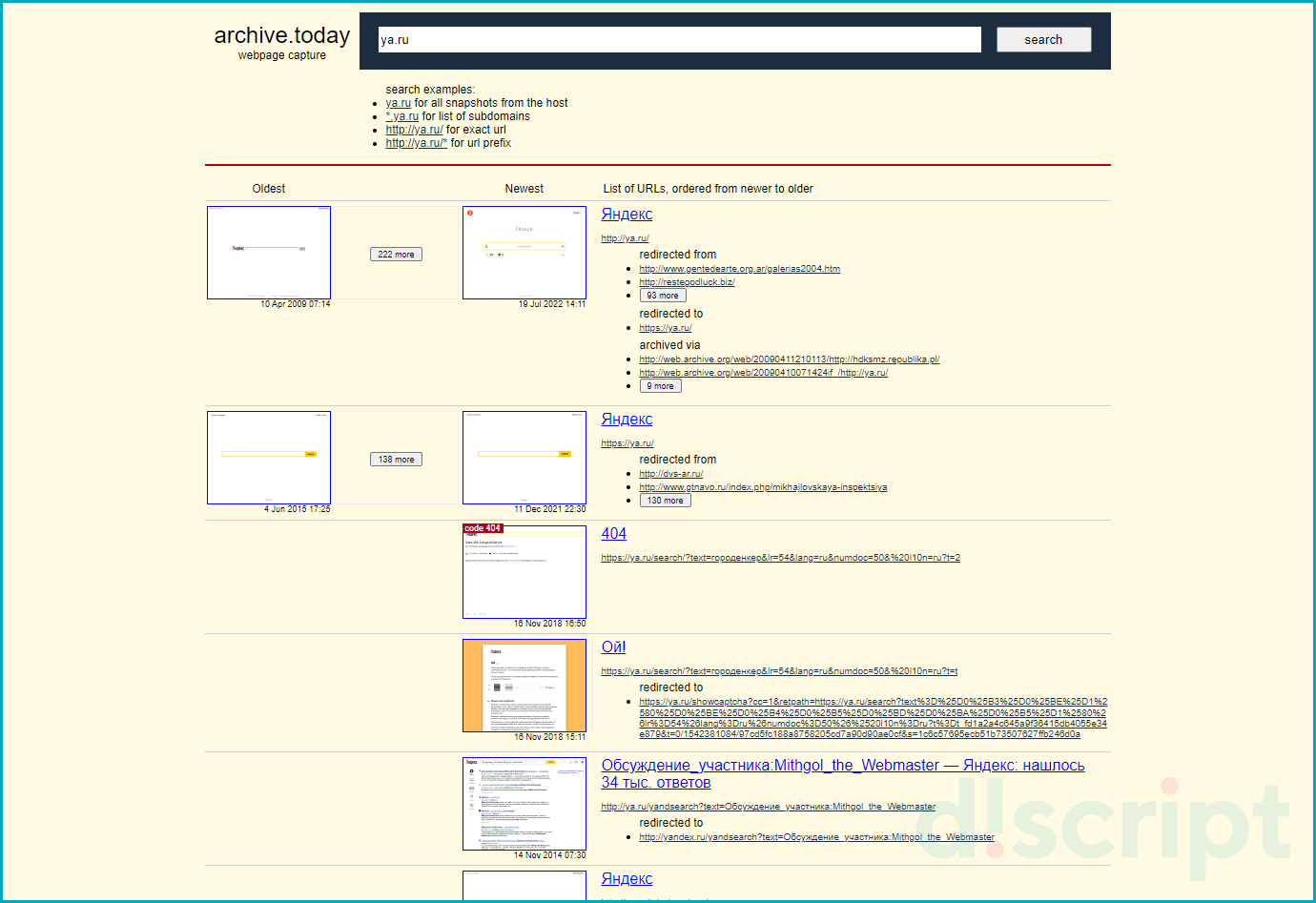
Страница с сохраненными снимками в сервисе Archive.Today
Вы можете скачать сохраненную копию виде архива. И восстановить версию страницы у себе на сервере.
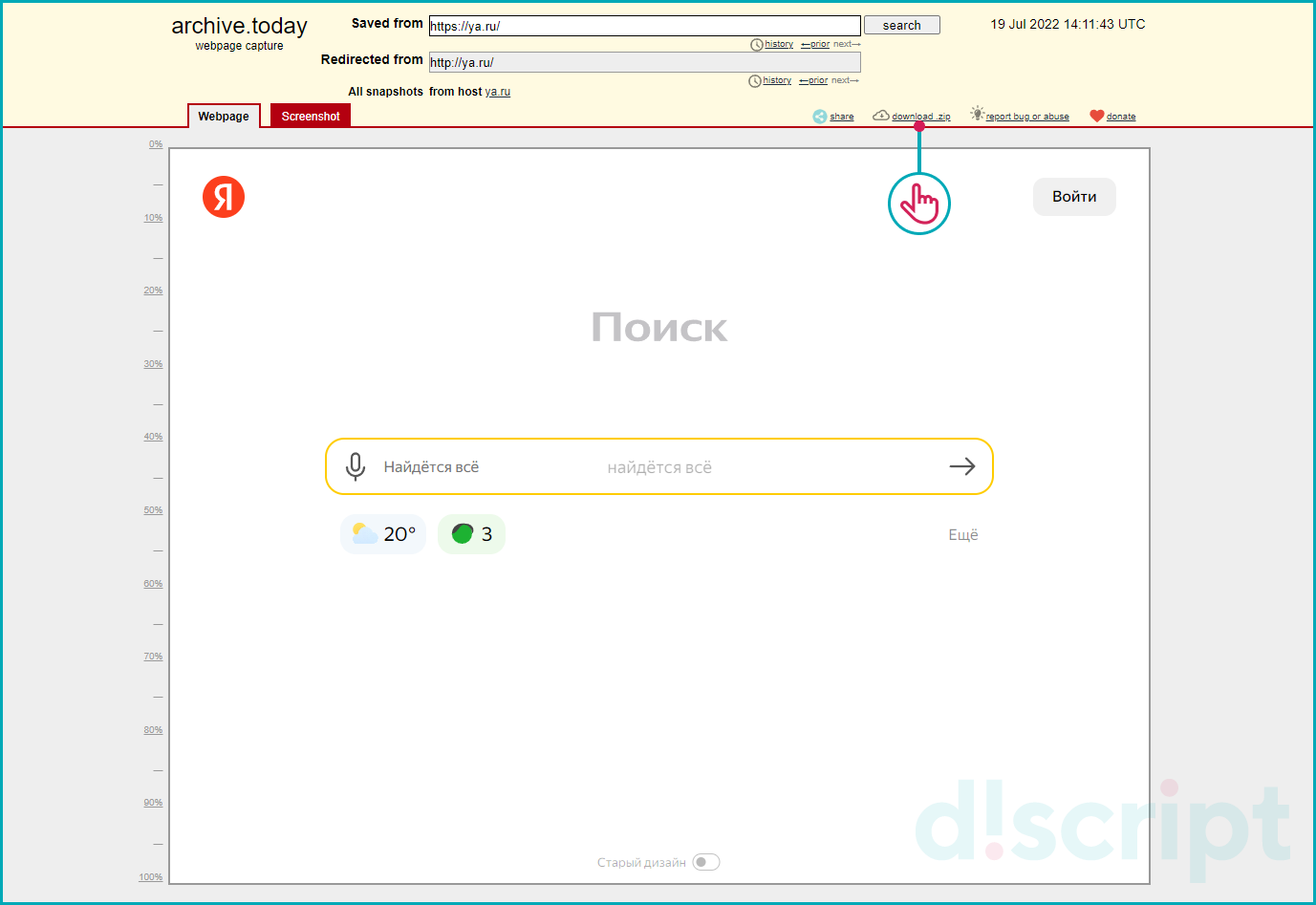
Сохранение страницы в сервисе Archive.Today
Расширения для браузеров
Существуют, плагины для браузеров, позволяющие создавать и просматривать сохраненные версии страниц.
Например, расширение Web Cache Viewer позволяет:
- Загружать веб-страницу из локального кэша на компьютере;
- Автоматически находить страницу при помощи сервиса Wayback Machine.
Перейдя по ссылке, рассмотренной, выше, нажмите кнопку «Установить».
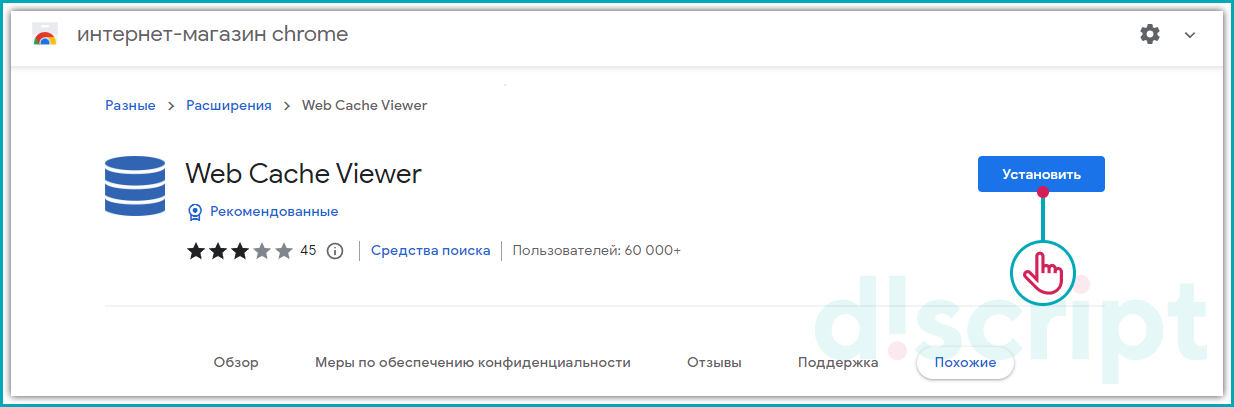
Сервис Web Cache Viewer
После инсталляции расширения в браузере, нажмите правой кнопкой мыши пустом месте страницы для просмотра версии из Google или Wayback Machine.
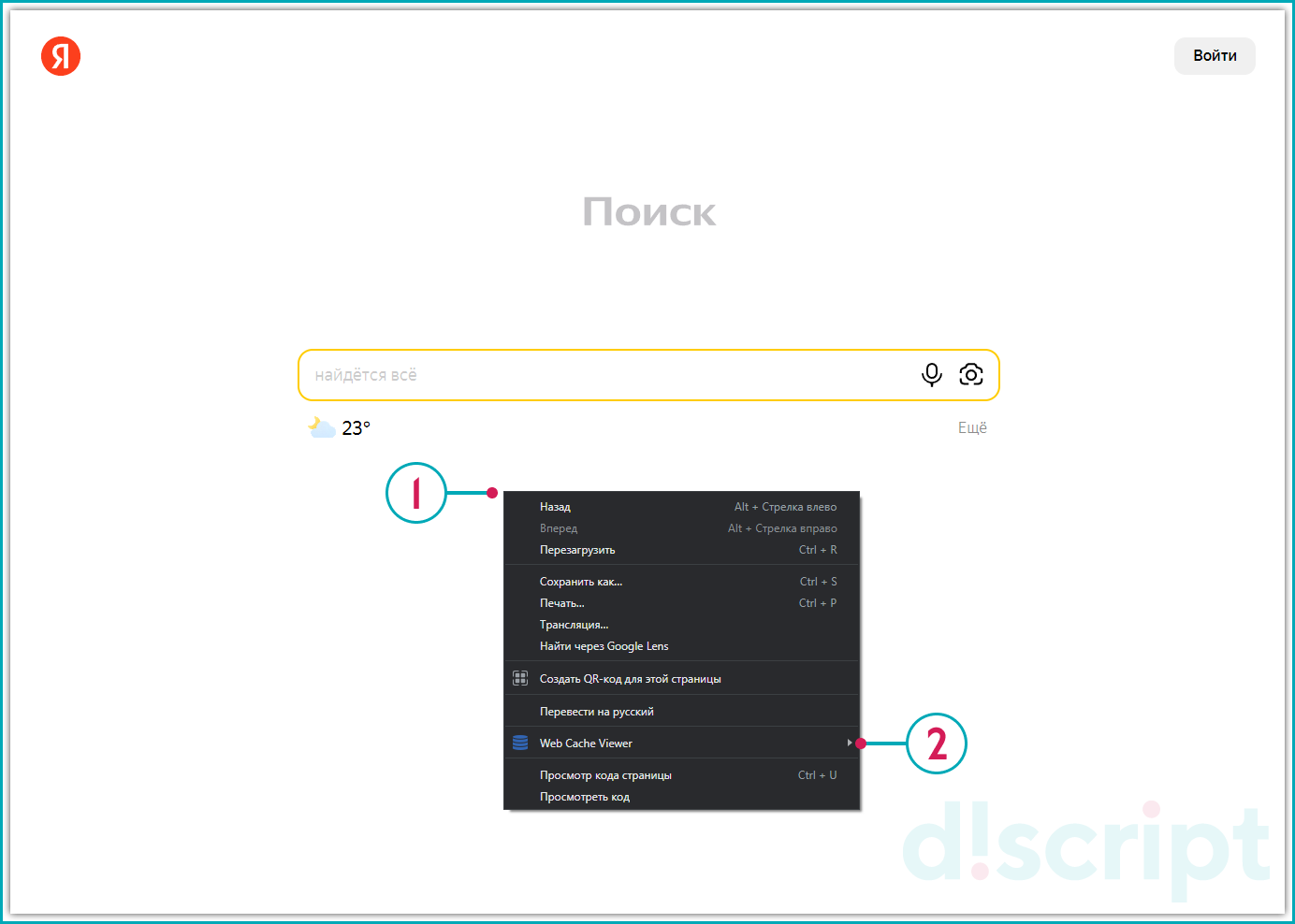
Просмотр версии из Google или Wayback Machine
Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
Cached Page
Веб-сайт Cached Page ищет копии веб-страниц в поиске Google, Интернет Архиве, WebSite. Используйте площадку, если описанные выше способы не помогли найти сохраненную копию веб-сайта.
Пропишите название сайта в специальную форму. Для поиска нажмите одну из трех кнопок. Сервис предложит произвести поиск веб-страницы в:
- Веб-кэш Google;
- Интернет Архив;
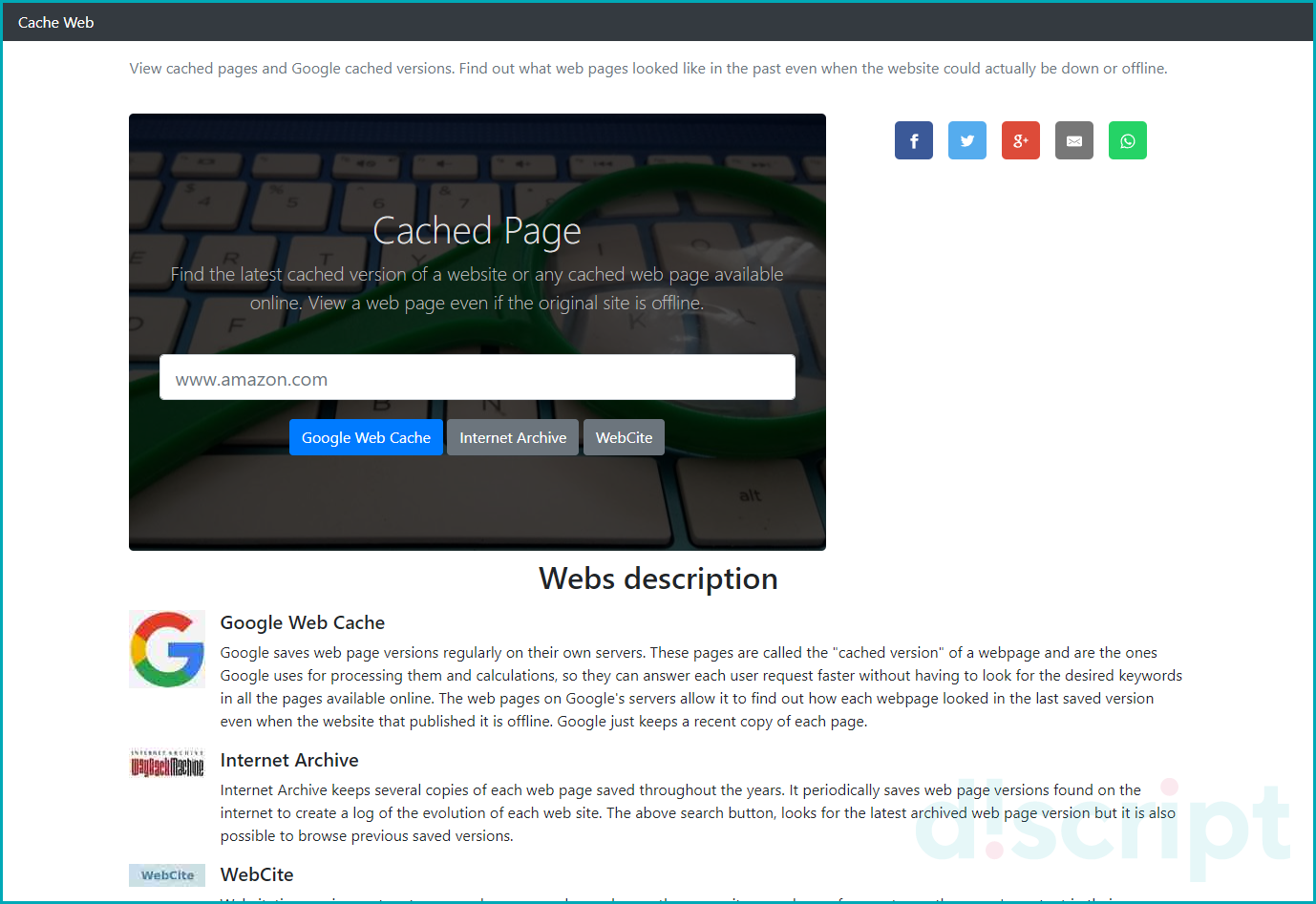
Поиск в сервисе Cached Page
Например, прописав в форму адрес https://discript.ru/prodvizhenie-sajtov/lyubercy/, и нажав кнопку «Архив Интернета», произойдет переход на страницу сервиса Wayback Machine. Если страница сохранена в БД сервиса, она отобразится на странице.
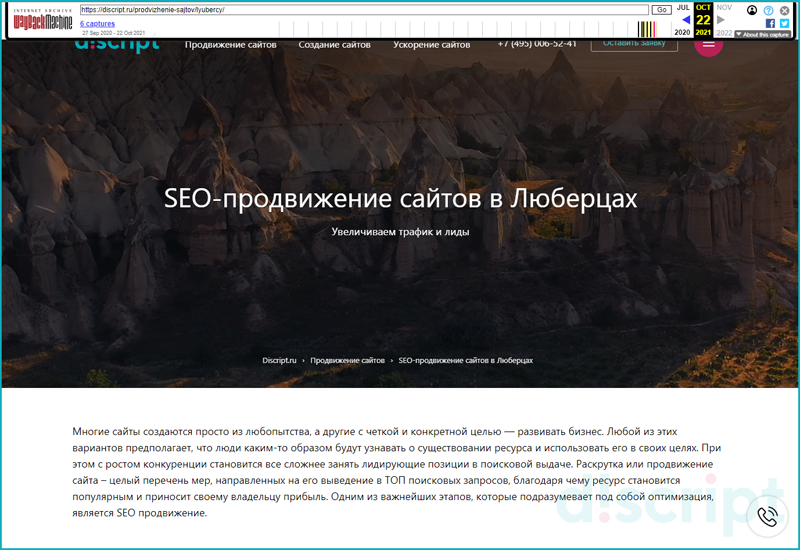
Отображение страницы в сервисе Wayback Machine
Выводы
Работая с сохраненными копиями страниц, можно выявить достаточного много полезных нюансов.
Сохраненные копии позволяют:
- Узнать, поисковый бот успел ли обойти вашу страницу после внесенных правок.
- Как бот воспринимает информацию со страницы. Все ли учитывает или остались места, которые ПС не видят.
- Выявить, какие элементы пропали и когда.
- Выявить, какие страницы успел обойти поисковый бот, после того, как сайт перестал быть доступным.
- Создать копии страниц.
- Восстановить копию сайта, когда забыли оплатить домен.
Сохраненная копия веб-страницы поможет определить, какая версия документа проиндексирована поисковыми роботами и участвует в ранжировании. Поэтому наличие «снимка» страницы в Яндексе и Google говорит об успешной проведенной индексации.
Другие статьи
Перейдя по ссылке на копию, сохраненную в кеше, можно узнать, как выглядела веб-страница, когда робот Google последний раз сканировал ее.
Важно! Если вы работаете с Search Console, используйте для отладки страницы инструмент проверки URL. Подробнее…
О ссылках на кешированные страницы
Google сохраняет резервные копии веб-страниц на случай, если они станут недоступны. Эти копии хранятся в кеше на серверах Google. Нажав на ссылку «Сохраненная копия», вы откроете резервную копию веб-сайта.
Вы можете воспользоваться копией из кеша Google, если нужная страница загружается слишком долго или не загружается вообще.
Как получить ссылку на кешированную страницу
Совет. Если вы хотите удалить кешированную страницу из результатов поиска Google, прочитайте эту статью.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Как посмотреть сохраненную копию страницы сайта
22.09.2021 |
Категория Разное
В данном видео, я хотел бы рассмотреть один интересный сервис, который представляет из себя архив сохраненных копий страниц интернета, благодаря которому можно получить доступ к удаленным или недоступным интернет страницам.
И так, что такое интернет архив, а это база сохраненных интернет страниц различных сайтов, благодаря которому, вы можете посмотреть определенную страницу в таком виде, как она выглядела в определенную дату.
Для чего это может понадобиться:
Доступ к удаленным страницам – допустим у вас осталась ссылка на какую-то интересную статью, но, на данный момент данной страницы уже не существует, а вам крайне важно посмотреть ту информацию. Так вот, можно с помощью этого архива получить доступ к сохраненной копии нужной вам страницы.
Просмотр истории изменений – тоже порой интересно посмотреть историю изменения сайта или какой-то конкретной страницы. Допустим я как-то увидел на сайте замануху в виде скидки и мне захотелось узнать, а действительно ли акция ограничена или у них постоянно на сайте висит этот баннер. И через историю сохраненных страниц можно было это проверить.
В любом случае, вы можете так же найти какие-то полезные моменты для применения, а я же покажу, как это сделать.
Наиболее известный сервис это arhive.org и к примеру, у меня есть необходимость посмотреть сайт, который уже давно был закрыт https://smartresponder.ru
Вы же указываете тот сайт, или ту страницу, которая вас интересует.
Допустим, мы можем посмотреть сохраненную версию сайта, на момент, когда проект только был создан, когда он активно работал и когда закрылся.
Не скажу что, данный архив сохраняет прям все содержимое сайта иначе это занимало много места, однако довольно многое в нем сохраняется.
Так же, пробовал походить по страницам какого-нибудь ДНС, чтобы помониторить цены в определенные даты, но ничего не получилось. Я так понимаю, что из-за того, что сайты интернет магазинов меняют свое содержимое практически каждый день, и хранить все эти копии было бы очень накладно.
Но, в любом случае для каких-то ваших задач он вполне подойдет.
Кому-то интересно посмотреть, как сайты выглядели в момент, когда только появились на свет. Допустим, как выглядел яндекс в первые дни своего существования.
Доброго времени суток, уважаемые читатели блога inetsovety.ru! В этой статье я хочу затронуть тему воровства контента и рассмотреть способы борьбы с теми, кто ворует готовые статьи и размещает на других сайтах.
Содержание
- Кто и почему копирует тексты с сайтов
- Как обнаружить, что с сайта скопировали статью
- Как найти регистратора хостинга и домена по адресу сайта
Кто и почему копирует тексты с сайтов
С проблемой воровства контента рано или поздно может столкнуться любой вебмастер, который создал свой сайт и пишет на него статьи. Конечно же не приятно, когда ты пишешь статью 2-3 часа, а какой-то хитро*опый человек просто копирует ее себе на сайт и даже не указывает автора этой статьи, а выдает статью за свою. Зачастую воровством статей и незаконным копированием и размещением у себя на сайте занимаются неопытные и глупые люди, которые считаю, что если скопировать статьи(-ю) с популярного и посещаемого блога, то таким образом, они получат много посетителей. Но так не бывает. Поскольку поисковые роботы совершенствуются и, если бы можно размещать у себя чужие статьи и получать много посетителей, то никто бы не писал уникальных статей, все бы просто размещали готовые.
Но на самом деле поисковые системы борются с говносайтами, которые размещают у себя не уникальные статьи. Сайты, на которых размещены статьи с других сайтов, попадают под фильтр, а иногда и в бан поисковиков. Т.е. человек надеется, что скопировав статьи с других сайтов, он увеличит посещаемость и будет получать от сайта прибыль, а на самом деле получается обратная картина — сайт с ворованным контентом попадает под фильтр, страницы не индексируются, а если и индексируются, то попадают на последние позиции в результатах поисковой выдачи, соответственно посетителей нет и дохода тоже. Воровством контента могут заниматься только идиоты и глупые люди, которые не понимают еще, что ничего хорошего из этого не получится. Эти глупцы просто теряют время, в место того, чтобы писать самим уникальные статьи и развивать сайт. Ведь время идет и его назад не вернешь…
Воровство контента еще и наказуемо судом, поскольку нарушаются авторские права. Если захотеть и приложить усилия, то можно добиться через наказания вора контента, и получить моральную компенсацию. Так как размещенный на сайте контент охраняется законом об авторском праве.
Как обнаружить, что с сайта скопировали статью
Как обнаружить сайты, на которых находятся скопированные статьи в Вашего сайта?
Во-первых можно проверить статью на уникальность с помощью специальных сервисов.
Во-вторых можно проверить сайт на наличие дублей сервисом [urlspan]copyscape.com[/urlspan]
Когда сайты, на которых находится ворованный контент выявлены, то можно заняться наказанием копипастеров.
Как найти регистратора хостинга и домена по адресу сайта
Как наказать копипастера — человека который скопировал без спроса с Вашего сайта статьи и разместил их у себя на сайте?
Нужно обратиться в техподдержу хостинга, на котором находится сайт, размещающий скопированные статьи у Вас статьи, объяснить ситуацию и привести доказательства. Любой адекватный хостинг провайдер дорожит своей репутацией и положительно отреагирует на Вашу жалобу. Также можно регистратору доменного имени сайта. В результате, если тот кто скопировал у Вас контент не удалит его у себя, то хостер или регистратор доменного имени просто откажет ему в обслуживании и заблокирует сайт.
Как найти на каком хостинге расположен сайт и где он зарегистрировал свой домен?
Все просто. Идете на сервис WHOIS — проверки доменов, вводите в строку поиска адрес сайта и получаете о нем информацию, например:

В строке nserver находятся данные о хостере, а в строке admin-contact находится ссылка на регистратора доменного имени этого сайта.
Если Ваши статьи скопировали и разместили на сайтах, которые находятся на бесплатном хостинге, то здесь еще проще. Пишите в техподдержку сервиса с жалобой о нарушении авторских прав и сайт с ворованным контентом блокируют и удаляют.
Вот ссылка на службу поддержки яндекс народа — http://feedback.yandex.ru/?from=narod
Как пожаловаться на сайт, размещенный на Юкоз читайте по ссылке https://inetsovety.ru/kuda-pozhalovatsya-na-plagiat-s-ucoz/
Куда писать, чтобы удалили ворованную статью с Blogger https://inetsovety.ru/kak-udalit-kopipast-s-blogger/
Теперь Вы знаете как вычислить и наказать человека, который ворует контент у Вас. Если же этих действий не достаточно, то тогда у Вас прямая дорога в суд с иском о нарушении авторских прав.
Пожалуй эту часть статьи о защите контента я буду заканчивать, а во второй части (читать) я расскажу о основных методах защиты контента от воровства. Не забудьте подписаться на доставку новых статей на имейл, чтобы не пропустить интересных материалов. Удачи Вам!
Как найти и удалить дубли страниц на сайте
Содержание:
-
В чем опасность -
Как найти дубли страниц -
Сервисы для вебмастеров -
При помощи операторов ПС -
Как исправить -
Как борются с дубликатами в Elit-Web
Дубли – это страницы сайта с одинаковым содержимым, они могут полностью повторять контент друг друга или частично. Часто они становятся причиной низких позиций ресурса. Мы хотим рассказать, почему могут возникать дубли и как от них избавится.
Полные дубликаты могут возникать, когда страница доступна под несколькими адресами, то есть не выбрано главное зеркало или не настроен 404 редирект. Часто их автоматически создает CMS в процессе разработки.
Частичные дубли часто получаются в результате ошибки разработчика или из-за особенностей CMS. Это могут быть страницы пагинации и сортировок с разными URL или ошибочно открытые для индексации служебные страницы.

В чем опасность
По сути, страницы одного сайта начинают соперничать друг с другом. Google и Яндекс не хранят в собственной базе несколько идентичных страниц, а выбирают только одну, наиболее релевантную. Они могут выбрать копию нужной вам страницы, в результате чего, позиции резко проседают. Из-за дубликатов страдают поведенческие факторы и естественный ссылочный вес, становится труднее собирать статистические данные.
Если дубликатов много, то поисковик может попросту не успеть проиндексировать их полностью. При этом следующей индексации придется ждать дольше, так как поисковые боты реже переходят на ресурс, где контент повторяется. А это также значительно замедляет продвижение.
Как найти дубли страниц
Сервисы для вебмастеров
Существует несколько способов. Наиболее простой – воспользоваться сервисами Google Search Console или «Яндекс.Вебмастер». Распознать дубликаты проще всего по повторяющимся метатегам title и description.
Для этого в панели инструментов Search Console перейдите в раздел «Оптимизация HTML» пункт «Повторяющееся метаописание», где будет указано количество таких страниц, а также их URL.
В вебмастере Яндекса, страницы с одинаковым метаописанием можно найти в разделе «Индексирование», а именно «Вид в поиске», где необходимо выделить исключенные страницы и выбрать категорию «Дубли».
Существует также много других сервисов для подобных задач, например или Screaming Frog. С их помощью можно получить полный список адресов страниц и автоматически выделить среди них те, у которых совпадают метатеги.
При помощи операторов ПС

При помощи оператора site: для Google или host: для Яндекса, можно вручную искать повторяющийся контент на страницах поисковой выдачи. Для этого введите в поисковую строку оператор перед адресом вашего сайта, а дальше нужный отрывок текста в кавычках (site:address.com”…”). Таким образом вы сможете отыскать не только полные, но и частичные дубли.
Если использовать оператор с адресом без текста, в выдаче вы увидите все проиндексированные страницы собственного ресурса. По одинаковым заголовком можно легко определить копии.
Как исправить
Удалить вручную. Подходит для борьбы с полными копиями, которые возникли в результате ошибок. Для этого достаточно найти их URL и удалить при помощи CMS.
Закрыть от индексации. Для этого в файле robot.txt следует использовать директиву disallow. Таким образом вы сможете закрыть индексацию указанных типов страниц.
При помощи тега rel=canonical. Позволяет решить проблему с разными адресами страниц пагинации и др.
Настроить редирект 301. Редирект перенаправляет со всех похожих URL на один основной.
Как борются с дубликатами в Elit-Web
Когда к нам на продвижение приходят сайты, разработанные не у нас, технические ошибки, в том числе дубли, – один из первых пунктов проверки.
Многим не удается найти все копии страниц. Автоматический поиск осуществляется исключительно по метатегам. А чтобы искать при помощи контента, необходимо знать, какой именно текст может повторятся. Потому даже после работ по внутренней оптимизации, могут остаться ошибки.
Мы устраняем ошибки, используя все доступные методы проверки. Также наши специалисты ориентируются на саму специфику CMS и работ, проведенных на сайте, чтобы удостоверится, что на сайте не осталось дублей. А потому если у вас возникли проблемы с продвижением, мы уверены, что сможем помочь.
