Нахождение крайних значений
Для нахождения крайних (наибольшего или наименьшего) значений в множестве данных используют функции МАКС и МИН.
Синтаксис функции МАКС:
МАКС(А),
где A – список от 1 до 30 элементов, среди которых требуется найти наибольшее значение. Элемент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются.
Функция МИН имеет такой же синтаксис, что и функция МАКС.
Функции МАКС и МИН только определяют крайние значения, но не показывают, в какой ячейке эти значения находятся.
В тех случаях, когда требуется найти не самое большое (самое маленькое) значение, а значение, занимающее определенное положение в множестве данных (например, второе или третье по величине), следует использовать функции НАИБОЛЬШИЙ или НАИМЕНЬШИЙ.
Синтаксис функции НАИБОЛЬШИЙ:
НАИБОЛЬШИЙ(А; В),
где A – список от 1 до 30 элементов, среди которых требуется найти значение. Элемент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются;
В – позиция (начиная с наибольшей) в множестве данных. Если требуется найти второе значение по величине, то указывается позиция 2, если третье, то позиция 3 и т. д.
Функция НАИМЕНЬШИЙ имеет такой же синтаксис, что и функция НАИБОЛЬШИЙ.
Например, для данных таблицы на рис. 7.15 второе по величине значение составит 9 % (ячейка Е4 ), а второе из наименьших – 1,5 % (ячейка Е5 ).
Расчет количества ячеек
Для определения количества ячеек, содержащих числовые значения, можно использовать функцию СЧЕТ.
Синтаксис функции:
СЧЕТ(А) ,
где A – список от 1 до 30 элементов, среди которых требуется определить количество ячеек, содержащих числовые значения. Элемент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются.
Например, в таблице на рис. 7.16 числовые значения в диапазоне А1:В17 содержат 12 ячеек.
Если требуется определить количество ячеек, содержащих любые значения (числовые, текстовые, логические), то следует использовать функцию СЧЕТЗ.
Синтаксис функции:
СЧЕТЗ(А) ,
где A – список от 1 до 30 элементов, среди которых требуется определить количество ячеек, содержащих любые значения. Элемент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки игнорируются.
Наоборот, если требуется определить количество пустых ячеек, следует использовать функцию СЧИТАТЬПУСТОТЫ.
Синтаксис функции:
СЧИТАТЬПУСТОТЫ(А),
где А – список от 1 до 30 элементов, среди которых требуется определить количество пустых ячеек. Элемент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на ячейки с нулевыми значениями игнорируются.
Можно также определять количество ячеек, отвечающих заданным условиям. Для этого используют функцию СЧЕТЕСЛИ.
Синтаксис функции:
СЧЕТЕСЛИ(А;В) ,
где А – диапазон проверяемых ячеек;
В – критерий в форме числа, выражения или текста, определяющего суммируемые ячейки;
Можно найти количество ячеек со значениями, отвечающими заданному условию. Например, в таблице на рис. 7.17 подсчитано количество партий, объем которых превышает 15. Можно найти количество ячеек со значениями, соответствующими заданному. Например, в таблице на рис. 7.18 подсчитано количество партий, относящихся к товару » Луна «.
Определение
принадлежности крайних вариант к
совокупности.
Основным
требованием при математической обработке
опытных данных является сохранение
всех этих данных. Однако, нередко бывает
так, что крайние варианты слишком
значительно отличаются от среднего
значения. Такие крайние варианты могут
быть результатом грубых ошибок в оценке
времени и поэтому должны быть исключены
из выборки.
Очевидно, что
при отбрасывании крайних вариант следует
исходить не из субъективных рассуждений
исследователя, а из научного анализа
данных ряда распределения.
Существует несколько
методов определения принадлежности
крайних вариант к совокупности. Наиболее
часто применяемым методом является
метод, основанный на применении таблицы
значений интеграла вероятностей. В этом
случае априори полагают наличие
нормального закона распределения для
полученной выборки. В нашем случае
имеется косвенное подтверждение наличия
нормального закона. Полагаем, что
параметры нормального распределения
равны:
![]()
и
![]()
.
Выбираем одну из крайних вариант,
например, наибольшую по своей величине
варианту tk
и определяем вероятность попадания
случайной точки в два симметрично
расположенные относительно математического
ожидания промежутка числовой оси
![]()
.
На приведенном ниже рисунке эти промежутки
соответствуют заштрихованным зонам
под графиком плотности нормального
распределения, а сама вероятность
численно равна сумме площадей
заштрихованных зон. Удобно искомую
вероятность определять через вероятность
противоположного события – вероятность
непопадания в выделенные промежутки
числовой оси. С учётом того, что вся
площадь под кривой плотности численно
равана единице и кривая – симметричная
относительно вертикальной оси
![]()
,
то интеграл вычисляем по половине
области интегрирования.


Если найденная
вероятность окажется практически малой
(меньше 0,05), то рассматриваемое крайнее
значение варианты может быть отброшено,
т. е. исключено из выборки, и не учитываться
в дальнейших исследованиях.
Определим
принадлежность крайних вариант к одной
и той же генеральной совокупности,
считая
![]()
![]()
Расчёт выполняем с помощью таблицы 6.
Таблица
6.
-
№
п. п.
Крайняя варианта
tk


Q
Заключение
1
6
-15
1,52
0,8715
0,1185
Q>0,05
2
58
37
3,76
0,9998
0,0002
Q<0,05
3
53
32
3,25
0,9989
0,0011
Q<0,05
4
45
24
2,44
0,9853
0,0147
Q<0,05
5
43
22
2,24
0,9749
0,0251
Q<0,05
6
40
19
1,93
0,9464
0,0536
Q>0,05
Вывод.
Варианты 43 (повторяется два раза), 45, 53
и 58 необходимо из выборки исключить как
маловероятные.
Для больших
выборок простейшим критерием для
исключения вариант из совокупности
может служить правило «трёх сигм»: если
выполняется неравенство
![]()
,
то варианта tk
может быть
исключена из выборки.
Определение
параметров «очищеной» выборки.
Для определения
среднего выборочного и дисперсии
«очищеной» выборки необходимо заново
построить интервальный вариационный
ряд, удовлетворяющий ранене сформулированными
требованиями.
Число интервалов
определяем по формуле:
![]()
В целях избежания малочисленных вариант
принимаем к=5.
Интервальный ряд для «очищеной» выборки
приведен в таблице 7. При составлении
таблицы принимали h
= 7 минут (временная протяжённость
интерваплов) и С = 16 – «ложный» нуль.
Таблица
7.
|
Интервалы |
Середины Интервалов ti |
Частота ni |
||||
|
5,5 – 12,5 |
9 |
10 |
-1 |
-10 |
10 |
0 |
|
12,5 -19,5 |
16 |
34 |
0 |
0 |
0 |
34 |
|
19,5 -26,5 |
23 |
21 |
1 |
21 |
21 |
84 |
|
26,5 – 33,5 |
30 |
5 |
2 |
10 |
20 |
45 |
|
33,5 – 40,5 |
37 |
4 |
3 |
12 |
36 |
64 |
|
|
|
|
|
Проверка правильности
вычислений: 66 + 87 + 74 = 227, т. е. расчёт
выполнен верно.
![]()
![]()
![]()
![]()
![]()
;
![]()
Статистическая
проверка статистической гипотезы о
наличии нормального
закона распределения.
Статистическую
проверку гипотезы о наличии нормального
закона распределения для исследуемой
генеральной совокупности осуществим
при помощи критериев согласия Пирсона
и Романовского. С этой целью построим
теоретическую кривую по выравнивающим
частотам для нормального закона и
сравним её с полигоном наблюдённых
частот.
Будем определять
выравнивающие частоты (т. е. ординаты
теоретической кривой) по формуле,
вытекающей из определения статистической
плотности вероятности, которая строится
по интервальному статистическому
вариационному ряду. Статистической
плотностью вероятности
![]()
называется функция, значение которой
на каждом интервале
![]()
постоянны и равны относительной частоте
события
![]()
поделённой на длину интервала
![]()
,
т. е.
![]()
Ступенчатый
график статистической плотности
вероятности называется гистограммой.
Заменяя в
последней формуле функцию
на нормированную функцию распределения
для нормального закона, получим выражение
для подсчёта выравнивающей (теоретической)
частоты
![]()
![]()
;
Здесь: n
– сумма
наблюдённых частот;
h
–
величина
интервала ряда;
![]()
![]()
— нормированная
функция плотности распре- деления
вероятностей нормального закона.
Значения функции берутся из таблицы
(см. приложение, таблица 1). Входом в
таблицу служат рассчитанные
![]()
.
Следует иметь
ввиду, что сумма выравнивающих
(теоретических) частот должна быть равна
сумме наблюдённых. Результат расчёта
приведен в таблице 8.
При расчёте было
принято: n
= 74;
![]()
![]()
![]()
![]()
Таблица
8.
|
Середина
интервала |
Наблюдённые
частоты |
|
|
|
Выравнивающ. частоты
|
|
2 |
0 |
-17,1 |
-2,4783 |
0,0184 |
1,38 |
|
9 |
10 |
-10,1 |
-1,4638 |
0,1374 |
10,31 |
|
16 |
34 |
-3,1 |
-0,4493 |
0,3605 |
27,06 |
|
23 |
21 |
3,9 |
0,5652 |
0,3400 |
25,52 |
|
30 |
5 |
10,9 |
1,5797 |
0,1163 |
8,73 |
|
37 |
4 |
17,9 |
2,5942 |
0,0140 |
1,051 |
|
|
|
По данным таблицы
8 в прямоугольной системе координат
строим точки
![]()
и
![]()
,
соединяя первые отрезками прямых, а
вторые (теоретические) – плавной кривой.
Сравнивая графики (см. ниже), можно
сделать вывод о том, что выравнивающие
и наблюдённые частоты не сильно отличаются
друг от друга, т. е. распределение оценок
времени близко к теоретическому,
построенному для нормального закона
распределения. Однако, чтобы уверенно
сказать, что данные эксперимента
соответствуют нормальному распределению,
следует применить более строгие, надёжные
количественные оценки. Такие количественные
оценки называют критериями согласия.
Эти критерии
позволяют судить о согласовании данныъх
наблюдений с выдвинутой статистической
гипотезой о наличии нормального закона
распределения.
Анализ
кумулятивного графика в соответствии
с правилом одного, двух и трёх «сигм»,
построенного по данным таблицы 5, позволил
нам выдвинуть гипотезу о наличии
нормального распределения в полученной
выборке. Эта гипотеза была использована
при вычислении выравнивающих частот,
которые, как видно из графика (см. ниже),
не совпадают с наблюдёнными.
Вполне логичен
вопрос, является ли расхождение между
выравнивающими и наблюдёнными частотами
случайным или значимым, т. е. реальными?
Если расхождение окажется случайным,
то можно сказать, что данные выборки
согласуются с выдвинутой гипотезой и,
следовательно, гипотезу можно принять.
Если же расхождение окажется значимым,
то данные выборки не согласуются с
гипотезой и её следует отвергнуть.

Имеется несколько
критериев согласия, в настоящем кратком
курсе ограничимся описанием только
двух: критерия Пирсона («хи – квадрат»)
и критерия Романовского.
В случае
применения критерия Пирсона вычисляется
сумма квадратов разностей между
наблюдёнными и выравнивающими частотами,
отнесённых к величинам выравнивающих
частот:

,
здесь: k
– число
интервалов.
Из формулы
видно, что чем больше согласуются
эмпирическое и теоретическое распределения,
тем меньше будет разность
![]()
и, следовательно, тем меньше будет
критерий
![]()
.
Таким образом,
критерий
в известной степени характеризует
близость эмпирического и теоретического
распределений. Имеются специальные
таблицы, в которых указана вероятность
того, что, в результате влияния случайных
факторов, величина критерия
примет значение не меньшее, чем вычисленное
по данным выборки число, обозначенное
как
![]()
Входом в таблицу
является уровень значимости (величина
вероятности, которую можно считать
малой) и число степеней свободы. Для
нормального закона число степеней
свободы f
определяется
по формуле: f
= k
– 3, где k
– число
интервалов ряда.
В качестве
границы между случайным и существенным
выбираем, например, 5% — ный уровень
значимости. Если вероятность
![]()
будет меньше 0,05, то наблюдённое значение
считается
не случайным, так как событие с такой
малой вероятностью полагается практически
невозможным. В таком случае расхождение
между гипотезой и наблюдёнными данными
тоже надо считать не случайным, а
существенным. Следовательно, малая
вероятность
указывает
на недостаточное согласие между гипотезой
и наблюдениями. Если же вероятность
будет
больше 0,05, то расхождение между гипотезой
и эмпирическими данными можно считать
случайным, а саму гипотезу считать
согласующейся с наблюдениями.
На практике
обычно не определяют вероятность
![]()
а сравнивают найденное
и табличное
![]()
(см. приложение, таблица 2). Если
![]()
,
то гипотеза не отвергается. Если же
![]()
,
то гипотезу о нормальном законе
распределения следует отвергнуть.
При использовании
критерия Пирсона требуется, чтобы в
каждом интервале было не меньше 5
наблюдений. Если это условие не выполнено,
необходимо частоты крайних интервалов
объединить между собой. Расчёт критерия
приведен
в таблице 9. Для её построения использованы
данные таблицы 8. Теоретические
(выравнивающие) частоты округлены до
целых значений.
Таблица
9.
-





10

-1
1
0,09
9,09
34
27
7
49
1,81
42,81
21
26
-5
25
0,97
16,96


-1
1
0,1
8,1



Проверку
правильности при вычислении критерия
необходимо проводить по формуле:

,
где n
– объём
выборки.
Проверка: 76,96 –
74 = 2,96, т. е. значение критерия вычислено
верно.
По таблице
значений
(см. приложение, таблица 2) для числа
степеней свободы f
=4 – 3 = 1 и
уровня значимости 0,05 находим критическое
значение критерия
![]()
.
Так как
,
то гипотезу о нормальном распределении
генеральной совокупности следует
считать правильной.
Критерий
Романовского
состоит в следующем: если выполняется
неравенство
![]()
То расхождение
между эмпирическим и теоретическим
распределениями можно считать
существенным. Если знак неравенства –
противоположный, то расхождение можно
считать случайным.
В нашем случае
![]()
![]()
.
Поэтому
![]()
,
т. е. расхождение носит случайный
характер.
Итак, справедливость
выдвинутой гипотезы подтверждается
двумя критериями и сравнением графиков
наблюдённых и выравнивающих частот.
Доверительные
границы для среднего выборочного
совокупности.
Для получения
представлеения о точности и надёжности
какого либо параметра распределения в
полученной выборке, в математической
статистике используют доверительный
интервапл и доверительную вероятность.
Пусть в результате
обработки опытных данных получена
точечная оценка, например, среднего
выборочного
![]()
.
Как оценить возможную при этом ошибку?
Поступают
следующим образом.
— Назначается
вероятность
![]()
из числа значений
![]()
0,9;
0,95; 0,99 такую, что событие с вероятностью
можно считать практически достоверным.
— Находится
такое значение
![]()
,
для которого вероятность неравенства
![]()
,
т. е. практически возможная ошибка по
абсолютной величине не превосходит
![]()
![]()
.
Здесь
![]()
— неизвестное точное значение среднего
выборочного (величина не случайная).
Перейдём от модульного неравенства под
знаком вероятности Р
к двойному безмодульному:
![]()
.
Геометрическая
интерпретация выражения такова:
неслучайная величина
с вероятностью
«накрывается» интервалом
![]()
,
границы которого — случайны. Точнее,
случаен центр интервала
,
определяющий положение интервала на
числовой оси, случайна и длина интервала.
Вероятность
называется доверительной
вероятностью;
Интервал,
«накрывающий» с вероятностью
неизвестное точное значение
среднего выборочного, называется
доверительным
интервалом,
а его границы – доверительными
границами.
На практике
задача определения доверительного
интервала при заданной доверительной
вероятности решается как приближёнными,
так и точными методами. Приближённый
метод даёт удовлетворительные по
точности результаты, если имеется
сравнительно большое число опытов (n
> 20). В нашем
случае вполне применим приближённый
метод.
Суть метода
заключается в замене в выражении для
неизвестных параметров
![]()
и
их точечными оценками. Так как среднее
выборочное есть сумма n
независимых, одинаково распределённых
случайных величин
![]()
![]()
(результат каждого наблюдения рассматриваем
как случайную величину)

,
то при достаточно большом n
её закон
распределения близок к нормальному.
Следовательно, согласно центральной
предельной теореме, случайная величина
распределена по нормальному закону с
параметрами
![]()
и
![]()
.
Тогда вероятность двойного неравенства
может быть выражена через нормированную
функцию распределения для нормального
закона:

.
Полагая в
последнем выражении
![]()
,
получим:

,
откуда:
![]()
.
Величину
![]()
находим для выбранной доверительной
вероятности
по таблице 1 приложения.
Итак, доверительный
интервал равен:
![]()
.
Если принять
доверительную вероятность
![]()
,
то с принятой вероятностью можно
утверждать, что неизвестное срднее
значение генеральной совокупности
лежит между числами:
![]()
.
Принимая n
= 74,
![]()
и
![]()
,
по таблице 1 находим
![]()
.
Тогда:
![]()
.
Или:
![]()
.
Порядок работы с
выборкой объёма n
> 30 может быть следующим.
-
Составляем сводку
данных. -
Составляем
интервальный ряд с последующим
определением выборочного среднего,
дисперсии и стандарта. -
Строим кумулятивный
график, по правилу одного, двух и трёх
«сигм» проверяем возможность выдвижения
гипотезы о наличии нормального закона
распределения выборки. -
Исключаем из
выборки маловероятные варианты. -
Рассчитываем
выборочное среднее, дисперсию и стандарт
для «очищенной» выборки. -
Рассчитываем
выравнивающие (теоретические) частоты
и строим график наблюдённых и
выравнивающих частот. -
Проверяем
согласование данных выборки с выдвинутой
гипотезой. -
Определяем
доверительные границы для среднего
выборочного.
Лекция
10.
Обработка
статистических данных при малом объёме
выборки.
Методика
обработки статистических данных в
случае, когда выборка оказывается малой
![]()
,
имеет ряд особенностей, на которых мы
и остановимся.
Пусть имеются
семь оценок времени для выполнения
одного и того же задания:
18; 24; 24; 28; 29; 32; 33 часа.
Найдём среднее
время, гнеобходимое для выполнения
задания.
![]()
часа.
Так как объём
выборки мал, то теряет смысл работа по
составлению интервального ряда,
построению кумулятивного графика.
Как и при большом
объёме выборки, так и при малом объёме,
прежде всего необходимо решить вопрос
о принадлежности крайних вариант к
генеральной совокупности. «Очистку»
выборки осуществим путём исключения
из выборки маловероятных вариант. При
этом надо иметь ввиду, что если при
большом объёме выборки относительный
«вес» нескольких сомнительных вариант
при вычислении усреднённых параметров
сравнительно невелик, то при малом
объёме выборки даже одно неправильное
решение может заметно исказить результат
усреднения.
Поэтому
отбрасывание «ошибочных» вариант при
малом объёме выборки является весьма
ответственным этапом статистической
обработки данных.
Исследование
принадлежности всех элементов малой
выборки к генеральной совокупности
основано на использовании распределения
Стьюдента (Госсет, статистик, англичанин).
Требуется ответить на вопрос: является
ли значимым или случайным наблюдённое
значение t?
На этот вопрос
даётся ответ таблицей значений критерия
t
при данном числе степеней свободы f
и данной
величине вероятности Р
(см. приложение, таблица 3). Значение t
определяется из формулы:

Здесь:
— среднее значение выборки;
— исследуемое
значение варианты;
![]()
— исправленное
среднее квадратичное отклонение выборки;
n–
объём выборки.
При этом:

,
где
— варианты (i=
1; 2; …;n).
Число степеней
свободы находится из соотношения:
![]()
.
Суть критерия
t
состоит в следующем: если нормированное
наблюдённое значение критерия t
для испытуемой варианты
превосходит
по абсолютной величине соответствующее
табличное значение
![]()
при Р
=0,05, то t
cчитается
значимым; в прортивном случае t
не является значимым и соответствующее
необходимо исключить из выборки.
Исследование на принадлежность полученной
из опыта крайней варианты
![]()
к генеральной совокупности приведено
в таблице 10. При вычислении полагали
![]()
;
n
= 7.
Таблица
10.
|
|
Критерий t |
||
|
18 — 26,9 = — 8,9 |
79,21 |
||
|
2(24 – 26.9) = — 5,8 |
33,64 |
||
|
28 – 26,9 = 1,1 |
1,21 |
||
|
29 – 26,9 = 2.1 |
4,41 |
||
|
32 – 26,9 = 5.1 |
26,01 |
||
|
33 – 26.9 = 6.1 |
37,21 |
||
|
|
|
|

Из таблицы 3
приложения для f
= 7 – 1 = 6 и Р
= 0,05 находим значение
![]()
.
Так как критерий
![]()
,
то t
– значимо и поэтому варианту
необходимо оставить в выборке.
Аналогично
предыдущему выполним расчёты для
элемента
![]()
.
Заметим, что если бы элемент
был бы исключён из выборки, то потребовалось
бы заново рассчитать
и
для объёма выборки n
= 6.
Так как
![]()
,
а
,
то соответствующий наблюдённый критерий
равен:

Как и в предыдущем
случае, имеет место неравенство:
поэтому
варианту
из выборки не исключаем.
Анализ на
систематический сдвиг выборочного
среднего.
Согласно критерию
А. А. Маркова, условием существования
выборочного среднего является отсутствие
систематического сдвига в погрешностях
элементов выборки. Для анализа на
систематический сдвиг выборочного
среднего используем критерий Аббе, суть
применения которого состоит в следующем:
1. Вычисляются
несмещённые оценки
![]()
и
![]()
по формулам:
![]()
![]()
Здесь:
— варианты;
![]()
среднее значение
«очищенной» выборки;
![]()
объём выборки.
2. Определяется
величина

3. Найденное
![]()
сравнивается с табличным
![]()
(см. приложение, таблица 4), которое
находится по параметру
для заданного уровня значимости р
= 0,05.
Если
![]()
,
то можно считать что оценки времени
содержат систематический сдвиг
выборочного среднего и их необходимо
пересмотреть.
Из таблицы 10
выбираем
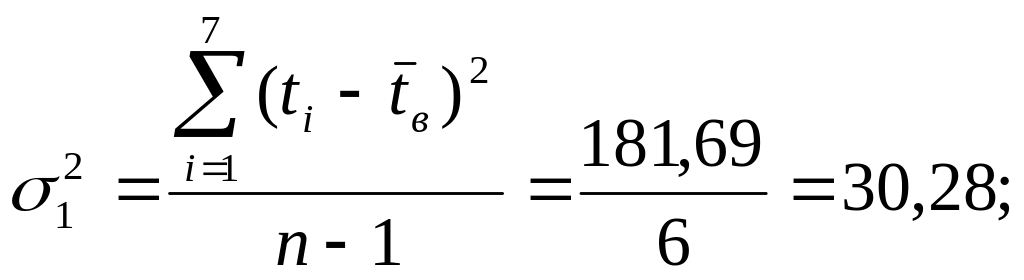
![]()
![]()
Найденное
сравниваем с табличным: для
![]()
и
![]()
из таблицы 4 приложения определяем
![]()
Так как
,
то оценки времени содержат систематический
сдвиг выборочного среднего и результаты
эксперимента следует пересмотреть.
Доверительные
границы для среднего значения в общей
совокупности.
Определение
точности средней выборочной с помощью
распределения Стьюдента изложено в
начале этой лекции, поэтому ограничимся
только решением примера. Будем считать,
что систематический сдвиг в оценке
выборочного среднего отсутствует. Тогда
из таблицы 3 приложения для
![]()
находим
![]()
Далее, для
![]()
и
строим доверительные границы для
выборочного среднего:
![]()
![]()
Итак, неизвестное
среднее значение генеральной совокупности
заключено в интервале:
![]()
Пример для решения
на практических занятиях.
Изучалась
потребность размеров мужской обуви в
г. Керчи в 1978 году. В результате многодневных
опросов покупателей, проводимых в
отделах «обуви» различных магазинов,
получилась следующая сводная таблица:
Таблица
1.
|
Размер |
|
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
|
|
Частота |
|
3 |
17 |
54 |
114 |
176 |
208 |
189 |
126 |
66 |
33 |
7 |
993 |
Найти основные
параметры распределения полученной
выборки.
Для получения
точечных оценок числовых характеристик
выборки и выдвижения гипотезы о наличии
того или иного закона распределения
гегнеральной совокупности составим
рассчётную таблицу 2. При переходе к
условным вариантам за «ложный» нуль С
примем варианту С = 40. Шаг таблицы
![]()
Тогда
![]()
.
Таблица
2.
|
Варианта |
Частота |
Относит. частота
|
Кумулят. распредел.
|
Условная варианта
|
|
|
|
35 |
3 |
0,003 |
0,002 |
-5 |
-0,02 |
0,08 |
|
36 |
17 |
0,017 |
0,012 |
-4 |
-0,07 |
0,27 |
|
37 |
54 |
0,055 |
0,048 |
-3 |
-0,17 |
0,50 |
|
38 |
114 |
0,115 |
0,133 |
-2 |
-0,230 |
0,460 |
|
39 |
176 |
0,177 |
0,279 |
-1 |
-0,18 |
0,18 |
|
40 |
208 |
0,209 |
0,472 |
0 |
0 |
0 |
|
41 |
189 |
0,190 |
0,671 |
1 |
0,19 |
0,19 |
|
42 |
126 |
0,127 |
0,830 |
2 |
0,25 |
0,51 |
|
43 |
66 |
0,067 |
0,928 |
3 |
0,204 |
0,60 |
|
44 |
33 |
0,033 |
0,978 |
4 |
0,13 |
0,53 |
|
45 |
7 |
0,007 |
0,997 |
5 |
0,04 |
0,18 |
|
993 |
1,0 |
|
|

Точечную оценку
среднего размера обуви получим по
формуле:
![]()
Оценка выборочной
дисперсии составляет:

Тогда:![]()
.
Стандарт
(точечная оценка с. к. о.) равен:
![]()
Сравним, далее,
параметры выборки с аналогичными
параметрами для нормального закона.
Для этого воспользуемся первым и
четвёртым столбцами таблицы 2 и построим
график кумулятивного распределения
(рис.1). Используя, далее, правило одного,
двух и трёх «сигм», сравним полученные
значения с цифрами, вытекающими из
нормального закона распределения.
а). По правилу
одного «сигма» имеем:
![]()
0.677.
Для нормального закона распределения
должно быть
![]()
б). По правилу
двух «сигм»:
![]()
0,95.
Должно быть 0,950.
в). По правилу
трёх «сигм»:
![]()
0,99.
Должно быть 0,997.

Близость
полученнывх цифр к параметрам нормального
распределения позволяет выдвинуть
гипотезу о наличии нормального закона
распределения в исследуемой выборке.
Определение
принадлежности крайних вариант выборки
к генеральной
совокупности.
Определение
принадлежности крайних вариант к одной
и той же гегнеральной совокупности
удобно выполнять с помощью таблицы 3.
При рассчёте принимали:
![]()
![]()
Вычисления
производились по формуле:
![]()
Таблица
3.
-
Крайняя варианта



Q
Заключение
35
-5,16
2,715
0,993
0,007
Q
<
0,0536
-4,16
2,189
0,971
0,025
Q < 0,05
37
-3,16
1,66
0,903
0,097
Q > 0,05
44
3,84
2,02
0,950
0,050
Q = 0,05
45
4,84
2,55
0,989
0,011
Q <
0,05
Вывод:
варианты 35, 36, 45 необходимо из выборки
исключить как маловероятные (их
вероятность менее 0,05).
Определение
параметров «очищенной» выборки.
Для определения
среднего размера и дисперсии «очищенной»
выборки построим таблицу 4.
Таблица 4.
-
Варианта
Частота
Условная вар.

37
54
-3
-0,168
0,504
38
114
-2
-0,236
0,472
39
176
-1
-0,182
0,182
40
208
0
0
0
41
189
1
0.195
0,195
42
126
2
0,261
0,522
43
66
3
0,205
0,615
44
33
4
0,137
0,548

Точечная оценка
среднего размера обуви равна:
![]()
Оценка выборочной
дисперсии составляет:
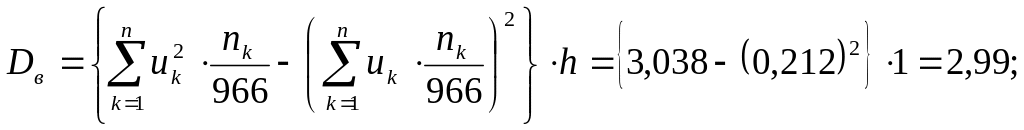
Оценка с. к. о.
равна:
![]()
Построим, далее,
графики наблюдённых и выравнивающих
частот, для чего составим таблицу 5,
используя полученные точечные оценки
числовых параметров «очищенной» выборки.
Таблица
5.
-
Варианта
Частота



37
54
-3,212
-1,864
0,070
39,25
38
114
-2,212
-1,284
0,180
102,2
39
176
-1,212
-0,723
0,310
176,08
40
208
-0,212
-0,123
0.398
226,06
41
189
0,788
0,457
0.360
204,48
42
126
1,788
1,038
0,232
130,07
43
66
2,788
1,618
0,107
62,48
44
33
3,788
2,198
0,040
22,70


При вычислении
выравнивающих (теоретических) частот
в таблице 5 полагали:
![]()

Графики
наблюдённых и выравнивающих частот
приведены на рис. 2. Точки, полученные
из эксперимента, соединены отрезками
прямых. Точки, полученные расчётным
путём, соединены гладкой кривой.
Сравнивая
графики, можно сделать вывод о том, что
выравнивающие и наблюдённые частоты
не значительно отличаются друг от друга,
т. е. распределение оценок размеров
обуви близко к теоретическому.
Но для того,
чтобы уверенно сказать, что данные
опроса покупателей свидетельствуют о
нормальном расмпределении спроса на
те или иные размеры обуви, необходимо
применить более строгие количественные
оценки, называемые критериями согласия.
Применим критерии
Пирсона и Романовского для проверки
выдвинутой статистической гипотезы о
наличии нормального закона распределения.
Для применения критерия Пирсона составим
таблицу 6.

Рис.
2.
Таблица
6.
-
Наблюдённая
частота
Теоретическая
частота




54
39
15
225
5,77
114
102
12
144
1,41
176
176
0
0
0
208
226
-18
324
1,43
189
205
-16
256
1,25
126
130
-4
16
0,12
66
63
3
9
0,14
33
23
10
100
4,35

966


Число степеней
свободы
![]()
Здесь n
– количество вариант. Для принятого
уровня значимости 0,01 и 5 степеней свободы
по таблице значений
![]()
(см.
таблицу 2 приложения) находим критическое
значение критерия
![]()
15,1.
Так как
,
то гипотезу о нормальном распределении
генеральной совокупрости следует
считать правильной.
Проверка гипотезы
при помощи критерия Романовского состоит
в следующем:
если
![]()
, то расхождение между эмпирическим и
теоретическим распределениями можно
считать существенным. Если же знак
неравенства — противоположный, то
расхождение можно считать случайным.
В нашем случае
![]()
,
т. е. расхождение – случайное.
В заключение
исследования вычислим доверительный
интервал для оценки математического
ожидания нормального распределения
признака при известных точечных оценках
среднего квадратического отклонения
![]()
и выборочного среднего
![]()
40,21.
Объём вфыборки равен
![]()
,
зададимся доверительной вероятностью
![]()
Для расчёта
используем формулу:
![]()
Здесь:
![]()
![]()
По таблице 1
приложения находим
![]()
Из равенства
![]()
Искомый
доверительный интервал равен:
40,21 –
0,108 <
![]()
< 40,21 + 0,108;
или:
40,102 <
< 40,318.
Пример
использования
результатов исследования при решении
практических задач.
Предприниматель,
имеющий обувной магазин, делает заказ
на партию мужской обуви ходового фасона
объёмом 500 пар. Для быстрой реализации
партии и максимального удовлетворения
спроса покупателей, заказанную обувь
необходимо количественно разбить по
размерам так, чтобы исключить
невостребованные размеры. Для достижения
этих целей можно использовать результат
проведенного исследования. Для разбивки
партии по размерам составляем рассчётную
таблицу 7.
Таблица
7.
-
Размер

=

Колич. пар
37
0,070
20,35
20
38
0,180
52,32
52
39
0,310
90,08
90
40
0,398
115,69
118
41
0,360
104,65
107
42
0,232
67,44
70
43
0,107
31,10
31
44
0,040
11,63
12
Приложения.
Стандартная функция
вероятностей (функция Гаусса).
![]()

где:
![]()
Нормированная
(стандартная) функция нормального
распределения (функция Лапласа).


Таблица
1.
|
х |
|
|
х |
х |
||||
|
0,00 |
0,3989 |
0,0000 |
22 |
3894 |
0871 |
44 |
3621 |
1700 |
|
01 |
3989 |
0040 |
23 |
3885 |
0910 |
45 |
3605 |
1736 |
|
02 |
3989 |
0080 |
24 |
3876 |
0948 |
46 |
3589 |
1772 |
|
03 |
3988 |
0120 |
25 |
3867 |
0987 |
47 |
3572 |
1808 |
|
04 |
3986 |
0160 |
26 |
3857 |
1026 |
48 |
3555 |
1844 |
|
05 |
3984 |
0190 |
27 |
3847 |
1064 |
49 |
3538 |
1879 |
|
06 |
3982 |
0239 |
28 |
3836 |
1103 |
0,50 |
0,3521 |
0,1915 |
|
07 |
3980 |
0279 |
29 |
3825 |
1141 |
51 |
3503 |
1950 |
|
08 |
3977 |
0319 |
0,30 |
0,3814 |
0,1179 |
52 |
3485 |
1985 |
|
09 |
3973 |
0359 |
31 |
3802 |
1217 |
53 |
3467 |
2019 |
|
0,10 |
0,3970 |
0,0398 |
32 |
3790 |
1255 |
54 |
3448 |
2054 |
|
11 |
3965 |
0438 |
33 |
3778 |
1293 |
55 |
3429 |
2088 |
|
12 |
3961 |
0478 |
34 |
3765 |
1331 |
56 |
3410 |
2123 |
|
13 |
3956 |
0517 |
35 |
3752 |
1368 |
57 |
3391 |
2157 |
|
14 |
3951 |
0557 |
36 |
3739 |
1406 |
58 |
3372 |
2190 |
|
15 |
3945 |
0596 |
37 |
3725 |
1443 |
59 |
3352 |
2224 |
|
16 |
3939 |
0636 |
38 |
3712 |
1480 |
0,60 |
0,3332 |
0,2257 |
|
17 |
3932 |
0675 |
39 |
3697 |
1517 |
61 |
3312 |
2291 |
|
18 |
3925 |
0714 |
0,40 |
0,3683 |
0,1554 |
62 |
3292 |
2324 |
|
19 |
3918 |
0753 |
41 |
3668 |
1591 |
63 |
3271 |
2357 |
|
0,20 |
0,3910 |
0,0793 |
42 |
3653 |
1628 |
64 |
3251 |
2389 |
|
21 |
3902 |
0832 |
43 |
3637 |
1664 |
65 |
3230 |
2422 |
(продолжение
см. ниже).
|
х |
х |
|
х |
|||||
|
66 |
3209 |
2454 |
08 |
2227 |
3599 |
1,50 |
0,1295 |
0,4332 |
|
67 |
3187 |
2486 |
09 |
2203 |
3621 |
51 |
1276 |
4345 |
|
68 |
3166 |
2517 |
1,10 |
0,2179 |
0,3643 |
52 |
1257 |
4357 |
|
69 |
3144 |
2549 |
11 |
2155 |
3665 |
53 |
1238 |
4370 |
|
0,70 |
0,3123 |
0,2580 |
12 |
2131 |
3686 |
54 |
1219 |
4382 |
|
71 |
3101 |
2611 |
13 |
2107 |
3708 |
55 |
1200 |
4394 |
|
72 |
3079 |
2642 |
14 |
2083 |
3729 |
56 |
1182 |
4406 |
|
73 |
3056 |
2673 |
15 |
2059 |
3749 |
57 |
1163 |
4418 |
|
74 |
3034 |
2703 |
16 |
2036 |
3770 |
58 |
1145 |
4429 |
|
75 |
3011 |
2734 |
17 |
2012 |
3790 |
59 |
1127 |
4441 |
|
76 |
2989 |
2764 |
18 |
1989 |
3810 |
1,60 |
0,1109 |
0,4452 |
|
77 |
2966 |
2794 |
19 |
1965 |
3830 |
61 |
1092 |
4463 |
|
78 |
2943 |
2823 |
1,20 |
0,1942 |
0,3849 |
62 |
1074 |
4474 |
|
79 |
2920 |
2852 |
21 |
1919 |
3869 |
63 |
1057 |
4484 |
|
0,80 |
0,2897 |
0,2881 |
22 |
1895 |
3888 |
64 |
1040 |
4495 |
|
81 |
2874 |
2910 |
23 |
1872 |
3907 |
65 |
1023 |
4505 |
|
82 |
2850 |
2939 |
24 |
1849 |
3925 |
66 |
1006 |
4515 |
|
83 |
2827 |
2967 |
25 |
1826 |
3944 |
67 |
0989 |
4525 |
|
84 |
2803 |
2995 |
26 |
1804 |
3962 |
68 |
0973 |
4535 |
|
85 |
2780 |
3023 |
27 |
1781 |
3980 |
69 |
0957 |
4545 |
|
86 |
2756 |
3051 |
28 |
1758 |
3997 |
1,70 |
0,0940 |
0,4554 |
|
87 |
2732 |
3078 |
29 |
1736 |
4015 |
71 |
0925 |
4564 |
|
88 |
2709 |
3106 |
1,30 |
0,1714 |
0,4032 |
72 |
0909 |
4573 |
|
89 |
2685 |
3133 |
31 |
1691 |
4049 |
73 |
0898 |
4582 |
|
0,90 |
0,2661 |
0,3159 |
32 |
1669 |
4066 |
74 |
0878 |
4591 |
|
91 |
2637 |
3186 |
33 |
1647 |
4082 |
75 |
0863 |
4599 |
|
92 |
2613 |
3212 |
34 |
1626 |
4099 |
76 |
0848 |
4608 |
|
93 |
2589 |
3238 |
35 |
1604 |
4115 |
77 |
0833 |
4616 |
|
94 |
2565 |
3264 |
36 |
1582 |
4131 |
78 |
0818 |
4625 |
|
95 |
2541 |
3289 |
37 |
1561 |
4147 |
79 |
0804 |
4633 |
|
96 |
2516 |
3315 |
38 |
1539 |
4162 |
1,80 |
0,0790 |
0,4641 |
|
97 |
2492 |
3340 |
39 |
1518 |
4177 |
81 |
0775 |
4649 |
|
98 |
2468 |
3365 |
1,40 |
0,1497 |
0,4192 |
82 |
0761 |
4656 |
|
99 |
2444 |
3389 |
41 |
1476 |
4207 |
83 |
0748 |
4664 |
|
1,00 |
0,2420 |
0,3413 |
42 |
1456 |
4222 |
84 |
0734 |
4671 |
|
01 |
2396 |
3438 |
43 |
1435 |
4236 |
85 |
0721 |
4678 |
|
02 |
2371 |
3461 |
44 |
1415 |
4251 |
86 |
0707 |
4686 |
|
03 |
2347 |
3485 |
45 |
1394 |
4265 |
87 |
0694 |
4693 |
|
04 |
2323 |
3508 |
46 |
1374 |
4279 |
88 |
0681 |
4699 |
|
05 |
2299 |
3531 |
47 |
1354 |
4292 |
89 |
0669 |
4706 |
|
06 |
2275 |
3554 |
48 |
1334 |
4306 |
1,90 |
0,0656 |
0,4713 |
|
07 |
2251 |
3577 |
49 |
1315 |
4319 |
91 |
0644 |
4719 |
|
х |
|
х |
х |
|||||
|
1,92 |
0,0632 |
0,4726 |
2,44 |
0,0203 |
0,4927 |
3,10 |
0,00327 |
0,4990 |
|
93 |
0620 |
4732 |
46 |
0194 |
4931 |
3,20 |
0,00238 |
0,4993 |
|
94 |
0608 |
4738 |
48 |
0184 |
4934 |
3,30 |
0,00172 |
0,4995 |
|
95 |
0596 |
4744 |
2,50 |
0,0175 |
0,4938 |
3,40 |
0,00123 |
0.4996 |
|
96 |
0584 |
4750 |
52 |
0167 |
4941 |
3,50 |
0.00087 |
0,4997 |
|
97 |
0573 |
4756 |
54 |
0158 |
4945 |
3.60 |
0,00061 |
0,4998 |
|
98 |
0562 |
4761 |
56 |
0151 |
4948 |
3,70 |
0,00042 |
0,4998 |
|
99 |
0551 |
4767 |
58 |
0143 |
4951 |
3,80 |
0,00029 |
0,4999 |
|
2,00 |
0,0540 |
0,4772 |
2,60 |
0,0136 |
0,4953 |
3,90 |
0,00020 |
0,4999 |
|
2,02 |
0,0519 |
0,4783 |
62 |
0129 |
4956 |
4,00 |
0,0001338 |
0,4999 |
|
04 |
0498 |
4793 |
64 |
0122 |
4959 |
4,50 |
0,000016 |
0,4999 |
|
06 |
0478 |
4803 |
66 |
0116 |
4961 |
5,00 |
0,0000015 |
0,4999 |
|
08 |
0459 |
4812 |
68 |
0110 |
4963 |
|||
|
10 |
0440 |
4821 |
2,70 |
0,0104 |
0,4965 |
|||
|
12 |
0422 |
4830 |
72 |
0,0099 |
0,4967 |
|||
|
14 |
0404 |
4838 |
74 |
0093 |
4969 |
|||
|
16 |
0387 |
4846 |
76 |
0088 |
4971 |
|||
|
18 |
0371 |
4854 |
78 |
0084 |
4973 |
|||
|
2,20 |
0,0355 |
0,4861 |
2,80 |
0,0079 |
0,4974 |
|||
|
2,22 |
0339 |
4868 |
82 |
0075 |
4976 |
|||
|
24 |
0325 |
4875 |
84 |
0071 |
4977 |
|||
|
26 |
0310 |
4881 |
86 |
0067 |
4979 |
|||
|
28 |
0297 |
4887 |
88 |
0063 |
4980 |
|||
|
2,30 |
0,0283 |
0,4893 |
2,90 |
0,0060 |
0,4981 |
|||
|
32 |
0270 |
4898 |
92 |
0056 |
4982 |
|||
|
34 |
0258 |
4904 |
94 |
0053 |
4984 |
|||
|
36 |
0246 |
4909 |
96 |
0050 |
4985 |
|||
|
38 |
0235 |
4913 |
98 |
0047 |
4986 |
|||
|
2,40 |
0,0224 |
0,4918 |
3,00 |
0,0044 |
0,4986 |
Квантили распределения
Пирсона
.
Таблица
2.
|
Число степ. |
Уровень значимости |
Уровень знач. 0,05 |
Уровень знач. 0,02 |
Уровнь знач. 0,01 |
|
1 |
2,7 |
3,8 |
5,4 |
6,6 |
|
2 |
4,6 |
6,0 |
7,8 |
9.2 |
|
3 |
6,3 |
7,8 |
9,8 |
11,3 |
|
4 |
7,8 |
9,5 |
11,7 |
13,3 |
|
5 |
9,2 |
11,1 |
13,4 |
15,1 |
|
6 |
10,6 |
12,6 |
15,0 |
16,8 |
|
7 |
12,0 |
14,1 |
16,6 |
18,5 |
|
8 |
13,4 |
15,5 |
18,2 |
20,1 |
|
9 |
14,7 |
16,9 |
19,7 |
21,7 |
Значение t
при данном числе степеней свободы f
и данной
величине
вероятности Р.
Таблица
3.
|
Число степеней
свободы f |
Уровень значимости |
Уровень значимости |
Уровень значимости |
|
1 |
6,314 |
12,706 |
31,821 |
|
2 |
2,920 |
4,303 |
6,965 |
|
3 |
2,353 |
3,182 |
4,541 |
|
4 |
2,132 |
2,776 |
3,747 |
|
5 |
2,015 |
2,571 |
3,365 |
|
6 |
1,943 |
2,447 |
3,143 |
|
7 |
1,895 |
2,365 |
2,998 |
|
8 |
1,860 |
2,306 |
2,896 |
|
9 |
1,833 |
2,262 |
2,821 |
|
10 |
1,812 |
2,228 |
2,764 |
|
11 |
1,796 |
2,201 |
2,718 |
|
12 |
1,782 |
2,179 |
2,681 |
|
13 |
1,771 |
2,160 |
2,650 |
|
14 |
1,761 |
2,145 |
2,624 |
|
15 |
1,753 |
2,131 |
2,602 |
|
16 |
1,746 |
2,120 |
2,583 |
|
17 |
1,740 |
2,110 |
2,567 |
|
18 |
1,734 |
2,101 |
2,552 |
|
19 |
1,729 |
2,093 |
2,539 |
|
20 |
1,725 |
2,086 |
2,528 |
|
120 |
1,658 |
1,980 |
2,358 |
Квантили
распределения величины r.
Таблица
4.
|
Объём выборки n |
Уровень значим. |
Уровень значим. |
Уровень значим. |
Объём выборки n |
Уровень значим. |
Уровень значим. |
Уровень значим. |
|
4 |
0,295 |
0,313 |
0,390 |
24 |
0,433 |
0,556 |
0,678 |
|
5 |
0,208 |
0,269 |
0,410 |
25 |
0,442 |
0,564 |
0,684 |
|
6 |
0,182 |
0,281 |
0,445 |
26 |
0,451 |
0,571 |
0,689 |
|
7 |
0,185 |
0,307 |
0,468 |
27 |
0,459 |
0,578 |
0,695 |
|
8 |
0,202 |
0,331 |
0,491 |
28 |
0,467 |
0,585 |
0,700 |
|
9 |
0,221 |
0,354 |
0,512 |
29 |
0,475 |
0,591 |
0,705 |
|
10 |
0,241 |
0,376 |
0,531 |
30 |
0,482 |
0,598 |
0,709 |
|
11 |
0,260 |
0,396 |
0,548 |
31 |
0,489 |
0,603 |
0,714 |
|
12 |
0,278 |
0,414 |
0,564 |
32 |
0,496 |
0,609 |
0,718 |
|
13 |
0,295 |
0,431 |
0,578 |
33 |
0,503 |
0,614 |
0,722 |
|
14 |
0,311 |
0,447 |
0,591 |
34 |
0,509 |
0,619 |
0,726 |
|
15 |
0,327 |
0,461 |
0,603 |
35 |
0,515 |
0,624 |
0,729 |
|
16 |
0,341 |
0,475 |
0,614 |
36 |
0,521 |
0,629 |
0,733 |
|
17 |
0,355 |
0,487 |
0,624 |
37 |
0,526 |
0,634 |
0,736 |
|
18 |
0,368 |
0,499 |
0,633 |
38 |
0,532 |
0,638 |
0,740 |
|
19 |
0,381 |
0,510 |
0,642 |
39 |
0,537 |
0,642 |
0,743 |
|
20 |
0,393 |
0,520 |
0,650 |
40 |
0,542 |
0,647 |
0,746 |
|
21 |
0,404 |
0,530 |
0,657 |
41 |
0,548 |
0,651 |
0,749 |
|
22 |
0,414 |
0,539 |
0,665 |
42 |
0,552 |
0,655 |
0,752 |
|
23 |
0,424 |
0,548 |
0,671 |
43 |
0,557 |
0,659 |
0,755 |

Adrien1018
Поиск минимума или максимума функции может быть очень полезным. Это часто возникает в задачах оптимизации, которые не имеют ограничений или в которых ограничения не препятствуют достижению функцией своего минимума или максимума.
На практике подобные проблемы возникают довольно часто. Примером может быть определение цены определенного товара. Если вы знаете спрос по данной цене (или хорошо оцениваете спрос), вы можете рассчитать цену, по которой вы получите наибольшую прибыль. Это можно сформулировать как нахождение максимума функции прибыли.
Минимум и максимум функции также называют крайними точками или крайними значениями функции. Они могут быть локальными или глобальными .
Локальные и глобальные экстремумы
Локальный минимум / максимум является точкой, в которой функция достигает самого низкого / наибольшее значение в некоторой области функции. Формально это означает, что для каждого локального минимума / максимума x существует эпсилон такой, что f (x) меньше / больше всех значений f (y) для всех y , у которых расстояние до x не превышает эпсилон. Это выглядит очень сложно, но на самом деле это означает, что f (x) является наименьшим / наибольшим значением для всех точек, близких к x. Однако могут быть значения, которые меньше / больше локального минимума / максимума, но находятся дальше.
Глобальный минимум наименьшее значение функция принимает во всей своей области. Эквивалентно, локальный максимум — это наибольшее значение функции. Следовательно, каждая глобальная экстремальная точка также является локальной экстремальной точкой, но обратное неверно.
У всех функций есть минимум и максимум?
Функция не обязательно должна иметь минимум или максимум. Например, функция f (x) = x не имеет ни минимума, ни максимума. Легко убедиться в этом. Предположим, что функция имеет минимум при x = y. Затем введите y-1, и функция будет иметь меньшее значение. Таким образом, мы получили противоречие, и y не было минимумом, а значит, минимум не существует. Эквивалентное доказательство может быть дано для максимума.
Функция f (x) = x 2 действительно имеет минимум, а именно при x = 0. Это легко проверить, поскольку f (x) никогда не может стать отрицательным, так как это квадрат. При x = 0 функция имеет значение 0, поэтому оно должно быть минимальным. У него нет максимума, который можно доказать с помощью того же аргумента, который мы использовали ранее.
Как найти крайние точки функции
На локальном минимуме функция меняет направление. Это потому, что это самая низкая точка в окрестностях. Следовательно, наклон функции меняется с отрицательного на положительный, поскольку функция уменьшалась, пока не достигла минимума, а затем снова начала увеличиваться. Это означает, что в локальном минимуме наклон равен нулю, а значит, производная функции должна быть равна нулю в точке, являющейся минимумом. То же верно и для локального максимума функции, поскольку там функция идет от возрастания к убыванию.
Следовательно, чтобы найти местоположение локальных максимумов и локальных минимумов, вы должны решить уравнение f ‘(x) = 0. Следовательно, вы должны сначала найти производную функции. Если вы не знакомы с производной функции или хотите узнать о ней больше, я рекомендую прочитать мою статью о поиске производной функции. В этой статье я предполагаю, что производная известна.
- Математика: что такое производная функции и как ее вычислить?
После того, как вы решили уравнение f (x) = 0, вы нашли места, в которых находятся экстремумы. Чтобы найти значение экстремумов, вам нужно заполнить место в функции. Из решений вы не можете напрямую увидеть, является ли это локальным минимумом или локальным максимумом, поскольку оба являются решениями одного и того же уравнения. Следовательно, чтобы определить это, вы должны построить график функции.
Кроме того, вы не можете прямо сказать, нашли ли вы глобальный минимум или максимум, или он только локальный. Также вы можете определить это с помощью графика функции.
Пример
В качестве примера мы будем использовать функцию f (x) = 1/3 x 3 — 4x. Сначала мы вычисляем производную функции, которая равна:
Затем решаем f ‘(x) = 0:
Это дает x = 2 или x = -2. Поэтому мы знаем, что локальные экстремумы расположены в точках 2 и -2. Заполняем оба значения, чтобы определить значение экстремумов:
Восстановите крайние значения вариационного ряда, если известно, что средняя частота пульса составляла 68 уд за минуту при среднем квадратическом отклонении 5 уд за минуту.
Решение:
В условиях нормального распределения существует следующая зависимость между величиной среднего квадратического отклонения и количеством наблюдений:
в пределах
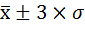
располагается 99,7%, количества наблюдений.
В действительности на практике почти не встречаются отклонения, которые превышают
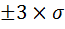 .
.
Поэтому крайние значения вариационного ряда будут равны:
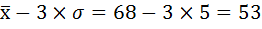
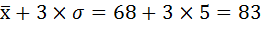
Пропорции
- Члены пропорции: крайние и средние
- Главное свойство пропорции
- Нахождение неизвестного члена пропорции
Равенство двух отношений называется пропорцией.
Пример.
10 : 5 = 6 : 3
или
Пропорцию
a : b = c : d
или
можно прочитать так: отношение a к b равно отношению c к d
, или a относится к b, как c относится к d
.
Члены пропорции: крайние и средние
Члены отношений, составляющих пропорцию, называются членами пропорции. Числа a и d называют крайними членами пропорции, а числа b и c — средними членами пропорции:

Эти названия условны, так как достаточно написать пропорцию в обратном порядке (переставить отношения местами):
c : d = a : b
или
и крайние члены станут средними, а средние — крайними.
Главное свойство пропорции
Произведение крайних членов пропорции равно произведению средних.
Пример. Рассмотрим пропорцию
Если воспользоваться вторым свойством равенства и умножить обе её части на произведение bd (для приведения обеих частей равенства от дробного вида к целому), то получим:

Сокращаем дроби и получаем:
ad = cb.
Из главного свойства пропорции следует:
- Крайний член равен произведению средних, разделённому на другой крайний. То есть для пропорции
 :
:
- Средний член равен произведению крайних, разделённому на другой средний. То есть для пропорции :
 :
:


Нахождение неизвестного члена пропорции
Свойства пропорции позволяют найти любой из членов пропорции, если он неизвестен. Рассмотрим пропорцию:
x : 8 = 6 : 3.
Тут неизвестен крайний член. Так как крайний член равен произведению средних, разделённому на другой крайний, то
x = (8 · 6) : 3 = 16.