
Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Задача
Дан ориентированный граф (G = (V, E)), а также вершина (s).
Найти длину кратчайшего пути от (s) до каждой из вершин графа. Длина пути — количество рёбер в нём.
BFS
BFS — breadth-first search, или же поиск в ширину.
Этот алгоритм позволяет решать следующую задачу.
Алгоритм работает следующим образом.
- Создадим массив (dist) расстояний. Изначально (dist[s] = 0) (поскольку расстояний от вершины до самой себя равно (0)) и (dist[v] = infty) для (v neq s).
- Создадим очередь (q). Изначально в (q) добавим вершину (s).
- Пока очередь (q) непуста, делаем следующее:
- Извлекаем вершину (v) из очереди.
- Рассматриваем все рёбра ((v, u) in E). Для каждого такого ребра пытаемся сделать релаксацию: если (dist[v] + 1 < dist[u]), то мы делаем присвоение (dist[u] = dist[v] + 1) и добавляем вершину (u) в очередь.
Визуализации:
-
https://visualgo.net/mn/dfsbfs
-
https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/visualize/
Интуитивное понимание алгоритма
Можно представить, что мы поджигаем вершину (s). Каждый шаг алгоритма — это распространение огня на соседние вершины. Понятно, что огонь доберётся до вершины по кратчайшему пути.
Заметьте, что этот алгоритм очень похож на DFS — достаточно заменить очередь на стек и поиск в ширину станет поиском в глубину. Действительно, оба алгоритма при обработке вершины просто записывают всех непосещенных соседей, в которые из неё есть ребро, в структуру данных, и после этого выбирает следующую вершину для обработки в структуре данных. В DFS это стек (благодаря рекурсии), поэтому мы сначала записываем соседа, идем в обрабатываем его полностью, а потом начинаем обрабатывать следующего соседа. В BFS это очередь, поэтому мы кидаем сразу всех соседей, а потом начинаем обрабатывать вообще другую вершину — ту непосещенную, которую мы положили в очередь раньше всего.
Оба алгоритма позволяют обойти граф целиком — посетить каждую вершину ровно один раз. Поэтому они оба подходят для таких задач как: * поиск компонент связности * проверка графа на двудольность * построение остова
Реализация на C++
n — количество вершин в графе; adj — список смежности
vector<int> bfs(int s) {
// длина любого кратчайшего пути не превосходит n - 1,
// поэтому n - достаточное значение для "бесконечности";
// после работы алгоритма dist[v] = n, если v недостижима из s
vector<int> dist(n, n);
dist[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
for (int u : adj[v]) {
if (dist[u] > dist[v] + 1) {
dist[u] = dist[v] + 1;
q.push(u);
}
}
}
return dist;
}Свойства кратчайших путей
Обозначение: (d(v)) — длина кратчайшего пути от (s) до (v).
Лемма 1. > Пусть ((u, v) in E), тогда (d(v) leq d(u) + 1).
Действительно, существует путь из (s) в (u) длины (d(u)), а также есть ребро ((u, v)), следовательно, существует путь из (s) в (v) длины (d(u) + 1). А значит кратчайший путь из (s) в (v) имеет длину не более (d(u) + 1),
Лемма 2. > Рассмотрим кратчайший путь от (s) до (v). Обозначим его как (u_1, u_2, dots u_k) ((u_1 = s) и (u_k = v), а также (k = d(v) + 1)).
> Тогда (forall (i < k): d(u_i) + 1 = d(u_{i + 1})).
Действительно, пусть для какого-то (i < k) это не так. Тогда, используя лемму 1, имеем: (d(u_i) + 1 > d(u_{i + 1})). Тогда мы можем заменить первые (i + 1) вершин пути на вершины из кратчайшего пути из (s) в (u_{i + 1}). Полученный путь стал короче, но мы рассматривали кратчайший путь — противоречие.
Корректность
Утверждение. > 1. Расстояния до тех вершин, которые были добавлены в очередь, посчитаны корректно. > 2. Вершины лежат в очереди в порядке неубывания расстояния, притом разность между кратчайшими расстояними до вершин в очереди не превосходит (1).
Докажем это по индукции по количеству итераций алгоритма (итерация — извлечение вершины из очереди и дальнейшая релаксация).
База очевидна.
Переход. Сначала докажем первую часть. Предположим, что (dist[v] + 1 < dist[u]), но (dist[v] + 1) — некорректное расстояние до вершины (u), то есть (dist[v] + 1 neq d(u)). Тогда по лемме 1: (d(u) < dist[v] + 1). Рассмотрим предпоследнюю вершину (w) на кратчайшем пути от (s) до (u). Тогда по лемме 2: (d(w) + 1 = d(u)). Следовательно, (d(w) + 1 < dist[v] + 1) и (d(w) < dist[v]). Но тогда по предположению индукции (w) была извлечена раньше (v), следовательно, при релаксации из неё в очередь должна была быть добавлена вершина (u) с уже корректным расстоянием. Противоречие.
Теперь докажем вторую часть. По предположению индукции в очереди лежали некоторые вершины (u_1, u_2, dots u_k), для которых выполнялось следующее: (dist[u_1] leq dist[u_2] leq dots leq dist[u_k]) и (dist[u_k] — dist[u_1] leq 1). Мы извлекли вершину (v = u_1) и могли добавить в конец очереди какие-то вершины с расстоянием (dist[v] + 1). Если (k = 1), то утверждение очевидно. В противном случае имеем (dist[u_k] — dist[u_1] leq 1 leftrightarrow dist[u_k] — dist[v] leq 1 leftrightarrow dist[u_k] leq dist[v] + 1), то есть упорядоченность сохранилась. Осталось показать, что ((dist[v] + 1) — dist[u_2] leq 1), но это равносильно (dist[v] leq dist[u_2]), что, как мы знаем, верно.
Время работы
Из доказанного следует, что каждая достижимая из (s) вершина будет добавлена в очередь ровно (1) раз, недостижимые вершины добавлены не будут. Каждое ребро, соединяющее достижимые вершины, будет рассмотрено ровно (2) раза. Таким образом, алгоритм работает за (O(V+ E)) времени, при условии, что граф хранится в виде списка смежности.
Неориентированные графы
Если дан неориентированный граф, его можно рассматривать как ориентированный граф с двумя обратными друг другу ориентированными рёбрами.
Восстановление пути
Пусть теперь заданы 2 вершины (s) и (t), и необходимо не только найти длину кратчайшего пути из (s) в (t), но и восстановить какой-нибудь из кратчайших путей между ними. Всё ещё можно воспользоваться алгоритмом BFS, но необходимо ещё и поддерживать массив предков (p), в котором для каждой вершины будет храниться предыдущая вершина на кратчайшем пути.
Поддерживать этот массив просто: при релаксации нужно просто запоминать, из какой вершины мы прорелаксировали в данную. Также будем считать, что (p[s] = -1): у стартовой вершины предок — некоторая несуществующая вершина.
Восстановление пути делается с конца. Мы знаем последнюю вершину пути — это (t). Далее, мы сводим задачу к меньшей, переходя к нахождению пути из (s) в (p[t]).
Реализация BFS с восстановлением пути
// теперь bfs принимает 2 вершины, между которыми ищется пути
// bfs возвращает кратчайший путь из s в t, или же пустой vector, если пути нет
vector<int> bfs(int s, int t) {
vector<int> dist(n, n);
vector<int> p(n, -1);
dist[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
for (int u : adj[v]) {
if (dist[u] > dist[v] + 1) {
p[u] = v;
dist[u] = dist[v] + 1;
q.push(u);
}
}
}
// если пути не существует, возвращаем пустой vector
if (dist[t] == n) {
return {};
}
vector<int> path;
while (t != -1) {
path.push_back(t);
t = p[t];
}
// путь был рассмотрен в обратном порядке, поэтому его нужно перевернуть
reverse(path.begin(), path.end());
return path;
}Проверка принадлежности вершины кратчайшему пути
Дан ориентированный граф (G), найти все вершины, которые принадлежат хотя бы одному кратчайшему пути из (s) в (t).
Запустим из вершины (s) в графе (G) BFS — найдём расстояния (d_1). Построим транспонированный граф (G^T) — граф, в котором каждое ребро заменено на противоположное. Запустим из вершины (t) в графе (G^T) BFS — найдём расстояния (d_2).
Теперь очевидно, что (v) принадлежит хотя бы одному кратчайшему пути из (s) в (t) тогда и только тогда, когда (d_1(v) + d_2(v) = d_1(t)) — это значит, что есть путь из (s) в (v) длины (d_1(v)), а затем есть путь из (v) в (t) длины (d_2(v)), и их суммарная длина совпадает с длиной кратчайшего пути из (s) в (t).
Кратчайший цикл в ориентированном графе
Найти цикл минимальной длины в ориентированном графе.
Попытаемся из каждой вершины найти кратчайший цикл, проходящий через неё, с помощью BFS. Это делается аналогично обычному BFS: мы должны найти расстояний от вершины до самой себя, при этом не считая, что оно равно (0).
Итого, у нас (|V|) запусков BFS, и каждый запуск работает за (O(|V| + |E|)). Тогда общее время работы составляет (O(|V|^2 + |V| |E|)). Если инициализировать массив (dist) единожды, а после каждого запуска BFS возвращать исходные значения только для достижимых вершин, решение будет работать за (O(|V||E|)).
Задача
Дан взвешенный ориентированный граф (G = (V, E)), а также вершина (s). Длина ребра ((u, v)) равна (w(u, v)). Длины всех рёбер неотрицательные.
Найти длину кратчайшего пути от (s) до каждой из вершин графа. Длина пути — сумма длин рёбер в нём.
Алгоритм Дейкстры
Алгоритм Дейкстры решает приведённую выше задачу. Он работает следующим образом.
- Создать массив (dist) расстояний. Изначально (dist[s] = 0) и (dist[v] = infty) для (v neq s).
- Создать булёв массив (used), (used[v] = 0) для всех вершин (v) — в нём мы будем отмечать, совершалась ли релаксация из вершины.
- Пока существует вершина (v) такая, что (used[v] = 0) и (dist[v] neq infty), притом, если таких вершин несколько, то (v) — вершина с минимальным (dist[v]), делать следующее:
- Пометить, что мы совершали релаксацию из вершины (v), то есть присвоить (used[v] = 1).
- Рассматриваем все рёбра ((v, u) in E). Для каждого ребра пытаемся сделать релаксацию: если (dist[v] + w(v, u) < dist[u]), присвоить (dist[u] = dist[v] + w(v, u)).
Иными словами, алгоритм на каждом шаге находит вершину, до которой расстояние сейчас минимально и из которой ещё не была произведена релаксация, и делает её.
Посчитаем, за сколько работает алгоритм. Мы (V) раз ищем вершину минимальным (dist), поиск минимума у нас линейный за (O(V)), отсюда (O(V^2)). Обработка ребер у нас происходит суммарно за (O(E)), потому что на каждое ребро мы тратим (O(1)) действий. Так мы находим финальную асимптотику: (O(V^2 + E)).
Реализация на C++
Рёбра будем хранить как pair<int, int>, где первое число пары — куда оно ведёт; а второе — длина ребра.
// INF - infinity - бесконечность
const long long INF = (long long) 1e18 + 1;
vector<long long> dijkstra(int s) {
vector<long long> dist(n, INF);
dist[s] = 0;
vector<bool> used(n);
while (true) {
// находим вершину, из которой будем релаксировать
int v = -1;
for (int i = 0; i < n; i++) {
if (!used[i] && (v == -1 || dist[i] < dist[v])) {
v = i;
}
}
// если не нашли подходящую вершину, прекращаем работу алгоритма
if (v == -1) {
break;
}
for (auto &e : adj[v]) {
int u = e.first;
int len = e.second;
if (dist[u] > dist[v] + len) {
dist[u] = dist[v] + len;
}
}
}
return dist;
}Восстановление пути
Восстановление пути в алгоритме Дейкстры делается аналогично восстановлению пути в BFS (и любой динамике).
Дейкстра на сете
Искать вершину с минимальным (dist) можно гораздо быстрее, используя такую структуру данных как очередь с приоритетом. Нам нужно хранить пары ((dist, index)) и уметь делать такие операции: * Извлечь минимум (чтобы обработать новую вершину) * Удалить вершину по индексу (чтобы уменьшить (dist) до какого-то соседа) * Добавить новую вершину (чтобы уменьшить (dist) до какого-то соседа)
Для этого используют, например, кучу или сет. Удобно помимо сета хранить сам массив dist, который его дублирует, но хранит элементы по порядку. Тогда, чтобы заменить значение ((dist_1, u)) на ((dist_2, u)), нужно удалить из сета значение ((dist[u], u)), сделать (dist[u] = dist_2;) и добавить в сет ((dist[u], u)).
Данный алгоритм будет работать за (V O(log V)) извлечений минимума и (O(E log V)) операций уменьшения расстояния до вершины (может быть сделано после каждого ребра). Поэтому алгоритм работает за (O(E log V)).
Заметьте, что этот алгоритм не лучше и не хуже, чем без сета, который работает за (O(V^2 + E)). Ведь если (E = O(V^2)) (граф почти полный), то Дейкстра без сета работает быстрее, а если, наример, (E = O(V)), то Дейкстра на сете работает быстрее. Учитывайте это, когда выбираете алгоритм.
| title | authors | editors | weight | date | published | |||
|---|---|---|---|---|---|---|---|---|
|
Поиск в ширину |
|
Сергей Слотин |
2 |
|
true |
Поиск в ширину (англ. breadth-first search) — один из основных алгоритмов на графах, позволяющий находить все кратчайшие пути от заданной вершины и решать многие другие задачи.
Поиск в ширину также называют обходом — так же, как поиск в глубину и все другие обходы, он посещает все вершины графа по одному разу, только в другом порядке: по увеличению расстояния до начальной вершины.
Описание алгоритма
На вход алгоритма подаётся невзвешенный граф и номер стартовой вершины $s$. Граф может быть как ориентированным, так и неориентированным — для алгоритма это не важно.
Основную идею алгоритма можно понимать как процесс «поджигания» графа: на нулевом шаге мы поджигаем вершину $s$, а на каждом следующем шаге огонь с каждой уже горящей вершины перекидывается на всех её соседей, в конечном счете поджигая весь граф.
Если моделировать этот процесс, то за каждую итерацию алгоритма будет происходить расширение «кольца огня» в ширину на единицу. Номер шага, на котором вершина $v$ начинает гореть, в точности равен длине её минимального пути из вершины $s$.

Моделировать это можно следующим образом. Создадим очередь, в которую будут помещаться горящие вершины, а также заведём булевый массив, в котором для каждой вершины будем отмечать, горит она или нет — или иными словами, была ли она уже посещена. Изначально в очередь помещается только вершина $s$, которая сразу помечается горящей.
Затем алгоритм представляет собой такой цикл: пока очередь не пуста, достать из её головы одну вершину $v$, просмотреть все рёбра, исходящие из этой вершины, и если какие-то из смежных вершин $u$ ещё не горят, поджечь их и поместить в конец очереди.
В итоге, когда очередь опустеет, мы по одному разу обойдём все достижимые из $s$ вершины, причём до каждой дойдём кратчайшим путём. Длины кратчайших путей можно посчитать, если завести для них отдельный массив $d$ и при добавлении в очередь пересчитывать по правилу $d_u = d_v + 1$. Также можно компактно сохранить дополнительную информацию для восстановления самих путей, заведя массив «предков», в котором для каждой вершины хранится номер вершины из которой мы в неё попали.
Реализация
Если мы всё равно поддерживаем массив расстояний, то отдельный булевый массив с метками горящих вершин можно не создавать, а вместо этого просто присвоить изначальное расстояние всех вершин некоторым некоторым специальным значением (например, -1), которое будет сигнализировать а том, что эту вершину мы ещё не просмотрели.
vector<int> g[maxn]; void bfs(int s) { queue<int> q; q.push(s); vector<int> d(n, -1), p(n); d[s] = 0; while (!q.empty()) { int v = q.front(); q.pop(); for (int u : g[v]) { if (d[u] == -1) { q.push(u); d[u] = d[v] + 1; p[u] = v; } } } }
Теперь, чтобы восстановить кратчайший путь до какой-то вершины $v$, это можно сделать через массив p:
while (v != s) {
cout << v << endl;
v = p[v];
}
Обратим внимание, что путь выведется в обратном порядке.
В неявных графах
Поиск в ширину часто применяется для поиска кратчайшего пути в неявно заданных графах.
В качестве конкретного примера, пусть у нас есть булева матрица размера $n times n$, в которой помечено, свободна ли клетка с координатами $(x, y)$, и требуется найти кратчайший путь от $(x_s, y_t)$ до $(x_y, y_t)$ при условии, что за один шаг можно перемещаться в свободную соседнюю по вертикали или горизонтали клетку.

Можно сконвертировать граф в явный формат: как-нибудь пронумеровать все ячейки (например по формуле $x cdot n + y$) и для каждой посмотреть на всех её соседей, добавляя ребро в $(x pm 1, y pm 1)$, если соответствующая клетка свободна.
Такой подход будет работать за оптимальное линейное время, однако с точки зрения реализации проще адаптировать не входные данные, а сам алгоритм обхода в глубину:
bool a[N][N]; // свободна ли клетка (x, y) int d[N][N]; // кратчайшее расстояние до (x, y) // чтобы немного упростить код struct cell { int x, y; }; void bfs(cell s, cell t) { queue<cell> q; q.push(s); memset(d, -1, sizeof d); d[s.x][x.y] = 0; while (!q.empty()) { auto [x, y] = q.front(); q.pop(); // просматриваем всех соседей for (auto [dx, dy] : {{-1, 0}, {+1, 0}, {0, -1}, {0, +1}}) { // считаем координаты соседа int _x = x + dx, _y = y + dy; // и проверяем, что он свободен и не был посещен ранее if (a[_x][_y] && d[_x][_y] == -1) { d[_x][_y] = d[x][y] + 1; q.push_back({_x, _y}); } } } }
Перед запуском bfs следует убедиться, что не произойдет выход за пределы границ. Вместо того, чтобы добавлять проверки на _x < 0 || x >= n и т. п. при просмотре возможных соседей, удобно сделать следующий трюк: изначально создать матрицу a с размерностями на 2 больше, чем нужно, и на этапе чтения данных заполнять её в индексации не с нуля, а с единицы. Тогда границы матрицы всегда будут заполнены нулями (то есть помечены непроходимыми) и алгоритм никогда в них не зайдет.
Применения и обобщения
Помимо нахождения расстояний в невзвешенном графе, обход в ширину можно использовать для многих задач, в которых работает обход в глубину, например для поиска компонент связности или проверки на двудольность.
Множественный BFS. Добавив в очередь изначально не одну, а несколько вершин, мы найдем для каждой вершины кратчайшее расстояние до одной из них.
Это полезно для задач, в которых нужно моделировать пожар, наводнение, извержение вулкана или подобные явления, в которых источник «волны» не один. Также так можно чуть быстрее находить кратчайший путь для конкретной пары вершин, запустив параллельно два обхода от каждой и остановив в тот момент, когда они встретятся.
Игры. С помощью BFS можно найти решение какой-либо задачи / игры за наименьшее число ходов, если каждое состояние системы можно представить вершиной графа, а переходы из одного состояния в другое — рёбрами графа.
В качестве (нетривиального) примера: собрать кубик Рубика за наименьшее число ходов.
Кратчайшие циклы. Чтобы найти кратчайший цикл в ориентированном невзвешенном графе, можно произвести поиск в ширину из каждой вершины. Как только в процессе обхода мы пытаемся пойти из текущей вершины по какому-то ребру в уже посещённую вершину, то это означает, что мы нашли кратчайший цикл для данной вершины, и останавливаем обход. Среди всех таких найденных циклов (по одному от каждого запуска обхода) выбираем кратчайший.
Такой алгоритм будет работать за $O(n^2)$: худшим случаем будет один большой цикл, в котором мы для каждой вершины пройдемся по всем остальным.
Ребра на кратчайшем пути. Мы можем за линейное время найти все рёбра, лежащие на каком-либо кратчайшем пути между заданной парой вершин $a$ и $b$. Для этого нужно запустить два поиска в ширину: из $a$ и из $b$.
Обозначим через $d_a$ и $d_b$ массивы кратчайших расстояний, получившиеся в результате этих обходов. Тогда каждое ребро $(u,v)$ можно проверить критерием
$$
d_a[u] + d_b[v] + 1 = d_a[b]
$$
Альтернативно, можно запустить один обход из $a$, и когда он дойдет до $b$, начать рекурсивно проходиться по всем обратным ребрам, ведущим в более близкие к $a$ вершины (то есть те, для которых $d[u] = d[v] — 1$), отдельно помечая их.
Аналогично можно найти все вершины на каком-либо кратчайшем пути.
0-1 BFS. Если веса некоторых ребер могут быть нулевыми, то кратчайшие пути искать не сильно сложнее.
Ключевое наблюдение: если от вершины $a$ до вершины $b$ можно дойти по пути, состоящему из нулевых рёбер, то кратчайшие расстояния от вершины $s$ до этих вершин совпадают.
Если в нашем графе оставить только $0$-рёбра, то он распадётся на компоненты связности, в каждой из которых ответ одинаковый. Если теперь вернуть единичные рёбра и сказать, что эти рёбра соединяют не вершины, а компоненты связности, то мы сведём задачу к обычному BFS.
Получается, запустив обход, мы можем при обработке вершины $v$, у которой есть нулевые ребра в непосещенные вершины, сразу пройтись по ним и добавить все вершины нулевой компоненты, проставив им такое же расстояние, как и у $v$.
Это можно сделать и напрямую, запустив BFS внутри BFS, однако можно заметить, что достаточно при посещении вершины просто добавлять всех её непосещенных соседей по нулевым ребрам в голову очереди, чтобы обработать их раньше, чем те, которые там уже есть. Это легко сделать, если очередь заменить деком:
vector<int> d(n, -1); d[s] = 0; deque<int> q; q.push_back(s); while (!q.empty()) { int v = q.front(); q.pop_front(); for (auto [u, w] : g[v]) { if (d[u] == -1) { d[u] = d[v] + w; if (w == 0) q.push_front(u); else q.push_back(u); } } }
Также вместо дека можно завести две очереди: одну для нулевых ребер, а другую для единичных, в внутри цикла while сначала просматривать первую, а только потом, когда она станет пустой, вторую. Этот подход уже можно обобщить.
1-k BFS. Теперь веса рёбер принимают значения от $1$ до некоторого небольшого $k$, и всё так же требуется найти кратчайшие расстояния от вершины $s$, но уже в плане суммарного веса.
Наблюдение: максимальное кратчайшее расстояние в графе равно $(n — 1) cdot k$.
Заведём для каждого расстояния $d$ очередь $q_d$, в которой будут храниться вершины, находящиеся на расстоянии $d$ от $s$ — плюс, возможно, некоторые вершины, до которых мы уже нашли путь длины $d$ от $s$, но для которых возможно существует более короткий путь. Нам потребуется $O((n — 1) cdot k)$ очередей.
Положим изначально вершину $s$ в $q_0$, а дальше будем брать вершину из наименьшего непустого списка и класть всех её непосещенных соседей в очередь с номером $d_v + w$ и релаксировать $d_u$, не забывая при этом, что кратчайшее расстояние до неё на самом деле может быть и меньше.
int d[maxn]; d[s] = 0; queue<int> q[maxd]; q[0].push_back(s); for (int dist = 0; dist < maxd; dist++) { while (!q[dist].empty()) { int v = q[dist].front(); q[dist].pop(); // если расстояние меньше и мы уже рассмотрели эту вершину, // но она всё ещё лежит в более верхней очереди if (d[v] > dist) continue; for (auto [u, w] : g[v]) { if (d[u] < d[v] + w) { d[u] = d[v] + w; q[d[u]].push(u); } } } }
Сложность такого алгоритма будет $O(k n + m)$, поскольку каждую вершину мы можем прорелаксировать и добавить в другую очередь не более $k$ раз, а просматривать рёбра, исходящие из вершины мы будем только когда обработаем эту вершину в самый первый раз.
На самом деле, нам так много списков не нужно. Если каждое ребро имеет вес не более $k$, то в любой момент времени не более $k$ очередей будут непустыми. Мы можем завести только $k$ списков, и вместо добавления в $(d_v + w)$-ый список использовать $(d_v+w) bmod k$.
Заметим, что алгоритм также работает когда есть общее ограничение на длину пути, а не только на вес каждого ребра. Для более общего случая, когда веса ребер могут быть любыми неотрицательными, есть алгоритм Дейкстры, который мы разберем в следующей статье.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Given an undirected unweighted graph. The task is to find the length of the shortest cycle in the given graph. If no cycle exists print -1.
Examples:
Input:
Output: 4
Cycle 6 -> 1 -> 5 -> 0 -> 6Input:
Output: 3
Cycle 6 -> 1 -> 2 -> 6
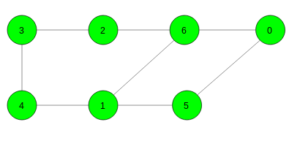
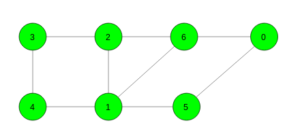
Prerequisites: Dijkstra
Approach: For every vertex, we check if it is possible to get the shortest cycle involving this vertex. For every vertex first, push current vertex into the queue and then it’s neighbours and if the vertex which is already visited comes again then the cycle is present.
Apply the above process for every vertex and get the length of the shortest cycle.
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
#define N 100200
vector<int> gr[N];
void Add_edge(int x, int y)
{
gr[x].push_back(y);
gr[y].push_back(x);
}
int shortest_cycle(int n)
{
int ans = INT_MAX;
for (int i = 0; i < n; i++) {
vector<int> dist(n, (int)(1e9));
vector<int> par(n, -1);
dist[i] = 0;
queue<int> q;
q.push(i);
while (!q.empty()) {
int x = q.front();
q.pop();
for (int child : gr[x]) {
if (dist[child] == (int)(1e9)) {
dist[child] = 1 + dist[x];
par[child] = x;
q.push(child);
}
else if (par[x] != child and par[child] != x)
ans = min(ans, dist[x] + dist[child] + 1);
}
}
}
if (ans == INT_MAX)
return -1;
else
return ans;
}
int main()
{
int n = 7;
Add_edge(0, 6);
Add_edge(0, 5);
Add_edge(5, 1);
Add_edge(1, 6);
Add_edge(2, 6);
Add_edge(2, 3);
Add_edge(3, 4);
Add_edge(4, 1);
cout << shortest_cycle(n);
return 0;
}
Java
import java.util.*;
class GFG
{
static final int N = 100200;
@SuppressWarnings("unchecked")
static Vector<Integer>[] gr = new Vector[N];
static void Add_edge(int x, int y)
{
gr[x].add(y);
gr[y].add(x);
}
static int shortest_cycle(int n)
{
int ans = Integer.MAX_VALUE;
for (int i = 0; i < n; i++)
{
int[] dist = new int[n];
Arrays.fill(dist, (int) 1e9);
int[] par = new int[n];
Arrays.fill(par, -1);
dist[i] = 0;
Queue<Integer> q = new LinkedList<>();
q.add(i);
while (!q.isEmpty())
{
int x = q.poll();
for (int child : gr[x])
{
if (dist[child] == (int) (1e9))
{
dist[child] = 1 + dist[x];
par[child] = x;
q.add(child);
} else if (par[x] != child && par[child] != x)
ans = Math.min(ans, dist[x] + dist[child] + 1);
}
}
}
if (ans == Integer.MAX_VALUE)
return -1;
else
return ans;
}
public static void main(String[] args)
{
for (int i = 0; i < N; i++)
gr[i] = new Vector<>();
int n = 7;
Add_edge(0, 6);
Add_edge(0, 5);
Add_edge(5, 1);
Add_edge(1, 6);
Add_edge(2, 6);
Add_edge(2, 3);
Add_edge(3, 4);
Add_edge(4, 1);
System.out.println(shortest_cycle(n));
}
}
Python3
from sys import maxsize as INT_MAX
from collections import deque
N = 100200
gr = [0] * N
for i in range(N):
gr[i] = []
def add_edge(x: int, y: int) -> None:
global gr
gr[x].append(y)
gr[y].append(x)
def shortest_cycle(n: int) -> int:
ans = INT_MAX
for i in range(n):
dist = [int(1e9)] * n
par = [-1] * n
dist[i] = 0
q = deque()
q.append(i)
while q:
x = q[0]
q.popleft()
for child in gr[x]:
if dist[child] == int(1e9):
dist[child] = 1 + dist[x]
par[child] = x
q.append(child)
elif par[x] != child and par[child] != x:
ans = min(ans, dist[x] +
dist[child] + 1)
if ans == INT_MAX:
return -1
else:
return ans
if __name__ == "__main__":
n = 7
add_edge(0, 6)
add_edge(0, 5)
add_edge(5, 1)
add_edge(1, 6)
add_edge(2, 6)
add_edge(2, 3)
add_edge(3, 4)
add_edge(4, 1)
print(shortest_cycle(n))
C#
using System;
using System.Collections.Generic;
class GFG
{
static readonly int N = 100200;
static List<int>[] gr = new List<int>[N];
static void Add_edge(int x, int y)
{
gr[x].Add(y);
gr[y].Add(x);
}
static int shortest_cycle(int n)
{
int ans = int.MaxValue;
for (int i = 0; i < n; i++)
{
int[] dist = new int[n];
fill(dist, (int) 1e9);
int[] par = new int[n];
fill(par, -1);
dist[i] = 0;
List<int> q = new List<int>();
q.Add(i);
while (q.Count!=0)
{
int x = q[0];
q.RemoveAt(0);
foreach (int child in gr[x])
{
if (dist[child] == (int) (1e9))
{
dist[child] = 1 + dist[x];
par[child] = x;
q.Add(child);
} else if (par[x] != child && par[child] != x)
ans = Math.Min(ans, dist[x] + dist[child] + 1);
}
}
}
if (ans == int.MaxValue)
return -1;
else
return ans;
}
static int[] fill(int []arr, int val)
{
for(int i = 0;i<arr.GetLength(0);i++)
arr[i] = val;
return arr;
}
public static void Main(String[] args)
{
for (int i = 0; i < N; i++)
gr[i] = new List<int>();
int n = 7;
Add_edge(0, 6);
Add_edge(0, 5);
Add_edge(5, 1);
Add_edge(1, 6);
Add_edge(2, 6);
Add_edge(2, 3);
Add_edge(3, 4);
Add_edge(4, 1);
Console.WriteLine(shortest_cycle(n));
}
}
Javascript
<script>
var N = 100200;
var gr = Array.from(Array(N),()=>Array());
function Add_edge(x, y)
{
gr[x].push(y);
gr[y].push(x);
}
function shortest_cycle(n)
{
var ans = 1000000000;
for(var i = 0; i < n; i++)
{
var dist = Array(n).fill(1000000000);
var par = Array(n).fill(-1);
dist[i] = 0;
var q = [];
q.push(i);
while (q.length!=0)
{
var x = q[0];
q.shift();
for(var child of gr[x])
{
if (dist[child] == 1000000000)
{
dist[child] = 1 + dist[x];
par[child] = x;
q.push(child);
} else if (par[x] != child && par[child] != x)
ans = Math.min(ans, dist[x] + dist[child] + 1);
}
}
}
if (ans == 1000000000)
return -1;
else
return ans;
}
function fill(arr, val)
{
for(var i = 0;i<arr.length;i++)
arr[i] = val;
return arr;
}
var n = 7;
Add_edge(0, 6);
Add_edge(0, 5);
Add_edge(5, 1);
Add_edge(1, 6);
Add_edge(2, 6);
Add_edge(2, 3);
Add_edge(3, 4);
Add_edge(4, 1);
document.write(shortest_cycle(n));
</script>
Time Complexity: O( |V| * (|V|+|E|)) for a graph G=(V, E)
Memory Complexity: O(V^2) for a graph G=(V, E)
Last Updated :
18 Mar, 2022
Like Article
Save Article
Задача¶
Дан ориентированный граф $G = (V, E)$, а также вершина $s$.
Найти длину кратчайшего пути от $s$ до каждой из вершин графа. Длина пути — количество рёбер в нём.
BFS¶
BFS — breadth-first search, или же поиск в ширину.
Этот алгоритм позволяет решать следующую задачу.
Алгоритм работает следующим образом.
- Создадим массив $dist$ расстояний. Изначально $dist[s] = 0$ (поскольку расстояний от вершины до самой себя равно $0$) и $dist[v] = infty$ для $v neq s$.
- Создадим очередь $q$. Изначально в $q$ добавим вершину $s$.
- Пока очередь $q$ непуста, делаем следующее:
- Извлекаем вершину $v$ из очереди.
- Рассматриваем все рёбра $(v, u) in E$. Для каждого такого ребра пытаемся сделать релаксацию: если $dist[v] + 1 < dist[u]$, то мы делаем присвоение $dist[u] = dist[v] + 1$ и добавляем вершину $u$ в очередь.
Визуализации:
-
https://visualgo.net/mn/dfsbfs
-
https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/visualize/
Интуитивное понимание алгоритма¶
Можно представить, что мы поджигаем вершину $s$. Каждый шаг алгоритма — это распространение огня на соседние вершины. Понятно, что огонь доберётся до вершины по кратчайшему пути.
Заметьте, что этот алгоритм очень похож на DFS — достаточно заменить очередь на стек и поиск в ширину станет поиском в глубину. Действительно, оба алгоритма при обработке вершины просто записывают всех непосещенных соседей, в которые из неё есть ребро, в структуру данных, и после этого выбирает следующую вершину для обработки в структуре данных. В DFS это стек (благодаря рекурсии), поэтому мы сначала записываем соседа, идем в обрабатываем его полностью, а потом начинаем обрабатывать следующего соседа. В BFS это очередь, поэтому мы кидаем сразу всех соседей, а потом начинаем обрабатывать вообще другую вершину — ту непосещенную, которую мы положили в очередь раньше всего.
Оба алгоритма позволяют обойти граф целиком — посетить каждую вершину ровно один раз. Поэтому они оба подходят для таких задач как:
- поиск компонент связности
- проверка графа на двудольность
- построение остова
Реализация на C++¶
n — количество вершин в графе; adj — список смежности
vector<int> bfs(int s) { // длина любого кратчайшего пути не превосходит n - 1, // поэтому n - достаточное значение для "бесконечности"; // после работы алгоритма dist[v] = n, если v недостижима из s vector<int> dist(n, n); dist[s] = 0; queue<int> q; q.push(s); while (!q.empty()) { int v = q.front(); q.pop(); for (int u : adj[v]) { if (dist[u] > dist[v] + 1) { dist[u] = dist[v] + 1; q.push(u); } } } return dist; }
Свойства кратчайших путей¶
Обозначение: $d(v)$ — длина кратчайшего пути от $s$ до $v$.
Лемма 1.
Пусть $(u, v) in E$, тогда $d(v) leq d(u) + 1$.
Действительно, существует путь из $s$ в $u$ длины $d(u)$, а также есть ребро $(u, v)$, следовательно, существует путь из $s$ в $v$ длины $d(u) + 1$. А значит кратчайший путь из $s$ в $v$ имеет длину не более $d(u) + 1$,
Лемма 2.
Рассмотрим кратчайший путь от $s$ до $v$. Обозначим его как $u_1, u_2, dots u_k$ ($u_1 = s$ и $u_k = v$, а также $k = d(v) + 1$).
Тогда $forall (i < k): d(u_i) + 1 = d(u_{i + 1})$.
Действительно, пусть для какого-то $i < k$ это не так. Тогда, используя лемму 1, имеем: $d(u_i) + 1 > d(u_{i + 1})$. Тогда мы можем заменить первые $i + 1$ вершин пути на вершины из кратчайшего пути из $s$ в $u_{i + 1}$. Полученный путь стал короче, но мы рассматривали кратчайший путь — противоречие.
Корректность¶
Утверждение.
- Расстояния до тех вершин, которые были добавлены в очередь, посчитаны корректно.
- Вершины лежат в очереди в порядке неубывания расстояния, притом разность между кратчайшими расстояними до вершин в очереди не превосходит $1$.
Докажем это по индукции по количеству итераций алгоритма (итерация — извлечение вершины из очереди и дальнейшая релаксация).
База очевидна.
Переход. Сначала докажем первую часть. Предположим, что $dist[v] + 1 < dist[u]$, но $dist[v] + 1$ — некорректное расстояние до вершины $u$, то есть $dist[v] + 1 neq d(u)$. Тогда по лемме 1: $d(u) < dist[v] + 1$. Рассмотрим предпоследнюю вершину $w$ на кратчайшем пути от $s$ до $u$. Тогда по лемме 2: $d(w) + 1 = d(u)$. Следовательно, $d(w) + 1 < dist[v] + 1$ и $d(w) < dist[v]$. Но тогда по предположению индукции $w$ была извлечена раньше $v$, следовательно, при релаксации из неё в очередь должна была быть добавлена вершина $u$ с уже корректным расстоянием. Противоречие.
Теперь докажем вторую часть. По предположению индукции в очереди лежали некоторые вершины $u_1, u_2, dots u_k$, для которых выполнялось следующее: $dist[u_1] leq dist[u_2] leq dots leq dist[u_k]$ и $dist[u_k] — dist[u_1] leq 1$. Мы извлекли вершину $v = u_1$ и могли добавить в конец очереди какие-то вершины с расстоянием $dist[v] + 1$. Если $k = 1$, то утверждение очевидно. В противном случае имеем $dist[u_k] — dist[u_1] leq 1 leftrightarrow dist[u_k] — dist[v] leq 1 leftrightarrow dist[u_k] leq dist[v] + 1$, то есть упорядоченность сохранилась. Осталось показать, что $(dist[v] + 1) — dist[u_2] leq 1$, но это равносильно $dist[v] leq dist[u_2]$, что, как мы знаем, верно.
Время работы¶
Из доказанного следует, что каждая достижимая из $s$ вершина будет добавлена в очередь ровно $1$ раз, недостижимые вершины добавлены не будут. Каждое ребро, соединяющее достижимые вершины, будет рассмотрено ровно $2$ раза. Таким образом, алгоритм работает за $O(V+ E)$ времени, при условии, что граф хранится в виде списка смежности.
Неориентированные графы¶
Если дан неориентированный граф, его можно рассматривать как ориентированный граф с двумя обратными друг другу ориентированными рёбрами.
Восстановление пути¶
Пусть теперь заданы 2 вершины $s$ и $t$, и необходимо не только найти длину кратчайшего пути из $s$ в $t$, но и восстановить какой-нибудь из кратчайших путей между ними. Всё ещё можно воспользоваться алгоритмом BFS, но необходимо ещё и поддерживать массив предков $p$, в котором для каждой вершины будет храниться предыдущая вершина на кратчайшем пути.
Поддерживать этот массив просто: при релаксации нужно просто запоминать, из какой вершины мы прорелаксировали в данную. Также будем считать, что $p[s] = -1$: у стартовой вершины предок — некоторая несуществующая вершина.
Восстановление пути делается с конца. Мы знаем последнюю вершину пути — это $t$. Далее, мы сводим задачу к меньшей, переходя к нахождению пути из $s$ в $p[t]$.
Реализация BFS с восстановлением пути¶
// теперь bfs принимает 2 вершины, между которыми ищется пути // bfs возвращает кратчайший путь из s в t, или же пустой vector, если пути нет vector<int> bfs(int s, int t) { vector<int> dist(n, n); vector<int> p(n, -1); dist[s] = 0; queue<int> q; q.push(s); while (!q.empty()) { int v = q.front(); q.pop(); for (int u : adj[v]) { if (dist[u] > dist[v] + 1) { p[u] = v; dist[u] = dist[v] + 1; q.push(u); } } } // если пути не существует, возвращаем пустой vector if (dist[t] == n) { return {}; } vector<int> path; while (t != -1) { path.push_back(t); t = p[t]; } // путь был рассмотрен в обратном порядке, поэтому его нужно перевернуть reverse(path.begin(), path.end()); return path; }
Проверка принадлежности вершины кратчайшему пути¶
Дан ориентированный граф $G$, найти все вершины, которые принадлежат хотя бы одному кратчайшему пути из $s$ в $t$.
Запустим из вершины $s$ в графе $G$ BFS — найдём расстояния $d_1$. Построим транспонированный граф $G^T$ — граф, в котором каждое ребро заменено на противоположное. Запустим из вершины $t$ в графе $G^T$ BFS — найдём расстояния $d_2$.
Теперь очевидно, что $v$ принадлежит хотя бы одному кратчайшему пути из $s$ в $t$ тогда и только тогда, когда $d_1(v) + d_2(v) = d_1(t)$ — это значит, что есть путь из $s$ в $v$ длины $d_1(v)$, а затем есть путь из $v$ в $t$ длины $d_2(v)$, и их суммарная длина совпадает с длиной кратчайшего пути из $s$ в $t$.
Кратчайший цикл в ориентированном графе¶
Найти цикл минимальной длины в ориентированном графе.
Попытаемся из каждой вершины найти кратчайший цикл, проходящий через неё, с помощью BFS. Это делается аналогично обычному BFS: мы должны найти расстояний от вершины до самой себя, при этом не считая, что оно равно $0$.
Итого, у нас $|V|$ запусков BFS, и каждый запуск работает за $O(|V| + |E|)$. Тогда общее время работы составляет $O(|V|^2 + |V| |E|)$. Если инициализировать массив $dist$ единожды, а после каждого запуска BFS возвращать исходные значения только для достижимых вершин, решение будет работать за $O(|V||E|)$.
Задача¶
Дан взвешенный ориентированный граф $G = (V, E)$, а также вершина $s$. Длина ребра $(u, v)$ равна $w(u, v)$. Длины всех рёбер неотрицательные.
Найти длину кратчайшего пути от $s$ до каждой из вершин графа. Длина пути — сумма длин рёбер в нём.
Алгоритм Дейкстры¶
Алгоритм Дейкстры решает приведённую выше задачу. Он работает следующим образом.
- Создать массив $dist$ расстояний. Изначально $dist[s] = 0$ и $dist[v] = infty$ для $v neq s$.
- Создать булёв массив $used$, $used[v] = 0$ для всех вершин $v$ — в нём мы будем отмечать, совершалась ли релаксация из вершины.
- Пока существует вершина $v$ такая, что $used[v] = 0$ и $dist[v] neq infty$, притом, если таких вершин несколько, то $v$ — вершина с минимальным $dist[v]$, делать следующее:
- Пометить, что мы совершали релаксацию из вершины $v$, то есть присвоить $used[v] = 1$.
- Рассматриваем все рёбра $(v, u) in E$. Для каждого ребра пытаемся сделать релаксацию: если $dist[v] + w(v, u) < dist[u]$, присвоить $dist[u] = dist[v] + w(v, u)$.
Иными словами, алгоритм на каждом шаге находит вершину, до которой расстояние сейчас минимально и из которой ещё не была произведена релаксация, и делает её.
Посчитаем, за сколько работает алгоритм. Мы $V$ раз ищем вершину минимальным $dist$, поиск минимума у нас линейный за $O(V)$, отсюда $O(V^2)$. Обработка ребер у нас происходит суммарно за $O(E)$, потому что на каждое ребро мы тратим $O(1)$ действий. Так мы находим финальную асимптотику: $O(V^2 + E)$.
Реализация на C++¶
Рёбра будем хранить как pair<int, int>, где первое число пары — куда оно ведёт; а второе — длина ребра.
// INF - infinity - бесконечность const long long INF = (long long) 1e18 + 1; vector<long long> dijkstra(int s) { vector<long long> dist(n, INF); dist[s] = 0; vector<bool> used(n); while (true) { // находим вершину, из которой будем релаксировать int v = -1; for (int i = 0; i < n; i++) { if (!used[i] && (v == -1 || dist[i] < dist[v])) { v = i; } } // если не нашли подходящую вершину, прекращаем работу алгоритма if (v == -1) { break; } for (auto &e : adj[v]) { int u = e.first; int len = e.second; if (dist[u] > dist[v] + len) { dist[u] = dist[v] + len; } } } return dist; }
Восстановление пути¶
Восстановление пути в алгоритме Дейкстры делается аналогично восстановлению пути в BFS (и любой динамике).
Дейкстра на сете¶
Искать вершину с минимальным $dist$ можно гораздо быстрее, используя такую структуру данных как очередь с приоритетом. Нам нужно хранить пары $(dist, index)$ и уметь делать такие операции:
- Извлечь минимум (чтобы обработать новую вершину)
- Удалить вершину по индексу (чтобы уменьшить $dist$ до какого-то соседа)
- Добавить новую вершину (чтобы уменьшить $dist$ до какого-то соседа)
Для этого используют, например, кучу или сет. Удобно помимо сета хранить сам массив dist, который его дублирует, но хранит элементы по порядку. Тогда, чтобы заменить значение $(dist_1, u)$ на $(dist_2, u)$, нужно удалить из сета значение $(dist[u], u)$, сделать $dist[u] = dist_2;$ и добавить в сет $(dist[u], u)$.
Данный алгоритм будет работать за $V O(log V)$ извлечений минимума и $O(E log V)$ операций уменьшения расстояния до вершины (может быть сделано после каждого ребра). Поэтому алгоритм работает за $O(E log V)$.
Заметьте, что этот алгоритм не лучше и не хуже, чем без сета, который работает за $O(V^2 + E)$. Ведь если $E = O(V^2)$ (граф почти полный), то Дейкстра без сета работает быстрее, а если, наример, $E = O(V)$, то Дейкстра на сете работает быстрее. Учитывайте это, когда выбираете алгоритм.
Базовые алгоритмы нахождения кратчайших путей во взвешенных графах
Время на прочтение
5 мин
Количество просмотров 240K
Наверняка многим из гейм-девелоперов (или просто людям, увлекающимися програмировагнием) будет интересно услышать эти четыре важнейших алгоритма, решающих задачи о кратчайших путях.
Сформулируем определения и задачу.
Графом будем называть несколько точек (вершин), некоторые пары которых соединены отрезками (рёбрами). Граф связный, если от каждой вершины можно дойти до любой другой по этим отрезкам. Циклом назовём какой-то путь по рёбрам графа, начинающегося и заканчивающегося в одной и той же вершине. И ещё граф называется взвешенным, если каждому ребру соответствует какое-то число (вес). Не может быть двух рёбер, соединяющих одни и те же вершины.
Каждый из алгоритмов будет решать какую-то задачу о кратчайших путях на взвешенном связном. Кратчайший путь из одной вершины в другую — это такой путь по рёбрам, что сумма весов рёбер, по которым мы прошли будет минимальна.
Для ясности приведу пример такой задачи в реальной жизни. Пусть, в стране есть несколько городов и дорог, соединяющих эти города. При этом у каждой дороги есть длина. Вы хотите попасть из одного города в другой, проехав как можно меньший путь.
Считаем, что в графе n вершин и m рёбер.
Пойдём от простого к сложному.
Алгоритм Флойда-Уоршелла
Находит расстояние от каждой вершины до каждой за количество операций порядка n^3. Веса могут быть отрицательными, но у нас не может быть циклов с отрицательной суммой весов рёбер (иначе мы можем ходить по нему сколько душе угодно и каждый раз уменьшать сумму, так не интересно).
В массиве d[0… n — 1][0… n — 1] на i-ой итерации будем хранить ответ на исходную задачу с ограничением на то, что в качестве «пересадочных» в пути мы будем использовать вершины с номером строго меньше i — 1 (вершины нумеруем с нуля). Пусть идёт i-ая итерация, и мы хотим обновить массив до i + 1-ой. Для этого для каждой пары вершин просто попытаемся взять в качестве пересадочной i — 1-ую вершину, и если это улучшает ответ, то так и оставим. Всего сделаем n + 1 итерацию, после её завершения в качестве «пересадочных» мы сможем использовать любую, и массив d будет являться ответом.
n итераций по n итераций по n итераций, итого порядка n^3 операций.
Псевдокод:
прочитать g // g[0 ... n - 1][0 ... n - 1] - массив, в котором хранятся веса рёбер, g[i][j] = 2000000000, если ребра между i и j нет
d = g
for i = 1 ... n + 1
for j = 0 ... n - 1
for k = 0 ... n - 1
if d[j][k] > d[j][i - 1] + d[i - 1][k]
d[j][k] = d[j][i - 1] + d[i - 1][k]
вывести d
Алгоритм Форда-Беллмана
Находит расстояние от одной вершины (дадим ей номер 0) до всех остальных за количество операций порядка n * m. Аналогично предыдущему алгоритму, веса могут быть отрицательными, но у нас не может быть циклов с отрицательной суммой весов рёбер.
Заведём массив d[0… n — 1], в котором на i-ой итерации будем хранить ответ на исходную задачу с ограничением на то, что в путь должно входить строго меньше i рёбер. Если таких путей до вершины j нет, то d[j] = 2000000000 (это должна быть какая-то недостижимая константа, «бесконечность»). В самом начале d заполнен 2000000000. Чтобы обновлять на i-ой итерации массив, надо просто пройти по каждому ребру и попробовать улучшить расстояние до вершин, которые оно соединяет. Кратчайшие пути не содержат циклов, так как все циклы неотрицательны, и мы можем убрать цикл из путя, при этом длина пути не ухудшится (хочется также отметить, что именно так можно найти отрицательные циклы в графе: надо сделать ещё одну итерацию и посмотреть, не улучшилось ли расстояние до какой-нибудь вершины). Поэтому длина кратчайшего пути не больше n — 1, значит, после n-ой итерации d будет ответом на задачу.
n итераций по m итераций, итого порядка n * m операций.
Псевдокод:
прочитать e // e[0 ... m - 1] - массив, в котором хранятся рёбра и их веса (first, second - вершины, соединяемые ребром, value - вес ребра)
for i = 0 ... n - 1
d[i] = 2000000000
d[0] = 0
for i = 1 ... n
for j = 0 ... m - 1
if d[e[j].second] > d[e[j].first] + e[j].value
d[e[j].second] = d[e[j].first] + e[j].value
if d[e[j].first] > d[e[j].second] + e[j].value
d[e[j].first] = d[e[j].second] + e[j].value
вывести d
Алгоритм Дейкстры
Находит расстояние от одной вершины (дадим ей номер 0) до всех остальных за количество операций порядка n^2. Все веса неотрицательны.
На каждой итерации какие-то вершины будут помечены, а какие-то нет. Заведём два массива: mark[0… n — 1] — True, если вершина помечена, False иначе, d[0… n — 1] — для каждой вершины будет храниться длина кратчайшего пути, проходящего только по помеченным вершинам в качестве «пересадочных». Также поддерживается инвариант того, что для помеченных вершин длина, указанная в d, и есть ответ. Сначала помечена только вершина 0, а g[i] равно x, если 0 и i соединяет ребро весом x, равно 2000000000, если их не соединяет ребро, и равно 0, если i = 0.
На каждой итерации мы находим вершину, с наименьшим значением в d среди непомеченных, пусть это вершина v. Тогда значение d[v] является ответом для v. Докажем. Пусть, кратчайший путь до v из 0 проходит не только по помеченным вершинам в качестве «пересадочных», и при этом он короче d[v]. Возьмём первую встретившуюся непомеченную вершину на этом пути, назовём её u. Длина пройденной части пути (от 0 до u) — d[u]. len >= d[u], где len — длина кратчайшего пути из 0 до v (т. к. отрицательных рёбер нет), но по нашему предположению len меньше d[v]. Значит, d[v] > len >= d[u]. Но тогда v не подходит под своё описание — у неё не наименьшее значение d[v] среди непомеченных. Противоречие.
Теперь смело помечаем вершину v и пересчитываем d. Так делаем, пока все вершины не станут помеченными, и d не станет ответом на задачу.
n итераций по n итераций (на поиск вершины v), итого порядка n^2 операций.
Псевдокод:
прочитать g // g[0 ... n - 1][0 ... n - 1] - массив, в котором хранятся веса рёбер, g[i][j] = 2000000000, если ребра между i и j нет
d = g
d[0] = 0
mark[0] = True
for i = 1 ... n - 1
mark[i] = False
for i = 1 ... n - 1
v = -1
for i = 0 ... n - 1
if (not mark[i]) and ((v == -1) or (d[v] > d[i]))
v = i
mark[v] = True
for i = 0 ... n - 1
if d[i] > d[v] + g[v][i]
d[i] = d[v] + g[v][i]
вывести d
Алгоритм Дейкстры для разреженных графов
Делает то же самое, что и алгоритм Дейкстры, но за количество операций порядка m * log(n). Следует заметить, что m может быть порядка n^2, то есть эта вариация алгоритма Дейкстры не всегда быстрее классической, а только при маленьких m.
Что нам нужно в алгоритме Дейкстры? Нам нужно уметь находить по значению d минимальную вершину и уметь обновлять значение d в какой-то вершине. В классической реализации мы пользуемся простым массивом, находить минимальную по d вершину мы можем за порядка n операций, а обновлять — за 1 операцию. Воспользуемся двоичной кучей (во многих объектно-ориентированных языках она встроена). Куча поддерживает операции: добавить в кучу элемент (за порядка log(n) операций), найти минимальный элемент (за 1 операцию), удалить минимальный элемент (за порядка log(n) операций), где n — количество элементов в куче.
Создадим массив d[0… n — 1] (его значение то же самое, что и раньше) и кучу q. В куче будем хранить пары из номера вершины v и d[v] (сравниваться пары должны по d[v]). Также в куче могут быть фиктивные элементы. Так происходит, потому что значение d[v] обновляется, но мы не можем изменить его в куче. Поэтому в куче могут быть несколько элементов с одинаковым номером вершины, но с разным значением d (но всего вершин в куче будет не более m, я гарантирую это). Когда мы берём минимальное значение в куче, надо проверить, является ли этот элемент фиктивным. Для этого достаточно сравнить значение d в куче и реальное его значение. А ещё для записи графа вместо двоичного массива используем массив списков.
m раз добавляем элемент в кучу, получаем порядка m * log(n) операций.
Псевдокод:
прочитать g // g[0 ... n - 1] - массив списков, в i-ом списке хранятся пары: first - вершина, соединённая с i-ой вершиной ребром, second - вес этого ребра
d[0] = 0
for i = 0 ... n - 1
d[i] = 2000000000
for i in g[0] // python style
d[i.first] = i.second
q.add(pair(i.second, i.first))
for i = 1 ... n - 1
v = -1
while (v = -1) or (d[v] != val)
v = q.top.second
val = q.top.first
q.removeTop
mark[v] = true
for i in g[v]
if d[i.first] > d[v] + i.second
d[i.first] = d[v] + i.second
q.add(pair(d[i.first], i.first))
вывести d