Критерий хи-квадрат – метод в математической статистике. Он показывает различия между фактическими данными в выборке и теоретическими результатами, которые предположил исследователь. С помощью метода оценивают, соответствует ли выборка законам распределения. Частный случай – критерий согласия Пирсона, который употребляется чаще всего.
При начале анализа информации исследователь предполагает, что фактические данные соответствуют какому-нибудь закону распределения. Например, результаты распределены равномерно. Это предположение называют нулевой гипотезой. Затем с помощью критерия хи квадрат исследователь проверяет, насколько фактические результаты отклоняются от предполагаемых. Так удается проверить, насколько верна нулевая гипотеза.
Понятие критерия хи-квадрат общее. В него входят разные методы. Но критерий Пирсона – самый популярный из них, поэтому названия иногда используют как синонимы. Критерий Пирсона помогает проверять гипотезы с помощью таблиц сопряженности, которые уже существуют и рассчитаны для многих распространенных ситуаций. Поэтому его удобно использовать.
Кто пользуется критерием хи-квадрат
Критерий часто используется в научных исследованиях, в маркетинге, в медицине и в других областях – везде, где бывает нужна статистика. Это популярный метод анализа, который помогает найти корреляцию или отвергнуть ее – а знание корреляции между разными факторами важно для прогнозов и стратегий.
- Ученые и статисты используют критерий хи-квадрат в расчетах, исследованиях, при интерпретации экспериментов и в других похожих задачах.
- ·Дата-аналитики и дата-саентисты применяют критерий в бизнес-целях. Например, с его помощью делают выводы о поведении пользователей или о тенденциях на рынке.
- Врачи и другие сотрудники здравоохранения могут использовать критерий при проведении клинических исследований и написании научных работ.
- Маркетологи и прочие диджитал-специалисты пользуются результатами, которые показывает критерий хи-квадрат, чтобы составить стратегию развития продукта.
Когда применяют критерий хи-квадрат
Критерий хи-квадрат используют, когда нужно определить наличие или отсутствие связи между двумя категориальными переменными — такими, которые могут принимать ограниченное количество уникальных значений. Категориальные переменные обычно не имеют числовых значений: например, цвет волос или любимое блюдо. Еще употребляют фразу «переменные, распределенные по номинальной шкале» – это означает примерно то же.
Например, исследование может пытаться установить, есть ли связь между образованием и доходом, или между полом и предпочтениями в музыке. В обоих случаях переменные категориальные – значит, критерий хи-квадрат использовать можно.
Есть еще несколько правил.
- С самого начала нужно отобрать правильные показатели – такие, которые вероятнее окажутся наглядными и репрезентативными. Они должны быть качественными и целочисленными, категориальными.
- Группы, которые сравниваются между собой, должны быть независимы друг от друга. Например, для сравнения одной и той же группы «до» и «после» какой-то манипуляции критерий не подойдет.
- Количество наблюдений для точных результатов – не менее 20 (иногда считается, что не менее 50).
- Ожидаемая частота – то, сколько раз значение теоретически должно появиться в выборке – должна быть больше или равна 5-10 для критерия Пирсона. Если она меньше, понадобится критерий Фишера.
Как выглядит распределение хи-квадрат
В критерии хи-квадрат используют определенное распределение – то, как распределяются показатели из выборки на графике. Распределение хи-квадрат описывается как «распределение суммы квадратов n независимых стандартных нормальных случайных величин». На практике это означает вот что.
Если реальные показатели распределяются по хи-квадрату – значит, наблюдаемые величины независимы друг от друга.
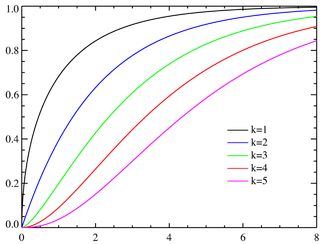
Первая картинка — это плотность распределения (вероятность получить в выборке каждое из чисел на горизонтальной оси), вторая — интегральная функция распределения (вероятность получить значение меньше, чем на горизонтальной оси).
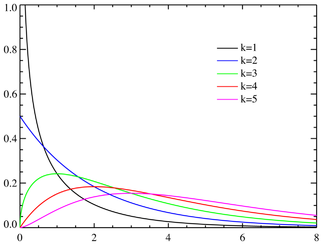
Стандартная нормальная величина – такая, которая подчиняется нормальному распределению. Нормальное распределение – это пик посередине графика, который сглаживается по краям. Если измерить подчиняющийся ему показатель много раз и построить график – получится такая картинка. Нормальное распределение значит, что на величину действует много случайных факторов.
Как выглядит распределение хи квадрат – зависит от количества степеней свободы (df). Степени свободы – это количество величин, которые мы измеряем. Например, распределение хи-квадрат с 5 степенями свободы представляет собой график, построенный по сумме квадратов 5 случайных переменных с нормальным распределением.
Как рассчитываются результаты по критерию Пирсона
Самый часто применяемый среди семейства критериев хи квадрат – критерий Пирсона. Он довольно универсален, и под его требования подпадает довольно много исследований. При использовании этого метода наблюдаемые значения сравниваются с ожидаемыми. Наблюдаемые значения – фактические результаты, которые исследователь получил в ходе эксперимента. Ожидаемые значения вычисляются по формуле: составляется таблица, потом сумма ее строк и столбцов умножается на определенное значение. Подбор значений зависит от количества степеней свободы.
Рассмотрим этот процесс подробнее.
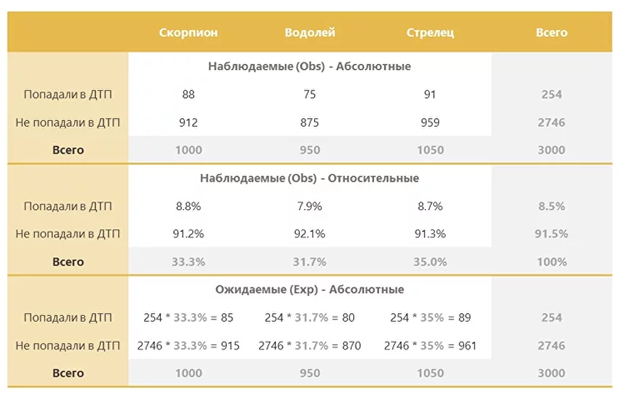
Создание таблицы. Первый шаг в применении критерия – составление таблицы реальных и ожидаемых значений. В таблице перечислены категориальные переменные, взаимосвязь которых проверяет исследователь. Таблица состоит из строк и столбцов, в каждой ячейке записано количество наблюдений в соответствующей категории.
Разобраться проще, если посмотреть на пример. Скажем, таблица может выглядеть вот так.
Формирование гипотез. Исследователь составляет две гипотезы — нулевую и альтернативную. Нулевая гипотеза говорит, что переменные не связаны друг с другом. Альтернативная гипотеза предполагает наличие связи между переменными. Обычно нулевую гипотезу формулируют так, чтобы ее опровержение доказывало существование связи между переменными.
Например, мы хотим узнать, есть ли связь между полом и предпочтениями в музыкальных жанрах. Тогда нулевая гипотеза будет говорить, что пол не влияет на предпочтения в музыке.
Ожидаемые значения. Затем нужно подсчитать ожидаемые значения — такие, какие должны получиться, если нулевая гипотеза верна. Их тоже нужно занести в таблицу, для этого в ней создают отдельный столбец. Так будет легче сравнить ожидаемые значения с реальными.
Ожидаемые значения рассчитываются так:
- берется общее число наблюдений для каждой переменной, записанной в таблице;
- общее число для каждого столбца умножается на общее число для каждой строки;
- полученные значения делятся на полное количество наблюдений.
Понять, как это работает, поможет картинка.

Расчеты. Когда исследователь подсчитал ожидаемые значения для каждой ячейки, он переходит к расчету статистики критерия хи-квадрат. Для каждой ячейки таблицы нужно:
- подсчитать квадрат разности между наблюдаемым и ожидаемым значением;
- разделить получившееся число на ожидаемое значение.
Подсчитанные значения нужно сложить. Получится число, которое называется статистикой критерия хи-квадрат. Чем больше это число, тем сильнее отличия между наблюдаемыми и ожидаемыми значениями — и тем вероятнее, что между факторами действительно есть связь.
Выводы. Маленькое значение статистики критерия хи-квадрат говорит, что нулевую гипотезу отвергнуть нельзя — но нельзя и подтвердить. А большое значение позволяет отвергнуть нулевую гипотезу и подтвердить связь между факторами. Остается вопрос: как понять, достаточно ли большое получилось число?
Специально для этого существуют таблицы критических значений. В них описаны «пограничные» значения статистики критерия хи-квадрат для разных условий. Если рассчитанный результат больше табличного — значит, нулевая гипотеза неверна, и связь есть. Если меньше — нулевую гипотезу нельзя отвергнуть.
Все, что должен сделать исследователь на этом этапе, — найти в таблице критическое значение критерия для своего случая. То есть — для нужного количества степеней свободы и уровня значимости. Уровень значимости — это число, которое показывает вероятность получить статистически значимый результат по ошибке. Исследователь выбирает этот уровень сам.
Некоторые другие критерии хи-квадрат
Критерий Пирсона — не единственный критерий хи квадрат. Выше мы говорили в основном о нем, но существуют и другие методики для разных ситуаций. Вот несколько примеров — в реальности их больше.
Критерий Тьюки. В отличие от критерия Пирсона, этот метод используется для сравнения нескольких групп – обычно трех и более. Он помогает оценить различия между средними значениями в группах и сделать вывод, насколько они значимы.
Критерий Фишера. Его применяют, если ожидаемая частота меньше 5. Ожидаемая частота говорит, сколько раз тот или иной результат должен появиться в таблице ожидаемых значений.
Поправка Йейтса. Это модификация критерия хи квадрат, которая используется для сравнения небольших выборок с ожидаемой частотой меньше 5. Дело в том, что если значения в таблице маленькие, классический критерий даст большую вероятность ошибки. Поправка помогает уменьшить этот риск. Она проще, чем критерий Фишера: от значений в таблице просто отнимается 0,5 или 1. После этого вычисляется статистика: она будет меньше, чем без поправки, поэтому риск ошибки окажется ниже.
Тесты семейства хи-квадрат
Критерий можно использовать для тестирования разных показателей. Тесты семейства хи-квадрат помогают проанализировать выборку, подтвердить или опровергнуть какую-нибудь гипотезу. Чаще всего говорят о тестах гомогенности, независимости и дисперсии.
Гомогенность. Тест гомогенности проверяет гипотезу, что распределение какой-либо переменной в разных группах – одинаковое. Например, с его помощью можно оценить, одинаково ли распределяются доходы населения в разных городах. При этом сам по себе критерий хи квадрат – непараметрический, то есть параметры распределения для него неважны. Значение имеют только наблюдения.
Независимость. Тест независимости проверяет, верно ли, что две категориальные переменные не связаны друг с другом. Он помогает определить, есть ли связь между разными переменными: пол и предпочтения в еде, образование и любимая музыка, и так далее. Обычно критерий хи-квадрат используют как раз для оценки независимости и поиска связей между переменными.
Дисперсия. С помощью этого теста исследователи оценивают дисперсию – то, насколько велик разброс между результатами в выборке. Тест дисперсии помогает оценить, одинакова ли дисперсия в разных выборках, соответствует ли она какому-то принятому значению – и так далее. Например, с помощью этого теста можно проанализировать разброс оценок учеников в разных классах: одинаковый ли этот разброс, соответствует ли он какому-то стандарту, и так далее.
Как начать применять критерий хи-квадрат
Объяснения выше могут показаться сложными. Это нормально. Статистические критерии редко рассчитывают вручную – обычно для этого используют специальное ПО или привычный всем Excel. «Ручные» расчеты чаще всего нужны при обучении, когда важно, чтобы ученик понял, как это работает.
Понять критерий хи-квадрат до конца можно, если начать им пользоваться. Так легче разобраться, чем при изучении теории. Поэтому мы рекомендуем тренироваться и выполнять задачи – можно начать с заданий из учебников и уроков в открытом доступе. Сначала будет сложно, но со временем понять принципы расчета будет легче.
Как выполнить тест хи-квадрат вручную (шаг за шагом)
17 авг. 2022 г.
читать 2 мин
Критерий согласия Хи-квадрат используется, чтобы определить, следует ли категориальная переменная гипотетическому распределению.
В следующем пошаговом примере показано, как вручную выполнить критерий согласия Хи-квадрат.
Хи-квадрат Проверка соответствия вручную
Предположим, мы считаем, что некоторая игральная кость является справедливой. Другими словами, мы считаем, что кости с одинаковой вероятностью выпадут на 1, 2, 3, 4, 5 или 6 при заданном броске.
Чтобы проверить это, мы бросаем его 60 раз и записываем число, на которое он выпадает каждый раз. Результаты приведены ниже:
- 1 : 8 раз
- 2 : 12 раз
- 3 : 18 раз
- 4 : 9 раз
- 5 : 7 раз
- 6 : 6 раз
Используйте следующие шаги, чтобы выполнить тест на соответствие хи-квадрат, чтобы определить, являются ли кости справедливыми.
Шаг 1: Определите нулевую и альтернативную гипотезы
- H 0 (ноль): кости с одинаковой вероятностью выпадут на каждом числе.
- H 1 (альтернативный вариант): кости не с равной вероятностью выпадут на каждом числе.
Шаг 2: Рассчитайте наблюдаемую и ожидаемую частоты
Далее создадим таблицу наблюдаемых и ожидаемых частот для каждого числа на костях:

Примечание.Если мы считаем, что кости правильные, это означает, что мы ожидаем, что они выпадут на каждое число одинаковое количество раз — в данном случае по 10 раз каждое.
Шаг 3: Рассчитайте тестовую статистику
Статистика критерия хи-квадрат, X 2 , рассчитывается как:
- Х 2 = Σ(ОЕ) 2 / Е
В следующей таблице показано, как рассчитать эту тестовую статистику:

В этом случае X 2 оказывается равным 9,8 .
Шаг 4: Найдите критическое значение
Далее нам нужно найти критическое значение в таблице распределения хи-квадрат , которое соответствует α = 0,05 и df = (#categories – 1).
В данном случае имеется 6 категорий, поэтому мы будем использовать df = 6 – 1 = 5 .
Мы видим, что критическое значение равно 11,07 .

Шаг 5: Отклонить или не отклонить нулевую гипотезу
Поскольку наша тестовая статистика меньше критического значения, мы не можем отвергнуть нулевую гипотезу. Это означает, что у нас нет достаточных доказательств, чтобы сказать, что игра в кости нечестна.
Дополнительные ресурсы
Следующие ресурсы предлагают дополнительную информацию о проверке пригодности Хи-квадрат:
Введение в критерий пригодности хи-квадрат
Как выполнить критерий согласия хи-квадрат в R
Хи-квадрат Калькулятор критерия согласия
До конца XIX века нормальное распределение считалась всеобщим законом вариации данных. Однако К. Пирсон заметил, что эмпирические частоты могут сильно отличаться от нормального распределения. Встал вопрос, как это доказать. Требовалось не только графическое сопоставление, которое имеет субъективный характер, но и строгое количественное обоснование.
Так был изобретен критерий χ2 (хи квадрат), который проверяет значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Это произошло в далеком 1900 году, однако критерий и сегодня на ходу. Более того, его приспособили для решения широкого круга задач. Прежде всего, это анализ категориальных данных, т.е. таких, которые выражаются не количеством, а принадлежностью к какой-то категории. Например, класс автомобиля, пол участника эксперимента, вид растения и т.д. К таким данным нельзя применять математические операции вроде сложения и умножения, для них можно только подсчитать частоты.
Наблюдаемые частоты обозначим О (Observed), ожидаемые – E (Expected). В качестве примера возьмем результат 60-кратного бросания игральной кости. Если она симметрична и однородна, вероятность выпадения любой стороны равна 1/6 и, следовательно, ожидаемое количество выпадения каждой из сторон равна 10 (1/6∙60). Наблюдаемые и ожидаемые частоты запишем в таблицу и нарисуем гистограмму.

Нулевая гипотеза заключается в том, что частоты согласованы, то есть фактические данные не противоречат ожидаемым. Альтернативная гипотеза – отклонения в частотах выходят за рамки случайных колебаний, расхождения статистически значимы. Чтобы сделать строгий вывод, нам потребуется.
- Обобщающая мера расхождения между наблюдаемыми и ожидаемыми частотами.
- Распределение этой меры при справедливости гипотезы о том, что различий нет.
Начнем с расстояния между частотами. Если взять просто разницу О — E, то такая мера будет зависеть от масштаба данных (частот). Например, 20 — 5 =15 и 1020 – 1005 = 15. В обоих случаях разница составляет 15. Но в первом случае ожидаемые частоты в 3 раза меньше наблюдаемых, а во втором случае – лишь на 1,5%. Нужна относительная мера, не зависящая от масштаба.
Обратим внимание на следующие факты. В общем случае количество категорий, по которым измеряются частоты, может быть гораздо больше, поэтому вероятность того, что отдельно взятое наблюдение попадет в ту или иную категорию, довольно мала. Раз так, то, распределение такой случайной величины будет подчинятся закону редких событий, известному под названием закон Пуассона. В законе Пуассона, как известно, значение математического ожидания и дисперсии совпадают (параметр λ). Значит, ожидаемая частота для некоторой категории номинальной переменной Ei будет являться одновременное и ее дисперсией. Далее, закон Пуассона при большом количестве наблюдений стремится к нормальному. Соединяя эти два факта, получаем, что, если гипотеза о согласии наблюдаемых и ожидаемых частот верна, то, при большом количестве наблюдений, выражение
![]()
имеет стандартное нормальное распределение.
Важно помнить, что нормальность будет проявляться только при достаточно больших частотах. В статистике принято считать, что общее количество наблюдений (сумма частот) должна быть не менее 50 и ожидаемая частота в каждой группе должна быть не менее 5. Только в этом случае величина, показанная выше, имеет стандартное нормальное распределение. Предположим, что это условие выполнено.
У стандартного нормального распределения почти все значение находятся в пределах ±3 (правило трех сигм). Таким образом, мы получили относительную разность в частотах для одной группы. Нам нужна обобщающая мера. Просто сложить все отклонения нельзя – получим 0 (догадайтесь почему). Пирсон предложил сложить квадраты этих отклонений.
![]()
Это и есть статистика для критерия Хи-квадрат Пирсона. Если частоты действительно соответствуют ожидаемым, то значение статистики Хи-квадрат будет относительно не большим (отклонения находятся близко к нулю). Большое значение статистики свидетельствует в пользу существенных различий между частотами.
«Большой» статистика Хи-квадрат становится тогда, когда появление наблюдаемого или еще большего значения становится маловероятным. И чтобы рассчитать такую вероятность, необходимо знать распределение статистики Хи-квадрат при многократном повторении эксперимента, когда гипотеза о согласии частот верна.
Как нетрудно заметить, величина хи-квадрат также зависит от количества слагаемых. Чем больше слагаемых, тем больше ожидается значение статистики, ведь каждое слагаемое вносит свой вклад в общую сумму. Следовательно, для каждого количества независимых слагаемых, будет собственное распределение. Получается, что χ2 – это целое семейство распределений.
И здесь мы подошли к одному щекотливому моменту. Что такое число независимых слагаемых? Вроде как любое слагаемое (т.е. отклонение) независимо. К. Пирсон тоже так думал, но оказался неправ. На самом деле число независимых слагаемых будет на один меньше, чем количество групп номинальной переменной n. Почему? Потому что, если мы имеем выборку, по которой уже посчитана сумма частот, то одну из частот всегда можно определить, как разность общего количества и суммой всех остальных. Отсюда и вариация будет несколько меньше. Данный факт Рональд Фишер заметил лет через 20 после разработки Пирсоном своего критерия. Даже таблицы пришлось переделывать.
По этому поводу Фишер ввел в статистику новое понятие – степень свободы (degrees of freedom), которое и представляет собой количество независимых слагаемых в сумме. Понятие степеней свободы имеет математическое объяснение и проявляется только в распределениях, связанных с нормальным (Стьюдента, Фишера-Снедекора и сам Хи-квадрат).
Чтобы лучше уловить смысл степеней свободы, обратимся к физическому аналогу. Представим точку, свободно движущуюся в пространстве. Она имеет 3 степени свободы, т.к. может перемещаться в любом направлении трехмерного пространства. Если точка движется по какой-либо поверхности, то у нее уже две степени свободы (вперед-назад, вправо-влево), хотя и продолжает находиться в трехмерном пространстве. Точка, перемещающаяся по пружине, снова находится в трехмерном пространстве, но имеет лишь одну степень свободы, т.к. может двигаться либо вперед, либо назад. Как видно, пространство, где находится объект, не всегда соответствует реальной свободе перемещения.
Примерно также распределение статистики может зависеть от меньшего количества элементов, чем нужно слагаемых для его расчета. В общем случае количество степеней свободы меньше наблюдений на число имеющихся зависимостей.
Таким образом, распределение хи квадрат (χ2) – это семейство распределений, каждое из которых зависит от параметра степеней свободы. Формальное определение следующее. Распределение χ2 (хи-квадрат) с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Далее можно было бы перейти к самой формуле, по которой вычисляется функция распределения хи-квадрат, но, к счастью, все давно подсчитано за нас. Чтобы получить интересующую вероятность, можно воспользоваться либо соответствующей статистической таблицей, либо готовой функцией в Excel.
Интересно посмотреть, как меняется форма распределения хи-квадрат в зависимости от количества степеней свободы.

С увеличением степеней свободы распределение хи-квадрат стремится к нормальному. Это объясняется действием центральной предельной теоремы, согласно которой сумма большого количества независимых случайных величин имеет нормальное распределение. Про квадраты там ничего не сказано )).
Проверка гипотезы по критерию Хи квадрат Пирсона
Вот мы и подошли к проверке гипотез по методу хи-квадрат. В целом техника остается прежней. Выдвигается нулевая гипотеза о том, что наблюдаемые частоты соответствуют ожидаемым (т.е. между ними нет разницы, т.к. они взяты из той же генеральной совокупности). Если этот так, то разброс будет относительно небольшим, в пределах случайных колебаний. Меру разброса определяют по статистике Хи-квадрат. Далее либо полученную статистику сравнивают с критическим значением (для соответствующего уровня значимости и степеней свободы), либо, что более правильно, рассчитывают наблюдаемый p-value, т.е. вероятность получить такое или еще больше значение статистики при справедливости нулевой гипотезы.
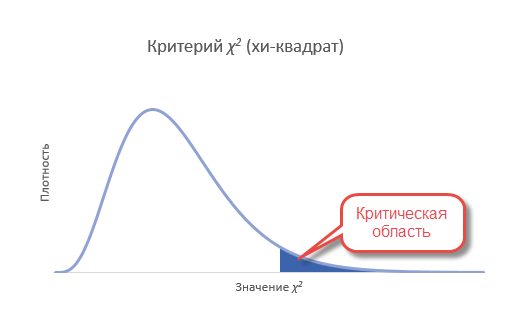
Т.к. нас интересует согласие частот, то отклонение гипотезы произойдет, когда статистика окажется больше критического уровня. Т.е. критерий является односторонним. Однако иногда (иногда) требуется проверить левостороннюю гипотезу. Например, когда эмпирические данные уж оооочень сильно похожи на теоретические. Тогда критерий может попасть в маловероятную область, но уже слева. Дело в том, что в естественных условиях, маловероятно получить частоты, практически совпадающие с теоретическими. Всегда есть некоторая случайность, которая дает погрешность. А вот если такой погрешности нет, то, возможно, данные были сфальсифицированы. Но все же обычно проверяют правостороннюю гипотезу.
Вернемся к задаче с игральной костью. Рассчитаем по имеющимся данным значение статистики критерия хи-квадрат.
![]()
Теперь найдем критическое значение при 5-ти степенях свободы (k) и уровне значимости 0,05 (α) по таблице критических значений распределения хи квадрат.

То есть квантиль 0,05 хи квадрат распределения (правый хвост) с 5-ю степенями свободы χ20,05; 5 = 11,1.
Сравним фактическое и табличное значение. 3,4 (χ2) < 11,1 (χ20,05; 5). Расчетный значение оказалось меньшим, значит гипотеза о равенстве (согласии) частот не отклоняется. На рисунке ситуация выглядит вот так.

Если бы расчетное значение попало в критическую область, то нулевая гипотеза была бы отклонена.
Более правильным будет рассчитать еще и p-value. Для этого нужно в таблице найти ближайшее значение для заданного количества степеней свободы и посмотреть соответствующий ему уровень значимости. Но это прошлый век. Воспользуемся ЭВМ, в частности MS Excel. В эксель есть несколько функций, связанных с хи-квадрат.

Ниже их краткое описание.
ХИ2.ОБР – критическое значение Хи-квадрат при заданной вероятности слева (как в статистических таблицах)
ХИ2.ОБР.ПХ – критическое значение при заданной вероятности справа. Функция по сути дублирует предыдущую. Но здесь можно сразу указывать уровень α, а не вычитать его из 1. Это более удобно, т.к. в большинстве случаев нужен именно правый хвост распределения.
ХИ2.РАСП – p-value слева (можно рассчитать плотность).
ХИ2.РАСП.ПХ – p-value справа.
ХИ2.ТЕСТ – по двум диапазонам частот сразу проводит тест хи-квадрат. Количество степеней свободы берется на одну меньше, чем количество частот в столбце (так и должно быть), возвращая значение p-value.
Давайте пока рассчитаем для нашего эксперимента критическое (табличное) значение для 5-ти степеней свободы и альфа 0,05. Формула Excel будет выглядеть так:
=ХИ2.ОБР(0,95;5)
Или так
=ХИ2.ОБР.ПХ(0,05;5)
Результат будет одинаковым – 11,0705. Именно это значение мы видим в таблице (округленное до 1 знака после запятой).
Рассчитаем, наконец, p-value для 5-ти степеней свободы критерия χ2 = 3,4. Нужна вероятность справа, поэтому берем функцию с добавкой ПХ (правый хвост)
=ХИ2.РАСП.ПХ(3,4;5) = 0,63857
Значит, при 5-ти степенях свободы вероятность получить значение критерия χ2 = 3,4 и больше равна почти 64%. Естественно, гипотеза не отклоняется (p-value больше 5%), частоты очень хорошо согласуются.
А теперь проверим гипотезу о согласии частот с помощью теста хи квадрат и функции Excel ХИ2.ТЕСТ.

Никаких таблиц, никаких громоздких расчетов. Указав в качестве аргументов функции столбцы с наблюдаемыми и ожидаемыми частотами, сразу получаем p-value. Красота.
Представим теперь, что вы играете в кости с подозрительным типом. Распределение очков от 1 до 5 остается прежним, но он выкидывает 26 шестерок (количество всех бросков становится 78).

p-value в этом случае оказывается 0,003, что гораздо меньше чем, 0,05. Есть серьезные основания сомневаться в правильности игральной кости. Вот, как выглядит эта вероятность на диаграмме распределения хи-квадрат.

Статистика критерия хи-квадрат здесь получается 17,8, что, естественно, больше табличного (11,1).
Надеюсь, мне удалось объяснить, что такое критерий согласия χ2 (хи-квадрат) Пирсона и как с его помощью проверяются статистические гипотезы.
Напоследок еще раз о важном условии! Критерий хи-квадрат исправно работает только в случае, когда количество всех частот превышает 50, а минимальное ожидаемое значение для каждой группы не меньше 5. Если в какой-либо категории ожидаемая частота менее 5, но при этом сумма всех частот превышает 50, то такую категорию объединяют с ближайшей, чтобы их общая частота превысила 5. Если это сделать невозможно, или сумма частот меньше 50, то следует использовать более точные методы проверки гипотез. О них поговорим в другой раз.
Ниже находится видео ролик о том, как в Excel проверить гипотезу с помощью критерия хи-квадрат.
Скачать файл с примером.
Поделиться в социальных сетях:
КРИТЕРИИ СОГЛАСИЯ
РАСПРЕДЕЛЕНИЙ И МНОГОФУНКЦИОНАЛЬНЫЙ
КРИТЕРИЙ «φ»
8.1. Критерий хи-квадрат
Критерий хи-квадрат
(другая форма записи — X2
греческая
буква «хи») один из наиболее часто
использующихся в психологических
исследованиях, поскольку он позволяет
решать большое число разных задач,
и, кроме того, исходные данные для него
могут быть получены в любой шкале,
начиная со шкалы наименований.
Критерий хи-квадрат
используется в двух вариантах:
* как расчет согласия
эмпирического распределения и
предполагаемого теоретического; в этом
случае проверяется гипотеза Н0
об отсутствии
различий между теоретическим и
эмпирическим распределениями;
» как расчет
однородности двух независимых
экспериментальных выборок; в этом
случае проверяется гипотеза Н0
об отсутствии
различий между двумя эмпирическими
(экспериментальными) распределениями.
Критерий построен
так, что при полном совпадении
экспериментального и теоретического
(или двух экспериментальных)
распределений
величина х2эмп
(хи-квадрат
эмпирическое) = 0, и
чем больше
расхождение между сопоставляемыми
распределениями, тем больше величина
эмпирического значения хм-квадрат.
Основная расчетная формула критерия
xи-квадрат
выгля-дитт так:
126
![]()
(8.1)
где fэ
— эмпирическая частота fm
— теоретическая
частота k
— количество
разрядов признака
Расчетная формула
критерия
хи-квадрат
для сравнения двух эмпирических
распределений в зависимости от вида
представленных данных может иметь
следующий вид:
![]()
(8.2)
где N
и М
— соответственно
число элементов в первой и во второй
выборке. Эти числа могут совпадать, а
могут быть и различными.
Для критерия
хи-квадрат
оценка уровней значимости (см. таблицу
12 Приложения 1) определяется по числу
степеней свободы, которое обозначается
греческой буквой v
(ню) и в большинстве случаев, вычисляется
по формуле: v
= k
— 1, где k
каждый раз
определяется по выборочным данным и
представляет собой число элементов в
выборке. Если при расчете критерия
используется таблица экспериментальных
данных, то величина v
рассчитывается следующим образом:
v
= (k
— 1) • (с — 1),
где k
— число
строк, а с —
число
столбцов.
Рассмотрим ряд
примеров решения задач с использованием
критерия хи-квадрат.
8.1.1. Сравнение эмпирического распределения с теоретическим
В разных задачах
подсчет теоретических частот осуществляется
по-разному. Рассмотрим примеры задач,
иллюстрирующих различные варианты
подсчета теоретических частот. Начнем
с равновероятного распределения
теоретических частот. В задачах такого
типа
127
(8.1, 8.2 и 8.3) в силу
требования равномерности распределения
все теоретические частоты должны быть
равны между собой.
Задача 8.1.
Предположим, что в эксперименте психологу
необходимо использовать шестигранный
игральный кубик с цифрами на гранях от
1 до 6. Для чистоты эксперимента необходимо
получить «идеальный» кубик, т.е.
такой, чтобы при достаточно большом
числе подбрасываний, каждая его грань
выпадала бы примерно равное число
раз. Задача состоит в выяснении того,
будет ли данный кубик близок к идеальному?
Решение, Для
решения этой задачи, психолог подбрасывал
кубик 60 раз, при этом количество выпадений
каждой грани (эмпирические частоты f})
распределилось
следующим образом:
Таблица
8.1
|
Грани |
1 |
2 |
3 |
4 |
5 |
6 |
|
f, |
12 |
9 |
11 |
14 |
8 |
6 |
|
1т— |
10 |
10 |
10 |
10 |
10 |
10 |
В «идеальном»
случае необходимо, чтобы каждая из 6 его
граней (теоретические частоты)
выпадала бы равное число раз:
60:6 = 10. Величина60:6
= 10 и будет, очевидно, теоретической
час-тотой (fm),
одинаковой
для каждой грани кубика.
Согласно данным
таблицы 8.1 легко подсчитать величину
Х2эмп
(хи-квадрат
эмпирическое) по формуле (8.1).
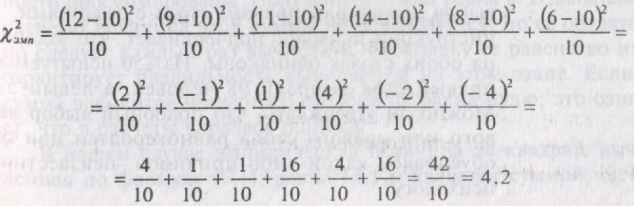
128
Теперь, для того
чтобы найти х2кр
, необходимо
обратиться к таблице 12 Приложения 1,
определив, предварительно число степеней
свободы v.
В нашем случае k
(число граней)
= б, следом вательно v
= 6 — 1 = 5. По таблице 12 Приложения 1 находим
величины х2кр
для уровней значимости 0,05 и 0,01:
х2кр
= 11,070
для Р< 0,05
х2кр
= 5,086 для Р<
0,01
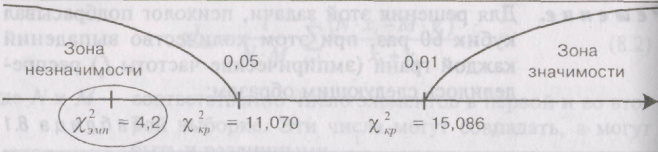
Строим «ось
значимости»
В нашем случае
х2эмп
попало в
зону незначимости и оказалось
равным 4,2, что
гораздо меньше 11,070 — критической
величины для 5% уровня значимости.
Следовательно, можно принимать гипотезу
Н0
о том, что
эмпирическое и теоретическое распределения
не различаются между собой. Таким
образом, можно утверждать, что
игральный кубик «безупречен».
Понятно, также,
что если бы х2эмп
попало в зону значимости, то следовало
бы принять гипотезу Н1
о наличии
различий и тем самым утверждать, что
наш игральный кубик был бы далеко не
«безупречен».
Задача 8.2.
В эксперименте испытуемый должен
произвести выбор левого или правого
стола с заданиями. В инструкции психолог
подчеркивает, что задания на обоих
столах одинаковы. Из 150 испытуемых правый
стол выбрали 98 человек, а левый 52. Можно
ли утверждать, что подобный выбор левого
или правого стола равновероятен или он
обусловлен какой-либо причиной,
неизвестной психологу?
129
Решение.
Подчеркнем,
что данная задача вновь на сопоставление
экспериментального распределения с
теоретическим. Каковы в этом случае
параметры теоретического распределения?
Предполагается, что выбор должен быть
равновероятным, т.е. правый и левый
стол должны выбрать одинаковое количество
испытуемых, а это 150:2 =75человек.
Проверим совпадение
эмпирического распределения с
теоретическим по критерию хи-квадрат.
Лучше всего для расчета критерия
использовать таблицу 8.2, последовательность
вычислений в которой соответствует
формуле (8.1).
Таблица
8.2
|
№ 1 |
№2 |
№3 |
№ 4 |
№ 5 |
№ 6 |
|
Альтернативы стола |
fэ |
fm |
(fэ—fm) |
(fэ—fm)2 |
|
|
1 |
98 |
75 |
23 |
529 |
7,05 |
|
2 |
52 |
75 |
-23 |
529 |
7,05 |
|
Суммы |
150 |
150 |
0 |
х2эмп |
В таблице 8.2
альтернатива 1 соответствует выбору
правого стола, а альтернатива 2 — выбору
левого. Второй и третий столбцы
таблицы соответственно эмпирические
и теоретические частоты. Следует
просуммировать эти два столбца, чтобы
проверить равенство сумм эмпирических
и теоретических частот. Четвертый
столбец соответствует разности между
эмпирическими и теоретическими
частотами (fэ
— fm).
В нижней
строчке столбца эти разности
просуммированы. Полученная сумма равна
0. В дальнейших расчетах величина этой
суммы не используется, но ее обязательно
следует каждый раз вычислять, поскольку
се равенство нулю гарантирует правильность
вычислений на этом этапе. Если же сумма
элементов четвертого столбца не равна
нулю, это означает, что в расчеты
вкралась ошибка.
В нашем случае
эмпирическая величина xw-квадрат,
вычисленная по формуле (8.1), равна
14,1 и является суммой чисел в
130
шестом столбце.
Для того чтобы найти табличные значения
х2кр
следует определить
число степеней свободы по формуле: v
= k
— 1, где k
— количество
альтернатив (строк). В нашем случае k
= 2, следовательно
v
= 2 — 1 = 1. По таблице 12 Приложения 1 находим:
х2кр = 3,841 для Р< 0,05
х2кр = б,635для Р< 0,01
Строим «ось
значимости»:
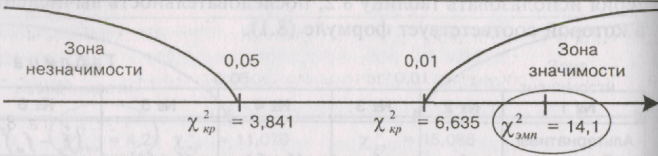
Полученные различия
оказались значимыми на уровне 1%. Иными
словами, испытуемые статистически
значимо предпочитают выбор правого
стола. В терминах статистических гипотез
этот вывод звучит так: выбор направления
оказался не случайным, поэтому нулевая
гипотеза Н0
о сходстве
отклоняется и на высоком уровне значимости
принимается альтернативная гипотеза
Н1
о различии.
Если психологу интересны причины
подобного выбора, то их следует выяснять
в специальном эксперименте.
Задача 8.3. Психолог
решает задачу: будет ли удовлетворенность
работой на данном предприятии распределена
равномерно по следующим альтернативам
(градациям):
1 —Работой вполне
доволен;
2 — Скорее доволен,
чем не доволен;
3 —Трудно сказать,
не знаю, безразлично;
4 — Скорее недоволен,
чем доволен;
5 — Совершенно
недоволен работой.
131
Решение. Для
решения этой задачи производится опрос
случайной выборки из 65 респондентов
(испытуемых) об удовлетворенности
работой: «В какой степени Вас устраивает
Ваша теперешняя работа?», причем
ответы должны даваться согласно
вышеозначенным альтернативам.
Полученные ответы
(эмпирические частоты) представлены в
таблице 8.3 в столбце № 2. В этой же таблице
в третьем столбце даны теоретические
частоты для данной выборки испытуемых,
которые, согласно предположению
психолога, должны быть
одинаковы и
равняться: — = 13 . В следующих столбцах
таблицы 8.3 приведены необходимые расчеты
по формуле (8.1).
Таблица
8.3
|
№ 1 |
№2 |
№ 3 |
№4 |
N° |
№6 |
|
Альтернативы |
fэ |
fm |
(fэ—fm) |
(fэ—fm)2 |
|
|
1 |
8 |
13 |
-5 |
25 |
1,92 |
|
2 |
22 |
13 |
+9 |
81 |
6,23 |
|
3 |
14 |
13 |
+ |
1 |
0,08 |
|
4 |
9 |
13 |
-4 |
16 |
1,23 |
|
5 |
12 |
13 |
-1 |
1 |
0,08 |
|
Суммы |
65 |
65 |
0 |
х2эмп |
Напомним, что сумма
величин (fэ
— fm)
в столбце №
4 должна равняться нулю. Это показатель
правильности вычислений.
В шестом столбце
таблицы подсчитана величина х2эмп
равная
9,54. Для того чтобы
найти табличные значения х2кр
для двух
Уровней значимости,
следует вначале определить число
степеней свободы по формуле: v
= k
— 1, где k
— количество
альтернатив
132
133
(строк). В нашем
случае k
= 5, следовательно
v
= 5 — 1 = 4. По таблице 12 Приложения 1
находим:
х2кр = 9,488
для Р< 0,05
х2кр =
13,277 для Р<
0,01

Строим «ось
значимости»:
Величина х2эмп
попала в
зону неопределенности. Можно считать,
однако, что полученные различия значимы
на уровне 5% и принять гипотезу Н1
о различии теоретического и эмпирического
распределений. Психолог может предположить,
что на 5% уровне значимости выбор
альтернатив респондентами не
равновероятен. Таким образом, можно
сказать, что эмпирическое распределение
выбора альтернатив значимо отличается
от теоретически предположенного
равномерного выбора альтернатив.
Причину этого, а также степень
отвержения или предпочтения работы
на данном предприятии психолог может
выяснить в специальном исследовании.
При решении
приведенных выше трех задач с
равновероятным распределением
теоретических частот не было необходимости
использовать специальные процедуры их
подсчета. Однако на практике чаще
возникают задачи, в которых распределение
теоретических частот не имеет
равновероятного характера. В этих
случаях для подсчета теоретических
частот используются специальные
формулы или таблицы. Рассмотрим задачу,
в которой в качестве теоретического
будет использоваться нормальное
распределение.
Задача 8.4. У
267 человек был измерен рост. Вопрос
состоит в том, будет ли полученное в
этой выборке распре-
деление роста
близко к нормальному? (Задача взята
из учебника Г.Ф. Лакина «Биометрия»,
1990). Решение.
Измерения
проводились с точностью до 0,1 см и все
полученные величины роста оказались в
диапазоне от 156,5 до 183,5 см. Для расчета
по критерию хи-квадрат
целесообразно разбить этот диапазон
на интервалы, величину интервала удобнее
всего взять равной 3 см, поскольку 183,5 —
156,5 = 27 и
27 делится нацело
на 3 [27 : 3=9]. Таким образом,
все экспериментальные
данные будут распределены по 9
интервалам. При этом центрами интервалов
будут следующие числа: 158 (поскольку
156,5 + 159,5 = 316 и 316:2
= 158), 161
322
(поскольку 159,5+
162,5 = 322 и 322:2 = 161), 164 и т.д. до 182.
При измерении
роста в каждый из этих интервалов попало
какое-то количество людей — эта величина
для каждого интервала и будет
эмпирической частотой, обозначаемой в
дальнейшем как fэi..
Чтобы применить
расчетную формулу 8.1 необходимо прежде
всего вычислить теоретические частоты.
Для этого по всем полученным значениям
эмпирических частот (по всем выборочным
данным) нужно вычислить:
1) среднее X
2) и среднеквадратическое
отклонение (а).
Для наших выборочных
данных величина среднего X
оказалась
равной 166,22 и среднеквадратическое а =
4,06.
![]()
Затем для каждого
выделенного интервала следует подсчитать
величины оi
по формуле (8.3) (где индекс i
изменяется от 1 до 9, т.к. у нас 9 интервалов):
(8.3)
134
135
Величины oi
называются
нормированными частотами. Удобнее
производить их расчет в приведенной
ниже таблице 8.4. Подсчитав эти величины,
необходимо занести их в соответствующую
строчку третьего столбца таблицы 8.4.
Затем по величинам
нормированных частот по таблице 11
Приложения 1 находятся величины f(oi),
которые
называются ординатами нормальной кривой
для каждой oi.
Величины
f(oi),
полученные
из таблицы 11 Приложения 1, заносятся в
соответствующую строчку четвертого
столбца таблицы 8.4. Величины, полученные
в третьем и четвертом столбцах таблицы
8.4, позво- ляют вычислить по соответствующей
формуле необходимые нам теоретические
частоты (обозначаемые как
fmi
) и
также занести их в пятый столбец таблицы
8.4.
Расчет теоретических
частот осуществляется для каждого
интервала по следующей формуле
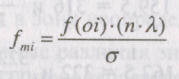
(8.4)
где п
= 267 (общая
величина выборки), λ
= 3 (величина интервала) и а —
среднеквадратичное отклонение.
Напомним, что после
подсчета эти величины заносятся в
соответствующую строчку пятого
столбца таблицы 8.4.
Таблица
8.4
|
№1 |
№2 |
№3 |
№4 |
№5 |
|
Центры хi |
Эмпирические fэi |
Ординаты |
Расчетные теоретические |
|
|
159 |
3 |
-2,77 |
0,0086 |
1,6 |
|
161 |
9 |
-2,03 |
0,0508 |
10,0 |
|
164 |
31 |
-1,29 |
0,1736 |
34,3 |
|
167 |
71 |
-0,55 |
0,3429 |
67,8 |
|
170 |
82 |
+0,19 |
0,3918 |
77,6 |
|
173 |
46 |
+0,93 |
0,2589 |
51,2 |
|
Продолжение |
таблица |
|||
|
176 |
19 |
+ |
0,0989 |
19,5 |
|
179 |
5 |
+2,41 |
0,0219 |
4,4 |
|
182 |
1 |
+3,15 |
0,0028 |
0,6 |
|
Суммы |
267 |
— |
— |
267,0 |
Рассмотрим более
детально, как получаются необходимые
нам показатели на примере первой строчки
таблицы 8.4.
Так, согласно
экспериментальным данным в первый
интервал, т.е. в интервал от 156,5 см до
159,5 см, попало 3 человека (или соответствующая
эмпирическая частота fэi=
3). Мы
помним, что величина средней X
для данной
выборки равна 169,22 см, а величина а = 4,06.
![]()
Проведем расчет
величины o
l
для первого интервала по формуле
(8.3):
Подставляем
полученную величину в первую строчку
третьего столбца таблицы 8.4. Дальнейший
расчет производится с модулями этих
чисел.
Величину f(oi)
= 0,0086 находим
в таблице 11 Приложения 1 на пересечении
строчки с числом 2,7 (десятые доли) и
столбца с числом 7 (сотые доли). Заносим
эту величину в первую строчку четвертого
столбца таблицы 8.4.
![]()
Теоретическую
частоту fmi,
получаем в соответствии с формулой
(8.4):
Заносим полученное
число в первую строчку пятого столбца
таблицы 8.4. Подобная процедура повторяется
далее для каждого
интервала.
Теперь у нас все
готово для работы с критерием хи-квадрат
по формуле 8.1 на основе стандартной
таблицы. В целях упрощения расчетов
сократим число интервалов до 7. Это
делается следующим образом: складываем
две верхние частоты и две ниж-
136
137
ние, т.е: 3 + 9=12 и 1+5
= 6. Тогда стандартная таблица для]
вычисления хи-квадрат
выглядит так:
Таблица 8.5
|
№ 1 |
№ 2 |
№ 3 |
№ 4 |
№5 |
№6 |
|
Альтернативы |
fэ |
fm |
(fэ |
(fэ |
|
|
1 |
12 |
11,6 |
+ |
0,16 |
0,01 |
|
2 |
31 |
34,3 |
-3,3 |
10,89 |
0,32 |
|
3 |
71 |
67,8 |
+ |
10,24 |
0,15 |
|
4 |
82 |
77,6 |
+ |
19,36 |
0,25 |
|
5 |
46 |
51,2 |
-5,2 |
27,04 |
0,53 |
|
6 |
19 |
19,5 |
-0,5 |
0,25 |
0,01 |
|
7 |
6 |
5,0 |
+ |
1,00 |
0,20 |
|
Суммы |
267 |
267 |
0 |
х2эмп= |
В случае оценки
равенства эмпирического распределения
нормальному число степеней свободы
определяется особым образом: из
общего числа интервалов вычитают число
3. В данном случае: 7-3 = 4. Таким образом,
число степеней свободы v
в нашем случае будет равно v
= 4. По таблице 12 Приложения I
находим:
х2кр= {9,488
для Р< 0,05
х2кр = {13,277
для Р< 0,01
Строим «ось
значимости»:

Полученная величина
эмпирического значения хи-квадрат
попала в зону незначимости, поэтому,
необходимо принять гипотезу Н0
об отсутствии
различий. Следовательно, существуют
все основания утверждать, что наше
эмпирическое распределение близко
к нормальному.
В заключении
подчеркнем, что, несмотря на некоторую
«громоздкость» вычислительных
процедур, этот способ расчета дает
наиболее точную оценку совпадения
эмпирического и нормального
распределений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #